A Variational Bayesian Inference-Inspired Unrolled Deep Network for MIMO Detection
Abstract
The great success of deep learning (DL) has inspired researchers to develop more accurate and efficient symbol detectors for multi-input multi-output (MIMO) systems. Existing DL-based MIMO detectors, however, suffer several drawbacks. To address these issues, in this paper, we develop a model-driven DL detector based on variational Bayesian inference. Specifically, the proposed unrolled DL architecture is inspired by an inverse-free variational Bayesian learning framework which circumvents matrix inversion via maximizing a relaxed evidence lower bound. Two networks are respectively developed for independent and identically distributed (i.i.d.) Gaussian channels and arbitrarily correlated channels. The proposed networks, referred to as VBINet, have only a few learnable parameters and thus can be efficiently trained with a moderate amount of training samples. The proposed VBINet-based detectors can work in both offline and online training modes. An important advantage of our proposed networks over state-of-the-art MIMO detection networks such as OAMPNet and MMNet is that the VBINet can automatically learn the noise variance from data, thus yielding a significant performance improvement over the OAMPNet and MMNet in the presence of noise variance uncertainty. Simulation results show that the proposed VBINet-based detectors achieve competitive performance for both i.i.d. Gaussian and realistic 3GPP MIMO channels.
Index Terms:
MIMO detection, variational Bayesian inference, unrolled deep networks.I Introduction
Massive multiple-input multiple-output (MIMO) is a promising technology for next-generation wireless communication systems [1, 2, 3]. In massive MIMO systems, the base station (BS), equipped with tens or hundreds of antennas, simultaneously serves a smaller number of single-antenna users sharing the same time-frequency resource [4]. The large number of antennas at the BS helps achieve almost perfect inter-user interference cancelation and has the potential to enhance the spectrum efficiency by orders of magnitude. Nevertheless, large-scale MIMO poses a significant challenge for optimal signal detection. To realize the full potential of massive MIMO systems, it is of significance to develop advanced signal detection algorithms that can strike a good balance between performance and complexity [5].
Signal detection in the MIMO framework has been extensively investigated over the past decades. It is known that the maximum likelihood (ML) detector is an optimal detector but has a computational complexity that scales exponentially with the number of unknown variables. Linear detectors such as zero-forcing (ZF) and linear minimum mean-squared error (LMMSE) have a relatively low computational complexity, but they suffer a considerable performance degradation as compared with the ML detector. Recently, Bayesian inference or optimization-based iterative detectors, e.g. [6, 7, 8, 9, 10, 11], were proposed. Empirical results show that these iterative schemes such as the approximate message passing (AMP) and expectation propagation (EP)-based detectors can achieve excellent performance with moderate complexity [9, 10]. Nevertheless, the AMP-based or EP-based methods utilize a series of approximation techniques to facilitate the Bayesian inference. When the channel matrix has a small size or is ill-conditioned, the approximation may not hold valid, in which case these methods may suffer severe performance degradation.
More recently, the great success of deep learning (DL) in a variety of learning tasks has inspired researchers to use it as an effective tool to devise more accurate and efficient detection and estimation schemes [12, 13, 14, 15, 16, 17, 18]. The application of purely data-driven DL-based schemes, however, faces the challenges of a long training time as a result of the complicated network structure and a large number of learnable parameters [19, 20]. To address this issue, model-driven DL-based schemes were recently proposed for MIMO detection [21, 22, 23]. The main idea of model-driven DL detector is to unfold the iterative algorithm as a series of neural network layers with some learnable parameters. Specifically, DetNet seems to be one of the earliest works to study the problem of MIMO detection by unfolding the projected gradient descent algorithm [24]. The number of learnable parameters for DetNet, however, is still large. Thus it needs a large number of samples to train the neural network. As an extension of DetNet, WeSNet aims to reduce the model size by introducing a sparsity-inducing regularization constraint in conjunction with trainable weight-scaling functions [25]. In order to further reduce the number of learnable parameters of the network, OAMPNet, a neural architecture inspired by the orthogonal AMP algorithm, was proposed [22]. The OAMPNet has only four learnable parameters per layer, and thus is easy to train. Compared with DetNet, OAMPNet can achieve competitive performance with much fewer training samples. Both DetNet and OAMPNet are trained in an offline mode, i.e. they aim to learn a single detector during training for a family of channel matrices. Recently, another work [23] examined the MIMO detection problem from an online training perspective. The proposed MMNet can achieve a considerable performance improvement over OAMPNet when sufficient online training is allowed. Nevertheless, online training means that the model parameters are trained and tested for each realization of the channel. When the test channel sample is different from the training channel sample, MMNet would suffer a substantial amount of performance degradation. It should be noted that both OAMPNet and MMNet require the knowledge of the noise variance for symbol detection. In practice, however, the prior information about the noise variance is usually unavailable and inaccurate estimation may result in substantial performance loss.
Recently, the information bottleneck (IB) theory attracts much attention for providing an information theoretic view of deep learning networks [26, 27]. The IB approach has found applications in a variety of learning problems. It can also be applied to solve the MIMO detection problem. Consider extracting the relevant information that some signal provides about another one that is of interest. IB formulates the problem of finding a representation that is maximally informative about , while being minimally informative about [26]. Accordingly, the optimal mapping of the data to is found by solving a Lagrangian formulation. This problem can be solved by approximating its variational bound by parameterizing the encoder, decoder and prior distributions with deep neural networks. Nevertheless, when applied to MIMO detection, the IB approach needs a large number of learnable parameters. Therefore it still faces the challenge encountered by purely data-driven DL-based schemes.
In this paper, we propose a variational Bayesian inference-inspired unrolled deep network for MIMO detection. Our proposed deep learning architecture is mainly inspired by the inverse-free Bayesian learning framework [28], where a fast inverse-free variational Bayesian method was proposed via maximizing a relaxed evidence lower bound. Specifically, we develop two unrolled deep networks, one for i.i.d. Gaussian channels and the other for arbitrarily correlated channels. Our proposed networks, referred to as the variational Bayesian inference-inspired network (VBINet), have a very few learnable parameters and thus can be efficiently trained with a moderate number of training samples. The proposed VBINet can work in both offline and online training modes. An important advantage of our proposed networks over OAMPNet and MMNet is that the VBINet can automatically learn the noise variance from data, which is highly desirable in practical applications. In addition, the proposed VBINet has a low computational complexity, and each layer of the neural network only involves simple matrix-vector calculations. Simulation results show that the proposed VBINet-based detector achieves competitive performance for both i.i.d. Gaussian and 3GPP MIMO channels. Moreover, it attains a significant performance improvement over the OAMPNet and MMNet in the presence of noise variance uncertainty.
