Accepted to EMNLP 2021
Sentence-Permuted Paragraph Generation
Abstract
Generating paragraphs of diverse contents is important in many applications. Existing generation models produce similar contents from homogenized contexts due to the fixed left-to-right sentence order. Our idea is permuting the sentence orders to improve the content diversity of multi-sentence paragraph. We propose a novel framework PermGen whose objective is to maximize the expected log-likelihood of output paragraph distributions with respect to all possible sentence orders. PermGen uses hierarchical positional embedding and designs new procedures for both training phase and inference phase. Experiments on three paragraph generation benchmarks demonstrate PermGen generates more diverse outputs with a higher quality than existing models.
1 Introduction
Paragraph generation is an important yet challenging task. It requires a model to generate informative and coherent long text that consists of multiple sentences from free-format sources such as a topic statement or some keywords Guo et al. (2018). Typical paragraph generation tasks include story generation Fan et al. (2018), news generation Leppänen et al. (2017), scientific paper generation Koncel-Kedziorski et al. (2019), etc. Recent advances in natural language generation models such as Transformer Vaswani et al. (2017) and BART Lewis et al. (2020) have demonstrated attractive performance of generating text paragraphs.
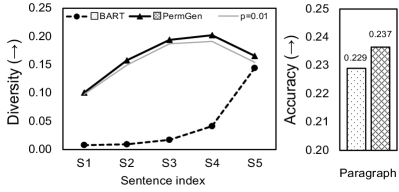
An important desired property of model-generated paragraphs is diversity – given the same source, an intelligent model is expected to create a variety of paragraphs in terms of content, semantic style, and word variability Li et al. (2016); Ippolito et al. (2019). For example, a story generation model should narrate a plot with different storylines Clark et al. (2018); a scientific paper generation model should suggest diverse contents to spark new ideas Wang et al. (2019). In order to create diversity, controllable methods Zhao et al. (2017); Cho et al. (2019); Yu et al. (2020) used additional inputs (e.g., aspects, styles). Sampling decoding algorithms Radford et al. (2019); Holtzman et al. (2020) searched next tokens widely from a vocabulary. However, existing models struggled to produce multi-sentence paragraphs of diverse contents, because they relied on the homogeneity of contexts (e.g., similar story beginnings) caused by the conventional autoregressive framework with fixed left-to-right sentence order (i.e., S1S2S3).
As an example, Figure 1 evaluates the diversity of each generated sentence at different positions of the story in ROCStories Mostafazadeh et al. (2016) by different models. As shown, BART (dashed line) tends to generate stories of very similar beginning and middle parts and only produce diverse text near the end of a story. This phenomenon stems from the fact that the left-to-right generation leads to homogeneity of context to the left, reducing the diversity of the generated paragraph.
Our idea is permuting the sentence orders in paragraph generation, while sticking with the left-to-right scheme to generate tokens in each sentence. It has two advantages. First, it provides an output sentence with a variety of contexts (and possibilities) from different orders. For example, creating the story ending first can probably produce a completely different story from generating the beginning first. Second, it retains the benefit of autoregressive model that originates from the word-by-word nature of human language production. So the coherence within sentences can be maintained, avoiding the harm of incomplete semantics from token-level permutation Shen et al. (2020).
In this work, we propose a sentence-permuted paragraph generation framework called PermGen. Instead of using the fixed forward order, PermGen maximizes the expected log-likelihood of the distribution in output paragraph w.r.t. all possible sentence orders. The optimization is based on -SGD (Murphy et al., 2019) which has guaranteed convergence property. Furthermore, PermGen employs a novel hierarchical position encoding scheme to represent the positions of tokens in permuted sentences. PermGen can be initialized with any Transformer-based models and any decoding algorithms such as beam search and nucleus sampling Holtzman et al. (2020).
We conduct experiments on three paragraph generation tasks: story generation, news generation, and paper abstract generation. Results show that PermGen can significantly improve the diversity of generated texts and achieve higher accuracy. Particularly, as shown in Figure 1, PermGen model can improve diversity for sentences at all positions while also improving the accuracy. Besides, we observe consistent improvements on both accuracy and diversity when PermGen is coupled with various pre-trained models and decoding algorithms.
2 Related Work
Paragraph Generation. The source can be either structured or unstructured such as database records Puduppully et al. (2019), knowledge graphs Zhao et al. (2020), images Ippolito et al. (2019), and keywords Yao et al. (2019). The expected outputs typically are stories Guan et al. (2019); Yao et al. (2019), essays Yang et al. (2019), news articles Dong et al. (2021), or scientific papers Hua and Wang (2019); Koncel-Kedziorski et al. (2019). This task poses unique challenges as it aims at generating coherent and diverse long-form texts. Our framework can use various forms of input such as a story title, keywords, and keyphrases, which can be generalized to broad domains.
Diverse Text Generation. Generating diverse sequences is of crucial importance in many text generation applications that exhibit semantically one-to-many relationships between source and the target sequences, such as machine translation Shen et al. (2019); Lachaux et al. (2020), summarization Cho et al. (2019), question generation Wang et al. (2020), and paraphrase generation Qian et al. (2019). Methods of improving diversity in text generation that have been widely explored from different perspectives in recent years. Sampling-based decoding is one of the effective solutions to improve diversity Fan et al. (2018); Holtzman et al. (2020), e.g., nucleus sampling Holtzman et al. (2020) samples next tokens from the dynamic nucleus of tokens containing the vast majority of the probability mass, instead of aiming to decode text by maximizing the likelihood. Another line of work focuses on introducing random noise Gupta et al. (2018) or changing latent variable Lachaux et al. (2020) to produce uncertainty, e.g., Gupta et al. (2018) employ a variational auto-encoder framework to generate diverse paraphrases according to the input noise. In addition, Shen et al. (2019) adopt a deep mixture of experts (MoE) to diversify machine translation, where a minimum-loss predictor is assigned to each source input; Shi et al. (2018) employ inverse reinforcement learning for unconditional diverse text generation.
Dynamic Order Generation. These methods have two categories. First, non-autoregressive generation is an emerging topic and commonly used in machine translation Gu et al. (2018); Ren et al. (2020). They generate all the tokens of a sequence in parallel, resulting in faster generation speed. However, they perform poorly for long sentences due to limited target-side conditional information Guo et al. (2019). Second, insertion-based generation is a partially autoregressive model that maximizes the entropy over all valid insertions of tokens Stern et al. (2019). POINTER Zhang et al. (2020) inherits the advantages from the insertion operation to generate text in a progressive coarse-to-fine manner. Blank language model (BLM) Shen et al. (2020) provides a formulation for generative modeling that accommodates insertions of various length.
Different from the above methods, our PermGen permutes the sentence orders for generating a paragraph, and it follows the left-to-right manner when producing each sentence.
3 Preliminaries
Problem Definition. Given input that can be a topic statement, some keywords, or a paper’s title, the goal is to produce a paragraph consisting of multiple sentences as a story, a news article, or a paper’s abstract. Suppose has sentences, denoted by , where is the -th sentence. can be easily obtained from training data to create sentence indices. During testing, models are expected to predict the sentence indices under maximum (i.e., 10).
3.1 Sentence-Level Transformer
Transformer Vaswani et al. (2017) follows the encoder-decoder architecture Sutskever et al. (2014) and uses stacked multi-head self-attention and fully connected layers for both the encoder and decoder. For simplicity, we represent the Transformer framework at the sentence level by using a recurrent notation that generates a probability distribution for sentence prediction by attending to both input and previous decoded sentences .
| (1) |
where and are the -th sentence and sentences before -th sentence under the left-to-right manner in target output. Transformer eschews recurrence and instead relies on the self-attention mechanism to draw global dependencies between the input and output. During the decoding phase, Transformer can predict each token based on both the input and previously predicted tokens via attention masks to improve efficiency. The objective of Transformer is to maximize the likelihood under the forward autoregressive factorization:
| (2) |
4 Proposed Method: PermGen
In a left-to-right generation scheme such as the canonical Seq2Seq design, each generated token is conditioned on left-side tokens only Sutskever et al. (2014). It ignores contextual dependencies from the right side. It also leads to limited diversity of generated text (as shown in Figure 1). To solve this problem, our PermGen, a novel sentence-permuted paragraph generation model, produces sentences not confined to the left-to-right order. Instead, PermGen attempts different sentence orders and selects the best-ranked output candidate.
