A Uniformly Most Powerful Unbiased Test for Regression Parameters by Orthogonalizing Predictors
Center for Healthcare Innovation
University of Manitoba, Canada
3rd floor Rm 351, 753 McDermot Ave, Winnipeg MB R3E 0T6
Razvan.Romanescu@umanitoba.ca
ORCID: 0000-0002-3175-5399
)
Abstract
In a multiple regression model where features (predictors) form an orthonormal basis, we prove that there exists a uniformly most powerful unbiased (UMPU) test for testing that the coefficient of a single feature is negative (or zero) versus positive. The test statistic used is the same as the coefficient t-test commonly reported by standard statistical software, and has the same null distribution. This result suggests that orthogonalizing features around the predictor of interest, prior to fitting the multiple regression, might be a way to increase power in single coefficient testing, compared to regressing on the raw, correlated features. This paper determines the conditions under which this is true, and argues that those conditions are fulfilled in a majority of applications.
1 Introduction
It is well known from practice that having correlated predictors in a multiple regression model leads to loss of power. In an extreme case, including perfectly correlated predictors leads to a model that is over-identified. Even if features are highly, but not perfectly, correlated, multicollinearity might make the model fit unstable. The amount of multicollinearity is sometimes measured via variance inflation factors (VIFs). Parameters that have high VIF are deemed to significantly increase multicollinearity of the model and might be excluded. However, sometimes it is desirable to keep related predictors as each might contain unique information.
Orthogonalizing the design matrix is an alternative way to deal with the multicollinearity problem. This is not a new concept, having been used in many ways in many fields, see, e.g., [3, 4]. Orthogonalizing the feature space via principal components or other methods (e.g., [8]) is a standard choice as a dimension reduction technique, especially when the number of features is large, and when interpretability is not particularly important. By contrast, uptake of this approach is limited, even non-existent, when the feature space is made up of a smaller number of meaningful predictors. This may be due to the open-ended modeling questions that it raises, namely, in which order to orthogonalize features, and how to interpret the newly created predictor set. In this paper we orthogonalize features sequentially, preserving the dimension of the design matrix, and select the new basis starting from one of the initial predictors as the first direction. We do this both for ease of interpretation, and because we want to increase power in testing the significance of one predictor that may be of particular importance in a multiple regression problem. Section 2 introduces the two main theoretical results of the paper. In Section 3, we show on a simulated example that power gains can be significant if the features are correlated, and we conclude in Section 4 with a discussion of where this approach might be most beneficial and how the new features might be interpreted.
1.1 Related work
Prior work on building UMPU tests is well established in inference theory and starts with testing the single parameter exponential family. The existence of UMP tests in this case is based on the Neyman-Pearson Lemma, and tests can be built by writing the likelihood ratio as a monotone function of the sufficient statistic. While this approach does not generalize directly to multi-parameter families, UMPU tests can be constructed for one parameter by condidioning on the sufficient statistics for the other parameters. This is the problem we consider here, namely making inference about the coefficient of a single fixed effect in multiple regression, while treating the other coefficients as nuisance. A UMP invariant (UMPI) test for the directional testing of a subset of coefficients being jointly zero, assuming knowledge of the coefficients’ signs, has been constructed by [6]. The invariance condition is a somewhat strong assumption, and this test does not attain the envelope of power, even though it is shown to perform reasonably well in simulations. The problem of efficient testing in the regression model has been solved for a general distribution by [2], by using the notions of asymptotically uniformly most powerful (AUMP), and effective scores. However, these are fairly advanced concepts based on local asymptotic normality, and no simple solution has been derived for the multivariate regression case, which is an important case in applied statistics. The treatment considered here is more elementary, and relates to familiar test statistics from regression analysis.
2 Regression on an orthonormal set of predictors
We introduce the main result, which concerns the one-sided test of a coefficient in a multiple regression model, where features are orthonormal. The proof generalizes Example 6.9.11 from [1] , which establishes the result in the more limited case of testing for the slope in a simple regression model in which intercept and error variance are unknown.
THEOREM 1. Suppose we observe data vector from the multiple regression model , where and are fixed covariates, for . Assume further that form an orthonormal basis for , and all parameters ( and ) are unknown. The test defined as
| (1) |
where is UMPU for testing vs .
