Abstract Rendering: Computing All that is Seen in Gaussian Splat Scenes
Abstract
We introduce abstract rendering, a method for computing a set of images by rendering a scene from a continuously varying range of camera positions. The resulting abstract image—which encodes an infinite collection of possible renderings—is represented using constraints on the image matrix, enabling rigorous uncertainty propagation through the rendering process. This capability is particularly valuable for the formal verification of vision-based autonomous systems and other safety-critical applications. Our approach operates on Gaussian splat scenes, an emerging representation in computer vision and robotics. We leverage efficient piecewise linear bound propagation to abstract fundamental rendering operations, while addressing key challenges that arise in matrix inversion and depth sorting—two operations not directly amenable to standard approximations. To handle these, we develop novel linear relational abstractions that maintain precision while ensuring computational efficiency. These abstractions not only power our abstract rendering algorithm but also provide broadly applicable tools for other rendering problems. Our implementation, AbstractSplat, is optimized for scalability, handling up to 750k Gaussians while allowing users to balance memory and runtime through tile and batch-based computation. Compared to the only existing abstract image method for mesh-based scenes, AbstractSplat achieves speedups while preserving precision. Our results demonstrate that continuous camera motion, rotations, and scene variations can be rigorously analyzed at scale, making abstract rendering a powerful tool for uncertainty-aware vision applications.
Keywords:
Abstract Rendering Gaussian Splat Abstract Image1 Abstract Rendering for Verification and Challenges
Rendering computes an image from the description of a scene and a camera. In this paper, we introduce abstract rendering, which computes the set of all images that can be rendered from a set of scenes and a continuously varying range of camera poses. The resulting infinite collection of images, called an abstract image, is represented by constraints on the image matrix, such as using interval matrices. An example abstract image generated from the continuous movement of a camera is shown in Figure 1. Abstract rendering provides a powerful tool for the formal verification of autonomous systems, virtual reality environments, robotics, and other safety-critical applications that rely on computer vision. For instance, when verifying a vision-based autonomous system, uncertainties in the agent’s state naturally translate into a set of camera positions. These uncertainties must be systematically propagated through the rendering process to analyze their impact on perception, control, and overall system safety. By enabling rigorous uncertainty propagation, abstract rendering supports verification of statements such as “No object is visible to the camera as it pans through a specified angle.”




Our abstract rendering algorithm operates on scenes represented by Gaussian splats—an efficient and differentiable representation for 3D environments [7]. A scene consists of a collection of 3D Gaussians, each with a distinct color and opacity. The rendering algorithm projects these splats onto the 2D image plane of a camera and blends them to determine the final color of each pixel. Gaussian splats are gaining prominence in computer vision and robotics due to their ability to be effectively learned from camera images and their capacity to render high-quality images in near real time [24]. They have transformed virtual reality applications by enabling the rapid creation of detailed 3D scenes [5, 11, 1]. In robotics and autonomous systems, Gaussian splatting has proven valuable for Simultaneous Localization and Mapping (SLAM) and scene reconstruction [17].
To rigorously propagate uncertainty in such settings, we represent all inputs—such as camera parameters and scene descriptions—as linear sets (i.e., vectors or matrices defined by linear constraints). This abstraction allows us to systematically propagate uncertainty through each rendering operation.
The rendering algorithm for Gaussian splats computes the color of each pixel in four steps. First, each 3D Gaussian is transformed from world coordinates to camera coordinates, and then to 2D pixel coordinates. The third step computes the effective opacity of each Gaussian at the pixel by evaluating its probability density. Finally, the colors of all Gaussians are blended, weighted by their effective opacities and sorted by their distance to the image plane.
The first two steps in the rendering process involve continuous transformations that can be precisely bounded above and below by piecewise linear functions. Although it is mathematically straightforward to propagate linear sets through these operations, achieving accurate bounds for high-dimensional objects (e.g., scenes with over 100k Gaussians and images with over 10k pixels) requires a GPU-optimized linear bound propagation method such as the ones implemented in CROWN [21, 23].
The third step evaluates Gaussian distributions over a linear set, which requires computing an interval matrix containing the inverses of multiple covariance matrices. Standard inversion methods (e.g., the adjugate approach) become numerically unstable near singularities and yield overly conservative bounds. We mitigate this by using a Taylor expansion around a stable reference—such as the midpoint of the input set—and by carefully tuning the expansion order and bounding the truncation error, we achieve inverse bounds that are sufficiently tight for abstract rendering.
The final step blends Gaussian colors based on depth. In abstract rendering, uncertain depths allow multiple possible sorting orders, and merging these orders leads to overly conservative bounds. For example, if several Gaussians with different colors can be frontmost, the resulting bound may unrealistically turn white. To address this, we replace depth-sorting with an index-free blending formulation that uses an indicator function to directly model pairwise occlusion, ensuring each Gaussian’s contribution is bounded independently.
Our abstract rendering algorithm, AbstractSplat, integrates these techniques and supports tunable time–memory tradeoffs for diverse hardware. Our experiments show that AbstractSplat scales from single-object scenes to those with over 750k Gaussians—handling both camera translations and rotations—and achieves 2–14 speedups over the only existing abstract image method for mesh-based scenes [4] while preserving precision. Tile and batch optimizations enable users to balance GPU memory usage (which scales quadratically with tile size) against runtime (which scales linearly with batch size). Moreover, our experiments confirm that regularizing near-singular Gaussians is critical for reducing over-approximation. Together, these contributions significantly advance rigorous uncertainty quantification in rendering.
In summary, the key contributions from our paper are: (1) We present the first abstract rendering algorithm for Gaussian splats. It can rigorously bound the output of 3D Gaussian splatting under scene and camera pose uncertainty in both position and orientation. This enables formal analysis of vision-based systems in dynamic environments. (2) We have developed a mathematical and a software framework for abstracting the key operations needed in the rendering algorithms. While many of these approximation can be directly handled by a library like CROWN [21], we developed new methods for handling challenging operations like matrix inversion and sorting. We believe this framework can be useful beyond Gaussian splats to abstract other rendering algorithms. (3) We present a carefully engineered implementation that leverages tiled rendering and batched computation to achieve excellent scalability of abstract rendering. This design enables a tunable performance–memory trade-off, allowing our implementation to adapt effectively to diverse hardware configurations.