The rest paper is organized as follows. Section II discusses the MIMO detection problem. Section III provides a brief overviews of some state-of-the-art DL-based detectors. Section IV proposes an iterative detector for i.i.d. Gaussian channels within the inverse-free variational Bayesian framework. A deep network (VBINet) is then developed by unfolding the iterative detector in Section V. The iterative detector is extended to correlated channels in Section VI, and an improved VBINet is developed in Section VII for arbitrarily correlated channels. Numerical results are provided in Section VIII, followed by conclusion remarks in Section IX.
II Problem Formulation
We consider the problem of MIMO detection for uplink MIMO systems, in which a base station equipped with antennas receives signals from single-antenna users. The received signal vector can be expressed as
| (1) |
where denotes the MIMO channel matrix, and denotes the additive complex Gaussian noise. It is clear that the likelihood function of the received signal is given by
| (2) |
where each element of the detected symbol belongs to a discrete constellation set . In other words, the prior distribution for is given as
| (3) |
where
| (4) |
in which stands for the Dirac delta function.
The optimal detector for (1) is the maximum-likelihood (ML) estimator formulated as follows [29, 23]
| (5) |
Although the ML estimator yields optimal performance, its computational complexity is prohibitively high. To address this difficulty, a plethora of detectors were proposed over the past few decades to strike a balance between complexity and detection performance. Recently, a new class of model-driven DL methods called algorithm unrolling or unfolding were proposed for MIMO detection. It was shown that model-driven DL-based detectors present a significant performance improvement over traditional iterative approaches. In the following, we first provide an overview of state-of-the-art model-driven DL-based detectors, namely, the OAMPNet [22] and the MMNET [23].
III Overview of State-Of-The-Art DL-Based Detectors
III-A OAMPNet
OAMPNet is a model-driven DL algorithm for MIMO detection, which is derived from the OAMP [30]. The advantage of OAMP over AMP is that it can be applied to unitarily-invariant matrices while AMP is only applicable to i.i.d Gaussian measurement matrices. OAMPNet can achieve better performance than OAMP, and can adapt to various channel environments by use of some learnable variables. Each iteration of the OAMPNet comprises the following two steps:
| (6) | ||||
| (7) |
where denotes the current estimate of , and is given as [30]:
| (8) |
in which is the LMMSE matrix, i.e.
| (9) |
is the error variance of , and can be calculated as
| (10) |
Here denotes the covariance matrix of the additive observation noise .
In the NLE step, the learnable variable is used to regulate the error variance , and the error variance of is given by
| (11) |
where , and (11) derives from the fact that . From (8) to (11), we see that calculations of , and require the knowledge of the noise variance . For the NLE step, it is a divergence-free estimator defined as
| (12) |
with
| (13) |
where and denote the th element of and , respectively, and is used to represent the probability density function of a Gaussian random variable with mean and variance . For OAMPNet, each layer has four learnable parameters, i.e. , in which and are used to optimize the LE estimator, whereas are employed to adjust the NLE estimator.
III-B MMNet
MMNet has two variants, one for i.i.d Gaussian channels and the other for arbitrarily correlated channels. Similar to OAMPNet, the noise variance is also assumed known in advance for MMNet. Each layer of the MMNet performs the following update:
| (14) | ||||
| (15) |
Here is chosen to be for i.i.d Gaussian channels and an entire trainable matrix for arbitrary channels. The error variance vector can be calculated as
| (16) |
where , and MMNet chooses as for i.i.d. Gaussian channels and an entire trainable vector for arbitrary channels. Here, is a learnable parameter, and is an all-one vector.
A major drawback of MMNet is that, for the correlated channel case, MMNet needs to train model parameters for each realization of . The reason is that for a specific , it is difficult to have the neural network generalized to a variety of channel realizations. Therefore, MMNet achieves impressive performance when online training is allowed, where the model parameters can be trained and tested for each realization of the channel; while MMNet fails to work when only offline training is allowed. Here offline training means that training is performed over randomly generated channels, and its performance is evaluated over another set of randomly generated channels.
IV IFVB Detector
Our proposed DL architecture is mainly inspired by the inverse-free variational Bayesian learning (IFVB) framework developed in [28], where a fast inverse-free variational Bayesian method was proposed via maximizing a relaxed evidence lower bound. In this section, we first develop a Bayesian MIMO detector within the IFVB framework.
IV-A Overview of Variational Inference
We first provide a review of the variational Bayesian inference. Let denote the hidden variables in the model. The objective of Bayesian inference is to find the posterior distribution of the latent variables given the observed data, i.e. . The computation of , however, is usually intractable. To address this difficulty, in variational inference, the posterior distribution is approximated by a variational distribution that has a factorized form as [31]
| (17) |
Note that the marginal probability of the observed data can be decomposed into two terms
| (18) |
where
| (19) |
and
| (20) |
where is the Kullback-Leibler divergence between and , and is the evidence lower bound (ELBO). Since is a constant, maximizing is equivalent to minimizing , and thus the posterior distribution can be approximated by the variational distribution through maximizing . The ELBO maximization can be conducted in an alternating fashion for each latent variable, which leads to [31]
| (21) |
where denotes an expectation with respect to the distributions for all .
IV-B IFVB-Based MIMO Detector
To facilitate the Bayesian inference, we place a Gamma hyperprior over the hyperparameter , i.e.
| (22) |
where and are small positive constants, e.g. . We have
| (23) |
Let denote the hidden variables in the MIMO detection problem, and let the variational distribution be expressed as . Variational inference is conducted by maximizing the ELBO, which yields a procedure which involves updates of the approximate posterior distributions for hidden variables and in an alternating fashion. Nevertheless, it is difficult to derive the approximate posterior distribution for due to the coupling of elements of in the likelihood function .
