Accelerating GPU-Based Out-of-Core Stencil Computation with On-the-Fly Compression
Abstract
Stencil computation is an important class of scientific applications that can be efficiently executed by graphics processing units (GPUs). Out-of-core approach helps run large scale stencil codes that process data with sizes larger than the limited capacity of GPU memory. However, the performance of the GPU-based out-of-core stencil computation is always limited by the data transfer between the CPU and GPU. Many optimizations have been explored to reduce such data transfer, but the study on the use of on-the-fly compression techniques is far from sufficient. In this study, we propose a method that accelerates the GPU-based out-of-core stencil computation with on-the-fly compression. We introduce a novel data compression approach that solves the data dependency between two contiguous decomposed data blocks. We also modify a widely used GPU-based compression library to support pipelining that overlaps CPU/GPU data transfer with GPU computation. Experimental results show that the proposed method achieved a speedup of 1.2 compared the method without compression. Moreover, although the precision loss involved by compression increased with the number of time steps, the precision loss was trivial up to 4,320 time steps, demonstrating the usefulness of the proposed method.
Keywords:
high performance computing; on-the-fly compression; stencil computation; simulation; GPGPUI Introduction
Stencil computation is an important computation paradigm that appears in many scientific applications, such as geophysics simulations [1, 2, 3], computational electromagnetics [4], and image processing [5]. The key principle of stencil computation is to iteratively apply a fixed calculation pattern (stencil, where the update of an element relies on the surrounding elements) to every element of the output datasets. Such a single-instruction multiple-data (SIMD) characteristic of stencil computation makes itself a perfect scenario to use the graphics processing units (GPUs) for acceleration. A GPU has thousands of cores and its memory bandwidth is 5–10 times higher than that of a CPU, thus excelling at accelerating both compute- and memory-intensive scientific applications [6, 7, 8, 9]. However, as a GPU has a limited capacity of device memory (tens of GBs), it fails to run a large stencil code directly whose data size exceeds its memory capacity.
A large entity of research on GPU-based out-of-core stencil computation has been performed to address this issue [10, 11, 12, 13, 3]. For a large dataset whose data size exceeds the capacity of the device memory, out-of-core computation first decomposes the dataset into smaller blocks and then streams the blocks to and from the GPU for processing. Nevertheless, the outcome of this approach is often limited by data transfer between the CPU and GPU because the interconnects fail to catch up with the development of the computation capability of GPUs as described in [9]. Data-centric strategies are thus necessary to reduce the data transfer between the CPU and GPU. Studies have introduced strategies such as temporal blocking and region sharing to reuse the on-GPU data and to avoid transferring extra data [10, 13, 3]. Nevertheless, we need to further optimize the methods to reduce data transfer time. according to [3], the performance of out-of-core stencil code is still limited by data transfer. A potential solution is to use on-the-fly compression to compress the data on the GPU before transferring back to the CPU, and decompress the data on the GPU before processing. Until now, however, studies on the acceleration of GPU-based out-of-core stencil computation with on-the-fly compression are really rare. According to a comprehensive review [14], research on leveraging lossy compression techniques in scientific applications mainly focuses on scenarios such as post-analysis and failure recovery. We think that the scarcity of relevant research raises two research questions:
-
•
Would the overhead of compression/decompression outweighs the reduced data transfer time?
-
•
Would the precision loss involved by data compression be so huge that the output becomes useless?
In this study, we (1) propose a method to accelerate out-of-core stencil computation with on-the-fly compression on the GPU and (2) try to give answers to the two above-mentioned questions. The contribution of this work is three-fold:
-
•
We introduced a novel approach to integrate an on-the-fly lossy compression into the workflow of a 25-point stencil computation. For large datasets that are decomposed into blocks, this approach solves the data dependency between two contiguous blocks and thus secures the accessibility to the common regions between two contiguous blocks after compression.
-
•
We modified a widely-used GPU-based compression library [15] to support pipelining, which is mandatory for the purpose of overlapping CPU-GPU data transfer with GPU computation.
-
•
We gathered experimental results to answer the aforementioned questions, i.e., on-the-fly compression is useful in reducing the overall execution time of out-of-core stencil computation, and the precision loss is tolerable. Therefore, the present study may lead to future research on leveraging compression techniques to accelerate out-of-core stencil computation on a GPU.