PROOF: As is typical when looking for a UMP test in the presence of nuisance parameters, we first wish to identify sufficient statistics for this inference. With normal data, the joint density will belong to the exponential family and can be written thus
| (2) |
From this, the sufficient statistics are corresponding to the natural parameter vector . According to [1] (pp. 147-148) there exists an unbiased UMP test where is determined from , where are the sufficient statistics for the important and nuisance parameters, respectively. The problem is that the joint conditional distribution is not yet straightforward to obtain as is not entirely independent of . In what follows, the plan is to use Theorem 6.9.2 part A from [1], which gives some relatively simpler conditions for a test to attain UMPU property, and is especially suited when data is normal.
Our objective now is to find a simpler characterization for the distribution of the sufficient statistics. Following and extending the reasoning in the aforementioned Example 6.9.11, let be an orthonormal basis for that includes the covariate vectors, i.e., , and are chosen such that , and . Further define . It is relatively straightforward to show that are iid . We also have that . This is true because is the length of the projection of the error vector on basis vector , and we express the squared length of vector in both coordinate bases.
In the regression model, we can identify the best fit parameters as the projection of data vector onto covariate directions . Let us call the corresponding estimators . The residual sum of squares is . The first sum expands to . It is then easy to obtain that , from the original definition of .
To recapitulate, we found summary statistics , and , which are all mutually independent. Plugging these into Equation 2,
| (3) |
we see that statistics are sufficient for . Next, define a new variable . Check that satisfies the conditions of Theorem 6.9.2, namely
-
1.
is independent of when . As when , we get . As the distribution of does not depend on any of the other parameters , it follows from Corollary 5.1.1 to Basu’s Theorem in [7] that is independent of .
-
2.
is increasing in for each . It is easy to show that for any value of .
Therefore, we can conclude that an UMP unbiased test for vs , which is equivalent to testing vs is
where and are determined by . Ignoring the middle case () which has probability zero, we determine from
Looking at test statistic , we see that this is identical to the test of a coefficient being significantly different from zero in the standard multiple regression model. Specifically, the quantity is the Studentt test statistic for coefficient that is commonly output by statistical software packages. The degrees of freedom are also the same: since we have considered the intercept to be one of the predictors (if this were included), we would have ”predictor variables” in the standard textbook formulation of the model, so the degrees of freedom associated with the sum of squares would be , the same as in the previous Theorem.
Having shown that the test of significance for one coefficient attains the envelope of power for orthonormal design matrices, the natural question that arises next is whether this implies that the test for correlated predictors is inefficient, and whether something can be done to improve power. It is known that highly correlated predictors in a regression lead to underpowered inference as well as stability issues in fitting. Such a model can be improved upon by orthogonalizing the predictors, which at the same time solves any problems of multicollinearity, as well as ensures optimal power in testing.
In keeping with our theme of maximizing the power of testing one covariate deemed more important than others, we want to hold a feature fixed, and orthogonalize the other features in a particular order, to build a basis around the fixed feature. The order of orthogonalization may be random, if desired, or it may be informed by some ranking of interest in the features. In particular, the algorithm to obtaining a new basis starting from a set of features is given in the text box Algorithm 1. For example, the closed form solution for a basis with up to three features is given in the Appendix. We may find the following notation useful to denote the new basis, because it keeps track of the order of orthogonalization:
Essentially, Algorithm 1 solves for an upper triangular matrix which transforms the original set of features into an orthogonal set, such that
The benefit of constructing an orthonormal basis of predictors is visible from the following.
COROLLARY. The one-sided t-test for coefficient in regression model , where , is UMPU for testing vs .
Proof: This follows directly from Theorem 1 due to the construction of the orthonormal basis.
We should note here that orthogonalizing the feature space is not a new idea, having come up in many fields at various times. For instance, principal components are routinely used in genetics to identify and account for systematic biases due to population substructure (e.g., ancestry), in a high dimensional space of predictors (individual genetic variants). The specific incarnation of orthogonalization Algorithm 1 has been described before in [10, 9] (and references within) and used specifically to preserve stability of coefficient estimates when building regression models in Chemistry. So the utility of orthogonal predictors is undeniable in applications. The next natural question to consider is whether testing the orthogonalized model is always more powerful than the naive model. While we have shown the coefficient test in an orthonormal set of predictors to be UMPU, still, the two parameterizations technically give rise to different models, as they include different predictor sets. Thus, which test is more powerful is not a foregone conclusion.
