Active Image Synthesis for Efficient Labeling
Abstract
The great success achieved by deep neural networks attracts increasing attention from the manufacturing and healthcare communities. However, the limited availability of data and high costs of data collection are the major challenges for the applications in those fields. We propose in this work AISEL, an active image synthesis method for efficient labeling, to improve the performance of the small-data learning tasks. Specifically, a complementary AISEL dataset is generated, with labels actively acquired via a physics-based method to incorporate underlining physical knowledge at hand. An important component of our AISEL method is the bidirectional generative invertible network (GIN), which can extract interpretable features from the training images and generate physically meaningful virtual images. Our AISEL method then efficiently samples virtual images not only further exploits the uncertain regions but also explores the entire image space. We then discuss the interpretability of GIN both theoretically and experimentally, demonstrating clear visual improvements over the benchmarks. Finally, we demonstrate the effectiveness of our AISEL framework on aortic stenosis application, in which our method lowers the labeling cost by while achieving a improvement in prediction accuracy.
Index Terms:
Active learning, Computer-aided diagnosis, Data augmentation, Generative adversarial networks, Small-data learning.1 Introduction
Deep neural networks (NNs) [1, 2, 3] have achieved superior performance in computer vision tasks [4, 5], and attracts increasing attention from other communities, including manufacturing [6] and healthcare [7]. When fed with a large amount of training data (at least in the thousands [8]), NNs have shown great success in extracting high-level features and modeling complex functions. However, the available data in actual life is often limited and expensive to collect. For example, in computer-aided diagnosis of aortic stenosis, a common yet severe heart disease [9], doctors are interested in using pre-surgical CT scans to efficiently identify the diseased patients. Here, a hospital may only have around a hundred historical records over the years, leading to unsatisfactorily performance for NNs.
In the meantime, thanks to the advances in domain research, underlining physical knowledge is often available for the learning problems in manufacturing and healthcare. Take the same aortic stenosis application as an example, the pathophysiological reason for the stenosis is mainly due to the deposited calcifications on the valve leaflets and the valve wall, and therefore change the blood flow pattern. The blood flow can be numerically simulated via computational fluid dynamics (CFD, see[10]), using the CT scans as the input geometry and boundary conditions. Incorporating such knowledge (i.e., simulation) would intuitively improve the learning model since it provides complementary information against the collected historical records. We present in this paper an active sampling method to incorporate underlining physical knowledge via a complementary dataset.
However, there are two major challenges involved in collecting such a complementary dataset. First, the inputs of the dataset (i.e., unlabeled images) are difficult to acquire in practice. This is particularly typical in the medical field, e.g., pre-surgical CT scans, due to clinical, logistic, and economic restrictions. Therefore, an effective synthesis model for image inputs is needed. Second, physical labeling methods are usually expensive. For example, it may take several hours of computation for a CFD model with complex geometry [10], and it would be even longer if considering the interaction of blood flow and soft biological tissue [11]. Within a practical turnaround, one can only afford a relatively small amount of labeled experiments. Therefore, an efficient sampling strategy is needed for data synthesis.
We propose in this work AISEL (an Active Image Synthesis framework for Efficient Labeling) to actively incorporate the underline physical knowledge in small-data learning. Our AISEL framework contains two major components. We first propose the generative invertible network (GIN) – a novel bidirectional image generative model – to encode the actual images (i.e., the training images) into the defined lower-dimensional feature space, in which candidate virtual images can then be generated. GIN can be viewed as an extension of the generative adversarial networks [12] by adding an inverse mapping for feature extraction to the generative mapping. Moreover, we propose a new uncertainty sampling method to actively select the candidate virtual images in the GIN feature space. In our sampling method, virtual images are efficiently selected to represent the distribution of uncertainty in the energy-distance sense, and therefore both exploit the highly uncertain regions and explore the entire space without overlap. Labels for selected virtual images are then obtained via the physical labeling approaches at hand. By merging the training data and our AISEL dataset, improved downstream models are observed on both toy computer vision/manufacturing applications and the medical application of aortic stenosis. This paper makes the following contributions:
-
1.
We incorporate physical knowledge into the learning process, via a complementary dataset. This ensures the incorporation of the additional information (by the physics-based labeling approaches), and therefore improves the downstream prediction performance.
-
2.
We propose an efficient image sampling method for complementary dataset. Specifically, it minimizes the predictive uncertainty and mitigates the possible high labeling cost.
-
3.
We propose a new bidirectional generative model – GIN for feature mapping and actively generating virtual images, conditional on the actual images. Noticeable visual improvements compared to the benchmarks are observed.
The paper is structured as follows. Section 2 summarizes the related works. Section 3 presents the proposed GIN with an emphasis on the difference with GAN. Section 4 discusses the new sampling method and features the whole AISEL learning framework. Section 5 demonstrates the effectiveness of our method in both toy examples and the motivating application of aortic stenosis. Section 6 concludes the work with directions for future research.
2 Related work
Data augmentation is widely used for different learning tasks with image inputs [13, 14], via image translation, rotation and flip, and changing of the tune and/or brightness to increase the training data size. Usually, it assumes such augmentation does not change the label. However, this may not hold in, e.g., medical images. Taking CT scans as an example, different substances of human tissues correspond to different ranges of image intensity, alterations of which may lead to a completely different interpretation of the pathophysiological condition [15]. This significantly limits the augmentation methods suitable for manufacturing and healthcare applications. As to be shown later, the predictive performance with simple augmentation is not good enough.
Generative adversarial networks (GAN) [12] opens an era of adversarial training for multiple learning challenges, e.g., image segmentation [16] and domain adaptation [17]. We adapt in this work a GAN-based method for the generative model, because (i) compared to variational autoencoder [18, 19], GAN achieves visually better performance, and (ii) compared to generative flow [20], GAN contains a generative mapping from the low-dimensional features space, which can be used for our new sampling method.
To achieve efficient image sampling, study design in the feature space is desirable and crucial. However, Most GAN-based methods feature only generation mapping. Exceptions are adversarially learned inference (ALI) [21] and bidirectional GAN (BiGAN) [22], which learns both generating mapping and its inverse by a coupled architecture of three NNs. The model is proposed mainly for inference and representation learning. However, complicated architectures and the coupled training of three NNs requires a large amount of data, which is not suitable for our small-data learning problems. Our GIN will be compared with BiGAN to show a noticeable improvement in visual quality.
Conditional GAN (CGAN) [23] and auxiliary classifier GAN (ACGAN) [24] can generate images with given labels. Such models can be used to generate both virtual images and the corresponding labels for data augmentation [24, 25]. In our AISEL framework, we only generate the input images, while the labels are acquired via physical experiments to incorporate complementary knowledge. We will show that the proposed method has noticeable better predictive accuracy compared to the ACGAN-based method.
Transfer learning is another popular approach for small-data learning tasks [26, 27]. Adapting the models trained on natural images (mostly, ImageNet [5]), researchers are able to fine-tune the pre-trained model coefficients to address the limitation imposed by the small sample size [7]. This approach explores the visual cues extracted from natural images and assumes they are also useful in interpreting the training data at hand. However, for learning tasks in manufacturing and healthcare, the rationality of such an assumption is unclear. For example, comparing CT scans to natural images, (i) noticeable differences in image appearances are observed, and (ii) pixel intensity value has intrinsically different meanings. Nevertheless, transfer learning will be served as a baseline for the proposed framework.
Active learning (or sequential experimental design [28] in statistics literature) methods are also used for small-data learning with an oracle labeling method available [29, 30]. They aim to select the next “good” input data for labeling. Active learning methods are popular in traditional machine learning, with recent improvements for deep learning models [31, 32]. Most active learning methods in the literature assume that a sizeable unlabeled dataset is available. However, in manufacturing and healthcare applications, the unlabeled images are also difficult to acquire in nature.
One of the few exceptions is generative adversarial active learning (GAAL) [33] in literature, which uses GAN to generate unlabeled data. However, GAAL is proposed specifically for the support vector machine classifier. Since the support vector machine performs poorly in complicated classification tasks (e.g., our aortic stenosis application), we will compare our method with a modified version of GAAL using a convolutional NN as the classifier.
Few-shot learning is another popular method for small-data learning tasks [34]. Though it can successfully handle learning tasks with very small training data, it usually requires many such tasks. Here, we only have one task, and therefore we will leave out few-shot learning baselines.
3 Generative invertible network
In this section, we propose the novel bidirectional GIN as the feature encoding and image generating model, for later efficient image sampling. We first present the GIN architecture with a detailed comparison to GAN. We then show the implementation detail and algorithm for the proposed GIN.
