Accelerated Magnonic Motional Cooling with Deep Reinforcement Learning
Abstract
Achieving fast cooling of motional modes is a prerequisite for leveraging such bosonic quanta for high-speed quantum information processing. In this work, we address the aspect of reducing the time limit for cooling below that constrained by the conventional sideband cooling techniques; and propose a scheme to apply deep reinforcement learning (DRL) to achieve this. In particular, we have shown how the scheme can be used effectively to accelerate the dynamic motional cooling of a macroscopic magnonic sphere, and how it can be uniformly extended for more complex systems, for example, a tripartite opto-magno-mechanical system to obtain cooling of the motional mode below the time bound of coherent cooling. While conventional sideband cooling methods do not work beyond the well-known rotating wave approximation (RWA) regimes, our proposed DRL scheme can be applied uniformly to regimes operating within and beyond the RWA, and thus this offers a new and complete toolkit for rapid control and generation of macroscopic quantum states for application in quantum technologies.
Introduction. Fast cooling of bosonic mechanical modes of macroscopic systems is a primary objective of the ongoing efforts in quantum technology Schäfermeier et al. (2016); Guo et al. (2019); Park and Wang (2009); Clark et al. (2017); Frimmer et al. (2016), and is a prerequisite for diverse prospective applications, such as the realization of macroscopic superposition states Abdi et al. (2016), gravitational tests of decoherence Bose et al. (1999); Marshall et al. (2003), ultra-precise measurements and sensing Schliesser et al. (2009); Manley et al. (2021), and bosonic quantum computing Bourassa et al. (2021). Macroscopic yttrium-iron-garnet (YIG, ) magnets have recently attracted strong interest towards such applications given the versatility of such systems in coupling to other modes falling in a wide frequency spectrum, e.g., with optical, microwave, and acoustic modes, as well as to superconducting qubits Zhang et al. (2016); Lachance-Quirion et al. (2019); Wang and Hu (2020); Li et al. (2018); Zhang et al. (2014); Wang et al. (2018). In addition, highly polished YIG spheres feature high magnonic -factor and exhibit large frequency tunability properties due to the magnetic field dependence of the excited magnon modes. Considering, in particular, the cooling of motional modes of such objects, the usual method of sideband cooling based on weak magnomechanical interaction, operates on a time scale longer than the mechanical period of oscillation and depends on the relaxation dynamics of the subsystems. Cooling of bosonic modes in such systems in a timescale less than the mode frequency is highly advantageous for quantum computation and bosonic error correction Joshi et al. (2021); Bourassa et al. (2021). By going over to the strong coupling regimes in magnon-phonon interactions, the speed of motional cooling can be highly enhanced giving rise to accelerated cooling. However, in such strong coupling regimes, the energy-nonconserving dynamics prevails because of the simultaneous presence of counter-rotating interactions, which makes it impossible to use sideband motional cooling techniques in this regime. In this work, we explore the usefulness of a machine learning based approach to address the aspect of reducing the time limit for cooling below that constrained by the conventional cooling techniques.
Recently, various machine learning (ML) approaches, aided with artificial neural networks as function approximators, have found widespread technological applications Goodfellow et al. (2016). Among the various ML approaches, reinforcement learning (RL) Sutton and Barto (2018), is considered to exhibit the closest resemblance to a human-like learning approach, in that the RL-agent tries to gather experience on its own by interacting with its environment in a trial and error approach. In RL terminology, the environment describes the virtual/real-world surrounding the agent, with all the physics hard-coded into it along with a reward function based on which the agent can classify its good moves from the bad ones. RL, when operated in combination with artificial neural networks, is known as deep reinforcement learning (DRL). DRL has become crucial in many industrial and engineering applications, primarily after recent seminal works by Google DeepMind researchers Silver et al. (2016, 2017). Following these developments, there have been several fascinating applications of DRL in various fundamental domains of science, including some in quantum physics in areas of quantum error correction, Carleo et al. (2019); Bukov et al. (2018); Fösel et al. (2018) quantum control Borah et al. (2021), and state engineering Wang et al. (2020); Niu et al. (2019); Zhang et al. (2019a); Xu et al. (2021); Zhang et al. (2019b); Mackeprang et al. (2020); Haug et al. (2020); Guo et al. (2021); Bilkis et al. (2020); Porotti et al. (2019).
In this work, we propose a DRL-based dynamical coupling scheme for accelerated motional cooling of a macroscopic object, that works for a generalized parameter setting of the coupling strength between the subsystems. In particular, we use the protocol to cool the acoustic phonon modes of a YIG sphere with a magno-mechanical interaction, and show that it works efficiently in the strong coupling regime, where other methods such as sideband cooling fail. Also, we show how going over to the strong coupling regime is particularly advantageous, as it lowers the cooling time well below the phonon oscillation period and two orders of magnitude below the sideband cooling time limit. We demonstrate the usefulness and generalizability of our DRL cooling protocol by extending its application to a tripartite system of a trapped YIG magnet with its magnonic modes coupled to the center-of-mass (COM) mode in the trap and an optical cavity mode; and show that despite the system being in the ultrastrong coupling regime, our DRL scheme can reveal nontrivial coupling modulations to cool the motional mode, which is usually not possible with coherent counter-intuitive protocols.
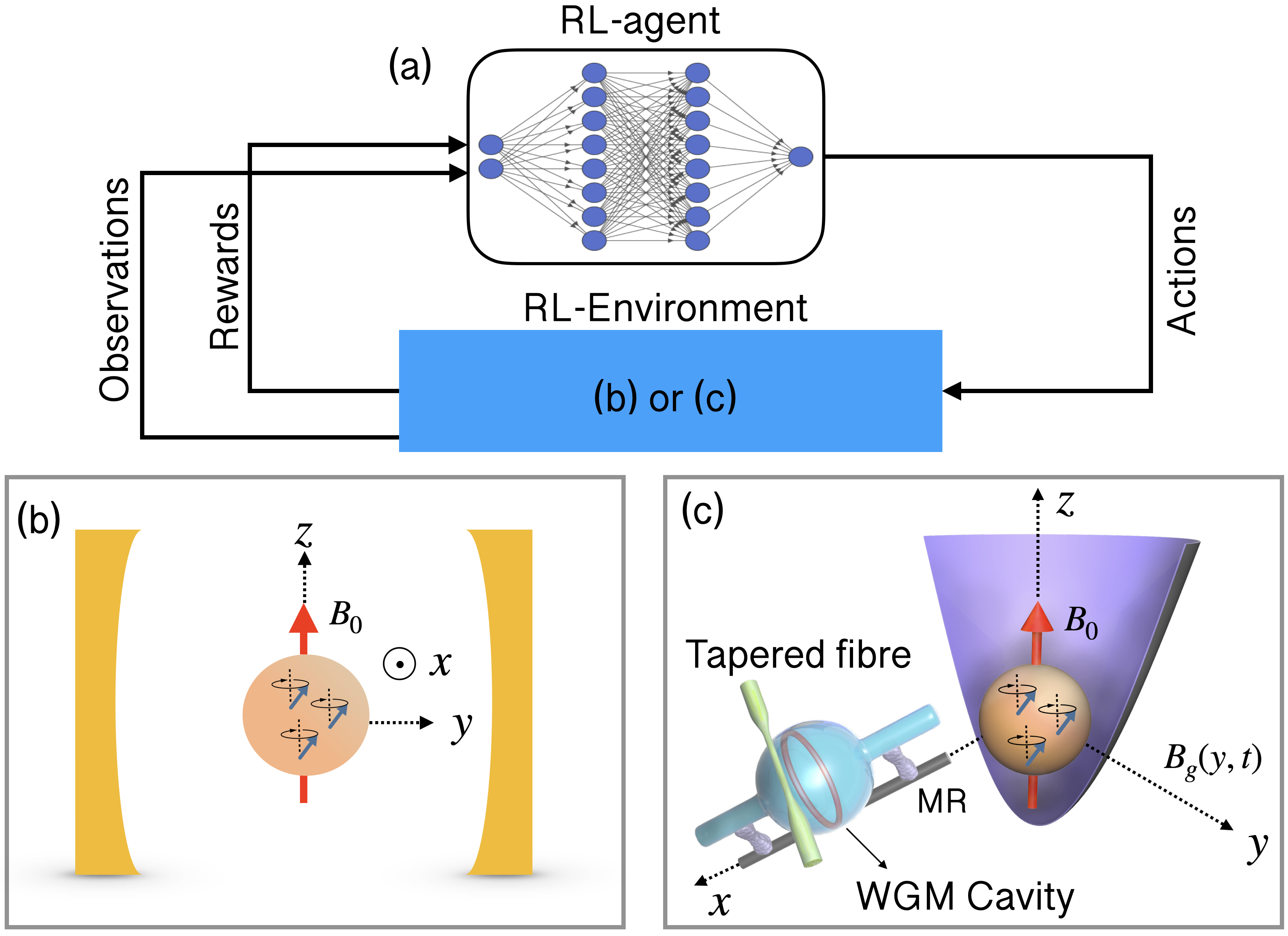
Bipartite magno-mechanical cooling. We consider a setup as shown in Fig. 1(b), where a highly polished YIG sphere is placed in a microwave cavity. With a large external homogeneous magnetic field, , applied in the -direction, the YIG sphere is magnetized to its saturation magnetization, , which gives rise to collective spin wave magnon modes Tabuchi et al. (2014); Zhang et al. (2014). The frequency of the Kittel mode, which is the uniform magnon mode in the YIG sphere, is given by, , where is the gyromagnetic ratio. Due to the magnetostriction properties, YIG spheres also exhibit high-Q acoustic modes which are coupled to the magnon modes Zhang et al. (2016); Li et al. (2018), and by driving the magnon modes with MW fields, the magno-mechanical coupling can be tuned and controlled Wang et al. (2018); Li et al. (2018). In the limit of adiabatic elimination for a low- cavity, the bipartite magno-mechanical Hamiltonian is given by (see Supplemental Material for detail),
| (1) |
where and are the magnonic and acoustic mode annihilation (creation) operators, is the resonance frequency of the acoustic mode and (drive frequency ) is the detuning. In such a bipartite system, while the beam-splitter interaction, , valid for weak magno-mechanical coupling, favours mechanical cooling at the red sideband ; the full coupling interaction accounting for the strong/ultrastrong coupling regimes, is not favourable in the usual sideband cooling approach. Sideband cooling works through anti-Stokes scattering of the excitation from the thermally populated mode, to the mode at zero entropy, . However, such cooling needs constant driving as it is a steady-state process that takes a duration of the order of the relaxation dynamics of the subsystems (see Supplemental Material). If one can access the strong coupling regime and manage to tame the counter-rotating interactions therein, there is a possibility of getting faster cooling than this limit. In the following, we design an algorithm based on DRL to model a dynamic variation of coupling, , to get faster cooling of the acoustic mode, that operates within and beyond the weak coupling regime.
