A Universal Transfer Theorem for Convex Optimization Algorithms
Using Inexact First-order Oracles
Abstract
Given any algorithm for convex optimization that uses exact first-order information (i.e., function values and subgradients), we show how to use such an algorithm to solve the problem with access to inexact first-order information. This is done in a “black-box” manner without knowledge of the internal workings of the algorithm. This complements previous work that considers the performance of specific algorithms like (accelerated) gradient descent with inexact information. In particular, our results apply to a wider range of algorithms beyond variants of gradient descent, e.g., projection-free methods, cutting-plane methods, or any other first-order methods formulated in the future. Further, they also apply to algorithms that handle structured nonconvexities like mixed-integer decision variables.
1 Introduction
Optimization is a core tool for almost any learning or estimation problem. Such problems are very often approached by setting up an optimization problem whose decision variables model the entity to be estimated, and whose objective and constraints are defined by the observed data combined with structural insights into the inference problem. Algorithms for any sufficiently general class of relevant optimization problems in such settings need to collect information about the particular instance by making (adaptive) queries about the objective before they can report a good solution. In this paper, we focus on the following important class of optimization problems over a fixed ground set
| (1.1) |
where is a (possibly nonsmooth) convex function. When the underlying ground set is all of or some fixed convex subset, (1.1) is the classical convex optimization problem. In this paper, we allow to be more general and to be used to model some known nonconvexity, e.g. integrality constraints by setting with , where is a fixed convex set. From an algorithmic perspective, the setup is that the algorithm has complete knowledge of what is, but does not a priori know and must collect information via queries. A standard model for accessing the function is through so-called first-order oracles. At any point during its execution, the algorithm can request the function value and the (sub)gradient of at any point .
Given access to such oracles, a first-order algorithm makes adaptive queries to this oracle and, after it judges that it has collected enough information about , it reports a solution with certain guarantees. A long line of research has gone into understanding exactly how many queries are needed to solve different classes of problems (with different sets of assumptions on and ), with tight upper and lower bounds on the query complexity (a.k.a. oracle or information complexity) known in the literature; see (Nesterov, 2004; Bubeck, 2015; Nemirovski, 1994; Basu, 2023; Basu et al., 2023) for expositions of these results.
A natural question that arises in this context is what happens if the response of the oracle is not exact, but approximate (with possibly desired accuracy). For example, the response of the oracle might be itself a solution to another computational problem which is solved only approximately, which happens when using function smoothing (Nesterov, 2005), and in minimax problems (Wang & Abernethy, 2018). Stochastic first-order oracles, modeling applications where only some estimate of the gradient is used, may also be viewed as inexact oracles whose accuracy is a random variable at each iteration. Thus, researchers have also investigated what one can say about algorithms that have access to inexact oracle responses (with possibly known guarantees on the inexactness). Early work on this topic appears in Shor (Shor, 1985) and Polyak (Polyak, 1987), and more recent progress can be found in (Devolder et al., 2014; Schmidt et al., 2011; Lan, 2009; Hintermüller, 2001; Kiwiel, 2006; d’Aspremont, 2008) and references therein. To the best of our knowledge, all previous work on inexact first-order oracles has focused either on how specific algorithms like (accelerated) gradient methods perform with inexact (sub)gradients with no essential change to the algorithm, or on how to adapt a particular class of algorithms to perform well with inexact information.
In this paper, we provide a different approach to the problem of inexact information. We provide a way to take any first-order algorithm that solves (1.1) with exact first-order information and, with absolutely no knowledge of the its inner workings, show how to make the same algorithm work with inexact oracle information. Thus, in contrast to earlier work, our result is not the analysis of specific algorithms under inexact information or the adaptation of specific algorithms to use inexact information. It is in this sense that we believe our results to be universal because they apply to a much wider class of algorithms than previous work, including gradient descent, cutting plane methods, bundle methods, projection-free methods etc., and also to any first-order method that is invented in the future for optimization problems of the form (1.1).
2 Formal statement of results and discussion
We begin with definitions of standard concepts that we need to state our results formally. We use to denote the standard Euclidean norm and to denote the Euclidean ball of radius centered at . When the center is the origin, we denote the ball by . A function is said to be -Lipschitz if for all . Let denote the standard family of instances of the optimization problem (1.1) consisting of all -Lipschitz (possibly non-differentiable) convex functions such that the minimizer is contained in the ball .111This is a standard assumption in the analysis of optimization algorithm – if no such bound is assumed, then it can be shown that no algorithm can report a good solution within a guaranteed number of steps for every instance (Nesterov, 2004). Alternatively, one may give the convergence rates in terms of the distance of the initial iterate of the algorithm and the optimal solution (one can think of as an upper bound on this distance). Our results can also be formulated in this language with no conceptual or technical changes. We now formalize the inexact first-order oracles that we will work with.
Definition 2.1.
An -approximate first-order oracle for a convex function takes as input a query point and returns a first-order pair satisfying and for some subgradient .
We now state our main results. We remind the reader that in (1.1) the underlying set need not be and may be nonconvex; below, when we talk about a first order algorithm for (1.1) we mean an algorithm that can solve (1.1) with access to first-order oracles for . We use to denote the optimal value of the instance .
Theorem 2.2.
Consider an algorithm for (1.1) such that for any instance , with access to function values and subgradients of , after iterations the algorithm reports a feasible solution with error at most , i.e., .
Then there is an algorithm that, with access to an -approximate first-order oracle for for any , after iterations the algorithm returns a feasible solution with value
where .
Although we state this theorem as an existence result, our proof is constructive and exactly formulates the desired algorithm via Procedures 1 and 2. Let us illustrate what this theorem says when applied to two classical algorithms for convex optimization (i.e., ): subgradient methods and cutting-plane methods (Nesterov, 2004). When using exact first-order information, the subgradient method produces after iterations a solution with error at most . Applying the procedures mentioned from Theorem 2.2 to this algorithm, one obtains an algorithm that uses only -approximate first-order information and after iterations produces a solution whose error is at most . If one can choose the accuracy of the inexact oracle, setting and gives a solution with error at most . Note that this does not involve knowing anything about the original algorithm; it simply illustrates the tradeoff between the oracle accuracy and final solution accuracy.
Similarly, for classical cutting-plane methods (e.g., center-of-gravity, ellipsoid, Vaidya) the error after iterations is at most . Thus, with access to -approximate first-order oracles, we can use our result to produce a solution with error at most . With the desired accuracy of , and , it gives a solution with error at most .