3.1 Image generating
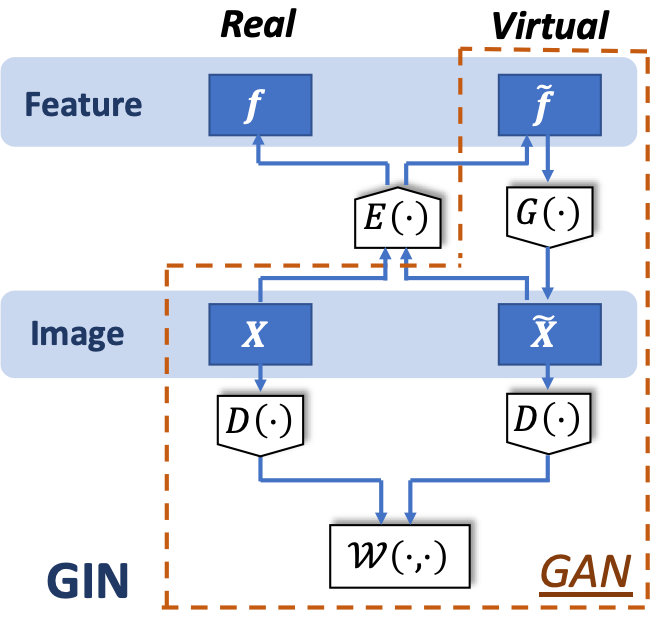
Following the standard GAN [12, 35], we model the training set images as realizations of the distribution of the images of interest . Here, denotes the space of images with pixel size , and is its Borel set [36]. Furthermore, in order to efficiently learn the generative mapping and later interpretation, we define a feature space . Here, is the pre-defined dimension of the feature space, usually assumed to be much lower than that of the image space. We set a non-informative, uniform measure on the feature space , which represents the lack of understanding of the feature space. The goal is to learn a generative mapping which best pushforwards the uniform measure and mimics the target measure . We use in this work the Wasserstein-1 metric [37] as the loss function:
| (1) |
where is the norm, and the infimum is obtained with respect to all the possible joint distribution whose marginals are and . We adopt the Kantorovich-Rubinstein dual form [37] of Wasserstein distance for efficient implementation:
| (2) |
Here is an evaluating function and represents that is Lipschitz-1 continuous [35].
We use a NN to approximate the generating mapping , named generator, and another NN for the evaluating function , named discriminator. The aim is to find the optimum of the following minimax function:
| (3) |
where is the empirical measure for the training images with size , and is the uniform measure to be pushforwarded. Iterative training strategy can be adapted. Further discussion on the numerical implementation and the convergence analysis can be found in Section 3.3.
3.2 Feature encoding
Assume for now the generating mapping is known. We are interested in finding an encoding mapping to embed the images back to the feature space, which, to be shown in Theorem 1, is an inverse of . Similar to the generating mapping, we use a NN to parametrize , named encoder. Since the task here is to extract the feature vectors from images, a convolutional neural network (CNN) is used with mean square error (MSE) loss:
| (4) |
where is the corresponding feature vector associated with the image . The reason we use an MSE loss is due to the desired regression task here: we want a strong metric to ensure the sample-to-sample inverse of . Furthermore, we want dedicated only on this inversion task, and therefore permits an efficient sampling method later in Section 4.1.
However, the difficulty is that the feature for the actual image is unknown. In other words, cannot be learned from the dataset of actual images at hand. Therefore, we revise (4) to
| (5) |
where is the generated virtual images. Another advantage of using the virtual data points is that the data size of the virtual images can be large, since one may generate as many virtual images as needed. We expect the encoder learned via (5) using virtual data points (instead of the actual images in training set) is still the inverse of the generator . Formally, we have the following Theorem:
Theorem 1.
This means the obtained and are inverses of each other in the sense of minimizing the reconstruction error. The proof of this theorem can be found in Appendix A.
The reason for introducing the encoding mapping as the inverse of generating mapping is twofold. First, we can use to encode the actual images as vectors in the feature space . They can then be used as lighthouses in , and provide intuitive understanding of the feature space (we will discuss this later in Section 5.2.2). Second and perhaps more important, in the following sampling method, we want to sample virtual images for better predictive performance with a limited labeling budget. In our AISEL method (see Section 4.1), the sampling is performed in rather than the image space , for its lower dimension and the physical meaning. Moreover, while sampling virtual images, we need guidance from the features of the actual images. For example, one may not want to sample images that are too similar to any of the actual images to better explore the whole . This can be achieved by introducing a separating distance between virtual images and actual images (we will come back to this in Section 4.1); this needs to encode the actual images to the feature space by .
3.3 Summary and algorithm for GIN
Putting everything together, the proposed GIN consists of three NNs: a generator for generating virtual images, an encoder for feature embedding, and a discriminator for computing the Wasserstein distance. Fig.1 illustrates the architecture of GIN. Note that in GIN, and is decoupled due to the limited training data. We present Algorithm 1 to train the proposed GIN. The first part of the algorithm is to train a generator parameterized by , and the second part is to train an encoder parameterized by . The generator and discriminator are coupled trained as GAN, while the additional encoder is separately trained by the virtual images sampled by . In the small-data situation, the proposed GIN along with the associated algorithm can achieve visual improvement in practice, compared to other methods like BiGAN; we will provide a detailed discussion in Section 5.1.2.
One may be interested in finding out how “real” the virtual images can be generated using the proposed Algorithm 1, since multiple heuristic strategies are involved (e.g., iterative training of and , and clip). Furthermore, note that the above computation is done with samples of actual images, i.e., the empirical probability measure , instead of the original probability measure . Therefore, we have the following theorem for asymptotic convergence.
Theorem 2.
Denote the target measure as and its empirical measure represented by the training set data as . Assuming both neural networks and are obtained as the optimum of target function (3). Let be the measure obtained by the proposed Algorithm 1. Specifically, it is a pushforwarded measure of by , i.e., for any . As the training data size approaches infinity, we have in distribution.
Theorem 2 suggests that, if we have enough training data, the generated images are real enough compared to the actual images. Specifically, it means the generated images and the measure have the following two properties. First and most importantly, the supports of the two measures are the same, i.e., , with probability 1.0. This is a natural corollary of Theorem 2. It means any generated virtual image can be regarded as a draw from the measure of actual images , i.e., , where denotes the probability density of . In other words, the generated images are always physically meaningful. Moreover, besides their support, the two probability measures themselves are the same asymptotically. This means the probability of generating the same group of images (e.g., CT scans of male patients, or CT scans of patients with no complications) is the same, which is an implicit requirement when endowing the feature space with physical meaning and for the following sampling method. Though in practice we are dealing with a small-data situation, it is still appealing to have this asymptotic convergence property.
4 AISEL Framework
We present now the proposed AISEL framework for small-data problems. For the simplicity of illustration, we assume the learning task is a classification problem with images inputs (this is the case of the motivating application); the proposed framework can be easily extended to regression tasks, which will not be elaborated on in this paper.
We adopt here the standard -class classification setting, which uses input images to predict the probability of assigning to each class . The native classifier , parameterized by a NN, refers to the model learned with only the small training data at hand. With the native model and GIN (i.e., generator and encoder ) at hand, we first propose the new sampling method to select virtual images. We then discuss the physical labeling methods and why they are crucial in improving performance. Finally, an algorithmic framework is presented for implementation.
4.1 Active image sampling
We start with using the entropy [38] to quantify the uncertainty of the native model . For any input image and the corresponding predicted label , we have
| (6) |
where, . The reason for using entropy to quantify uncertainty can be explained as: (i) If we are sure about the class label of the input image, e.g., and ; the corresponding entropy is zero, meaning no uncertainty exists. (ii) Consider another extreme situation that . One can easily check this maximizes the entropy, reflecting the maximal uncertainty for the label of that image.
The image space is too high dimensional to handle in reality. Since GIN is already obtained, we can measure the uncertainty (i.e., entropy), for any in the feature space:
| (7) |
Here, we select the features of the complementary dataset in the feature space , rather than in the high-dimensional image space . Besides the dimensionality, our can capture the intrinsic structure of the image space – selecting features in (and then generating images via ) can ensure the existence of physical meaning. This is because any generated images with any is physically meaningful thanks to the , while randomly sampled is most likely a matrix without any visual clue.
The entropy can also be viewed as a (unnormalized) probability density on the measurable space . We denote this uncertainty measure as .
We then propose to select the best set of virtual images, by matching its empirical distribution to the uncertainty measure:
| (8) |
Here, is a distance metric, denote the selected features, and denotes the empirical measure for . Intuitively, (8) means to assign more points to higher uncertainty regions (of the native model), and therefore exploit those regions. Furthermore, if taking the Bayesian perspective, it can be viewed as changing the initial uniform distribution, i.e., the non-informative prior, to the posterior distribution of uncertainty given the actual training dataset.
Motivated by the literature in the statistical community [39, 40], we select the energy distance as the metric between distributions. Therefore, we minimize:
| (9) |
Note again, the above sampling optimization is conducted in the feature space. We observe from (9) that the selected features not only try to match the target uncertainty measure in the expectation sense (the first term), but also separate from one another (the second term). The separating property is of great importance; this is because any two selected features that are too close to each other can be viewed as a waste of the expensive labeling process.
