Achievable Fairness on Your Data With Utility Guarantees
Abstract
In machine learning fairness, training models that minimize disparity across different sensitive groups often leads to diminished accuracy, a phenomenon known as the fairness-accuracy trade-off. The severity of this trade-off inherently depends on dataset characteristics such as dataset imbalances or biases and therefore, using a uniform fairness requirement across diverse datasets remains questionable. To address this, we present a computationally efficient approach to approximate the fairness-accuracy trade-off curve tailored to individual datasets, backed by rigorous statistical guarantees. By utilizing the You-Only-Train-Once (YOTO) framework, our approach mitigates the computational burden of having to train multiple models when approximating the trade-off curve. Crucially, we introduce a novel methodology for quantifying uncertainty in our estimates, thereby providing practitioners with a robust framework for auditing model fairness while avoiding false conclusions due to estimation errors. Our experiments spanning tabular (e.g., Adult), image (CelebA), and language (Jigsaw) datasets underscore that our approach not only reliably quantifies the optimum achievable trade-offs across various data modalities but also helps detect suboptimality in SOTA fairness methods.
1 Introduction
A key challenge in fairness for machine learning is to train models that minimize disparity across various sensitive groups such as race or gender [9, 35, 10]. This often comes at the cost of reduced model accuracy, a phenomenon termed accuracy-fairness trade-off [36, 32]. This trade-off can differ significantly across datasets, depending on factors such as dataset biases, imbalances etc. [1, 8, 11].
To demonstrate how these trade-offs are inherently dataset-dependent, we consider a simple example involving two distinct crime datasets. Dataset A has records from a community where crime rates are uniformly distributed across all racial groups, whereas Dataset B comes from a community where historical factors have resulted in a disproportionate crime rate among a specific racial group. Intuitively, training models which are racially agnostic is more challenging for Dataset B, due to the unequal distribution of crime rates across racial groups, and will result in a greater loss in model accuracy as compared to Dataset A.
This example underscores that setting a uniform fairness requirement across diverse datasets (such as requiring the fairness violation metric to be below 10% for both datasets), while also adhering to essential accuracy benchmarks is impractical. Therefore, choosing fairness guidelines for any dataset necessitates careful consideration of its individual characteristics and underlying biases. In this work, we advocate against the use of one-size-fits-all fairness mandates by proposing a nuanced, dataset-specific framework for quantifying acceptable range of accuracy-fairness trade-offs. To put it concretely, the question we consider is:

Given a dataset, what is the range of permissible fairness violations corresponding to each accuracy threshold for models in a given class ?
This question can be addressed by considering the optimum accuracy-fairness trade-off, which shows the minimum fairness violation achievable for each level of accuracy. Unfortunately, this curve is typically unavailable and hence, various optimization techniques have been proposed to approximate this curve, ranging from regularization [8, 33] to adversarial learning [45, 40].
However, approximating the trade-off curve using these aforementioned methods has some serious limitations. Firstly, these methods require retraining hundreds if not thousands of models to obtain a good approximation of the trade-off curve, making them computationally infeasible for large datasets or models. Secondly, these works do not account for finite-sampling errors in the obtained curve. This is problematic since the empirical trade-off evaluated over a finite dataset may not match the exact trade-off over the full data distribution.
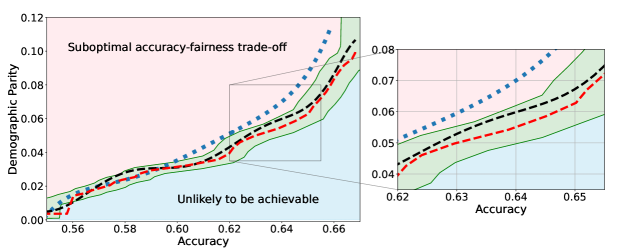
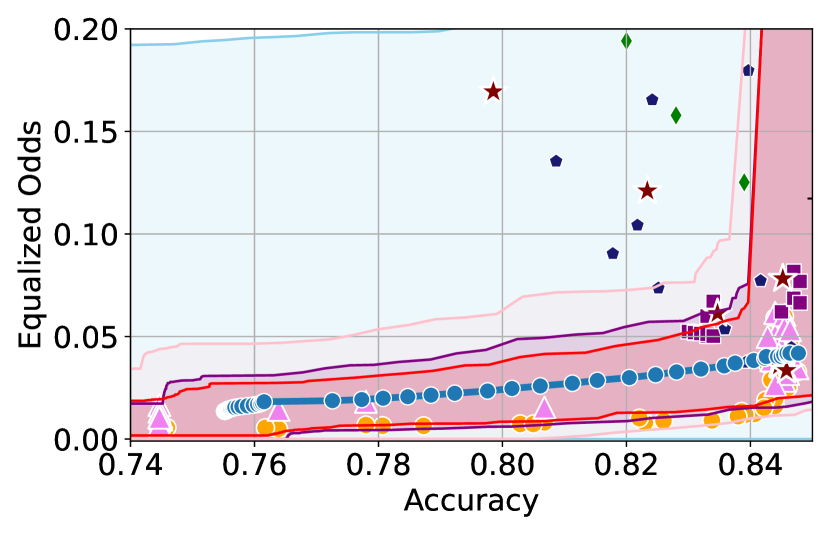
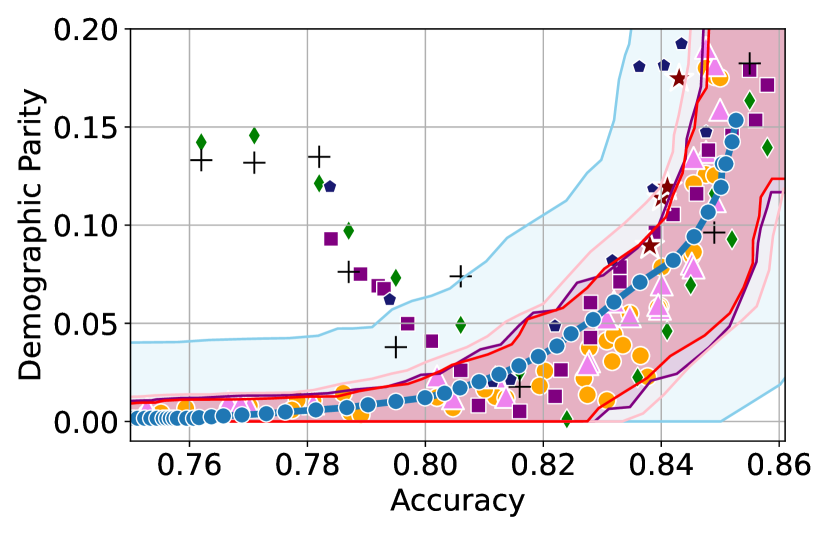
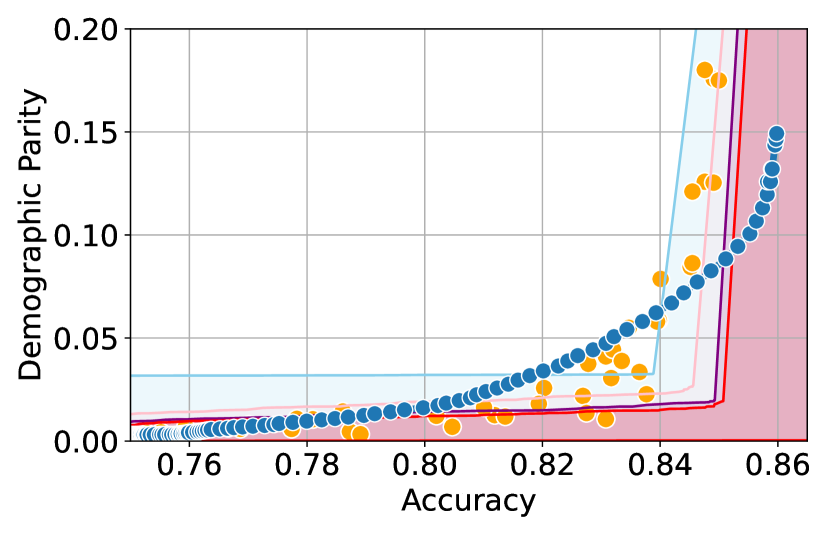
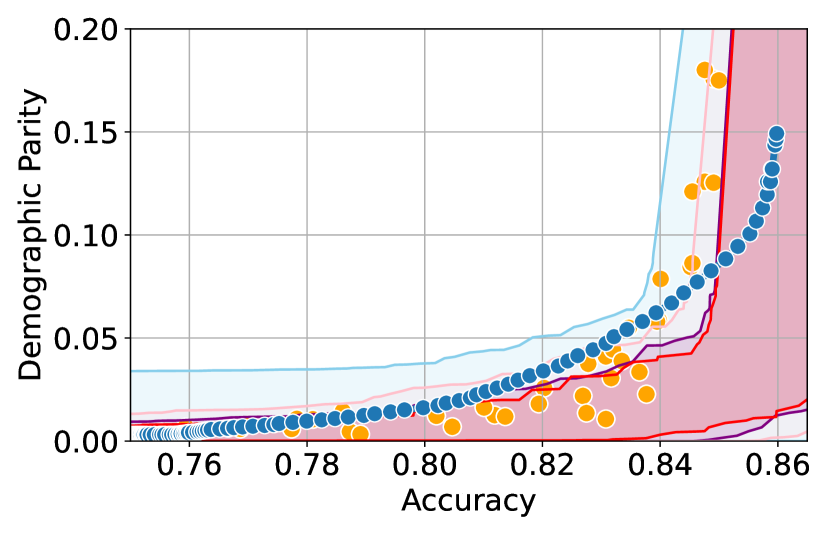
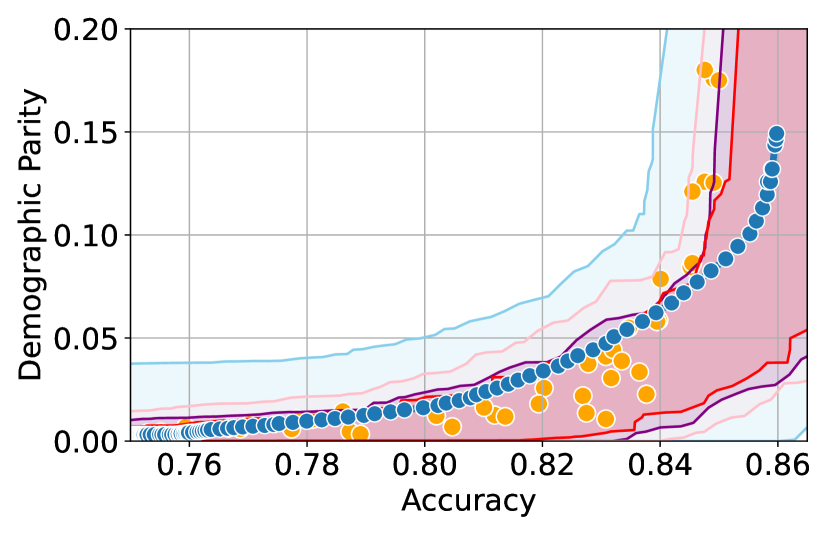
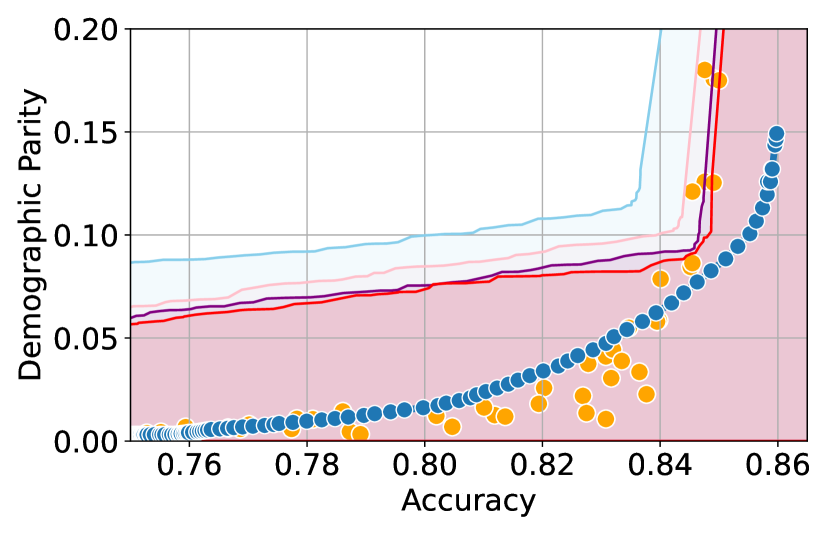
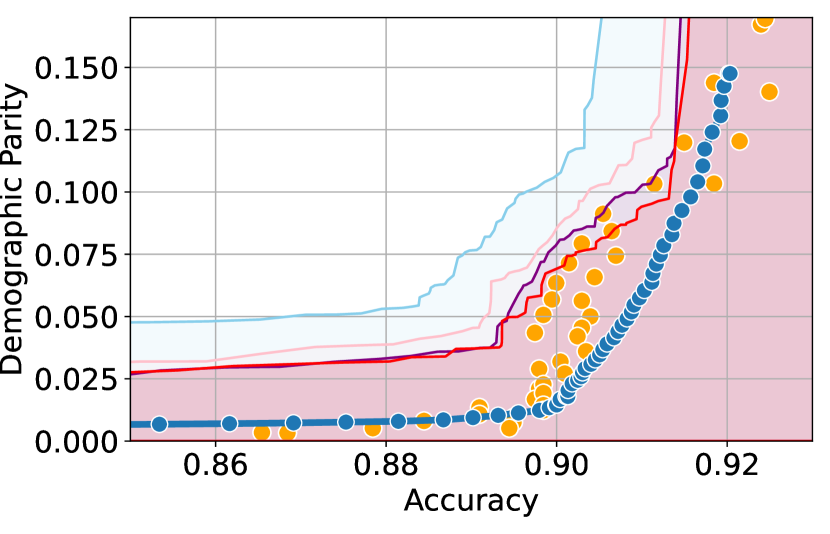
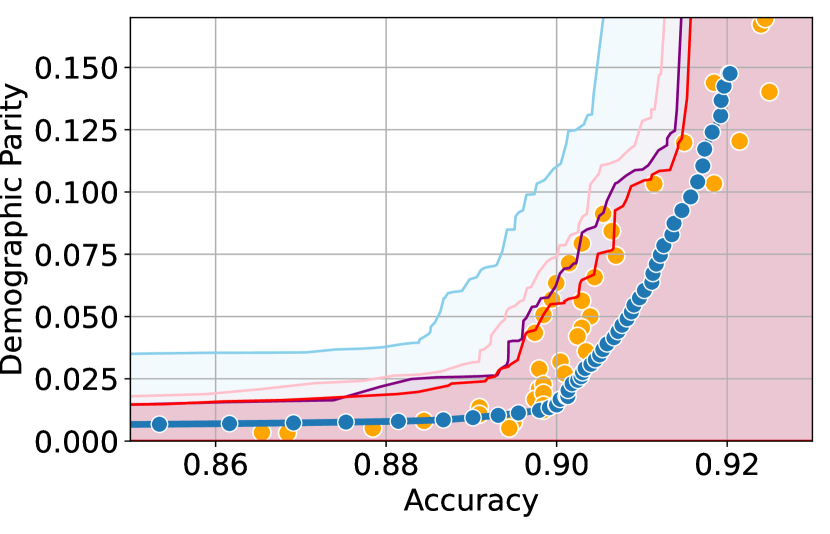
We illustrate this phenomenon in Figure 1 where the black and red trade-off curves are obtained using the same model but evaluated over two different test data draws. Here, relying solely on the estimated curves without accounting for the uncertainty could lead us to make the incorrect conclusion that the methodology used to obtain the black trade-off curve is sub-optimal (compared to the red curve) as it achieves a higher fairness violation for accuracies in the range . However, this discrepancy arises solely due to finite-sampling errors.
In this paper, we address these challenges by introducing a computationally efficient method of approximating the optimal accuracy-fairness trade-off curve, supported by rigorous statistical guarantees. Our methodology not only circumvents the need to train multiple models (leading to at least a 10-fold reduction in computational cost) but is also the first to quantify the uncertainty in the estimated curve, arising from both, finite-sampling error as well as estimation error. To achieve this, our approach adopts a novel probabilistic perspective and provides guarantees that remain valid across all finite-sample draws. This also allows practitioners to distinguish if an apparent suboptimality in a baseline could be explained by finite-sampling errors (as in the black curve in Figure 1), or if it stems from genuine deficiencies in the fairness interventions applied (as in the blue curve).
The contributions of this paper are three-fold:
-
•
We present a computationally efficient methodology for approximating the accuracy-fairness trade-off curve by training only a single model. This is achieved by adapting a technique from [15] called You-Only-Train-Once (YOTO) to the fairness setting.
-
•
To account for the approximation and finite-sampling errors, we introduce a novel technical framework to construct confidence intervals (using the trained YOTO model) which contain the optimal accuracy-fairness trade-off curve with statistical guarantees. For any accuracy threshold chosen at inference time, this gives us a statistically backed range of permissible fairness violations , allowing us to answer our previously posed question:
Given a dataset, the permissible range of fairness violations corresponding to an accuracy threshold of is for models in a given class .
-
•
Lastly, we showcase the vast applicability of our method empirically across various data modalities including tabular, image and text datasets. We evaluate our framework on a suite of SOTA fairness methods and show that our intervals are both reliable and informative.
2 Preliminaries
Notation
Throughout this paper, we consider a binary classification task, where each training sample is composed of triples, . denotes a vector of features, indicates a discrete sensitive attribute, and represents a label. To make this more concrete, if we take loan default prediction as the classification task, represents individuals’ features such as their income level and loan amount; represents their racial identity; and represents their loan default status. Having established the notation, for completeness, we provide some commonly used fairness violations for a classifier model when :
Demographic Parity (DP)
The DP condition states that the selection rates for all sensitive groups are equal, i.e. for any . The absolute DP violation is:
Equalized Opportunity (EOP)
The EOP condition states that the true positive rates for all sensitive groups are equal, i.e. for any . The absolute EOP violation is:
2.1 Problem setup
Next, we formalise the notion of accuracy-fairness trade-off, which is the main quantity of interest in our work. For a model class (e.g., neural networks) and a given accuracy threshold , we define the optimal accuracy-fairness trade-off as,
| (1) |
Here, and denote the fairness violation and accuracy of over the full data distribution. For an accuracy which is unattainable, we define and we focus on models trained using gradient-based methods. Crucially, our goal is not to estimate the trade-off at a fixed accuracy level, but instead to reliably and efficiently estimate the entire trade-off curve . In contrast, previous works [1, 11] impose an apriori fairness constraint during training and therefore each trained model only recovers one point on the trade-off curve corresponding to this pre-specified constraint.
If available, this trade-off curve would allow practitioners to characterise exactly how, for a given dataset, the minimum fairness violation varies as model accuracy increases. This not only provides a principled way of selecting data-specific fairness requirements, but also serves as a tool to audit if a model meets acceptable fairness standards by checking if its accuracy-fairness trade-off lies on this curve. Nevertheless, obtaining this ground-truth trade-off curve exactly is impossible within the confines of a finite-sample regime (owing to finite-sampling errors). This means that even if baseline A’s empirical trade-off evaluated on a finite dataset is suboptimal compared to the empirical trade-off of baseline B, this does not necessarily imply suboptimality on the full data distribution.
We illustrate this in Figure 1 where both red and black trade-off curves are obtained using the same model but evaluated on different test data splits. Here, even though the black curve appears suboptimal compared to the red curve for accuracies in , this apparent suboptimality is solely due to finite-sampling errors (since the discrepancy between the two curves arises only due to different evaluation datasets). If we rely only on comparing empirical trade-offs, we would incorrectly flag the methodology used to obtain the black curve as suboptimal.
To address this, we construct confidence intervals (CIs), shown as the green region in Figure 1, that account for such finite-sampling errors. In this case both trade-offs fall within our CIs which correctly indicates that this apparent suboptimality could stem from finite-sample variability. Conversely, a baseline’s trade-off falling above our CIs (as in the blue curve in Figure 1) offers a confident assessment of suboptimality, as this cannot be explained away by finite-sample variability. Therefore, our CIs equip practitioners with a robust auditing tool. They can confidently identify suboptimal baselines while avoiding false conclusions caused by considering empirical trade-offs alone.
High-level road map
To achieve this, our proposed methodology adopts a two-step approach:
-
1.
Firstly, we propose loss-conditional fairness training, a computationally efficient methodology of estimating the entire trade-off curve by training a single model, obtained by adapting the YOTO framework [15] to the fairness setting.
-
2.
Secondly, to account for the approximation and finite-sampling errors in our estimates, we introduce a novel methodology of constructing confidence intervals on the trade-off curve using the trained YOTO model. Specifically, given , we construct confidence intervals which satisfy guarantees of the form:
Here, and are random variables obtained using a held-out calibration dataset (see Section 3.2) and the probability is taken over different draws of .