Relationship to Existing Research
The only closely related work computes abstract images for triangular mesh scenes [4]. To handle camera-pose uncertainty, that method collects each pixel’s RGB values into intervals over all possible viewpoints. In practice, this amounts to computing partial interval depth-images for each triangle and merging them using a depth-based union, resulting in an interval image that over-approximates all concrete images for that region of poses. This work considers only camera translations, not rotations. Our method works with Gaussian splats which involve more complex operations and are learnable. Our algorithm also has certain performance and accuracy advantages as discussed in Section 4.3.
Differentiable rendering [16] algorithms are based on ray-casting [8, 9, 10] or rasterization [4, 6, 7]. Although these techniques are amenable to gradient-based sensitivity analysis, they are not concerned with rigorous uncertainty propagation through the rendering process. We addresses this gap for Gaussian splatting. Our mathematical framework could be extended to other rasterization pipelines and even to ray-casting methods where similar numerical challenges arise.
Abstract interpretation [2, 14] is effective for verifying large-scale software systems, however, applying it directly to rendering presents unique challenges. Rendering involves high-dimensional geometric transformations (e.g., perspective projection, matrix inversion) and discontinuous operations (e.g., sorting) that exceed the typical scope of tools designed for control-flow analysis [3, 13] or neural network verification [12, 21]. Our method adapts abstract interpretation principles specifically to the rendering domain, providing a tailored approach for bounding rendering-specific operations while balancing precision and scalability.
Finally, although neural network robustness verification [12, 18, 21] analyzes how fixed image perturbations affect network outputs, our work operates upstream by generating the complete set of images a system may encounter under scene and camera uncertainty. This distinction is critical for safety-critical applications, where environmental variations—such as lighting and object motion—must be rigorously modeled before perception occurs.
2 Background: Linear Approximations and Rendering
Our abstract rendering algorithm in Section 3 computes linear bounds on pixel colors derived from bounds on the scene and the camera parameters. In this section, we give an overview of the standard rendering algorithm for 3D Gaussian splat scenes and introduce linear over-approximations of functions.
2.1 Linear Over-approximations of Basic Operations
For a vector , we denote its element by . Similarly, for a matrix , is the element in the row and column. For two vectors (or matrices) of the same shape, denotes element-wise comparison. For both a vector and matrix , we denote as its Frobenius norm. We use boldface to distinguish set-valued variables from their fixed-valued counterparts, (e.g., v.s. ). A linear set or a polytope is a set , where are the constraints defining the set. An interval is a special linear set. A piecewise linear relation on is a relation of the form , where defines linear constraints on with respect to . A constant relation is a special piecewise linear relation where and are zero matrices. We define a class of functions that can be approximated arbitrarily precisely with piecewise linear lower and upper bounds over any compact input set.
Definition 1
A function is called linearly over-approximable if, for any compact and , there exist piecewise linear maps such that for all , and .
For any linearly over-approximable function and any linear set of inputs , is a piecewise linear relation that over-approximates function over .
Proposition 1
Any continuous function is linearly over-approximable.
Although Proposition 1 implies piecewise linear bounds on continuous functions can be adjusted sufficiently tight by shrinking the neighborhood, finding accurate bounds over larger neighborhoods remains a significant challenge. Our implementation of abstract rendering uses CROWN [21] for computing such bounds. Except for , , and , all the basic operations listed in Table 1 are continuous and therefore linearly over-approximable. Moreover, since is a piecewise constant function, it can be tightly bounded on each subdomain by partitioning at , allowing it to be treated as a linearly over-approximable function. This is formalized in Corollary 1.
Corollary 1
All operations in Table 1, except for and , are linearly over-approximable.
Operation
Inputs
Output
Math Representation
Element-wise add ()
Element-wise multiply ()
Division ()
Matrix multiplication ()
Matrix inverse ()
Matrix power ()
Summation ()
Product ()
Matrix transpose ()
Element-wise exponential ()
Frobenius norm ()
Element-wise indicator ()
Sorting ()
permute based on
Given an input interval , piecewise linear bounds and corresponding piecewise linear relations for operators , and are shown in Table 2. These bounds confirm these operations’ linearly over-approximability.
| Operation | Linear lower bound | Linear upper bound |
|---|---|---|
2.2 Rendering Gaussian Splat Scenes
A Gaussian splat scene models a three dimensional scene as a collection of Gaussians with different means, covariances, colors, and transparencies. The rendering algorithm for Gaussian splat scenes projects these 3D Gaussians as 2D splats on the camera’s image plane [7].
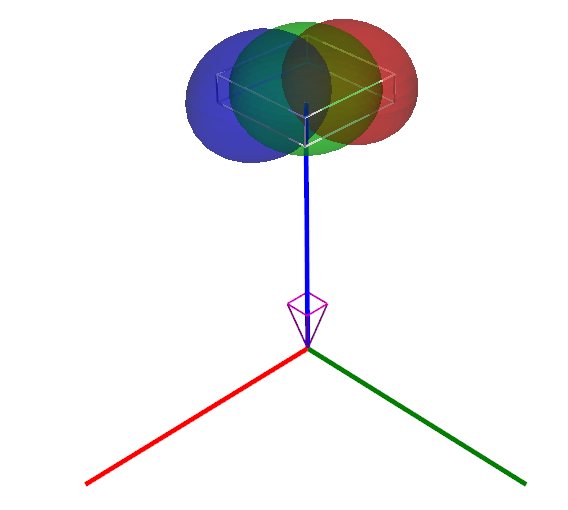
Given a world coordinate frame , a 3D Gaussian is a tuple where, is its mean position in the world coordinates, is its covariance matrix111The covariance matrix is represented by its Cholesky factor , i.e., ., is its opacity, and is its colors in RGB channels. A scene is a collection of Gaussians in the world coordinate frame, indexed by a finite set . A visualization of a scene with three Gaussians is shown on the right side of Figure 2.
