https://subpath-linear-approx-model.github.io/
Accelerating Image Generation with
Sub-Path Linear Approximation Model
Abstract
Diffusion models have significantly advanced the state of the art in image, audio, and video generation tasks. However, their applications in practical scenarios are hindered by slow inference speed. Drawing inspiration from the consistency models, we propose the Sub-Path Linear Approximation Model (SPLAM), which can accelerate diffusion models while maintaining high-quality image generation. SPLAM treats the PF-ODE trajectory as a series of PF-ODE sub-paths divided by sampled points, and harnesses sub-path linear (SL) ODEs to form a progressive and continuous error estimation along each individual PF-ODE sub-path. The optimization on such SL-ODEs allows SPLAM to construct denoising mapping with smaller cumulative approximated error. An efficient distillation method is also developed to facilitate the incorporation of pre-trained diffusion models, such as latent diffusion models. The extensive experimental results demonstrate SPLAM achieves remarkable training efficiency, requiring only 6 A100 GPU days to produce a high-quality generative model capable of 2 to 4-step generation. Comprehensive evaluations on LAION, MS COCO 2014, and MS COCO 2017 datasets also illustrate that SPLAM surpasses the existing acceleration methods in few-step generation tasks, achieving state-of-the-art performance both on FID and the quality of the generated images. .
Keywords:
Diffusion Models Accelerating Diffusion Models Diffusion Model Distillation Consistency Models1 Introduction
Diffusion models, also known as score-based generative models, have emerged as a potent paradigm in generative computer vision, enabling the synthesis of highly realistic images by progressively refining random noise into structured visual content [9, 46, 29, 32, 45]. Despite their impressive ability, one of the primary challenges associated with diffusion models lies in their computational intensity, often requiring hundreds of iteration steps to produce a single image. This has spurred a surge of research focused on accelerating diffusion models to retain high-quality outputs while significantly reducing the computation cost during the inference phase [42, 23, 24, 36, 50, 49, 21, 44, 26, 20].
Within the spectrum of acceleration techniques, consistency models [44, 26] have garnered attention as they forge a consistent denoising mapping across points on Probability Flow (PF) ODE trajectories. The learning strategy brings consistency models a notable consistency property and could estimate the overall prediction errors as a summation of incremental errors, which are computed as the difference between the predicted results of adjacent trajectory points. In this paper, we recognize that the approximation of denoising mappings by consistency models is essentially a minimization process targeting the endpoints of sub-paths along ODE trajectories. We observe that the approximated performance is currently limited by the accumulation of errors that arise from either an overabundance of approximation operations, or the heightened challenge of optimizing individual sub-path errors as the skipping step size expands.
To address these challenges, we propose a novel approach in this paper, designated as the Sub-Path Linear Approximation Model (SPLAM). SPLAM adheres to the foundational concept of cumulative approximation of PF-ODE trajectories but innovates through its sustained learning from Sub-Path Linear (SL) ODEs. Specifically, we dissect the sub-path learning objective based on the noise prediction design [9, 14] into two interrelated aspects, and establish the SL-ODEs to give respective progressive or continuous estimation for each component, by a carefully designed linear interpolation between the endpoints of sub-paths. We then utilize the SL-ODEs to approximate the complete PF-ODE trajectories which allows a more nuanced optimization. Consequently, the prediction error of our approach is assessed through iterative solutions of all SL-ODEs, enabling a reduction of cumulative errors and an enhancement in image generation quality. Furthermore, we also develop an efficient distillation procedure for our SPLAM which enables the incorporation with pre-trained latent diffusion models [34] (e.g., Stable Diffusion). Our contributions can be summarized as below:
-
1.
We identify that the optimization process for consistency models essentially minimizes the cumulative approximated error along PF-ODE sub-path endpoints, and observe that the performance of such approximations is hindered by the proliferating number of approximations or the amplified difficulty in optimizing single sub-path errors for as skipping step size increases.
-
2.
To address these challenges, we propose a novel approach as Sub-Path Linear Approximation Model (SPLAM). SPLAM employs Sub-Path Linear (SL) ODEs to continuously approximate the complete PF-ODE trajectories and progressively optimize the sub-path learning objectives, which could construct the denoising mappings with smaller cumulative approximated errors.
-
3.
Leveraging the proposed SPLAM and SL-ODE framework, we put forth an efficient distillation method. When integrated with powerful pre-trained models like Stable Diffusion, our approach allows more efficient training and respectively attains impressive FIDs as 10.09, 10.06, 20.77 in LAION, MS COCO 2014, MS COCO 2017 datasets, achieving better performance and close inference latency to all previous accelerating approaches.
2 Related Work
Diffusion Models [9, 1, 46, 40, 14, 30, 34] have solidified their status as a cornerstone in the realm of generative models, outshining previous approaches in creating rich and detailed images. Song et al. [46] model this process from continuous-time perspective with a stochastic differential equation (SDE), which iteratively denoise an initial noise distribution leveraging the learned score of the data distribution to steer the process towards data points [9, 45, 46]. This reverse diffusion process has been verified to be particularly adept at capturing the intricate structures and variations inherent in complex data sets. They also demonstrate that there exists an ordinary differential equation (ODE), dubbed as Probability Flow (PF) ODE, which shares the marginal probability densities with the reverse-time SDE and thus yields a deterministic sampling trajectory [14, 46]. In contrast to other generative models like VAEs [15, 41] and GANs [6], diffusion models demonstrate remarkable robustness in training and excel in producing samples with substantial diversity and high fidelity, thereby offering a robust solution for modeling complex distributions in an ever-expanding array of generative tasks.