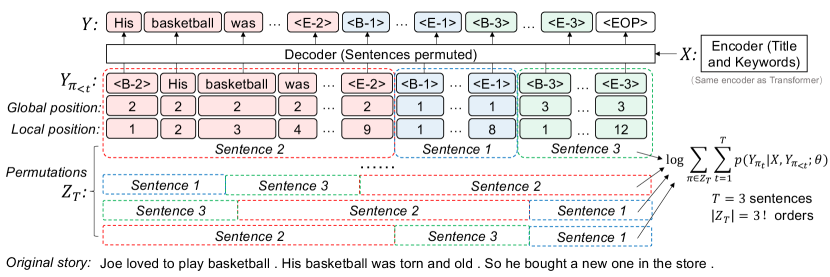
As shown in Figure 2, PermGen uses the Transformer encoder but changes the sentence orders during the decoding phase. It should be noted that PermGen follows the left-to-right manner when generating tokens in each sentence. Thus, we represent the Transformer decoder as:
| (3) |
where and are the -th sentence and the sentences before the -th sentence under the permutation order in the target output. Taking the first permuted order in Figure 2 as an example, we have , , , .
We note that as PermGen is based on the encoder-decoder Transformer architecture, which can be initialized either randomly or from a pre-trained Transformer model with the same structure. Therefore, in the experiments, we evaluate PermGen which is i) trained from scratch, and ii) initialized with BART (Lewis et al., 2020). Next, we will introduce three modules of PermGen: (1) hierarchical positional embedding, (2) sentence-permuted learning, and (3) sentence-based decoding.

4.1 Hierarchical Positional Embedding
In Transformer, positional embeddings are added to every token’s embedding. Traditionally, the positional embedding encodes the absolute position from 1 to the sequence length to model how a token at one position attends to tokens at other positions Vaswani et al. (2017); Lewis et al. (2020).
We propose the hierarchical positional embedding that consists of a global position and a local position. Given a token, the global position is the position (index) of the sentence that contains this token; the local position is the position of the token in the sentence (see the two lines of position numbers in Figure 2). Given a paragraph , its embedding matrix is given below, where rows are its tokens and columns are embedding dimensions:
| (4) |
where is the token embedding, and are the global positional embeddings and local positional embeddings.
Compared to the absolute positional embedding, the hierarchical positional embedding has two advantages. First, the embedding of two-level positions is more informative about the paragraph structure than that of the absolute position. Second, when we permute the sentence orders in paragraph generation, the absolute positions of tokens might not be available. For example, if the second sentence is generated earlier than the first sentence, the absolute positions of its tokens cannot be determined because the length of the first sentence is unknown. In comparison, hierarchical position does not have this issue.
In addition, for the -th sentence in , we add two special tokens (i.e., <B-> and <E->) to indicate the beginning and end of the sentence. Thus, the decoder can determine the sentence index based on the predicted special tokens. We also append a special token <EOP> to the paragraph to indicate the end of the generation process.
4.2 Sentence-permuted Learning
This module learns by varying sentence orders in paragraph generation and acts as the key component in PermGen. For example, given a sentence order , PermGen first generates the second sentence from the leftmost token to the rightmost, then generates the fourth sentence, and so on. Formally, we denote as the set of all possible sentence orders, i.e., the permutations of sentence indices of length . It follows that . Given input and target output paragraph of sentences, PermGen maximizes the following likelihood:
| (5) |
However, computing the negative log-likelihood in Eq. (5) is prohibitive because the back-propagation computational graph branches out for every permutation in the sum. Therefore, we apply the Jensen’s inequality to lower-bound the log-likelihood:
By maximizing the lower bound, we do not favor any particular sentence order, but encourage the model to generate equally well in all orders.
Note that maximizing this lower bound is equivalent to minimizing the following expectation:
| (6) |
Since computing this expectation is still intractable, we apply the -SGD Murphy et al. (2019) stochastic optimization, which randomly samples a permutation for gradient computation.
Definition 1
(-SGD): Let be a mini-batch i.i.d. sampled uniformly from the training data . At step , consider the stochastic gradient descent update
| (7) |
where is the gradient, and random permutations are sampled independently: . Besides, the learning rate is s.t. , and .
We note that -SGD is a Robbins-Monro stochastic approximation of gradient descent Robbins and Monro (1951). When it’s applied to permutation sampling, the optimization almost surely converges to the optimal , as implied by the following proposition.
Proposition 1
(-SGD Convergence): The optimization of -SGD converges to the optimal for in Eq. (6) with probability one.
Proof: We refer to Prop.2.2 in Murphy et al. (2019).
4.3 Sentence-based Decoding
In decoding, PermGen adopts the following steps:
-
•
Step 1: Initialize a set of indices of sentences that have been generated: ;
-
•
Step 2: If , sample a token from {<B-> {1, , }}111When trying to generate multiple candidates, we use the sampling without replacement strategy. For example, if we need to generate 3 candidates each with 5 sentences, their beginning tokens can be B-1, B-3 and B-4, respectively. ; otherwise, predict a token from {<B-> {1, , }} {<EOP>}. If the token is <EOP>, end; otherwise, append <B-> to the generated text;
-
•
Step 3: Generate tokens from <E-> for the -th sentence in an autoregressive way, where is the set of normal text tokens. Stop when <E-> is generated;
-
•
Step 4: , then go back to Step 2.
As stated in step 2, when <EOP> is generated, the whole generation ends. Then, the sentences in the generated paragraph can be reordered according to sentence indices and special tokens. Note that in step 3, since PermGen adopts autoregressive generation, it can employ any decoding strategy such as beam search or sampling algorithm (e.g. truncated sampling Fan et al. (2018), nucleus sampling Holtzman et al. (2020)). For example, truncated sampling samples the next word from the top probable choices, instead of aiming to decode text by maximizing the likelihood.
Rank with log-probability. We compute the log-likelihood of each candidate as the same as in beam search Vijayakumar et al. (2016) and sampling methods Holtzman et al. (2020):
| (8) |
where is the total number of tokens in and is the -th token in generated paragraph .
Complexity reduction. Since the number of possible sentence orders grows as for a -sentence paragraph, exact inference is an extremely time consuming process. To reduce the complexity during inference, we employ an approximate inference by taking advantage of the special token prediction mentioned in step 2. The special token prediction happens when a end-of-sentence (i.e., <E->) is generated. Instead of traversing each remaining possible sentence index, the model only chooses the most likely sentence index through special token predictions. It should be noted that we reuse the classifier in decoder by simply masking tokens not in {<B->}, without training any new classifiers. Therefore, the decoding time is roughly linear in the number of candidates to be generated.
5 Experiments
We conduct experiments on three text generation tasks: story generation, news generation, and paper abstract generation. For all tasks, we compare PermGen with multiple baseline models on diversity and accuracy of their generated texts. We also perform human evaluation on story generation.
