Active Learning with Expected Error Reduction
Abstract
Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) Roy & McCallum (2001) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as Gal & Ghahramani (2016)). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (Koh et al., 2021). The results indicate that our method outperforms all other methods except one in the data shift scenario – a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (Ash et al., 2019).
\commentActive learning has been studied extensively as a method for data collection. Among the many approaches in the literature, Expected Error Reduction (EER) Roy & McCallum (2001) has been shown to be effective in the selection of samples to label: select the sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model be retrained for every candidate, and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper, we take a new look at EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method. Furthermore, we formally compare our selection criteria to that used by other methods based on information theoretic considerations such as BALD. We then empirically compare the performance of our method, using Monte Carlo dropout for parameter sampling, against state of the art methods in the deep active learning literature, on four standard benchmarks and three WILDS datasets, each with and without data shift, for a total of 14 data settings. Our results indicate that our method outperforms all other methods except one, and only in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost.
1 Introduction
Active learning studies how adaptivity in data collection can decrease the data requirement of machine learning systems (Settles, 2009) and has been applied to a variety of applications such as medical image analysis where unlabeled samples are plentiful but labeling via annotation or experimentation is expensive. In such cases, intelligently selecting samples to label can dramatically reduce the cost of creating a training set. A range of active learning algorithms have been proposed in recent decades (Lewis & Gale, 1994; Tong & Koller, 2001; Roy & McCallum, 2001). Current research trends have shifted towards active learning for deep learning models (Sener & Savarese, 2018; Ash et al., 2019; Gal et al., 2017; Sinha et al., 2019), which present a new set of constraints that traditional methods do not always address.
Another application of active learning has been in addressing data shift (Rabanser et al., 2019; Schrouff et al., 2022), a problem which can be summarized as deploying a model to a distribution that is different from the training distribution, and is characteristic of real world machine learning applications. This is a critical aspect of model deployment because distributional shifts can cause significant degradation in model performance. Active learning has been proposed as a method to mitigate the effects of data shift by identifying salient out-of-distribution samples to add to the training data (see, for example, Kirsch et al. (2021) and Zhao et al. (2021)).
In this paper we propose a new derivation of the Expected Error Reduction (EER) active learning method (Roy & McCallum, 2001) and apply it to deep neural networks in experiments with and without data shift, expanding upon the original setting of simple classifiers such as Naive Bayes. At its core, EER chooses a sample that maximally reduces the generalization "error" or "loss" in expectation. The original implementation of EER requires retraining the classifier model for every possible candidate sample, for every possible label. The cost of this constant retraining is intractable in the deep neural network context. To circumvent this, we present a formulation that estimates the value of a label for reducing the classifier’s loss without retraining the neural network. We achieve this by casting EER in the context of Bayesian methods and drawing samples from the model posterior conditioned on the data. Although sampling from the Bayesian posterior of model parameters directly can be difficult, there are a variety of methods to approximate this distribution such as Monte Carlo dropout (Gal & Ghahramani, 2016), ensembles (Beluch et al., 2018), and Langevin dynamics (Welling & Teh, 2011).
Perhaps the earliest Bayesian data collection method is Expected Information Gain (Lindley, 1956) which is equivalent to selecting the sample with the label that has the highest mutual information with the model parameters. This method has been explored by Gal et al. (2017) for active learning in the context of deep neural networks, and is referred to as BALD. While BALD maximizes the information encoded by model parameters about the dataset, the fundamental goal of classification is to identify the model parameters that minimize test error. This imperfect alignment in the objective is what motivates our exploration of EER. Similar to Roy & McCallum (2001), we consider two variants of the method: one based on zero-one loss, which we refer to as minimization of zero-one loss (MEZL), and the other on log-likelihood loss, which we refer to as minimization of log-likelihood loss (MELL). Our derivation also enables us to cast EER in an information theoretic setting that allows for a theoretical comparison with BALD. Both BALD and MELL reduce the epistemic uncertainty, but MELL additionally removes task irrelevant information (see 7.3). We hypothesize that this explains why MELL outperforms BALD empirically (see Section 8.2).
In our experiments we compare MELL and MEZL against state of the art active learning methods including BADGE (Ash et al., 2019), BALD (Gal et al., 2017), and Coreset (Sener & Savarese, 2018) on seven image classification datasets. For each dataset, we perform experiments in both a setting with and without data shift. We remark that unlike the work of Kirsch et al. (2021) where the goal is to avoid labeling out of distribution samples, we are interested in the realistic scenario of reducing model error on a test set that may be drawn from a different distribution than the seed set. In our results, MELL consistently performs better or on par with all other approaches in both the no data shift and data shift settings, with the largest gains above BALD coming in the data shift setting.
The only approach that compares favorably to ours is BADGE, which outperforms MELL and MEZL on two datasets under data shift: Camelyon17 and MNIST. However, MELL and MEZL require orders of magnitude less computation cost (see Section 8.2 and Appendix A.2) and are model agnostic – they can be applied to neural networks, random forests, linear models, etc. We also remark that optimizing the log likelihood (MELL) performs better than zero-one loss objective (MEZL) (see Section 9 for an explanation).
In summary, the contributions of this paper are:
-
1.
A Bayesian reformulation of the EER framework to enable computational efficiency with deep neural networks.
-
2.
An empirical evaluation of the effectiveness of the proposed method, comparing it to other state of the art deep active learning approaches on seven datasets, each with and without data shift.
We introduce our active learning setting in Section 5 before deriving our method in Section 7. Next, we provide an empirical evaluation in Section 8. Finally, we discuss the implications, context, and related work in Section 9 and conclude with Section 10.
2 Introduction
Active learning studies how adaptivity in data collection can decrease the data requirement of machine learning systems Settles (2009), and has been applied to a variety of applications such as medical image analysis where unlabeled samples are plentiful, but labeling via annotation or experimentation is expensive. In such cases, intelligently selecting samples to reduce the number of samples necessary to train a model can significantly reduce costs. A range of active learning algorithms have been proposed in recent decades Lewis & Gale (1994); Tong & Koller (2001); Roy & McCallum (2001) and current research trends have shifted towards active learning for deep learning methods Sener & Savarese (2018); Ash et al. (2019); Gal et al. (2017); Sinha et al. (2019) which present a new set of constraints that traditional methods do not always address.
Another trend in recent literature has been on addressing data shift Rabanser et al. (2019); Schrouff et al. (2022): the problem of deploying a model to a distribution that is different from the training distribution. This is a critical aspect of model deployment that is common in real world applications because distributional shifts can cause significant degradation in model performance. There has also been recent interest in the intersection of active learning and data shift, characterizing methods under general data shift Kirsch et al. (2021), and under label shift Zhao et al. (2021). Active learning has been proposed as a method to mitigate the effects of data shift by identifying salient out-of-distribution samples to be added to the training data.
In this paper we explore a model-agnostic Bayesian derivation of EER, a method which has been shown to perform well under the setting of simple classifiers such as Naive Bayes Roy & McCallum (2001). We extend this work by deriving a formulation that is compatible with deep neural networks and show that it performs extremely well under contemporary settings. Intuitively, Bayesian methods capture uncertainty by using a distribution over model parameters rather than a single point estimate. Our method is general in that we only assume a probabilistic Bayesian model from which we can draw samples from the model posterior conditioned on data. Leveraging this, we are able to estimate the value of a label without retraining the neural network as would be required in the original formulation of EER. Although sampling from the exact Bayesian posterior can be difficult, there are a variety of methods to approximate this distribution such as Monte Carlo dropout Gal & Ghahramani (2016); Gal et al. (2017), ensembles Beluch et al. (2018), and Langevin dynamics Welling & Teh (2011).
Perhaps the earliest Bayesian data collection method is Expected Information Gain Lindley (1956) which is equivalent to selecting the sample with the label that has the highest mutual information with the model parameters, also known as BALD Gal et al. (2017). While BALD maximizes the information encoded by model parameters about the dataset, the primary goal of classification is to identify the model parameters that minimize test error. This mismatch in the objective is what motivates the EER framework Roy & McCallum (2001): choose the sample that maximally reduces the generalization “error” or “loss” in expectation. In EER, this calculation is accomplished by retraining the model for every possible candidate point, for every possible label. The original paper performs experiments on Naive Bayes, which is computationally cheap to train. However, it is well established that deep neural networks are expensive to train and thus it would be infeasible to apply EER directly.
As a result of this, we explore a computationally efficient mathematical reformulation of EER for deep active learning. Our proposal circumvents the need for retraining by utilizing Monte Carlo dropout to approximately sample from the parameter posterior, and provides a way to use these samples to calculate the EER criteria. Similar to Roy & McCallum (2001), this derivation includes two variants: one based on zero-one loss, which we refer to as minimization of zero-one loss (MEZL), and the other on log-likelihood loss, which we refer to as minimization of log-likelihood loss (MELL). Our derivation also enables us to cast EER in an information theoretic setting and compare it with other methods based on reducing the uncertainty of the target model. In particular, we find that MELL is a close cousin of BALD in terms of reducing epistemic uncertainty, but additionally removes irrelevant information which we propose as an explanation for why MELL outperforms BALD in some of the experimental results (see Section 7.3).
In our empirical evaluation, we expand upon existing literature by characterizing the performance of MELL, MEZL, and other state of the art active learning methods under realistic data shift scenarios by evaluating them on WILDS datasets, as well as on standard datasets CIFAR10, CIFAR100, SVHN, and MNIST with induced shift. Unlike in prior work Kirsch et al. (2021) where the goal is to avoid labeling out of distribution samples, we are interested in the realistic scenario of reducing model error on a test set that may be drawn from a different distribution than the seed set. In addition to these experiments, we also investigate the standard active learning scenario where the test and seed sets are drawn from the same distribution. In our results, MELL consistently performs better or on par with all other information theoretic approaches in both the no data shift and data shift settings, with the largest gains above BALD coming in the data shift setting.
The only approach that compares favorably to ours is BADGE Ash et al. (2019), which outperforms MELL and MEZL on two datasets under data shift: Camelyon17 and MNIST. However, MELL and MEZL require orders of magnitude less computation cost (see Appendix A.2 and are model agnostic – they can be applied to neural networks, random forests, linear models, etc. relying only on Bayesian sampling.
Finally, we note from the experiments that optimizing the log likelihood (MELL) performs better than zero-one loss objective (MEZL). We offer an explanation of this phenomenon in Section 9.
In summary, the contributions of this paper are:
-
1.
A Bayesian reformulation of the EER framework to enable computational efficient selection of samples that will reduce the expected loss in the context of deep neural networks.
-
2.
An empirical evaluation of the effectiveness of the proposed method, comparing it with other state of the art deep active learning approaches on seven datasets, both with and without data shift.
3 Introduction
Active learning studies how adaptivity in data collection can decrease the data requirement of machine learning systems Settles (2009), and has been applied to a variety of applications such as medical image analysis where unlabeled samples are plentiful, but labeling via annotation or experimentation is expensive. In such cases, intelligently selecting samples to reduce the number of samples necessary to train a model can significantly reduce costs. A range of active learning algorithms have been proposed in recent decades Lewis & Gale (1994); Tong & Koller (2001); Roy & McCallum (2001) and current research trends have shifted towards active learning for deep learning methods Sener & Savarese (2018); Ash et al. (2019); Gal et al. (2017); Sinha et al. (2019) which present a new set of constraints that traditional methods do not always address.
