DIV=12, paper=a4, abstract=on
A comparative numerical study of meshing functionals for variational mesh adaptation††thanks: Supported in part by NSF (U.S.A.) through grant DMS-1115118 and NSERC (Canada) through grant A8781.
Abstract
We present a comparative numerical study for three functionals used for variational mesh adaptation. One of them is a generalization of Winslow’s variable diffusion functional while the others are based on equidistribution and alignment. These functionals are known to have nice theoretical properties and work well for most mesh adaptation problems either as a stand-alone variational method or combined within the moving mesh framework. Their performance is investigated numerically in terms of equidistribution and alignment mesh quality measures. Numerical results in 2D and 3D are presented.
-
AMS subject classifications: 65N50, 65K10
keywords:
variational mesh adaptation, mesh adaptation, moving mesh, equidistribution, alignment, mesh quality measures1 Introduction
Variational mesh adaptation is an important type of mesh adaptation method and has received considerable attention from scientists and engineers; e.g., see the books [15, 19, 23, 24] and references therein. It also serves as the base of a number of commonly used adaptive moving mesh methods (e.g., see [5, 12, 14, 22]). In the variational approach, an adaptive mesh is generated as the image of a reference mesh under a coordinate transformation and such a coordinate transformation is determined as a minimizer of a certain meshing functional. A number of meshing functionals have been developed in the past (cf. the above mentioned books). For example, Winslow [25] proposed an equipotential method based on variable diffusion. Brackbill and Saltzman [3] developed a method by combining mesh concentration, smoothness, and orthogonality. Dvinsky [6] used the energy of harmonic mappings as his meshing functional, while Knupp [20] and Knupp and Robidoux [21] developed functionals based on the idea of conditioning the Jacobian matrix of the coordinate transformation. More recently, Huang [7] and Huang and Russell [15] proposed functionals based on the so-called equidistribution and alignment conditions.
With variational mesh adaptation, the mesh concentration is typically controlled through a scalar or a matrix-valued function, often referred to as the metric tensor or monitor function and defined based on some error estimates and/or physical considerations. While most of the meshing functionals have been developed with physical or geometric intuitions and have various levels of success in the adaptive numerical solution of partial differential equations (PDEs) and other applications, there is only a limited understanding on how the metric tensor affects the behavior of the mesh. An attempt to alleviate this lack of understanding was made by Cao et al. [4] for a generalization of Winslow’s variable diffusion functional. They showed that a significant change in an eigenvalue of the metric tensor along the corresponding eigendirection (first increasing and then decreasing, or vice versa) will result in adaptation of coordinate lines along this direction, although this adaptation competes with far more complicated effects, including those from changes in eigenvectors and other eigenvalues and the effects of the shapes of the physical and computational domains and the mesh point distribution on the boundaries. In [7, 15], two functionals have been developed based directly on the equidistribution and alignment conditions. These two conditions provide a complete characterization of the mesh elements through the metric tensor [7]. Minimizing the functionals leads to meshes which tend to satisfy the conditions in an integral sense. Nevertheless, this characterization is only qualitative, and how closely the mesh satisfies the conditions depends on the boundary correspondence between the computational and physical domains and the mesh point distribution on the boundaries. Thus, numerical studies, especially comparative ones, are useful, and often necessary, in understanding how the mesh adaptation for those meshing functionals is controlled precisely by the metric tensor. There do exist a few comparative numerical studies for meshing functionals. For example, a gallery of (adaptive and non-adaptive) meshes is given in [19] for a number of meshing functionals. Some comparative meshes are given in [15] for the harmonic mapping functional [6] and the subsequent functional based on equidistribution and alignment [7].
The main objective of this work is to present a comparative study for three of the most appealing meshing functionals, a generalization of Winslow’s variable diffusion functional (cf. Eq.˜6) and two functionals based on equidistribution and alignment (cf. Eqs.˜11 and 13). They are selected because Eqs.˜6 and 11 have been known to work well for many problems (e.g., see [1, 2, 7, 13, 14, 22]) while Eq.˜13 is similar to Eq.˜11 and has some very nice theoretical properties (cf. Section˜3.2). Another motivation is to present some three dimensional numerical results for those functionals. Critical for our study is to perform the substantial computations using the improved implementation of the variational methods introduced in [11]. In a sharp contrast to the situation in two dimensions, very little work has been done with variational mesh adaptation and adaptive moving mesh methods in three dimensions (e.g., see [15, 22]). It is particularly interesting to see how the functionals perform in this case.