The schematic workflow of the DRL scheme applied to the physical model (RL-environment) is shown in Fig. 1(a). The RL-agent consists of a neural network model that is optimized for selected choices of actions that lead to desirable changes, and to net maximum rewards. The RL-agent is modelled using the recently proposed Soft Actor-Critic (SAC) Haarnoja et al. (2018) algorithm that is based on the maximization of the entropy, of the policy, as well as the long-term discounted cumulative return , i.e., where, denotes the optimizable weights of the neural networks, is the discount factor and is the regularization coefficient that determines the stochasticity of the policy. The policy, sets the rules for the particular actions to be applied on the RL-environment (see Supplemental Material for further details).
The dynamics of the system is described by the quantum master equation (QME) for the density matrix with the Hamiltonian as,
| (2) |
with dissipations and thermal fluctuations given by the Lindblad superoperators, where, ’s are the damping rates of the modes; and the thermal occupation of each bosonic mode is given by, , where is the bath temperature and is the Boltzmann constant. Solving the full QME to obtain the mean occupancy is a computationally intensive task. DRL typically requires several thousands of episodes of training, and solving the full QME within each episode is too resource sensitive for complex systems such as the ones we consider in this work. We employ an alternative approach to compute the mean occupancies in each mode using a set of linear differential equations for the second-order moments obtained from the QME, given by, where , , , are one of the operators (); and are the corresponding coefficients. Instantaneous solutions of these equations and the controls, , are used as the observations for the RL-agent in Fig. 1(a), and the reward function is chosen as, . Here is the cooling quotient of the phonon number with respect to thermal occupancy, at temperature , where represents the mean value of the phonon population. Further details of the DRL controller can be found in Supplementary Information.
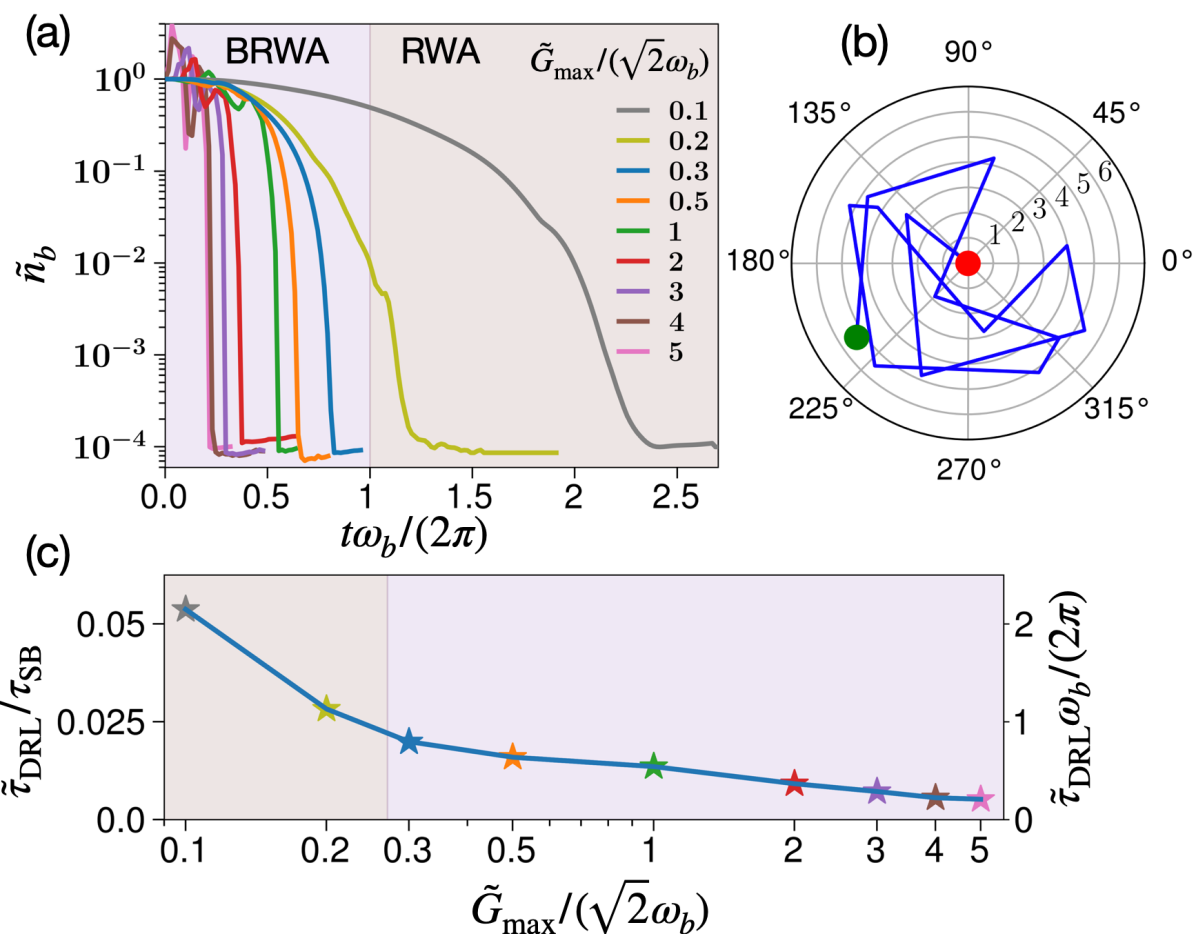
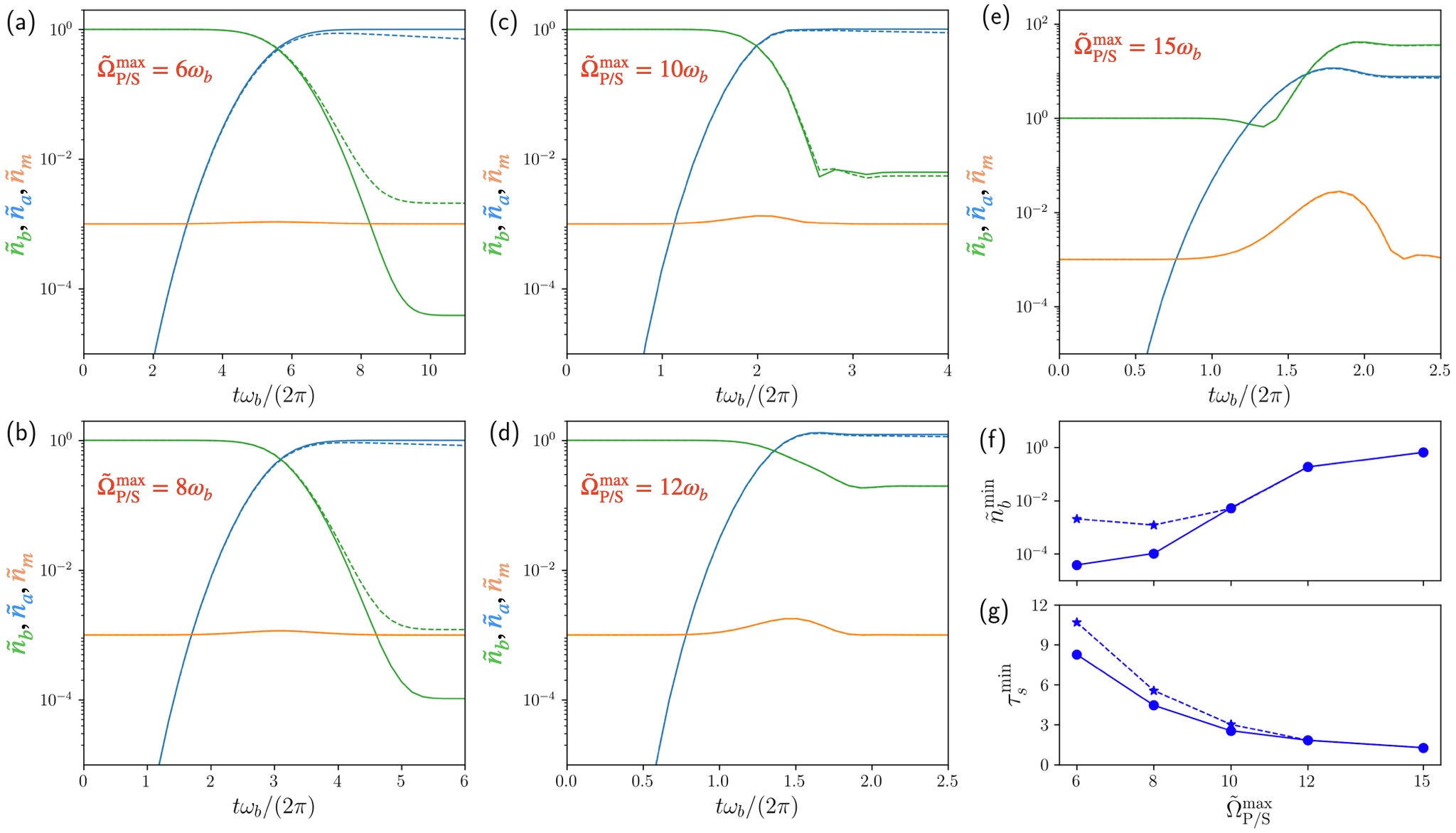
In Fig. 2(a), we show the cooling quotient, for the DRL-optimized controls, as a function of (the maximum of the coupling parameter). We consider , and damping rates as, and . It is found that as the coupling is increased towards the ultrastrong coupling regime (), the cooling becomes much faster. The DRL-optimized complex pulse sequence is shown as a polar plot for in Fig. 2(b). We denote the minimum time for cooling achieved by our method as . Fig. 2(c) compares this time as a function of with respect to the sideband cooling time limit, , which represents the shortest cooling time limit possible with these methods, that work only when the rotating wave approximation (RWA) is applicable (see Supplemetal Material). With the DRL-based coupling modulations, we can achieve very low limits of cooling time compared to sideband cooling techniques, showing a lowering of approximately two orders of magnitude; which for the ultrastrong coupling regime, is further lowered.