Another trend in recent literature has been on addressing data shift Steve: cite more (like three or so) papers, like surveys: the problem of deploying a model to a distribution that is different from the training distribution. This is a critical aspect of model deployment that is common in real world applications because distributional shifts can cause significant degradation in model performance and emphasize biases in the training data Steve: emphasize biases? what do we mean by this?. There has also been recent interest in the intersection of active learning and data shift, characterizing methods under general data shift Kirsch et al. (2021), and under label shift Zhao et al. (2021). Active learning has been proposed as a method to mitigate the effects of data shift by identifying salient out-of-distribution samples to be added to the training data.
In this paper we explore a model-agnostic Bayesian derivation of EER, a method which has been shown to perform well under the setting of simple classifiers such as Naive Bayes Roy & McCallum (2001). We extend this work by deriving a formulation that is compatible with deep neural networks and show that it performs extremely well under contemporary settings. Intuitively, Bayesian methods capture uncertainty by using a distribution over model parameters rather than a single point estimate. Our method is general in that we only assume a probabilistic Bayesian model from which we can draw samples from the model posterior conditioned on data. Leveraging this, we are able to estimate the value of a label without retraining the neural network as would be required in the original formulation of EER. Although sampling from the exact Bayesian posterior can be difficult, there are a variety of methods to approximate this distribution such as Monte Carlo dropout Gal & Ghahramani (2016); Gal et al. (2017), ensembles Beluch et al. (2018), and Langevin dynamics Welling & Teh (2011).
Perhaps the earliest Bayesian data collection method is Expected Information Gain Lindley (1956) which is equivalent to selecting the sample with the label that has the highest mutual information with the model parameters, also known as BALD Gal et al. (2017). While BALD maximizes the information encoded by model parameters about the dataset, the primary goal of classification is to identify the model parameters that minimize test error. This mismatch in the objective is what motivates the EER framework Roy & McCallum (2001): choose the sample that maximally reduces the generalization “error” or “loss” in expectation. In EER, this calculation is accomplished by retraining the model for every possible candidate point, for every possible label. The original paper performs experiments on Naive Bayes, which is computationally cheap to train. However, it is well established that deep neural networks are expensive to train and thus it would be infeasible to apply EER directly.
As a result of this, we explore a computationally efficient mathematical reformulation of EER for deep active learning. Our proposal circumvents the need for retraining by utilizing Monte Carlo dropout to approximately sample from the parameter posterior, and provides a way to use these samples to calculate the EER criteria. Similar to Roy & McCallum (2001), this derivation includes two variants: one based on zero-one loss, which we refer to as minimization of zero-one loss (MEZL), and the other on log-likelihood loss, which we refer to as minimization of log-likelihood loss (MELL). Our derivation also enables us to cast EER in an information theoretic setting and compare it with other methods based on reducing the uncertainty of the target model. In particular, we find that MELL is a close cousin of BALD in terms of reducing epistemic uncertainty, but additionally removes irrelevant information which we propose as an explanation for why MELL outperforms BALD in some of the experimental results (see Section 7.3).
In our empirical evaluation, we expand upon existing literature by characterizing the performance of MELL, MEZL, and other state of the art active learning methods under realistic data shift scenarios by evaluating them on WILDS datasets, as well as on standard datasets CIFAR10, CIFAR100, SVHN, and MNIST with induced shift. Unlike in prior work Kirsch et al. (2021) where the goal is to avoid labeling out of distribution samples, we are interested in the realistic scenario of reducing model error on a test set that may be drawn from a different distribution than the seed set. In addition to these experiments, we also investigate the standard active learning scenario where the test and seed sets are drawn from the same distribution. In our results, MELL consistently performs better or on par with all other information theoretic approaches in both the no data shift and data shift settings.
The only approach that compares favorably to ours is BADGE Ash et al. (2019), which outperforms MELL and MEZL on two datasets under data shift: Camelyon17 and MNIST. However, as shown in Figure 2, BADGE is multiple orders of magnitude more expensive in terms of computational cost Steve: this is a bit too defensive/in-depth for the intro, maybe just say in simpler terms that BADGE is very computationally expensive and not model-agnostic. In fact, BADGE is so computationally inefficient that several of the experiments did not complete after 14 days. In addition, we note that BADGE is not model free Steve: define “model free”. If I remember correctly, one of the reviewers complained that Bayesian methods use a model, as it requires access to the last-layer activation of the neural network. Finally, we note from the experiments that optimizing the log likelihood (MELL) performs better than zero-one loss objective (MEZL). We offer an explanation of this phenomenon in Section 9.
In summary, the contributions of this paper are:
-
1.
A Bayesian reformulation of the classic expected error reduction (EER) framework to enable computational efficiency with deep neural networks.
-
2.
An empirical evaluation of the effectiveness of the proposed method, comparing it with other state of the art deep active learning approaches on seven datasets, both with and without data shift.
4 Introduction
Active learning Settles (2009) studies how adaptivity in data collection can decrease the data requirement of machine learning systems. In a variety of applications such as medical image analysis, unlabeled samples are plentiful while acquiring labels via annotation or experimentation is expensive. In such cases, intelligently selecting samples for labeling can significantly reduce costs. A range of active learning algorithms have been proposed in recent decades Lewis & Gale (1994); Tong & Koller (2001); Roy & McCallum (2001). Current research trends have shifted towards active learning for deep learning methods Sener & Savarese (2018); Ash et al. (2019); Gal et al. (2017); Sinha et al. (2019) which present a new set of constraints.
In this paper we explore a model-agnostic Bayesian framework, and derive a computationally efficient version of EER, which has been shown to perform very well in a non-deep learning method Roy & McCallum (2001), and which we show performs extremely well empirically in contemporary settings. Intuitively, Bayesian methods capture uncertainty by using a distribution over model parameters, rather than a single point estimate. We use that to our advantage to estimate the value of a label, without the need for retraining. Our method is general in that we only assume a probabilistic Bayesian model from which we can draw samples from the model posterior conditioned on data. Although sampling from the exact Bayesian posterior can be difficult, there are a variety of methods to produce approximate samples such as Monte Carlo dropout Gal & Ghahramani (2016); Gal et al. (2017), ensembles Beluch et al. (2018), and Langevin dynamics Welling & Teh (2011).
Perhaps the earliest Bayesian data collection method is Expected Information Gain Lindley (1956) which is equivalent to labeling the point whose label has the highest mutual information with the model parameters, also known as BALD Gal et al. (2017). While this criterion is appropriate if we want to identify the model parameters, often in machine learning the model parameters are only a means to an end, namely, to minimize the test error. This gap motivates the EER framework Roy & McCallum (2001): choose the point that maximally reduces the generalization “error” or loss in expectation. In Roy & McCallum (2001), this calculation is accomplished by retraining the model for every possible candidate point pseudo-labeled for every possible label. While retraining for Naive Bayes, as in Roy & McCallum (2001), is computationally cheap, retraining deep neural networks is generally computationally expensive.
We revisit EER and provide a computationally efficient mathematical reformulation for deep active learning. Our proposal circumvents the need for retraining by utilizing Monte Carlo dropout to approximately sample from the parameter posterior and deriving a way to use these samples to calculate the EER criteria. Similar to Roy & McCallum (2001), this derivation includes two variants: one based on the zero-one loss (which we call MEZL), and one on the log-likelihood loss (called MELL). Our derivation enables us to cast EER in an information theoretic setting, and to formally compare it to other methods based on reducing the uncertainty of the target model. In particular, we find MELL is a close cousin of BALD in terms of reducing epistemic uncertainty, but additionally removes irrelevant information with respect to a specific validation set, which may explain why MELL outperforms BALD in three cases (see Section 7.3).
Our empirical evaluation shows the efficacy of MELL and MEZL against state of the art deep active learning approaches on several benchmark datasets. In our results, MELL performs consistently better or equal to all other information theoretic approaches in both the no data shift and data shift settings. The only approach that appears to compare favorably to ours in terms of consistently performing at the top is BADGE Ash et al. (2019). In two experiments involving data shift, Camelyon17 and MNIST, our approach performs slightly worse. Yet, as shown in Figure 2, BADGE is an order of magnitude more expensive in terms of computational time. This is to the extent that some experiments timed out after 14 days of continuous computation, preventing us from performing a full comparison for all datasets. In addition, we note that BADGE is not model free, as it requires access to the last-layer activation of the neural network. We also note in our experiments that decreasing the log likelihood (MELL) performs better than decreasing the zero-one loss (MEZL). We offer an explanation of this phenomenon in Section 9.
In summary, the contributions of this paper are:
-
1.
A Bayesian reformulation of the classic expected error reduction (EER) framework to enable computational efficiency with deep neural networks.
-
2.
An empirical evaluation of the effectiveness of the proposed method, comparing it to other state of the art deep active learning approaches on seven datasets, each with and without data shift.
We introduce our active learning setting in Section 5 before deriving our method in Section 7. Next, we provide an empirical evaluation in Section 8. Finally, we discuss the implications, context, and related work in Section 9 and conclude with Section 10.
We explore a model-agnostic Bayesian framework, similar to that of Gal et al. (2017), and derive a computationally efficient version of Expected Error Reduction (EER) which also performs extremely well empirically. Intuitively, Bayesian methods capture uncertainty by using a distribution over model parameters, rather than a single point estimate. Our method is general in that we only assume a probabilistic Bayesian model from which we can draw samples from the model posterior conditioned on data. Although sampling from the exact Bayesian posterior can be difficult, there are a variety of methods to produce approximate samples such as Monte Carlo dropout Gal & Ghahramani (2016); Gal et al. (2017), ensembles Beluch et al. (2018), and Langevin dynamics Welling & Teh (2011).
Perhaps the earliest Bayesian data collection method is Expected Information Gain Lindley (1956) which is equivalent to labeling the point whose label has the highest mutual information with the model parameters, also known as BALD Gal et al. (2017). While this criterion is appropriate if we want to identify the model parameters, often in machine learning the model parameters are only a means to an end, the test error. This gap motivates the EER framework Roy & McCallum (2001): choose the point that maximally reduces the generalization “error” or loss in expectation. In Roy & McCallum (2001), this calculation is accomplished by retraining the model for every possible candidate point pseudo-labeled for every possible label. While retraining for Naive Bayes, as in Roy & McCallum (2001), is computationally cheap, retraining deep neural networks is generally computationally expensive.
In this paper, we revisit EER and provide a computationally efficient mathematical reformulation for deep active learning. Our proposal circumvents the need for retraining by utilizing Monte Carlo dropout to approximately sample from the parameter posterior and deriving a way to use these samples to calculate the EER criteria. Similar to Roy & McCallum (2001), this derivation includes two variants: one based on the zero-one loss (which we call MEZL), and one on the log-likelihood loss (called MELL). Our derivation enables us to cast EER in an information theoretic setting, and to formally compare it to other methods based on reducing the uncertainty of the target model. In particular, we find MELL is a close cousin of BALD in terms of reducing epistemic uncertainty, but additionally removes irrelevant information with respect to a specific validation set, which may explain why MELL outperforms BALD in three cases (see Section 7.3).
We empirically evaluate the efficacy of MELL and MEZL against state of the art deep active learning approaches on several benchmark datasets. In our results, MELL performs consistently better or equal to all other information theoretic approaches in both the no data shift and data shift settings. The only approach that appears to compare favorably to ours in terms of consistently performing at the top is BADGE Ash et al. (2019). Indeed, two experiments involving data shift, Camelyon17 and MNIST our approach performs slightly worse. Yet, as shown in Figure 2, BADGE is an order of magnitude more expensive in terms of computational time. This is to the extent that some experiments timed out after 14 days of continuous computation, preventing us from performing a full comparison for all datasets. In addition, we note that BADGE is not model free, as it requires the last-layer activation of the neural network. We note in our experiments that decreasing the log likelihood (MELL) performs better than decreasing the zero-one loss (MEZL). We offer an explanation of this phenomenon in Section 9.