An outline of the paper is given as follows. We describe the basic ideas of the variational mesh adaptation and its direct discretization (that is, first to discretize and then optimize) in Section˜2. In Section˜3 we introduce the three functionals to be studied for the numerical comparison, a generalization of Winslow’s variable diffusion functional and two functionals based on equidistribution and alignment. Numerical results and example adaptive meshes are given in Section˜4, followed by conclusions in Section˜5.
2 Variational mesh adaptation
In variational mesh adaptation, an adaptive mesh is generated as the image of a reference mesh under a coordinate transformation. Denote the physical domain by (), and assume that we are given a computational domain and a quasi-uniform mesh thereon (in this work we consider only simplicial meshes). In many situations we can choose to be the unit square/cube or simply . Denote the coordinate transformation by and its inverse by . Such a coordinate transformation (more precisely, its inverse) is determined as a minimizer of a meshing functional. Most of the existing meshing functionals can be cast in a general form as
| (1) |
where is a smooth function, is the Jacobian matrix of , denotes the determinant of , and is the metric tensor supplied by the user to control mesh concentration. We assume that is a symmetric and uniformly positive definite -by- matrix-valued function on . Notice that Eq.˜1 is formulated in terms of the inverse coordinate transformation. One reason for this is that this form is less likely to produce singular meshes [6]. Another reason is that is a function of and thus finding the functional derivative of will not directly involve the derivatives of . This is convenient since in practice is known only at the vertices of a mesh and its derivatives are not cheap to find. The main disadvantage of the formulation in this form is that (or its numerical approximation) does not give the physical mesh directly. This is remedied either by interchanging the roles of the independent and dependent variables in the Euler-Lagrange equation of (e.g., see [15]) or, in a recently developed implementation (see below), computing the new physical mesh from a computational one using linear interpolation.
A minimizer of Eq.˜1 can be found numerically in the MMPDE (moving mesh PDE) framework. A conventional implementation [15] is to find the functional derivative of Eq.˜1 and then define the MMPDE as the gradient flow equation of the functional. Having been transformed by interchanging the roles of the dependent and independent variables, the MMPDE can be discretized on and a system of equations for the nodal velocities is obtained. Finally, the new mesh is obtained by integrating the mesh equation over a time step.
A much simpler implementation was proposed recently by Huang and Kamenski [11]. Instead of utilizing the MMPDE directly, the new implementation first discretizes the functional on the current mesh and then, following the idea of the MMPDE, defines the mesh equation as the gradient equation of the discretized functional (with respect to the computational coordinates of the vertices). To be specific, denote by , , and , the coordinates of the vertices of the current physical mesh (), the reference mesh (), and the computational mesh (), respectively. We assume that these meshes have the same numbers of the elements and vertices and the same connectivity. For any element (with vertices , ), the corresponding element in is denoted by (with vertices , ). The edge matrices for and are defined as
Let be the element patch associated with vertex (i.e., the collection of the elements containing as a vertex). Then, the equation for the nodal velocities reads as
| (2) |
where is the volume of , is the local mesh velocity associated with vertex in , denotes the local index of in , is a constant parameter used to adjust the time scale of mesh movement, and is a positive function used to make the mesh equation to have desired invariance properties. Although the parameter can be absorbed in , using two parameters has the advantage that the role of each parameter is clear: for the time scale of mesh movement while for the invariance properties. Ideally, should be chosen such that the mesh movement has the same scale as the physical equation. Unfortunately, there is no theoretical analysis for this yet and trial and error is still the most practical way to choose . Numerical experience shows that a value in the range seems to work well for most problems [15]. In our computation, we choose such that the equation is invariant under the scaling transformation for all non-zero constants (cf. Section˜3): in variational mesh adaptation it is the relative distribution of over the physical domain (instead of its absolute distribution) that determines the variation of the mesh density and therefore it is essential for the moving mesh equation to be invariant under the scaling transformation of .
The local velocities are given by
| (3) |
where the derivatives of with respect to and (see Eqs.˜7, 12 and 14 below) are evaluated as
The second equation in Eq.˜3 is an inherent property resulting directly from the differentiation of the discretized meshing functional; it states that the centroid of stays fixed if only the contribution from is taken into account.
