11email: {m.meeus22,florent.guepin20,a.cretu,deMontjoye}@imperial.ac.uk
Achilles’ Heels: Vulnerable Record Identification in Synthetic Data Publishing
Abstract
Synthetic data is seen as the most promising solution to share individual-level data while preserving privacy. Shadow modeling-based Membership Inference Attacks (MIAs) have become the standard approach to evaluate the privacy risk of synthetic data. While very effective, they require a large number of datasets to be created and models trained to evaluate the risk posed by a single record. The privacy risk of a dataset is thus currently evaluated by running MIAs on a handful of records selected using ad-hoc methods. We here propose what is, to the best of our knowledge, the first principled vulnerable record identification technique for synthetic data publishing, leveraging the distance to a record’s closest neighbors. We show our method to strongly outperform previous ad-hoc methods across datasets and generators. We also show evidence of our method to be robust to the choice of MIA and to specific choice of parameters. Finally, we show it to accurately identify vulnerable records when synthetic data generators are made differentially private. The choice of vulnerable records is as important as more accurate MIAs when evaluating the privacy of synthetic data releases, including from a legal perspective. We here propose a simple yet highly effective method to do so. We hope our method will enable practitioners to better estimate the risk posed by synthetic data publishing and researchers to fairly compare ever improving MIAs on synthetic data.
Keywords:
Synthetic Data Privacy Membership inference attacks.1 Introduction
There is increased demand from businesses, governments, and researchers to make data widely available to support research and innovation [16], including the development of Artificial Intelligence (AI) models. Data, however, most often relates directly or indirectly to individuals, raising privacy concerns.
Synthetic data is seen as a promising solution to share individual-level data while preserving privacy [6]. Synthetic data is generated by sampling new data values from a statistical model whose parameters are computed from the original, private data. A large range of techniques have been proposed to generate synthetic data [42, 28, 38]. Synthetic data, if truly privacy-preserving, can be shared and used freely as it no longer falls under the scope of data protection legislation such as the European Union’s General Data Protection Regulation (EU GDPR) or California’s CCPA. Consequently, synthetic data has garnered significant interest from statistical offices [4], health care agencies [27] and the financial sector [16].
Ensuring that synthetic data preserves privacy is, however, difficult. On the one hand, while the statistical model aggregates the original data, it is well known that aggregation alone is not sufficient to preserve privacy [10, 30]. On the other hand, ensuring that synthetic data generation models achieve formal privacy guarantees is difficult and comes at a cost in utility [3, 35].
Membership Inference Attacks (MIA) are a key tool to evaluate the privacy guarantees offered by synthetic data generation models, differentially private or not, in practice [20]. If successful, an MIA is able to infer that a particular record was part of the original data used to train the synthetic data generation model. Increasingly advanced MIAs have been proposed against synthetic data [35, 20]. They are run on a per-record basis, instantiating an attacker that aims to distinguish between two worlds: (1) a world in which the synthetic dataset released was generated from a model fitted on data including the target record and (2) the alternative world in which the model was fitted on data excluding the target record. MIAs on synthetic data have already successfully disproved the believe that aggregation alone is sufficient to preserve privacy as well as detected issues with differentially private synthetic data generation models [35].
Fully evaluating the privacy risk of a dataset using MIAs is however out-of-reach. Indeed state-of-the-art MIAs rely on shadow models which require training a large number, often in the order of thousands, of synthetic data generators to learn the optimal decision boundary for each record. Running a state-of-the-art MIA on a record takes in our experiments, depending on the generator and the dataset, approximately 1.5 to 6 hours on dedicated computation facilities. Even for the (relatively) small datasets of 1,000 records we consider, fully estimating the privacy risk of a dataset, would take up to 250 days of compute.
Current evaluation of the privacy risk posed by synthetic data, and of their privacy-utility trade-off, is thus currently the result of ever more advanced MIAs evaluated on only a handful of records selected using ad-hoc methods. Stadler et al. [35] evaluate their attack on ten records, half random and half hand-picked outliers selected based on a rare attribute value, while Houssiau et al. [20] evaluate their attack on one record selected based on the lowest log-likelihood.
Such ad-hoc approaches to selecting vulnerable records could strongly underestimate the privacy risks of a synthetic data release, missing highly vulnerable records or wrongly concluding that most records are not at risk.
Contribution. We here propose what is, to the best of our knowledge, the first vulnerable record identification strategy for synthetic data.
We formalize the problem and propose a principled and simple metric to identify vulnerable records in the original, private dataset: the mean distance to its closest neighbors. While simple, we show our method to outperform previous ad-hoc approaches by 7.2 percentage points (p.p.) on average on two datasets and two generators. Both when comparing the performance of ever improving attack methodologies as well as to estimate the potential privacy risk in real world synthetic data publishing, this is a significant difference.
We then extensively evaluate our method. First, we evaluate its applicability across different MIA approaches. We develop a fundamentally different MIA approach and show the risk estimated using our vulnerable record identification method to be consistently and significantly higher compared to prior methods. More specifically, in contrast with Houssiau et al. [20], who train a meta-classifier to infer the membership of a record based on hand-engineered aggregate statistics computed on the synthetic dataset, we develop an attack that trains a meta-classifier directly on the synthetic dataset viewed as a set of records. After performing the same extensive empirical evaluation, we find that the performance of our attack increases also significantly when computed on records identified by our method, by 5.2 p.p. on average across datasets and generators. Next, we evaluate the sensitivity of our results on both the number of neighbors included in our metric as well as the distance metric. In both cases, we find that the results do not change significantly and confirm that our chosen metric is justified. Finally, we evaluate our metric on a differentially private synthetic data generator for varying values of the privacy budget . We confirm that MIAs fail when the privacy budget is decreased to , and find that our metric consistently identifies more vulnerable records for larger values of .
With this principled method, we hope to eliminate the need to rely on ad-hoc record selection and potentially underestimate the privacy risk in synthetic data publishing. A formal vulnerable record identification method would enable (1) researchers to fairly compare future state-of-the-art attacks and (2) practitioners to, in line with EU legislations, evaluate the privacy protection of synthetic data on the worst-case scenario.
2 Background
2.1 Synthetic Data Generation
We consider an entity (e.g., a company) that wants to give a third-party access to a private dataset for analysis. A dataset is a multiset of records , where each record relates to a unique individual. In the case of narrow datasets, multiple individuals can however have the same record. We assume the dataset to be sensitive, containing information such as healthcare records or financial transactions. We assume each record to consist of attributes , where denotes the space of values that can be taken by the -th attribute. We denote by the universe of possible records, and assume the dataset to be sampled i.i.d. from a distribution over .
An increasingly popular approach to release data while mitigating the privacy risk is to instead generate and publish a synthetic dataset [13]. Synthetic data is generated from a statistical model trained to have similar statistical properties to the real data.