5.1 Tasks and Benchmarks
Task 1: Story generation
In this task, models learn to generate story paragraphs from the title and multiple keywords. We use ROCStories dataset Mostafazadeh et al. (2016) and follow the same data preparation as in Yao et al. (2019). ROCStories has 98,162 / 9,817 / 9,803 paragraphs for training / development / test sets, respectively. The stories in the corpus capture causal and temporal commonsense relations between daily events.
| Dataset | ROCStories | AGENDA | DailyMail |
| # Train | 98,162 | 38,720 | 49,102 |
| # Dev. | 9,817 | 1,000 | 2,000 |
| # Test | 9,803 | 1,000 | 2,000 |
| Title in input | |||
| Avg.in.words | 9.65 | 16.09 | 7.91 |
| Avg.out.words | 50.16 | 76.12 | 95.62 |
| Avg.out.sents | 4.92 | 3.08 | 3.88 |
| * The DailyMail dataset does not have news title for each | |||
| article. We only generate the first paragraph of news in | |||
| DailyMail. The average length is 3.88 sentences. | |||
| Methods | Pre- Train | ROCStories | AGENDA | DailyMail | ||||||
| Diversity | Accuracy | Diversity | Accuracy | Diversity | Accuracy | |||||
| Dist-2() | Self-B-4() | B-4() | Dist-2() | Self-B-4() | B-4() | Dist-2() | Self-B-4() | B-4() | ||
| POINTER | 0.0743 | 0.9405 | 0.0492 | 0.1898 | 0.9267 | 0.0379 | 0.1228 | 0.9619 | 0.0243 | |
| BLM | 0.0560 | 0.9573 | 0.1477 | 0.1465 | 0.9396 | 0.1679 | 0.0831 | 0.9889 | 0.1164 | |
| GPT-2 | 0.0915 | 0.9194 | 0.0726 | 0.1665 | 0.9331 | 0.1247 | 0.1577 | 0.9287 | 0.1072 | |
| BERTGen | 0.0672 | 0.9456 | 0.1576 | 0.1463 | 0.9356 | 0.1462 | 0.1167 | 0.9774 | 0.1728 | |
| T5 | 0.0684 | 0.9403 | 0.1895 | 0.1323 | 0.9421 | 0.1688 | 0.1086 | 0.9779 | 0.1529 | |
| Transformer | 0.0806 | 0.9341 | 0.1809 | 0.1489 | 0.9265 | 0.1540 | 0.1109 | 0.9678 | 0.1496 | |
| BART | 0.0839 | 0.9330 | 0.2445 | 0.1697 | 0.9278 | 0.1922 | 0.1306 | 0.9720 | 0.1935 | |
| PermGen | 0.0992 | 0.8548 | 0.1848 | 0.2203 | 0.5679 | 0.1678 | 0.1934 | 0.7757 | 0.1592 | |
| 0.1059 | 0.7993 | 0.2482 | 0.2492 | 0.5940 | 0.2059 | 0.2065 | 0.6627 | 0.1991 | ||
| Methods | Pre- Train | ROCStories | AGENDA | DailyMail | ||||||
| Diversity | Accuracy | Diversity | Accuracy | Diversity | Accuracy | |||||
| Dist-2() | Self-B-4() | B-4() | Dist-2() | Self-B-4() | B-4() | Dist-2() | Self-B-4() | B-4() | ||
| BART | 0.0839 | 0.9330 | 0.2445 | 0.1697 | 0.9278 | 0.1922 | 0.1306 | 0.9720 | 0.1935 | |
| Hi-BART | 0.0812 | 0.9356 | 0.2349 | 0.1673 | 0.9265 | 0.1880 | 0.1289 | 0.9705 | 0.1899 | |
| PermGen | 0.1059 | 0.7993 | 0.2482 | 0.2492 | 0.5940 | 0.2059 | 0.2065 | 0.6627 | 0.1991 | |
Task 2: Paper abstract generation
In this task, models need to generate paper abstracts from paper title and a list of keywords. We use the AGENDA dataset Koncel-Kedziorski et al. (2019) that consists of 40,720 paper titles and abstracts in the Semantic Scholar Corpus taken from the proceedings of 12 AI conferences. Each abstract is paired with several keywords. We follow the settings in Koncel-Kedziorski et al. (2019) to directly generate paper abstracts from the keywords. We follow the same data partition, which has 38,720 / 1,000 / 1,000 for training / development / test sets, respectively.
Task 3: News generation
In this task, models are trained to generate news articles from a list of keyphrases. We use DailyMail dataset See et al. (2017), a corpus of online news articles. We randomly sample 53,102 news articles and extract keyphrases from each sentence using RAKE Rose et al. (2010). It contains 49,102 / 2,000 / 2,000 news articles for training / development / test sets.

5.2 Baseline Methods
We compared with three pre-trained Transformer-based models: BART Lewis et al. (2020), T5 Raffel et al. (2020) and BERTGen Rothe et al. (2020). These models have demonstrated state-of-the-art performance in various tasks. We also compare with GPT-2 Radford et al. (2019) and two recent non-autoregressive generation models: BLM Shen et al. (2020) and POINTER Zhang et al. (2020).
BLM
Shen et al. (2020) Blank Language Model (BLM) generates sequences by dynamically creating and filling in blanks. The blanks control which part of the sequence to fill out, making it ideal for word-to-sequence expansion tasks.
POINTER
Zhang et al. (2020) POINTER operates by progressively inserting new tokens between existing tokens in a parallel manner. This procedure is recursively applied until a sequence is completed. This coarse-to-fine hierarchy makes the generation process intuitive and interpretable.
Truncated Sampling
Fan et al. (2018) It randomly samples words from top-k candidates of the distribution at the decoding step.
Nucleus Sampling
Holtzman et al. (2020) It avoids text degeneration by truncating the unreliable tail of the probability distribution, sampling from the dynamic nucleus of tokens containing the vast majority of the probability mass.
5.3 Implementation Details
We use pre-trained parameters from BART-base Lewis et al. (2020) to initialized our model, which takes a maximum 512 input token sequence and consists of a 6-layer transformer encoders and another 6-layer transformer decoders Vaswani et al. (2017) with 12 attention heads and 768 word dimensions. For model fine tuning, we use Adam with learning rate of 3e-5, = 0.9, = 0.999, L2 weight decay of 0.01, learning rate warm up over the first 10,000 steps, and linear decay of learning rate. Our models are trained with a 4-card 32GB memory Tesla V100 GPU, and implemented with the Huggingface’s Transformer Wolf et al. (2020).
5.4 Evaluation Metrics
We use metrics introduced in previous work Ott et al. (2018); Vijayakumar et al. (2018); Zhu et al. (2018) to evaluate accuracy and diversity.
5.4.1 Accuracy metrics
Top-1 metric ().
Oracle metric ().
This measures the highest accuracy comparing the best hypothesis among the top- with the target Vijayakumar et al. (2018).
5.4.2 Diversity metrics
Corpus diversity ().
Distinct- Li et al. (2016) measures the total number of unique -grams normalized by the total number of generated -gram tokens to avoid favoring long sentences. Entropy- Zhang et al. (2018) reflects how evenly the empirical -gram distribution is for a given sentence when word frequency is taken into account (i.e. low weights for high-frequency words).
Pairwise diversity ().
Referred as “self-” (e.g., self-BLEU) Zhu et al. (2018), it measures the within-distribution similarity. This metric computes the average of sentence-level metrics between all pairwise combinations of hypotheses generated from each source sequence . Lower pairwise metric indicates high diversity between generated hypotheses.