In summary, the contributions of this paper are:
-
1.
A Bayesian reformulation of the classic expected error reduction (EER) framework to enable computational efficiency with deep neural networks.
-
2.
An empirical evaluation of the effectiveness of the proposed method, comparing it to other state of the art deep active learning approaches on seven datasets, each with and without data shift.
The rest of the paper is organized as follows. We introduce our active learning setting in Section 5 before deriving our method in Section 7. Next, we provide an empirical evaluation in Section 8. Finally, we discuss the implications, context, and related work in Section 9 and conclude with Section 10.
Bayesian active learning is a principled framework for designing adaptive data collection methods. In particular, Bayesian methods capture uncertainty by using a distribution over model parameters, rather than a single point estimate.
A distribution over parameters enables the definition of quantities such as the mutual information between the model parameters and an “experiment”. (cite Lindley)
Our contributions:
-
•
A reformulation of the classic expected error reduction (EER) framework into a Bayesian setting to enable computational efficiency.
-
•
An information-theoretic decomposition giving intuition behind the ranking of a few methods.
-
•
An explanation of why decreasing the negative log likelihood works better than decreasing the zero-one loss in the EER framework.
-
•
An empirical evaluation of the effectiveness of the proposed methods.
=================
Distribution shifts are commonly encountered in machine learning applications. When deployed in real world settings, there is no guarantee that the data distribution encountered during evaluation will be equivalent to that which is used during the training process. As a result of these shifts, metrics observed during the training process may not be representative of the model’s true performance once deployed \danieladd citations for data shift.
Among other approaches, active learning has been used as one method for addressing this issue by supplementing the training set with new samples drawn from the target distribution. Existing methods include techniques for diversity sampling in the target distribution subspace Sener & Savarese (2018), using an auxiliary classifier to identify novel samples Sinha et al. (2019), and entropy estimation Holub2008EntropybasedAL.
In this paper, we revisit the existing method of EER and extend it for active learning for deep learning by reframing it in the context of Bayesian sampling Roy & McCallum (2001). The original method is based on computing a score for each unlabeled sample such that it minimizes the expected error over the unlabeled dataset, where expected error is approximated with either log-likelihood or accuracy. However, the method is not actionable for modern deep learning applications, as it requires the retraining of the predictive model for each potential unlabeled sample. Our method, which we refer to as expected accuracy maximization (MEZL), circumvents this by utilizing Monte Carlo dropout in approximating the conditional label distribution required in computing the expected error.
Additionally, we characterize existing active learning methods under data shift scenario. Many surveys in this field of research remain firmly within the regime where both source and target domains are assumed to be from the same distribution. However, given the prevalence of distribution shift, it is important to consider performance under realistic conditions.
The remainder of the paper is formatted as following: section 2 describes the setting under which the experiments are performed, while section 3 describes MEZL and its variants in detail. Section 4 will provide a theoretical motivation for the methods. Lastly, we provide experimental results on a variety of datasets, both with and without distribution shift.
-
•
Distribution shifts are common in applications: large amount of labeled data from some distribution and a small amount of labels from the evaluation distribution.
-
•
On one hand, problem setup is the equivalent to standard active learning plus additional non-evaluation data.
-
•
On the other hand, this setting has new challenges and opportunities.
Partially resolves the “learning representation” challenge
Bigger gains from active learning for different but overlapping distributions.
Challenge: how to gracefully reduce to standard active learning if non-evaluation data is harmful.
Steve: Please start with a paragraph on why active learning is important… Look at my attempt below - needing better english etc
Methods for adaptive data collection, also known as active learning, have been extensively studied in the literature. There are approaches based on defining and reducing the epistemic uncertainty , for estimating differences between the pool of unlabelled samples and the training data , and many other variants. Among the many methods, we single out the method of Expected Error Reduction (EER), as it directly estimates the impact of labelling a sample on the accuracy of a model. The original EER algorithm Roy & McCallum (2001) is based on computing a score for each unlabeled sample such that it minimizes the expected error over the unlabeled dataset. The expected error is approximated with either log-likelihood or accuracy. By addressing directly the impact of a label on the accuracy of the model, this method brings the promise of a strategy that should improve on any other approach. Indeed, this method was shown empirically to be extremely successful with moderate size models cite Steve: need citation. However, as originally presented, EER is not actionable for modern deep learning applications, as it requires the retraining of the predictive model for each potential unlabeled sample.
5 Setting
We study a classification setting where we have an input space and a discrete label space . We wish to find a function such that the misclassification error (zero-one loss), , is small according to some data distribution.
In this paper we consider pool-based active learning where there is an “unlabeled” pool drawn from some distribution where the labels of the samples are hidden. In each of the iterations, an active learning algorithm chooses samples from , the labels are revealed, and the samples are added to the training set. Often, active learning algorithms calculate a score for each sample and choose to query the set of unlabeled samples with the highest scores. We consider two settings for the initial training set : when it is not sampled from , and when it is sampled from . We refer to these scenarios as active learning with and without “data shift” respectively. In both cases, we evaluate on samples from .
We take the Bayesian perspective that the model parameters are a random variable drawn from a known prior. As is typical, we assume that the labels of samples are conditionally independent given . At a given iteration, let be the labeled data collected thus far and be the posterior. We view the remaining unlabeled pool as fixed but the labels as random variables .
In standard supervised learning, we have access to samples from the data distribution to infer the classification function . We study pool-based active learning, where there is an unlabeled pool composed of elements from drawn from the data distribution but with their corresponding outputs from hidden. Then, in each of iterations, an active learning algorithm chooses unlabeled points per iteration from and the labels are revealed. Often, active learning algorithms choose the set of unlabeled points to be queried as the points with the highest scores . In this way, the differences between active learning algorithms is in how the scores are calculated. See Algorithm LABEL:alg for pseudo-code. The initial set of labeled data is usually sampled randomly from either the data distribution or a different, related distribution. In the case that the initial is sampled from a different distribution, we say this problem has “data shift”, that is, the initial data and the evaluation distribution are different. Here, we assume that the unlabeled pool, test set, and validation set are sampled from the same distribution.
We take a Bayesian perspective so that the model parameters are a random variable drawn from a known prior. As is typical, we assume that the labels are conditionally independent given . At a given iteration, let be the labeled data collected thus far and be the posterior. We view the remaining unlabeled pool as fixed but the labels as random variables .
6 Method
The guiding principle of our reformulation of EER is to score a candidate sample by the expected reduction in loss if we sampled the candidate’s label. In this section, we provide a formalization of this idea that only requires the pairwise marginals for the labels. These marginals can be approximated in a computationally efficient way using Bayesian sampling methods such as Monte Carlo dropout (Gal & Ghahramani, 2016).
Candidates for labeling are selected from . Additionally, we assume access to a small secondary set of unlabeled data for validation , which is used for the evaluation of the expected loss reduction. Note that we do not assume that the two sets and are drawn from the same distributions. In contrast, Roy & McCallum (2001) use the same set for both validation and pool of candidates. This distinction affords us more flexibility, especially in the data shift case.
Because retraining a deep neural network for every candidate sample is computationally infeasible, our aim is to approximate the expected reduction in error. We use Bayesian sampling to approximate the effect of observing the label for every candidate sample on the error over the validation dataset and add the candidate and label that precipitates the highest reduction in error to the training set. We formalize this in Equation 1 below. The is the difference between two terms: the first term represents the total sum of the expected loss over , and the second term estimates the expected loss over when we fix the label of the candidate sample . Although we do not know the ground truth label of the candidate sample, we can take the expectation with respect to the posterior to compute an approximation for each possible label. The probabilities in the equation below are implicitly conditioned on samples from the validation set and on the candidate sample .
| (1) |
Here, represents the optimal prediction (relative to a particular probability distribution), is the set of possible predictions, and is the loss. Note that the first term in Equation 1 is constant with respect to the samples of , and thus does not have any effect on comparing samples. Thus Equation 9 is a reduced form where we estimate the score based solely on the second term; the negation of the expected loss on after the estimating the candidate sample’s label.
| (2) |
Throughout the remainder of this work, we will continue to use and to index samples in and respectively and omit the conditioning on , , and for brevity.
We remark on the following aspects of our definition of EER ():
-
•
Because we focus on a Bayesian approach, we are able to sidestep the model retraining requirement in EER and work with expectations. Appendix A.1 shows that only the quantities and are needed.
-
•
In Equation 9, the loss is computed with respect to the validation set (note that the ground truth labels for the validation set are not used). This affords additional flexibility in case the samples are not drawn from the target distribution.
In the next subsections, we derive criteria for two different losses: the negative log-likelihood loss (MELL) and the zero-one loss (MEZL).
6.1 MELL
To obtain the expression for MELL, we substitute the general loss, , for the (negative) log-likelihood loss, , into Equation 9. For the log-likelihood loss, the set of possible predictions is the probability simplex over the classes, , and thus is the vector . We use the non-negativity of the KL divergence to find the optimal prediction for each as (see the proof in Appendix A.1), and by the definition of conditional entropy we obtain the succinct expression, , where is the conditional entropy. Using yields the final expression:
| (3) |
To estimate these quantities we need to compute and . Because the parameters render the labels conditionally independent, we can draw samples from the posterior as and perform the following unbiased Monte Carlo approximation of these probabilities:
| (4) | ||||
| (5) |
Sampling parameters from the posterior distribution can be approximately generated in a variety of ways. In our implementation, we use Monte Carlo dropout for its computational efficiency. Another approximate method is Cyclical SG-MCMC, proposed in Zhang et al. (2019). In our experiments we find that Monte Carlo dropout performs better empirically than Cyclical SG-MCMC (see Figure 4 in Appendix A.4.2).
6.2 MEZL
For the zero-one loss we substitute the general loss, , for into Equation 9, where the set of possible predictions is simply the output set and the optimal prediction for is . Then using some algebra, we obtain
| (6) |
We can ignore the term since it remains constant with respect to . Like MELL, the MEZL criteria requires knowing the pairwise marginals of the labels which can be estimated using Monte Carlo methods and the conditional independence of the labels given the parameters, as in Equation 5.
6.3 Information decomposition
As before, let be the label of a sample in and be the label of a sample in . is the random variable for the posterior distribution of the parameters. Using an information-theoretic identity, the total uncertainty of a sample in the pool can be decomposed into the epistemic uncertainty and the aleatoric uncertainty, namely
Because we cannot reduce the aleatoric uncertainty , BALD judiciously minimizes the epistemic uncertainty rather than the total uncertainty. There is a similar decomposition of the mutual information into the interaction information and the conditional mutual information . Although the interaction information can in general be negative, the assumption that the labels are conditionally independent given the parameters implies that . Thus,
| (7) | ||||
| (8) |
Intuitively, is the information that is irrelevant to the prediction of the validation sample . The term is then the only relevant information. Note that if we take the score of a pool sample as the sum of the task-relevant information with respect to all validation samples, we recover MELL. Hence MELL can be seen as an algorithm like BALD, after removing the information that is not relevant to a validation set.
In Appendix A.6, we look more closely at these terms for the case of a linear Bayesian model. We show that the irrelevant information term (second term) in decomposition 20 dominates the BALD sampling objective and thus samples with the largest norm are selected. In contrast, MELL focuses on the samples with larger impact on the validation set.
7 Method
The general design of our formulation of Roy & McCallum (2001) is to score a candidate sample by the expected reduction in loss if we had access to the candidate sample’s label, and if we predicted optimally given our knowledge thus far. In this section, we provide a formalization of this idea that only requires the pairwise marginals for the labels. These can be approximated with Monte Carlo in a computationally efficient way using Bayesian sampling methods, such as Monte Carlo dropout (Gal & Ghahramani, 2016).