We refer to the statistical model as the synthetic data generator. Formally, this is a randomized function mapping a private dataset to a synthetic dataset of records. The synthetic data generator can take the form of a probabilistic model such as a Bayesian Network [42] or a Generative Adversarial Network (GAN) such as CTGAN [39].
2.2 Differential Privacy
Differential Privacy (DP) [12] is a formal privacy guarantee. Originally developed to protect the release of aggregate statistics, it has since been extended to machine learning models and recently to synthetic data generators.
DP relies on a notion of neighboring datasets. Two datasets are neighboring, if they differ by only one record. Intuitively, a DP randomized function ensures that one attacker cannot infer the difference between and bounded by a certain probability, effectively providing formal guarantees against privacy risks and, in particular, membership inference attacks.
Formally, the definition of differential privacy is the following:
Definition 1 (-Differential Privacy)
A randomised function is said to be -Differentially Private (-DP) if for every pair of neighboring datasets , and for all subsets of outputs , the following inequality holds: .
The parameter is referred to as the privacy budget. It quantifies the privacy leakage of a data release, with smaller providing more protection. Achieving DP with small to reasonable values of can however require significant noise to be added to a machine learning model, decreasing its utility. Efficiently achieving DP guarantees for ML models, including synthetic data generation models, is an active area of research. In this paper, we used the DP generator PrivBayes from the work of Zhang et al. [42]. We refer the reader to Sec. 1 for details.
2.3 Membership Inference Attacks
Threat Model. Membership Inference Attacks (MIAs) aim to infer whether a target record is part of the original dataset used to generate a synthetic dataset , i.e., whether . The traditional attacker in MIAs is assumed to have access to the published synthetic dataset, , as well as to an auxiliary dataset, , with the same underlying distribution as : . Additionally, the attacker is assumed to have access to the target record and to know the generative model type and its hyperparameters, but not to have access to the model [35, 20].
Privacy Game. MIAs are instantiated as a privacy game. The game consists of a challenger and an attacker and is instantiated on a target record . The challenger samples datasets of records from , such that all records are different from . With equal probability, the challenger adds to or a random, different record , with , to . The challenger then trains a generator on and uses it to generate a synthetic dataset . The challenger shares with an attacker whose goal is to infer whether or not . If the attacker correctly infers, they win the game. The privacy risk is estimated by playing the game multiple times and reporting the average.
Shadow Modeling. State-of-the-art MIAs against synthetic data generators rely on the shadow modeling technique [34, 35, 20]. With this technique, the attacker leverages their access to the auxiliary dataset as well as the knowledge of the model, to train multiple instances of (called ) and evaluate the impact of the presence or absence of a target record on the resulting model. An attacker aiming to perform an MIA will proceed as follows. They will first create (e.g. by sampling) multiple datasets from , such that . Note that we ensure . The attacker then adds to half of the and a random record , distinct from , to the other half. Using the completed (now ) and the knowledge of model , the attacker will now train multiple shadow generators . The attacker will then use the to produce synthetic datasets , each labeled with either IN if or OUT otherwise. Using the labeled dataset, the attacker can now train a meta-classifier to distinguish between cases where the target record was and was not part of the training dataset. More specifically, would be trained using and the constructed binary label IN or OUT. At inference time, the attacker would then query the on the released for records of interest, and return its prediction.
3 Related Works
Membership Inference Attacks (MIAs) were first developed by Homer et al. [19] to study whether the contribution of an individual to a Genome-Wide Associated Study can be inferred from released genomic aggregates. Their attack was based on a statistical test aiming to distinguish between aggregates that include the individual and aggregates computed on individuals randomly drawn from a reference population. Sankararaman et al. [33] extended the analysis soon after and showed the risk of membership inference to increase with the number of aggregates released , but decrease with the number of individuals in the dataset. MIAs have since been widely used to evaluate the privacy risk in aggregate data releases such as location [30] or survey data [5].
MIAs Against Machine Learning (ML) Models. Shokri et al. [34] proposed the first MIA against ML models. Their attack relies on a black-box access to the model and the shadow modeling technique (see Sec. 2.3 in the context of synthetic data generators). MIAs against ML models have since been extensively studied in subsequent works [41, 32, 36, 26, 23], both from a privacy perspective but also to better understand what a model learns. These works have, for instance, shown the risk to be higher in overfitted models [41] and smaller datasets [34], and to be mitigated by differentially private training, albeit at a cost in utility [21, 23].
Disparate Vulnerability of Records. Previous work on MIA against ML models has shown that not all records are equally vulnerable to MIAs. The measured risk has e.g. been shown to vary with the label [34] and to be higher for outlier records [24, 7] and members of subpopulations [8]. Feldman proposed a theoretical model demonstrating that models may, in fact, need to memorise rare or atypical examples in order to perform optimally when trained on long-tailed distributions such as those found in modern datasets [14, 15]. Carlini et al. [7] showed this effect to be relative, as removing the most vulnerable records increases the vulnerability of remaining ones. Importantly for this work, Long et al. [24] argued that attacks should be considered a risk even when they only perform well on specific records. Long et al. proposed an approach to select vulnerable records prior to running the attack so as to increase its efficiency and precision. While their work [24] shows that records further away from their neighbors are more vulnerable, it only considers ML classification models.
MIAs Against Synthetic Tabular Data. MIAs have been extended to synthetic tabular data, the focus of our work. From a methodological standpoint, they fall broadly into two classes. The first class of methods directly compares synthetic data records to the original, private records, searching for exact or near-matches [11, 25, 40, 17]. The second class of methods instantiates the shadow modeling technique in the black-box setting, assuming the adversary has knowledge of the algorithm used to generate synthetic data and to an auxiliary dataset. Stadler et al. [35] trained a meta-classifier on aggregate statistics computed on the synthetic shadow datasets, specifically the mean and standard deviation of the attributes, correlation matrices and histograms. Houssiau et al. [20] extended this work using -way marginal statistics computed over subsets of the attribute values of the targeted record. They also extended the threat model from the standard black-box setting, which assumes knowledge of the generative model used, to the no-box setting that lacks this assumption. In this paper, we focus exclusively on shadow modeling-based attacks which are the state of the art.
4 Identifying Vulnerable Records
We here propose and validate a simple, yet effective, approach to identify vulnerable records in synthetic data publishing. Our approach is motivated by findings of previous works in the ML literature that records further away from their neighbors present a higher risk compared to randomly selected records. To identify such records, we compute a distance metric between every pair of records in the dataset , with ***Note that since the dataset can contain repeated records (i.e., two or more individuals sharing the same attributes), the closest record to can be a duplicate such that the distance between them is zero: .. Then, for every record , we define its vulnerability score as the average distance to its closest neighbors in the dataset.
Definition 2 (Vulnerability Score)
Given a dataset , a record , and a distance metric , the vulnerability score of the record is defined as , where is the re-ordering of the other records according to their increasing distance to , i.e., , with for every .