| Inputs: (Title) Mounting popularity ; (Keywords) started, company, friends, hard, year, slogging, reward, traction, excited |
| Beam search-1: I started a new company with some friends . It was hard at first . After a year of slogging , I got a reward . The reward was a lot of traction . Now we are all excited to start working together . |
| Beam search-2: I started a new company with some friends . It was hard at first . After a year of slogging , I got a reward . The reward was a lot of traction . Now we are all excited . |
| Beam search-3: I started a new company with some friends . It was hard at first . After a year of slogging , I got a reward . The reward was a lot of traction . We are excited to keep doing this . |
| Nucleus sampling-1: I started a new company with some friends . It was hard at first . After a year of slogging , the reward was a lot of traction . Now we are doing really well . I am excited to start working with my friends . |
| Nucleus sampling-2: I started a new company with some friends . It was hard at first . After a year of slogging , I got a lot of reward . The reward was a lot of traction . Now we are all excited to start working together . |
| Nucleus sampling-3: I started a new company with my friends . It was hard at first . After a year of slogging , we got a lot of reward . We got traction and are doing really well . We are excited to keep doing this . |
| PermGen-1 (reordered from [2, 1, 3, 5, 4]*): I started a new company with some friends . I tried really hard for almost a year . It took a lot of slogging , but as a reward I got traction . Now we are all doing it together . I ’m excited to be doing it again . |
| PermGen-2 (reordered from [3, 1, 2, 5, 4]): I started a new company with some friends . It ’s been hard . I ’ve been slogging through it as a reward for getting traction . My friends are really excited . I ’m excited to see what it ’s all about . |
| PermGen-3 (reordered from [5, 1, 2, 3, 4]): I started a new company with some of my friends . It was hard at first . After a year of slogging , I got a lot of reward . I have many traction on social media . I am excited to start working with my friends . |
| * “Reordered from [2, 1, 3, 5, 4]” means that PermGen first generates the 2 sentence, and then generates the 1 sentence, and so on. Finally, we reorder the generated story according to the ascending order of sentence index as shown in Figure 3. |
| Win | Lose | Tie | |
| PermGen | 64.00% | 14.00% | 22.00% |
| v.s. Beam | (12.71%) | (7.70%) | (10.73%) |
| PermGen | 54.80% | 8.80% | 36.40% |
| v.s. Truncated | (4.10%) | (5.31%) | (5.43%) |
| PermGen | 56.00% | 11.60% | 32.40% |
| v.s. Nucleus | (8.67%) | (4.27%) | (5.57%) |
| Accuracy | Fluency | Coherency | |
| BART | 3.34 | 3.93 | 3.85 |
| PermGen | 3.42 | 3.97 | 3.88 |
5.5 Experimental results
5.5.1 PermGen v.s. Transformers
As shown in Table 2, PermGen can improve both the diversity and the accuracy of generated text when initialized with either non-pretrained (Transformer) or pre-trained (BART) Transformers. For example, compared with BART which has the best performance among baselines, PermGen reduced Self-BLEU-4 by 43.2% and improved BLEU-4 by +1.5% on AGENDA. And we observe similar improvement on all other paragraph generation tasks. More evaluation results are in Table 7 in Appendix.
POINTER achieves the lowest performance in paragraph generation tasks. This is because its insertion operation ignores dependency between generated words so it cannot well capture the inter-sentence coherence during long-text generation.
It should be noted that since BART performed the best among all baseline methods, we apply PermGen on BART in the following evaluations.
5.5.2 Ablation Study
As we mentioned, the absolute positions in Transformer Vaswani et al. (2017) of tokens might not be available when we permute the sentence orders in paragraph generation. So, we propose the hierarchical positional embedding that consists of a global position and a local position. In this section, we conduct ablation study to show the adding hierarchical position embedding to BART (short as Hi-BART) does not improve diversity, compared to the original BART model. Hi-BART even underperforms than original BART (see Table 3). This is mainly because the newly added hierarchical position embeddings are randomly initialized, without any pre-training on large corpora.
5.5.3 PermGen v.s. Decoding Methods
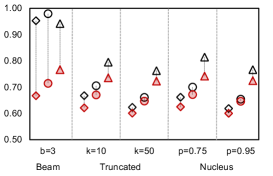
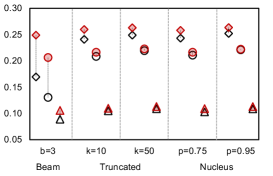
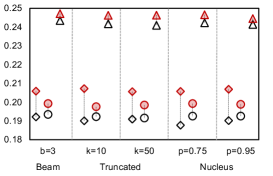
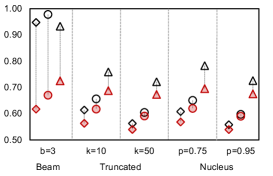
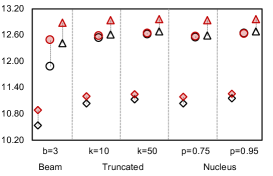
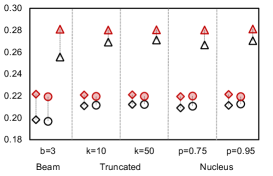
We investigate the quality of text generated by PermGen (built on BART) when coupled with beam search, truncated sampling and nucleus sampling. Figure 4 shows that on average, PermGen can significantly boost diversity by 5.81% in Self-BLEU-3 and 6.83% in Self-BLEU-4, respectively, and improve accuracy by +1.2% and +1.5% in terms of Top1-BLEU-4 and Oracle-BLEU-4.
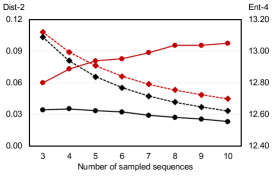
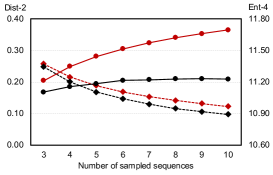
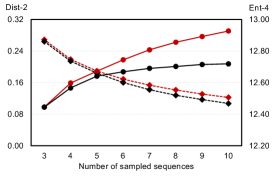
As the diversity of generated text depends on the number of produced candidates, we compare the diversity of generation between BART and PermGen with various number of output candidates, . Figure 5 shows that as increases, PermGen can consistently generate more diverse content, measured by the ratio of distinct 2-grams, Distinct-2 (dashed line). Meanwhile, measured by Entropy-4 (solid line), the proportion of novel words in generated candidates from PermGen is rising as increases, while BART shows a flat or even falling trend.
5.5.4 Human Evaluations
We sample 100 inputs from ROCStories test set and each evaluated method generates top-3 stories. Every story is assigned to five annotators with NLP background. For diversity, the annotators are given two sets of top-3 stories from two methods each time and instructed to pick the set that is more diverse. The choices are “win,” “lose,” or “tie.” Then, the annotators give an accuracy score from 1 to 5 to measure semantic similarity between the top-1 generated story and ground truth story. Finally, the annotators need to give a fluency and coherency score from 1 to 5 for each generated story.
5.5.5 Case Study
Table 4 demonstrates generated stories from different diversity-promoting methods, including beam search, nucleus sampling and our PermGen. Overall, we observe that PermGen can generate more diverse stories than the other two methods. We notice that stories generated by beam search often differ only by punctuation and minor morphological variations, and typically only the last sentence (or last several words) is different from others. Nucleus sampling achieves better diversity than beam search, but the stories are still following similar storylines. In comparison, PermGen can generate semantically richer and more diverse contents.
6 Conclusions
In this paper, we proposed a novel sentence-permuted paragraph generation model, PermGen. PermGen maximizes the expected log likelihood of output paragraph w.r.t. all possible sentence orders. Experiments on three paragraph generation tasks demonstrated that PermGen outperformed original Transformer by generating more accurate and diverse text. The result is consistent on various Transformer models and decoding methods.
Acknowledgements
This work is supported by National Science Foundation IIS-1849816 and CCF-1901059.
References
- Banerjee and Lavie (2005) Satanjeev Banerjee and Alon Lavie. 2005. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the ACL workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation.
- Cho et al. (2019) Jaemin Cho, Minjoon Seo, and Hannaneh Hajishirzi. 2019. Mixture content selection for diverse sequence generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Clark et al. (2018) Elizabeth Clark, Anne Spencer Ross, Chenhao Tan, Yangfeng Ji, and Noah A Smith. 2018. Creative writing with a machine in the loop: Case studies on slogans and stories. In 23rd International Conference on Intelligent User Interfaces.
- Dong et al. (2021) Xiangyu Dong, Wenhao Yu, Chenguang Zhu, and Meng Jiang. 2021. Injecting entity types into entity-guided text generation. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Fan et al. (2018) Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL).
- Gu et al. (2018) Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2018. Non-autoregressive neural machine translation. International Conference for Learning Representation (ICLR).
- Guan et al. (2019) Jian Guan, Yansen Wang, and Minlie Huang. 2019. Story ending generation with incremental encoding and commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence.
- Guo et al. (2018) Jiaxian Guo, Sidi Lu, Han Cai, Weinan Zhang, Yong Yu, and Jun Wang. 2018. Long text generation via adversarial training with leaked information. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- Guo et al. (2019) Junliang Guo, Xu Tan, Di He, Tao Qin, Linli Xu, and Tie-Yan Liu. 2019. Non-autoregressive neural machine translation with enhanced decoder input. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- Gupta et al. (2018) Ankush Gupta, Arvind Agarwal, Prawaan Singh, and Piyush Rai. 2018. A deep generative framework for paraphrase generation. In Proceedings of the AAAI Conference on Artificial Intelligence.
- Holtzman et al. (2020) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. International Conference for Learning Representation (ICLR).
