A Unified Framework for Semiparametrically Efficient Semi-Supervised Learning
Abstract
We consider statistical inference under a semi-supervised setting where we have access to both a labeled dataset consisting of pairs and an unlabeled dataset . We ask the question: under what circumstances, and by how much, can incorporating the unlabeled dataset improve upon inference using the labeled data? To answer this question, we investigate semi-supervised learning through the lens of semiparametric efficiency theory. We characterize the efficiency lower bound under the semi-supervised setting for an arbitrary inferential problem, and show that incorporating unlabeled data can potentially improve efficiency if the parameter is not well-specified. We then propose two types of semi-supervised estimators: a safe estimator that imposes minimal assumptions, is simple to compute, and is guaranteed to be at least as efficient as the initial supervised estimator; and an efficient estimator, which — under stronger assumptions — achieves the semiparametric efficiency bound. Our findings unify existing semiparametric efficiency results for particular special cases, and extend these results to a much more general class of problems. Moreover, we show that our estimators can flexibly incorporate predicted outcomes arising from “black-box” machine learning models, and thereby achieve the same goal as prediction-powered inference (PPI), but with superior theoretical guarantees. We also provide a complete understanding of the theoretical basis for the existing set of PPI methods. Finally, we apply the theoretical framework developed to derive and analyze efficient semi-supervised estimators in a number of settings, including M-estimation, U-statistics, and average treatment effect estimation, and demonstrate the performance of the proposed estimators via simulations.
1 Introduction
Supervised learning involves modeling the association between a set of responses and a set of covariates on the basis of labeled realizations , where . In the semi-supervised setting, we also have access to additional unlabeled realizations of , , without associated realizations of . This situation could arise, for instance, when observing is more expensive or time-consuming than observing .
Suppose that , and .The joint distribution of can be expressed as . Suppose that consists of independent and identically distributed (i.i.d.) realizations of , and consists of i.i.d. realizations of that are also independent of .
We further assume that the marginal distribution and the conditional distribution are separately modeled. That is, belongs to a marginal model , and belongs to a conditional model . The model of the joint distribution can thus be expressed as
| (1) |
Consider a general inferential problem where the parameter of interest is a Euclidean-valued functional . The ground truth is , which we denote as for simplicity. This paper centers around the following question: how, and by how much, can inference using improve upon inference on using only ?
1.1 The three settings
We now introduce three settings that will be used throughout this paper.
-
1.
In the supervised setting, only labeled data are available. Supervised estimators can be written as .
-
2.
In the ordinary semi-supervised (OSS) setting, both labeled data and unlabeled data are available. OSS estimators can be written as .
- 3.
The ISS setting is primarily of theoretical interest: in reality, we rarely know . Analyzing the ISS setting will facilitate analysis of the OSS setting.
1.2 Main results
Our main contributions are as follows:
-
1.
For an arbitrary inferential problem, we derive the semiparametric efficiency lower bound under the ISS setting. We show that knowledge of can be used to potentially improve upon a supervised estimator when the parameter of interest is not well-specified, in the sense of Definition 3.1. This generalizes existing results that semi-supervised learning cannot improve a correctly-specified linear model [Kawakita and Kanamori, 2013, Buja et al., 2019a, Song et al., 2023, Gan and Liang, 2023].
-
2.
In the OSS setting, the data are non-i.i.d., and consequently classical semiparametric efficiency theory is not applicable. We establish the semiparametric efficiency lower bound in this setting: to our knowledge, this is the first such result in the literature. As in the ISS setting, an efficiency gain over the supervised setting is possible when the parameter of interest is not well-specified.
-
3.
To achieve efficiency gains over supervised estimation when the parameter is not well-specified, we propose two types of semi-supervised estimators — the safe estimator and the efficient estimator — both of which build upon an arbitrary initial supervised estimator. The safe estimator requires minimal assumptions, and is always at least as efficient as the initial supervised estimator. The efficient estimator imposes stronger assumptions, and can achieve the semi-parametric efficiency bound. Compared to existing semi-supervised estimators, the proposed estimators are more general and simpler to compute, and enjoy optimality properties.
-
4.
Suppose we have access to a “black box” machine learning model, , that can be used to obtain predictions of on unlabeled data. We show that our safe estimator can be adapted to make use of these predictions, thereby connecting the semi-supervised framework of this paper to prediction-powered inference (PPI) [Angelopoulos et al., 2023a, b], a setting of extensive recent interest. This contextualizes existing PPI proposals through the lens of semi-supervised learning, and directly leads to new PPI estimators with better theoretical guarantees and empirical performance.
1.3 Related literature
While semi-supervised learning is not a new research area [Bennett and Demiriz, 1998, Chapelle et al., 2006, Bair, 2013, Van Engelen and Hoos, 2020], it has been the topic of extensive recent theoretical interest.
Recently, Zhang et al. [2019] studied semi-supervised mean estimation and proposed a semi-supervised regression-based estimator with reduced asymptotic variance; Zhang and Bradic [2022] extended this result to the high-dimensional setting and developed an approach for bias-corrected inference. Both Chakrabortty and Cai [2018] and Azriel et al. [2022] considered semi-supervised linear regression, and proposed asymptotically normal estimators with improved efficiency over the supervised ordinary least squares estimator. Deng et al. [2023] further investigated semi-supervised linear regression under a high-dimensional setting and proposed a minimax optimal estimator. Wang et al. [2023] and Quan et al. [2024] extended these findings to the setting of semi-supervised generalized linear models. Some authors have considered semi-supervised learning for more general inferential tasks, such as M-estimation [Chakrabortty, 2016, Song et al., 2023, Yuval and Rosset, 2022] and U-statistics [Kim et al., 2024], and in different sub-fields of statistics, such as causal inference [Cheng et al., 2021, Chakrabortty and Dai, 2022] and extreme-valued statistics [Ahmed et al., 2024]. However, there exists neither a unified theoretical framework for the semi-supervised setting, nor a unified approach to construct efficient estimators in this setting.
Prediction-powered inference (PPI) refers to a setting in which the data analyst has access to not only and , but also a “black box” machine learning model such that . The goal of PPI is to conduct inference on the association between and while making use of , , and the black box predictions given by . To the best of our knowledge, despite extensive recent interest in the PPI setting [Angelopoulos et al., 2023a, b, Miao et al., 2023, Gan and Liang, 2023, Miao and Lu, 2024, Zrnic and Candès, 2024a, b, Gu and Xia, 2024], no prior work formally connects prediction-powered inference with the semi-supervised paradigm.
1.4 Notation
For any natural number , . Let denote the Cartesian product of two sets and . Let denote the smallest eigenvalue of a matrix . For two symmetric matrices , we write that if and only if is positive semi-definite. We use uppercase letters to denote random variables and lowercase letters to denote their realizations. For a vector , let be its Euclidean norm. The random variable takes values in the probability space . For a measurable function , let denote its expectation, and its variance-covariance matrix. For another measurable function , let denote the covariance matrix between and . Let be the space of all vector-valued measurable functions such that , and let denote the sub-space of functions with expectation 0, i.e. any satisfies .
1.5 Organization of the paper
The rest of our paper is organized as follows. Section 2 contains a very brief review of some concepts in semiparametric efficiency theory. In Sections 3 and 4, we derive semi-parametric efficiency bounds and construct efficient estimators under the ISS and OSS settings. In Sections 5 and 6, we connect the proposed framework to prediction-powered inference and missing data, respectively. In Section 7, we instantiate our theoretical and methodological findings in the context of specific examples: M-estimation, U-statistics, and the estimation of average treatment effect. Numerical experiments and concluding remarks are in Sections 8 and 9, respectively. Proofs of theoretical results can be found in the Supplement.
2 Overview of semiparametric efficiency theory
We provide a brief introduction to concepts and results from semiparametric efficiency theory that are essential for reading later sections of the paper. See also Supplement E.2. A more comprehensive introduction can be found in Chapter 25 of Van der Vaart [2000] or in Tsiatis [2006].
Consider i.i.d. data sampled from , and suppose there exists a dominating measure such that each element of can be represented by its corresponding density with respect to . Interest lies in a Euclidean functional , and . Consider a one-dimensional regular parametric sub-model such that for some . defines a score function at . The set of score functions at from all such one-dimensional regular parametric sub-models of forms the tangent set at relative to , and the closed linear span of the tangent set is the tangent space at relative to , which we denote as . By definition, the tangent space .
An estimator of is regular relative to if, for any regular parametric sub-model such that for some ,
for all under , where is a random variable whose distribution depends on but not on . is asymptotically linear with influence function if
The influence function depends on through some functional , where is a general metric space with metric , and . The functional need not be finite-dimensional. The functional of interest is typically involved in , but they are usually not the same. A regular and asymptotically linear estimator is efficient for at relative to if its influence function satisfies for any . If this holds, then is the efficient influence function of at relative to .
Semiparametric efficiency theory aims to provide a lower bound for the asymptotic variances of regular and asymptotically linear estimators.
Lemma 2.1.
Suppose there exists a regular and asymptotically linear estimator of . Let denote the efficient influence function of at relative to . Then, it follows that for any regular and asymptotically linear estimator of such that ,
Lemma 2.1 states that any regular and asymptotically linear estimator of relative to has asymptotic variance no smaller than the variance of the efficient influence function, . This is referred to as the semiparametric efficiency lower bound. For a proof of Lemma 2.1, see Theorem 3.2 of Bickel et al. [1993].
3 The ideal semi-supervised setting
3.1 Semiparametric efficiency lower bound
Under the ISS setting, we have access to labeled data , and the marginal distribution is known. Thus, the model reduces from (1) to
| (2) |
A smaller model space leads to an easier inferential problem, and thus a lower efficiency bound. We let
| (3) |
denote the conditional efficient influence function. Our first result establishes the semiparametric efficiency bound under the ISS setting.
Theorem 3.1.
Thus, knowledge of can improve efficiency at if and only if , i.e. if and only if is not a constant almost surely.
3.2 Inference with a well-specified parameter
It is well-known that a correctly-specified regression model cannot be improved with additional unlabeled data [Kawakita and Kanamori, 2013, Buja et al., 2019a, Song et al., 2023, Gan and Liang, 2023]; Chakrabortty [2016] further extended this result to the setting of M-estimation. In this section, we formally characterize this phenomenon, and generalize it to an arbitrary inferential problem, in the ISS setting.
The next definition is motivated by Buja et al. [2019b].
Definition 3.1 (Well-specified parameter).
Let be the data-generating distribution, and a model of the marginal distribution such that . A functional is well-specified at relative to if any satisfies
We emphasize that well-specification is a joint property of the functional of interest , the conditional distribution , and the marginal model . Definition 3.1 states that if the parameter is well-specified, then a change to the marginal model does not change . Intuitively, if this is the case, then knowledge of in the ISS setting will not affect inference on .
Theorem 3.2.
Under the conditions of Theorem 3.1, let be the efficient influence function of at relative to . If is well-specified at relative to , then
| (6) |
where is the conditional efficient influence function as in (3). Moreover, if , then any influence function of a regular and asymptotically linear estimator of satisfies
| (7) |
where the notation denotes the conditional influence function,
| (8) |
As a direct corollary of Theorem 3.2, if is well-specified, then knowledge of does not improve the semiparametric efficiency lower bound.
Corollary 3.3.
Under the conditions of Theorem 3.1, suppose that is well-specified at relative to . Then, the semiparametric efficiency lower bound of relative to is the same as the semiparametric efficiency lower bound of relative to .
3.3 Safe and efficient estimators
Together, Theorems 3.1 and 3.2 imply that when the parameter is not well-specified, we can potentially use knowledge of for more efficient inference. We will now present two such approaches, both of which build upon an initial supervised estimator. Under minimal assumptions, the safe estimator is always at least as efficient as the initial supervised estimator. By contrast, under a stronger set of assumptions, the efficient estimator achieves the efficiency lower bound (5) under the ISS setting.