Finally, we rank the records in decreasingly by their vulnerability score and return the top- records as the most vulnerable records. In the unlikely event that the last record(s) included in the top- and the first one(s) not included have the exact same value for the vulnerability score, then a random subset is chosen.
Our distance metric carefully distinguishes between categorical and continuous attributes. Recall that the dataset consists of attributes. When the space of values that can be taken by an attribute is discrete, e.g., the gender of an individual , we refer to the attribute as categorical, while when the space of values is continuous, e.g., the income of an individual, we refer to the attribute as continuous. Denote by and the subsets of continuous and categorical attributes, with and . We preprocess each record as follows:
-
1.
We convert every categorical attribute , with and possible values to a one-hot encoded vector:
(1) i.e., a binary vector having 1 in the -th position if and only if the attribute value is equal to . Here, denotes the indicator function. We then concatenate the one-hot encoded categorical attributes into a single vector:
(2) -
2.
We normalise every continuous attribute , with to range between 0 and 1, using min-max scaling:
(3) that is, we scale the values using the minimum and maximum values of the attribute estimated from the dataset . We then concatenate the normalised continuous attributes into a single vector:
(4)
Using this notation, we define our distance metric between two records and as follows:
| (5) |
where denotes the dot product between two vectors, denotes scalar multiplication, and is the Euclidean norm of a vector .
The resulting distance is a generalisation of the cosine distance across attribute types. It ranges between 0 and 1, with larger values indicating records to be less similar. The distance is equal to 0 if and only if the records are identical.
5 Experimental Setup
5.1 State-of-the-art MIA Against Synthetic Tabular Data
Houssiau et al. [20] developed an MIA that instantiates the shadow modeling technique (see Sec. 2.3 for details) by training a random forest classifier on a subset of -way marginal statistics that select the targeted record. The authors evaluated this approach on only one outlier record and found it to outperform other methods. Throughout our experiments, we found the attack to consistently outperform alternative methods and thus confirm it to be the state-of-the-art attack against synthetic tabular data. We refer to it as the query-based attack.
Given a target record and a synthetic dataset sampled from a generator fitted on a dataset , this attack computes counting queries to determine how many records in the synthetic dataset match a subset of attribute values of target record . We denote by the -th attribute for every in the following: . Counting queries are equal to -way marginal statistics computed on the attribute values of the target record, multiplied by the dataset size .
Our intuition behind this attack is twofold. First, when these statistics are preserved between the original and synthetic datasets, the answers are larger by 1, on average, when compared to when , since the queries select the target record. Second, the impact of the target record on the synthetic dataset is likely to be local, i.e., more records matching a subset of its attribute values are likely to be generated when , leading to statistically different answers to the same queries depending on the membership of .
Like Houssiau et al. [20], we randomly sample a predetermined number of attribute subsets and feed the answers to the associated , computed on the synthetic shadow dataset, to a random forest meta-classifier. For computational efficiency reasons, we here use a C-based implementation of the query computation [9] instead of the authors’ Python-based implementation [20].
We further extend the method to also account for continuous columns by considering the less-than-or-equal-to operator on top of the equal operator that was previously considered exclusively. For each categorical attribute we then use , while using the for each continuous attribute.
5.2 Baselines for Identifying Vulnerable Records
We compare our approach against three baselines to identify vulnerable records:
Random: randomly sample target records from the entire population.
Rare Value (Groundhog) [35] sample a target record that either has a rare value for a categorical attribute or a value for a continuous attribute that is larger than the 95th percentile of the respective attribute.
Log-likelihood (TAPAS) [20]: sample target records having the lowest log-likelihood, assuming attribute values are independently drawn from their respective empirical distributions.
Note that this approach is defined by the authors only for categorical attributes : for each record , they compute the frequency of the value in the entire dataset, resulting in . The likelihood of a record is defined by the product of across all attributes. We here extend this approach to also account for continuous attributes by discretising them according to percentiles.
To evaluate the different methods to select vulnerable records, we run the query-based MIA described in Sec. 5.1 on the ten records identified by each of the three methods as well as our own approach.
5.3 Synthetic Data Generation Models
We evaluate our results against three generative models using the implementation available in the reprosyn repository [1].
SynthPop first estimates the joint distribution of the original, private data to then generate synthetic records. This joint distribution consists of a series of conditional probabilities which are fitted using classification and regression trees. With a first attribute randomly selected, the distribution of each other attribute is sequentially estimated based on both observed variables and previously generated synthetic columns. Initially proposed as an R package [28], the reprosyn repository uses a re-implementation in Python [18].
| || | || | |||
|---|---|---|---|---|
| Adult | 10000 | 5000 | 4000 | 200 |
| UK Census | 50000 | 25000 | 4000 | 200 |
BayNet uses Bayesian Networks to model the causal relationships between attributes in a given dataset. Specifically, the attributes are represented as a Directed Acyclic Graph, where each node is associated with an attribute and the directed edges model the conditional independence between the corresponding attributes. The corresponding conditional distribution of probabilities is estimated on the data using a GreedyBayes algorithm (for more details we refer to Zhang et al. [42]). Synthetic records can then be sampled from the product of the computed conditionals, i.e. the joint distribution.
PrivBayes is a differentially private version of the BayNet algorithm described above. Here, a first Bayesian Network is trained under an -DP algorithm. The conditional probabilities are then computed using an -DP technique, leading to a final -DP mechanism. From this approximate distribution, we can generate synthetic records without any additional cost of privacy budget. Note that for PrivBayes becomes equivalent to BayNet. Again, we refer the reader to Zhang et al. [42] for a more in-depth description.
5.4 Datasets
We evaluate our method against two publicly available datasets.
UK Census [29] is the 2011 Census Microdata Teaching File published by the UK Office for National Statistics. It contains an anonymised fraction of the 2011 Census from England and Wales File (1%), consisting of 569741 records with 17 categorical columns.
Adult [31] contains an anonymized set of records from the 1994 US Census database. It consists of 48842 records of 15 columns. 9 of those columns are categorical, and 6 are continuous.
5.5 Parameters of the Attack
Table 1 shows the parameters we use for the attack. We use a given dataset (e.g. Adult) to select our most at-risk records as the target records. We then partition randomly into and . is the auxiliary knowledge made available to the attacker, while is used to sample datasets used to compute the attack performance. represents the number of shadow datasets used, sampled from the auxiliary knowledge . We considered, in all experiments, the size of the release synthetic dataset () to be equal to the size of the private dataset , . To create the shadow datasets, while ensuring that does not contain the target record, we randomly sample records in . Then we add the target record in half of the datasets, and in the other half, we used another record randomly sampled from .
We run the query-based attack using queries randomly sampled from all possible count queries ( in total) and a random forest meta-classifier with 100 trees, each with a maximum depth of 10.
In order to measure the attack performance, we compute the Area Under the receiver operating characteristic Curve (AUC) for the binary classification of membership on datasets.