Tripartite opto-magno-mechanical cooling. Now, we show that the proposed scheme can be extended effectively to more complex systems, for example a higher-order tripartite opto-magno-mechanical system, where we intend to cool the motional mode through non-trivial three-mode interactions. For this, we consider a system comprising a levitated YIG sphere in a harmonic trap Seberson et al. (2020); Rusconi et al. (2017); Huillery et al. (2020), along with a driven WGM optical microresonator placed along the -direction with a magnetostrictive rod (MR) attached to it, as depicted in Fig. 1(c), which will be used as the RL-environment in Fig. 1(a) in the DRL model. In a large external homogeneous magnetic field, , applied in the -direction, the YIG sphere is magnetized to the saturation magnetization, , and the homogeneously magnetized fundamental magnon mode (Kittel mode) produces a change in the axial length of the MR, which modulates the WGM optical mode frequency Forstner et al. (2014); Xia et al. (2015); Yu et al. (2016); Guo et al. (2019). This gives rise to a coupling between the WGM optical mode and the magnon mode of the form, , where is the optical frequency shift. The magnon mode can also be coupled to the COM motion of the YIG sphere, by applying a spatially inhomogeneous external time-dependent magnetic field, Hoang et al. (2016); Delord et al. (2018), which satisfies the weak driving, , and small-curl, conditions (see the Supplemental Material for more information). Considering a time-varying gradient magnetic field of the form, , ( in units of ), the interaction Hamiltonian for the COM motion in the -direction (frequency ) and the magnon mode is given by, with , where is the saturation magnetization, and is the mass density of YIG. In the rotating frame of the cavity drive and the displacement picture of the average field in each mode Khosla et al. (2017), the complete Hamiltonian is described by
| (3) |
where is the cavity detuning, and is the driving-enhanced optomagnonic coupling rate. One can modulate via the external drive, whereas the phonon-magnon coupling can be modulated using the time-varying magnetic field gradient. In order to cool the COM motion, we intend to transfer the phonon population from the COM mode to the optical mode without populating the magnon mode. The damping rates of the cavity, magnon, and COM modes are given by, ’s, and the corresponding thermal populations at temperature are , with . Since the optical cavity mode oscillates at high frequency, its corresponding thermal bath even at room temperature yields zero thermal occupancy, however, the phonon and magnon baths are occupied.
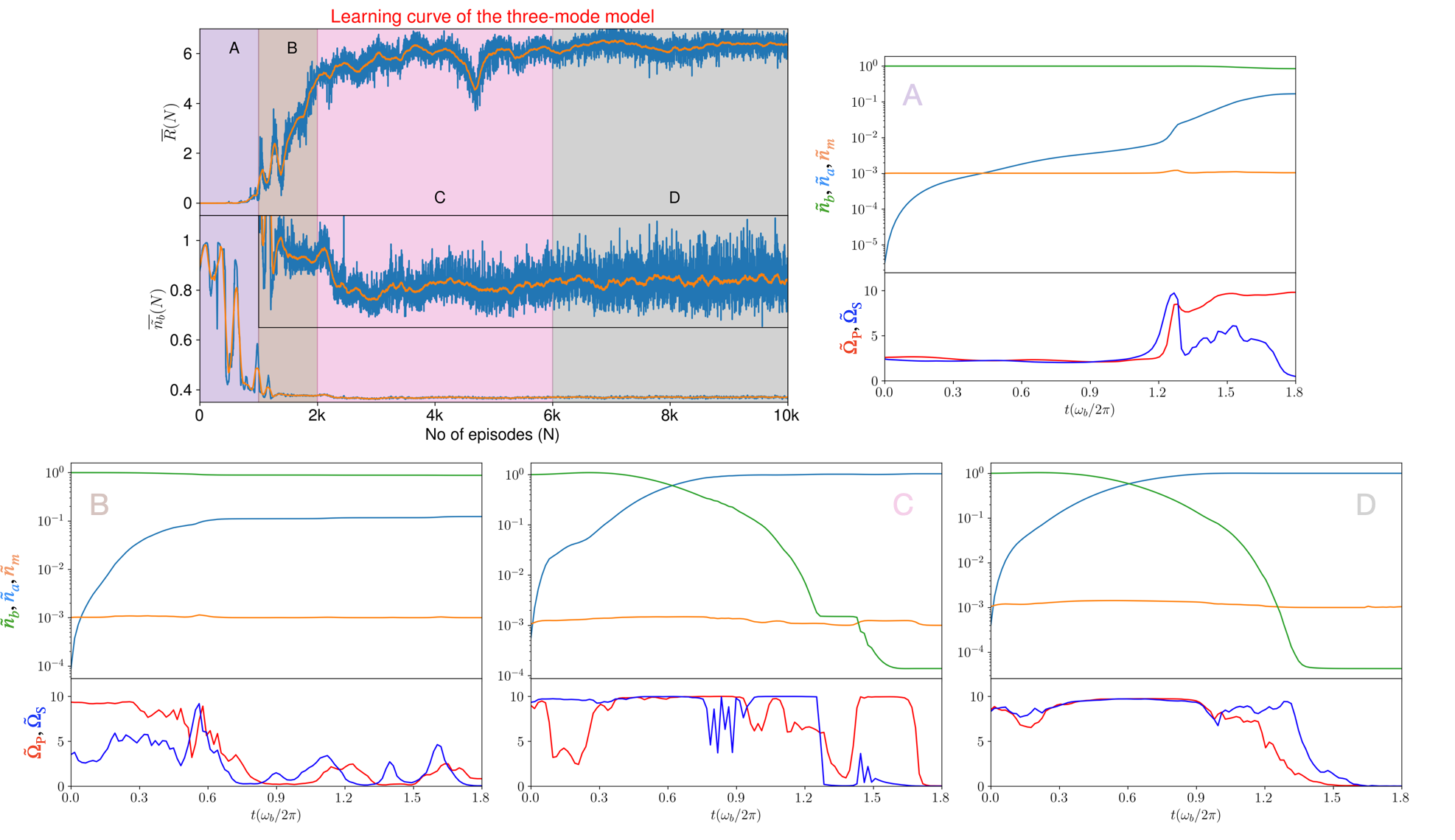
Similar to the bipartite system discussed above, we next use the second-order moment equations to solve the dynamics of the system and the DRL scheme is used to optimize the controls, by maximizing the net reward signal per episode, , where is a constant chosen such that the magnon mode does not get populated. Given the fact that the COM mode frequencies of the YIG are of the order of ’s of , and the magnon frequency is , the ideal choice of for is . With such a high frequency difference with the intermediate magnon mode at , this constitutes a largely detuned system (). In such a system while the magnon mode is usually decoupled, the ideal time limit to obtain swap between mechanical quanta and optical mode with the ideal Raman pulses is given by (see the Supplemental Material). However, this is the limit for the situation as long as the RWA is valid. It is also noted that the effectiveness of this kind of cooling is highly reduced in presence of damping, and going beyond the RWA to decrease the cooling time limit is not possible because of the counter-rotating dynamics. We apply the DRL strategy to work in a regime where ’s are sufficiently high to access the cooling limit not obtainable by these conventional means, and also keep the counter-rotating dynamics in control. While the use of the method of coupled second order moments reduces the computation resources drastically, simulating the dynamics with the choice of the realistic parameter with high coupling strengths, for example , turns out to be a computationally highly intensive problem, due to the very stiff solution of the set of differential equations. Hence, we adopt a two-step training procedure for the problem. In this protocol, we first use an auxiliary system with and , for which solution of the set of equations can be obtained without much computational effort. The trained auxiliary model is then used as a supervisor/teacher for the actual system, that we call primary, with and . Training the primary system for a few hundred episodes with periodic evaluation of the RL-agent yields the best trained model. In the literature of RL, such a scheme is known as imitation learning, and is a feature of generalizability of RL-trained model.
