Adaptive Convolution for CNN-based Speech Enhancement Models
Abstract
Deep learning-based speech enhancement methods have significantly improved speech quality and intelligibility. Convolutional neural networks (CNNs) have been proven to be essential components of many high-performance models. In this paper, we introduce adaptive convolution, an efficient and versatile convolutional module that enhances the model’s capability to adaptively represent speech signals. Adaptive convolution performs frame-wise causal dynamic convolution, generating time-varying kernels for each frame by assembling multiple parallel candidate kernels. A Lightweight attention mechanism leverages both current and historical information to assign adaptive weights to each candidate kernel, guiding their aggregation. This enables the convolution operation to adapt to frame-level speech spectral features, leading to more efficient extraction and reconstruction. Experimental results on various CNN-based models demonstrate that adaptive convolution significantly improves the performance with negligible increases in computational complexity, especially for lightweight models. Furthermore, we propose the adaptive convolutional recurrent network (AdaptCRN), an ultra-lightweight model that incorporates adaptive convolution and an efficient encoder-decoder design, achieving superior performance compared to models with similar or even higher computational costs.
Index Terms:
Speech enhancement, adaptive convolution, kernel attention, convolutional neural networks.I Introduction
Speech enhancement (SE) aims to improve the quality and intelligibility of speech signals contaminated by background noise. It serves as a critical front-end processing task for various applications, including mobile communications, teleconferencing, earphones, hearing aids, and automatic speech recognition systems [1]. Traditional SE methods [2, 3], primarily based on signal processing techniques, usually struggle in non-stationary noise conditions. Over the past decade, deep learning-based methods have demonstrated remarkable success in addressing diverse and complex acoustic scenarios by leveraging deep neural networks (DNNs) to recover clean speech in an end-to-end manner. However, the superior performance of DNN-based methods is typically accompanied by high computational complexity and large model sizes. Most state-of-the-art (SOTA) models [4, 5] require considerable computational resources, often involving billions of multiply-accumulate (MAC) operations per second, which limits their deployment on resource-constrained edge devices. While many lightweight SE models suitable for real-time applications [6, 7] have been proposed in recent years, they may encounter performance degradation in challenging acoustic environments.
Convolutional neural networks (CNNs) have been widely utilized in SE tasks, particularly as encoder-decoder architectures for extracting and reconstructing speech features. Convolutional recurrent network (CRN) [8] operates in the time-frequency domain, employing a convolutional encoder-decoder and recurrent neural network (RNN) to capture local spectrogram patterns and model the dependence between consecutive frames. Deep complex CRN (DCCRN) [9] enhances the performance of CRN by incorporating complex-valued operations to better handle the phase information of speech signals. Dual-path CRN (DPCRN) [10] extends the CRN architecture by integrating dual-path RNN (DPRNN) [11], improving the modeling of spectral patterns within individual frames. DeepFilterNet [12, 13] achieves two-stage enhancement of envelope and periodic components through two encoder-decoders combined with deep filtering technique.
Recently, the development of several ultra-lightweight models with computational complexity below 100 MMACs has demonstrated the potential of lightweight CRN architectures in effectively addressing the challenges posed by complex acoustic conditions. Grouped temporal CRN (GTCRN) [7] efficiently simplifies DPCRN by incorporating grouped strategies and introduces subband feature extraction (SFE) and temporal recurrent attention (TRA) modules to boost performance. Another network proposed in [14], FSPEN, utilizes fullband and subband encoder-decoder alongside an inter-frame path extension approach to improve feature extraction and modeling efficiency with a low computational cost. ULCNet [15] adopts a two-stage processing framework, incorporating channel-wise feature reorientation and a modified power-law compression technique to achieve both reduced computational costs and enhanced speech quality. Moreover, LiSenNet [16] leverages various modules and techniques, including subband convolution, convolutional gated linear unit, noise detection, and phase refinement, to optimize its lightweight design.
The design of convolutional blocks is a critical aspect of CRN-based model development. For lightweight SE models, convolutional encoder-decoder designs often emphasize leveraging fullband and subband features of speech spectrums [14, 16], while paying less attention to the general architectural design of convolutional blocks. In contrast, the design of CNNs has been extensively explored in the field of computer vision (CV). ResNet [17] introduces a residual block specifically designed for deeper networks, providing a refined convolutional block structure. MobileNetV2 [18] proposes the inverted residual block, reducing parameters and computational complexity with minimal accuracy loss. ConvNeXt [19] further “modernized” the ResNet architecture, enabling CNNs to rival or even outperform Transformer-based models in certain tasks. Additionally, recent research [20] highlights the potential of the “star operation” (element-wise multiplication), which underpins the design of StarNet, achieving high performance with low latency.