Furthermore, the selected features should also be separated from the features of the actual images, again to avoid waste. This can be taken into account by the following modification of (9):
| (10) |
where is the size of the actual dataset and let for actual images with indies . Comparing (10) to (9), we notice the difference lies in the second term, where the separating property is incorporated not only between the selected features but also between the selected features and the features of actual images. We use (10) for sampling features, and then generate an AISEL dataset via . The following theorem ensures the generated AISEL dataset follows the target uncertainty measure in distribution.
Theorem 3.
Here, we show the convergence in the distribution of the images (rather than the features), as the images are the quantity of interest. Therefore, a continuous assumption on is needed according to continuous mapping theorem. The proof can be found in Appendix C; it follows from [40].
The proposed sampling strategy (10) reveals an important trade-off. Consider the first term, where the selected features are forced to be close to the target uncertainty measure. Since the density of our target measure (6) is high when the uncertainty is high, the selected features can be viewed as exploiting the highly uncertain regions. Now consider the second term, where the separating distance is maximized. This suggests the selected features should be away from (i) one another and (ii) the features for actual images. Therefore, selected features are forced to be spread out and fill the whole feature space – they explore the entire feature space. Putting both parts together, selected features for virtual images jointly exploit the highly uncertain regions and explore the entire image space. This trade-off of our AISEL dataset will be shown as the key to improve the classification performance.
We want to make a few remarks here. First, the proposed sampling method, specifically the uncertainty measure (7), is specifically for the classification problem at hand. With a different uncertainty measure, the proposed approach is also suitable for regression problems. For example, one may obtain the measure via predictive variance using kernel regression [41] or kriging [42] methods. Second, our method is motivated by active learning literature [29], where the next input is selected from a pool of candidates with maximal uncertainty. Different from those methods, our method (i) conducts sampling in a much lower-dimensional GIN feature space due to the intrinsic structure of image space and computational efficiency and (ii) sample a batch of images for labeling to both explore and exploit the design space. Moreover, it is worth pointing out that the proposed method is possible only when both the generating mapping and the encoding mapping are available via GIN. In particular, is used to generating images based on the selected features, while is used to embed the features of the actual images to guide the sampling. That is the key reason why we propose a bidirectional GIN in Section 3. Last but not least, the proposed method can also be used to balance the label distribution with a modification of our uncertainty measure (7). See Appendix F for more discussion.
4.2 Labeling by physical principles
A key component of the proposed AISEL framework, different from data augmentation, is the incorporation of physical knowledge while learning. This is due to the circumstances of real-world applications in manufacturing and healthcare: (i) the size of the historical records is small, leading to a poor learning model; and (ii) thanks to the advances in domain research, physical knowledge is oftentimes available yet expensive in implementation. Therefore, we want to build a bridge to efficiently combine both the historical data (via the learning model) and physical knowledge (via physical labeling). The resulting model can be viewed as one that has learned from data and been taught by physical knowledge, and therefore better performance can be achieved.
Here, we efficiently incorporate physical knowledge via a complementary AISEL dataset. Specifically, we separately acquire the input image and the output label. For virtual images, (10) is used to efficiently sample a set of features to minimize the predictive uncertainty, and GIN is then used to map those features to images. Meanwhile, for the labels, we use the physical labeling method at hand. We then combine the actual dataset and AISEL dataset to learn the downstream classification model. With the proposed uncertainty sampling method, our AISEL dataset (i) contains complementary information from physical knowledge, and (ii) efficiently exploit and explore the image space, and therefore improves the downstream learning performance.
Lots of different physics-based labeling approaches are available. For example, finite element analysis [43] and computational fluid dynamics [10] can solve partial differential equations (i.e., representation of physical knowledge) numerically. These methods can be used to label the input images in, e.g., manufacturing applications. Physical experiments can also be applied. With the advances in additive manufacturing, tissue-mimicking 3D printing [44] with an in-vitro study [45] can be used for medicine-related learning tasks. If none of the above exists, one can also consult the experts or use certain empirical physical relationships; these methods can be used in computer vision problems. The specific approach should be made on a case-by-case basis, with the available resources at hand.
It is important to note that labeling one input image via physical-based approaches is usually expensive. For example, in medicine-related applications, it may take several hours of computation for a CFD model with complex geometry [10], and it would be even longer if considering the interaction of blood flow and soft biological tissue [11]. This is one of the reasons for introducing an efficient and effective sampling method to design our AISEL dataset. Viewed this way, our approach can also be used to address the problem where an expensive simulator available, and we want to use that simulator actively for the classification tasks.
4.3 Summary of the AISEL framework
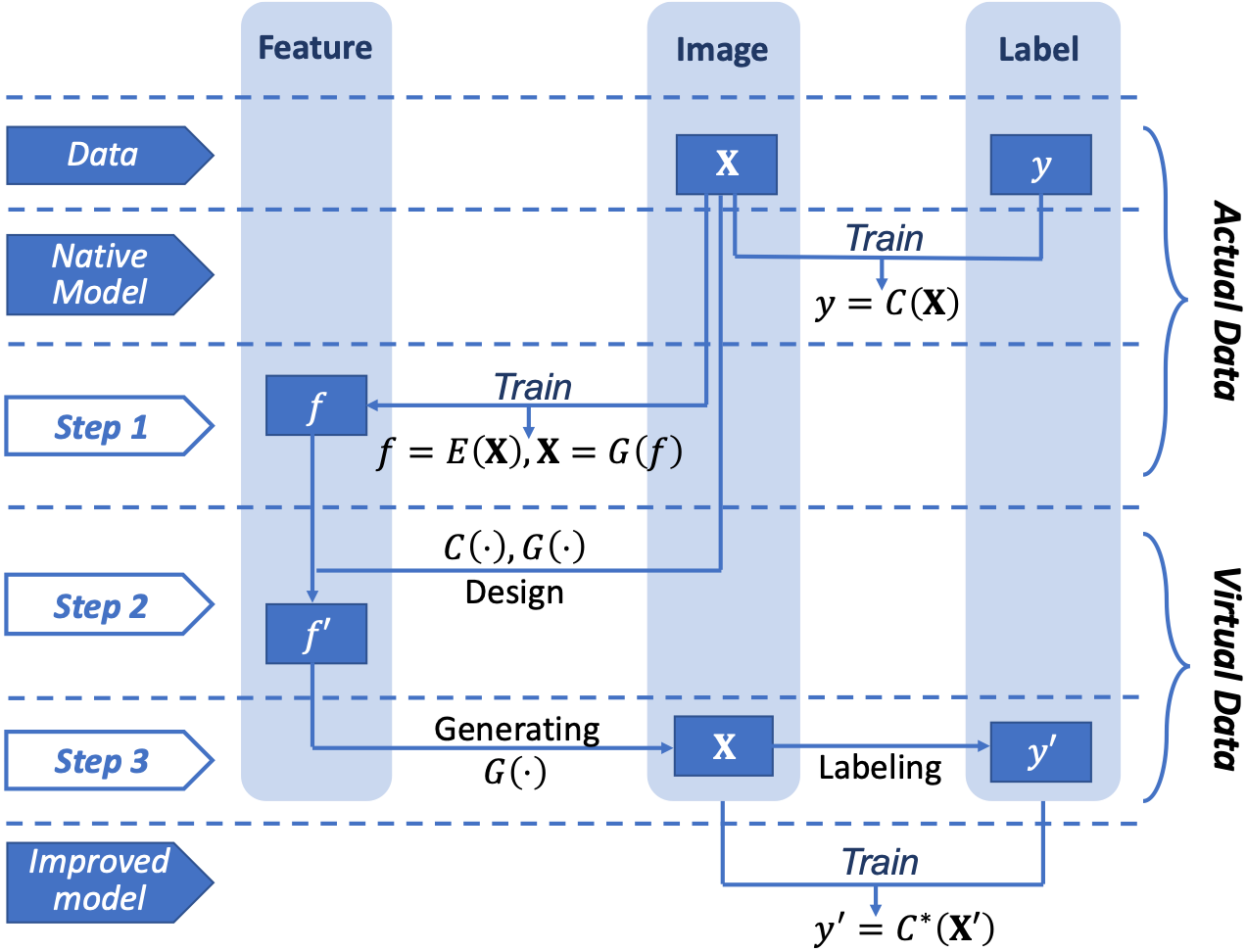
In summary, we propose an AISEL framework to efficiently incorporate physical knowledge at hand and improve the classification performance. The native model can be first obtained using the small training data. As illustrated in Fig.2, our AISEL framework contains three steps. First, the proposed GIN is trained using the actual images, providing a feature space , and bidirectional mappings between it and the image space (i.e., the generating mapping and the encoding mapping ). Second, the uncertainty of at different locations in is quantified via entropy, and then the features for virtual images are sampled via (10). Third, virtual images are generated by , and then labeled by the physics-based approach. Finally, the additional AISEL dataset is merged to the original training set, and an improved classifier can be trained. With the proposed AISEL framework to actively incorporate complementary knowledge via labeling, we will show later in the experiments, can achieve better classification accuracy.
