AdaK-NER: An Adaptive Top- Approach
for Named Entity Recognition with Incomplete Annotations
Abstract
State-of-the-art Named Entity Recognition (NER) models rely heavily on large amounts of fully annotated training data. However, accessible data are often incompletely annotated in the industry like Financial Technology. Normally the unannotated tokens are regarded as non-entities by default, while we underline that these tokens could either be non-entities or part of any entity. Here, we study NER modeling with incomplete annotated data where only a fraction of the named entities are labeled, and the unlabeled tokens are equivalently multi-labeled by every possible label. Taking multi-labeled tokens into account, the numerous possible paths can distract the training model from the gold path (ground truth label sequence), and thus hinders the learning ability. In this paper, we propose AdaK-NER, named the adaptive top- approach, to help the model focus on a smaller feasible region where the gold path is more likely to be located. We demonstrate the superiority of our approach through extensive experiments on both English and Chinese datasets, averagely improving in F-score on the CoNLL-2003 and over on two Chinese datasets from Financial Technology compared with the prior state-of-the-art works.
1 Introduction
Named Entity Recognition (NER) Li et al. (2020); Sang and De Meulder (2003); Peng et al. (2019) is a fundamental task in Natural Language Processing (NLP). NER task aims at recognizing the meaningful entities occurring in the text, which can benefit various downstream tasks, such as question answering Cao et al. (2019), event extraction Wei et al. (2020), and opinion mining Poria et al. (2016). Especially, by detecting relevant entities in Financial Technology, NER helps financial professionals efficiently leverage the information of news, which is paramount in making high-quality decisions.
Strides in statistical models, such as Conditional Random Field (CRF) Lafferty et al. (2001) and pre-trained language models like BERT Devlin et al. (2018), have equipped NER with new learning principles Li et al. (2020). Pre-trained model with rich representation ability can discover hidden features automatically while CRF can capture the dependencies between labels with the BIO or BIOES tagging scheme.
However, most existing methods rely on large amounts of fully annotated information for training NER models Li et al. (2020); Jia et al. (2020). Fulfilling such requirements is expensive and laborious in the industry like Financial Technology. Annotators, are not likely to be fully equipped with comprehensive domain knowledge, only annotate the named entities they recognize and let the others off, resulting in incomplete annotations. They typically do not specify the non-entity Surdeanu et al. (2010), so that the recognized entities are the only available annotations. Figure 1(a) shows examples of both gold path111A path is a label sequence for a given sentence. and incomplete path.
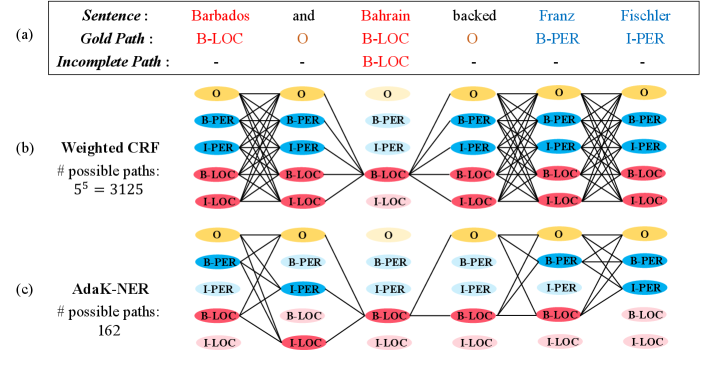
For corpus with incomplete annotations, each unannotated token can either be part of an entity or non-entity, making the token equivalently multi-labeled by every possible label. Since conventional CRF algorithms require fully annotated sentences, a strand of literature suggests assigning weights to possible labels Shang et al. (2018); Jie et al. (2019). Fuzzy CRF Shang et al. (2018) focused on filling the unannotated tokens by assigning equal probability to every possible path. Further, Jie Jie et al. (2019) introduced a weighted CRF method to seek a more reasonable distribution for all possible paths, attempting to pay more attention to those paths with high potential to be gold path.
Ideally, through comprehensive learning on distribution, the gold path can be correctly discovered. However, this perfect situation is difficult to achieve in practical applications. Intuitively, taking all possible paths into consideration will distract the model from the gold path, as the feasible region (the set of possible paths where we search for the gold path) grows exponentially with the length of the unannotated tokens increasing, which might cause failure to identify the gold path.