The most straightforward way to increase a model’s capacity is to increase its width and depth, i.e., by adding more channels and layers. However, this approach inevitably results in a significant increase in computational complexity. Dynamic convolution (DyConv) [21] is an effective method to address this challenge. It enhances the representation capability of models by dynamically aggregating multiple parallel candidate convolution kernels based on input-dependent attentions, without increasing the network’s depth or width. Due to the utilization of lightweight attention mechanism, DyConv introduces minimal computational overhead at the expense of an increased number of parameters. ParameterNet [22] leverages this characteristic to improve model’s capacity, addressing the challenge that models with low computational cost cannot benefit from large-scale pretraining in vision and language tasks. Omni-dimensional dynamic convolution (ODConv) [23] improves the attention mechanism by applying complementary attention across spatial, channel, filter, and candidate kernel dimensions of the kernel space, achieving comparable performance to DyConv with fewer candidate kernels. KernelWarehouse [24] generalizes dynamic convolution further, achieving an effective trade-off between parameter efficiency and representation capability.
Dynamic convolution is initially designed for CV tasks, where it aggregates information from an entire image to compute kernel attention weights, resulting in a fixed kernel configuration at the image level rather than the pixel level [21]. This design presents challenges when applied to SE tasks. Specifically, performing dynamic convolution on the spectrogram of an entire utterance introduces non-causality, making it unsuitable for real-time applications. Moreover, for highly non-stationary noisy speech, an utterance-level kernel configuration may be suboptimal for different signal segments or frames. One intuitive understanding is that the optimal convolution kernels for speech frames and noise frames are likely to differ significantly. Therefore, it is essential to develop causal dynamic convolution capable of adapting to the frame-level local features of the signal.
In this paper, we introduce adaptive convolution, a frame-wise causal dynamic convolution mechanism. Adaptive convolution generates time-varying kernels for each frame rather than relying on a fixed kernel configuration across different input features. Given that convolution kernels can be regarded as filters, the proposed method is analogous to adaptive filtering, as both approaches adjust filter coefficients in real time based on the statistical characteristics of the input signal. Note that the proposed method differs from the adaptive convolution commonly used in CV. In typical CV applications [25, 26, 27], adaptive convolution calculates the kernels at each spatial position across the entire feature map using modules with complex structures, which leads to a significant increase in computational overhead. In contrast, our low-complexity adaptive convolution performs frame-level kernel assembling, allowing for better utilization of the time-varying features of speech, where all frequency bins within an individual frame share the same kernel. Moreover, kernel generation of the adaptive convolution in CV often relies on external, task-specific information, whereas ours is directly guided by the input features.
The adaptive convolution kernel is obtained by aggregating multiple parallel candidate kernels through frame-level attention weights derived from input features. This enables the convolution operation to adapt to frame-level speech spectral features, facilitating more efficient feature extraction and reconstruction. The attention mechanism plays a critical role in ensuring the effectiveness of adaptive convolution. We explore several channel modeling approaches for kernel attention, including more lightweight single-frame and multi-frame modeling, as well as higher-performance temporal modeling. Additionally, for convolutional blocks composed of multiple depthwise and pointwise convolution layers, we propose a multi-head mechanism to jointly generate kernel attention for these layers. This mechanism can also simultaneously generate optional input and output temporal channel attention maps, further enhancing the capability to model non-stationary speech signals.
To validate its effectiveness, we conduct extensive experiments on several CNN-based models of diverse structures and scales, including DPCRN [10] of different sizes, DCCRN [9], GTCRN [7], and LiSenNet [16], by replacing vanilla convolutions with adaptive convolutions. Experimental results demonstrate that adaptive convolution is an efficient and versatile convolutional module that significantly enhances the performance of various models, particularly those with lower computational burdens. Although adaptive convolution increases the number of parameters, the resulting increment in computational complexity, which is more crucial for many applications, is negligible. Moreover, the results reveal that increasing the number of candidate convolution kernels can further improve model performance. Ablation experiments also highlight the advantages of the proposed adaptive convolution over non-causal, utterance-level dynamic convolution, underscoring the importance of frame-wise kernel adjustment. Additionally, by visualizing the kernel attention weights, we clearly demonstrate that adaptive convolution can effectively assign appropriate candidate kernels to frames with varying spectral features.
To further illustrate the practical value of the proposed adaptive convolution, we propose an ultra-lightweight model, adaptive convolution recurrent network (AdaptCRN). Inspired by ConvNeXt [19] and StarNet [20] blocks, we design a lightweight and efficient encoder-decoder architecture that integrates adaptive convolution. We also incorporate strategies such as grouped RNN [7, 28] and spectral compression to further enhance performance and reduce model scale. Experimental results show that AdaptCRN achieves competitive performance with only 38M MACs per second and 135K parameters, outperforming several other SOTA lightweight models with similar or even significantly higher computational cost.