The remainder of this study is organized as follows: Previous studies that accelerate stencil and similar scientific applications with compression techniques are introduced in Section II. Stencil computation, its background and challenges in the acceleration of stencil computation with on-the-fly compression are briefly described in Section III. Section IV discusses the selection of an appropriate GPU-based compression library. The proposed method used to integrate the compression processes into the workflow of out-of-core stencil computation is described in Section V. In Section VI, experimental results are presented and analyzed. Finally, Section VII concludes the present study and proposes future research directions.
II Previous Work
Nagayasu et al. [16] proposed a decompression pipeline for accelerating out-of-core volume rendering of time-varying data. Their method was specified to compress and decompress RGB data and the decompression procedure was partially performed on the CPU.
Tao et al. [17] proposed a lossy checkpointing scheme, which significantly improved the checkpointing performance of iterative methods with lossy compressors. In the presence of system failures, their method reduced the fault tolerance overhead for iterative methods by 23%–70% compared with traditional checkpointing and 20%–58% compared with lossless-compressed checkpointing.
Calhoun et al. [18] proposed metrics to evaluate loss of accuracy caused by using lossy compression to reduce the snapshot data used for checkpoint restart. In this study, Calhoun and colleagues improved efficiency in checkpoint restart for partial differential equation (PDE) simulations by compressing the snapshot data, and found that this compression did not affect overall accuracy in the simulation, as demonstrated by the proposed evaluation metrics.
Wu et al. [19] proposed a method to simulate large quantum circuits using lossy or lossless compression techniques adaptively. Thanks to their method, they managed to increase the simulation size by 2–16 qubits. However, their method was designed for CPU-based supercomputers and thus the compression libraries cannot be used for GPU-based scenarios. Moreover, the adaptive selection between lossy and lossless compression, i.e., using lossy compression if lossless one failed, is impractical in GPU-based applications because such failures heavily impair the computational performance.
Jin et al. [20] proposed a method to use GPU-based lossy compression for extreme-scale cosmological simulations. Their findings show that GPU-based lossy compression can enable sufficient accuracy on post-analysis for cosmological simulations, as well as high compression and decompression throughputs. Instead of compressing datasets for post-analysis, our method aims to improve the performance of GPU-based out-of-core stencil computation by compressing or/and decompressing datasets at run-time.
Tian et al. [21] proposed Cusz, an efficient GPU-based error-bounded lossy compression framework for scientific computing. This framework reported high compression and decompression throughputs and a good compression ratio. However, according to their study, Cusz has sequential subprocedures, which prevents us to use this framework as on-the-fly compression in our work due to the concern of the overhead to shift from GPU to CPU computation.