- Hua and Wang (2019) Xinyu Hua and Lu Wang. 2019. Sentence-level content planning and style specification for neural text generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP).
- Ippolito et al. (2019) Daphne Ippolito, Reno Kriz, Joao Sedoc, Maria Kustikova, and Chris Callison-Burch. 2019. Comparison of diverse decoding methods from conditional language models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL).
- Koncel-Kedziorski et al. (2019) Rik Koncel-Kedziorski, Dhanush Bekal, Yi Luan, Mirella Lapata, and Hannaneh Hajishirzi. 2019. Text generation from knowledge graphs with graph transformers. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT).
- Lachaux et al. (2020) Marie-Anne Lachaux, Armand Joulin, and Guillaume Lample. 2020. Target conditioning for one-to-many generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings.
- Leppänen et al. (2017) Leo Leppänen, Myriam Munezero, Mark Granroth-Wilding, and Hannu Toivonen. 2017. Data-driven news generation for automated journalism. In Proceedings of the 10th International Conference on Natural Language Generation (COLING).
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL).
- Li et al. (2016) Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. A diversity-promoting objective function for neural conversation models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT).
- Mostafazadeh et al. (2016) Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL).
- Murphy et al. (2019) Ryan L Murphy, Balasubramaniam Srinivasan, Vinayak Rao, and Bruno Ribeiro. 2019. Janossy pooling: Learning deep permutation-invariant functions for variable-size inputs. International Conference for Learning Representation (ICLR).
- Ott et al. (2018) Myle Ott, Michael Auli, David Grangier, and Marc’Aurelio Ranzato. 2018. Analyzing uncertainty in neural machine translation. In International Conference on Machine Learning (ICML).
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL).
- Puduppully et al. (2019) Ratish Puduppully, Li Dong, and Mirella Lapata. 2019. Data-to-text generation with content selection and planning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- Qian et al. (2019) Lihua Qian, Lin Qiu, Weinan Zhang, Xin Jiang, and Yong Yu. 2019. Exploring diverse expressions for paraphrase generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research.
- Ren et al. (2020) Yi Ren, Jinglin Liu, Xu Tan, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2020. A study of non-autoregressive model for sequence generation. Proceedings of the 58th annual meeting of the Association for Computational Linguistics (ACL).
- Robbins and Monro (1951) Herbert Robbins and Sutton Monro. 1951. A stochastic approximation method. Mathematical Statistics.
- Rose et al. (2010) Stuart Rose, Dave Engel, Nick Cramer, and Wendy Cowley. 2010. Automatic keyword extraction from individual documents. Text mining: applications and theory.
- Rothe et al. (2020) Sascha Rothe, Shashi Narayan, and Aliaksei Severyn. 2020. Leveraging pre-trained checkpoints for sequence generation tasks. Transactions of the Association for Computational Linguistics (TACL).
- See et al. (2017) Abigail See, Peter J Liu, and Christopher D Manning. 2017. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL).
- Shen et al. (2019) Tianxiao Shen, Myle Ott, Michael Auli, and Marc’Aurelio Ranzato. 2019. Mixture models for diverse machine translation: Tricks of the trade. In International Conference on Machine Learning (ICML).
- Shen et al. (2020) Tianxiao Shen, Victor Quach, Regina Barzilay, and Tommi Jaakkola. 2020. Blank language models. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP).
- Shi et al. (2018) Zhan Shi, Xinchi Chen, Xipeng Qiu, and Xuanjing Huang. 2018. Toward diverse text generation with inverse reinforcement learning. In Proceedings of the 27th International Joint Conference on Artificial Intelligence.
- Stern et al. (2019) Mitchell Stern, William Chan, Jamie Kiros, and Jakob Uszkoreit. 2019. Insertion transformer: Flexible sequence generation via insertion operations. In International Conference on Machine Learning (ICML).
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NeurIPS).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems (NeurIPS).
- Vedantam et al. (2015) Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. In Proceedings of conference on computer vision and pattern recognition (CVPR).
- Vijayakumar et al. (2018) Ashwin K Vijayakumar, Michael Cogswell, Ramprasaath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2018. Diverse beam search for improved description of complex scenes. In AAAI Conference on Artificial Intelligence.
- Vijayakumar et al. (2016) Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. 2016. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv preprint arXiv:1610.02424.
- Wang et al. (2019) Qingyun Wang, Lifu Huang, Zhiying Jiang, Kevin Knight, Heng Ji, Mohit Bansal, and Yi Luan. 2019. Paperrobot: Incremental draft generation of scientific ideas. In 57th Annual Meeting of the Association for Computational Linguistics (ACL).
- Wang et al. (2020) Zhen Wang, Siwei Rao, Jie Zhang, Zhen Qin, Guangjian Tian, and Jun Wang. 2020. Diversify question generation with continuous content selectors and question type modeling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings (EMNLP).
- Wolf et al. (2020) Thomas Wolf et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Yang et al. (2019) Pengcheng Yang, Lei Li, Fuli Luo, Tianyu Liu, and Xu Sun. 2019. Enhancing topic-to-essay generation with external commonsense knowledge. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL).
- Yao et al. (2019) Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2019. Plan-and-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- Yu et al. (2020) Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, and Meng Jiang. 2020. A survey of knowledge-enhanced text generation. arXiv preprint arXiv:2010.04389.
- Zhang et al. (2018) Yizhe Zhang, Michel Galley, Jianfeng Gao, Zhe Gan, Xiujun Li, Chris Brockett, and Bill Dolan. 2018. Generating informative and diverse conversational responses via adversarial information maximization. Advances in Neural Information Processing Systems (NeurIPS).
- Zhang et al. (2020) Yizhe Zhang, Guoyin Wang, Chunyuan Li, Zhe Gan, Chris Brockett, and Bill Dolan. 2020. Pointer: Constrained text generation via insertion-based generative pre-training. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP).
- Zhao et al. (2020) Liang Zhao, Jingjing Xu, Junyang Lin, Yichang Zhang, Hongxia Yang, and Xu Sun. 2020. Graph-based multi-hop reasoning for long text generation. arXiv preprint arXiv:2009.13282.
- Zhao et al. (2017) Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi. 2017. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
- Zhu et al. (2018) Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. 2018. Texygen: A benchmarking platform for text generation models. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval (SIGIR).