To address this issue, one promising direction is to prune the size of feasible region during training. We assume the unknown gold path is among or very close to the top- paths with the highest possibilities. Specifically, we utilize a novel adaptive -best loss to help the training model focus on a smaller feasible region where the gold path is likely to be located. Furthermore, once a path is identified as a disqualified sequence, it will be removed from the feasible region. This operation can thus drastically eliminate redundancy without undermining the effectiveness. For this purpose, a candidate mask is built to filter out the less likely paths, so as to restrict the size of the feasible region.
Trained in this way, our AdaK-NER overcomes the shortcomings of Fuzzy CRF and weighted CRF, resulting in a significant improvement on both precision and recall, and a higher score as well.
In summary, the contributions of this work are:
-
•
We present a -best mechanism for improving incomplete annotated NER, aiming to focus on the gold path effectively from the most possible candidates.
-
•
We demonstrate both qualitatively and quantitatively that our approach achieves state-of-the-art performance compared to various baselines on both English and Chinese datasets.
2 Proposed Approach
Let be a training sentence of length , token . Correspondingly, denotes the complete label sequence, . The NER problem can be defined as inferring based on .
Under the incomplete annotation framework, we introduce the following terminologies. A possible path refers to a possible complete label sequence consistent with the annotated tokens. For example, a possible incomplete annotated label sequence for can be , where token is annotated as and other missing labels are labeled as . with , is a possible path for , where all the missing labels are replaced by some elements in . Set denotes all possible complete paths for with incomplete annotation . is the available incompletely annotated dataset.
For NER task, CRF Lafferty et al. (2001) is a traditional approach to capture the dependencies between the labels by modeling the conditional probability of a label sequence given an input sequence of length as:
| (1) |
denotes the map from a pair of and to an arbitrary feature vector, is the model parameter, is the probability of predicted by the model. Once has been estimated via minimizing negative log-likelihood:
| (2) |
the label sequence can be inferred by:
| (3) |
The original CRF learning algorithm requires a fully annotated sequence , thus the incompletely annotated data is not directly applicable to it. Jie Jie et al. (2019) modified the loss function as follows:
| (4) |
where is an estimated distribution of all possible complete paths for .
We illustrate their model in (Figure 1b). Note that when is a uniform distribution, the above CRF model is Fuzzy CRF Shang et al. (2018) which puts equal probability to all possible paths in . Jie Jie et al. (2019) claimed that should be highly skewed rather than uniformly distributed, therefore they presented a -fold cross-validation stacking method to approximate distribution .
Nonetheless, as Figure 1(b) shows, a sentence with only words ( annotated, unannotated) have possible paths. We argued that identifying the gold path from all possible paths is like looking for a needle in a haystack. This motivates us to reduce redundant paths during training. We propose two major strategies (adaptive -best loss and candidate mask) to induce the model to focus on the gold path (Figure 1(c)), and two minor strategies (annealing technique and iterative sample selection) to further improve the model effectiveness in NER task. The workflow is summarized in Algorithm 1.
2.1 Adaptive -best Loss
Viterbi decoding algorithm is a dynamic programming technique to find the most possible path with only linear complexity, thus it could be used to predict a path for an input based on the parameters provided by the NER model. -best Viterbi decoding Huang and Chiang (2005) extends the original Viterbi decoding algorithm to extract the top- paths with the highest probabilities. In the incomplete data, the gold path is unknown. We hypothesize it is very likely to be the same with or close to one of the top- paths. This inspires us to introduce an auxiliary -best loss component to help the model focus on a smaller yet promising region. Weight is added to balance the weighted CRF loss and the auxiliary loss, and thus we modify (4) into:
| (5) | ||||
where represents the top- paths decoded by constrained -best Viterbi algorithm222The constrained decoding ensures the resulting complete paths are compatible with the incomplete annotations. with parameters , and is an adaptive weight coefficient.
2.2 Estimating with Candidate Mask
We divide the training data into folds and employ -fold cross-validation stacking to estimate for each hold-out fold Jie et al. (2019). We propose an interpolation mode to adjust by increasing the probabilities for paths with high confidence and decreasing for the others. The probability of each possible path is a temperature softmax of :
| (6) |
where denotes the temperature and is the model trained by holding out the -th fold. A higher temperature produces a softer probability distribution over the paths, resulting in more diversity and also more mistakes Hinton et al. (2015). We iterate the cross-validation until converges.