Zhou et al. [22] designed high-performance MPI libraries with on-the-fly compression for modern GPU clusters. In their work, they reduced the inter-node communication time by compressing the messages transferred between nodes, and the size of messages was up to 32 MB. On the other hand, our method compressed large datasets for stencil computation that were more than 10 GB to reduce the data transfer time between the CPU and GPU (i.e., intra-node communication time). Moreover, our method is specified to deal with out-of-core stencil computation, solving the data dependency between decomposed data blocks.
III Stencil Computation
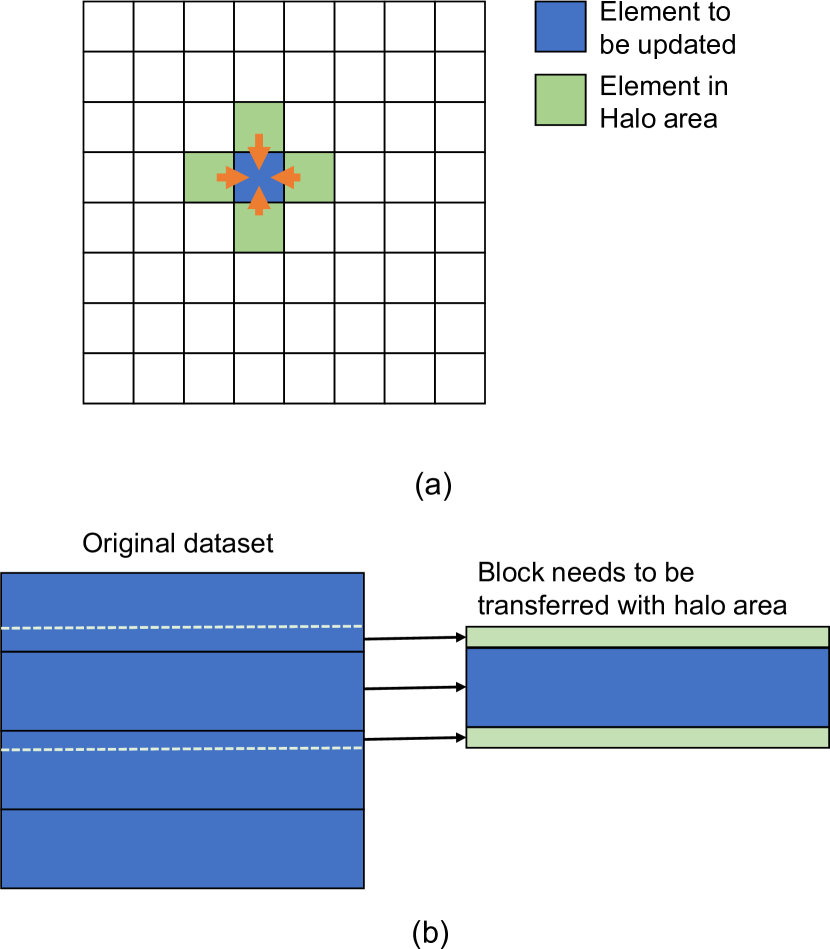
Stencil computation is an iterative computation that updates each element in one or more datasets according to a fixed pattern that computes with the neighbor elements of the element to be updated. A hello-world application of stencil computation is the solver of Laplace’s equation, which can describe the phenomenon of heat conduction: A five-point stencil code, where the temperature of each element at the (t+1)-th time step is obtained by taking the average temperature of the four surrounding elements at the t-th time step (Fig. 1(a)).
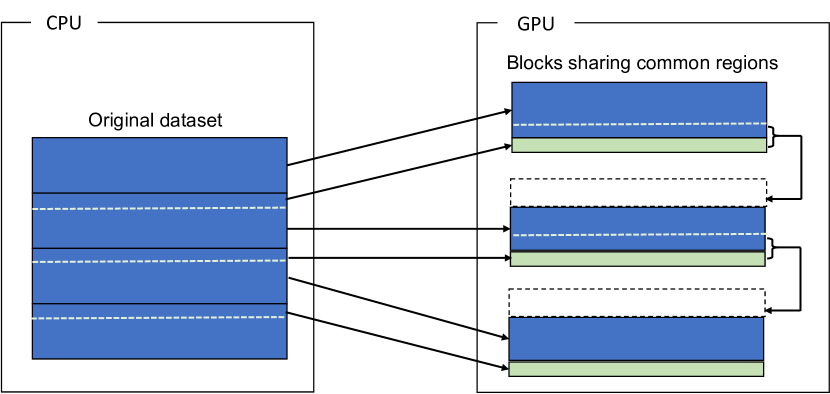
To use out-of-core stencil computation, we decompose the large datasets into smaller blocks and stream the blocks to and from the GPU for processing. Because of the data dependency of stencil computation, when we transfer a block to the GPU for computation, we must also piggyback the neighbor data (“halo area” in jargon) with the block (Fig. 1(b)). The more time steps we want to compute on a block on the GPU, the larger halo area we must transfer along with the block. But because two contiguous blocks share common regions, a block can get the common regions from its former block and provide the common regions with its later block. By doing so, we can in effect reduce the amount of data transfer equivalent to the size of halo areas (Fig. 2).
One challenge in integrating on-the-fly compression into the workflow of out-of-core stencil computation is that we must solve the aforementioned data dependency. Naively compressing each block prevents the use of halo areas, whereas compressing each block with its halo areas not only consumes more memory space but also prevents contiguous blocks sharing common regions. Therefore, sophisticated compression strategy is necessary, and will be introduced in Section V-A.
IV On-the-fly Compression
Another concern in using on-the-fly compression in out-of-core computation is the overheads of compression and decompression that are often considerable. GPU-based compression libraries such as cuZFP [15], Cusz [21], and nvComp [23] reported high speeds in compression and decompression. The cuZFP and Cusz libraries are lossy compression, whereas the nvComp is lossless.
In this study, we used cuZFP because this library is performant and its source code is (relatively) easy to modify to implement functionalities we want. The cuZFP library allows users to specify the compression ratio. Users can specify the number of bits to use to preserve a value. For example, specifying 32 bits to preserve a double-precision floating-point (i.e., double-type) value achieves a compression ratio of 2:1.
We avoid using the lossless nvComp due to the concern of compression ratio. In the preliminary experiments, we found the size of data compressed with nvComp was larger than that of the uncompressed data. We therefore avoid the use of nvComp because we cannot estimate the upper bound of the size of the compressed data, so we must allocate device memory every time the compression happens instead of reusing pre-allocated device buffers with fixed sizes. The reason why we avoided using Cusz was explained in Section II.