In our setting, the data samples for labeling are selected from a pool of unlabeled candidate samples . Additionally, we assume that there is a distinct set of unlabeled data for validation denoted as . The set is used for the evaluation of the expected loss reduction. These two distinct data sets and might have different distributions; in contrast, Roy & McCallum (2001) used same set for the validation and for the candidate pool. This distinction allows more flexibility in the data shift setting, as the candidate pool and validation set could be from different data distributions.
Note that while Roy & McCallum (2001) use the unlabeled pool for both candidates and evaluation of expected loss, we assume we have both an unlabeled pool for the candidates and an unlabeled validation set for evaluation of the expected loss. This allows more flexibility in the data shift setting, as the candidate pool and validation set could be from different data distributions.
For every candidate sample, our aim is to estimate the expected reduction in error-loss if we could observe the actual label of the sample and then retrain the model by adding the sample to the training set. As expressed in the equation below, the reduction in loss is the difference between the current loss and the expected loss with respect to the optimal prediction under the condition that we know the actual label of the candidate sample.
For the probabilities in the expectations below, we implicitly condition on the pool of unlabeled samples and the set of unlabeled validation samples in and consider the distribution over the labels of those sample. Additionally, we implicitly condition on any previously labeled data .
where represents the optimal prediction given our current state of information, is the set of possible predictions, and is the loss. Note that the first term is equal for all candidate samples and does not have effect on ranking these samples based on expected loss reduction. So we only need to estimate the second term to rank the samples. Thus, we can estimate the score for a candidate sample based solely on the second term; the negative expected loss after the sample’s observed label. Thus, the score for the sample is:
| (9) |
Throughout this work, we will use the index for samples from the candidate pool and the index for samples from the validation set.
The reduction in loss is the difference between the current loss (with respect to an optimal prediction given the current information) and the expected (with respect to the candidate sample’s label) loss (with respect to the optimal prediction if we additionally knew the label of the candidate sample). Note that the current loss is constant for all candidate points so we can take the score to simply be the negative expected loss after the candidate’s label observation. The score for the sample is:
where is intuitively the optimal prediction given our current information, is the set of possible predictions, and is the loss. Throughout this work, we will use the index for the candidate pool and the index for the validation set.
The score definition and computation strategy in our work is different from Roy & McCallum (2001):
- •
-
•
In this work, we focus on a Bayesian approach in contrast to Roy & McCallum (2001) which uses point estimates. Because we are able to maintain a distribution over the quantities of interest instead of point estimates, we are able to sidestep the model retraining. In Appendix A.1, we will show that it is only required to compute the quantities and to evaluate the score for the common loss functions such as cross-entropy which is done quite efficiently.
-
•
In 9, the loss is computed with respect to the validation set . In the data shift setting, the data sample in are drown from the target domain while the samples are drown from the source domain. This is in contrast to EER, and also to most of the other methods in active learning literature such as BALD and BADGE. 22todo: 2add more explanation
Note that we assume that we have access to the probabilities and . This is standard in Bayesian modeling; we rely on the model to know what would happen if we chose to label a sample.
As in Roy & McCallum (2001), in the next subsections, we derive criteria for two different losses: the negative log-likelihood loss and the zero-one loss. For the (negative) log-likelihood loss, the possible predictions are in the probability simplex over the classes, and for the zero-one loss, the set of possible predictions is in the output set . In both cases, we are maximizing the negative expected loss which is equivalent to minimizing the expected loss. Thus, we refer to these two criteria as Minimization of Expected Log-likelihood Loss (MELL) and Minimization of Expected Zero-one Loss (MEZL).
7.1 MELL
Plugging the specific loss of MELL into the general principle:
| (10) |
We can use the non-negativity of the KL divergence to find the optimal prediction is , see the proof in Appendix A.1. Then, by the definition of conditional entropy,
| (11) |
where is the conditional entropy. Because ,
| (12) |
Noting that does not depend on , this term does not affect the ordering of the scores of the points in the pool. Thus, the MELL criterion is equivalent to maximizing the sum of the mutual information between the candidate point and each point in the validation set. As a result, we only require the pairwise marginal probabilities of the labels to calculate the MELL criterion. Intuitively, this is because we need to know the effect of labeling one point on the confidence of another point.
For computational purposes, we note that , so:
| (13) |
Because the parameters render the labels conditionally independent, we can draw samples from the posterior as and perform an unbiased Monte Carlo approximation of the probabilities,
| (14) | ||||
| (15) | ||||
| (16) |
Sampling parameters from the posterior distribution can be approximately generated in a variety of ways. In our implementation, we use Monte Carlo dropout for its computational efficiency; see Gal & Ghahramani (2016). An alternative is using the Cyclical SG-MCMC method proposed in Zhang et al. (2019). We compared two methods in 4. We did not observe advantage in using Cyclical SG-MCMC for sampling from posterior distribution vs dropout. 33todo: 3please confirm – did we check the cyclical method? and found no difference??? 44todo: 4Ehsan: yes I add result in appendix
7.2 MEZL
In this section, we derive the algorithm for minimization of expected zero-one loss. Plugging and into the principle, we get,
| (17) |
The optimal prediction is simply . Then, with a step of algebra,
| (18) |
We can ignore the term at the end because it is constant with respect to . Therefore, like MELL, the MEZL criteria requires knowing the pairwise marginals of the labels, which can be estimated using Monte Carlo parameter samples and the conditional independence of the labels given the parameters,
| (19) |
Unfortunately, MEZL can dramatically fail for a reason we explore in Section 9.1. Briefly, when calculating the score for a point , a point in the validation set only contributes to the if observing point would change the MAP prediction on point .
7.3 Information decomposition
As before, let be the label of a sample in the pool, be the label of a sample in the validation set, and be a random variable for the posterior distribution of the parameters. Using an information-theoretic identity, the total uncertainty () of a sample in the pool can be decomposed into the epistemic uncertainty () and the aleatoric uncertainty (), namely
Because we cannot reduce the aleatoric uncertainty, BALD judiciously minimizes the epistemic uncertainty rather than the total uncertainty. There is a similar decomposition of the mutual information () into the interaction information and the conditional mutual information . Although interaction information can in general be negative, because of the conditional independence of the labels given the parameters in our case, .
| (20) | ||||
| (21) |
Intuitively, is the orthogonal information, the information that is irrelevant to the prediction of the validation point . More precisely, the orthogonal information is the information between and if we knew . On the other hand, is the task-relevant information, the information after the orthogonal information has been removed.
Thus, if we take the score of a pool point as the sum of the task-relevant information with respect to all validation points, we recover MELL. Put another way, MELL can be seen as BALD after removing the information that is not relevant to a validation set.
In Appendix A.6, we look at and for linear Bayesian model. We show that the first term is bounded and the second term goes to infinity for large enough .
Proposition 1.
Let be a linear Bayesian model where and . Then, there exists constant such that
for all samples . Furthermore, for large enough .
In linear case, BALD selects sample with highest norm . Assume that is drawn from a continuous unbounded distribution. The selected samples by BALD as . So the irreverent information term (second term) in decomposition 20 dominants the BALD sampling objective and thus samples with the largest norm are selected. In contrast, the MELL objective is the relevant mutual information (first term) in decomposition 20, thus it is not confused samples from the pool with large magnitude. Furthermore, we observe in linear setting that this term is approximately the average correlation between the candidate and the validation set. Finally, note that BADGE can not distinguished between different points in linear case, since the gradient of all points are .
8 Experiments
8.1 Setup
We experiment with active learning on 7 image classification datasets – CIFAR10, CIFAR100, SVHN, MNIST, Camelyon17, iWildCam, and FMoW – each in a setting of data shift and no data shift, for a total of 14 experiments.
Each experiment follows the standard active learning setup as described in Section 5. In the no shift setting, there is no distribution shift between seed, pool, test, and validation sets. In the shift setting, pool, test, and validation come from the same distribution, while seed is from a different distribution. Please refer to Appendix A.3.2 for more details about the datasets and how shifts were induced in each. Section A.3.3 details the experimental parameters.
We compare MELL and MEZL to several existing methods in the literature that are representative of the state of the art in active learning. We use Random, consisting of uniform random sampling from the pool as a baseline. We compare to three information-theoretic methods: BALD (Gal et al., 2017), where the candidates are scored by their mutual information with the parameters estimated using Monte Carlo dropout; Entropy_MC (Lewis & Gale, 1994), which relies on entropy-based uncertainty sampling using probabilities from Monte Carlo dropout; and Entropy, which also relies on entropy-based uncertainty sampling, this time using probabilities from the softmax output. The formal relation of these methods to MELL was detailed in Section 7.3. In addition, we also compare against two empirically successful methods based on diversity sampling approaches that require access to the last layer of the task model (not model-free). The first one is Coreset (Sener & Savarese, 2018), which relies on batch sampling a group which provides representative coverage of the unlabeled pool using the penultimate layer representation. We remark that that our experimental results for Coreset are generated using a greedy approximation of the method for computational efficiency. The second one is BADGE (Ash et al., 2019), which chooses samples that are diverse and high-magnitude when represented in a hallucinated gradient space with respect to model parameters in the final layer. The scoring functions for these methods can be found in Section A.3.1
8.2 Results
| BADGE | BALD | Coreset | Entropy_MC | Entropy | MEZL | Random | |
|---|---|---|---|---|---|---|---|
| MELL wins | 0 | 4 | 3 | 6 | 7 | 2 | 10 |
| MELL ties | 7 | 10 | 11 | 8 | 6 | 12 | 4 |
| MELL losses | 2 | 0 | 0 | 0 | 1 | 0 | 0 |
Our experiments find that MELL is the best performer or tied with best on 12 out of the 14 experiments, suggesting that MELL performs well across a variety of domains. According to Table 1, MELL never performs worse than BALD and Coreset, outperforming BALD on 4 experiment and Coreset on 3. We show the active learning curves for the experiments where MELL outperformed BALD or Coreset in Figure 1.
For the cases where MELL outperforms BALD, we find that the performance gap is particularly wide for the data shift cases. We believe this is because BALD selects samples which maximize the information gain about the model posterior, which may not be particularly helpful for the target distribution, whereas MELL selects samples with the specific criteria of reducing error on the target distribution.
In the case of data shift (see Table 5), we have two exceptions: in MNIST, BADGE outperforms MELL, and in Camelyon17 both BADGE and Entropy outperform MELL. We first note that Entropy under-performs with respect to MELL in 7 other settings. BADGE on the other hand, performs on par with MELL in all the cases where the computation finishes. For iWildCam and FMoW, the computations required by BADGE didn’t finish after 14 days of execution. Indeed, BADGE achieves its performance at a steep cost in terms of computation time. Figure 2 shows the exact cost for the case of Camelyon17 with shift. Note that most of the overhead is on the active learning method itself and not on the training of the task model. This behavior is consistent in all of the experiments. We offer some further insight in terms of computational complexity in Appendix A.2.
In addition, we point out that it has been noted that Camelyon17 is an outlier among datasets. From Miller et al. (2021): “One possible reason for the high variation in accuracy [on Camelyon17] is the correlation across image patches. Image patches extracted from the same slides and hospitals are correlated because patches from the same slide are from the same lymph node section, and patches from the same hospital were processed with the same staining and imaging protocol. In addition, patches in [Camelyon17] are extracted from a relatively small number of slides.” Because of this test time dependence between images (in addition to train time dependence), Miller et al. (2021) notes the presence of “instabilities in both training and evaluation”.
