11email: {shixian.shi, cyn244124, sly.zsl, zhijie.yzj}@alibaba-inc.com
Achieving Timestamp Prediction While Recognizing with Non-Autoregressive End-to-End ASR Model
Abstract
Conventional ASR systems use frame-level phoneme posterior to conduct force-alignment (FA) and provide timestamps, while end-to-end ASR systems especially AED based ones are short of such ability. This paper proposes to perform timestamp prediction (TP) while recognizing by utilizing continuous integrate-and-fire (CIF) mechanism in non-autoregressive ASR model - Paraformer. Foucing on the fire place bias issue of CIF, we conduct post-processing strategies including fire-delay and silence insertion. Besides, we propose to use scaled-CIF to smooth the weights of CIF output, which is proved beneficial for both ASR and TP task. Accumulated averaging shift (AAS) and diarization error rate (DER) are adopted to measure the quality of timestamps and we compare these metrics of proposed system and conventional hybrid force-alignment system. The experiment results over manually-marked timestamps testset show that the proposed optimization methods significantly improve the accuracy of CIF timestamps, reducing 66.7% and 82.1% of AAS and DER respectively. Comparing to Kaldi force-alignment trained with the same data, optimized CIF timestamps achieved 12.3% relative AAS reduction.
Keywords:
end-to-end ASR non-autoregressive ASR timestamp force alignment1 Introduction
Timestamp prediction is one of the most important and widely used subtasks of automatic speech recognition (ASR). Kinds of speech related tasks (text-to-speech, key-word spotting) [1, 2], speech/language analysis [3, 4, 5] and ASR training strategies [6] can be conducted with a reliable timestamp predicting system. At present, conventional hybrid HMM-GMM or HMM-DNN systems are mostly used to conduct force-alignment (FA) - the given transcriptions are expanded to phoneme sequences for processing Viterbi decoding in WFST (weighted finite state transducers) composed by acoustic model, lexicon and language model. Recent years have seen the rapid growth of end-to-end (E2E) ASR models [7, 8, 9, 10], which skip the complex training process and preparation of language related expert knowledge and convert speech to text with a single neural network. Generally, E2E ASR models are classified into two categorise: Time-synchronous models including CTC and RNN-Transducer, token-synchronous models including listen-attend-and-spell (LAS) and Transformer based AED models. The former utilize CTC-like criterion over frame-level encoder output and predict posterior probabilities of tokens together with blank while the later conduct cross-attention between acoustic information and character information to achieve soft alignment. These models have shown strong competitiveness and have replaced conventional ASR model in many scenarios. At the same time, however, due to the inherent deficiency of timestamp prediction ability of these models, some ASR systems have to use an additional conventional ASR model to predict the timestamp of recognition results, which introduce computation overhead and training difficulty.
In this paper, we propose to achieve timestamp prediction while recognizing with non-autoregressive E2E ASR model Paraformer [11]. Continuous integrate-and-fire (CIF) [12] is a soft and monotonic alignment mechanism proposed for E2E ASR which is adopted by Paraformer as predictor, it predicts the number of output tokens by integrating frame-level weights, once the accumulated weights exceed the fire threshold, the encoder output of these frames will be summed up to one step of acoustic embedding. One of the core ideas of achieving non-autoregressive decoding in Paraformer is to generate character embedding which has the same length as output sequence. The modeling characteristic of Parafirner CIF delights us to conduct timestamp prediction basing on CIF output. Focusing on the distribution of original CIF inside Paraformer, we propose scaled-CIF training strategies and three post-processing methods to achieve timestamp prediction of high quality and also explore to measure the timestamp prediction systems with AAS and DER metrics. The following part of this paper is organized as below. Timestamp prediction and FA related works are introduced in section 2. We briefly introduce CIF and Paraformer and look into original CIF distribution in section 3. Section 4 comes about the proposed methods including scaled-CIF and post-processing strategies while section 5 describe out experiments and results in detail. Section 6 ends the paper with our conclusion.
Our contributions are:
-
•
From the aspects of timestamp quality, the proposed scaled-CIF and post-processing strategies improve the accuracy of timestamp and outperforms the conventional hybrid model trained with the same data.
-
•
This paper propose to predict timestamps naturally while recognizing with Paraformer, such system can predict accurate timestamp of recognition results and reduce computation overhead which is of value in commercial usage.