3 Methodology
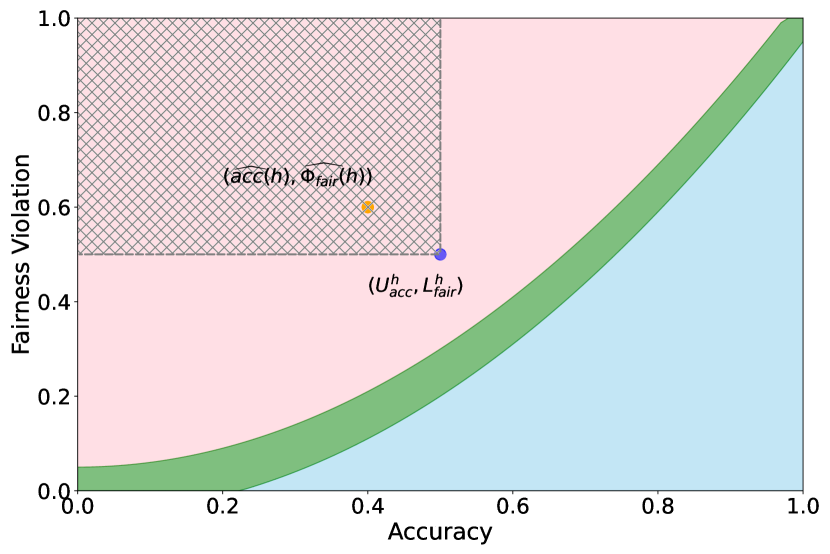
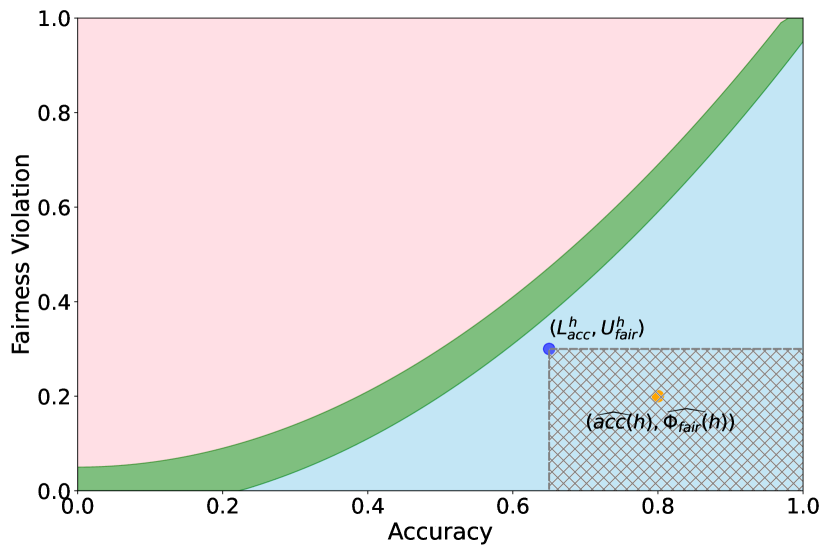
First, we demonstrate how our 2-step approach offers a practical and statistically sound method for estimating . Figure 1 provides an illustration of our proposed confidence intervals (CIs) and shows how they can be interpreted as a range of ‘permissible’ values of accuracy-fairness trade-offs (the green region). Specifically, if for a classifier , the accuracy-fairness pair lies above the CIs (i.e., the pink region in Figure 1), then is likely to be suboptimal in terms of the fairness violation, i.e., there likely exists with and . On the other hand, it is unlikely for any model to achieve a trade-off below the CIs (the blue region in Figure 1). Next, we outline how to construct such intervals.
3.1 Step 1: Efficient estimation of trade-off curve
The first step of constructing the intervals is to approximate the trade-off curve by recasting the problem into a constrained optimization objective. The optimization problem formulated in Eq. (1) is however, often too complex to solve, because the accuracy and fairness violations are both non-smooth [1]. These constraints make it hard to use standard optimization methods that rely on gradients [25]. To get around this issue, previous works [1, 8] replace the non-smooth constrained optimisation problem with a smooth surrogate loss. Here, we consider parameterized family of classifiers (such as neural networks) trained using the regularized loss:
| (2) |
where, is the cross-entropy loss for the classifier and is a smooth relaxation of the fairness violation [8, 29]. For example, when the fairness violation is DP, [8] consider
for different choices of , including the identity and sigmoid functions. We include more examples of such regularizers in Appendix F.3. The parameter in modulates the accuracy-fairness trade-off with lower values of favouring higher accuracy over reduced fairness violation.
Now that we defined the optimization objective, obtaining the trade-off curve becomes straightforward by simply optimizing multiple models over a grid of regularization parameters . However, training multiple models can be computationally expensive, especially when this involves large-scale models (e.g. neural networks). To circumvent this computational challenge, we introduce loss-conditional fairness training obtained by adapting the YOTO framework proposed by [15].
3.1.1 Loss-conditional fairness training
As we describe above, a popular approach for approximating the accuracy-fairness trade-off involves training multiple models over a discrete grid of hyperparameters with the regularized loss . To avoid the computational overhead of training multiple models, [15] propose ‘You Only Train Once’ (YOTO), a methodology of training one model , which takes as an additional input using Feature-wise Linear Modulation (FiLM) [34] layers. YOTO is trained such that at inference time recovers the classifier obtained by minimising in Eq. (2).
Recall that we are interested in minimising the family of losses , parameterized by (Eq. (2)). Instead of fixing , YOTO solves an optimisation problem where the parameter is sampled from a distribution . As a result, during training the model observes many values of and learns to optimise the loss for all of them simultaneously. At inference time, the model can be conditioned on a chosen value and recovers the model trained to optimise . Hence, once adapted to our setting, the YOTO loss becomes:
Having trained a YOTO model, the trade-off curve can be approximated by simply plugging in different values of at inference time and thus avoiding additional training. From a theoretical point of view, [15, Proposition 1] proves that under the assumption of large enough model capacity, training the loss-conditional YOTO model performs as well as the separately trained models while only requiring a single model. Although the model capacity assumption might be hard to verify in practice, our experimental section has shown that the trade-off curves estimates obtained using YOTO are consistent with the ones obtained using separately trained models.
It should be noted, as is common in optimization problems, that the estimated trade-off curve may not align precisely with the true trade-off curve . This discrepancy originates from two key factors. Firstly, the limited size of the training and evaluation datasets introduces errors in the estimation of . Secondly, we opt for a computationally tractable loss function instead of the original optimization problem in Eq. (1). This may result in our estimation yielding sub-optimal trade-offs, as can be seen from Figure 1. Therefore, to ensure that our procedure yields statistically sound inferences, we next construct confidence intervals using the YOTO model, designed to contain the true trade-off curve with high probability.
3.2 Step 2: Constructing confidence intervals
As mentioned above, our goal here is to use our trained YOTO model to construct confidence intervals (CIs) for the optimal trade-off curve defined in Eq. (1). Specifically, we assume access to a held-out calibration dataset which is disjoint from the training data. Given a level , we construct CIs using , which provide guarantees of the form:
| (3) |
Here, it is important to note that and are random variables obtained from the calibration data , and the guarantee in Eq. (3) holds marginally over and . While our CIs in this section require the availability of the sensitive attributes in , in Appendix D we also extend our methodology to the setting where sensitive attributes are missing. In this section, for notational convenience we use to denote the YOTO model for .
The uncertainty in our trade-off estimate arises, in part, from the uncertainty in the accuracy and fairness violations of our trained model. Therefore, our methodology of constructing CIs on , involves first constructing CIs on test accuracy and fairness violation for a given value of using , denoted as and respectively satisfying,
One way to construct these CIs involves using assumption-light concentration inequalities such as Hoeffding’s inequality. To be more concrete, for the accuracy :
Lemma 3.1 (Hoeffding’s inequality).
Given a classifier , we have that,
Here, and .
Lemma 3.1 illustrates that we can use Hoeffding’s inequality to construct confidence interval on such that the true will lie inside the CI with probability . Analogously, we also construct CIs for fairness violations, , although this is subject to additional nuanced challenges, which we address using a novel sub-sampling based methodology in Appendix B. Once we have CIs over and for a model , we next outline how to use these to derive CIs for the minimum achievable fairness , satisfying Eq. (3). We proceed by explaining how to construct the upper and lower CIs separately, as the latter requires additional considerations regarding the trade-off achieved by YOTO.
3.2.1 Upper confidence intervals
We first outline how to obtain one-sided upper confidence intervals on the optimum accuracy-fairness trade-off of the form , which satisfies the probabilistic guarantee in Eq. (3). To this end, given a classifier , our methodology involves constructing one-sided lower CI on the accuracy and upper CI on the fairness violation . We make this concrete below:
Proposition 3.2.
Given , let be lower and upper CIs on and , i.e.
Then, .
Proposition 3.2 shows that for any model , the upper CI on model fairness, , provides a valid upper CI for the trade-off value at , i.e. . This can be used to construct upper CIs on for a given accuracy level . To understand how this can be achieved, we first find such that the lower CI on the accuracy of model , , satisfies . Then, since by definition is a monotonically increasing function, we know that . Since Proposition 3.2 tells us that is an upper CI for , it follows that is also a valid upper CI for .
Intuitively, Proposition 3.2 provides the ‘worst-case’ optimal trade-off, accounting for finite-sample uncertainty. It is important to note that this result does not rely on any assumptions regarding the optimality of the trained classifiers. This means that the upper CIs will remain valid even if the YOTO classifier is not trained well (and hence achieves sub-optimal accuracy-fairness trade-offs), although in such cases the CI may be conservative.
Having explained how to construct upper CIs on , we next move on to the lower CIs.
3.2.2 Lower confidence intervals
Obtaining lower confidence intervals on is more challenging than obtaining upper confidence intervals. We begin by explaining at an intuitive level why this is the case.
Suppose that is such that , then since denotes the minimum attainable fairness violation (Eq. (1)), we have that . Therefore, any valid upper confidence interval on will also be valid for . However, a lower bound on cannot be used as a lower bound for the minimum achievable fairness in general. A valid lower CI for will therefore depend on the gap between fairness violation achieved by , , and minimum achievable fairness violation (i.e., term in Figure 2(a)). We make this concrete by constructing lower CIs depending on explicitly.
Proposition 3.3.
Given , let be upper and lower CIs on and , i.e.
Then, , where .
Proposition 3.3 can be used to derive lower CIs on at a specified accuracy level , using a methodology analogous to that described in Section 3.2.1. Intuitively, this result provides the ‘best-case’ optimal trade-off, accounting for finite-sample uncertainty. However, unlike the upper CI, the lower CI includes the term, which is typically unknown. To circumvent this, we propose a strategy for obtaining plausible approximations for in practice in the following section.
3.2.3 Sensitivity analysis for
Recall that quantifies the difference between the fairness loss of classifier and the minimum attainable fairness loss , and is an unknown quantity in general (see Figure 2(a)). Here, we propose a practical strategy for positing values for which encode our belief on how close the fairness loss is to . This allows us to construct CIs which not only incorporate finite-sampling uncertainty from calibration data, but also account for the possible sub-optimality in the trade-offs achieved by . The main idea behind our approach is to calibrate using additional separately trained standard models without imposing significant computational overhead.
Details
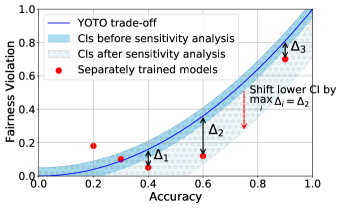
Our sensitivity analysis uses additional models trained separately using the standard regularized loss (Eq. (2)) for some randomly chosen values of . Let denote the models which achieve a better empirical trade-off than the YOTO model on , i.e. the empirical trade-offs for models in lie below the YOTO trade-off curve (see Figure 2(b)). We choose for our YOTO model to be the maximum gap between empirical trade-offs of these separately trained models in and the YOTO model. It can be seen from Proposition 3.3 that, in practice, this will result in a downward shift in the lower CI until all the separately trained models in lie above the lower CI. As a result, our methodology yields increasingly conservative lower CIs as the number of additional models increases.
Even though the procedure above requires training additional models , it does not impose the same computational overhead as training models over the full range of values. We show empirically in Section 5 that in practice 2 models are usually sufficient to obtain informative and reliable intervals. Additionally, we also show that when YOTO achieves the optimal trade-off (i.e., ), our sensitivity analysis leaves the CIs unchanged, thereby preventing unnecessary conservatism.
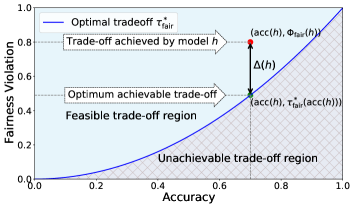
Asymptotic analysis of
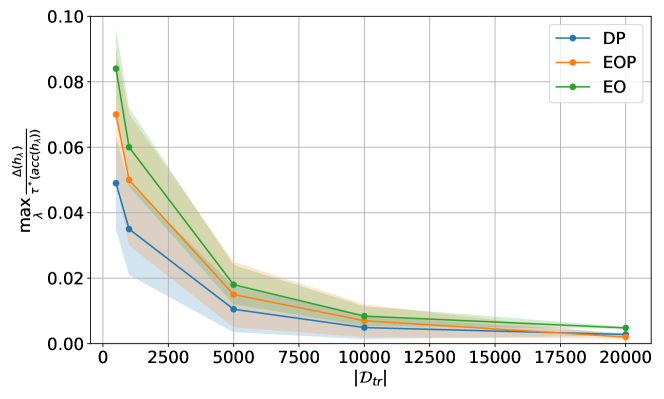
While the procedure described above provides a practical solution for obtaining plausible approximations for , we next present a theoretical result which provides reassurance that this gap should become negligible as the number of training data increases.
Theorem 3.4.
Let denote the fairness violation and accuracy for evaluated on training data and let
| (4) |
Then, given , under standard regularity assumptions, we have that with probability at least , for some where suppresses dependence on .
Theorem 3.4 shows that as the training data size increases, the error term will become negligible with a high probability for any model which minimises the empirical training loss in Eq. (4). In this case, should not have a significant impact on the lower CIs in Proposition 3.3 and the CIs will reflect the uncertainty in arising mostly due to finite calibration data. We also verify this empirically in Appendix F.7. It is worth noting that Theorem 3.4 relies on the same assumptions as used in Theorem 2 in [1], which have been provided in Appendix A.2.
4 Related works
Many previous fairness methods in the literature, termed in-processing methods, introduce constraints or regularization terms to the optimization objective. For instance, [1, 10] impose a priori uniform constraints on model fairness at training time. However, given the data-dependent nature of accuracy-fairness trade-offs, setting a uniform fairness threshold may not be suitable. Other in-processing methods [37, 24] consider information-theoretic bounds on the optimal trade-off in infinite data limit, independent of a specific model class. While these works offer valuable theoretical insights, there is no guarantee that these frontiers are attainable by models within a given model class . We verify this empirically in Appendix F.6 by showing that, for the Adult dataset, the frontiers proposed in [24] are not achieved by any SOTA method we considered. In contrast, our method provides guarantees on the achievable trade-off curve within realistic constraints of model class and data availability.
Various other regularization approaches [39, 33, 8, 14, 41, 42, 43] have also been proposed, but these often necessitate training multiple models, making them computationally intensive. Alternative strategies include learning ‘fair’ representations [44, 30, 31], or re-weighting data based on sensitive attributes [18, 22]. These, however, provide limited control over accuracy-fairness trade-offs.
Besides this, post-processing methods [19, 38] enforce fairness after training but can lead to other forms of unfairness such as disparate treatment of similar individuals [16]. Moreover, many post-hoc approaches such as [3, 2] still require solving different optimisation problems for different fairness thresholds. Other methods such as [46, 27] involve learning a post-hoc module in addition to the base classifier. As a result, the computational cost of training the YOTO model is similar to (and in many cases lower than) the combined cost of training a base model and subsequently applying a post-processing intervention to this pre-trained classifier. We confirm this empirically in Section 5.

| Adult dataset | COMPAS dataset | CelebA dataset | Jigsaw dataset |
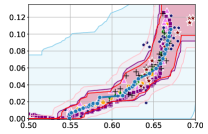
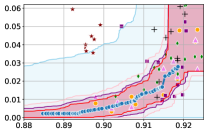
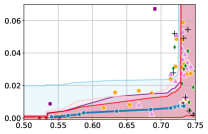
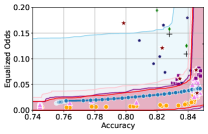
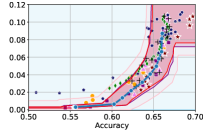
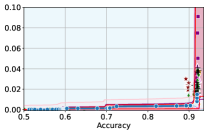
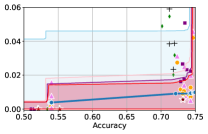
5 Experiments
In this section, we empirically validate our methodology of constructing confidence intervals on the fairness trade-off curve, across diverse datasets with neural networks as model class . These datasets range from tabular (Adult and COMPAS ), to image-based (CelebA), and natural language processing datasets (Jigsaw). Recall that our approach involves two steps: initial estimation of the trade-off via the YOTO model, followed by the construction of CIs using calibration data .
To evaluate our methodology, we implement a suite of baseline algorithms including SOTA in-processing techniques such as regularization-based approaches [8], a SOTA kernel-density based method [12] (denoted as ‘KDE-fair’), as well as the reductions method [1]. Additionally, we also compare against adversarial fairness techniques [45] and a post-processing approach (denoted as ‘RTO’) [2] and consider the three most prominent fairness metrics: Demographic Parity (DP), Equalized Odds (EO), and Equalized Opportunity (EOP). We provide additional details and results in Appendix F, where we also consider a synthetic setup with tractable . The code to reproduce our experiments is provided at github.com/faaizT/DatasetFairness.
5.1 Results
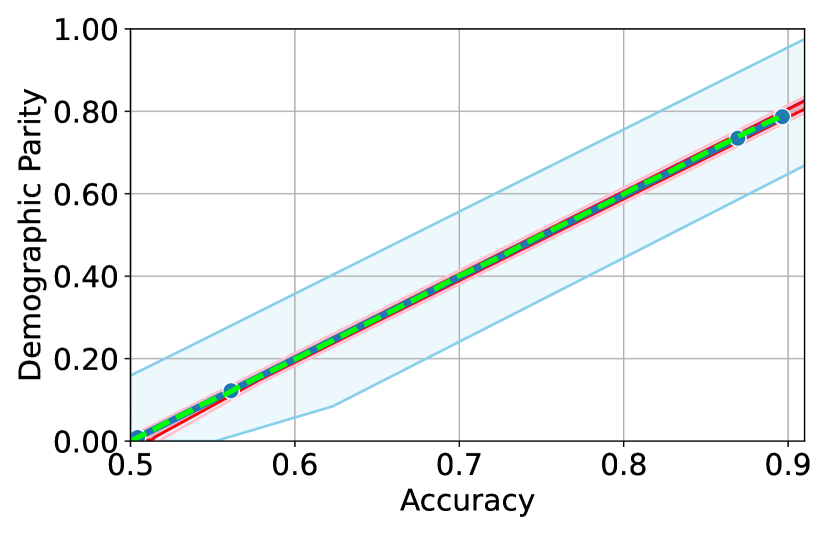
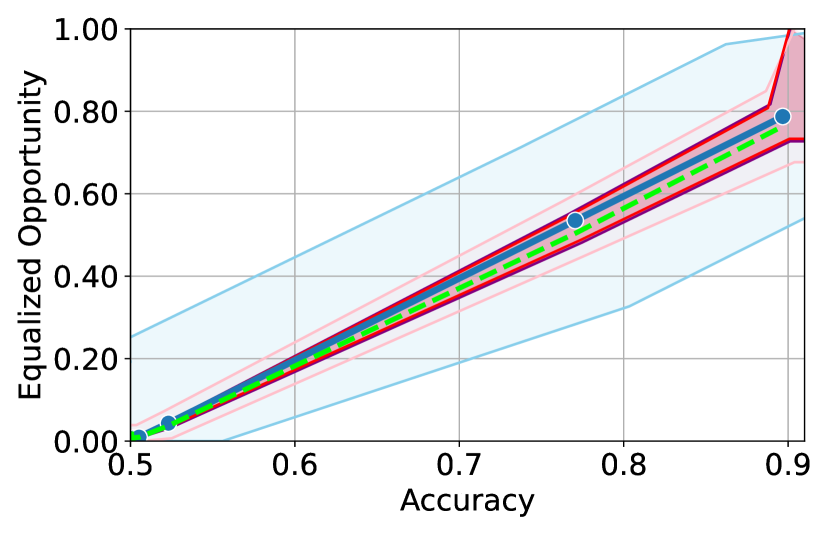
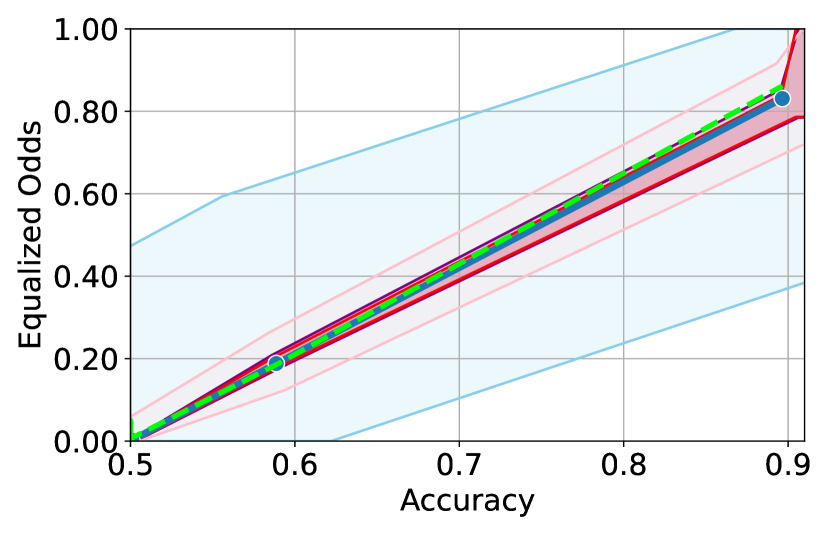
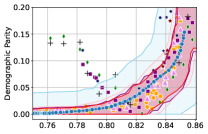
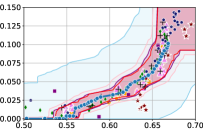
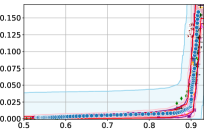
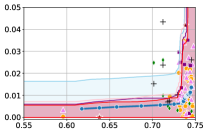
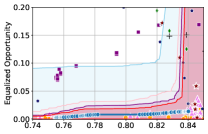
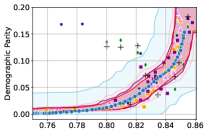
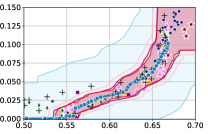
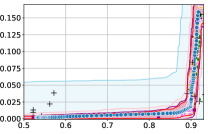
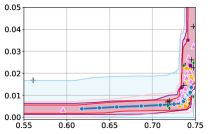
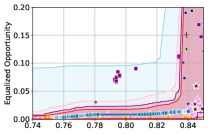
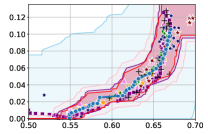
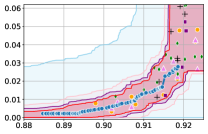
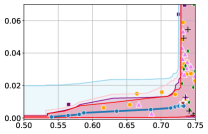
Figure 3 shows the results for different datasets and fairness violations, obtained using a 10% data split as calibration dataset . For each dataset, we construct 4 CIs that serve as the upper and lower bounds on the optimal accuracy-fairness trade-off curve. These intervals are computed at a 95% confidence level using various methodologies, including 1) Hoeffding’s, 2) Bernstein’s inequalities which both offer finite sample guarantees as well as, 3) bootstrapping [17], and 4) asymptotic intervals based on the Central Limit Theorem [26] which are valid asymptotically. There are 4 key takeaways:
| Category | Baseline | Unlikely | Permissible | Sub-optimal | Training time |
|---|---|---|---|---|---|
| In-processing | adversary [45] | 0.03 0.03 | 0.51 0.07 | 0.45 0.07 | 100 min40 |
| logsig [8] | 0.0 0.0 | 0.66 0.1 | 0.33 0.1 | 100 min40 | |
| reductions [1] | 0.0 0.0 | 0.79 0.1 | 0.21 0.1 | 90 min40 | |
| linear [8] | 0.01 0.0 | 0.85 0.05 | 0.14 0.06 | 100 min40 | |
| KDE-fair [12] | 0.0 0.0 | 0.97 0.05 | 0.03 0.06 | 85 min40 | |
| separate | 0.0 0.0 | 0.98 0.01 | 0.02 0.02 | 100 min40 | |
| YOTO (Ours) | 0.0 0.0 | 1.0 0.0 | 0.0 0.0 | 105 min1 | |
| Post-processing | RTO [2] | 0.0 0.0 | 0.65 0.2 | 0.35 0.05 | 95 min (training base classifier) |
| + 10min40 (post-hoc optimisations) |
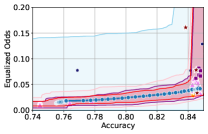
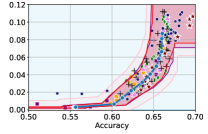
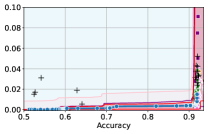
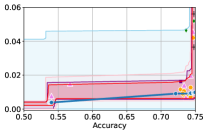
Takeaway 1: Trade-off curves are data dependent. The results in Figure 3 confirm that the accuracy-fairness trade-offs can vary significantly across the datasets. For example, achieving near-perfect fairness (i.e. ) seems significantly easier for the Jigsaw dataset than the COMPAS dataset, even as the accuracy increases. Likewise, for Adult and COMPAS, the DP increases gradually with increasing accuracy, whereas for CelebA, the increase is sharp once the accuracy increases above 90%. Therefore, using a uniform fairness threshold across datasets [as in 1] may be too restrictive, and our methodology provides more dataset-specific insights about the entire trade-off curve instead.