The above mesh equation should be modified properly for boundary vertices. For example, if is a fixed boundary vertex, we replace the corresponding equation by
When is allowed to move on a boundary curve/surface represented by
then the mesh velocity needs to be modified such that its normal component along the curve or surface is zero, i.e.,
Mesh equation Eq.˜2 defines the movement of the nodes of the computational mesh starting from the reference mesh at . The equation can be integrated in time to obtain the computational mesh at . For notational simplicity, we denote the computational mesh at by as well. Notice that the physical mesh is fixed during the time integration from to . Meshes and define a correspondence
The new physical mesh is computed by means of linear interpolation as
where is the reference mesh on . The computational mesh plays the role of an intermediate variable.
Recall that the mesh concentration in variational mesh adaptation is controlled through the metric tensor . Such a metric tensor can be defined based on physical or geometric considerations or some error estimates. For example, for the norm of the error of piecewise linear interpolation on simplicial meshes, the optimal metric tensor [9, 16] (also see [15, (5.192)]) is
| (4) |
where is the Hessian of function , is the eigen-decomposition of with the eigenvalues being replaced by their absolute values, and the regularization parameter is chosen such that
In practical computation, is typically unknown, and only the approximations to its values at the vertices are available. For this reason (and even in situations where an analytical expression for is available), the Hessian in Eq.˜4 is replaced by an approximation obtained by a Hessian recovery technique from the nodal values of or the approximations of the nodal values of . A number of such techniques are known to produce nonconvergent recovered Hessians from a linear finite element approximation (e.g., see Kamenski [17]). Nevertheless, it is shown by Kamenski and Huang [18] that a linear finite element solution of an elliptic BVP converges at a second order rate as the mesh is refined if the recovered Hessian used to generate the adaptive mesh satisfies a closeness assumption. Numerical experiment shows that this closeness assumption is satisfied by the approximate Hessian obtained with commonly used Hessian recovery methods. We use a Hessian recovery method based on a least squares fit: a quadratic polynomial is constructed locally for each vertex via least squares fitting to neighboring nodal function values and an approximate Hessian at the vertex is then obtained by differentiating the polynomial.
3 Meshing functionals
Here we introduce the three meshing functionals used in the numerical study. A generalization of Winslow’s variable diffusion functional and the two functionals based on equidistribution and alignment are selected because they are reasonably simple, have nice theoretical properties, and are known to work well for many problems.
3.1 Winslow’s functional based on variable diffusion
The first functional is the variable diffusion proposed by Winslow [25]. It uses the system of elliptic PDEs
for generating adaptive meshes, where is the weight function. This system mimics a (steady-state) diffusion process with a heterogeneous diffusion coefficient . It is the Euler-Lagrange equation of the functional
| (5) |
where is the trace of a matrix. A generalization of this functional to allow a diffusion tensor is
| (6) |
This functional has been used by a number of researchers, e.g., see Huang and Russell [13, 14], Li et al. [22], and Beckett et al. [2]. It is coercive and convex [15, Example 6.2.1]. Thus, under a suitable boundary condition (such as the Dirichlet boundary condition with being mapped onto ), the functional Eq.˜6 has a unique minimizer.
3.2 Functionals based on equidistribution and alignment
The other functionals are based on the equidistribution and alignment conditions. These conditions provide a full mathematical characterization of a non-uniform mesh. Indeed, any non-uniform mesh can be viewed as a uniform one in the metric specified by a tensor. Moreover, a mesh is uniform in the metric specified by the metric tensor if and only if it satisfies the equidistribution and alignment conditions associated with [10, 15]. In the continuous form, they are
| equidistribution: | (8) | |||
| alignment: | (9) |
where
| (10) |
These conditions require the mesh elements to have the same size (equidistribution) and be equilateral (alignment) in the metric , respectively. The alignment condition also implies that the elements are aligned with in the sense that the principal directions of the circumscribed ellipsoid of each element coincide with the eigen-directions of while the lengths of the principal axes of the ellipsoid are reciprocally proportional to the square roots of the eigenvalues of .
The first functional based on equidistribution and alignment, proposed in [7], is
| (11) |
where and are dimensionless parameters. Loosely speaking, the first and second terms correspond to the equidistribution and alignment conditions, respectively. The terms are dimensionally homogeneous and the balance between them is controlled by the dimensionless parameter . For , , and , the functional is coercive and polyconvex and has a minimizer [15, Example 6.2.2]. Moreover, for and it reduces to
which is exactly the energy functional of a harmonic mapping from to (cf. [6]).
For the functional Eq.˜11, we have
| (12) |
In the computation, we use . is the smallest integer to satisfy for , 2, and 3. The choice of is in the range for the functional to be polyconvex while giving a bigger weight to the equdistribution condition. This set of the values works well for all tested problems. The balancing function in Eq.˜2 is chosen to be , so that Eq.˜2 is invariant under the scaling transformation .
