ABC: Auxiliary Balanced Classifier for Class-imbalanced Semi-supervised Learning
Abstract
Existing semi-supervised learning (SSL) algorithms typically assume class-balanced datasets, although the class distributions of many real-world datasets are imbalanced. In general, classifiers trained on a class-imbalanced dataset are biased toward the majority classes. This issue becomes more problematic for SSL algorithms because they utilize the biased prediction of unlabeled data for training. However, traditional class-imbalanced learning techniques, which are designed for labeled data, cannot be readily combined with SSL algorithms. We propose a scalable class-imbalanced SSL algorithm that can effectively use unlabeled data, while mitigating class imbalance by introducing an auxiliary balanced classifier (ABC) of a single layer, which is attached to a representation layer of an existing SSL algorithm. The ABC is trained with a class-balanced loss of a minibatch, while using high-quality representations learned from all data points in the minibatch using the backbone SSL algorithm to avoid overfitting and information loss. Moreover, we use consistency regularization, a recent SSL technique for utilizing unlabeled data in a modified way, to train the ABC to be balanced among the classes by selecting unlabeled data with the same probability for each class. The proposed algorithm achieves state-of-the-art performance in various class-imbalanced SSL experiments using four benchmark datasets.
1 Introduction
Recently, numerous deep neural network (DNN)-based semi-supervised learning (SSL) algorithms have been proposed to improve the performance of DNNs by utilizing unlabeled data when only a small amount of labeled data is available. These algorithms have shown effective performance in various tasks. However, most existing SSL algorithms assume class-balanced datasets, whereas the class distributions of many real-world datasets are imbalanced. It is well known that classifiers trained on class-imbalanced data tend to be biased toward the majority classes. This issue can be more problematic for SSL algorithms that use predicted labels of unlabeled data for their training, because the labels predicted by the algorithm trained on class-imbalanced data become even more severely imbalanced [18]. For example, Figure 1 (b) presents biased predictions of ReMixMatch [3], a recent SSL algorithm, trained on CIFAR--LT, which is a class-imbalanced dataset with the amount of Class 0 being 100 times more than that of Class 9, as depicted in Figure 1 (a). Although there are various class-imbalanced learning techniques, they are usually designed for labeled data, and thus cannot be simply combined with SSL algorithms under class-imbalanced SSL (CISSL) scenarios. Recently, a few CISSL algorithms have been proposed, but the CISSL problem is still underexplored.
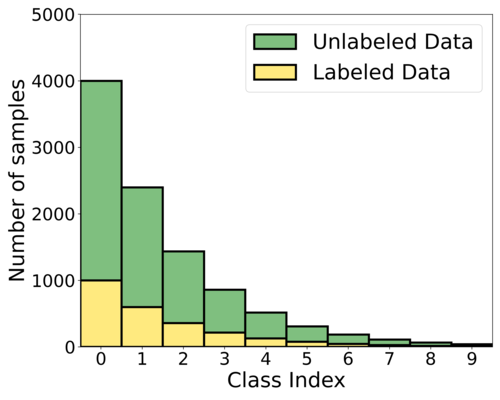 |
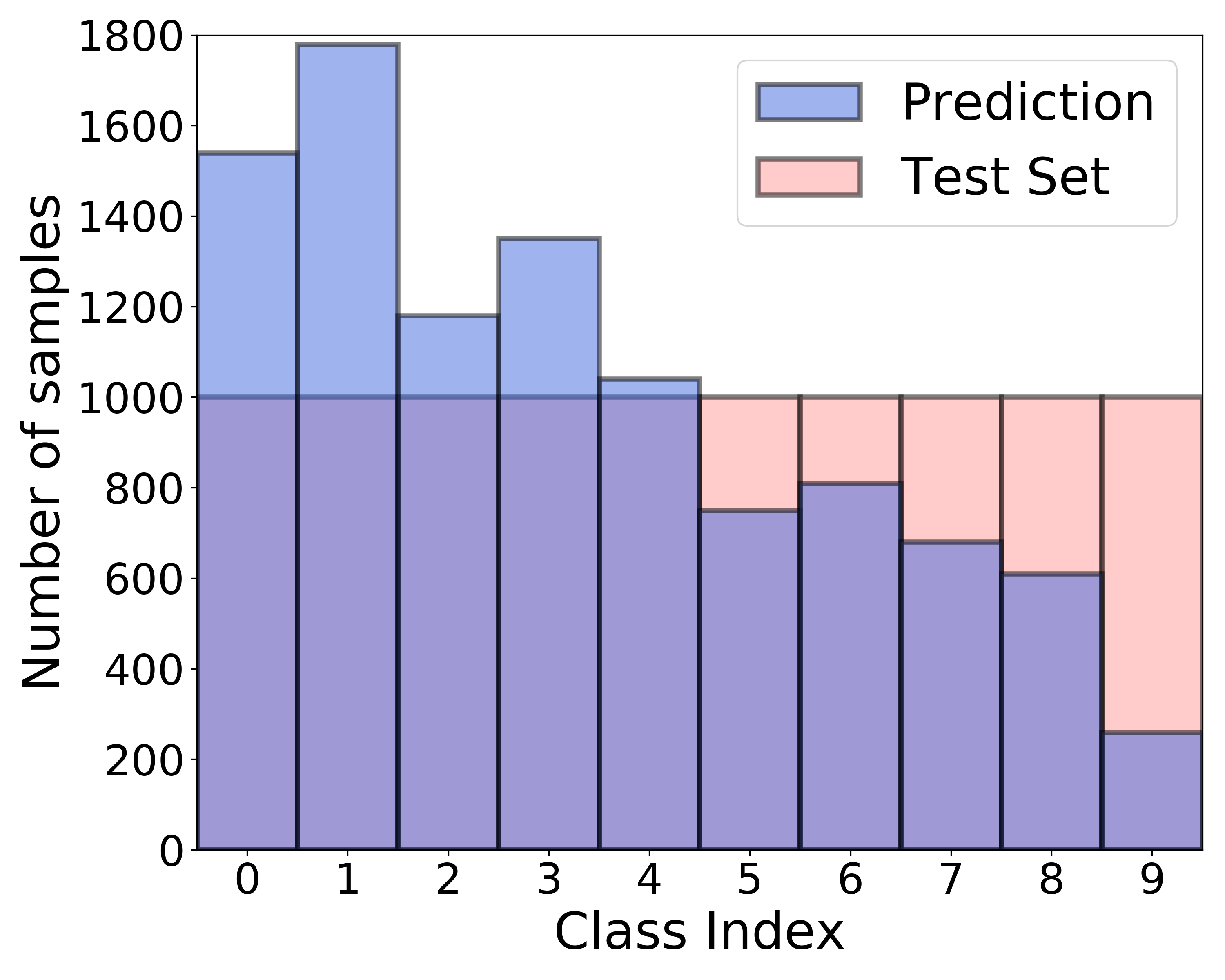
|
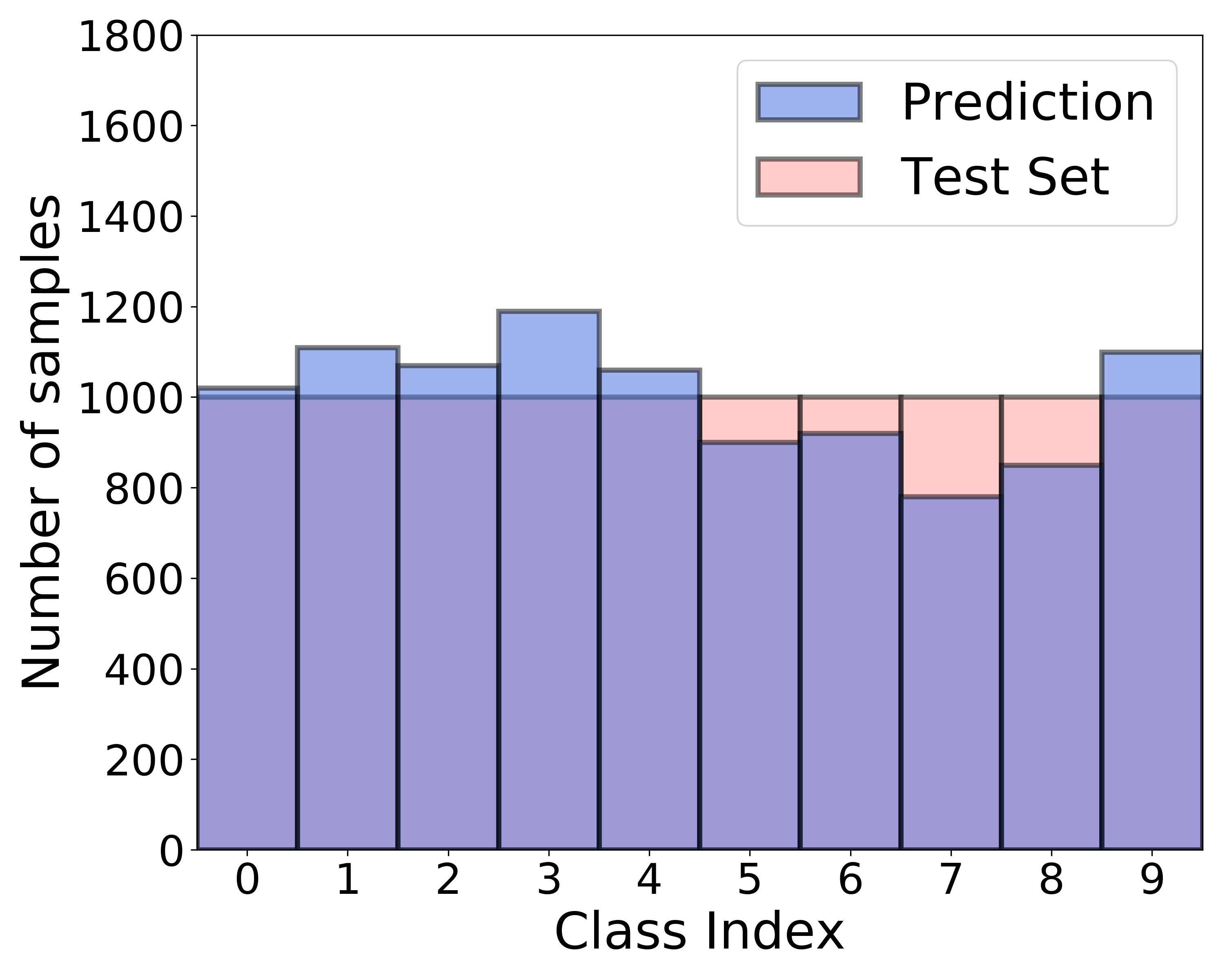
|
| (a) Class-imbalanced training set | (b) ReMixMatch | (c) Proposed algorithm |
We propose a new CISSL algorithm that can effectively use unlabeled data, while mitigating class imbalance by using an existing DNN-based SSL algorithm [3, 29] as the backbone and introducing an auxiliary balanced classifier (ABC) of a single layer. The ABC is attached to a representation layer immediately preceding the classification layer of the backbone, based on the argument that a classification algorithm (i.e., backbone) can learn high-quality representations even if its classifier is biased toward the majority classes [17]. The ABC is trained to be balanced across all classes by using a mask that rebalances the class distribution, similar to re-sampling in previous SSL studies [2, 7, 13, 16]. Specifically, the mask stochastically regenerates a class-balanced subset of a minibatch on which the ABC is trained. The ABC is trained simultaneously with the backbone, so that the ABC can use high-quality representations learned from all data points in the minibatch using the backbone. In this way, the ABC can overcome the limitations of the previous resampling techniques, overfitting on minority-class data or loss of information on majority-class data [6, 27].
Moreover, to place decision boundaries in low-density regions by utilizing unlabeled data, we use consistency regularization, a recent SSL technique, which enforces the classification outputs of two augmented or perturbed versions of the same unlabeled example to remain unchanged. In particular, we encourage the ABC to be balanced across classes when using consistency regularization by selecting unlabeled examples with the same probability for each class using a mask. Figure 1 (c) illustrates that compared to the results of ReMixMatch in Figure 1 (b), the class distribution of the predicted labels becomes more balanced using the proposed algorithm trained on the same dataset. Our experimental results under various scenarios demonstrate that the proposed algorithm achieves state-of-the-art performance. Through qualitative analysis and an ablation study, we further investigate the contribution of each component of the proposed algorithm. The code for the proposed algorithm is available at https://github.com/LeeHyuck/ABC.