Takeaway 2: Our CIs are both reliable and informative. Recall that, any trade-off which lies above our upper CIs is guaranteed to be sub-optimal with probability , thereby enabling practitioners to effectively distinguish between genuine sub-optimalities and those due to finite-sample errors. Table 1 lists the proportion of sub-optimal empirical trade-offs for each baseline and provides a principled comparison of the baselines. For example, the adversarial, RTO and logsig baselines have a significantly higher proportion of sub-optimal trade-offs than the KDE-fair and separate baselines.
On the other hand, the validity of our lower CIs depends on the optimality of our YOTO model and the lower CIs may be too tight if YOTO is sub-optimal. Therefore, for the lower CIs to be reliable, it must be unlikely for any baseline to achieve a trade-off below the lower CIs. Table 1 confirms this empirically, as the proportion of models which lie below the lower CIs is negligible. In Appendix E, we also account for the uncertainty in baseline trade-offs when assessing the optimality, hence yielding more robust inferences. The results remain similar to those in Table 1.
Takeaway 3: YOTO trade-offs are consistent with SOTA. We observe that the YOTO trade-offs align well with most of the SOTA baselines considered while reducing the computational cost by approximately 40-fold (see the final column of Table 1). In some cases, YOTO even achieves a better trade-off than the baselines considered. See, e.g., the Jigsaw dataset results (especially for EOP). Moreover, we observe that the baselines yield empirical trade-offs which have a high variance as accuracy increases (see Jigsaw results in Figure 3, for example). This behaviour starkly contrasts the smooth variations exhibited by our YOTO-generated trade-off curves along the accuracy axis.
Takeaway 4: Sensitivity analysis does not cause unnecessary conservatism. We use 2 randomly chosen separately trained models to perform our sensitivity analysis for Figure 3. We find that this only causes a shift in lower CIs for 2 out of the 12 trade-off curves presented (i.e. for DP and EO trade-offs on the Adult dataset), leaving the rest of the CIs unchanged. Therefore, in practice sensitivity analysis does not impose significant computational overhead, and only changes the CIs when YOTO achieves a suboptimal trade-off. Additional results have been included in Appendix C.
6 Discussion and Limitations
In this work, we propose a computationally efficient approach to capture the accuracy-fairness trade-offs inherent to individual datasets, backed by sound statistical guarantees. Our proposed methodology enables a nuanced and dataset-specific understanding of the accuracy-fairness trade-offs. It does so by obtaining confidence intervals on the accuracy-fairness trade-off, leveraging the computational benefits of the You-Only-Train-Once (YOTO) framework [15]. This empowers practitioners with the ability to, at inference time, specify desired accuracy levels and promptly receive corresponding permissible fairness ranges. By eliminating the need for repetitive model training, we significantly streamline the process of obtaining accuracy-fairness trade-offs tailored to individual datasets.
Limitations Despite the evident merits of our approach, it also has some limitations. Firstly, our methodology requires distinct datasets for training and calibration, posing difficulties when data is limited. Under such constraints, the YOTO model might not capture the optimal accuracy-fairness trade-off, and moreover, the resulting confidence intervals could be overly conservative. Secondly, our lower CIs incorporate an unknown term . While we propose sensitivity analysis for approximating this term and prove that it is asymptotically negligible under certain mild assumptions in Section 3.2.3, a more exhaustive understanding remains an open question. Exploring informative upper bounds for under weaker conditions is a promising avenue for future investigations.
Acknowledgments
We would like to express our gratitude to Sahra Ghalebikesabi for her valuable feedback on an earlier draft of this paper. We also thank the anonymous reviewers for their thoughtful and constructive comments, which enhanced the clarity and rigor of our final submission.
References
- [1] A. Agarwal, A. Beygelzimer, M. Dudík, J. Langford, and H. Wallach. A reductions approach to fair classification. 03 2018.
- [2] I. M. Alabdulmohsin and M. Lucic. A near-optimal algorithm for debiasing trained machine learning models. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 8072–8084. Curran Associates, Inc., 2021.
- [3] W. Alghamdi, H. Hsu, H. Jeong, H. Wang, P. W. Michalak, S. Asoodeh, and F. P. Calmon. Beyond adult and compas: Fairness in multi-class prediction, 2022.
- [4] A. N. Angelopoulos, S. Bates, C. Fannjiang, M. I. Jordan, and T. Zrnic. Prediction-powered inference, 2023.
- [5] J. Angwin, J. Larson, S. Mattu, and L. Kirchner. Machine bias, 2016.
- [6] P. L. Bartlett and S. Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. In D. Helmbold and B. Williamson, editors, Computational Learning Theory, pages 224–240, Berlin, Heidelberg, 2001. Springer Berlin Heidelberg.
- [7] B. Becker and R. Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20.
- [8] H. Bendekgey and E. B. Sudderth. Scalable and stable surrogates for flexible classifiers with fairness constraints. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems, 2021.
- [9] S. Caton and C. Haas. Fairness in machine learning: A survey. CoRR, abs/2010.04053, 2020.
- [10] L. E. Celis, L. Huang, V. Keswani, and N. K. Vishnoi. Classification with fairness constraints: A meta-algorithm with provable guarantees. In Proceedings of the Conference on Fairness, Accountability, and Transparency, FAT* ’19, page 319–328, New York, NY, USA, 2019. Association for Computing Machinery.
- [11] L. E. Celis, L. Huang, V. Keswani, and N. K. Vishnoi. Fair classification with noisy protected attributes: A framework with provable guarantees. In M. Meila and T. Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 1349–1361. PMLR, 18–24 Jul 2021.
- [12] J. Cho, G. Hwang, and C. Suh. A fair classifier using kernel density estimation. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 15088–15099. Curran Associates, Inc., 2020.
- [13] J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018.
- [14] M. Donini, L. Oneto, S. Ben-David, J. S. Shawe-Taylor, and M. Pontil. Empirical risk minimization under fairness constraints. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
- [15] A. Dosovitskiy and J. Djolonga. You only train once: Loss-conditional training of deep networks. In International Conference on Learning Representations, 2020.
- [16] EEOC. Uniform guidelines on employee selection procedures, 1979.
- [17] B. Efron. Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 7(1):1–26, 1979.
- [18] A. Grover, J. Song, A. Agarwal, K. Tran, A. Kapoor, E. Horvitz, and S. Ermon. Bias Correction of Learned Generative Models Using Likelihood-Free Importance Weighting. Curran Associates Inc., Red Hook, NY, USA, 2019.
- [19] M. Hardt, E. Price, and N. Srebro. Equality of opportunity in supervised learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 3323–3331, Red Hook, NY, USA, 2016. Curran Associates Inc.
- [20] Jigsaw and Google. Unintended bias in toxicity classification, 2019.
- [21] S. M. Kakade, K. Sridharan, and A. Tewari. On the complexity of linear prediction: Risk bounds, margin bounds, and regularization. In D. Koller, D. Schuurmans, Y. Bengio, and L. Bottou, editors, Advances in Neural Information Processing Systems, volume 21. Curran Associates, Inc., 2008.
- [22] F. Kamiran and T. Calders. Data pre-processing techniques for classification without discrimination. Knowledge and Information Systems, 33, 10 2011.
- [23] J. S. Kim, J. Chen, and A. Talwalkar. Fact: A diagnostic for group fairness trade-offs. CoRR, abs/2004.03424, 2020.
- [24] J. S. Kim, J. Chen, and A. Talwalkar. Model-agnostic characterization of fairness trade-offs. CoRR, abs/2004.03424, 2020.
- [25] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [26] L. Le Cam. The central limit theorem around 1935. Statistical Science, 1(1):78–91, 1986.
- [27] E. Z. Liu, B. Haghgoo, A. S. Chen, A. Raghunathan, P. W. Koh, S. Sagawa, P. Liang, and C. Finn. Just train twice: Improving group robustness without training group information. CoRR, abs/2107.09044, 2021.
- [28] Z. Liu, P. Luo, X. Wang, and X. Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- [29] M. Lohaus, M. Perrot, and U. V. Luxburg. Too relaxed to be fair. In H. D. III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 6360–6369. PMLR, 13–18 Jul 2020.
- [30] C. Louizos, K. Swersky, Y. Li, M. Welling, and R. Zemel. The variational fair autoencoder, 2017.
- [31] K. Lum and J. Johndrow. A statistical framework for fair predictive algorithms, 2016.
- [32] N. Martinez, M. Bertran, and G. Sapiro. Minimax pareto fairness: A multi objective perspective. In H. D. III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 6755–6764. PMLR, 13–18 Jul 2020.
- [33] M. Olfat and Y. Mintz. Flexible regularization approaches for fairness in deep learning. In 2020 59th IEEE Conference on Decision and Control (CDC), pages 3389–3394, 2020.
- [34] E. Perez, F. Strub, H. de Vries, V. Dumoulin, and A. C. Courville. Film: Visual reasoning with a general conditioning layer. CoRR, abs/1709.07871, 2017.
- [35] B. Ustun, Y. Liu, and D. Parkes. Fairness without harm: Decoupled classifiers with preference guarantees. In K. Chaudhuri and R. Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 6373–6382. PMLR, 09–15 Jun 2019.
- [36] A. Valdivia, J. Sánchez-Monedero, and J. Casillas. How fair can we go in machine learning? assessing the boundaries of accuracy and fairness. International Journal of Intelligent Systems, 36(4):1619–1643, 2021.
- [37] H. Wang, L. He, R. Gao, and F. Calmon. Aleatoric and epistemic discrimination: Fundamental limits of fairness interventions. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [38] D. Wei, K. N. Ramamurthy, and F. Calmon. Optimized score transformation for fair classification. In S. Chiappa and R. Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 1673–1683. PMLR, 26–28 Aug 2020.
- [39] S. Wei and M. Niethammer. The fairness-accuracy pareto front. Statistical Analysis and Data Mining: The ASA Data Science Journal, 15(3):287–302, 2022.
- [40] J. Yang, A. A. S. Soltan, D. W. Eyre, Y. Yang, and D. A. Clifton. An adversarial training framework for mitigating algorithmic biases in clinical machine learning. npj Digital Medicine, 6:55, 2023.
- [41] M. Zafar, I. Valera, M. Rodriguez, and K. P. Gummadi. Fairness constraints: A mechanism for fair classification. 07 2015.
- [42] M. B. Zafar, I. Valera, M. Gomez Rodriguez, and K. P. Gummadi. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In Proceedings of the 26th International Conference on World Wide Web, WWW ’17, page 1171–1180, Republic and Canton of Geneva, CHE, 2017. International World Wide Web Conferences Steering Committee.
- [43] M. B. Zafar, I. Valera, M. Gomez-Rodriguez, and K. P. Gummadi. Fairness constraints: A flexible approach for fair classification. Journal of Machine Learning Research, 20(75):1–42, 2019.
- [44] R. Zemel, Y. Wu, K. Swersky, T. Pitassi, and C. Dwork. Learning fair representations. In S. Dasgupta and D. McAllester, editors, Proceedings of the 30th International Conference on Machine Learning, volume 28 of Proceedings of Machine Learning Research, pages 325–333, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR.
- [45] B. H. Zhang, B. Lemoine, and M. Mitchell. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’18, page 335–340, New York, NY, USA, 2018. Association for Computing Machinery.
- [46] A. Ţifrea, P. Lahoti, B. Packer, Y. Halpern, A. Beirami, and F. Prost. Frappé: A group fairness framework for post-processing everything, 2024.
Appendix A Proofs
A.1 Confidence intervals on
Proof of Lemma 3.1.
This lemma is a straightforward application of Heoffding’s inequality. ∎
Proof of Proposition 3.2.
Here, we prove the result for general classifiers . Let be the lower and upper CIs for and respectively,
Then, using a straightforward application union bounds, we get that
Using the definition of the optimal fairness-accuracy trade-off , we get that the event
From this, it follows that
∎
Proof of Proposition 3.3.
We prove the result for general classifiers . Let be the upper and lower CIs for and respectively,
Then, using an application of union bounds, we get that
Then, using the fact that , we get that
where in the second last inequality above, we use the fact that is a monotonically increasing function. ∎
A.2 Asymptotic convergence of
In this Section, we provide the formal statement for Theorem 3.4 along with the assumptions required for this result.
Assumption A.1.
is -Lipschitz.
Assumption A.2.
Let denote the Rademacher complexity of the classifier family , where is the number of training examples. We assume that there exists and such that .
It is worth noting that Assumption A.2, which was also used in [1, Theorem 2], holds for many classifier families with , including norm-bounded linear functions, neural networks and classifier families with bounded VC dimension [21, 6].
Theorem A.3.
Proof of Theorem A.3.
Let
Next, we define
Then, we have that
We know using Assumption A.1 that
Moreover,
Putting the two together, we get that
| (5) |
Next, we consider the term . First, we observe that
Next, using [1, Lemma 4] with , we get that with probability at least , we have that
This implies that with probability at least ,
and hence,
Again, using [1, Lemma 4] with , we get that with probability at least , we have that
Finally, putting this together using union bounds, we get that with probability at least ,
and hence,
Using the definition of , we have that . Therefore, with probability at least ,
| (6) |
Next, to bound the term above, we consider a general formulation for the fairness violation , also presented in [1],
where , are some known functions and are events with positive probability defined with respect to .
Using this, we note that for any
Let . Then, from [1, Lemma 6], we have that if , then with probability at least , we have that
A straightforward application of the union bounds yields that if for all , then with probability at least , we have that
Therefore, in this case for any , we have that with probability at least ,
and therefore,
| (7) |
Finally, putting Eq. (5), Eq. (6) and Eq. (7) together using union bounds, we get that with probability at least , we have that
∎
Appendix B Constructing the confidence intervals on
In this section, we outline methodologies of obtaining confidence intervals for a fairness violation . Specifically, given a model , with and , we outline how to find which satisfies,
| (8) |
Similar to [1] we express the fairness violation as:
where , are some known functions and are events with positive probability defined with respect to . For example, when considering the demographic parity (DP), i.e. , we have , with , , and . Moreover, as shown in [1], the commonly used fairness metrics like Equalized Odds (EO) and Equalized Opportunity (EOP) can also be expressed in similar forms.
Our methodology of constructing CIs on involves first constructing intervals on satisfying:
| (9) |
Once we have a , the confidence interval satisfying Eq. (8) can simply be constructed as:
In what follows, we outline two different ways of constructing the confidence intervals on satisfying Eq. (9).
B.1 Separately constructing CIs on
One way to obtain intervals on would be to separately construct confidence intervals on , denoted by , which satisfies the joint guarantee
| (10) |
Given such set of confidence intervals which satisfy Eqn. Eq. (10), we can obtain the confidence intervals on by using the fact that
Where, the notation denotes the set . One naïve way to obtain such which satisfy Eq. (10) is to use the union bounds, i.e., if are chosen such that
then, we have that
Here, for an event , we use to denote the complement of the event. This methodology therefore reduces the problem of finding confidence intervals on to finding confidence intervals on for . Now note that are all expectations and we can use standard methodologies to construct confidence intervals on an expectation. We explicitly outline how to do this in Section B.3.
Remark
The methodology outlined above provides confidence intervals with valid finite sample coverage guarantees. However, this may come at the cost of more conservative confidence intervals. One way to obtain less conservative confidence intervals while retaining the coverage guarantees would be to consider alternative ways of obtaining confidence intervals which do not require constructing the CIs separately on . We outline one such methodology in the next section.
B.2 Using subsampling to construct the CIs on directly
Here, we outline how we can avoid having to use union bounds when constructing the confidence intervals on . Let denote the subset of data , for which the event is true. In the case where the events are all mutually exclusive and hence are all disjoint subsets of data (which is true for DP, EO and EOP), we can also construct these intervals by randomly sampling without replacement datapoints from for . We use the fact that
is an unbiased estimator of . Moreover, since are all disjoint datasets, the datapoints are all independent across different values of , and therefore, are i.i.d.. In other words,
and are all i.i.d. samples and unbiased estimators of . Therefore, like in the previous section, our problem reduces to constructing CIs on an expectation term (i.e. ), using i.i.d. unbiased samples (i.e. ) and we can use standard methodologies to construct these intervals.
Benefit of this methodology
This methodology no longer requires us to separately construct confidence intervals over and combine them using union bounds (for example). Therefore, intervals obtained using this methodology may be less conservative than those obtained by separately constructing confidence intervals over .
Limitation of this methodology
For each subset of data , we can use at most data points to construct the confidence intervals. Therefore, in cases where is very small, we may end up discarding a big proportion of the calibration data which could in turn lead to loose intervals.
B.3 Constructing CIs on expectations
Here, we outline some standard techniques used to construct CIs on the expectation of a random variable. These techniques can then be used to construct CIs on (using either of the two methodologies outlined above) as well as on . In this section, we restrict ourselves to constructing upper CIs. Lower CIs can be constructed analogously.
Given dataset , our goal in this section is to construct upper CIs on which satisfies
Hoeffding’s inequality
We can use Hoeffding’s inequality to construct these intervals as formalised in the following result:
Lemma B.1 (Hoeffding’s inequality).
Let , be i.i.d. samples with mean . Then,
Bernstein’s inequality
Bernstein’s inequality provides a powerful tool for bounding the tail probabilities of the sum of independent, bounded random variables. Specifically, for a sum comprised of independent random variables with , each with a maximum variance of , and for any , the inequality states that
where denotes an upper bound on the absolute value of each random variable. Re-arranging the above, we get that
This allows us to construct upper CIs on .
Central Limit Theorem
The Central Limit Theorem (CLT) [26] serves as a cornerstone in statistics for constructing confidence intervals around sample means, particularly when the sample size is substantial. The theorem posits that, for a sufficiently large sample size, the distribution of the sample mean will closely resemble a normal (Gaussian) distribution, irrespective of the original population’s distribution. This Gaussian nature of the sample mean empowers us to form confidence intervals for the population mean using the normal distribution’s characteristics.
Given as independent and identically distributed (i.i.d.) random variables with mean and variance , the sample mean approximates a normal distribution with mean and variance for large . An upper confidence interval for is thus:
where represents the critical value from the standard normal distribution corresponding to a cumulative probability of .
Bootstrap Confidence Intervals
Bootstrapping, introduced by [17], offers a non-parametric approach to estimate the sampling distribution of a statistic. The method involves repeatedly drawing samples (with replacement) from the observed data and recalculating the statistic for each resample. The resulting empirical distribution of the statistic across bootstrap samples forms the basis for confidence interval construction.
Given a dataset , one can produce bootstrap samples by selecting observations with replacement from the original data. For each of these samples, the statistic of interest (for instance, the mean) is determined, yielding bootstrap estimates. An upper bootstrap confidence interval for is given by:
with denoting the -quantile of the bootstrap estimates. It’s worth noting that there exist multiple methods to compute bootstrap confidence intervals, including the basic, percentile, and bias-corrected approaches, and the method described above serves as a general illustration.
Appendix C Sensitivity analysis for
Recall from Proposition 3.3 that the lower confidence intervals for include a term which is defined as
In other words, quantifies how ‘far’ the fairness loss of classifier (i.e. ) is from the minimum attainable fairness loss for classifiers with accuracy , (i.e. ). This quantity is unknown in general and therefore, a practical strategy of obtaining lower confidence intervals on may involve positing values for which encode our belief on how close the fairness loss is to . For example, when we assume that the classifier achieves the optimal accuracy-fairness tradeoff, i.e. then .