The second functional based on equidistribution and alignment is
| (13) |
where , , and () are parameters. The first three terms in Eq.˜13 are dimensionally homogeneous in and while the last term has the same dimension in as the other terms. This functional was proposed in [15, (6.120)] to avoid singularity of the coordinate transformation. Indeed, if , then the functional is coercive and polyconvex and has a minimizer satisfying in [15, Example 6.2.3].
In the computation, we choose , , , , , and the balancing function . These choices are based on the functional Eq.˜11 and the desire to keep the fourth term relatively small.
For this functional, we have
| (14) |
4 Numerical experiments
In the following we consider a number of examples in two and three dimensions. For a given function we consider defined in Eq.˜4 which is optimal for minimizing the norm of the linear interpolation error of this function and compare meshes obtained from using the functionals of Winslow Eq.˜6 (W), Huang Eq.˜11 (H), and Huang and Russell Eq.˜13 (HR).
To assess the quality of the generated meshes, we compare the norm of the linear interpolation error and the equidistribution and alignment mesh quality measures, which describe how far the mesh is from being uniform in the metric defined by . The element-wise quality measures are based on Eq.˜8 and Eq.˜9 and defined as
| (15) |
while for the overall mesh quality measures we take their root-mean-squared values,
| (16) |
If the mesh is uniform with respect to , then ; if the mesh is far from being uniform with respect to , then and will become large. In other words, these quality measures describe how well the volume (measured by ) and the shape and orientation (measured by ) of mesh elements correspond to the desired size and shape prescribed by (see [8] for more details on the mesh quality measures).
4.1 Two dimensions
First, we consider two dimensional meshes constructed for the unit square and the test functions
Example 4.1.
Example 4.2.
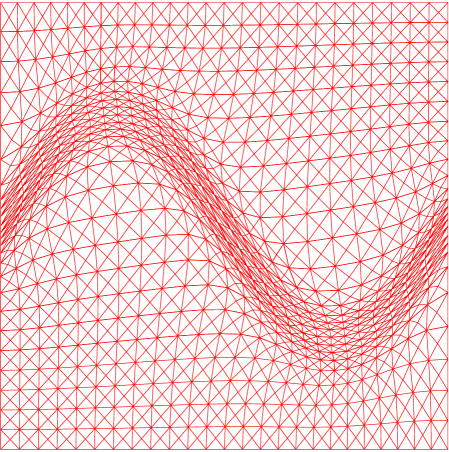
Example meshes, close-ups, as well as the mesh quality measures and the interpolation error are given in Figs.˜1 and 2.
For these examples, all three functionals provide good size and shape adaptation. A closer look at the mesh quality measures shows that, although all three functionals provide comparable meshes which are reasonably close to the prescribed metric tensor, meshes constructed using H and HR functionals have better correspondence to the prescribed metric tensor. In both two-dimensional examples, H and HR functionals provide very similar grids which are closer to the prescribed size and shape (that is, smaller values of and ). This is also reflected in the error of the linear interpolation: HR functional Eq.˜13 provides the smallest error, followed by H functional Eq.˜11 and then W functional Eq.˜6. It seems that W functional is a bit too aggressive in moving nodes towards the neighborhood of areas of interest, providing a higher density of the nodes along the anisotropic features of the given function while coarsening out the mesh nearby, leading to a steeper element size gradation. Interestingly, for both examples the convergence of the linear interpolation error for W functional (Figs.˜1(f) and 2(f)) slows down near and returns to the order as the mesh is refined ( is the number of mesh elements). It is unclear to us what causes this for W functional.
For Example˜4.1 we also compute adaptive meshes for the metric tensor which is optimal for the semi norm error (see, e.g., [10] for details on the metric tensor). The results shown in Fig.˜3 are essentially the same as in Fig.˜1: HR functional Eq.˜13 provides the smallest error, followed by H functional Eq.˜11 and then W functional Eq.˜6. For this metric tensor, the error for the H and HR functionals (Fig.˜3(f)) is slightly larger than in Fig.˜1(f), which is not surprising, since the metric tensor chosen for Fig.˜1 is optimal for the error. Thus, adding the equidistribution property to the meshing functional seems to help to obtain meshes which are closer to fulfilling the prescribed properties. Interestingly, the error for the W functional seems to be a bit smaller if the metric tensor is used. This can be explained by the fact that the W functional does not incorporate the equidistribution property and, thus, doesn’t exactly generate a mesh which is uniform with respect to the provided metric tensor. Thus, it is not quite clear if one is able to generate the optimal mesh when using the W functional.


