To address this difficulty, we, instead, maximize a lower bound on the ELBO , also referred to as a relaxed ELBO. To obtain a relaxed ELBO, we first recall the following fundamental property for a smooth function.
Lemma 1.
If the continuously differentiable function has bounded curvature, i.e. there exists a matrix such that , then, for any , we have
| (24) |
Invoking Lemma 1, a lower bound on can be obtained as
| (25) |
where
| (26) |
Here needs to satisfy , and the inequality (25) becomes equality when . Finding a matrix satisfying is not difficult. In particular, we wish to be a diagonal matrix in order to help obviate the difficulty of matrix inversion. An appropriate choice of is
| (27) |
where denotes the largest eigenvalue of , and is a small positive constant, say, .
Utilizing (25), a relaxed ELBO on can be obtained as
| (28) |
where
| (29) |
In order to satisfy a rigorous distribution, the relaxed ELBO can be further expressed as
| (30) |
where
| (31) |
and the normalization term guarantees that follows a rigorous distribution, and the exact expression of is
| (32) |
Our objective is to maximize the relaxed ELBO with respect to and the parameter . This naturally leads to a variational expectation-maximization (EM) algorithm. In the E-step, the posterior distribution approximations are computed in an alternating fashion for each hidden variable, with other variables fixed. In the M-step, is maximized with respect to , given fixed. Details of the Bayesian inference are provided below.
A. E-step
1) Update of : Ignoring those terms that are independent of , the approximate posterior distribution can be obtained as
| (33) |
where
| (34) | ||||
| (35) |
Since is chosen to be a diagonal matrix, calculation of is simple and no longer involves computing the inverse of a matrix. Also, as the covariance matrix is a diagonal matrix and the prior distribution has a factorized form, the approximate posterior also has a factorized form, which implies that elements of are mutually independent.
Thus, the mean of the th element of can be easily calculated as
| (36) |
where is the th element of , is the th diagonal element of . The expectation of can be computed as
| (37) |
2) Update of : The variational distribution can be calculated by
| (38) |
Thus follows a Gamma distribution given as
| (39) |
in which
| (40) |
and
| (41) |
where denotes the covariance matrix of . Due to the independence among entries in , is a diagonal matrix and its th diagonal element is given by
| (42) |
Finally, we have
| (43) |
B. M-step
Substituting into , an estimate of can be found via the following optimization
| (44) |
Setting the derivative of the logarithm function to zero yields:
| (45) |
As and , the solution of is
| (46) |
IV-C Summary of IFVB Detector
For clarity, the proposed IFVB detector is summarized as an iterative algorithm with each iteration consisting of two steps, namely, a linear estimation (LE) step and a nonlinear estimation (NLE) step:
| (47) | ||||
| (48) |
where and denote the current estimate of and , respectively. The linear estimator in equation (47) derives from (35) and (46). Here with a slight abuse of notation, we use to represent the current estimate of . The nonlinear estimator (48) is a vector form of (36). In (48), the covariance matrix can be calculated as (cf. (34)), with updated as
| (49) |
where
| (50) |
and the th diagonal element of can be calculated as
| (51) |
in which and denote the th elements of and , respectively.
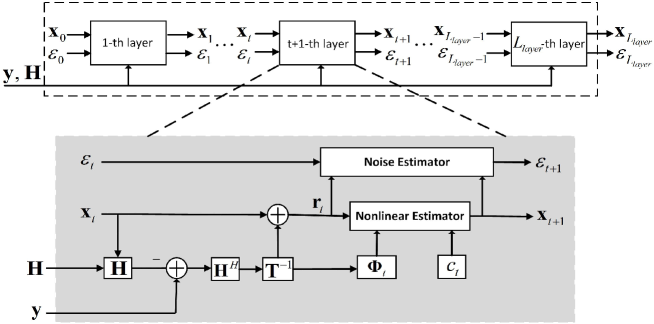
V Proposed VBINet-Based Detector
In this section, we propose a model-driven DL detector (referred to as VBINet) which is developed by unfolding the iterative IFVB detector. The network architecture is illustrated in Fig. 1, in which the network consists of cascade layers with some trainable parameters. The trainable parameters of all layers are denoted as , where is a diagonal matrix common to all layers. We will explain these trainable parameters in detail later. For the th layer, the input includes , , , and , where and denote the th layer’s estimate of the signal and the noise variance, respectively. Given , each layer performs the following updates:
| (52) | ||||
| (53) | ||||
| (54) |
where
| (55) | |||
| (56) | |||
| (57) |
in which is the th diagonal element of the diagonal matrix .
We see that the update formulas (52)–(57) are similar to the IFVB detector’s update formulas (47)–(51). Nevertheless, there are two major differences. Firstly, in the LE step, the diagonal matrix is no longer pre-specified; instead, it is a trainable diagonal matrix. The reason for doing this is to make the network learnable and flexible. Specifically, we believe that given in (27) may not be the best, and hope that we can find a more suitable diagonal matrix through training. Secondly, in the NLE step, is updated by applying an adaptive damping scheme with a learnable parameter . In the adaptive damping scheme, the damping parameter can help control the convergence rate and improve the robustness of the system [34].
One may wonder why not use an individual for each layer of the network. The reason is that using a common diagonal matrix for all layers can substantially reduce the number of learnable variables, which facilitates training when the number of training data is limited. Also, notice that the iterative algorithm developed in the previous section uses a same throughout its iterative process. This suggests that using an individual for each layer may not be necessary. To corroborate our conjecture, we conducted experiments to compare these two schemes. Simulation results show that using an individual for each layer does not achieve a clear performance improvement over the scheme of using a common diagonal matrix .
Moreover, due to the use of the term in the NLE step, the covariance matrix of , denoted by , cannot be updated via (51). Note that in the IFVB detector, according to (48), the NLE outputs the mean value of the variable . Meanwhile, in the VBINet, the output of the NLE is the mean of a new variable defined as
| (58) |
Thus the mean of is given by
| (59) |
and the th diagonal element of the diagonal covariance matrix of the random variable is given by
| (60) |
in which denotes the th element of . This explains how (57) is derived.