We next consider the family of -smooth functions, i.e., the family of -Lipschitz convex functions that are differentiable with -Lipschitz gradient maps, whose minimizers are contained in . This is a classical family of objective functions in convex optimization that admits the celebrated accelerated method of Nesterov (1983) (see (d’Aspremont et al., 2021) for a survey). We give the following universal transfer theorem for algorithms for smooth objective functions.
Theorem 2.3.
Consider an algorithm for (1.1) such that for any instance in , with access to function values and subgradients of , after iterations the algorithm reports a feasible solution with error at most , i.e., .
Then for any , there is an algorithm that, with access to an -approximate first-order oracle for , after iterations the algorithm returns a feasible solution with value
where , .
As an illustration, we apply this transfer theorem to the accelerated algorithm of Nesterov (1983) for continuous optimization (): Under perfect first-order information, it obtains error after iterations. Using our transfer theorem as a wrapper gives an algorithm that, using only -approximate first-order information, obtains error ; if the accuracy of the oracle is set to , this gives an algorithm with error . While this does not recover in full the acceleration of Nesterov’s method, the key take away is that a significant amount of acceleration (i.e., error rates better than those possible for non-smooth functions) can be preserved under inexact oracles in a universal way, for any accelerated algorithm requiring exact information.
Remark 2.4.
For the sake of exposition, we have assumed that the accuracy of the oracle is fixed and the additional error is . However, one can allow different oracle accuracies at each query point and the additional error is (and the parameter ).
2.1 Allowing inexactness in the constraint set
So far we have assumed that the algorithm has complete knowledge of the constraints . Now, we extend our results to include algorithms that can work with larger classes of constraints that are not fully known up front. In other words, just like the algorithm needs to collect information about , it also needs to collect information about , via another oracle, to be able to solve the problem. To capture the most general algorithms of this type, we formalize this setting by assuming is of the form , where belongs to a class of closed, convex sets and is possibly nonconvex but completely known (e.g., with ).
| (2.1) |
The algorithm then must collect information about , for which we use the common model of allowing the algorithm access to a separation oracle. Upon receiving a query point , a separation oracle either reports correctly that is inside or otherwise returns a separating hyperplane that separates from . We note that a separation oracle for is in some sense comparable to a first-order oracle for a convex function ; since the pair can be viewed as providing a supporting hyperplane for the epigraph of at , using an oracle that returns separating hyperplanes for provides a comparable way of collecting information about the constraints.
Let us first precisely define the inexact version of a separation oracle.
Definition 2.5.
For a closed, convex set and a query point , an -approximate separation oracle reports a separation response such that if then (with no requirement on ), and otherwise and is a unit vector such that there exists some unit vector satisfying for all and . Given such a (for ), we call the hyperplane through induced by this normal vector an -approximate separating hyperplane for .
We now state our results for algorithms that work with separation oracles. Note that for this, instances of (1.1) have to specify both and , as opposed to just , since only is known but not . We use to denote the set of all instances where is an -Lipschitz convex function and is a compact, convex set that contains a ball of radius and is contained in . We use to denote the minimum value of (2.1). The “strict feasibility" assumption of containing a -ball is standard in convex optimization with constraints given via separation oracles. Otherwise, it can be shown that no algorithm will be able to find even an approximately feasible point in a finite number of steps (Nesterov, 2004). The first result we state is for pure convex problems, i.e., .
Theorem 2.6.
Consider an algorithm for (2.1) with , such that for any instance in , with access to function values and subgradients of and separating hyperplanes for , after iterations the algorithm reports a feasible solution with error at most , i.e., .
Then there is an algorithm that, with access to an -approximate first-order oracle for and an -approximate separation oracle for for any and , after iterations the algorithm returns a feasible solution with value
where and .
We can handle more general, nonconvex with separation oracles under a slightly stronger “strict feasibility" assumption on : let denote the subclass of instances from where the minimizer of (2.1) is -deep inside , i.e., .
Theorem 2.7.
Consider an algorithm for (2.1), such that for any instance in , with access to function values and subgradients of and separating hyperplanes for , after iterations the algorithm reports a feasible solution with error at most , i.e., .
Then there is an algorithm that, with access to an -approximate first-order oracle for and an -approximate separation oracle for for any and , after iterations the algorithm returns a feasible solution with value
where and .
Remark 2.8.
The objective functions in the above results were allowed to be any -Lipschitz, possibly nondifferentiable, convex function. One can state versions of these results for algorithms that work for the smaller class of -smooth functions (e.g., accelerated projected gradient methods), just as Theorem 2.3 is a version of Theorem 2.2 for -smooth objectives. The reason is that the analysis for handling constraints is independent of the arguments needed to handle the objective using inexact oracles; however, for space constraints, we leave the details out of this manuscript. Additionally, one can prove versions of all our theorems for strongly convex objective functions, but we leave these out of the manuscript as well to convey the main message of the paper more crisply.
2.2 Relation to existing work
Previous work on inexact first-order information focused on how certain known algorithms perform or can be made to perform under inexact information, most recently on (accelerated) proximal-gradient methods. For instance, (Devolder et al., 2014) analyze the performance of (accelerated) gradient descent in the presence of inexact oracles, with no change to algorithm. They show that simple gradient descent (for unconstrained problems) will return a solution with additional error and accelerated gradient descent incurs an additional error of (similar to our guarantees). We provide a more thorough comparison of our setting and results with those of (Devolder et al., 2014) in Appendix C.
Similarly, (Schmidt et al., 2011) does an analysis for (accelerated) proximal gradient methods, with more complicated forms of the additional error, depending on how well the proximal problems are solved. (Gasnikov & Tyurin, 2019) and (Cohen et al., 2018) also study gradient methods in inexact settings, with their analyses being specific to particular algorithms.