However, the assumption may not hold in general because we only have a finite training dataset and consequently the empirical loss minimisation may not yield the optima to the true expected loss. Moreover, the regularised loss used in training is a surrogate loss which approximates the solution to the constrained minimisation problem in Eq. (1). This means that optimising this regularised loss is not guaranteed to yield the optimal classifier which achieves the optimal fairness . Therefore, to incorporate any belief on the sub-optimality of the classifier , we may consider conducting sensitivity analyses to plausibly quantify .
Let be the YOTO model. Our strategy for sensitivity analysis involves training multiple standard models by optimising the regularised losses for few different choices of .
Importantly, we do not require covering the full range of values when training separate models , and our methodology remains valid even when is a single model. Next, let be such that
| (11) |
Here, and denote the finite sample estimates of the fairness loss and model accuracy respectively. We treat the model as a model which attains the optimum trade-off when estimating subject to the constraint . Specifically, we use the maximum empirical error as a plausible surrogate value for , where , i.e., we posit for any
Next, we can use this posited value of to construct the lower confidence interval using the following corollary of Proposition 3.3:
Corollary C.1.
Consider the YOTO model . Given , let be such that
Then, we have that
This result shows that if the goal is to construct lower confidence intervals on and we obtain that , then using the monotonicity of we have that . Therefore the interval serves as a lower confidence interval for .
When YOTO satisfies Pareto optimality, as : Here, we show that in the case when YOTO achieves the optimal trade-off, then our sensitivity analysis leads to as the calibration data size increases for all . Our arguments in this section are not formal, however, this idea can be formalised without any significant difficulty.
First, the concept of Pareto optimality (defined below) formalises the idea that YOTO achieves the optimal trade-off:
Assumption C.2 (Pareto optimality).
In the case when YOTO satisfies this optimality property, then it is straightforward to see that for all . In this case, as , we get that Eq. (11) roughly becomes
Here, Assumption C.2 implies that , and therefore
Intuition behind our sensitivity analysis procedure
Intuitively, the high-level idea behind our sensitivity analysis is that it checks if we train models separately for fixed values of (i.e. models in ), how much better do these separately trained models perform in terms of the accuracy-fairness trade-offs as compared to our YOTO model. If we find that the separately trained models achieve a better trade-off than the YOTO model for specific values of , then the sensitivity analysis adjusts the empirical trade-off obtained using YOTO models (using the term defined above). If, on the other hand, we find that the YOTO model achieves a better trade-off than the separately trained models in , then the sensitivity analysis has no effect on the lower confidence intervals as in this case .
C.1 Experimental results

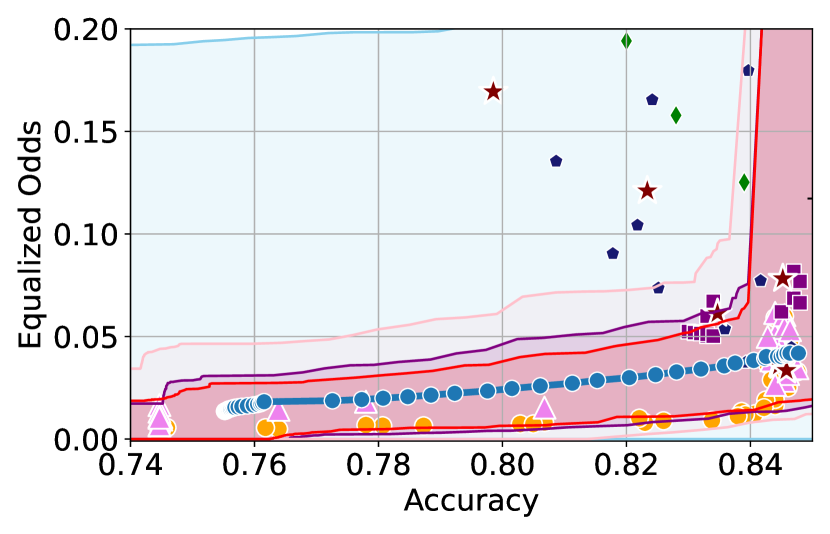
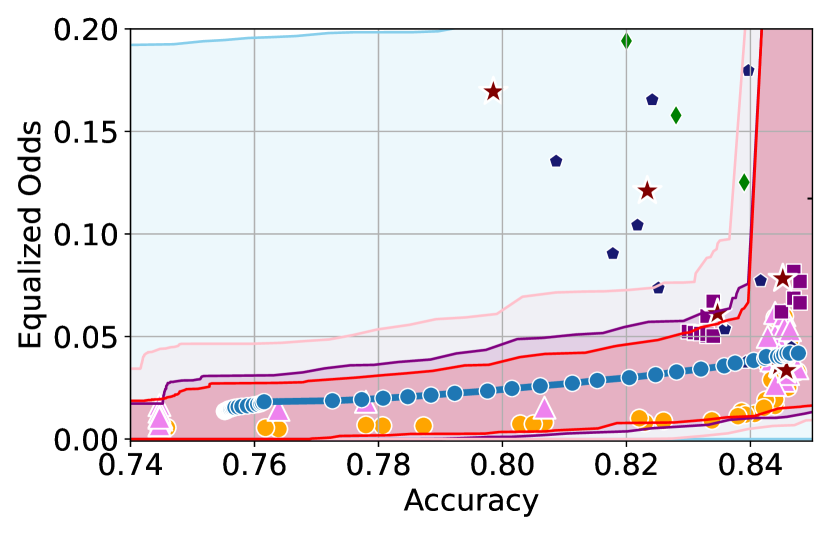
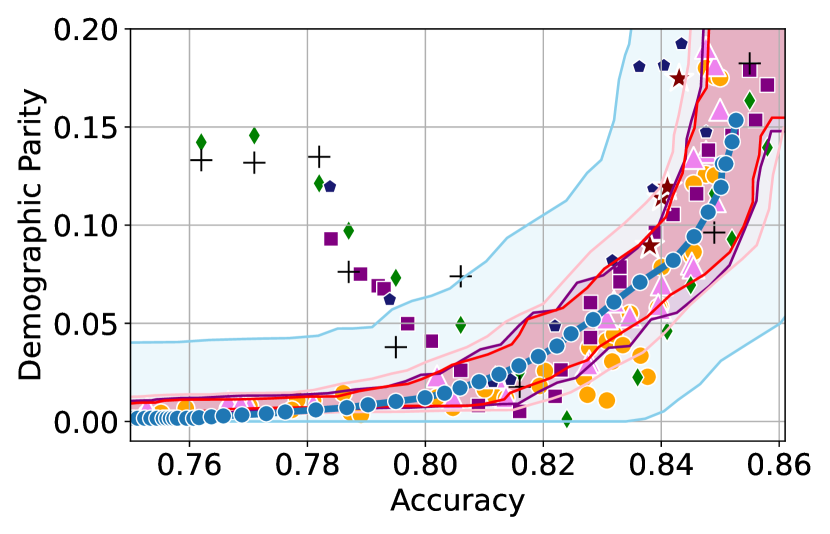
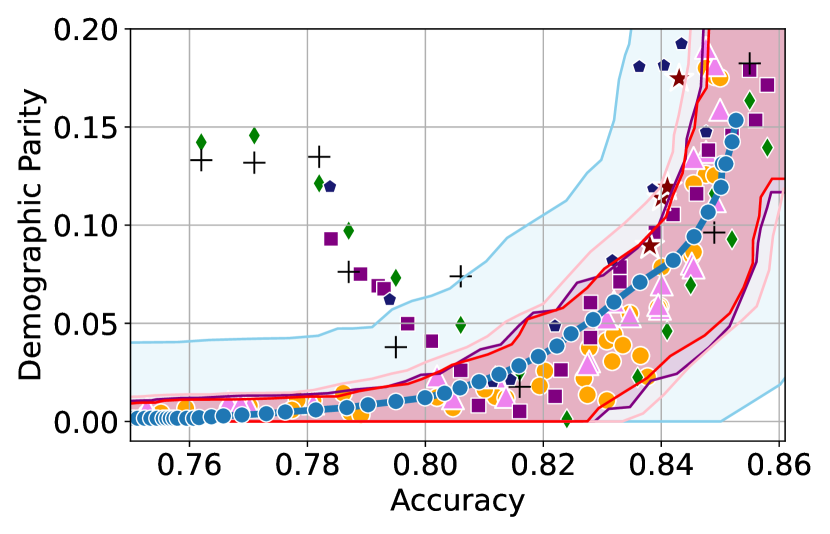
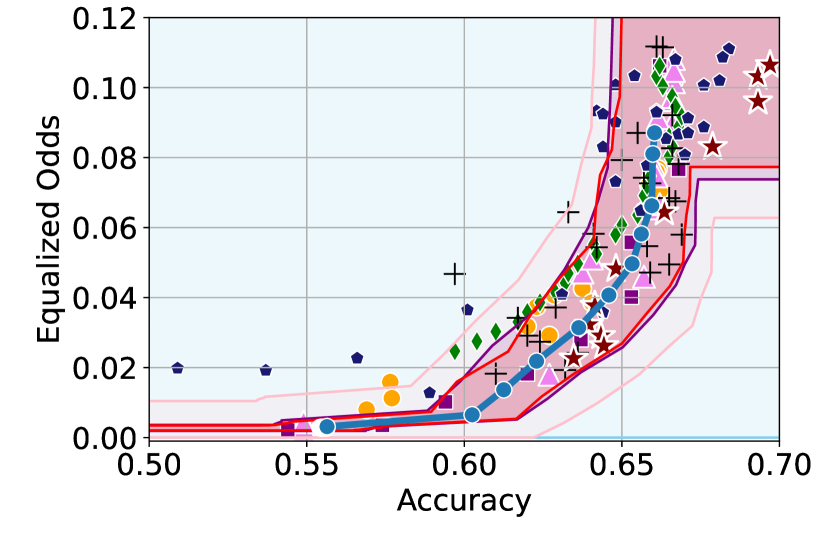
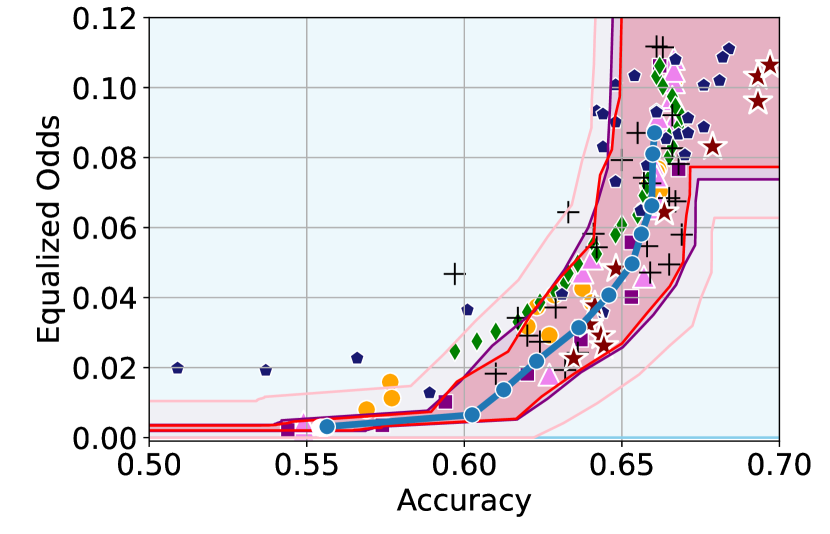
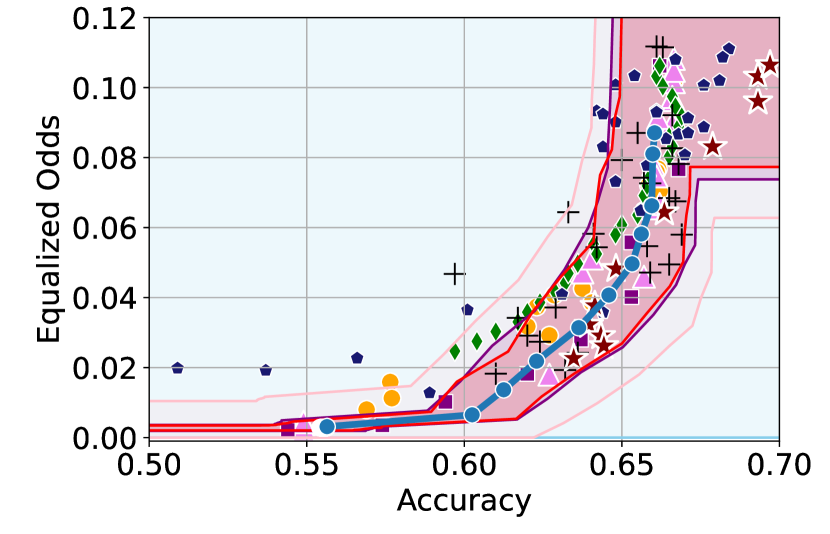
Here, we include empirical results showing how the CIs constructed change as a result of our sensitivity analysis procedure. In Figures 6 and 6, we include examples of CIs where the empirical trade-off obtained using YOTO is sub-optimal. In these cases, the lower CIs obtained without sensitivity analysis (i.e. when we assume ) do not cover the empirical trade-offs for the separately trained models. However, the figures show that the sensitivity analysis procedure adjusts the lower CIs in both cases so that they encapsulate the empirical trade-offs that were not captured without sensitivity analysis.
Recall that represents the set of additional separately trained models used for the sensitivity analysis. It can be seen from Figures 6 and 6 that in both cases our sensitivity analysis performs well with as little as two models (i.e. ), which shows that our sensitivity analysis does not come at a high computational cost.
Tables 2 and 3 contain results corresponding to these figures and show the proportion of trade-offs which lie in the three trade-off regions shown in Figure 1 with and without sensitivity analysis. It can be seen that in both tables, when , the proportion of trade-offs which lie below the lower CIs (blue region in Figure 1) is negligible.
Additionally, in Figure 6 we also consider an example where YOTO achieves a better empirical trade-off than most other baselines considered, and therefore there is no need for sensitivity analysis. In this case, Figure 6 (and Table 4) show that sensitivity analysis has no effect on the CIs constructed since in this case sensitivity analysis gives us for . This shows that in cases where sensitivity analysis is not needed (for example, if YOTO achieves optimal empirical trade-off), our sensitivity analysis procedure does not make the CIs more conservative.
| Baseline | Sub-optimal | Unlikely | Permissible | Unlikely | Permissible | Unlikely | Permissible |
|---|---|---|---|---|---|---|---|
| () | () | () | () | () | () | ||
| KDE-fair | 0.00 | 0.15 | 0.85 | 0.00 | 1.00 | 0.00 | 1.00 |
| RTO | 0.60 | 0.00 | 0.40 | 0.00 | 0.40 | 0.00 | 0.40 |
| adversary | 0.64 | 0.00 | 0.36 | 0.00 | 0.36 | 0.00 | 0.36 |
| linear | 0.60 | 0.00 | 0.40 | 0.00 | 0.40 | 0.00 | 0.40 |
| logsig | 0.35 | 0.00 | 0.65 | 0.00 | 0.65 | 0.00 | 0.65 |
| reductions | 0.93 | 0.00 | 0.07 | 0.00 | 0.07 | 0.00 | 0.07 |
| separate | 0.00 | 0.54 | 0.46 | 0.00 | 1.00 | 0.00 | 1.00 |
| Baseline | Sub-optimal | Unlikely | Permissible | Unlikely | Permissible | Unlikely | Permissible |
|---|---|---|---|---|---|---|---|
| () | () | () | () | () | () | ||
| KDE-fair | 0.03 | 0.10 | 0.87 | 0.00 | 0.97 | 0.00 | 0.97 |
| RTO | 0.67 | 0.00 | 0.33 | 0.00 | 0.33 | 0.00 | 0.33 |
| adversary | 0.91 | 0.00 | 0.09 | 0.00 | 0.09 | 0.00 | 0.09 |
| linear | 0.40 | 0.33 | 0.27 | 0.00 | 0.60 | 0.00 | 0.60 |
| logsig | 0.73 | 0.05 | 0.23 | 0.00 | 0.27 | 0.00 | 0.27 |
| reductions | 0.87 | 0.00 | 0.13 | 0.00 | 0.13 | 0.00 | 0.13 |
| separate | 0.03 | 0.25 | 0.71 | 0.00 | 0.97 | 0.00 | 0.97 |
| Baseline | Sub-optimal | Unlikely | Permissible | Unlikely | Permissible | Unlikely | Permissible |
|---|---|---|---|---|---|---|---|
| () | () | () | () | () | () | ||
| KDE-fair | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 |
| RTO | 0.15 | 0.00 | 0.85 | 0.00 | 0.85 | 0.00 | 0.85 |
| adversary | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 |
| linear | 0.21 | 0.00 | 0.79 | 0.00 | 0.79 | 0.00 | 0.79 |
| logsig | 0.55 | 0.00 | 0.45 | 0.00 | 0.45 | 0.00 | 0.45 |
| reductions | 0.30 | 0.00 | 0.70 | 0.00 | 0.70 | 0.00 | 0.70 |
| separate | 0.03 | 0.80 | 0.17 | 0.80 | 0.17 | 0.80 | 0.17 |
Appendix D Scarce sensitive attributes
Our methodology of obtaining confidence intervals on assumes access to the sensitive attributes for all data points in the held-out dataset . However, in practice, we may only have access to for a small proportion of the data in . In this case, a naïve strategy would involve constructing confidence intervals using only the data for which is available. However, since such data is scarce, the confidence intervals constructed are very loose.
Suppose that we additionally have access to a predictive model which predicts the sensitive attributes using the features . In this case, another simple strategy would be to simply impute the missing values of , with the values predicted using . However, this will usually lead to a biased estimate of the fairness violation , and hence is not very reliable unless the model is highly accurate. In this section, we show how to get the best of both worlds, i.e. how to utilise the data with missing sensitive attributes to obtain tighter and more accurate confidence intervals on .
Formally, we consider where denotes a data subset of size that contains sensitive attributes (i.e. we observe ) and denotes the data subset of size for which we do not observe the sensitive attributes , and . Additionally, for both datasets, we have predictions of the sensitive attributes made by a machine-learning algorithm , where . Concretely we have that and
High-level methodology
Our methodology is inspired by prediction-powered inference [4] which builds confidence intervals on the expected outcome using data for which the true outcome is only available for a small proportion of the dataset. In our setting, however, it is the sensitive attribute that is missing for the majority of the data (and not the outcome ).
For , let be a fairness violation (such as DP or EO), and let be the corresponding fairness violation computed on the data distribution where is replaced by the surrogate sensitive attribute . For example, in the case of DP violation, and denote:
We next construct the confidence intervals on using the following steps:
-
1.
Using , we construct intervals on satisfying
(12) Even though the size of is small, we choose a methodology which yields tight intervals for when with a high probability.
-
2.
Next, using the dataset , we construct intervals on satisfying
(13) This interval will also be tight as the size of , .
Finally, using the union bound idea we combine the two confidence intervals to obtain the confidence interval for . We make this precise in the following result:
When constructing the CIs over using imputed sensitive attributes in step 2 above, the prediction error of introduces an error in the obtained CIs (denoted by ). Step 1 rectifies this by constructing a CI over the incurred error , and therefore combining the two allows us to obtain intervals which utilise all of the available data while ensuring that the constructed CIs are well-calibrated.
Example: Demographic parity
Having defined our high-level methodology above, we concretely demonstrate how this can be applied to the case where the fairness loss under consideration is DP. As described above, the first step involves constructing intervals on using a methodology which yields tight intervals when with a high probability. To this end, we use bootstrapping as described in Algorithm 1.
Even though bootstrapping does not provide us with finite sample coverage guarantees, it is asymptotically exact and satisfies the property that the confidence intervals are tight when with a high probability. On the other hand, concentration inequalities (such as Hoeffding’s inequality) seek to construct confidence intervals individually on and and subsequently combine them through union bounds argument, for example. In doing so, these methods do not account for how close the values of and might be in the data.
To make this concrete, consider the example where and hence . When using concentration inequalities to construct the confidence intervals on and , we obtain identical intervals for the two quantities, say . Then, using union bounds we obtain that with probability at least . In this case even though , the width of the interval does not depend on the closeness of and and therefore is not tight. Bootstrapping helps us circumvent this problem, since in this case for each resample of the data , the finite sample estimates and will be equal. We outline the bootstrapping algorithm below.
Using Algorithm 1 we construct a confidence interval on of size , which approximately satisfies Eq. (12). Next, using standard techniques we can obtain an interval on using which satisfies Eq. (13). Like before, the interval is likely to be tight as we use to construct it, which is significantly larger than . Finally, combining the two as shown in Lemma D.1, we obtain the confidence interval on .