This paper is organized as follows: Section II reviews the dynamic convolution. Section III introduces the proposed adaptive convolution, detailing its attention mechanism and implementation. Section IV presents the proposed ultra-lightweight model, AdaptCRN. Section V describes the experimental setup. Section VI reports the experimental results, verifying the effectiveness and generalization of adaptive convolution, evaluating the performance of AdaptCRN, and visualizing the relationship between the kernel attention of adaptive convolution and speech spectral features. Finally, Section VII draws the conclusions of the paper.
II Related work
II-A Dynamic Convolution
DyConv [21] is an effective method to enhance the representation capability of models with negligible additional computational complexity. It employs input-dependent dynamic kernels instead of static counterparts, making the kernels nonlinear functions of the input features. The dynamic kernels are generated by aggregating a set of parallel candidate kernels with identical kernel size and input/output channels . The kernel aggregation is guided by the attention weights and can be expressed as
| (1) |
where represents the resulting dynamic kernel, is the number of candidate kernels, denotes the -th candidate kernel consisting of filters , and is the attention weight assigned to . The attention weights are computed using a squeeze-and-excitation mechanism. Specifically, global spatial information is first compressed through global average pooling (GAP), followed by a fully connected (FC) layer, a rectified linear unit (ReLU) activation, another FC layer, and a softmax function. Due to the small size of the convolution kernels and the lightweight nature of the attention mechanism, DyConv is computationally efficient at the cost of an increased number of parameters. Dynamic convolution similarly handles bias, but for simplicity, this detail is not included in the formulas.
The softmax function ensures that the attention weights sum to one, as expressed by . This normalization helps constrain the kernel space, facilitating the learning of the attention model. During training, candidate kernels with low attention weights are often difficult to optimize. To address this, DyConv incorporates temperature annealing in the softmax function, encouraging a near-uniform attention distribution in the early training stages. Specifically, the features are scaled by a temperature coefficient, which varies during training, before applying the softmax function. A higher temperature produces a flatter distribution of attention weights, facilitating the learning of all kernels. As training progresses, the temperature is gradually reduced, allowing the model to assign more distinct attention weights and improving its ability to select the most relevant kernels.
II-B Omni-dimensional Dynamic Convolution
ODConv [23] introduces a multi-dimensional attention mechanism to enhance the performance of DyConv. It employs a parallel strategy to learn complementary attention weights for convolutional kernels across four dimensions of the kernel space: spatial, channel (input channel), filter (output channel), and candidate kernel dimensions. Specifically, in addition to kernel attention, ODConv assigns distinct attention weights, denoted as , , and , to different spatial locations, input channels, and output channels of the -th candidate kernel. It can be represented as
| (2) |
where denotes element-wise multiplication across different dimensions. The attention weights for each dimension are computed using a multi-head mechanism. The additional spatial, channel, and filter attention weights are all generated using the sigmoid function. For simple implementation, these weights can be shared across all candidate kernels, allowing the subscript of the corresponding attention descriptor in Eq. 2 to be omitted. By leveraging this refined kernel adjustment mechanism, ODConv achieves comparable or superior performance to standard DyConv while requiring fewer convolutional kernels and significantly fewer extra parameters.
III Adaptive Convolution
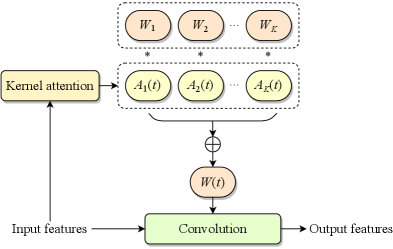
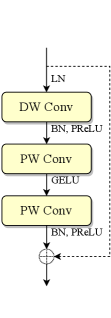
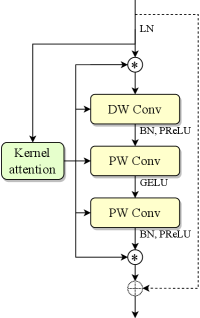
Performing dynamic convolution on the spectrogram of an entire utterance inevitably introduces non-causality, and the resulting kernels may fail to adapt to the significant differences between distinct signal segments or frames. Therefore, we propose adaptive convolution, a frame-wise causal dynamic convolution mechanism, which enables the convolution operation to adapt to frame-level speech spectral features. Similar to adaptive filtering, adaptive convolution dynamically adjusts the convolutional kernel in real time based on the statistical characteristics of the input signal. As depicted in Fig. 1(a), the adaptive kernel is generated by aggregating multiple parallel candidate kernels with frame-level attention weights derived from input features, represented as
| (3) |
where denotes the frame index, emphasizing the time-varying nature of the kernel. The adaptive kernel is then applied in a causal convolution with the features of the corresponding frame to produce the output. For simplicity, we keep the biases of the convolution layers static rather than adaptive.
