Achieving and Understanding Out-of-Distribution Generalization in Systematic Reasoning in Small-Scale Transformers
Abstract
Out-of-distribution generalization (OODG) is a longstanding challenge for neural networks. This challenge is quite apparent in tasks with well-defined variables and rules, where explicit use of the rules could solve problems independently of the particular values of the variables, but networks tend to be tied to the range of values sampled in their training data. Large transformer-based language models have pushed the boundaries on how well neural networks can solve previously unseen problems, but their complexity and lack of clarity about the relevant content in their training data obfuscates how they achieve such robustness. As a step toward understanding how transformer-based systems generalize, we explore the question of OODG in small scale transformers trained with examples from a known distribution. Using a reasoning task based on the puzzle Sudoku, we show that OODG can occur on a complex problem if the training set includes examples sampled from the whole distribution of simpler component tasks. Successful generalization depends on carefully managing positional alignment when absolute position encoding is used, but we find that suppressing sensitivity to absolute positions overcomes this limitation. Taken together our results represent a small step toward understanding and promoting systematic generalization in transformers.
Large transformer-based ‘foundation’ models [2] have attracted recent attention by showing some success in mathematical reasoning tasks, demonstrating a degree of systematicity and compositionality [4, 18, 9]. However, it is unclear how their ability to behave systematically emerges, due to the massive sizes of the training data and model parameters. Are they demonstrating the ability to generalize out-of-distribution to novel problems? Or are they succeeding because the data they are trained on samples from the entire space of possible training examples?
To investigate how a domain-agnostic model may learn to generalize to out-of-distribution examples, we train a small scale transformer-based network to learn solution strategies based on the popular puzzle game Sudoku. We use a 6x6 Sudoku grid rather than the traditional 9x9, which provides sufficient complexity for investigating algorithmic reasoning while offering more tractability and lower compute requirements. The general rule of Sudoku still applies: every -celled row, column, and outlined region of the grid must contain exactly one instance of each of the alternative digits.
Sudoku is well-suited for this inquiry for several reasons. First, it is governed by a small set of rules that are inherently abstract, relational, and form sophisticated interactions and dependencies that require careful algorithmic and deductive reasoning. These rules form group properties and symmetries [5, 15] that translate one puzzle to another such that learning to solve a subset of examples of a class of puzzles would enable the solver to solve all puzzles with the same relational properties, provided that the abstract rules and relations are induced and the new examples can be mapped onto them. The symmetries in Sudoku enable an elegant means to probe for systematicity by designing training and test sets that share core relational features yet differ superficially in a well-defined manner. Second, Sudoku has been shown to be challenging to neural networks, and has only been successfully solved using a graph network architecture [1] with built-in domain-specific inductive biases enforcing the relevant, task-specific, symmetries [13]. While this is a useful strategy for building models that solve Sudoku, it offers little guidance towards understanding how a domain-agnostic neural network can learn in a way that enables systematic generalization. Finally, Sudoku has been used to study reasoning, learning, and generalization in humans [8, 12], offering an interesting benchmark for what forms of behavior one ought to expect from a solver with human-level general intelligence.
We focus on one solution strategy in Sudoku called the Hidden Single technique and introduce a transformer neural network architecture and training set to explore out-of-distribution generalization (OODG). Building on this network, we present the following findings: First, a single forward pass in the network is insufficient to learn the Hidden Single strategy; sequential, multi-step reasoning is necessary. Second, we decompose the Hidden Single strategy into two subtasks, and show that including training examples on these subtasks sampled from the full space of instances of such problems allows the model to exhibit substantial OODG of the Hidden Single strategy.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8a2d225e-469b-44c3-8e47-107ae678ad60/6x6_grid.png)
| Hidden Single | Full House | Naked Single | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
1 Task Description
We base our tasks on the three simplest Sudoku techniques. Full House (FH) involves identifying a cell in which all other cells in one of its houses (row, column, or 2x3 box) are filled such that the empty cell’s digit must be the only remaining digit. Naked Single (NS) involves identifying a cell in which 5 of the 6 possible digits already exist in its neighborhood (row, column, and 2x3 box) such that the empty cell’s digit must be the remaining digit. Hidden Single (HS) involves identifying a cell in which all other cells in one of its houses cannot contain one of the digits, either due to already containing a different digit or the digit being present in ’s neighborhood, so that the only remaining cell that can contain the digit in the house is .
