A Unified Low-level Foundation Model for Enhancing Pathology Image Quality
Abstract
Foundation models have revolutionized computational pathology by achieving remarkable success in high-level diagnostic tasks, yet the critical challenge of low-level image enhancement remains largely unaddressed. Real-world pathology images frequently suffer from degradations such as noise, blur, and low resolution due to slide preparation artifacts, staining variability, and imaging constraints, while the reliance on physical staining introduces significant costs, delays, and inconsistency. Although existing methods target individual problems like denoising or super-resolution, their task-specific designs lack the versatility to handle the diverse low-level vision challenges encountered in practice. To bridge this gap, we propose the first unified Low-level Pathology Foundation Model (LPFM), capable of enhancing image quality in restoration tasks, including super-resolution, deblurring, and denoising, as well as facilitating image translation tasks like virtual staining (H&E and special stains), all through a single adaptable architecture.Our approach introduces a contrastive pre-trained encoder that learns transferable, stain-invariant feature representations from 190 million unlabeled pathology images, enabling robust identification of degradation patterns. A unified conditional diffusion process dynamically adapts to specific tasks via textual prompts, ensuring precise control over output quality. Trained on a curated dataset of 87,810 whole slied images (WSIs) across 34 tissue types and 5 staining protocols, LPFM demonstrates statistically significant improvements (p<0.01) over state-of-the-art methods in most tasks (56/66), achieving Peak Signal-to-Noise Ratio (PSNR) gains of 10-15% for image restoration and Structural Similarity Index Measure (SSIM) improvements of 12–18% for virtual staining. More importantly, LPFM represents a transformative advancement for digital pathology, as it not only overcomes fundamental image quality barriers but also establishes a new paradigm for stain-free, cost-effective, and standardized pathological analysis, which is crucial for enabling scalable and equitable deployment of AI-assisted pathology worldwide.
keywords:
Computational Pathology, Image Restoration, Virtual Staining, Foundation Model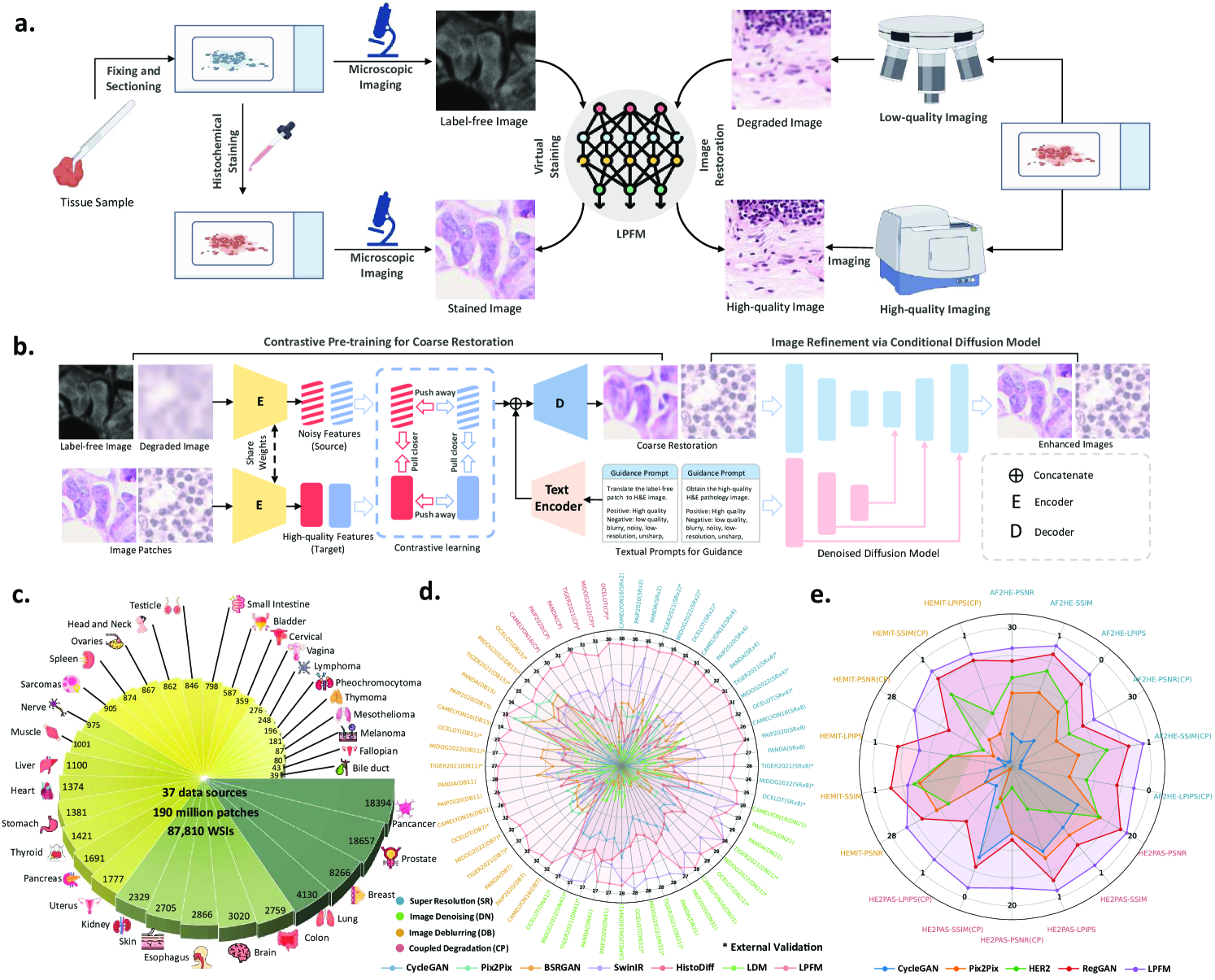
1 Introduction
The advent of digital pathology has revolutionized modern medicine by transitioning traditional glass slides into high-resolution whole slide images (WSIs), enabling computerized analysis [1], enhanced collaborative diagnostics across institutions [2], and AI-assisted decision support [3]. This digital transformation began with slide scanning technologies [4] and has since evolved into an essential component of precision medicine [5, 6], allowing pathologists to examine tissue morphology at unprecedented scales [7] while facilitating large-scale collaborative research [8, 9]. However, diagnostic utility is frequently compromised by multiple degradation problems in the imaging pipeline [10, 11]. During slide preparation, tissue sections may suffer from folding [12], tearing [13], or staining inhomogeneity [14], while scanning introduces optical blur [15], noise [16], and resolution limitations [17].
These degradations collectively obscure critical cellular features including nuclear pleomorphism [18, 19], inflammatory infiltrates [20], and subtle pathological changes [21], potentially leading to diagnostic uncertainty. The limitations of physical rescanning are manifold [22, 9]: time constraints [18], prohibitive costs [23], technical irreversibility of preparation artifacts [4], and frequent biopsy exhaustion [7]. This has spurred computational approaches to enhance image quality through both restoration techniques (e.g., noise reduction [10], deblurring [24], super-resolution [5]) and virtual staining methods [25, 26]. Current solutions remain fragmented [27, 17], typically addressing either restoration or staining separately [28, 29], with denoising models potentially altering stain characteristics [13] and staining networks amplifying artifacts [30]. The field lacks unified generative frameworks capable of handling diverse low-level vision tasks [31, 32], forcing clinics to maintain incompatible specialized systems [2]. Pathology imaging particularly suffers from this fragmentation despite shared underlying challenges [33, 34].
Our work addresses this critical gap by introducing the first unified low-level generative foundation model for enhancing pathology image quality, including pathology image restoration and translation. Unlike existing task-specific models that process artifacts and stains in isolation, our approach recognizes that these challenges are fundamentally interconnected aspects of pathological image formation. This unified treatment enables synergistic improvements; for instance, stain-aware denoising and artifact-resistant stain transfer emerge naturally from the shared representation. We develop a novel pre-training paradigm using large-scale multi-tissue, multi-stain datasets, capturing both universal characteristics of pathological image degradation and stain-invariant morphological features. Furthermore, we pioneer a prompt-controlled framework that dynamically switches between low-level pathological tasks without architectural modifications. By integrating these innovations, we establish the first unified low-level pathology foundation model in computational pathology that moves beyond fragmented solutions to comprehensive image generation.
2 Results
In this section, we conducted comprehensive evaluations across 66 distinct experimental tasks, systematically organized into six fundamental low-level vision categories: (i) super-resolution (18 tasks with varying scale factors and degradation models), (ii) image deblurring (18 tasks covering different kernel sizes), (iii) image denoising (18 tasks with varying noise intensities), (iv) coupled degradation restoration (6 tasks addressing composite artifacts), (v) virtual staining (3 tasks for stain transformation), and (vi) virtual staining for degraded pathology image (3 tasks combining physical degradations with stain conversion). Fig. 1 presents a comprehensive overview of the proposed low-level pathology foundation model (LPFM) for pathology image restoration and virtual staining. As shown in Fig. 1b, LPFM included a contrastive pretraining framework that tackled multiple coupled degradation problems, generating coarsely restored and virtually stained images. The pretraining framework was trained through a contrastive loss by pulling closer the latent features of paired degraded images and their high-quality counterparts, while pushing away the features of unpaired samples.
Building on the coarsely restored images, we proposed a conditional diffusion model that improved image quality through a guided denoising process, utilizing both the coarse restorations and textual prompts as conditional inputs. In Fig. 1d-e, our LPFM demonstrated superior performance across all tasks, establishing itself as the first unified foundation model capable of handling multiple low-level vision challenges in computational pathology. The key advantages of LPFM include exceptional generalization across tissue types and staining protocols, and robust performance on isolated/coupled degradations (present tense for enduring conclusions). To ensure a thorough assessment of image quality, we employed three complementary metrics: PSNR [35] for pixel-level fidelity, SSIM [36] for structural similarity, and LPIPS [37] for perceptual quality. These metrics were consistently used in our experiments (Sec. 4.3) to provide quantitative comparisons. All experiments were conducted on partitioned datasets with 95% confidence intervals and significance testing, ensuring reliable evaluation.
2.1 Super Resolution
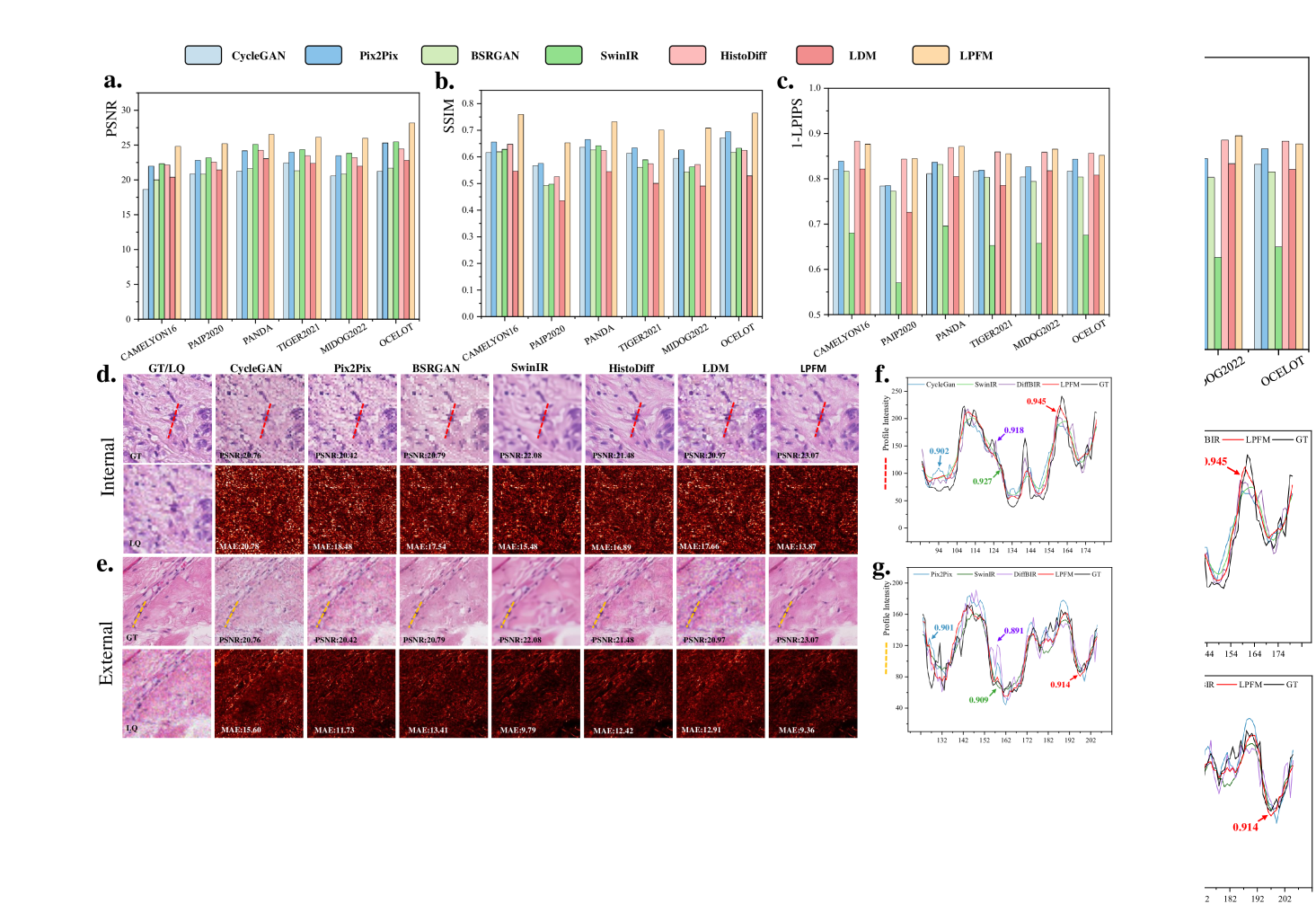
Super resolution refers to computational techniques that reconstruct high-resolution images from low-resolution inputs by recovering lost high-frequency details and fine structures. In digital pathology, this process enhances the visibility of diagnostically critical features that may be obscured due to limitations in scanning resolution or image acquisition conditions. The ability to faithfully reconstruct these microscopic details is particularly important because pathologists routinely examine tissue specimens at multiple magnification levels, where fine cellular and subcellular features directly inform diagnostic decisions. Therefore, it is important to evaluate the super-resolution abilities of different models. In this section, we conducted experiments on a total of 18 tasks, including 9 internal tests and 9 external tests. The detailed experimental results are presented in Extended Data (Tab. 1-6). More generated samples are shown in Extended Data (Fig. 14).
To simulate realistic image degradation for super-resolution evaluation, we generated low-resolution counterparts by downscaling original high-resolution pathology images by factors of 2, 4, and 8 using the comprehensive degradation model detailed in Sec. 4.1.2. For internal validation, we employed three benchmark datasets (CAMELYON16[38], PANDA[39], and PAIP2020[40]), which were rigorously partitioned into training (70%), validation (10%), and test (20%) sets with no data overlap to ensure unbiased evaluation. All model comparisons were performed exclusively on the held-out test sets under standardized conditions. To further validate generalization capability, we incorporated external test datasets (TIGER2021, MIDOG2022 and OCELOT[41]) representing diverse tissue types, staining protocols, and scanner variations, providing robust assessment across different clinical scenarios and imaging conditions.
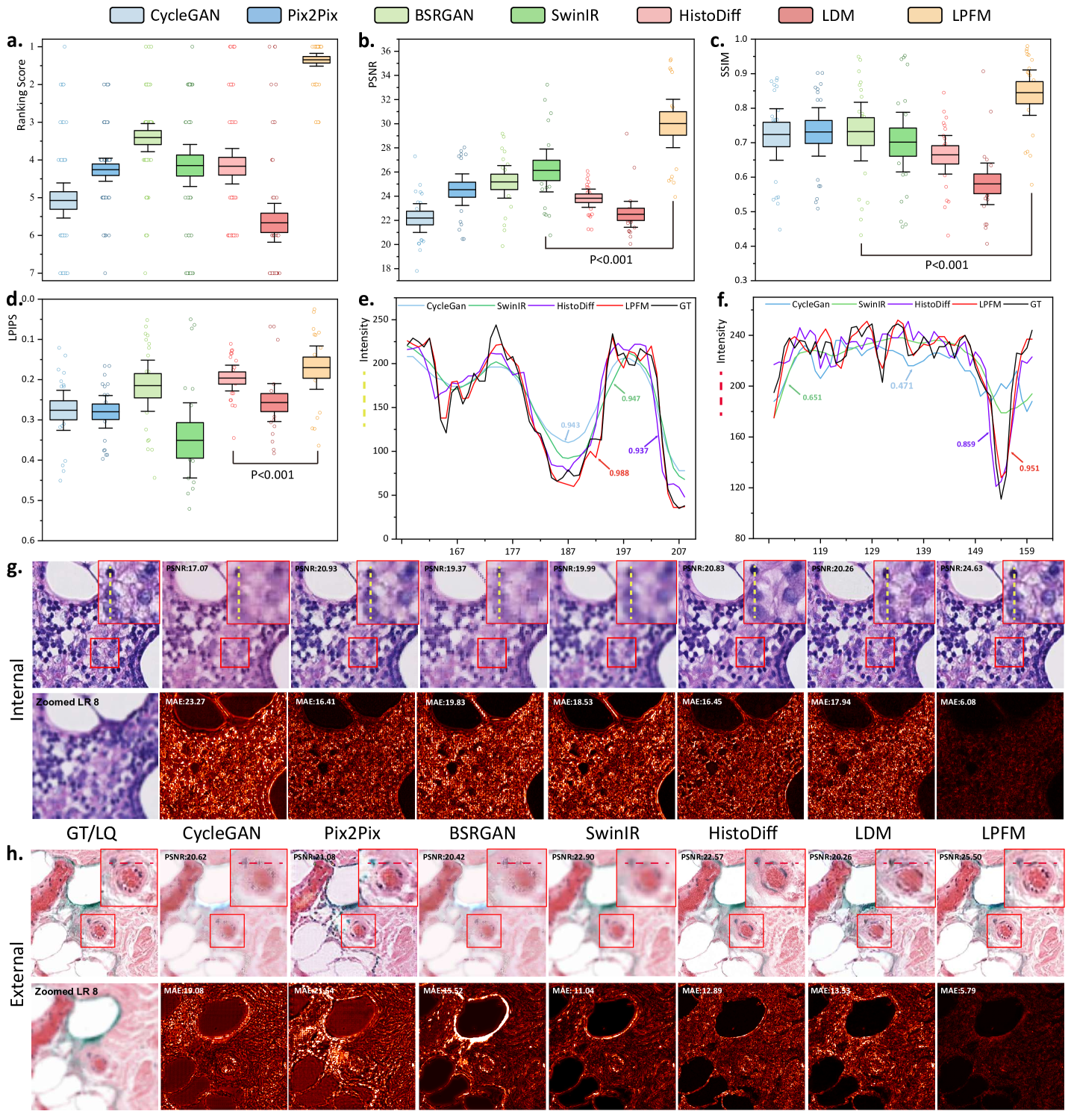
To comprehensively evaluate the performance of different methods across multiple super-resolution tasks, we conducted a thorough ranking analysis where each of the 18 super-resolution tasks was ranked according to all three metrics (Fig. 2a). Our proposed method demonstrated superior and consistent performance across the comprehensive evaluation. In the 18 super-resolution tasks assessed by three metrics, our approach achieved an outstanding average ranking of 1.33 across all evaluation criteria (Fig. 2a). More impressively, in 15 out of these 18 tasks, our method simultaneously secured either first or second place rankings in all three metrics (PSNR, SSIM, and LPIPS). Specifically, the LPFM attained remarkable quantitative results with average values of 30.27 dB (PSNR), 0.85 (SSIM), and 0.1647 (LPIPS) across all tasks, surpassing the second-best methods by significant margins of 4.14 dB and 0.12 in PSNR and SSIM, respectively (Fig. 2b-d).
Furthermore, we showed some generated visual samples of various methods in internal and external datasets (Fig. 2g-h). The mean absolute error (MAE) of the generated images and GT images was computed to evaluate the visual quality of the generated images. LPFM achieved the lowest MAE for the samples in internal and external samples. Additionally, we analyzed the intensity profiles of the generated samples in internal and external datasets produced by the top four best-performance models alongside the GT images (Fig. 2e-f). To better validate the fidelity of reconstructed details, we conducted pixel-wise Pearson Correlation analysis [42] between the generated images and GT images. The results demonstrated that LPFM achieved the highest correlation coefficient. As shown in Fig. 2e-f, the intensity curve of LPFM-generated images exhibited nearly perfect alignment with the GT profile, particularly in preserving critical high-frequency components that correspond to cellular boundaries and nuclear details. The quantitative correlation analysis, combined with our previous metric evaluations, provided comprehensive evidence that LPFM delivered both perceptually convincing and accurate super-resolution results for pathology images.
2.2 Image Deblurring
In computational pathology, effective deblurring enhances critical diagnostic features by restoring sharp boundaries and fine cellular details that may be lost due to optical limitations or focus variations during slide scanning. This capability directly impacts diagnostic accuracy in applications such as tumor margin assessment and mitotic figure detection.
Our evaluation framework comprised 18 deblurring tasks (9 internal and 9 external tests), with complete results available in Extended Data (Tab. 13-18). We simulated clinically relevant blur conditions using Gaussian kernels with varying parameters (kernel sizes: 7-15, : 1.5-3.5) as detailed in Sec. 4.1.2. The same rigorous dataset partitioning (CAMELYON16, PANDA, PAIP2020) and external validation protocol (OCELOT, MIDOG2022, TIGER2021) described in Sec. 2.1 were maintained. More generated samples are shown in Extended Data (Fig. 15).
The statistical analysis showed that LPFM achieved the best average ranking scores across PSNR, SSIM and LPIPS metrics for the 18 deblurring tasks (Fig. 3a). Specifically, LPFM ranked among the top two methods in all three metrics for 16 out of 18 tasks (84.2% of cases), demonstrating remarkable consistency across different evaluation criteria. Notably, LPFM achieved the highest PSNR values in all 18 tasks, with an average score of 27.36 dB that significantly outperformed the second-best method (24.17 dB, +3.19 dB improvement). For structural similarity assessment, LPFM maintained superior performance with SSIM scores consistently leading all comparison methods across various blur conditions (Fig. 3c). The average SSIM of 0.770 substantially exceeded competing approaches, with particularly notable advantages in challenging cases involving large kernel sizes where LPFM achieved up to 0.948 SSIM versus 0.824-0.845 for other methods. Perceptual quality evaluation through LPIPS further confirmed LPFM’s advantages (Fig. 3d), with an average score of 0.220 representing 31.5% reduction in perceptual distance compared to traditional methods (CycleGAN: 0.293) and 17.3% improvement over recent diffusion-based approaches (HistoDiff: 0.266).