We propose Algorithm 2 for our AISEL framework. In our implementation, the native model and improved model are parameterized by CNN, for its popularity in the image classification tasks. Other, perhaps more advanced architecture (e.g., ResNet [46]) can also be used. The optimization of (10) can efficiently implement by the convex-concave procedure (CCP, see [40]). Note that for all the NNs, especially the native model and the GIN, data augmentation methods (e.g., rotation and horizontal flip) are used. Note that our method can also be used for sequential implementation – run Algorithm 2 interactively to generate a series of AISEL datasets and therefore provide even better improvement, if budget allows.
5 Experiments
We first conduct toy computer vision experiments, and provide more insights on our AISEL framework. We then deploy the proposed method to the medical application of aortic stenosis, with emphasis on the pathophysiological meaning of the proposed framework.
5.1 Toy computer vision applications
We conduct experiments on small versions (400 in total for training) of two single-channel (i.e., grayscale) computer vision datasets – Fashion [47] and MNIST [48]. The two datasets are of particular interest due to their visual similarity to the images in the manufacturing process and modeling. For example, the images captured by a thermal camera (or simulated via finite element analysis), representing a gray-level temperature contour, can be used to predict the throughput in steel manufacture and conduct quality control in semiconductor manufacturing [49]. In the following subsections, we illustrate the visual performance of the proposed GIN, and the improvement in classification by our AISEL method, only on the Fashion dataset; similar observation also applies for MNIST (see Appendix E).
5.1.1 Fashion dataset
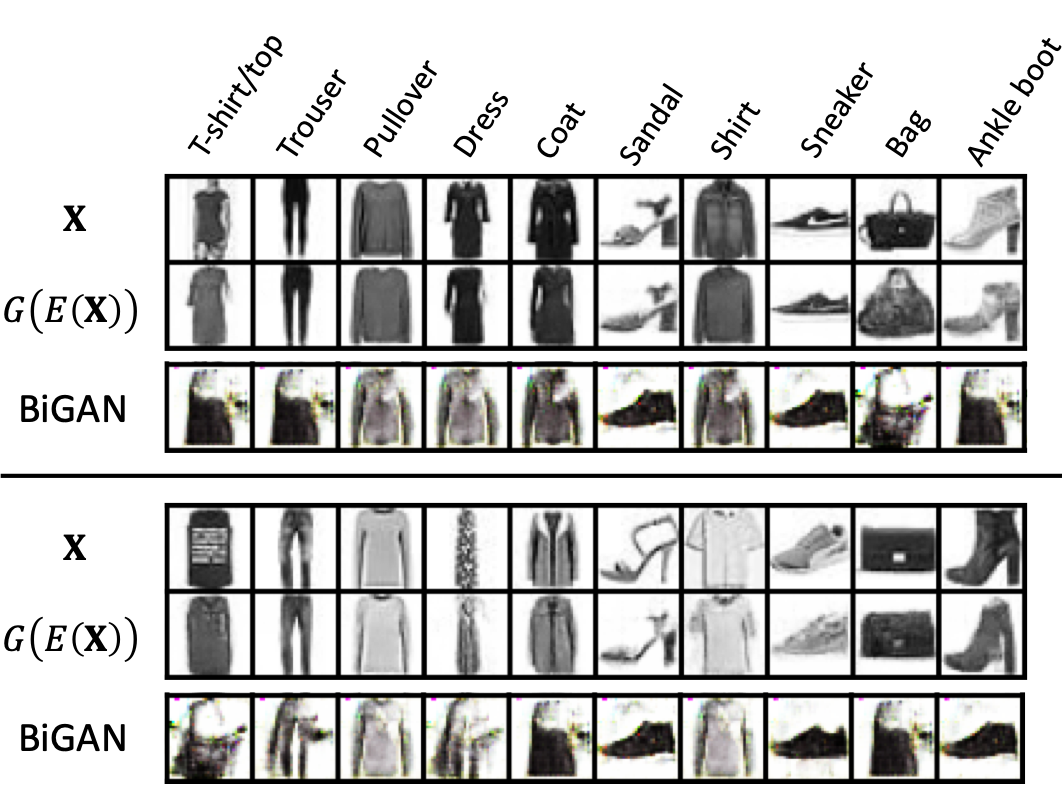
The Fashion dataset [47] is an MNIST-like dataset of Zalando’s article images. As shown in Fig.3 (see the rows ), it contains ten classes of outfits. We observe that the images associated with classes “T-shirt/top”, “coat” and “shirt” are visually similar in nature, resulting in a more challenging classification task than MNIST. Lots of works have been dedicated to classifying the Fashion dataset [50], and the leading accuracy is by WideResNets [51]. We use this model as our labeling approach (see Section 5.1.3 for a detailed discussion).
The original Fashion dataset contains a large amount of training data (60,000 in total). To mimic the real small-data situation in manufacturing, we randomly sample 400 as our training set, with roughly 40 data per label. The original test set (10,000 in total) remains untouched.
5.1.2 Visual results of GIN
We test first the proposed GIN. The dimension of the feature space is set to be , i.e., . This is only for visualization purposes; for actual employment (and in the later application of aortic stenosis), we suggest using a higher for better performance. The detailed architecture of the three NNs can be found in Appendix D. Fig.3 shows the generated images (see the rows ). Visually, they look sharp and reasonable without apparent mode dropping.
Reconstruction test. To visually show the encoder is the inverse of generator , we conduct the following reconstruction test: for any actual image , its feature is extracted , and then a reconstructed image is generated based on that feature , which is compared with the actual visually. The test results of all ten classes are shown in Fig.3, with denoting the actual images, and denoting the reconstructing ones. The similarity between the two is noticeable, especially in the sense of the same class. Note that we have already proven that and are inverses of each other in an ideal situation (see Theorem 1), and here we show the inverse can be achieved in practice.

| Native (400) | Transfer | ACGAN | Rand (+400) | Rand (+5000) | AISEL (+400) | AL (+400) | Oracle (800) | Oracle (all) | |
|---|---|---|---|---|---|---|---|---|---|
| Fashion | 72.8% | 74.3% | 72.3% | 76.4% | 80.7% | 81.9% | 78.2% | 81.3% | 96.7% |
| MNIST | 88.2% | 87.4% | 85.9% | 90.2% | 91.6% | 91.2% | 90.4% | 91.3% | 99.2% |
Comparison with BiGAN. We compare our GIN with BiGAN in literature, which also features a bidirectional mapping [22]. The architecture of BiGAN is set to be similar to GIN, with the same feature dimension and hidden layers. Fig.3 (see the rows “BiGAN”) shows the reconstruction test conducted by BiGAN using the same set of actual images as GIN. Further tuning (e.g., learning rate and hidden dimensions) of the BiGAN is also conducted, with similar performance (also see Fig.4 in [22]). In contrast, our GIN is easier to tune, and more importantly, achieves noticeable improved visual performance – better reconstruction results with no mode dropping even in this small-data situation. The reason for this difference contributes to the essentially different objectives of the two methods. BiGAN uses one discriminator to supervise both the generator and the encoder for representation learning purpose or even latent regression [21]. On the contrary, the objective of our GIN is to find the best inverse mapping for efficient sampling. Therefore, sequential order of training and is implemented in the proposed GIN to ensure the sample-to-sample inverse is explicitly trained by MSE metric. Therefore, we leave out the comparison of BiGAN for downstream classification.
5.1.3 AISEL framework

Now we test the rest of our AISEL framework. The native model is set to be a CNN with detailed architecture specified in Appendix D. The classification accuracy of the native model is only , since only 400 data are used as the training set. We then generate an AISEL dataset with size 400. Note that the labels are obtained by the oracle model (using all 60,000 training data and WideResNet architecture, denoted as “Oracle (all)” in Table III), mimicking the process of labeling by a domain expert. An improved classification model can then be obtained by the actual data and AISEL data. Final classification accuracy on the same test set is , an almost increase. This improvement shows that the proposed AISEL framework can indeed improve the predictive accuracy in the classification tasks. The reasons are that (i) the additional knowledge, i.e., labeling by the oracle model, is incorporated in the learning process, and (ii) the proposed sampling method ensures that our AISEL dataset explores the feature space. The latter will be discussed in detail below, with comparison to different baseline methods. Table III shows the final classification performance of the proposed method on both Fashion and MNIST, compared to the baselines.