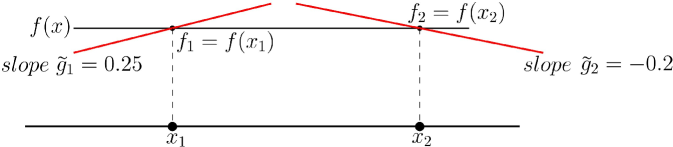
In contrast, our result does not assume any knowledge of the internal logic of the algorithm. We must, therefore, use the algorithm in a “black-box” manner. We are able to do this by using the inexact oracles to construct a modified instance whose optimal solution is similar in quality to that of the true instance, and where this inexact information from the true instance can be interpreted as exact information for the modified instance. Thus, we can effectively run the algorithm as a black-box on this modified instance and leverage its error guarantee. Constructing this modified instance in an online fashion requires technical ideas that are new, to the best of our knowledge, in this literature. For instance, it is not even true that given approximate function values and subgradients of a convex function, we can find another convex function that has these as exact function values and subgradients; see Figure 1. Thus, one cannot directly use the inexact information as is (contrary to what is done in many of the papers dealing with inexact information for specific algorithms), in the general case we consider. The key is to modify the inexact information so that the information the algorithm receives admits an extension into a convex function/set that is still close to the original instance. When dealing with -smooth objectives, the arguments are especially technically challenging since we have to report approximate function and gradient values that allow for a smooth extension that also approximates the unknown objective well. This involves careful use of new, localized smoothing techniques and maximal couplings of probability distributions. Such smoothing guarantees based on the proximity to the class of smooth functions may be of independent interest (see Theorem 4.1).
New applications: Since our results apply to algorithms for any ground set , we are able to handle mixed-integer convex optimization, i.e., , with inexact oracles. Recently, there have been several applications of such optimization problems in machine learning and statistics (Bertsimas et al., 2016; Mazumder & Radchenko, 2017; Bandi et al., 2019; Dedieu et al., 2021; Dey et al., 2022; Hazimeh et al., 2022, 2023). General algorithms for mixed-integer convex optimization, as well as specialized ones designed for specific applications in the above papers, all involve a sophisticated combination of techniques like branch-and-bound, cutting planes and other heuristics. To the best of our knowledge, the performance of these algorithms has never been analyzed under the presence of inexact oracles which can cause issues for all of these components of the algorithm. Our results apply immediately to all these algorithms, precisely because the internal workings of the algorithm are abstracted away in our analysis. This yields the first ever versions of these methods that can work with inexact oracles. Moreover, can be used to model other types of structured nonconvexities (e.g., complementarity constraints (Cottle et al., 2009)) and our results show how to adapt algorithms in those settings to work with inexact oracles. Note that this holds for the cases where the convex set is explicitly known a priori (Theorems 2.2 and 2.3), or must be accessed via separation oracles (Theorems 2.6 and 2.7).
3 Universal transfer for Lipschitz functions
In this section we prove our transfer result stated in Theorem 2.2. The proof relies on the following key concept: Given a set of points (e.g., queries made by an optimization algorithm), we say that the sequence of first-order pairs222We use first-order pair as just a more “visual” name for a pair in . has an -Lipschitz convex extension, or simply -extension, if there is a function that is convex, -Lipschitz, and such that and for all , i.e., the first-order information of at the queried points is exactly .
As mentioned in the introduction, the main idea is to feed to the convex optimization algorithm a sequence of pairs ’s that have an -Lipschitz extension that is close to the original function . Since the information is consistent with what the algorithm expects when interacting exactly with the function , it will approximately optimize the latter which will then give an approximately optimal solution to the neighboring function .
Unfortunately, it is easy to see approximate first-order information from for the queried points ’s does not necessarily have a Lipschitz convex extension (see Figure 1). Thus, the main subroutine of our algorithm Approximate-to-Exact given below is that given an approximate first-order oracle for , it constructs first-order pairs ’s in an online fashion (i.e. only depends on ) with the desired extension properties. For a function , let denote its sup-norm.
Theorem 3.1 (Online first-order Lipschitz-extensibility).
Consider an -Lipschitz convex function , and a sequence of points . There is an online procedure that, given -approximate first-order oracle access to , produces first-order pairs that have a -extension satisfying . (Moreover, the procedure only probes the approximate oracle at the given points .)
With this at hand, given any first-order algorithm we can run it using only approximate first-order information in the following natural way:
Procedure 1.
Approximate-to-Exact(, ) For each timestep : 1. Receive query point from . 2. Send point to the -approximate oracle for and receive the information . 3. Use the online procedure from Theorem 3.1 to construct the first-order pair . 4. Send to the algorithm . Return the point in returned by .Proof of Theorem 2.2.
Consider a first-order algorithm that, for any -Lipschitz convex function, after iterations returns a point such that , We show that running Procedure 1 with as input, which only uses an -approximate oracle for , returns a point such that with .
To see this, let be an -extension for the first-order pairs sent to the algorithm in Procedure 1 with , guaranteed by Theorem 3.1. This means that the execution of the first-order algorithm during our procedure is exactly the same as executing directly on the convex function . Thus, by the error guarantee of , the point returned by after iterations (which is the same point returned by our procedure) is almost optimal for , i.e., . Since and are pointwise within of each other, the value of the solution with respect to the original function satisfies
which proves the desired result. ∎
3.1 Computing Lipschitz-extensible first-order pairs
In this section we describe the procedure that constructs the first-order pairs with a Lipschitz convex extension that satisfies , proving Theorem 3.1. Before getting into the heart of the matter, we show that the latter property can be significantly weakened: instead of requiring both and for all , we can relax the latter to only hold for the queried points .
Lemma 3.2.
Consider a sequence of points , and a sequence of first-order pairs . Consider and , and suppose that there is an -extension of these first-order pairs that satisfies:
| (3.1) | |||
| (3.2) |
Then the first-order pairs have an -extension such that . In particular, setting
provides such an extension.
Proof.
Define the function as by taking the maximum between and a downward-shifted . We will show that this function is the desired convex extension of the first-order pairs .
First, to show , by the definition of one has for all . Furthermore, because of the guarantee that , we also have for all ; together these imply that . Since and are -Lipschitz convex functions, so is .
It remains to be shown that is an extension of the first-order pairs, that is, to show and for all . Given property (3.2), we have , and so . The fact that also implies that every vector in is a subgradient of at , namely . To see this, recall that since is convex, for we have . Using the fact that , we thus have for all , and so any is also a subgradient for at , as desired to conclude the proof. ∎
Given Lemma 3.2, to prove Theorem 3.1 it suffices to do the following. Consider a sequence of points . Using an -approximate first-order oracle to access the function (at the points ), we need to produce a sequence of first-order pairs in an online fashion that have an -extension achieving the approximations (3.1) and (3.2). We do this as follows.
At iteration we maintain the function , that is, the maximum of the linear functions induced by the first-order pairs constructed up to this point. We would like to define the pairs to guarantee that for all , is an -extension for these pairs, and satisfies (3.1) and (3.2) for . In this case, gives the desired function.