Visual comparisons presented in Fig. 3g-h showed LPFM consistently producing sharper cellular boundaries and better-preserved nuclear details compared to other methods. Quantitative analysis revealed LPFM achieved the lowest MAE across internal and external datasets, with internal samples showing 7.02 (versus 19.45 for the second-best method) and external datasets demonstrating 14.48 (versus 15.41 for the second-best method). The evaluation of structural consistency through the pixel-level PCC analysis further confirmed LPFM’s exceptional performance, achieving 0.987 on internal datasets and maintaining strong generalization with 0.953 on external datasets (Fig. 3e-f). These results collectively validated LPFM’s capability to faithfully restore diagnostically critical features while maintaining structural consistency.
2.3 Image Denoising
Noise corruption in pathology images presents a significant challenge for both clinical diagnosis and computational analysis. Multiple factors introduce noise, including electronic sensor limitations during slide scanning, uneven staining artifacts, tissue preparation inconsistencies, and optical imperfections in imaging systems. These noise patterns obscure critical cellular and subcellular features essential for accurate diagnosis, including nuclear membrane integrity, chromatin distribution patterns, and subtle morphological characteristics. Therefore, it is necessary to remove possible noise inside pathology images and restore high-quality images for downstream tasks. To evaluate the noise restoration performance of various methods, we conducted 18 denoising experiments, including 9 internal and 9 external tests. The detailed experimental results are presented in Extended Data (Tab. 7-12). More generated samples are shown in Extended Data (Fig. 16).
To evaluate denoising performance, we generated synthetic datasets by corrupting high-quality pathology images with Gaussian noise at varying intensities ( = 21, 31, 41), following the degradation model in Sec. 4.1.2. We used the same internal datasets (CAMELYON16, PANDA, PAIP2020) with a 7:1:2 train/val/test split and further validated generalization on external datasets (OCELOT, MIDOG2022, TIGER2021).
The ranking analysis of 18 denoising tasks revealed the superior performance of LPFM (Fig. 4a), which achieved an outstanding average ranking score of 1.48, significantly outperforming the second-best method SwinIR (average ranking 2.65) by 1.17. LPFM ranked among the top two methods in all three evaluation metrics (PSNR, SSIM, and LPIPS) for 14 out of the 18 tasks, showcasing its remarkable robustness in balancing different aspects of image quality. The substantial performance gap between LPFM and competing methods was particularly evident in high-noise scenarios (=41) where LPFM maintained superior detail preservation while effectively suppressing noise artifacts.
The comprehensive evaluation across all 18 denoising tasks revealed an interesting performance landscape among the compared methods (Fig. 4b-d). While LPFM did not achieve the highest scores in PSNR (SwinIR led with 27.02 dB average) or LPIPS (HistoDiff led with 0.172 average), it demonstrated exceptional balance across all three metrics (PSNR, SSIM, and LPIPS). Crucially, LPFM’s superior SSIM (average 0.837), which measures structural similarity, indicated that it best maintained critical tissue and cellular details essential for pathological diagnosis, even if its PSNR or LPIPS was marginally lower than the best performing methods. This balance is vital in medical imaging where over-smoothing (high PSNR but loss of detail) or perceptual artifacts (good LPIPS but unnatural textures) can compromise diagnostic accuracy.
Visual and quantitative analysis of denoising performance was provided in Fig. 4g-h. In terms of MAE metric, LPFM showed differentiated performance across internal and external datasets. On internal test sets, LPFM achieved an MAE of 9.56, slightly higher than SwinIR’s 7.76. However, in external validation datasets, LPFM showed superior generalization with the lowest MAE of 8.14, outperforming SwinIR’s 8.52. Structural consistency analysis through the pixel-level PCC (Pearson Correlation Coefficient) showed similar trends. On internal data, LPFM achieved a high PCC of 0.906 (second to SwinIR’s 0.922), while on external data it reached 0.953 - nearly identical to SwinIR’s 0.954. These results indicated that both methods preserved local structures well, with SwinIR having a marginal advantage on familiar data distributions. While SwinIR achieved strong quantitative scores, its outputs frequently exhibited over-smoothing artifacts that erased diagnostically important cellular details and tissue textures. In contrast, LPFM maintained superior perceptual quality, preserving nuclear boundaries and chromatin patterns, even if some pixel-level metrics showed slight disadvantages.
2.4 Virtual Staining
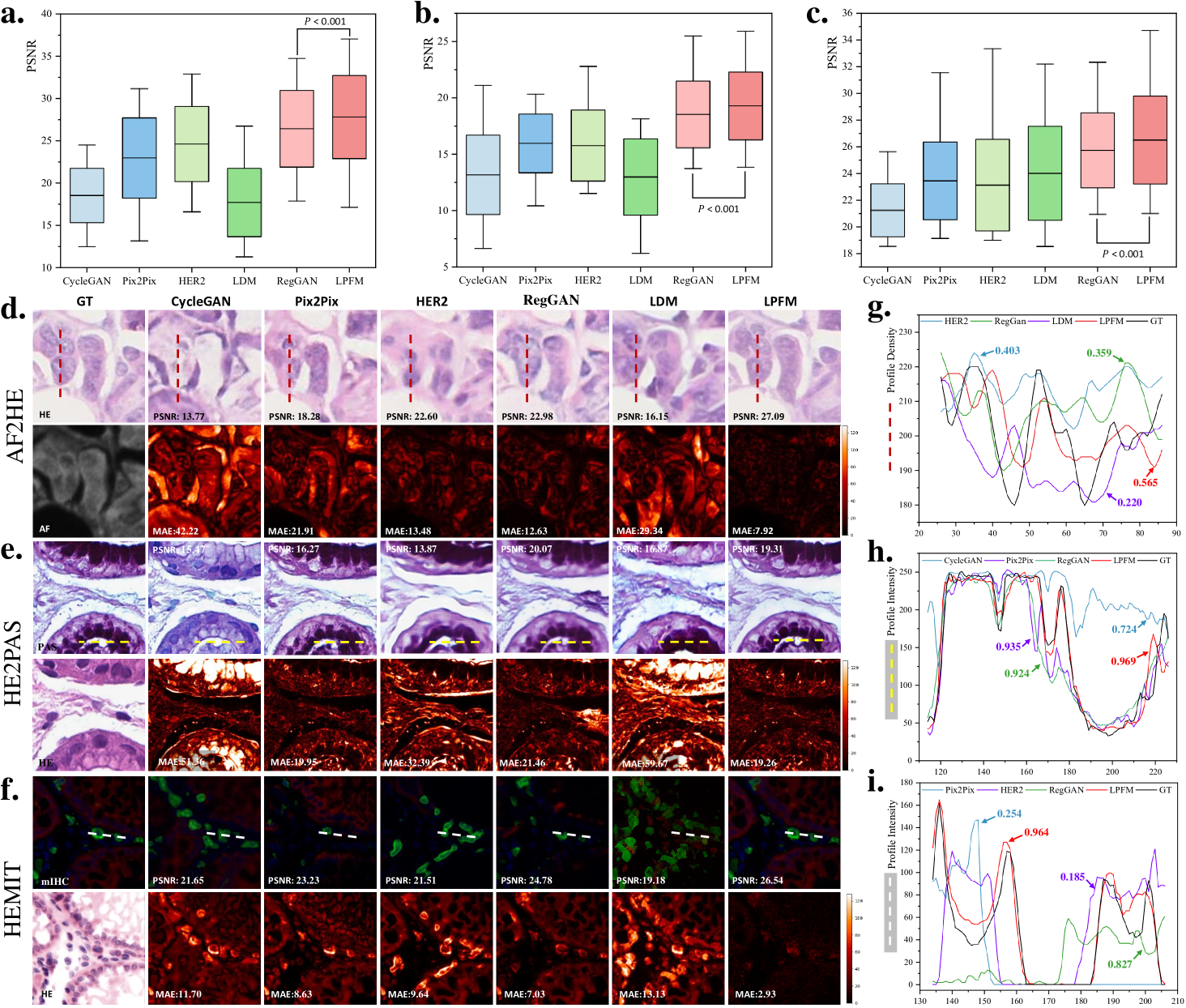
Virtual staining, enabled by AI models, offers a transformative approach in pathology by digitally replicating the appearance of chemically stained tissue samples without the need for physical dyes. This technology significantly accelerates diagnostic workflows, generating high-quality stained images in minutes rather than the hours or days required for traditional chemical staining methods, while also reducing costs associated with reagents and laboratory labor.
For the virtual staining tasks, we employed multiple paired staining datasets, including AF2HE [43], HE2PAS, and HEMIT [44] datasets, to rigorously validate the performance of LPFM and various compared methods. Each dataset served a distinct purpose: AF2HE evaluated the model’s ability to transform autofluorescence (AF) images into H&E stains, crucial for rapid preliminary diagnostics; HE2PAS assessed the conversion between H&E and Periodic Acid-Schiff-Alcian Blue (PAS-AB) stains, important for detecting glycoproteins and mucins in conditions like kidney and liver diseases; and HEMIT tested the model’s capability to predict multiplex immunohistochemistry (mIHC) staining from H&E, enabling advanced biomarker analysis without repeated physical staining. These datasets were selected to cover diverse staining modalities and clinical scenarios, ensuring robust validation across different tissue structures and diagnostic needs. The detailed experimental results are presented in Extended Data (Tab. 19-21). More generated samples are shown in Extended Data (Fig. 18-20).
To comprehensively evaluate our approach, we compared LPFM against several widely used methods for virtual staining tasks, each with distinct architectures and advantages. CycleGAN, an unsupervised generative adversarial network (GAN), excelled in unpaired image-to-image translation through its cyclic consistency loss, making it suitable when strictly paired training data was unavailable. Pix2Pix, a conditional GAN, leveraged paired data for precise pixel-to-pixel translation, offering superior performance in scenarios where exact input-output alignments were critical. HER2 specialized in histopathology image translation by incorporating hierarchical feature extraction, enhancing structural preservation in complex tissue architectures. RegGAN introduced a registration-based loss to improve spatial alignment between input and output images, particularly beneficial for maintaining morphological accuracy in virtual staining tasks. Lastly, Latent Diffusion Models (LDM) employed a denoising diffusion process in latent space, combining the generative power of diffusion models with computational efficiency.
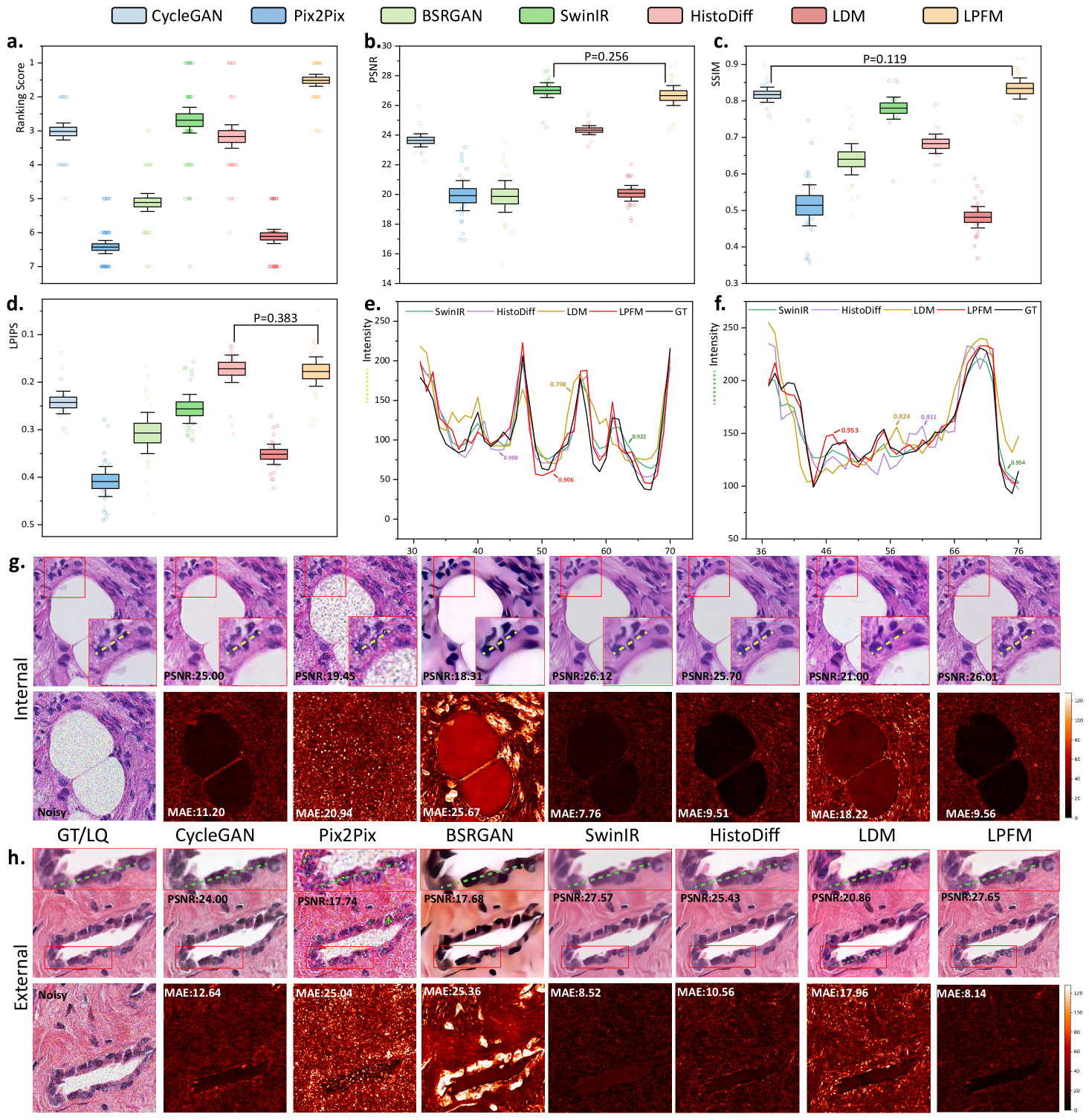
Our proposed LPFM demonstrated superior performance across all three virtual staining datasets (AF2HE, HE2PAS, and HEMIT) when compared to existing methods, as evidenced by both quantitative metrics and qualitative assessments. Quantitatively, LPFM achieved the highest average PSNR values (Fig. 5a-c). Specifically, in the AF2HE task, LPFM achieved a PSNR of 27.81 dB, representing a 5.3% improvement over the second-best method RegGAN (26.42 dB). The superior performance was further confirmed in the HE2PAS and HEMIT tasks where LPFM attained PSNR values of 19.29 dB and 26.51 dB respectively, corresponding to 4.1% and 3.0% improvements over RegGAN.
The architectural innovations in LPFM yielded substantial benefits in both structural preservation and perceptual quality. For structural similarity, LPFM achieved SSIM scores of 0.763, 0.563, and 0.820 across the three tasks, outperforming the second-best methods by 4.5%, 33.8%, and 10.7% respectively. The perceptual quality metrics (LPIPS) showed consistent advantages, with LPFM demonstrating 20.1%, 7.0%, and 20.0% reductions in perceptual error compared to the leading alternatives for each task.
Qualitatively, LPFM-generated virtual stains (Fig. 5d-f) exhibited remarkable fidelity to chemical staining results, with significantly reduced artifacts and better preservation of critical diagnostic features compared to other methods. The MAE heatmaps revealed that LPFM produced the smallest errors in challenging regions such as cell nuclei boundaries (H&E), glomerular basement membranes (PAS-AB), and biomarker expression patterns (mIHC). The intensity profile analyses (Fig. 5g-i) further confirmed this advantage, with LPFM showing the highest Pearson correlation coefficients (PCC) with ground truth stained images, particularly in capturing fine-grained histological features.
2.5 Restoration for Coupled Degradations
Real-world pathology images often suffer from multiple coexisting degradations, including blur, noise, and low resolution. While existing methods perform well on single degradation types, their effectiveness significantly decreases when handling such composite cases. This performance drop primarily occurs because optimizing for one degradation type may interfere with addressing others, and models trained on isolated degradations fail to capture the complex interactions present in actual clinical images.
To rigorously evaluate model robustness under such challenging conditions, we constructed a comprehensive degradation framework by applying multiple sequential distortions to high-quality pathology images from our datasets. These distortions included randomized combinations of Gaussian blur, Poisson noise, and low resolution with parameters carefully sampled to reflect real clinical imaging conditions. The degradation process preserved the biological relevance of the images while introducing realistic artifacts.
We evaluated our method using a rigorous two-tier validation strategy. First, internal testing was conducted on held-out datasets from the training distribution, including CAMELYON16, PAIP2020 and PANDA. Second, external evaluation was performed on completely independent datasets, including MIDOG2022, TIGER2021 and OCELOT, to assess generalization capability. The detailed experimental results are presented in Extended Data (Tab. 22-23). More generated samples are shown in Extended Data (Fig. 17).
As shown in Fig. 6a-c, the quantitative results demonstrated LPFM’s consistent advantages over competing approaches. In terms of PSNR, LPFM achieved a mean score of 26.15 dB, outperforming the second-best method SwinIR (24.05 dB) by a significant margin of 2.10 dB. This improvement was particularly notable in the OCELOT dataset where LPFM reached 28.20 dB, suggesting exceptional generalization capability to diverse tissue types. The SSIM results further confirmed this trend, with LPFM (0.720) substantially exceeding Pix2Pix (0.642) and other methods, indicating better structural preservation. LPFM maintained this performance advantage across all six datasets, demonstrating remarkable robustness to different degradation patterns and tissue characteristics.
LPIPS metrics, which assess perceptual quality, revealed additional insights. While HistoDiff achieved competitive LPIPS scores (0.138), LPFM demonstrated more balanced performance across all quality metrics. This suggested that while some methods might optimize for specific aspects of image quality, LPFM successfully maintained excellence in both pixel-level accuracy (PSNR) and perceptual similarity (LPIPS). The detailed experimental results are presented in Extended Data (Tab. 22-23).
Visual analysis of the results (Fig. 6d-e) corroborated these quantitative findings. Compared to other methods, LPFM better preserved nuclear details and tissue architecture while more effectively suppressing artifacts. This was especially evident in the error maps where LPFM showed minimal deviation from ground truth. The intensity profile (Fig. 6f-g) comparisons further demonstrated LPFM’s accuracy in maintaining original image characteristics, with Pearson correlation coefficients consistently exceeding 0.9 across all test cases.
2.6 Virtual Staining for Degraded Images
Clinical histopathology workflows frequently encounter degraded tissue specimens due to suboptimal staining, sectioning artifacts, or imaging imperfections. As illustrated in Fig. 7a-d, these degradations significantly impact virtual staining quality, motivating our rigorous evaluation of method robustness. Our experiments simulated realistic degradation scenarios by applying compound artifacts to H&E images from both HE2PAS and HEMIT datasets, then processing them through pretrained models without architectural modifications.
Our experimental design simulated this clinical challenge through a two-stage process (Fig. 6a-d). First, we applied coupled degradations (blur: =2.5, noise: =31, and 4 downsampling) to high-quality H&E images from HE2PAS and HEMIT datasets. These degraded inputs then underwent virtual staining to PAS-AB and mIHC respectively, without any intermediate restoration steps. This direct transformation tested the model’s ability to simultaneously address staining conversion and artifact suppression.
The quantitative results in Figure 7e-h demonstrated LPFM’s exceptional stability across degradation conditions. On HE2PAS (Figure 7e), LPFM maintained a narrow PSNR distribution (17.94-18.24 dB) for degraded inputs, outperforming RegGAN’s wider range (12.68-13.09 dB) while preserving superior mean PSNR (18.09 dB vs 12.89 dB). This robustness became more pronounced in Fig. 7f where LPFM showed merely 6.2
The HEMIT dataset results (Figure 7g) revealed an even more striking advantage - LPFM actually achieved higher PSNR on degraded inputs (26.99 dB) than on high-quality ones (26.49 dB), suggesting its unique capability to compensate for certain artifacts. As shown in Figure 7h, this inverse relationship contrasted sharply with other methods’ expected performance degradation, particularly HER2’s 3.1% drop. Visual comparisons in Figure 7c-d confirmed that LPFM successfully suppressed noise while preserving critical histological features in mIHC staining, whereas CycleGAN introduced false positive signals and Pix2Pix lost structural detail.
3 Discussion
The development of the Low-level Pathology Foundation Model (LPFM) represents a significant advancement in computational pathology by unifying diverse image restoration and virtual staining tasks within a single, adaptable framework. Our comprehensive evaluation across 66 distinct tasks demonstrates that this unified approach not only matches but frequently surpasses the performance of specialized models while offering unprecedented flexibility for clinical and research applications. The success of LPFM stems from its integration of several key innovations. The contrastive pre-training strategy enables the model to learn robust, stain-invariant feature representations that generalize across diverse tissue types and degradation patterns. This is complemented by a unified conditional diffusion framework that dynamically adapts to specific tasks through textual prompts, allowing clinicians to guide the enhancement process based on diagnostic priorities. Training on an extensive dataset encompassing 34 tissue types and 5 staining protocols further ensures broad applicability, from routine H&E analysis to specialized staining techniques. Notably, LPFM excels in handling coupled degradations, where it achieves a 2.10 dB PSNR improvement over leading specialized methods. This capability is particularly valuable given that clinical images often exhibit multiple concurrent artifacts that require simultaneous correction.
Textual Prompt Guidance. The prompt-guided architecture introduces a novel level of interactivity to pathology image processing. By allowing users to specify enhancement priorities through natural language instructions, the system adapts to diverse diagnostic needs without requiring architectural modifications. As shown in Fig. 10 and 11, the system dynamically adapts its image restoration or virtual staining targets based on natural language instructions without requiring architectural modifications.This flexibility addresses a major limitation of conventional approaches that enforce rigid processing pipelines, potentially enabling more personalized and context-aware low-level tasks.