2 Related Work
Semi-supervised learning (SSL) Recently, several SSL techniques that utilize unlabeled data have been proposed. Entropy minimization [12] encourages the classifier outputs to have low entropy for unlabeled data, as in pseudo-labels [22]. Mixup regularization [4, 32] makes the decision boundaries farther away from the data clusters by encouraging the prediction for an interpolation of two inputs to be the same as the interpolation of the prediction for each input. Consistency regularization [26, 24, 30] encourages a classifier to produce similar predictions for perturbed versions of the same unlabeled input. To create perturbed unlabeled inputs, various data augmentation techniques have been used. For example, FixMatch [29] and ReMixMatch [3] used strong augmentation methods such as Cutout [10] and RandomAugment [8]. FixMatch and ReMixMatch are used as the backbone of the proposed algorithm; they are described in Section 3.2.
Class-imbalanced learning (CIL) As a popular approach for CIL, re-sampling techniques [16, 7, 2, 13] balance the number of training samples for each class in the training set. As another popular approach, re-weighting techniques [23, 14, 33] re-weight the loss for each class by a factor inversely proportional to the number of data points belonging to that class. Although these approaches are simple, they have some drawbacks. For example, oversampling from minority classes can cause overfitting, whereas undersampling from majority classes can cause information loss [6]. In the case of re-weighting, gradients can be calculated to be abnormally large when the class imbalance is severe, resulting in unstable training [6, 1]. Many attempts have been made to alleviate these problems, such as effective re-weighting [9] and meta-learning-based re-weighting [28, 15]. New forms of losses have also been proposed [6, 27]. In [36, 19], knowledge is transferred from the data of majority classes to the data of minority classes. These CIL algorithms were designed for labeled data and require label information; thus, they are not applicable to unlabeled data. In [17], it was found that biased classification is mainly due to the classification layer and that a classification algorithm can learn meaningful representations even from a class-imbalanced training set. Based on this finding, we design the ABC to use high-quality representations learned from class-imbalanced data utilizing FixMatch [29] and ReMixMatch [3].
Class-imbalanced semi-supervised learning (CISSL) There have been few studies on CISSL. In [35], it was found that more accurate decision boundaries can be obtained in class-imbalanced settings through self-supervised learning and semi-supervised learning. DARP [18] refines biased pseudo-labels by solving a convex optimization problem. CReST [34], a recent self-training technique, mitigates class imbalance by using pseudo-labeled unlabeled data points classified as minority classes with a higher probability than those classified as majority classes.
3 Methodology
3.1 Problem setting
Suppose that we have a labeled dataset , where is the th labeled data point and is the corresponding label. We also have an unlabeled dataset , where is the th unlabeled data point. We express the ratio of the amount of labeled data as . Generally, , because label acquisition is costly and laborious. We denote the number of labeled data points of class as , i.e., , and assume that the classes are sorted according to cardinality in descending order, i.e., . We denote the ratio of the class imbalance as . Under class-imbalanced scenarios, . Following previous CIL studies, we define the half of the classes containing a large amount of data as the majority classes, and the other half of the classes, containing a small amount of data, as the minority classes. Following [34], we assume that and share the same class distribution, i.e., the labeled and unlabeled datasets are class-imbalanced to the same extent. From and , we generate minibatches and for each iteration of training, where is the minibatch size. Using these minibatches for training, we aim to learn a model that performs effectively on a class-balanced test set.
3.2 Backbone SSL algorithm
We attach the ABC to the backbone’s representation layer, so that it can utilize the high-quality representations learned by the backbone. We use FixMatch [29] or ReMixMatch [3] as the backbone, as these two have achieved state-of-the-art SSL performance. FixMatch uses the classification loss calculated from the weakly augmented labeled data point generated by flipping and cropping the image, and the consistency regularization loss calculated from the weakly augmented unlabeled data point and strongly augmented unlabeled data point generated by Cutout [10] and RandomAugment [8]. ReMixMatch predicts the class label of the weakly augmented unlabeled data point using distribution alignment and sharpening, and assigns the predicted label to the strongly augmented unlabeled data point . These strongly augmented unlabeled data point and strongly augmented labeled data point are used to conduct mixup regularization. ReMixMatch also conducts consistency regularization in a manner similar to FixMatch and self-supervised learning using the rotation of the image [11, 39]. FixMatch and ReMixMatch have greatly improved the SSL performance by learning high-quality representations using strong data augmentation. However, these algorithms can be significantly biased toward the majority classes in class-imbalanced settings.
Using FixMatch and ReMixMatch as the backbone of the proposed algorithm, we ensure that the ABC enjoys high-quality representations learned by the backbone, while replacing the backbone’s biased classifier. To train the ABC, we reuse the weakly augmented data and strongly augmented data used by the backbone to decrease the computational cost. Although we use FixMatch and ReMixMatch as the backbone in this study, the ABC can also be combined with other DNN-based SSL algorithms, as long as they use weakly augmented data and strongly augmented data.
3.3 ABC for class-imbalanced Semi-supervised learning
To train the ABC to be balanced, we first generate mask for each labeled data point using a Bernoulli distribution with the parameter set to be inversely proportional to the number of data points of each class. This setting makes generate mask 1 with high probability for the data points in the minority classes, but with low probability for those in the majority classes. Then, the classification loss is multiplied by the generated mask, so that the ABC can be trained with a balanced classification loss. Multiplying the classification loss by the mask can be interpreted as oversampling of the data points in the minority classes, whereas it can be interpreted as undersampling of those in the majority classes. In representation learning, oversampling and undersampling techniques have shown overfitting and information loss problems, respectively. In contrast, the ABC can overcome these problems because it uses the representations learned by the backbone, which is trained on all data points in the minibatch. The use of the mask to construct the balanced loss, instead of directly creating a balanced subset, allows the backbone and the ABC to be trained from the same minibatches. Therefore, the representations of minibatches calculated for training the backbone can be used again for training the ABC. Consequently, the proposed algorithm only requires a slightly increased time cost compared to training the backbone alone. This is confirmed in Section 4.3. The overall procedure of balanced training with mask for the ABC attached to a representation layer of the backbone is presented in Figure 2. The classification loss for the ABC, , with mask is expressed as
| (1) |
| (2) |
where is the standard cross-entropy loss, is an augmented labeled data point, is the predicted class distribution using the ABC for , and is the one-hot label for .
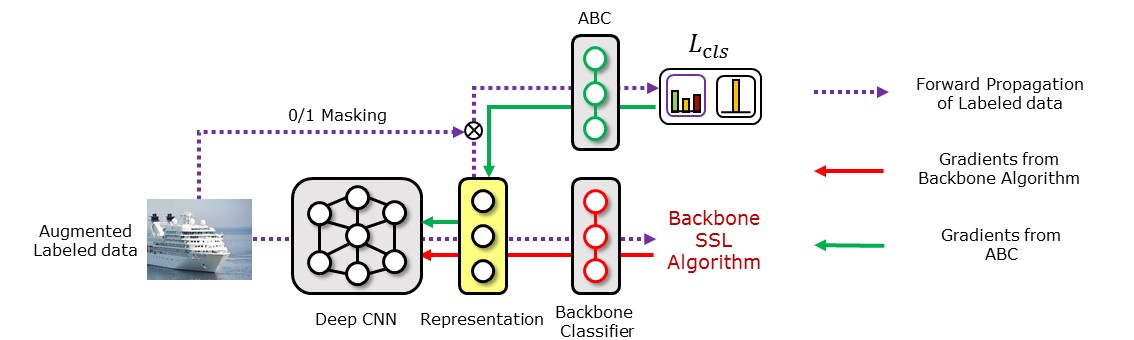
3.4 Consistency regularization for ABC
To increase the margin between the decision boundary and the data points using unlabeled data, we conduct consistency regularization for the ABC, similar to the way in FixMatch. Specifically, we first obtain the predicted class distribution for a weakly augmented unlabeled data point using the ABC and use it as a soft pseudo-label . Then, for two strongly augmented unlabeled data points and , we train the ABC to produce their predicted class distributions, and , to be close to .
In class-imbalanced settings, because most unlabeled data points belong to majority classes, most weakly augmented unlabeled data points can be predicted as the majority classes. Then, consistency regularization would be conducted with a higher frequency for the majority classes, which can cause a classifier to be biased toward the majority classes. To prevent this issue, we conduct consistency regularization in a modified manner that is suitable for class-imbalance problems. Specifically, whereas FixMatch minimizes entropy by converting the predicted class distribution for a weakly augmented data point into a one-hot pseudo-label, we directly use the predicted class distribution as a soft pseudo-label. We do not pursue entropy minimization for the ABC because it can accelerate biased classification toward certain classes. Moreover, we once again generate mask for each unlabeled data point based on a soft pseudo label , and multiply the consistency regularization loss for by the generated mask, so that the ABC can be trained with a class-balanced consistency regularization loss. Note that existing resampling techniques are not applicable to unlabeled data, because they require a label for each data point. In contrast, we make it possible to resample unlabeled data by using the soft pseudo-label and the mask. The consistency regularization loss, , with mask is expressed as
| (3) |
| (4) |
where is the indicator function, is the highest predicted assignment probability for any class, representing the confidence of prediction, and is the confidence threshold. To avoid the unwanted effects of inaccurate soft pseudo-labels during consistency regularization, we only use the weakly augmented unlabeled data points whose confidence is higher than the threshold , similar to that in FixMatch. To take full advantage of few unlabeled data points with prediction confidence values that are higher than the confidence threshold in the early stage of training, we gradually decrease the parameter of the Bernoulli distribution for from 1 to , where is the one-hot pseudo-label obtained from . Following previous studies [3, 24, 29, 4], we do not backpropagate gradients for pseudo-label prediction. The overall procedure for consistency regularization for the ABC is shown in Appendix A.
3.5 End-to-end training
Unlike a recent CIL trend to finetune a classifier in a balanced manner after representation learning is completed (i.e., decoupled learning of representations and a classifier) [17, 27], we obtain a balanced classifier by training the proposed algorithm end-to-end. We train the proposed algorithm with the sum of losses from Sections 3.3 and 3.4, and the loss for the backbone, . The total loss function is expressed as
| (5) |
Whereas we use the sum of the losses for the backbone and ABC for training the proposed algorithm, we predict the class labels of new data points using only the ABC. In our experiments in Sections 4.4 and 4.5, we show that the proposed algorithm trained end-to-end produces better performance than competing algorithms with decoupled learning of representations and a classifier, and we analyze possible reasons. We present the pseudo code of the proposed algorithm in Appendix B.
4 Experiments
4.1 Experimental setup
We created class-imbalanced versions of CIFAR-10, CIFAR-100 [21], and SVHN [25] datasets to conduct experiments under various ratios of class imbalance and various ratios of the amount of labeled data . For class-imbalance types, we first consider long-tailed (LT) imbalance in which the number of data points exponentially decreases from the largest to the smallest class, i.e., , where . We also consider step imbalance [5] in which the whole majority classes have the same amount of data and the whole minority classes also have the same amount of data. Two types of class imbalance for the considered datasets are illustrated in Appendix C. For the main setting, we set , , and for CIFAR- and SVHN, and , and for CIFAR-. Similar to [18], we set of CIFAR-100 to be relatively small because CIFAR- has only 500 training data points for each class. To evaluate the performance of the proposed algorithm on large-scale datasets, we also conducted experiments on 7.5M data points of 256 by 256 images from the LSUN dataset [37].
We compared the performance of the proposed algorithm with that of various baseline algorithms. Specifically, we considered the following baseline algorithms:
-
•
Deep CNN (vanilla algorithm): This is trained on only labeled data with the cross-entropy loss.
-
•
BALMS [27] (CIL algorithm): This state-of-the-art CIL algorithm does not use unlabeled data.
- •
-
•
FixMatch+CReST+PDA and ReMixMatch+CReST+PDA (CISSL algorithms): CReST+PDA [34] mitigates class imbalance by using unlabeled data points classified as the minority classes with a higher probability than those classified as the majority classes.
-
•
ReMixMatch+DARP and FixMatch+DARP (CISSL algorithms): These algorithms use DARP [18] to refine the pseudo labels obtained from ReMixMatch or FixMatch.
-
•
ReMixMatch+DARP+cRT and FixMatch+DARP+cRT (CISSL algorithms): Compared to ReMixMatch+DARP and FixMatch+DARP, these algorithms finetune the classifier using cRT [17].
For the structure of the deep CNN used in the proposed and baseline algorithms, we used Wide ResNet-- [38]. We trained the proposed algorithm for iterations with a batch size of 64. The confidence threshold was set to based on experiments with various values of in Appendix D. We used the Adam optimizer [20] with a learning rate of , and used Cutout [10] and RandomAugment [8] for strong data augmentation, following [18]. Similar to [3, 4], we evaluated the performance of the proposed algorithm using an exponential moving average of the parameters over iterations with a decay rate of , instead of scheduling the learning rate. In Tables 1-5, we used the overall accuracy and the accuracy only for minority classes as performance measures. We repeated the experiments five times under the main setting, and three times under the step imbalance and other settings of and . We report the average and standard deviation of the performance measures over repeated experiments. For the vanilla algorithm, FixMatch+DARP+cRT, and ReMixMatch+DARP+cRT, which suffered from overfitting, we measured performance every 500 iterations and recorded the best performance. Further details of the experimental setup are described in Appendix E.