For each technique, we create a task in which the model is presented with a 6x6 Sudoku grid and a string sequence prompt that provides the context for solving the problem, including the coordinates of the cell to solve for, the candidate digit, the name of the technique to use, and, for the Hidden Single (HS) and Full House (FH) tasks, the house type to inspect. By specifying all these details as part of the prompt, we simplify the task from conducting a search for a valid solution to verifying whether a goal cell should contain a candidate digit according to the rules of the specified technique.
The target sequence formats for each of the three tasks were designed to support composition of elements of the Full House and Naked Singles (NS) tasks (see Table 1). The HS task format steps through all of the cells other than the target cell in the specified target house, and checks to see if the specified digit can go in any of these cells. If it cannot, the answer is yes, it must go in the target cell.The FH task performs a similar iteration strategy, but identifies whether the cell contains a digit at all at each step. The NS task addresses the component of the HS task not present in the FH task, which is to identify whether a given cell can contain a candidate digit based on direct contradictions within its (row, column, or box) neighborhood. In the HS task, the network can draw on the FH strategy when it encounters full cells in the target house (column 2 in the example) and on the naked single strategy when it encounters empty cells.
2 Experiments
We use a 3-layer transformer encoder [16] to which all grid and text embeddings are passed, and from which output vectors are then mapped to output text tokens (See Training Details in the Supplementary Materials). Grid cells inputs specify the x and y coordinates of each cell and indicate if the cell is empty or if not which digit it contains. Text tokens are pared with sinusoidal position encodings as in [16]. We use teacher-forcing during training and greedy autoregressive generation during evaluation.
We first check if the network could solve the tasks by producing the final yes/no responses immediately after the prompt. After training 5 model instances on 50,000 HS puzzles uniformly sampled from the full problem space, we find that these models only solve 87.8% of held-out puzzles, compared to the 99.9% of models trained to produce the full sequence of reasoning steps. Taking complete success at within-distribution generalization as a pre-requisite, we use the full sequences as exemplified in Table 1 in all remaining experiments, which focus on out of distribution generalization in our models.
Out-of-distribution generalization.
We define within-distribution (WD) puzzles as those that conform to the restrictions used to construct the training set and out-of-distribution (OOD) puzzles as those that do not conform to these restrictions. All models included in our analyses solved held-out WD puzzles with near perfect accuracy, so we only report OODG performance in our results for conciseness.