Accelerating Diffusion Models. While diffusion models have demonstrated their superiority in generating high-quality samples, the generation speed remains a major hindrance due to requiring thousands of sampling steps, which poses difficulties for practical and efficient applications. To address these issues, a surge of advancements has emerged aiming to accelerate the inference process. Some works concentrate on designing non-training fast diffusion samplers [23, 24, 46, 14, 19, 2, 55, 12], potentially cutting down the steps from one thousand to a modest 20-50. In the realm of distillation [8], efforts have been undertaken [36, 55, 25, 28, 3, 7, 53] to condense the inference steps of pre-trained diffusion models to fewer than 10. Progressive distillation (PD) [36] seeks to amortize the integration of PF-ODE into a new sampler that takes half as many sampling steps, displaying efficacy with as few as 2/4 steps. Consistency models [44, 26, 27, 43], as a nascent class of models, offer the promise of high-quality one-step generation by mapping any point along the PF-ODE trajectory back to the origin. Representing flow-based approaches [21, 20, 18, 47], InstaFlow [21, 20] propose a reflow technique to straighten the trajectories of probability flows and refine the coupling between noises and images, which achieves a one-step SD model. Concurrently, some strategies are exploring the inclusion of GAN-like objectives into diffusion models to afford fast generative capabilities[49, 37, 17, 50]. DMD [50] additionally proposes a distribution matching method that enables one-step high-quality image generation.
3 Preliminaries
Diffusion Models are a class of generative models that gradually transform data into a noisy state through Gaussian perturbations and subsequently learn to reverse this process to reconstruct the original data by progressively denoising it. Denote as the data sampled from the original distribution and as functions that define a noise schedule. Diffusion models transition the data to a noise-corrupted marginal distribution, which can be expressed as:
| (1) |
for any time step .
Song et al. [46] describe the diffusion process using a stochastic differential equation (SDE):
| (2) |
where and denote the drift and diffusion coefficients, respectively, and signifies the standard Brownian motion at time . They also derive an ordinary differential equation (ODE) corresponding to this SDE, which defines the trajectories of solutions sampled at time according to :
| (3) |
referred to as the Probability Flow (PF) ODE. In the reverse denoising process, models are taught to learn a score function , adhering to the PF-ODE. Therefore, diffusion models are also recognized as score-based generative models. Based on the diffusion process, latent diffusion models (LDMs) additionally employ a VAE encoder and decoder to compress the image into latent space as and reconstruct it by the decoder: , and implement the diffusion process on the compressed vector via latent space [34]. With the latent diffusion process, the pre-trained large-scale LDMs like Stable Diffusion (SD) Models could achieve more precise PF-ODE solutions and thus generate high-quality images.
Consistency Model has been proposed by Song et al. [44] as a novel paradigm within the family of generative models. Considering a solution trajectory of the PF-ODE , consistency models comply with a consistency function that projects every pair along the trajectory back to the starting point: , for any , to obtain a one-step generator. Here, represents a small positive constant, thereby making a viable surrogate for . An important characteristic of the consistency models is the self-consistency property:
| (4) |
which is leveraged as the training constraint for the consistency models, whether when distilling knowledge from a pre-trained model or training from scratch. The model is parameterized as follows:
| (5) |
where and are differentiable functions ensuring that and , guaranteeing that , and is a deep neural network. For the distillation approach called as Consistency Distillation, the training objective is formulated as:
| (6) |
where serves as a one-step estimation of based on from , a update function of a one-step ODE solver, and is a chosen distance metric. Consistency models also utilize the EMA strategy to stabilize the training, and is the running average of . Latent Consistency Models (LCMs) [26] introduce consistency model into the distillation for latent diffusion models. To accelerate the training of consistency models, LCM employs a skipping step size to ensure consistency between the current timestep and -step away. With a conditional input and a guidance scale to achieve the CFG strategy [10], the modified learning objective for the latent consistency distillation is formulated as:
| (7) |
4 Methodology
4.1 Approximation Strategy for Denoiser
One-step Denoiser Parameterization. To synthesize an image from a sampled input at a large time step in one-step, a natural approach is to adopt the strategy from [9] that employs a neural network to predict a standard Gaussian distribution, which implements the denoising mapping parameterized as . By redefining the target distribution for as and , this predictive formulation can be recast into a canonical denoiser function defined in [14] that aims to minimize the denoising error as follows:
| (8) |
where is an estimation of the error vector (e.g., a L2 distance). However, the Eq. 8 is hard to be optimized in practice. For instance, when decreases over time step which implies , the training is likely to collapse and the denoiser is taught to generally give a zero output.
Approximation Strategy in Consistency Models. We observe that, consistency models [44, 26] provide a solution to the aforementioned issues by leveraging the consistency property. As we presume that we have obtained a good prediction result , from a time step ahead of for steps, this property yields an approximated error estimation of Eq. 8 as :
| (9) |
By incorporating the expressions for and , we derive the approximated error estimation based on as:
| (10) |
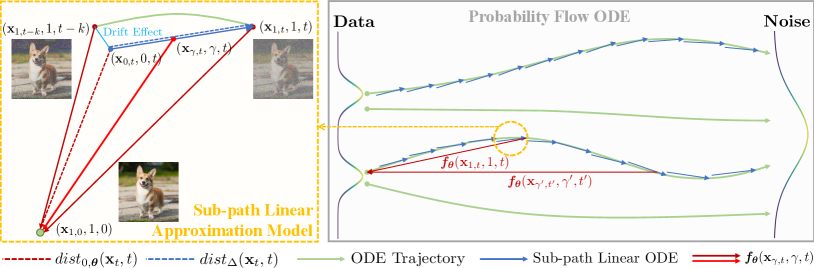
where the mentioned impact on optimization is reduced as the coefficient is amplified by . When is limited to 1, the error between the mapping result and the trajectory origin can be quantified by the accumulation of incremental approximated errors [44]: . Ideally if the error of one single approximation can be bounded, we can reduce the cumulative error by decreasing the number of approximations. This technique, also called Skipping-Step in LCM [26], extends to optimize the error for skipping sampled points on the trajectories as for a fixed skipping step size . However, our insights reveal this precondition does not hold for extended situations. Denote as the sub-path between and from the original PF-ODE trajectory, we discern that the learning objective in Eq. 10 for can be decomposed into two complementary components: 1) , which gauges the incremental distance from to attributable to the drift and diffusion processes, and 2) , which captures the denoising contribution from previous time steps that should be coherently propagated to subsequent time steps . Thus we rewrite Eq. 10 as a sub-path learning objective:
| (11) |
In Eq. 11, the learning process of equates to modeling the denoising distribution , which deviates from Gaussian for larger skipping step sizes and is found to be intractable to estimate [48, 23, 24, 49, 14]. Consequently, the approximated error escalates uncontrollably with increased due to reliance on the flawed learning. Although LCM sets an empirical of 20 to balance the pros and cons, the fundamental issues remain unaddressed and unexplored.