Effectiveness of Contrastive Pre-training. As demonstrated in Fig. 12, contrastive learning provides fundamental improvements to the model’s ability to handle both image restoration and virtual staining tasks. The visual comparisons clearly show that the contrastive pre-trained version better preserves fine cellular structures and tissue morphology compared to the non-contrastive baseline. This improvement is particularly evident in the mean average error (MAE) mapswhere the contrastive approach shows significantly reduced errors in diagnostically important regions. The quantitative results across all three evaluation metrics consistently confirm these visual observations, demonstrating that contrastive learning enables more robust feature representations for diverse pathology image processing tasks.
Effectiveness of Pathology Image Refinement. The refinement module plays a crucial role in enhancing output quality, as shown in Fig. 13. The conditional diffusion-based refinement effectively suppresses artifacts while preserving critical diagnostic features in both restoration and virtual staining tasks. Visual examination of the results reveals that the refined outputs maintain better structural consistency with the ground truth, particularly in challenging regions such as tissue boundaries and cellular details. The quantitative metrics consistently support these observations, with the refined versions showing superior performance across all evaluation criteria. The improvement is maintained across different types of image degradation and staining transformations, demonstrating the general applicability of the refinement approach.
Potential Limitation. Despite these advances, certain limitations must be acknowledged. While LPFM generalizes well across multiple scanners and staining protocols, its performance may vary when confronted with radically novel imaging modalities not represented in the training data. Additionally, like all generative models, there remains a small risk of introducing plausible but artifactual features in severely degraded inputs. These observations highlight important directions for future research, including extension to 3D pathology data, development of interactive refinement mechanisms, and creation of explainability tools to clarify enhancement decisions.
Clinical Implications. From a clinical perspective, LPFM’s virtual staining capabilities could transform diagnostic workflows. The model’s ability to generate high-quality PAS-AB and mIHC stains from H&E images with consistent structural preservation offers practical advantages, including reduced reagent costs, faster turnaround times, and conservation of precious biopsy material. These benefits would be especially impactful for rare specimens or when additional stains are needed retrospectively. While our quantitative and qualitative analyses confirm that virtually stained images maintain diagnostically critical features such as nuclear membranes and glycoprotein distributions, further clinical validation studies will be essential to assess diagnostic concordance with conventional staining methods. The broader implications of this work extend beyond immediate clinical applications. By demonstrating that a single model can excel at multiple low-level vision tasks while maintaining diagnostic reliability, LPFM reduces the computational overhead associated with deploying multiple specialized solutions in pathology workflows. This unification could improve the interoperability of computational tools while making advanced image enhancement more accessible to resource-limited settings. Moreover, the prompt-based control mechanism establishes a template for collaborative human-AI interaction in medical image interpretation where clinician expertise guides algorithmic processing to align with diagnostic requirements. Some examples of prompts controlling the generation are shown in Extended Data (Fig. 10-11).
Future works. Two critical directions warrant further investigation. First, extending LPFM to 3D pathology data represents a natural evolution, as volumetric imaging becomes increasingly important for comprehensive tissue analysis. This extension would enable artifact correction and virtual staining across z-stack acquisitions while presenting new computational challenges in processing high-dimensional pathology data. Second, large-scale clinical validation studies are essential to rigorously quantify diagnostic concordance between enhanced and ground-truth images across diverse disease subtypes and staining protocols, particularly focusing on whether model-generated features maintain diagnostic fidelity in critical regions like tumor margins or micrometastases.
In conclusion, LPFM advances the field of computational pathology by providing a versatile, high-performance solution for image quality enhancement that addresses both common and challenging real-world scenarios. The model’s ability to handle diverse tasks through a unified framework—while maintaining or improving upon the performance of specialized alternatives—suggests that foundation models can achieve transformative impact in medical imaging, much as they have in other domains. As the field progresses, the integration of such models into clinical workflows, coupled with ongoing technical refinements and rigorous validation, promises to enhance the accuracy, efficiency, and accessibility of pathological diagnosis.
4 Methods
4.1 Preparation Process
To ensure the robustness and generalizability of our model on image restoration and virtual staining tasks, we collected a comprehensive, multi-source dataset encompassing diverse tissue types and staining protocols. Our dataset includes H&E (Hematoxylin and Eosin), IHC (Immunohistochemistry), mIHC (multiplex immunohistochemistry) images, and PAS (Periodic Acid-Schiff) stained slides from multiple organs (e.g., liver, kidney, breast, and lung) (Extended Data Tab. 27).
4.1.1 Whole Slide Image Tiling and Stitching
Due to the extremely high resolution of WSIs (often exceeding 100,000 100,000 pixels), direct processing is computationally infeasible. Thus, we partition each WSI into smaller, manageable patches of size 256 256 pixels with 32 pixel overlapping, ensuring sufficient spatial context for image restoration and virtual staining while maintaining computational efficiency. After image restoration and virtual staining, the processed patches are reassembled into a complete WSI using grid-based stitching with 32-pixel overlapping boundaries to eliminate seam artifacts. Bilinear interpolation is applied to ensure smooth transitions between adjacent patches.
4.1.2 Degradation Simulation for Restoration Tasks
To generate paired training data for our image restoration tasks, we simulate three clinically relevant degradation types through carefully designed transformations of high-quality WSIs. Each degradation method was developed in consultation with pathologists to ensure biological plausibility. We mainly analyze three typical degradation types in pathology images, including low-resolution, blurry and noisy problems, which commonly occur during whole-slide image acquisition due to various factors such as optical limitations, tissue preparation artifacts, and scanning imperfections. Below we detail the specific implementations for each degradation type.
Low Resolution: In whole-slide imaging systems, resampling operations play a critical role in generating multi-resolution pyramids for pathological analysis. Our model incorporates three clinically validated interpolation methods (area-based, bilinear, and bicubic) that reflect the resampling algorithms used in commercial whole-slide scanners. Area-based interpolation best preserves nuclear morphology and intensity distributions, while bilinear maintains smooth tissue transitions and bicubic captures fine chromatin textures, though it may introduce slight edge enhancements. We intentionally exclude nearest-neighbor interpolation due to its tendency to create jagged nuclear borders and artificial discontinuities in tissue architecture that could mimic pathological features. During training, we randomly select among the three approved methods to ensure robustness across different scanner implementations. This approach was validated through consultation with pathologists, who confirmed it successfully maintains three key diagnostic features: nuclear membrane integrity for tumor grading, stromal texture for invasion assessment, and chromatin patterns for molecular characterization. Importantly, the method realistically simulates the multi-resolution acquisition process inherent to digital pathology workflows.
Image Blur: In computational pathology, blur artifacts commonly arise from optical defocus, tissue sectioning imperfections, and scanner vibrations. We model these effects using anisotropic Gaussian kernels that account for the directional variability observed in pathological imaging. The blur kernel is defined as:
| (1) |
where the covariance matrix controls the blur’s directionality; is the spatial coordinates; is the normalization constant. The covariance matrix could be further represented as follows:
| (2) | ||||
This formulation captures both isotropic defocus blur (when ) and anisotropic artifacts from scanner motion or uneven tissue surfaces (when ). The rotation matrix accounts for directional effects commonly seen in whole-slide scanning. We exclude unrealistically sharp kernels that could distort nuclear morphology and other diagnostically important features.
Image Noise: Noise artifacts primarily originate from two distinct physical processes: electronic sensor noise and quantum photon fluctuations. We model these phenomena using a composite noise formulation that accounts for the unique characteristics of pathological imaging. Additive Gaussian noise captures the electronic readout noise inherent in CCD/CMOS sensors, with its intensity modulated by the standard deviation of the normal distribution . This noise component manifests as color noise (when independently sampled across RGB channels), reflecting different scanner architectures.
Poisson noise models the fundamental quantum limitations of photon detectionwhere the variance scales linearly with signal intensity according to the Poisson distribution . This noise source is particularly relevant in high-magnification imaging of weakly stained regionswhere photon counts are inherently limited. The combination of these noise types effectively reproduces the characteristic graininess observed in low-light conditions while maintaining the structural integrity of diagnostically critical features such as nuclear membranes and chromatin patterns. Therefore, the noisy image can be represents as:
| (3) |
where represents the noise-free image intensity at pixel , denotes additive Gaussian noise. models Poisson-distributed quantum noise:
| (4) |
Our implementation preserves the Poisson noise’s signal-dependent nature while avoiding artificial amplification of staining variations, ensuring biologically plausible noise characteristics throughout the dynamic range of pathological specimens.
4.2 Network Architecture
The objective of this work is to develop a unified low-level pathology foundation model for image restoration and virtual staining. To ensure robust interactivity and enable precise control across multiple tasks, our model employs a prompt-based conditioning mechanism, which dynamically guides the generation process toward the desired output modality (e.g., restoration, virtual staining, or coupled degradation reversal).
Our framework employs a two-stage training approach to achieve high-fidelity pathology image generation through progressive refinement. In the first stage, a contrastive learning-based autoencoder learns to extract consistent low-level features and produce coarse restorations guided by task-specific prompts. Building upon this foundation, the second stage trains a denoising diffusion model that takes both the coarse reconstruction and prompt embedding as inputs to generate detailed, high-quality outputs. The diffusion model progressively refines the image through an iterative denoising process, while maintaining anatomical consistency from the coarse input and adhering to task-specific requirements through prompt conditioning. This hierarchical approach allows our unified model to first capture global structural information and then synthesize precise local details, enabling flexible performance across diverse tasks, including image restoration and virtual staining, without requiring architectural modifications. The diffusion model’s conditioning on both the initial reconstruction and textual prompts ensures that the final output not only preserves the input’s structural integrity but also accurately reflects the desired transformation specified by the prompt, whether it involves stain conversion, artifact removal, or resolution enhancement.
During the inference stage, our unified low-level pathology foundation model takes a user-defined prompt and noisy image as input to generate high-quality image through a controlled reverse diffusion process. The pretrained encoder first processes the textual or embedding-based prompt to extract task-specific conditioning signals, while the diffusion model progressively denoises the initial random noise across multiple timesteps. This iterative refinement enables the synthesis of both structurally accurate and task-aligned results - whether restoring low-quality H&E pathology images (prompt: "Obtain high-quality H&E pathology image") or generating specific stains (prompt: "Synthesize H&E staining") - while maintaining tissue-level consistency.
Contrastive Pretrainig for Coarse Restoration
In the pre-training phase, we aim to pretrain a low-level autoencoder that can extract consistent low-level features and produce coarse restorations guided by task-specific prompts. Following LDM[28] and CLIP[45], we pretrain the KL-Autoencoder as the low-level pathology image autoencoder to generate the coarse restorations and directly use the CLIP[45] text encoder to obtain the textual features for guidance.
Given the WSIs, we firstly pre-process the WSIs into 256256 pathology patches as early mentioned in sec. 4.1.1. As shown in Extended Data Fig. 8a, we adopt a unified training paradigm for low-level pathology tasks by leveraging contrastive learning to capture shared feature representations across different staining protocols and image quality levels. This approach enables the model to learn robust latent embeddings that are invariant to degradation types and staining variations in histopathology images. The contrastive loss operates in the latent space, pulling together features from different views (e.g., degraded/restored or differently stained versions) of the same tissue while pushing apart features from different tissue samples:
| (5) |
where and are positive pairs (different views of same tissue), are negative samples (different tissues), is the feature encoder, and is a temperature parameter.
For high-quality reference images in restoration tasks and target-stain images in virtual staining tasks, the KL-autoencoder is optimized to reconstruct the original input through the objective:
| (6) |
where and represent the encoder and decoder respectively. Simultaneously, when processing degraded inputs for restoration or source-stain images for virtual staining, the model is trained to generate enhanced outputs that approximate the target distribution using a composite loss function:
| (7) |
where represent the paired degraded or source-stained pathology images. The reconstruction loss ensures pixel-level accuracy by minimizing absolute differences between generated and target images. However, pixel-wise losses alone often produce blurry results, so we incorporate a perceptual loss (LPIPS) [37] that operates in the feature space of a pretrained VGG network [46]:
| (8) |
where denotes features from layer of a pretrained VGG network, and are spatial dimensions of the feature maps.
To achieve more realistic quality for pathology images, we employ an adversarial loss that aligns the generated image distribution with original pathology images through a discriminator.
| (9) |
where discriminator is trained to distinguish between real () and generated () images. Therefore, the final pretraining loss can be denoted as:
| (10) |
The textual prompts encoded by the CLIP text encoder are injected into the encoder through cross-attention layers, providing explicit guidance to steer the reconstruction toward the desired output. This integrated approach ensures the autoencoder learns semantically meaningful representations while maintaining flexibility across diverse pathology image processing tasks.
Conditional Diffusion for Image Refinement :
Building upon the pretrained autoencoder’s coarse restorations, we implement a conditional diffusion model to recover fine pathological details through noise-to-image synthesis. As shown in Extended Data Fig. 8b, we aim to remove the additive noises in the pathology images with the coarse image generation and textual prompts.
Our framework builds upon diffusion probabilistic models, which learn a target data distribution through iterative denoising of normally distributed variables. These models formulate the generation process as the reverse of a fixed Markov chain spanning timesteps, effectively implementing a sequence of denoising autoencoders . Following the standard controllable diffusion framework[47], we train a U-Net to iteratively denoise corrupted versions of high-quality pathology images. For a target image progressively noised to at timestep , the model is trained to predict and remove noise from corrupted versions of input images , following the reweighted variational lower bound objective:
| (11) |
with t uniformly sampled from .
In our diffusion model development, we adopt a two-phase training strategy to ensure robust noise modeling and precise conditional control. First, we pretrain a standard denoising diffusion model without any conditional inputs, optimizing the baseline objective from Eq. 11. This initial phase establishes fundamental denoising capabilities for pathology images. After convergence, we freeze these parameters and introduce a trainable controllable module that shares the U-Net[48] encoder with the fixed diffusion model. The complete architecture then processes both the coarse reconstruction and textual prompt embedding through and minimize the joint optimization:
| (12) |
where represents the predicted noised inside the image from the diffusion model. It should be noted that all the denoised process could be directly applied in the latent space of the pretrained autoencoder from the first stage. This latent diffusion approach can reduce computational costs as the dimensionality of the latent space is much lower than that of the original image space.
Inference Stage
In the inference stage, our model synthesizes high-quality pathology images through an iterative denoising process that combines coarse image reconstructions and textual prompts in Fig. 9. The generation begins with pure Gaussian noise and progressively refines it over T timesteps using the trained diffusion model conditioned on both the encoded coarse image and the prompt embedding . At each timestep t, the model predicts the noise component using:
| (13) |
and updates the image estimate through:
| (14) |
where defines the noise schedule and for . This process maintains anatomical fidelity through the z-conditioning while allowing precise control over stain characteristics and artifact correction via the prompt c. The complete inference typically converges in 50-100 steps using the DDIM scheduler, producing outputs that balance clinical utility with prompt-specific transformations. Our experiments demonstrate that this approach successfully generates diagnostically valid images while adhering to diverse transformation goals specified through textual prompts.
4.3 Evaluation Metrics
To quantitatively evaluate the performance of different methods in image restoration and virtual staining tasks, we employ three popular metrics: Peak Signal-to-Noise Ratio (PSNR) [35], Structural Similarity Index Measure (SSIM) [36], and Learned Perceptual Image Patch Similarity (LPIPS) [37]. These metrics assess different aspects of image quality, including pixel-level fidelity, structural similarity, and perceptual consistency.
Peak Signal-to-Noise Ratio (PSNR): PSNR measures the pixel-level similarity between the generated image and the ground truth. It is defined as:
| (15) |
where is the maximum possible pixel value (e.g., 255 for 8-bit images), and (Mean Squared Error) computes the average squared difference between the generated and reference images, is the total number of pixels, is the pixel value from the ground truth image, and is the corresponding pixel value from the generated image. A lower MAE indicates better pixel-wise accuracy. A higher PSNR or a lower MAE indicates better pixel-wise reconstruction accuracy. However, these metrics may not fully align with human perception, as they do not account for structural or semantic differences.
Structural Similarity Index Measure (SSIM): SSIM evaluates the structural similarity between two images considering luminance, contrast, and structure.
| (16) |
where , are the local means, , are the standard deviations, , is the cross-covariance, and , are small constants for stability. SSIM ranges from 0 to 1, with higher values indicating better preservation of structural details. Unlike PSNR, SSIM better correlates with human judgment by capturing perceptual quality.
Learned Perceptual Image Patch Similarity (LPIPS): LPIPS measures perceptual similarity using deep features extracted from a pre-trained neural network (e.g., VGG or AlexNet). The metric computes the weighted distance between deep feature representations of the generated and reference images:
| (17) |
where , denote deep features at layer , and are learned weights. A lower LPIPS score indicates better perceptual alignment with human vision, as it captures high-level semantic similarities rather than low-level pixel differences.
To make it clear, a good generated image should have high PSNR, high SSIM, and low LPIPS. High PSNR suggests strong pixel-wise accuracy but does not guarantee visually pleasing results. High SSIM indicates better structural preservation, such as edges and textures. Low LPIPS reflects superior perceptual quality, meaning the generated image is more realistic to human observers. By combining these metrics, we comprehensively assess the performance of different methods in terms of pixel fidelity, structural consistency, and perceptual quality.
4.4 Compared Methods
To thoroughly evaluate the performance of our proposed LPFM framework, we conduct extensive comparisons with eight state-of-the-art methods that represent the current spectrum of approaches in computational pathology image enhancement. These baseline methods encompass three major architectural paradigms: (1) generative adversarial networks (CycleGAN, Pix2Pix, BSRGAN, RegGAN), (2) transformer-based models (SwinIR), and (3) diffusion models (LDM, HistoDiff), along with (4) specialized hierarchical networks (HER2). This diverse selection enables us to assess LPFM’s advantages across different architectural designs and application scenarios, from general image-to-image translation to pathology-specific enhancement tasks. Each comparator was carefully selected based on its demonstrated effectiveness in either medical image analysis or general computer vision tasks with potential pathology applications.
CycleGAN [49]: This pioneering unpaired image-to-image translation framework employs cycle-consistent adversarial networks to learn bidirectional mappings between domains without requiring aligned training pairs. Its ability to handle unpaired data makes it particularly valuable for virtual staining applications where precisely registered stain pairs are often unavailable. The model consists of two generators (, ) and corresponding discriminators trained with adversarial and cycle-consistency losses.
Pix2Pix [26]: As a seminal conditional GAN architecture, Pix2Pix establishes the foundation for supervised pixel-to-pixel translation tasks. The model combines a U-Net generator with a PatchGAN discriminator, trained using both adversarial and L1 reconstruction losses. When paired training data is available (e.g., registered H&E-to-IHC stain pairs), Pix2Pix serves as a strong baseline for both virtual staining and restoration tasks, though it requires precise image alignment.
BSRGAN [50]: This blind super-resolution network introduces a comprehensive degradation model that simulates real-world imaging artifacts including blur, noise, and compression. The architecture combines a U-shaped network with residual dense blocks and channel attention mechanisms. BSRGAN’s ability to handle unknown and complex degradation patterns makes it particularly suitable for restoring historical pathology slides with varying quality issues.
SwinIR [11]: Representing the transformer-based paradigm, SwinIR leverages shifted window attention mechanisms within a hierarchical architecture for image restoration. The model processes images through shallow feature extraction, deep feature transformation using Swin Transformer blocks, and high-quality reconstruction modules. SwinIR demonstrates particular effectiveness in super-resolution and denoising tasks due to its ability to capture long-range dependencies in tissue structures.
LDM [28]: This latent diffusion model operates in a compressed perceptual space to achieve efficient high-resolution image generation. LDM combines an autoencoder for latent space projection with a diffusion process that gradually denoises images conditioned on task-specific inputs. The model’s memory efficiency enables processing of whole-slide images at high resolutions while maintaining computational tractability.
HistoDiff [51]: Specifically designed for histopathology, this diffusion model incorporates tissue-specific priors through a morphology-aware attention mechanism. The architecture integrates a pre-trained nuclei segmentation network to guide the diffusion process, ensuring preservation of diagnostically critical cellular features during enhancement. HistoDiff demonstrates particular strengths in stain normalization and artifact correction tasks.
HER2 [52]: This hierarchical enhancement network processes pathology images through parallel pathways at multiple magnification levels (5, 10, 20). The architecture employs cross-scale feature fusion and attention-guided skip connections to maintain consistency across scales. HER2 has shown excellent performance in virtual IHC staining tasks by explicitly modeling tissue structures at different resolution levels.
RegGAN [53]: This registration-enhanced GAN introduces spatial alignment constraints during training through a differentiable STN module. The model jointly optimizes for image translation quality and morphological consistency by incorporating landmark-based registration losses. RegGAN demonstrates superior performance in applications requiring precise spatial correspondence, such as sequential staining prediction and multi-modal image harmonization.
4.5 Datasets
Pretraining datasets. In this study, we curate the datasets including 87,810 whole-slide images (WSIs) and 190 million patches from 37 public datasets. Our unified low-level pathology foundation model is pretrained on all the datasets excluding MIDOG2022 [54], TIGER2021 [55], and OCELOT [56] which are reserved for external validation. The pretraining corpus comprises large-scale multi-organ cohorts including TCGA [57] (30,159 slides), GTEx [58] (25,711 slides), and CPTAC [59] (7,255 slides), alongside organ-specific references such as PANDA [39] (prostate, 10,616 slides), CAMELYON16/17 [4, 60] (breast, 1,397 slides combined), and BRACS [60] (breast tumor subtypes, 547 slides). Rare morphologies are represented by AML-Cytomorphology_LMU [61] (blood, 18K patches) and Osteosarcoma_Tumor [62] (bone, 1,144 patches), while stain diversity is ensured through HEMIT [44] (H&E/mIHC pairs), AF2HE [43](translate autofluorescence to H&E stain), and PASAB (translate H&E stain to PAS-AB stain). Artifact robustness derives from PAIP2019/2020 [63, 40] (liver/colon artifacts) and Post-NAT-BRCA [64] (post-treatment breast tissue), with stain translation priors learned from ACROBAT2023 [65] (H&E/IHC breast) and SPIE2019 [66] (multi-stain patches). This curated diversity enables our two-stage framework to first extract universal features from TCGA’s 120M patches and GTEx’s 31M patches, then refine them via targeted datasets like DiagSet [67] (prostate microstructures) and BCNB [68] (breast tumor margins), ultimately supporting prompt-guided adaptation across restoration and virtual staining tasks. More informations about the datasets are presented in Extended Data Tab. 30.