For that, suppose the above holds for ; we will show how to define to maintain this invariant for . We should think of constructing by taking the maximum of and a new linear function . To ensure that is an extension of the first-order pairs thus far, we need to make sure that:
-
1.
This is necessary to ensure that , and also guarantees .
-
2.
This is necessary to ensure that , and also guarantees .
To construct with these properties, we probe the approximate first-order oracle for at , and receive an answer . If setting violates the first item above, we simply use the first-order information of at , i.e., we set and .
If the second item above is violated instead, we shift the value down as little as possible to ensure the desired property, i.e., we set for appropriate . With this shifted value, the first item may now be violated, in which case we again just use the current first-order information of .
These steps are formalized in the following procedure.
Procedure 2.
Set . For each : 1. Query the -approximate oracle for at , receiving the first-order pair . 2. Let 3. Let , and then set , .We remark that this requires storing historical values of and (this seems unavoidable to ensure convexity of ). In terms of computational complexity, we remark that the procedure takes a total of operations. We now prove that the functions ’s have the desired properties.
Lemma 3.3.
For every , the function is an -extension of the first-order information pairs .
Proof.
Since is the maximum over affine functions, it is convex. Moreover, all of its subgradients come from the set , and by the approximation guarantee of the oracle we have that for some subgradient , , where we used that fact that is -Lipschitz; thus, is -Lipschitz.
We prove by induction on that is an extension of the desired pairs (the base case can be readily verified). Recall , where . By the definition of , for all , this maximum is achieved by the function , giving, by induction, that for all , ; this also implies that for such ’s, , the last inclusion again following by induction. These give the extension property for the pairs with .
It remains to verify that this also holds for . Now the maximum in the definition of is achieved by the function : if , the procedure sets and we have ; otherwise the procedure sets and so . Again this implies that . This concludes the proof of the lemma. ∎
Proof.
Again we prove this by induction on . Fix . Let be the error the inexact oracle makes on the function value. We claim that the shift used in iteration of Procedure 2 satisfies . To see this, the -approximation of the oracle guarantees that there is a subgradient such that , and so for every
| (3.3) |
the first underbrace following since is a subgradient of , and the last inequality following from the induction hypothesis (inequality (3.2)); the optimality of then guarantees that it is at most , proving the claim.
Now we show that satisfies the desired bounds, namely for all , and for all . From the inductive hypothesis, for we have , giving the first bound for these . For , notice that . Therefore,
where in the second inequality we used the upper bound on the shift , and in the next inequality we used the guarantee from the approximate oracle.
For the upper bound , by the inductive hypothesis . Moreover, the same development as in (3.3) reveals that
where the last inequality again uses that due to the guarantee of the approximate oracle. Thus, , giving the desired bound. This concludes the proof of the lemma.
∎
4 Universal transfer for smooth functions
In this section we prove our transfer theorem for smooth functions stated in Theorem 2.3. Recall that a function is -smooth if it has -Lipschitz gradients:
As in the proof of the previous transfer theorem, the core element is the following: Given the sequence of iterates of a black-box optimization algorithm and access to an approximate first-order oracle to the smooth objective function , construct in an online fashion first-order pairs and, implicitly, a smooth function close to the original such that provide exactly the value and gradient of at .
Theorem 4.1 (Online first-order smooth-extensibility).
Consider an -smooth, -Lipschitz convex function , and a sequence of points . Then, for , there is an online procedure that given -approximate first-order oracle access to , produces first-order pairs that have an -smooth -extension satisfying , where . Moreover, the procedure only probes the approximate oracle at the given points .
In the previous section, the extension was created by adding a new linear function at every iteration; this produced the piecewise linear (non-smooth) functions in the previous section. Having to construct a smooth extension creates a challenge. Our approach is to apply a smoothing procedure to these piecewise linear functions, in an online manner. One issue is that most standard smoothing procedures (e.g., via inf-convolution (Beck & Teboulle, 2012) or Gaussian smoothing (Nesterov, 2005)) may use the values of the non-smooth base function over the whole domain; in our online construction, at a given point in time we have determined the value of the function only in a neighborhood of the previous iterates, and the updated functions can change at points outside these small neighborhoods. Thus, we employ a localized smoothing procedure. Moreover, we need the procedure to leverage the fact that the non-smooth base function is close to a smooth one, and produce stronger smoothing guarantees by making use thereof. We start by describing this smoothing technique and its properties, and then describe the full procedure that gives Theorem 4.1.
Randomized smoothing of almost smooth functions.
Given a function and a radius , we define the smoothed function by where is uniformly distributed on the unit ball . It is well-known that when is convex and -Lipschitz, then is differentiable, also -Lipschitz, and, most importantly, is -smooth (Yousefian et al., 2012). However, we show that the smoothing parameter can be significantly improved when the function is already close to a smooth function. The proof is deferred to Appendix A.1.
Lemma 4.2.
Let be a convex function such that there exists an -smooth convex function with , for . Then, for the smoothed function (so restricted to the ball ) satisfies:
-
1.
is -smooth
-
2.
for all .
Construction of the smooth-extension.
As mentioned, in each iteration we will maintain a piecewise linear function constructed very similarly to the proof of Theorem 3.1. Now we will also maintain the smoothened version of this function that uses the randomized smoothing discussed above (for a particular value of ). Our transfer procedure then returns the first-order information and of the latter. The final smooth function compatible with the first-order information returned by the procedure will be given, as in Lemma 3.2, by taking the maximum between the final and a shifted version of the original function .
The main difference in how the functions ’s are constructed, compared to the proof of Theorem 3.1, is the following. Previously, in order to ensure that (and so the final extension) was compatible with the first-order pairs output in earlier iterations, we needed to “protect” the points and ensure that the function values and gradients at these points did not change over time, e.g., we needed . But now the first-order pair output for the query point depends not only on the value of at , but also on the values on the whole ball that are used to determine the smoothed function at . Thus, we will now need to “protect” these balls and ensure that the function values over them do not change in later iterations.
We now formalize the construction of the functions , the first-order information returned, and the final extension in Procedure 3.
Procedure 3.
Set and . For each : 1. Query the -approximate oracle for at , receiving the first-order pair . 2. Define the function by setting for all 3. Output the first-order information of the randomly smoothed function : and Define the function by , where denotes pointwise maximum.Acknowledgments
We would like to thank the reviewers for their detailed and insightful feedback that has corrected inaccuracies in the previous proofs and have improved the presentation of the paper.