III-A Kernel Attention
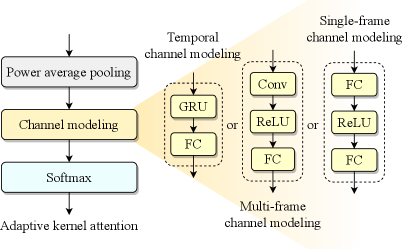
The attention mechanism is pivotal to the effectiveness of adaptive convolution, as it assigns attention weights to each parallel candidate kernel, determining the kernel composition for the current frame. As shown in Fig. 1(b), kernel attention aggregates the input features along the frequency dimension through power average pooling to derive the descriptor for the time-channel energy distribution, where represent the number of channels, frames and frequency bins, respectively. The corresponding pooling is formulated as
| (4) |
where and denote the channel and frequency bin indices, respectively. is subsequently processed through channel modeling and a softmax function to compute the time-varying attention weights for each candidate kernel. During training, we omit the temperature annealing strategy described in Section II-A for the softmax function, as our experiments indicate that it does not improve kernel optimization in adaptive convolution. This is likely because different candidate kernels dominate different frames, and the attention weights for many frames do not exhibit one-hot characteristics, eusuring sufficient optimization of all kernels even without temperature annealing.
For causal convolution, an intuitive channel modeling approach is to apply squeeze-and-excitation mechanism to the feature of the current frame. The compressed feature is processed through an FC layer, a ReLU activation, and another FC layer sequentially. Notably, in the deeper layers of the model, the single-frame channel modeling approach implicitly leverages historical information. This is because preceding layers, such as convolution layers with large temporal receptive fields and inter-frame RNNs, may have already incorporated information from previous frames. Additionally, we explore a multi-frame channel modeling approach, which consists of a stack of a one-dimensional (1-D) convolution layer, a ReLU activation, and an FC layer. The 1-D convolution explicitly incorporates information from previous frames, thereby extending the receptive field of channel modeling. Inspired by TRA [7], a lightweight temporal channel attention mechanism, we adopt a similar strategy by using gated recurrent unit (GRU) to model channel features along the time dimension. Specifically, a GRU followed by an FC layer is employed for temporal channel modeling. This leads to better utilization of inter-frame correlations, thus yielding more efficient adaptive kernels, albeit at the cost of introducing more parameters compared to single-frame modeling.
Benefiting from the lightweight design of kernel attention, adaptive convolution introduces negligible computational complexity to the model, which is critical in practical applications. However, this comes with an increase in parameters, as each adaptive convolution layer contains parallel candidate convolution kernels, resulting in a convolutional parameter count that is times the original.
III-B Joint Attention
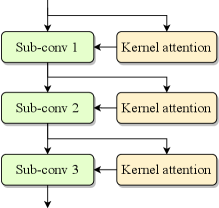
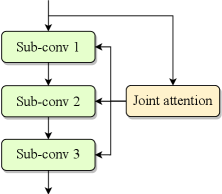
Efficient convolutional blocks, such as residual blocks [17] and ConvNeXt blocks [19], typically consist of multiple depthwise and pointwise convolution layers. Replacing each sub-layer with adaptive convolution results in the natural structure depicted in Fig. 1(c). Given the strong correlations and similarities among hidden features across sub-layers within an individual block, we propose a joint attention mechanism that generates kernel attention weights for multiple sub-layers simultaneously at the beginning of the block using a multi-head strategy. Fig. 1(d) showcases an example of joint multi-layer attention applied to a block with three sub-layers. Specifically, in the channel modeling stage, the final FC layer is replaced with multiple parallel heads, each producing the kernel attention weights for a specific sub-layer. To enhance computational efficiency, we adopt a highly parallelized implementation by increasing the output channels of the FC layer to , where is the number of sub-layers. The output feature is then split along the channel dimension to derive the kernel attention weights for each sub-layer. The joint multi-layer attention simplifies the model structure by computing the adaptive kernels for all sub-convolutions within a single attention layer. Additionally, it slightly reduces the model size and MACs, particularly in configurations that use temporal channel modeling.
Inspired by ODConv [23], the joint attention mechanism can be further extended to generate attention maps for other dimensions of the kernel space, including the input channel, output channel, and spatial dimensions. They are generated by adding attention heads, followed by sigmoid activation. These optional structures enable more precise adjustment of convolution kernels, enhancing their adaptability to the time-varying speech statistical characteristics.
III-C Multi-frame Parallelism
Adaptive convolution generates independent convolution kernels for each frame in a causal manner, preventing parallel computation across different frames of an utterence. While this limitation does not affect streaming inference, where frames are processed sequentially, it poses a challenge for parallel computing across all frames in an audio sample. In addition to explicitly implementing convolution through matrix multiplication, we propose two approaches to enable multi-frame parallelism.