V Proposed Method
In this section, we introduce our proposed method, including separate compression that solves the data dependency between contiguous blocks and thus allows us to compress the decomposed datasets freely, and a pipelining version of cuZFP that supports overlapping compression/decompression with CPU-GPU data transfer.
V-A Separate Compression
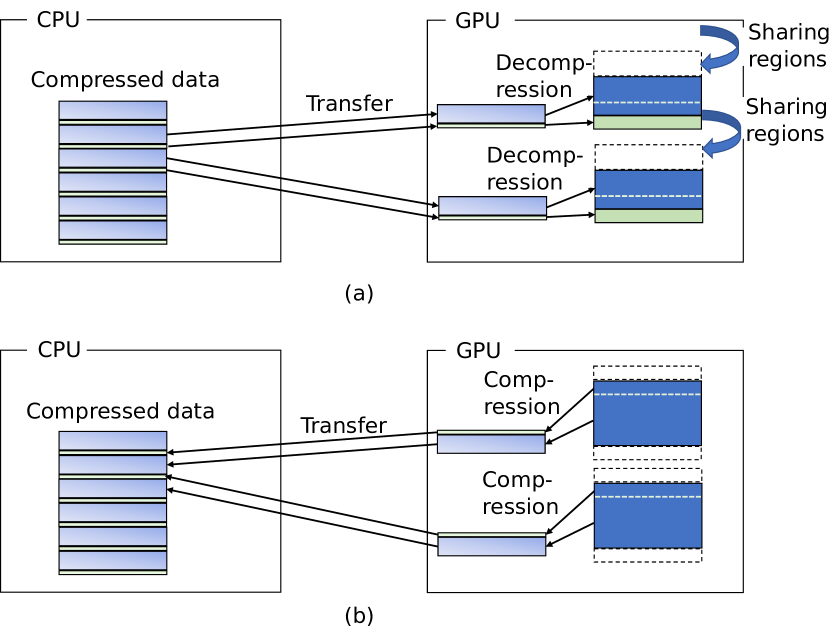
As shown in Fig. 2, two contiguous blocks have common regions that are shareable. Precisely, the bottom halo areas needed by the -th block fall in the ()-th block, and the top halo areas needed by the ()-th block fall in the the ()-th block. Therefore, the common regions between the two blocks consist of the top areas and a part of the ()-th block whose size is equivalent to that of the top halo areas. If we transfer the ()-th block with its bottom halo areas, we can avoid transferring the common regions for the ()-th block.
Summarily, each block only needs to be transferred with its reminder and bottom halo areas, so the two parts, i.e., reminder and half common region, must be exclusively readable and writable to the according contiguous blocks. Based on the observation, we propose a separate compression approach that compress the two parts separately. As shown in Fig. 3(a), before computation, the -th compressed reminder and common region are decompressed and therefore the -th block can be computed on and provide the data needed by the - th block. As shown in Fig. 3(b), after computation, the -th block are compressed as the -th reminder and -th common region.
V-B Pipelining cuZFP
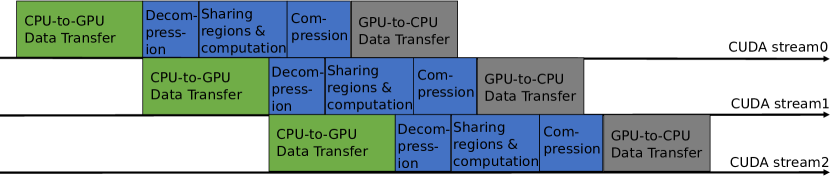
The cuZFP library [15] is mainly designed as a standalone tool that can be seamlessly used for post-analysis and CPU-centric scientific computations. However, as an on-the-fly process in the out-of-core stencil computation, we must modify the source code to support pipelining that overlaps CPU/GPU data transfer with GPU computations. Thanks to the excellent coding quality of the cuZFP project, we managed to modify the source code to add such functionality with a reasonable amount of programming effort. In the pipelining cuZFP, we use three CUDA [24] streams to perform operations (Fig. 4).