D.1 Experimental results

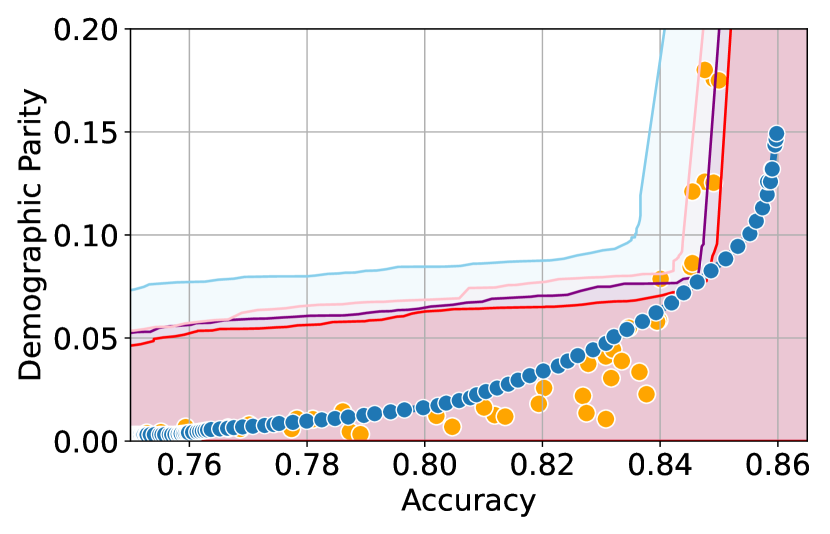
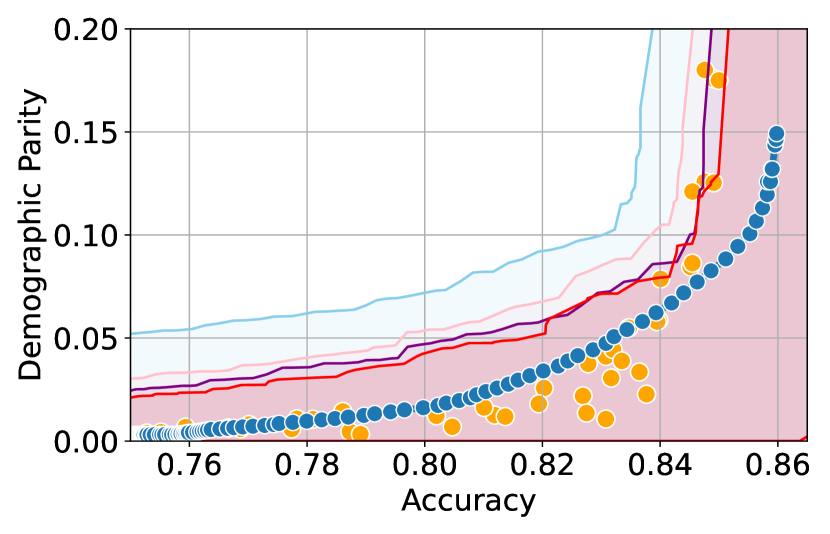
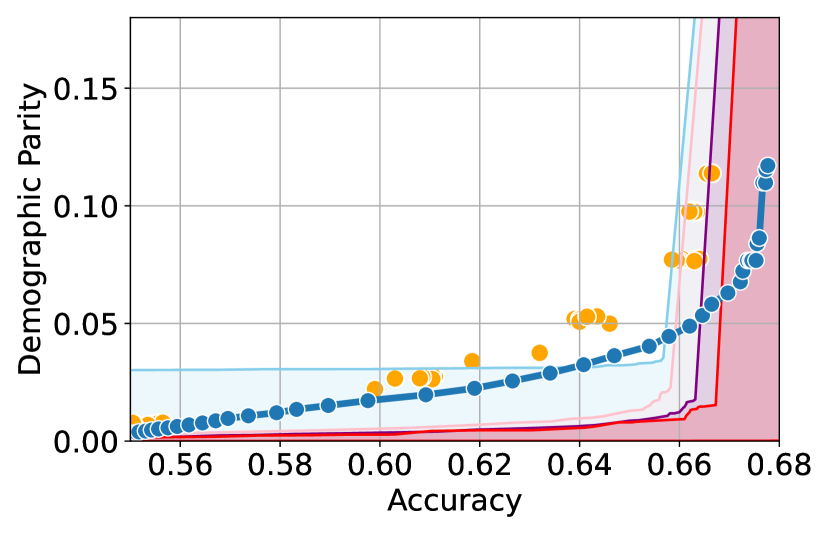
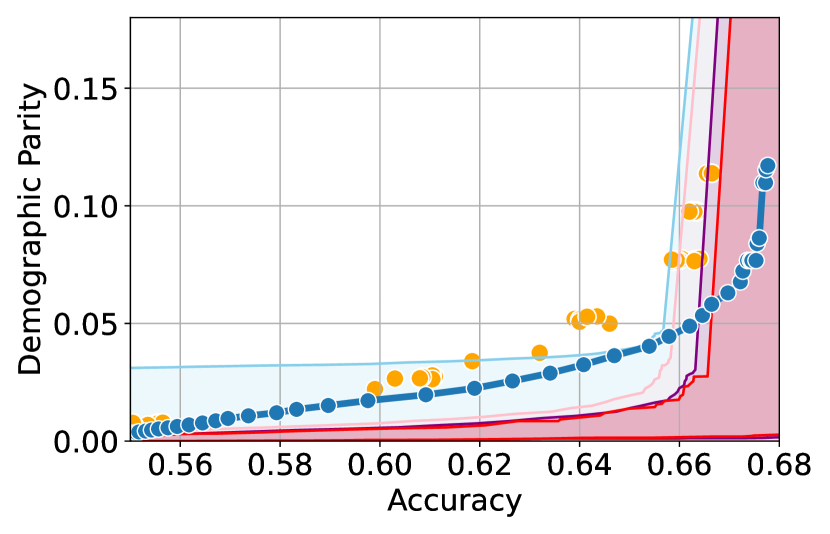
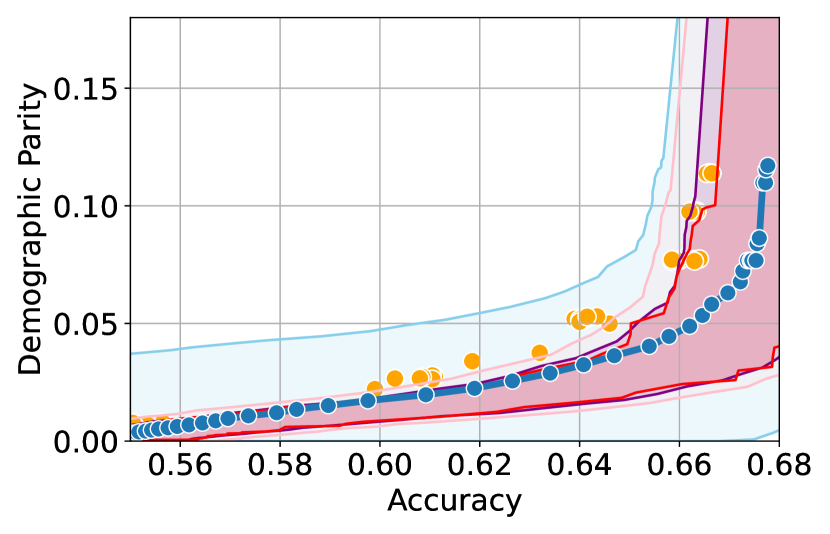
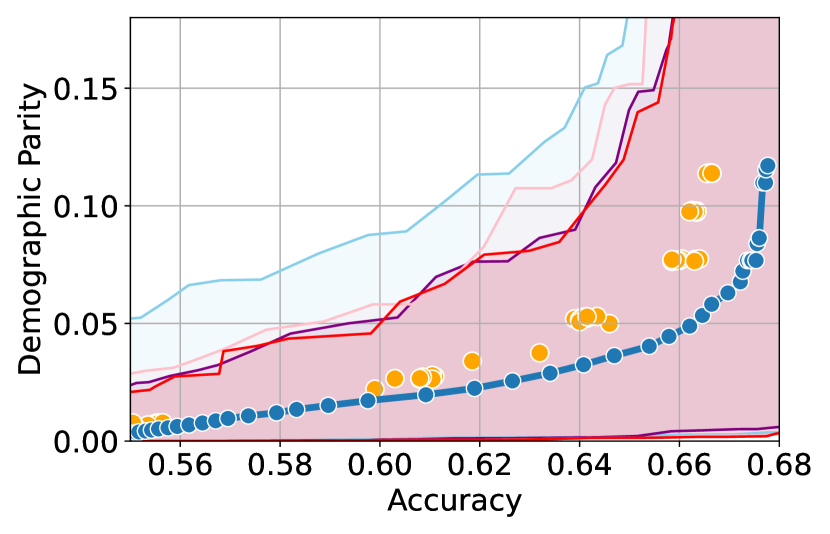
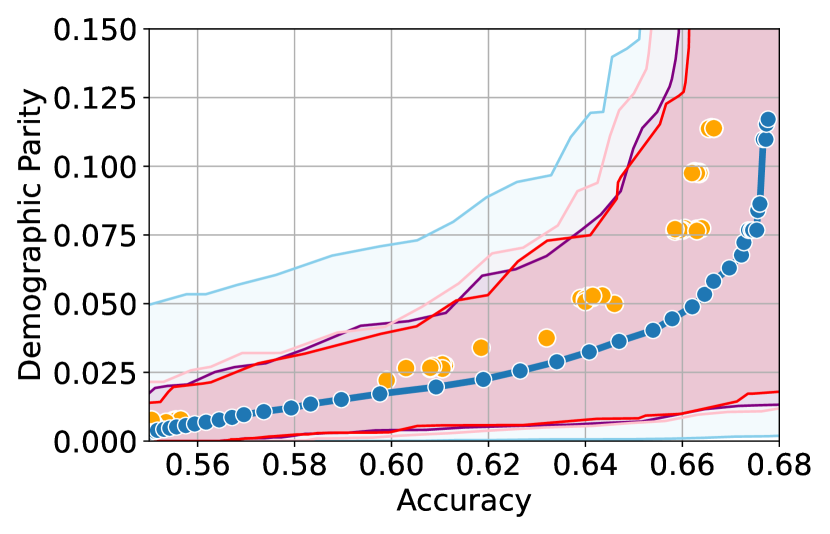
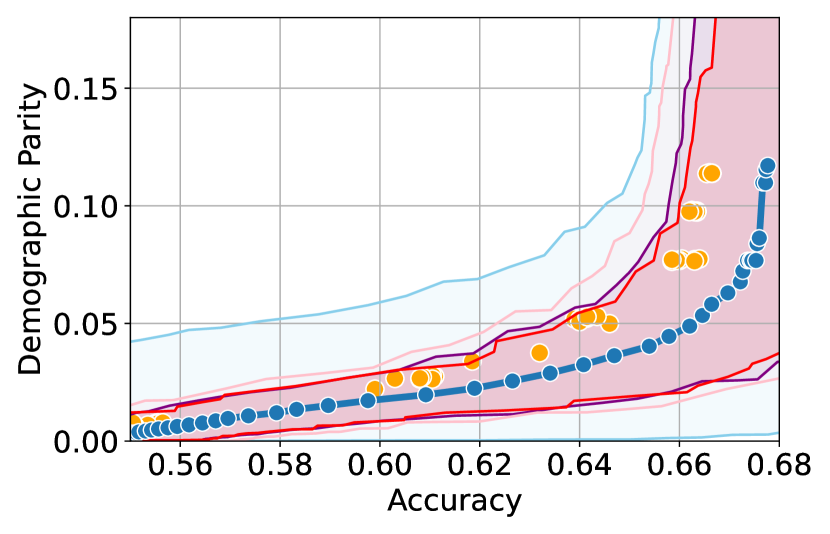

Here, we present experimental results in the setting where the sensitive attributes are missing for majority of the calibration data. Figures 10-12 show the results for different datasets and predictive models with varying accuracies. Here, the empirical fairness violation values for both YOTO and separately trained models are evaluated using the true sensitive attributes over the entire calibration data.
CIs with imputed sensitive attributes are mis-calibrated
Figures 10, 10 and 12 show results for Adult, COMPAS and CelebA datasets, where the CIs are computed by imputing the missing sensitive attributes with the predicted sensitive attributes . The figures show that when the accuracy of is below 90%, the CIs are highly miscalibrated as they do not entirely contain the empirical trade-offs for both YOTO and separately trained models.
Our methodology corrects for the mis-calibration
In contrast, Figures 10, 10 and 12 which include the corresponding results using our methodology, show that our methodology is able to correct for the mis-calibration in CIs arising from the prediction error in . Even though the CIs obtained using our methodology are more conservative than those obtained by imputing the missing sensitive attributes with , they are more well-calibrated and contain the empirical trade-offs for both YOTO and separately trained model.
Imputing missing sensitive attributes may work when has high accuracy
Finally, Figures 7(c), 8(c) and 11(c) show that the CIs with imputed sensitive attributes are relatively better calibrated as the accuracy of increases to 90%. In this case, the CIs with imputed sensitive attributes mostly contain empirical trade-offs. This shows that in cases where the predictive model has high accuracy, it may be sufficient to impute missing sensitive attributes with when constructing the CIs.
Appendix E Accounting for the uncertainty in baseline trade-offs
In this section, we extend our methodology to also account for uncertainty in the baseline trade-offs when assessing the optimality of different baselines. Recall that our confidence intervals constructed on satisfy the guarantee
This means that if the accuracy-fairness tradeoff for a given model , , lies above the confidence intervals (i.e. in the pink region in Figure 13), then we can confidently infer that the model achieves a suboptimal trade-off. This is because we know from the probabilistic guarantee above that the optimal trade-off must lie in the intervals with probability at least .
Here, denote the accuracy and fairness violations for model on the full data distribution. However, in practice, we only have access to finite data and therefore can only compute the empirical values of accuracy and fairness violations which we denote by . This means that when checking if the accuracy-fairness trade-off lies inside the confidence intervals , we must account for the uncertainty in the empirical estimates . This can be achieved by constructing confidence regions satisfying
| (14) |
Baseline’s best-case accuracy-fairness trade-off
If the confidence region lies entirely above the confidence intervals (i.e. in the pink region in Figure 13(a)), then using union bounds we can confidently conclude that with probability we have that the model achieves suboptimal fairness violation, i.e.
This allows practitioners to confidently check if a model is suboptimal in terms of its accuracy-fairness trade-off. This is different from simply checking if the empirical trade-off achieved by the model lies in the permissible trade-off region (green region in Figure 1) as it also accounts for the finite-sampling uncertainty in the tradeoff achieved by model . However, this means that the criterion for flagging a baseline model as suboptimal becomes more conservative.
Next, we show how to construct confidence regions satisfying Eq. (14).
Lemma E.1.
For a classifier , let be the upper and lower CIs on respectively,
Then, .
Lemma E.1 shows that forms the confidence region for the accuracy-fairness trade-off . We illustrate this in Figure 13(a). If this confidence region lies entirely above the permissible region (i.e. in the pink region in Figure 13), we can confidently conclude that the model achieves suboptimal accuracy-fairness trade-off. From Figure 13(a) it can be seen that this will occur if lies above the permissible region.

Intuitively, can be seen as an optimistic best-case accuracy-fairness trade-off achieved by the model , since at this point in the confidence region the accuracy is maximised and fairness violation is minimised. Therefore if this best-case trade-off lies above the permissible region, then this intuitively indicates that the worst-case optimal trade-off is still better than the best-case trade-off achieved by the model , leading us to the confident conclusion that achieves suboptimal accuracy-fairness trade-off.
Baseline’s worst-case accuracy-fairness trade-off
Conversely, if the confidence region lies entirely below the confidence intervals (i.e. in the blue region in Figure 13), then using union bounds we can confidently conclude that with probability we have that the model achieves a better trade-off than the YOTO model . Formally, this means that
where
This would indicate that the YOTO model does not achieve the optimal trade-off and can be used to further calibrate the values when constructing the lower confidence interval using Proposition 3.3. Again, this is different from simply checking if the empirical trade-off achieved by the model lies in the unlikely-to-be-achieved trade-off region (blue region in Figure 13) as it also accounts for the finite-sampling uncertainty in the tradeoff achieved by model .
Next, we show to construct such confidence region using an approach analogous to the one outlined above:
Lemma E.2.
For a classifier , let be the lower and upper CIs on respectively,
Then, .
Lemma E.2 shows that forms the confidence region for the accuracy-fairness trade-off . If this confidence region lies entirely below the permissible region (i.e. in the blue region in Figure 13), we can confidently conclude that the model achieves a better accuracy-fairness trade-off than the YOTO model. From Figure 13(b) it can be seen that this will occur if lies below the permissible region.
Intuitively, can be seen as a conservative worst-case accuracy-fairness trade-off achieved by the model . Therefore if this worst-case trade-off lies below the permissible region, then this intuitively indicates that the best-case YOTO trade-off is still worse than the worst-case trade-off achieved by the model , leading us to the confident conclusion that achieves a better accuracy-fairness trade-off than the YOTO model. This can subsequently be used to calibrate the suboptimality gap for the YOTO model, denoted by in Proposition 3.3.
E.1 Experimental results
Here, we present the results with the empirical baseline trade-offs replaced by best or worst-case trade-offs as appropriate. More specifically, in Figure 14,
-
•
if the empirical trade-off for a baseline lies in the suboptimal region (as in Figure 13(a)), then we plot the best-case trade-off for the baseline,
-
•
if the empirical trade-off for a baseline lies in the unlikely-to-be-achievable trade-off region (as in Figure 13(b)), then we plot the worst-case trade-off for the baseline,
-
•
if the empirical trade-off for a baseline lies in the permissible region, then we simply plot the empirical trade-off .
Therefore, in Figure 14 if a baseline’s best-case trade-off lies above the permissible trade-off region, then we can confidently conclude that the baseline achieves suboptimal accuracy-fairness trade-off with probability . Similarly, a baseline’s worst-case trade-off lying below the permissible trade-off region would suggest that the YOTO trade-off achieves a suboptimal trade-off and that the value of needs to be adjusted accordingly.
Table 5 shows the proportion of best-case trade-offs which lie above the permissible trade-off region and the proportion of worst-case trade-offs which lie below the permissible region. Firstly, the table shows that the proportion of worst-case trade-offs which lie in the ‘unlikely’ region is negligible, empirically confirming that our confidence intervals on optimal trade-off are indeed valid. Secondly, we can see that there are a considerable proportion of baselines whose best-case trade-off lies above the permissible region, highlighting that our methodology remains effective in flagging suboptimalities in SOTA baselines even when we account for the possible uncertainty in baseline trade-offs. This shows that our methodology yields CIs which are not only reliable but also informative.

| Adult dataset | COMPAS dataset | CelebA dataset | Jigsaw dataset |
| Baseline | Unlikely | Permissible | Sub-optimal |
|---|---|---|---|
| KDE-fair | 0.0 0.0 | 1.00.0 | 0.00.0 |
| RTO | 0.0 0.0 | 0.77 0.05 | 0.23 0.04 |
| adversary | 0.0 0.0 | 0.79 0.1 | 0.20.08 |
| linear | 0.080.05 | 0.810.06 | 0.110.05 |
| logsig | 0.05 0.02 | 0.71 0.09 | 0.250.1 |
| reductions | 0.00.0 | 0.82 0.09 | 0.18 0.08 |
| separate | 0.030.02 | 0.95 0.08 | 0.02 0.03 |
Appendix F Experimental details and additional results
In this section, we provide greater details regarding our experimental setup and models used. We first begin by defining the Equalized Odds metric which has been used in our experiments, along with DP and EOP.
Equalized Odds (EO):
EO condition states that, both the true positive rates and false positive rates for all sensitive groups are equal, i.e. for any and . The absolute EO violation is defined as:
Next, we provide additional details regarding the YOTO model.
F.1 Practical details regarding YOTO model
As described in Section 3, we consider optimising regularized losses of the form
When training YOTO models, instead of fixing , we sample the parameter from a distribution . As a result, during training the model observes many different values of and learns to optimise the loss for all of them simultaneously. At inference time, the model can be conditioned on a chosen parameter value and recovers the model trained to optimise . The loss being minimised can thus be expressed as follows:
The fairness losses considered for the YOTO model are:
Here, denotes the sigmoid function.
In our experiments, we sample a new for every batch. Moreover, we use the log-uniform distribution as per [15] as the sampling distribution , where the uniform distribution is . To condition the network on parameters, we follow in the footsteps of [15] to use Feature-wise Linear Modulation (FiLM) [34]. For completeness, we include the description of the architecture next.
Initially, we determine which network layers should be conditioned, which can encompass all layers or just a subset. For each chosen layer, we condition it based on the weight parameters . Given a layer that yields a feature map with dimensions , where and denote the spatial dimensions and stands for the channels, we introduce the parameter vector to two distinct multi-layer perceptrons (MLPs), denoted as and . These MLPs produce two vectors, and , each having a dimensionality of . The feature map is then transformed by multiplying it channel-wise with and subsequently adding . The resultant transformed feature map is given by:
Next, we provide exact architectures we used for each dataset in our experiments.
F.1.1 YOTO Architectures
Adult and COMPAS dataset
Here, we use a simple logistic regression as the main model, with only the scalar logit outputs of the logistic regression being conditioned using FiLM. The MLPs both have two hidden layers, each of size 4, and ReLU activations. We train the model for a maximum of 1000 epochs, with early stopping based on validation losses. Training these simple models takes roughly 5 minutes on a Tesla-V100-SXM2-32GB GPU.
CelebA dataset
For the CelebA dataset, our architecture is a convolutional neural network (ConvNet) integrated with the FiLM (Feature-wise Linear Modulation) mechanism. The network starts with two convolutional layers: the first layer has 32 filters with a kernel size of , and the second layer has 64 filters, also with a kernel. Both convolutional layers employ a stride of 1 and are followed by a max-pooling layer that reduces each dimension by half.
The feature maps from the convolutional layers are flattened and passed through a series of fully connected (MLP) layers. Specifically, the first layer maps the features to 64 dimensions, and the subsequent layers maintain this size until the final layer, which outputs a scalar value. The activation function used in these layers is ReLU.
To condition the network on the parameter using FiLM, we design two multi-layer perceptrons (MLPs), and . Both MLPs take the parameter as input and have 4 hidden layers. Each of these hidden layers is of size 256. These MLPs produce the modulation parameters and , which are used to perform feature-wise linear modulation on the outputs of the main MLP layers. The final output of the network is passed through a sigmoid activation function to produce the model’s prediction. We train the model for a maximum of 1000 epochs, with early stopping based on validation losses. Training this model takes roughly 1.5 hours on a Tesla-V100-SXM2-32GB GPU.
Jigsaw dataset
For the Jigsaw dataset, we employ a neural network model built upon the BERT architecture [13] integrated with the Feature-wise Linear Modulation (FiLM) mechanism. We utilize the representation corresponding to the [CLS] token, which carries aggregate information about the entire sequence. To condition the BERT’s output on the parameter using FiLM, we design two linear layers, which map the parameter to modulation parameters and , both of dimension equal to BERT’s hidden size of 768. These modulation parameters are then used to perform feature-wise linear modulation on the [CLS] representation. The modulated representation is passed through a classification head, which consists of a linear layer mapping from BERT’s hidden size (768) to a scalar output. In terms of training details, our model is trained for a maximum of 10 epochs, with early stopping based on validation losses. Training this model takes roughly 6 hours on a Tesla-V100-SXM2-32GB GPU.
F.2 Datasets
We used four real-world datasets for our experiments.
Adult dataset
The Adult income dataset [7] includes employment data for 48,842 individuals where the task is to predict whether an individual earns more than $50k per year and includes demographic attributes such as age, race and gender. In our experiments, we consider gender as the sensitive attribute.