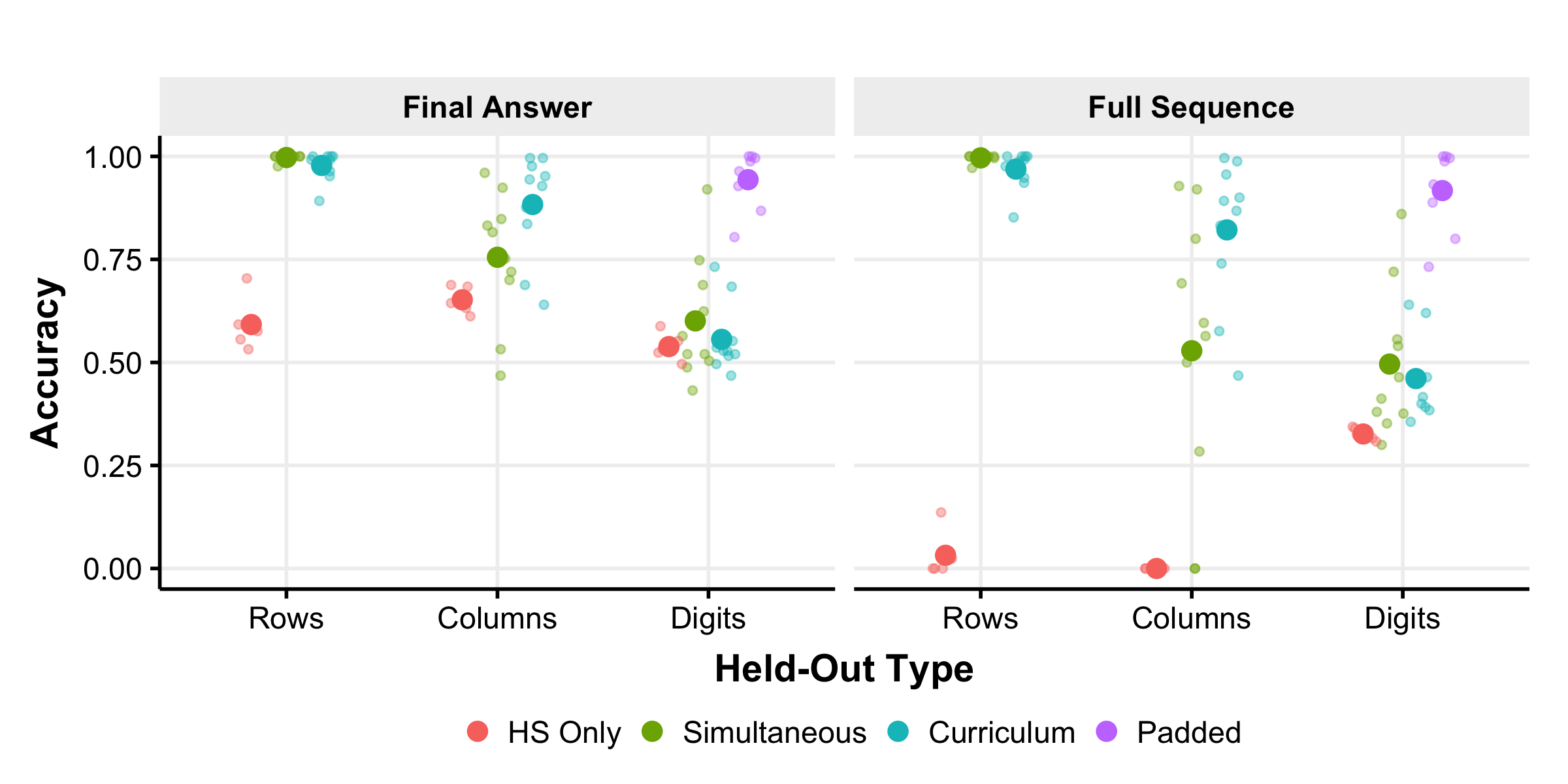
Based on the natural symmetries of Sudoku grids and the train/test split used in [12], we devised three distributional splitting schemes to probe for OODG. Our first condition, Rows, recognizes that the application of the HS, FH, or NS techniques is isometric relative to the row in question. Thus, a successful model of abstract relational reasoning should solve HS puzzles applied to any of the 6 rows, even when trained on a strict subset of the 6 rows. We train the models using HS puzzles applied to 4 of the 6 rows (i.e. the goal cell will only appear on these 4 rows), then test its OOD performance on the remaining 2 rows. In our second condition, Columns, we exclude all HS puzzles that are performed over columns from the training set, and test the models on these column puzzles. The abstract principle of process of elimination remains the same, and the main challenge is knowing which cells to iterate over. Our final condition, Digits, uses the fact that swapping digits only superficially changes the puzzle without affecting the underlying structure (see Figure 2. We train the model on puzzles with 4 of the 6 digits as the candidate digit identified in the problem prompt and test the model on puzzles with the remaining 2.