Lastly, in line with the auditing scenario, we use neighbors in the private dataset to select the most vulnerable records using our vulnerability score .
| Method | UK census | Adult | ||
|---|---|---|---|---|
| Synthpop | BayNet | Synthpop | BayNet | |
| Random | ||||
| Rare value (Groundhog) | ||||
| Log-likelihood (TAPAS) | ||||
| Distance (ours) | ||||
6 Results
6.1 Performance of Vulnerable Record Identification Methods
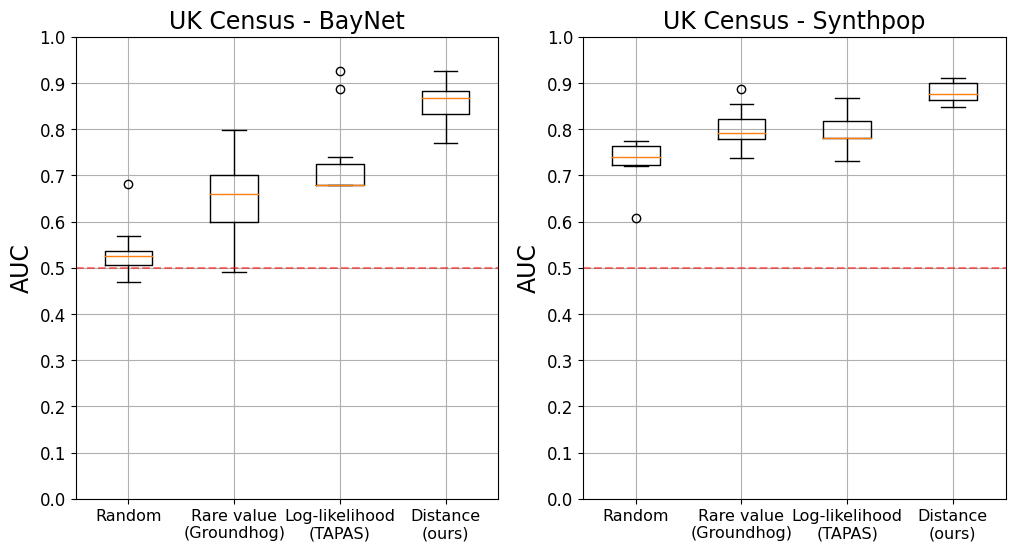
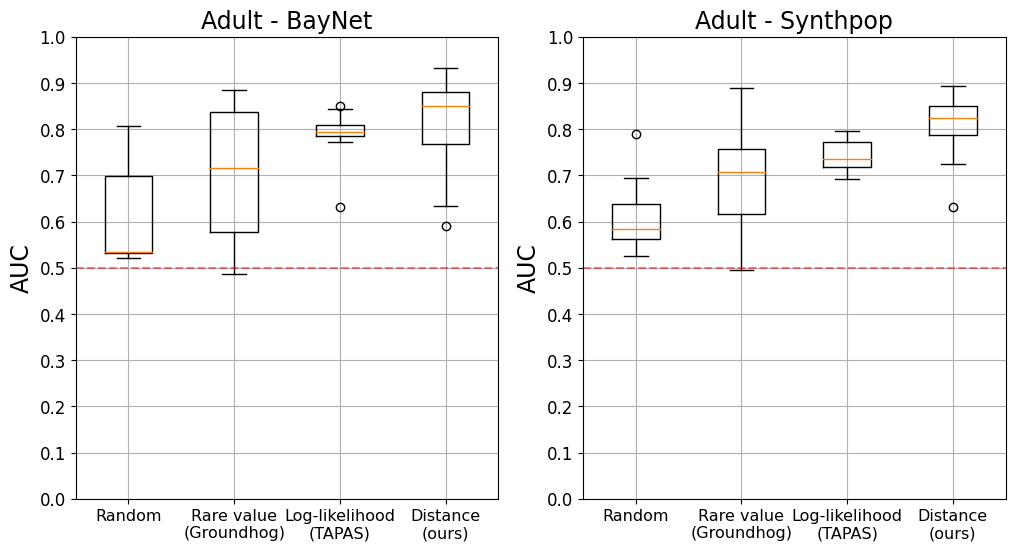
We evaluate the effectiveness of vulnerable record identification methods across the two datasets UK Census and Adult, and two synthetic data generators Synthpop and BayNet. For each dataset, each of the four record identification methods selects 10 target records. We then perform the MIA, as a privacy game, on each of these records and report its AUC.
Figure 1 show that our vulnerable record identification method consistently outperforms both the random baseline and the two ad-hoc techniques previously used in the literature. The median risk of records identified by our method is indeed consistently higher than all other methods, up to 18.6 p.p. higher on the UK Census dataset using BayNet. On average, the AUC of the records we identified are 7.2 p.p. higher than the AUC of the records selected by other methods (Table 2). Importantly, our method also consistently manages to identify records that are more or equivalently at-risk compared to other methods.
6.2 Applicability of the Method to New Attacks
MIAs against synthetic data is an active area of research with a competition [2] now being organised to develop better, more accurate, MIAs. To evaluate the effectiveness of our vulnerable record identification, we developed a new attack which we aimed to be as different as possible to the existing state of the art. We call this new attack target attention.