4.2 Sub-Path Linear Approximation Model
To improve the learning objective in Eq. 11, in this paper we introduce a new approach for accelerating diffusion models termed Sub-path Linear Approximation Model (SPLAM). SPLAM introduces Sub-Path Linear (SL) ODEs to approximate the sub-paths on the PF-ODE trajectories as a linear interpolation between the according sub-path endpoints. As the optimization based on such SL-ODEs gives a respectively progressive and continuous estimation for the decomposed two terms in Eq. 11, our SPLAM is trained based on the conducted SL-ODE learning objectives, and achieves smaller overall prediction errors and better generation quality. We also develop an efficient distillation procedure for latent diffusion models [34], with Multiple Estimation strategy which improves the estimated results of teacher models.
4.2.1 Sub-Path Linear ODE
Based on the above analysis, in this paper, we introduce Sub-Path Linear (SL) ODEs to model approximated sub-paths in the original PF-ODE trajectories, which gives a progressive estimation for . For a sampled sub-path on a solution trajectory dictated by Eq. 3, we interpolate a linear path from to , guided by the vector direction of . To distinguish the impacts of and , we account for the drift component in the linear approximated path, causing a shift on coefficient from to . The points on the approximated path are thus computed as:
| (12) | ||||
for a sampled and .
Since and conform to distributions governed by the PF-ODE, our linear transformation effectively defines a linear ODE from distribution to over , where has the property :
| (13) |
We denote it as Sub-Path Linear (SL) ODE. To apply the approximation strategy on the SL-ODE, the Denoiser and generation function replacing with are given by:
| (14) | ||||
Incorporating these into Eq. 11, we derive the sub-path learning objective for our SPLAM model as :
| (15) |
which gives a progressive estimation for the otherwise intractable objective. The value for can be precisely estimated from the distribution and but has a complex expression. Empirically we utilize an approximate result as . Compared to consistency models which adopt Eq. 10 or Eq. 11, our maintains a progressive estimation for and a consistent estimation for , which enables the learning for large skipping step size. The overall prediction error can still be assessed by the aggregate of approximated errors between the sub-path endpoints and the approximated error between these points is continuously optimized through the SL-ODEs. Consequently, the optimization for the approximated errors in our SPLAM could be significantly improved. Our approach could further benefit from the increased skipping step size, allowing our method to generate images of higher quality with reduced sampling steps in more efficient training.
4.2.2 Sub-Path Linear Approximation Distillation
In this paper, we adopt pre-trained Stable Diffusion (SD) models [34] to obtain the solution PF-ODE trajectories which we build our SL-ODEs upon, and we call the approach Sub-path Linear Approximation Distillation (SPLAD). To achieve conditional generation with the conditional input , the noise prediction model is parameterized as [46, 23]. We also introduce into the prediction models for solving our SL-ODEs, and leverage the conditioned training where is converted to Fourier embeddings and fed into the models as an input. Specifically, to predict in the latent space, the generation function for SPLAM is defined as:
| (16) |
where mirrors Eq. 14 while replacing with the conditional form . The functions and are leveraged to ensure that (we regard as the same expression of since for most time steps). Integrating this with Eq. 9, our SPLAD approach minimizes the following objective:
| (17) |
where denotes the uniform distribution, and is a pre-determined skipping step size. The in Eq. 9 is omitted due to its negligible effect on optimization in practice. The term is estimated using ODE solvers derived from teacher models. In this paper DDIM [42] is employed as our choice from the advanced solvers of LDMs. Moreover, to improve the estimation of , we apply the Multiple Estimation which executes the solver multiple times with a reduced skipping step size . Denoting and initializing , the multiple estimation is iteratively executed as:
| (18) |
for , where denotes no conditional inputs and is a fixed guidance scale which controls the effect of conditional generation [10] from the conditional input .
The pseudo-code for SPLAD is presented in Algorithm 1. SPLAD shares a similar training pipeline with consistency models[44, 26] but can be distinguished as it optimizes the sub-path learning objectives based on the SL-ODEs and utilizes the -conditioned training. For a pair of input noise and time step , SPLAM gives the prediction of the denoised latent as:
| (19) |
for one-step generation, adhering strictly to the condition. We also use the same iterative sample strategy as illustrated in [44] which could improve the quality of the generated images. In practice, we set the embedding to for , thereby allowing the weights associated with trained -embeddings to be discarded post-training. Thus our Sub-Path Linear Approximation Model (SPLAM) necessitates no additional parameters beyond the training phase and can be utilized the same as teacher models.
5 Experiments
In this section, we conduct experiments to examine the performance of our proposed Sub-Path Linear Approximation Model (SPLAM). Firstly, we describe the experiment configuration and implementation details, and evaluate our models comprehensively on the text-to-image task (Sec. 5.1). Secondly, we verify the effectiveness of our algorithm design through detailed ablation studies (Sec. 5.2). Finally, we present the qualitative results of our SPLAM. (Sec. 5.3).
5.1 Text-to-Image Generation
5.1.1 Experimental Configuration
On text-to-image generation task, we train two models with pre-trained Stable Diffusion-V1.5 (SDv1.5) and Stable Diffusion-V2.1-base (SDv2.1-base) as teacher models respectively. Following the setting of [26], the training dataset is one subset of LAION-5B[39]: LAION-Aesthetics-6+. We choose DDIM-Solver as the ODE solver at skipping step .