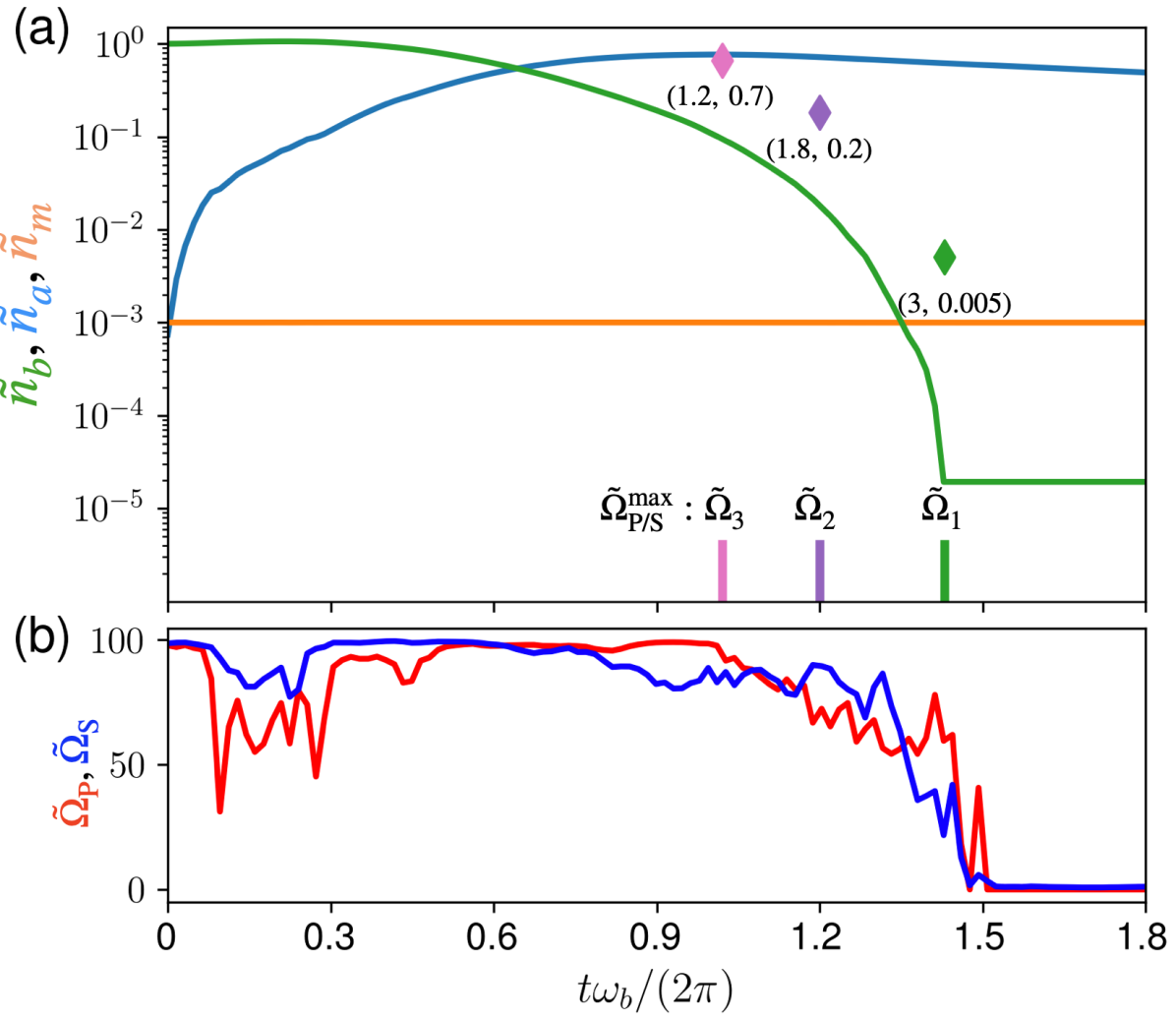
In Fig. 3(a), the cooling quotients of the photon, magnon and phonon modes, , are shown, where ’s are the mean occupancies and is the phonon thermal bath population. The cooling time limit for this system is given by (see the Supplemental Material). The plot shows the population dynamics in the three modes for the DRL-based coupling parameters with a maximum allowed value, . One can see that while the magnon mode is kept at a constant population, there is a scattering between the mechanical and optical mode that gives rise to five orders of cooling in the mechanical mode. This draws an analogy to the stimulated Raman adiabatic passage (STIRAP) techniques for three-mode systems. However, it is well-known that such adiabatic techniques require longer time and only works ideally as long as the counter-rotating terms are not present (see the Supplemental Material). On the contrary, the coupling parameters found by our DRL protocol are non-trivial, which are shown in Fig. 3(b), and the overall time required for cooling is reduced below the adiabatic limit even for high values of coupling. In the bottom panel of Fig. 3(a) we show the cooling time required by our DRL method for even larger values, and higher coupling parameters yield even lower time limits.
Conclusion. To conclude, in this work we address the aspect of reducing the time required for cooling bosonic motional modes below the time limit accessible by well-known cooling methods with scattering techniques. While such conventional methods of cooling do not work in strong and ultrastrong coupling regimes where the RWA is not valid, we design a DRL-based algorithm that works within and beyond such regimes, and show that by accessing the ultrastrong coupling limit with DRL-designed pulses the cooling limit can be broken resulting in accelerated cooling. We further show how the protocol can be adapted for cooling in a tripartite system with an opto-magno-mechanical interaction, that represents more complexity for the DRL-control owing to the huge dimensionality in the Hilbert space; and find nontrivial three-mode interactions leading to accelerated cooling breaking the coherent cooling time limits. Thus, this study outlines a comprehensive toolbox for application of DRL for fast and efficient quantum control in a magnonic system within and beyond RWA restrictions, which can be adapted to other quantum systems of interest. For future and ongoing efforts in quantum technology, this is expected to play a pivotal role, especially in conjunction with various laboratory experiments.
I acknowledgments
Acknowledgements.
The authors thank Okinawa Institute of Science and Technology (OIST) Graduate University for the super-computing facilities provided by the Scientific Computing and Data Analysis section of the Research Support Division, and for financial support. The authors are grateful for the help and support provided by Jeffery Prine from the Digital Content, Brand, and Design Section of the Communication and Public Relations Division at OIST.Bijita Sarma Sangkha Borah A Kani Jason Twamley
Supporting Information
S1 Reinforcement learning and soft actor-critic algorithm
Reinforcement learning (RL) has been one of the most exciting fields of machine learning (ML) following a few revolutionary works carried out during 2013-2016 by the DeepMind and Google Silver et al. (2017, 2016). Although these applications were demonstrated initially for different board games, researchers all around the world are now looking into its potential uses for different technological applications. In RL, a software agent (we will call it the RL-agent), makes some observations and applies some actions on an environment (we call it the RL-environment), that causes a change in the dynamics of the environment and, in return, the RL-agent receives some scalar values as rewards. The objective of the RL-agent is to maximize the total rewards obtained in a particular time range (we call it an episode). This approach of training is particularly different from typical training approaches where the ML-model is trained based on predefined data with labels (supervised learning), or with no labels (unsupervised learning).