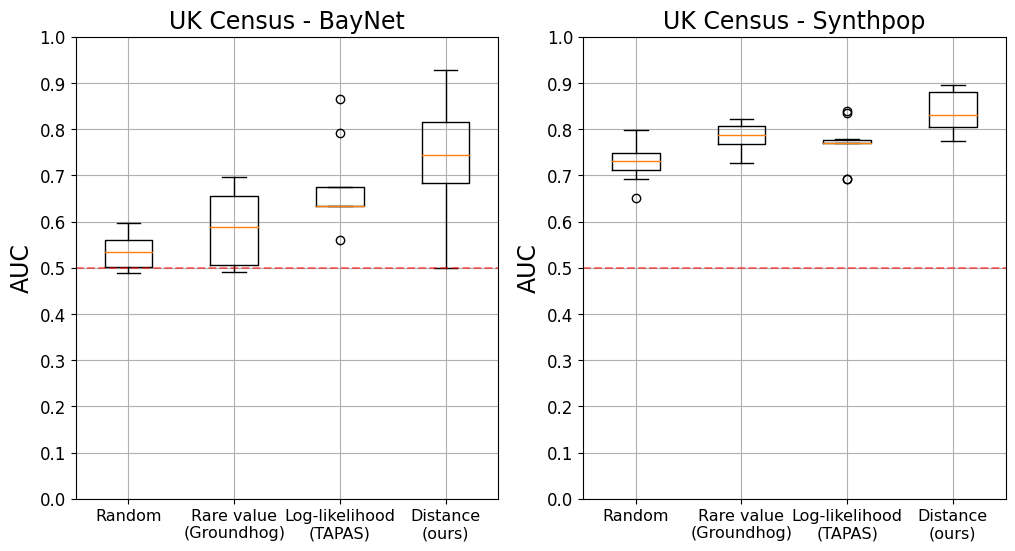
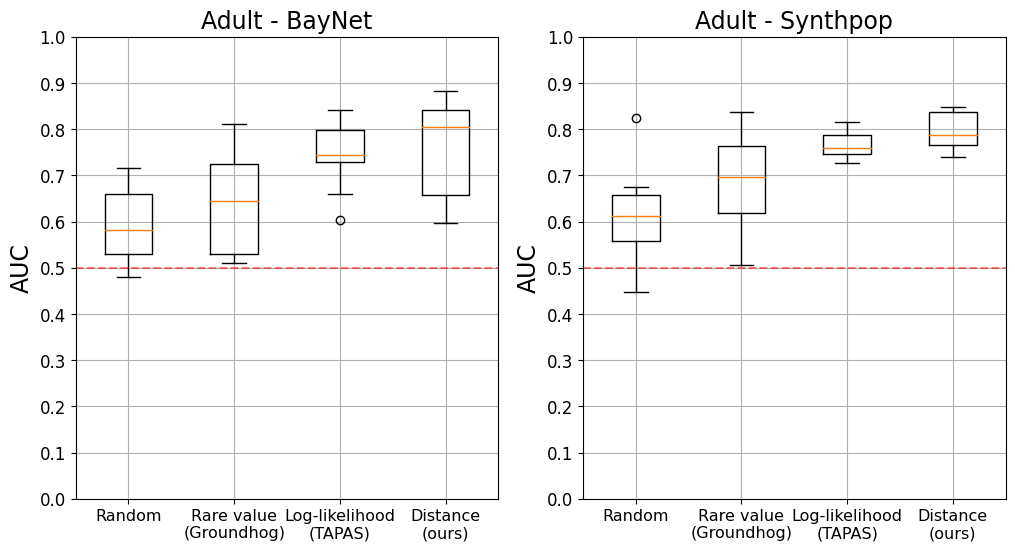
In contrast with the state-of-the-art method, which first computes features from a synthetic dataset to then use these as input for a meta-classifier, our new attack takes as input (a part of) the synthetic dataset to directly predict membership. As such, the model would be able to extract directly from the synthetic dataset the information that is most useful for the MIA. To our knowledge, it is the first method that is record-focused and allows for trainable feature extraction. For more information about the new method, we refer the reader to Appendix 0.A. We then follow the same methodology as above to evaluate the effectiveness of the four vulnerable record identification methods when using the target attention approach.
Figure 2 shows that, again, our vulnerable record identification method strongly outperforms both the random baseline and the two ad-hoc techniques previously used in the literature. The mean risk of records identified by our method is again consistently higher than all other methods, up to 10.89 p.p. higher on UK Census using BayNet. Across datasets and generators, the records we identify are 5.2 p.p. more at risk than the records selected by other methods (Appendix 0.A).
6.3 Robustness Analysis for
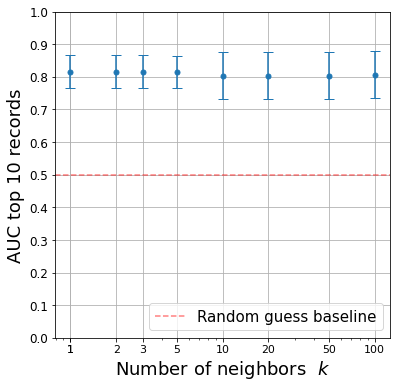
Throughout the paper, we use , meaning that our vulnerability score is computed using the 5 closest records to the record of interest. We here evaluate the impact of a specific choice of for the record identification and associated results. More specifically, we compute the mean distance for each record using values of ranging from 1 to 50 and report the mean AUC for the ten records selected by the method on the Adult dataset using Synthpop.
Figure 3(a) shows our method to be robust to specific choices of . The mean AUC of the top ten records varies indeed only slightly for different values of . Looking at the top 10 records selected for different values of , we find that only a handful of records are distinct, suggesting our method to not be too sensitive to specific values of .
6.4 Robustness Analysis for the Cosine Distance
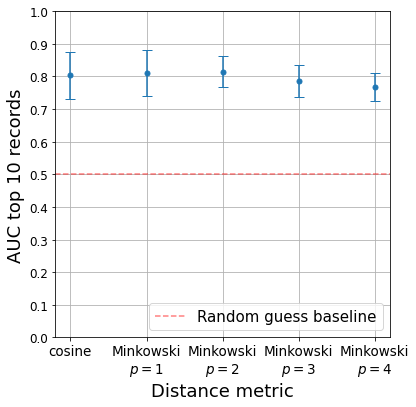
We here rely on a generalized form of cosine distance across attribute types. We now evaluate the susceptibility of our results to different choices of distance metrics. We do this using several versions of the Minkowski distance between two vectors . For a given value , the Minkowski distance is defined as . Similarly to Eq. 5, we generalise this distance metric for two records to:
| (6) |
Notably, the Minkowski distance with closely relates to the cosine distance. As before, we compute the mean distance for each record using Minkowski distances with ranging from 1 to 4 and report the mean AUC for the ten records selected by the method on the Adult dataset using Synthpop.
Figure 3(b) shows the attack performance to, again, be robust to different choices of distance metric. In particular, mean AUC is not significantly different for the cosine distance and , while slightly decreasing for higher values. Cosine being the standard distance metric in the literature, we prefer to use it.
6.5 Vulnerable Records and Differentially Private Generators
An active line of research aims at developing differentially private (DP) synthetic data generators. As discussed above however, developing models that achieve DP with meaningful theoretical while maintaining high utility across tasks remains a challenge. MIAs are thus an important tool to understand the privacy protection offered by DP models for various values of .