Remark 1: We see that the total number of learnable parameters of VBINet is , as each layer shares the same learnable variable while are generally different for different layers. Suppose that the number of users is and the number of layers is set to . The total number of learnable parameters of VBINet is . As a comparison, the OAMPNet has parameters to be learned for the same problem being considered. Due to the small number of learnable parameters, the proposed VBINet can be effectively trained even with a limited number of training data samples.
Remark 2: An important advantage of the proposed VBINet over state-of-the-art deep unfolding-based detectors such as the OAMPNet and the MMNet is that the VBINet can automatically estimate the noise variance , while both the OAMPNet and the MMNet require the knowledge of , and an inaccurate knowledge of the noise variance results in a considerable amount of performance degradation, as will be demonstrated later in our experiments. Another advantage of the proposed VBINet is that the update formulas can be efficiently implemented via simple matrix/vector operations. No matrix inverse operation is needed.
Remark 3: The proposed VBINet can provide an approximate posterior probability of the transmitted symbols, which is useful for channel decoders relying on the estimate of the posterior probability of the transmitted symbols [35]. Thus the proposed VBINet can be well suited for joint symbol detection and channel decoding.
VI IFVB Detector: Extension To Correlated Channels
The proposed IFVB detector performs well on channel matrices with independent and identically distributed (i.i.d.) entries. Nevertheless, similar to AMP and other message-passing-based algorithms, its performance degrades considerably on realistic, spatially-correlated channel matrices. To address this issue, we discuss how to improve the proposed IFVB detector to accommodate arbitrarily correlated channel matrices.
The key idea behind the improved IFVB detector is to conduct a truncated singular value decomposition (SVD) of the channel matrix , where , , and . Define and . The received signal vector in (1) can be equivalently written as
| (61) |
Instead of detecting , we aim to estimate based on the above observation model. Let denote the hidden variables, and let denote the prior distribution of . Thus the ELBO is given as
| (62) |
where
| (63) |
in which still follows a Gamma distribution as assumed in (22).
Similar to what we did in the previous section, we resort to a relaxed ELBO to facilitate the variational inference. Let . Invoking Lemma 1, a lower bound on can be obtained as
| (64) |
where
| (65) |
and the inequality becomes equality when . Here, we consider a specialized form of , where the first term is a diagonal matrix independent of and the second term is a function of . We will show that such an expression of leads to an LMMSE-like estimator for the LE step.
Utilizing (64), a relaxed ELBO can be obtained as
| (66) |
where
| (67) |
Similarly, we aim to maximize the relaxed ELBO with respect to and the parameter , which leads to a variational EM algorithm. In the E-step, given , the approximate posterior distribution of is updated. In the M-step, the parameter can be updated by maximizing with fixed. Details of the variational EM algorithm are provided below.
A. E-step
1) Update of : The variational distribution can be calculated as
| (68) |
where in , we have
| (69) | ||||
| (70) |
in which
| (71) |
Note that the approximate posterior distribution is difficult to obtain because the prior has an intractable expression. To address this issue, we, instead, examine the posterior distribution . Recalling that , we have
| (72) |
where
| (73) | ||||
| (74) |
To calculate , we neglect the cross-correlation among entries of , i.e., treat the off-diagonal entries of as zeros. This trick helps obtain an analytical approximate posterior distribution , and meanwhile has been empirically proven effective. Let represent the th diagonal element of . The first and second moments of can be updated as
| (75) |
Thus we arrive at follows a Gaussian distribution with its mean and covariance matrix , where
| (76) |
Since follows a Gaussian distribution, the approximate posterior of also follows a Gaussian distribution, and its mean and covariance matrix can be readily obtained as
| (77) |
| (78) |
2) Update of : The variational distribution can be calculated as
| (79) |
in which
| (80) |
Thus the hyperparameter follows a Gamma distribution, i.e.
| (81) |
where and are given by
| (82) |
Also, we have
| (83) |
B. M-step
Substituting into , the parameter can be optimized via
| (84) |
Setting the derivative of the logarithm function to zero yields
| (85) |
Since and , the solution of is given by
| (86) |
VI-A Summary of The Improved IFVB Detector
For the sake of clarity, the improved IFVB detector can be summarized as an iterative algorithm with each iteration consisting of a linear estimation step and a nonlinear estimation step:
| (87) | ||||
| (88) | ||||
| (89) | ||||
| (90) |
where , and and denote the th elements of and , respectively. The linear estimator in equations (87) and (88) derives from (70) and (73). The nonlinear estimator in equations (89) and (90) follows from (75) and (77). In (89), the variance can be obtained as
| (91) |
where denotes the th row of , and . Here is updated as
| (92) |
where
| (93) |
in which
| (94) |
and the th diagonal element of the diagonal matrix can be calculated as
| (95) |
Discussions: For the Improved IFVB Detector, a specialized form of is considered. The reason is that such a specialized form will lead to an LMMSE-like estimator for the LE step, i.e. (see (87)). Here, denotes the current estimate of in the LE step, and denotes the previous estimate of . If we treat as a random variable following a Gaussian distribution with zero mean and covariance matrix , and let . It can be readily verified that is in fact an LMMSE estimator of given the observation: . It is known that the LMMSE estimator can compensate for the noise and effectively improve the estimation performance. This is the reason why we choose such a specialized form of .