VI Experimental Results
| No. of | Data type | Dim. info. | Entire |
|---|---|---|---|
| datasets | data size | ||
| 4 | Double | (1152+2HALO)3 | 46 GB |
| HALO4 |
| GPU | NVIDIA Tesla V100-PCIe |
| Device memory | 32 GB |
| CPU | Xeon Silver 4110 |
| Host memory | 500 GB |
| OS | Ubuntu 16.04.6 |
| CUDA | 10.1 |
| cuZFP | 0.5.5 |
In this section, we analyze the experimental results to evaluate the benefits of using on-the-fly compression in out-of-core stencil computation on a GPU. The stencil code we used is an acoustic wave propagator from a previous work [3] of ours. The code is a 25-point stencil computation that has two read-write datasets, a write-only dataset, and a read-only dataset. The two read-write datasets store the updated elements of the volume, and needed to be transferred to and from the GPU. The write-only dataset stores intermediate results at run-time and does not need to be transferred at all. The read-only dataset are constant values that must be referenced at run-time, and needed to be transferred to the GPU. The values are of double-type because it is more preferable compared to single-precision floating-point format (i.e. float-type) in iterative scientific applications. According to our previous work [25], the CPU version of a code using float-type data leads to outputs different from that of the GPU version. Such divergence becomes a more severe problem with the increase of the total number of iterations. On the other hand, when using double-type, results of the CPU and GPU versions of the same code were consistent. Table I shows the detail of the datasets used by the stencil code.
Moreover, we used four codes in our experiments to evaluate the performance and precision loss. The four codes include:
-
1.
The original stencil code.
-
2.
The stencil code with one read-write dataset compressed using a 32/64 rate (i.e., using 32 bits to preserve each double value).
-
3.
The stencil code with the read-only dataset compressed using a 32/64 rate.
-
4.
The stencil code with one read-write dataset and the read-only dataset compressed using a 24/64 rate. Note that we used 24 bits to preserve each double value due to the limited device memory capacity.
The configuration to run the stencil codes is as the one described in [3] where the number of division is 8 and the number of temporal blocking time steps is 12. Accordingly, we divide the data into 8 blocks, and when a block is transferred to the GPU, it will be computed on for 12 times before transferred back to the CPU. For the total time steps, we used numbers from 480 to 4320 with an increment of 480. For specifications of the testbed for all experiments performed, see Table II.
VI-A Evaluation of Performance Benefits
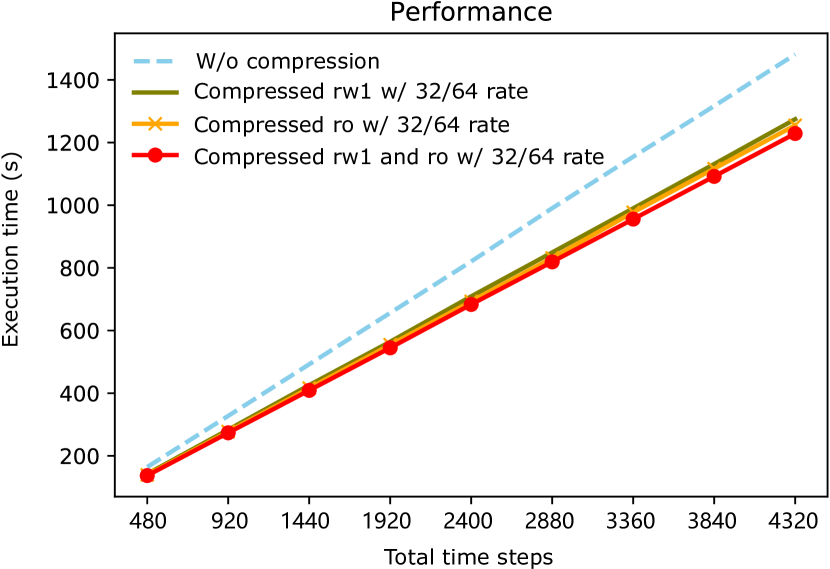
As shown in Fig. 5, the three codes using on-the-fly compression ran faster than the original code. The code compressing a read-write dataset and a read-only dataset outperformed the others, running 1.20 as fast as the original code. The code compressing a read-only dataset and the code compressing a read-write dataset achieved speedups of 1.18 and 1.16, respectively. Based on these results, our proposed method is beneficial for GPU-based out-of-core stencil computation in terms of performance. A detailed analysis of the achieved performance improvement will be given in next section.