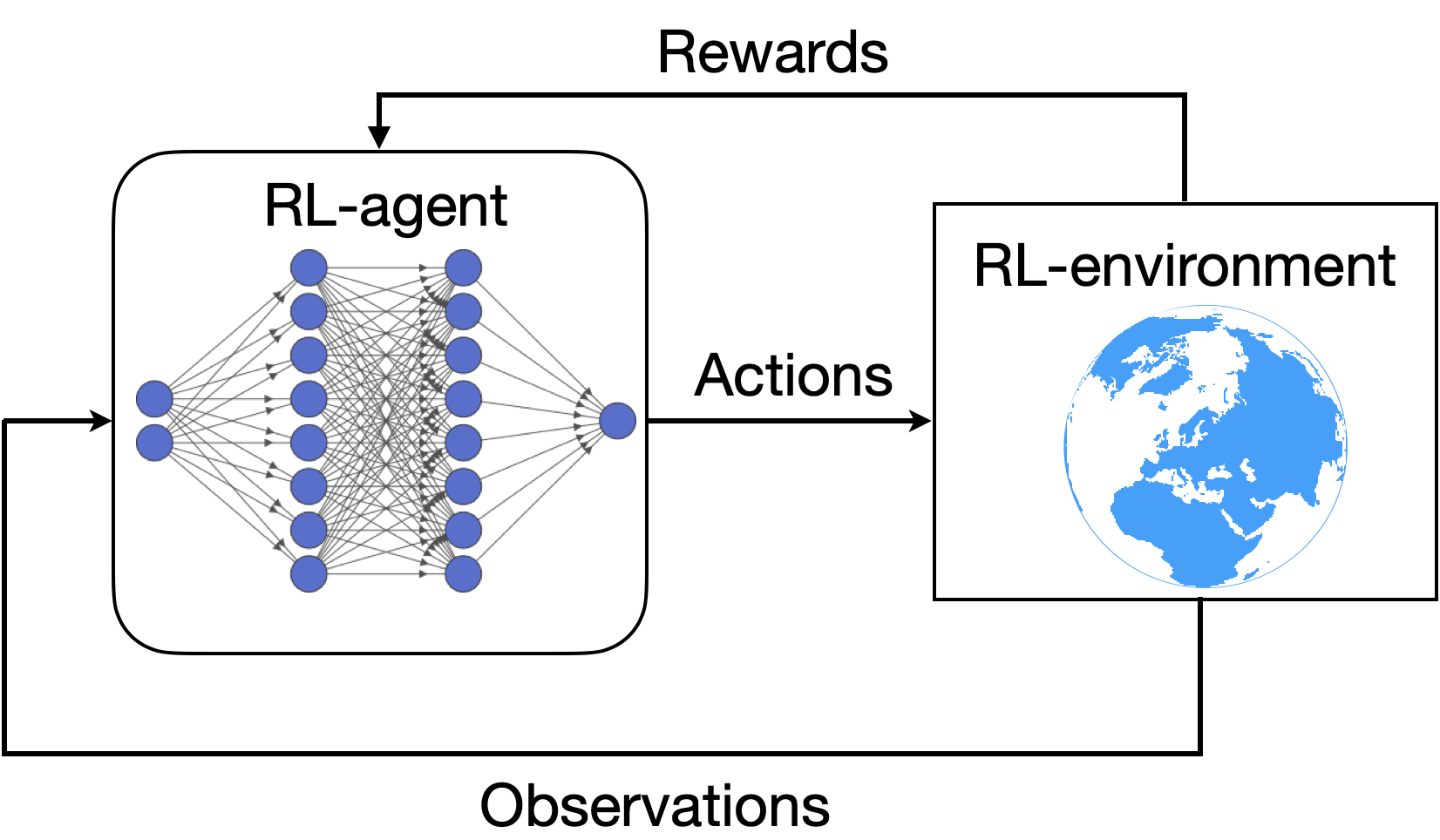
The workflow of a typical RL is shown in Fig. S1. Here, the block named as the RL-agent is depicted as comprising a set of neural network layers which act as function approximators. This type of RL is known as deep reinforcement learning (or DRL for short). On the other hand, the block in the right depicts the RL-environment, which is the world wherein the RL-agent lives and can affect change via actions on the dynamics of the environment. In RL terminology, the environment signifies the real/virtual space in which the rules of the physics of the problem/system are encoded along with a reward estimation function returning some real scalar values that determine whether the applied action has led to desirable changes or not. In practice, the RL-agent makes a certain number of interactions by first randomly applying some actions on the RL-environment based on which the weights of the nonlinear neural network function estimators are updated. The procedure is repeated several hundreds/thousands of times, depending on the complexity of the problem. Such a learning process is analogous to the learning process of a human, where the agent learns by conducting trial and error experiments on the RL-environment. Depending on the type of the RL algorithm used, the neural network based agent can explore even newer possibilities not usually explored, thus outperforming the analogous supervised learning agent.
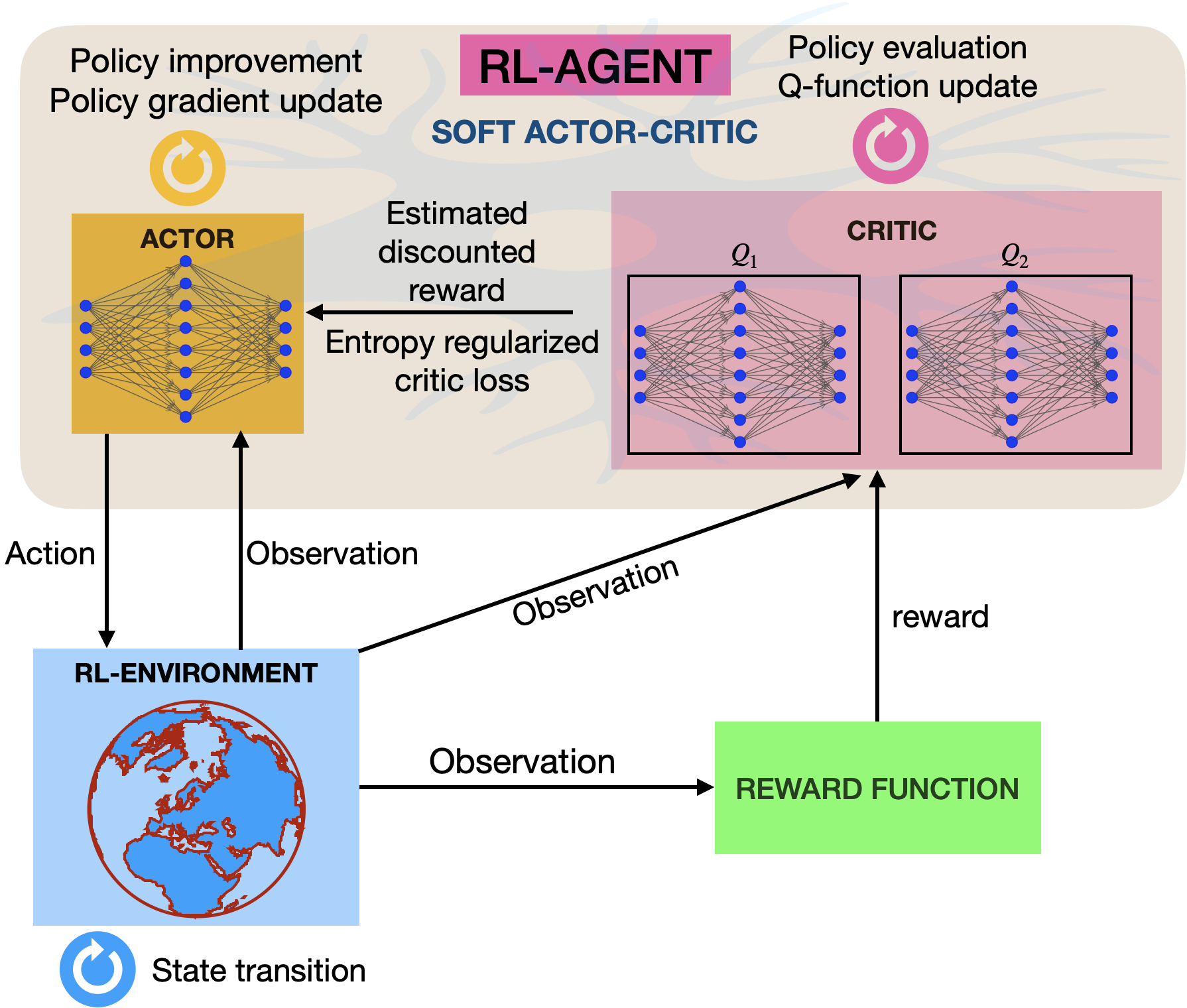
The algorithm that the RL-agent uses to determine the actions is called its policy, which in the case of DRL, represents the neural network itself that takes the observations as the input, and outputs the actions. A policy can be deterministic in which case the action of the RL-agent is determined by the policy parameters for a given state at time : , or stochastic in which the actions are sampled from a probability distribution conditioned on : . The task of the RL-agent is to optimize the policy parameters () to maximize the net discounted rewards over a trajectory , for the discount factor . To achieve that, the expected return over the discounted rewards is optimized to obtain the optimal policy .
As a fundamental concept in RL, the value function gives a prediction of the expected, cumulative, discounted, future reward, and provides a measure of how well a given state or state-action pair behaves to generate a higher net return. The state value is defined as the expected return for following policy from state . On the other hand, the action value is the expected return for selecting action in state and then following policy . The value functions obey the so-called Bellman equations Sutton and Barto (2018), which can be solved self-consistently. For example, the action-value function obeys,
| (S4) |
There are several approaches to optimize the policy, that can be broadly categorized into three types, namely (a) policy-gradient-based, (b) value-based and (c) actor-critic based methods. In value-based approaches, such as the Q-learning methods, the policy is optimized to get the net maximum value functions solving the Bellman equations as discussed above. On the other hand, in policy gradient methods the policy parameters are optimized by using gradient descent algorithms:
| (S5) |
where represents the expectation value over the trajectory . This basic approach can be improved by using a baseline function, , to reduce the variance of gradient estimation and forms the basis of the more advanced state-of-the-art DRL actor-critic algorithms. In the most generalized form, the policy gradient methods work by optimizing the following objective (loss) function:
| (S6) |
where, is a stochastic policy, and is an estimator of the advantage function at timestep t, since is an estimate of .
An actor-critic algorithm learns both a policy and a state-value function, and the value function is used for bootstrapping, i.e., updating a state from subsequent estimates, to reduce variance and accelerate learning Sutton and Barto (2018), while the critic updates action-value function parameters, and the actor updates policy parameters, in the direction suggested by the critic.
The Soft Actor-Critic (SAC) algorithm is a recently proposed actor-critic algorithm Haarnoja et al. (2018) in the field of reinforcement learning. The main difference of SAC compared to other actor-critic methods is that its policy is optimized in an entropy-regularized manner and is inherently stochastic. The policy is trained to maximize a tradeoff between expected return and entropy, with an increase in entropy leading to more exploration and, in addition, preventing the policy from converging prematurely. The following discussion closely follows the theory presented in Achiam (2021).