CAMELYON16 Dataset. The CAMELYON16[4] dataset comprises 270 hematoxylin and eosin (H&E) stained whole slide images (WSIs) of lymph node sections with pixel-level annotations for breast cancer metastases, containing a total of 400 annotated tumor regions. The WSIs were scanned at 40 magnification (0.25 um/pixel resolution) using Philips and Hamamatsu scanners, providing diversity in imaging characteristics. The dataset is particularly valuable for studying micro- and macro-metastases detection, with tumor regions ranging from 0.2 mm to over 5 cm in diameter. For our experiments, the WSIs were processed into 1,706,890 non-overlapping 256 256 patches, divided into training (1,194,823 patches), validation (170,689 patches), and test (341,378 patches) sets.
PAIP2020 Dataset. The PAIP2020[40] challenge dataset provides 50 H&E stained WSIs of liver resection specimens from hepatocellular carcinoma patients, including 30 training cases and 20 test cases. Scanned at 20 magnification (0.5 um/pixel) using Leica Aperio AT2 scanners, these images include detailed annotations for 15,742 viable tumor regions, 8,916 necrotic areas, and extensive non-tumor liver parenchyma. After processing, we obtained 892,450 patches (624,715 training, 89,245 validation, and 178,490 test) of size 256256 pixels. The dataset exhibits diverse tumor morphologies including trabecular, pseudoglandular, and compact growth patterns, making it particularly suitable for studying hepatic histopathology.
PANDA Dataset. As the largest publicly available prostate cancer dataset, PANDA[39] contains approximately 11,000 prostate biopsy WSIs (10,616 with Gleason grades) from the Radboud University Medical Center and Karolinska Institute. Scanned using three different scanner models (Hamamatsu, Philips, and Leica) at 20 magnification, the dataset covers the full spectrum of Gleason patterns (3-5) with expert-annotated Gleason scores. For our study, we utilized 8,492 WSIs (5,944 training, 1,699 validation, and 849 test), which were processed into 4.2 million 256256 patches (2.94M training, 840K validation, 420K test). The inclusion of multiple scanning systems makes this dataset valuable for studying scanner-invariant feature learning.
MIDOG2022 Dataset. The MIDOG2022[54] challenge dataset consists of 200 breast cancer WSIs (160 training, 40 test) from four different scanners (Hamamatsu, Roche, Leica, and Philips) with 5,712 annotated mitotic figures. The images were acquired at 40 magnification with 0.25 um/pixel resolution. After processing, we obtained 423,580 patches (296,506 training, 42,358 validation, 84,716 test) of size 256256 pixels. This dataset is uniquely designed to address domain shift challenges in digital pathology, containing carefully matched cases across scanners while maintaining consistent staining protocols.
TIGER2021 Dataset. The TIGER2021[55] dataset includes 500 WSIs (400 training, 100 test) of H&E stained prostatectomy specimens, containing 2.3 million annotated tumor cells and 1.8 million annotated non-tumor cells. The images were scanned at 40 magnification (0.25 um/pixel) using Philips Ultra Fast Scanners. For our experiments, we processed these into 1,125,400 patches (787,780 training, 112,540 validation, 225,080 test) of size 256256 pixels. The dataset provides comprehensive annotations for Gleason patterns 3-5 across multiple tissue cores.
OCELOT Dataset. The OCELOT[56] dataset contains 394 WSIs (315 training, 79 test) of H&E stained tissue sections from multiple cancer types (208 lung, 106 pancreas, 80 cervix) with focus on tumor microenvironment analysis. The images were acquired at 20 magnification (0.5 um/pixel) using Hamamatsu NanoZoomer scanners, yielding 936,250 processed patches (655,375 training, 93,625 validation, 187,250 test) of size 256256 pixels. Unique features include detailed annotations for 42,368 tumor regions, 38,915 stroma regions, and 15,742 lymphocyte clusters, as well as corresponding immunohistochemistry (IHC) slides for 126 selected cases.
AF2HE Dataset. The AF2HE [43] dataset comprises 15 samples of breast and liver cancer tissues. The samples were first imaged as whole slide images (WSI) using the autofluorescence (AF) technique without any chemical staining. The same slide was then stained with H&E to capture stained images. The WSIs were roughly aligned, and cropped into 128 128 patches and divided into a training set of 50,447 pairs and a test set of 4,422 pairs.
HE2PAS Dataset. This dataset was collected from the Prince of Wales Hospital in Hong Kong and comprises of 10,727 H&E and PAS-AB pairs for training and 1,191 pairs for testing. The image size is 128 128. Additionally, we collected another 2841 patches sampled from high-risk slides as the external validation.
HEMIT Dataset. The dataset utilized in this study was curated by Bian et al [44], and comprises cellular-wise registered pairs of H&E and multiplex immunohistochemistry (mIHC) images, sourced from the ImmunoAlzer project. We employed the official train-validation-test split (3717:630:945) across all methods. To mitigate computational complexity, we resize the image to scale of 512 512 from the original images. The three channels of the mIHC images correspond to 4’,6-diamidino-2-phenylindole (DAPI, red channel), Pan Cytokeratin (panCK, green channel), and cluster of differentiation 3 (CD3, blue), respectively
4.6 Code Availability
The code will be available on Github(https://github.com/ziniBRC/LPFM).
4.7 Ethics Declarations
This project has been reviewed and approved by the Human and Artefacts Research Ethics Committee (HAREC) of Hong Kong University of Science and Technology. The protocol number is HREP-2024-0429.
4.8 Author Contribution
Z.L. and H.C. conceived and designed the work. Z.L., Z.X., J.M. and W.L. curated the data included in the paper. Z.X. and Z.L. contributed to the technical implementation of the LPFM framework and performed the experimental evaluations. Z.L, J.H., F.H., and X.W. wrote the manuscript with inputs from all authors. R.C.K.C. supplied data and offered medical guidance. T.T.W.W. provided autofluorescence data. All authors reviewed and approved the final paper. H.C. supervised the research.
4.9 Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 62202403), Innovation and Technology Commission (Project No. MHP/002/22 and ITCPD/17-9), Research Grants Council of the Hong Kong Special Administrative Region, China (Project No: T45-401/22-N) and National Key R&D Program of China (Project No. 2023YFE0204000).
References
- [1] Ma, J., Chan, R., Wang, J., Fei, P. & Chen, H. A generalizable pathology foundation model using a unified knowledge distillation pretraining framework. \JournalTitleNature Biomedical Engineering (2025).
- [2] Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. \JournalTitleNature Medicine 30, 850–862 (2024).
- [3] Song, A. H. et al. Artificial intelligence for digital and computational pathology. \JournalTitleNature Reviews Bioengineering 1, 930–949 (2023).
- [4] Bejnordi, B. E. et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. \JournalTitleJama 318, 2199–2210 (2017).
- [5] Ma, J., Chan, R. & Chen, H. Pathbench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology. \JournalTitlearXiv:2505.20202 (2025).
- [6] Lai, B., Fu, J. et al. Artificial intelligence in cancer pathology: Challenge to meet increasing demands of precision medicine. \JournalTitleInternational Journal of Oncology 63, 1–30 (2023).
- [7] Xu, Y. et al. A multimodal knowledge-enhanced whole-slide pathology foundation model. \JournalTitlearXiv preprint arXiv:2407.15362 (2024).
- [8] Srinidhi, C. L., Ciga, O. & Martel, A. L. Deep neural network models for computational histopathology: A survey. \JournalTitleMedical image analysis 67, 101813 (2021).
- [9] Yan, F., Chen, H., Zhang, S., Wang, Z. et al. Pathorchestra: A comprehensive foundation model for computational pathology with over 100 diverse clinical-grade tasks. \JournalTitlearXiv:2503.24345 (2025).
- [10] Zhuang, J. et al. Mim: Mask in mask self-supervised pre-training for 3d medical image analysis. \JournalTitleIEEE Transactions on Medical Imaging (2025).
- [11] Liang, J. et al. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF international conference on computer vision, 1833–1844 (2021).
- [12] Jin, C., Chen, H. et al. Hmil: Hierarchical multi-instance learning for fine-grained whole slide image classification. \JournalTitleIEEE Transactions on Medical Imaging 44, 1796–1808 (2025).
- [13] Echle, A. et al. Deep learning in cancer pathology: a new generation of clinical biomarkers. \JournalTitleBritish journal of cancer 124, 686–696 (2021).
- [14] Wang, H. et al. Rethinking multiple instance learning for whole slide image classification: A bag-level classifier is a good instance-level teacher. \JournalTitleIEEE Transactions on Medical Imaging 43, 3964–3976 (2024).
- [15] Xiong, C., Chen, H., King, I. et al. Takt: Target-aware knowledge transfer for whole slide image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention (2024).
- [16] Zhang, K., Zuo, W., Chen, Y., Meng, D. & Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. \JournalTitleIEEE transactions on image processing 26, 3142–3155 (2017).
- [17] Chen, L. et al. Next token prediction towards multimodal intelligence: A comprehensive survey. \JournalTitlearXiv preprint arXiv:2412.18619 (2024).
- [18] Bulten, W. et al. Automated deep-learning system for gleason grading of prostate cancer using biopsies: a diagnostic study. \JournalTitleThe Lancet Oncology 21, 233–241 (2020).
- [19] Tolkach, Y., Dohmgörgen, T., Toma, M. & Kristiansen, G. High-accuracy prostate cancer pathology using deep learning. \JournalTitleNature Machine Intelligence 2, 411–418 (2020).
- [20] Siemion, K. et al. What do we know about inflammatory myofibroblastic tumors?–a systematic review. \JournalTitleAdvances in Medical Sciences 67, 129–138 (2022).
- [21] Coudray, N. et al. Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning. \JournalTitleNature medicine 24, 1559–1567 (2018).
- [22] Wang, J., Yue, Z., Zhou, S., Chan, K. C. & Loy, C. C. Exploiting diffusion prior for real-world image super-resolution. \JournalTitleInternational Journal of Computer Vision 132, 5929–5949 (2024).
- [23] Krithiga, R. & Geetha, P. Breast cancer detection, segmentation and classification on histopathology images analysis: a systematic review. \JournalTitleArchives of Computational Methods in Engineering 28, 2607–2619 (2021).
- [24] Xia, B. et al. Diffir: Efficient diffusion model for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 13095–13105 (2023).
- [25] Guo, Z., Chen, H. et al. Focus: Knowledge-enhanced adaptive visual compression for few-shot whole slide image classification. In Proceedings of the Computer Vision and Pattern Recognition Conference (2025).
- [26] Isola, P., Zhu, J.-Y., Zhou, T. & Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1125–1134 (2017).
- [27] Xie, S. et al. Towards unifying understanding and generation in the era of vision foundation models: A survey from the autoregression perspective. \JournalTitlearXiv preprint arXiv:2410.22217 (2024).
- [28] Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10684–10695 (2022).
- [29] Qu, L. et al. Tokenflow: Unified image tokenizer for multimodal understanding and generation. \JournalTitlearXiv preprint arXiv:2412.03069 (2024).
- [30] Liang, M. et al. Multi-scale self-attention generative adversarial network for pathology image restoration. \JournalTitleThe Visual Computer 39, 4305–4321 (2023).
- [31] Xiong, J. et al. Autoregressive models in vision: A survey. \JournalTitlearXiv preprint arXiv:2411.05902 (2024).
- [32] Li, T., Tian, Y., Li, H., Deng, M. & He, K. Autoregressive image generation without vector quantization. \JournalTitleAdvances in Neural Information Processing Systems 37, 56424–56445 (2025).
- [33] Han, J. et al. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. \JournalTitlearXiv preprint arXiv:2412.04431 (2024).
- [34] Fan, L. et al. Fluid: Scaling autoregressive text-to-image generative models with continuous tokens. \JournalTitlearXiv preprint arXiv:2410.13863 (2024).
- [35] Huynh-Thu, Q. & Ghanbari, M. Scope of validity of psnr in image/video quality assessment. \JournalTitleElectronics letters 44, 800–801 (2008).
- [36] Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. \JournalTitleIEEE transactions on image processing 13, 600–612 (2004).
- [37] Johnson, J., Alahi, A. & Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, 694–711 (Springer, 2016).
- [38] Litjens, G. et al. 1399 h&e-stained sentinel lymph node sections of breast cancer patients: the camelyon dataset. \JournalTitleGigaScience 7, giy065 (2018).
- [39] Bulten, W. et al. Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge. \JournalTitleNature medicine 28, 154–163 (2022).
- [40] Kim, K. et al. Paip 2020: Microsatellite instability prediction in colorectal cancer. \JournalTitleMedical Image Analysis 89, 102886 (2023).
- [41] Ryu, J. et al. Ocelot: Overlapped cell on tissue dataset for histopathology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 23902–23912 (2023).
- [42] Benesty, J., Chen, J., Huang, Y. & Cohen, I. Pearson correlation coefficient. In Noise reduction in speech processing, 1–4 (Springer, 2009).
- [43] Dai, W., Wong, I. H. & Wong, T. T. A weakly supervised deep generative model for complex image restoration and style transformation. \JournalTitleAuthorea Preprints (2022).
- [44] Bian, C. et al. Immunoaizer: A deep learning-based computational framework to characterize cell distribution and gene mutation in tumor microenvironment. \JournalTitleCancers 13, 1659 (2021).
- [45] Radford, A. et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763 (PmLR, 2021).
- [46] Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. \JournalTitlearXiv preprint arXiv:1409.1556 (2014).
- [47] Zhang, L., Rao, A. & Agrawala, M. Adding conditional control to text-to-image diffusion models.
- [48] Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, 234–241 (Springer, 2015).
- [49] Zhu, J.-Y., Park, T., Isola, P. & Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Computer Vision (ICCV), 2017 IEEE International Conference on (2017).
- [50] Zhang, K., Liang, J., Van Gool, L. & Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In IEEE International Conference on Computer Vision, 4791–4800 (2021).
- [51] Xu, X., Kapse, S. & Prasanna, P. Histo-diffusion: A diffusion super-resolution method for digital pathology with comprehensive quality assessment. \JournalTitlearXiv preprint arXiv:2408.15218 (2024).
- [52] DoanNgan, B., Angus, D., Sung, L. et al. Label-free virtual her2 immunohistochemical staining of breast tissue using deep learning. \JournalTitleBME frontiers (2022).
- [53] Rong, R. et al. Enhanced pathology image quality with restore–generative adversarial network. \JournalTitleThe American Journal of Pathology 193, 404–416 (2023).
- [54] Aubreville, M. et al. Domain generalization across tumor types, laboratories, and species—insights from the 2022 edition of the mitosis domain generalization challenge. \JournalTitleMedical Image Analysis 94, 103155 (2024).
- [55] Shephard, A. et al. Tiager: Tumor-infiltrating lymphocyte scoring in breast cancer for the tiger challenge. \JournalTitlearXiv preprint arXiv:2206.11943 (2022).
- [56] Ryu, J. et al. Ocelot: Overlapped cell on tissue dataset for histopathology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 23902–23912 (2023).
- [57] Weinstein, J. N. et al. The cancer genome atlas pan-cancer analysis project. \JournalTitleNature genetics 45, 1113–1120 (2013).
- [58] Carithers, L. J. et al. A novel approach to high-quality postmortem tissue procurement: the gtex project. \JournalTitleBiopreservation and biobanking 13, 311–319 (2015).
- [59] Edwards, N. J. et al. The cptac data portal: a resource for cancer proteomics research. \JournalTitleJournal of proteome research 14, 2707–2713 (2015).
- [60] Bandi, P. et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. \JournalTitleIEEE transactions on medical imaging 38, 550–560 (2018).
- [61] Matek, S. S. M. C., C. & Spiekermann, K. A single-cell morphological dataset of leukocytes from aml patients and non-malignant controls. \JournalTitleThe Cancer Imaging Archive (2019).
- [62] Leavey, P. et al. Osteosarcoma data from ut southwestern/ut dallas for viable and necrotic tumor assessment [data set]. \JournalTitleCancer Imaging Arch 14 (2019).
- [63] Kim, Y. J. et al. Paip 2019: Liver cancer segmentation challenge. \JournalTitleMedical image analysis 67, 101854 (2021).
- [64] Tafavvoghi, M., Bongo, L. A., Shvetsov, N., Busund, L.-T. R. & Møllersen, K. Publicly available datasets of breast histopathology h&e whole-slide images: a scoping review. \JournalTitleJournal of Pathology Informatics 15, 100363 (2024).
- [65] Weitz, P. et al. A multi-stain breast cancer histological whole-slide-image data set from routine diagnostics. \JournalTitleScientific Data 10, 562 (2023).
- [66] Petrick, N. et al. Spie-aapm-nci breastpathq challenge: an image analysis challenge for quantitative tumor cellularity assessment in breast cancer histology images following neoadjuvant treatment. \JournalTitleJournal of Medical Imaging 8, 034501–034501 (2021).
- [67] Koziarski, M. et al. Diagset: a dataset for prostate cancer histopathological image classification. \JournalTitleScientific Reports 14, 6780 (2024).
- [68] Xu, F. et al. Predicting axillary lymph node metastasis in early breast cancer using deep learning on primary tumor biopsy slides. \JournalTitleFrontiers in oncology 11, 759007 (2021).
- [69] Wilkinson, S. et al. Nascent prostate cancer heterogeneity drives evolution and resistance to intense hormonal therapy. \JournalTitleEuropean urology 80, 746–757 (2021).
- [70] Huo, X. et al. A comprehensive ai model development framework for consistent gleason grading. \JournalTitleCommunications Medicine 4, 84 (2024).
- [71] Wang, C.-W. et al. Weakly supervised deep learning for prediction of treatment effectiveness on ovarian cancer from histopathology images. \JournalTitleComputerized Medical Imaging and Graphics 99, 102093 (2022).
- [72] Wang, C.-W. et al. Histopathological whole slide image dataset for classification of treatment effectiveness to ovarian cancer. \JournalTitleScientific Data 9, 25 (2022).
- [73] Vrabac, D. et al. Dlbcl-morph: Morphological features computed using deep learning for an annotated digital dlbcl image set. \JournalTitleScientific Data 8, 135 (2021).
- [74] Pataki, B. Á. et al. Huncrc: annotated pathological slides to enhance deep learning applications in colorectal cancer screening. \JournalTitleScientific Data 9, 370 (2022).
- [75] Kemaloğlu, N., Aydoğan, T. & Küçüksille, E. U. Deep learning approaches in metastatic breast cancer detection. \JournalTitleArtificial Intelligence for Data-Driven Medical Diagnosis 3, 55 (3).
- [76] Aresta, G. et al. Bach: Grand challenge on breast cancer histology images. \JournalTitleMedical image analysis 56, 122–139 (2019).
- [77] Gamper, J. & Rajpoot, N. Multiple instance captioning: Learning representations from histopathology textbooks and articles. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16549–16559 (2021).
- [78] Liu, S. et al. Bci: Breast cancer immunohistochemical image generation through pyramid pix2pix. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1815–1824 (2022).
- [79] Xu, G. et al. Camel: A weakly supervised learning framework for histopathology image segmentation. In Proceedings of the IEEE/CVF International Conference on computer vision, 10682–10691 (2019).
- [80] Janowczyk, A. & Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. \JournalTitleJournal of pathology informatics 7, 29 (2016).
- [81] Borkowski, A. A. et al. Lung and colon cancer histopathological image dataset (lc25000). \JournalTitlearXiv preprint arXiv:1912.12142 (2019).
- [82] Silva-Rodríguez, J., Colomer, A., Sales, M. A., Molina, R. & Naranjo, V. Going deeper through the gleason scoring scale: An automatic end-to-end system for histology prostate grading and cribriform pattern detection. \JournalTitleComputer methods and programs in biomedicine 195, 105637 (2020).