We first provide some intuition behind the two estimators. Suppose that is a functional that takes values in a metric space with metric and . Let denote an initial supervised estimator of that is regular and asymptotically linear with influence function . Motivated by the form of the efficient influence function (4) under the ISS setting, we aim to use knowledge of to obtain an estimator of the conditional influence function . This will lead to a new estimator of the form
| (9) |
In what follows, we let denote an estimator of .
3.3.1 The safe estimator
Let denote an arbitrary measurable function of , and define
| (10) |
(Since is known in the ISS setting, we can compute given .)
To construct the safe estimator, we will estimate by regressing onto , leading to regression coefficients
| (11) |
where the expectation in (11) is possible since is known. Then the safe ISS estimator takes the form
| (12) |
To establish the convergence of , we made the following assumptions.
Assumption 3.1.
(a) The initial supervised estimator is a regular and asymptotically linear estimator of with influence function . (b) There exists a set such that , the class of functions is -Donsker, and for all , , where is a square integrable function. (c) There exists an estimator of such that and .
Assumptions 3.1 (b) and (c) state that we can find a consistent estimator of the functional on which the influence function of depends, such that asymptotically belongs to a realization set on which the class of functions is a Donsker class. The Donsker condition is standard in semiparametric statistics, and leads to -converegnce while allowing for rich classes of functions. We validate Assumption 3.1 for specific inferential problems in Section 7. In the special case when is finite-dimensional, the next proposition provides sufficient conditions for Assumption 3.1.
Proposition 3.4.
Suppose that (i) is a finite-dimensional functional; (ii) there exists a bounded open set such that , and for all , , where is a square integrable function; and (iii) there exists an estimator of such that . Then, Assumptions 3.1 (b) and (c) hold.
Define the population regression coefficient as
| (13) |
The next theorem establishes the asymptotic behavior of in (12).
Theorem 3.5.
Suppose that is a supervised estimator that satisfies Assumption 3.1, and is an estimator of as in Assumption 3.1 (c). Let be a square-integrable function such that and is non-singular, and let be its centered version (10). Then, for in (13), defined in (12) is a regular and asymptotically linear estimator of with influence function
and asymptotic variance . Moreover,
| (14) |
Theorem 3.5 establishes that is always at least as efficient as the initial supervised estimator under the ISS setting.
Remark 3.1 (Choice of regression basis function ).
Theorem 3.5 reveals that the asymptotic variance of is the sum of two terms. The first term, , does not depend on . The second term, , can be interpreted as the approximation error that arises from approximating with . Thus, is more efficient when is a better approximation of .
3.3.2 The efficient estimator
To construct the efficient estimator, we will approximate by regressing onto a growing number of basis functions. Let denote the Hölder class of functions on ,
| (15) |
Assumption 3.2.
Under Assumption 3.1, the set additionally satisfies that: , where is the conditional influence function and is the class of functions defined as,
In the definition of , is the -th coordinate of a vector-valued function , , and .
Under Assumption 3.2, there exists a set of basis functions of , such as a spline basis or a polynomial basis, such that any can be represented as an infinite linear combination , for coefficients . Define as the concatenation of the first basis functions. The optimal -approximation of by the first basis functions is then , where is the population regression coefficient,
It can be shown that the approximation error arising from the first basis functions satisfies
| (16) |
where is the dimension of [Newey, 1997].
To estimate the conditional influence function , we define the centered basis functions
| (17) |
and regress onto . (Note that (17) can be computed because is known.) The resulting regression coefficients are
| (18) |
The nonparametric least squares estimator of is , and the efficient ISS estimator is
| (19) |
Define . The next theorem establishes the theoretical properties of .
Theorem 3.6.
Suppose that is a supervised estimator that satisfies Assumptions 3.1 and 3.2 and is an estimator of as in Assumption 3.1 (c). Further suppose that is a set of basis functions of for which satisfies (16) and
Let be the centered version of as in (17). If , , , and , then in (19) is a regular and asymptotically linear estimator of with influence function
under the ISS setting. Moreover, its asymptotic variance is , which satisfies
| (20) |
for arbitrary , , and as in Theorem 3.5.
Theorem 3.6 shows that the efficient estimator is always at least as efficient as both the safe estimator and the initial supervised estimator . Further, (20) and Theorem 3.1 suggest that if the initial supervised estimator is efficient under the supervised setting, then the efficient estimator is efficient under the ISS setting.
4 The ordinary semi-supervised setting
4.1 Semiparametric efficiency lower bound
Because the OSS setting offers more information about the unknown parameter than the supervised setting but less information than the ISS setting, it is natural to think that the semiparametric efficiency bound in the OSS setting should be lower than in the supervised setting but higher than in the ISS setting. In this section, we will formalize this intuition.
In the OSS setting, the full data are not jointly i.i.d.. Therefore, the classic theory of semiparametric efficiency for i.i.d. data, as described in Section 2, is not applicable. Bickel and Kwon [2001] provides a framework for efficiency theory for non-i.i.d. data. Inspired by their results, our next theorem establishes the semiparametric efficiency lower bound under the OSS setting. To state Theorem 4.1, we must first adapt some definitions from Section 2 to the OSS setting. Additional definitions necessary for its proof are deferred to Appendix E.3.
Definition 4.1 (Regularity in the OSS setting).
An estimator of is regular relative to a model if, for every regular parametric sub-model such that for some ,
| (21) |
for all under and , where is some random variable whose distribution depends on but not on .
Definition 4.2 (Asymptotic linearity in the OSS setting).
An estimator of is asymptotically linear with influence function , where
| (22) |
for some and , if
| (23) |
for .
Remark 4.1.
In the OSS setting, the arguments of the influence function are in the product space . Furthermore, since , this product space can also be written as . Thus, to avoid notational confusion, when referring to a function on this space, we use arguments : that is, these subscripts are intended to disambiguate the role of the two arguments in the product space.
The form of the influence function (22) arises from the fact that the data consist of two i.i.d. parts, and , which are independent of each other. By Definition 4.2, if is asymptotically linear, then
That is, the asymptotic variance of an asymptotically linear estimator is the the sum of the variances of the two components of its influence function.
Armed with these two definitions, Lemma 2.1 can be generalized to the OSS setting. Informally, there exists a unique efficient influence function of the form (22), and any regular and asymptotically linear estimator whose influence function equals the efficient influence function is an efficient estimator. Additional details are provided in Appendix E.3.
The next theorem identifies the efficient influence function and the semiparametric efficiency lower bound under the OSS.
Theorem 4.1.
Let be defined as in (1), and let . If the efficient influence function of at relative to is , then the efficient influence function of at relative to under the OSS setting is
| (24) |
where is the conditional efficient influence function defined in (3). Moreover, the semiparametric efficiency bound can be expressed as
| (25) | ||||
Theorem 4.1 confirms our intuition for the efficiency bound under the OSS setting. By definition, the efficiency bound under the supervised setting is . The second line of (25) reveals that the efficiency bound under the OSS setting is smaller by the amount . Moreover, in Theorem 3.1 we showed that the efficiency bound under the ISS setting is . The third line of (25) shows that the efficiency bound under the OSS setting exceeds this by the amount .
The efficiency bound (25) depends on the limiting proportion of unlabeled data, . Intuitively, when is large, we have more unlabeled data, and the efficiency bound in (25) improves. The special cases where and are particularly instructive. When , the amount of unlabeled data is negligible, and hence we should expect no improvement in efficiency over the supervised setting: this intuition is confirmed by setting in (25). When , there are many more labeled than unlabeled observations; thus, it is as if we know the marginal distribution . Letting , the efficiency lower bound agrees with that under the ISS (5).
We saw in Corollary 3.3 that when the functional of interest is well-specified, the efficiency bound under the ISS setting is the same as in the supervised setting. As an immediate corollary of Theorem 4.1 and Theorem 3.2, we now show that the same result holds under the OSS setting.
Corollary 4.2.
Thus, an efficient supervised estimator of a well-specified parameter can never be improved via the use of unlabeled data.
4.2 Safe and efficient estimators
Similar to Section 3.3, in this section we provide two types of OSS estimators, a safe estimator and an efficient estimator, both of which build upon and improve an initial supervised estimator.
Recall from Remark 3.2 that the safe and efficient estimators proposed in the ISS setting require knowledge of . Of course, in the OSS setting, is unavailable. Thus, we will simply replace in (12) and (19) with , the empirical marginal distribution of the labeled and unlabeled covariates, .
4.2.1 The safe estimator
For an arbitrary measurable function of , , recall that in the ISS setting, the safe estimator (12) made use of its centered version . Since is unknown under the OSS setting, we define the empirically centered version of as
| (26) |
Now, regressing onto yields the regression coefficients
| (27) |
The regression estimator of the conditional influence function is thus , and the corresponding safe OSS estimator is defined as
| (28) |
Under the same conditions as in Theorem 3.5, we establish the asymptotic behavior of .
Theorem 4.3.
Suppose that is a supervised estimator that satisfies Assumption 3.1, and is an estimator of as in Assumption 3.1 (c). Let be a square-integrable function such that and is non-singular, and let be its empirically centered version (26). Suppose that . Then, the estimator defined in (28) is a regular and asymptotically linear estimator of in the sense of Definitions 4.1 and 4.2, with influence function
| (29) |
under the OSS setting, where is defined in (13). Furthermore, the asymptotic variance of takes the form
| (30) |
and satisfies
| (31) |
Theorem 4.3 shows that is always at least as efficient as the initial supervised estimator under the OSS setting. Thus, it is a safe alternative to when additional unlabeled data are available.
4.2.2 The efficient estimator
As in Section 3.3, we require that the initial supervised estimator satisfy Assumption 3.2. Then, for a suitable set of basis functions of (defined in Assumption 3.2), we define . We then center with its empirical mean, , leading to
| (32) |
The nonparametric least squares estimator of the conditional influence function is , where
| (33) |
are the coefficients obtained from regressing onto . The efficient OSS estimator is then
| (34) |
The next theorem establishes the asymptotic properties of .
Theorem 4.4.
Suppose that the supervised estimator satisfies Assumptions 3.1 and 3.2, and is an estimator of as in Assumption 3.1 (c). Further, suppose that is a set of basis functions of such that satisfies (16) for any , and . Suppose that , , and , and . Then, defined in (34) is a regular and asymptotically linear estimator of in the sense of Definitions 4.1 and 4.2, and has influence function
| (35) |
Furthermore, the asymptotic variance of takes the form
| (36) |
and satisfies
| (37) |
where is defined as (30).
As in Section 3.3, the efficient OSS estimator, , is always at least as efficient as both the safe OSS estimator, , and the initial supervised estimator . Furthermore, (37) together with Theorem 4.1 show that if the initial supervised estimator is efficient under the supervised setting, then the efficient OSS estimator is efficient under the OSS setting.
Remark 4.2.
We noted in Section 4.1 that the efficiency bound in the OSS falls between the efficiency bounds in the ISS and supervised settings. We can see from Theorems 4.3 and 4.4 that a similar property holds for the safe and efficient estimators. Specifically, (31) and (37) show that the safe and efficient OSS estimators are more efficient than the initial supervised estimator , but are less efficient than the safe and efficient ISS estimators, respectively. This is again due to the fact that under the OSS, unlabeled observations provide more information than is available under the supervised setting, but less than is available under the ISS. Similarly, as , i.e. as the proportion of unlabeled data becomes negligible, the OSS estimators are asymptotically equivalent to the initial supervised estimator. On the other hand, when , the OSS estimators are asymptotically equivalent to the corresponding ISS estimators.