The first and fourth authors would like to acknowledge support from Air Force Office of Scientific Research (AFOSR) grant FA95502010341 and National Science Foundation (NSF) grant CCF2006587. The second author was supported in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES, Brasil) - Finance Code 001, and by Bolsa de Produtividade em Pesquisa 12751/2021-4 from CNPq.
Impact Statement
This paper presents work whose goal is to advance the fields of Machine Learning and Optimization. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
References
- Bandi et al. (2019) Bandi, H., Bertsimas, D., and Mazumder, R. Learning a mixture of gaussians via mixed-integer optimization. INFORMS Journal on Optimization, 1(3):221–240, 2019.
- Basu (2023) Basu, A. Complexity of optimizing over the integers. Mathematical Programming, Series B, 200:739–780, 2023.
- Basu et al. (2023) Basu, A., Jiang, H., Kerger, P., and Molinaro, M. Information complexity of mixed-integer convex optimization. arXiv preprint arXiv:2308.11153, 2023.
- Beck & Teboulle (2012) Beck, A. and Teboulle, M. Smoothing and first order methods: A unified framework. SIAM Journal on Optimization, 22(2):557–580, 2012. doi: 10.1137/100818327. URL https://doi.org/10.1137/100818327.
- Bertsekas (1973) Bertsekas, D. P. Stochastic optimization problems with nondifferentiable cost functionals. Journal of Optimization Theory and Applications, 12:218–231, 1973.
- Bertsimas et al. (2016) Bertsimas, D., King, A., and Mazumder, R. Best subset selection via a modern optimization lens. The Annals of Statistics, 44(2):813–852, 2016.
- Bubeck (2015) Bubeck, S. Convex optimization: Algorithms and complexity. Found. Trends Mach. Learn., 8(3–4):231–357, nov 2015. ISSN 1935-8237. doi: 10.1561/2200000050. URL https://doi.org/10.1561/2200000050.
- Chen & Qi (2005) Chen, C.-P. and Qi, F. The best bounds in Wallis’ inequality. Proceedings of the American Mathematical Society, (133):397–401, 2005.
- Cohen et al. (2018) Cohen, M., Diakonikolas, J., and Orecchia, L. On acceleration with noise-corrupted gradients. In International Conference on Machine Learning, pp. 1019–1028. PMLR, 2018.
- Cottle et al. (2009) Cottle, R. W., Pang, J.-S., and Stone, R. E. The linear complementarity problem, volume 60. Siam, 2009.
- d’Aspremont (2008) d’Aspremont, A. Smooth optimization with approximate gradient. SIAM Journal on Optimization, 19(3):1171–1183, 2008.
- Dedieu et al. (2021) Dedieu, A., Hazimeh, H., and Mazumder, R. Learning sparse classifiers: Continuous and mixed integer optimization perspectives. The Journal of Machine Learning Research, 22(1):6008–6054, 2021.
- Devolder et al. (2014) Devolder, O., Glineur, F., and Nesterov, Y. First-order methods of smooth convex optimization with inexact oracle. Mathematical Programming, 146:37–75, 2014.
- Dey et al. (2022) Dey, S. S., Mazumder, R., and Wang, G. Using -relaxation and integer programming to obtain dual bounds for sparse pca. Operations Research, 70(3):1914–1932, 2022.
- d’Aspremont et al. (2021) d’Aspremont, A., Scieur, D., and Taylor, A. Acceleration methods. Foundations and Trends® in Optimization, 5(1-2):1–245, 2021. ISSN 2167-3888. doi: 10.1561/2400000036. URL http://dx.doi.org/10.1561/2400000036.
- Gasnikov & Tyurin (2019) Gasnikov, A. and Tyurin, A. Fast gradient descent for convex minimization problems with an oracle producing a (, l)-model of function at the requested point. Computational Mathematics and Mathematical Physics, 59:1085 – 1097, 2019. URL https://api.semanticscholar.org/CorpusID:202124988.
- Hazimeh et al. (2022) Hazimeh, H., Mazumder, R., and Saab, A. Sparse regression at scale: Branch-and-bound rooted in first-order optimization. Mathematical Programming, 196(1-2):347–388, 2022.
- Hazimeh et al. (2023) Hazimeh, H., Mazumder, R., and Radchenko, P. Grouped variable selection with discrete optimization: Computational and statistical perspectives. The Annals of Statistics, 51(1):1–32, 2023.
- Hintermüller (2001) Hintermüller, M. A proximal bundle method based on approximate subgradients. Computational Optimization and Applications, 20:245–266, 2001.
- Kiwiel (2006) Kiwiel, K. C. A proximal bundle method with approximate subgradient linearizations. SIAM Journal on optimization, 16(4):1007–1023, 2006.
- Lan (2009) Lan, G. Convex optimization under inexact first-order information. Georgia Institute of Technology, 2009.
- Lindvall (2002) Lindvall, T. Lectures on the Coupling Method. Dover Books on Mathematics Series. Dover Publications, Incorporated, 2002. ISBN 9780486421452. URL https://books.google.com.br/books?id=GB290HEW724C.
- Mazumder & Radchenko (2017) Mazumder, R. and Radchenko, P. The discrete dantzig selector: Estimating sparse linear models via mixed integer linear optimization. IEEE Transactions on Information Theory, 63(5):3053–3075, 2017.
- Nemirovski (1994) Nemirovski, A. Efficient methods in convex programming. Lecture notes, 1994.
- Nesterov (1983) Nesterov, Y. A method of solving a convex programming problem with convergence rate . Dokl. Akad. Nauk SSSR, 269(3):543–547, 1983.
- Nesterov (2005) Nesterov, Y. Smooth minimization of non-smooth functions. Mathematical Programming, 103:127–152, 2005.
- Nesterov (2004) Nesterov, Y. E. Introductory Lectures on Convex Optimization, volume 87 of Applied Optimization. Kluwer Academic Publishers, Boston, 2004. ISBN 1-4020-7553-7.
- Nesterov (2018) Nesterov, Y. E. Lectures on convex optimization, volume 137. Springer, 2018.
- Polyak (1987) Polyak, B. Introduction to optimization. Translations Series in Mathematics and Engineering. New York: Optimization Software Inc. Publications Division, 1987.
- Schmidt et al. (2011) Schmidt, M., Roux, N., and Bach, F. Convergence rates of inexact proximal-gradient methods for convex optimization. Advances in neural information processing systems, 24, 2011.