Extended Data
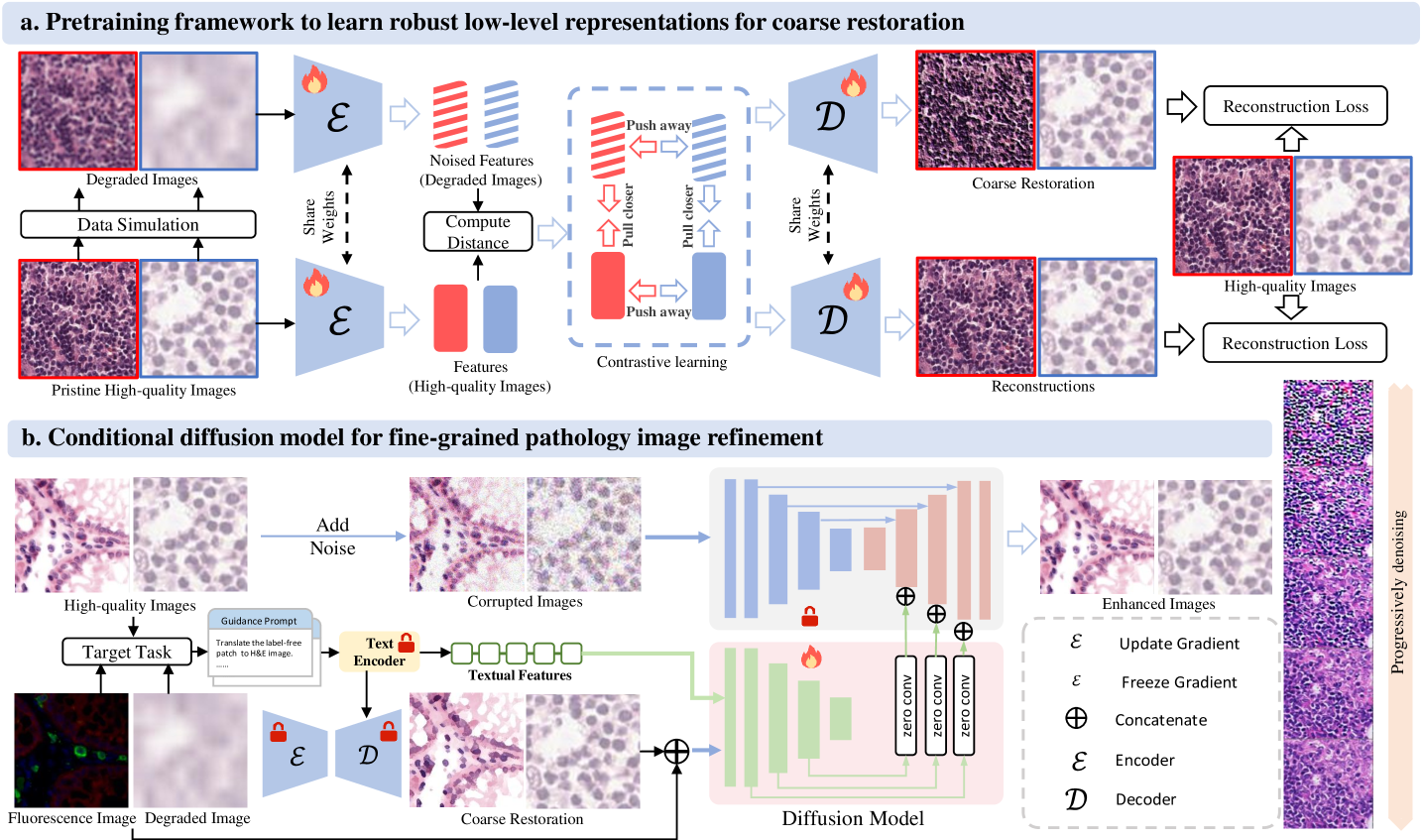
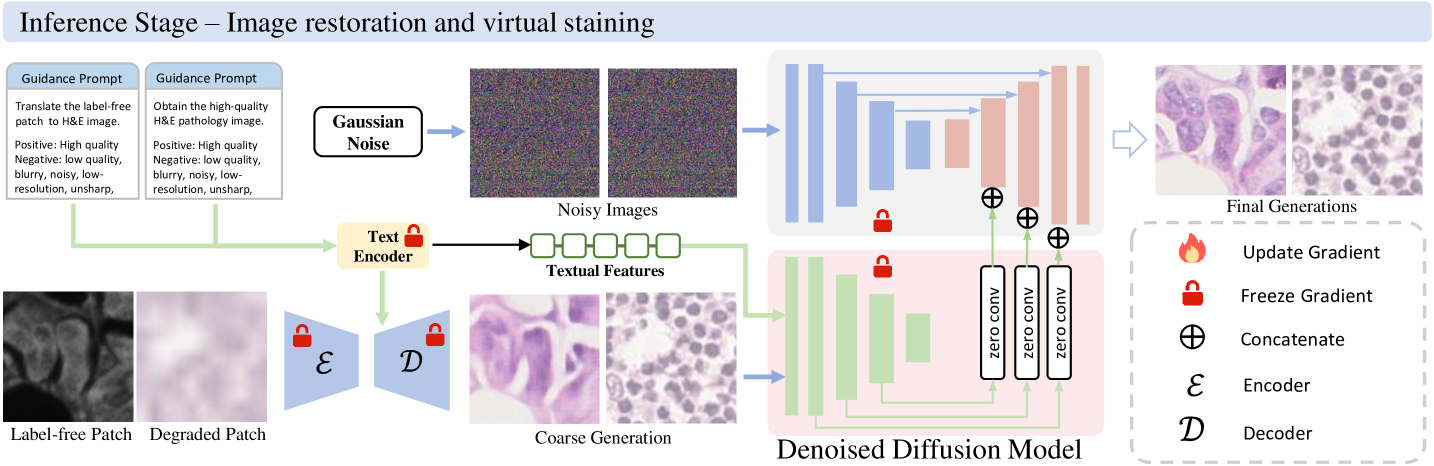
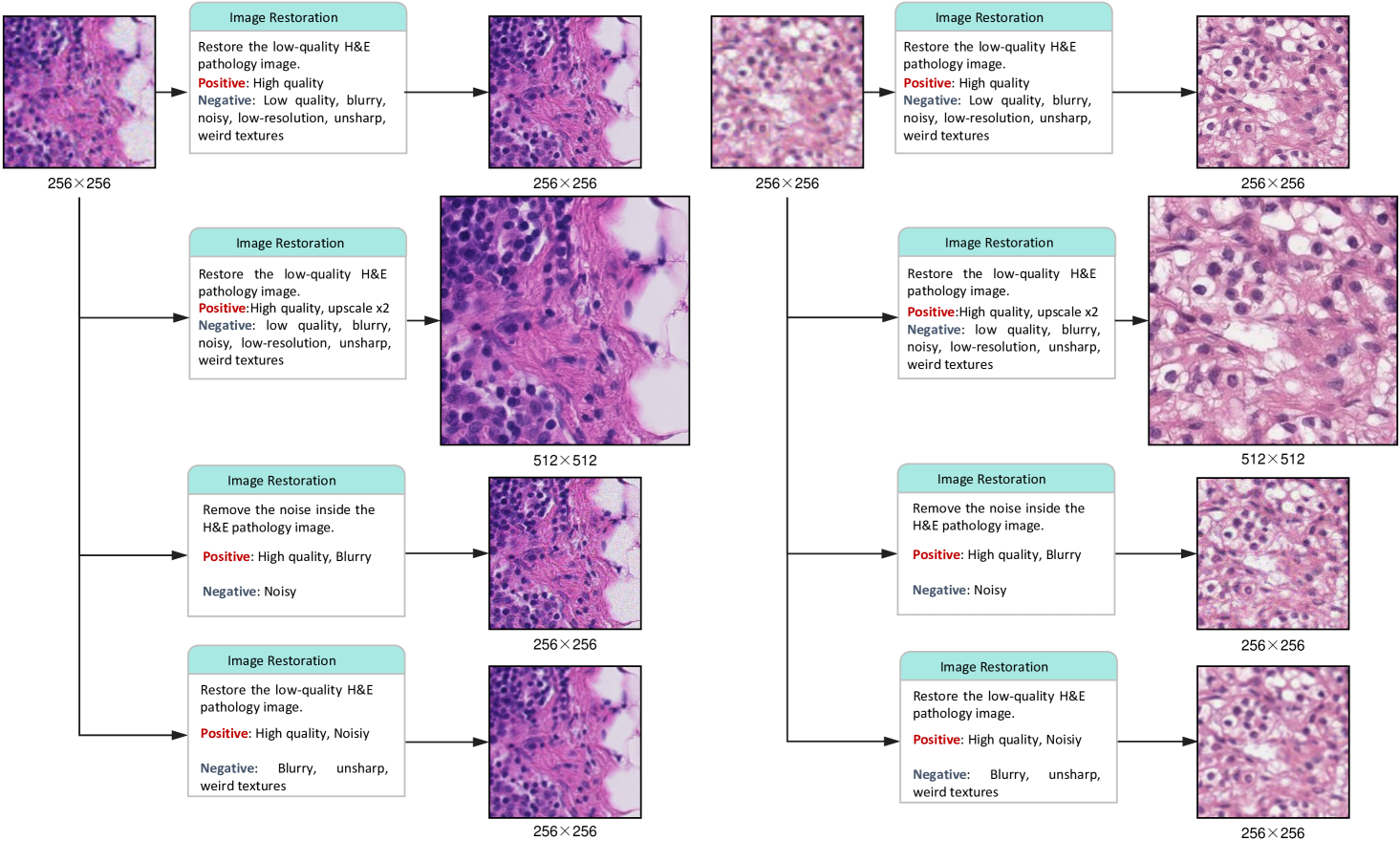
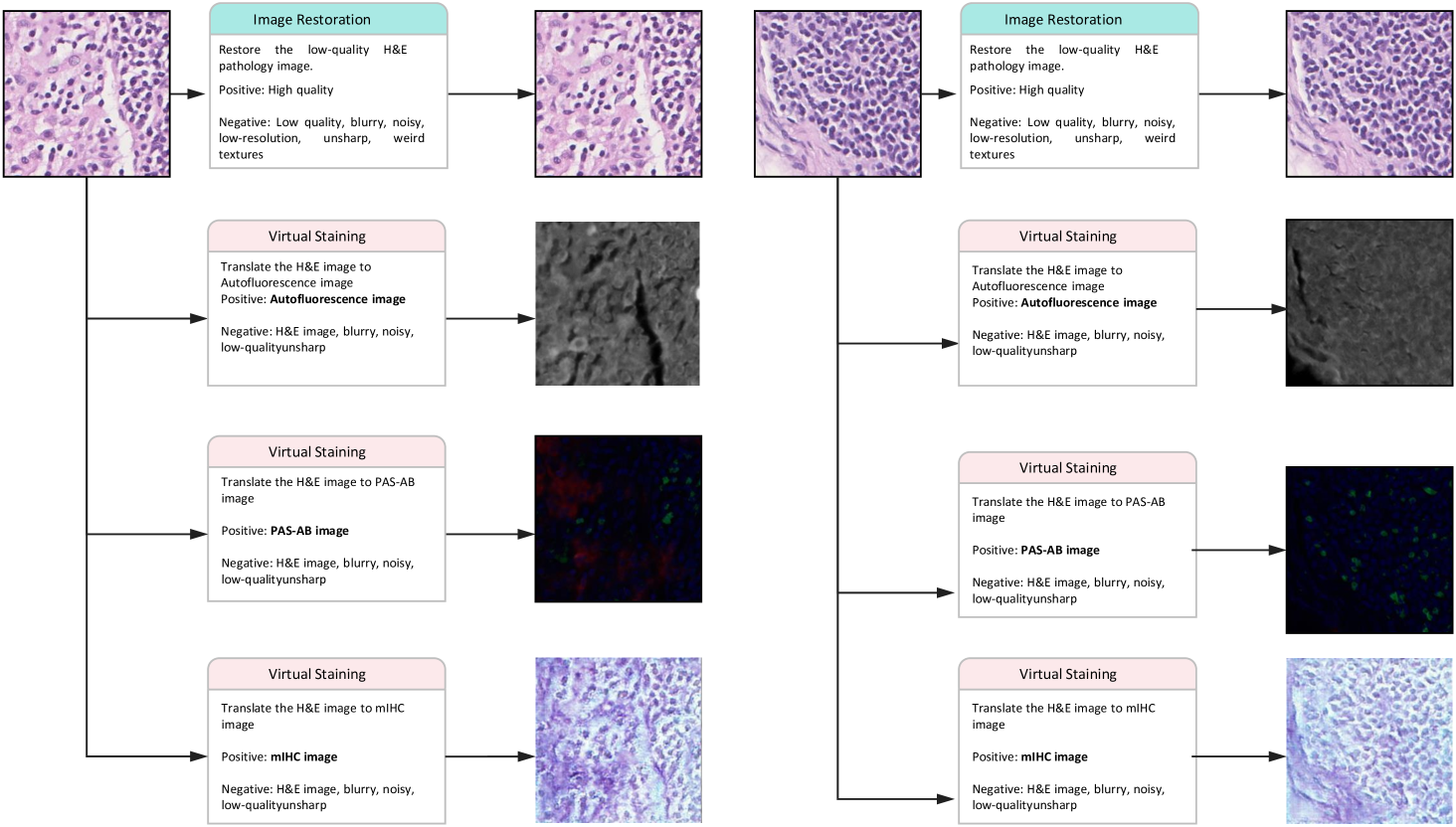
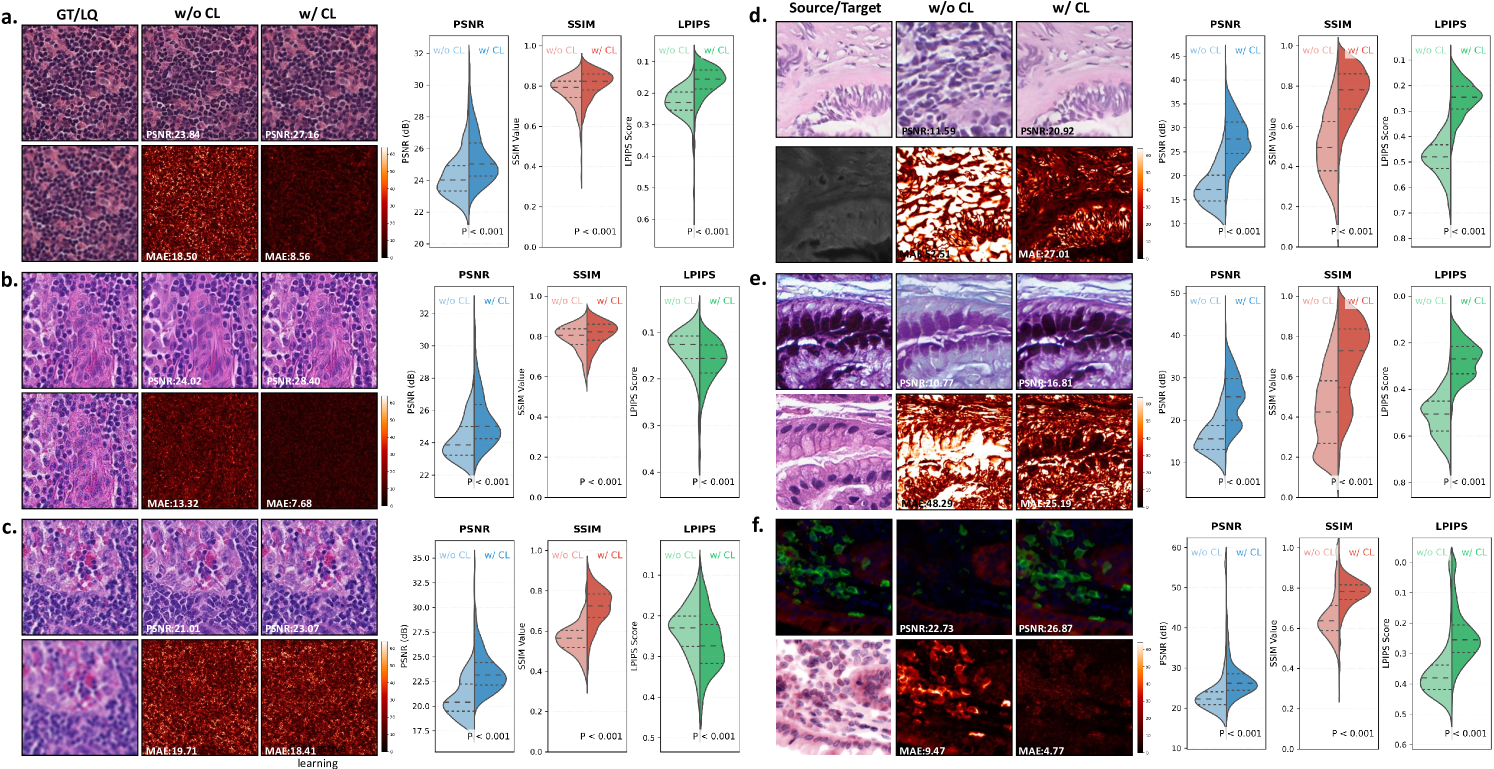
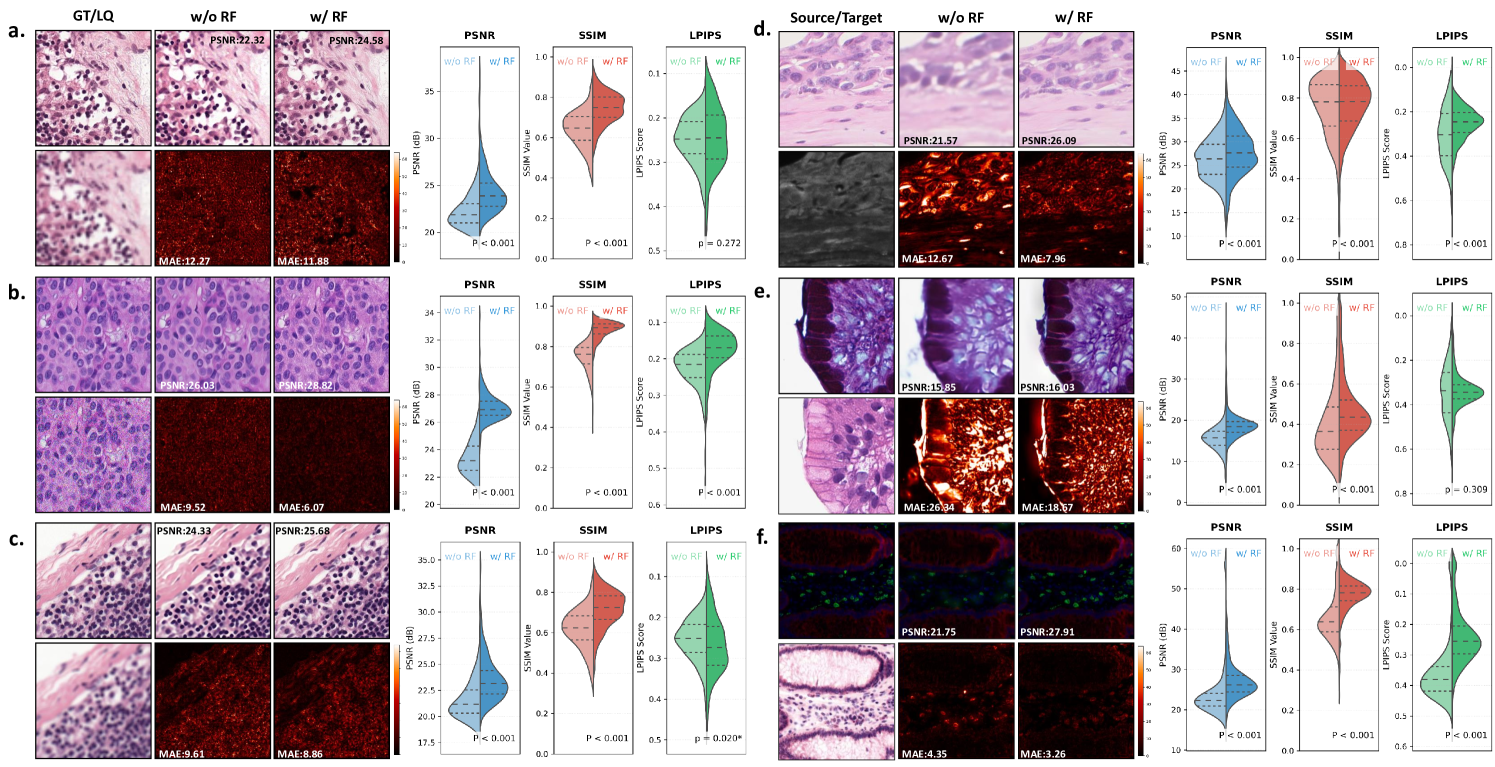

| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 17.806 (17.505, 18.107) | 0.535 (0.525, 0.545) | 0.451 (0.445, 0.456) |
| Pix2Pix | 20.452 (20.104, 20.801) | 0.574 (0.563, 0.584) | 0.387 (0.380, 0.394) | |
| BSRGAN | 19.866 (19.584, 20.147) | 0.535 (0.523, 0.546) | 0.324 (0.316, 0.333) | |
| SwinIR | 20.755 (20.361, 21.149) | 0.543 (0.531, 0.556) | 0.455 (0.442, 0.469) | |
| HistoDiff | 21.264 (21.000, 21.528) | 0.605 (0.594, 0.616) | 0.196 (0.188, 0.204) | |
| LDM | 20.047 (19.742, 20.352) | 0.545 (0.533, 0.557) | 0.300 (0.294, 0.305) | |
| LPFM | 25.611 (25.323, 25.900) | 0.795 (0.787, 0.804) | 0.202 (0.195, 0.208) | |
| 4 | CycleGAN | 20.078 (19.718, 20.439) | 0.766 (0.757, 0.776) | 0.315 (0.309, 0.321) |
| Pix2Pix | 24.831 (24.582, 25.081) | 0.824 (0.816, 0.832) | 0.238 (0.231, 0.245) | |
| BSRGAN | 25.328 (25.143, 25.513) | 0.875 (0.870, 0.880) | 0.090 (0.084, 0.095) | |
| SwinIR | 25.019 (24.623, 25.416) | 0.814 (0.807, 0.820) | 0.221 (0.213, 0.229) | |
| HistoDiff | 24.233 (24.051, 24.415) | 0.773 (0.762, 0.784) | 0.234 (0.226, 0.242) | |
| LDM | 21.395 (21.090, 21.699) | 0.634 (0.623, 0.646) | 0.251 (0.246, 0.255) | |
| LPFM | 30.726 (30.465, 30.988) | 0.940 (0.937, 0.943) | 0.083 (0.079, 0.088) | |
| 2 | CycleGAN | 22.187 (21.762, 22.611) | 0.868 (0.858, 0.878) | 0.204 (0.195, 0.213) |
| Pix2Pix | 27.456 (27.244, 27.668) | 0.902 (0.895, 0.909) | 0.166 (0.158, 0.173) | |
| BSRGAN | 27.958 (27.756, 28.159) | 0.949 (0.945, 0.953) | 0.086 (0.079, 0.093) | |
| SwinIR | 30.283 (29.902, 30.663) | 0.952 (0.950, 0.953) | 0.073 (0.070, 0.076) | |
| HistoDiff | 25.436 (25.217, 25.655) | 0.845 (0.838, 0.851) | 0.111 (0.104, 0.118) | |
| LDM | 21.764 (21.448, 22.080) | 0.659 (0.649, 0.669) | 0.228 (0.224, 0.232) | |
| LPFM | 35.330 (35.173, 35.487) | 0.980 (0.979, 0.982) | 0.025 (0.022, 0.028) |
| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 20.259 (20.171, 20.346) | 0.448 (0.445, 0.452) | 0.297 (0.295, 0.300) |
| Pix2Pix | 20.452 (20.104, 20.801) | 0.574 (0.563, 0.584) | 0.387 (0.380, 0.394) | |
| BSRGAN | 21.176 (20.892, 21.460) | 0.432 (0.418, 0.447) | 0.373 (0.366, 0.381) | |
| SwinIR | 22.457 (22.108, 22.806) | 0.456 (0.440, 0.472) | 0.521 (0.508, 0.534) | |
| HistoDiff | 21.241 (20.973, 21.508) | 0.431 (0.416, 0.446) | 0.265 (0.257, 0.273) | |
| LDM | 20.647 (20.367, 20.926) | 0.407 (0.391, 0.422) | 0.383 (0.378, 0.389) | |
| LPFM | 23.934 (23.585, 24.283) | 0.578 (0.563, 0.592) | 0.364 (0.353, 0.376) | |
| 4 | CycleGAN | 24.396 (24.341, 24.452) | 0.776 (0.774, 0.778) | 0.121 (0.119, 0.122) |
| Pix2Pix | 24.831 (24.582, 25.081) | 0.824 (0.816, 0.832) | 0.238 (0.231, 0.245) | |
| BSRGAN | 24.839 (24.644, 25.035) | 0.777 (0.770, 0.784) | 0.121 (0.118, 0.125) | |
| SwinIR | 25.733 (25.380, 26.087) | 0.724 (0.715, 0.733) | 0.264 (0.256, 0.272) | |
| HistoDiff | 22.941 (22.721, 23.161) | 0.643 (0.631, 0.655) | 0.170 (0.163, 0.177) | |
| LDM | 21.982 (21.736, 22.228) | 0.516 (0.503, 0.529) | 0.306 (0.302, 0.311) | |
| LPFM | 29.606 (29.321, 29.891) | 0.881 (0.876, 0.886) | 0.121 (0.116, 0.126) | |
| 2 | CycleGAN | 24.331 (24.050, 24.611) | 0.887 (0.880, 0.893) | 0.183 (0.176, 0.190) |
| Pix2Pix | 27.456 (27.244, 27.668) | 0.902 (0.895, 0.909) | 0.166 (0.158, 0.173) | |
| BSRGAN | 28.919 (28.690, 29.149) | 0.940 (0.937, 0.943) | 0.052 (0.048, 0.056) | |
| SwinIR | 30.869 (30.514, 31.224) | 0.927 (0.924, 0.930) | 0.064 (0.062, 0.066) | |
| HistoDiff | 24.745 (24.560, 24.930) | 0.757 (0.748, 0.767) | 0.144 (0.136, 0.151) | |
| LDM | 22.668 (22.393, 22.942) | 0.565 (0.553, 0.577) | 0.260 (0.256, 0.264) | |
| LPFM | 35.237 (35.026, 35.447) | 0.971 (0.970, 0.972) | 0.032 (0.029, 0.034) |
| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 20.059 (19.763, 20.355) | 0.586 (0.570, 0.603) | 0.413 (0.403, 0.422) |
| Pix2Pix | 22.769 (22.480, 23.058) | 0.592 (0.574, 0.611) | 0.352 (0.346, 0.358) | |
| BSRGAN | 24.018 (23.690, 24.346) | 0.611 (0.591, 0.631) | 0.374 (0.361, 0.387) | |
| SwinIR | 24.567 (24.230, 24.903) | 0.640 (0.621, 0.659) | 0.369 (0.352, 0.386) | |
| HistoDiff | 22.423 (22.136, 22.711) | 0.572 (0.554, 0.589) | 0.176 (0.168, 0.184) | |
| LDM | 21.849 (21.562, 22.135) | 0.535 (0.513, 0.557) | 0.316 (0.310, 0.323) | |
| LPFM | 26.229 (25.893, 26.564) | 0.721 (0.706, 0.736) | 0.282 (0.273, 0.291) | |
| 4 | CycleGAN | 22.027 (21.696, 22.358) | 0.765 (0.754, 0.776) | 0.318 (0.308, 0.329) |
| Pix2Pix | 24.910 (24.646, 25.174) | 0.750 (0.736, 0.763) | 0.284 (0.277, 0.290) | |
| BSRGAN | 26.638 (26.330, 26.946) | 0.775 (0.762, 0.788) | 0.241 (0.231, 0.252) | |
| SwinIR | 28.230 (27.868, 28.591) | 0.821 (0.811, 0.832) | 0.821 (0.811, 0.832) | |
| HistoDiff | 24.300 (24.031, 24.569) | 0.691 (0.677, 0.704) | 0.135 (0.126, 0.144) | |
| LDM | 22.636 (22.365, 22.907) | 0.604 (0.585, 0.622) | 0.258 (0.252, 0.265) | |
| LPFM | 31.474 (31.157, 31.791) | 0.902 (0.896, 0.908) | 0.149 (0.143, 0.155) | |
| 2 | CycleGAN | 24.932 (24.474, 25.390) | 0.881 (0.873, 0.889) | 0.213 (0.199, 0.226) |
| Pix2Pix | 27.149 (26.869, 27.430) | 0.846 (0.836, 0.856) | 0.217 (0.208, 0.226) | |
| BSRGAN | 27.694 (27.389, 27.999) | 0.853 (0.845, 0.860) | 0.140 (0.133, 0.147) | |
| SwinIR | 33.229 (32.862, 33.597) | 0.947 (0.944, 0.951) | 0.050 (0.048, 0.052) | |
| HistoDiff | 25.164 (24.917, 25.410) | 0.740 (0.728, 0.751) | 0.127 (0.118, 0.135) | |
| LDM | 23.588 (23.328, 23.849) | 0.651 (0.635, 0.667) | 0.211 (0.205, 0.217) | |
| LPFM | 34.474 (34.224, 34.725) | 0.956 (0.954, 0.959) | 0.088 (0.082, 0.094) |
| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 20.333 (19.983, 20.683) | 0.542 (0.528, 0.556) | 0.402 (0.398, 0.407) |
| Pix2Pix | 21.871 (21.487, 22.255) | 0.537 (0.522, 0.552) | 0.376 (0.370, 0.382) | |
| BSRGAN | 22.154 (21.803, 22.505) | 0.507 (0.490, 0.523) | 0.350 (0.340, 0.361) | |
| SwinIR | 22.528 (22.133, 22.923) | 0.471 (0.452, 0.490) | 0.483 (0.474, 0.493) | |
| HistoDiff | 22.435 (22.130, 22.740) | 0.513 (0.497, 0.530) | 0.234 (0.225, 0.244) | |
| LDM | 21.112 (20.766, 21.458) | 0.463 (0.445, 0.480) | 0.354 (0.347, 0.361) | |
| LPFM | 25.272 (24.870, 25.673) | 0.670 (0.657, 0.684) | 0.321 (0.313, 0.328) | |
| 4 | CycleGAN | 22.961 (22.656, 23.267) | 0.759 (0.749, 0.770) | 0.286 (0.280, 0.292) |
| Pix2Pix | 24.498 (24.195, 24.802) | 0.729 (0.718, 0.741) | 0.284 (0.278, 0.290) | |
| BSRGAN | 26.360 (26.095, 26.625) | 0.790 (0.781, 0.799) | 0.101 (0.094, 0.107) | |
| SwinIR | 24.781 (24.438, 25.125) | 0.609 (0.594, 0.624) | 0.402 (0.393, 0.412) | |
| HistoDiff | 24.092 (23.820, 24.363) | 0.667 (0.653, 0.680) | 0.153 (0.144, 0.161) | |
| LDM | 21.981 (21.641, 22.321) | 0.547 (0.532, 0.563) | 0.292 (0.285, 0.298) | |
| LPFM | 30.898 (30.586, 31.209) | 0.895 (0.890, 0.900) | 0.161 (0.156, 0.166) | |
| 2 | CycleGAN | 27.299 (26.905, 27.692) | 0.878 (0.868, 0.888) | 0.175 (0.168, 0.183) |
| Pix2Pix | 27.743 (27.499, 27.986) | 0.855 (0.847, 0.864) | 0.188 (0.182, 0.195) | |
| BSRGAN | 29.171 (28.861, 29.481) | 0.907 (0.901, 0.912) | 0.068 (0.062, 0.073) | |
| SwinIR | 26.547 (26.173, 26.922) | 0.693 (0.676, 0.710) | 0.358 (0.345, 0.370) | |
| HistoDiff | 25.752 (25.503, 26.002) | 0.750 (0.738, 0.762) | 0.128 (0.120, 0.136) | |
| LDM | 22.940 (22.581, 23.299) | 0.601 (0.586, 0.615) | 0.243 (0.237, 0.249) | |
| LPFM | 34.273 (34.050, 34.495) | 0.954 (0.951, 0.957) | 0.089 (0.085, 0.093) |
| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 20.370 (20.035, 20.705) | 0.523 (0.513, 0.533) | 0.280 (0.272, 0.288) |
| Pix2Pix | 21.654 (21.356, 21.953) | 0.509 (0.498, 0.519) | 0.375 (0.369, 0.381) | |
| BSRGAN | 21.581 (21.419, 21.743) | 0.477 (0.469, 0.485) | 0.352 (0.345, 0.360) | |
| SwinIR | 23.001 (22.798, 23.204) | 0.529 (0.521, 0.538) | 0.445 (0.438, 0.453) | |
| HistoDiff | 22.499 (22.334, 22.663) | 0.529 (0.522, 0.536) | 0.210 (0.205, 0.215) | |
| LDM | 21.072 (20.908, 21.236) | 0.453 (0.445, 0.460) | 0.335 (0.331, 0.339) | |
| LPFM | 25.115 (24.918, 25.311) | 0.662 (0.654, 0.669) | 0.295 (0.291, 0.299) | |
| 4 | CycleGAN | 24.209 (23.954, 24.465) | 0.794 (0.788, 0.800) | 0.140 (0.135, 0.146) |
| Pix2Pix | 24.859 (24.598, 25.121) | 0.749 (0.740, 0.758) | 0.256 (0.249, 0.263) | |
| BSRGAN | 25.602 (25.469, 25.736) | 0.784 (0.779, 0.788) | 0.111 (0.106, 0.116) | |
| SwinIR | 26.803 (26.589, 27.016) | 0.782 (0.777, 0.787) | 0.223 (0.218, 0.228) | |
| HistoDiff | 24.710 (24.552, 24.868) | 0.712 (0.707, 0.717) | 0.135 (0.130, 0.139) | |
| LDM | 22.064 (21.904, 22.224) | 0.538 (0.531, 0.545) | 0.275 (0.272, 0.279) | |
| LPFM | 30.786 (30.587, 30.984) | 0.904 (0.900, 0.907) | 0.138 (0.135, 0.140) | |
| 2 | CycleGAN | 23.489 (23.118, 23.860) | 0.852 (0.844, 0.859) | 0.189 (0.182, 0.195) |
| Pix2Pix | 28.035 (27.690, 28.380) | 0.870 (0.863, 0.877) | 0.165 (0.157, 0.173) | |
| BSRGAN | 27.057 (26.897, 27.216) | 0.867 (0.863, 0.870) | 0.092 (0.089, 0.096) | |
| SwinIR | 31.969 (31.753, 32.184) | 0.942 (0.940, 0.943) | 0.060 (0.058, 0.061) | |
| HistoDiff | 26.077 (25.944, 26.209) | 0.790 (0.785, 0.794) | 0.118 (0.113, 0.123) | |
| LDM | 22.603 (22.433, 22.774) | 0.575 (0.569, 0.582) | 0.235 (0.232, 0.238) | |
| LPFM | 34.586 (34.435, 34.738) | 0.965 (0.964, 0.967) | 0.061 (0.059, 0.063) |
| Scale | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 8 | CycleGAN | 19.533 (18.742, 20.324) | 0.540 (0.500, 0.579) | 0.427 (0.415, 0.440) |
| Pix2Pix | 21.215 (20.206, 22.224) | 0.527 (0.483, 0.571) | 0.397 (0.384, 0.409) | |
| BSRGAN | 23.118 (22.058, 24.177) | 0.526 (0.469, 0.582) | 0.444 (0.419, 0.468) | |
| SwinIR | 22.363 (21.362, 23.364) | 0.463 (0.403, 0.523) | 0.471 (0.442, 0.500) | |
| HistoDiff | 22.305 (21.390, 23.220) | 0.532 (0.481, 0.582) | 0.345 (0.332, 0.359) | |
| LDM | 21.016 (20.151, 21.882) | 0.463 (0.410, 0.517) | 0.374 (0.360, 0.388) | |
| LPFM | 25.382 (24.161, 26.602) | 0.674 (0.627, 0.721) | 0.322 (0.300, 0.344) | |
| 4 | CycleGAN | 21.654 (20.908, 22.399) | 0.767 (0.744, 0.790) | 0.310 (0.295, 0.325) |
| Pix2Pix | 24.178 (23.120, 25.235) | 0.739 (0.702, 0.775) | 0.304 (0.286, 0.323) | |
| BSRGAN | 25.642 (24.624, 26.659) | 0.742 (0.707, 0.777) | 0.282 (0.264, 0.300) | |
| SwinIR | 24.708 (23.625, 25.791) | 0.607 (0.559, 0.655) | 0.399 (0.374, 0.424) | |
| HistoDiff | 24.391 (23.527, 25.254) | 0.697 (0.664, 0.729) | 0.264 (0.249, 0.279) | |
| LDM | 26.360 (26.095, 26.625) | 0.790 (0.781, 0.799) | 0.101 (0.094, 0.107) | |
| LPFM | 31.364 (30.107, 32.621) | 0.915 (0.900, 0.930) | 0.146 (0.133, 0.158) | |
| 2 | CycleGAN | 23.454 (22.674, 24.234) | 0.863 (0.841, 0.885) | 0.217 (0.192, 0.242) |
| Pix2Pix | 27.312 (26.353, 28.271) | 0.860 (0.834, 0.886) | 0.211 (0.189, 0.233) | |
| BSRGAN | 26.181 (25.205, 27.156) | 0.833 (0.814, 0.852) | 0.180 (0.168, 0.192) | |
| SwinIR | 26.564 (25.509, 27.618) | 0.710 (0.673, 0.747) | 0.348 (0.326, 0.371) | |
| HistoDiff | 24.959 (24.097, 25.821) | 0.720 (0.689, 0.751) | 0.251 (0.237, 0.265) | |
| LDM | 29.171 (28.861, 29.481) | 0.907 (0.901, 0.912) | 0.068 (0.062, 0.073) | |
| LPFM | 34.624 (33.847, 35.402) | 0.966 (0.960, 0.971) | 0.074 (0.064, 0.084) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 18.282 (17.972, 18.592) | 0.412 (0.397, 0.428) | 0.417 (0.408, 0.426) |