Jie Jie et al. (2019) estimated for each while the size of grows exponentially on the number of unannotated tokens in . To reduce the number of possible paths for estimation, we build candidate mask based on the -best candidates and the self-built candidates.
-best Candidates.
During the end of each iteration, we train a model on the whole training data . In the next iteration, we use the trained model to identify -best candidates set for each sample by constrained -best Viterbi decoding. contains top- possible paths with the highest probabilities, where .
Self-built Candidates.
In the current iteration, after training a model on folds, we use to predict a path for each sample in the hold-out fold, and extract entities from the predicted path. Then we merge all entities identified by models , resulting an entity dictionary . For each sample we conjecture that its named entities should lie in the dictionary . Consequently, in the next iteration we form a self-built candidate for each of length . is the corresponding entity label if the token is part of an entity in , otherwise is O label.
We utilize the above candidates (i.e., the -best candidates set and the self-built candidate ) to construct a candidate mask for . For each unannotated in , the possible label set consists of (1) O label (2) , (3) .
For example, as Figure 1(c) shows, the unannotated token ‘Barbados’ is predicted as B-PER and B-LOC in the above candidate paths, we treat B-PER, B-LOC and O label as the possible labels of ‘Barbados’ and mask the other labels.
With this masking scheme, we can significantly narrow down the feasible region of (Figure 1(c)) when estimating . After estimating , we can train a model through the modified loss:
| (7) | ||||
where contains the possible paths restricted by the candidate mask.
| Dataset | Train | Dev | Test | |||
|---|---|---|---|---|---|---|
| #entity | #sent | #entity | #sent | #entity | #sent | |
| CoNLL-2003 | ||||||
| Taobao | ||||||
| Youku | ||||||
2.3 Annealing Technique for
Intuitively, the top- paths decoded by the algorithm could be of poor quality at the beginning of training, because the model’s parameters used in decoding haven’t been trained adequately. Therefore, we employ an annealing technique to adapt during training as:
where is the current training step, is the total number of training steps, and is the hyper-parameter used to control the accelerated speed of . The coefficient increases rapidly at the latter half of the training, enforcing the model to extracting more information from the top- paths.
2.4 Iterative Sample Selection
Due to the incomplete annotation, there exist some samples whose distributions are poorly estimated. We use an idea of sample selection to deal with these samples. In each iteration, after training a model on folds, we utilize to decode a most possible path for , and assign a probability score to at the meantime. Iterative sample selection is to select the samples with probability scores beyond a threshold to construct new training data, which are used in the training phase of -fold cross-validation in the next iteration (more Algorithm details can be found in Algorithm 1). We use this strategy to help model identify the gold path effectively with high-quality samples.
3 Experiments
3.1 Dataset
To benchmark AdaK-NER against its SOTA alternatives in realistic settings, we consider one standard English dataset and two Chinese datasets from Financial Technology Industry: () CoNLL-2003 English Sang and De Meulder (2003): annotated by person (PER), location (LOC) and organization (ORG) and miscellaneous (MISC). () Taobao333http://www.taobao.com: a Chinese e-commerce site. The model type (PATTERN), product type (PRODUCT), brand type (BRAND) and the other entities (MISC) are recognized in the dataset. () Youku444http://www.youku.com: a Chinese video-streaming website with videos from various domains. Figure type (FIGURE), program type (PROGRAM) and the others (MISC) are annotated. Statistics for datasets are presented in Table 1.
We randomly remove a proportion of entities and all O labels to construct the incomplete annotation, with representing the ratio of entities that keep annotated. We employ two schemes for removing entities:
- •
-
•
Entity-based Scheme is removing all occurrences of a randomly selected entity until the desired amount remains Mayhew et al. (2019); Effland and Collins (2021); Wang et al. (2019). For example, if the entity ‘Bahrain’ is selected, then every occurrence of ‘Bahrain’ will be removed. This slightly complicated scheme matches the situation that some entities in a special domain could not be recognized by non-expert annotators.
According to the low recall of entities tagged by non-speaker annotators in Mayhew Mayhew et al. (2019), we set and in our experiments.
3.2 Experiment Setup
Evaluation Metrics.