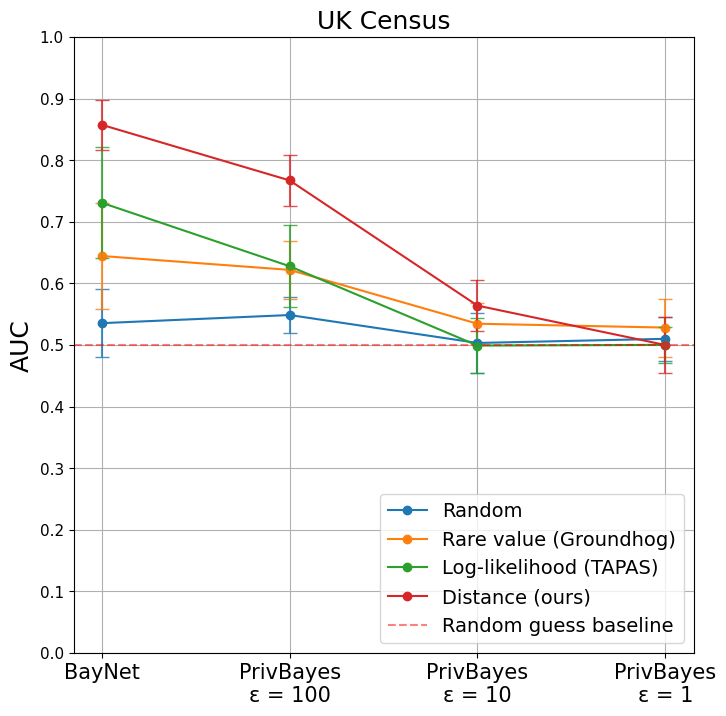
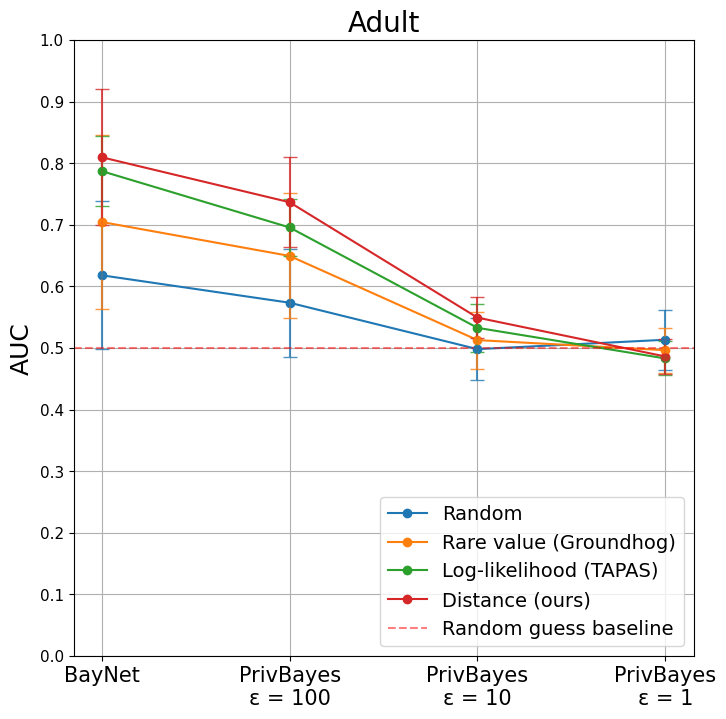
We here evaluate the performance of our vulnerable record identification approach when DP generators are used. Specifically, we report the mean and standard deviation AUC for the 10 records identified as being at risk by our approach and by the three baselines for varying values of using PrivBayes [42].
Figure 4 shows that our approach outperforms both the random baseline and the two ad-hoc techniques previously used in the literature. As expected though, the AUC drops when decreases. The attack still performs quite well for and manages to identify at-risk records for . Importantly, the general utility of synthetic data generated by PrivBayes for low value of is being debated.
7 Discussion
Our results show that our simple distance-based method is able to consistently identify vulnerable records, and more effectively so than previously proposed ad-hoc methods. We believe this to be due to limitations of previous work. Indeed Rare value (Groundhog) only considers the value of one specific attribute to determine whether a record is at risk while Log-likelihood (TAPAS) assumes independence across all attributes to compute a record’s likelihood, an assumption that is typically not met in real-world datasets. In contrast, our distance-based metric considers the neighborhood of the record, therefore encompassing all attributes without making any assumptions on the underlying distribution.
Across datasets and generators, we find that records identified by our method are on average 7.2 p.p. more vulnerable than previous work when using the state-of-the-art MIA. In practice, we believe this to be highly significant. Researchers and practitioners who wish to evaluate new attack methods and the privacy risk of synthetic data publishing are indeed unable to evaluate all records in the dataset, due to the computational cost of shadow modeling. Accurately identifying the records that are most at risk is thus as essential as using the state-of-the-art MIA when evaluating the privacy risk of a synthetic dataset. Indeed, data protection laws such as the EU GDPR require to consider the privacy protection offered to all data subjects when evaluating if a data release is anonymous.
When we use only categorical columns, such as in UK Census, results show that we reduce the standard deviation in the results by a factor of two, across generators. With our method we obtained a standard deviation of 0.021 instead of 0.041 for Synthpop and 0.040 instead of 0.090 for BayNet. This shows that our method selects records with high precision of having high vulnerability.
Lastly, apart from being effective, our principled method is compellingly easy. By being independent of the synthetic data generator and the dataset, it allows for pragmatic and efficient cross-generator and dataset comparison.
Future Work. We here distinguished between categorical features and continuous attributes. Future research could explore if considering ordinal as a subset of the categorical features could lead to a better record selection. Similarly, we here focused on the difference in metrics between the cosine similarity and the Minkowski metrics of order . We leave for future work to see if other distances, such as Minkowski of higher order, the Chebyshev distance or Hamming distance, could lead to a better record selection.
Additionally, one could study whether removing the most vulnerable records is an effective defense against attacks. Prior work on MIAs against ML models suggests that, when vulnerable records are removed, other records then become more vulnerable [7]. We leave for future work whether this holds true for MIAs against synthetic data.
Finally, we presented results on three widely used synthetic data generators. Future work should evaluate whether more specific metrics could be beneficial for other generators such as GANs.
8 Conclusion
Due to computational costs, the identification of vulnerable records is as essential as the actual MIA methodology when evaluating the privacy risks of synthetic data, including with respect to data protection regulations such as the EU GDPR. We here propose and extensively evaluate a simple yet effective method to select vulnerable records in synthetic data publishing, which we show to strongly outperform previous ad-hoc approaches.
8.0.1 Acknowledgements
We acknowledge computational resources and support provided by the Imperial College Research Computing Service. ***http://doi.org/10.14469/hpc/2232.