We also had 3 conditions for how we trained the models. In the first training condition, HS Only, we included 110,000 HS puzzles as part of the training set and not the FH or NS puzzles, and trained the model for 70,000 gradient updates (each based on 192 examples). The second condition, Simultaneous, included 50,000 HS puzzles and 30,000 FH and NS puzzles each, and the model was trained on all 3 tasks simultaneously for 70,000 updates. The FH and NS puzzles were sampled completely at random without any systematic constraints. The last condition, Curriculum, uses the same materials as Simultaneous, but trains the model on the FH and NS puzzles for the first 20,000 updates, reaching ceiling performance, before training on all 3 tasks for 50,000 more updates.
Figure 1 summarizes the out-of-distribution generalization results in each condition. First, we compute the accuracy based on the final yes/no answer at the end of the output sequence, and we find that models trained only on HS puzzles struggle to exceed chance (50%), suggesting that the model has no inherent inductive bias towards generalizing in these dimensions. When trained with the FH and NS tasks, the model succeeds in generalizing to the held-out rows and columns to a high degree, especially when trained using the curriculum-based setup. We consider the strong generalization in the Columns condition (though somewhat less complete than in the Rows condition) to be an important finding, since the Columns condition contained no training on column-wise puzzles, while the Rows condition included 4 of the 6 rows. The models did not generally perform well on held out digits, although one of the seeds in the simultaneous condition generalized well. The relational neural network [13] also fails to transfer to held-out digits, but humans who learn to solve HS puzzles with a restricted set of targets show no decrement in performance when tested on digits held-out from a training tutorial [12].
We also measure the accuracy for entire sequences, in which a problem is considered solved if the entire model output sequence matches the target sequence, including the intermediate steps. This not only magnifies the differences, but also indicates that the models that generalize successfully do so in its entire reasoning process, not just at the correct final output.