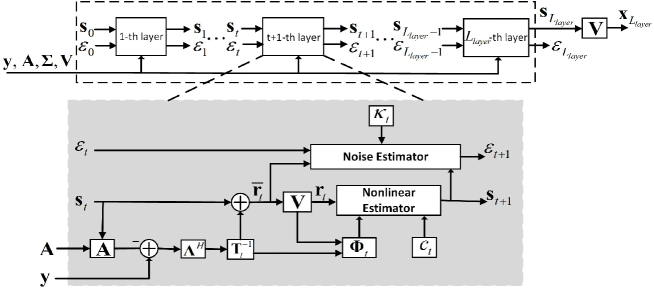
VII VBINet Detector for Correlated Channels
In this section, we propose a model-driven DL detector (referred to as Improved-VBINet) by unfolding the improved IFVB detector. The network architecture of Improved-VBINet is illustrated in Fig. 2, in which the network consists of cascade layers. The trainable parameters of all layers are denoted as , where the diagonal matrix and are related to the diagonal matrix . For the th layer, the input includes , , , , , and , where and denote the th layer’s estimate of the signal and the noise variance, respectively. Given , each layer performs the following updates:
| (96) | ||||
| (97) | ||||
| (98) | ||||
| (99) | ||||
| (100) |
where
| (101) | |||
| (102) | |||
| (103) | |||
| (104) | |||
| (105) |
We see that the update formulas (96)–(105) are similar to the improved IFBL detector’s update formulas (87)–(95). Nevertheless, there are several major differences. Firstly, in the LE step, which is calculated according to certain rules is replaced by a trainable diagonal matrix due to the use of the learnable variables . Specifically, the linear estimator module turns out to have a form similar to the LMMSE estimator, i.e.
| (106) |
Secondly, in the NLE step, is updated by applying an adaptive damping scheme with a learnable parameter . Due to the use of the term in the NLE step, the output of the NLE is the mean of a new variable defined as
| (107) |
Recalling that , thus the mean of is given by
| (108) |
and the covariance matrix of the random variable is given by
| (109) |
Here is a diagonal matrix whose diagonal elements can be calculated according to (95). To further reduce the complexity, we approximate as , where is a learnable parameter. Thus we have
| (110) |
This explains how (105) is derived.
Remark 1: We see that the total number of learnable parameters of the improved-VBINet is , as each layer shares the same learnable variable but are generally different for different layers. The total number of learnable parameters of the Improved-VBINet is comparable to that of OAMPNet.
VII-A Computational Complexity Analysis
We discuss the computational complexity of our proposed VBINet detectors. Specifically, for the i.i.d. Gaussian channels, at each layer the complexity of the proposed VBINet detector is dominated by the multiplication of an matrix and an vector. Therefore the overall complexity of the proposed VBINet is of order . For the correlated channels, the proposed Improved-VBINet detector requires to conduct a truncated SVD decomposition of an matrix in the initialization stage. Therefore the overall complexity of the proposed Improved-VBINet detector is of order . Similar to the proposed VBINet, the complexity of MMNet is of order . As for the OAMPNet, it requires to perform an inverse of an matrix per layer, which results in a complexity of in total. Since we usually have for massive MIMO detection, the complexity of the OAMPNet is much higher than our proposed method. This is also the reason why, for large-scale scenarios, training and test of OAMPNet becomes computationally prohibitive.
VIII Simulation Results
In this section, we compare the proposed VBINet-based detector111Codes are available at https://www.junfang-uestc.net/codes/VBINet.rar with state-of-the-art methods for i.i.d. Gaussian, correlated Rayleigh and realistic 3GPP MIMO channel matrices. In the following, we first discuss the implementation details of the proposed method and other competing algorithms.
VIII-A Implementation Details
During training, the learnable parameters are optimized using stochastic gradient descent. Thanks to the auto-differentiable machine-learning frameworks such as TensorFlow [36] and PyTorch [37], the learnable parameters can be easily trained when the loss function is determined. In our experiments, the loss function used for training is given by
| (111) |
in which denotes the square error between the output of the -th layer and the true signal .
In addition to the classical detectors such as the ZF and LMMSE, we compare our proposed method with the iterative algorithm OAMP and the following two state-of-the-art DL-based detectors: OAMPNet [22] and MMNet [23]. The ML detector is also included to provide a performance upper bound for all detectors. Given a set of training samples, the neural network is trained by the Adam optimizer [38] in the PyTorch framework.
In our simulations, the training and test samples are generated according to the model (1), in which both the transmitted signal , the channel , and the observation noise are randomly generated. Specifically, the channel is either generated from an i.i.d. Gaussian distribution or generated according to a correlated channel model as described below. The number of training iterations is denoted as , and the batch size for each iteration is denoted as . The signal-to-noise ratio (SNR) is defined as
| (112) |
The training samples in each training iteration includes samples drawn from different SNRs within a certain range. For all detectors, the output signal will be rounded to the closest point on the discrete constellation set . Details of different detectors are elaborated below.
: It is a simple yet classical decoder which has a form as .
: The LMMSE detector takes a form of . Here is the average power of the QAM signal. In our simulation, we set .
: The algorithm is summarized in IV-C. The maximum number of iterations is set to .
: It is an iterative algorithm developed based on the AMP algorithm. The maximum number of iterations is set to .
: OAMPNet is a DL-based detector developed by unfolding the OAMP detector [22]. In our simulations, the number of layers of the OMAPNet is set to , and each layer has learnable variables.
: The MMNet-iid [23] is specifically designed for i.i.d. Gaussian channels. In our simulations, the number of layers of the MMNet-iid is set to , and each layer has learnable variables.
: The MMNet [23] can be applied to arbitrarily correlated channel matrices, which needs to learn a matrix for each layer, and the total number of learnable parameters is per layer.
: The architecture of our proposed VBINet is shown in Section V, which has layers and learnable variables.
: Applicable for arbitrarily correlated matrices, the proposed Improved-VBINet has layers and learnable variables.
: It is implemented by using a highly optimized Mixed Integer Programming package Gurobi [39] 222The code is shared by [23]..
VIII-B Results
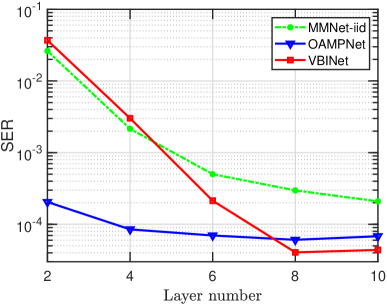
VIII-B1 Convergence Evaluation
The convergence property of our proposed network is evaluated. Fig. 3 depicts the symbol error rate (SER) of different detectors as a function of the number of layers with QPSK modulation and i.i.d. Gaussian channels, where we set , , , and . We see that our proposed VBINet-based detector converges in less than layers, and after convergence, the proposed detector can achieve a certain amount of performance improvement over the OAMPNet and MMNet-iid.