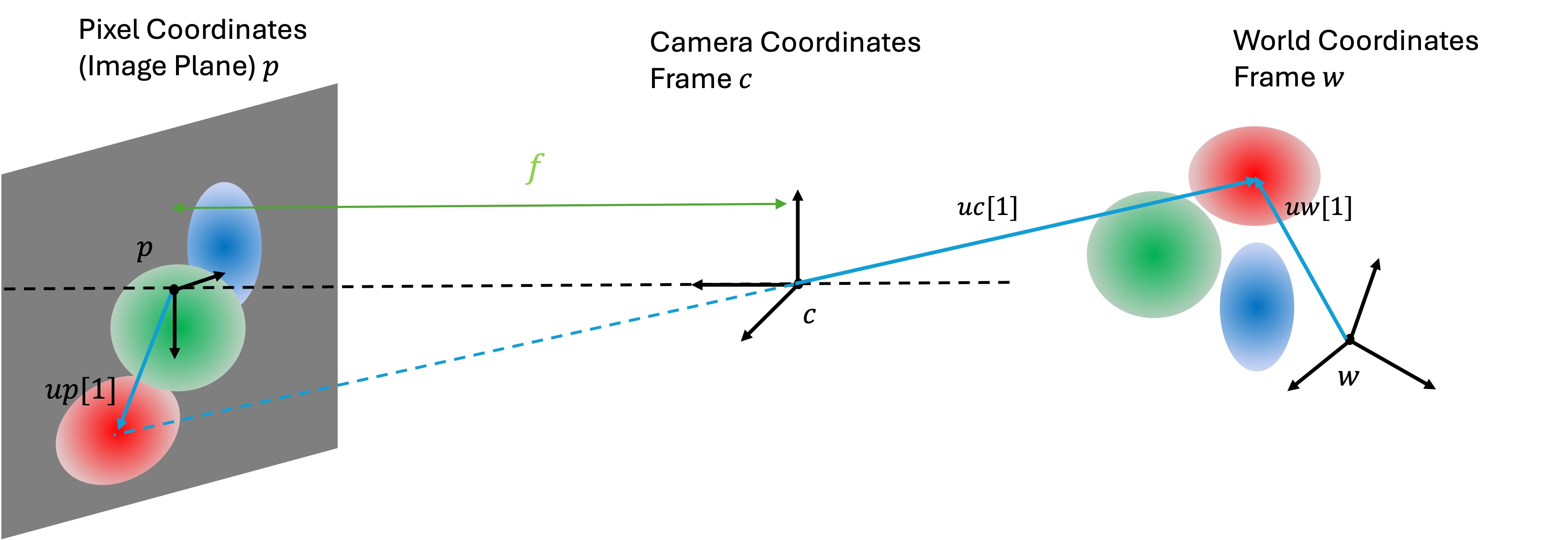
A camera is defined by a translation and a rotation matrix relative to the world coordinates, a focal length , and an offset . The position and the rotation define the extrinsic matrix of the camera, and the latter parameters define the intrinsic matrix. Together, they define how 3D objects in the world are transformed to 2D pixels on the camera’s image plane. An Image of size (denoted as ) is defined by a collection of pixel colors, where each pixel color .
Given a scene and a camera , the image seen by the camera is obtained by projecting the 3D Gaussians in the scene onto the camera’s image plane and blending their colors. Each pixel’s color is blended based on the distance between the pixel’s position and the 2D Gaussian’s mean, as well as the depth ordering of the 3D Gaussians from the image plane. In detail, the rendering algorithm GaussianSplat (shown in Listing 1) computes the color of each pixel in the following four steps. The first three steps are for each Gaussian and the final step is on the aggregate.
- Step 1.
- Step 2.
-
Transforms each of the Gaussians from 3D camera coordinates () to 2D pixel coordinates () on the image plane (Line 1-1) (Figure 2) by applying the intrinsic matrix to and the projective transformation to . And computes depth to image plane for Gaussian simply as the third coordinate of (as the camera axis is orthogonal to the image plane).
- Step 3.
-
Next, computes the inverse of covariance for the 2D Gaussian in Step 2 (Line 1). Effective opacity of each Gaussian at pixel position is computed as opacity weighed by the probability density of the 2D Gaussian at pixel (Line 1-1). The complicated expression for is the familiar definition of the Gaussian distribution with covariance written using the operators in Table 1.
- Step 4.
-
Finally, the color of the pixel is determined by blending the colors of all the Gaussian weighted by their effective opacities and adjusted according to their depth to the image plane (Line 1).
This last step is implemented in the BlendSort (shown in Listing 2) function: it sorts the Gaussians based on their depth to the image plane , resulting in reordered effective opacities and Gaussian colors (Line 2-2). Then for each Gaussian, its transparency is computed as (Line 2). The transmittance of Gaussian is obtained as the cumulative product of transparency of all Gaussians in front of it (Line 2). Finally, the pixel color is determined by summation of all Gaussian colors , weighted by their respective transmittance and effective opacities (Line 2).
For rendering the whole image, GaussianSplat is executed for each pixel. Although, this algorithm looks involved, we note that Steps 1 and 2 only use the , , operations in Table 1. Step 3 involves computing the inverse of the covariance matrix and Step 4 requires sorting the depth.
Abstract rendering problem.
Our goal is to design an algorithm that for all pixel , it takes as input a linear set of scenes and cameras , and outputs a linear set of pixel color such that , for each and .
3 Abstract Rendering
Our approach for creating the abstract rendering algorithm, AbstractSplat, takes a linear set of scenes and cameras as input and step-by-step derives the piecewise linear relation between each intermediate variable and input through GaussianSplat. This process continues until the final step, where the piecewise linear relation between pixel values and inputs is established. The final piecewise linear relation is then used to compute linear bounds on each pixel, and by iterating over all pixels in the image, we obtain linear bounds for the entire image.