The first approach involves converting kernel aggregation into the aggregation of convolution outputs. During training, the convolution results for each candidate kernel are computed first, whose results are then aggregated using kernel attention to produce the final output through a weighted sum. This process is mathematically equivalent to adaptive kernel aggregation, as demonstrated by
| (5) | |||
where and denote the input and output features of the -th frame, respectively, represents the output obtained by applying the -th candidate kernel independently, which can be computed in parallel as usual, and denotes the convolution operation. However, this method is restricted to the training stage due to the significantly increase in computational complexity, approximately times the original.
The second approach leverages grouped convolution to simulate streaming inference while enabling multi-frame parallelism without increasing computational complexity. Inspired by DyConv [21], which addresses parallelism issues for different images in a batch by merging the batch dimension into the channel dimension and assigning each image to a different group, we extend this concept to incorporate both batch and time dimensions. Specifically, an unfold operation is first performed along the time dimension of the input features with kernel size of , where denotes the size of the convolution kernel along the time dimension. This operation extracts a sliding window of features for each time step of the convolution. Subsequently, the batch and time dimensions are merged into the channel dimension, forming an input tensor of shape , where is the batch size. The reshaped input is then divided into groups, and convolution is performed with the assembled adaptive kernels.
IV AdaptCRN
Adaptive convolution achieves significant performance improvements with negligible increases in computational complexity, making it an effective component for ultra-lightweight models designed for real-time applications, which typically impose strict constraints on computational resources. Additionally, due to the inherently small parameter budgets of ultra-lightweight models, the total number of parameters remains within an acceptable range even when adaptive convolution is incorporated. Therefore, we propose the adaptive convolution recurrent network (AdaptCRN), an ultra-lightweight model that leverages adaptive convolution to enhance performance while maintaining efficiency.
IV-A Overall Architecture
AdaptCRN works in the short-time Fourier transform (STFT) domain and takes the spectral magnitude as well as the real and imaginary parts as input. Its architecture consists of a spectral compression module, an encoder with 5 layers of adaptive blocks, 2 grouped DPRNN modules, a decoder with 5 layers of adaptive blocks, and a spectral decompression module, as shown in Fig. 2(a). Skip connections are employed between corresponding layers of the encoder and decoder to facilitate optimization and alleviate information loss.
Grouped DPRNN [7] combines grouped RNN [28] and DPRNN [10, 11] to model spectral patterns in a single frame and inter-frame dependence within a certain frequency bin, while reducing the model complexity. Consistent with [7], we adopt grouped GRUs and eliminate representation rearrangement between time steps within the grouped RNN to improve efficiency. Furthermore, in our implementation, we remove the representation rearrangement after the grouped RNN, as the grouped RNN in DPRNN is directly followed by an FC layer, which inherently performs inter-group information fusion. Moreover, representation rearrangement is equivalent to swapping the rows of the FC layer’s weight matrix, which does not alter the final output.
The model predicts the spectral magnitude mask rather than the complex ratio mask (CRM). Our observations indicate that for trained ultra-lightweight models, the imaginary part of CRM is usually close to 0, making it effectively equivalent to a magnitude mask. To enhance mask learning across different frequency bins, we employ a learnable sigmoid function [16, 29] as the activation for the magnitude mask. Further details about the model are described in Secs. IV-B, IV-C, IV-D.

IV-B Spectral Compression
The spectral compression module comprises frequency dimension compression and dynamic range compression. For frequency dimension compression [7], low-frequency components below 2 kHz remain unaltered, while high-frequency bins above 2 kHz are downsampled using a triangular filter based on the equivalent rectangular bandwidth (ERB) scale. This retains crucial harmonic information in low-frequency bins while downsampling the frequency dimension. Dynamic range compression equalizes spectral energy, clarifies the spectral structure, and facilitates the model’s feature extraction. Specifically, logarithmic operation is applied to compress spectral magnitudes, while a magnitude power law is used to compress the real and imaginary parts. The specific spectral compression is formulated as
| (6) |
| (7) |
where denote the noisy spectrum and its real and imaginary parts, respectively, the superscript c represents the compressed features, and denotes the frequency dimension downsampling operation based on the ERB scale. For the compressed features, we employ the SFE module from [7] to integrate information from adjacent subbands into the channel dimension. The spectral decompression module upsamples the frequency dimension of the single-channel output of the decoder to produce the predicted mask. The decompression is achieved by applying the transpose of the frequency dimension downsampling matrix.