THEOREM 2. In the following two parameterizations of the same multiple regression model:
| (A) | ||||
| (B) |
where and design matrix is obtained from via Algorithm 1. Assuming that the sign of , where is the first row of , is known, and we wish to compare the t-tests for vs ; and vs , defined via statistics and , respectively, with . Then the power of is higher than the power of iff .
Proof: To see the connection between the two parameterizations, write model as
| (4) |
By putting we see this to be equivalent to model , which is written in terms of parameters . The ordinary least squares estimate for is
where we have used that is full rank. Furthermore, using the well known formula for the variance-covariance matrix of the OLS estimate, we have
The standard error of the estimate vector is computed by replacing with , which is the same for both parameterizations. Let also . Thus we can simplify and , making the t-test statistic for :
The power function for is
where and quantities are as defined in the proof of Theorem 1. Because , we have , and . Similarly, the power function for is
Since and both and are independent of we conclude that
A couple of explanatory remarks are in order.
REMARK 1. For practical purposes, tests and have the same meaning: they are testing for a significant association between and the first term in the regression (either or , which are essentially the same feature). The interpretation of a positive result is the same, namely the first term being significantly associated with the outcome after controlling for all the other meaningful effects, regardless of how those effects are parameterized. Therefore we should use the most powerful between and when making inference, as long as both specifications (A) and (B) are equally acceptable in the application.
REMARK 2. The interpretation of this result is that using the t-test for the naive model results in higher power only if the cumulative effect sizes of the original features in the direction of are greater than the marginal effect of alone. To see this, notice that , so that the components of features in the direction of are given by vector . Multiplying these by the effect sizes in each perpendicular direction (i.e., ) gives the contributions of other predictors to the coefficient for .
Even though orthogonalizing predictors may not always be the most powerful strategy to test coefficients, a closer look at quantity reveals that situations when the naive test is more powerful, i.e., when are quite unlikely to occur in applications. This is because we need a combination of favourable factors to make , including:
-
1.
Large effect sizes (larger than ) for all (or very large for some) of the orthogonal components of the other predictors. While this is certainly possible in applications, if all or most other predictors had a higher effect size than the predictor of interest, an analyst would have to wonder whether the effect of interest is genuine, or if there are flaws in the design of the experiment. A notable exception is the intercept, which in many applications has the the most significant effect. However, this effect can be easily eliminated by centering the output data.
-
2.
The other predictors have to be correlated (either positively or negatively) with and the predictor’s component times its effect size has to be in the direction of , as pointed out in Remark 2. This has to happen for all or a select subset of the other predictor having very high effect sizes. While having correlated inputs seems to be more the rule than the exception in applications, there is no reason why the direction of the correlation has to agree with the effect size for the orthogonal component! Orthogonality generally suggests independence of effects; thus, for a regression with correlated predictors, we would intuitively expect only a chance that all contributions be in the same direction as .
Overall, the requirement that both points 1 and 2 have to be satisfied in order that makes this to be quite an unlikely case in practice. Therefore, we can conclude that, as a rule of thumb, model will be more powerful at testing a single predictor (the one around which the orthogonalizing was done) compared to model , in most situations.
3 Simulation study
We illustrate how to apply orthogonalization to improve power in testing using variables in the ’mtcars’ dataset in R. In this popular example dataset [5] we regress gas mileage for different cars on the characteristics of their engine. This application was chosen specifically due to the high correlations among predictors (0.90). Selecting a couple of features, number of cylinders and displacement, we find the following relationship for consumption in miles per gallon by fitting the standard regression model: , where the error standard deviation is . We now wish to see whether power improves when we orthogonalize the inputs, and, to check this, we will simulate replicated datasets, each of which keeps all of the same car models, but simulates random values for mpg based on the following model:
| mpg | |||
Notice that this matches the original data fit when , and we will vary to achieve smaller or larger effect sizes, while keeping the relative effects of the predictors constant. We orthogonalize the inputs on number of cylinders first, and compare the power curve for testing coefficient of cyl against the power of the corresponding test from the original regression (the ”naive model”). Later, we will do the orthogonalization on disp first and test that parameter’s coefficient. When fitting both the naive and orthogonal models, we will center all variables first, including the response mpg, and we will fit without an intercept term. This is to avoid a highly significant linear combination of basis vectors that matches the intercept vector (i.e., the vector of ones), in the orthogonal model. We assume the signs of the coefficients in both the naive and orthogonalized models to be known, which makes it sensible to conduct one-sided tests. This assumption is realistic in practice, where analysts often know the directions of effects, at least for the most important features. The sign of can be computed, if desired, to check whether a power boost can be expected by the orthogonal approach. To do this, multiply the regression equation by , which makes the outcome negative miles per gallon, and the coefficients and . Vector (the first row of ) can be computed by following the formulas in the Appendix; thus, holding as the fixed direction, . Using the coefficient values as in the data generating model, we get which means that the test using the orthonormal regression will be more powerful.