We consider the following performance metrics: Precision (), Recall (), and balanced F-score (). These metrics are calculated based on the true entities and the recognized entities. score is the main metric to evaluate the final NER models of baselines and our approach.
| Ratio | Model | CoNLL-2003 | Taobao | Youku | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BERT CRF | ||||||||||
| BERT Fuzzy CRF | ||||||||||
| BERT weighted CRF | ||||||||||
| AdaK-NER | ||||||||||
| BERT CRF | ||||||||||
| BERT Fuzzy CRF | ||||||||||
| BERT weighted CRF | ||||||||||
| AdaK-NER | ||||||||||
| BERT CRF | ||||||||||
| Ratio | Model | CoNLL-2003 | Taobao | Youku | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BERT CRF | ||||||||||
| BERT Fuzzy CRF | ||||||||||
| BERT weighted CRF | ||||||||||
| AdaK-NER | ||||||||||
| BERT CRF | ||||||||||
| BERT Fuzzy CRF | ||||||||||
| BERT weighted CRF | ||||||||||
| AdaK-NER | ||||||||||
| BERT CRF | ||||||||||
Baselines.
We consider several strong baselines to compare with the proposed methods, including BERT with conventional CRF (or CRF for abbreviation) Lafferty et al. (2001), BERT with Fuzzy CRF Shang et al. (2018), and BERT with weighted CRF presented by Jie Jie et al. (2019). CRF regards all unannotated tokens as O label to form complete paths, while Fuzzy CRF treats all possible paths compatible with the incomplete path with equal probability. Weighted CRF assigns an estimated distribution to all possible paths derived from the incomplete path to train the model.
Training details.
We employ BERT model Devlin et al. (2018) as the neural architecture for baselines and our AdaK-NER. Specifically, we use pretrained Chinese BERT with whole word masking Cui et al. (2019) for the Chinese datasets and pretrained BERT with case-preserving WordPiece Devlin et al. (2018) for CoNLL-2003 English dataset. Unless otherwise specified, we set the hyperparameter over [top ] as 5 by default for illustrative purposes. Based on the fact that a larger -fold value has a negligible effect Jie et al. (2019), we choose to split the training data into folds (i.e., ). We initialize distribution by assign each unannotated token as O label to form complete paths, and iteratively updated by k-fold cross-validation stacking. Empirically, we set the iteration number to 10, which is enough for our model to converge.
3.3 Experimental Results
To validate the utility of our model, we consider a wide range of real-world tasks experimentally with entity keeping ratio and . We present the results with Random-based Scheme in Table 2 and Entity-based Scheme in Table 3. We compare the performance of our method to other competing solutions, with each baseline carefully tuned to ensure fairness. In all cases, CRF has high precision and low recall because it labels all the unannotated tokens as O label. In contrast, taking all possible paths into account yields the mismatch of the gold path, hence Fuzzy CRF recalls more entities. Weighted CRF outperforms CRF and Fuzzy CRF, indicating that distribution should be highly skewed rather than uniformly distributed.
With adaptive -best loss, candidate mask, annealing technique and iterative sample selection approach, our approach AdaK-NER performs strongly, exhibits high precision and high recall on all datasets and gives best results in score over the other three models. The improvement is especially remarkable on Chinese Taobao and Youku datesets for , as it delivers over and increase in score with Random-based Scheme, while over and increase with Entity-based Scheme.
Note that in CoNLL-2003 and Youku, the score of AdaK-NER with Random-based Scheme is only roughly lower than that of CRF trained on complete data (), while we build AdaK-NER on the training data with only entities available (). In the other Chinese dataset, our model also achieves encouraging improvement compared to the other methods and presents a step toward more accurate incomplete named entity recognition.
Entity-based Scheme is more restrictive, however, our model still achieves best score compared with other methods. The overall results show AdaK-NER achieves state-of-the-art performance compared to various baselines on both English and Chinese datasets with incomplete annotations.
| Model | CoNLL-2003 | Taobao | Youku | ||||||
|---|---|---|---|---|---|---|---|---|---|
| w/o -best loss | |||||||||
| w/o weighted loss | |||||||||
| w/o annealing | |||||||||
| w/o -best candidates | |||||||||
| w/o self-built candidates | |||||||||
| w/o candidate mask | |||||||||
| w/o sample selection | |||||||||
| AdaK-NER | |||||||||
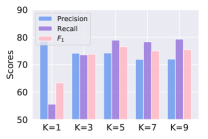
The Effect of .