5 Connection to prediction-powered inference
Suppose now that in addition to and , the data analyst also has access to machine learning prediction models , , which are independent of and (e.g., they were trained on independent data). For instance, may arise from black-box machine learning models such as neural networks or large language models. It is clear that this is a special case of semi-supervised learning, as can be treated as fixed functions conditional on the data upon which they were trained.
Recently, Angelopoulos et al. [2023a] proposed prediction-powered inference (PPI), which provides a principled approach for making use of . Subsequently, a number of PPI variants have been proposed to further improve statistical efficiency or extend PPI to other settings [Angelopoulos et al., 2023b, Miao et al., 2023, Gan and Liang, 2023, Miao and Lu, 2024, Gu and Xia, 2024]. In this section, we re-examine the PPI problem through the lens of our results in previous sections, and apply these insights to improve upon existing PPI estimators.
Since are independent of , existing PPI estimators fall into the category of OSS estimators, and can be shown to be regular and asymptotically linear in the sense of Definitions 4.1 and 4.2. Therefore, Theorem 4.1 suggests that their asymptotic variances are lower bounded by the efficiency bound (25). We show in Supplement C that existing PPI estimators cannot achieve the efficiency bound (25) in the OSS setting, unless strong assumptions are made on the machine learning prediction models. Furthermore, if the parameter of interest is well-specified in the sense of Definition 3.1, then by Corollary 4.2 these estimators cannot be more efficient than the efficient supervised estimator. In other words, independently trained machine learning models, however sophisticated and accurate, cannot improve inference when the parameter is well-specified.
Remark 5.1.
Our insight that independently trained machine learning models cannot improve inference in a well-specified model stands in apparent contradiction to the simulation results of Angelopoulos et al. [2023b], who find that PPI does lead to improvement over supervised estimation in generalized linear models. This is because they have simulated data such that , i.e. the machine learning model is not independent of and . A modification to their simulation study to achieve independence (in keeping with the setting of their paper) corroborates our insight, i.e., PPI does not outperform the supervised estimator.
Next, we take advantage of the insights developed in previous sections to propose a class of OSS estimators that incorporates the machine learning models and improves upon the existing PPI estimators. We begin with an initial supervised estimator that is regular and asymptotically linear with influence function , and we suppose that is an estimator of . As in Section 4.2, we estimate the conditional influence function defined in (3) with regression. Specifically, consider
| (38) |
which arises from replacing the true response in with the machine learning model , for . Its empirically centered version is
| (39) |
Then the regression estimator of the conditional influence function is , where
| (40) |
are the coefficients obtained from regressing onto . Motivated by the safe OSS estimator, in (28), the safe PPI estimator is defined as
| (41) |
We now investigate the asymptotic behavior of the estimator (41). Note that Theorem 4.3 is not applicable, as the regression basis in (39) is random due to the involvement of . Consider an arbitrary class of measurable functions indexed by ,
| (42) |
We make the following assumptions on .
Assumption 5.1.
(a) and is non-singular; (b) Under Assumption 3.1, is -Donsker, and for all , , where is a square-integrable function.
Similar to Assumption 3.1, Assumption 5.1 requires that the class of functions is a Donsker class; when is finite-dimensional, the next proposition provides sufficient conditions for Assumption 5.1.
Proposition 5.1.
Define as the centered version of , and
| (43) |
as the population coefficients for the regression of onto . The next proposition establishes the asymptotic behavior of .
Proposition 5.2.
Suppose that is a supervised estimator that satisfies Assumption 3.1, defined as (42) is a class of measurable functions that satisfies Assumption 5.1, and is an estimator of as in Assumption 3.1 (c). Suppose further that . Then the estimator defined in (41) is a regular and asymptotically linear estimator of in the sense of Definitions 4.1 and 4.2, and has influence function
| (44) |
in the OSS setting, where is defined as in (43). Furthermore, the asymptotic variance of takes the form
and satisfies
| (45) |
Proposition 5.2 can be viewed as an extension of Theorem 4.3, where in Theorem 4.3 the function class is a singleton class that does not depend on . Our proposed PPI estimator (41) flexibly incorporates multiple black-box machine learning models, and enjoys several advantages over existing PPI estimators:
- 1.
- 2.
-
3.
While existing PPI estimators are only applicable to M- and Z-estimators, our proposal is much more general: it is applicable to arbitrary inferential problems and requires only a regular and asymptotically linear initial supervised estimator.
We provide a detailed discussion of the efficiency of existing PPI estimators in Appendix C.
6 Connection with missing data
The missing data framework provides an alternative approach for modeling the semi-supervised setting [Robins and Rotnitzky, 1995, Chen et al., 2008, Zhou et al., 2008, Li and Luedtke, 2023, Graham et al., 2024]. Here we relate the proposed framework to the classical theory of missing data.
To establish a formal relationship between the two paradigms, we consider a missing completely at random (MCAR) model under which the semiparametric efficiency bound coincides with that derived in Theorem 4.1 in the OSS setting. Let be i.i.d. data, where , is a binary missingness indicator such that the response is observed if and only if , and is a Bernoulli distribution with known probability where . Assume that , where is defined in (1) as in previous sections. The underlying model of is thus
| (46) |
The next proposition derives the efficiency bound relative to (46).
Proposition 6.1.
Let be defined as in (1) and let . Suppose that the efficient influence function of at relative to is , and recall that is the conditional efficient influence function. Consider i.i.d. data generated from with model (46). Then the efficient influence function of at relative to is
and the corresponding semiparametric efficiency lower bound is
A comparison of (6.1) and (25) reveals that, for any fixed , the efficiency bound under the MCAR model (46) is the same as under the OSS setting. Thus, the amount of information useful for inference under the two paradigms is the same. However, in the MCAR model the data are fully i.i.d.; by contrast, in the OSS setting the data are not fully i.i.d., and instead consist of two independent i.i.d. parts from and , respectively. In fact, the OSS setting corresponds to the MCAR model conditional on the event . As the distribution of is completely known under the MCAR model, conditioning does not alter the information available, and so it is not surprising that the efficiency bounds are the same.
The semi-supervised setting allows for , i.e., for the possibility that the sample size of the unlabeled data far exceeds that of the labeled data, . As discussed in Section 4.1, this case corresponds to the ISS setting, with efficiency lower bound given by Theorem 3.1. Our proposed safe and efficient OSS estimators also allow for , as shown in Theorems 4.3 and 4.4. By contrast, it is difficult to theoretically analyze the efficiency lower bound when using the missing data framework, and estimators developed for missing data require the probability of missingness to be strictly smaller than 1.
7 Applications
In this section, we apply the proposed framework to a variety of inferential problems, including M-estimation, U-statistics, and average treatment effect estimation. Constructing the safe OSS estimator (12) or the PPI estimator (41) requires finding an initial supervised estimator and an estimator that satisfies Assumption 3.1. To construct the efficient OSS estimator (34), the initial supervised estimator also needs to satisfies Assumption 3.2, which cannot be verified in practice.
7.1 M-estimation
First, we apply the proposed framework to M-estimation, a setting also considered in Chapter 2 of Chakrabortty [2016] and Song et al. [2023]. For a function , we define the target parameter as the maximizer of
Given i.i.d. labeled data , we use the M-estimator
| (47) |
as the initial supervised estimator of . Under regularity conditions such as those stated in Theorems 5.7 and 5.21 of Van der Vaart [2000], the M-estimator (47) is a regular and asymptotically linear estimator of with influence function
| (48) |
where and . The functional that appears in (48) is
which is finite-dimensional. Therefore, validating Assumption 3.1 is equivalent to validating the conditions stated in Proposition 3.4, which we now do for two canonical examples of M-estimation problems.
Example 7.1 (Mean).
Define for some function . The target parameter is the expectation . The M-estimator (47) in this case is the sample mean
which is regular and asymptotically linear with influence function . The functional in this example is , as and does not depend on the underlying distribution. A consistent estimator of is the sample mean . Furthermore, is -Lipschitz in , and the conditions of Proposition 3.4 are satisfied.
Example 7.2 (Generalized linear models).
Define , where is a convex and infinitely-differentiable function. Let and denote its first and second-order derivatives, respectively. Here corresponds to the log-likelihood of a canonical exponential family distribution with natural parameter and log partition function , i.e., a generalized linear model (GLM). However, we do not assume that the underlying distribution belongs to this model. The target parameter maximizes , and can be viewed as the best Kullback–Leibler approximation of the underlying distribution by the GLM model. The M-estimator (47) in this case is the GLM estimator
which is regular and asymptotically linear with influence function
A consistent estimator of the functional is
Under mild conditions, it can be shown that satisfies the conditions of Proposition 3.4. Claims made in this example are proved in Supplement D.
Application to Z-estimation or estimating equations is similar and thus omitted.
7.2 U-statistics
Next, we apply the proposed framework to U-statistics. Let be a symmetric kernel function. The target parameter is defined as
where the expectation is taken over i.i.d. random variables . To estimate , the supervised estimator is
| (49) |
We assume that is non-degenerate:
| (50) |
where is the conditional expectation with the first argument fixed at , i.e.,
| (51) |
Under this condition, is a regular and asymptotically linear estimator with influence function
| (52) |
where is again the order of the kernel [for a proof, see Theorem 12.3 of Van der Vaart, 2000]. The functional in (52) is . This is an infinite-dimensional functional that takes values in , where is the space of uniformly bounded functions equipped with the uniform metric . Denoting and , it follows that (52) is -Lipschitz with respect to the metric .
We have already established that U-statistics (49) are regular and asymptotically linear with -Lipschitz influence functions. Therefore, it remains to validate the remaining parts of (b) and (c) of Assumption 3.1, which we now do for two canonical examples of U-statistics.
Example 7.3 (Variance).
Define . The target of inference is then the variance . The U-statistic in this case is the sample variance,
which is regular and asymptotically linear with influence function when is non-degenerate. In this simple example, the functional is finite-dimensional, and a consistent estimator of is . Therefore, invoking Proposition 3.4, Assumption 3.1 is satisfied.
Example 7.4 (Kendall’s ).
Consider and define . The target of inference is
which measures the dependence between and . The U-statistic is Kendall’s ,
which is the average number of pairs with concordant sign. When is non-degenerate, is regular and asymptotically linear with influence function
where . A natural estimator of in this case is
In Supplement D, we validate the conditions in Assumption 3.1 under additional assumptions on .
7.3 Average treatment effect
We consider application of the proposed framework to the estimation of the average treatment effect (ATE). Suppose we have for confounders , binary treatment , and outcome . Let and represent the counterfactual outcomes under control and treatment, respectively. Under appropriate assumptions, the ATE, defined as , can be expressed as , where for . For simplicity, we consider the target of inference
| (53) |
Inference for the ATE, , follows similarly.
We define and , and consider the model
It can be shown [Robins et al., 1994, Hahn, 1998] that the efficient influence function relative to is
| (54) |
where . In this case, is infinite-dimensional and takes values in the product space , where is the space of uniformly bounded functions equipped with the uniform metric .
We consider three examples.
Example 7.5 (Additional data on confounders).
Suppose that additional observations of the confounders are available, i.e. . The conditional efficient influence function in this case is
By Theorem 4.1, the efficient influence function under the OSS is
| (55) |
where — in keeping with Remark 4.1 — we have used as arguments to the influence function. We note that if has no confounding effect, i.e. , then and the efficiency bound (55) is the same as in the supervised setting.
Example 7.6 (Additional data on confounders and treatment).
Suppose that additional observations of both the confounders and the treatment indicators are available, i.e. . The conditional efficient influence function in this case is
By Theorem 4.1, the efficient influence function under the OSS is
| (56) | ||||
where again the subscripts in (LABEL:eq:efficiency_OSS_UA) are in keeping with Remark 4.1. If has no confounding effect and has no treatment effect, i.e. if , then and the efficiency bound (LABEL:eq:efficiency_OSS_UA) is the same as in the supervised setting.