2 Related Works
In this section we briefly introduce the mechanism of sequence-to-sequence modeling and discuss about the recent works related to timestamp predicton and force-alignment. Time-synchronous models and token-synchronous solve unequal length sequence prediction in different ways. Transducer [8] performs forward and backward algorithm as shown in 1 (a), it is allowed to move in time axis or label axis to establish connection between token sequence and time sequence of unequal length. However, it turns out that a well trained CTC [7] or Transducer model tends to predict posterior probabilities with sharp peaks (single frame with extremely high probability for a token except blank) [13], and the position of the peak can not reflect the real time of the token, especially when the modeling units have long duration. AED based E2E models like Transformer conduct cross-attention between encoder and decoder, the score matrix inside cross-attention can be regarded as alignment but it is soft and nonmonotonic, so it’s hard to conduct timestamp prediction in origin AED-based models like Transformer. CIF is a time-synchronous method which is also adopted by AED based models [11, 21]. It generates monotonic alignment by predicting integrate weights in frame level which can be naturally treated as timestamps.
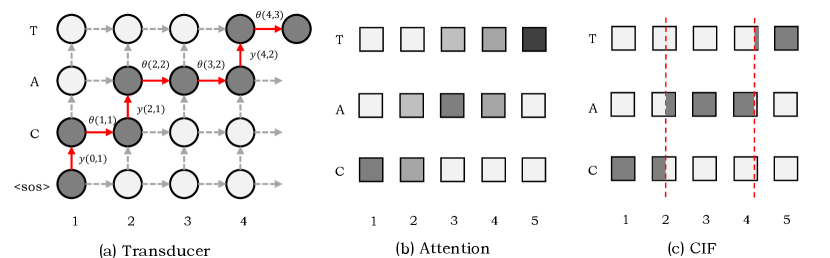
Recently, neural network based timestamp prediction and force-alignment strategies without conventional hybrid systems are explored. Kürzinger et al. [14] proposed CTC-segmentation for German speech recognition, which determines the alignment through forward and backward probabilities of CTC model. The proposed alignment system beats the conventional ones including HTK [17] and Kaldi [18] in German task. Li et al. [15] proposed NEUFA to conduct force-alignment, which deploys bidirectional attention mechanism to achieve bidirectional relation learning for parallel text and speech data. The proposed boundary detector takes the attention weights from both ASR and TTS directions as inputs to predict the left and right boundary signals for each phoneme. Their system achieves better accuracies at different tolerances comparing to MFA [19]. Besides, systems like ITSE [16] also achieves an accurate, lightweight text-to-speech alignment module implemented without expertise such as pronunciation lexica.
These works, however, conduct force-alignment outside of ASR models to get timestamps. For an ASR model which is required to obtain timestamp prediction ability, such models introduce additional computation overhead, which might be unacceptable for ASR systems in commercial usage. The excepted timestamp prediction models inside ASR system is supposed to introduce less computation overhead and predict accuracy timestamps naturally.
3 Preliminaries
3.1 Continuous Integrate-and-Fire
Continuous integrate-and-fire (CIF) is a soft and monotonic alignment mechanism for E2E ASR different from time-synchronized models and label-synchronized models. CIF performs integrate process over the output of encoder and predicts frame-level weights , once the accumulated weights exceed the fire threshold, these frames will sum up to acoustic embedding which is synchronized with output tokens. Such process is illustrated in Fig 2. In ASR models, the modeling character of CIF is of great value. The frame-level weights actually conduct alignment between acoustic representation and output tokens, and the fire location indicates the token boundary. Such capacity delights us to explore the feasibility of using CIF to predict accurate timestamps of decoded tokens naturally in the process of recognition.

3.2 Paraformer
We adopt Paraformer - a novel NAR ASR model which achieves non-autoregressive decoding capacity by utilizing CIF and two-pass training strategy inside an AED backbone. Avoiding the massive computation overhead introduced by autoregressive decoding and beam-search, Paraformer gains more than 10x speedup with even lower error rate comparing to Conformer baseline. The overall framework of Paraformer is illustrated in Fig 3.