| Pix2Pix | 20.800 (20.482, 21.118) | 0.652 (0.644, 0.659) | 0.399 (0.392, 0.407) | |
| BSRGAN | 20.597 (20.229, 20.965) | 0.530 (0.515, 0.544) | 0.458 (0.447, 0.469) | |
| SwinIR | 20.137 (19.800, 20.473) | 0.476 (0.463, 0.490) | 0.463 (0.457, 0.469) | |
| HistoDiff | 20.877 (20.589, 21.165) | 0.562 (0.551, 0.573) | 0.238 (0.230, 0.247) | |
| LDM | 20.276 (19.937, 20.615) | 0.558 (0.545, 0.571) | 0.284 (0.280, 0.289) | |
| LPFM | 23.524 (23.240, 23.807) | 0.717 (0.704, 0.729) | 0.254 (0.247, 0.261) | |
| 11 | CycleGAN | 20.675 (20.410, 20.940) | 0.653 (0.642, 0.664) | 0.300 (0.293, 0.306) |
| Pix2Pix | 20.599 (20.280, 20.917) | 0.651 (0.643, 0.658) | 0.398 (0.390, 0.405) | |
| BSRGAN | 22.216 (21.870, 22.561) | 0.692 (0.682, 0.703) | 0.354 (0.345, 0.363) | |
| SwinIR | 21.573 (21.260, 21.885) | 0.581 (0.569, 0.593) | 0.407 (0.400, 0.413) | |
| HistoDiff | 23.000 (22.756, 23.245) | 0.707 (0.696, 0.717) | 0.164 (0.157, 0.172) | |
| LDM | 20.999 (20.656, 21.343) | 0.605 (0.593, 0.617) | 0.265 (0.260, 0.270) | |
| LPFM | 25.812 (25.505, 26.118) | 0.824 (0.815, 0.833) | 0.208 (0.200, 0.216) | |
| 7 | CycleGAN | 24.127 (23.811, 24.444) | 0.884 (0.878, 0.891) | 0.172 (0.167, 0.178) |
| Pix2Pix | 25.092 (24.821, 25.363) | 0.839 (0.831, 0.846) | 0.235 (0.226, 0.245) | |
| BSRGAN | 23.881 (23.544, 24.218) | 0.821 (0.815, 0.827) | 0.196 (0.189, 0.203) | |
| SwinIR | 23.650 (23.382, 23.918) | 0.701 (0.689, 0.712) | 0.337 (0.329, 0.345) | |
| HistoDiff | 25.436 (25.217, 25.655) | 0.845 (0.838, 0.851) | 0.111 (0.104, 0.118) | |
| LDM | 21.587 (21.246, 21.929) | 0.644 (0.632, 0.655) | 0.242 (0.238, 0.247) | |
| LPFM | 31.249 (31.009, 31.490) | 0.948 (0.946, 0.951) | 0.106 (0.101, 0.111) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 19.449 (19.206, 19.692) | 0.296 (0.279, 0.314) | 0.405 (0.400, 0.410) |
| Pix2Pix | 22.615 (22.358, 22.872) | 0.591 (0.581, 0.602) | 0.393 (0.388, 0.398) | |
| BSRGAN | 22.238 (21.904, 22.572) | 0.428 (0.410, 0.445) | 0.479 (0.470, 0.487) | |
| SwinIR | 21.700 (21.381, 22.020) | 0.379 (0.362, 0.396) | 0.536 (0.529, 0.543) | |
| HistoDiff | 21.179 (20.874, 21.484) | 0.603 (0.590, 0.615) | 0.287 (0.280, 0.294) | |
| LDM | 20.556 (20.240, 20.872) | 0.402 (0.386, 0.419) | 0.366 (0.361, 0.372) | |
| LPFM | 22.968 (22.625, 23.310) | 0.492 (0.474, 0.509) | 0.369 (0.364, 0.375) | |
| 11 | CycleGAN | 20.812 (20.592, 21.032) | 0.507 (0.492, 0.522) | 0.317 (0.313, 0.322) |
| Pix2Pix | 22.518 (22.314, 22.721) | 0.580 (0.570, 0.591) | 0.380 (0.376, 0.384) | |
| BSRGAN | 22.402 (22.140, 22.664) | 0.516 (0.500, 0.531) | 0.240 (0.234, 0.245) | |
| SwinIR | 22.508 (22.202, 22.815) | 0.438 (0.422, 0.455) | 0.501 (0.493, 0.508) | |
| HistoDiff | 22.114 (21.828, 22.401) | 0.674 (0.663, 0.685) | 0.246 (0.239, 0.253) | |
| LDM | 21.311 (21.012, 21.610) | 0.457 (0.442, 0.472) | 0.338 (0.333, 0.344) | |
| LPFM | 24.986 (24.666, 25.305) | 0.669 (0.656, 0.681) | 0.288 (0.283, 0.293) | |
| 7 | CycleGAN | 22.888 (22.659, 23.118) | 0.843 (0.837, 0.848) | 0.209 (0.205, 0.213) |
| Pix2Pix | 26.028 (25.828, 26.228) | 0.761 (0.752, 0.770) | 0.254 (0.248, 0.259) | |
| BSRGAN | 25.555 (25.364, 25.745) | 0.805 (0.799, 0.812) | 0.100 (0.097, 0.103) | |
| SwinIR | 21.700 (21.381, 22.020) | 0.379 (0.362, 0.396) | 0.536 (0.529, 0.543) | |
| HistoDiff | 23.659 (23.389, 23.929) | 0.755 (0.746, 0.764) | 0.209 (0.203, 0.216) | |
| LDM | 22.076 (21.782, 22.369) | 0.520 (0.506, 0.534) | 0.296 (0.291, 0.301) | |
| LPFM | 31.249 (31.009, 31.490) | 0.948 (0.946, 0.951) | 0.106 (0.101, 0.111) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 20.323 (20.021, 20.624) | 0.492 (0.470, 0.515) | 0.372 (0.363, 0.381) |
| Pix2Pix | 24.675 (24.341, 25.010) | 0.718 (0.705, 0.731) | 0.329 (0.324, 0.335) | |
| BSRGAN | 24.249 (23.936, 24.563) | 0.622 (0.602, 0.642) | 0.344 (0.331, 0.356) | |
| SwinIR | 23.570 (23.255, 23.886) | 0.566 (0.544, 0.588) | 0.417 (0.403, 0.430) | |
| HistoDiff | 21.569 (21.268, 21.869) | 0.449 (0.433, 0.464) | 0.365 (0.359, 0.371) | |
| LDM | 22.566 (22.249, 22.884) | 0.563 (0.542, 0.584) | 0.292 (0.284, 0.299) | |
| LPFM | 25.550 (25.215, 25.886) | 0.691 (0.674, 0.708) | 0.270 (0.262, 0.279) | |
| 11 | CycleGAN | 21.923 (21.603, 22.244) | 0.649 (0.632, 0.666) | 0.302 (0.292, 0.312) |
| Pix2Pix | 24.074 (23.811, 24.337) | 0.693 (0.680, 0.707) | 0.330 (0.325, 0.335) | |
| BSRGAN | 25.311 (25.006, 25.615) | 0.715 (0.699, 0.730) | 0.285 (0.274, 0.297) | |
| SwinIR | 24.678 (24.359, 24.998) | 0.620 (0.601, 0.640) | 0.387 (0.374, 0.400) | |
| HistoDiff | 22.226 (21.963, 22.489) | 0.529 (0.516, 0.542) | 0.328 (0.323, 0.334) | |
| LDM | 23.148 (22.853, 23.443) | 0.602 (0.582, 0.622) | 0.264 (0.256, 0.271) | |
| LPFM | 27.866 (27.525, 28.207) | 0.800 (0.788, 0.812) | 0.214 (0.206, 0.221) | |
| 7 | CycleGAN | 24.114 (23.720, 24.507) | 0.843 (0.835, 0.851) | 0.226 (0.215, 0.238) |
| Pix2Pix | 27.248 (26.979, 27.517) | 0.824 (0.814, 0.833) | 0.243 (0.236, 0.250) | |
| BSRGAN | 26.670 (26.360, 26.980) | 0.810 (0.800, 0.820) | 0.194 (0.185, 0.202) | |
| SwinIR | 26.253 (25.931, 26.575) | 0.689 (0.672, 0.706) | 0.354 (0.342, 0.366) | |
| HistoDiff | 23.688 (23.452, 23.923) | 0.638 (0.626, 0.649) | 0.282 (0.276, 0.287) | |
| LDM | 23.715 (23.434, 23.996) | 0.639 (0.621, 0.656) | 0.230 (0.222, 0.237) | |
| LPFM | 31.796 (31.478, 32.115) | 0.911 (0.905, 0.916) | 0.135 (0.129, 0.140) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 20.627 (20.254, 20.999) | 0.418 (0.400, 0.436) | 0.370 (0.364, 0.376) |
| Pix2Pix | 24.118 (23.794, 24.442) | 0.660 (0.650, 0.671) | 0.360 (0.354, 0.366) | |
| BSRGAN | 23.271 (22.866, 23.676) | 0.535 (0.517, 0.554) | 0.409 (0.398, 0.419) | |
| SwinIR | 22.626 (22.231, 23.021) | 0.477 (0.459, 0.496) | 0.480 (0.470, 0.489) | |
| HistoDiff | 23.053 (22.675, 23.432) | 0.550 (0.534, 0.566) | 0.316 (0.309, 0.323) | |
| LDM | 21.657 (21.288, 22.026) | 0.489 (0.471, 0.507) | 0.332 (0.325, 0.340) | |
| LPFM | 24.342 (23.945, 24.740) | 0.613 (0.598, 0.628) | 0.314 (0.307, 0.321) | |
| 11 | CycleGAN | 22.698 (22.331, 23.065) | 0.611 (0.597, 0.626) | 0.283 (0.277, 0.288) |
| Pix2Pix | 23.847 (23.566, 24.128) | 0.650 (0.639, 0.661) | 0.345 (0.340, 0.350) | |
| BSRGAN | 24.703 (24.328, 25.079) | 0.658 (0.643, 0.672) | 0.331 (0.321, 0.341) | |
| SwinIR | 23.672 (23.301, 24.044) | 0.545 (0.528, 0.561) | 0.438 (0.429, 0.448) | |
| HistoDiff | 23.733 (23.381, 24.086) | 0.610 (0.596, 0.625) | 0.281 (0.275, 0.288) | |
| LDM | 22.290 (21.934, 22.647) | 0.539 (0.522, 0.555) | 0.303 (0.296, 0.310) | |
| LPFM | 26.851 (26.485, 27.218) | 0.762 (0.752, 0.773) | 0.245 (0.239, 0.251) | |
| 7 | CycleGAN | 26.713 (26.332, 27.093) | 0.853 (0.845, 0.861) | 0.182 (0.176, 0.188) |
| Pix2Pix | 27.040 (26.811, 27.269) | 0.801 (0.793, 0.809) | 0.239 (0.233, 0.245) | |
| BSRGAN | 26.319 (25.928, 26.710) | 0.793 (0.785, 0.801) | 0.203 (0.197, 0.209) | |
| SwinIR | 25.194 (24.859, 25.529) | 0.632 (0.617, 0.646) | 0.391 (0.381, 0.400) | |
| HistoDiff | 25.045 (24.719, 25.372) | 0.689 (0.676, 0.702) | 0.240 (0.234, 0.246) | |
| LDM | 22.822 (22.475, 23.169) | 0.580 (0.565, 0.595) | 0.268 (0.261, 0.275) | |
| LPFM | 31.277 (30.976, 31.578) | 0.905 (0.900, 0.910) | 0.144 (0.139, 0.148) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 19.918 (19.671, 20.166) | 0.364 (0.350, 0.378) | 0.364 (0.359, 0.369) |
| Pix2Pix | 23.359 (23.096, 23.622) | 0.634 (0.625, 0.642) | 0.353 (0.349, 0.358) | |
| BSRGAN | 23.115 (22.831, 23.399) | 0.522 (0.507, 0.537) | 0.393 (0.386, 0.400) | |
| SwinIR | 22.286 (22.022, 22.549) | 0.447 (0.433, 0.461) | 0.441 (0.435, 0.447) | |
| HistoDiff | 22.734 (22.483, 22.984) | 0.522 (0.510, 0.534) | 0.307 (0.302, 0.313) | |
| LDM | 21.435 (21.179, 21.691) | 0.460 (0.448, 0.472) | 0.320 (0.315, 0.326) | |
| LPFM | 24.326 (24.040, 24.613) | 0.604 (0.590, 0.617) | 0.290 (0.284, 0.295) | |
| 11 | CycleGAN | 20.675 (20.410, 20.940) | 0.653 (0.642, 0.664) | 0.300 (0.293, 0.306) |
| Pix2Pix | 23.160 (22.960, 23.360) | 0.629 (0.623, 0.635) | 0.335 (0.331, 0.339) | |
| BSRGAN | 24.455 (24.270, 24.639) | 0.645 (0.637, 0.653) | 0.315 (0.310, 0.320) | |
| SwinIR | 23.157 (22.985, 23.329) | 0.514 (0.506, 0.522) | 0.403 (0.399, 0.407) | |
| HistoDiff | 23.302 (23.155, 23.449) | 0.592 (0.586, 0.599) | 0.268 (0.264, 0.271) | |
| LDM | 22.028 (21.863, 22.194) | 0.517 (0.509, 0.524) | 0.292 (0.288, 0.295) | |
| LPFM | 26.399 (26.205, 26.594) | 0.753 (0.747, 0.760) | 0.224 (0.221, 0.227) | |
| 15 | CycleGAN | 24.296 (23.915, 24.677) | 0.851 (0.845, 0.857) | 0.167 (0.163, 0.170) |
| Pix2Pix | 26.275 (25.994, 26.556) | 0.803 (0.795, 0.811) | 0.211 (0.204, 0.217) | |
| BSRGAN | 26.192 (26.010, 26.375) | 0.795 (0.791, 0.799) | 0.180 (0.177, 0.183) | |
| SwinIR | 24.593 (24.437, 24.749) | 0.605 (0.598, 0.613) | 0.366 (0.361, 0.370) | |
| HistoDiff | 24.521 (24.376, 24.666) | 0.674 (0.668, 0.679) | 0.232 (0.228, 0.235) | |
| LDM | 22.565 (22.402, 22.728) | 0.562 (0.555, 0.569) | 0.257 (0.253, 0.260) | |
| LPFM | 31.253 (31.061, 31.446) | 0.916 (0.913, 0.919) | 0.119 (0.116, 0.121) |
| Kernel Size | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| 15 | CycleGAN | 19.946 (19.225, 20.667) | 0.400 (0.337, 0.463) | 0.385 (0.370, 0.399) |
| Pix2Pix | 23.518 (22.496, 24.540) | 0.670 (0.641, 0.699) | 0.373 (0.356, 0.389) | |
| BSRGAN | 23.257 (22.214, 24.300) | 0.539 (0.479, 0.600) | 0.418 (0.391, 0.445) | |
| SwinIR | 22.487 (21.473, 23.501) | 0.470 (0.410, 0.530) | 0.468 (0.439, 0.496) | |
| HistoDiff | 22.559 (21.608, 23.511) | 0.544 (0.495, 0.594) | 0.342 (0.327, 0.358) | |
| LDM | 21.333 (20.323, 22.343) | 0.474 (0.418, 0.531) | 0.351 (0.335, 0.367) | |
| LPFM | 24.480 (23.278, 25.681) | 0.616 (0.562, 0.671) | 0.309 (0.287, 0.332) | |
| 7 | CycleGAN | 21.696 (21.100, 22.291) | 0.637 (0.594, 0.679) | 0.304 (0.292, 0.316) |
| Pix2Pix | 23.340 (22.469, 24.210) | 0.660 (0.629, 0.691) | 0.361 (0.345, 0.376) | |
| BSRGAN | 24.395 (23.382, 25.407) | 0.650 (0.601, 0.700) | 0.342 (0.320, 0.365) | |
| SwinIR | 23.558 (22.492, 24.624) | 0.536 (0.481, 0.591) | 0.433 (0.405, 0.460) | |
| HistoDiff | 23.167 (22.226, 24.109) | 0.616 (0.575, 0.657) | 0.305 (0.290, 0.320) | |
| LDM | 21.919 (20.915, 22.923) | 0.524 (0.471, 0.577) | 0.325 (0.308, 0.341) | |
| LPFM | 26.929 (25.593, 28.266) | 0.772 (0.734, 0.809) | 0.238 (0.218, 0.257) | |
| 15 | CycleGAN | 23.946 (23.270, 24.622) | 0.866 (0.847, 0.884) | 0.199 (0.182, 0.216) |
| Pix2Pix | 26.700 (25.854, 27.546) | 0.824 (0.803, 0.845) | 0.250 (0.228, 0.272) | |
| BSRGAN | 25.648 (24.637, 26.659) | 0.795 (0.769, 0.821) | 0.222 (0.209, 0.236) | |
| SwinIR | 25.150 (24.059, 26.241) | 0.633 (0.587, 0.679) | 0.387 (0.362, 0.411) | |
| HistoDiff | 24.483 (23.614, 25.351) | 0.701 (0.669, 0.733) | 0.261 (0.246, 0.276) | |
| LDM | 22.355 (21.416, 23.295) | 0.566 (0.518, 0.613) | 0.286 (0.270, 0.302) | |
| LPFM | 31.792 (30.588, 32.997) | 0.926 (0.913, 0.939) | 0.126 (0.115, 0.138) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 24.032 (23.818, 24.246) | 0.837 (0.829, 0.846) | 0.195 (0.186, 0.204) | |
| Pix2Pix | 16.940 (16.551, 17.328) | 0.498 (0.482, 0.514) | 0.479 (0.465, 0.494) | |
| BSRGAN | 15.267 (14.923, 15.612) | 0.557 (0.541, 0.573) | 0.302 (0.291, 0.314) | |
| SwinIR | 26.534 (26.393, 26.675) | 0.851 (0.843, 0.860) | 0.157 (0.147, 0.166) | |
| HistoDiff | 23.271 (23.080, 23.461) | 0.731 (0.720, 0.742) | 0.127 (0.121, 0.134) | |
| LDM | 18.392 (18.167, 18.617) | 0.519 (0.507, 0.530) | 0.310 (0.304, 0.317) | |
| LPFM | 27.106 (26.963, 27.249) | 0.882 (0.877, 0.888) | 0.175 (0.168, 0.182) | |