In GaussianSplat, the first two steps involve linear operations, making it straightforward to derive the linear relation at each step as a combination of the current relation and the linear bounds of the ongoing operations. However, matrix inversion in step 3, using the adjugate method222In the adjugate method, the matrix inverse is computed by dividing the adjugate matrix by the determinant, can introduce large over-approximation errors due to uncertainty in the denominator, particularly when the matrix approaches singularity. Step 4 further exacerbates these errors with sorting, as depth order uncertainty may cause a single Gaussian to be mapped to multiple indices, leading to over-counting in the pixel color summation, and potentially causing pixel color overflow in extreme cases.
To address these issues, we first introduce a Taylor expansion-based Algorithm MatrixInv in Section 3.1, capable of mitigating the uncertainty of division to be arbitrarily small by setting a sufficiently high Taylor order. Then in Section 3.2, we propose BlendInd (shown in Listing 3) in replacement to BlendSort, which eliminates indices uncertainty and improves bound tightness by implementing Gaussian color blending without the need for operation. Finally, we present a detailed explanation of AbstractSplat and prove its soundness in Section 3.3.
3.1 Abstracting Matrix Inverse by Taylor Expansion
Linear bounds on division often lead to greater over-approximation errors compared to addition or multiplication. Thus, we propose a Taylor expansion-based algorithm, MatrixInv (shown in Listing 4), which expresses the matrix inverse as a series involving only addition and multiplication. Though division is used to bound the remainder term, its impact can be minimized by increasing the Taylor order, effectively reducing the remainder to near zero.
The MatrixInv function takes non-singular matrix as input and uses a reference matrix along with a Taylor expansion order as parameters. It outputs and , representing the lower and upper bounds of operation. Given fixed input , Algorithm MatrixInv operates as follows: First, it calculates the deviation from the reference matrix, denoted as (Line 4). Next, it checks the norm of to ensure that the Taylor expansion does not diverge as the order increases (Line 4). Then, it computes the order Taylor approximation , and sum them to obtain order Taylor polynomial (Line 4 - Line 4), and computes an upper bound of the remainder norm (Line 4). Finally, the lower (upper) bound of matrix inverse () is achieved by subtracting (adding) to (Line 4 - Line 4).
Lemma 1
Given any non-singular matrix , the output of Algorithm MatrixInv satisfies that:
Lemma 1 demonstrates that MatrixInv produces valid bounds for the operation with fixed input. When applied to a linear set of input matrices, the linear bounds of and are derived through line-by-line propagation of linear relations. Together, these bounds define the overall linear bounds for the operation on the given input set. To mitigate computational overhead from excessive matrix multiplications, we make the following adjustments for tighter bounds while using a small : (1) select as the inverse of the center matrix within the input bounds; (2) iteratively divide the input range until the assertion at Line 4 is satisfied; and (3) increase until falls below the given tolerance. Example 1 highlights the benefits of using MatrixInv for matrix inversion.
Example 1
Given the constant lower and upper bounds of input matrices,
we combine lower bound of and upper bound of as overall bounds for operation, and take the norm difference as a measure of bound tightness. Using the adjugate method, we get , while MatrixInv improves this to , which closely aligns with the empirical value of .
3.2 Abstracting Color Blending by Replacing Sorting Operator
In BlendSort, the operation orders Gaussians by increasing depth so that those closer to the camera receive lower indices, enabling cumulative occlusion computation. However, we observe that instead of sorting, one can directly identify occluding Gaussians through pairwise depth comparisons. Our algorithm, BlendInd, iterates over Gaussian pairs and uses a boolean operator to select those with smaller depths relative to a given Gaussian. This approach avoids the complications associated with index-based accumulation (for example, the potential for counting the occlusion effect of the same Gaussian multiple times) and ultimately yields significantly tighter bounds on the pixel colors.
Algorithm BlendInd takes as input the effective opacity , Gaussian colors , and Gaussian depths relative to the image plane, and outputs the pixel color . Its proceeds as follows: First, it computes the transparency between each pair of Gaussians, denoted as matrix (Line 3). If the Gaussian is behind the (), then outputs and value of is less than , indicating that the contribution of the Gaussian’s color is attenuated; otherwise, outputs and value of is set to be exact , meaning the contribution of the Gaussian’s color is unaffected by the . Next, the combined transmittance for all Gaussians is computed (Line 3). Finally, the pixel color is obtained by aggregating the colors of all Gaussians, weighted accordingly (Line 3).
Lemma 2
For any given inputs — effective opacities , colors and depth :
Lemma 2 demonstrates that BlendSort and BlendInd are equivalent, i.e., replacing BlendSort with BlendInd in GaussianSplat yields same output values for same inputs. Furthermore, under input perturbation, BlendInd produces tighter linear bounds than BlendSort, as shown in Example 2.
Example 2
Consider a scene with three Gaussians (red, green, blue) and a camera at the origin facing upward, with a perturbation of ±0.3 applied to each coordinate. At pixel (10,2) in a 20×20 image, the red channel’s upper bound is 0.6526 using BlendSort, 0.575 using BlendInd, and 0.574 via empirical sampling. Similar results are observed for the green and blue channels. Figure 3 visualizes the upper bounds on the RGB channels for the entire image.



3.3 Abstract Rendering Algorithm AbstractSplat
Our abstract rendering algorithm, AbstractSplat, is derived from modifications to GaussianSplat, as follows:
- (1)
-
All input arguments and variables in GaussianSplat are replaced with their linear set-valued counterparts (with boldface font).
- (2)
- (3)
- (4)
- (5)
-
The final output of AbstractSplat is a linear set of colors representing the set of possible colors for pixel .
The complete abstract rendering algorithm computes the set of possible colors for every pixels in the image. The next theorem establishes the soundness of AbstractSplat, which follows from the fact that all the operations involved in AbstractSplat are linear relational operations of linearly over-approximable functions.
Theorem 3.1
AbstractSplat computes sound piecewise linear over-approximations of GaussianSplat for any linear sets of inputs and .
Proof
Let us fix the input linear sets of scenes , cameras , and a pixel . Consider any specific scene and camera . At Line 1, , because Line 1 in GaussianSplat only contains linearly over-approximable operations (e.g. , ), and are generated by their corresponding linearly relational operation. Similar containment relationship continues through to Line 1, where .