4.2 Experimental results
The performance of the competing algorithms under the main setting are summarized in Table 1. We can observe that the proposed algorithm achieved the highest overall performance, with improved performance for minority classes. Interestingly, VAT, an SSL algorithm, showed similar performance to the vanilla algorithm, and worse performance than BALMS, a CIL algorithm. Similarly, FixMatch and ReMixMatch, which do not consider class imbalance, showed poor performance for minority classes. Although BALMS mitigated class imbalance, it produced poor overall performance, as it did not use unlabeled data for training. This demonstrates the importance of using unlabeled data for training, even in the class-imbalanced setting. FixMatch+CReST+PDA and ReMixMatch+CReST+PDA mitigated class imbalance by using unlabeled data points classified as the minority classes with a higher probability, but produced lower performance than the proposed algorithm. This may be because even if all unlabeled data points classified as minority classes are additionally used for training, their amount is still less than that of the data in majority classes, while the proposed algorithm uses class-balanced minibatches by generating the mask. Fixmatch+DARP and ReMixMatch+DARP slightly mitigated class imbalance by refining biased pseudo-labels, but resulted in lower performance than the proposed algorithm. This may be because even perfect pseudo labels cannot change the underlying class-imbalanced distribution of the training data. By additionally using a rebalancing technique cRT, FixMatch(ReMixMatch)+DARP+cRT performed better than FixMatch(ReMixMatch)+DARP. However, FixMatch(ReMixMatch)+DARP+cRT still performed worse than FixMatch(ReMixMatch)+ABC, although it also uses high-quality representations learned by FixMatch(ReMixMatch) and techniques for mitigating class imbalance. The superior performance of FixMatch(ReMixMatch)+ABC over FixMatch(ReMixMatch)+DARP+cRT is probably because FixMatch(ReMixMatch)+ABC was trained end-to-end, and the ABC was also trained using unlabeled data. We discuss this in more detail in Sections 4.4 and 4.5. Overall, the algorithms combined with ReMixMatch performed better than the algorithms combined with FixMatch. In addition to the overall accuracy and minority-class-accuracy, we also compared the performance of the competing algorithms in terms of the geometric mean (G-mean) of class-wise accuracy under the main setting in Appendix F.
| CIFAR--LT | SVHN-LT | CIFAR--LT | ||
| Algorithm | , | , | , | |
| Vanilla | / | / | / | |
| VAT [24] | / | / | / | |
| BALMS [27] | / | / | / | |
| FixMatch [29] | / | / | / | |
| w/ CReST+PDA [34] | / | / | / | |
| w/ DARP [18] | / | / | / | |
| w/ DARP+cRT [18] | / | / | / | |
| w/ ABC | 81.1 / 72.0 | 92.0 / 87.9 | 56.3 / 43.4 | |
| ReMixMatch [3] | / | / | / | |
| w/ CReST+PDA [34] | / | / | / | |
| w/ DARP [18] | / | / | / | |
| w/ DARP+cRT [18] | / | / | / | |
| w/ ABC | 82.4 / 75.7 | 93.9 / 92.5 | 57.6 / 46.7 | |
To evaluate the performance of the proposed algorithm in various settings, we conducted experiments using ReMixMatch, FixMatch, and the CISSL algorithms considered in Table 1, while changing the ratio of class imbalance and the ratio of the amount of labeled data . The results for CIFAR- are presented in Table 2, and the results for SVHN and CIFAR- are presented in Appendix G. In Table 2, we can observe that the proposed algorithm achieved the highest overall accuracy with greatly improved performance for minority classes for all settings. Because FixMatch+DARP+cRT and ReMixMatch+DARP+cRT do not use unlabeled data for classifier tuning, the difference in performance between FixMatch(ReMixMatch)+DARP+cRT and the proposed algorithm increased as the ratio of the amount of labeled data decreased and as the ratio of class imbalance increased. In addition, the difference in performance between FixMatch(ReMixMatch)+CReST+PDA and the proposed algorithm tended to increase as the ratio of class imbalance increased, because the difference between the number of labeled data points belonging to the majority classes and the number of unlabeled data points classified as the minority classes increases with .
We also conducted experiments under a step-imbalance setting, where the class imbalance was more noticeable. This setting assumes a more severely imbalanced class distribution than the LT imbalance settings, because half of the classes have very scarce data. The experimental results for CIFAR- are presented in Table 3, and the results for SVHN and CIFAR- are presented in Appendix H. In Table 3, we can see that the proposed algorithm achieved the best performance, and the performance margin is greater than that of the LT imbalance settings. ReMixMatch+CReST+PDA showed relatively low performance compared to the other algorithms.
To evaluate the performance of the proposed algorithm on a large-scale dataset, we also conducted experiments on the LSUN dataset [37], which is naturally a long-tailed dataset. Among the algorithms considered in Tables 2 and 3, those combined with CReST were excluded for comparison, because CReST requires loading of the whole unlabeled data in the repeated process of updating pseudo-labels, which is not possible for the large-scale LSUN dataset. Instead, we additionally considered FixMatch+cRT and ReMixMatch+cRT for comparison. The experimental results are presented in Table 4. The proposed algorithm showed better performance than the other baseline algorithms. DARP resulted in degradation of the performance, possibly because the scale of the LSUN dataset is very large. Specifically, DARP solves a convex optimization with all unlabeled data points to refine the pseudo labels. As the scale of the unlabeled dataset increases, this optimization problem becomes more difficult to solve and, consequently, the pseudo-labels could be refined inaccurately. Unlike the results for other datasets, the algorithms combined with FixMatch performed better than the algorithms combined with ReMixMatch.
4.3 Complexity of the proposed algorithm
The proposed algorithm requires additional parameters for the ABC, but the number of the additional parameters is negligible compared to the number of parameters of the backbone. For example, the ABC additionally required only and of the number of backbone parameters for CIFAR- with classes and CIFAR- with classes, respectively. Moreover, because the ABC shares the representation layer of the backbone, it does not significantly increase the memory usage and training time. Furthermore, we could train the proposed algorithm on the large-scale LSUN dataset without a significant increase in computation cost, because the entire training procedure could be carried out using minibatches of data. In contrast, the algorithms combined with DARP required convex optimization for all pseudo-labels, which significantly increased the computation cost as the number of classes or the amount of data increased. Similarly, it required significant time to train the algorithms combined with CReST, because CReST requires iterative re-training with a labeled set expanded by adding unlabeled data points with pseudo-labels. We present the floating point operations per second (FLOPS) for each algorithm using Nvidia Tesla-V100 in Appendix I.
4.4 Qualitative analysis of high-quality representations and balanced classification
The ABC can use high-quality representations learned by the backbone when performing balanced classification. To verify this, in Figure 3, we present t-distributed stochastic neighbor embedding (t-SNE) [31] of the representations of the CIFAR- test set learned by the ABC (without SSL backbone), FixMatch+ABC, and ReMixMatch+ABC on CIFAR--LT under the main setting. Different colors indicate different classes. As expected, “ABC (without SSL backbone)" failed to learn class-separable representations because sufficient data were not used for training while using the mask. In contrast, by training the backbone (FixMatch or ReMixMatch) together with the ABC, the proposed algorithm could use the entire data and learn high-quality representations. In this example, ReMixMatch produced more separable representations than FixMatch, which shows that the choice of the backbone affects the performance of the proposed algorithm, as expected.
 |

|

|
| (a)ABC (without SSL backbone) | (b)FixMatch+ABC | (c) ReMixMatch+ABC |
The proposed algorithm can also mitigate class imbalance by using the ABC. To verify this, we compare the confusion matrices of the predictions on the test set of CIFAR- using ReMixMatch, ReMixMatch+DARP+cRT, and ReMiMatch+ABC trained on CIFAR- under the main setting in Figure 4. In the confusion matrices, the value in the th row and the th column represents the ratio of the amount of data belonging to the th class to the amount of data predicted as the th class. Each cell has a darker red color when the ratio is larger. We can see that ReMixMatch often misclassified data points in the minority classes (e.g., classes and into classes and ). This may be because ReMixMatch does not consider class imbalance, and thus biased pseudo-labels were used for training. ReMixMatch+DARP+cRT produced a more balanced class-distribution compared to ReMixMatch by additionally using DARP+cRT. However, a significant number of data points in the minority classes were still misclassified as majority classes. In contrast, ReMixMatch+ABC classified the test data points in the minority classes with higher accuracy, and produced a significantly more balanced class distribution than ReMixMatch+DARP+cRT, as shown in Figure 4 (c). As both ReMixMatch+DARP+cRT and ReMixMatch+ABC use ReMixMatch to learn representations, the performance gap between these two algorithms results from the different characteristics of the ABC versus DARP+cRT as follows. First, DARP+cRT does not use unlabeled data for training its classifier after representations learning is completed, whereas the ABC uses unlabeled data with unbiased pseudo-labels for its training. Second, whereas DARP+cRT decouples the learning of representations and training of a classifier, the ABC is trained end-to-end interactively with representations learned by the backbone. We also present the confusion matrices of the predictions on the test set of CIFAR- using FixMatch, FixMatch+DARP+cRT, and FixMatch+ABC as well as the confusion matrices of the pseudo-labels on the same dataset using ReMixMatch, ReMixMatch+DARP+cRT, ReMixMatch+ABC, FixMatch, FixMatch+DARP+cRT, and FixMatch+ABC in Appendix J. Moreover, we compare the ABC and the classifier of DARP+cRT in more detail using the validation loss plots in Appendix K.