Example 7.7 (Additional data on confounders and treatment, and availability of surrogates).
When measuring the primary outcome is time-consuming or expensive, we may use a surrogate marker as a replacement for , to facilitate more timely decisions on the treatment effect [Wittes et al., 1989]. Suppose that , and that additional observations of the confounders, the treatment indicators, and the surrogate markers are available: that is, . The conditional efficient influence function in this case is
By Theorem 4.1, the efficient influence function under the OSS is
| (57) | ||||
Here , and the subscripts in (57) are again in keeping with Remark 4.1. If , then and the efficiency bound (LABEL:eq:efficiency_OSS_UA) is the same as in the supervised setting.
8 Numerical experiments
In this section, we illustrate the proposed framework numerically in the context of mean estimation and generalized linear models. Numerical experiments for variance estimation and Kendall’s can be found in Sections F.2 and F.3 of the Appendix.
In each example, the covariates are two-dimensional and generated as i.i.d. . We compute the proposed estimators (28), (34), and (41) as follows:
-
•
For the estimator , we use .
-
•
For the estimator , we use a basis of tensor product natural cubic splines, with basis functions.
-
•
For the estimator , we use where is a prediction model. We consider two prediction models: (i) a random forest model trained on independent data, which represents an informative prediction model; and (ii) randomly-generated Gaussian noise, which represents a non-informative prediction model.
Each of these estimators is constructed by modifying an efficient supervised estimator, whose performance we also consider. Additionally, we include the PPI++ estimator proposed by Angelopoulos et al. [2023b], using the same two prediction models as for .
In each simulation setting, we also estimate the semiparametric efficiency lower bounds in the ISS setting (5) and in the OSS setting (25).
For each method, we report the coverage of the 95% confidence interval, as well as the standard error; all results are averaged over 1,000 simulated datasets.
8.1 Mean estimation
We consider Example 7.1 with . In this example, the supervised estimator is the sample mean, which has influence function . The conditional influence function is
which depends on through the conditional expectation. We generate the response as , where . We consider three settings for :
-
1.
Setting 1 (linear model):
-
2.
Setting 2 (non-linear model):
-
3.
Setting 3 (well-specified model, in the sense of Definition 3.1):
For each model, we set , and vary the proportion of unlabeled observations, . The semiparametric efficiency lower bound in the ISS setting (5) and in the OSS setting (25) are estimated separately on a sample of observations.
Table 1 of Appendix F.1 reports the coverage of 95% confidence intervals for each method. All methods achieve the nominal coverage.
Figure 1 displays the standard error of each method, averaged over 1,000 simulated datasets.
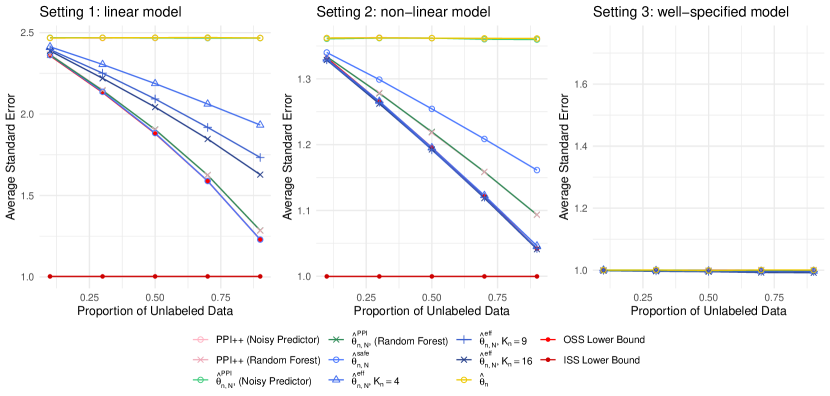
We begin with a discussion of Setting 1 (linear model). The estimator achieves the efficiency lower bound in the OSS setting, since with suffices to accurately approximate the true conditional influence function. In fact, , which uses a greater number of basis functions, performs worse: those additional basis functions contribute to increased variance without improving bias. Both PPI++ and using a random forest prediction model perform well, whereas the version of those methods that uses a pure-noise prediction model performs comparably to the supervised estimator, i.e., incorporating a useless prediction model does not lead to deterioration of performance. Since there is only one parameter of interest in the context of mean estimation, i.e. , the PPI++ estimator is asymptotically equivalent to with with the same prediction model : thus, there is no difference in performance between PPI++ and . However, as we will show in Section 8.2, when there are multiple parameters, i.e. , can outperform the PPI++ estimator.
We now consider Setting 2 (non-linear model). Because the conditional influence function is non-linear, the best performance for is achieved when the number of basis functions is sufficiently large. Furthermore, this performance is substantially better than that of with . Other than this, the results are quite similar to Setting 1.
8.2 Generalized linear model
We consider Example 7.2 with a Poisson GLM. In this example, the supervised estimator is the Poisson GLM estimator, which has influence function
The conditional influence function is then
We generate the response as . However, unlike in Section 8.1, the conditional influence function is not a linear function of regardless of the form of . Therefore, we only consider two settings for :
-
1.
Setting 1 (non-linear model):
-
2.
Setting 2 (well-specified model, in the sense of Definition 3.1):
For each model, we set , and vary the proportion of unlabeled observations, . The semiparametric efficiency lower bound in the ISS setting (5) and in the OSS setting (25) are estimated separately on a sample of observations.
Table 2 of Appendix F.1 reports the coverage of 95% confidence intervals for each method. All methods achieve the nominal coverage.
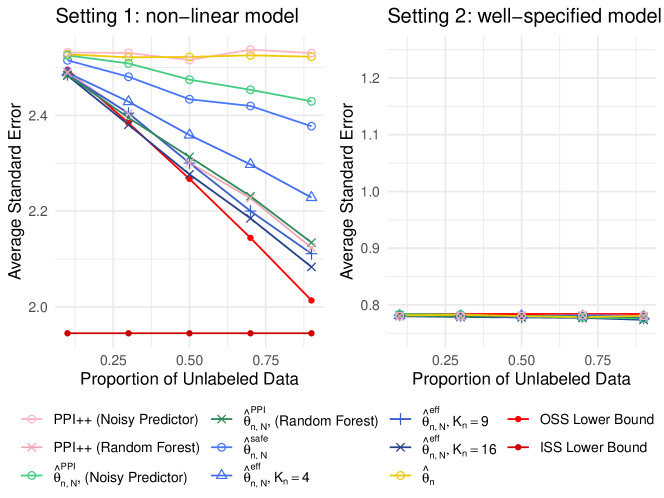
Figure 2 displays the standard error of the first parameter for each method, averaged over 1,000 simulated datasets. Results for the standard error of the second parameter are similar, and are displayed in Figure 3 in Appendix F.1.
We first consider Setting 1 (non-linear model). Consistent with the results for Setting 2 of Section 8.1, the estimator approximates the efficiency lower bound in the OSS setting when the number of basis functions is sufficiently large. Meanwhile, the estimator with improves upon the supervised estimator, but is not efficient as it cannot accurately approximate the true conditional influence function . Both PPI++ and perform well with a random forest prediction model. In addition, we make the following observations that differ from the results shown in Section 8.1:
-
1.
significantly improves upon the supervised estimator even with a pure-noise prediction model. To see this, recall that estimates the conditional influence function by regressing onto where is a prediction model. (In practice, the unknown function is replaced with a consistent estimator .) Define . In the case of a Poisson GLM, we have that
and
Thus, in the case of a Poisson GLM, the projection of onto in is non-zero, even if — in the extreme case — .
By contrast, in the case of mean estimation in Section 8.1, the projection of onto in equals zero when is independent of . Thus, for mean estimation, a pure-noise prediction model is completely useless.
-
2.
is more efficient than the PPI++ estimator of Angelopoulos et al. [2023b] when both use the noisy prediction model. This is because PPI++ uses a scalar weight to minimize the trace of the asymptotic covariance matrix, which is sub-optimal in efficiency when . On the other hand, considers a regression approach to find the best linear approximation of the conditional influence function , as in (41).
Finally, we consider Setting 2 (well-specified model). No method improves upon the OSS lower bound, in keeping with Corollary 4.2.
9 Discussion
We have proposed a general framework to study statistical inference in the semi-supervised setting. We established the semiparametric efficiency lower bound for an arbitrary inferential problem under the semi-supervised setting, and showed that no improvement can be made when the model is well-specified. Furthermore, we proposed a class of easy-to-compute estimators that build upon existing supervised estimators and that can achieve the efficiency lower bound for an arbitrary inferential problem.
This paper leaves open several directions for future work. First, our results require a Donsker condition on the influence function of the supervised estimator. This may not hold, for example, when the functional is high-dimensional or infinite-dimensional. Recent advances in double/debiased machine learning [Chernozhukov et al., 2018, Foster and Syrgkanis, 2023] may provide an avenue for obtaining efficient semi-supervised estimators in the presence of high- or infinite-dimensional nuisance parameters. Second, a general theoretical framework for efficient semi-supervised estimation in the presence of covariate shift also remains a relatively open problem, despite some promising preliminary work [Ryan and Culp, 2015, Aminian et al., 2022].
Acknowledgments
We thank Abhishek Chakrabortty for pointing out that an earlier version of this paper overlooked connections with Chapter 2 of his dissertation [Chakrabortty, 2016] in the special case of M-estimation.
References
- Zhang et al. [2019] Anru Zhang, Lawrence D Brown, and T Tony Cai. Semi-supervised inference: General theory and estimation of means. The Annals of Statistics, 47(5):2538–2566, 2019.
- Cheng et al. [2021] David Cheng, Ashwin N Ananthakrishnan, and Tianxi Cai. Robust and efficient semi-supervised estimation of average treatment effects with application to electronic health records data. Biometrics, 77(2):413–423, 2021.
- Kawakita and Kanamori [2013] Masanori Kawakita and Takafumi Kanamori. Semi-supervised learning with density-ratio estimation. Machine Learning, 91:189–209, 2013.
- Buja et al. [2019a] Andreas Buja, Lawrence Brown, Richard Berk, Edward George, Emil Pitkin, Mikhail Traskin, Kai Zhang, and Linda Zhao. Models as approximations i. Statistical Science, 34(4):523–544, 2019a.
- Song et al. [2023] Shanshan Song, Yuanyuan Lin, and Yong Zhou. A general m-estimation theory in semi-supervised framework. Journal of the American Statistical Association, pages 1–11, 2023.
- Gan and Liang [2023] Feng Gan and Wanfeng Liang. Prediction de-correlated inference. arXiv preprint arXiv:2312.06478, 2023.
- Angelopoulos et al. [2023a] Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference. Science, 382(6671):669–674, 2023a.
- Angelopoulos et al. [2023b] Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. Ppi++: Efficient prediction-powered inference. arXiv preprint arXiv:2311.01453, 2023b.
- Bennett and Demiriz [1998] Kristin Bennett and Ayhan Demiriz. Semi-supervised support vector machines. Advances in Neural Information Processing Systems, 11, 1998.
- Chapelle et al. [2006] Olivier Chapelle, Mingmin Chi, and Alexander Zien. A continuation method for semi-supervised svms. In Proceedings of the 23rd International Conference on Machine Learning, pages 185–192, 2006.
- Bair [2013] Eric Bair. Semi-supervised clustering methods. Wiley Interdisciplinary Reviews: Computational Statistics, 5(5):349–361, 2013.
- Van Engelen and Hoos [2020] Jesper E Van Engelen and Holger H Hoos. A survey on semi-supervised learning. Machine Learning, 109(2):373–440, 2020.
- Zhang and Bradic [2022] Yuqian Zhang and Jelena Bradic. High-dimensional semi-supervised learning: in search of optimal inference of the mean. Biometrika, 109(2):387–403, 2022.