COMPAS dataset
The COMPAS recidivism data comprises collected by ProPublica [5], includes information for 6172 defendants from Broward County, Florida. This information comprises 52 features including defendants’ criminal history and demographic attributes, and the task is to predict recidivism for defendants. The sensitive attribute in this dataset is the defendants’ race where represents ‘African American’ and corresponds to all other races.
CelebA dataset
The CelebA dataset [28] consists of 202,599 celebrity images annotated with 40 attribute labels. In our task, the objective is to predict whether an individual in the image is smiling. The dataset comprises features in the form of image pixels and additional attributes such as hairstyle, eyeglasses, and more. The sensitive attribute for our experiments is gender.
Jigsaw Toxicity Classification dataset
The Jigsaw Toxicity Classification dataset [20] contains online comments from various platforms, aimed at identifying and mitigating toxic behavior online. The task is to predict whether a given comment is toxic or not. The dataset includes features such as the text of the comment and certain metadata such as the gender or race to which each comment relates. In our experiments, the sensitive attribute is the gender to which the comment refers, and we only filter the comments which refer to exactly one of ‘male’ or ‘female’ gender. This leaves us with 107,106 distinct comments.
F.3 Baselines
The baselines considered in our experiments include:
-
•
Regularization based approaches [8]: These methods seek to minimise fairness loss using regularized losses as shown in Section 3. We consider different regularization terms as smooth relaxations of the fairness violation as proposed in the literature [8]. To make this concrete, when the fairness violation under consideration is DP, we consider
with denoted as ‘linear’ in our results and where , denoted as ‘logsig’ in our results. In addition to these methods, we also consider separately trained models with the same regularization term as the YOTO models, i.e.,
Here, denotes the sigmoid function. We denote these models as ‘separate’ in our experimental results as they are the separately trained counterparts to the YOTO model. For each relaxation, we train models for a range of values uniformly chosen in interval.
-
•
Reductions Approach [1]: This method transforms the fairness problem into a sequence of cost-sensitive classification problems. Like the regularization approaches this requires multiple models to be trained. Here, to try and reproduce the trade-off curves, we train the reductions approach with a range of different fairness constraints uniformly in .
-
•
KDE-fair [12]: This method employs a kernel density estimation trick to quantify fairness measures, capturing the degree of irrelevancy of prediction outputs to sensitive attributes. These quantified fairness measures are expressed as differentiable functions with respect to classifier model parameters, allowing the use of gradient descent to solve optimization problems that respect fairness constraints. We focus on binary classification and well-known definitions of group fairness: Demographic Parity (DP), Equalized Odds (EO) and Equalized Opportunity (EOP).
-
•
Randomized Threshold Optimizer (RTO) [2]: This scalable post-processing algorithm debiases trained models, including deep neural networks, and is proven to be near-optimal by bounding its excess Bayes risk. RTO optimizes the trade-off curve by applying adjustments to the trained model’s predictions to meet fairness constraints. In our experiments, we first train a standard classifier which is referred to as the base classifier. Next, we use the RTO algorithm to apply adjustments to the trained model’s prediction to meet fairness constraints. To reproduce the trade-off curves, we apply post-hoc adjustments to the base classifier for a range of fairness violation constraints.
-
•
Adversarial Approaches [45]: These methods utilize an adversarial training paradigm where an additional model, termed the adversary, is introduced during training. The primary objective of this adversary is to predict the sensitive attribute using the predictions generated by the main classifier . The training process involves an adversarial game between the primary classifier and the adversary, striving to achieve equilibrium. This adversarial dynamic ensures that the primary classifier’s predictions are difficult to use for determining the sensitive attribute , thereby minimizing unfair biases associated with . Specifically, for DP constraints, the adversary takes the logit outputs of the classifier as the input and predicts . In contrast for EO and EOP constraints, the adversary also takes the true label as the input. For EOP constraint, the adversary is only trained on data with .
The training times for each baseline on the different datasets have been listed in Table 6.
| Adult | COMPAS | CelebA | Jigsaw | |
| adversary | 3 min | 3 min | 90 min | 310 min |
| linear/logsig/separate | 4 min | 3 min | 80 min | 310 min |
| KDE-fair | 2 min | 2 min | 60 min | 280 min |
| reductions | 3 min | 2 min | 70 min | 290 min |
| YOTO | 4 min | 3 min | 90 min | 320 min |
| RTO (base classifier training) | 3 min | 3 min | 70 min | 310 min |
| RTO (Post-hoc optimisation per fairness constraint) | 1 min | 1 min | 10 min | 30 min |