Although the Rows and Columns conditions successfully demonstrate out-of-distribution generalization, the Digits condition generally does not, as shown by the roughly 50% accuracy in Figure 1. This is surprising, since human participants show no change in performance when the digits in the grid are swapped [12]. Its peculiarity is magnified by the fact unlike the Rows and Columns conditions, full sequence accuracy is well above the floor even when the models are trained with only HS puzzles.
Digit generalization mis-attention.
Inspecting the model generated outputs, we find that the models correctly identify the relevant cells to iterate over, and the last line indicating the final answer is consistent with its intermediary outputs. In other words, the errors are made when determining whether or not the cells can contain the candidate digit. Moreover, these errors only occur at empty cells, not at cells already containing a digit.
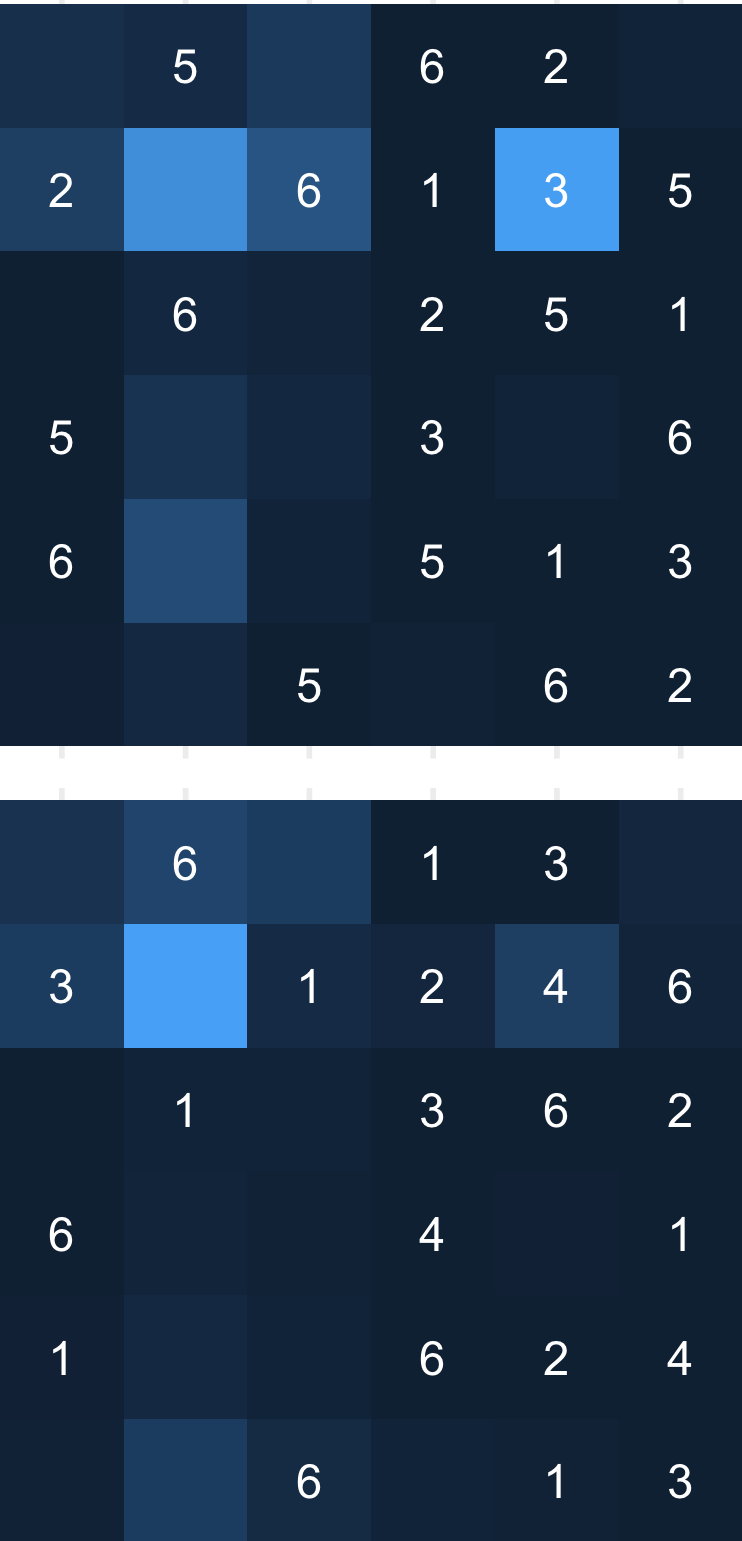
To gain further insight, we analyze the attention maps generated by the transformer that indicate which information the model considers. We probe the model by taking held-out puzzles and rotating the digits in each grid such that 1 becomes 2, 2 becomes 3, 6 becomes 1, etc., thus producing 6 identical sets of puzzles that only differ by the digits involved, and each puzzle in the set has a unique candidate digit. We inspect how the model queries the grid as it produces the yes/no responses at the end of each substep in the HS problem by taking the maximum attention weight given for each cell from the last transformer layer. Figure 2 shows an example of one model’s attentional map on the HS problem shown in Table 1 when considering whether the candidate digit can be placed at the cell on (2, 2). In the within-distribution problem, where 3 is the candidate digit, the model attends to and correctly identifies the 3 in the same row. In contrast, the model does not attend to the same position in the out-of-distribution puzzle where 4 is the candidate digit. This form of mis-attention is characteristic of the errors in the Digits condition.
| Hidden Single | Naked Single Unpadded | Naked Single Padded | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
Improving digit generalization.