4.2 Three dimensions
In three dimensions, we consider the unit cube and the following test functions.
Example 4.3.
Example 4.4.
Example 4.5.
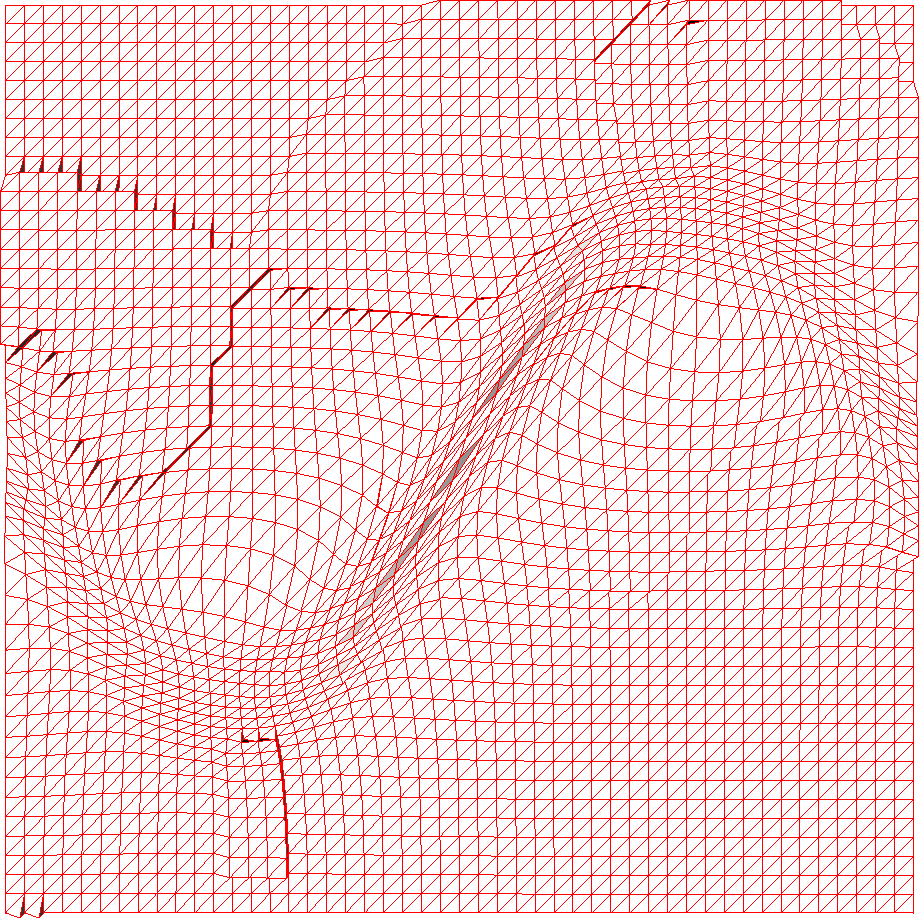
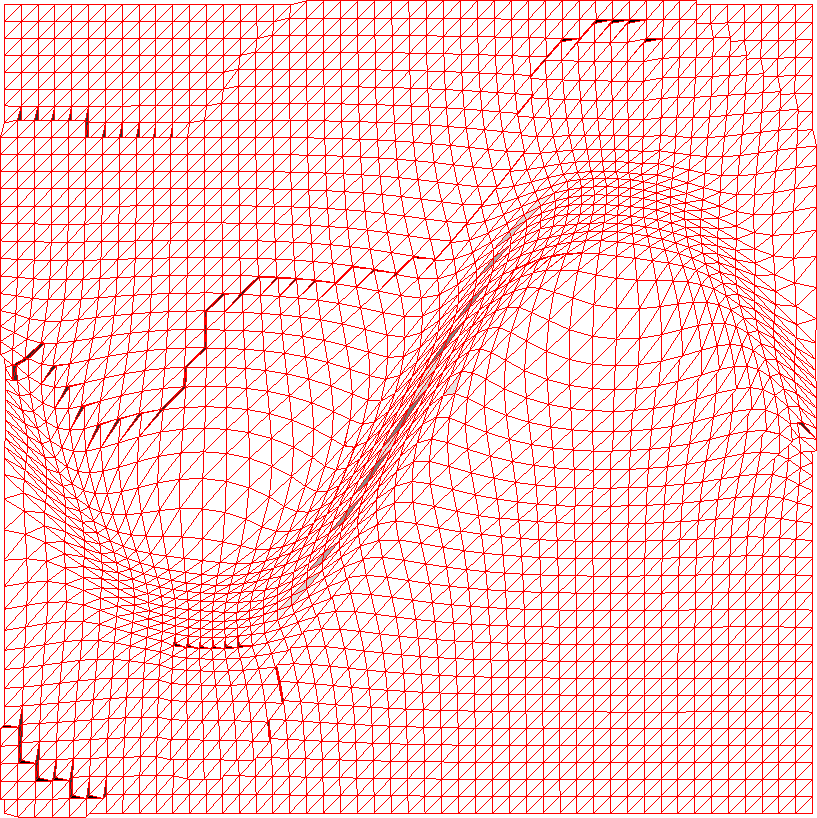
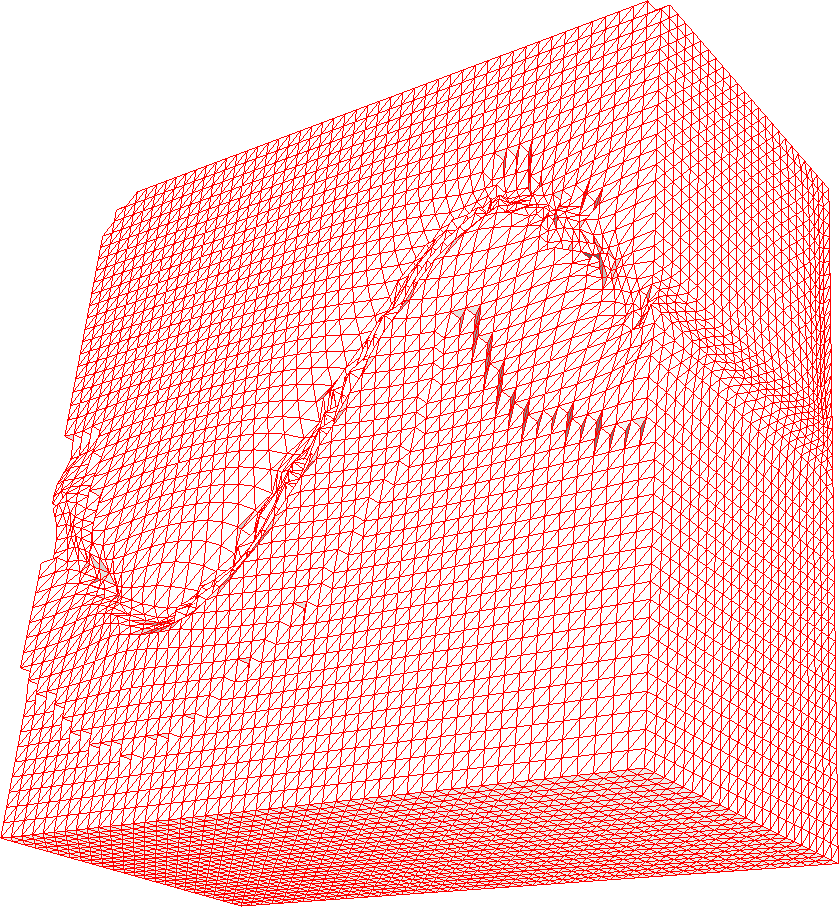
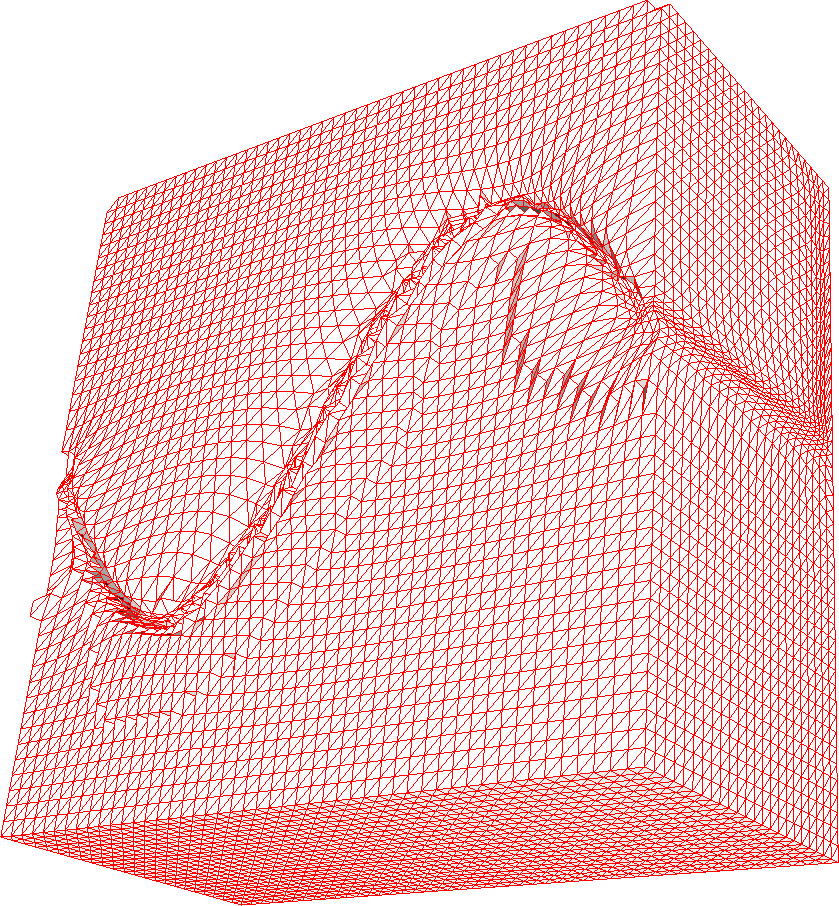
As in two dimensions, all three functionals provide good size and shape adaptation, with and being reasonably small. The best mesh size control is given by HR functional (Figs. 4(g), 5(g), and 6(g)), although for the considered examples, HR has a slightly worse mesh alignment quality than the others (Figs. 4(h), 5(h), and 6(h)).
A closer look at the example meshes (slice cuts) reveals that, as in 2D, W functional —based on variable diffusion— is noticeably more aggressive in moving nodes toward the steep features or, alternatively, one can say that the functionals Eqs.˜11 and 13 based on equidistribution and alignment distribute the nodes with the better correspondence with the given . For coarse meshes, all three functionals provide similar results (see convergence plots in Figs. 4(i), 5(i), 6(i)); however, for fine meshes, sizing of mesh elements obtained by means of W functional is not quite as good as for H and HR functionals, as indicated by a larger .