F.4 Additional results

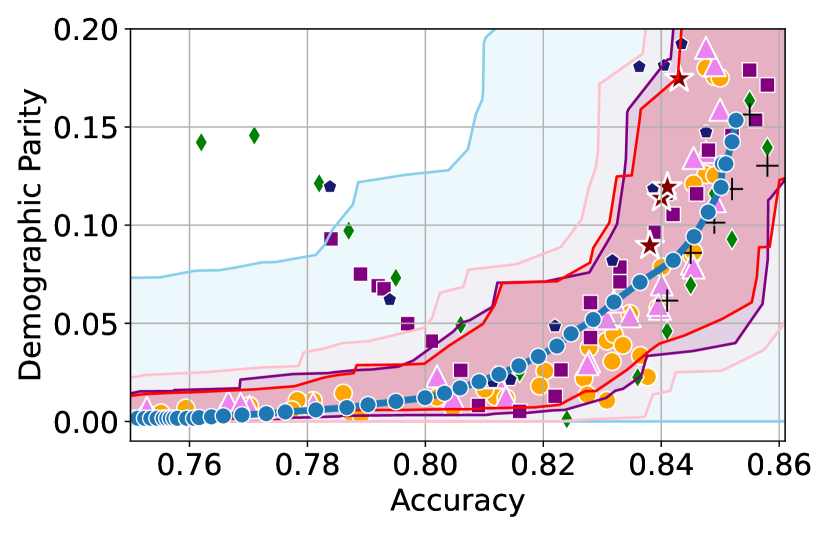
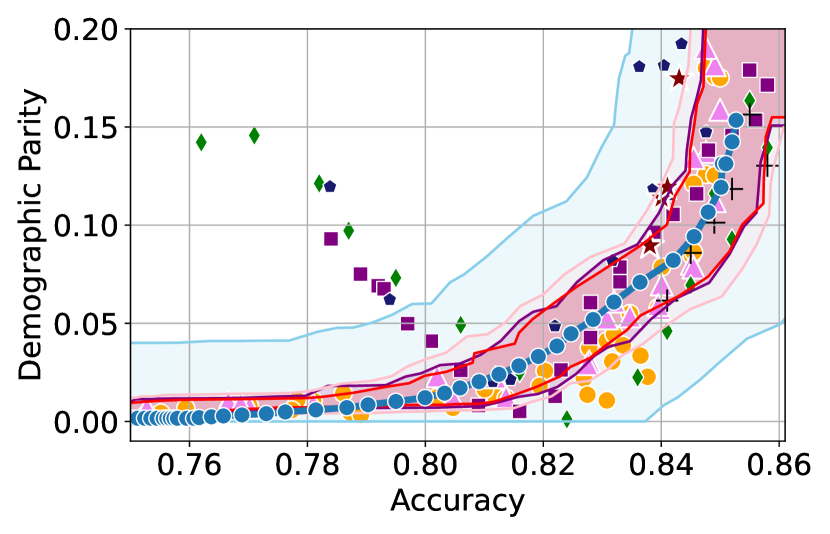
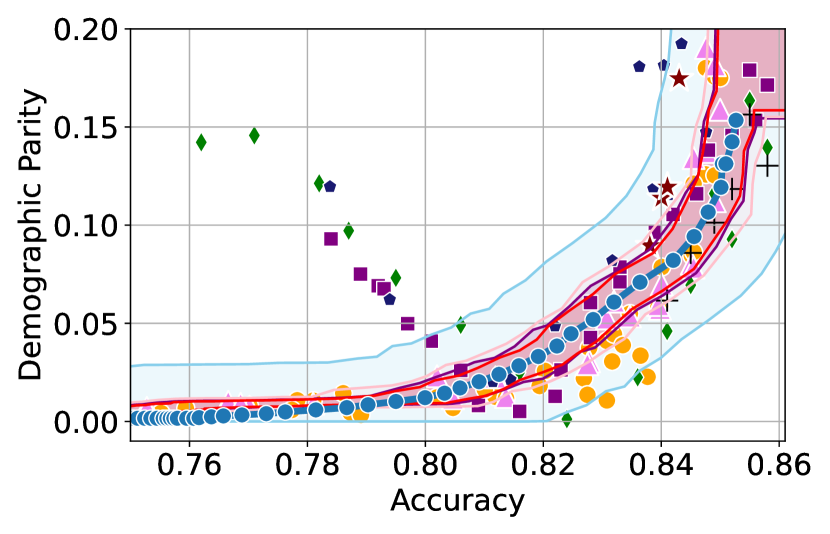
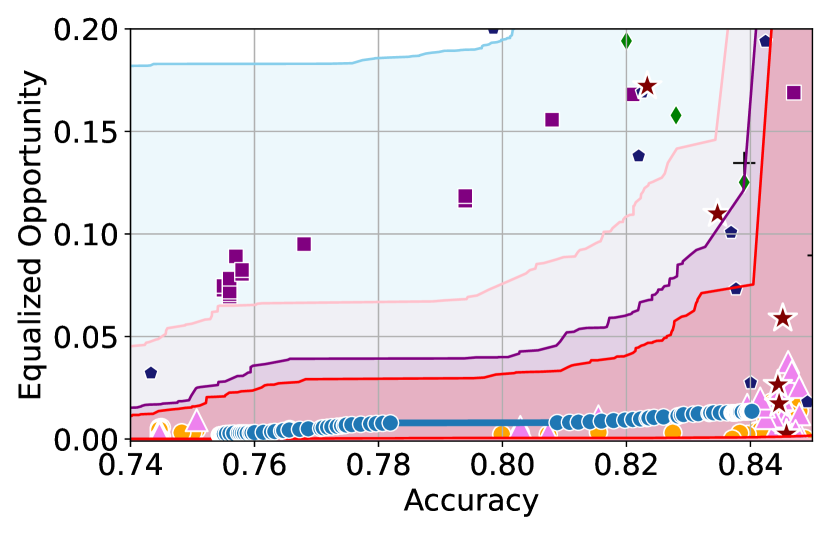
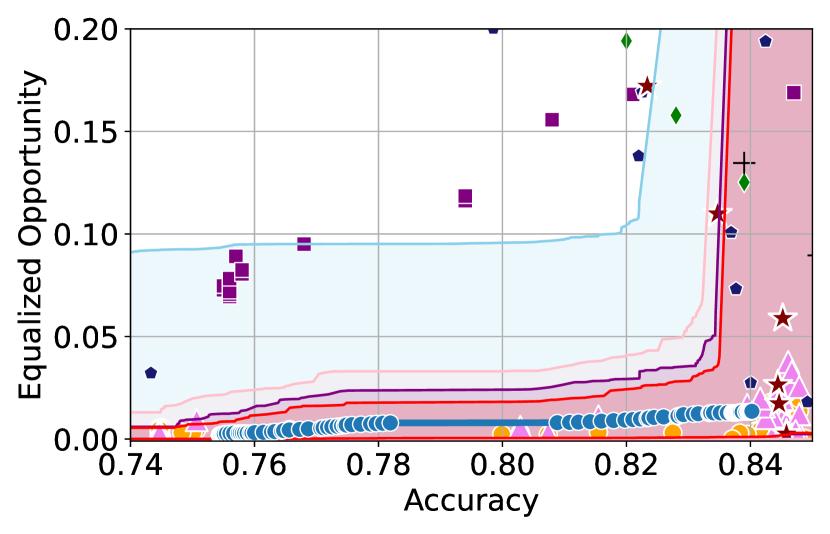
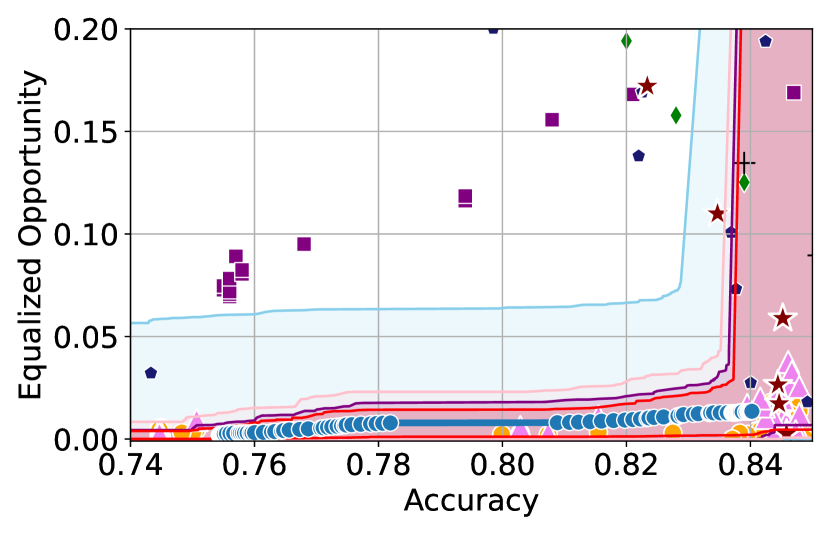
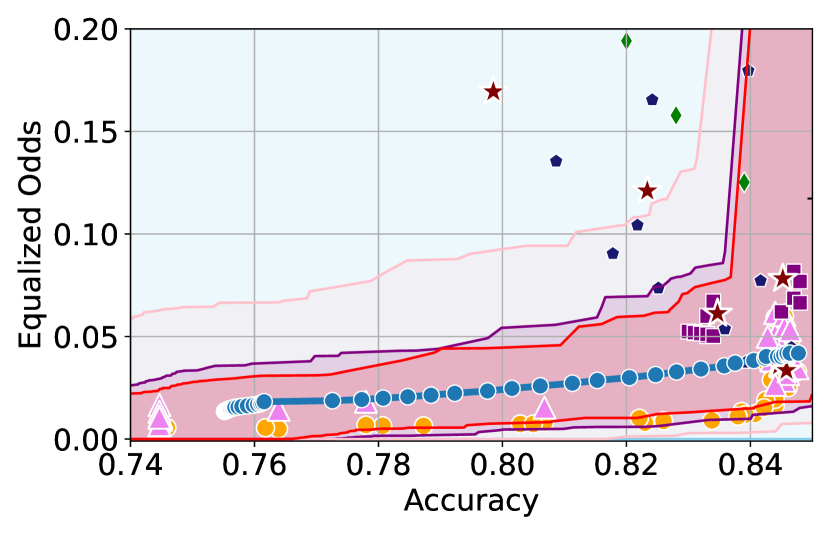
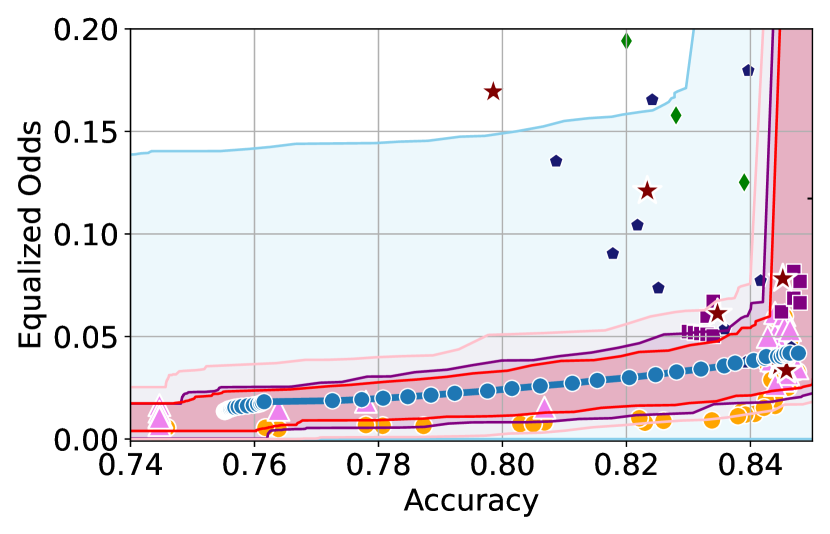
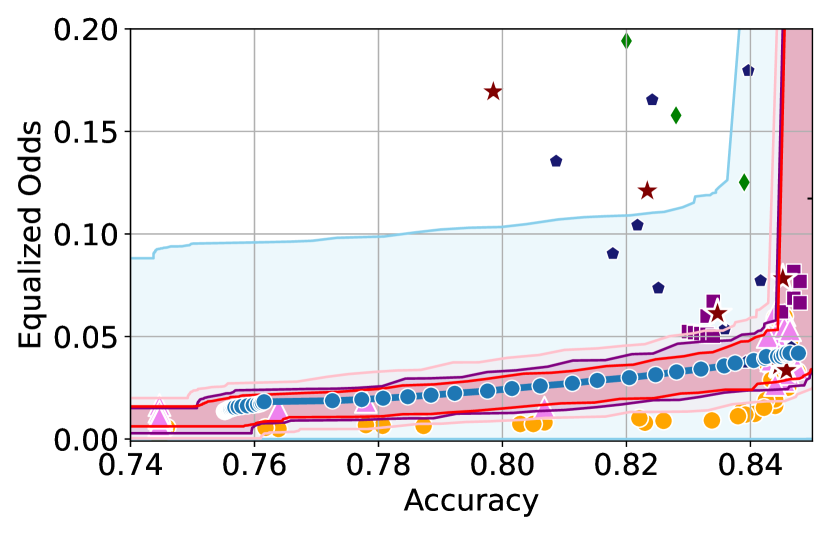

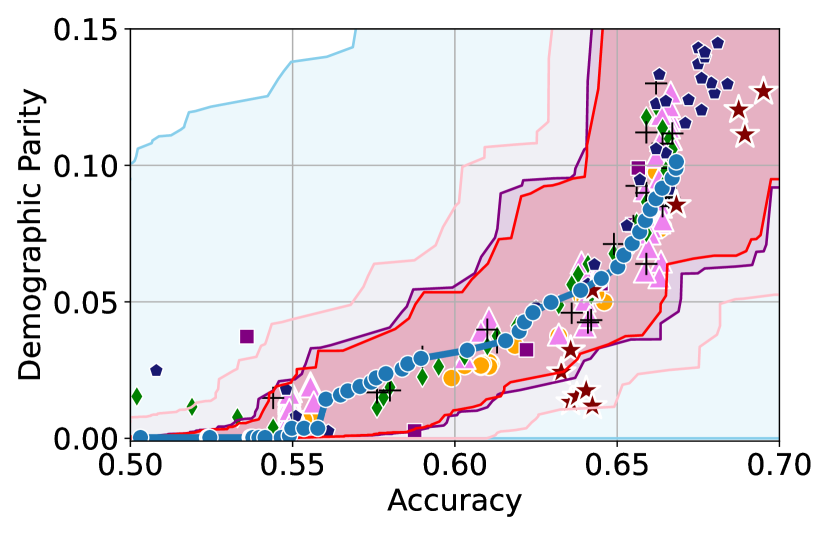
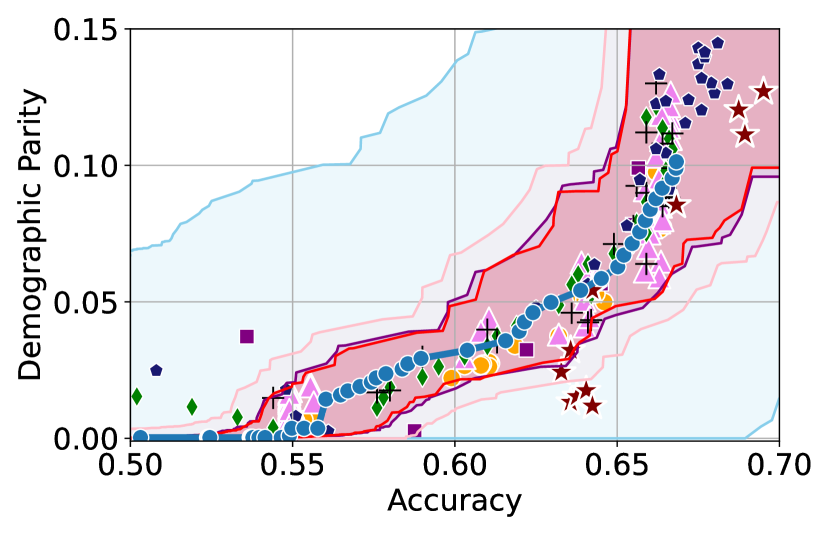
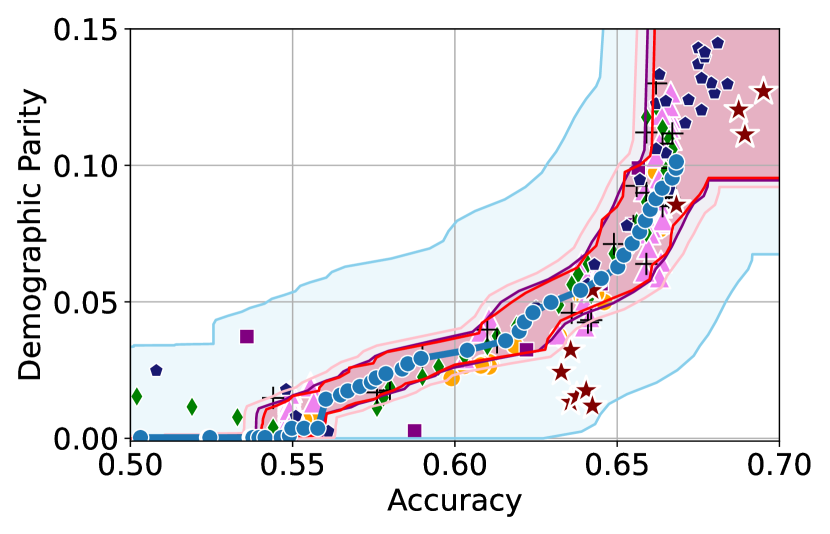
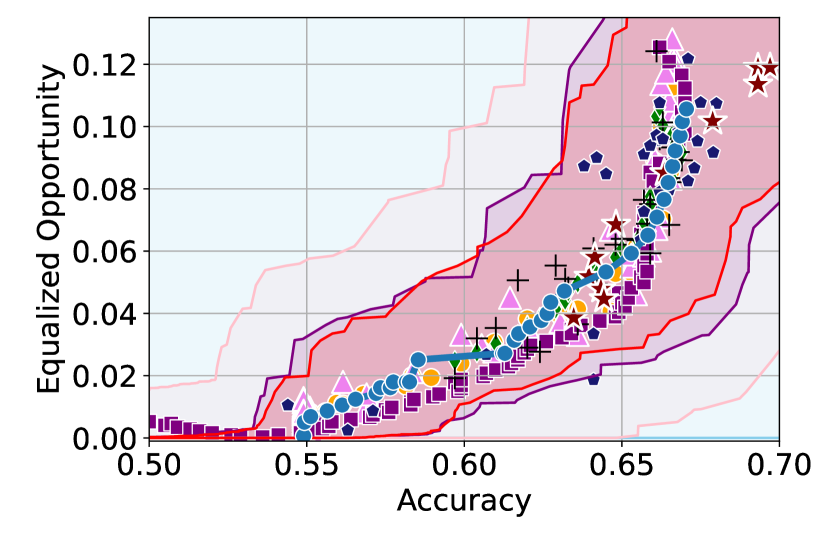
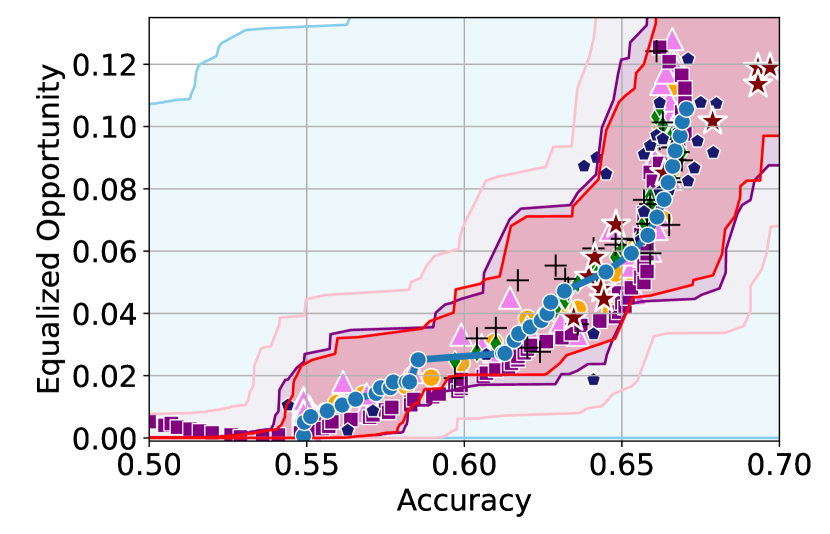
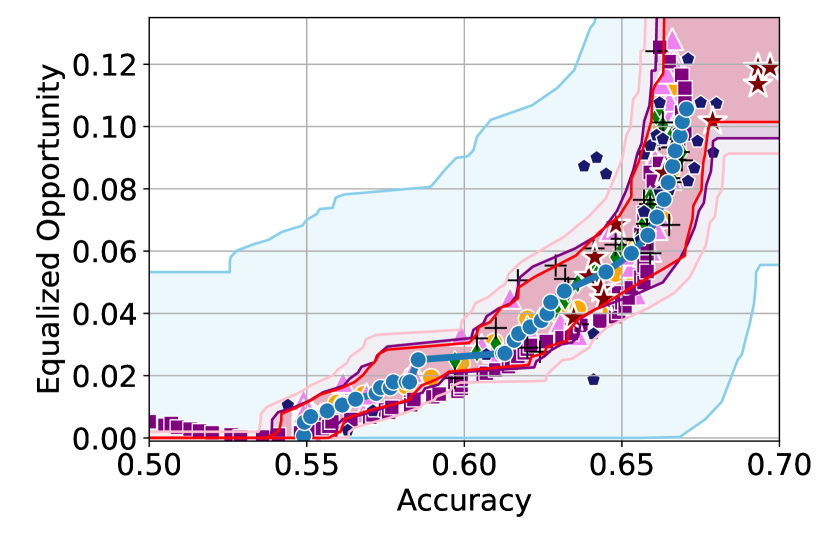
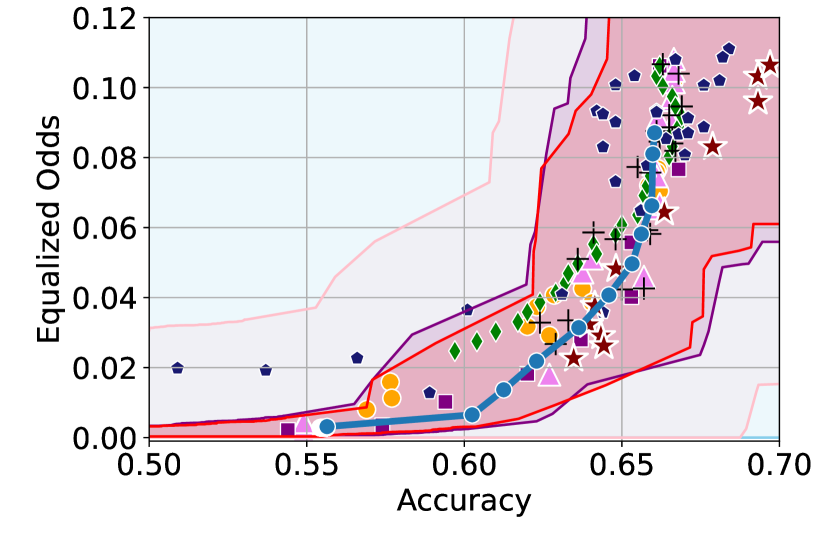
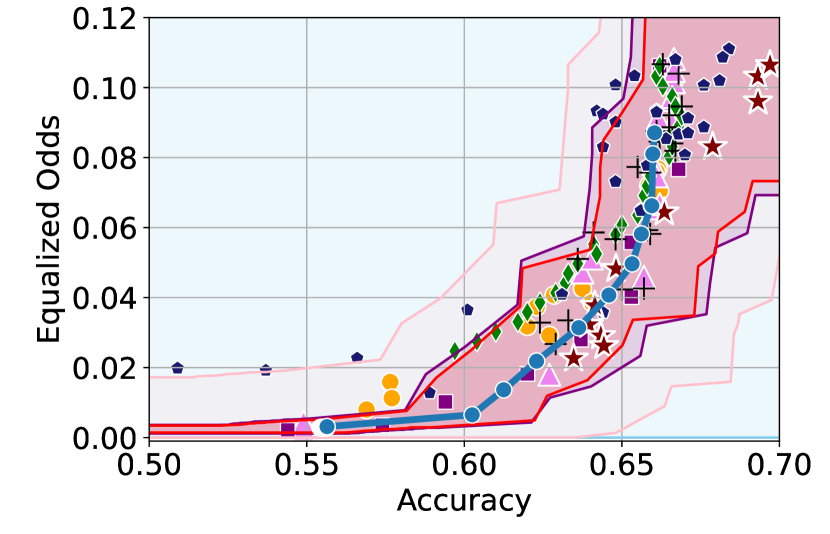
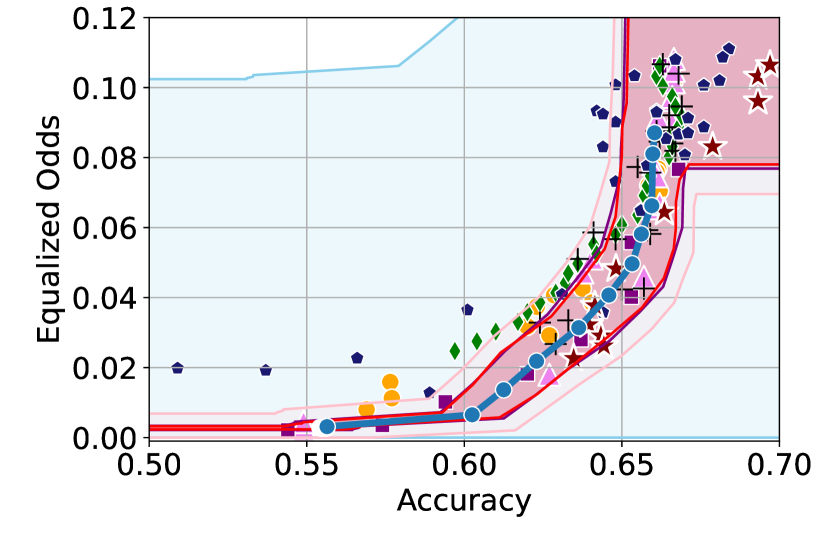

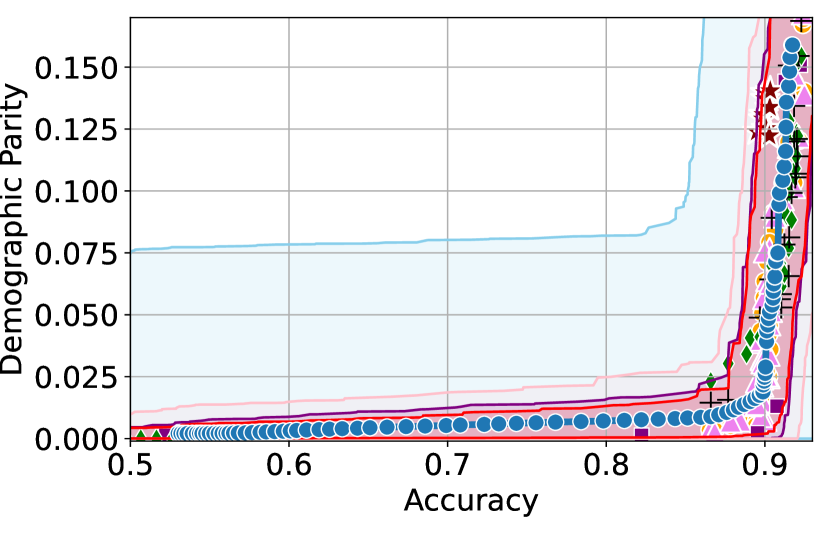
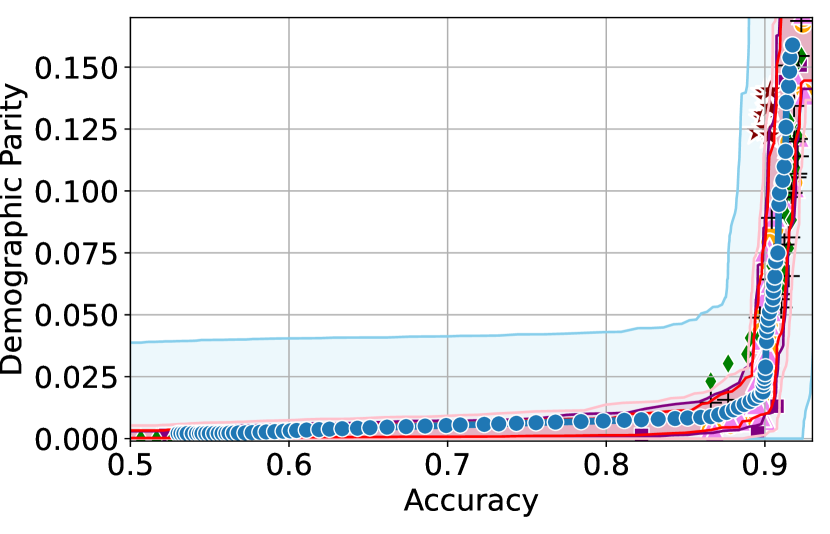
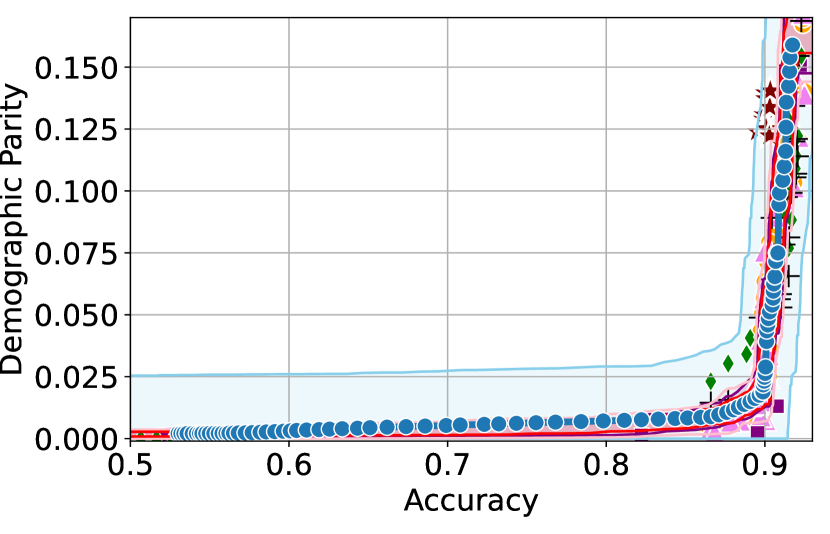
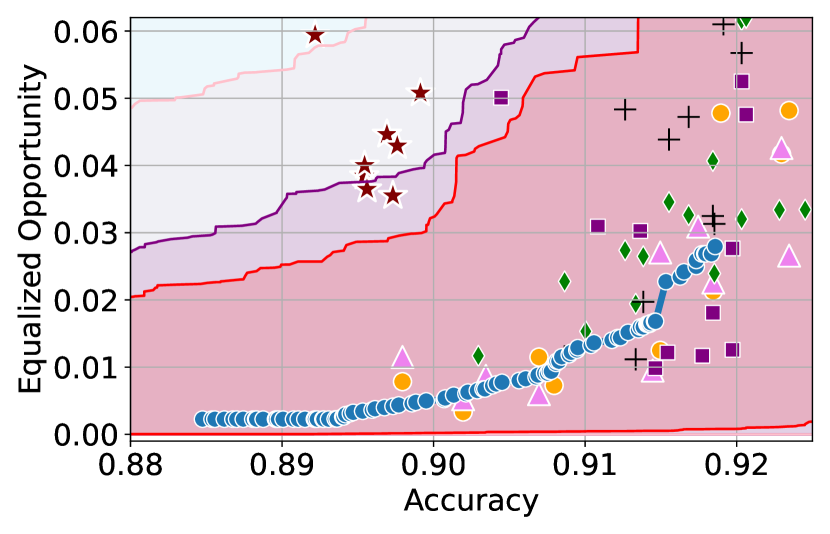
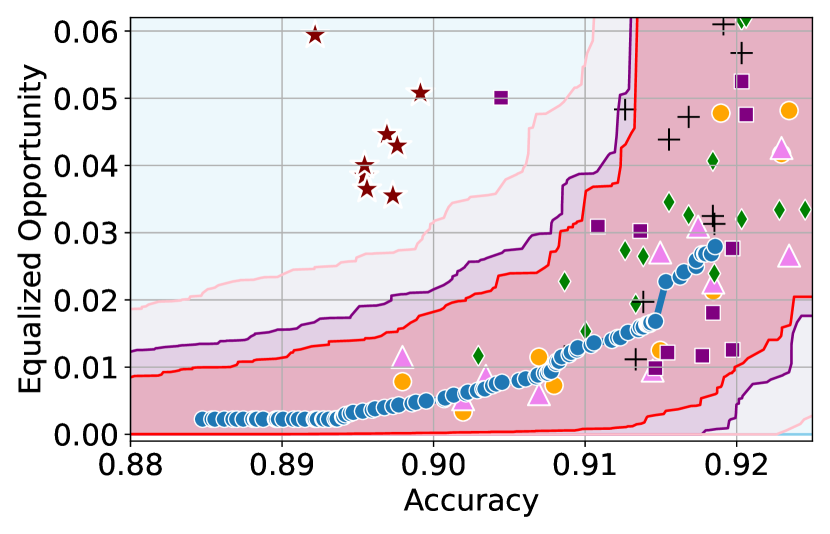
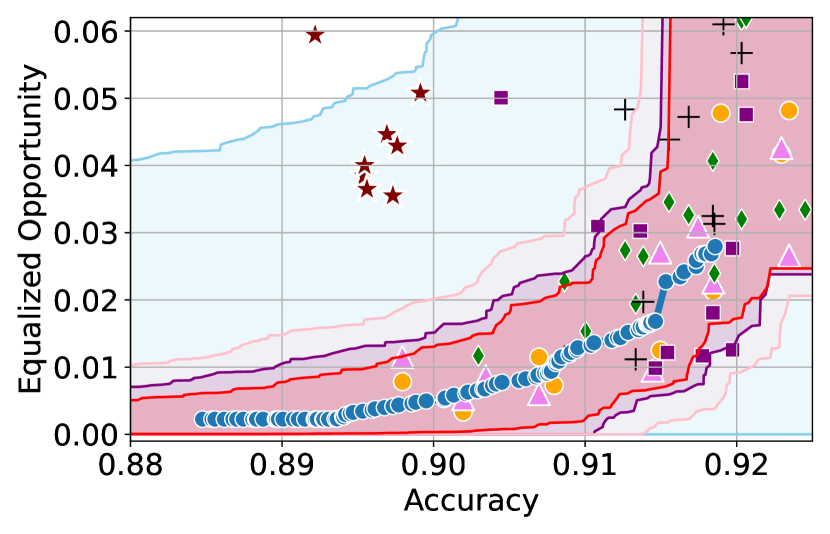
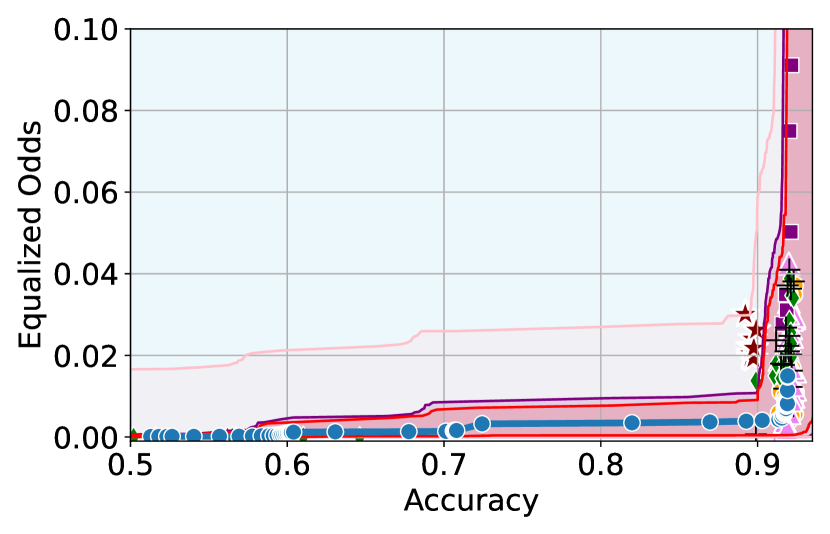
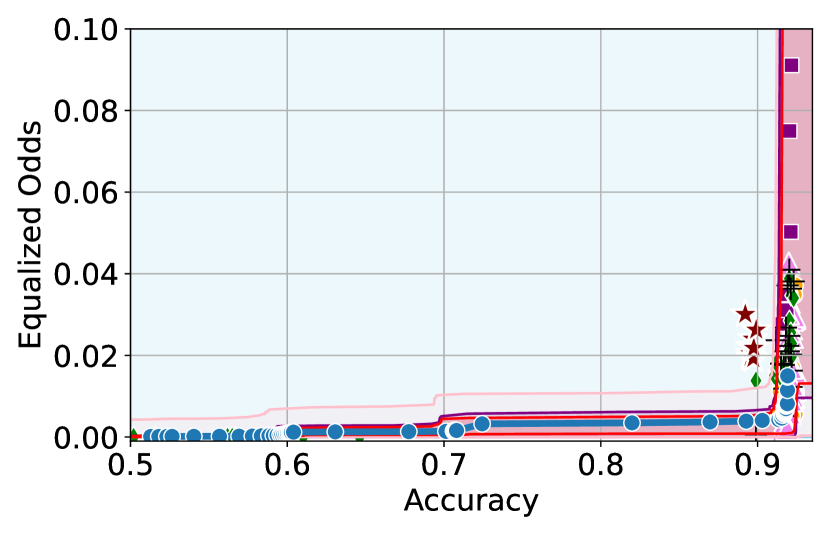
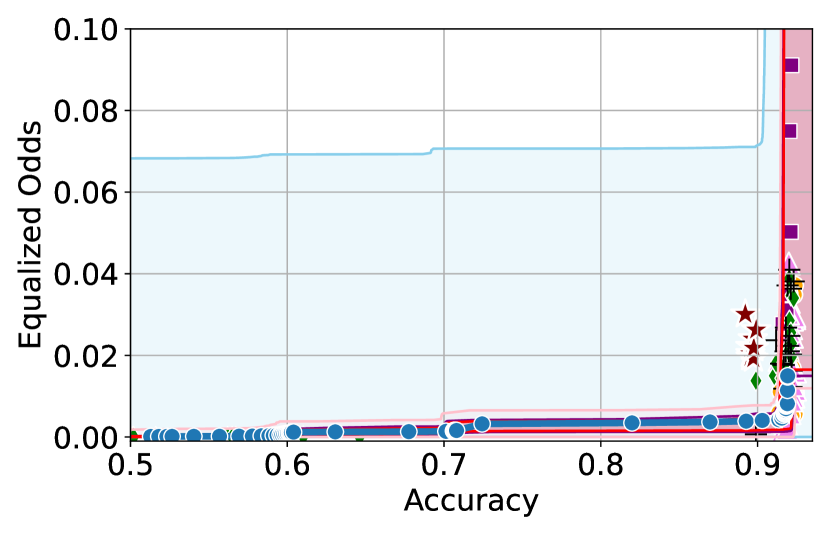

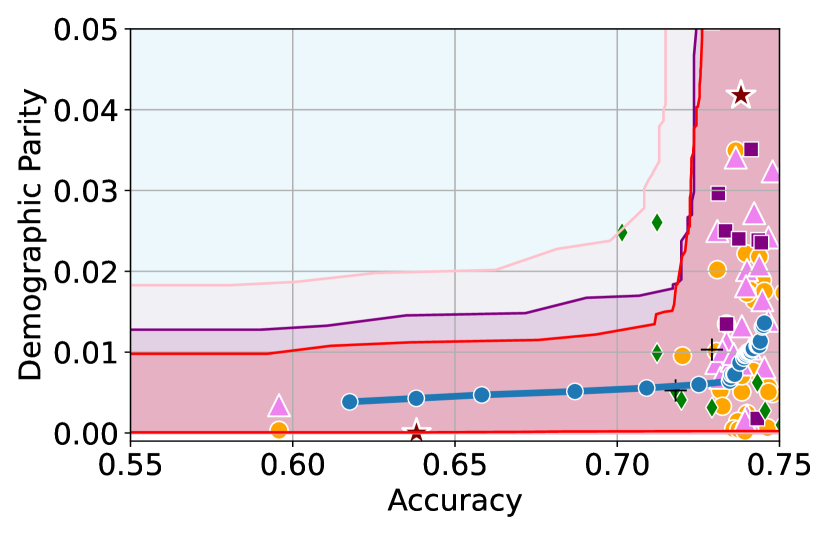
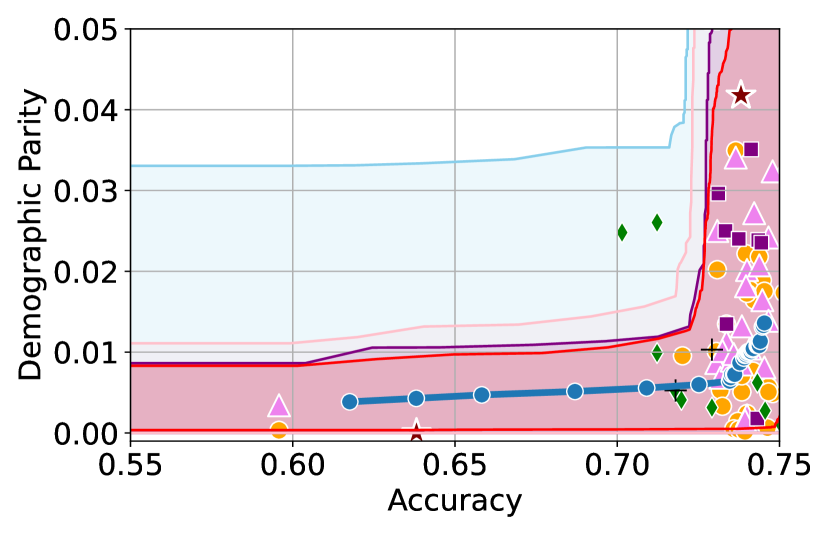
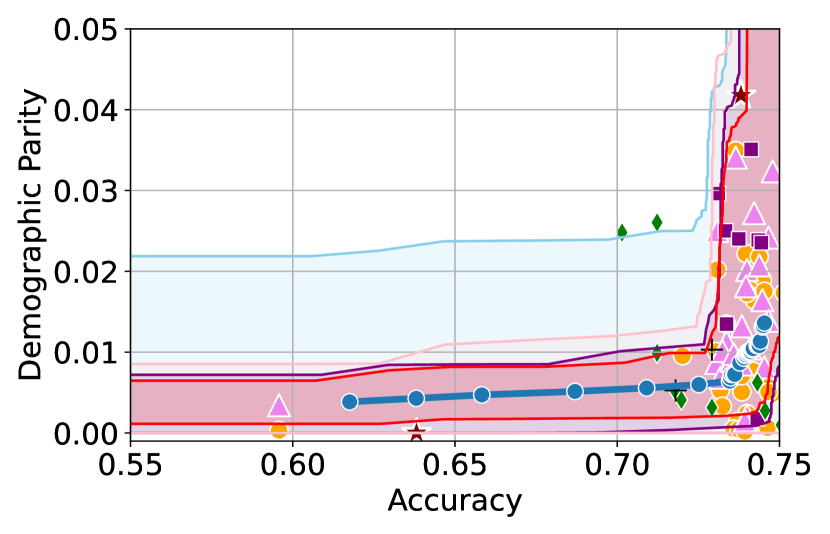
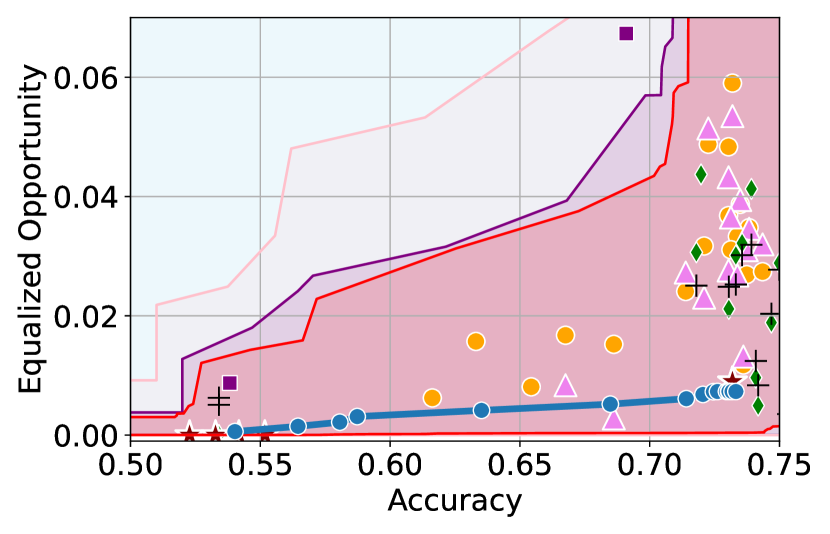
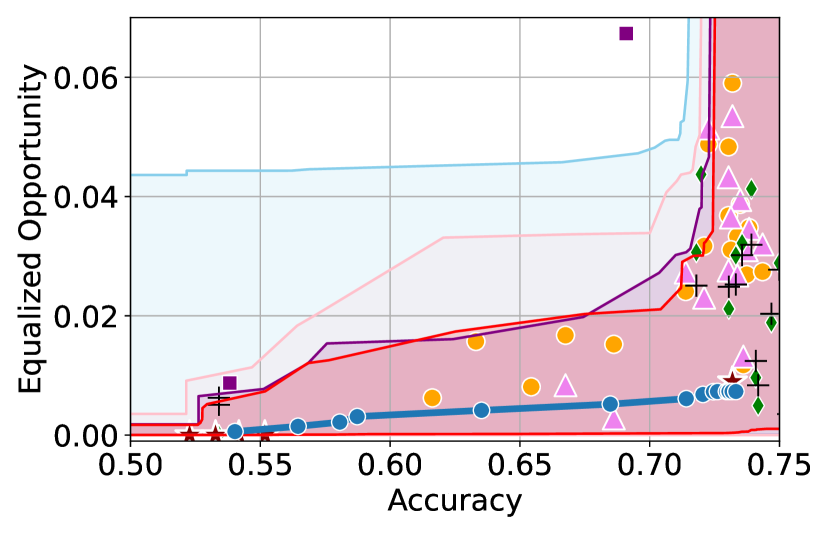
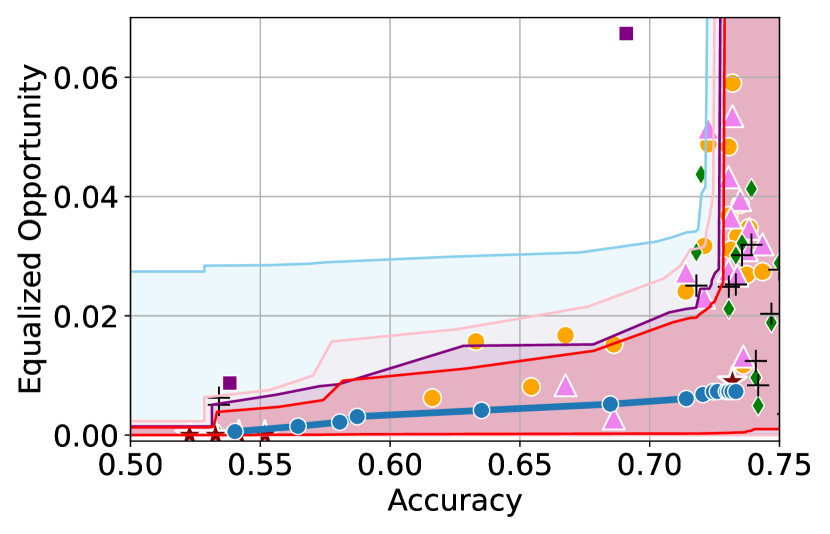
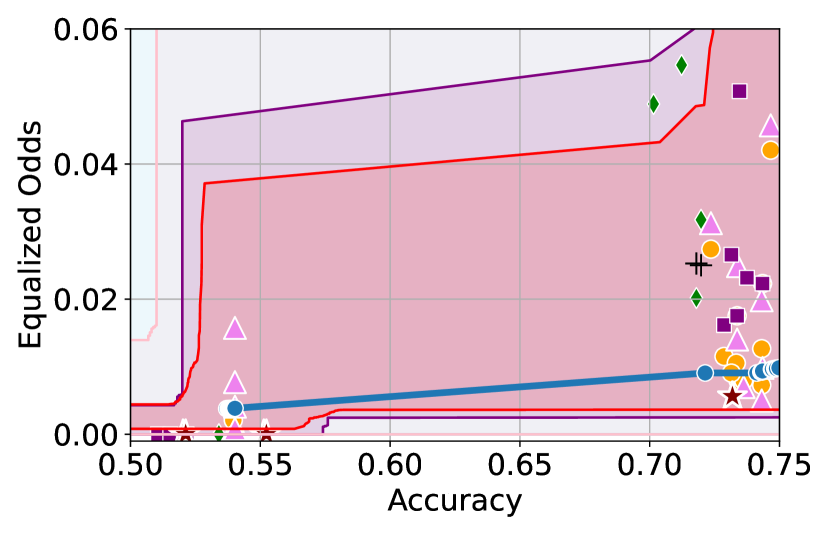
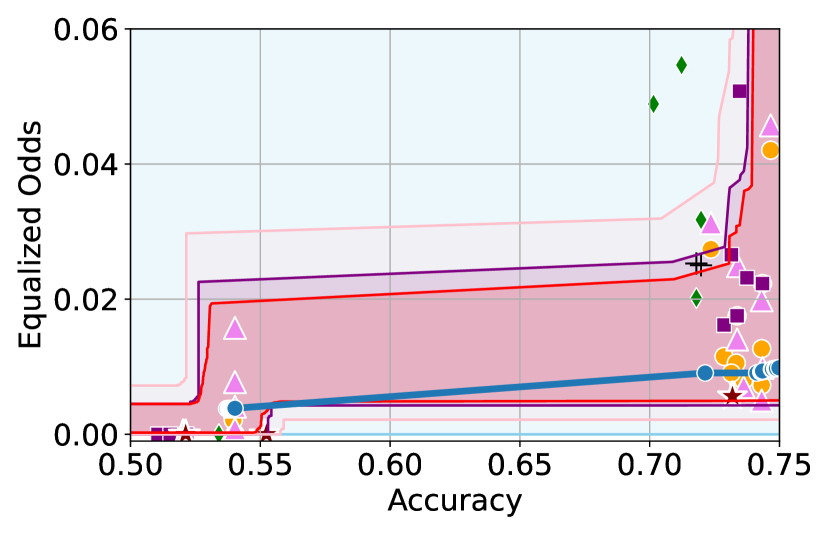
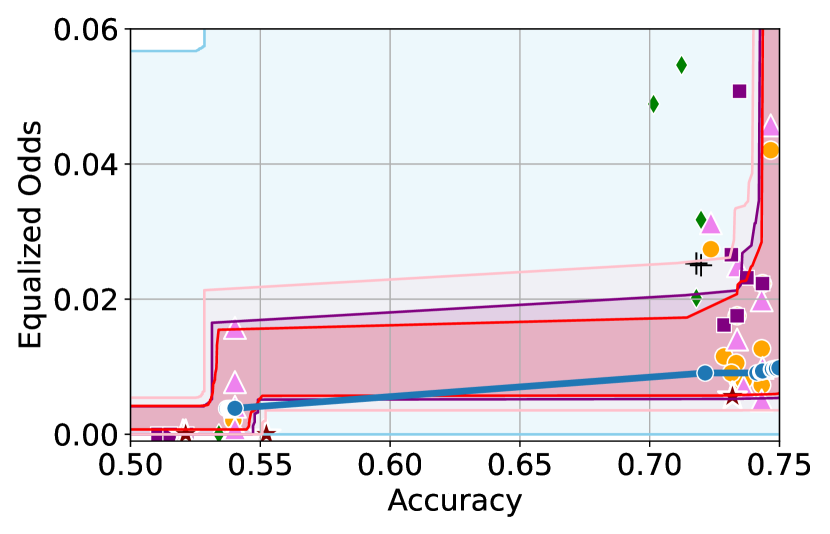
In Figures 17-26 we include additional results for all datasets and fairness violations with an increasing number of calibration data . It can be seen that as the number of calibration data increases, the CIs constructed become increasingly tighter. However, the asymptotic, Bernstein and bootstrap CIs are informative even when the calibration data is as little as 500 for COMPAS data (Figures 20-20) and 1000 for all other datasets. These results show that the larger the calibration data , the tighter the constructed CIs are likely to be. However, even in cases where the calibration dataset is relatively small, we obtain informative CIs in most cases.
Tables 7 - 18 show the proportion of the baselines which lie in the three trade-off regions, ‘Unlikely’, ‘Permissible’ and ‘Sub-optimal’ for the Bernstein’s CIs, across the different datasets and fairness metrics. Overall, it can be seen that our CIs are reliable since the proportion of trade-offs which lie below our CIs is small. On the other hand, the tables show that our CIs can detect a significant number of sub-optimalities in our baselines, showing that our intervals are informative.
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.67 | 0.33 |
| adversary | 0.15 | 0.85 | 0.0 |
| linear | 0.0 | 0.82 | 0.18 |
| logsig | 0.05 | 0.2 | 0.75 |
| reductions | 0.0 | 0.83 | 0.17 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 0.99 | 0.01 |
| RTO | 0.0 | 0.96 | 0.04 |
| adversary | 0.0 | 1.0 | 0.0 |
| linear | 0.0 | 1.0 | 0.0 |
| logsig | 0.01 | 0.36 | 0.62 |
| reductions | 0.03 | 0.77 | 0.2 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.89 | 0.11 |
| adversary | 0.0 | 1.0 | 0.0 |
| linear | 0.0 | 0.76 | 0.24 |
| logsig | 0.0 | 0.45 | 0.55 |
| reductions | 0.0 | 0.7 | 0.3 |
| separate | 0.1 | 0.87 | 0.03 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.33 | 0.67 |
| adversary | 0.0 | 0.0 | 1.0 |
| linear | 0.13 | 0.47 | 0.4 |
| logsig | 0.0 | 0.27 | 0.73 |
| reductions | 0.0 | 0.13 | 0.87 |
| separate | 0.03 | 0.95 | 0.02 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.07 | 0.89 | 0.04 |
| RTO | 0.0 | 0.5 | 0.5 |
| adversary | 0.0 | 0.36 | 0.64 |
| linear | 0.0 | 0.5 | 0.5 |
| logsig | 0.0 | 0.09 | 0.91 |
| reductions | 0.0 | 0.17 | 0.83 |
| separate | 0.02 | 0.95 | 0.03 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.4 | 0.6 |
| adversary | 0.0 | 0.36 | 0.64 |
| linear | 0.0 | 0.4 | 0.6 |
| logsig | 0.0 | 0.65 | 0.35 |
| reductions | 0.0 | 0.1 | 0.9 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.56 | 0.44 |
| adversary | 0.0 | 0.18 | 0.82 |
| linear | 0.0 | 0.88 | 0.12 |
| logsig | 0.05 | 0.95 | 0.0 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 0.91 | 0.09 |
| RTO | 0.0 | 0.45 | 0.55 |
| adversary | 0.0 | 0.27 | 0.73 |
| linear | 0.15 | 0.82 | 0.03 |
| logsig | 0.0 | 0.73 | 0.27 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 1.0 | 0.0 |
| RTO | 0.0 | 0.71 | 0.29 |
| adversary | 0.0 | 0.27 | 0.73 |
| linear | 0.0 | 0.97 | 0.03 |
| logsig | 0.0 | 0.73 | 0.27 |
| separate | 0.0 | 1.0 | 0.0 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 0.92 | 0.08 |
| RTO | 0.0 | 0.5 | 0.5 |
| adversary | 0.0 | 0.09 | 0.91 |
| linear | 0.0 | 0.76 | 0.24 |
| logsig | 0.0 | 0.4 | 0.6 |
| separate | 0.0 | 0.88 | 0.12 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 0.83 | 0.17 |
| RTO | 0.0 | 0.62 | 0.38 |
| adversary | 0.06 | 0.94 | 0.0 |
| linear | 0.14 | 0.59 | 0.27 |
| logsig | 0.0 | 0.29 | 0.71 |
| separate | 0.0 | 0.47 | 0.53 |
| Unlikely | Plausible | Sub-optimal | |
|---|---|---|---|
| KDE-fair | 0.0 | 0.75 | 0.25 |
| RTO | 0.0 | 0.57 | 0.43 |
| adversary | 0.0 | 1.0 | 0.0 |
| linear | 0.0 | 0.73 | 0.27 |
| logsig | 0.0 | 0.4 | 0.6 |
| separate | 0.0 | 0.87 | 0.13 |
F.5 Additional details for Figure 1