For evaluation, we adopt the commonly used FID and CLIP Score metrics. The results are reported on both SDv1.5 and SDv2.1-base backbones, thus verifying the generalizability of our method. For the experiment of distilling SDv2.1-base, we bench-mark our model on two test sets, LAION-Aesthetics-6+ as used in LCM [26] and MSCOCO2014-30k for zero-shot generalization. We also reproduce a SDv2.1-base LCM according to the training configuration outlined in [26] while replacing the -condition with the fixed guidance scale, which has also improved the performance. We generally set the guidance scale for distilling SDv2.1-base to 8 and skipping step size to 20, which is consistent with [26]. For the experiment of distilling SDv1.5, we compare our model with state-of-the-art generative models including foundation diffusion models, GANs, and accelerated diffusion models. The guidance scale is set to to obtain the optimal FID, and we adopt the huber [43] loss for our SPLAD metric. The skipping step size is set to 100 for SPLAM which has shown fast convergence. We examine our method on two commonly used benchmarks, MSCOCO2014-30k and MSCOCO2017-5k. More implementation details are provided in the supplementary materials.
| Methods | LAION-Aesthetics-6+ | COCO-30k | ||||||||||
| FID | CLIP-Score | FID | CLIP-Score | |||||||||
| 1 Step | 2 Steps | 4 Steps | 1 Step | 2 Steps | 4 Steps | 1 Step | 2 Steps | 4 Steps | 1 Steps | 2 Steps | 4 Steps | |
| DDIM [42] | 183.29 | 81.05 | 22.38 | 6.03 | 14.13 | 25.89 | 431.26 | 229.44 | 32.77 | 2.88 | 7.72 | 28.76 |
| DPM Solver [23] | 185.78 | 72.81 | 18.53 | 6.35 | 15.10 | 26.64 | 206.37 | 73.87 | 22.04 | 10.56 | 22.87 | 31.18 |
| DPM Solver++ [24] | 185.78 | 72.81 | 18.43 | 6.35 | 15.10 | 26.64 | 206.35 | 73.82 | 22.11 | 10.57 | 22.87 | 31.16 |
| LCM∗ [26] | 35.36 | 13.31 | 11.10 | 24.14 | 27.83 | 28.69 | - | - | - | - | - | - |
| LCM (fix ) [26] | 32.41 | 12.17 | 10.43 | 26.99 | 30.13 | 30.76 | 43.87 | 15.71 | 14.88 | 27.66 | 31.07 | 31.52 |
| SPLAM | 32.64 | 12.06 | 10.09 | 27.13 | 30.18 | 30.76 | 40.52 | 14.59 | 13.81 | 27.83 | 31.00 | 31.45 |
5.1.2 Main Results
| Family | Methods | Latency | FID |
| Unaccelerated | DALL-E [33] | - | 27.5 |
| DALL-E2 [32] | - | 10.39 | |
| Parti-750M [51] | - | 10.71 | |
| Parti-3B [51] | 6.4s | 8.10 | |
| Parti-20B [51] | - | 7.23 | |
| Make-A-Scene [5] | 25.0s | 11.84 | |
| Muse-3B [4] | 1.3 | 7.88 | |
| GLIDE [29] | 15.0s | 12.24 | |
| LDM [34] | 3.7s | 12.63 | |
| Imagen [35] | 9.1s | 7.27 | |
| eDiff-I [1] | 32.0s | 6.95 | |
| GANs | LAFITE [54] | 0.02s | 26.94 |
| StyleGAN-T [38] | 0.10s | 13.90 | |
| GigaGAN [13] | 0.13s | 9.09 | |
| Accelerated Diffusion | DPM++ (4step) [24] | 0.26s | 22.36 |
| UniPC (4step) [52] | 0.26s | 19.57 | |
| LCM-LoRA (4step) [27] | 0.19s | 23.62 | |
| InstaFlow-0.9B [21] | 0.09s | 13.10 | |
| InstaFlow-1.7B [21] | 0.12s | 11.83 | |
| UFOGen [49] | 0.09s | 12.78 | |
| DMD [50] | 0.09s | 11.49 | |
| LCM (2step) [26] | 0.12s | 14.29 | |
| SPLAM (2step) | 0.12s | 12.31 | |
| LCM (4step) [26] | 0.19s | 10.68 | |
| SPLAM (4step) | 0.19s | 10.06 | |
| Teacher | SDv1.5 [34]† | 2.59s | 8.03 |
| Methods | #Step | Latency | FID |
| DPM Solver++ [24]† | 4 | 0.21s | 35.0 |
| 8 | 0.34s | 21.0 | |
| Progressive Distillation [36] | 1 | 0.09s | 37.2 |
| 2 | 0.13s | 26.0 | |
| 4 | 0.21s | 26.4 | |
| CFG-Aware Distillation [16] | 8 | 0.34s | 24.2 |
| InstaFlow-0.9B [21] | 1 | 0.09s | 23.4 |
| InstaFlow-1.7B [21] | 1 | 0.12s | 22.4 |
| UFOGen [49] | 1 | 0.09s | 22.5 |
| LCM [26] | 2 | 0.12s | 25.22 |
| 4 | 0.19s | 21.41 | |
| SPLAM | 2 | 0.12s | 23.07 |
| 4 | 0.19s | 20.77 |
| Family | Methods | Latency | FID |
| Accelerated Diffusion | DPM++ (4step) | 0.26s | 22.44 |
| UniPC (4step) [52] | 0.26s | 23.30 | |
| LCM-LoRA (4step) [27] | 0.19s | 23.62 | |
| DMD [50] | 0.09s | 14.93 | |
| LCM (2step) [26] [26] | 0.12s | 15.56 | |
| SPLAM (2step) | 0.12s | 14.50 | |
| LCM (4step) [26] [26] | 0.19s | 14.53 | |
| SPLAM (4step) | 0.19s | 13.39 | |
| Teacher | SDv1.5 [34]† | 2.59s | 13.05 |
The results for SDv2.1-base are presented in Tab. 1, we use DDIM [42], DPM [23], DPM++ [24] and LCM [26] as baselines. It reveals that our SPLAM surpasses baseline methods nearly across both test sets, at each step, and on both FID and CLIP Score metrics. We suppose that the close results on LAION are caused by overfitting, since the test set and train set are sourced from the same data collection. For SDv1.5 under the guidance scale , the quantitative results are demonstrated in Tab. 2(a) and Tab. 2(c). Our model with 4 steps gets FID-30k of 10.06 and FID-5k of 20.77, which outperforms all other accelerated diffusion models, including flow-based method InstaFlow [21] and techniques that introduce GAN objectives such as UFOGen [49] and DMD [50]. Furthermore, SPLAM showcases commensurate results with state-of-the-art foundation generative models such as DALL-E2 [32]. Even in two steps, SPLAM has achieved a competitive performance of FID-30k 12.31 with parallel algorithms. In practical scenarios, a higher guidance scale is typically favored to enhance the resultant image quality. Accordingly, we trained our SPLAM with set to 8 and bench-mark it against a range of advanced diffusion methodologies, as delineated in Tab. 2(c). In this regime, SPLAM also demonstrates significant advantages, achieving state-of-the-art performance with a four-step FID-30k of 13.39 which exceeds other models by a large margin and is close to the teacher model. Notably, the FID-30k of our model with only two steps reaches 14.50, surpassing the four-step LCM and DMD. While DMD training consumes over one hundred A100 GPU days, which is more than 16 times our training duration.