Our claim on aleatoric and epistemic uncertainty is based on the fact that cases where uncertainty sampling methods perform on-par with BALD indicates that there is likely little to no aleatoric uncertainty present in those datasets, since BALD is equivalent to Entropy without the aleatoric uncertainty, as discussed in 7.3. This is the case on iWildCam, SVHN, and Camelyon17.
and As shown in Tables LABEL:tab:saturation-no-shift-table and Table LABEL:tab:saturation-shift-table, there is no alternative method that excels in all situations. The referenced tables are calculated by computing a threshold that is a percentage of the maximum achieved accuracy across all methods for a particular dataset. Then, saturation points are determined as the first budget level at which the method meets or surpasses the threshold level.
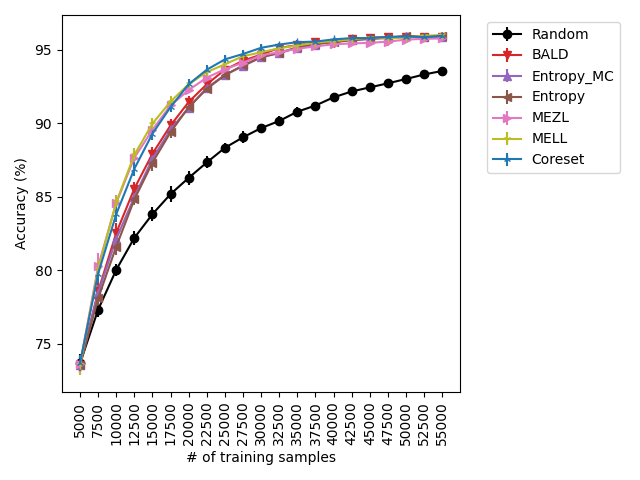
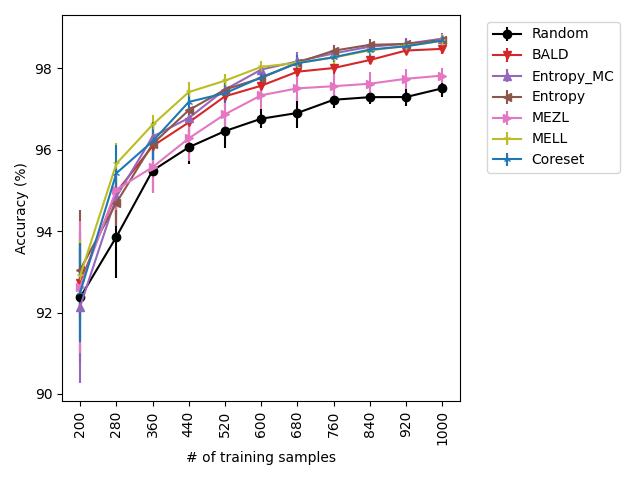
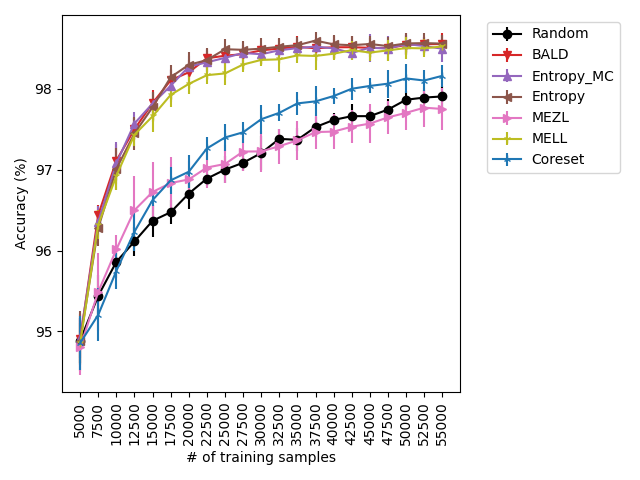
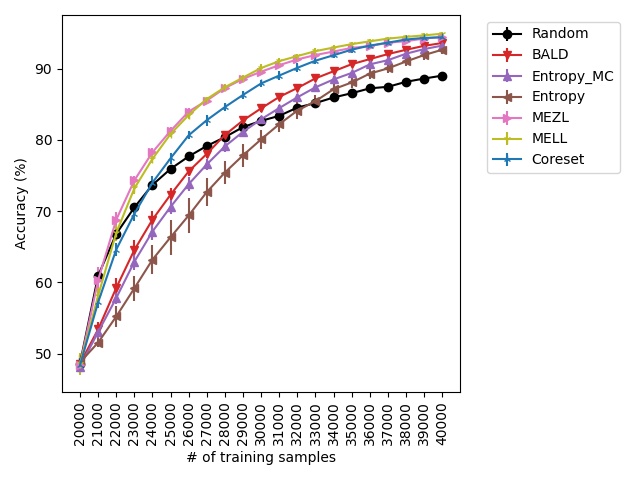
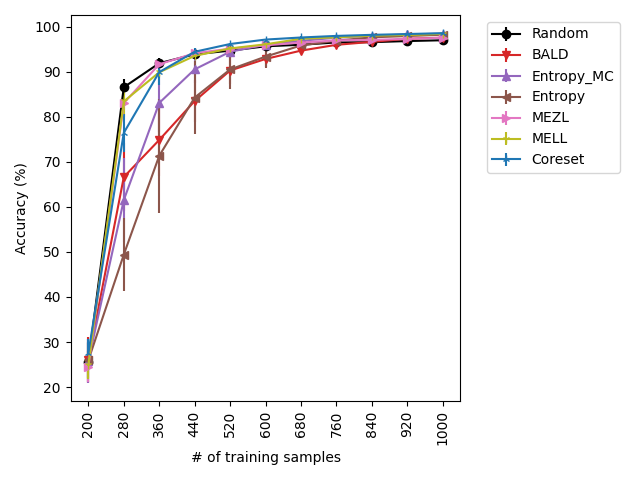
MEZL performs on par with random selection or significantly underperforms the best methods on MNIST, CIFAR10, SVHN, and Camelyon17. This underperformance is due to the fact that MEZL is only sensitive to validation samples that are near the decision boundary. A further discussion of this phenomenon is in Section 9.1.
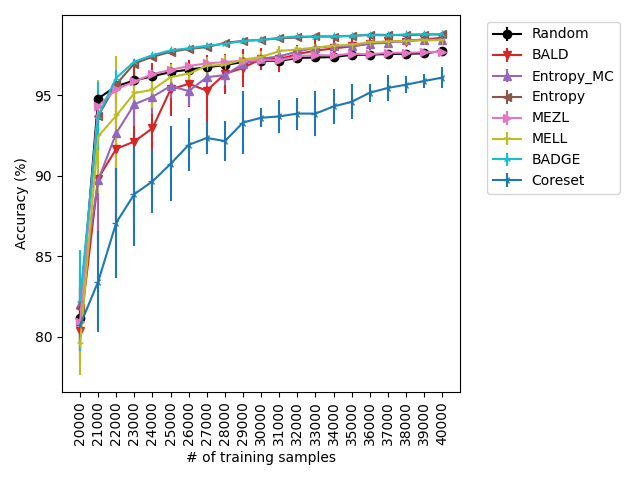
For the experiments with shift present, we begin by observing that MELL and MEZL significantly outperform all other methods on iWildCam with natural shift induced by splitting data by the location of where the images were captured Figure LABEL:fig-3. Notably, BALD and the uncertainty methods perform significantly worse relative to MELL and MEZL, whereas they were on-par for the iWildCam with no shift experiment. All other datasets show the same pattern – MELL is the winner on SVHN along with uncertainty sampling and BALD, and is comparable to baseline methods for CIFAR10, CIFAR100, and FMoW. Remarkably, uncertainty sampling without Monte Carlo sampling is the clear winner on Camelyon17 with shift.
While BADGE performs best or on par with the best active learning strategies for every dataset we ran it on, BADGE takes significantly longer to run than the other strategies. Figure 2 shows the mean time that each experiment on CIFAR10_shift took to complete, averaged over 10 trials for each strategy. For every dataset, BADGE is the slowest strategy by orders of magnitude.
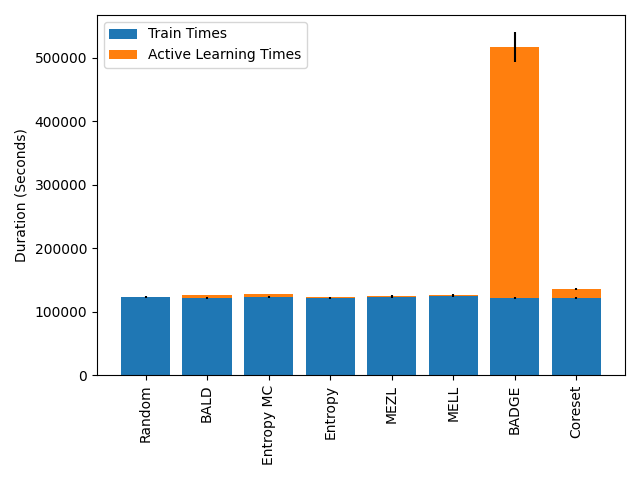
To summarize, we find that MELL outperforms or is comparable to existing state of the art methods for active learning in a variety of situations. There is no other method that performs consistently in all scenarios at the same level of computational efficiency. Our experiments hint that MELL may be appropriate for a wide range of tasks and might partially eliminate the need to make a decision about which active learning method to use. Active learning accuracy curves for all experiments and tables containing the AUCs of these experiments can be found in Appendix A.4.1.
Using the experimental setup discussed above, we present a selection of observed results in LABEL:fig:1; additional results are included in the appendix. In all dataests that were evaluated, we found that MELL either outperforms or is on-par with state of the art methods. On CIFAR10 (LABEL:fig-1) and SVHN, we found that all methods perform similarly, significantly outperforming random selection. MEZL outperforms random selection, but underperforms relative to the remaining methods the reasons for which are discussed in 4.3. For CIFAR100, all dropout methods are on-par with random selection, while both uncertainty sampling methods underperform. LABEL:fig-2 shows that in low data regimes for MNIST, MELL outperforms all other methods. Interestingly, uncertainty methods outperform the other dropout methods in the low data scenario as well. \juliaLet’s move the figure legends inside the plots to save space
With the iWilds datasets we characterized the performance of the methods with shift present. LABEL:fig-3 shows that MELL and MEZL outperform all other methods. For FMoW, we see once again that MELL and MEZL outperform the baseline methods, while performing on-par with BALD. Results on Camelyon are an outlier in that uncertainty sampling outperforms all other methods. However, it is well-documented that the dataset is unusual in that the samples are not IID. Steve: citation for this?
Our results suggest that MELL represents a significant advancement in the field of active learning, providing a way to accurately approximate the estimated error reduction. In all cases, MELL displays either improved or commensurate performance compared with state of the art methods.
9 Discussion
A result of the information theoretic basis of our scores, plus the use of Bayesian estimates, is that the only requirement for the computation of MELL and MEZL is the estimation of the pairwise marginal probabilities of labels. Thus, these scores can be applied to deep neural networks, random forests, linear models, etc., with very little modification. This clearly constrasts with methods such as Coreset and BADGE which make use of the last-layer activation of the neural network. In that precise sense, our approach is model free.
In addition, we characterized the differences between (a) entropy-based uncertainty sampling, (b) the expected information gain score (BALD), and (c) minimization of expected log-likelihood loss (MELL), in a precise information-theoretic light that explains the formal relationship between these methods. We remark that these methods are myopic in the way they score each sample independent of the others and greedily rank the outcomes. In Appendix A.5, we discuss the possibility of extending MELL to a non-myopic algorithm.