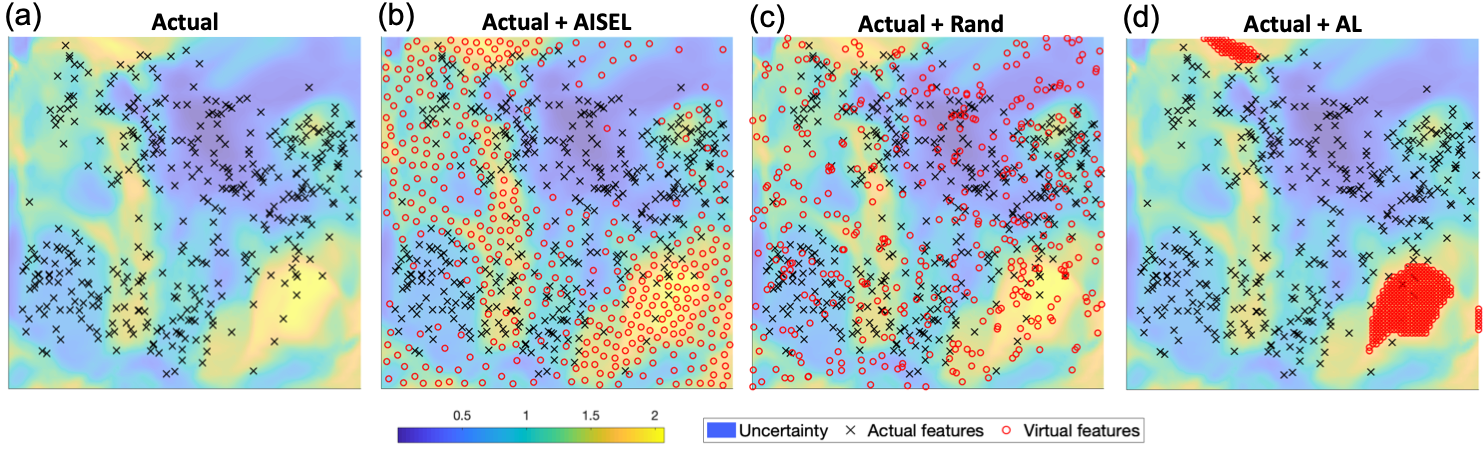
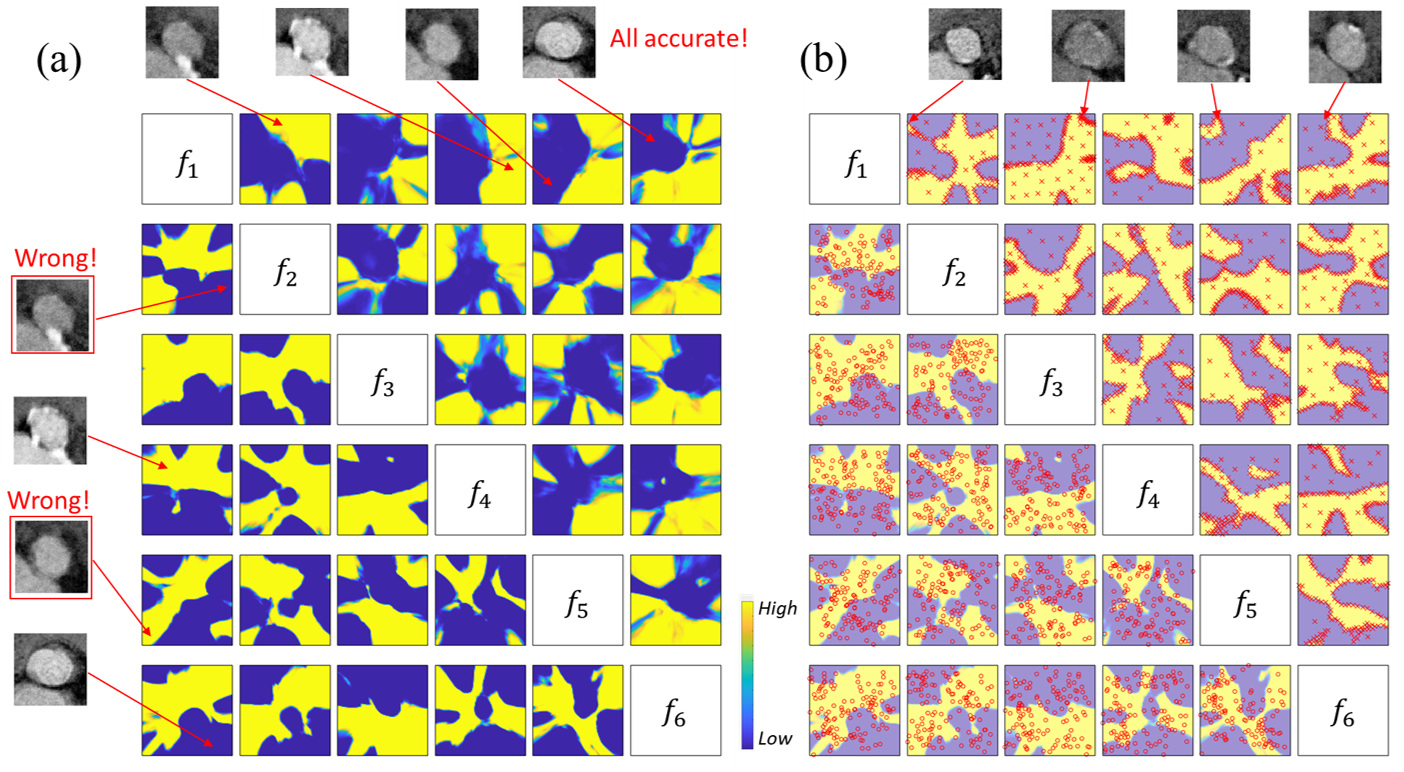
Features of AISEL dataset. We first visualize the actual features (i.e., the embedded features of the actual images) in the feature space . Fig.4 (a) shows the 400 actual features (in black crosses) on , with the background visualizing the uncertainty measure (7). Specifically, yellow regions indicate high uncertainly of the native model . Fig.4 (b) shows the features for 400 AISEL dataset (in red circles) together with the actual features. We observed the key trade-off as mentioned: our AISEL features jointly (i) exploits the highly uncertain regions and (ii) explores the whole feature space. On one hand, objective (i) is achieved by sampling more points in the regions where uncertainty is high, i.e., those with a yellow background. Visually, the AISEL features approximately follow the uncertainty measure. On the other hand, objective (ii) is achieved by spreading the AISEL features over the whole feature space with no features too close to one another. Visually, there are no big “holes”, and no two points overlap. Therefore, our AISEL method achieves a high () classification accuracy.
Comparison with GIN-based random sampling. We compare the proposed sampling method to random sampling. Specifically, we uniformly sample 400 features, generate virtual images using those features, and then label them using the same oracle model (i.e., Oracle (all)). Fig.4 (c) shows the randomly generated features. We see that those features are (i) not exploiting (i.e., placing more points in) the highly uncertain regions, and (ii) overlapping with one another and to the actual features, leading to poor exploration. Therefore, the classification accuracy of the 400 randomly sampled virtual images is only , which is noticeably lower () than the proposed AISEL method. If increasing the number of random virtual images to 5000, the classification accuracy can be increased to . Our AISEL method achieves slightly higher accuracy (), however much less virtual images, and therefore much lower labeling cost.
Comparison with active learning. We compare the proposed sampling method to an active learning (AL) method. Specifically, we adapt a similar setting in GAAL [33] in literature, using the GIN to generate a potential unlabeled dataset. To sample a virtual dataset, we set a grid (with size ) on the feature space, and then select the top 400 features among the grid, whose uncertainty is the highest. Virtual images are then generated and labeled by the oracle model. Fig.4 (d) shows the features selected by our setting of AL. We observe that, though the selected features locate in the highly uncertain regions, they are too close to one another. Furthermore, the selected features do not explore the whole feature space. The final classification performance of this AL is , which is slightly better than the random sampling (). However, our AISEL method, jointly explore and exploit the feature space, achieves a better classification performance ().
Comparison with ACGAN. Another approach also for small-data tasks is the ACGAN-based data augmentation method [25], which generates a set of images based on the chosen labels. We train an ACGAN [24] using the actual dataset at hand. The complexity of the ACGAN is set to be similar to our GIN. Fig.5 visualizes the generated images of all ten classes. We see that due to the limited training size (400 in total), the images can sometimes be wrongly labeled – in Fig.5, the generated “Trouser” is visually more close to “Dress”. The final classification accuracy is , i.e., it offers similar classification accuracy as the native model. This is because adapting ACGAN, the labels of the augmented dataset are obtained by the training set without complementary information. The data size is increased, however, those labels may not be accurate; therefore, little improvement is observed in this experiment. In our AISEL framework, we use an additional labeling method (i.e., by the oracle model with an accuracy of ) for more precise labels. Therefore, our method achieves better predictive performance.
Comparison with transfer learning. Transfer learning is also popular for small-data tasks. In our setting of transfer learning, we adapt a pre-trained ResNet18 [46] (by ImageNet [5]) and only fine-tune the last fully connected layer using the training data (400 in total) at hand. The classification accuracy of the transfer learning is , only slightly better than the native model with an accuracy of . The reason for this is that images of the Fashion dataset are virtual different from the natural images in the ImageNet. This observation is typical in the applications of manufacturing and healthcare, where the input images are, e.g., images from a thermal camera or flow velocity contour. In the transfer learning setting [52], we implicitly assume the parameters learned by ImageNet data can use be used to interpret the current Fashion dataset at hand. From the result of classification accuracy, the above assumption may not be valid. Our AISEL framework incorporates more accurate knowledge from physical experiments or experts, and therefore better classification model can be obtained.