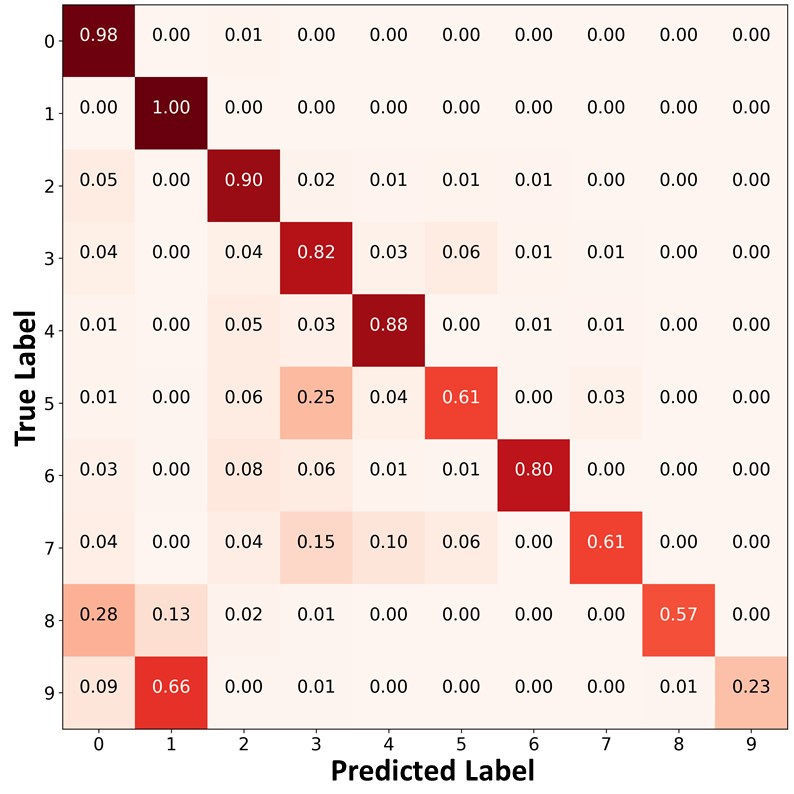 |
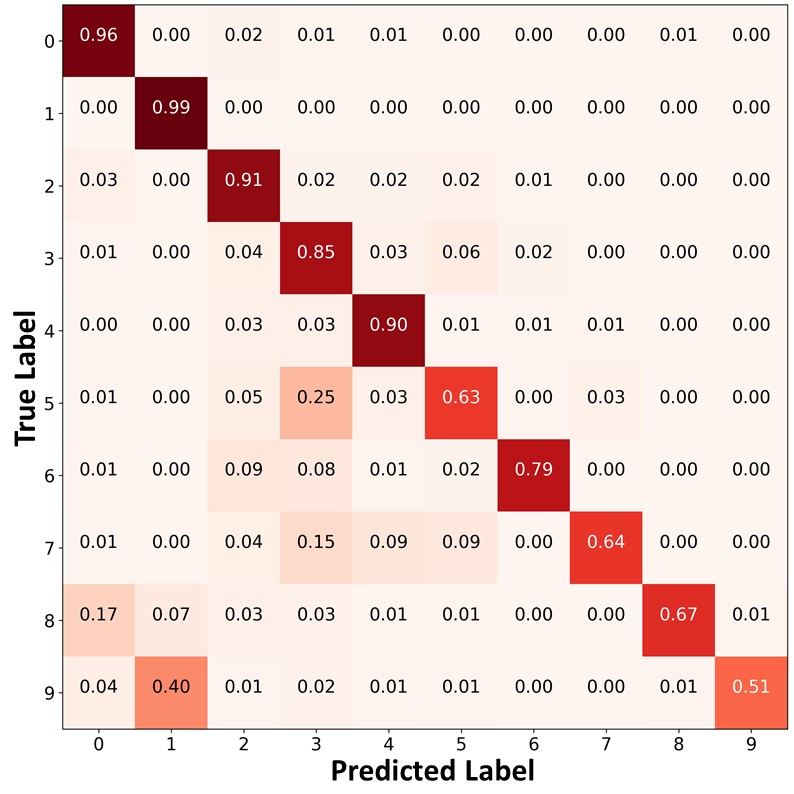 |
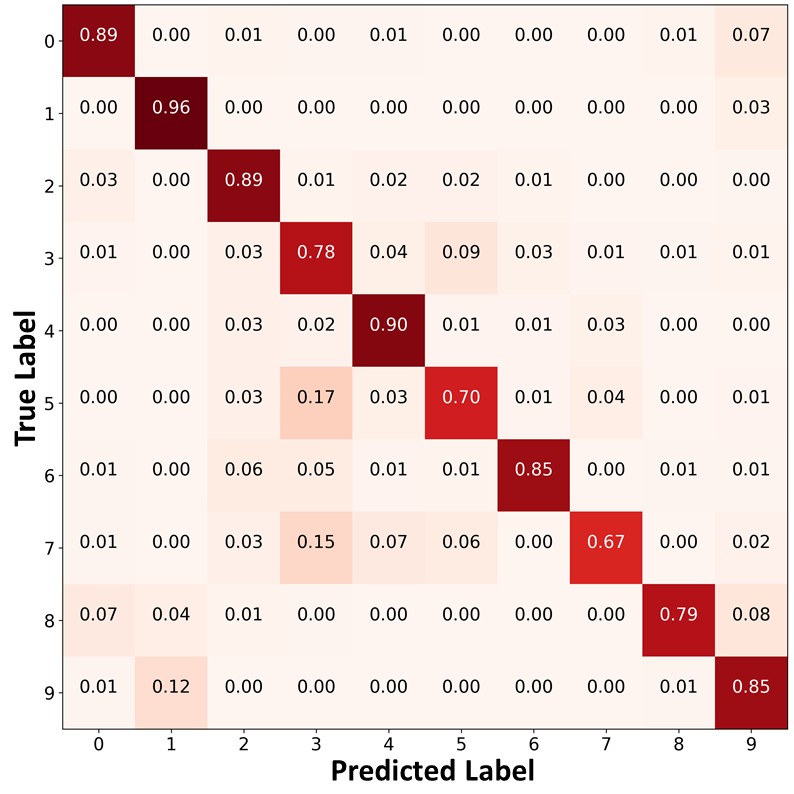 |
|
| (a)ReMixMatch | (b)ReMixMatch+DARP+cRT | (c) ReMixMatch+ABC |
4.5 Ablation study
We conducted an ablation study on CIFAR--LT in the main setting to investigate the effect of each element of the proposed algorithm. The results for ReMixMatch+ABC are presented in Table 5, where each row indicates the proposed algorithm with the described conditions in that row. The results are summarized as follows. 1) If we did not gradually decrease the parameter of the Bernoulli distribution when conducting consistency regularization, then an overbalance problem occurred because of unlabeled data misclassified as minority classes. 2) Without consistency regularization for the ABC, the decision boundary did not clearly separate each class. 3) Without using the mask for and , the ABC was trained to be biased toward the majority classes. 4) Without confidence threshold for consistency regularization, training became unstable and, consequently, the ABC was trained to be biased toward certain classes. 5) Similarly, if hard pseudo-labels, instead of soft pseudo-labels, were used for consistency regularization, then the ABC was biased toward certain classes. 6) If the ABC was solely used without the backbone, the performance decreased because the ABC could not use high-quality representations learned by the backbone. 7) When we used a re-weighting technique [13] instead of a mask for the ABC, training became unstable because of abnormally large gradients calculated for training on the data of the minority classes. 8) The decoupled training of the backbone and ABC resulted in decreased classification performance, as was also analyzed in Section 4.4. Similarly, we present the results of the ablation study for FixMatch+ABC in Appendix L.
| Ablation study | Overall | Minority |
|---|---|---|
| ReMixMatch+ABC (proposed algorithm) | ||
| Without gradually decreasing the parameter of for consistency regularization | ||
| Without consistency regularization for the ABC | ||
| Without using the 0/1 mask for the consistency regularization loss | ||
| Without using the 0/1 mask for the classification loss | ||
| Without using the confidence threshold for consistency regularization | ||
| Using hard pseudo labels for consistency regularization | ||
| Without training backbone (ABC without SSL backbone) | ||
| Training the ABC with a re-weighting technique | ||
| Decoupled training of the backbone and ABC |
5 Conclusion
We introduced the ABC, which is attached to a state-of-the-art SSL algorithm, for CISSL. The ABC can utilize high-quality representations learned by the backbone, while being trained to make class-balanced predictions. The ABC also utilizes unlabeled data by conducting consistency regularization in a modified way for class-imbalance problems. The experimental results obtained under various settings demonstrate that the proposed algorithm outperforms the baseline algorithms. We also conducted a qualitative analysis and an ablation study to verify the contribution of each element of the proposed algorithm. The proposed algorithm assumes that the labeled and unlabeled data are class-imbalanced to the same extent. In the future, we plan to release this assumption by adopting a module for estimating class distribution. Deep learning algorithms can be applied to many societal problems. However, if the training data are imbalanced, the algorithms could be trained to make socially biased decisions in favor of the majority groups. The proposed algorithm can contribute to solving these issues. However, there is also a potential risk that the proposed algorithm could be used as a tool to identify minorities and discriminate against them. It should be ensured that the proposed method cannot be used for any purpose that may have negative social impacts.
6 Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (2018R1C1B6004511, 2020R1A4A10187747).
References
- An et al., [2021] An, J., Ying, L., and Zhu, Y. (2021). Why resampling outperforms reweighting for correcting sampling bias with stochastic gradients. In International Conference on Learning Representations.
- Barandela et al., [2003] Barandela, R., Rangel, E., Sánchez, J. S., and Ferri, F. J. (2003). Restricted decontamination for the imbalanced training sample problem. In Iberoamerican congress on pattern recognition, pages 424–431. Springer.
- [3] Berthelot, D., Carlini, N., Cubuk, E. D., Kurakin, A., Sohn, K., Zhang, H., and Raffel, C. (2019a). Remixmatch: Semi-supervised learning with distribution matching and augmentation anchoring. In International Conference on Learning Representations.
- [4] Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., and Raffel, C. A. (2019b). Mixmatch: A holistic approach to semi-supervised learning. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Buda et al., [2018] Buda, M., Maki, A., and Mazurowski, M. A. (2018). A systematic study of the class imbalance problem in convolutional neural networks. Neural Networks, 106:249–259.
- Cao et al., [2019] Cao, K., Wei, C., Gaidon, A., Arechiga, N., and Ma, T. (2019). Learning imbalanced datasets with label-distribution-aware margin loss. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Chawla et al., [2002] Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357.
- Cubuk et al., [2020] Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V. (2020). Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703.
- Cui et al., [2019] Cui, Y., Jia, M., Lin, T.-Y., Song, Y., and Belongie, S. (2019). Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9268–9277.
- DeVries and Taylor, [2017] DeVries, T. and Taylor, G. W. (2017). Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552.
- Gidaris et al., [2018] Gidaris, S., Singh, P., and Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. In International Conference on Learning Representations.
- Grandvalet and Bengio, [2005] Grandvalet, Y. and Bengio, Y. (2005). Semi-supervised learning by entropy minimization. In Saul, L., Weiss, Y., and Bottou, L., editors, Advances in Neural Information Processing Systems, volume 17. MIT Press.
- He and Garcia, [2009] He, H. and Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on knowledge and data engineering, 21(9):1263–1284.
- Huang et al., [2016] Huang, C., Li, Y., Loy, C. C., and Tang, X. (2016). Learning deep representation for imbalanced classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5375–5384.
- Jamal et al., [2020] Jamal, M. A., Brown, M., Yang, M.-H., Wang, L., and Gong, B. (2020). Rethinking class-balanced methods for long-tailed visual recognition from a domain adaptation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7610–7619.
- JAPKOWICZ, [2000] JAPKOWICZ, N. (2000). The class imbalance problem: Significance and strategies. In Proc. 2000 International Conference on Artificial Intelligence, volume 1, pages 111–117.
- Kang et al., [2020] Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., and Kalantidis, Y. (2020). Decoupling representation and classifier for long-tailed recognition. In International Conference on Learning Representations.
- [18] Kim, J., Hur, Y., Park, S., Yang, E., Hwang, S. J., and Shin, J. (2020a). Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H., editors, Advances in Neural Information Processing Systems, volume 33, pages 14567–14579. Curran Associates, Inc.
- [19] Kim, J., Jeong, J., and Shin, J. (2020b). M2m: Imbalanced classification via major-to-minor translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13896–13905.
- Kingma and Ba, [2015] Kingma, D. P. and Ba, J. (2015). Adam: A method for stochastic optimization. In ICLR, 2015.
- Krizhevsky, [2009] Krizhevsky, A. (2009). Learning multiple layers of features from tiny images. Technical report, Department of Computer Science, University of Toronto.
- Lee et al., [2013] Lee, D.-H. et al. (2013). Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3.
- Mikolov et al., [2013] Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Burges, C. J. C., Bottou, L., Welling, M., Ghahramani, Z., and Weinberger, K. Q., editors, Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc.
- Miyato et al., [2018] Miyato, T., Maeda, S.-i., Koyama, M., and Ishii, S. (2018). Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 41(8):1979–1993.
- Netzer et al., [2011] Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., and Ng, A. Y. (2011). Reading digits in natural images with unsupervised feature learning. In NIPS Workshop, 2011.
- Park et al., [2018] Park, S., Park, J., Shin, S.-J., and Moon, I.-C. (2018). Adversarial dropout for supervised and semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32.
- Ren et al., [2020] Ren, J., Yu, C., sheng, s., Ma, X., Zhao, H., Yi, S., and Li, h. (2020). Balanced meta-softmax for long-tailed visual recognition. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H., editors, Advances in Neural Information Processing Systems, volume 33, pages 4175–4186. Curran Associates, Inc.
- Ren et al., [2018] Ren, M., Zeng, W., Yang, B., and Urtasun, R. (2018). Learning to reweight examples for robust deep learning. In International Conference on Machine Learning, pages 4334–4343. PMLR.
- Sohn et al., [2020] Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C. A., Cubuk, E. D., Kurakin, A., and Li, C.-L. (2020). Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems, 33.
- Tarvainen and Valpola, [2017] Tarvainen, A. and Valpola, H. (2017). Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Van der Maaten and Hinton, [2008] Van der Maaten, L. and Hinton, G. (2008). Visualizing data using t-sne. Journal of machine learning research, 9(11).
- Verma et al., [2019] Verma, V., Lamb, A., Kannala, J., Bengio, Y., and Lopez-Paz, D. (2019). Interpolation consistency training for semi-supervised learning. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 3635–3641. International Joint Conferences on Artificial Intelligence Organization.
- Wang et al., [2017] Wang, Y.-X., Ramanan, D., and Hebert, M. (2017). Learning to model the tail. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Wei et al., [2021] Wei, C., Sohn, K., Mellina, C., Yuille, A., and Yang, F. (2021). Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. arXiv preprint arXiv:2102.09559.
- Yang and Xu, [2020] Yang, Y. and Xu, Z. (2020). Rethinking the value of labels for improving class-imbalanced learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H., editors, Advances in Neural Information Processing Systems, volume 33, pages 19290–19301. Curran Associates, Inc.
- Yin et al., [2018] Yin, X., Yu, X., Sohn, K., Liu, X., and Chandraker, M. (2018). Feature transfer learning for deep face recognition with under-represented data. arXiv e-prints, pages arXiv–1803.
- Yu et al., [2015] Yu, F., Zhang, Y., Song, S., Seff, A., and Xiao, J. (2015). Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365.
- Zagoruyko and Komodakis, [2016] Zagoruyko, S. and Komodakis, N. (2016). Wide residual networks. arXiv preprint arXiv:1605.07146.
- Zhai et al., [2019] Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. (2019). S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1476–1485.