5.2 Ablation Study
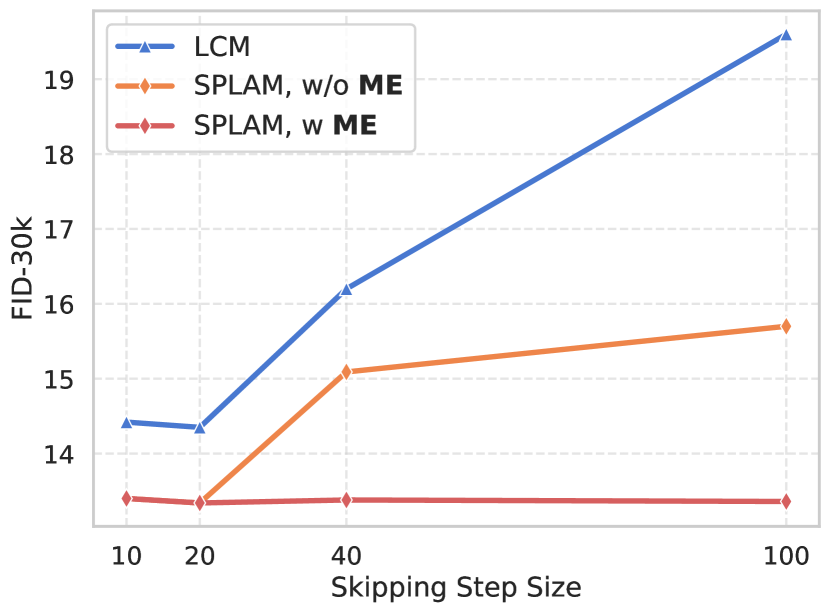

Skipping Step Size & Training Cost
Fig. 2(a) ablates the skipping step size during training, where we compare SPLAM with or without the multiple estimation strategy (Sec. 4.2.2) and LCM.
We can observe that:
1) Without multiple estimation, when the skipping step size is increasing, LCM suffers a more drastic decline in performance due to heightened optimization challenges for sub-path learning.
Through leveraging our proposed Sub-Path Linear ODE, SPLAM can progressively learn the and effectively alleviate this collapse.
2) Equipped with the multiple estimation strategy, SPLAM is capable of stably maintaining high image fidelity with large steps.
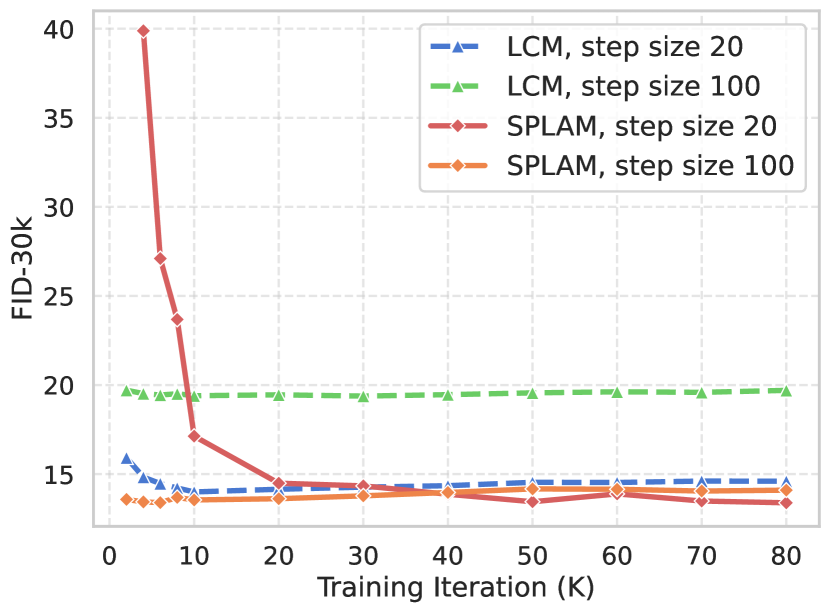
Moreover, we compare the convergence trends between our method and LCM during training, as depicted in Fig. 2(b).
When , although our metrics initially converge more slowly during the early stages, the performance of our method gradually surpasses LCM by a large margin.
It indicates that our training strategy provides a more effective learning objective, enabling SPLAM to achieve a better result, while LCM quickly becomes overfitted.
As raised to 100, larger skipping step size brings SPLAM faster convergence that needs just 2K to 6K iterations which requires about only 6 A100 GPU days training, facilitating practical applications with fewer resources.
Note that LCM needs 10k+ iterations for optimal performance which costs about 16 A100 GPU days and can not be applied to larger skipping step size due to the serious performance gap.