As discussed in Section 2.1 and 2.2, the parameter can affect the learning procedure from two aspects. We compare the performance of different on Taobao dataset with Random-based Scheme and . The hyperparameter over [top ] is selected from on the validation set. As illustrated in Figure 2, a relatively large delivers better empirical results, and the metrics (precision, recall and ) are pretty close when . Meanwhile, a smaller can narrow down the possible paths more effectively in theory. Hence we favor which might be a balanced choice.
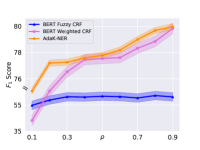
The Effect of .
We further examine annotation rate () interacts with learning. We plot score on Taobao dataset with Random-based Scheme across varying annotation rate in Figure 2. The annotation removed with large inherits the annotation removed with the small . All the performance deliver better results with the increase of . Our model consistently outperforms weighted CRF and Fuzzy CRF, and the improvement is significant when is relatively small, which indicates our model is especially powerful when the annotated tokens are fairly sparse.
3.4 Ablation Study
To investigate the effectiveness of the proposed strategies used in AdaK-NER, we conduct the following ablation with Random-based Scheme and . As shown in Table 4, the adaptive -best loss contributes most to our model on the three datasets. It helps our model achieve higher recall while preserving acceptable precision. Especially on Youku dataset, removing it would cause a significant drop on recall by . The weighted CRF loss is indispensable, and annealing method could help our model achieve better results. Candidate mask is attributed to promote precision while keeping high recall. Both -best candidates and self-built candidates facilitate the model performance. Iterative sample selection makes a positive contribution to our model on CoNLL-2003 and Taobao, whereas it slightly hurts the performance on Youku. In general, incorporating these techniques enhances model performance on incomplete annotated data.
4 Related Works
Pre-trained Language Models
has been an emerging direction in NLP since Google launched BERT Devlin et al. (2018) in 2018. With the powerful Transformer architecture, several pre-trained models, such as BERT and generative pre-training model (GPT), and their variants have achieved state-of-the-art performance in various NLP tasks including NER Devlin et al. (2018); Liu et al. (2019). Yang Yang et al. (2019) proposed a pre-trained permutation language model (XLNet) to overcome the limitations of denoising autoencoding based pre-training. Liu Liu et al. (2019) demonstrated that more data and more parameter tuning could benefit pre-trained language models, and released a new pre-trained model (RoBERTa). To follow the trend, we use BERT as our neural model in this work.
Statistical Modeling
has been widely employed in sequence labeling. Classical models learn label sequences through graph-based representation, with prominent examples such as Hidden Markov Model (HMM), Maximum Entropy Markov Models (MEMM) and Conditional Random Fields (CRF) Lafferty et al. (2001). Among them, CRF is an optimal model, since it resolves the labeling bias issue in MEMM and doesn’t require the unreasonable independence assumptions in HMM. However, conventional CRF is not directly applicable to the incomplete annotation situation. Ni Ni et al. (2017) select the sentences with the highest confidence, and regarding missing labels as O. Another line of work is to replace CRF with Partial CRF Nooralahzadeh et al. (2019); Huang et al. (2019) or Fuzzy CRF Shang et al. (2018), which assign unlabeled words with all possible labels and maximize the total probability Yang et al. (2018). Although these works have led to many promising results, they still need external knowledge for high-quality performance. Jie Jie et al. (2019) presented a weighted CRF model which is most closely related to our work. They estimated a proper distribution for all possible paths derived from the incomplete annotations. Our work enhances Fuzzy CRF by reducing the possible paths by a large margin, aiming to better focus on the gold path.
5 Conclusion
In this paper, we explore how to build an effective NER model by only using incomplete annotations. We propose two major strategies including introducing a novel adaptive -best loss and a mask based on -best candidates and self-built candidates to help our model better focus on the gold path. The results show that our approaches can significantly improve the performance of NER model with incomplete annotations.
References
- Cao et al. [2019] Yu Cao, Meng Fang, and Dacheng Tao. Bag: Bi-directional attention entity graph convolutional network for multi-hop reasoning question answering. arXiv preprint arXiv:1904.04969, 2019.
- Cui et al. [2019] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. Cross-lingual machine reading comprehension. arXiv preprint arXiv:1909.00361, 2019.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Effland and Collins [2021] Thomas Effland and Michael Collins. Partially supervised named entity recognition via the expected entity ratio loss. arXiv preprint arXiv:2108.07216, 2021.