At Line 1, by Lemma 1, we establish that . Since each operation involved in MatrixInv is linearly over-approximable, it follows that and . Thus, for the set , defined as the union of and , it implies .
Similarly, at Line 1 and Line 1, a corresponding containment relationship exists for the same reason as in Line 1. At Line 1, by Lemma 2, we have , and since all operations involved in BlendInd are also linearly over-approximable, it follows that , and therefore, .
As the result of AbstractSplat over-approximates that of GaussianSplat line by line, it follows that for any specific scene and camera , we have , thus completing the proof.
4 Experiments with Abstract Rendering
We implemented the abstract rendering algorithm AbstractSplat described in Section 3. As mentioned earlier, the linear approximation of the continuous operations in Table 1 is implemented using CROWN [21].
AbstractSplat on GPUs.
GPUs excel at parallelizing tasks that apply the same operation simultaneously across large datasets, such as numerical computations and rendering. Consider a pixel image of a scene with Gaussians. A naive per-pixel implementation requires computations for effective opacities , while BlendInd requires operations. For realistic values (), this can become prohibitive. Our implementation adopts a tile-based approach, similar to original Gaussian Splatting [7], where the whole image is partitioned into small tiles and the computation of effective opacity is batched per tile, allowing independent parallel processing
Batching within each tile increases memory usage. Let denote the tile size and the batch size for processing Gaussians; then storing the linear bounds for pixels and Gaussians scales at . Similarly, directly computing depth-based occlusion for all Gaussian pairs in BlendInd are infeasible, so we batch the inner loop only, fixing a batch size for the outer loop to balance throughput and memory consumption.
Thus, the choices of tile size and batch size provide two tunable knobs for balancing performance and memory. Larger and yield faster computation but higher memory usage, while smaller values conserve memory at the cost of speed. By adjusting these parameters, users can optimize AbstractSplat for their available computing resources.
4.1 Benchmarks and Evaluation Plan
We evaluate AbstractSplat on six different Gaussian-splat scenarios chosen to cover a variety of scales and scene complexities. These scenes are as follows: BullDozer [9] is a scene with a LEGO bulldozer against an empty background. This scene makes it apparent how camera pose changes influence the rendered image. PineTree and OSM are scenes from [4] originally described by triangular meshes. We converted them into Gaussian splats by training on images rendered from the mesh scenes. The resulting 3D Gaussian scenes are visually indistinguishable from the original meshes. Airport is a large-scale scene created from an airport environment in the Gazebo simulator. Garden and Stump [7] are real-world scenarios with large number of Gaussians.
All the scenes were trained using the Splatfacto implementation of Gaussian splatting from Nerfstudio [15]. For each scene, we generate multiple test cases by varying the nominal (unperturbed) camera pose. Table 3 summarizes the details of these scenes.
| BullDozer | 56989 | BD-1 | [-0.68,0.08,3.12] | [-0.3,5.2,2.7] |
|---|---|---|---|---|
| PineTree | 113368 | PT-1 | [0.0,1.57,0.0] | [194.5, -0.1, 4.5] |
| PT-2 | [0.0,1.57,0.0] | [135.0, -0.1, 4.5] | ||
| PT-3 | [0.0,0.0,0.0] | [80.0, 12.0, 40.0] | ||
| OSM | 144336 | OSM-1 | [0.0,1.57,0.0] | [160.0,-0.1,20.0] |
| OSM-2 | [0.0,1.57,0.0] | [160.0,-0.1,4.5] | ||
| OSM-3 | [0.0,-1.57,0.0] | [-160.0,0.0,10.0] | ||
| Airport | 878217 | AP-1 | [-1.71, -1.12, -1.73] | [-2914.7, 676.5, -97.5] |
| AP-2 | [-1.36, -1.50, -1.36] | [-2654.9, 122.7, 26.7] | ||
| Garden | 524407 | GD-1 | [-0.72, 0.31, 2.99] | [1.7, 3.7, 1.4] |
| Stump | 751333 | ST-1 | [1.96, 0.10, 0.09] | [0.6, -1.8,-2.6] |
We define two metrics to quantify the precision of abstract images: (1) Mean Pixel Gap ()
computes the average Euclidean distance across the RGB channels between the upper and lower bound. This gives an overall measure of bound tightness across the entire image. (2) Max Pixel Gap ()
measures the largest pixel-wise norm indicating the worst-case losses in any single pixel’s bound. A smaller or value corresponds to more precise abstract rendering.
4.2 AbstractSplat is Sound
We applied AbstractSplat to the scenes in Table 4 under various camera poses and perturbations. In these experiments, the input to AbstractSplat is a set of cameras , where and denote the perturbation radii for position and orientation, and is the nominal pose. We recorded two metrics, and , and compared them against empirical estimates obtained by randomly sampling poses from . Different scenes were rendered at varying resolutions. For some test cases, we further partitioned into smaller subsets. We then computed bounds on the pixel colors for each subset and took their union. This practice improves the overall bound as the relaxation becomes tighter in each subset. Table 4 summarizes the results from these experiments.
| Ours | Empirical | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PT-3 | [2,0,0] | N/A | 10 | 246s | 0.27 | 1.73 | 0.06 | 1.37 | |
| PT-3 | [10,0,0] | N/A | 100 | 48min | 0.47 | 1.73 | 0.18 | 1.37 | |
| PT-3 | [10,0,0] | N/A | 200 | 82min | 0.41 | 1.73 | 0.18 | 1.37 | |
| BD-1 | N/A | 20 | 45min | 0.85 | 1.73 | 0.31 | 1.69 | ||
| BD-1 | N/A | 40 | 74min | 1.01 | 1.73 | 0.67 | 1.67 | ||
| BD-1 | N/A | [0,0,0.1] | 10 | 22min | 0.51 | 1.73 | 0.22 | 1.57 | |
| BD-1 | N/A | [0,0,0.3] | 60 | 138min | 0.64 | 1.73 | 0.47 | 1.67 | |
| AP-1 | N/A | 1 | 20min | 0.64 | 1.72 | 0.07 | 1.27 | ||
| AP-2 | N/A | 1 | 20min | 0.40 | 1.64 | 0.02 | 0.62 | ||
| GD-1 | N/A | 1 | 306s | 1.10 | 1.73 | 0.08 | 0.83 | ||
| ST-1 | N/A | 1 | 10min | 0.12 | 1.53 | 0.01 | 0.41 | ||
| OSM-3 | 0.01 | 0.001 | 1 | 143s | 0.69 | 1.73 | 0.04 | 1.01 | |
| OSM-3 | 0.02 | 0.002 | 1 | 145s | 1.19 | 1.73 | 0.07 | 1.20 | |
First, pixel-color bounds produced by AbstractSplat are indeed sound. This is not surprising given Theorem 3.1, but given a good sanity check for our code. In all cases, the intervals computed strictly contain the empirically observed range of pixel colors from random sampling, confirming that our over-approximation is indeed conservative.