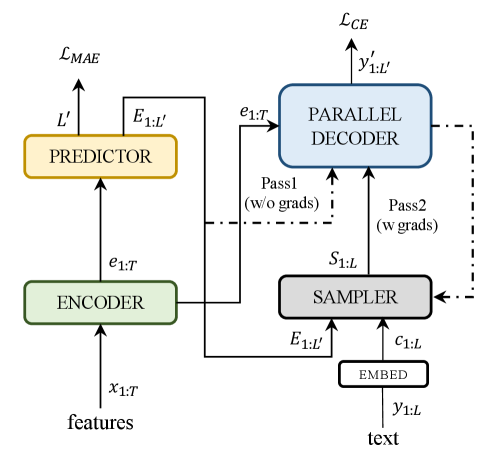
Paraformer contains three modules, namely encoder, predictor and parallel decoder (sampler interpolates acoustic embeding and char embedding without parameters). Encoder is same as AR encoders of Conformer which contains self-attention, convolution and feed-forward networks (FFN) layers to generate acoustic representation from down-sampled Fbank features. Predictor uses CIF to predict the number of output tokens and generate acoustic embedding . Parallel decoder and sampler conduct two-pass training with the vectors above: is directly sent to decoder to calculate cross-attention with , and decode all tokens in NAR form at once. Then sampler interpolates and char embedding according to the edit distance between hypothesis and . The interpolated vector (named semantic embedding, noted by ) is sent to parallel decoder again to conduct the same calculation, which makes up the second pass. Note that the forward process of the first pass is gradient-free, cross-entropy (CE) loss is calculated between output of the second pass and ground truth. In the training process, as the accuracy of first pass decoding raises, makes up increasing proportion of . In the inference stage, Paraformer use the first pass to decode.
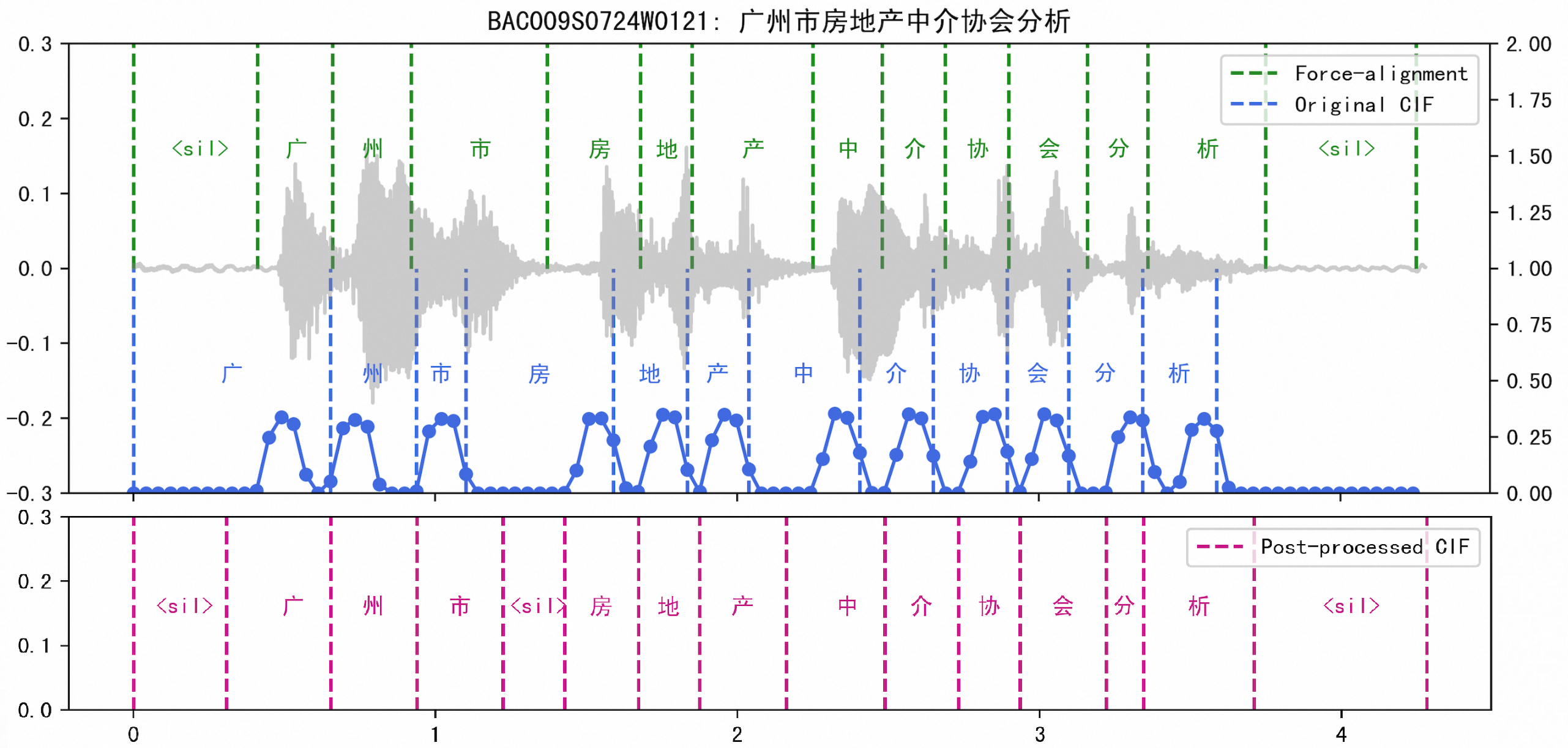
CIF is of vital importance in Paraformer as it predicts the number of output tokens and generates monotonic token boundaries implicitly. Fig 4 shows the origin fire place comparing to the timestamp generated by kaldi force-alignment system. Weights shows that the pattern of CIF is regard less of the real length of tokens, for an ASR model with 4-times down-sampling layer (60 ms each time step), the integrate process for each token finishes in around 4 frames, which leads to a large offset for end point timestamp of character with long duration.
4 Methods
Considering of the pattern of CIF weights and the characteristic of Paraformer, we optimize the timestamp prediction strategy from two aspects. In the training process, we propose to scale the CIF weights after sigmoid function in order to alleviate the sharpness of weights and also cut off the gradient towards encoder of irrelevant position. Then we adopt several post-processing strategies for weights to achieve more precise timestamp prediction.
4.1 Scaled-CIF Training
Original CIF calculates with sigmoid activation function after feed-forward network, sharp spikes and glitches can be observed from the curve in Fig 4. We propose to scale and smooth the CIF weights with the operation below:
| (1) |