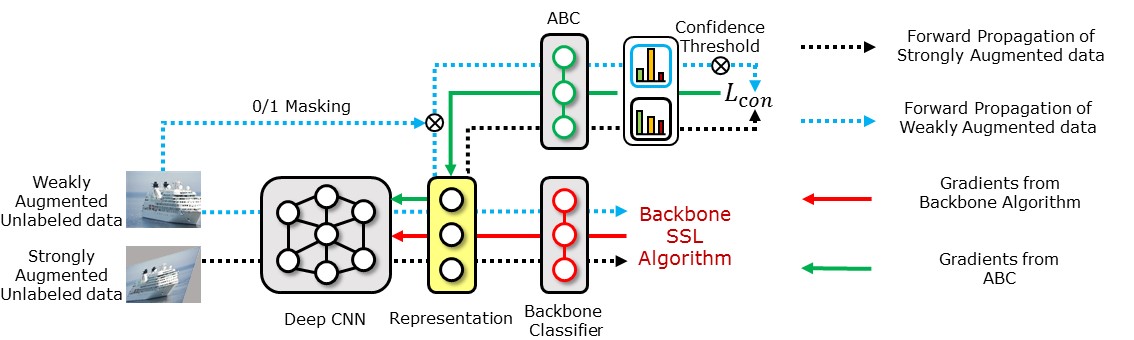
Appendix A Overall procedure of consistency regularization for ABC
Figure 5 illustrates the overall procedure of consistency regularization for the ABC. Detailed procedure is described in Section 3.4 of the main paper.
Appendix B Pseudo code of the proposed algorithm
The pseudo code of the proposed algorithm is presented in Algorithm 1. The for loop (lines 2 14) can be run in parallel. The classification loss and consistency regularization loss are expressed in detail in Sections 3.3 and 3.4 of the main paper.
Input: ,
Output: Classification model
Parameters : (Parameters of Wide ResNet-- and ABC)
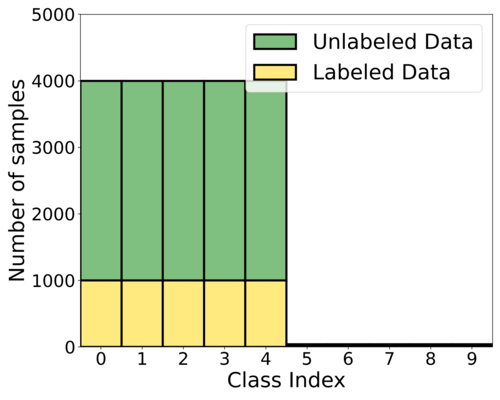
Appendix C Two types of class imbalance for the considered datasets
|
|
| (a) Long-tailed imbalance | (b) Step imbalance |
Two types of class imbalance for the considered datasets are illustrated in Figure 6. For both types of imbalance, we set , , and . In Figure 6 (b), we can see that each minority class has a very small amount of data. Existing SSL algorithms can be significantly biased toward majority classes under step imbalanced settings.
Appendix D Specification of the confidence threshold
| ReMixMatch+ABC | CIFAR-10-LT, , | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.98 | 0.95 | 0.9 | 0.85 | 0.8 | 0.75 | 0.7 | |
| Mean and STD | 78.9, 0.36 | 81.8, 0.34 | 82.3, 0.2 | 81.3, 0.32 | 81.5, 0.39 | 81.2, 0.63 | 80.0, 2.87 | 79.0, 5.76 |
In general, the confidence threshold should be set high enough, but not too high. If is low, training becomes unstable because many misclassified unlabeled data points would be used for training. However, if is too high, most of the unlabeled data points would not be used for consistency regularization. Based on these insights, we set as 0.95 in our experiments. We confirmed via experiments that this value of enabled high accuracy as well as stability. Specifically, we conducted experiments on CIFAR--LT for the main setting while changing the value of . We measured the validation accuracy of ReMixMatch+ABC during the last 50 epochs (1 epoch=500 iterations) of training and calculated the mean and standard deviation (STD) of these values. As can be seen from Table 6, the proposed algorithm achieved the highest mean and lowest STD of the validation accuracy when was 0.95. When was set higher or lower than 0.95, the mean of the validation accuracy decreased. In particular, as the value of decreased from 0.95, the STD increased rapidly, indicating instability of the training.
Appendix E Further details of the experimental setup
We describe further details of the experimental setup. To train the ReMixMatch, we gradually increased the coefficient of the loss associated with the unlabeled data points, following [18]. We found that without this gradual increase, the validation loss of the ReMixMatch did not converge. To train the FixMatch, we used the labeled dataset once more as an unlabeled dataset by removing the labels for the experiments using CIFAR- following the previous study [29], but not for the experiments using CIFAR- and SVHN, because it did not improve the performance. We followed the default settings for the ReMixMatch [3] and FixMatch [29], unless mentioned otherwise.
To train the ABC, we also gradually decreased the parameter of for calculating the classification loss in the experiments using CIFAR- and SVHN under the step imbalanced setting. This prevents unstable training by allowing each labeled data point of the majority classes to be more frequently used for training.
Appendix F Geometric mean (G-mean) of class-wise accuracy under the main setting
To evaluate whether the proposed algorithm performs in a balanced way for all classes, we also measured the performance for the main setting using the geometric mean (G-mean) of class-wise accuracy with correction to avoid zeroing. We set the hyperparameter for the correction to avoid zeroing as 1, which indicates that the minimum class-wise accuracy is 1. The results in Table 7 demonstrates that the proposed algorithm performed in a balanced way.
Appendix G Experimental results on SVHN and CIFAR- under various settings
For the experiments using SVHN with and , the solution of the convex optimization problem of ReMixMatch+DARP+cRT for refining the pseudo labels did not converge, and thus we could not measure the performance. The experimental results for SVHN and CIFAR- under various settings showed the same trend as those for CIFAR-, which is described in Section 4.2 of the main paper.
Appendix H Experimental results on SVHN and CIFAR- under the step imbalanced setting
Experimental results for SVHN and CIFAR- under the step imbalanced setting showed the same tendency as that for CIFAR-, which is described in Section 4.2 of the main paper.
Appendix I Floating point operations per second (FLOPS) of each algorithm
As we mentioned in Section 4.3 of the main paper, computation cost required for the algorithms combined with DARP increased as the number of classes or the amount of data increased. In contrast, computation cost required for the proposed algorithm did not significantly increased because the whole training procedure can be carried out using minibatches. FLOPS of FixMatch+CReST and ReMixMatch+CReST are the same as those of FixMatch and ReMixMatch, but the algorithms combined with CReST required iterative re-training with a labeled set expanded by adding unlabeled data points with pseudo labels. We measured FLOPS using Nvidia Tesla-V100. For the experiments on CIFAR- and CIFAR-, we used only one GPU, whereas we used four GPUs in parallel for the experiments on LSUN.
Appendix J Further qualitative analysis and quantitative comparison
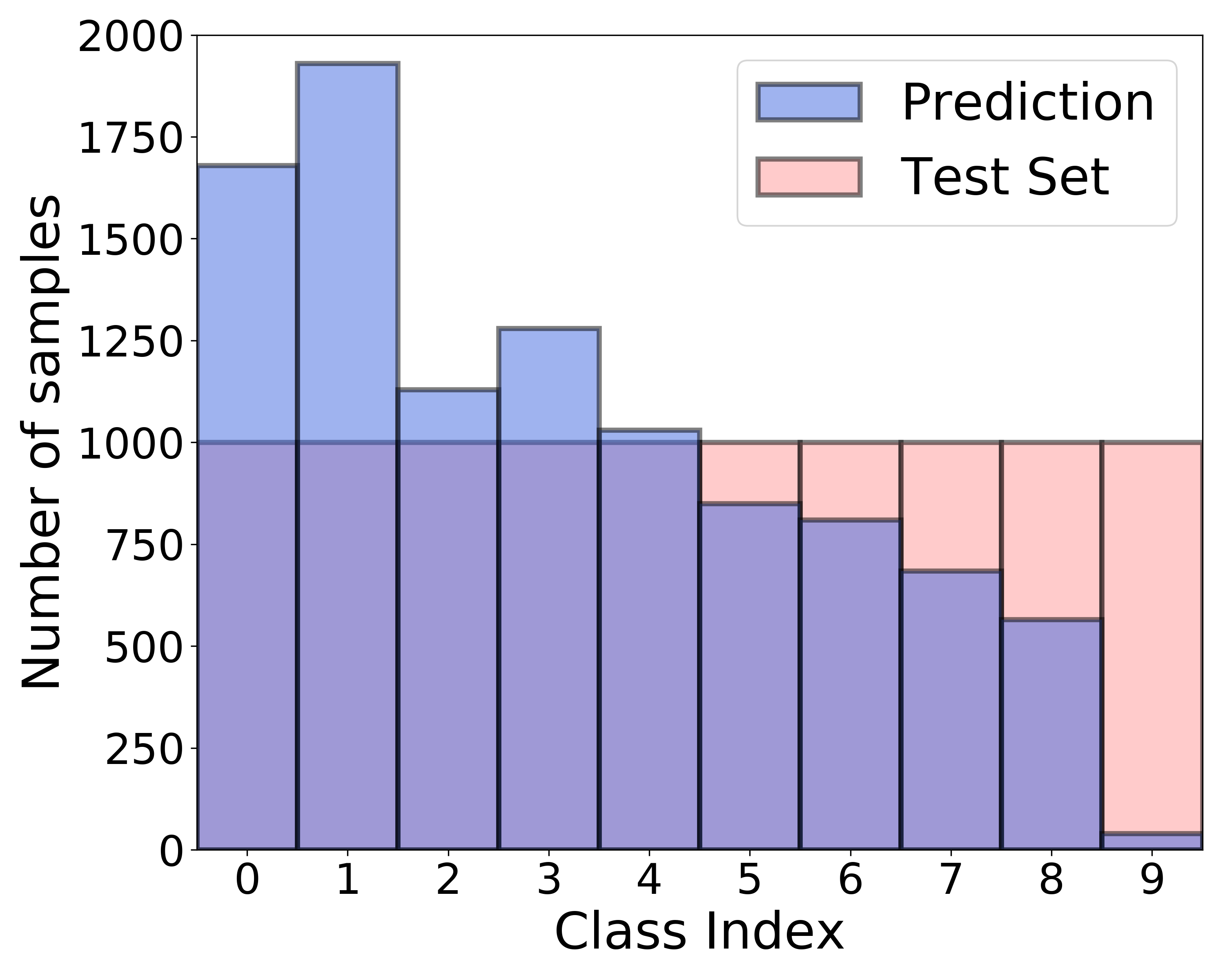
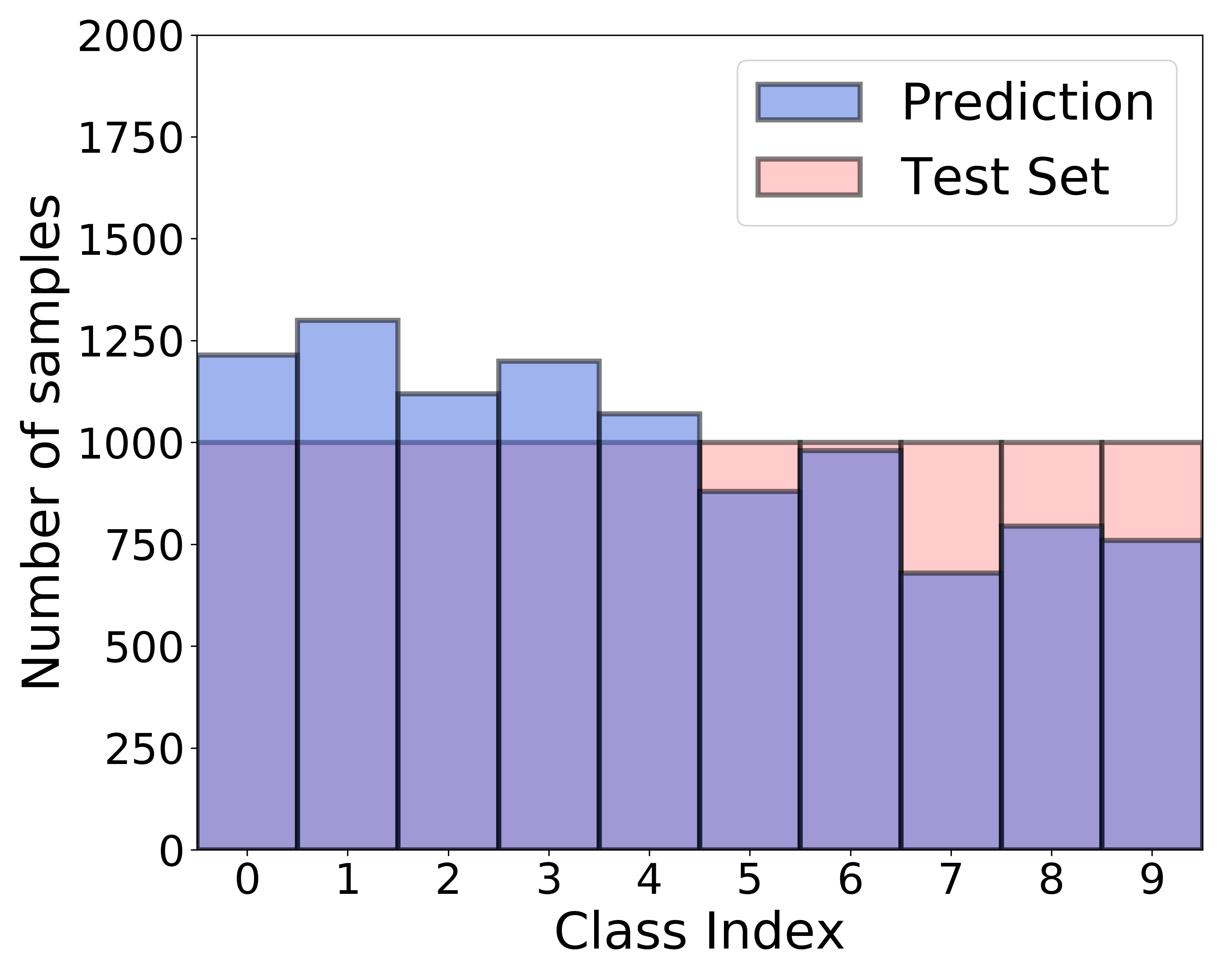
Figure 7 (b) presents biased predictions of FixMatch [29], a recent SSL algorithm, trained on CIFAR- with the amount of Class 0 being 100 times more than that of Class 9 as depicted in Figure 7 (a). In contrast, Figure 7 (c) presents that the class distribution of the predicted labels became more balanced using the FixMatch+ABC trained on the same dataset. These results are consistent with those in Figure 1 of the main paper.