- Chakrabortty and Cai [2018] Abhishek Chakrabortty and Tianxi Cai. Efficient and adaptive linear regression in semi-supervised settings. The Annals of Statistics, 46(4):1541–1572, 2018.
- Azriel et al. [2022] David Azriel, Lawrence D Brown, Michael Sklar, Richard Berk, Andreas Buja, and Linda Zhao. Semi-supervised linear regression. Journal of the American Statistical Association, 117(540):2238–2251, 2022.
- Deng et al. [2023] Siyi Deng, Yang Ning, Jiwei Zhao, and Heping Zhang. Optimal and safe estimation for high-dimensional semi-supervised learning. Journal of the American Statistical Association, pages 1–12, 2023.
- Wang et al. [2023] Tong Wang, Wenlu Tang, Yuanyuan Lin, and Wen Su. Semi-supervised inference for nonparametric logistic regression. Statistics in Medicine, 42(15):2573–2589, 2023.
- Quan et al. [2024] Zhuojun Quan, Yuanyuan Lin, Kani Chen, and Wen Yu. Efficient semi-supervised inference for logistic regression under case-control studies. arXiv preprint arXiv:2402.15365, 2024.
- Chakrabortty [2016] Abhishek Chakrabortty. Robust semi-parametric inference in semi-supervised settings. PhD thesis, 2016.
- Yuval and Rosset [2022] Oren Yuval and Saharon Rosset. Semi-supervised empirical risk minimization: Using unlabeled data to improve prediction. Electronic Journal of Statistics, 16(1):1434–1460, 2022.
- Kim et al. [2024] Ilmun Kim, Larry Wasserman, Sivaraman Balakrishnan, and Matey Neykov. Semi-supervised u-statistics. arXiv preprint arXiv:2402.18921, 2024.
- Chakrabortty and Dai [2022] Abhishek Chakrabortty and Guorong Dai. A general framework for treatment effect estimation in semi-supervised and high dimensional settings. arXiv preprint arXiv:2201.00468, 2022.
- Ahmed et al. [2024] Hanan Ahmed, John HJ Einmahl, and Chen Zhou. Extreme value statistics in semi-supervised models. Journal of the American Statistical Association, pages 1–14, 2024.
- Miao et al. [2023] Jiacheng Miao, Xinran Miao, Yixuan Wu, Jiwei Zhao, and Qiongshi Lu. Assumption-lean and data-adaptive post-prediction inference. arXiv preprint arXiv:2311.14220, 2023.
- Miao and Lu [2024] Jiacheng Miao and Qiongshi Lu. Task-agnostic machine learning-assisted inference. arXiv preprint arXiv:2405.20039, 2024.
- Zrnic and Candès [2024a] Tijana Zrnic and Emmanuel J Candès. Active statistical inference. arXiv preprint arXiv:2403.03208, 2024a.
- Zrnic and Candès [2024b] Tijana Zrnic and Emmanuel J Candès. Cross-prediction-powered inference. Proceedings of the National Academy of Sciences, 121(15):e2322083121, 2024b.
- Gu and Xia [2024] Yanwu Gu and Dong Xia. Local prediction-powered inference. arXiv preprint arXiv:2409.18321, 2024.
- Van der Vaart [2000] Aad W Van der Vaart. Asymptotic statistics, volume 3. Cambridge University Press, 2000.
- Tsiatis [2006] Anastasios A Tsiatis. Semiparametric theory and missing data, volume 4. Springer, 2006.
- Bickel et al. [1993] Peter J Bickel, Chris AJ Klaassen, Ya’acov Ritov J.Klaasen, and Jon A Wellner. Efficient and Adaptive Estimation for Semiparametric Models, volume 4. Springer, 1993.
- Buja et al. [2019b] Andreas Buja, Lawrence Brown, Arun Kumar Kuchibhotla, Richard Berk, Edward George, and Linda Zhao. Models as approximations ii. Statistical Science, 34(4):545–565, 2019b.
- Newey [1997] Whitney K Newey. Convergence rates and asymptotic normality for series estimators. Journal of Econometrics, 79(1):147–168, 1997.
- Bickel and Kwon [2001] Peter J Bickel and Jaimyoung Kwon. Inference for semiparametric models: some questions and an answer. Statistica Sinica, pages 863–886, 2001.
- Robins and Rotnitzky [1995] James M Robins and Andrea Rotnitzky. Semiparametric efficiency in multivariate regression models with missing data. Journal of the American Statistical Association, 90(429):122–129, 1995.
- Chen et al. [2008] Xiaohong Chen, Han Hong, and Alessandro Tarozzi. Semiparametric efficiency in gmm models with auxiliary data. The Annals of Statistics, 36(2):808–843, 2008.
- Zhou et al. [2008] Yong Zhou, Alan T K Wan, and Xiaojing Wang. Estimating equations inference with missing data. Journal of the American Statistical Association, 103(483):1187–1199, 2008.
- Li and Luedtke [2023] Sijia Li and Alex Luedtke. Efficient estimation under data fusion. Biometrika, 110(4):1041–1054, 2023.
- Graham et al. [2024] Ellen Graham, Marco Carone, and Andrea Rotnitzky. Towards a unified theory for semiparametric data fusion with individual-level data. arXiv preprint arXiv:2409.09973, 2024.
- Robins et al. [1994] James M Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of regression coefficients when some regressors are not always observed. Journal of the American statistical Association, 89(427):846–866, 1994.
- Hahn [1998] Jinyong Hahn. On the role of the propensity score in efficient semiparametric estimation of average treatment effects. Econometrica, pages 315–331, 1998.
- Wittes et al. [1989] Janet Wittes, Edward Lakatos, and Jeffrey Probstfield. Surrogate endpoints in clinical trials: cardiovascular diseases. Statistics in Medicine, 8(4):415–425, 1989.
- Chernozhukov et al. [2018] Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters, 2018.
- Foster and Syrgkanis [2023] Dylan J Foster and Vasilis Syrgkanis. Orthogonal statistical learning. The Annals of Statistics, 51(3):879–908, 2023.
- Ryan and Culp [2015] Kenneth Joseph Ryan and Mark Vere Culp. On semi-supervised linear regression in covariate shift problems. The Journal of Machine Learning Research, 16(1):3183–3217, 2015.
- Aminian et al. [2022] Gholamali Aminian, Mahed Abroshan, Mohammad Mahdi Khalili, Laura Toni, and Miguel Rodrigues. An information-theoretical approach to semi-supervised learning under covariate-shift. International Conference on Artificial Intelligence and Statistics, pages pp. 7433–7449, 2022.
- van der Vaart and Wellner [2013] Aad van der Vaart and Jon Wellner. Weak convergence and empirical processes: with applications to statistics. Springer Science & Business Media, 2013.
- Hansen [2022] Bruce Hansen. Econometrics. Princeton University Press, 2022.
- van der Laan [1995] Mark J van der Laan. Efficient and inefficient estimation in semiparametric models. 1995.
- Gill et al. [1995] Richard D Gill, Mark J Laan, and Jon A Wellner. Inefficient estimators of the bivariate survival function for three models. In Annales de l’IHP Probabilités et statistiques, volume 31, pages 545–597, 1995.
- Pfanzagl [1990] Johann Pfanzagl. Estimation in semiparametric models. Springer, 1990.
- Van Der Vaart [1991] Aad Van Der Vaart. On differentiable functionals. The Annals of Statistics, pages 178–204, 1991.
- van der Laan and Robins [2003] Mark J van der Laan and James Robins. Unified approach for causal inference and censored data. Unified Methods for Censored Longitudinal Data and Causality, pages 311–370, 2003.
Appendix A Additional notation
We introduce additional notation that is used in the appendix. For a matrix , let denote its operator norm and let denote its Frobenius norm. For a set , let denote its interior. Consider the probability space . Letting be a measurable function over , we adopt the following notation from the empirical process literature: , , and . Similarly, for a measurable function , , , and . For two subspaces and such that , let represent their direct sum in .
Appendix B Proof of main results
Proof of Theorem 3.1..
In the first step, we characterize the tangent space of the reduced model , which is defined in (2). Note that the reduced model satisfies the conditions of Lemma E.11, i.e., the marginal distribution and the conditional distribution are separately modeled. Therefore, by Lemma E.11, the tangent space of the reduced model can be expressed as , where is the conditional model. Since is a singleton set, , and hence the tangent space of becomes .
Recall that is the conditional efficient influence function . In the second step, we show that for all ,
| (58) |
We prove this by contradiction. Suppose there exists such that . Consider the decomposition
As , , and , therefore by the property of direct sum, and is the unique decomposition of such that , and . Further, by definition of the efficient influence function, . Recall the model defined in (1). By Lemma E.11, the tangent space relative to is
Similarly, by the property of direct sum, there exists a unique decomposition such that and . However, , and hence . By definition, , and . Therefore, is another decomposition of such that , and . This contradicts the uniqueness of direct sum. Therefore, we have established (58) for all .
In the third step, we show that is a gradient relative to the model . Consider any one-dimensional regular parametric sub-model of . Since the marginal model is a singleton set , this maps one-to-one to a one-dimensional regular parametric sub-model of such that . Suppose that such that is the conditional density of for some . Denote as the score function relative to at , which then satisfies . Note that the score function relative to at remains , as the marginal distribution is known. Consider the function as a function of , . By definition, the efficient influence function is a gradient relative to , hence
where the last equality used the fact that and
As the above holds for an arbitrary one-dimensional regular parametric sub-model of , is a gradient relative to at .
Finally, combining step 1 to step 3 above, is a gradient relative to at and satisfies for all . Therefore, by definition, is the efficient influence function of at relative to . By Lemma E.1, the variance, , can be represented as
which proves the final claim of the theorem. ∎
Proof of Theorem 3.2.
To prove the first part of the theorem, consider any element . Without loss of generality, suppose is a regular parametric sub-model of with score function at . (Otherwise, because the tangent space is a closed linear space by definition, we can always find a sequence of functions that are score functions of regular parametric sub-models of , and the following arguments hold by the continuity of the inner product.) Then, the model is a regular parametric sub-model of with score function at . Since is parameterized by , we can write as a function of , . Because is well-specified at relative to , is a constant function, , and hence . By pathwise-differentiability,
for any gradient of at relative to . Since this holds true for any , we see that any gradient satisfies
Consider the the efficient influence function of relative to at , which is a gradient of relative to at by definition. Further, by the definition of the efficient influence function, for all it holds that
As , we see that , and hence
for all . Therefore
-almost surely.
To prove the second part of the theorem, recall that is a gradient by definition. Therefore, by Lemma E.10, the set of gradients relative to can be expressed as
| (59) |
where represents the orthogonal complement of a subspace. If , then
In proving the first part of the theorem, we have shown that under well-specification. Therefore, for any gradient relative to , by (59), we have
for all , which implies that . For a regular and asymptotically linear estimator with influence function , Lemma E.9 implies that is a gradient of at relative to . Therefore , which implies that -almost surely. ∎
Proof of Corollary 3.3.
Suppose the efficient influence function for at relative to is . Since is well-specified, Theorem 3.2 implies that the conditional efficient influence function . Therefore, by Theorem 3.1, the efficient influence function for at relative to as (1) remains . We have proved that the efficient influence relative to the reduced model is in the proof of Theorem 3.1. ∎
Proof of Proposition 3.4.
We first show that (i) and (ii) of Proposition 3.4 implies Assumption 3.1 (b). Since is a bounded Euclidean subset and is -Lipshitz in over , by example 19.6 of Van der Vaart [2000], the class is -Donsker. To see that Assumption 3.1 (c) holds, note that by consistency of , for any open set such that .
∎
Proof of Theorem 3.5.
Denote . First, we will show that
| (60) |
where is defined as in (11), and is defined as in (13). To this end, we write
By Assumption 3.1 and Lemma E.5, we have,
| (61) |
Next,
| (62) | ||||
By Assumption 3.1, when , we have , and it follows that
Since and by Assumption 3.1, and , we have that
Further, by Assumption 3.1, , and hence
| (63) |
Proof of Theorem 3.6.