IV-C Adaptive Block
Inverted residual blocks, ConvNeXt blocks, and StarNet blocks are modern CNN designs that have been proven to be lightweight and efficient. These blocks share a similar structure comprising one depthwise convolution (DW Conv) layer and two pointwise convolution (PW Conv) layers. Inspired by these designs, we propose the basic block for AdaptCRN, as depicted in Fig. 2(b). The input features are first processed by layer normalization (LN) along the channel and frequency dimensions, which smooths the energy distribution and preserves spectral patterns across different channels and subbands. The element-wise affine transformation in LN acts as a set of fixed filters to preprocess spectral features. Subsequently, the features pass through a DW Conv layer followed by two PW Conv layers in sequence. Both the DW Conv and the second PW Conv are followed by batch normalization (BN) and parametric ReLU (PReLU) activation, while Gaussian error linear unit (GELU) activation is applied between the two PW Conv layers. We also consider the star operation from StarNet as a replacement for GELU, which is defined as , with the input features and the ReLU6 activation function. However, experimental results do not indicate a performance advantage over GELU. Additionally, when frequency dimension downsampling is not required, skip connections are employed to directly add the input features to the output features, mitigating information loss in deeper layers.
By incorporating adaptive convolution into the basic block, we derive the adaptive block, as illustrated in Fig 2(c). This block employs joint attention to generate both the input/output temporal channel attention maps and the adaptive kernel attention weights for the three sub-layers. Notably, adaptive convolution introduces high nonlinearity to the model, which is particularly evident when the activation function between the two PW Conv layers is removed. Typically, two PW Conv layers without activation can be reparameterized into a single layer, expressed as
| (8) |
where denote the kernels of the two PW Conv layers, respectively, and the bias term is omitted for simplicity, as its inclusion does not alter the result. However, with adaptive convolution, the reparameterization changes to
| (9) | |||
making two adaptive PW Conv layers with candidate kernels equivalent to a single layer with kernels. This observation inspires a trade-off between model size and computational complexity. By reducing the number of layers while increasing the number of candidate kernels, we can decrease computational overhead at the expense of increased parameters. Additionally, since the resulting kernels and their corresponding kernel attention weights are derived from two groups of kernels, they reside in a low-rank space relative to directly optimizing independent kernels. Consequently, the reparameterized results may exhibit slightly reduced performance compared to directly optimizing a single layer with kernels.
IV-D Loss Function
We apply the negative scale invariant SNR (SI-SNR) [30] loss and the power-compressed specturm loss as the loss functions, defined as
| (10) |
| (11) |
| (12) |
where and represent clean and enhanced waveforms, and are their corresponding spectrograms, the subscripts r, i represent the real and imaginary parts of the spectrograms, respectively, denotes the inner product operator, and represents the mean squared error (MSE). The overall loss function for model training is given by
| (13) | |||
where are the empirical weights.
V Experimental Setup
V-A Datasets
We evaluate our proposed methods on two datasets. The first dataset is constructed using clean and noise samples from the 5th Deep Noise Suppression Challenge (DNS5) dataset [31]. Clean and noise clips are mixed at random SNR levels ranging from -5 dB to 15 dB and scaled to random amplitudes ranging from 0.01 to 0.99 of the full scale to improve the model’s adaptation to magnitude dynamics. Approximately 200 hours of 10-second noisy-clean paired samples are generated for training, while 1,000 samples are generated for validation and testing, respectively. All utterances are resampled to 16 kHz for the experiments.
Additionally, we use the Voicebank+DEMAND dataset [32] to further evaluate the proposed ultra-lightweight model. It is a widely used benchmark for SE tasks, which contains paired clean and pre-mixed noisy speech. The training set comprises 11,572 utterances from 28 speakers, while the test set consists of 872 utterances from 2 speakers. SNR levels for training are set to 0, 5, 10, and 15 dB, and for testing, they are set to 2.5, 7.5, 12.5, and 17.5 dB. All utterances are downsampled from 48 kHz to 16 kHz.
V-B Baseline Models and Ablation Study
To evaluate the effectiveness of the proposed adaptive convolution, we integrate it into diverse models with varying scales and architectures, including DPCRN [10] of different sizes, DCCRN [9], GTCRN [7], and LiSenNet [16]. DPCRN, as a well-established baseline, serves as a foundational structure for modern CRN-based SE tasks. We utilize three scaled versions of DPCRN, denoted as DPCRN-light, DPCRN-middle, and DPCRN-large.
Ablation experiments are conducted on DPCRN-light to varify the effectiveness of the proposed channel modeling techniques and the joint channel and spatial attention mechanism. Additionally, we validate the advantage of frame-level kernel adjustment by comparing with utterance-level global dynamic convolution, which employs non-causal attention with global pooling. We further investigate the impact of expanding the kernel space by increasing the number of candidate kernels, as well as the performance of directly optimizing the kernels.
For the proposed AdaptCRN, ablation experiments are performed to validate the contributions of incorporating adaptive convolution, joint channel attention, joint multi-layer kernel attention, and dynamic range compression of input features. The nonlinearity introduced by adaptive convolution is validated through experiments on cascaded PW Conv layers and their equivalent single-layer structure. Moreover, by comparing AdaptCRN with DPCRN-light [10], DeepFilterNet [12], GTCRN [7], LiSenNet [16], ULCNet [15], and FSPEN [14], we demonstrate the superior performance of the proposed model.