References
- [1] Alan Turing Institute: Resprosyn. https://github.com/alan-turing-institute/reprosyn (2022)
- [2] Allard, T.: Snake challenge (2023), https://www.codabench.org/competitions/879/
- [3] Annamalai, M.S.M.S., Gadotti, A., Rocher, L.: A linear reconstruction approach for attribute inference attacks against synthetic data. arXiv preprint arXiv:2301.10053 (2023)
- [4] Bates, A., Spakulová, I., Dove, I., Mealor, A.: Ons methodology working paper series number 16—synthetic data pilot. https://www.ons.gov.uk/methodology/methodologicalpublications/generalmethodology/onsworkingpaperseries/onsmethodologyworkingpaperseriesnumber16syntheticdatapilot (2019), accessed on 02/06/2023
- [5] Bauer, L.A., Bindschaedler, V.: Towards realistic membership inferences: The case of survey data. In: Annual Computer Security Applications Conference. pp. 116–128 (2020)
- [6] Bellovin, S.M., Dutta, P.K., Reitinger, N.: Privacy and synthetic datasets. Stan. Tech. L. Rev. 22, 1 (2019)
- [7] Carlini, N., Jagielski, M., Zhang, C., Papernot, N., Terzis, A., Tramer, F.: The privacy onion effect: Memorization is relative. Advances in Neural Information Processing Systems 35, 13263–13276 (2022)
- [8] Chang, H., Shokri, R.: On the privacy risks of algorithmic fairness. In: 2021 IEEE European Symposium on Security and Privacy (EuroS&P). pp. 292–303. IEEE (2021)
- [9] Cretu, A.M., Houssiau, F., Cully, A., de Montjoye, Y.A.: Querysnout: Automating the discovery of attribute inference attacks against query-based systems. In: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. pp. 623–637 (2022)
- [10] Dinur, I., Nissim, K.: Revealing information while preserving privacy. In: Proceedings of the twenty-second ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. pp. 202–210 (2003)
- [11] Domingo-Ferrer, J., Ricci, S., Soria-Comas, J.: Disclosure risk assessment via record linkage by a maximum-knowledge attacker. In: 2015 13th Annual Conference on Privacy, Security and Trust (PST). pp. 28–35. IEEE (2015)
- [12] Dwork, C.: Differential privacy. In: Automata, Languages and Programming: 33rd International Colloquium, ICALP 2006, Venice, Italy, July 10-14, 2006, Proceedings, Part II 33. pp. 1–12. Springer (2006)
- [13] Edge, D., Yang, W., Lytvynets, K., Cook, H., Galez-Davis, C., Darnton, H., White, C.M.: Design of a privacy-preserving data platform for collaboration against human trafficking. arXiv preprint arXiv:2005.05688 (2020)
- [14] Feldman, V.: Does learning require memorization? a short tale about a long tail. In: Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing. pp. 954–959 (2020)
- [15] Feldman, V., Zhang, C.: What neural networks memorize and why: Discovering the long tail via influence estimation. Advances in Neural Information Processing Systems 33, 2881–2891 (2020)
- [16] Financial Conduct Authority: Synthetic data to support financial services innovation. https://www.fca.org.uk/publication/call-for-input/synthetic-data-to-support-financial-services-innovation.pdf (2022), accessed on 02/06/2023
- [17] Giomi, M., Boenisch, F., Wehmeyer, C., Tasnádi, B.: A unified framework for quantifying privacy risk in synthetic data. arXiv preprint arXiv:2211.10459 (2022)
- [18] Hazy: Synthpop. https://github.com/hazy/synthpop (2019)
- [19] Homer, N., Szelinger, S., Redman, M., Duggan, D., Tembe, W., Muehling, J., Pearson, J.V., Stephan, D.A., Nelson, S.F., Craig, D.W.: Resolving individuals contributing trace amounts of dna to highly complex mixtures using high-density snp genotyping microarrays. PLoS genetics 4(8), e1000167 (2008)
- [20] Houssiau, F., Jordon, J., Cohen, S.N., Daniel, O., Elliott, A., Geddes, J., Mole, C., Rangel-Smith, C., Szpruch, L.: Tapas: a toolbox for adversarial privacy auditing of synthetic data. In: NeurIPS 2022 Workshop on Synthetic Data for Empowering ML Research (2022)
- [21] Jayaraman, B., Evans, D.: Evaluating differentially private machine learning in practice. In: USENIX Security Symposium (2019)
- [22] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [23] Leino, K., Fredrikson, M.: Stolen memories: Leveraging model memorization for calibrated white-box membership inference. In: 29th USENIX security symposium (USENIX Security 20). pp. 1605–1622 (2020)
- [24] Long, Y., Wang, L., Bu, D., Bindschaedler, V., Wang, X., Tang, H., Gunter, C.A., Chen, K.: A pragmatic approach to membership inferences on machine learning models. In: 2020 IEEE European Symposium on Security and Privacy (EuroS&P). pp. 521–534. IEEE (2020)
- [25] Lu, P.H., Wang, P.C., Yu, C.M.: Empirical evaluation on synthetic data generation with generative adversarial network. In: Proceedings of the 9th International Conference on Web Intelligence, Mining and Semantics. pp. 1–6 (2019)
- [26] Nasr, M., Shokri, R., Houmansadr, A.: Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In: 2019 IEEE symposium on security and privacy (SP). pp. 739–753. IEEE (2019)
- [27] NHS England: A&e synthetic data. https://data.england.nhs.uk/dataset/a-e-synthetic-data (2020), accessed on 02/06/2023
- [28] Nowok, B., Raab, G.M., Dibben, C.: synthpop: Bespoke creation of synthetic data in r. Journal of statistical software 74, 1–26 (2016)
- [29] Office for National Statistics: Census microdata teaching files (2011), https://www.ons.gov.uk/census/2011census/2011censusdata/censusmicrodata/microdatateachingfile
- [30] Pyrgelis, A., Troncoso, C., De Cristofaro, E.: Knock knock, who’s there? membership inference on aggregate location data. arXiv preprint arXiv:1708.06145 (2017)
- [31] Ronny, K., Barry, B.: UCI machine learning repository: Adult data set (1996), https://archive.ics.uci.edu/ml/datasets/Adult
- [32] Salem, A., Zhang, Y., Humbert, M., Berrang, P., Fritz, M., Backes, M.: Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models. arXiv preprint arXiv:1806.01246 (2018)
- [33] Sankararaman, S., Obozinski, G., Jordan, M.I., Halperin, E.: Genomic privacy and limits of individual detection in a pool. Nature genetics 41(9), 965–967 (2009)
- [34] Shokri, R., Stronati, M., Song, C., Shmatikov, V.: Membership inference attacks against machine learning models. In: 2017 IEEE symposium on security and privacy (SP). pp. 3–18. IEEE (2017)
- [35] Stadler, T., Oprisanu, B., Troncoso, C.: Synthetic data–anonymisation groundhog day. In: 31st USENIX Security Symposium (USENIX Security 22). pp. 1451–1468 (2022)
- [36] Truex, S., Liu, L., Gursoy, M.E., Yu, L., Wei, W.: Demystifying membership inference attacks in machine learning as a service. IEEE Transactions on Services Computing 14(6), 2073–2089 (2019)
- [37] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [38] Xu, L., Skoularidou, M., Cuesta-Infante, A., Veeramachaneni, K.: Modeling tabular data using conditional gan. Advances in Neural Information Processing Systems 32 (2019)
- [39] Xu, L., Skoularidou, M., Cuesta-Infante, A., Veeramachaneni, K.: Modeling tabular data using conditional gan. In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019), https://proceedings.neurips.cc/paper_files/paper/2019/file/254ed7d2de3b23ab10936522dd547b78-Paper.pdf
- [40] Yale, A., Dash, S., Dutta, R., Guyon, I., Pavao, A., Bennett, K.P.: Assessing privacy and quality of synthetic health data. In: Proceedings of the Conference on Artificial Intelligence for Data Discovery and Reuse. pp. 1–4 (2019)
- [41] Yeom, S., Giacomelli, I., Fredrikson, M., Jha, S.: Privacy risk in machine learning: Analyzing the connection to overfitting. In: 2018 IEEE 31st computer security foundations symposium (CSF). pp. 268–282. IEEE (2018)
- [42] Zhang, J., Cormode, G., Procopiuc, C.M., Srivastava, D., Xiao, X.: Privbayes: Private data release via bayesian networks. ACM Trans. Database Syst. 42(4) (oct 2017). https://doi.org/10.1145/3134428, https://doi.org/10.1145/3134428
Appendix 0.A Appendix: Target Attention
Inspired by developments in natural language processing [37], the target attention model computes record-level embeddings. Through a modified attention mechanism, these embedding are able to interact with the embedding of the target record, which in turn leads to a dataset-level embedding that is used as input for a binary classifier. The detailed steps are laid out below.