In entropy-regularized RL, the agent gets a bonus reward at each time step proportional to the entropy of the policy,
| (S7) |
where denotes the entropy computed from the probability distribution , and is the trade-off coefficient. The corresponding value functions in this setting, and are changed to,
| (S8) | ||||
| (S9) |
With these definitions, and are connected by,
| (S10) |
The Bellman equation for becomes,
| (S11) |
where, the expectation over the next states, and the states, come from the replay buffer, while the next actions are sampled fresh from the policy. SAC concurrently learns a policy and two Q-functions and set up the loss functions for each Q-function, and takes the minimum Q-value between the two Q approximators,
| (S12) |
where the target is given by
| (S13) |
For the studies reported in this article, we design the RL-environments using the framework template of OpenAI-Gym Brockman et al. (2016). The RL-agents are modelled using SAC policy, with two critic models following the implementation available in the open-source software package Stable-Baselines3 Raffin et al. (2019). For modelling the neural networks and optimization of the network parameters we have used the PyTorch Paszke et al. (2019) ML module.
The bipartite magno-mechanical model and sideband cooling time limit
The effective two-mode magno-mechanical model shown in Fig. 1(b) in the main text consists of a YIG sphere put in a microwave (MW) cavity, where a uniform magnetic field, is applied in the -direction that induces spin wave magnons precessing in the -plane. The magnetic field component of the cavity mode couples to the magnons through magnetic dipole coupling Tabuchi et al. (2014); Zhang et al. (2014). The YIG sphere also acts as an excellent mechanical resonator because of the magnetostrictive effect, that gives rise to vibrational acoustic phonon modes Zhang et al. (2016); Li et al. (2018). We consider the magnon modes to be driven by a MW field with frequency and amplitude Wang et al. (2018); Li et al. (2018). The Hamiltonian of the system in a frame rotating with the magnon drive frequency is given by,
| (S14) |
where , and are the annihilation (creation) operators for the cavity, magnon and phonon modes respectively, are the detunings, is the magnon-photon coupling strength and is the magno-mechanical coupling rate. The Rabi frequency is given by , where is the gyromagnetic ratio, is the total number of spins, where is the spin density of YIG and is the volume of the sphere.
The quantum Langevin equations for the average dynamics of the fluctuation operators are given by
| (S15) | ||||
where is the driving-enhanced magno-mechanical coupling. When the cavity has a low Q-factor, with a damping rate of the order of , the cavity field can be adiabatically eliminated, that gives rise to an effective magno-mechanical Hamiltonian of the form,
| (S16) |
where the effective parameters are given by, , . Hence, when the sphere is put at a node of the cavity magnetic field, or the cavity damping is very high, effectively the system reduces to a two-mode coupled system with a magno-mechanical interaction.
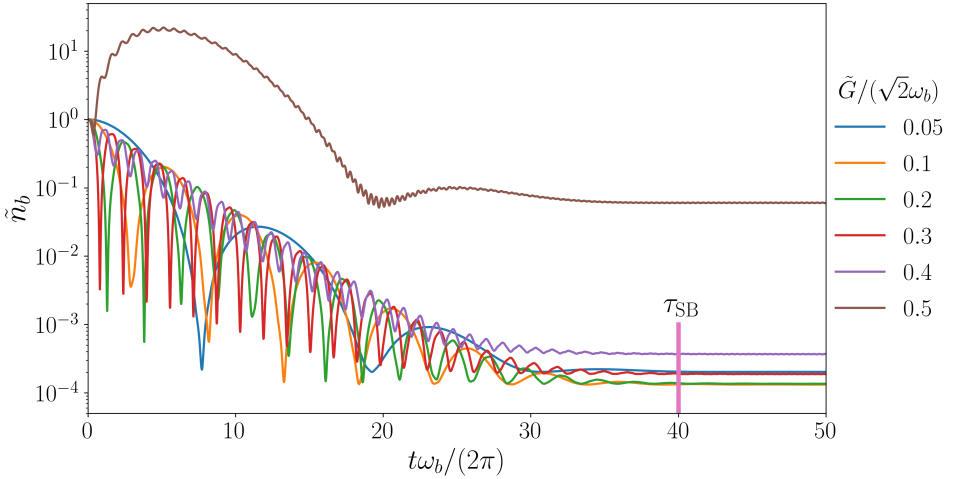
The magnon and mechanical modes have largely different frequencies, with and , therefore the magnon mode behaves as a ‘cold’ sink at zero temperature for the ‘hot’ mechanical mode. At the red sideband, , by virtue of the resonant interaction in the weak coupling regime, between the mechanical mode and magnon anti-Stokes sideband, it gives rise to transfer of thermal quanta from the mechanical mode to the magnon mode, which is the working principle of the well-known sideband cooling technique. In Fig. S3 we show the sideband cooling dynamics with several values of , in the regime . The time limit for such irreversible cooling is denoted by . From the figure, one can get an estimate of the steady-state cooling time limit and the optimum cooling quotient, . Considering an optimum cooling quotient of, , the best steady-state cooling from such sideband cooling mechanism is found to occur at a time limit of the order of . As can be seen from the figure, such sideband cooling is not possible with higher values of the magno-mechanical coupling, because of the effect of the counter-rotating terms beyond RWA. In our DRL-scheme, we show that cooling can be obtained even in the strong coupling regime with proper choice of coupling modulations. And more interestingly, it leads to lower time limit for cooling.
S2 The DRL controller for the bipartite magno-mechanical system
For the two-mode magno-mechanical system, the control parameter is the coupling strength , which can be complex in nature (see Eq. 1 of the main text of the article). In the DRL model, the real and imaginary parts of are considered as the two actions that are learned by the DRL-agent through trial and error. In a given iteration of the RL workflow at time , the RL-agent chooses two actions based on which the system (RL-environment) makes the dynamics to , where during which remains fixed. The observations that the RL-agent gets from the RL-environment comprise the instantaneous values of the moments obtained by solving the second order coupled differential equations. The actions of the RL-agent are also added to the list of observations, which we found to be advantageous for learning. The SAC controller is made based on the following settings of hyperparameters,
| Network hidden layer size: | |
|---|---|
| Activation function: | Rectified Linear Unit (ReLU) |
| Learning rate: | |
| Buffer size: | 1000000 |
| Batch size: | 512 |
| Soft update coefficient, : | 0.005 |
| Discount factor, : | 0.99 |
| Entropy regularization | |
| coefficient, : | Adaptive starting from 0.1. |
The goal of the problem is to optimize the neural network parameters such that it learns the non-trivial combinations of the controls, , so that the phonon occupancy of the YIG sphere is reduced thereby cooling it significantly. For that the agent is given the following reward function,
| (S17) |
where is the thermal phonon number, is the number operator of the mechanical mode, and denotes the expectation value of the operator . The task of the RL-agent would be to maximize the net reward, over an episode. Note that this, in theory, represents a highly challenging task as for each control (action), the number of possible combinations in a given episode is , where is the number of total time steps allowed within an episode, and is the number of possible discretization of the control strength bounded by . Since in our case, the actions are continuous the problem is even harder.
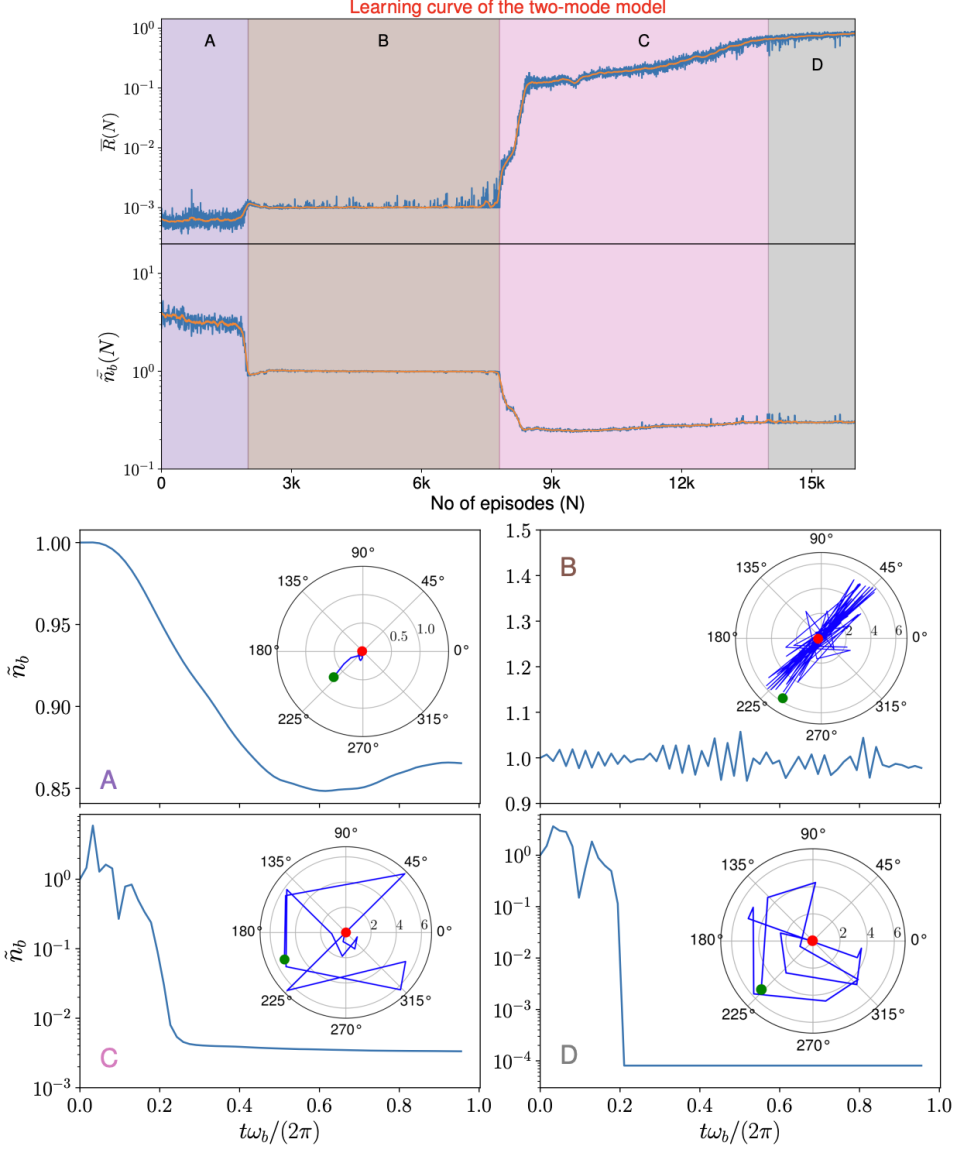
The RL-agent is trained for the following set of cases: . The learning curve for is shown in Fig. S4. In these plots, we have shown how the RL-agent gradually learns the non-intuitive control sequences by optimizing the neural network weights to achieve the goal of attaining larger net returns determined by Eq. S17. We have also shown the performance of the RL-agent at different stages to demonstrate the learning process, as explained in the caption of Fig. S4 in more detail.