In this work, we formalize the expected error reduction (EER) principle (see Eq. (9)) and derive two active learning scoring criteria from this general, conceptually clean principle. While we assume that the model is probabilistic and predict , our algorithms are model-free in that they do not use any structure of the model in addition to be probabilistic base; they could be used with any probabilistic model, whether neural networks or random forests. In fact, MELL and MEZL don’t even require a parametric model; they only require the pairwise marginal probabilities of labels. In contrast, coreset (Sener & Savarese, 2018) and BADGE (Ash et al., 2019) are not model-free since they make use of the last-layer activation of the neural network. In addition, we characterized the differences between (a) entropy-based uncertainty sample, (b) expected information gain method known as BALD, and (c) minimization of expected log-likelihood loss (MELL), in a precise information-theoretic light that explains the relative ordering of these methods. In A.5 , we discuss the possibility of extending “model free” MELL to non-myopic algorithm.
An important difference between our work and the original EER framework is that we make use of an unlabeled validation set rather than relying on the unlabeled pool of samples. When there is no data shift, this is a small difference. Knowledge of the labels of the validation set is not required, and we could create the validation set by subsampling the unlabeled pool before the algorithm runs. However, in settings where the unlabeled pool is from a different distribution than the test set and we don’t have label access to or much data in the test set, this is an important distinction. It affords us the flexibility to focus the scoring function at a specific set, with the expectation that the algorithm will specialize to the implicit distribution in that set.
9.1 Failure mode of MEZL
MEZL performs significantly worse than MELL on some datasets because MEZL is only sensitive to validation samples near the decision boundary. More precisely, if observing the candidate label does not change the prediction on a validation sample, then the zero-one loss reduction is .
If the prediction does not depend on the value , then we can bring the expectation of inside the . Then, by the law of total expectation, the two terms are equal and there is no reduction in the zero-one loss on label . Intuitively, this is a problem because observing some candidates in the pool could increase the confidence on many validation samples without necessarily changing the prediction of any of these samples. These candidates would be regarded as useless by MEZL, although they are useful in the long term since reducing uncertainty over several iterations can reduce zero-one loss. Perhaps counter-intuitively, directly minimizing the next-step expected negative log-likelihood loss yields lower zero-one loss over many steps than directly minimizing the next-step zero-one loss.
10 Conclusion
In this work, we re-examine the EER algorithm (Roy & McCallum, 2001) from a Bayesian and information theoretic perspective. Our method avoids the requirement of frequent model retraining, required in the original algorithm, which is infeasible in current deep learning models. Instead we make use of estimation techniques such as dropout that make Bayesian active learning strategies computationally efficient. Empirically, the algorithms we propose are effective on standard benchmark datasets against state of the art methods in the literature.
We performed experiments with datasets under conditions of data shift, which have not been thoroughly examined in the active learning literature. We remark that the proper examination of active learning in conditions of shift demands further study. In particular, there are a variety of questions related to designing and adapting active learning methods to the data shift setting that take advantage of the information afforded by the validation sets. We leave these questions for future research, having established results in this work as initial benchmarks.
References
- Ash et al. (2019) Ash, J. T., Zhang, C., Krishnamurthy, A., Langford, J., and Agarwal, A. Deep batch active learning by diverse, uncertain gradient lower bounds. arXiv preprint arXiv:1906.03671, 2019.
- Bandi et al. (2018) Bandi, P., Geessink, O., Manson, Q., Van Dijk, M., Balkenhol, M., Hermsen, M., Bejnordi, B. E., Lee, B., Paeng, K., Zhong, A., et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. IEEE transactions on medical imaging, 38(2):550–560, 2018.
- Beery et al. (2020) Beery, S., Cole, E., and Gjoka, A. The iwildcam 2020 competition dataset, 2020.
- Beluch et al. (2018) Beluch, W. H., Genewein, T., Nürnberger, A., and Köhler, J. M. The power of ensembles for active learning in image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9368–9377, 2018.
- Chaloner & Verdinelli (1995) Chaloner, K. and Verdinelli, I. Bayesian experimental design: A review. Statistical Science, pp. 273–304, 1995.
- Christie et al. (2018) Christie, G., Fendley, N., Wilson, J., and Mukherjee, R. Functional map of the world. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6172–6180, 2018.
- Gal & Ghahramani (2016) Gal, Y. and Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pp. 1050–1059. PMLR, 2016.
- Gal et al. (2017) Gal, Y., Islam, R., and Ghahramani, Z. Deep bayesian active learning with image data. In International Conference on Machine Learning, pp. 1183–1192. PMLR, 2017.
- Hartigan (2014) Hartigan, J. Bounding the maximum of dependent random variables. Electronic Journal of Statistics, 8(2):3126–3140, 2014.
- Kirsch et al. (2021) Kirsch, A., Rainforth, T., and Gal, Y. Test distribution-aware active learning: A principled approach against distribution shift and outliers. 2021.
- Koh et al. (2021) Koh, P. W., Sagawa, S., Marklund, H., Xie, S. M., Zhang, M., Balsubramani, A., Hu, W., Yasunaga, M., Phillips, R. L., Gao, I., Lee, T., David, E., Stavness, I., Guo, W., Earnshaw, B. A., Haque, I. S., Beery, S., Leskovec, J., Kundaje, A., Pierson, E., Levine, S., Finn, C., and Liang, P. Wilds: A benchmark of in-the-wild distribution shifts. 2021.
- Krizhevsky et al. (2009) Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009.
- LeCun (1998) LeCun, Y. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- Lewis & Gale (1994) Lewis, D. D. and Gale, W. A. A sequential algorithm for training text classifiers. In SIGIR’94, pp. 3–12. Springer, 1994.
- Lindley (1956) Lindley, D. V. On a measure of the information provided by an experiment. The Annals of Mathematical Statistics, pp. 986–1005, 1956.
- Miller et al. (2021) Miller, J. P., Taori, R., Raghunathan, A., Sagawa, S., Koh, P. W., Shankar, V., Liang, P., Carmon, Y., and Schmidt, L. Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. In International Conference on Machine Learning, pp. 7721–7735. PMLR, 2021.
- Netzer et al. (2011) Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., and Ng, A. Y. Reading digits in natural images with unsupervised feature learning. 2011.
- Rabanser et al. (2019) Rabanser, S., Günnemann, S., and Lipton, Z. Failing loudly: An empirical study of methods for detecting dataset shift. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/846c260d715e5b854ffad5f70a516c88-Paper.pdf.
- Roy & McCallum (2001) Roy, N. and McCallum, A. Toward optimal active learning through monte carlo estimation of error reduction. ICML, Williamstown, 2:441–448, 2001.
- Schrouff et al. (2022) Schrouff, J., Harris, N., Koyejo, O., Alabdulmohsin, I., Schnider, E., Opsahl-Ong, K., Brown, A., Roy, S., Mincu, D., Chen, C., Dieng, A., Liu, Y., Natarajan, V., Karthikesalingam, A., Heller, K. A., Chiappa, S., and D’Amour, A. Maintaining fairness across distribution shift: do we have viable solutions for real-world applications? CoRR, abs/2202.01034, 2022. URL https://arxiv.org/abs/2202.01034.
- Sener & Savarese (2018) Sener, O. and Savarese, S. Active learning for convolutional neural networks: A core-set approach. 2018.
- Settles (2009) Settles, B. Active learning literature survey. 2009.
- Simonyan & Zisserman (2014) Simonyan, K. and Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Sinha et al. (2019) Sinha, S., Ebrahimi, S., and Darrell, T. Variational adversarial active learning. 2019.
- Tong & Koller (2001) Tong, S. and Koller, D. Support vector machine active learning with applications to text classification. Journal of machine learning research, 2(Nov):45–66, 2001.
- Virtanen et al. (2020) Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Welling & Teh (2011) Welling, M. and Teh, Y. W. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11), pp. 681–688. Citeseer, 2011.
- Zhang et al. (2019) Zhang, R., Li, C., Zhang, J., Chen, C., and Wilson, A. G. Cyclical stochastic gradient mcmc for bayesian deep learning. arXiv preprint arXiv:1902.03932, 2019.
- Zhao et al. (2021) Zhao, E., Liu, A., Anandkumar, A., and Yue, Y. Active learning under label shift. In The 24th International Conference on Artificial Intelligence and Statistics, AISTATS 2021, April 13-15, 2021, Virtual Event, volume 130 of Proceedings of Machine Learning Research, pp. 3412–3420. PMLR, 2021. URL http://proceedings.mlr.press/v130/zhao21b.html.
Checklist
-
1.
For all authors…
-
(a)
Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes]
-
(b)
Did you describe the limitations of your work? [Yes] In section A.5, we discuss how MELL and MEZL are motivated by the best decision for labeling a single sample rather than the optimal strategy for a batch of samples.
-
(c)
Did you discuss any potential negative societal impacts of your work? [N/A]
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes]
-
(a)
-
2.
If you are including theoretical results…
- (a)
- (b)
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [No] All datasets are publicly available and experimental parameters needed to reproduce main results can be found in A.3.3. However, code is not provided.
-
(b)
Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes] Training details are in A.3.3.
-
(c)
Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [Yes] Error bars calculated with 10 random seeds are on all figures and tables.
- (d)
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
- (a)
-
(b)
Did you mention the license of the assets? [No] The datasets we used are all public and common in research settings. All datasets are cited in the paper. They all have licenses that allow for non-commercial research.
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [N/A]
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)
Appendix A Appendix
A.1 Log likelihood loss optimal prediction
In Section 6.1, it was noted that the optimal prediction probability is . Let be the vector representation of ; in other words, . So,
| (22) |
To show that is the optimal prediction, we must show its value is always equal or less than the value of any other . Note that the KL divergence is always non-negative,
| (23) | ||||
| (24) |
A.2 Computational complexity
For MELL and MEZL, the amount of computation required for each candidate sample and validation sample is proportional to , where is the number of posterior samples and is the number of classes. Thus the leading order term in the active learning algorithm (not including the train time) is . We can decrease the computational complexity dependence on and by subsampling at each active learning iteration. For BADGE (Ash et al., 2019), the main cost comes from the -means++ algorithm run times (once per active learning iteration) for a total computational cost of , where is the embedding dimension. Because may be quite large, and we cannot subsample to reduce the dependence on , the high computational cost of running BADGE might be expected.
A.3 Experimental Details
A.3.1 Score Functions
Below, we have the scoring functions for the baseline methods.
Entropy, Entropy_MC, BALD, and Random assign each data sample a score, and then query the labels of the samples with the top scores.
Given a function unif that samples randomly from the uniform distribution over , Random has the following scoring function:
For Entropy:
where is the trained model parameters.
For Entropy_MC:
where
For BALD:
BADGE and Coreset choose samples in batches.
For BADGE Ash et al. (2019), gradient embeddings are computed according to:
where is the model parameters at the last layer, is the output of model , and is the hypothetical label on . The k-means++ seeding algorithm is then run on these gradient embeddings to choose samples.
Coreset seeks to solve the following problem:
In other words, choose a batch of data samples, such that the maximum distance between data samples in the unlabeled set and their closest center is minimized. Since computing this is NP-Hard, a k-greedy center approach is first used to initialize batch , and a mixed integer program is run as a sub-routine to iteratively approach the optimal Sener & Savarese (2018).
A.3.2 Datasets
CIFAR10 and CIFAR100 (Krizhevsky et al., 2009) are standard image classification datasets. SVHN (Netzer et al., 2011) and MNIST (LeCun, 1998) are digit recognition datasets, with the former containing color data from house numbers and the latter with black and white handwritten digits. iWildCam (Beery et al., 2020), Camelyon17 (Bandi et al., 2018), and FMoW (Christie et al., 2018) are drawn from the WILDS repository of datasets (Koh et al., 2021). iWildCam contains images of wildlife captured using camera traps around the world. Camelyon17 contains microscope images of tissue samples taken from various patients, with the goal of identifying whether the image contains metastasized cancer cells. Finally, FMoW contains satellite imagery with the task of classifying the type of building or land represented in the image.