The model apparently fails to transfer its success in the NS task to correctly perform the NS task when it is embedded within the HS task. We trace the source of this difficulty to a superficial difference between the prompt sequences used in the NS and HS tasks. Unlike the FH task which is aligned token-for-token with the HS task, the NS task requires much fewer steps and has a shorter prompt compared to the HS and FH tasks. Furthermore, the position of the digit in the NS prompt is not aligned with its position in the FH and HS prompts. We test the importance of this by padding the NS prompt with null tokens so that the position of the “digit” token is aligned with the position in the HS and FH prompts. We also added 4 extra “row column yes/no” lines in the target sequence with random coordinates to match the format of the other two tasks. Training the models on all 3 tasks simultaneously on this Padded dataset allows them to reach 94.4% final answer accuracy and 91.7% full sequence accuracy in the Digits condition. We also tried adding the 4 extra row-column query lines but not the null-token padding does not help the model generalize at all, and found that this leaves the OODG accuracy near 50%. This suggests that the knowledge transfer from the NS to the HS tasks is impeded by the model’s over-reliance on the token position as encoded with the sinusoidal encoding scheme. It appears that the model learns to attend to the digit aligned with a specific position token in the FH task, and transfers this reliance to the HS task; while in the NS task (unless padding is introduced to align the tokens) the model relies on a different position token, and has not learned to read the held-out digits from this position.
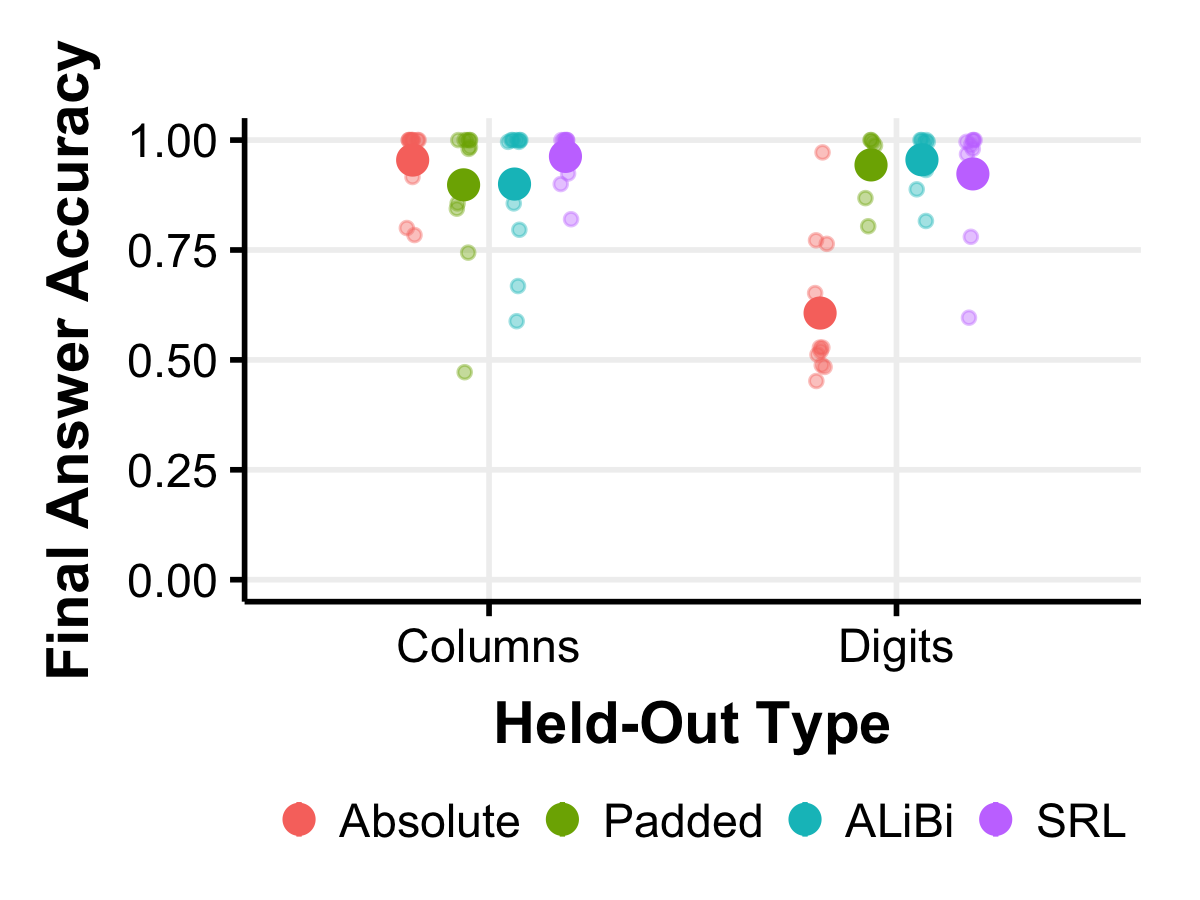
However effective padding is in our Sudoku tasks, it is an impractical general solution for improving alignment between tasks for transfer learning. To address this issue, we test alternative approaches to handling positional information that have been found to reduce sensitivity to absolute token positions. Because causal masking allows transformers to learn absolute positions of tokens even in the absence of any positional information in the inputs [6], we selected methods that not only remove absolute position information, and that may bias the model against relying on these position tokens anyway. Specifically, we use sorted random labels (SRL) [10], which replace exact position indices with an ordered sequence of position labels sampled from a larger set, and attention with linear biases (ALiBi) [14], which eliminates position vectors altogether in favor of adding biases to attention scores that scale with relative distance between tokens. We apply these methods to the unpadded dataset to test whether these enable out-of-distribution generalization to held-out digits and find that final answer accuracy increases to 95.5% and 92.3% for ALiBi and SRL respectively.
3 Discussion