It suffices to prove the case of , i.e., we only one parameter. For , the analysis follows by separately analyzing each of the components. This does not affect the convergence rate since we treat as fixed (rather than increasing with the sample size ).
When , by Assumption 3.2, , where is the Hölder class (15) with parameter and . By Theorem 2.7.1 of van der Vaart and Wellner [2013], is -Donsker when . Let be a basis of that satisfies (16) for all . Since , clearly we also have as this is only a linear transformation of . If we can show that
then by Lemma E.4 and the fact that ,
Then
and the results of Theorem 3.6 follow.
It remains to show that
Denoting and , we have:
where is defined as (18). We first look at I. By the fact that
| (64) |
we have:
By (64), without loss of generality, we can suppose that has identity covariance, i.e., . For I, when , it follows that
Since by Assumption 3.1, we have
Now, we consider the term . By Theorem 12.16.1 of Hansen [2022],
Therefore,
where we used continuous mapping for the function. Since is square integrable, we then have
which implies that
For II, by the bias-variance decomposition,
where we used the fact that . Therefore,
| (65) | ||||
by (16). This shows
Combining the results of I and II, we have shown that , which finishes the proof. ∎
Proof of Theorem 4.1..
By Lemma E.14, pathwise differentiablity at implies pathwise differentiability at . Since the efficient influence function at relative to is , is a gradient at relative to , and by Lemma E.14, the function
is a gradient at relative to .
First we consider the case of . We first derive the -projection of onto , where the Hilbert space and its norm are defined in Section E.3. The form of is characterized by Lemma E.13. Recall that is the conditional expectation of on . The projection problem can be expressed as
| (66) | ||||
where we used the definition of and the fact that . Since is the efficient influence function at and , we have , which we proved in the proof of Theorem 3.1. Therefore, for the first term in (66), the minimizer takes . Similarly, we have . Then, it can be straightforwardly verified that minimizes the second term in (66). Therefore, the -projection of onto is
We now consider the general case of and validate that is indeed the efficient influence function by definition. Clearly, since is a linear space, for all . Denote . For any element , it can be straightforwardly validated by the definition of that
Consider any one-dimensional regular parametric sub-model of such that and its score function at is . Then, . Write as a function of . By pathwise differentiability and the fact that ,is a gradient at relative to ,
which shows that is a gradient. Since further for all , by definition is the efficient influence function at relative to .
Proof of Theorem 4.3..
Recall that
Then, for the estimator defined in (28),
| (67) | ||||
as . By CLT, we have , and . Further, by the fact that , for any function , it holds that .
First we show that I=.By Assumption 3.1 and Lemma E.5, , and since , , we have:
Since , it follows that
Proof of Theorem 4.4..
As , we have
Similar to the proof of Theorem 3.6, we only prove the case of . The general case proceeds by analyzing each coordinate individually. By Assumption 3.2, . As is a basis of , we have that . Therefore, if we can show that
| (68) |
then by Lemma E.4, . By definition, . Therefore, using the fact that ,
It then follows that is a regular and asymptotically linear estimator with influence function
By Lemma E.1, the asymptotic variance of can be represented as
which would prove Theorem 4.4.
To complete the argument, we next prove (68). Denoting , and , we have:
From (65) in the proof of Theorem 3.6, we already have
Therefore, it remains to prove that . Notice that
| I | |||
Moreover,
Therefore, without loss of generality, we can consider normalizing with and let . Then, we can write
Denoting as the approximation error, and , can be decomposed as:
| (69) | ||||
Therefore, denoting , it follows that
We first consider :
where, by Lemma E.8, we have that
Further, by Theorem 12.16.1 of Hansen [2022],
Therefore it follows that
which implies . Now, for the term III,
where we used Lemma E.8 to show that and are . For the term IV, first note that by the property of projection and (16), we have
Therefore,
where we again used Lemma E.8. Further,
Therefore, by Markov’s inequality and thus so is IV. Next, consider the term V. Recall that , and hence
for any measurable function of . Thus,
Moreover,
Therefore, by Markov’s inequality and so is V. Finally, for VI, by the fact that and continuous mapping, we have:
Then,
Putting these results together, we see that , which then finishes the proof. ∎
Proof of Proposition 5.2.
By Assumption 5.1, the restricted class of functions is -Donsker, and it satisfies by Lemma E.5. Therefore, by Lemma E.7, the centered class satisfies the conditions of Lemma E.5, and it then follows that , and
| (71) |
As a result,
where we used the fact that by centering and by centering and CLT. Following a similar argument, . Further, by (71),
and similarly
Therefore, (70) can be further modified as:
| (72) |
For convenience, let
We now show that . First,
For II, note that by Lemma E.5 we have . Thus,
| (73) | ||||
Next, consider the term . By Lemma E.7, the centered class satisfies the conditions of Lemma E.6. Therefore applying Lemma E.6, the two terms and are both . Then,
Combining these two results, we have:
| (74) | ||||
Finally, since , by continuous mapping,
We showed that III in the proof of Theorem 4.3.
Proof of Proposition 6.1..
First, we show that the tangent space relative to at , denoted as , is
where is the tangent space at relative to and is the tangent space at relative to .
We first show that . Consider any one-dimensional regular parametric sub-model of , which can be represented as
where is a one-dimensional regular parametric sub-model of such that
where corresponds to the density of for some . Denote the score function of at as , where is score function of at , and is the score function of at . The density of is thus
and its score function at is . Because is a one-dimensional regular parametric sub-model of , which has the form (1), it must be true that is a one-dimensional regular parametric sub-model of , and is a one-dimensional regular parametric sub-model of . Therefore, the corresponding score function satisfies that and , and hence . We have by the fact that is a closed linear space.
Now we show the other direction, i.e., . Consider an arbitrary element of where and . Suppose is the score function of some parametric sub-model of at and is the score function of some parametric sub-model of at . Then is the score function at of
where , which proves and hence .
Pathwise differentiability of at relative to implies, for any one-dimensional parametric sub-model such that corresponds to the density of ,
where is the score function of at , and . This maps one-to-one to a parametric sub-model of with score function . We thus have:
This implies that the function
is a gradient of at relative to . As shown in the proof of Theorem 3.1, and for . Therefore, we see that
for all . By definition, is the efficient influence function of at relative to . Note the above derivations correspond to the sample size . Therefore we need to additionally multiply a factor of to obtain the efficient influence function corresponding to the sample size . By independence of and , the semiparametric efficiency lower bound can be expressed as:
where in the last step we use Lemma E.1 to show that . ∎
Appendix C Connection to prediction-powered inference
In this section, we analyze existing PPI estimators through the lens of the proposed framework. We will show that (i) many existing PPI estimators can be analyzed in a unified manner, including our proposed safe PPI estimator (41); (ii) the proposed safe PPI estimator is optimally efficient among the PPI estimators; (iii) none of the PPI estimators achieves the efficiency bound of Theorem 4.1, without strong assumptions on the machine learning prediction model.
We consider the setting of M-estimation as described in Section 7.1 of the main text. (Our results can be extended to Z-estimation.) Let denote a machine learning prediction model trained on independent data. Let denote , and let . Further, denote as the supervised M-estimator (47), and suppose that suitable conditions hold such that is regular and asymptotically linear with influence function in (48). Finally, suppose that the conditions of Proposition 5.2 hold.
First, we present a unified approach to analyze existing PPI estimators, as well as the proposed safe PPI estimator (41). Consider semi-supervised estimators of that are regular and asymptotically linear in the sense of Definitions 4.1 and E.2, with influence function
| (76) |
where . The above class includes a number of existing PPI estimators, such as the proposal of Angelopoulos et al. [2023a, b], Miao et al. [2023], Gan and Liang [2023], and the proposed safe PPI estimator (41), with different estimators corresponding to different choices of . Specifically, the original PPI estimator [Angelopoulos et al., 2023a] considers . Angelopoulos et al. [2023b] improve the original PPI estimator by introducing a tuning weight and considering . They show that the value of that minimizes the trace of the asymptotic variance of their estimator is
Miao et al. [2023] instead lets , which is a diagonal matrix with tuning weights . They set the weights to minimize the element-wise asymptotic variance:
for each , where is the -th element of . Finally, Gan and Liang [2023] considers
for a tuning weight and show that the optimal weight is .
Now, consider the proposed safe PPI estimator (41) with and with , where . Then, (43) can be written as
By Proposition 5.2, (41) is regular and asymptotically linear with influence function
| (77) | ||||
where
Therefore, (43) has influence function in the form of (76) with . In fact, this is the same influence function as Gan and Liang [2023] with the optimal weight .
Next, we show that (77) has the smallest asymptotic variance among all PPI estimators with influence function of the form (76). That is, the proposed safe estimator (41) is at least as efficient as existing PPI estimators. Recall that under the OSS setting, the asymptotic variance of an estimator with influence function is .
Proposition C.1.
For all , the following holds:
Proof.
By the linearity of inner product,
for arbitrary and . Therefore, it suffices to prove that the cross term satisfies
for all , which we now prove.
By definition, we have
| (78) | ||||
Recall that . Therefore, we have
Plugging this into (78), it then follows that
which then finishes the proof. ∎
Proposition C.1 shows that (41) provides optimal efficiency among estimators with influence function of the form (76). We note that, for fair comparison, we consider the case where there is only one machine learning model for all estimators. However, the proposed safe PPI estimator can incorporate multiple machine learning models in a principled way, whereas it is unclear how to do this for most existing PPI estimators. Moreover, our estimator can deal with general inferential problems beyond M-estimation, such as U-statistics.
Our next result shows that estimators with influence function of the form (76) cannot achieve the semiparametric efficiency bound in the OSS setting unless strong assumptions are imposed on the machine learning prediction model . To discuss efficiency in M-estimation (or Z-estimation), we informally consider a nonparametric model in the form of (1) such that the supervised M-estimator (47) is efficient (in the supervised setting). Proposition C.2 provides a necessary condition for estimators with influence function (76) to be efficient in the OSS setting.
Proposition C.2.
Proof.
To better interpret condition (79), we consider a simple case where our target of inference is the expectation of : , and the loss function is . Therefore, it follows that , , , and . We see that, in this case, condition (79) is equivalent to
for some and . In other words, a necessary condition for these estimators to be efficient is that the machine learning prediction model is a linear transformation of the true regression function. Of course, this is unlikely to hold for black-box machine learning predictions in practice.
We end this section by noting that although the safe PPI estimator (41) may not be efficient, the proposed efficient estimator (34) can always achieve the semiparametric efficiency bound under regularity conditions. Further, as we show in numerical experiments in Section 8, the safe PPI estimator has good performance when using a good prediction model.
Appendix D Proof of claims in Section 7
D.1 Proof of claim in Example 7.2
Recall that the GLM estimator
| (80) |
which is regular and asymptotically linear with influence function
under regularity conditions, where .
Proposition D.1.
Suppose that both and are compact subsets. Then, the GLM estimator satisfies the conditions of Proposition 3.4 with estimator
Proof.
We first prove that satisfies the local Lipshitz condition of Proposition 3.4. Denote and . Consider the metric . Assuming that both and are compact, which is a mild assumption, we have:
Since , we can find a sufficiently small neighborhood containing such that . Since is differentiable,
where as is continuous, is compact, and is bounded. Additionally, we have
Similarly, we can always find a sufficiently small neighborhood containing such that
Putting these results together, we obtain
where
Next, we show that a consistent estimator of is . Since is continuous, is a continuous (matrix-valued) function of for every . Then, is a Gilvenko-Cantelli class (which means that it is Gilvenko-Cantelli component-wise) by Example 19.9 of Van der Vaart [2000] and compactness of . Therefore,
Similarly,
where as is continuous and both and are compact. Therefore, it follows that
as is consistent. Putting these results together, we have
and by continuous mapping,
∎
D.2 Proof of claim in Example 7.4
Here, we validate the remaining parts of Assumption 3.1 for Example 7.4 under additional assumptions. Following the notation of Example 7.4, recall that the supervised estimator is Kendall’s :
| (81) |
which is regular and asymptotically linear with influence function
where . For simplicity, denote . By imposing additional assumptions on , the next proposition guarantees that (81) satisfies Assumption 3.1.