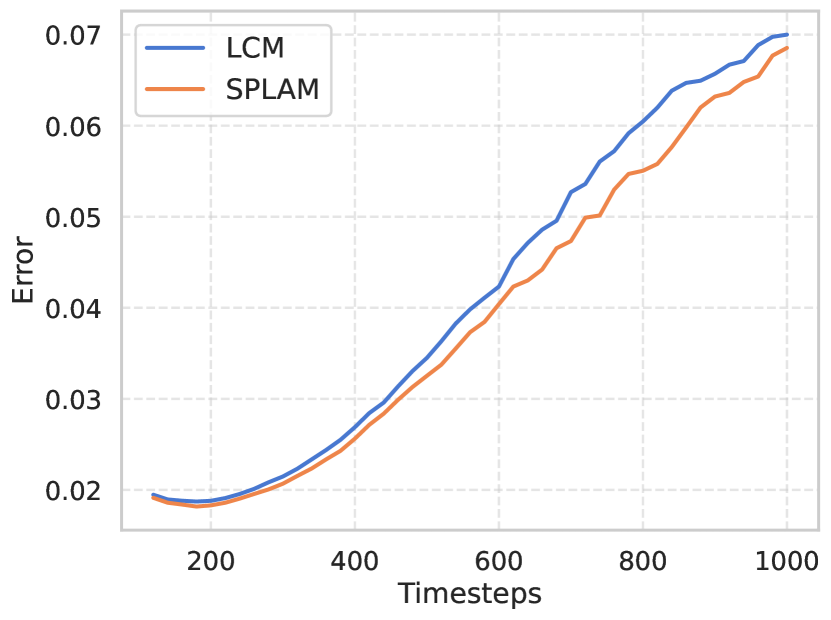
Approximated Error Estimation for SPLAM.
To illustrate the efficacy of our approach, we directly estimate the denoising mapping error between two adjacent samples on the PF-ODE:
, which is firstly defined in Eq. 6.
The results are shown in Fig. 2(c).
We randomly selected 1000 samples from the COCO dataset and simulated adjacent points on the ODE by adding the same noise with adjacent timesteps.
We utilize and the corresponding 50 timesteps for the DDIM scheduler, disregarding steps smaller than 100 due to their relatively larger simulation deviation.
It can be seen that, especially at larger timesteps, the error of our SPLAM is further reduced (about at ).
This observation substantiates that SPLAM indeed contributes to minimizing approximated errors, boosting the model’s capacity for high-quality image generation.
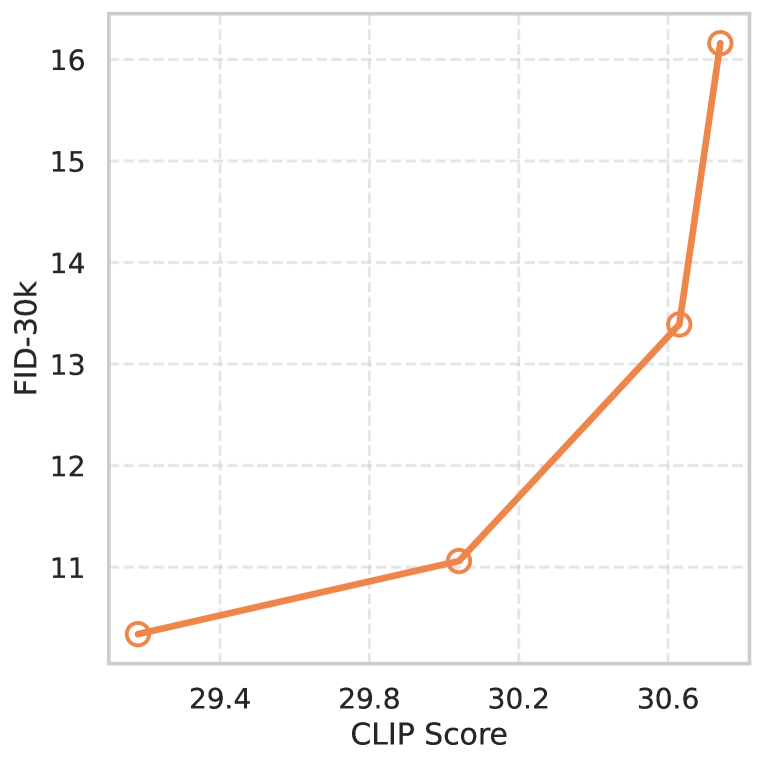
The Effect of Guidance Scale . The guidance scale is a critical hyper-parameter in Stable Diffusion [34, 10], with its adjustment allowing users to alter the semantic alignment and the quality of the generated image. In this study, we also examine the impact of varying the guidance scale for our SPLAM based on SDv1.5, which is visualized in Fig. 3. As well as vanilla Stable Diffusion, while a higher value contributes to better sample quality as reflected by CLIP Scores, it concurrently leads to a degradation in FID performance and oversaturation.



5.3 Qualitative Results
To emphasize the boosted generation quality of our SPLAM, we display the 1,2 and 4-step generation results with the comparison to LCM [26] in Fig. 4. Moreover, we compare our SPLAM distilled from SDv1.5 [34] with the most advanced accelerating diffusion models in Fig. 5, which demonstrate that our SPLAM has achieved the best generation quality across the existing methods.
6 Conclusion
In this paper, we propose a novel approach Sub-Path Linear Approximation Models (SPLAM) for accelerating diffusion models. SPLAM leverages the approximation strategy in consistency models and considers the PF-ODE trajectories as a series of interconnected sub-paths delineated by sampled points. Guided by the optimization direction charted by each sub-path, Sub-Path Linear (SL) ODEs also enable our approach to progressively and continuously optimize the approximated learning objectives and thus construct the denoising mappings with smaller cumulative errors. We also develop an efficient distillation procedure for SPLAM to enable the incorporation of latent diffusion models. Extensive experiments on LAION, MS COCO 2014 and MS COCO 2017 datasets have consistently demonstrated the superiority of our method across existing accelerating diffusion approaches in a few-step generation with a fast training convergence.
Acknowledgments
This work is supported by the National Key RD Program of China (No. 2022ZD0160900), the National Natural Science Foundation of China (No. 62076119, No. 61921006), the Fundamental Research Funds for the Central Universities (No. 020214380119), and the Collaborative Innovation Center of Novel Software Technology and Industrialization.