Figure 1 shows the power curves for both models, and for the two ways of orthogonalizing the features. Testing for the coefficient of the first feature is visibly more powerful than testing for in the naive model. The situation is almost identical when switching the order of cyl and disp, showing that the approach works regardless of which variable we choose as important.
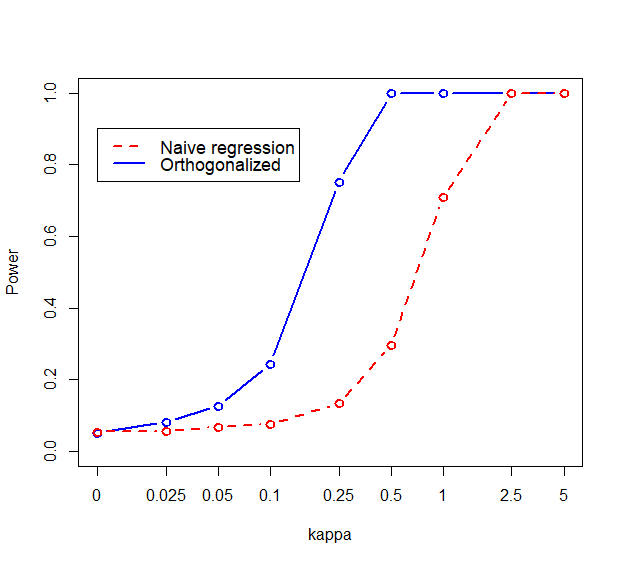
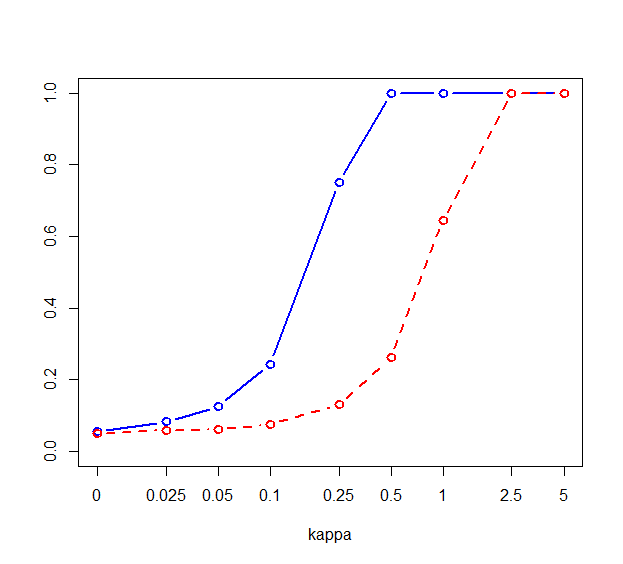
4 Discussion
There are some strong arguments for orthogonalizing highly correlated variables in regression. This paper has focused on the power advantage, and the knowledge that the coefficient tests are UMPU in this case. There are even more obvious advantages to this approach, still. One is that of eliminating collinearity without having to throwing away predictors, which loses potentially valuable information. Another advantage is that this approach does away with the need to include interaction terms. Indeed, with predictors there are potentially interaction terms that can (or should) be considered, and many more three way interactions. With an orthogonal set of predictors, this is no longer the case as features are uncorrelated. This will significantly preserve power in inferences about the parameters.
The disadvantage of this approach, which has become apparent from discussions with statistical practitioners (consultants), is that of interpretability. Interpreting the remainder of one predictor after regressing on a few others may not be easy, and in many cases, this will not be desirable. For instance, health studies typically include demographic variables in analysis, such as age and sex, among others; these should probably be kept as such, for the sake of interpretability. We do not advocate that orthogonalization should be used routinely, and for all features. However, here are a few cases where it might be sensible to include this approach, at least for a subset of the feature space:
-
1.