V-C Implementation Details
The STFT is computed with a segment length of 32 ms, an overlap of 50%, a fast Fourier transform (FFT) length of 512, and a square-root Hanning window for analysis and synthesis. For adaptive convolution, the number of candidate kernels is set to 8, except in experiments specifically investigating its effect. The number of hidden channels for channel modeling is set to 32, while the convolution kernel size of the 1D-Conv used in multi-frame channel modeling is set to 3. Optional joint channel and spatial attention mechanisms are not used unless specified in ablation experiments.
For the three scaled versions of DPCRN, the number of DPRNN blocks is set to 2. The convolution kernel sizes for the encoder layers are configured as {(2,5), (2,3), (2,3), (2,3), (2,3)}, with frequency dimension strides of 2 for the first three layers and 1 for the last two layers. The number of output channels per layer is set to {16, 16, 16, 32, 32} for DPCRN-light, {32, 32, 32, 64, 64} for DPCRN-middle and {32, 32, 32, 64, 128} for DPCRN-large. The hidden dimensions of DPRNN are set to 32, 64, and 128, respectively. The decoder mirrors the configuration of the encoder. For GTCRN, LiSenNet, and DCCRN, the model hyperparameter settings remain consistent with their respective original papers, with the exception that the lookahead in the decoder of DCCRN is removed to ensure causality. For GTCRN, its main branch of the GT-Conv block contains three sub-layers and a TRA layer for generating the temporal channel attention map. When the vallina convolution are replaced with adaptive convolution, we employ joint multi-layer kernel attention to generate kernel attention weights for the three sub-layers, and the TRA is replaced with joint output channel attention to produce the temporal channel attention map.
For AdaptCRN, as detailed in Section IV-B, the amplitude, real part, and imaginary part of the noisy spectrum are fed into the spectral compression module. The first 65 low-frequency bands remain unaltered, while the 192 high-frequency bands are mapped to 64 bands. 9-channel, 129-dimensional features per frame are obtained using SFE with a kernel size of 3. The hidden channels of all adaptive blocks are set to 16, except in the final block, where the hidden channels between the two PW Convs are reduced to 4. In the encoder, the convolution kernel sizes of the first two layers are (1,5) with a frequency dimension stride of 2, while the last three layers use kernel sizes of (3,3) with a stride of 1. In the decoder, the last two layers employ depthwise transposed convolutions, with the remaining settings matching the encoder. The grouped DPRNN consists of 2 groups, with a frequency dimension of 33. The hidden channels of the intra-frame and inter-frame RNNs are set to 8 and 16, respectively. The single-channel output of the final adaptive block undergoes spectral decompression followed by a learnable sigmoid function to generate the amplitude mask.
All models are trained using the Adam optimizer with an initial learning rate of 0.001. For DNS5 dataset, 10,000 samples are randomly selected for training in each epoch, with a batch size of 8. For DPCRN-light, GTCRN, LiSenNet, DCCRN, and AdaptCRN, the learning rate is halved at epochs 120, 150, 170, 180, 190, and 200. For DPCRN-middle and DPCRN-large, the learning rate is halved if the validation loss does not decrease for 10 consecutive epochs. For the Voicebank+DEMAND dataset, a cosine annealing scheduler is employed for learning rate decay over 300 epochs with a minimum learning rate of 1e-5. All models are trained with the cost function described in Section IV-D, with , , and .
V-D Evaluation Metrics
We employ a set of commonly used speech objective metrics for evaluation, including SI-SNR [30], wide-band perceptual evaluation of speech quality (PESQ) [33], short-time objective intelligibility (STOI) [34] and its extended version (ESTOI) [35], and deep noise suppression mean opinion score (DNSMOS) [36]. DNSMOS is a non-intrusive speech quality metric, which provides three scores including speech quality (SIG), background noise quality (BAK), and overall quality (OVRL). Higher values indicate better performance for all metrics.
VI Experimental Results
VI-A Experimental Results for adaptive convolution
VI-A1 Ablation study results for kernel attention
Table I presents the results of ablation experiments conducted on DPCRN-light, exploring the configuration of kernel attention for adaptive convolution. In these experiments, the number of candidate convolution kernels is fixed at 8. The table reports trainable parameter numbers, MACs, and evaluation results on DNS5 test set for three channel modeling approaches: single-frame, multi-frame, and temporal channel modeling. The results demonstrate that the adaptive convolution with any channel modeling approach significantly outperforms the vanilla convolution across all metrics, achieving approximately a 0.1 gain in PESQ and a 0.05 improvement in DNSMOS-OVRL, with only a negligible increase in computational complexity. Among the three approaches, temporal channel modeling introduces more parameters but achieves the most substantial performance gains. This indicates that utilizing a GRU for temporal channel modeling effectively leverages historical information, enabling the generation of more suitable adaptive kernels for each frame.