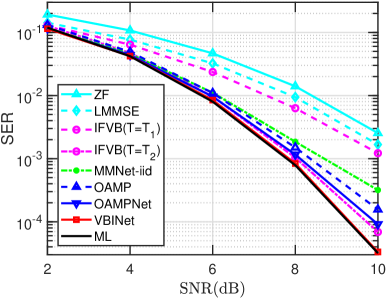
VIII-B2 I.I.D. Gaussian Channels
We first examine the detection performance of our proposed detector on i.i.d. Gaussian channels. We consider an offline training mode, in which training is performed over randomly generated channels and the performance is evaluated over another set of randomly generated channels.
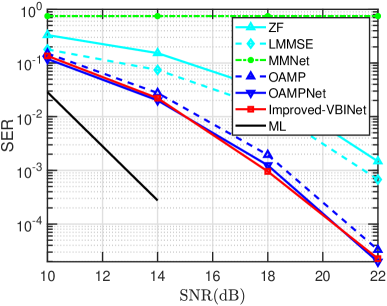
Fig. 4 plots the SER of respective algorithms as a function of the SNR, where QPSK modulation is considered, and we set , , , and . It can be observed that the ML detector achieves the best performance among all detectors, and the SER gap between our proposed VBINet and the ML detector is negligible. Moreover, the proposed VBINet outperforms the OAMPNet. We also see that the VBINet presents a clear performance advantage over the IFVB, which is because a more suitable learned by VBINet will lead to better performance. For the IFVB, we use two different choices of to show the impact of on the detection performance. Specifically, the first choice of is set to and the second choice of is set to , where is a diagonal matrix which takes the diagonal entries of . We see that the latter choice leads to much better performance, which indicates that the performance of IFVB depends largely on the choice of . This is also the motivation why we learn in the VBINet.
VIII-B3 Correlated Rayleigh Channels
We now examine the performance of respective detectors on correlated Rayleigh channels. The correlated Rayleigh channel is modeled as
| (113) |
where entries of follow i.i.d. Gaussian distribution with zero mean and unit variance, and respectively denote the receive and transmit correlation matrices. Note that the receive and transmit correlation matrices can be characterized by a correlation coefficient [40], and a larger means that the channel matrix has a larger condition number. Again, in this experiment, offline training is considered.
In Fig. 5, we plot the SER of respective algorithms as a function of SNR, where we set , , , , and . It can be observed that all DL detectors suffer a certain amount of performance degradation as the channel becomes ill-conditioned. Besides, MMNet fails to work in the offline training mode, where the test channels are different from the channels generated during the training phase. This is because in the LE step, the MMNet treats as an entire trainable matrix. As a result, the trained neural network can only accommodate a particular channel realization. We also observe that both our proposed Improved-VBINet and OAMPNet work well in the offline training mode, and the proposed Improved-VBINet achieves performance slightly better than the OAMPNet.
VIII-B4 3GPP MIMO Channels
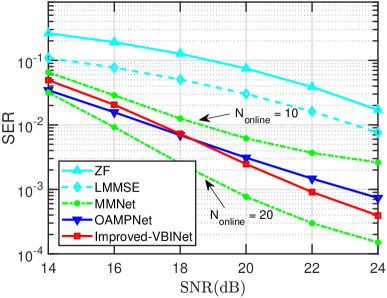
Next, we compare the performance of different detectors on realistic 3GPP 3D MIMO channels which are generated by the QuaDRiGa channel simulator [41, 42]. The parameters used to generate the channels are set the same as those in [23], except that the bandwidth is set to MHz, the number of effective sub-carriers is set to , and the number of sequences is . In this experiments, online training is considered, where the model parameters are trained and tested on the same realization of the channel. Specifically, we first train the neural network associated with the first subcarrier’s channel. The trained model parameters are then used as initial values of the neural network of the second subcarrier, and the second subcarrier’s network is employed as a start to train the third subcarrier’s network, and so on. Due to the channel correlation among adjacent subcarriers, the rest subcarriers’ neural networks can be efficiently trained with a small amount of data samples.
Fig. 6 depicts the SER of respective algorithms as a function of SNR, where we set , , and the QPSK modulation is considered. For the first subcarrier, the number of training iterations is and the batch size is , while for all subsequent subcarriers, the number of online training iterations is and the batch size is . In Fig. 6, we also report results of the MMNet when the number of online training iterations is set to . We see that our proposed Improved-VBINet achieves performance similar to the OAMPNet. Also, it can be observed that MMNet achieves the best performance when a sufficient amount of data is allowed to be used for training. Nevertheless, the performance of MMNet degrades dramatically with a reduced amount of training data. Note that MMNet needs to learn an entire matrix at each layer. With a large number of learnable parameters, the MMNet can well approximate the best detector when sufficient training is performed, whereas incurs a significant amount of performance degradation when training is insufficient.
VIII-B5 Noise Uncertainty
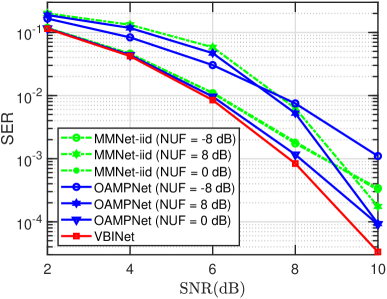
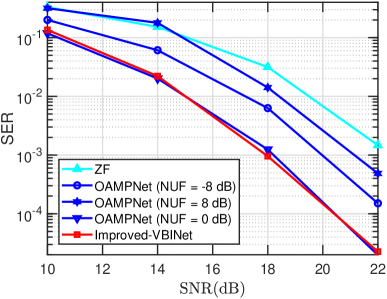
Next, we examine the impact of noise variance uncertainty on the performance of different DL-based detectors. As mentioned earlier, different from our proposed VBINet which is capable of estimating the noise variance automatically, both OAMPNet and MMNet require the knowledge of noise variance for training and test. Note that the noise variance can be assumed known during the training phase, as we usually have access to the model parameters used to generate the training data samples. But the same assumption does not hold true for the test data. As a result, when evaluating the performance on the test data, both OAMPNet and MMNet have to replace the noise variance by its estimate. Let the estimated noise variance be . We also define the noise uncertainty factor (NUF) as . In this experiment, an offline training mode is considered.