Proposition D.2.
Proof.
We first validate part (b) of Assumption 3.1. Clearly, , and we have shown that the influence function of U-statistics of kernel is -Lipshitz in Section 7.2. Therefore, it remains to prove that is -Donsker. Re-write as
which is the pairwise sum of two sets: where and . By Example 2.10.9 of van der Vaart and Wellner [2013], if both and are -Donsker, then their pairwise sum is also -Donsker. For , by triangle inequality of the norm , therefore is a subset of functions with uniform sectional variation norm bounded by . By Example 1.2 of van der Laan [1995], this implies that is -Donsker. For , it is a set indexed by a finite-dimensional parameter where is bounded and is -Lipschitz in . Hence, by Example 19.6 of Van der Vaart [2000], is -Donsker.
We now validate part (c) of Assumption 3.1 with . Since any indicator function on has uniform sectional variation norm bounded by 1, we have
Further, by asymptotic linearity of the U-statistics , we have . Therefore,
by the definition of . Further, since the class of indicator functions is -Gilvenko Cantelli, it follows that
Combined with the consistency of , we have , which completes the proof. ∎
D.3 Proof of claim in Remark 7.1
We prove a general result.
Proposition D.3.
Proof.
By the linearity of inner product,
for arbitrary and . Therefore, it suffices to prove that the cross term satisfies
By the definition of ,
where in the second-to-last equality we used the fact that
by taking the conditional expectation on and noting that . ∎
Appendix E Additional results
E.1 Technical lemmas
Lemma E.1 (Decomposition of conditional variances).
For a random variables and . Let be any functions such that and . Then,
Proof.
By the conditional variance formula,
and
It follows that
∎
Lemma E.2 (Multivariate pythagorean theorem).
For any function , let
denote its linear span in . For any ,
where denote the projection operator that project onto a linear space .
Proof.
See Theorem 3.3 of Tsiatis [2006]. ∎
Lemma E.3.
For a random variable , and let be any functions such that and . Then,
Proof.
Consider any non-random vector such that . By the definition of operator norm,
by Cauchy-Schwartz inequality. ∎
Lemma E.4 (Lemma 19.24 of Van der Vaart [2000].).
Let denote a -Donsker class of measurable functions over , and let denote a sequence of random functions that takes value in and satisfies
for some element . Then,
Lemma E.5.
Let be a class of measurable functions on indexed by , where is a metric space with metric . Let such that . Suppose that there exists a set such that , the class of functions is -Donsker, and for all there exists a square-integrable function such that almost surely. In addition, suppose there exists an estimator of such that and . Then, the following hold:
-
•
,
-
•
,
-
•
,
-
•
; and if additionally , then
Proof.
Since the class is -Donsker, it is also -Gilvenko-Cantelli, hence
By assumption for all , therefore when , we have
Further, by assumption , it then follows that . Therefore, by Lemma E.4, . Then,
Therefore, . Further, if , . ∎
Lemma E.6.
Proof.
When ,
Therefore the statement follows from the fact . ∎
Lemma E.7.
Proof.
Since for all , -Donsker follows immediately. ∎
Lemma E.8.
Let be i.i.d. random vectors with mean zero and variance , where satisfies and . Let be any fixed vector such that . Then
-
•
-
•
Proof.
We have:
Therefore, by Markov’s inequality, for any ,
which we see that let leads to the result. The seond equation can be proved in a similar manner. ∎
E.2 Additional definitions and results in semiparametric efficiency theory
Following the notation in Section 2, we provide additional definitions and results from classical semiparametric efficiency theory. Recall that for a model that contains , the tangent set at relative to is the set of score functions at from all one-dimensional regular parametric sub-models of , and the corresponding tangent space is the closed linear span of the tangent set. A Euclidean functional is pathwise differentiable at relative to if, for an arbitrary smooth one-dimensional parametric sub-model of such that for some , it holds that , where is a gradient of at relative to , and is the score function of at . The next lemma relates the set of gradients to the set of influence functions of regular asymptotically linear estimators.
Lemma E.9.
Let be an asymptotically linear estimator of with influence function , then is pathwise differentiable at relative to with a gradient if and only if is a regular estimator of over .
For a proof, see [Pfanzagl, 1990, Van Der Vaart, 1991]. Lemma E.9 implies the equivalence between the set of gradients and the set of influence functions of regular asymptotically linear estimators. If a gradient satisfies for all , then it is the canonical gradient or efficient influence function of at relative to . The next lemma characterizes the set of gradients for a pathwise differentiable parameter.
Lemma E.10 (Characterization of the set of gradients).
Let be a functional that is pathwise differentiable at relative to . Then the set of gradients of relative to can be represented as , where is any gradient of .
Proof.
See Theorem 3.4 of Tsiatis [2006]. ∎
Recall the model (1):
which models the marginal distribution and the conditional distribution separately. We next characterize the tangent space relative to (1).
Lemma E.11.
Let be defined as in (1). Then, the tangent space can be written as
where is the tangent space at relative to , and is the tangent space at relative to .
Proof.
See Lemma 1.6 of van der Laan and Robins [2003]. ∎
E.3 Semiparametric efficiency theory under the OSS setting
In this section, we extend the classical semiparametric efficiency theory to the OSS setting, building on ideas from Bickel and Kwon [2001]. We first review some notation. Let be a random variable that takes value in the probability space , where is a sigma-algebra on . Let be the corresponding probability space of over . Consider the product probability space
where represents the product sigma-algebra of and , and represents the product measure of and . Note that the probability measure here depends only on as is the corresponding marginal distribution of over . Suppose belong to a model . As usual, we assume that there is some common dominating measure for such that can be equivalently represented by its density functions with respect to . Our goal here is to estimate a Euclidean functional from the data , where and . The full data is thus generated by
Let and . The empirical distribution of is , where is the empirical distribution of and is the empirical distribution of .
We first establish the local asymptotic normality property of .
Lemma E.12.
For any regular parametric sub-model such that for some , let be the marginal distribution of over . Denote Then, for any ,
| (83) | ||||
where is the score function of at , is the score function of at , and . Moreover, and are mutually contiguous.
Here and in the following text, a regular parametric model is interpreted in the sense of quadratic-mean differentiability of the density function at . See Chapter 7 of Van der Vaart [2000] for details.
Proof.
By Theorem 7.2 of Van der Vaart [2000], we have
and
Then, it follows that
The convergence in distribution then follows from CLT and independence, and contiguity follows from Le Cam’s first lemma. ∎
Define as
| (84) |
From Lemma E.12, can be viewed as the score function of the parametric model at with information matrix . It is clear that is measurable and is an element of the space
| (85) |
Consider any vector-valued functions and . Therefore, and . Define
| (86) | ||||
It is straightforward to verify that this is indeed an inner product, and is a Hilbert space. The information matrix can then be represented as
Consider an arbitrary model of . We now extend the notion of a tangent space to the OSS setting. Similar to the i.i.d. setting, the tangent set relative to at is defined as the set of all score functions at of one-dimensional regular parametric sub-models of . The tangent space at relative to , denoted as , is then the closed linear span of the tangent set in . Note that . Next, we characterizes the tangent space at relative to model (1).
Lemma E.13.
The tangent space relative to , denoted as , can be expressed as
Proof.
It is straightforward to see that is a closed linear space since both and are closed linear spaces by the definition of tangent space.
First, we show that . Consider any one-dimensional regular parametric sub-model of such that is the density of for some . Let , and denote the score function of , , and at , respectively. Then we have . Since , and by the definition of (1), it holds that is a one-dimensional regular parametric sub-model of , and is a one-dimensional regular parametric sub-model of . Therefore, and . By Lemma E.12, the score function of at can be written as
By Lemma E.11, . Therefore, . Then, follows from the fact that is a closed linear space.
For the other direction, consider arbitrary elements and . Then, without loss of generality, there must exists a one-dimensional regular parametric sub-model of such that is the density of , and is the score function of at . Similarly, there must exists a one-dimensional regular parametric sub-model of such that is the density of , and is the score function of at . Consider the model , which is a one-dimensional regular parametric sub-model of by its definition, with score function at . By Lemma E.11, . Therefore, by Lemma E.12, we see that the socre at relative to this parametric sub-model is , and hence . ∎
Next, we consider the extention of pathwise differentiability to the OSS setting.
Definition E.1 (Pathwise differentiability).
A Euclidean functional is pathwise differentiable relative to at if, any one-dimensional regular parametric sub-model where such that for some , as a function of satisfies
for some , where is the score function of at . Then, is a gradient of relative to at .
If a gradient satisfies for all , then it is a canonical gradient or the efficient influence function of relative to at . The next lemma establishes the connection between pathwise differentiability under the OSS setting and pathwise differentiability in the usual sense.
Lemma E.14.
If is a pathwise differentiable relative to at , then it is pathwise differentiable relative to at . Moreover, if is a gradient of relative to at , then
is a gradient of relative to at , where
is the conditional gradient.
Proof.
Let be a gradient of relative to at . For simplicity, denote , and . For any one-dimensional regular parametric sub-model of , pathwise differentiability at implies
where and is the score function of at . ∎
We now extend the definitions of regular and asymptotically linear estimators to the OSS setting as in Section 4.1. The definition of regularity remains unchanged as Definition 4.1 in the main text. We present an equivalent definition of asymptotic linearity here for convenience.
Definition E.2 (Asymptotic linearity).
An estimator of is asymptotically linear with influence function if
| (87) |
It is easy to verify, by expanding and using the fact that , that definition E.2 is equivalent to Definition 4.2. Clearly, if is an asymptotically linear estimator of with influence function , its asymptotic variance is .
Similar to Lemma E.9, we first establish the equivalence between the set of gradients and the set of influence functions under the OSS setting.
Lemma E.15.
Proof.
Following the notation of Lemma E.12, consider a one-dimensional regular parametric sub-model . By asymptotic linearity and Lemma E.12, we have
By contiguity and Le Cam’s third lemma, it follows that
under . By regularity of , it follows that
under . This implies that
Pathwise differentiability then follows by the definition of a derivative. ∎
Finally, we extend Lemma 2.1 to the OSS setting.
Lemma E.16.
Hence, the asymptotic variance of any regular and asymptotically linear estimator of is lower bounded by .
Proof.