| Method | Pre-train | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | CIDEr |
| AGENDA | |||||||
| BLM | 0.4632 | 0.3248 | 0.2338 | 0.1679 | 0.2282 | 0.4940 | |
| GPT-2 | 0.4009 | 0.2608 | 0.1795 | 0.1247 | 0.2117 | 0.6508 | |
| BERTGen | 0.4435 | 0.2936 | 0.2046 | 0.1462 | 0.2202 | 0.6288 | |
| T5 | 0.4724 | 0.3235 | 0.2314 | 0.1688 | 0.2237 | 0.6203 | |
| Transformer | 0.4481 | 0.3084 | 0.2175 | 0.1540 | 0.2265 | 0.6307 | |
| BART | 0.4765 | 0.3409 | 0.2539 | 0.1922 | 0.2418 | 0.7982 | |
| PermGen | 0.4537 | 0.3183 | 0.2308 | 0.1678 | 0.2294 | 0.6192 | |
| 0.5043 | 0.3627 | 0.2719 | 0.2059 | 0.2500 | 0.8175 | ||
| DailyMail | |||||||
| BLM | 0.3902 | 0.2540 | 0.1718 | 0.1164 | 0.2013 | 0.3627 | |
| GPT-2 | 0.3518 | 0.2188 | 0.1510 | 0.1072 | 0.1911 | 0.5433 | |
| BERTGen | 0.4350 | 0.3088 | 0.2299 | 0.1728 | 0.2301 | 0.4316 | |
| T5 | 0.4208 | 0.2895 | 0.2089 | 0.1529 | 0.2188 | 0.3813 | |
| Transformer | 0.4379 | 0.2958 | 0.2098 | 0.1496 | 0.2221 | 0.5869 | |
| BART | 0.4727 | 0.3368 | 0.2534 | 0.1935 | 0.2379 | 0.7252 | |
| PermGen | 0.4484 | 0.3024 | 0.2178 | 0.1592 | 0.2225 | 0.7059 | |
| 0.4764 | 0.3407 | 0.2586 | 0.1991 | 0.2390 | 0.7549 | ||
| ROCStories | |||||||
| BLM | 0.4653 | 0.3075 | 0.2098 | 0.1477 | 0.2275 | 0.7060 | |
| GPT-2 | 0.3157 | 0.1824 | 0.1133 | 0.0726 | 0.1592 | 0.4458 | |
| BERTGen | 0.4753 | 0.3155 | 0.2184 | 0.1576 | 0.2393 | 0.8628 | |
| T5 | 0.5347 | 0.3655 | 0.2584 | 0.1895 | 0.2480 | 1.3108 | |
| Transformer | 0.5180 | 0.3526 | 0.2482 | 0.1809 | 0.2457 | 1.1342 | |
| BART | 0.5688 | 0.4159 | 0.3143 | 0.2445 | 0.2744 | 1.6165 | |
| PermGen | 0.5238 | 0.3566 | 0.2522 | 0.1848 | 0.2465 | 1.1775 | |
| 0.5830 | 0.4238 | 0.3196 | 0.2482 | 0.2769 | 1.7385 | ||
| Method | Per-train | Dist-2 | Dist-3 | Ent-1 | Ent-2 | Ent-3 | Ent-4 | Self-BLEU-4 |
| AGENDA | ||||||||
| BLM | 0.1465 | 0.2593 | 6.2633 | 9.3736 | 10.5771 | 10.8762 | 0.9396 | |
| GPT-2 | 0.1665 | 0.2709 | 6.3327 | 9.0065 | 10.0387 | 10.4467 | 0.9331 | |
| BERTGen | 0.1463 | 0.2457 | 6.1160 | 9.1015 | 10.2476 | 10.6362 | 0.9356 | |
| T5 | 0.1323 | 0.2178 | 5.9393 | 8.6682 | 9.8081 | 10.2888 | 0.9421 | |
| Transformer | 0.1489 | 0.2546 | 5.9858 | 8.6806 | 9.8452 | 10.3447 | 0.9265 | |
| BART | 0.1697 | 0.2815 | 6.2168 | 9.0698 | 10.1473 | 10.5333 | 0.9476 | |
| PermGen | 0.2203 | 0.4564 | 6.1674 | 9.0272 | 10.3163 | 10.8839 | 0.5979 | |
| 0.2492 | 0.4852 | 6.3864 | 9.4862 | 10.7269 | 11.1911 | 0.6173 | ||
| DailyMail | ||||||||
| BLM | 0.0831 | 0.1379 | 6.4465 | 9.0287 | 10.3353 | 10.9684 | 0.9889 | |
| GPT-2 | 0.1577 | 0.2511 | 7.4221 | 10.5923 | 11.6718 | 11.9437 | 0.9287 | |
| BERTGen | 0.1167 | 0.1980 | 6.8704 | 10.3130 | 11.5898 | 11.8999 | 0.9744 | |
| T5 | 0.1086 | 0.1763 | 6.7553 | 9.7788 | 11.0747 | 11.5242 | 0.9779 | |
| Transformer | 0.1109 | 0.1942 | 6.9249 | 10.0132 | 11.3008 | 11.7343 | 0.9678 | |
| BART | 0.1306 | 0.2163 | 7.1025 | 10.3602 | 11.5483 | 11.8704 | 0.9778 | |
| PermGen | 0.1934 | 0.3790 | 7.1776 | 10.6234 | 11.9798 | 12.3989 | 0.7757 | |
| 0.2065 | 0.4140 | 7.2142 | 10.6632 | 12.0205 | 12.4793 | 0.6701 | ||
| ROCStories | ||||||||
| BLM | 0.0560 | 0.1402 | 5.5457 | 8.8401 | 10.8404 | 11.8790 | 0.9573 | |
| GPT-2 | 0.0915 | 0.1902 | 6.4372 | 9.8739 | 11.4976 | 12.0918 | 0.9194 | |
| BERTGen | 0.0672 | 0.1626 | 5.8283 | 9.3407 | 11.3309 | 12.2154 | 0.9456 | |
| T5 | 0.0684 | 0.1631 | 5.8398 | 9.3663 | 11.3523 | 12.2285 | 0.9403 | |
| Transformer | 0.0806 | 0.1971 | 5.7978 | 9.3205 | 11.4086 | 12.4069 | 0.9341 | |
| BART | 0.0839 | 0.2103 | 5.8986 | 9.4791 | 11.5186 | 12.4204 | 0.9330 | |
| PermGen | 0.0992 | 0.2786 | 5.7773 | 9.2959 | 11.4553 | 12.6124 | 0.8548 | |
| 0.1059 | 0.2953 | 5.9669 | 9.6523 | 11.7972 | 12.8034 | 0.7247 | ||
| Sampling | Setting | Method | Dist-2 | Dist-3 | Ent-1 | Ent-2 | Ent-3 | Ent-4 | Self-BLEU-3/4 | |
| AGENDA | ||||||||||
| Beam search | Original | 0.1697 | 0.2815 | 6.2168 | 9.0698 | 10.1473 | 10.5333 | 0.9531 | 0.9476 | |
| PermGen | 0.2492 | 0.4852 | 6.3864 | 9.4862 | 10.7269 | 11.1911 | 0.6675 | 0.6173 | ||
| Truncated sampling | k=10 | Original | 0.2410 | 0.4489 | 6.2751 | 9.2836 | 10.5489 | 11.0561 | 0.6680 | 0.6139 |
| PermGen | 0.2599 | 0.5114 | 6.3993 | 9.5307 | 10.8008 | 11.2772 | 0.6217 | 0.5630 | ||
| k=50 | Original | 0.2491 | 0.4923 | 6.2773 | 9.3190 | 10.6157 | 11.1347 | 0.6239 | 0.5626 | |
| PermGen | 0.2632 | 0.5205 | 6.4038 | 9.5549 | 10.8411 | 11.3239 | 0.6010 | 0.5397 | ||
| Nucleus sampling | p=.75 | Original | 0.2434 | 0.4716 | 6.2771 | 9.2946 | 10.5610 | 11.0647 | 0.6619 | 0.6080 |
| PermGen | 0.2583 | 0.5076 | 6.3911 | 9.5135 | 10.7804 | 11.2588 | 0.6255 | 0.5682 | ||
| p=.95 | Original | 0.2522 | 0.4962 | 6.2889 | 9.3377 | 10.6308 | 11.1448 | 0.6190 | 0.5579 | |
| PermGen | 0.2636 | 0.5221 | 6.3996 | 9.5507 | 10.8385 | 11.3204 | 0.6006 | 0.5393 | ||
| DailyMail | ||||||||||
| Beam search | Original | 0.1306 | 0.2163 | 7.1025 | 10.3602 | 11.5483 | 11.8704 | 0.9798 | 0.9778 | |
| PermGen | 0.2065 | 0.4140 | 7.2142 | 10.6632 | 12.0205 | 12.4793 | 0.7146 | 0.6701 | ||
| Truncated sampling | k=10 | Original | 0.2087 | 0.4278 | 7.1406 | 10.5733 | 12.0173 | 12.5324 | 0.7055 | 0.6561 |
| PermGen | 0.2166 | 0.4421 | 7.2171 | 10.6979 | 12.0915 | 12.5711 | 0.6704 | 0.6175 | ||
| k=50 | Original | 0.2194 | 0.4553 | 7.1485 | 10.6153 | 12.0872 | 12.6152 | 0.6612 | 0.6046 | |
| PermGen | 0.2228 | 0.4573 | 7.2222 | 10.7221 | 12.1282 | 12.6154 | 0.6472 | 0.5909 | ||
| Nucleus sampling | p=.75 | Original | 0.2109 | 0.4315 | 7.1439 | 10.5835 | 12.0270 | 12.5400 | 0.7004 | 0.6508 |
| PermGen | 0.2166 | 0.4409 | 7.2188 | 10.6994 | 12.0894 | 12.5671 | 0.6719 | 0.6198 | ||
| p=.95 | Original | 0.2213 | 0.4600 | 7.1523 | 10.6254 | 12.1002 | 12.6307 | 0.6544 | 0.5972 | |
| PermGen | 0.2222 | 0.4566 | 7.2197 | 10.7195 | 12.1300 | 12.6168 | 0.6465 | 0.5902 | ||
| ROCStories | ||||||||||
| Beam search | Original | 0.0839 | 0.2103 | 5.8986 | 9.4791 | 11.5186 | 12.4204 | 0.9420 | 0.9330 | |
| PermGen | 0.1059 | 0.2953 | 5.9669 | 9.6523 | 11.7972 | 12.8034 | 0.7669 | 0.7247 | ||
| Truncated sampling | k=10 | Original | 0.1053 | 0.2834 | 5.9041 | 9.5370 | 11.6702 | 12.6739 | 0.7955 | 0.7591 |
| PermGen | 0.1099 | 0.3088 | 5.9716 | 9.6702 | 11.8335 | 12.8547 | 0.7359 | 0.6878 | ||
| k=50 | Original | 0.1093 | 0.2970 | 5.9094 | 9.5552 | 11.7055 | 12.7234 | 0.7633 | 0.7213 | |
| PermGen | 0.1114 | 0.3141 | 5.9761 | 9.6801 | 11.8497 | 12.8732 | 0.7235 | 0.6734 | ||
| Nucleus sampling | p=.75 | Original | 0.1032 | 0.2746 | 5.9047 | 9.5309 | 11.6501 | 12.6400 | 0.8147 | 0.7829 |
| PermGen | 0.1092 | 0.3069 | 5.9730 | 9.6685 | 11.8292 | 12.8459 | 0.7421 | 0.6953 | ||