In Fig. 7, we plot the SER of respective algorithms as a function of SNR with different NUFs, where i.i.d. Gaussian channels and QPSK modulation are considered, and we set , , , and . It can be observed that both MMNet-iid and OAMPNet incur a considerable amount of performance loss when the estimated noise variance deviates from the true one. The performance gap between OAMPNet and VBINet becomes more pronounced when the estimate of the noise variance is inaccurate. Fig. 8 plots the SER of respective DL detectors as a function of SNR for correlated Rayleigh channels, where we set . Since MMNet fails to work in the offline training mode for correlated channels, its results are not included. Again, we see that OAMPNet suffer a substantial performance degradation when an inaccurate noise variance is used.
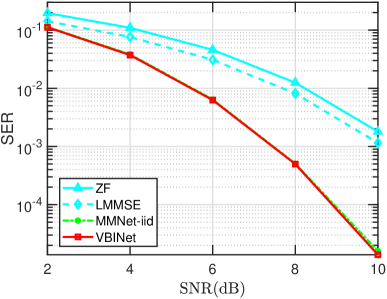
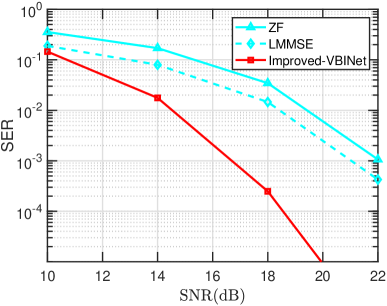
VIII-B6 Large-Scale MIMO Scenarios
We examine the detection performance of our proposed method in the large-scale MIMO scenario, in which the number of antennas at the BS is up to 128. In our experiments, the QPSK modulation is adopted, and we set , , , and . For the correlated Rayleigh channel, is set to . Fig. 9 and Fig. 10 plot the SERs of respective algorithms as a function of SNR for i.i.d. Gaussian and correlated Rayleigh channels, respectively. Note that in the LE step of the OAMPNet, is updated as , which involves computing the inverse of a matrix of size at each layer. Hence for large-scale scenarios, training and test of OAMPNet becomes computationally prohibitive. For this reason, the results of OAMPNet are not included. Also, the results of MMNet are not included for correlated Rayleigh channels as it aims to learn an entire matrix for each layer and thus fails to work well in the offline training mode. Results in Fig. 9 and Fig. 10 show that the proposed VBINet can achieve superior performance while with a low computational complexity.
IX Conclusions
In this paper, we proposed a model-driven DL network for MIMO detection based on a variational Bayesian framework. Two networks are respectively developed for i.i.d. Gaussian channels and arbitrarily correlated channels. The proposed networks, referred to as VBINet, have only a few learnable parameters and thus can be efficiently trained with a moderate amount of training. Simulation results show that the proposed detectors provide competitive performance for both i.i.d. Gaussian channels and realistic 3GPP MIMO channels. Moreover, the VBINet-based detectors can automatically determine the noise variance, and achieve a substantial performance improvement over existing DL-based detectors such as OAMPNet and MMNet in the presence of noise uncertainty.
References
- [1] Q. Zhang, X. Cui, and X. Li, “Very tight capacity bounds for MIMO-correlated Rayleigh-fading channels,” IEEE Transactions on Wireless Communications, vol. 4, no. 2, pp. 681–688, 2005.
- [2] A. Shahmansoori, G. E. Garcia, G. Destino, G. Seco-Granados, and H. Wymeersch, “Position and orientation estimation through millimeter-wave MIMO in 5G systems,” IEEE Transactions on Wireless Communications, vol. 17, no. 3, pp. 1822–1835, 2017.
- [3] L. Lu, G. Y. Li, A. L. Swindlehurst, A. Ashikhmin, and R. Zhang, “An overview of massive MIMO: Benefits and challenges,” IEEE journal of selected topics in signal processing, vol. 8, no. 5, pp. 742–758, 2014.
- [4] H. Q. Ngo, E. G. Larsson, and T. L. Marzetta, “Energy and spectral efficiency of very large multiuser MIMO systems,” IEEE Transactions on Communications, vol. 61, no. 4, pp. 1436–1449, 2013.
- [5] D. Kong, X.-G. Xia, and T. Jiang, “A differential QAM detection in uplink massive MIMO systems,” IEEE Transactions on Wireless Communications, vol. 15, no. 9, pp. 6371–6383, 2016.
- [6] M. E. Tipping, “Sparse Bayesian learning and the relevance vector machine,” Journal of machine learning research, vol. 1, no. Jun, pp. 211–244, 2001.
- [7] D. L. Donoho, A. Maleki, and A. Montanari, “Message passing algorithms for compressed sensing: I. motivation and construction,” in 2010 IEEE information theory workshop on information theory (ITW 2010, Cairo). IEEE, 2010, pp. 1–5.
- [8] W. Chen, D. Wipf, Y. Wang, Y. Liu, and I. J. Wassell, “Simultaneous Bayesian sparse approximation with structured sparse models,” IEEE Trans. Signal Processing, vol. 64, no. 23, pp. 6145–6159, 2016.
- [9] S. Wu, L. Kuang, Z. Ni, J. Lu, D. Huang, and Q. Guo, “Low-complexity iterative detection for large-scale multiuser MIMO-OFDM systems using approximate message passing,” IEEE Journal of Selected Topics in Signal Processing, vol. 8, no. 5, pp. 902–915, 2014.
- [10] T. P. Minka, “A family of algorithms for approximate Bayesian inference,” Ph.D. dissertation, Massachusetts Institute of Technology, 2001.
- [11] J. Jaldén and B. Ottersten, “The diversity order of the semidefinite relaxation detector,” IEEE Transactions on Information Theory, vol. 54, no. 4, pp. 1406–1422, 2008.
- [12] T. Wang, C.-K. Wen, H. Wang, F. Gao, T. Jiang, and S. Jin, “Deep learning for wireless physical layer: Opportunities and challenges,” China Communications, vol. 14, no. 11, pp. 92–111, 2017.