We find, using carefully designed datasets utilizing isomorphic symmetries in Sudoku, that our transformer-based model generalized well to out-of-distribution Hidden Singles puzzles when trained in a concurrent training regime including exposure to the full distribution of the Full House and Naked Single subtasks. These results may help shed light on the generalization abilities of larger transformer models, where it is hard to know what is covered in their training set, but where it seems reasonable to believe that exposure to component tasks and complex compositions of component tasks are interspersed throughout the data. While these models may receive restricted experience with complex multi-step problems, their ability to solve new ones may depend in part on more complete coverage of component sub-problems in their training data. Future research should explore this hypothesis in larger and more naturalistic data sets.
The initial version of our model used positional input tokens tied to absolute input position, and we found that this led to undue reliance on the exact input position of the candidate digit the model was asked to solve for, impeding generalization. By using alternative approaches to position encoding, we were able to overcome this problem. The work contributes to the growing body of findings indicating that failures of generalization in algorithmic tasks can be due at least in part to features of the positional encoding scheme used. This issue is less likely to arise in a large transformer predicting long strings of tokens using variants of similar problems that would vary naturally in string length and therefor prevent reliance on exact input positions. Nevertheless, these findings may be relevant to understanding the performance of large transformer-based models, especially in large language models such as GPT-3 [3] where suppressing sensitivity to token positions seems to improve perplexity scores [6]. Future research that corrects deficiencies related to positional encoding could have important implications for the success of larger models, perhaps helping them to achieve stronger performance in abstract reasoning than they have achieved thus far.
In any case, we are still a long way from understanding when and whether transformers are truly capable of few-shot learning and a high level of out-of-distribution transfer of the kind we have observed in some human participants in the hidden single task [12]. While GPT-3 was initially presented as a successful few shot-learner [3], many instances of the tasks the model supposedly learned few shot might have been embedded in its training data, and prompting with few shot examples might better be seen as a way of priming the model to be more likely to generate sequences corresponding to a task it has been exposed to in its training data many times. Even when such models are fine tuned with instructions and few-shot examples there is considerable uncertainty about exactly why such fine tuning is helpful [11, 17], and much more work is needed to clarify these issues.
References
- [1] Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- [2] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [3] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- [4] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021.
- [5] Bertram Felgenhauer and Frazer Jarvis. Mathematics of sudoku i. Mathematical Spectrum, 39(1):15–22, 2006.