- Hinton et al. [2015] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Huang and Chiang [2005] Liang Huang and David Chiang. Better k-best parsing. In Proceedings of the Ninth International Workshop on Parsing Technology, 2005.
- Huang et al. [2019] Xiao Huang, Li Dong, Elizabeth Boschee, and Nanyun Peng. Learning a unified named entity tagger from multiple partially annotated corpora for efficient adaptation. arXiv preprint arXiv:1909.11535, 2019.
- Jia et al. [2020] Chen Jia, Yuefeng Shi, Qinrong Yang, and Yue Zhang. Entity enhanced bert pre-training for chinese ner. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6384–6396, 2020.
- Jie et al. [2019] Zhanming Jie, Pengjun Xie, Wei Lu, Ruixue Ding, and Linlin Li. Better modeling of incomplete annotations for named entity recognition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 729–734, 2019.
- Lafferty et al. [2001] John Lafferty, Andrew McCallum, and Fernando CN Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. 2001.
- Li et al. [2020] Xiaonan Li, Hang Yan, Xipeng Qiu, and Xuanjing Huang. Flat: Chinese ner using flat-lattice transformer. arXiv preprint arXiv:2004.11795, 2020.
- Li et al. [2021] Yangming Li, lemao liu, and Shuming Shi. Empirical analysis of unlabeled entity problem in named entity recognition. In International Conference on Learning Representations, 2021.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Mayhew et al. [2019] Stephen Mayhew, Snigdha Chaturvedi, Chen-Tse Tsai, and Dan Roth. Named entity recognition with partially annotated training data. arXiv preprint arXiv:1909.09270, 2019.
- Ni et al. [2017] Jian Ni, Georgiana Dinu, and Radu Florian. Weakly supervised cross-lingual named entity recognition via effective annotation and representation projection. arXiv preprint arXiv:1707.02483, 2017.
- Nooralahzadeh et al. [2019] Farhad Nooralahzadeh, Jan Tore Lønning, and Lilja Øvrelid. Reinforcement-based denoising of distantly supervised ner with partial annotation. Association for Computational Linguistics, 2019.
- Peng et al. [2019] Minlong Peng, Xiaoyu Xing, Qi Zhang, Jinlan Fu, and Xuanjing Huang. Distantly supervised named entity recognition using positive-unlabeled learning. arXiv preprint arXiv:1906.01378, 2019.
- Poria et al. [2016] Soujanya Poria, Erik Cambria, and Alexander Gelbukh. Aspect extraction for opinion mining with a deep convolutional neural network. Knowledge-Based Systems, 108:42–49, 2016.
- Sang and De Meulder [2003] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050, 2003.
- Shang et al. [2018] Jingbo Shang, Liyuan Liu, Xiang Ren, Xiaotao Gu, Teng Ren, and Jiawei Han. Learning named entity tagger using domain-specific dictionary. arXiv preprint arXiv:1809.03599, 2018.
- Surdeanu et al. [2010] Mihai Surdeanu, Ramesh Nallapati, and Christopher Manning. Legal claim identification: Information extraction with hierarchically labeled data. In Workshop Programme, page 22, 2010.
- Wang et al. [2019] Zihan Wang, Jingbo Shang, Liyuan Liu, Lihao Lu, Jiacheng Liu, and Jiawei Han. Crossweigh: Training named entity tagger from imperfect annotations. arXiv preprint arXiv:1909.01441, 2019.
- Wei et al. [2020] Qiang Wei, Zongcheng Ji, Zhiheng Li, Jingcheng Du, Jingqi Wang, Jun Xu, Yang Xiang, Firat Tiryaki, Stephen Wu, Yaoyun Zhang, et al. A study of deep learning approaches for medication and adverse drug event extraction from clinical text. Journal of the American Medical Informatics Association, 27(1):13–21, 2020.
- Yang et al. [2018] Yaosheng Yang, Wenliang Chen, Zhenghua Li, Zhengqiu He, and Min Zhang. Distantly supervised ner with partial annotation learning and reinforcement learning. In Proceedings of the 27th International Conference on Computational Linguistics, pages 2159–2169, 2018.
- Yang et al. [2019] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pages 5753–5763, 2019.