- [13] Y. Wei, M.-M. Zhao, M. Hong, M.-J. Zhao, and M. Lei, “Learned conjugate gradient descent network for massive MIMO detection,” IEEE Transactions on Signal Processing, vol. 68, pp. 6336–6349, 2020.
- [14] H. Ye, G. Y. Li, and B.-H. Juang, “Power of deep learning for channel estimation and signal detection in OFDM systems,” IEEE Wireless Communications Letters, vol. 7, no. 1, pp. 114–117, 2017.
- [15] Y. Bai, W. Chen, J. Chen, and W. Guo, “Deep learning methods for solving linear inverse problems: Research directions and paradigms,” Signal Processing, p. 107729, 2020.
- [16] Q. Hu, Y. Cai, Q. Shi, K. Xu, G. Yu, and Z. Ding, “Iterative algorithm induced deep-unfolding neural networks: Precoding design for multiuser MIMO systems,” IEEE Transactions on Wireless Communications, vol. 20, no. 2, pp. 1394–1410, 2020.
- [17] X. Ma, Z. Gao, F. Gao, and M. Di Renzo, “Model-driven deep learning based channel estimation and feedback for millimeter-wave massive hybrid MIMO systems,” IEEE Journal on Selected Areas in Communications, 2021.
- [18] Z. Huang, A. Liu, Y. Cai, and M.-J. Zhao, “Deep stochastic optimization for algorithm-specific pilot design in massive MIMO,” in 2021 IEEE Statistical Signal Processing Workshop (SSP). IEEE, 2021, pp. 191–195.
- [19] M.-S. Baek, S. Kwak, J.-Y. Jung, H. M. Kim, and D.-J. Choi, “Implementation methodologies of deep learning-based signal detection for conventional MIMO transmitters,” IEEE Transactions on Broadcasting, vol. 65, no. 3, pp. 636–642, 2019.
- [20] N. Farsad and A. Goldsmith, “Neural network detection of data sequences in communication systems,” IEEE Transactions on Signal Processing, vol. 66, no. 21, pp. 5663–5678, 2018.
- [21] M.-W. Un, M. Shao, W.-K. Ma, and P. Ching, “Deep MIMO detection using ADMM unfolding,” in 2019 IEEE Data Science Workshop (DSW). IEEE, 2019, pp. 333–337.
- [22] H. He, C.-K. Wen, S. Jin, and G. Y. Li, “Model-driven deep learning for MIMO detection,” IEEE Transactions on Signal Processing, vol. 68, pp. 1702–1715, 2020.
- [23] M. Khani, M. Alizadeh, J. Hoydis, and P. Fleming, “Adaptive neural signal detection for massive MIMO,” IEEE Transactions on Wireless Communications, vol. 19, no. 8, pp. 5635–5648, 2020.
- [24] N. Samuel, T. Diskin, and A. Wiesel, “Deep MIMO detection,” in 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2017, pp. 1–5.
- [25] A. Mohammad, C. Masouros, and Y. Andreopoulos, “Complexity-scalable neural-network-based mimo detection with learnable weight scaling,” IEEE Transactions on Communications, vol. 68, no. 10, pp. 6101–6113, 2020.
- [26] I. E. Aguerri and A. Zaidi, “Distributed variational representation learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, pp. 120–138, 2021.
- [27] A. Zaidi and I. E. Aguerri, “Distributed deep variational information bottleneck,” in 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 2020.
- [28] H. Duan, L. Yang, J. Fang, and H. Li, “Fast inverse-free sparse bayesian learning via relaxed evidence lower bound maximization,” IEEE Signal Processing Letters, vol. 24, no. 6, pp. 774–778, 2017.
- [29] X. Zhu and R. D. Murch, “Performance analysis of maximum likelihood detection in a MIMO antenna system,” IEEE Transactions on Communications, vol. 50, no. 2, pp. 187–191, 2002.
- [30] J. Ma and L. Ping, “Orthogonal amp,” IEEE Access, vol. 5, pp. 2020–2033, 2017.
- [31] D. G. Tzikas, A. C. Likas, and N. P. Galatsanos, “The variational approximation for Bayesian inference,” IEEE Signal Processing Magazine, vol. 25, no. 6, pp. 131–146, 2008.
- [32] Y. Sun, P. Babu, and D. P. Palomar, “Majorization-minimization algorithms in signal processing, communications, and machine learning,” IEEE Transactions on Signal Processing, vol. 65, no. 3, pp. 794–816, 2016.
- [33] J. R. Magnus and H. Neudecker, Matrix differential calculus with applications in statistics and econometrics. John Wiley & Sons, 2019.
- [34] S. Rangan, P. Schniter, A. K. Fletcher, and S. Sarkar, “On the convergence of approximate message passing with arbitrary matrices,” IEEE Transactions on Information Theory, vol. 65, no. 9, pp. 5339–5351, 2019.
- [35] R. Chen, X. Wang, and J. S. Liu, “Adaptive joint detection and decoding in flat-fading channels via mixture Kalman filtering,” IEEE Transactions on Information Theory, vol. 46, no. 6, pp. 2079–2094, 2000.
- [36] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al., “Tensorflow: Large-scale machine learning on heterogeneous distributed systems,” arXiv preprint arXiv:1603.04467, 2016.
- [37] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
- [38] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [39] Gurobi Optimization. Inc. , “Gurobi optimizer reference manual,” 2021. [Online]. Available: https://www. gurobi. com
- [40] S. L. Loyka, “Channel capacity of MIMO architecture using the exponential correlation matrix,” IEEE Communications letters, vol. 5, no. 9, pp. 369–371, 2001.
- [41] S. Jaeckel, L. Raschkowski, K. Börner, and L. Thiele, “QuaDRiGa: A 3-D multi-cell channel model with time evolution for enabling virtual field trials,” IEEE Transactions on Antennas and Propagation, vol. 62, no. 6, pp. 3242–3256, 2014.
- [42] ”3GPP TR 38.901 V16.1.0”, Technical Specification Group Radio Access Network; Study on channel model for frequencies from 0.5 to 100 GHz (Release 14), 2019. [Online]. Available: https://www.3gpp.org/ftp/Specs/archive/