For each dataset, we conduct one experiment with and one experiment without data shift. In the no shift setting, the initial training (seed), validation, unlabeled, and test sets are drawn uniformly at random from the available data (we ignore train/test/validation splits that come from the dataset). In the data shift settings, we split the dataset into a source and a target set, where source and target come from different distributions. The initial training (seed) set is sampled uniformly at random from the source set. The validation, unlabeled, and test sets are sampled uniformly at random from the target set.
We create the shift setting in CIFAR10, CIFAR100, SVHN, and MNIST by assigning the images with lowest average pixel brightness to the source and all other images in the dataset to the target set. Shifted settings for Camelyon17, iWildCam, and FMoW are naturally occurring in how the datasets were collected. Using their split columns in the metadata files, we assign for Camelyon17, for iWildCam, and for FMoW to the source set. We assign for Camelyon17, for iWildCam, and for FMoW to the target set.
A.3.3 Experimental Parameters
In each experiment, we initialize our training (seed), validation, unlabeled, and test sets to , , , and samples respectively. At each active learning iteration, we train a task classifier with the VGG16 architecture (Simonyan & Zisserman, 2014) and an unweighted cross-entropy loss function. Then, an active learning method is used to query samples from the unlabeled pool to label, adding them to the training set before the next iteration. We run each experiment 10 times with different random seeds. See Table 2 for details on task model training parameters and Table 3 for details on experiment parameters.
| Train Iterations | Batch Size | Learning Rate | Optimizer (Weight Decay, Momentum) | Loss |
|---|---|---|---|---|
| 46875 | 64 | 0.01 (0.001) | SGD (5e-4, 0.9) | Cross-Entropy |
Dataset Image Size Shift CIFAR10 None 5000 5000 40000 2500 10000 16 100 25000 100 shift 20000 5000 25000 1000 10000 20 100 10000 100 CIFAR100 None 5000 5000 40000 2500 10000 16 100 25000 100 shift 20000 5000 25000 1000 10000 20 100 10000 100 SVHN None 5000 5000 50000 2500 10000 20 100 25000 100 shift 20000 5000 35000 1000 10000 20 100 10000 100 MNIST None 200 5000 44800 80 10000 10 100 800 100 shift 200 5000 44800 80 10000 10 100 800 100 Camelyon17 None 5000 5000 100000 2500 10000 20 100 25000 100 shift 20000 5000 100000 1000 10000 20 100 10000 100 iWildCam None 5000 5000 100000 2500 10000 20 100 25000 100 shift 20000 5000 100000 1000 10000 20 100 10000 100 FMoW None 5000 5000 100000 2500 10000 20 100 25000 100 shift 20000 5000 97000 1000 10000 20 100 10000 100
A.4 Additional Results
A.4.1 Full Results
Below, we show the active learning accuracy curves on all datasets with and without shift for all methods in Figure 3. We also show the area under the curve (AUC) of the accuracy curves in the no shift setting in Table 4 and with shift in Table 5.
Dataset (no shift) MELL MEZL Random BALD Entropy MC Entropy Coreset BADGE CIFAR10 81.74 81.43 80.65 81.63 81.65 81.66 81.58 81.68 0.29 0.40 0.36 0.29 0.29 0.35 0.37 0.41 CIFAR100 43.96 43.82 43.83 43.94 42.83 42.68 44.30 - 0.26 0.34 0.28 0.34 0.32 0.34 0.28 SVHN 91.73 91.48 90.41 91.75 91.80 91.80 91.71 91.80 0.15 0.15 0.12 0.12 0.15 0.14 0.15 0.15 MNIST 97.50 96.71 96.23 97.10 97.27 97.28 97.35 97.60 0.11 0.27 0.28 0.18 0.20 0.19 0.17 0.18 iWildCam 92.47 92.24 88.03 91.84 91.64 91.57 92.40 - 0.20 0.15 0.24 0.21 0.16 0.18 0.21 Camelyon17 98.02 97.06 97.02 98.12 98.11 98.13 97.28 98.12 0.10 0.19 0.10 0.09 0.11 0.10 0.10 0.11 fMoW 36.43 36.43 35.10 36.48 34.90 34.75 36.67 - 0.44 0.35 0.33 0.46 0.44 0.38 0.33
Dataset (shift) MELL MEZL Random BALD Entropy MC Entropy Coreset BADGE CIFAR10 84.11 83.75 83.10 84.09 84.13 84.34 84.19 84.28 0.26 0.35 0.34 0.23 0.26 0.24 0.28 0.26 CIFAR100 48.51 48.46 48.16 48.46 47.93 47.35 48.19 48.12 0.36 0.34 0.38 0.53 0.46 0.40 0.35 0.31 SVHN 91.09 90.76 89.52 91.09 91.10 91.28 90.84 91.26 0.25 0.35 0.29 0.28 0.27 0.29 0.28 0.25 MNIST 91.96 91.71 91.92 86.03 88.14 84.06 91.55 93.32 0.52 0.42 0.32 2.28 1.77 3.54 0.53 0.32 iWildCam 85.17 85.22 79.84 80.14 78.92 76.54 83.37 - 0.33 0.37 0.32 0.32 0.39 1.11 0.47 Camelyon17 96.59 96.63 96.59 95.79 96.15 97.62 92.20 97.67 0.60 0.07 0.12 1.25 0.53 0.10 0.54 0.17 fMoW 33.08 33.17 32.33 33.17 32.12 31.84 33.22 - 0.27 0.36 0.40 0.27 0.29 0.34 0.30
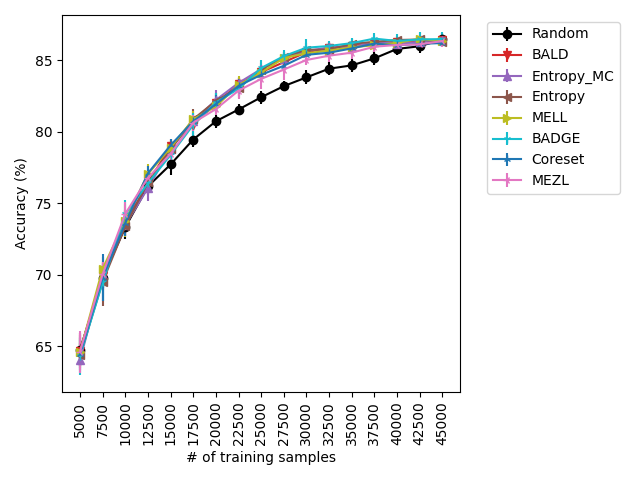
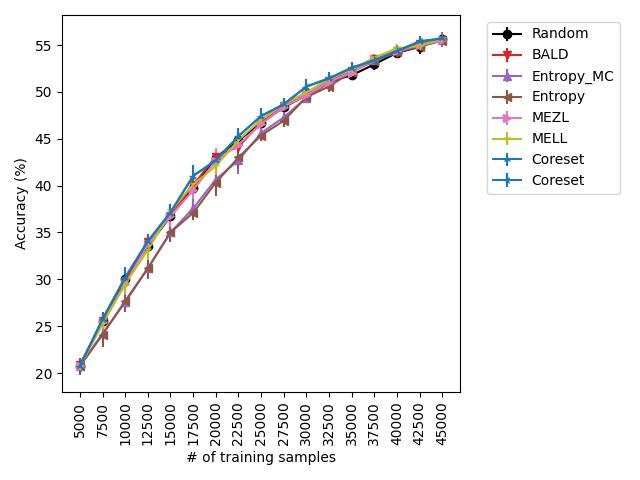
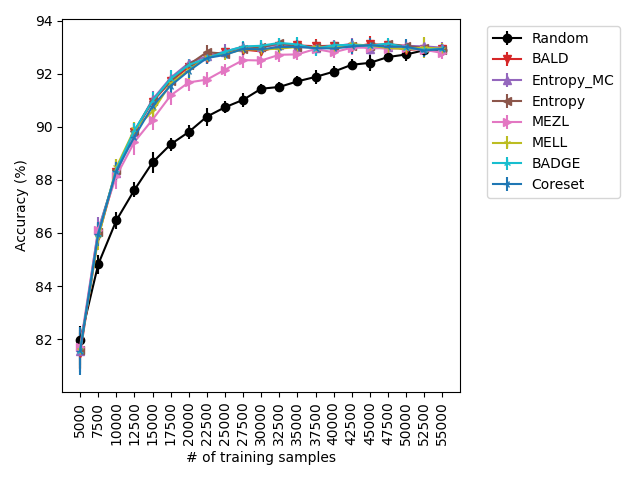
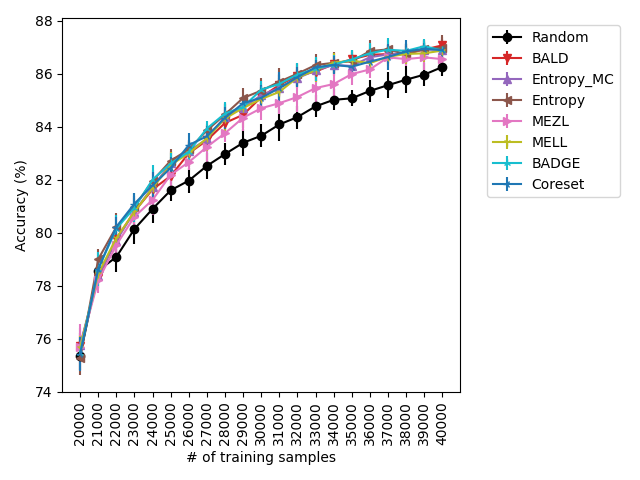
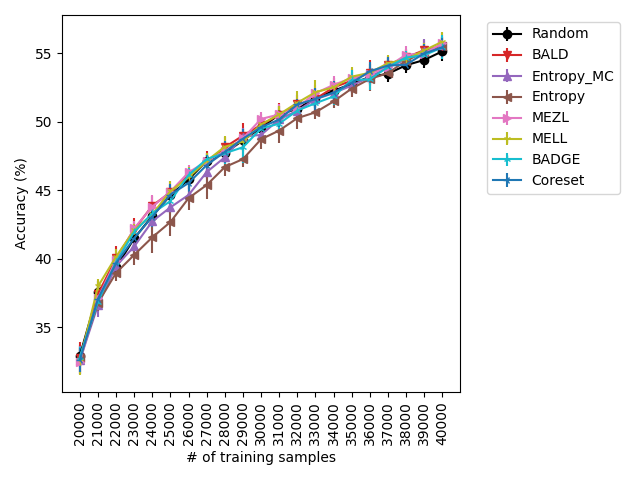
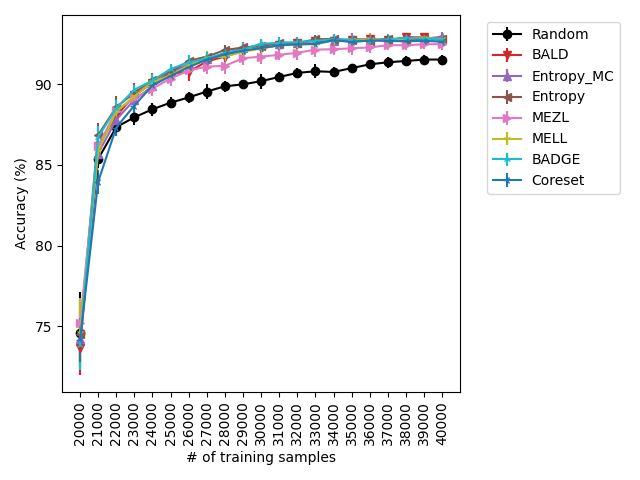
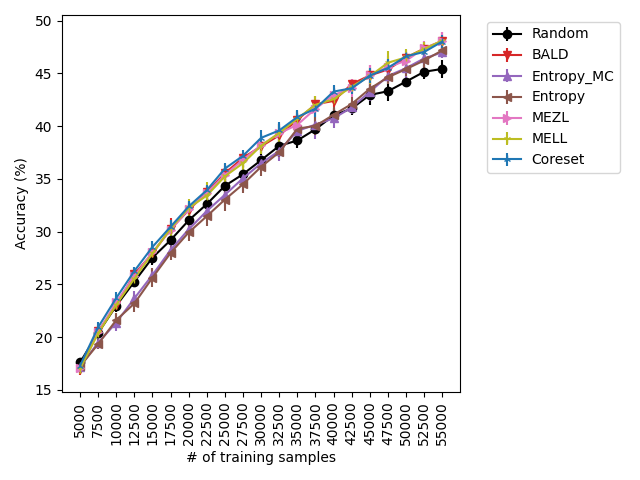
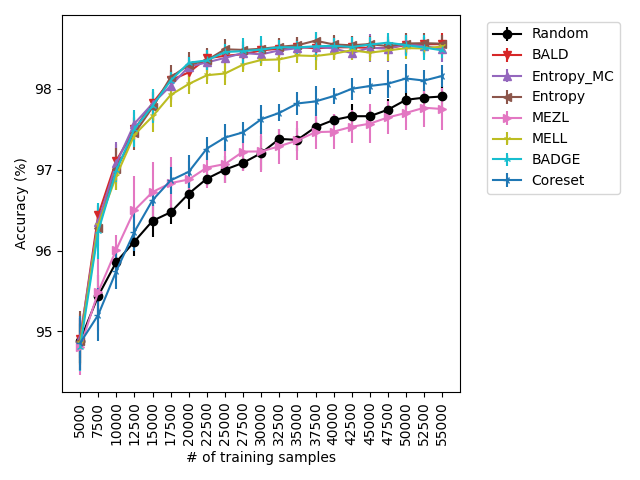
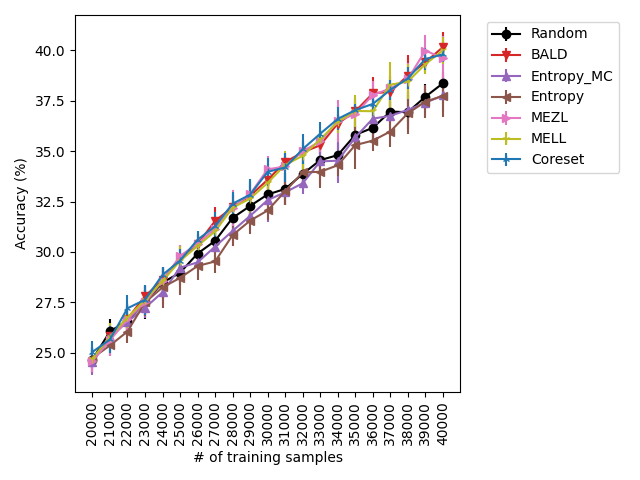
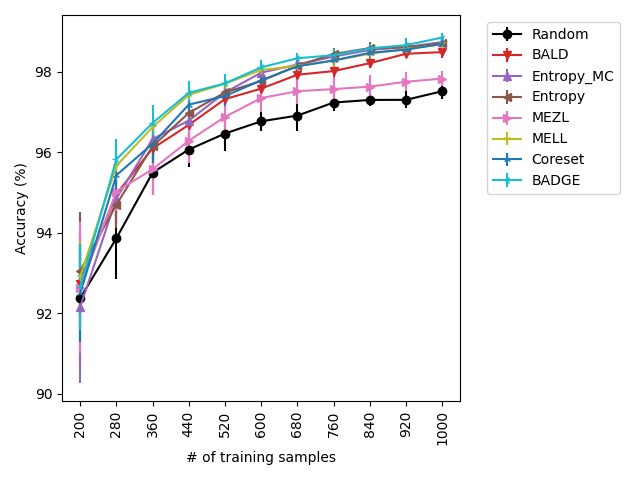
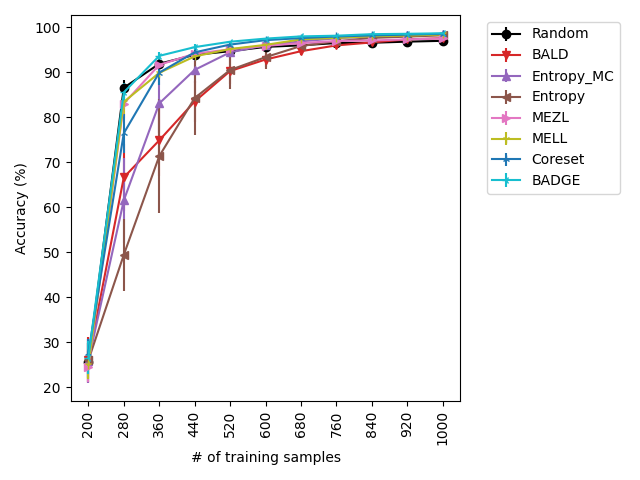
A.4.2 Cyclical SG-MCMC Sampling Method
In this experiment, we compare using Cyclical SG-MCMC as our Bayesian sampling method against Monte Carlo dropout. We train all task models by Cyclical SG-MCMC proposed in Zhang et al. (2019). The initial step-size is and the number of cycles is . We collect samples per cycle. Collected samples are used as the samples from posterior distribution in MELL_MCMC. For all other methods, we use dropout to collect samples from the posterior distribution. According to the experiment, we did not observe any significant improvement to using Cyclical SG-MCMC compared to drop-out in the active learning context.