First, ReLU function and smooth the glitches of , cutting off the gradient towards encoder of irrelevant position, which is supposed to be beneficial for ASR task. Besides, scaling the output of ReLU with relieves the spikes of the curve, trying to achieve level and smooth weights.
4.2 Weights Post-Processing
Another optimization comes about from the aspect of post-processing. According to the distribution of alphas observed in Fig 4, most of the weights begins to accumulate from the exact frame but the accumulation ends in fixed steps (4 frames in the figure), which delights us to conduct the following 4 processing strategies:
Begin/end Silence As the begging place of CIF is always precise, the beginning frames with weights under a threshold is considered as silence. So as to the frames at the end but we set an interval of 3 frames.
Fire Delay Original CIF timestamps are always unreliable for the end point prediction for long-lasting tokens. We propose to conduct fire delay operation when frames with low weights are observed, such frames with be grouped to the previous token except the last frame.
Silence Insertion When the low-weight frames last longer than , we insert a silence token in between.
Weight Averaging111In this paper, we conduct experiments with 4-times down-sampling encoder, this methods is thus not validated. For ASR models with higher down-sampling rate, the process of integrate finishes even faster. When using 6-times low frame rate features, the CIF tends to output weights around 1.0 or 0.0, which makes CIF weights no longer stand for the accumulation procedure. Then we proposed to weaken the weight spikes.
and are model related hyper-parameters, for Paraformer model with original CIF predictor and 4-times down-sampling encoder embedder, we set and , the timestamp thus generated of the demo utterance above is shown in Fig 4. Subjectively, the proposed post-processing strategies optimize the quality of CIF timestamps in a simple but efficient way.
4.3 Evaluation Metrics
In addition to the visual analysis of timestamps, we propose to use accumulated averaging shift (AAS) and diarization error rate (DER) as the evaluation metrics of timestamp accuracy.
AAS The first metrics measures the averaging time shift of each token. The time shift of begging timestamp and end timestamp are summed up and averaged over the entire testset. Formally, we calculate the metrics between timestamp and timestamp as
| (2) |
where is for the number of aligned token pairs222Considering the transcriptions of two timestamps might differ, only paired tokens according to edit distance are included in the calculation..