Comparison with native model using 800 actual data. Another interesting baseline, though not feasible in real applications, is directly using 800 actual data to train an oracle model. In our setting, the first 400 data is the same as the 400 for the native model, and the remaining 400 is again randomly selected from the actual training set of the Fashion dataset. The same architecture as the improved model is used. We observe the classification accuracy is (denoted as “oracle (800)” in Table III), which is similar to our AISEL method with accuracy . This is again due to our efficient sampling method, which both explores and exploits the image space. Meanwhile, this also verifies the good generating performance of our GIN.
5.2 Aortic stenosis application
We now go back to the motivating application of aortic stenosis (AS). An anonymous image dataset containing 168 patients with aortic stenosis is collected (by Piedmont Healthcare, Atlanta). For each patient, pre-surgical CT scans and the corresponding calcification amount are acquired. The learning task is to classify the calcification level as high or low, which is an important yet challenging clinical problem. Four-fold cross validation strategy is used (see Appendix D), leading to only 126 data as the training set. We first provide more background information on the medical problem and our dataset. We then visualize the GIN performance, with a focus on the pathophysiological meaning. Finally, we discuss the classification accuracy, compared with baselines.

5.2.1 Background on aortic stenosis
Aortic stenosis (AS) is one of the most common and most serious valvular heart diseases. Transcatheter aortic valve replacement (TAVR) is a less-invasive treatment option for severe AS patients who are at high risk for open-heart surgery. One of the major post-procedural complications of TAVR is the paravalvular leakage (PVL), i.e., blood flow leakage around the implanted artificial valve due to incomplete sealing between the implant and the native aortic valve, which is often caused by the calcifications presented at the aortic annulus region (a ring-shaped anatomic structure connecting the left ventricle and the aortic valve). Therefore, in clinical practice, the amount and the distribution of annular calcifications are of great importance to predicting the occurrence of post-TAVR PVL. However, in-vitro study [45] is quite costly, requiring expensive operation costs of CT scanner, as well as several days of an experimenter’s time per virtual patient. Because of this, we simplify the task of PVL prediction to the task of calcification evaluation, which is deemed as an important clinical indicator of PVL risk. Due to the variant contrast level in the aortic root and the fast motion of the valve leaflets, it remains challenging to accurately evaluate calcification near the aortic annulus in pre-TAVR CT images.
5.2.2 Pathophysiological interpretability of GIN
We first visualize the performance of GIN. Here, the dimension of the feature space is , i.e., , considering the complexity of the CT scans. The detailed architecture of the GIN can be found in Appendix D.
| Native Model (126) | Randomly Generated (+1134) | AISEL (+1134) | Randomly Generated (+10000) | |||||||||||||
| Fold | Accu. | Sens. | Spec. | F1 | Accu. | Sens. | Spec. | F1 | Accu. | Sens. | Spec. | F1 | Accu. | Sens. | Spec. | F1 |
| 1 | 64.29 | 52.17 | 78.95 | 61.54 | 69.05 | 60.87 | 78.95 | 68.29 | 76.19 | 73.91 | 78.95 | 74.42 | 78.57 | 78.26 | 78.95 | 77.27 |
| 2 | 56.96 | 47.26 | 66.67 | 48.65 | 64.29 | 61.90 | 66.67 | 60.00 | 73.81 | 76.19 | 71.43 | 71.43 | 76.19 | 71.43 | 80.95 | 73.17 |
| 3 | 57.14 | 50.00 | 63.64 | 52.63 | 71.43 | 52.94 | 84.00 | 58.82 | 80.95 | 76.47 | 84.00 | 76.92 | 85.71 | 82.35 | 88.00 | 82.05 |
| 4 | 59.52 | 55.00 | 63.64 | 56.41 | 64.29 | 60.00 | 68.18 | 60.00 | 71.43 | 75.00 | 68.18 | 69.77 | 73.81 | 70.00 | 77.27 | 70.00 |
| Ave | 59.48 | 51.11 | 68.23 | 54.81 | 67.27 | 58.93 | 74.45 | 61.78 | 75.60 | 75.39 | 75.64 | 73.14 | 78.57 | 75.51 | 81.29 | 75.62 |
Pathophysiologically-interpretable feature space. To better visualize the 20-dimensional feature space , Fig.7 shows a randomly selected 2D cross-section of with the generated virtual valve images located at their projected feature locations; the full and enlarged version of the figure is shown in Fig.10 in appendix G. We notice that the variation of the virtual images on the feature grids is continuous and smooth. Furthermore, we observe that the two axes of the 2D cross-section shown in Fig.7 (also see Fig.10) have pathophysiological meaning. As shown in the red box (enlarged images on the left side), the vertical axis can be interpreted as the change of the calcification (i.e., the regions of high intensity in the CT images) amount. As shown in the blue box (enlarged images on the right side), the horizontal axis can be interpreted as the change of valve shape and the calcification location. Similar observations can be found in the other vertical or horizontal groups of images, which demonstrate the potential pathophysiological interpretability of .

Reconstruction test. Similar to the toy experiments, Fig.6 shows the reconstruction test comparing the actual CT scans and the reconstructed images . Visually, the reconstructed images are almost identical to the actual images with similar background color and valve geometry. Furthermore, the most important pathophysiological indicators, i.e., the location and size of the calcifications are well-recovered. This shows that: (i) using GIN can capture the features of important pathophysiological meaning, and (ii) and are inverses of each other. In Fig.6, we also compare the proposed GIN with BiGAN (see Section 5.1.2), with better performance observed.
5.2.3 Improving classification by our AISEL method
Here, we use the CT scans at the annulus to predict the calcification level (see Section 5.2.1). The native model utilizes a simple CNN structure, with the detailed architecture described in Appendix D. Table II summarizes the classification accuracy, sensitivity and specificity of the four-fold cross validation using the native model. For each fold, we generate an AISEL dataset with the size of 1134. In addition, two randomly sampled virtual dataset, with the size and are also generated as comparison. We will leave out the other baselines, since a detailed comparison is already conducted in the toy experiments (see Section 5.1). As for labeling the virtual patients, an empirical approach is performed: a mixture model of two Gaussians is used to model the pixel intensity, based on whether the pixels are classified as normal tissues or calcifications. The volume of the calcification region is then calculated. After that, a manual check is performed by a radiologist and the calcification levels are corrected if needed. Note that if budget allows, a more sophisticated labeling approach can be used.
Classification performance. The three generated virtual datasets (proposed, random with size 1134 and 10000) are fused with the actual dataset to obtain improved classifiers. Table II summarizes the prediction accuracy together with the sensitivity, specificity, and F1 score of the different classifiers. We see that the native model performs the poorest over the test set, with less than averaged accuracy. The prediction accuracy improves to when using randomly generated samples with the size of 1134. Using our AISEL method, the averaged accuracy improves to with the same size (126 actual + 1134 virtual), a improvement of against the native model and compared to the random sampling method. Furthermore, if increasing the size of the randomly generated virtual dataset to 10000, which may lead to overly expensive labeling costs, the prediction accuracy is higher, but not noticeably higher, than our AISEL dataset with a size of . As a summary, promising results in Table II suggest: (i) the proposed AISEL method efficiently incorporate physical knowledge, and therefore yields better prediction performance; (ii) with the same data size, the proposed sampling strategy, both exploring and exploring the design space, leads to a better downstream classifier than random sampling; and (iii) small AISEL dataset can achieve similar predictive performance compared to a much bigger randomly generated dataset, which reduces the labeling cost of conducting physical experiments.
6 Conclusion and future work
In this paper, we proposed the AISEL framework to efficiently sample a virtual dataset to incorporate complementary physical knowledge for small-data learning problems, with applications to manufacturing and healthcare. We first propose a novel generative invertible network (GIN), which can find the bidirectional mapping of generating virtual images and extracting the features of the actual images. We then propose a new sampling strategy, which both explores and exploits the image space to minimize the predictive uncertainty. Our AISEL method can achieve better performance in toy experiments, compared to the state-of-the-art baselines. Furthermore, in the motivating applications of aortic stenosis, our method lowers the labeling cost by while achieving a improvement in prediction accuracy.
Looking ahead, we are pursuing several directions for future research. From a methodological point of view, we are interested in other approaches to incorporating physical knowledge. Methods in [53, 54] appear to be attractive options. In the application point of view, further study of predicting post-surgical blood pattern is of interest. While our method can still be used, the difficulties lie in the physical labeling process. Tissue-mimicking 3D printing technology [44] and in-vitro studies [45] appear to be suitable.