We start by preprocessing the synthetic dataset used as input . First, we compute the one-hot-encoded values for all categorical attributes and apply this consistently to all the synthetic records and the target record. The continuous attributes remain untouched. Second, we compute all the unique records in the dataset and their multiplicity. Third, we compute the distance following equation (1) between all unique synthetic records and the target record. Finally, we rank all unique synthetic record by increasing distance to the target record and, optionally, only keep the top closest records, where is a parameter.
The final pre-processed synthetic dataset is a matrix containing the top X unique records, their multiplicity and the distance, ranked by the latter, where denotes the number of features after one-hot-encoding of the categorical attributes added by 2 to account for the multiplicity and the distance. For consistency, the target record is processed in the same way, with one-hot-encoded categorical attributes, multiplicity and distance , resulting in the pre-processed target record .
Fig. 5 illustrates our target attention model, which we describe in Alg. 1. The model takes as input the pre-processed synthetic dataset . First, a multilayer perceptron (MLP) is used to compute embeddings of both the pre-processed records as well as the target record. Second, after computing a query vector for the target record and keys and values for the records, an attention score is computed for each record. After applying a softmax function across all attention scores, all record values are summed weighted by the respective attention score to eventually lead to the dataset-level embedding which is used as input for a final MLP as binary classifier. The output of the entire network is a single float, which after applying a sigmoid function results in a probability of membership. This model is then trained with all synthetic shadow datasets using a binary cross-entropy loss function with the known binary value for membership.
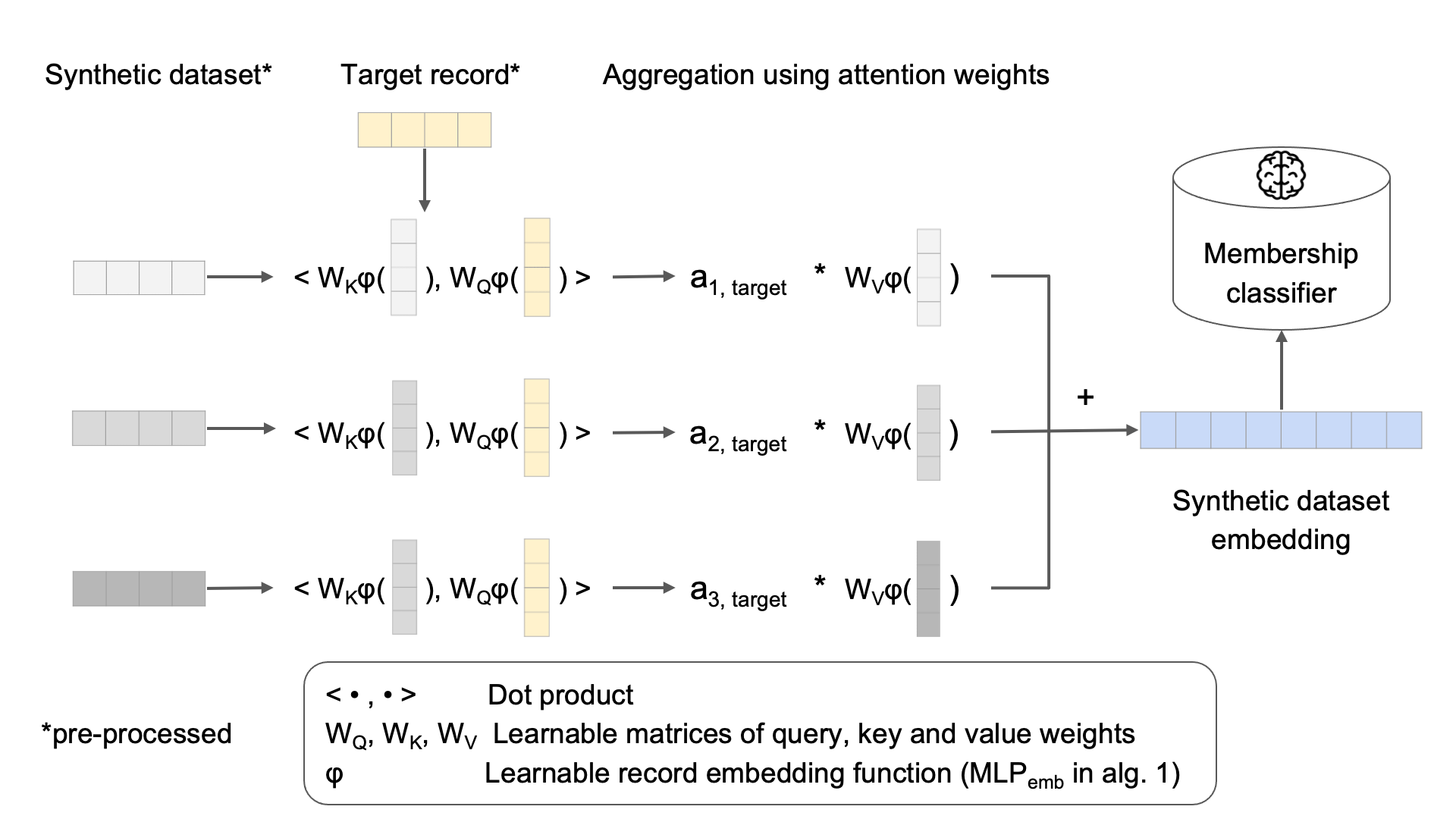
Throughout the experiments, we used , and . Both and consist of one hidden layer with 20 and 10 nodes respectively, and use ReLU as activation and a dropout ratio of 0.15. The network is trained for 500 epochs, using the Adamax optimizer [22] with a learning rate of and batch size of . 10% of the training data is used as validation data and the model that achieves the lowest validation loss is selected. Results in Table 3 display the details of results compiled in Figure 2.
| Method | UK census | Adult | ||
|---|---|---|---|---|
| Synthpop | BayNet | Synthpop | BayNet | |
| Random | ||||
| Rare value (Groundhog) | ||||
| Log-likelihood (TAPAS) | ||||
| Distance (ours) | ||||