DER Speaker diarization systems are evaluated by DER, which calculates the proportion of frames which are classified correctly. DER is the sum of three different error types: False alarm of speech, missed detection of speech and confusion between speaker labels. Treating tokens as speakers, we introduce this metrics to measure the quality of timestamp.
| (3) |
5 Experiments and Results
5.1 Datasets
Two datasets are used in our experiments. First, Aishell-1 is used for training the Paraformer model and visualizing timestamps. Aishell-1 contains 178 hours speech data with transcription, which is a widely used open-source Mandarin ASR corpus. Besides, we use a TTS dataset called M7 for evaluation, which contains 5550 Mandarin utterances. Except transcriptions, M7 also contains manually marked timestamps in token level, which is regarded as reference in the calculation of AAS and DER.
5.2 Experiment Setup
The Paraformer model is trained from scratch using ESPnet toolkit with the following setups. The model contains 12-layer Conformer encoder (implemented as with kernel size 15) and 6-layer Transformer decoder with attention dimension and feed-forward network dimension . The input layer of encoder conducts 4-times down-sampling for Fbank features, one step of encoder output thus stands for 40ms. The model is jointly trained with CTC loss () and we set dropout rate for entire model. 3-times speed perturbation is adopted for Aishell-1 data and we apply spec-augment with 2 frequence masks range in and 2 time masks range in for each utterance. We use dynamic batch size () and . No language model is used in the inference stage. For scaled-CIF, we use and 333For ASR models of different frame rate and encoder down-sampling rate, we fine it better to adjust scaling coefficients and , so as to the post-processing hyper-parameters and to achieve better performance..
We prepare the force-alignment system with Kaldi toolkit as baseline timestamp, the training setup and model configuration is exactly same as open-source recipe Aishell-1, from flat-start to HMM-GMM. Timestamps of phonemes are extracted from lattice using model tri5a, and then converted to characters timestamps.
5.3 Quality of Timestamp
In this section we evaluate the quality of the timestamps and analyse the effect of the proposed methods. Table 1 shows the AAS and DER metircs of the timestamps from different models over testset M7. First we test the force-alignment system with ground truth transcription and Paraformer recognition results. It turns out that using these two kinds of transcription lead to slight difference of DER and almost the same AAS, which is because the majority error of Paraformer’s recognition results is substitution error, reference and hypothesis have nearly the same expanded phoneme sequences, thus AAS of FA-GT and FA-HYP differs little.
| Exp | Sys | AAS (sec) | DER (%) | |||
|---|---|---|---|---|---|---|
| force-alignment systems | FA-GT | FA with groundtruth | 0.080 | 6.34 | ||
| FA-HYP | FA with decoded trans | 0.081 | 7.50 | |||
| CIF timestamps | CIF-0 | origin CIF timestamp | 0.213 | 45.39 | ||
| CIF-1 | +begin/end silence | 0.161 | - | |||
| CIF-2 | +fire-delay | 0.124 | - | |||
| CIF-3 | +silence insertion | 0.112 | 17.09 | |||
| scaled-CIF timestamps | SCIF-0 | scaled-CIF timestamp | 0.143 | 29.75 | ||
| SCIF-1 | +begin/end silence | 0.098 | - | |||
| SCIF-2 | +fire-delay | 0.080 | - | |||
| SCIF-3 | +silence insertion | 0.071 | 8.11 |
Comparing CIF-0 and FA-HYP, it is obvious that original CIF weights as timestamps is of unacceptable quality. With the addition of post-processing strategies, the accuracy of CIF timestamps has been improved step by step, CIF-3 achieves 47.4% AAS reduction. Among the three post-processing methods, fire delay is the most effective and also the most tricky one. Scaled-CIF brings further help to timestamps prediction, 32.9% AAS reduction and 34.5% DER reduction are observed without any post-processing strategies. In SCIF-3, CIF timestamps outperforms force-alignment systems in AAS (11.3% relatively), but DER is still higher.