By Lemma E.15, is a gradient of relative to . For any , without loss of generality, let be any one-dimensional regular parametric sub-model of with score function at . (Otherwise, is the limit of a sequence of score functions of parametric sub-models, and the following holds by the continuity of the inner product.) Write as a function of . By pathwise differentiability,
which shows that . Since this holds for arbitrary , we have in . By definition, for all , where is the vector whose -th coordinate is and the rest are zeros. Therefore, . It follows that
∎
Appendix F Additional numerical results
F.1 Extended results for mean estimation and generalized linear model
Tables 1, 2, and 3 report the coverage of 95% confidence intervals for methods of mean estimation and generalized linear models presented in Sections 8.1 and 8.2. All methods achieve the nominal coverage.
| Setting | Method | |||||
|---|---|---|---|---|---|---|
| 0.967 | 0.944 | 0.946 | 0.938 | 0.954 | ||
| 0.949 | 0.933 | 0.947 | 0.942 | 0.951 | ||
| 0.944 | 0.944 | 0.944 | 0.953 | 0.942 | ||
| 0.960 | 0.957 | 0.948 | 0.949 | 0.945 | ||
| 1 | 0.950 | 0.939 | 0.941 | 0.951 | 0.948 | |
| (Random Forest) | 0.948 | 0.953 | 0.936 | 0.956 | 0.947 | |
| (Noisy Predictor) | 0.946 | 0.952 | 0.950 | 0.951 | 0.948 | |
| PPI++ (Random Forest) | 0.962 | 0.951 | 0.954 | 0.940 | 0.938 | |
| PPI++ (Noisy Predictor) | 0.950 | 0.949 | 0.946 | 0.942 | 0.946 | |
| 0.954 | 0.966 | 0.941 | 0.954 | 0.960 | ||
| 0.948 | 0.949 | 0.964 | 0.942 | 0.948 | ||
| 0.952 | 0.950 | 0.961 | 0.941 | 0.947 | ||
| 0.946 | 0.955 | 0.955 | 0.938 | 0.942 | ||
| 2 | 0.944 | 0.945 | 0.957 | 0.941 | 0.937 | |
| (Random Forest) | 0.956 | 0.968 | 0.953 | 0.945 | 0.944 | |
| (Noisy Predictor) | 0.939 | 0.961 | 0.951 | 0.956 | 0.948 | |
| PPI++ (Random Forest) | 0.953 | 0.950 | 0.971 | 0.948 | 0.940 | |
| PPI++ (Noisy Predictor) | 0.947 | 0.953 | 0.956 | 0.944 | 0.938 | |
| 0.946 | 0.956 | 0.950 | 0.954 | 0.941 | ||
| 0.948 | 0.952 | 0.958 | 0.932 | 0.949 | ||
| 0.948 | 0.958 | 0.963 | 0.943 | 0.950 | ||
| 0.936 | 0.967 | 0.941 | 0.939 | 0.946 | ||
| 3 | 0.951 | 0.954 | 0.961 | 0.942 | 0.944 | |
| (Random Forest) | 0.957 | 0.963 | 0.962 | 0.946 | 0.941 | |
| (Noisy Predictor) | 0.957 | 0.952 | 0.956 | 0.937 | 0.949 | |
| PPI++ (Random Forest) | 0.939 | 0.959 | 0.960 | 0.939 | 0.946 | |
| PPI++ (Noisy Predictor) | 0.940 | 0.948 | 0.948 | 0.960 | 0.934 |
| Setting | Method | |||||
|---|---|---|---|---|---|---|
| 0.933 | 0.950 | 0.944 | 0.950 | 0.938 | ||
| 0.950 | 0.950 | 0.949 | 0.943 | 0.940 | ||
| 0.950 | 0.945 | 0.945 | 0.938 | 0.934 | ||
| 0.949 | 0.940 | 0.944 | 0.935 | 0.935 | ||
| 1 | 0.940 | 0.936 | 0.946 | 0.931 | 0.931 | |
| (Random Forest) | 0.948 | 0.942 | 0.938 | 0.939 | 0.939 | |
| (Noisy Predictor) | 0.942 | 0.941 | 0.949 | 0.934 | 0.939 | |
| PPI++ (Random Forest) | 0.952 | 0.952 | 0.951 | 0.947 | 0.941 | |
| PPI++ (Noisy Predictor) | 0.952 | 0.943 | 0.945 | 0.946 | 0.934 | |
| 0.948 | 0.943 | 0.949 | 0.948 | 0.940 | ||
| 0.944 | 0.951 | 0.944 | 0.953 | 0.945 | ||
| 0.947 | 0.940 | 0.936 | 0.942 | 0.950 | ||
| 0.947 | 0.945 | 0.930 | 0.942 | 0.944 | ||
| 2 | 0.952 | 0.932 | 0.940 | 0.946 | 0.944 | |
| (Random Forest) | 0.952 | 0.943 | 0.955 | 0.947 | 0.956 | |
| (Noisy Predictor) | 0.954 | 0.952 | 0.923 | 0.937 | 0.953 | |
| PPI++ (Random Forest) | 0.941 | 0.949 | 0.943 | 0.955 | 0.945 | |
| PPI++ (Noisy Predictor) | 0.942 | 0.951 | 0.944 | 0.953 | 0.947 |
| Setting | Method | |||||
|---|---|---|---|---|---|---|
| 0.947 | 0.950 | 0.946 | 0.937 | 0.952 | ||
| 0.943 | 0.949 | 0.949 | 0.941 | 0.945 | ||
| 0.936 | 0.942 | 0.945 | 0.943 | 0.950 | ||
| 0.944 | 0.944 | 0.956 | 0.936 | 0.953 | ||
| 1 | 0.938 | 0.937 | 0.950 | 0.937 | 0.939 | |
| (Random Forest) | 0.942 | 0.954 | 0.948 | 0.943 | 0.953 | |
| (Noisy Predictor) | 0.947 | 0.958 | 0.947 | 0.944 | 0.947 | |
| PPI++ (Random Forest) | 0.939 | 0.948 | 0.947 | 0.956 | 0.953 | |
| PPI++ (Noisy Predictor) | 0.940 | 0.946 | 0.950 | 0.946 | 0.940 | |
| 0.960 | 0.942 | 0.949 | 0.939 | 0.950 | ||
| 0.960 | 0.953 | 0.949 | 0.952 | 0.943 | ||
| 0.952 | 0.944 | 0.947 | 0.939 | 0.950 | ||
| 0.955 | 0.945 | 0.942 | 0.946 | 0.943 | ||
| 2 | 0.950 | 0.945 | 0.943 | 0.935 | 0.941 | |
| (Random Forest) | 0.948 | 0.949 | 0.950 | 0.937 | 0.954 | |
| (Noisy Predictor) | 0.958 | 0.959 | 0.943 | 0.944 | 0.955 | |
| PPI++ (Random Forest) | 0.960 | 0.954 | 0.949 | 0.952 | 0.943 | |
| PPI++ (Noisy Predictor) | 0.960 | 0.952 | 0.947 | 0.951 | 0.943 |
In the GLM setting of Section 8.2, Figure 3 displays the standard error of estimators of the second parameter. The results are similar to those described in Section 8.2.
F.2 Variance estimation
We consider Example 7.3. The supervised estimator is the sample variance with influence function . The conditional influence function is
We generate the response as , where . We consider two settings for :
-
1.
Setting 1 (non-linear model): .
-
2.
Setting 2 (well-specified model, in the sense of Definition 3.1): .
For each model, we set , and vary the proportion of unlabeled observations, . The semiparametric efficiency lower bound in the ISS setting (5) and in the OSS setting (25) are estimated separately on a sample of observations.
Table 4 reports the coverage of 95% confidence intervals for each method. All methods achieve the nominal coverage.
| Setting | Method | |||||
|---|---|---|---|---|---|---|
| 0.943 | 0.943 | 0.947 | 0.946 | 0.955 | ||
| 0.950 | 0.949 | 0.957 | 0.949 | 0.952 | ||
| 0.945 | 0.937 | 0.956 | 0.956 | 0.951 | ||
| 1 | 0.946 | 0.943 | 0.953 | 0.949 | 0.941 | |
| 0.945 | 0.941 | 0.944 | 0.959 | 0.948 | ||
| (Random Forest) | 0.948 | 0.948 | 0.951 | 0.951 | 0.943 | |
| (Noisy Predictor) | 0.948 | 0.961 | 0.942 | 0.957 | 0.956 | |
| 0.945 | 0.937 | 0.951 | 0.937 | 0.944 | ||
| 0.945 | 0.954 | 0.949 | 0.954 | 0.955 | ||
| 0.940 | 0.947 | 0.958 | 0.944 | 0.942 | ||
| 2 | 0.945 | 0.964 | 0.940 | 0.948 | 0.938 | |
| 0.943 | 0.939 | 0.945 | 0.946 | 0.942 | ||
| (Random Forest) | 0.949 | 0.957 | 0.948 | 0.948 | 0.946 | |
| (Noisy Predictor) | 0.950 | 0.946 | 0.940 | 0.950 | 0.954 |
Figure 4 displays the standard error of each method, averaged over 1,000 simulated datasets.
The results are similar to those of Section 8. In Setting 1 (non-linear model), achieves the efficiency lower bound in the OSS setting with a sufficient number of basis functions. On the other hand, with improves upon the supervised estimator, but is not efficient as it cannot accurately approximate the non-linear conditional influence function. with random forest predicted responses also performs well, while the version of those methods with a pure-noise prediction model is no worse than the supervised estimator. For Setting 2 (well-specified model), no method improves upon the OSS lower bound, as indicated by Corollary 4.2.
F.3 Kendall’s
We consider Example 7.4. The supervised estimator is
with influence function
The conditional influence function is
where is an independent copy of . We generate the response as and , where . We set , and consider two settings for :
-
1.
Setting 1 (non-linear model): .
-
2.
Setting 2 (well-specified model, in the sense of Definition 3.1): .
For each model, we set , and vary the proportion of unlabeled observations, . Due the complexity of the data-generating model, we did not estimate the ISS and OSS lower bound.
Table 5 reports the coverage of 95% confidence intervals for each method. All methods achieve the nominal coverage.
| Setting | Method | |||||
|---|---|---|---|---|---|---|
| 0.943 | 0.950 | 0.928 | 0.942 | 0.939 | ||
| 0.952 | 0.938 | 0.942 | 0.944 | 0.947 | ||
| 0.955 | 0.948 | 0.947 | 0.944 | 0.942 | ||
| 1 | 0.937 | 0.951 | 0.937 | 0.941 | 0.929 | |
| 0.954 | 0.955 | 0.933 | 0.947 | 0.942 | ||
| (Random Forest) | 0.946 | 0.946 | 0.942 | 0.930 | 0.942 | |
| (Noisy Predictor) | 0.937 | 0.948 | 0.945 | 0.937 | 0.936 | |
| 0.956 | 0.966 | 0.933 | 0.951 | 0.942 | ||
| 0.946 | 0.934 | 0.944 | 0.949 | 0.936 | ||
| 0.948 | 0.954 | 0.944 | 0.940 | 0.941 | ||
| 2 | 0.947 | 0.950 | 0.933 | 0.938 | 0.938 | |
| 0.935 | 0.953 | 0.937 | 0.942 | 0.947 | ||
| (Random Forest) | 0.949 | 0.950 | 0.944 | 0.940 | 0.944 | |
| (Noisy Predictor) | 0.949 | 0.951 | 0.942 | 0.943 | 0.949 |
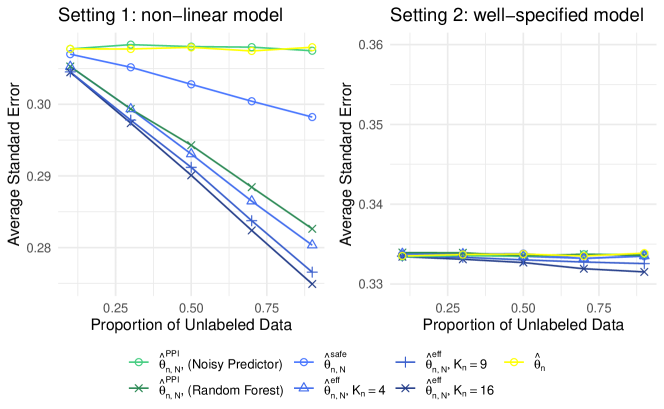
The results are similar to those of Section 8. In Setting 1 (non-linear model), with has the lowest standard error. with improves upon the supervised estimator, but is not as efficient as . with random forest predicted responses also performs well, while its counterpart with pure-noise prediction models has comparable standard error to the supervised estimator. For Setting 2 (well-specified model), no methods improves upon the OSS lower bound as indicated by Corollary 4.2. We note that the apparent slight improvement of standard error in the second panel by is the result of a relatively small sample size.