Tripartite opto-magno-mechanical model and the cooling time limit
For the tripartite system model, we consider the cooling of a levitated spherical YIG ferrimagnet with high spin density, trapped in a harmonic potential wherein spin-wave magnon modes are excited by applying an external bias magnetic field. In a large external homogeneous magnetic field, , applied in the -direction, the YIG sphere is magnetized to its saturation magnetization, , whereas the small magnetization fluctuations, around the fully magnetized state is given by, . For the homogeneously magnetized fundamental magnon mode (Kittel mode), precessing around the -axis with an eigen-frequency, , the magnetization fluctuation is given by Fletcher and Bell (1959), which induces a magnetic field, outside the sphere, where, is the zero-point magnetization, is the vacuum permeability, is the bosonic magnon operator, and are the radius and the volume of the sphere. As schematically shown in the main text, a driven WGM optical microsphere with a magnetostrictive rod (MR) attached to it, is placed near the YIG magnet. The magnon mode field modulates the axial length of the MR, which modulates the WGM optical mode frequency that is depicted by a coupling of the form between the WGM optical mode and the magnon bosonic mode , where is the optical frequency shift i.e. the single photon magnon-cavity coupling.
The magnon mode can also be coupled to the COM motion of the YIG sphere, by applying a spatially inhomogeneous external time-dependent magnetic field, Hoang et al. (2016); Delord et al. (2018), which satisfies the weak driving, , and small-curl, conditions. The COM motion of the magnet with frequencies , and , in and directions, is depicted by the Hamiltonian, , where the bosonic ladder operators describe annihilation and creation of a motional quantum along the direction . The quantum Hamiltonian describing the interaction between the COM motion, and the spin-wave magnetization due to the gradient magnetic field is given by, . Considering a time-varying gradient magnetic field of the form, , ( in units of ), the interaction Hamiltonian for the COM motion in the -direction (frequency for ) and the magnon mode is given by, with , where is the mass density of YIG. Taking into account all these interactions, in the rotating frame of the cavity drive and the displacement picture of the average field in each mode Wang and Clerk (2012), the Hamiltonian is given by
| (S18) |
where is the cavity detuning, and is the driven optomagnonic coupling.
In this tripartite system, the optical and COM modes are not directly coupled, however both are coupled to the magnon mode. In the large detuning condition, , and under RWA, the model can be reduced to a bipartite effective system with the form of Hamiltonian,
| (S19) |
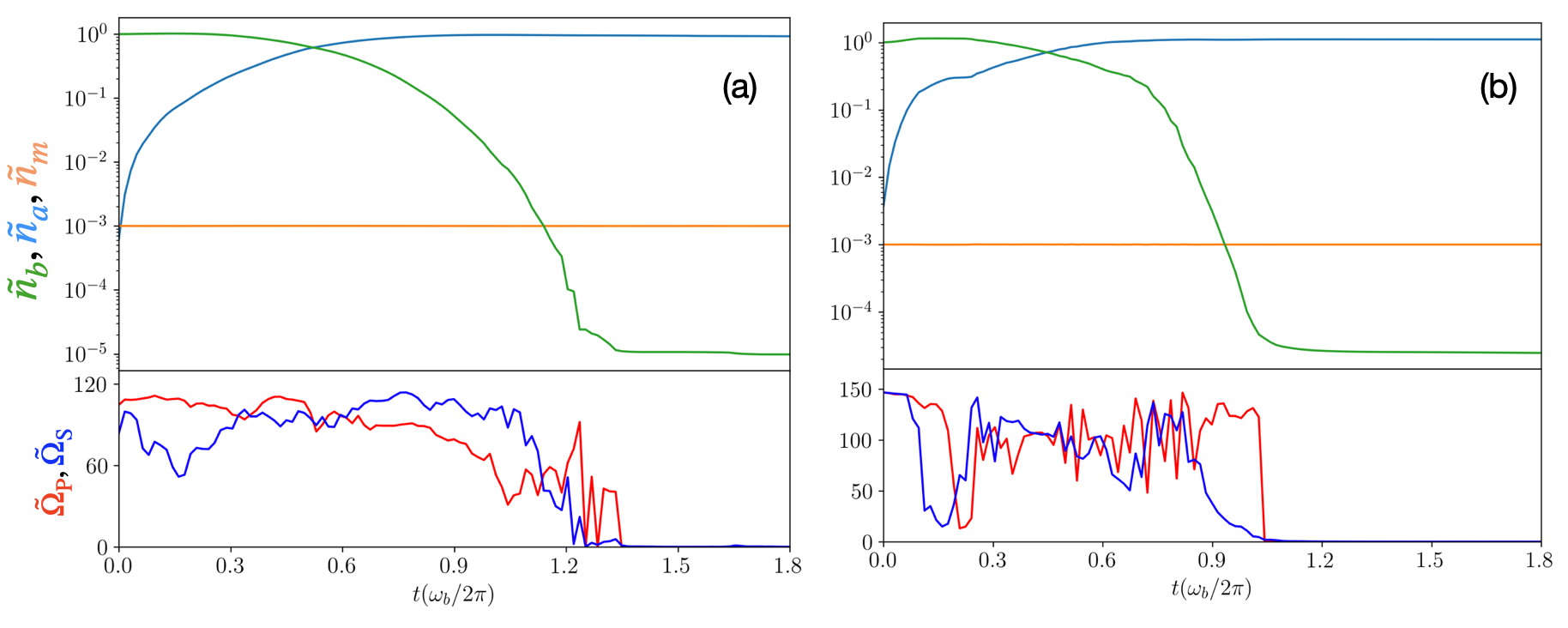
where and . This results in a transfer time limit of . In the three-mode system given by the full tripartite model under RWA, a widely applicable scheme of population transfer between the uncoupled modes in an irreversible manner is to apply STIRAP-like ideal pulses Bergmann et al. (1998). However, only when the total operation time of pulse sequences, , adiabatic effective population transfer can occur between the optical and COM modes in this system. In Fig. S5, we show the cooling dynamics with ideal STIRAP-like Gaussian pulses. This is obtained with counter-intuitive sequence of the coupling parameters for transfer of quanta from the COM mode to the optical mode. The cooling time is of the order of the limit given from the above expression, , which shows that these pulses are not adiabatic, but rather gives the shortest time for excitation transfer. The performance of the cooling quotient can be seen from the figure. As the time limit is the shortest possible time for cooling, one has to compromise on the effective cooling achieved. For the coupling parameters in the range, , the RWA is valid, whereas for higher values of beyond , the counter-rotating terms have significant effect. Therefore, even if the increase of coupling parameters shows sign of the lowering of transfer time, it is not possible to obtain effective cooling in these cases. On the contrary, our proposed DRL-scheme finds finely-tuned pulses to go beyond such limits to obtain effective and much faster cooling.
S3 The DRL controller for the tripartite opto-magno-mechanical system
The tripartite system is modelled similarly to the two-mode model described earlier, except the fact that an additional Gaussian noise layer is added to the final layer of the network to facilitate more exploration to uncover the non-triviality. Here the controls are, , which are taken to be real and positive. As earlier, the observables are the instantaneous solutions of the coupled differential equations of the second order moments of the quantum master equation of the tripartite system, along with the controls, . In a given episode, the RL-agent makes a total of 150 interactions with the RL-environment in timesteps of , each time applying its actions, maintaining a generous exploration-exploitation trade-off. The reward function, for this particular case is,
| (S20) |
where is the thermal phonon number, is the number operator of the phonon (magnon) modes, and is chosen which guarantees to shuffle population out of the phonon mode and into the optical cavity mode leading to cooling of the phonon mode, without transferring to the magnon modes.
Given the large computational overhead to solve the coupled second order moment equations for the tripartite opto-magno-mechanical system with state-of-the-art experimental parameter choice of , the problem is solved in two steps. In the first step, we train an auxiliary system with and , for which solution of the set of equations can be obtained without much computational effort. The trained auxiliary model is then used as a supervisor/teacher for the actual system, that we call primary, with and . Training the actual system for a few hundred episodes with periodic evaluation of the RL-agent yields the best trained model. In the literature of RL, this can be considered as a form of imitation learning.