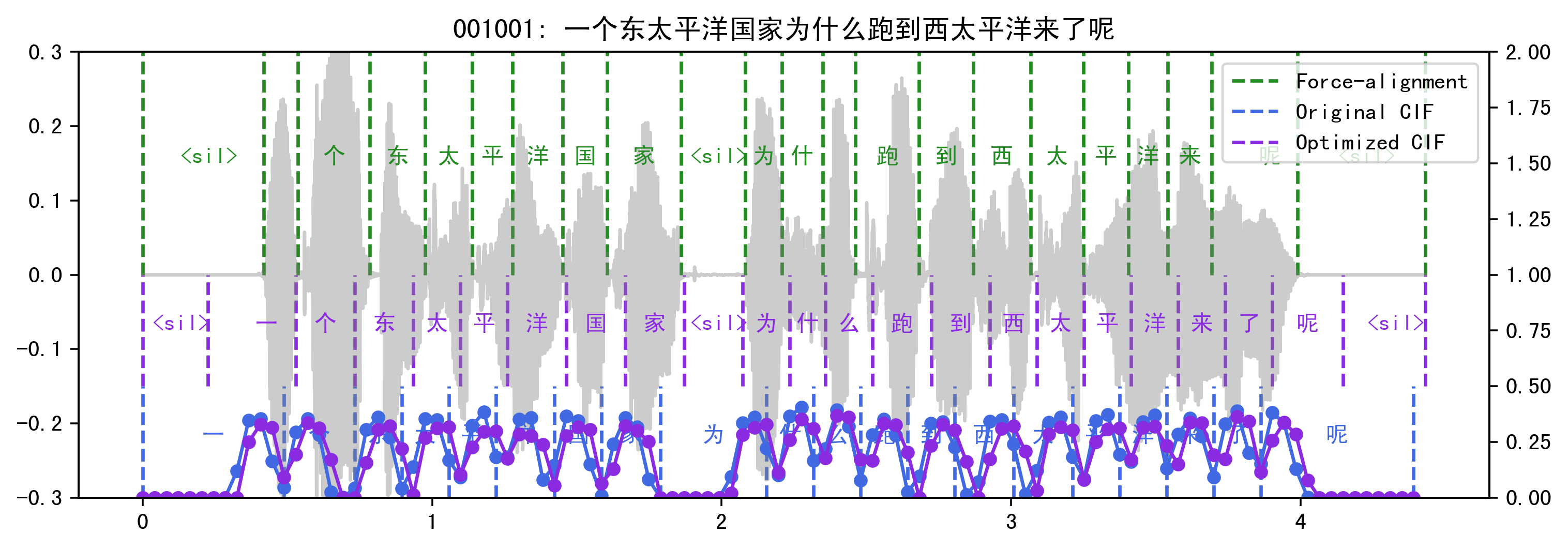
Fig 5 shows comparison of manually marked timestamps, original CIF timestamps and optimized timestamps. Comparing the blue curve and the purple curve, it can be observed that the peak of the curve is weakened to some extent, and the glitches in the curve disappear (not obvious in the figure). Considering the start and ending time of each token, the effect of fire delay is obvious, especially when the token is followed by low weight frames (like character ’家’ in the demo).
5.4 ASR Results
Results in section 5.3 shows that scale-CIF significantly improves timestamp prediction accuracy, and we find it is also benificial for ASR. Comparing to vanilla Conformer AR model, Paraformer achieves better recognition accuracy and even lower real time factor (RTF) [11]. On Aishell-1 task, Paraformer gets 4.6%, 5.2% CER over dev and test set and the RTF is 0.0065 (RTF of Conformer is 0.1800 under the same test environment). In our experiments, Paraformer with scaled-CIF outperforms the baseline, CER on Aishell-1 dev and test set are 4.5% and 5.2% respectively. On testset M7, Paraformer gets 11.70% CER with origin CIF and 11.26% with scaled CIF (3.76% relative CER reduction). Such results prove that smoothing the weights of CIF and cutting off the gradient towards encoder of irrelevant frames are beneficial for recognition task of Paraformer.
6 Conclusion
As the inherent deficiency of predicting timestamps with AED based models, we propose to predict timestamps according to CIF weights while recognition with Paraformer. In this paper, we first explore the characteristic of CIF in Paraformer for Mandarin. It turns out that the integrate of CIF weights tends to start from the right place but the process ends in fixed number of steps, regardless of tokens’ real length. Besides, sharp peaks and glitches are observed in CIF weights. Such behavior delights us to improve the accuracy of CIF timestamp with scaled-CIF and post-processing strategies. We compare the CIF timestamp with force-alignment results of conventional HMM-GMM systems, and evaluate the quality of timestamps with AAS and DER metrics. The results in Table 1 show that with the help of the proposed methods, CIF timestamps achieve comparable performance as the FA baseline, 12.3% relative AAS reduction is observed while DER is a little worse. Comparing CIF timestamps before and after optimization, 66.7% AAS reduction and 82.1% DER reduction is achieved. In summarize, the proposed scaled-CIF and post-processing strategies improve the accuracy of timestamp and out system outperforms the conventional hybrid model trained with the same data, and such system reduces computation overhead which might be of value in commercial usage.