| p=.95 | Original | 0.1088 | 0.2955 | 5.9108 | 9.5545 | 11.7011 | 12.7160 | 0.7669 | 0.7260 | |
| PermGen | 0.1111 | 0.3132 | 5.9747 | 9.6778 | 11.8463 | 12.8702 | 0.7252 | 0.6753 | ||
| Sampling | Setting | Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | CIDEr |
| AGENDA | ||||||||
| Beam search | Original | 0.4765 | 0.3409 | 0.2539 | 0.1922 | 0.2418 | 0.7982 | |
| PermGen | 0.5043 | 0.3627 | 0.2719 | 0.2059 | 0.2500 | 0.8175 | ||
| Truncated sampling | k=10 | Original | 0.4718 | 0.3374 | 0.2513 | 0.1901 | 0.2408 | 0.7191 |
| PermGen | 0.5035 | 0.3620 | 0.2716 | 0.2058 | 0.2495 | 0.8317 | ||
| k=50 | Original | 0.4777 | 0.3403 | 0.2529 | 0.1910 | 0.2415 | 0.7874 | |
| PermGen | 0.5062 | 0.3626 | 0.2709 | 0.2047 | 0.2496 | 0.8465 | ||
| Nucleus sampling | p=.75 | Original | 0.4720 | 0.3361 | 0.2496 | 0.1878 | 0.2399 | 0.7174 |
| PermGen | 0.5021 | 0.3611 | 0.2705 | 0.2047 | 0.2487 | 0.8254 | ||
| p=.95 | Original | 0.4764 | 0.3391 | 0.2519 | 0.1902 | 0.2407 | 0.7818 | |
| PermGen | 0.5071 | 0.3639 | 0.2721 | 0.2053 | 0.2502 | 0.8114 | ||
| DailyMail | ||||||||
| Beam search | Original | 0.4727 | 0.3368 | 0.2534 | 0.1935 | 0.2379 | 0.7252 | |
| PermGen | 0.4764 | 0.3407 | 0.2586 | 0.1991 | 0.2390 | 0.7549 | ||
| Truncated sampling | k=10 | Original | 0.4728 | 0.3357 | 0.2522 | 0.1923 | 0.2385 | 0.7206 |
| PermGen | 0.4772 | 0.3404 | 0.2578 | 0.1978 | 0.2374 | 0.8080 | ||
| k=50 | Original | 0.4742 | 0.3362 | 0.2519 | 0.1916 | 0.2379 | 0.7311 | |
| PermGen | 0.4785 | 0.3409 | 0.2580 | 0.1982 | 0.2380 | 0.8389 | ||
| Nucleus sampling | p=.75 | Original | 0.4726 | 0.3360 | 0.2525 | 0.1926 | 0.2383 | 0.7070 |
| PermGen | 0.4784 | 0.3416 | 0.2592 | 0.1993 | 0.2385 | 0.8048 | ||
| p=.95 | Original | 0.4740 | 0.3367 | 0.2528 | 0.1926 | 0.2384 | 0.7204 | |
| PermGen | 0.4785 | 0.3412 | 0.2584 | 0.1983 | 0.2383 | 0.8118 | ||
| ROCStories | ||||||||
| Beam search | Original | 0.5688 | 0.4159 | 0.3143 | 0.2445 | 0.2744 | 1.6165 | |
| PermGen | 0.5830 | 0.4238 | 0.3196 | 0.2482 | 0.2769 | 1.7385 | ||
| Truncated sampling | k=10 | Original | 0.5680 | 0.4139 | 0.3117 | 0.2418 | 0.2734 | 1.6213 |
| PermGen | 0.5829 | 0.4226 | 0.3179 | 0.2463 | 0.2761 | 1.7322 | ||
| k=50 | Original | 0.5681 | 0.4135 | 0.3112 | 0.2410 | 0.2729 | 1.6168 | |
| PermGen | 0.5834 | 0.4231 | 0.3181 | 0.2464 | 0.2764 | 1.7379 | ||
| Nucleus sampling | p=.75 | Original | 0.5681 | 0.4144 | 0.3123 | 0.2423 | 0.2735 | 1.6152 |
| PermGen | 0.5823 | 0.4225 | 0.3180 | 0.2466 | 0.2761 | 1.7330 | ||
| p=.95 | Original | 0.5678 | 0.4135 | 0.3115 | 0.2415 | 0.2730 | 1.6207 | |
| PermGen | 0.5833 | 0.4231 | 0.3183 | 0.2466 | 0.2762 | 1.7363 | ||
| Sampling | Setting | Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | CIDEr |
| AGENDA | ||||||||
| Beam search | Original | 0.4941 | 0.3529 | 0.2624 | 0.1983 | 0.2469 | 1.0208 | |
| PermGen | 0.5052 | 0.3723 | 0.2858 | 0.2217 | 0.2556 | 1.0371 | ||
| Truncated sampling | k=10 | Original | 0.4983 | 0.3627 | 0.2746 | 0.2110 | 0.2516 | 1.0291 |
| PermGen | 0.5068 | 0.3723 | 0.2852 | 0.2209 | 0.2561 | 1.0247 | ||
| k=50 | Original | 0.5017 | 0.3642 | 0.2758 | 0.2123 | 0.2522 | 1.0451 | |
| PermGen | 0.5061 | 0.3720 | 0.2851 | 0.2211 | 0.2548 | 1.0285 | ||
| Nucleus sampling | p=.75 | Original | 0.4960 | 0.3604 | 0.2726 | 0.2091 | 0.2510 | 0.9920 |
| PermGen | 0.5006 | 0.3688 | 0.2830 | 0.2195 | 0.2540 | 1.0549 | ||
| p=.95 | Original | 0.4984 | 0.3624 | 0.2744 | 0.2114 | 0.2510 | 1.0441 | |
| PermGen | 0.5095 | 0.3741 | 0.2863 | 0.2215 | 0.2556 | 1.0121 | ||
| DailyMail | ||||||||
| Beam search | Original | 0.4817 | 0.3428 | 0.2578 | 0.1968 | 0.2408 | 0.9001 | |
| PermGen | 0.4847 | 0.3567 | 0.2777 | 0.2193 | 0.2448 | 0.8544 | ||
| Truncated sampling | k=10 | Original | 0.4888 | 0.3545 | 0.2716 | 0.2115 | 0.2448 | 0.9212 |
| PermGen | 0.4853 | 0.3568 | 0.2779 | 0.2196 | 0.2447 | 0.8678 | ||
| k=50 | Original | 0.4891 | 0.3550 | 0.2723 | 0.2122 | 0.2444 | 0.9197 | |
| PermGen | 0.4878 | 0.3580 | 0.2784 | 0.2197 | 0.2454 | 0.8902 | ||
| Nucleus sampling | p=.75 | Original | 0.4888 | 0.3540 | 0.2710 | 0.2106 | 0.2444 | 0.9192 |
| PermGen | 0.4857 | 0.3573 | 0.2784 | 0.2199 | 0.2451 | 0.8240 | ||
| p=.95 | Original | 0.4896 | 0.3554 | 0.2727 | 0.2127 | 0.2446 | 0.9152 | |
| PermGen | 0.4871 | 0.3580 | 0.2783 | 0.2194 | 0.2455 | 0.8809 | ||
| ROCStories | ||||||||
| Beam search | Original | 0.5801 | 0.4282 | 0.3264 | 0.2556 | 0.2789 | 1.7947 | |
| PermGen | 0.5991 | 0.4505 | 0.3513 | 0.2810 | 0.2875 | 2.0115 | ||
| Truncated sampling | k=10 | Original | 0.5834 | 0.4377 | 0.3390 | 0.2692 | 0.2824 | 1.8148 |
| PermGen | 0.5988 | 0.4501 | 0.3508 | 0.2803 | 0.2871 | 2.0160 | ||
| k=50 | Original | 0.5849 | 0.4394 | 0.3410 | 0.2712 | 0.2830 | 1.8393 | |
| PermGen | 0.5989 | 0.4503 | 0.3510 | 0.2805 | 0.2872 | 2.0137 | ||
| Nucleus sampling | p=.75 | Original | 0.5829 | 0.4362 | 0.3369 | 0.2667 | 0.2818 | 1.8135 |
| PermGen | 0.5989 | 0.4500 | 0.3508 | 0.2803 | 0.2872 | 2.0107 | ||
| p=.95 | Original | 0.5852 | 0.4392 | 0.3405 | 0.2706 | 0.2831 | 1.8293 | |
| PermGen | 0.5989 | 0.4505 | 0.3515 | 0.2812 | 0.2870 | 2.0232 | ||
| Inputs: (Title) Hierarchical Semantic Classification: Word Sense Disambiguation with World Knowledge. (Keyphrases) learning architecture; lexical semantic classification problems; task-specific training data; background data; hierarchical learning architecture; word sense disambiguation task |
| Beam search-1: This paper presents a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . The learning architecture is built on top of a hierarchical learning architecture that is able to integrate both tasks-specific and background data in a principled way . We evaluate the hierarchical learning on a word sense disambiguation task and show that the hierarchical learns architecture outperforms a state-of-the-art approach . |
| Beam search-2: This paper presents a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . The learning architecture is built on top of a hierarchical learning architecture that is able to integrate both tasks-specific and background data in a principled way . We evaluate the hierarchical learning on a word sense disambiguation task and show that the hierarchical learns architecture is competitive with state-of-the-art methods . |
| Beam search-3: This paper presents a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . The learning architecture is built on top of a hierarchical learning architecture that is able to integrate both tasks-specific and background data in a principled way . We evaluate the hierarchical learning on a word sense disambiguation task and show that the hierarchical learns architecture outperforms the state-of-the-art . |