VI-B Detailed Analysis of Achieved Performance Improvement
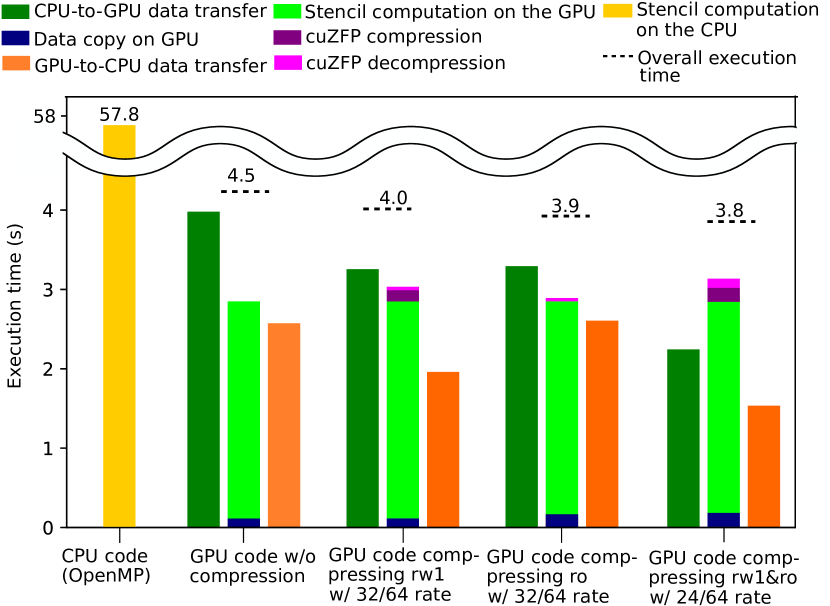
In this experiment, we ran the four GPU-based codes individually for 12 time steps and profiled the breakdown of execution time. Moreover, we also ran a CPU-based code for 12 time steps to show the advanced performance of GPU-based code, compared to that of the CPU-based code. The CPU-based code was parallelized with OpenMP [26] and executed with 40 CPU threads. As shown in Fig. 6, we can see the three codes using compression reduced the CPU-to-GPU time (dark green bars) that limited the overall performance. The most interesting finding is that the fourth GPU-based code shifted from data-transfer-bounding to computation-bounding compared to the former three GPU-based codes, which is favorable because it theoretically means that the data transfer time can be fully hidden by the computation time.
Moreover, although the code compressing the read-only dataset did not reduce the GPU-to-CPU data transfer time, it did not involve significant compression time (dark purple). Therefore, the code compressing the read-only dataset slightly outperformed the code compressing a read-write dataset. Nevertheless, the gaps between the overall execution time and the bounding operation time (i.e., longest bar) of the three codes with compression are larger than that of the original GPU-based code. This suggests that the compression or/and decompression involved some unidentified overheads that compromised the efficiency of overlapping data transfer with GPU computation, otherwise the overall execution time should have been similar to the bounding operation time. Therefore, we need more sophisticated measures to orchestrate the pipelining to achieve further improvement.
VI-C Evaluation of Precision Loss
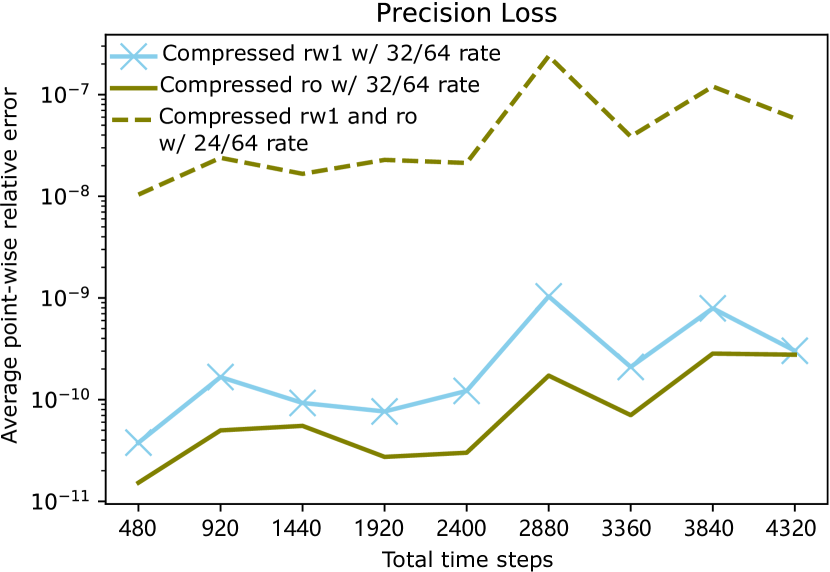
Besides showing performance benefits, demonstrating that the compression involves no significant precision loss is crucial. After completing the total time steps, we sampled 115,200 points (i.e., 100 points per plane) and compared the point values of the three codes using compression with that of the original code to calculate the average point-wise relative errors (Fig. 7). Although the relative errors increased with an increase in the total time steps, they were still far from significant at 4,320 time steps. The code compressing the read-only dataset had the lowest precision loss because the read-only dataset does not need to be compressed repeatedly. The code compressing one read-write dataset and the read-only dataset using 24/64 rate resulted in the largest precision loss due to the fewer bits we used to preserve the double values. Nevertheless, the code is useful because the relative error was trivial (between and ). Given this, the proposed method will not lead to intolerable precision loss at least for a moderate number of time steps.