For Figure 1, we consider a calibration data of size 2000. For the optimal model, we trained a YOTO model on the COMPAS dataset with the architecture given in F.1.1. We train the model for a maximum of 1000 epochs, with early stopping based on validation losses. Once trained, we obtained the red and black curves by first splitting randomly into two subsets, and evaluating the trade-offs on each split separately. On the other hand, for the sub-optimal model, we use another YOTO model with the same architecture but stop the training after 20 epochs. This results in the trained model achieving a sub-optimal trade-off as shown in the figure. We evaluated this trade-off curve on the entire calibration data.
F.6 Experimental results with FACT Frontiers

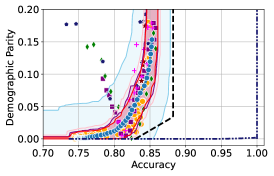
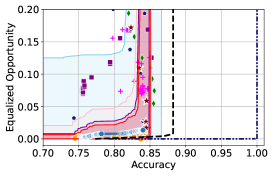
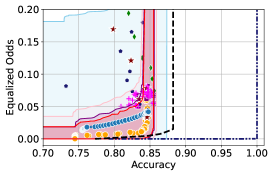
MA FACT and MS FACT yield conservative Pareto Frontiers.
In Figure 27 we include the results for the Adult dataset along with the model-specific (MS) and model-agnostic (MA) FACT Pareto frontiers, obtained using the methodology in [23]. It can be seen that both Pareto frontiers, MS FACT and MA FACT are overly conservative, with the MA FACT being completely non-informative on the Adult dataset. The model-agnostic FACT trade-off considers the best-case trade-off for any given dataset and does not depend on a specific model class. As a result, there is no guarantee that this Pareto frontier is achievable. This is evident from the fact that the MA FACT yields a non-informative Pareto frontier on the Adult dataset in Figure 27, which is non-achievable in practice.
The model-specific FACT trade-off curve is comparatively more realistic as it is derived using a pre-trained model. However, it is important to note that the trade-off for this pre-trained model may not lie on the obtained MS FACT frontier. In fact, MS FACT may still not be achievable by any model in the given model class, as it does not provide any guarantee of being achievable either. This can be seen from Figure 27 which shows that the MS-FACT frontier is not achieved by any of the SOTA baselines under consideration. In these experiments, we used a logistic regression classifier as a pre-trained model for obtaining the MS FACT frontier.
F.7 Synthetic data experiments
In real-world settings, the ground truth trade-off curve remains intractable because we only have access to a finite dataset. In this section, we consider a synthetic data setting, where the ground truth trade-off curve can be obtained, to verify that the YOTO trade-off curves are consistent with the ground truth and that the confidence intervals obtained using our methodology contain .
Dataset
Here, we consider a setup with , and . Specifically, and we define the conditional distributions as:
Moreover, we define the labels as follows:
where and . Here, introduces some ‘noise’ to the labels and means that perfect accuracy is not achievable by linear classifiers. If perfect accuracy was achievable, the optimal values for Equalized Odds and Equalized Opportunity would be 0 (and would be achieved by the perfect classifier), therefore our use of ‘noisy’ labels ensures that the ground truth trade-off curves will be non-trivial.
YOTO model training Using the data generating mechanism, we generate training datapoints, which we use to train the YOTO model. The YOTO model for this dataset comprises of a simple logistic regression as the main model, with only the scalar logit outputs of the logistic regression being conditioned using FiLM. The MLPs both have two hidden layers, each of size 4, and ReLU activations. We train the model for a maximum of 1000 epochs, with early stopping based on validation losses. Training these simple model only requires one CPU and takes roughly 2 minutes.
Ground truth trade-off curve To obtain the ground truth trade-off curve , we consider the family of classifiers
for . Next, we calculate the trade-offs achieved by this model family for a fine grid of values between -3 and 3, using a dataset of size 500,000 obtained using the data-generating mechanism described above. The large dataset size ensures that the finite sample errors in accuracy and fairness violation values are negligible. This allows us to reliably plot the trade-off curve .
F.7.1 Results
Figure 28 shows the results for the synthetic data setup for three different fairness violations, obtained using a calibration dataset of size 2000. It can be seen that for each fairness violation considered, the YOTO trade-off curve aligns very well with the ground-truth trade-off curve . Additionally, we also consider four different confidence intervals obtained using our methodology, and Figure 28 shows that each of the four confidence intervals considered contain the ground-truth trade-off curve. This empirically verifies the validity of our confidence intervals in this synthetic setting.
Additionally, in Figure 29 we plot how the worst-case values for change (relative to the optimal trade-off ) as the number of training data increases. Here, we use as a short-hand notation for the YOTO model and the quantity on the -axis, can be intuitively thought of as the worst-case error percentage between YOTO trade-off and the optimal trade-off. The figure empirically verifies our result in Theorem 3.4 by showing that as the number of training data increases, the error term declines across all fairness metrics.