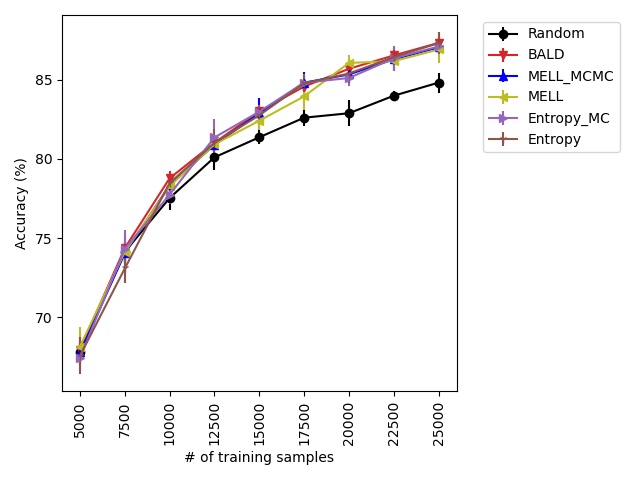
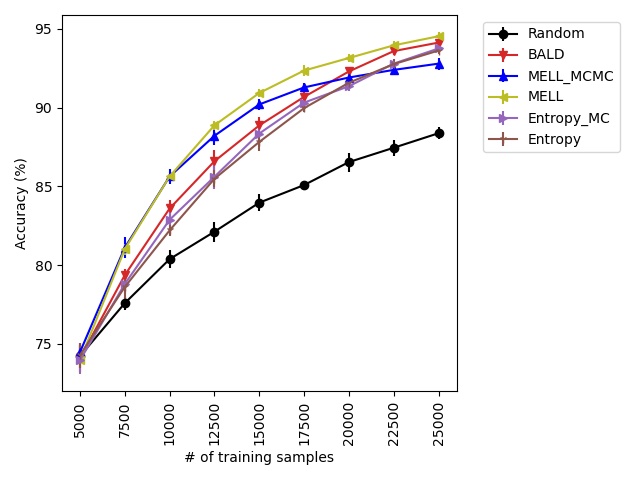
A.5 General Bayesian active learning guarantees
To the best of our knowledge, finding a computationally efficient (polynomial-time) algorithm with guarantees for the model-free Bayesian active learning setting is an open challenge. All Bayesian active learning algorithms mentioned here (MELL, MEZL, BALD, Entropy) are myopic, in that they are motivated by the best decision if the budget only allowed for a single query, and have clear failure modes. In particular consider the following simple distribution over pool samples and one validation sample. That is , and
Suppose we wish to predict by querying a subset of . In this case, the optimal strategy is to query and from which we can compute . However, existing algorithms value all possible queries equally. Because each has the same distribution, uncertainty sampling with entropy will behave randomly. If we set the parameters for BALD to be the joint distribution, conditioning on any single variable decreases the entropy slightly, but by the same amount for each query. MEZL and MELL will also behave randomly because no query by itself gives any information about .
An algorithm based on planning ahead by two queries will behave optimally for this task, but at a large computational burden. Furthermore, planning ahead by two queries will fail for a slightly more difficult distribution, such as the case where . More generally, if an algorithm only examines -wise marginals of the labeling distribution, we can always construct a distribution such that all queries appear equal to the algorithm, but the optimal strategy only requires queries to remove all uncertainty about the validation set.
Designing a non-myopic strategy with guarantees remains an interesting area for future research. We can extend expected error reduction to the batching scenario with the log likelihood loss. We wish to find a batch of size at most that maximizes:
| (26) |
It is straightforward to show that
It is possible to estimate via Monte Carlo dropout. However, optimization 26 is NP and is not a sub-modular. Therefore, finding an efficient approximation algorithm for 26 needs further investigation.
A.6 Analysis of MELL for Bayesian Linear Model
Consider the simple Bayesian linear model. Here, is a multivariate normal distribution where and and , , and assume that is positive-definite. For a given sample , the distribution of its label is
Therefore,
Then, we have
| (27) |
BALD selects the samples with highest mutual information between model parameters and the label of the sample. Therefore, BALD chooses the samples with highest for . This criterion is known in Bayesian Experimental Design literature; for instance Chaloner & Verdinelli (1995). Assume that the samples in pool is drawn from a continuous unbounded data distribution, then as where . For instance, if the underlying distribution for the pool data set is Gaussian then we can use the properties of the maxima of Gaussian distribution in Hartigan (2014) and show that111Here, means that there exists positive constants , and such that for all .
which implies that if is the selected sample by BALD, then as .
MELL selects the samples with highest mutual information between the sample’s label and the labels of the validation set. Let be the candidate sample and is a sample drawn from validation set with corresponding labels and . The labels for these two samples are jointly Gaussian and one can easily show that , and . So the correlation between these two r.v. can be derived by
| (28) |
Using the mutual information formula for jointly-Gaussian distribution, we can show that
| (29) |
For small enough ,
Therefore, MELL selects the most correlated samples with the validation set, in contrast to BALD which is selecting samples with the largest norm.
Recall from decomposition 20, we have
| (30) |
In the next proposition, we show that the first term of right hand side is bounded and the second term goes to infinity for large enough . As we mentioned earlier, the selected samples by BALD as if are drawn from an unbounded distribution. So the irreverent information term (second term) in decomposition 30 dominants the BALD sampling objective and thus samples with the largest norm are selected. In contrast, the MELL objective is the relevant mutual information (first term) in decomposition 30, thus it is not confused by samples from the pool with large magnitude.
Proposition 2.
Let be a linear Bayesian model where and are independent. Then, there exists constant such that
for all . Furthermore, for large enough .
Remark.
We show that
Proof.
Given that and , we have
| (31) |
for every . Here we use the independence assumption between parameters and noise. Letting , observe that
Using Inequality 31, we can conclude that
Observe that , and . Thus,
Taking from both sides and using the fact that , we have
By taking the expectation and using Equation 29, we can conclude that
for all . The second part of the proposition is a direct result of decomposition 30 and the observation that for linear model. ∎