- Shor (1985) Shor, N. Z. Minimization methods for non-differentiable functions. Springer Series in Computational Mathematics, 1985.
- Wang & Abernethy (2018) Wang, J.-K. and Abernethy, J. D. Acceleration through optimistic no-regret dynamics. Advances in Neural Information Processing Systems, 31, 2018.
- Yousefian et al. (2011) Yousefian, F., Nedić, A., and Shanbhag, U. V. On stochastic gradient and subgradient methods with adaptive steplength sequences. arXiv preprint arxiv:1105.4549, 2011.
- Yousefian et al. (2012) Yousefian, F., Nedić, A., and Shanbhag, U. V. On stochastic gradient and subgradient methods with adaptive steplength sequences. Automatica, 48(1):56–67, 2012. ISSN 0005-1098. doi: https://doi.org/10.1016/j.automatica.2011.09.043. URL https://www.sciencedirect.com/science/article/pii/S0005109811004833.
Appendix
Appendix A Universal transfer for smooth functions
In this section we present the missing proofs for our transfer theorem for smooth functions from Section 4. We start by recalling the definition of a smooth function.
Definition A.1.
A function is said to be -smooth if it is differentiable and its gradient is Lipschitz continuous with a Lipschitz constant , namely
An -smooth function possesses the following useful upper bounding property: for :
| (A.1) |
A.1 Proof of Lemma 4.2
Let and be the convex functions over the ball satisfying the statement of the lemma, i.e., and is -smooth. Recall that the smoothed function is defined as for , where is a random vector uniformly distributed on the unit ball and .
The first observation is that since is close to and the latter is smooth, their (sub)gradients are close to each other; the same also holds between and .
Lemma A.2.
We have the following:
-
1.
for every and every subgradient .
-
2.
for every .
Proof.
To prove the first item, fix and let be such that
Since , notice that has norm at most , which by assumption of is at most ; thus, is in the domain of and .
Then using -smoothness of , , and convexity of , we have
and so
Plugging the definition of on this expression gives
and so , which gives the first item of the lemma.
For the second item, again let be uniformly distributed in . This random variable is sufficiently regular that gradients and expectations commute, namely , were denotes any subgradient of (Bertsekas, 1973).Then applying Jensen’s inequality, for any we get
Also, for any unit-norm vector we have
where the last inequality follows from Item 1 of the lemma (since , has norm at most and so the item can indeed be applied) and -smoothness of (which is equivalent to (Nesterov, 2018)). This concludes the proof. ∎
The second element that we will need is a bound on the total variation between the the uniform distributions on the two same-radius balls with different centers.
Lemma A.3.
Let be the uniformly distributed on and be uniformly distributed on . Then there is a random variable where has the same distribution as and the same distribution as , and where .
Proof sketch.
This folklore result can be obtained as follows. Let be the uniform distribution over . Since and are the distribution of and , by the Maximal Coupling Lemma (Theorem 5.2 of (Lindvall, 2002)) there is a random variable where and and . Moreover, it is known that the right hand side is at most , see for example inequality (39) of (Yousefian et al., 2011) (plus the estimate from (Chen & Qi, 2005)). ∎
We are now ready to prove Lemma 4.2.
Proof of Lemma 4.2.
Item 1: We prove that for all . In fact, it suffices to prove this for where , since the inequality can then be chained to obtain the result for any pair of points.
Then fix with . Using the notation from Lemma A.3, and and . Applying Jensen’s inequality,
We upper bound the last term by applying triangle inequality and then Lemma A.2:
where the second inequality uses that is -smooth, and the last inequality uses the assumption . Plugging this into the previous inequality gives
as desired.
Second item: We now show that . Fix , and again let be uniformly distributed in the unit ball. Using the assumption and convexity of , we have
Since has mean zero, taking expectations gives . Similarly, since is -smooth
and taking expectations gives . Together, these yield , thus proving the result. This concludes the proof of the theorem. ∎
A.2 Proof of Theorem 4.1
Throughout this section, fix an -smooth -Lipschitz function . Recall that we have a sequence of queried points and access to an -approximate first-order oracle for . Our goal is to produce, in an online fashion, a sequence of first-order pairs for the queried points and a function that is smooth, Lipschitz, and compatible with these first-order pairs (i.e., and ).
As mentioned, in each iteration we will keep a piecewise linear function and their smoothened version (by using the randomized smoothing from the previous section for a specific value of ). Our transfer procedure then returns the first-order information and of the latter. The final smooth function compatible with the first-order information output by the procedure will be given, as in Lemma 3.2, by using the maximum between the final and a shifted version of the original function . Also recall that in order to ensure the compatibility of with the first-order information output throughout the process, we need to “protect” the points and ensure that the function values and gradients at these points did not change across iterations, i.e. and . Since depends on the values of at the ball around , we need to “protect” on these balls, namely to have for all .
For convenience, we recall the exact construction of the functions , the first-order information returned, and the final extension . In hindsight, set , and for every define the shift .
We now prove the main properties of the functions , formulated in the following lemma. The first two are similar to (3.1) and (3.2) used in our non-smooth transfer result and guarantee, loosely speaking, that is close to the original function . The third property is precisely the “ball protection” idea discussed above.
Lemma A.4.
For all , the function satisfies the following:
-
1.
for every
-
2.
For every , we have for all
-
3.
For every , we have for every . In particular and .
Proof.
We prove these properties by induction on .
First item: Since the property holds by induction for and , it suffices to show that
| (A.2) |
for all . For that, since comes from an -approximate first-order oracle, by definition and ; in particular, for every (since also , by assumption). Then using convexity of we get
| (A.3) |
which implies (A.2) as desired, since .
Second item: Again since this property holds by induction for , it suffices to show
| (A.4) |
for all . Since is -smooth, for every such we have
| (A.5) |
Since , reorganizing the terms gives (A.4) as desired.
Third item: To show that for every , we have for every , it suffices to show that for every
| (A.6) |
for all . For that, first notice that for all we have , and the latter can be lower bounded by the affine term added during iteration . Combining this with (A.5), applied to iteration , we get for all
where the last inequality uses (A.3). Since , this implies (A.6) as desired.
To conclude the proof of this item, notice that (respectively ) only depends on the values of (resp. ) on the ball . Since we just showed the value of and agree on this ball, we get . Similarly, the gradient only depends on the values of on an arbitrarily small open neighborhood of the ball , and the same holds for . Since the bigger ball contains such a neighborhood, we again obtain . This concludes the proof of the lemma. ∎
We are now ready to prove Theorem 4.1.