The (auxiliary) RL-agent is trained for the following set of cases: . The learning curve for the first case is shown in Fig. S6. In these plots, we have shown how the RL-agent gradually learns the non-intuitive control sequences by optimizing the neural network weights to achieve the goal of attaining larger net returns determined by Eq. S20. We have also shown the performance of the RL-agent at different stages of the learning process, as explained in the caption of Fig. S6 in more detail.
References
- Schäfermeier et al. (2016) C. Schäfermeier, H. Kerdoncuff, U. B. Hoff, H. Fu, A. Huck, J. Bilek, G. I. Harris, W. P. Bowen, T. Gehring, and U. L. Andersen, Nat. Commun. 7, 1 (2016).
- Guo et al. (2019) J. Guo, R. Norte, and S. Gröblacher, Phys. Rev. Lett. 123, 223602 (2019).
- Park and Wang (2009) Y.-S. Park and H. Wang, Nat. Phys. 5, 489 (2009).
- Clark et al. (2017) J. B. Clark, F. Lecocq, R. W. Simmonds, J. Aumentado, and J. D. Teufel, Nature 541, 191 (2017).
- Frimmer et al. (2016) M. Frimmer, J. Gieseler, and L. Novotny, Phys. Rev. Lett. 117, 163601 (2016).
- Abdi et al. (2016) M. Abdi, P. Degenfeld-Schonburg, M. Sameti, C. Navarrete-Benlloch, and M. J. Hartmann, Phys. Rev. Lett. 116, 233604 (2016).
- Bose et al. (1999) S. Bose, K. Jacobs, and P. L. Knight, Phys. Rev. A 59, 3204 (1999).
- Marshall et al. (2003) W. Marshall, C. Simon, R. Penrose, and D. Bouwmeester, Phys. Rev. Lett. 91, 130401 (2003).
- Schliesser et al. (2009) A. Schliesser, O. Arcizet, R. Rivière, G. Anetsberger, and T. J. Kippenberg, Nat. Phys. 5, 509 (2009).
- Manley et al. (2021) J. Manley, M. D. Chowdhury, D. Grin, S. Singh, and D. J. Wilson, Phys. Rev. Lett. 126, 061301 (2021).
- Bourassa et al. (2021) J. E. Bourassa, N. Quesada, I. Tzitrin, A. Száva, T. Isacsson, J. Izaac, K. K. Sabapathy, G. Dauphinais, and I. Dhand, PRX Quantum 2, 040315 (2021).
- Zhang et al. (2016) X. Zhang, C.-L. Zou, L. Jiang, and H. X. Tang, Sci. Adv. 2, e1501286 (2016).
- Lachance-Quirion et al. (2019) D. Lachance-Quirion, Y. Tabuchi, A. Gloppe, K. Usami, and Y. Nakamura, Appl. Phys. Express 12, 070101 (2019).
- Wang and Hu (2020) Y.-P. Wang and C.-M. Hu, J. Appl. Phys. 127, 130901 (2020).
- Li et al. (2018) J. Li, S.-Y. Zhu, and G. Agarwal, Phys. Rev. Lett. 121, 203601 (2018).
- Zhang et al. (2014) X. Zhang, C.-L. Zou, L. Jiang, and H. X. Tang, Phys. Rev. Lett. 113, 156401 (2014).
- Wang et al. (2018) Y.-P. Wang, G.-Q. Zhang, D. Zhang, T.-F. Li, C.-M. Hu, and J. You, Phys. Rev. Lett. 120, 057202 (2018).
- Joshi et al. (2021) A. Joshi, K. Noh, and Y. Y. Gao, Quant. Sci. Tech. 6, 033001 (2021).
- Goodfellow et al. (2016) I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning, Vol. 1 (MIT press Cambridge, 2016).
- Sutton and Barto (2018) R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed. (The MIT Press, 2018).
- Silver et al. (2016) D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, Nature 529 (2016), 10.1038/nature16961.
- Silver et al. (2017) D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis, Nature 550, 354 (2017).
- Carleo et al. (2019) G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová, Rev. Mod. Phys. 91, 045002 (2019).
- Bukov et al. (2018) M. Bukov, A. G. R. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, Phys. Rev. X 8, 031086 (2018).
- Fösel et al. (2018) T. Fösel, P. Tighineanu, T. Weiss, and F. Marquardt, Phys. Rev. X 8, 031084 (2018).
- Borah et al. (2021) S. Borah, B. Sarma, M. Kewming, G. J. Milburn, and J. Twamley, Phys. Rev. Lett. 127, 190403 (2021).
- Wang et al. (2020) Z. T. Wang, Y. Ashida, and M. Ueda, Phys. Rev. Lett. 125, 100401 (2020).
- Niu et al. (2019) M. Y. Niu, S. Boixo, V. N. Smelyanskiy, and H. Neven, npj Quantum Inf. 5, 33 (2019).
- Zhang et al. (2019a) X.-M. Zhang, Z. Wei, R. Asad, X.-C. Yang, and X. Wang, npj Quantum Inf. 5, 85 (2019a).
- Xu et al. (2021) H. Xu, L. Wang, H. Yuan, and X. Wang, Phys. Rev. A 103, 042615 (2021).
- Zhang et al. (2019b) X.-M. Zhang, Z. Wei, R. Asad, X.-C. Yang, and X. Wang, npj Quantum Inf. 5, 85 (2019b).
- Mackeprang et al. (2020) J. Mackeprang, D. B. R. Dasari, and J. Wrachtrup, Quantum Mach. Intell. 2, 5 (2020).
- Haug et al. (2020) T. Haug, W.-K. Mok, J.-B. You, W. Zhang, C. E. Png, and L.-C. Kwek, Mach. Learn.: Sci. Technol. 2, 01LT02 (2020).
- Guo et al. (2021) S.-F. Guo, F. Chen, Q. Liu, M. Xue, J.-J. Chen, J.-H. Cao, T.-W. Mao, M. K. Tey, and L. You, Phys. Rev. Lett. 126, 060401 (2021).
- Bilkis et al. (2020) M. Bilkis, M. Rosati, R. M. Yepes, and J. Calsamiglia, Phys. Rev. Res. 2, 033295 (2020).
- Porotti et al. (2019) R. Porotti, D. Tamascelli, M. Restelli, and E. Prati, Commun. Phys. 2 (2019), 10.1038/s42005-019-0169-x.
- Tabuchi et al. (2014) Y. Tabuchi, S. Ishino, T. Ishikawa, R. Yamazaki, K. Usami, and Y. Nakamura, Phys. Rev. Lett. 113, 083603 (2014).
- Haarnoja et al. (2018) T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” (2018), arXiv:1801.01290 [cs.LG] .
- Seberson et al. (2020) T. Seberson, T. Seberson, P. Ju, J. Ahn, J. Bang, T. Li, T. Li, T. Li, T. Li, F. Robicheaux, and F. Robicheaux, J. Opt. Soc. Am. B, JOSAB 37, 3714 (2020).
- Rusconi et al. (2017) C. C. Rusconi, V. Pöchhacker, K. Kustura, J. I. Cirac, and O. Romero-Isart, Phys. Rev. Lett. 119, 167202 (2017).
- Huillery et al. (2020) P. Huillery, T. Delord, L. Nicolas, M. Van Den Bossche, M. Perdriat, and G. Hétet, Phys. Rev. B 101, 134415 (2020).
- Forstner et al. (2014) S. Forstner, E. Sheridan, J. Knittel, C. L. Humphreys, G. A. Brawley, H. Rubinsztein-Dunlop, and W. P. Bowen, Advanced Materials 26 (2014), 10.1002/adma.201401144.
- Xia et al. (2015) K. Xia, M. R. Vanner, and J. Twamley, Sci. Rep. 4, 5571 (2015).
- Yu et al. (2016) C. Yu, J. Janousek, E. Sheridan, D. L. McAuslan, H. Rubinsztein-Dunlop, P. K. Lam, Y. Zhang, and W. P. Bowen, Phys. Rev. Appl. 5, 1 (2016).
- Hoang et al. (2016) T. M. Hoang, J. Ahn, J. Bang, and T. Li, Nat. Commun. 7, 1 (2016).
- Delord et al. (2018) T. Delord, P. Huillery, L. Schwab, L. Nicolas, L. Lecordier, and G. Hétet, Phys. Rev. Lett. 121, 053602 (2018).
- Khosla et al. (2017) K. E. Khosla, G. A. Brawley, M. R. Vanner, and W. P. Bowen, Optica 4, 1382 (2017).
- Achiam (2021) J. Achiam, “Spinning Up in Deep Reinforcement Learning,” (2021), [Online; accessed 15. Jul. 2021].
- Brockman et al. (2016) G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” (2016), arXiv:1606.01540 [cs.LG] .
- Raffin et al. (2019) A. Raffin, A. Hill, M. Ernestus, A. Gleave, A. Kanervisto, and N. Dormann, “Stable baselines3,” https://github.com/DLR-RM/stable-baselines3 (2019).
- Paszke et al. (2019) A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, in Advances in Neural Information Processing Systems 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019) pp. 8024–8035.
- Fletcher and Bell (1959) P. Fletcher and R. Bell, J. Appl. Phys. 30, 687 (1959).
- Wang and Clerk (2012) Y.-D. Wang and A. A. Clerk, Phys. Rev. Lett. 108, 153603 (2012).
- Bergmann et al. (1998) K. Bergmann, H. Theuer, and B. W. Shore, Rev. Mod. Phys. 70, 1003 (1998).