Appendix
Appendix 0.A Implementation Details
Common Settings: On text-to-image generation task, we train two models with pre-trained Stable Diffusion-V1.5 (SDv1.5) and Stable Diffusion-V2.1-base (SDv2.1-base) as teacher models respectively. Following the setting of [26], the training dataset is one subset of LAION-5B[39]: LAION-Aesthetics-6+, which comprises 12M text-image pairs with predicted aesthetics scores higher than 6. We choose DDIM-Solver [42] as the ODE solver and uniformly set the solver skipping step size to 20 across all experiments. The training process is optimized using the AdamW optimizer [22], with a learning rate configured to 8e-6 and a weight decay of 0. To ensure the stability of gradient updates, we implement gradient clipping with an L2 norm threshold of 10, and apply Exponential Moving Average (EMA) with a decay rate of 0.95. The models are trained with a total batch size of 1024 distributed across 16 A100 GPUs consistently. For evaluation, we adopt the common practice that uses Fréchet Inception Distance (FID) which measures image quality, and CLIP Score [31] which measures text-to-image alignment, which we employ LAION OpenCLIP ViT-G/14 [11] to calculate. For LAION, as stated in [26], we generate 30k images from 10k text prompts as the evaluation set. For MSCOCO2014-30k (Zero-shot FID-30k) and MSCOCO 2017-5k, we follow the evaluation protocol described in [35] and [28], respectively.
For SDv2.1-base: To make a fair comparison between LCM and our approach, we train our SPLAM with skipping step size and L2 distance metric function, which is consistent with [26] (the multiple estimation strategy is disabled since ). The difference is that we trained our models with a fixed guidance scale . We also reproduce an SDv2.1-base LCM according to the training configuration outlined in [26] while replacing the -condition with the fixed guidance scale, which has also improved the performance. For training costs, one GPU day can process 1.6K iterations with batch size of 1024 and without multiple estimation (ME) strategy. We train SPLAM on SDv2.1-base with 80k iterations, which costs about 60 A100 GPU days.
For SDv1.5: The guidance scale is set to to obtain the optimal FIDs, and we adopt the huber loss in [43] as we find that it provides faster convergence and better performance on two-step and one-step. Guidance scale is also conducted and all ablation studies are under SDv1.5 with by default. For training costs, we train SPLAM on SDv1.5 with multiple estimation (ME) described in Sec. 4.2 in the main paper, which executes solver for times in one iteration. In our platform, when =100 and , one GPU day can process nearly half the amount of data compared to previously. As the skipping step size set to has shown fast convergence, it just costs 6k training iterations which require only 6 GPU days.
Appendix 0.B Derivation of and
The perturbation process of DDPM [9] which corresponds to Variance Preserving (VP) SDE [46], could be given by the following Markov chain:
| (20) |
where . For VP is the controlling schedule with , and is defined as .
A nice property of the above process is that we can sample at any arbitrary time step in a closed form:
| (21) | ||||
Accordingly, we have the posterior:
| (22) |
To obtain the posterior for , where , we compute as described in Eq. (12) in the main paper, and substitute Eq. 20 and Eq. 21 into it:
| (23) | ||||
Thus could be represented as a merging of two independent variables. Since we have , the closed-form expression for the mean and variance in should be:
| (24) | ||||
where as defined in this noise schedule.
Subsequently, we can compute the error between the derived result and the empirical value that we have employed in the main paper:
| (25) | ||||
As denoted in Eq. 25, the estimated error for any endpoints on the PF-ODE trajectories, specifically when or , and thus ensures the fidelity for generation. It is observed that as the value of increases, a concomitant rise in error is typically expected. However, in our experimental analysis, we discovered that even for the scenario where , training with or yields nearly the same results. This indicates that the training on SL-ODEs could tolerate such small errors in the intermediate sampled points.
Appendix 0.C Strategies for Constructing Sub-path ODE
To construct approximated paths for the sup-paths on the PF-ODE trajectories, another intuitive way except for our SL ODEs is to directly connect the corresponding endpoints and , and we call it as Direct Linking (DL) ODE. The DL-ODE thus can be formulated as:
| (26) | ||||
And the approximated learning objective for DL ODEs is:
| (27) |
where the noise schedule is defined by the marginal distribution of : . We have derived the expression of , which should be :
| (28) | ||||
Comparing Eq. 28 and Eq. (15) in the main paper, the learning on SPLAM could separate the optimization process for and , whereas the DL-ODE provides a blended estimation. We apply both strategies to the distillation process from SDv1.5, and denote the optimized models as Opt for the training on DL-ODEs and Opt for our SPLAM learning. The tested FIDs are shown in Tab. 3. While DL-ODE also makes a continuous estimation for the sub-path learning objective and surely outperforms LCM, the entangled optimization for and still restricts its optimized performance. In contrast, our approach consistently yields optimal FIDs, reaffirming its superiority in generating high-quality images.
| Methods | FID-5k | FID-30k |
| LCM [26] | 24.68 | 14.53 |
| Opt | 24.20 | 13.89 |
| Opt (SPLAM) | 23.76 | 13.39 |
Appendix 0.D Additional Generated Results
0.D.1 Comparsion to LCM with pre-trained DreamShaper.
Since LCM has only released one version††https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7 of SDv1.5 based model that is distilled from DreamShaper-v7, we train a SPLAM on DreamShaper-v7 as well and compare it to LCM, as shown in Fig. 6 and Fig. 7.








0.D.2 More Generated images with SD pre-trained Models.
Here we provide more generated images from our SPLAM, which are compared with LCM [26], the newly released one-step generation approach InstaFlow [21] and Stable Diffusion [34]. Unless otherwise specified, our SPLAM’s generated results are based on the model distilled from the open source SDv1.5, and the results for LCM are generated from our reproduction. The images are shown in Figs. 8, 9, 10 and 11.