| Nucleus sampling-1: We present a learning architecture for lexical semantic classification problems that does not require any task-specific training data or background data . The learning architecture can be trained on a variety of tasks without any knowledge of the nature of the tasks or the sources of the training data . We show that this can be achieved by combining task-sparse and sparse training data , and show that the resulting hierarchical learning architecture outperforms state-of-the-art methods on a word sense disambiguation task . |
| Nucleus sampling-2: We present a learning architecture for lexical semantic classification problems that does not require any task-specific training data or background data . The learning architecture is designed to learn from both the tasks-specific and background data simultaneously . We apply this hierarchical learning architecture to a word sense disambiguation task and show that hierarchical learning architectures outperforms state-of-the-art methods on both tasks . |
| Nucleus sampling-3: We present a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . Our learning architecture is able to take advantage of both tasks by exploiting the relationship between task-sensor and background data in a principled way . We apply our hierarchical learning architecture to a word sense disambiguation task , and show that hierarchical learning architectures outperforms state-of-the-art methods . |
| PermGen order-1 [1, 2, 3]: We present a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . Our learning architecture learns to partition the data in different domains into different subsets , such that the distribution of a given word is consistent across different domains . We show that our hierarchical learning architecture outperforms the state-of-the-art methods on a word sense disambiguation task , and present the results of a large-scale empirical evaluation . |
| PermGen order-2 [2, 1, 3]: This paper presents a new learning architecture for lexical semantic classification problems that does not rely on task specific training data . We propose a learning architecture that leverages both task-specific and background data . We apply this hierarchical learning architecture to a word sense disambiguation task , and show that hierarchical learning architecture outperforms state-of-the-art methods . |
| PermGen order-3 [3, 1, 2]: We describe a learning architecture for lexical semantic classification problems that does not require task-specific training data or background data . Our learning architecture is built on top of a hierarchy of networks that learn to classify words based on their senses , and a network that ties together the tasks-specific and background data to form a hierarchy . We apply this hierarchical learning architecture to a word sense disambiguation task , and show that hierarchical learning architecture outperforms state-of-the-art methods . |
| Inputs: white british londoners; left; census figures show; white flight; equivalent; white britons; white britons; minority |
| Beam search-1: More than 700,000 white British Londoners have left the country in the last decade . Census figures show that a “ white flight ” has taken place in the capital since the 1990s . This is equivalent to more than one in four white Britons having left the UK . White Britons are now a minority of the population in London , according to new figures . |
| Beam search-2: More than 700,000 white British Londoners have left the country in the last decade . Census figures show that a “ white flight ” has taken place in the capital since the 1990s . This is equivalent to more than one in four white Britons having left the UK . White Britons are now a minority of the population in London . |
| Beam search-3: More than 700,000 white British Londoners have left the country in the last decade . Census figures show that a “ white flight ” has taken place in the capital since the 1990s . This is equivalent to more than one in four white Britons having left the UK . White Britons are now a minority of the population in London , according to a new study . |
| Nucleus sampling-1: More than 700,000 white British Londoners have left the country since 2001 , according to new figures . Census figures show that the “ white flight ” of incomers has overtaken those from elsewhere in the country . It is equivalent to more than one in four white Britons having left the UK . White Britons are now a minority of the population in England and Wales . |
| Nucleus sampling-2: More than 100,000 white British Londoners have left the country , according to new figures . Census figures show that a “ white flight ” of incomers has taken place in the capital . This is equivalent to more than half of all white Britons being in the UK . White Britons are now a minority of the population in London , new figures have revealed . |
| Nucleus Sampling-3: More than 50,000 white British Londoners have left the country . Census figures show that a ‘ white flight ’ of incomers has taken place in the capital . This is equivalent to more than one in four white Britons having left the UK . White Britons are now a minority of the population in London , according to new figures . |
| PermGen order-1 [1, 2, 3, 4]: The equivalent of more than 10,000 white British Londoners have left the country , it has been revealed . Census figures show that a “ white flight ” of people moving to the capital has overtaken London for the first time . The equivalent of more than 10,000 white Britons has left the country for the first time in more than a decade . White Britons have become a minority in the capital since 1994 , but are now only a minority . |
| PermGen order-2 [3, 2, 4, 1]: More than 50,000 white British Londoners have left the country for the first time , new figures have revealed . Census figures show that a “ white flight ” of people from outside Europe has overtaken the city ’s residents for the first time . The equivalent of around 40 per cent of all white Britons now live in the UK . White Britons now make up a minority of the population in London. |
| PermGen order-3 [4, 2, 1, 3]: More than 50,000 white British Londoners have left the country in the last three years . Census figures show that the number of “ white flight ” migrants has risen by more than 50 per cent in just three years . This is equivalent to more than one in four white Britons in the UK . The number of white Britons in the minority has risen by more than 50 per cent in just three years . |