AbstractSplat handles a variety of 3D Gaussian scenes—from single-object (e.g., BullDozer) and synthetic (PineTree, OSM) to large-scale realistic scenes with hundreds of thousands of Gaussians (Airport, Garden, Stump)—with reasonable runtime even at resolution. Moreover, it accommodates both positional and angular (roll, pitch, yaw) camera perturbations.
Figure 1 visualizes the computed lower and upper pixel-color bounds for row 4 in Table 4, corresponding to a 10 cm horizontal shift in the camera position. Every pixel color from renderings within this range falls within our bounds. Our upper bound is brighter and the lower bound darker compared to the empirical bounds. The over-approximation is largely due to repeated operations in BlendInd.
As the size of increases, the pixel-color bounds naturally slacken. For example, in rows 12–13 of Table 4, a larger perturbation range yields higher and values and a wider gap from empirical estimates. Conversely, partitioning the input into finer subsets tightens the bounds: in rows 2–3 (PT-3), increasing partitions from 100 to 200 noticeably reduces , and a similar trend is observed in rows 6–7 for yaw perturbations.
Overall, these experiments confirm that our method yields sound over approximations for GaussianSplat and can flexibly trade off runtime for tighter bounds by adjusting input partition granularity.
4.3 Comparing with Image Abstraction Method of [4]
We compare AbstractSplat with the baseline approach from [4], which computes interval images from triangular meshes under a set of camera positions. We selected four test cases from the scenes in [4] and introduced various sets of cameras . We recorded two metrics, and , under both our approach and the baseline. To match with [4], all images are rendered at pixels. Table 5 summarizes our results.
| Ours | Baseline [4] | |||||||
|---|---|---|---|---|---|---|---|---|
| PT-1 | 0.01 | N/A | 125s | 0.07 | 0.74 | 222s | 0.05 | 1.25 |
| PT-1 | 0.02 | N/A | 124s | 0.24 | 1.54 | 251s | 0.05 | 1.25 |
| PT-1 | N/A | 67s | 0.33 | 1.72 | N/A | N/A | N/A | |
| PT-2 | 0.01 | N/A | 84s | 0.07 | 1.36 | 110s | 0.03 | 1.62 |
| PT-2 | 0.02 | N/A | 88s | 0.14 | 1.60 | 120s | 0.03 | 1.62 |
| PT-2 | N/A | 35s | 0.08 | 1.52 | N/A | N/A | N/A | |
| OSM-1 | 0.01 | N/A | 105s | 0.11 | 0.66 | 26min | 0.11 | 1.59 |
| OSM-1 | 0.03 | N/A | 111s | 0.32 | 1.54 | 29min | 0.14 | 1.65 |
| OSM-1 | N/A | 53s | 0.51 | 1.70 | N/A | N/A | N/A | |
| OSM-2 | 0.01 | N/A | 108s | 0.11 | 0.84 | 26min | 0.10 | 1.60 |
| OSM-2 | 0.03 | N/A | 104s | 0.30 | 1.63 | 29min | 0.12 | 1.65 |
| OSM-2 | N/A | 59s | 0.51 | 1.73 | N/A | N/A | N/A | |
Overall, our algorithm achieves faster runtime than the baseline in most tests. For PT-1, our method is about 2 faster, while in the OSM cases, it is roughly 14 faster. In terms of , our approach often yields tighter worst-case bounds, especially with small input perturbations, indicating a more precise upper bound on pixel colors. However, as the perturbation grows, our can become larger (i.e., less tight) compared to the baseline. However, because our method runs faster, we can split into smaller subsets to refine these bounds when needed, as discussed in Section 4.2. Lastly, our method also supports perturbations in camera orientation, whereas the baseline does not handle those. This flexibility allows us to cover a broader range of real-world camera variations while retaining reasonable performance. Note that the rendering algorithm discussed in [4] could potentially be abstracted by our method since it can be written using operations in Table 1.
4.4 Scalability of AbstractSplat
We evaluate the scalability of AbstractSplat by varying the tile size (), batch size (), and image resolution () while keeping the same scene and camera perturbations (see Table 6). The table reports the number of Gaussians processed and peak GPU memory usage.
Increasing the tile size from to reduces computation time but increases memory usage roughly quadratically with the tile dimension. Similarly, as increases, runtime drops while memory consumption grows proportionally; however, beyond a certain batch size—roughly the number of Gaussians per tile—the performance gains diminish, and too small a batch size negates memory savings due to overhead in BlendInd. Additionally, processing more Gaussians and higher resolutions linearly increase both runtime and memory demands.
Overall, these results highlight a clear trade-off between speed and memory usage. By adjusting , , and , users can balance performance and resource requirements to best suit their hardware.
| GPU Mem (MB) | ||||||
|---|---|---|---|---|---|---|
| PT-1 | 10000 | 317243 | 283s | 2166 | ||
| PT-1 | 2000 | 189054 | 256s | 9968 | ||
| PT-1 | 4000 | 189054 | 162s | 10838 | ||
| PT-1 | 10000 | 189054 | 110s | 14856 | ||
| PT-1 | 30000 | 189054 | 91s | 21452 | ||
| PT-1 | 30000 | 216671 | 107s | 19384 | ||
| PT-1 | 30000 | 232509 | 256s | 12694 |
4.5 Long Spikey Guassians Cause Corase Analysis
An interesting observation from our experiments is that long, narrow Gaussians in a scene can lead to significantly more conservative bounds in our method. Figure 4 illustrates this phenomenon using the same test case (BD-1) under a small yaw perturbation of -0.005-0 rad.