References
- [1] Balaji, Y., Nah, S., Huang, X., Vahdat, A., Song, J., Kreis, K., Aittala, M., Aila, T., Laine, S., Catanzaro, B., et al.: ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022)
- [2] Bao, F., Li, C., Zhu, J., Zhang, B.: Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. arXiv preprint arXiv:2201.06503 (2022)
- [3] Berthelot, D., Autef, A., Lin, J., Yap, D.A., Zhai, S., Hu, S., Zheng, D., Talbot, W., Gu, E.: Tract: Denoising diffusion models with transitive closure time-distillation. arXiv preprint arXiv:2303.04248 (2023)
- [4] Chang, H., Zhang, H., Barber, J., Maschinot, A., Lezama, J., Jiang, L., Yang, M.H., Murphy, K., Freeman, W.T., Rubinstein, M., et al.: Muse: Text-to-image generation via masked generative transformers. In: ICML (2023)
- [5] Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D., Taigman, Y.: Make-a-scene: Scene-based text-to-image generation with human priors. In: ECCV (2022)
- [6] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative Adversarial Nets. In: NIPS (2014)
- [7] Gu, J., Zhai, S., Zhang, Y., Liu, L., Susskind, J.M.: Boot: Data-free distillation of denoising diffusion models with bootstrapping. In: ICML 2023 Workshop on Structured Probabilistic Inference & Generative Modeling (2023)
- [8] Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: NeurIPS 2014 Deep Learning Workshop (2015)
- [9] Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
- [10] Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: arXiv preprint arXiv:2207.12598 (2022)
- [11] Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021). https://doi.org/10.5281/zenodo.5143773, https://doi.org/10.5281/zenodo.5143773, if you use this software, please cite it as below.
- [12] Jolicoeur-Martineau, A., Li, K., Piché-Taillefer, R., Kachman, T., Mitliagkas, I.: Gotta go fast when generating data with score-based models. arXiv preprint arXiv:2105.14080 (2021)
- [13] Kang, M., Zhu, J.Y., Zhang, R., Park, J., Shechtman, E., Paris, S., Park, T.: Scaling up gans for text-to-image synthesis. In: CVPR (2023)
- [14] Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. In: NeurIPS (2022)
- [15] Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2014)
- [16] Li, Y., Wang, H., Jin, Q., Hu, J., Chemerys, P., Fu, Y., Wang, Y., Tulyakov, S., Ren, J.: Snapfusion: Text-to-image diffusion model on mobile devices within two seconds. Advances in Neural Information Processing Systems 36 (2024)
- [17] Lin, S., Wang, A., Yang, X.: Sdxl-lightning: Progressive adversarial diffusion distillation. arXiv preprint arXiv:2402.13929 (2024)
- [18] Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
- [19] Liu, L., Ren, Y., Lin, Z., Zhao, Z.: Pseudo numerical methods for diffusion models on manifolds. In: ICLR (2022)
- [20] Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2023)
- [21] Liu, X., Zhang, X., Ma, J., Peng, J., Liu, Q.: Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. arXiv preprint arXiv:2309.06380 (2023)
- [22] Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
- [23] Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. In: NeurIPS (2022)
- [24] Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. In: arXiv preprint arXiv:2211.01095 (2022)
- [25] Luhman, E., Luhman, T.: Knowledge distillation in iterative generative models for improved sampling speed. arXiv preprint arXiv:2101.02388 (2021)
- [26] Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023)
- [27] Luo, S., Tan, Y., Patil, S., Gu, D., von Platen, P., Passos, A., Huang, L., Li, J., Zhao, H.: Lcm-lora: A universal stable-diffusion acceleration module. arXiv preprint arXiv:2310.04378 (2023)
- [28] Meng, C., Rombach, R., Gao, R., Kingma, D., Ermon, S., Ho, J., Salimans, T.: On distillation of guided diffusion models. In: CVPR (2023)
- [29] Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In: ICML (2022)
- [30] Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning. pp. 8162–8171. PMLR (2021)
- [31] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
- [32] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
- [33] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: ICML (2021)
- [34] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
- [35] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language understanding. In: NeurIPS (2022)
- [36] Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: ICLR (2022)
- [37] Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distillation. arXiv preprint arXiv:2311.17042 (2023)
- [38] Sauer, A., Schwarz, K., Geiger, A.: Stylegan-xl: Scaling stylegan to large diverse datasets. In: SIGGRAPH (2022)
- [39] Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. In: NeurIPS (2022)
- [40] Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsupervised learning using nonequilibrium thermodynamics. In: ICML (2015)
- [41] Sohn, K., Lee, H., Yan, X.: Learning structured output representation using deep conditional generative models. Advances in neural information processing systems 28 (2015)
- [42] Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
- [43] Song, Y., Dhariwal, P.: Improved techniques for training consistency models. arXiv preprint arXiv:2310.14189 (2023)
- [44] Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: ICML (2023)
- [45] Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: NeurIPS (2019)
- [46] Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. In: ICLR (2021)
- [47] Tong, A., Malkin, N., Huguet, G., Zhang, Y., Rector-Brooks, J., Fatras, K., Wolf, G., Bengio, Y.: Improving and generalizing flow-based generative models with minibatch optimal transport. arXiv preprint arXiv:2302.00482 (2023)
- [48] Xiao, Z., Kreis, K., Vahdat, A.: Tackling the generative learning trilemma with denoising diffusion gans. In: ICLR (2022)
- [49] Xu, Y., Zhao, Y., Xiao, Z., Hou, T.: Ufogen: You forward once large scale text-to-image generation via diffusion gans. arXiv preprint arXiv:2311.09257 (2023)
- [50] Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. arXiv preprint arXiv:2311.18828 (2023)
- [51] Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789 2(3), 5 (2022)
- [52] Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. arXiv preprint arXiv:2302.04867 (2023)
- [53] Zheng, H., Nie, W., Vahdat, A., Azizzadenesheli, K., Anandkumar, A.: Fast sampling of diffusion models via operator learning. In: ICML (2023)
- [54] Zhou, Y., Zhang, R., Chen, C., Li, C., Tensmeyer, C., Yu, T., Gu, J., Xu, J., Sun, T.: Towards language-free training for text-to-image generation. In: CVPR (2022)
- [55] Zhou, Z., Chen, D., Wang, C., Chen, C.: Fast ode-based sampling for diffusion models in around 5 steps. arXiv preprint arXiv:2312.00094 (2023)