Acknowledgments
The authors would like to thank Dr. Shizhen Liu at Piedmont Heart Institute in Atlanta, GA, for providing medical knowledge. The authors also want to thank Dr. Zih Huei Wang at Feng Chia University in Taiwan and Dr. Geet Lahoti at Kabbage, Inc. for the insightful discussions.
References
- [1] W. S. McCulloch and W. Pitts, “A logical calculus of the ideas immanent in nervous activity,” The bulletin of mathematical biophysics, vol. 5, no. 4, pp. 115–133, 1943.
- [2] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, p. 436, 2015.
- [3] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013.
- [4] Y. LeCun, K. Kavukcuoglu, C. Farabet et al., “Convolutional networks and applications in vision.” in ISCAS, vol. 2010, 2010, pp. 253–256.
- [5] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” in CVPR09, 2009.
- [6] J. Wang, Y. Ma, L. Zhang, R. X. Gao, and D. Wu, “Deep learning for smart manufacturing: Methods and applications,” Journal of Manufacturing Systems, vol. 48, pp. 144–156, 2018.
- [7] G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, J. A. Van Der Laak, B. Van Ginneken, and C. I. Sánchez, “A survey on deep learning in medical image analysis,” Medical image analysis, vol. 42, pp. 60–88, 2017.
- [8] S. S. Du, Y. Wang, X. Zhai, S. Balakrishnan, R. Salakhutdinov, and A. Singh, “How many samples are needed to learn a convolutional neural network?” stat, vol. 1050, p. 21, 2018.
- [9] B. F. Stewart, D. Siscovick, B. K. Lind, J. M. Gardin, J. S. Gottdiener, V. E. Smith, D. W. Kitzman, C. M. Otto et al., “Clinical factors associated with calcific aortic valve disease,” Journal of the American College of Cardiology, vol. 29, no. 3, pp. 630–634, 1997.
- [10] J. D. Anderson and J. Wendt, Computational fluid dynamics. Springer, 1995, vol. 206.
- [11] P. A. Thompson and S. M. Troian, “A general boundary condition for liquid flow at solid surfaces,” Nature, vol. 389, no. 6649, p. 360, 1997.
- [12] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672–2680.
- [13] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman, “Return of the devil in the details: Delving deep into convolutional nets,” in Proceedings of the British Machine Vision Conference. BMVA Press, 2014.
- [14] J. Wang and L. Perez, “The effectiveness of data augmentation in image classification using deep learning,” Convolutional Neural Networks Vis. Recognit, p. 11, 2017.
- [15] J. Chen, Y. Xie, K. Wang, Z. H. Wang, G. Lahoti, C. Zhang, M. A. Vannan, B. Wang, and Z. Qian, “Generative invertible networks (gin): Pathophysiology-interpretable feature mapping and virtual patient generation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2018, pp. 537–545.
- [16] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232.
- [17] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
- [18] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” stat, vol. 1050, p. 1, 2014.
- [19] S. Zhao, J. Song, and S. Ermon, “Towards deeper understanding of variational autoencoding models,” arXiv preprint arXiv:1702.08658, 2017.
- [20] D. P. Kingma and P. Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions,” in Advances in Neural Information Processing Systems, 2018, pp. 10 215–10 224.
- [21] V. Dumoulin, I. Belghazi, B. Poole, A. Lamb, M. Arjovsky, O. Mastropietro, and A. Courville, “Adversarially learned inference,” stat, vol. 1050, p. 2, 2016.
- [22] J. Donahue, P. Krähenbühl, and T. Darrell, “Adversarial feature learning,” arXiv preprint arXiv:1605.09782, 2016.
- [23] M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014.
- [24] A. Odena, C. Olah, and J. Shlens, “Conditional image synthesis with auxiliary classifier gans,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 2642–2651.
- [25] M. Frid-Adar, E. Klang, M. Amitai, J. Goldberger, and H. Greenspan, “Synthetic data augmentation using gan for improved liver lesion classification,” in 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018). IEEE, 2018, pp. 289–293.
- [26] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?” in Advances in neural information processing systems, 2014, pp. 3320–3328.
- [27] L. Shao, F. Zhu, and X. Li, “Transfer learning for visual categorization: A survey,” IEEE transactions on neural networks and learning systems, vol. 26, no. 5, pp. 1019–1034, 2014.
- [28] B. J. Winer, “Statistical principles in experimental design.” 1962.
- [29] B. Settles, “Active learning literature survey,” University of Wisconsin–Madison, Computer Sciences Technical Report 1648, 2009.
- [30] B. Settles, “Active learning,” Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 6, no. 1, pp. 1–114, 2012.
- [31] Y. Gal, R. Islam, and Z. Ghahramani, “Deep bayesian active learning with image data,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 1183–1192.
- [32] M. Ducoffe and F. Precioso, “Adversarial active learning for deep networks: a margin based approach,” arXiv preprint arXiv:1802.09841, 2018.
- [33] J.-J. Zhu and J. Bento, “Generative adversarial active learning,” arXiv preprint arXiv:1702.07956, 2017.
- [34] Y. Wang and Q. Yao, “Few-shot learning: A survey,” arXiv preprint arXiv:1904.05046, 2019.
- [35] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein generative adversarial networks,” in International Conference on Machine Learning, 2017, pp. 214–223.
- [36] S. I. Resnick, A Probability Path. Springer Science & Business Media, 2013.
- [37] C. Villani, Optimal transport: old and new. Springer Science & Business Media, 2008, vol. 338.
- [38] C. E. Shannon, “A mathematical theory of communication,” Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
- [39] V. R. Joseph, T. Dasgupta, R. Tuo, and C. J. Wu, “Sequential exploration of complex surfaces using minimum energy designs,” Technometrics, vol. 57, no. 1, pp. 64–74, 2015.
- [40] S. Mak, V. R. Joseph et al., “Support points,” The Annals of Statistics, vol. 46, no. 6A, pp. 2562–2592, 2018.
- [41] E. A. Nadaraya, “On estimating regression,” Theory of Probability & its Applications, vol. 9, no. 1, pp. 141–142, 1964.
- [42] G. Matheron, “Principles of geostatistics,” Economic Geology, vol. 58, no. 8, pp. 1246–1266, 1963.
- [43] O. C. Zienkiewicz, R. L. Taylor, O. C. Zienkiewicz, and R. L. Taylor, The finite element method. McGraw-hill London, 1977, vol. 36.
- [44] J. Chen, K. Wang, C. Zhang, and B. Wang, “An efficient statistical approach to design 3d-printed metamaterials for mimicking mechanical properties of soft biological tissues,” Additive Manufacturing, vol. 24, pp. 341–352, 2018.
- [45] Z. Qian, K. Wang, S. Liu, X. Zhou, V. Rajagopal, C. Meduri, J. R. Kauten, Y.-H. Chang, C. Wu, C. Zhang et al., “Quantitative prediction of paravalvular leak in transcatheter aortic valve replacement based on tissue-mimicking 3d printing,” JACC: Cardiovascular Imaging, vol. 10, no. 7, pp. 719–731, 2017.
- [46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [47] H. Xiao, K. Rasul, and R. Vollgraf. (2017) Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.
- [48] Y. LeCun, “The mnist database of handwritten digits,” http://yann. lecun. com/exdb/mnist/, 1998.
- [49] J. Chen, S. Mak, V. R. Joseph, and C. Zhang, “Adaptive design for Gaussian process regression under censoring,” arXiv preprint arXiv:1910.05452, 2019.
- [50] Zalando Research, “fashion mnist,” https://github.com/zalandoresearch/fashion-mnist, 2017.
- [51] S. Zagoruyko and N. Komodakis, “Wide residual networks,” arXiv preprint arXiv:1605.07146, 2016.
- [52] S. J. Pan, Q. Yang et al., “A survey on transfer learning,” IEEE Transactions on knowledge and data engineering, vol. 22, no. 10, pp. 1345–1359, 2010.
- [53] J. Chen, S. Mak, V. R. Joseph, and C. Zhang, “Function-on-function kriging, with applications to 3D printing of aortic tissues,” arXiv preprint arXiv:1910.01754, 2019.
- [54] M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal of Computational Physics, vol. 378, pp. 686–707, 2019.
Appendix A Proof of Theorem 1.
Since the generator is obtained by (3) with the training error , i.e.,
| (A.1) |
This means we have obtained the transportation map , s.t.,
| (A.2) |
For any realization of the random variable , one can find a using the following optimization scheme:
| (A.3) |
We denote this as . If we denote the conditional measure of as . Given and , clearly, we have,
| (A.4) |
Furthermore, recall the dual formula of the Wasserstein distance:
| (A.5) |
Specifically, if let the function , we have :
| (A.6) |
With , and the Lipschitz-L continues assumption on , we have:
| (A.7) |
Now, replace the realization with the random variable and take the expectation over ,
| (A.8) |
Considering the way we choose and the inequality (A.4), for the second term above, we have
| (A.9) |
As for the first term, we have:
| (A.10) |
With the Lipschitz-L continues assumption on :
| (A.11) |
Note that is obtained by (5) with training error . Recall Equation (A.6),
| (A.12) |
Finally, we have
| (A.13) |
Appendix B Proof of Theorem 2.
we denote the target measure as with its empirical representation as , while as measure obtained by proposed approach with its empirical representation as .