|
|
|
| (a) Class-imbalanced training set | (b) FixMatch | (c) FixMatch+ABC |
Because the use of the mask for the ABC plays a similar role of re-sampling techniques, we compare the representations of proposed algorithm with those of SMOTE (oversampling technique) [7]+CNN, and random undersampling [13]+CNN. Figure 8 (a), (b) and (c) present the t-SNE representations obtained using SMOTE+CNN, undersampling+CNN, and ABC only. Because re-sampling techniques can only be applied to labeled data, they cannot be combined with the SSL algorithms, and thus they were combined with CNN instead. SMOTE+CNN and undersampling+CNN learned less separable representations than the ABC only. These results show that using the mask instead of re-sampling techniques is more effective because we could utilize unlabeled data. In addition, the 0/1 mask enabled the ABC to be combined with the backbone, so that the ABC could use the high-quality representations learned by the backbone as shown in Figure 8 (d).
 |
 |
 |
 |
| (a) SMOTE [7]+CNN | (b) Undersampling [13]+CNN | (c) ABC only | (d) ReMixMatch+ABC |
We also compared the performance of the proposed algorithm with those of SMOTE+CNN and undersampling+CNN. The results in Table 13 show the importance of using unlabeled data for training and using the high-quality representations obtained from backbone.
| Performance of each algorithm in Figure 8 and FixMatch+ABC | Overall | Minority |
|---|---|---|
| ReMixMatch+ABC | ||
| FixMatch+ABC | ||
| Without training backbone (ABC only) | ||
| SMOTE+CNN | ||
| Undersampling+CNN |
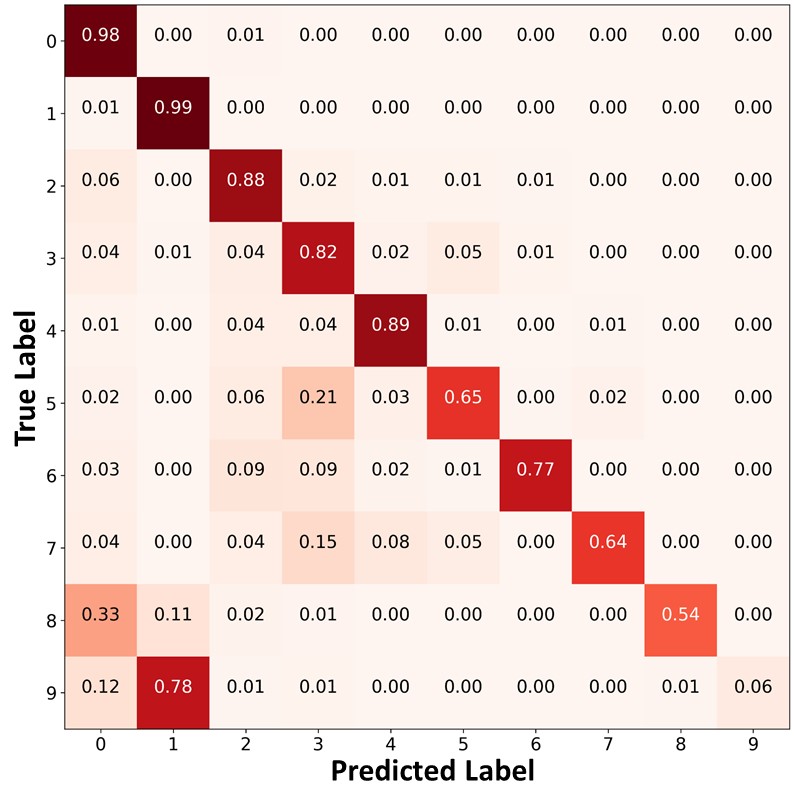
Figure 9 presents the confusion matrices of FixMatch, FixMatch+DARP+cRT, and FixMatch+ABC trained on CIFAR--LT, , . Similar to Figure 4 of the main paper, FixMatch and FixMatch+DARP+cRT often misclassified test data points in the minority classes (e.g., classes and into classes and ). In contrast, FixMatch+ABC classified the test data points in the minority classes with higher accuracy, and produced a significantly more balanced class-distribution than FixMatch and FixMatch+DARP+cRT.
 |
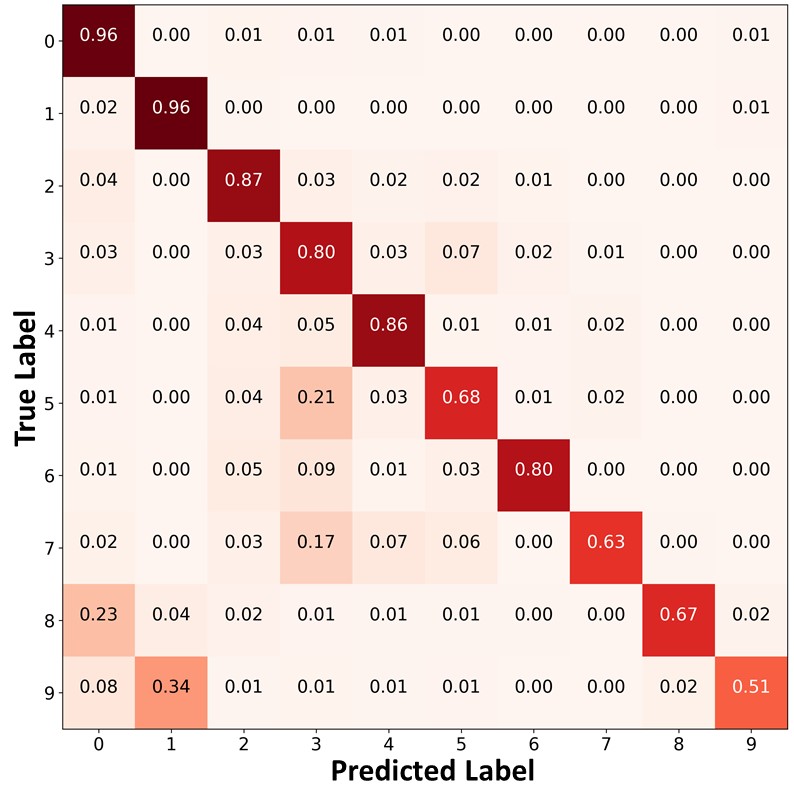 |
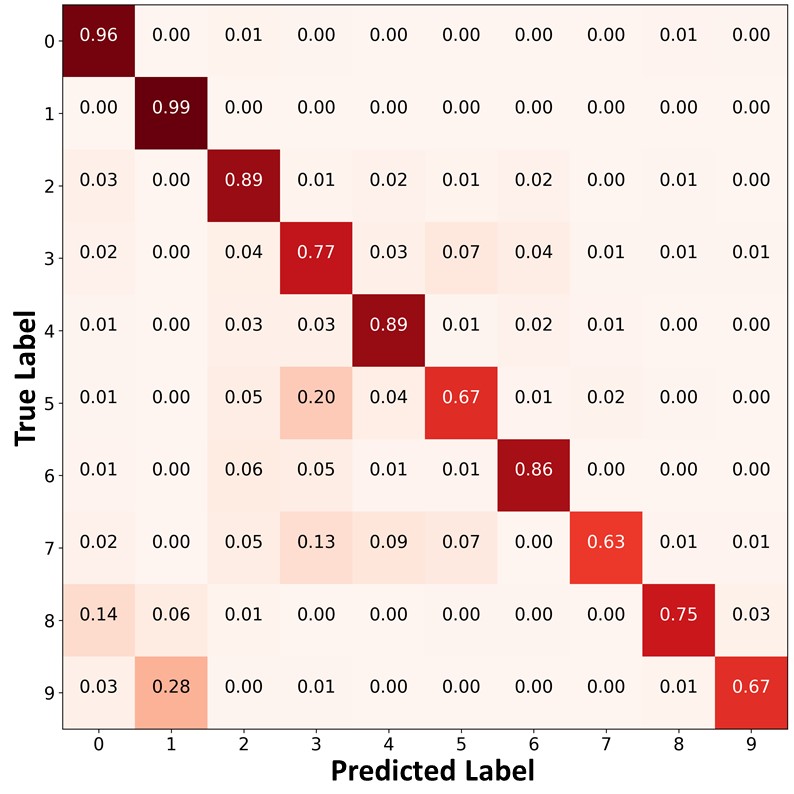 |
|
| (a)FixMatch | (b)FixMatch+DARP+cRT | (c) FixMatch+ABC |
Figure 10 presents the confusion matrices of the predictions on the unlabeled data. Similar to Figure 9 and Figure 4 of the main paper, FixMatch+ABC and ReMixMatch+ABC classified the unlabeled data points in the minority classes with higher accuracy, and produced a significantly more balanced pseudo labels than other algorithms. By using these balanced pseudo labels for training, the proposed algorithm could make a more balanced prediction on the test set.