Altogether, the linear interpolation error (Figs. 4(i), 5(i), and 6(i)) suggests that HR functional provides the best mesh, followed by H and W functionals. One may notice from Figs.˜5(i) and 6(i) that the convergence of the linear interpolation error for W functional slows down near for Examples˜4.4 and 4.5, although it seems to improve as the mesh is refined (Fig.˜6(i)). The reason for this behaviour is not clear to us. On the other hand, W functional has the simplest form and seems to be more economic to compute than the other two. From tentative comparison, mesh generation using W functional uses about one fifth to an half of the CPU time used with H or HR functional. Qualitatively, this is not difficult to understand since W functional is convex whereas the others are not (although they are polyconvex).














5 Conclusions
Among the three functionals in this study, Huang and Russell’s functional consistently provides the best mesh for piecewise linear interpolation in both two and three dimensions. In all examples it leads to the best equidistribution quality and the smallest interpolation error. Interestingly, while it results in the best mesh alignment quality in two dimensions, the functional gives a slightly worse mesh alignment than the other two functionals in three dimensions.
Meshes obtained by means of Winslow’s functional have the worst mesh equidistribution (element size) quality and the largest interpolation error in four out of five examples, although in three dimensions its mesh alignment is quite good and even better than that of the meshes obtained using Huang and Russell’s functional. An explanation to this behavior could be the fact that this functional does not have an explicit mechanism to control the equidistribution property.
The behavior of Huang’s functional is somewhere in between Winslow’s and Huang and Russell’s functionals: both in mesh quality measures and interpolation error. It provides better mesh sizing than Winslow’s functional but not quite as good as Huang and Russell’s. On the other hand, it provides the best (or very close to the best) mesh alignment in all examples.
While being able to produce correct and good quality mesh concentration, Winslow’s functional seems to have the tendency to move more points toward the area of interest and is slightly less reliable than the other two functionals especially when the mesh is fine. On the other hand, it has a very simple form and is more economic to compute than the others. It can be a good choice for mesh adaptation at least for coarser meshes, for which all of the three functionals produce comparable meshes.