| CycleGAN | 24.814 (24.574, 25.055) | 0.866 (0.858, 0.874) | 0.169 (0.161, 0.178) | |
| Pix2Pix | 18.983 (18.580, 19.386) | 0.604 (0.589, 0.620) | 0.409 (0.394, 0.425) | |
| BSRGAN | 18.015 (17.717, 18.312) | 0.671 (0.659, 0.682) | 0.234 (0.224, 0.245) | |
| SwinIR | 27.201 (27.064, 27.339) | 0.854 (0.845, 0.863) | 0.170 (0.160, 0.180) | |
| HistoDiff | 24.207 (24.016, 24.397) | 0.791 (0.782, 0.800) | 0.139 (0.131, 0.146) | |
| LDM | 19.280 (19.041, 19.519) | 0.552 (0.541, 0.564) | 0.292 (0.287, 0.298) | |
| LPFM | 28.773 (28.629, 28.918) | 0.915 (0.911, 0.919) | 0.048 (0.045, 0.051) | |
| CycleGAN | 25.942 (25.678, 26.206) | 0.899 (0.893, 0.906) | 0.137 (0.130, 0.145) | |
| Pix2Pix | 22.510 (22.259, 22.762) | 0.747 (0.734, 0.760) | 0.279 (0.266, 0.291) | |
| BSRGAN | 21.055 (20.808, 21.302) | 0.780 (0.772, 0.787) | 0.164 (0.157, 0.172) | |
| SwinIR | 27.671 (27.525, 27.818) | 0.856 (0.847, 0.865) | 0.176 (0.165, 0.186) | |
| HistoDiff | 24.394 (24.253, 24.536) | 0.786 (0.775, 0.796) | 0.157 (0.147, 0.167) | |
| LDM | 20.149 (19.874, 20.423) | 0.587 (0.576, 0.598) | 0.272 (0.268, 0.277) | |
| LPFM | 27.590 (27.352, 27.828) | 0.917 (0.914, 0.920) | 0.116 (0.111, 0.122) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 22.248 (21.928, 22.568) | 0.751 (0.742, 0.760) | 0.309 (0.301, 0.317) | |
| Pix2Pix | 17.343 (17.222, 17.464) | 0.357 (0.346, 0.368) | 0.488 (0.482, 0.493) | |
| BSRGAN | 17.907 (17.744, 18.070) | 0.487 (0.471, 0.503) | 0.437 (0.424, 0.450) | |
| SwinIR | 24.526 (24.346, 24.706) | 0.580 (0.566, 0.594) | 0.247 (0.236, 0.259) | |
| HistoDiff | 24.073 (23.893, 24.253) | 0.725 (0.715, 0.736) | 0.154 (0.147, 0.160) | |
| LDM | 18.203 (17.968, 18.437) | 0.369 (0.355, 0.383) | 0.423 (0.418, 0.429) | |
| LPFM | 26.173 (26.023, 26.322) | 0.757 (0.745, 0.769) | 0.194 (0.187, 0.201) | |
| CycleGAN | 22.838 (22.502, 23.174) | 0.797 (0.789, 0.805) | 0.271 (0.263, 0.278) | |
| Pix2Pix | 19.278 (19.129, 19.426) | 0.448 (0.436, 0.459) | 0.439 (0.432, 0.445) | |
| BSRGAN | 19.312 (19.165, 19.460) | 0.569 (0.553, 0.585) | 0.378 (0.365, 0.391) | |
| SwinIR | 26.793 (26.634, 26.952) | 0.756 (0.743, 0.768) | 0.275 (0.262, 0.287) | |
| HistoDiff | 23.561 (23.375, 23.748) | 0.685 (0.674, 0.696) | 0.175 (0.168, 0.181) | |
| LDM | 19.112 (18.867, 19.356) | 0.402 (0.387, 0.416) | 0.394 (0.389, 0.399) | |
| LPFM | 26.265 (26.069, 26.462) | 0.835 (0.830, 0.840) | 0.206 (0.202, 0.211) | |
| CycleGAN | 23.241 (22.882, 23.600) | 0.845 (0.838, 0.852) | 0.227 (0.220, 0.234) | |
| Pix2Pix | 21.717 (21.546, 21.888) | 0.562 (0.551, 0.573) | 0.372 (0.364, 0.380) | |
| BSRGAN | 21.263 (21.125, 21.401) | 0.677 (0.663, 0.691) | 0.281 (0.269, 0.293) | |
| SwinIR | 27.193 (27.015, 27.371) | 0.755 (0.742, 0.769) | 0.287 (0.274, 0.299) | |
| HistoDiff | 23.194 (22.995, 23.393) | 0.580 (0.566, 0.594) | 0.194 (0.187, 0.201) | |
| LDM | 20.060 (19.802, 20.317) | 0.440 (0.425, 0.454) | 0.360 (0.355, 0.364) | |
| LPFM | 28.041 (27.825, 28.258) | 0.890 (0.887, 0.894) | 0.160 (0.156, 0.164) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 23.331 (22.953, 23.709) | 0.779 (0.768, 0.791) | 0.297 (0.287, 0.306) | |
| Pix2Pix | 18.201 (18.039, 18.362) | 0.366 (0.358, 0.374) | 0.474 (0.467, 0.481) | |
| BSRGAN | 19.186 (18.817, 19.555) | 0.621 (0.602, 0.641) | 0.308 (0.294, 0.322) | |
| SwinIR | 24.809 (24.597, 25.021) | 0.740 (0.731, 0.750) | 0.170 (0.157, 0.183) | |
| HistoDiff | 24.809 (24.597, 25.021) | 0.655 (0.641, 0.670) | 0.145 (0.138, 0.152) | |
| LDM | 20.405 (20.115, 20.695) | 0.501 (0.481, 0.520) | 0.390 (0.385, 0.394) | |
| LPFM | 26.315 (26.108, 26.522) | 0.808 (0.794, 0.823) | 0.144 (0.138, 0.152) | |
| CycleGAN | 23.937 (23.534, 24.339) | 0.816 (0.806, 0.825) | 0.265 (0.255, 0.275) | |
| Pix2Pix | 20.018 (19.837, 20.199) | 0.464 (0.455, 0.473) | 0.429 (0.421, 0.436) | |
| BSRGAN | 21.334 (21.067, 21.602) | 0.691 (0.675, 0.707) | 0.248 (0.236, 0.260) | |
| SwinIR | 27.366 (27.048, 27.684) | 0.809 (0.784, 0.833) | 0.184 (0.162, 0.206) | |
| HistoDiff | 25.284 (25.034, 25.534) | 0.702 (0.689, 0.716) | 0.124 (0.119, 0.129) | |
| LDM | 21.202 (20.937, 21.468) | 0.534 (0.514, 0.553) | 0.361 (0.356, 0.365) | |
| LPFM | 25.829 (25.530, 26.127) | 0.816 (0.808, 0.823) | 0.124 (0.117, 0.130) | |
| CycleGAN | 24.588 (24.156, 25.021) | 0.855 (0.847, 0.863) | 0.228 (0.218, 0.238) | |
| Pix2Pix | 22.244 (22.044, 22.443) | 0.593 (0.584, 0.603) | 0.367 (0.357, 0.376) | |
| BSRGAN | 23.520 (23.293, 23.746) | 0.761 (0.749, 0.774) | 0.187 (0.176, 0.197) | |
| SwinIR | 28.332 (28.142, 28.522) | 0.796 (0.783, 0.809) | 0.195 (0.184, 0.207) | |
| HistoDiff | 25.493 (25.276, 25.710) | 0.694 (0.681, 0.707) | 0.123 (0.118, 0.129) | |
| LDM | 22.020 (21.766, 22.274) | 0.567 (0.549, 0.586) | 0.329 (0.324, 0.334) | |
| LPFM | 27.675 (27.331, 28.020) | 0.875 (0.869, 0.880) | 0.114 (0.109, 0.120) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 22.886 (22.542, 23.230) | 0.758 (0.747, 0.768) | 0.297 (0.289, 0.305) | |
| Pix2Pix | 18.148 (17.994, 18.302) | 0.379 (0.368, 0.391) | 0.470 (0.463, 0.477) | |
| BSRGAN | 18.677 (18.425, 18.930) | 0.567 (0.552, 0.583) | 0.367 (0.356, 0.379) | |
| SwinIR | 26.546 (26.336, 26.757) | 0.773 (0.762, 0.783) | 0.311 (0.302, 0.319) | |
| HistoDiff | 24.174 (23.934, 24.415) | 0.624 (0.611, 0.638) | 0.157 (0.151, 0.164) | |
| LDM | 19.296 (18.997, 19.595) | 0.429 (0.414, 0.444) | 0.404 (0.398, 0.409) | |
| LPFM | 24.338 (24.093, 24.584) | 0.739 (0.730, 0.747) | 0.289 (0.283, 0.296) | |
| CycleGAN | 23.570 (23.217, 23.922) | 0.799 (0.790, 0.809) | 0.264 (0.256, 0.271) | |
| Pix2Pix | 20.148 (19.962, 20.335) | 0.477 (0.465, 0.489) | 0.419 (0.411, 0.426) | |
| BSRGAN | 20.141 (19.949, 20.334) | 0.638 (0.624, 0.652) | 0.305 (0.294, 0.317) | |
| SwinIR | 27.321 (27.113, 27.530) | 0.772 (0.761, 0.784) | 0.319 (0.310, 0.328) | |
| HistoDiff | 24.556 (24.309, 24.803) | 0.650 (0.637, 0.663) | 0.142 (0.136, 0.148) | |
| LDM | 20.285 (19.989, 20.582) | 0.465 (0.450, 0.481) | 0.371 (0.366, 0.376) | |
| LPFM | 26.159 (25.889, 26.428) | 0.814 (0.808, 0.820) | 0.227 (0.221, 0.233) | |
| CycleGAN | 24.099 (23.727, 24.472) | 0.843 (0.835, 0.851) | 0.226 (0.219, 0.234) | |
| Pix2Pix | 22.735 (22.531, 22.939) | 0.603 (0.592, 0.614) | 0.349 (0.340, 0.358) | |
| BSRGAN | 22.321 (22.136, 22.506) | 0.723 (0.712, 0.735) | 0.222 (0.211, 0.233) | |
| SwinIR | 27.894 (27.680, 28.107) | 0.772 (0.761, 0.784) | 0.323 (0.314, 0.333) | |
| HistoDiff | 24.893 (24.644, 25.141) | 0.673 (0.661, 0.685) | 0.131 (0.125, 0.137) | |
| LDM | 21.246 (20.933, 21.558) | 0.505 (0.489, 0.520) | 0.335 (0.330, 0.340) | |
| LPFM | 27.993 (27.705, 28.282) | 0.872 (0.867, 0.877) | 0.179 (0.174, 0.184) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 22.793 (22.492, 23.094) | 0.763 (0.756, 0.770) | 0.263 (0.256, 0.269) | |
| Pix2Pix | 19.109 (18.917, 19.300) | 0.473 (0.459, 0.487) | 0.420 (0.412, 0.428) | |
| BSRGAN | 17.747 (17.432, 18.063) | 0.530 (0.518, 0.542) | 0.370 (0.360, 0.381) | |
| SwinIR | 26.754 (26.552, 26.955) | 0.773 (0.763, 0.783) | 0.291 (0.285, 0.297) | |
| HistoDiff | 24.006 (23.834, 24.178) | 0.626 (0.617, 0.636) | 0.161 (0.155, 0.167) | |
| LDM | 19.268 (19.096, 19.441) | 0.426 (0.416, 0.437) | 0.353 (0.347, 0.359) | |
| LPFM | 24.737 (24.570, 24.904) | 0.750 (0.744, 0.756) | 0.233 (0.228, 0.237) | |
| CycleGAN | 23.320 (22.986, 23.654) | 0.803 (0.797, 0.810) | 0.231 (0.225, 0.237) | |
| Pix2Pix | 20.991 (20.786, 21.195) | 0.571 (0.558, 0.584) | 0.363 (0.354, 0.371) | |
| BSRGAN | 20.342 (20.159, 20.525) | 0.627 (0.617, 0.637) | 0.300 (0.289, 0.311) | |
| SwinIR | 27.228 (27.023, 27.433) | 0.770 (0.760, 0.781) | 0.304 (0.297, 0.311) | |
| HistoDiff | 24.385 (24.208, 24.562) | 0.655 (0.646, 0.664) | 0.149 (0.144, 0.155) | |
| LDM | 20.309 (20.115, 20.502) | 0.462 (0.451, 0.473) | 0.325 (0.319, 0.330) | |
| LPFM | 26.733 (26.542, 26.923) | 0.828 (0.824, 0.832) | 0.175 (0.171, 0.178) | |
| CycleGAN | 24.023 (23.647, 24.399) | 0.847 (0.842, 0.853) | 0.192 (0.186, 0.198) | |
| Pix2Pix | 23.180 (22.987, 23.373) | 0.685 (0.673, 0.696) | 0.292 (0.283, 0.300) | |
| BSRGAN | 22.676 (22.519, 22.832) | 0.722 (0.714, 0.731) | 0.213 (0.204, 0.222) | |
| SwinIR | 27.492 (27.284, 27.700) | 0.768 (0.757, 0.779) | 0.313 (0.306, 0.320) | |
| HistoDiff | 24.752 (24.566, 24.937) | 0.681 (0.673, 0.690) | 0.139 (0.134, 0.145) | |
| LDM | 21.255 (21.039, 21.471) | 0.498 (0.487, 0.509) | 0.295 (0.290, 0.300) | |
| LPFM | 28.614 (28.406, 28.821) | 0.886 (0.883, 0.889) | 0.134 (0.131, 0.137) |
| Noise Level | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CycleGAN | 22.686 (21.691, 23.681) | 0.776 (0.757, 0.795) | 0.301 (0.282, 0.321) | |
| Pix2Pix | 16.995 (16.160, 17.830) | 0.368 (0.342, 0.393) | 0.490 (0.464, 0.517) | |
| BSRGAN | 17.458 (16.468, 18.449) | 0.537 (0.489, 0.585) | 0.477 (0.453, 0.500) | |
| SwinIR | 26.829 (26.510, 27.147) | 0.804 (0.778, 0.830) | 0.287 (0.265, 0.310) | |
| HistoDiff | 24.184 (23.336, 25.033) | 0.653 (0.617, 0.689) | 0.309 (0.295, 0.324) | |
| LDM | 19.317 (18.391, 20.243) | 0.430 (0.386, 0.475) | 0.405 (0.386, 0.423) | |
| LPFM | 24.514 (23.737, 25.291) | 0.760 (0.742, 0.777) | 0.278 (0.260, 0.297) | |
| CycleGAN | 23.285 (22.241, 24.328) | 0.814 (0.797, 0.831) | 0.268 (0.248, 0.287) | |
| Pix2Pix | 18.705 (17.766, 19.644) | 0.462 (0.435, 0.489) | 0.446 (0.418, 0.474) | |
| BSRGAN | 19.467 (18.754, 20.180) | 0.628 (0.588, 0.669) | 0.410 (0.387, 0.433) | |
| SwinIR | 27.652 (27.256, 28.048) | 0.805 (0.778, 0.832) | 0.297 (0.274, 0.319) | |
| HistoDiff | 24.295 (23.569, 25.021) | 0.677 (0.644, 0.710) | 0.291 (0.276, 0.305) | |
| LDM | 20.348 (19.447, 21.249) | 0.469 (0.422, 0.515) | 0.375 (0.356, 0.394) | |
| LPFM | 26.450 (25.592, 27.308) | 0.832 (0.818, 0.847) | 0.222 (0.204, 0.241) | |
| CycleGAN | 23.984 (22.890, 25.077) | 0.854 (0.839, 0.869) | 0.228 (0.208, 0.248) | |
| Pix2Pix | 21.281 (20.441, 22.121) | 0.596 (0.570, 0.622) | 0.377 (0.349, 0.404) | |
| BSRGAN | 21.887 (21.363, 22.411) | 0.734 (0.703, 0.764) | 0.323 (0.303, 0.344) | |
| SwinIR | 28.272 (27.641, 28.902) | 0.806 (0.779, 0.832) | 0.302 (0.280, 0.324) | |
| HistoDiff | 24.503 (23.814, 25.192) | 0.699 (0.668, 0.730) | 0.272 (0.258, 0.287) | |
| LDM | 21.300 (20.340, 22.260) | 0.510 (0.462, 0.558) | 0.339 (0.321, 0.356) | |
| LPFM | 28.335 (27.377, 29.294) | 0.888 (0.878, 0.899) | 0.177 (0.158, 0.196) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGan | 18.538 (18.443, 18.538) | 0.395 (0.389, 0.395) | 0.402 (0.399, 0.402) |
| Pix2Pix | 22.963 (22.823, 22.963) | 0.584 (0.579, 0.584) | 0.294 (0.291, 0.294) |
| HER2 | 24.624 (24.492, 24.624) | 0.667 (0.662, 0.667) | 0.257 (0.254, 0.257) |
| RegGan | 26.424 (26.290, 26.424) | 0.731 (0.727, 0.731) | 0.190 (0.188, 0.190) |
| LDM | 17.708 (17.589, 17.708) | 0.503 (0.498, 0.503) | 0.481 (0.479, 0.481) |
| LPFM | 27.805 (27.661, 27.805) | 0.763 (0.759, 0.763) | 0.153 (0.150, 0.153) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGAN | 13.174 (12.974, 13.374) | 0.385 (0.373, 0.396) | 0.406 (0.402, 0.411) |
| Pix2Pix | 15.956 (15.808, 16.104) | 0.421 (0.414, 0.428) | 0.390 (0.385, 0.396) |
| HER2 | 15.772 (15.593, 15.951) | 0.309 (0.298, 0.320) | 0.503 (0.497, 0.508) |
| RegGAN | 18.529 (18.360, 18.697) | 0.467 (0.458, 0.476) | 0.339 (0.335, 0.344) |
| LDM | 12.982 (12.791, 13.174) | 0.309 (0.303, 0.316) | 0.488 (0.482, 0.494) |