In the left images, the bounds are visibly too loose because the scene contains many “spiky” Gaussians with near-singular covariance matrices. Even small perturbations in such covariances—when inverting them—can cause very large ranges in the conic form as discussed in Section 3.1. For example, consider one Gaussian in the image coordinate frame with tight covariance bounds:
After inversion, this becomes:
Such drastic changes in the inverse bleeds into large values from the Gaussians, overestimated effective opacities , and ultimately, loose pixel-color bounds.
To mitigate this issue, we retrained the scene while penalizing thin Gaussians to avoid near-singular covariances. The resulting bounds (shown in the right images of Fig. 4) are significantly tighter. Thus, the structure of the 3D Gaussian scene itself can substantially impact the precision of our analysis, and regularizing or penalizing long, thin Gaussians provides a practical way to reduce over-approximation.




4.6 Abstract Rendering Sets of Scene
While prior experiments focused on camera pose uncertainty, AbstractSplat also supports propagating sets of 3D Gaussian scene parameters (e.g., color, mean position, opacity). This capability enables analyzing environmental variations or dynamic scenes represented as evolving Gaussians. We validate this with three experiments on the PT-1, fixing the camera pose and perturbing specific Gaussian attributes.






In the first experiment, we perturb the red channel of the Gaussians representing the two trees by 0–0.5. The resulting pixel-color bounds (Fig.5 Left) fully encompass the empirical range, confirming that our method captures chromatic uncertainty. In the second experiment, a 1 m perturbation along the +y-axis is applied to the tree Gaussians’ mean positions; the bounds (Fig.5 Mid) capture both spatial displacement and occlusion effects, demonstrating that AbstractSplat effectively propagates geometric uncertainty. Finally, by scaling the original opacities by 0.1 (capping them) and adding a +0.1 perturbation, we test transparency variations. The resulting bounds (Fig. 5 Right) remain sound, though somewhat looser due to multiplicative interactions in BlendInd.
These experiments highlight the flexibility of AbstractSplat: by abstracting Gaussian parameters, we can model environmental dynamics such as object motion, material fading, or scene evolution. This capability aligns with recent work on dynamic 3D Gaussians [19, 22, 20] and underscores the potential for robustness analysis in vision systems operating in non-static environments.
5 Discussion and Future Work
We presented the first method for rigorously bounding the output of 3D Gaussian splatting under camera pose uncertainty, enabling formal analysis of vision-based systems operating in dynamic environments. By reformulating depth-sorting as an index-free blending process and bounding matrix inverses via Taylor expansions, our approach avoids combinatorial over-approximation while maintaining computational tractability. Experiments demonstrate scalability to scenes with over 750k Gaussians.
Potential directions include refining the blending process to reduce error accumulation, exploring higher-order bounds or symbolic representations for pixel correlations, and extending the framework to closed-loop system verification. Adapting our approach to other rendering paradigms (e.g., NeRF, mesh-based rendering) could further unify uncertainty-aware analysis across computer vision pipelines. It is worth further investigating abstract rendering for scene variations.
References
- [1] Anonymous: GS-VTON: Controllable 3d virtual try-on with gaussian splatting (2025), https://openreview.net/forum?id=8eenzfwKqU
- [2] Bouissou, O., Conquet, E., Cousot, P., Cousot, R., Feret, J., Ghorbal, K., Goubault, E., Lesens, D., Mauborgne, L., Miné, A., Putot, S., Rival, X., Turin, M.: Space Software Validation using Abstract Interpretation. In: The International Space System Engineering Conference : Data Systems in Aerospace - DASIA 2009. vol. 1, pp. 1–7. EUROSPACE, European Space Agency, Istambul, Turkey (May 2009), https://inria.hal.science/inria-00528590
- [3] Cousot, P., Cousot, R., Feret, J., Mauborgne, L., Miné, A., Monniaux, D., Rival, X.: The astreé analyzer. In: Sagiv, M. (ed.) Programming Languages and Systems. pp. 21–30. Springer Berlin Heidelberg, Berlin, Heidelberg (2005)
- [4] Habeeb, P., D’Souza, D., Lodaya, K., Prabhakar, P.: Interval image abstraction for verification of camera-based autonomous systems. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 43(11), 4310–4321 (2024). https://doi.org/10.1109/TCAD.2024.3448306
- [5] Jiang, Y., Yu, C., Xie, T., Li, X., Feng, Y., Wang, H., Li, M., Lau, H., Gao, F., Yang, Y., Jiang, C.: Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. arXiv preprint arXiv:2401.16663 (2024)
- [6] Johnson, J., Ravi, N., Reizenstein, J., Novotny, D., Tulsiani, S., Lassner, C., Branson, S.: Accelerating 3d deep learning with pytorch3d. In: SIGGRAPH Asia 2020 Courses. SA ’20, Association for Computing Machinery, New York, NY, USA (2020). https://doi.org/10.1145/3415263.3419160, https://doi.org/10.1145/3415263.3419160
- [7] Kerbl, B., Kopanas, G., Leimkuehler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 42(4) (Jul 2023). https://doi.org/10.1145/3592433, https://doi.org/10.1145/3592433
- [8] Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: Learning dynamic renderable volumes from images. ACM Trans. Graph. 38(4), 65:1–65:14 (Jul 2019)
- [9] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
- [10] Rematas, K., Ferrari, V.: Neural voxel renderer: Learning an accurate and controllable rendering tool. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5416–5426 (2020). https://doi.org/10.1109/CVPR42600.2020.00546
- [11] Schieber, H., Young, J., Langlotz, T., Zollmann, S., Roth, D.: Semantics-controlled gaussian splatting for outdoor scene reconstruction and rendering in virtual reality (2024), https://arxiv.org/abs/2409.15959