(i) As the training data size approach infinity, , this because using Pinsker’s inequality,
| (B.1) |
where is the K-L divergence of two distribution. From [35], we know the as , i.e., existing a small , for any ,
| (B.2) |
For more discussion and justification, please refer to [35].
(ii) As the data size approach infinity, . Since the training dataset is sampled from the target measure , its empirical cumulative distribution function (CDF) converges to target CDF , i.e., for any ,
| (B.3) |
(iii) Similar to (ii), as the data size approach infinity, .
We have the difference in the obtained CDF and the target CDF:
| (B.4) |
Combining (i), (ii) and (iii), we know as the training data size large enough, with any ,
| (B.5) |
i.e., as the training data size approach infinity, in distribution.
Appendix C Proof of Theorem 3.
Note that the objective function in (10) is not a energy distance. However, we have
| (C.1) | ||||
| (C.2) | ||||
| (C.3) |
Here, is the number of virtual points and is the number of actual points. Here, we set for actual points with indies and let be the empirical measure for features . Note that the minimizing is only on the virtual dataset, i.e., with subscripts .
Note that for energy distance
| (C.4) |
As , the second term in (C.4) approaches to zero, and equivalently we are minimizing . Following [40], we have in distribution.
Furthermore, with the continuity condition on the , we have
| (C.5) |
directly following the continuous mapping theorem.
Appendix D Details of the implementation
We explain the implementation details here.
Four-fold cross validation. A four-fold cross validation strategy is used in the aortic stenosis application. We have 168 data in total. Three quarters of the data () after rotation augmentation is used as the training set, while the remaining quarter () will be the testing set. Since the architecture of the classifier is pre-defined, and there are no hyperparameters that need to be tuned, the validation set is not needed.
Training GIN. For the synthetic dataset, the generator adapts 5-layer vanilla NN with 512, 512, 1024, 1024, 1024 hidden nodes in each hidden layer, respectively, and ReLu activation. The discriminator also adapts 5-layer vanilla NN with 1024, 1024, 1024, 512, 512 hidden nodes, and ReLu activation. As for the encoder , it has 10 convolutional layers with 128, 256, 256, 512, 512, 1024, 1024, 1024, 512, 256 hidden nodes in each hidden layer, respectively, leaky ReLu activation and batch normalization. In our implementation, we train the GIN for 2000 epochs, with a constant learning rate of . For the aortic stenosis applications, the architecture and the training strategy are similar, except that the numbers of the hidden nodes and training epochs are doubled.

Training native and improved models. For the toy computer vision datasets, both the native model and the improved model have three convolutional layers with 32, 64 and 64 hidden nodes, respectively. Leaky ReLu activation and batch normalization are also included in each layer. After the convolutional layers, two fully connected layers with 512 and 64 hidden nodes are used, respectively, with ReLu activation and batch normalization. Cross-entropy loss is used. In our implementation, we train the CNN for 80 epochs. The initial learning rate is , with decay to a half every 20 epochs. We select the above for the best empirical performance in preliminary experiments. For the aortic stenosis application, both and have the similar three convolutional layers with leaky ReLu activation and batch normalization. The three convolutional layers have 32, 64 and 128 hidden nodes, respectively. After the convolutional layers, three fully connected layers with 512, 128 and 32 hidden nodes are used, respectively, with ReLu activation and batch normalization. Cross-entropy loss and the same decay of learning rate is used. Note that the complexity for both and is low, especially compared to the encoder . This is mainly because of the difference in the classification task for and regression task for .
Appendix E Toy MNIST experiments
We conduct the same experiments on the MNIST dataset as the Fashion dataset in Section 5.1; the setup and the implementation details are the same as that in the Fashion experiments. Fig.8 shows the visual comparison of the proposed GIN and baselines. We see that in Fig.8 (b), our GIN can generate shape images, with visual superior reconstruction performance than the BiGAN. As for ACGAN (see Fig.8 (a)), we observe that the performance is not as good as the proposed GIN.
The final classification performance is already shown in Table III. Our AISEL method achieves predictive accuracy of , a improvement compared to the native model. Meanwhile, our method outperforms the baselines, e.g., transfer learning, ACGAN-based method, and active learning. As for the GIN-based random augmentation, our method achieves (i) better performance when the same amount of virtual data (400) is used and (ii) similar performance when 5000 data is used in the baseline. This superior performance is again contributing to the exploration and exploitation of the feature space (see Fig.9).
Appendix F Balancing the label distribution
The proposed sampling method can also be used to balance the label distribution. Note that the uncertainty measure defined in (7) is not normalized. In order to balance the data, we modify the uncertainty measure as
| (F.1) |
where notation denotes the label (rather than the predictive probability) of the native model, is the indicator function. The denominator normalizes the density with respect to different classes, and therefore balances the label distribution.
| Native (300) | Undersampling | Oversampling | Random (+600) | AISEL (+300) | AISEL (+600) | |
|---|---|---|---|---|---|---|
| F1 score | 0.9448 | 0.9589 | 0.9624 | 0.9728 | 0.9734 | 0.9801 |
| AUC | 0.9782 | 0.9839 | 0.9846 | 0.9905 | 0.9937 | 0.9964 |
| Accuracy | 94.60% | 95.90% | 96.25% | 96.95% | 97.05% | 98.00% |

We then apply this to learn a classification model from the truncated and imbalanced Fashion dataset. For the sake of simplicity, we consider two-class classification (i.e., using the two classes “Top” and “Coat”). The training dataset is designed to be both small () and imbalanced (size of classes, ). We then applied the proposed AISEL framework as discussed in Section 5.1.1 using the same setup as discussed in Appendix D. Table III lists the performance of the proposed AISEL method (with balancing via (F.1)), random sampling (without balancing), and the standard baselines of under-sampling and over-sampling. Compared with the native model, the two sampling strategies improve predictive performance marginally. In contrast, the improvement in predictive accuracy using the proposed AISEL method is around and with and virtual data points, respectively. Meanwhile, the proposed AISEL method mitigates the imbalance of the training dataset with improvements of at least and in the F1 score and AUC, respectively. Furthermore, compared to the randomly generated virtual dataset of size , the proposed AISEL method (with balancing) achieves noticeable improvements, even with a smaller data size of .
Appendix G More on aortic stenosis application
Due to the limited space, Fig.7 in Section 5.2.2 only shows the partial 2D cross-section of the feature space. Fig.10 visualizes the whole and enlarged 2D cross-section feature space. The two axes of the 2D cross-section shown in Fig.10 have pathophysiological meaning. As shown in the red box (enlarged images on the left side), the vertical axis can be interpreted as the change of the calcification (i.e., the regions of high intensity in the CT images) amount. As shown in the blue box (enlarged images on the right side), the horizontal axis can be interpreted as the change of valve shape and the calcification location.
In order to better visualize the sampled AISEL dataset and demonstrate how it helps in improving the classification accuracy, we conduct the experiments in the Section 5.2.3 with the dimension of the feature space , i.e., . Furthermore in the two-class classification problem, we use , with low value denoting the low calcification situation and high value for high calcification situation. The prediction contour of the model learned by the first three folds of the training data (the remaining fold is for testing) is shown in the lower-left half of Fig.11 (a). Every small figure visualizes a 2D subspace of with the remaining features set to be zero. Note that all combinations of the two features (totally 15 for six features) are shown in the lower-left half of Fig.11 (a). Yellow means high calcification (i.e., ), while blue means low calcification (i.e., ). Meanwhile, four testing valves are shown in the left side of Fig.11 (a). The obtained native model only accurately classifies two of them, which indicates the poor performance of the native model.
Designed AISEL data are shown in upper left region of Fig.11 (b). Note that for every figure, only of the feature of AISEL dataset closest to the 2D cross-section plane are included for better visualization purpose. Most of AISEL features, as expected, are located on the boundary of the prediction contour of the native model, while the rest features are uniformly spread over the whole space. This again shows the exploration and exportation properties of the proposed AISEL method. Four examples of the selected virtual images in the AISEL dataset are also visualized on the top, with an arrow pointing their features in the feature space. Visually, they are indeed confusing for predicting the calcification amount. After physical labeling by a radiologist, they will help improve the classifier. As a comparison, the actual images (totally, 126) projected in every 2D cross-section are shown in the lower right region of Fig.11 (b). Note that the actual images are randomly distributed in the whole 6D space with no apparent pattern.
The prediction contour of the improved classifier using our AISEL method is shown in the top left half of Fig.11 (a). We can see the finer structure is learned indicating a more sophisticated model is obtained. Meanwhile, the four characteristic images tested by the native model is also tested by the . The classification of all four is accurate, showing a noticeable improvement in the prediction accuracy.