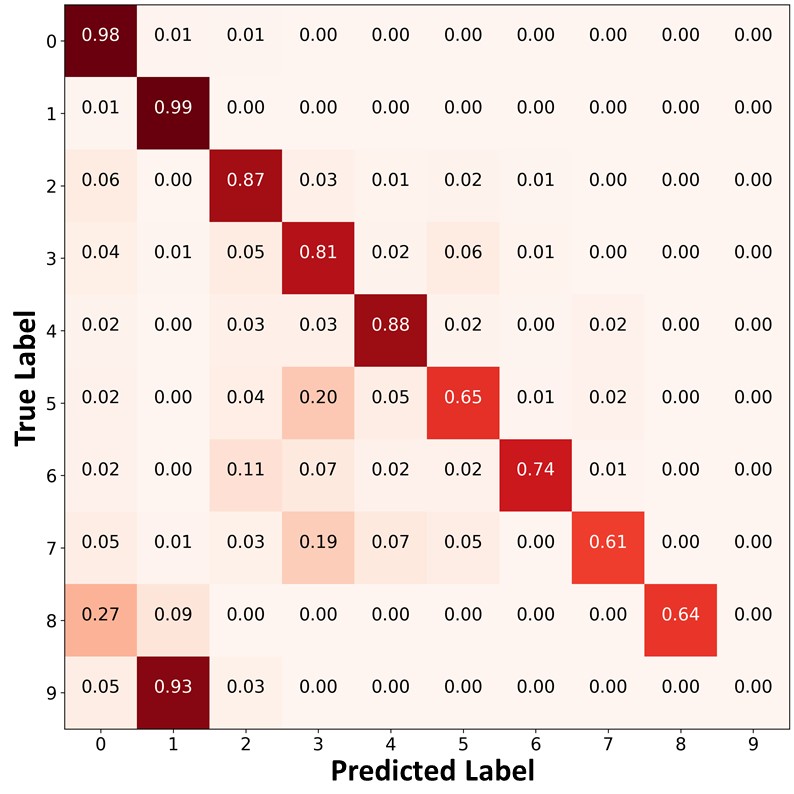 |
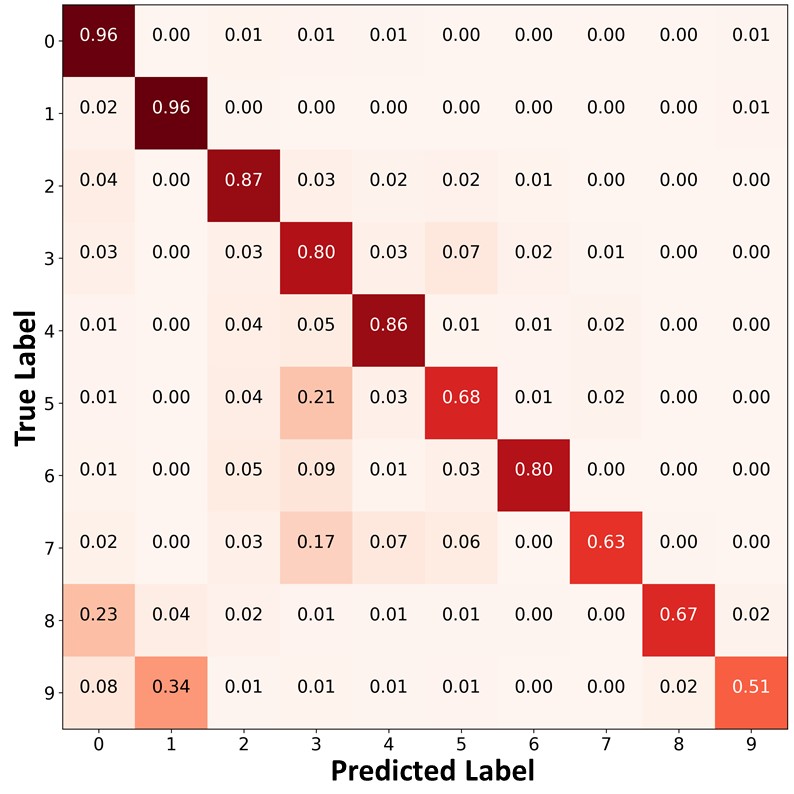 |
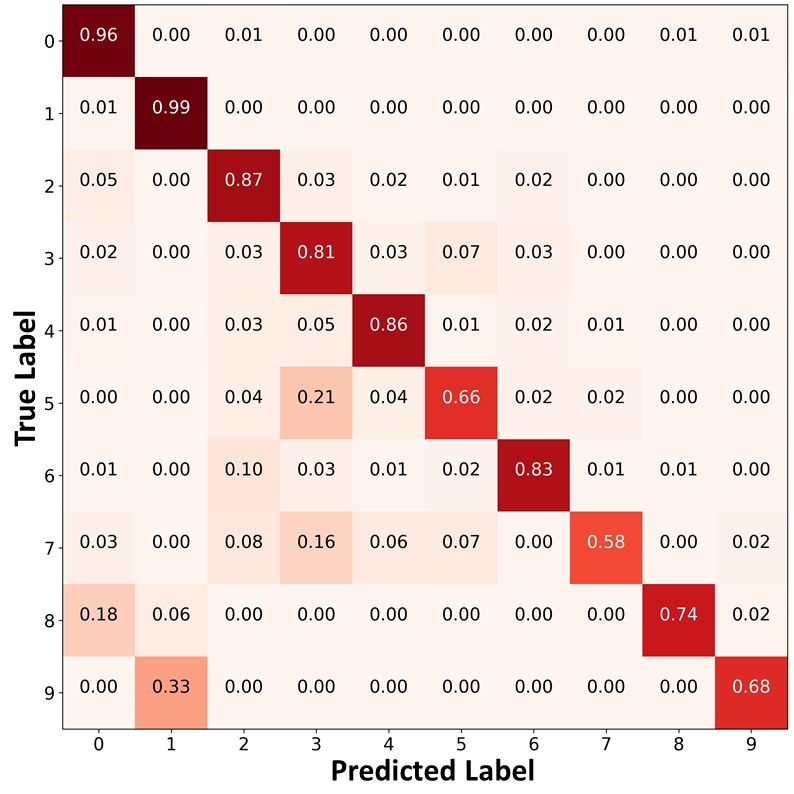 |
| (a)FixMatch | (b)FixMatch+DARP+cRT | (c) FixMatch+ABC |
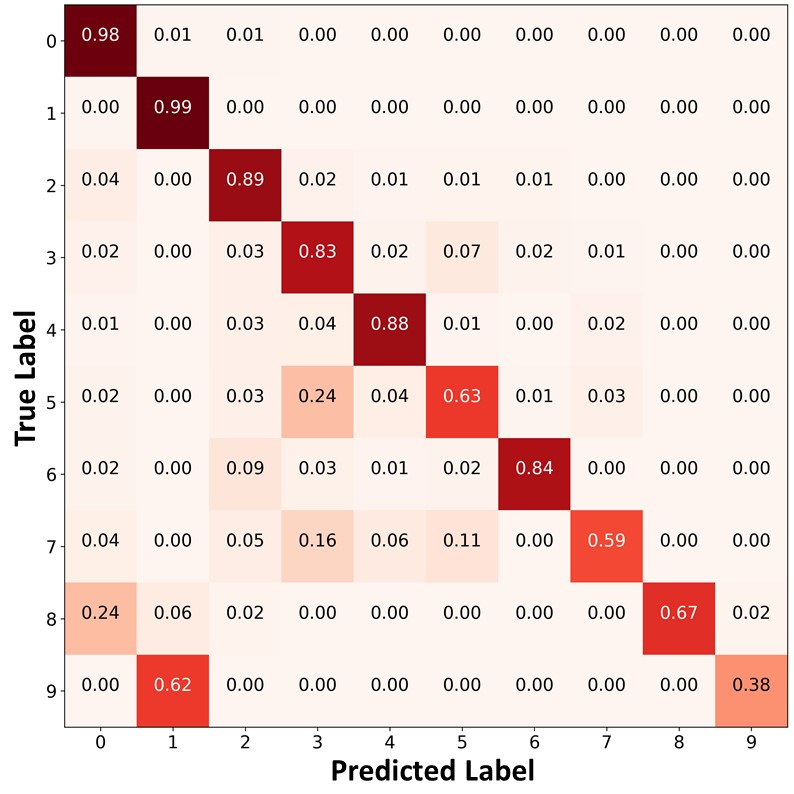
|
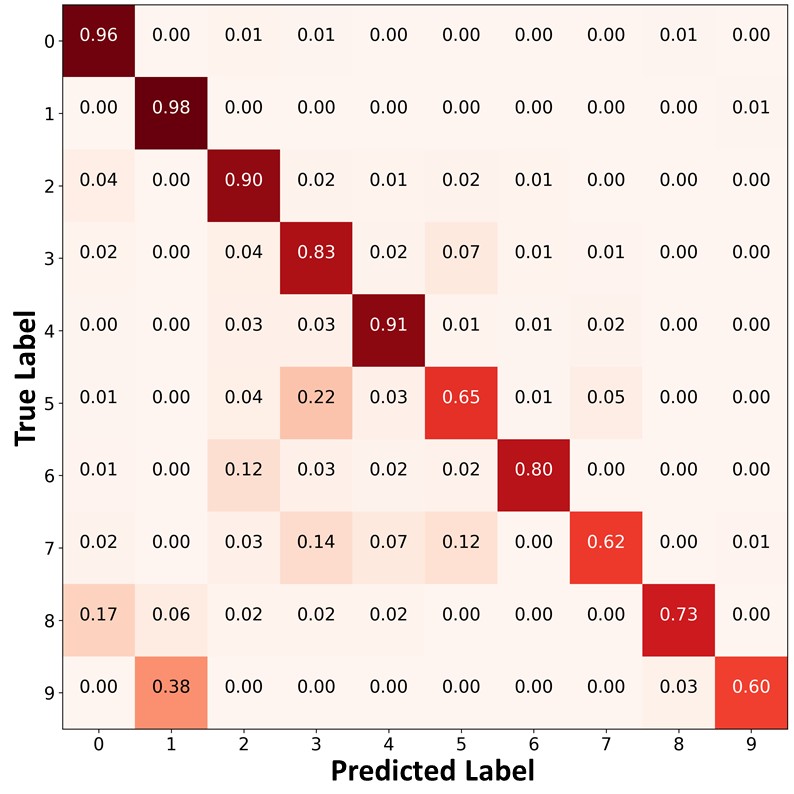 |
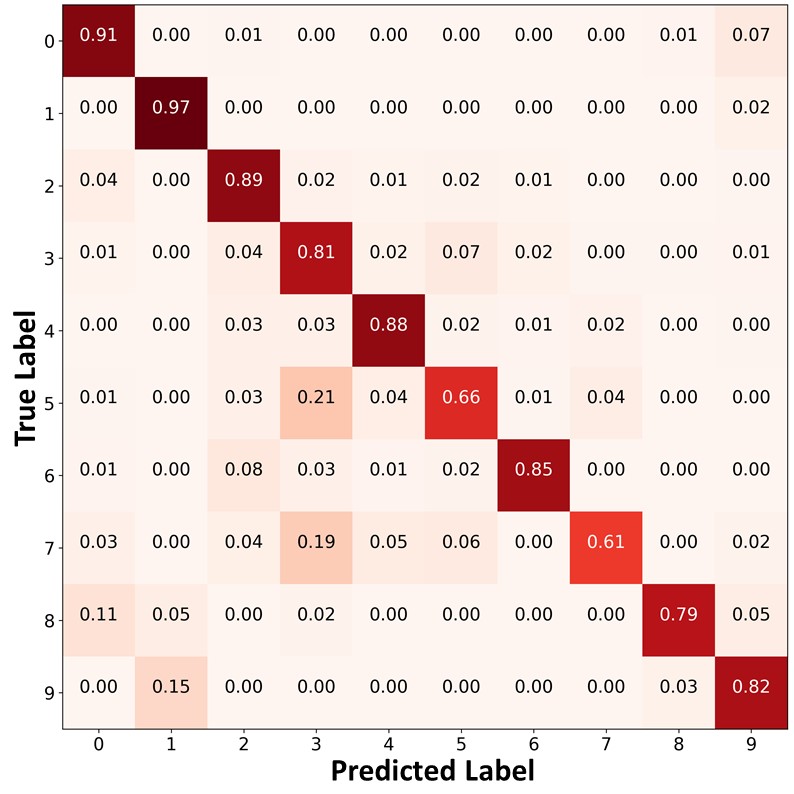 |
| (d)ReMixMatch | (e)ReMixMatch+DARP+cRT | (f) ReMixMatch+ABC |
Appendix K Detailed comparison between the end-to-end training of the proposed algorithm and decoupled learning of representations and a classifier
Although FixMatch+DARP+cRT and ReMixMatch+DARP+cRT also use the representations learned by ReMixMatch [3] and FixMatch [29], they showed worse performance than the proposed algorithm. The performance gap between FixMatch(ReMixMatch)+DARP+cRT and the proposed algorithm results from the different characteristics of the ABC versus DARP+cRT as follows. First, whereas DARP+cRT decouples learning of representations and training of a classifier, the ABC is trained end-to-end interactively with representations that the backbone learns. Second, DARP+cRT does not use unlabeled data for training of its classifier after representations learning is finished, while the ABC is trained with unlabeled data to conduct consistency regularization so that decision boundaries can be placed in a low density region. To verify these reasons, we compare the validation loss graphs of the algorithms based on end-to-end training and decoupled learning of representations and a classifier in Figure 11. We recorded the validation loss of 100 epochs after the representations were fixed, where 1 epoch was set as 500 iterations. For the proposed algorithm, we recorded the validation loss of the last 100 epochs. In Figure 9 (a) and (b), we can see that the validation loss of the algorithms based on decoupled learning of representations and a classifier tended to increase after a few epochs. The validation loss was reduced by conducting consistency regularization (C/R) using unlabeled data, but it still tended to increase. In the case of ReMixMatch+DARP+cRT+C/R* and FixMatch+DARP+cRT+C/R*, which do not fix the representations (algorithms marked with *), high-quality representations learned by the backbone were gradually replaced by the representations learned with a re-balanced classifier, which caused overfitting on minority classes. We can observe a similar tendency in Figure 9 (c) under the supervised learning setting. In contrast, the validation loss of ReMixMatch+ABC, FixMatch+ABC, and the proposed algorithm under supervised learning setting decreased steadily and achieved the lowest validation loss. The performances of the algorithms based on end-to-end training and decoupled learning of representations and a classifier are summarized in Table 14.