| LPFM | 19.292 (19.121, 19.463) | 0.563 (0.555, 0.572) | 0.316 (0.311, 0.320) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGAN | 21.741 (21.484, 21.998) | 0.556 (0.549, 0.563) | 0.532 (0.525, 0.540) |
| Pix2Pix | 25.011 (24.474, 25.549) | 0.736 (0.730, 0.743) | 0.395 (0.388, 0.403) |
| HER2 | 24.246 (23.833, 24.658) | 0.750 (0.743, 0.757) | 0.393 (0.384, 0.402) |
| RegGAN | 25.982 (25.678, 26.287) | 0.810 (0.803, 0.817) | 0.258 (0.252, 0.264) |
| LDM | 24.763 (24.432, 25.094) | 0.627 (0.619, 0.635) | 0.263 (0.257, 0.269) |
| LPFM | 26.992 (26.733, 27.251) | 0.770 (0.765, 0.774) | 0.241 (0.235, 0.246) |
| Cohort | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| CAMELYON16 | CycleGAN | 18.643 (18.150, 19.135) | 0.617 (0.592, 0.642) | 0.180 (0.168, 0.191) |
| Pix2Pix | 21.978 (21.352, 22.603) | 0.657 (0.629, 0.685) | 0.161 (0.148, 0.174) | |
| BSRGAN | 20.020 (19.660, 20.379) | 0.619 (0.597, 0.641) | 0.183 (0.172, 0.194) | |
| SwinIR | 22.336 (21.864, 22.808) | 0.629 (0.607, 0.650) | 0.320 (0.304, 0.336) | |
| HistoDiff | 22.176 (21.656, 22.696) | 0.648 (0.624, 0.671) | 0.117 (0.108, 0.126) | |
| LDM | 20.394 (19.980, 20.809) | 0.547 (0.531, 0.563) | 0.178 (0.165, 0.191) | |
| LPFM | 24.833 (24.157, 25.510) | 0.760 (0.738, 0.781) | 0.148 (0.135, 0.162) | |
| PAIP2020 | CycleGAN | 20.849 (20.452, 21.246) | 0.568 (0.541, 0.595) | 0.216 (0.202, 0.230) |
| Pix2Pix | 22.824 (22.253, 23.396) | 0.576 (0.546, 0.606) | 0.215 (0.199, 0.230) | |
| BSRGAN | 20.822 (20.363, 21.281) | 0.493 (0.468, 0.517) | 0.227 (0.214, 0.240) | |
| SwinIR | 23.190 (22.713, 23.666) | 0.498 (0.476, 0.521) | 0.429 (0.411, 0.448) | |
| HistoDiff | 22.591 (22.120, 23.061) | 0.526 (0.501, 0.551) | 0.156 (0.143, 0.169) | |
| LDM | 21.448 (21.068, 21.827) | 0.436 (0.418, 0.453) | 0.274 (0.256, 0.292) | |
| LPFM | 25.228 (24.570, 25.886) | 0.653 (0.625, 0.681) | 0.228 (0.210, 0.246) | |
| PANDA | CycleGAN | 21.263 (20.844, 21.682) | 0.637 (0.612, 0.662) | 0.189 (0.176, 0.201) |
| Pix2Pix | 24.193 (23.639, 24.746) | 0.666 (0.637, 0.694) | 0.163 (0.150, 0.176) | |
| BSRGAN | 21.619 (21.302, 21.936) | 0.627 (0.601, 0.652) | 0.168 (0.156, 0.180) | |
| SwinIR | 25.106 (24.621, 25.591) | 0.642 (0.617, 0.666) | 0.304 (0.286, 0.323) | |
| HistoDiff | 24.264 (23.796, 24.732) | 0.624 (0.598, 0.650) | 0.131 (0.120, 0.142) | |
| LDM | 23.049 (22.661, 23.438) | 0.545 (0.524, 0.566) | 0.195 (0.181, 0.208) | |
| LPFM | 26.527 (25.922, 27.132) | 0.732 (0.707, 0.757) | 0.176 (0.160, 0.192) |
| Cohort | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| TIGER2021 | CycleGAN | 22.449 (21.968, 22.930) | 0.614 (0.589, 0.639) | 0.183 (0.170, 0.195) |
| Pix2Pix | 23.988 (23.448, 24.529) | 0.634 (0.607, 0.661) | 0.181 (0.167, 0.194) | |
| BSRGAN | 21.327 (20.985, 21.669) | 0.561 (0.537, 0.584) | 0.197 (0.184, 0.209) | |
| SwinIR | 24.370 (23.901, 24.839) | 0.589 (0.569, 0.609) | 0.347 (0.331, 0.363) | |
| HistoDiff | 23.471 (23.003, 23.939) | 0.575 (0.552, 0.597) | 0.140 (0.129, 0.151) | |
| LDM | 22.381 (21.983, 22.779) | 0.501 (0.484, 0.517) | 0.214 (0.200, 0.228) | |
| LPFM | 26.123 (25.510, 26.735) | 0.701 (0.677, 0.725) | 0.186 (0.172, 0.201) | |
| MIDOG2022 | CycleGAN | 20.580 (20.174, 20.987) | 0.595 (0.571, 0.619) | 0.196 (0.183, 0.208) |
| Pix2Pix | 23.467 (22.968, 23.965) | 0.627 (0.601, 0.652) | 0.173 (0.160, 0.186) | |
| BSRGAN | 20.837 (20.526, 21.149) | 0.543 (0.524, 0.563) | 0.206 (0.195, 0.216) | |
| SwinIR | 23.834 (23.482, 24.187) | 0.563 (0.545, 0.580) | 0.342 (0.329, 0.356) | |
| HistoDiff | 23.217 (22.839, 23.595) | 0.571 (0.551, 0.591) | 0.141 (0.131, 0.151) | |
| LDM | 21.967 (21.635, 22.300) | 0.491 (0.476, 0.505) | 0.182 (0.169, 0.194) | |
| LPFM | 26.002 (25.440, 26.565) | 0.708 (0.685, 0.731) | 0.168 (0.155, 0.181) | |
| OCELOT | CycleGAN | 21.226 (20.243, 22.209) | 0.671 (0.600, 0.742) | 0.183 (0.146, 0.219) |
| Pix2Pix | 25.317 (23.594, 27.039) | 0.695 (0.616, 0.774) | 0.157 (0.116, 0.197) | |
| BSRGAN | 21.705 (20.312, 23.098) | 0.618 (0.547, 0.689) | 0.196 (0.156, 0.235) | |
| SwinIR | 25.468 (23.729, 27.206) | 0.633 (0.573, 0.692) | 0.324 (0.277, 0.371) | |
| HistoDiff | 24.477 (22.793, 26.161) | 0.625 (0.559, 0.691) | 0.143 (0.116, 0.170) | |
| LDM | 22.811 (21.565, 24.057) | 0.529 (0.481, 0.576) | 0.192 (0.151, 0.233) | |
| LPFM | 28.202 (26.104, 30.300) | 0.765 (0.695, 0.835) | 0.155 (0.111, 0.200) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGan | 16.215 (16.120, 16.310) | 0.325 (0.319, 0.331) | 0.482 (0.479, 0.485) |
| Pix2Pix | 20.538 (20.398, 20.678) | 0.494 (0.489, 0.499) | 0.374 (0.371, 0.377) |
| HER2 | 22.124 (21.992, 22.256) | 0.577 (0.572, 0.582) | 0.337 (0.334, 0.340) |
| RegGan | 23.824 (23.690, 23.958) | 0.641 (0.637, 0.645) | 0.270 (0.268, 0.272) |
| LPFM | 25.205 (25.061, 25.349) | 0.683 (0.679, 0.687) | 0.233 (0.230, 0.236) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGAN | 12.156 (12.016, 12.295) | 0.308 (0.300, 0.316) | 0.529 (0.525, 0.532) |
| Pix2Pix | 12.083 (11.966, 12.200) | 0.173 (0.166, 0.180) | 0.591 (0.587, 0.594) |
| HER2 | 7.288 (7.176, 7.401) | 0.193 (0.187, 0.199) | 0.603 (0.600, 0.607) |
| RegGAN | 12.885 (12.679, 13.092) | 0.330 (0.323, 0.337) | 0.395 (0.388, 0.402) |
| LPFM | 18.091 (17.940, 18.242) | 0.378 (0.368, 0.388) | 0.251 (0.247, 0.256) |
| Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|
| CycleGAN | 20.916 (20.832, 21.000) | 0.415 (0.410, 0.420) | 0.684 (0.680, 0.688) |
| Pix2Pix | 21.254 (21.125, 21.383) | 0.489 (0.482, 0.496) | 0.599 (0.593, 0.605) |
| HER2 | 21.924 (21.723, 22.125) | 0.638 (0.630, 0.645) | 0.536 (0.529, 0.543) |
| RegGAN | 24.200 (23.945, 24.456) | 0.690 (0.683, 0.696) | 0.374 (0.368, 0.381) |
| LPFM | 26.489 (26.304, 26.674) | 0.714 (0.708, 0.720) | 0.355 (0.348, 0.361) |
| Primariy Site | Number of Slides |
|---|---|
| Organs | Slide |
| Bile duct | 39 |
| Fallopian | 43 |
| Melanoma | 80 |
| Mesothelioma | 87 |
| Thymoma | 181 |
| Pheochromocytoma and Paraganglioma | 196 |
| Minor Salivary Gland | 247 |
| Lymphoma | 248 |
| Vagina | 276 |
| Cervical | 359 |
| Colorectal | 372 |
| Pituitary | 428 |
| Unknown | 433 |
| Bladder | 587 |
| Small Intestine - Terminal Ileum | 798 |
| Testicle | 846 |
| Head and Neck | 862 |
| Ovaries | 867 |
| Spleen | 874 |
| Sarcomas | 905 |
| Adrenal | 944 |
| Nerve | 975 |
| Muscle | 1,001 |
| Liver | 1,100 |
| Heart | 1,374 |
| Stomach | 1,381 |
| Thyroid | 1,421 |
| Pancreas | 1,691 |
| Uterus | 1,777 |
| Adipose | 1,793 |
| Kidney | 2,329 |
| Artery | 2,499 |
| Skin | 2,705 |
| Colon | 2,759 |
| Esophagus | 2,866 |
| Brain | 3,020 |
| Lung | 4,130 |
| Breast | 8,266 |
| Pancancer | 18,394 |
| Prostate | 18,657 |
| Sum | 87,810 |
| Dataset | Source | Slide | Organ | Stain |
|---|---|---|---|---|
| CPTAC-BRCA | CPTAC | 653 | Breast | HE |
| CPTAC-CCRCC | CPTAC | 783 | Kidney | HE |
| CPTAC-CM | CPTAC | 411 | Skin | HE |
| CPTAC-COAD | CPTAC | 372 | Colorectal | HE |
| CPTAC-GBM | CPTAC | 462 | Brain | HE |
| CPTAC-HNSCC | CPTAC | 390 | Head and Neck | HE |
| CPTAC-LSCC | CPTAC | 1081 | Lung | HE |
| CPTAC-LUAD | CPTAC | 1137 | Lung | HE |
| CPTAC-OV | CPTAC | 221 | Ovaries | HE |
| CPTAC-PDA | CPTAC | 557 | Pancreas | HE |
| CPTAC-SAR | CPTAC | 305 | Sarcomas | HE |
| CPTAC-UCEC | CPTAC | 883 | Uterus | HE |
| CPTAC | CPTAC | 7,255 | Multi Organs | HE |
| Dataset | Source | Slide | Organ | Stain |
|---|---|---|---|---|
| TCGA-ACC | TCGA | 227 | Adrenal glands | HE |
| TCGA-BLCA | TCGA | 457 | Bladder | HE |
| TCGA-BRCA | TCGA | 1,133 | Breast | HE |
| TCGA-CESC | TCGA | 279 | Cervical | HE |
| TCGA-CHOL | TCGA | 39 | Bile duct | HE |
| TCGA-COAD | TCGA | 459 | Colon | HE |
| TCGA-DLBC | TCGA | 44 | Lymphoma | HE |
| TCGA-ESCA | TCGA | 158 | Esophagus | HE |
| TCGA-Frozen | TCGA | 18,394 | Pancancer | HE |
| TCGA-GBM | TCGA | 860 | Brain | HE |
| TCGA-HNSC | TCGA | 472 | Head and Neck | HE |
| TCGA-KICH | TCGA | 121 | Kidney | HE |
| TCGA-KIRC | TCGA | 519 | Kidney | HE |
| TCGA-KIRP | TCGA | 300 | Kidney | HE |
| TCGA-LGG | TCGA | 844 | Brain | HE |
| TCGA-LIHC | TCGA | 379 | Liver | HE |
| TCGA-LUAD | TCGA | 541 | Lung | HE |
| TCGA-LUSC | TCGA | 512 | Lung | HE |
| TCGA-MESO | TCGA | 87 | Mesothelioma | HE |
| TCGA-OV | TCGA | 107 | Ovaries | HE |
| TCGA-PAAD | TCGA | 209 | Pancreas | HE |
| TCGA-PCPG | TCGA | 196 | Pheochromocytoma and Paraganglioma | HE |
| TCGA-PRAD | TCGA | 449 | Prostate | HE |
| TCGA-READ | TCGA | 165 | Colon | HE |
| TCGA-SARC | TCGA | 600 | Sarcomas | HE |
| TCGA-SKCM | TCGA | 475 | Skin | HE |
| TCGA-STAD | TCGA | 442 | Stomach | HE |
| TCGA-TGCT | TCGA | 254 | Testicle | HE |
| TCGA-THCA | TCGA | 519 | Thyroid | HE |
| TCGA-THYM | TCGA | 181 | Thymoma | HE |
| TCGA-UCEC | TCGA | 566 | Uterus | HE |
| TCGA-UCS | TCGA | 91 | Uterus | HE |
| TCGA-UVM | TCGA | 80 | Melanoma | HE |
| TCGA | TCGA | 30,159 | Multi Organs | HE |
| Dataset | Data Type | Number | Data Type | Number | Organ | Stain |
|---|---|---|---|---|---|---|
| TCGA [57] | Slide | 30,159 | Patch | 120,496,200 | Multi Organs | HE |
| GTEx_Portal [58] | Slide | 25,711 | Patch | 31,892,017 | Multi Organs | HE |
| PANDA [39] | Slide | 10,616 | Patch | 905,206 | Prostate | HE |
| CPTAC [59] | Slide | 7,255 | Patch | 11,768,225 | Multi Organs | HE |
| DiagSet [67] | Slide | 5,096 | Patch | 2,500,385 | Prostate | HE |
| ACROBATS2023 [65] | Slide | 1,943 | Patch | 76,128 | Breast | HE and IHC |
| NADT-Prostate [69] | Slide | 1,404 | Patch | 919,847 | Prostate | HE and IHC |
| BCNB [68] | Slide | 1,058 | Patch | 263,734 | Breast | HE |
| CAMELYON17 [60] | Slide | 998 | Patch | 4,612,382 | Breast | HE |
| BRACS [60] | Slide | 547 | Patch | 2,992,229 | Breast | HE |
| AGGC2022 [70] | Slide | 413 | Patch | 2,130,584 | Prostate | HE |
| MIDOG2022 [54] | Slide | 403 | Patch | 43,342 | Unknown | HE |
| CAMELYON16 [4] | Slide | 400 | Patch | 1,706,890 | Breast | HE |
| Ovarian_Bevacizumab_Response [71, 72] | Slide | 284 | Patch | 1,472,653 | Ovaries | HE |
| PAIP2021 | Slide | 240 | Patch | 1,048,840 | Colon,Prostate,Pancreas | HE |
| DLBCL [73] | Slide | 204 | Patch | 1,524,388 | Lymphoma | HE |
| HunCRC [74] | Slide | 200 | Patch | 3,369,925 | Colon | HE |
| MIDOG2021 [54] | Slide | 200 | Patch | 24,025 | Breast | HE |
| TIGER2021 [55] | Slide | 175 | Patch | 312,835 | Breast | HE |
| SLN-Breast [75] | Slide | 130 | Patch | 139,166 | Breast | HE |
| PAIP2020 [40] | Slide | 118 | Patch | 1,362,725 | Colon | HE |
| PAIP2019 [63] | Slide | 96 | Patch | 505,356 | Liver | HE |
| Post-NAT-BRCA [64] | Slide | 96 | Patch | 241,547 | Breast | HE |
| BACH [76] | Slide | 40 | Patch | 108,256 | Breast | HE |
| AF2HE [43] | Slide | 15 | Patch | 54,869 | Liver | AF and HE |
| PASAB | Slide | 10 | Patch | 11,918 | Unknown | PAS and HE |
| AML-Cytomorphology_LMU [61] | Slide | - | Patch | 18,365 | Blood | HE |
| ARCH [77] | Slide | - | Patch | 7,579 | Unknown | HE |
| BCI [78] | Slide | - | Patch | 7,792 | Breast | HE and IHC |
| CAMEL [79] | Slide | - | Patch | 12,757 | Unknown | HE |
| HEMIT [44] | Slide | - | Patch | 10,854 | Colon | HE and mIHC |
| Janowczyk [80] | Slide | - | Patch | 142 | Unknown | HE |
| LC25000 [81] | Slide | - | Patch | 25,000 | Lung,Colon | HE |
| OCELOT [56] | Slide | - | Patch | 800 | Pancancer | HE |
| Osteosarcoma_Tumor [62] | Slide | - | Patch | 1,144 | Osteosarcoma | HE |
| SICAPv2 [82] | Slide | - | Patch | 18,783 | Prostate | HE |
| SPIE2019 [66] | Slide | - | Patch | 4,006 | Unknown | HE and IHC |
| Sum | Slide | 87,810 | Patch | 190,590,894 | Multi Organs | Multi Stains |