VII Conclusions and Future Work
In this study, we introduced a method to accelerate GPU-based out-of-core stencil computation with on-the-fly compression. To realize the method, we proposed a novel approach to compress the decomposed data, solving the data dependency between contiguous blocks. We also modified the cuZFP library [15] to support pipelining for overlapping data transfer with GPU computation. Experimental results show that the proposed method achieved a speedup of 1.2 at the expense of a trivial precision loss, i.e., an average point-wise relative error between and . The results answer the two research questions mentioned in Section I. First, the reduction of CPU-GPU data transfer time achieved by using on-the-fly compression outweighs the overhead of compression/decompression, improving the overall performance of GPU-based out-of-core stencil computation. Secondly, the on-the-fly compression does not cause severe precision loss for thousands of time steps. Future work includes (1) comparing other on-the-fly compression algorithms to cuZFP and (2) orchestrating the pipelining for better efficiency in overlapping data transfer with GPU computation.
Acknowledgments
This study was supported in part by the Japan Society for the Promotion of Science KAKENHI under grants 20K21794, and “Program for Leading Graduate Schools” of the Ministry of Education, Culture, Sports, Science, and Technology, Japan. We collaborated with Mauricio Hanzich and Albert Farrés (Computer Applications in Science and Engineering (CASE) Department, Barcelona Supercomputing Center (BSC)) to implement the stencil code used in this work.
References
- [1] M. Serpa, E. Cruz, M. Diener, A. Krause, A. Farrés, C. Rosas, J. Panetta, M. Hanzich, P. Navaux, “Strategies to Improve the Performance of a Geophysics Model for Different Manycore Systems,” In Proceedings of 2017 International Symposium on Computer Architecture and High Performance Computing Workshops (SBAC-PADW), pp. 49–54. 2017.
- [2] A. Farres, C. Rosas, M. Hanzich, M. Jordà, A. Peña, “Performance Evaluation of Fully Anisotropic Elastic Wave Propagation on NVIDIA Volta GPUs,” In Proceedings of 81st EAGE Conference and Exhibition, pp. 1–5. 2019.
- [3] J. Shen, F. Ino, A. Farrés, M. Hanzich, “A Data-Centric Directive-Based Framework to Accelerate Out-of-Core Stencil Computation on a GPU,” IEICE Transactions on Information and Systems, E103-D, pp. 2421–2434. 2020.
- [4] S. Adams, J. Payne, R. Boppana, “Finite Difference Time Domain (FTDT) Simulations Using Graphics Processors,” In Proceedings of High Performance Computing Modernization Program Users Group Conf. (HPCMP-UGC), pp. 334–338. 2007.
- [5] S. Tabik, M. Peemen, L. Romero, “A tuning approach for iterative multiple 3d stencil pipeline on GPUs: Anisotropic Nonlinear Diffusion algorithm as case study,” The Journal of Supercomputing, 74(4), pp. 1580–1608. 2018.
- [6] T. Okuyama, M. Okita, T. Abe, Y. Asai, H. Kitano, T. Nomura, K. Hagihara, “Accelerating ODE-based Simulation of General and Heterogeneous Biophysical Models using a GPU,” IEEE Transactions on Parallel and Distributed Systems, 25(8), pp. 1966–1975. 2014.
- [7] K. Ikeda, F. Ino, K. Hagihara, “Efficient Acceleration of Mutual Information Computation for Nonrigid Registration using CUDA,” IEEE J. Biomedical and Health Informatics, 18(3), pp. 956–968. 2014.
- [8] J. Shen, K. Shigeoka, F. Ino, K. Hagihara, “An out-of-core branch and bound method for solving the 0-1 knapsack problem on a GPU,” In Proceedings of the 17th International conference on algorithms and architectures for parallel processing (ICA3PP 2017), pp.254–267. Aug. 2017.