With highly correlated variables that measure roughly the same thing. In socioeconomic studies, as an example, gross and net income are both measures of income and likely to be highly correlated. If it is meaningful to keep both, then the interpretation of the coefficient for each might be difficult, because if two predictors are close to collinear, then it is likely that the fit to data will result in a positive coefficient for one, and a negative coefficient for the other. Of course, this does not mean that gross and net income have opposite effects, rather, this is likely to be an artifact of multicollinearity. In this case, it makes more sense to decide on one predictor (e.g., gross income) to be interpreted as the main effect for income, and include the orthogonal component of net income as an extra effect due to, say, differential taxation of individuals that earn the same salary before tax.
-
2.
When there is a natural ordering in importance of predictors. For example, to an engineer looking at the fuel efficiency of different engines, it might be apparent that engine volume (displacement) is mainly what drives consumption, while number of cylinders might be simply a design choice that correlates with larger, more powerful engines. In this case, there would be a causal relationship between and , with being an intermediary variable of secondary importance that mediates the effect of . It would then make sense to orthogonalize on as the main predictor, with the remainder term being the extra contribution of that is not related to engine size. This example spells out how an orthogonal remainder can be interpreted.
-
3.
In model building, since adding extra terms to the model does not change the estimated effects of previous predictors. As a follow-up to the previous point, when building a linear model through e.g., forward regression, one undesirable feature is that coefficients change every time a new term is added. This problem disappears when using orthogonalized predictors, as adding an extra dimension to the orthonormal basis does not change the projection of the data vector on the previous basis vectors. As such, parameters of full and reduced models will not lead to potentially contradictory interpretations.
Given all the advantages of orthogonalization, it is surprising that this approach has not gained more popularity in statistical practice.
Acknowledgements
RGR is based at the George & Fay Yee Centre for Healthcare Innovation. Support for CHI is provided by University of Manitoba, Canadian Institutes for Health Research, Province of Manitoba, and Shared Health Manitoba.
References
- [1] P.K. Bhattacharya and Prabir Burman. Hypothesis Testing. In Theory and Methods of Statistics, pages 125–177. Elsevier, 2016.
- [2] Sungsub Choi, W. J. Hall, and Anton Schick. Asymptotically uniformly most powerful tests in parametric and semiparametric models. The Annals of Statistics, 24(2), April 1996.
- [3] Merlise Clyde, Heather Desimone, and Giovanni Parmigiani. Prediction Via Orthogonalized Model Mixing. 2024.
- [4] Michele Forina, Silvia Lanteri, Monica Casale, and M. Conception Cerrato Oliveros. Stepwise orthogonalization of predictors in classification and regression techniques: An “old” technique revisited. Chemometrics and Intelligent Laboratory Systems, 87(2):252–261, June 2007.
- [5] Harold V. Henderson and Paul F. Velleman. Building Multiple Regression Models Interactively. Biometrics, 37(2):391, June 1981.
- [6] Maxwell L. King and Murray D. Smith. Joint one-sided tests of linear regression coefficients. Journal of Econometrics, 32(3):367–383, August 1986.
- [7] Erich L. Lehmann and Joseph P. Romano. Testing statistical hypotheses. Springer texts in statistics. Springer, New York, 3. ed., correct. at 4. print edition, 2008.
- [8] Xiaochang Lin, Jiewen Guan, Bilian Chen, and Yifeng Zeng. Unsupervised Feature Selection via Orthogonal Basis Clustering and Local Structure Preserving. IEEE Transactions on Neural Networks and Learning Systems, 33(11):6881–6892, November 2022.
- [9] Milan Randić. Mathematical chemistry illustrations: a personal view of less known results. Journal of Mathematical Chemistry, 57(1):280–314, January 2019.
- [10] Milan Šoškić, Dejan Plavšić, and Nenad Trinajstić. Link between Orthogonal and Standard Multiple Linear Regression Models. Journal of Chemical Information and Computer Sciences, 36(4):829–832, January 1996. Publisher: American Chemical Society.
Appendix
Going through the orthogonalization steps, we obtain the following new basis in closed form for up to three predictors
| (5) |
where
| (6) |
The corresponding matrix so that is