Proof of Theorem 4.1.
We need to prove that the function defined in Procedure 3 satisfies:
-
1.
.
-
2.
is -smooth
-
3.
is -Lipschitz
-
4.
is an extension for the first-order pairs output by the procedure
First item: Define the function , so . Using Item 1 of Lemma A.4, we see that for all , and by definition we have , thus for all . Then using Item 2 of Lemma 4.2 we get for all (we can indeed use this lemma since the definition and the assumption imply that and ).
Second item: This follows Item 1 of Lemma 4.2 instead.
Third item: The subgradients of are (a convex combination of a subset of the) vectors , and so is -Lipschitz. Since the vectors came from an -approximate oracle for , we have , and since is -Lipschitz we get ; it follows that is -Lipschitz. Next, the subgradients of come either from subgradients of or gradients of (or a convex combination thereof), and so is Lipschitz. Finally, for every we have ( being uniformly distributed in the unit ball again)
where denotes any subgradient at and the first inequality follows from Jensen’s inequality. This proves that is -Lipschitz.
Fourth item: We need to show that for all , and . By definition, and . Moreover, by Item 3 of Lemma A.4, using instead of gives the same quantities, namely and . We claim that for every , and are equal inside the ball , which then implies that and , as desired. To show the equality in the ball , it suffices that the other term in the max defining does not “cut off” , namely that for every . But this follows from Item 2 of Lemma A.4.
Substituting the value and in the items above concludes the proof of Theorem 4.1. ∎
Appendix B Separation oracles: proofs of Theorems 2.6 and 2.7
We now consider the original constrained problem , and show how to run any first-order algorithm using only approximate first-order information about and approximate separation information from , proving Theorems 2.6 and 2.7. The main additional element is to convert the approximate separation information for into an exact information for a related set so it can be used in a black-box fashion by , as the previous section did for the first-order information of . For simplicity, we assume throughout that the algorithm only queries points in (the ball containing the feasible set ), since points outside it can be separated exactly.
Given a set of points , we say a sequence of separation responses has a convex extension if there is a convex set such that there exists an exact (i.e., -approximate) separation oracle for giving responses for the query points . We will also refer to such responses as consistent with . As in the previous section, responses from an -approximate separation oracle may not by themselves admit a convex extension, and need to be modified in order to allow a consistent, convex extension; for example, approximate separating hyperplanes may not be consistent with a convex set, or may "cut off" points previously reported as feasible. When we say a point is cut off by a separating hyperplane through with normal vector , we mean that , i.e. that is not in the induced halfspace. Note that when given an exact separating hyperplane for some , no point in is cut off by it, whereas approximate separating hyperplanes have no such guarantee. With this in mind, we now give a theorem serving as a feasibility analogue to Theorem 3.1.
Definition B.1.
For any convex set and any , we define , which will be called -deep points of .
Theorem B.2 (Online Convex Extensibility).
Consider a convex set and a sequence of points . There is an online procedure that, given access to an -approximate separation oracle for , produces separation responses that have a convex extension satisfying . Moreover, the procedure only probes the approximate oracle at the points .
Note that the guarantee means that for any point that is -deep in , i.e., in , the response produced says Feasible, whereas for any it says Infeasible and gives a hyperplane separating from (which cannot cut too deep into , i.e., it contains ). At a high-level, such responses allow one to cut off infeasible solutions, but guarantee that there are still (-deep) solutions with small -value available.
With this additional procedure at hand, we extend Procedure 1 from the main text in the following way to solve constrained optimization: in each step of the procedure, we also send the point queried by the algorithm to the -approximate separation oracle for , receive the response , pass it through Theorem B.2 to obtain the new response , and send the latter back to . We call this procedure Approximate-to-Exact-Constr, and formally state it as follows:
Procedure 4.
Approximate-to-Exact-Constr
For each timestep :
1.
Receive query point from
2.
Send point to the -approximate first-order oracle and to the -approximate separation oracle, and receive the approximate first-order information , and separation response .
3.
Use the online procedures from Theorems 3.1 and B.2 to construct the first-order pair and separation response .
4.
Send to the algorithm .
Return the point returned by .
The proof that this procedure yields Theorem 2.6 is analogous to the one for the unconstrained case of Theorem 2.2, so we only sketch it to avoid repetition.
Proof sketch of Theorem 2.6.
Let and be the Lipschitz and convex extensions to the answers sent to that are guaranteed by Theorems 3.1 and B.2, respectively. Approximate-to-Exact-Constr has the same effect as running on the instance . One can show that this instance belongs to . Then if is the error guarantee of as in the statement of the theorem, this ensures that we return a solution satisfying
where . Since contains a solution with value (e.g., Lemma 4.7 of (Basu, 2023)), we have . Finally, using the guarantee , we obtain that , concluding the proof of the theorem. ∎
The proof of Theorem 2.7 follows effectively the same reasoning as for Theorem 2.6; we also sketch it here. The main difference is that one needs to ensure the optimal solution of 2.1 is contained in contained in the auxiliary feasible region the algorithm uses; otherwise the additional restrictions imposed by may lead to arbitrarily bad solutions, or even being empty (consider for example the case of being a singleton on the boundary of that is then cut off by an approximate separation response). However, since is guaranteed to contain and we assume that , the fact that is -deep in implies that it is also in .
Proof sketch of Theorem 2.7.
Again, let and be the Lipschitz and convex extensions as in the previous proof, so that the instance belongs to and returns a solution satisfying where . Recall that is assumed to be given and known by the algorithm. Since the optimal solution for is assumed to be in , and contains , contains the optimal solution to to the true instance, . Finally, using the guarantee , we obtain that , concluding the proof of the theorem. ∎
B.1 Computing convex-extensible separation responses
We now prove Theorem B.2. The result requires the existence of a convex extension for the responses that we construct, and we need . We provide a procedure that produces the responses together with sets so that is consistent with the responses up to this round, i.e., , and is sandwiched between and . The set will consist of all the points that were not excluded by the separating hyperplanes of the responses up to this round. Thus, our main task is to ensure that as evolves, it does not exclude the points that the responses up to now have reported as Feasible (ensuring consistency with previous responses). We also want to ensure that none of the deep points is excluded.
Before stating the formal procedure, we give some intuition on how this is accomplished. Suppose one has satisfying the desired properties. One receives a new point and separation response from the approximate oracle, and we need to construct a response and an updated set to maintain the desired properties.