- [12] Singh, G., Gehr, T., Püschel, M., Vechev, M.: An abstract domain for certifying neural networks. Proc. ACM Program. Lang. 3(POPL) (Jan 2019). https://doi.org/10.1145/3290354, https://doi.org/10.1145/3290354
- [13] Singh, G., Püschel, M., Vechev, M.: Making numerical program analysis fast. In: Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation. p. 303–313. PLDI ’15, Association for Computing Machinery, New York, NY, USA (2015). https://doi.org/10.1145/2737924.2738000, https://doi.org/10.1145/2737924.2738000
- [14] Souyris, J., Delmas, D.: Experimental assessment of astrée on safety-critical avionics software. In: Saglietti, F., Oster, N. (eds.) Computer Safety, Reliability, and Security. pp. 479–490. Springer Berlin Heidelberg, Berlin, Heidelberg (2007)
- [15] Tancik, M., Weber, E., Ng, E., Li, R., Yi, B., Kerr, J., Wang, T., Kristoffersen, A., Austin, J., Salahi, K., Ahuja, A., McAllister, D., Kanazawa, A.: Nerfstudio: A modular framework for neural radiance field development. In: ACM SIGGRAPH 2023 Conference Proceedings. SIGGRAPH ’23 (2023)
- [16] Tewari, A., Thies, J., Mildenhall, B., Srinivasan, P., Tretschk, E., Yifan, W., Lassner, C., Sitzmann, V., Martin-Brualla, R., Lombardi, S., Simon, T., Theobalt, C., Nießner, M., Barron, J.T., Wetzstein, G., Zollhöfer, M., Golyanik, V.: Advances in neural rendering. Computer Graphics Forum 41(2), 703–735 (2022). https://doi.org/https://doi.org/10.1111/cgf.14507, https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.14507
- [17] Tosi, F., Zhang, Y., Gong, Z., Sandström, E., Mattoccia, S., Oswald, M.R., Poggi, M.: How nerfs and 3d gaussian splatting are reshaping slam: a survey (2024), https://arxiv.org/abs/2402.13255
- [18] Tran, H.D., Bak, S., Xiang, W., Johnson, T.T.: Verification of deep convolutional neural networks using imagestars. In: 32nd International Conference on Computer-Aided Verification (CAV). Springer (July 2020). https://doi.org/10.1007/978-3-030-53288-8_2
- [19] Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20310–20320 (June 2024)
- [20] Xu, C., Kerr, J., Kanazawa, A.: Splatfacto-w: A nerfstudio implementation of gaussian splatting for unconstrained photo collections (2024), https://arxiv.org/abs/2407.12306
- [21] Xu, K., Shi, Z., Zhang, H., Wang, Y., Chang, K.W., Huang, M., Kailkhura, B., Lin, X., Hsieh, C.J.: Automatic perturbation analysis for scalable certified robustness and beyond. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
- [22] Yang, Z., Yang, H., Pan, Z., Zhang, L.: Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting. In: International Conference on Learning Representations (ICLR) (2024)
- [23] Zhang, H., Weng, T.W., Chen, P.Y., Hsieh, C.J., Daniel, L.: Efficient neural network robustness certification with general activation functions. Advances in Neural Information Processing Systems 31, 4939–4948 (2018), https://arxiv.org/pdf/1811.00866.pdf
- [24] Zhu, S., Wang, G., Kong, X., Kong, D., Wang, H.: 3d gaussian splatting in robotics: A survey (2024), https://arxiv.org/abs/2410.12262
Appendix 0.A Appendix
0.A.1 Proofs of Lemmas used for Abstract Rendering
Proposition 2
Any continuous function is linearly over-approximable.
Proof
We present a simple proof for scalar and this can be extended to higher dimensions. We fix and a finite slope . Since is continuous, for any , there must exist an open neighborhood around , such that ,
| (1) |
Equivalently,
| (2) |
We construct candidate linear upper and lower bounds over as:
| (3) |
We can check that these linear functions and are valid lower and upper bounds for over , because :
| (4) | |||
| (5) |
Additionally, difference between and is tightly bounded, as :
Now, for any compact set , the collection forms an open cover of . By the definition of compactness, there exists a finite subcover of , denoted by . We can now define piecewise linear functions on as follows:
| (6) | ||||
where is the index set of that cover . Consequently, we have
| (7) |
and
| (8) |
Thus, is linearly over-approximable.
∎
Lemma 3
Given any non-singular matrix , the output of Algorithm MatrixInv satisfies that:
Proof
For any non-singular matrices and , denote their difference as . The order Taylor Polynomial and remainder of matrix inverse of , estimated at , can be written as follows:
| (9) | |||
| (10) |
Assuming that , the remainder can be bounded by:
| (11) | ||||
Using the bound in inequality 11, we obtain bounds on :
| (12) |
Thus, we establish lower and upper bound for as:
| (13) |
Lemma 4
For any given inputs — effective opacities , colors and depth , it follows:
Proof
We first derive the math expression of pixel color from BlendSort. By denoting as a mapping , where refers to the index set of Gaussians, at Line 2, at Line 2 and at Line 2 can be written as follows.
| (14) | |||
| (15) | |||
| (16) |
According to the definition of operation, we have:
| (17) |
Then by replacing with , and multiplying , (17) becomes:
| (18) |
For any fixed index , by multiplying all the case in the second branch of (18), it follows:
| (19) |
By applying Equation 16, Equation 18 and Equation 19 into Line 2, can be written as follows:
| (20) | ||||
Then by applying Equation 20 into Line 2, the pixel color computed via Algorithm BlendSort can be expressed as:
| (21) | ||||
Since the summation and product operations are invariant to the reordering of input elements, and both indices and iterate over the entire index set , the reordering mapping in Equation 21 can be eliminated, resulting in:
| (22) | ||||
Next, we derive the math expression for in Algorithm BlendInd. at Line 3 and at Line 3 can be written as:
| (23) | |||
| (24) |
Then, by applying Equation 24 into Line 3 of Algorithm BlendInd, the expression for becomes:
| (25) |
Note that the expressions for are identical in both Equation 22 and Equation 25. This demonstrates that Algorithms BlendSort and BlendInd yield the same input-output relationship while applying different operations, thus completing this proof. ∎