- [6] Adi Haviv, Ori Ram, Ofir Press, Peter Izsak, and Omer Levy. Transformer language models without positional encodings still learn positional information. arXiv preprint arXiv:2203.16634, 2022.
- [7] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [8] NY Louis Lee, Geoffrey P Goodwin, and Philip N Johnson-Laird. The psychological puzzle of sudoku. Thinking & Reasoning, 14(4):342–364, 2008.
- [9] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.
- [10] Yuxuan Li and James L McClelland. Systematic generalization and emergent structures in transformers trained on structured tasks. arXiv preprint arXiv:2210.00400, 2022.
- [11] Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837, 2022.
- [12] Andrew Joohun Nam and James L McClelland. What underlies rapid learning and systematic generalization in humans. arXiv preprint arXiv:2107.06994, 2021.
- [13] Rasmus Palm, Ulrich Paquet, and Ole Winther. Recurrent relational networks. Advances in neural information processing systems, 31, 2018.
- [14] Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409, 2021.
- [15] Ed Russell and Frazer Jarvis. Mathematics of sudoku ii. Mathematical Spectrum, 39(2):54–58, 2006.
- [16] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [17] Albert Webson and Ellie Pavlick. Do prompt-based models really understand the meaning of their prompts? arXiv preprint arXiv:2109.01247, 2021.
- [18] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
4 Supplementary Materials
4.1 Training Details
The core of our model is a 3-layer transformer encoder [16] supported by embedding layers for grid digits, grid cell positions, and input text, and finally an output text decoder layer. The input for each cell consists of three one hot vectors: six-unit vectors for the row and column, and a seven-unit vector for the digit in the cell, with the seventh used when the cell is empty. The row and column coordinates are encoded by a 128-dim embedding layer and the resulting vectors are concatenated as a single 256-dim vector. The digits are encoded with a 256-dim embedding layer and the digit and coordinate vectors are summed to form a single 256-dim grid cell embedding. All text tokens are encoded by a 256-dim embedding layer and position information is added to the vectors using the sinusoidal positional encoding scheme introduced in [16]. The 36 grid cell vectors and all token vectors are passed to the transformer, which is composed of 3 encoder layers with 8 heads and 1024-dim feed-forward layers, and the output vectors are decoded using a linear layer to form the final logit values for the predicted output tokens.
During training, we use teacher-forcing to predict the next token at each sequence position and cross-entropy with the target sequence. We mask the loss so that in the loss is only applied after the ’digit’ token in the hidden single and full house tasks, and after the column number token in the naked single tasks. The loss is computed using cross-entropy and the model is optimized using Adam [7] with a learning rate of 0.0001. When training with multiple tasks at once, we sum the losses in one batch from each of the tasks before computing the gradient for backpropagation. We keep the same batch size of 192 samples for each task, regardless of how many tasks are trained at once.
4.2 Attention Map
To obtain the attention map as shown in Figure 2, we evaluated the model on the Hidden Single problem shown in Table 1. We generated 5 additional problems based on the problem in Table 1 by shifting the digit 1 to 5 times such that what was originally a 1 would be a 2 in the second problem, then a 3, and so on, yielding 6 puzzles that are identical in every way except the individual digits involved. For example, the top figure in Figure 2 shows the problem as is shown in Table 1, whereas the bottom figure shows the same puzzle with all digits incremented by 1, wrapping around 6 back to 1. In the bottom puzzle, the prompt would state “digit 4” to account for the increment.
After evaluating the model, we take the attentional weights from the final transformer layer where the input token was the second “2” from the line stating “row 2 column 2”, since the output of this position would be a “yes” or a “no”. To visualize the attention across all 8 heads, we take the maximum attention weight so that if a single head attended highly to the position, it would appear in the figure. Figure 2 only shows attention to the 36 cells in the grid for visualization purposes, though the model could and does attend to other tokens in the prompt and output sequence.