- [9] J. Shen, K. Shigeoka, F. Ino, K. Hagihara, “GPU‐based branch‐and‐bound method to solve large 0‐1 knapsack problems with data‐centric strategies,” Concurrency and Computation: Practice and Experience, 31(4), p.e4954. 2019.
- [10] G. Jin, J. Lin, T. Endo, “Efficient utilization of memory hierarchy to enable the computation on bigger domains for stencil computation in CPU-GPU based systems,” In Proceedings of 2014 International Conference on High Performance Computing and Applications (ICHPCA), pp. 1–6. Dec. 2014.
- [11] M. Sourouri, S. Baden, X. Cai X, “Panda: A Compiler Framework for Concurrent CPU+GPU Execution of 3D Stencil Computations on GPU-accelerated Supercomputers,” International Journal of Parallel Programming, 45(3), pp.711–729. 2017.
- [12] T. Shimokawabe, T. Endo, N. Onodera, T. Aoki, “A stencil framework to realize large-scale computations beyond device memory capacity on GPU supercomputers,” In Proceedings of 2017 IEEE International Conference on Cluster Computing (CLUSTER 2017), pp.525–529. 2017.
- [13] N. Miki, F. Ino, K. Hagihara, “PACC: A Directive-based Programming Framework for Out-of-Core Stencil Computation on Accelerators,” International Journal of High Performance Computing and Networking, 13(1), pp. 19–34. 2019.
- [14] F. Cappello, S. Di, A. Gok, “Fulfilling the promises of lossy compression for scientific applications,” In Smoky Mountains Computational Sciences and Engineering Conference, pp. 99–116. Aug. 2020.
- [15] P. Lindstrom, “Fixed-Rate Compressed Floating-Point Arrays,” IEEE Transactions on Visualization and Computer Graphics, 20(12), pp. 2674–2683. 2014. doi:10.1109/TVCG.2014.2346458.
- [16] D. Nagayasu, F. Ino, K. Hagihara, “A decompression pipeline for accelerating out-of-core volume rendering of time-varying data,” Computers & Graphics, 32(3), pp.350–362. 2008.
- [17] D. Tao, S. Di, X. Liang, Z. Chen, F. Cappello, “Improving performance of iterative methods by lossy checkponting,” In Proceedings of the 27th international symposium on high-performance parallel and distributed computing (HPDC 2018), pp. 52–65. Jun. 2018.
- [18] J. Calhoun, F. Cappello, L. Olson, M. Snir, W. Gropp, “Exploring the feasibility of lossy compression for PDE simulations,” The International Journal of High Performance Computing Applications, 33(2), pp. 397–410. 2019.
- [19] X. Wu, S. Di, E. Dasgupta, F. Cappello, H. Finkel, Y. Alexeev, F. Chong, “Full-state quantum circuit simulation by using data compression,” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC 2019), pp. 1–24. Nov. 2019.
- [20] S. Jin, P. Grosset, C. Biwer, J. Pulido, J. Tian, D. Tao, J. Ahrens, Understanding GPU-based lossy compression for extreme-scale cosmological simulations. In Proceedings of the 34th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2020), pp. 105–115. May. 2020.
- [21] J. Tian, S. Di, K. Zhao, C. Rivera, M. Fulp, R. Underwood, S. Jin, X. Liang, J. Calhoun, D. Tao, F. Cappello, “Cusz: An efficient gpu-based error-bounded lossy compression framework for scientific data,” In Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques (PACT 2020), pp. 3–15. Sep. 2020.
- [22] Q. Zhou, C. Chu, N. Kumar, P. Kousha, S. Ghazimirsaeed, H. Subramoni, D. Panda, “Designing High-Performance MPI Libraries with On-the-fly Compression for Modern GPU Clusters,” In Proceedings of the 35th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2021), pp. 444–453. May. 2021.
- [23] NvComp: A library for fast lossless compression/decompression on the GPU, https://github.com/NVIDIA/nvcomp
- [24] CUDA C++ Programming Guide v11.4, https://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf
- [25] J. Shen, J. Mei, M. Walldén, F. Ino, “Integrating GPU support for FreeSurfer with OpenACC,” In Proceedings of the IEEE 6th International Conference on Computer and Communications (ICCC 2020), pp. 1622–1628. Dec. 2020.
- [26] R. Pas, E. Stotzer, C. Terboven. Using OpenMP–The Next Step: Affinity, Accelerators, Tasking, and SIMD. MIT press. 2017.