Suppose reports that is Feasible. Our procedure ignores this information, keeps and creates a response that is Feasible if and only if (also sending a hyperplane separating from if ; notice that since this hyperplane does not cut into , we do not need to update this set). Notice that is indeed consistent with the response .
The interesting case is when reports that is Infeasible (so ) but . Thus, cannot belong to (recall we will construct ), and so to ensure consistency our response needs to report Infeasible and a separating hyperplane that excludes . The first idea is to simply use separating hyperplane reported by the approximate oracle. But this can exclude points that were deemed Feasible by our previous responses (we call these points ), which would violate consistency. Thus, we first rotate this hyperplane as little as possible such that it contains all points in , and report this rotated hyperplane (adding it to to obtain ). While this rotation protects the points , we also need to argue that it does not stray too much away from the original approximate separating hyperplane so as to not cut into .
We now describe the formal procedure in detail. We use to denote the halfspace with normal passing through the point .
Procedure 5.
Initialize and . For each : 1. Query the -approximate feasibility oracle for at , receiving the response 2. If and . Define the response , and set and . 3. ElseIf but . Set be any unit vector such that the halfspace contains . Define the response . Set and . 4. Else (so ). Let be a unit vector such that the induced halfspace contains that is the closest to with this property, i.e. Define the response . Set and .We remark that in Line 4, there indeed exists a halfspace supported at that contains all points in : in this case (since ) and by definition , so any halfspace separating from will do.
Lemma B.3.
For every , the set , with computed by Procedure 5, is a convex extension to the responses . Moreover, all these sets satisfy .
Proof.
It suffices to prove this for each iteration, so suppose with responses satisfy the lemma. If Lines 2 or 3 of the procedure were executed, it is straightforward to see satisfies the lemma. If Line 4 executes, , and so the response is consistent with since . As by construction and , is consistent with all responses made. It remains to show that contains , for which showing contains it suffices. Notice that since there exists an exact halfspace separating that is -close to (due to the -approximate oracle), and contains and thus , we have . The triangle inequality then reveals , and then it is easy to see that contains , concluding the proof. ∎
Appendix C A closer comparison with related work
In this section, we give a more detailed comparison between our work and the results and settings in closely related work of (Devolder et al., 2014). Therein, the authors define a similar setting using their own notion of inexact first-order oracles and analyze the behavior of a few primal, dual and accelerated gradient methods for convex optimization problems under these oracles. In particular, they show that accelerated gradient methods must accumulate errors in the inexact information setting. As noted, their analysis gives guarantees for specific algorithms, as opposed to our “universal” algorithm-independent guarantees. In summary, for the algorithms they provide results for, implementing our method mostly requires less noise to achieve equivalent convergence rates. We begin by comparing the oracles used.
Comparing the inexact oracles:
The notion of inexact first-order oracle in (Devolder et al., 2014) uses two parameters, as opposed to the single parameter in our Definition 2.1. Nevertheless, an oracle from the Devolder et al. setting corresponds to an oracle in our setting for any family of convex functions on , with appropriate settings of the noise parameters, and vice versa. We provide the definition for an inexact oracle used by Devolder et al. here:
Definition C.1.
Let be a convex function on . A first-order -oracle queried at some point returns a pair such that for all we have
Note that while this definition is valid for any convex function, not just -smooth functions, the motivation for the definition comes from the -smooth inequalities. The parameter can be viewed as the “noise" while is the smoothness constant of the family of functions considered, which is taken for granted throughout (Devolder et al., 2014). We will refer to the oracle of Definition 2.1 as the -approximate oracle and that of Definition C.1 as the -oracle in this section.
Here is what one can say when comparing the two oracles. For the family of -smooth functions, an -approximate oracle corresponds to a -oracle with (see Example from Section 2.3 in (Devolder et al., 2014)). For -Lipschitz functions, an -approximate oracle is equivalent to a (, )-oracle obtained by setting and arbitrary (if the response of the -approximate oracle is , the response of the -oracle is and ). This follows from the Lipschitz bound combined with the fact that for any .
In the other direction, if one is given a -oracle from the Devolder et al. setting for any family of convex functions on , this provides an -approximate oracle in our sense for (see eqn. (8) in (Devolder et al., 2014)).
Comparison of the noise levels needed for convergence rates:
Next, we compare the noise levels needed to achieve comparable convergence rates across our approach and the results of Devolder et al. We look at three different function classes for this comparison.
-
a)
Nonsmooth, -Lipschitz functions: As mentioned above, Devolder et al. do not explicitly do an analysis for this family; they focus on -smooth functions. However, one can carry out an analysis of the subgradient method given an -approximate oracle similar to the Devolder et al. analysis in the smooth case. The additional error incurred by the inexactness of the oracle is indeed still . Therefore, if one uses subgradient descent without any modifications, one needs to set to get overall error after iterations. Using our black-box reduction however, one needs to set for the same convergence rate.
-
b)
Comparison for -smooth functions with gradient descent: Devolder et al.’s analysis of gradient descent with their notion of oracle gives additional error. Thus, they need to set to get convergence. From the discussion above, an -approximate oracle corresponds to a -oracle with . In other words, Devolder et al.’s result says that suffices to get convergence, if gradient descent is run without modification with an -approximate oracle. From our black-box analysis for the -smooth case, we cannot guarantee a convergence rate better than , no matter what choice of , since we lose the factor due to our smoothing technique. Thus, our technique does not achieve the rate for gradient descent for -smooth functions.
-
c)
Comparison for -smooth functions with acceleration: Devolder et al.’s analysis of Nesterov’s acceleration with the -oracle gives additional error. Thus, they need to set to get the standard convergence. From the discussion above, an -approximate oracle in our setting corresponds to a -oracle with . In other words, Devolder et al.’s result says that suffices to get convergence. To get just rate, one can set in the analysis of Devolder et al. (the additional error term from the oracle noise dominates in this case). From our black-box analysis for -smooth functions, we need to set as well, but note that we lose a factor of ( being the dimension) additionally. So our final rate is , whereas the Devolder et al. analysis does not accrue any dimension-dependent factors.
Overall, the algorithm-specific analyses in (Devolder et al., 2014) give better convergence rates for equivalent noise levels, or equivalently have less stringent noise requirements to achieve a target convergence rate. This is not too surprising, since our black-box approach is much more general to work with any first-order algorithm, and can be viewed as a kind of trade-off to the generality of our results.