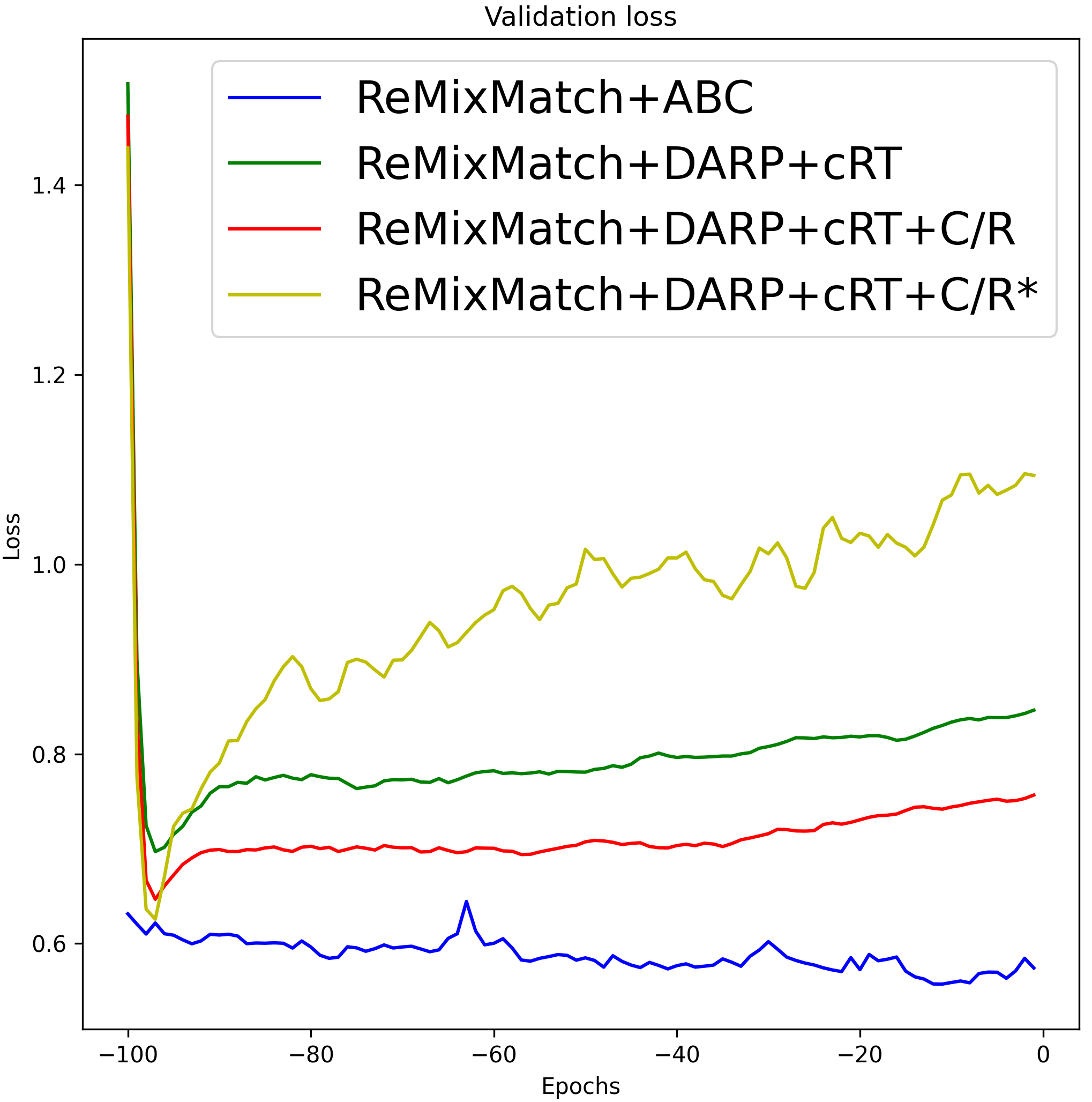 |
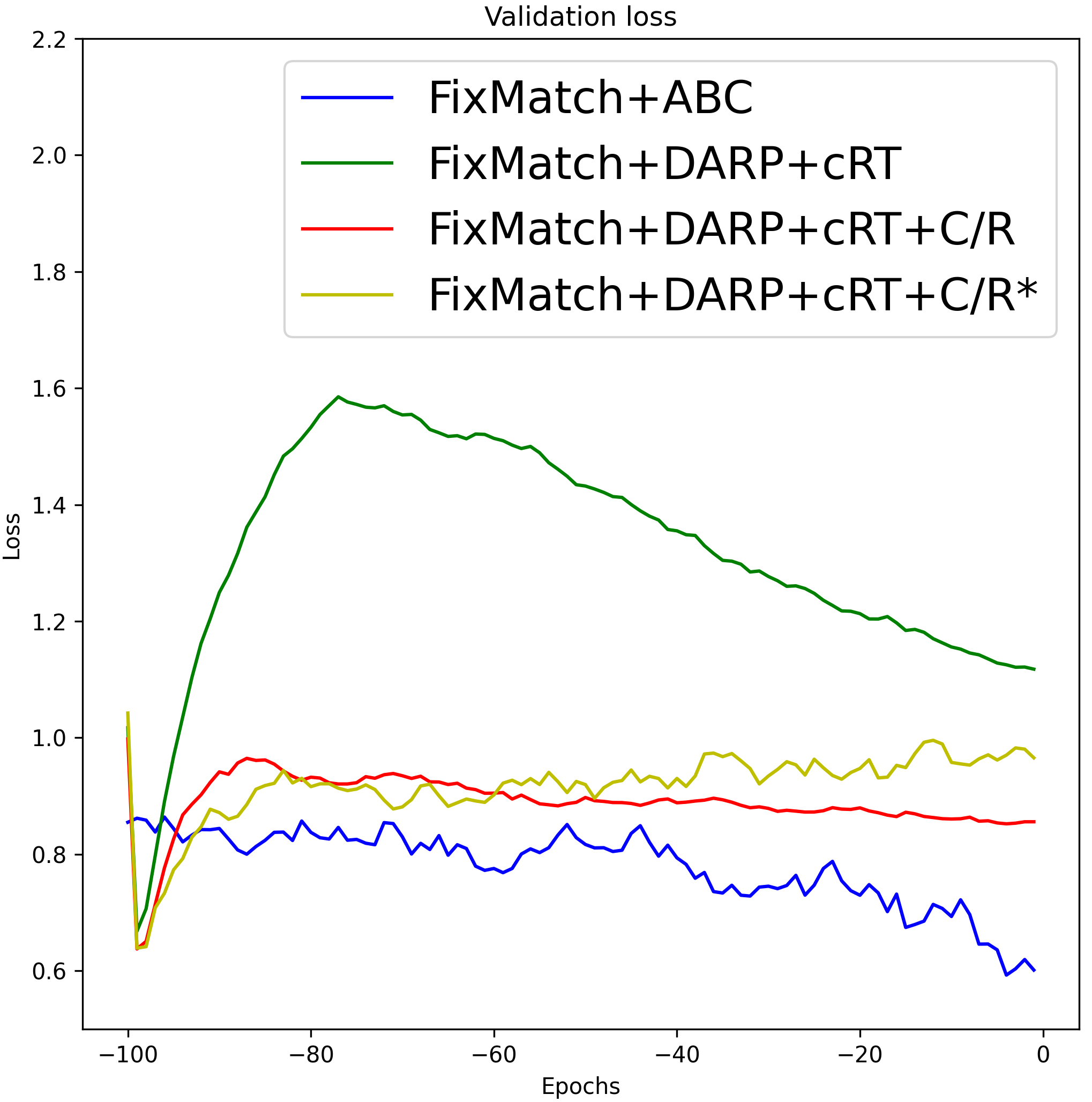 |
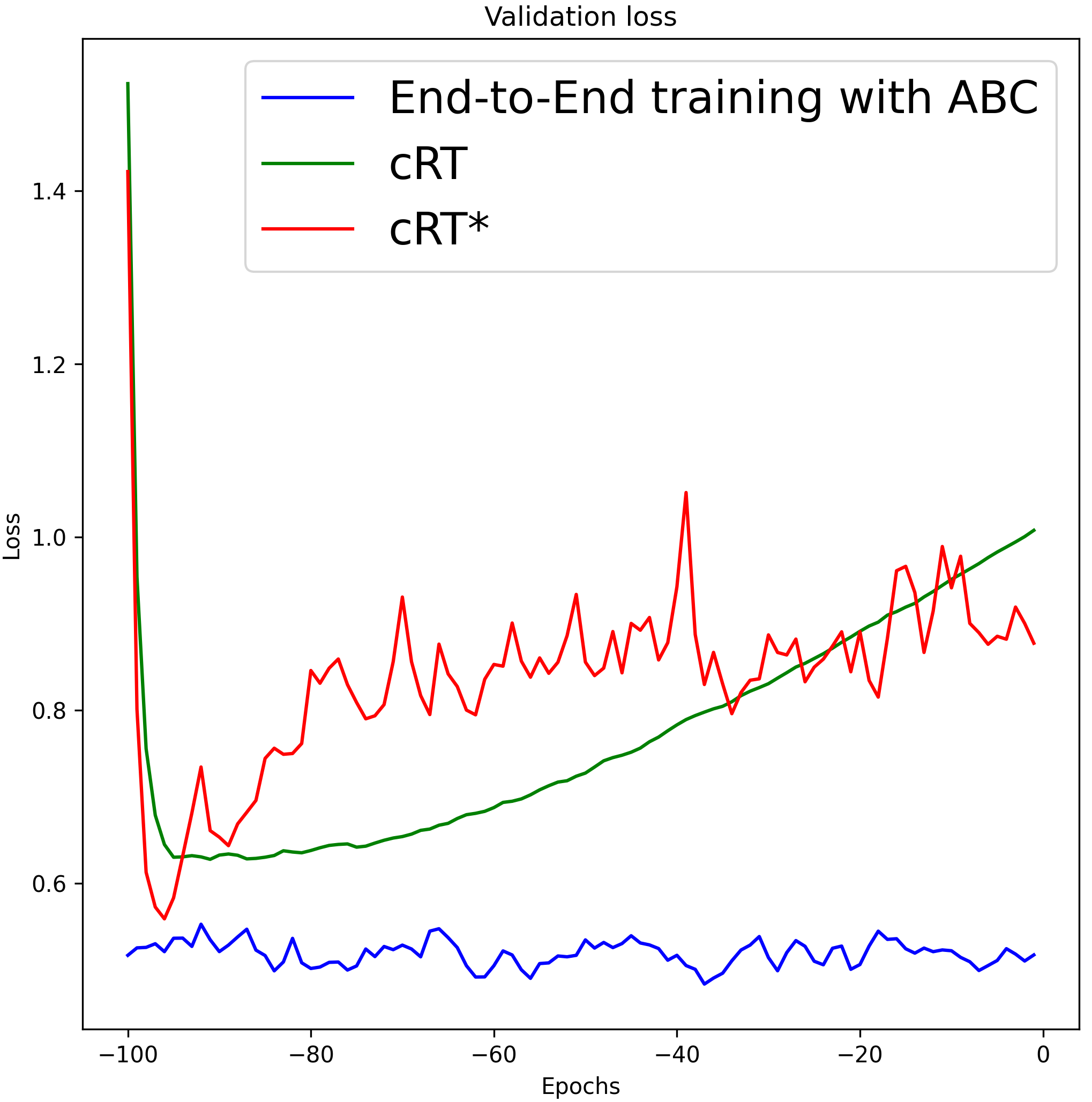 |
| (a)With ReMixMatch | (b)With FixMatch | (c) Supervised setting |
| Performance of the algorithms based on end-to-end training versus decoupled learning | Overall | Minority |
| Under the semi-supervised learning setting | ||
| ReMixMatch+ABC (end-to-end training) | ||
| ReMixMatch+DARP+cRT+C/R* (Decoupled learning) | ||
| ReMixMatch+DARP+cRT+C/R (Decoupled learning) | ||
| ReMixMatch+DARP+cRT (Decoupled learning) | ||
| FixMatch+ABC (end-to-end training) | ||
| FixMatch+DARP+cRT+C/R* (Decoupled learning) | ||
| FixMatch+DARP+cRT+C/R (Decoupled learning) | ||
| FixMatch+DARP+cRT (Decoupled learning) | ||
| Under the supervised learning setting | ||
| End-to-End training of CNN with the ABC (end-to-end training) | ||
| cRT* (Decoupled learning of representations and the classifier of CNN) | ||
| cRT (Decoupled learning of representations and the classifier of CNN) |
Appendix L Ablation study for FixMatch [29] + ABC on CIFAR-10
Results in Table 15 show a similar tendency as that for ReMixMatch+ABC in Section 4.5 of the main paper.
| Ablation study | Overall | Minority |
|---|---|---|
| FixMatch+ABC (proposed algorithm) | ||
| Without gradually decreasing the parameter of for consistency regularization | ||
| Without consistency regularization for the ABC | ||
| Without using the 0/1 mask for the consistency regularization loss | ||
| Without using the 0/1 mask for the classification loss | ||
| Without using the confidence threshold for consistency regularization | ||
| Using hard pseudo labels for consistency regularization | ||
| Without training backbone (ABC only) | ||
| Training the ABC with a re-weighting technique | ||
| Decoupled training of the backbone and ABC |