In the future, we will explore the CIF timestamps of different languages and different frame-rate, and modify the silence insertion strategy with dynamic silence length threshold according to the phoneme.
References
- [1] Yang, Z., Sun, S., Li, J., Zhang, X., Wang, X., Ma, L., Xie, L. (2022). CaTT-KWS: A Multi-stage Customized Keyword Spotting Framework based on Cascaded Transducer-Transformer. arXiv preprint arXiv:2207.01267.
- [2] Ren, Y., Ruan, Y., Tan, X., Qin, T., Zhao, S., Zhao, Z., Liu, T. Y. (2019). Fastspeech: Fast, robust and controllable text to speech. Advances in Neural Information Processing Systems, 32.
- [3] Labov, W., Rosenfelder, I., Fruehwald, J. (2013). One hundred years of sound change in Philadelphia: Linear incrementation, reversal, and reanalysis. Language, 30-65.
- [4] DiCanio, C., Nam, H., Whalen, D. H., Timothy Bunnell, H., Amith, J. D., García, R. C. (2013). Using automatic alignment to analyze endangered language data: Testing the viability of untrained alignment. The Journal of the Acoustical Society of America, 134(3), 2235-2246.
- [5] Yuan, J., Liberman, M., Cieri, C. (2006). Towards an integrated understanding of speaking rate in conversation. In Ninth International Conference on Spoken Language Processing.
- [6] Fu, L., Li, X., Wang, R., Zhang, Z., Wu, Y., He, X., Zhou, B. (2021). SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition. arXiv preprint arXiv:2110.04187.
- [7] Graves, A., Fernández, S., Gomez, F., Schmidhuber, J. (2006, June). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (pp. 369-376).
- [8] Graves, A. (2012). Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711.
- [9] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- [10] Chan, W., Jaitly, N., Le, Q., Vinyals, O. (2016, March). Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 4960-4964). IEEE.
- [11] Gao, Z., Zhang, S., McLoughlin, I., Yan, Z. (2022). Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. arXiv preprint arXiv:2206.08317.
- [12] Dong, L., Xu, B. (2020, May). Cif: Continuous integrate-and-fire for end-to-end speech recognition. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6079-6083). IEEE.
- [13] Zeyer, A., Schlüter, R., Ney, H. (2021). Why does CTC result in peaky behavior?. arXiv preprint arXiv:2105.14849.
- [14] Kürzinger, L., Winkelbauer, D., Li, L., Watzel, T., Rigoll, G. (2020, October). CTC-segmentation of large corpora for german end-to-end speech recognition. In International Conference on Speech and Computer (pp. 267-278). Springer, Cham.
- [15] Li, J., Meng, Y., Wu, Z., Meng, H., Tian, Q., Wang, Y., Wang, Y. (2022, May). Neufa: Neural Network Based End-to-End Forced Alignment with Bidirectional Attention Mechanism. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8007-8011). IEEE.
- [16] Yang, R., Cheng, G., Zhang, P., Yan, Y. (2022). An E2E-ASR-Based Iteratively-Trained Timestamp Estimator. IEEE Signal Processing Letters, 29, 1654-1658.
- [17] Young, S. J., Young, S. (1993). The HTK hidden Markov model toolkit: Design and philosophy.
- [18] Daniel Povey, Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Yanmin Qian, and Petr Schwarz. The Kaldi speech recognition toolkit. IEEE 2011 workshop on automatic speech recognition and understanding. 2011 . IEEE.
- [19] McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., Sonderegger, M. (2017, August). Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Interspeech (Vol. 2017, pp. 498-502).
- [20] Watanabe, S., Hori, T., Karita, S., Hayashi, T., Nishitoba, J., Unno, Y., … Ochiai, T. (2018). Espnet: End-to-end speech processing toolkit. arXiv preprint arXiv:1804.00015.
- [21] Yu, F., Luo, H., Guo, P., Liang, Y., Yao, Z., Xie, L., … Zhang, S. (2021, December). Boundary and context aware training for CIF-based non-autoregressive end-to-end ASR. In 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 328-334). IEEE.