Finally, it should be pointed out that the numerical experiment we conducted in this work is limited and more work is needed to have an extensive and more complete understanding of the behavior of the meshing functionals especially in three dimensions. Moreover, the newly developed implementation of the variational methods in [11] has been crucial to the current study to perform substantial computations in two and three dimensions. It is our hope that it can serve as an efficient tool for use in future studies of mesh adaptation and movement.
References
- [1] G. Beckett, J. A. Mackenzie, A. Ramage, and D. M. Sloan. Computational solution of two-dimensional unsteady PDEs using moving mesh methods. J. Comput. Phys., 182:478–495, 2002.
- [2] G. Beckett, J. A. Mackenzie, and M. L. Robertson. A moving mesh finite element method for the solution of two-dimensional Stefan problems. J. Comput. Phys., 168:500–518, 2001.
- [3] J. U. Brackbill and J. S. Saltzman. Adaptive zoning for singular problems in two dimensions. J. Comput. Phys., 46:342–368, 1982.
- [4] W. Cao, W. Huang, and R. D. Russell. A study of monitor functions for two dimensional adaptive mesh generation. SIAM J. Sci. Comput., 20:1978–1994, 1999.
- [5] H. D. Ceniceros and T. Y. Hou. An efficient dynamically adaptive mesh for potentially singular solutions. J. Comput. Phys., 172:609–639, 2001.
- [6] A. S. Dvinsky. Adaptive grid generation from harmonic maps on Riemannian manifolds. J. Comput. Phys., 95:450–476, 1991.
- [7] W. Huang. Variational mesh adaptation: isotropy and equidistribution. J. Comput. Phys., 174:903–924, 2001.
- [8] W. Huang. Measuring mesh qualities and application to variational mesh adaptation. SIAM J. Sci. Comput., 26:1643–1666, 2005.
- [9] W. Huang. Metric tensors for anisotropic mesh generation. J. Comput. Phys., 204:633–665, 2005.
- [10] W. Huang. Mathematical principles of anisotropic mesh adaptation. Comm. Comput. Phys., 1:276–310, 2006.
- [11] W. Huang and L. Kamenski. A geometric discretization and a simple implementation for variational mesh generation and adaptation. J. Comput. Phys. (submitted), 2015. (arXiv:1410.7872).
- [12] W. Huang, Y. Ren, and R. D. Russell. Moving mesh partial differential equations (MMPDEs) based upon the equidistribution principle. SIAM J. Numer. Anal., 31:709–730, 1994.
- [13] W. Huang and R. D. Russell. A high dimensional moving mesh strategy. Appl. Numer. Math., 26:63–76, 1998.
- [14] W. Huang and R. D. Russell. Moving mesh strategy based upon a gradient flow equation for two dimensional problems. SIAM J. Sci. Comput., 20:998–1015, 1999.
- [15] W. Huang and R. D. Russell. Adaptive Moving Mesh Methods. Springer, New York, 2011. Applied Mathematical Sciences Series, Vol. 174.
- [16] W. Huang and W. Sun. Variational mesh adaptation II: error estimates and monitor functions. J. Comput. Phys., 184:619–648, 2003.
- [17] L. Kamenski. Anisotropic Mesh Adaptation Based on Hessian Recovery and A Posteriori Error Estimates. Verlag Dr. Hut, München, 2009. PhD Thesis, Technische Universität Darmstadt.
- [18] L. Kamenski and W. Huang. How a nonconvergent recovered Hessian works in mesh adaptation. SIAM J. Numer. Anal., 52:1692–1708, 2014. (arXiv:1211.2877).
- [19] P. Knupp and S. Steinberg. Fundamentals of Grid Generation. CRC Press, Boca Raton, 1994.
- [20] P. M. Knupp. Jacobian-weighted elliptic grid generation. SIAM J. Sci. Comput., 17:1475–1490, 1996.
- [21] P. M. Knupp and N. Robidoux. A framework for variational grid generation: conditioning the Jacobian matrix with matrix norms. SIAM J. Sci. Comput., 21:2029–2047, 2000.
- [22] R. Li, T. Tang, and P. W. Zhang. Moving mesh methods in multiple dimensions based on harmonic maps. J. Comput. Phys., 170:562–588, 2001.
- [23] V. D. Liseikin. Grid Generation Methods. Springer, Berlin, 1999.
- [24] J. F. Thompson, Z. A. Warsi, and C. W. Mastin. Numerical Grid Generation: Foundations and Applications. North-Holland, New York, 1985.
- [25] A. M. Winslow. Adaptive mesh zoning by the equipotential method. Technical Report UCID-19062, Lawrence Livemore Laboratory, 1981 (unpublished).