Building on temporal channel modeling, we further investigate the impact of incorporating optional joint channel and spatial attention. The results in Table I reveal that adding joint channel attention alone yields an improvement in performance, with minimal additional parameters and computational cost. In contrast, adding spatial attention does not provide noticeable benefits. This suggests that joint channel attention can further calibrate signal energy at the frame level, enhancing the model’s performance.
Moreover, we evaluate the performance of utterance-level global dynamic convolution, where kernel attention is derived using global average power pooling across the entire spectrogram followed by a squeeze-and-excitation mechanism. The results show that its performance is comparable to adaptive convolution with single-frame channel modeling but is inferior to the other two channel modeling approaches, even though it employs a highly non-causal mechanism. This highlights the importance of frame-level kernel adjustments, which are more effective for modeling the time-varying feature of speech signals.
VI-A2 Number of candidate kernels
Table II reports the performance of adaptive convolution with varying numbers of candidate kernels applied to DPCRN-light on DNS5 test set, with configured as 4, 8, 16, 32, and 64. The results indicate that expanding the kernel space by increasing the number of candidate kernels is an effective strategy to improve performance. This observation provides a flexible approach to trading model parameters for enhanced performance, with only a minimal increase in computational complexity. However, the performance gains diminish as further increases. Specifically, increasing from 32 to 64 yields a slight decrease in DNSMOS, although PESQ improves by 0.02. This suggests that the efficiency of parameter utilization decreases as the kernel space expands, and the performance improvement from adaptive convolution may approach saturation.
Additionally, we investigate the scenario of directly optimizing the convolution kernel, where the kernel attention module predicts the full parameters of the convolution kernel rather than the weights for candidate kernels. While this approach may provide greater flexibility, it significantly increases computational complexity due to the large output dimension of the attention module, and its performance remains suboptimal. These results highlight the challenges of directly optimizing convolutional kernels and underscore the advantages of leveraging a weighted sum of candidate kernels.
| Para. (K) | MACs (M) | SI-SNR | ESTOI | PESQ | DNSMOS | |||
| OVRL | SIG | BAK | ||||||
| Noisy | - | - | 5.366 | 0.625 | 1.391 | 2.147 | 2.918 | 2.340 |
| Vanilla convolution | 80.78 | 194.57 | 14.431 | 0.752 | 2.313 | 2.910 | 3.197 | 4.018 |
| Globle dynamic convolution | 358.62 | 194.58 | 15.060 | 0.758 | 2.410 | 2.924 | 3.210 | 4.023 |
| Single-frame channel modeling | 358.62 | 195.44 | 14.924 | 0.761 | 2.390 | 2.946 | 3.229 | 4.034 |
| Multi-frame channel modeling | 378.21 | 196.67 | 14.956 | 0.762 | 2.406 | 2.957 | 3.239 | 4.038 |
| Temporal channel modeling | 410.21 | 198.79 | 15.147 | 0.765 | 2.427 | 2.964 | 3.246 | 4.040 |
| + Joint channel attention | 426.71 | 199.83 | 15.177 | 0.766 | 2.445 | 2.974 | 3.257 | 4.043 |
| + Joint spatial attention | 412.45 | 198.93 | 15.133 | 0.766 | 2.427 | 2.971 | 3.252 | 4.045 |
| + Joint channel/spatial attention | 428.95 | 199.97 | 15.192 | 0.766 | 2.445 | 2.970 | 3.253 | 4.040 |
| Number of candidate kernels | Para. (K) | MACs (M) | SI-SNR | ESTOI | PESQ | DNSMOS | ||
| OVRL | SIG | BAK | ||||||
| Noisy | - | - | 5.366 | 0.625 | 1.391 | 2.147 | 2.918 | 2.340 |
| Vanilla convolution | 80.78 | 194.57 | 14.431 | 0.752 | 2.313 | 2.910 | 3.197 | 4.018 |
| 257.59 | 198.70 | 14.900 | 0.759 | 2.401 | 2.946 | 3.227 | 4.039 | |
| 410.21 | 198.79 | 15.147 | 0.765 | 2.427 | 2.964 | 3.246 | 4.040 | |
| 715.44 | 198.96 | 15.172 | 0.766 | 2.437 | 2.976 | 3.258 | 4.045 | |
| 1325.90 | 199.30 | 15.278 | 0.769 | 2.453 | 2.982 | 3.266 | 4.043 | |
| 2546.83 | 199.99 | 15.280 | 0.770 | 2.472 | 2.979 | 3.262 | 4.042 | |
| Directly optimizing the kernels | 1353.17 | 277.25 | 15.139 | 0.767 | 2.451 | 2.969 | 3.252 | 4.042 |
| Model | Convolution | Para. (K) | MACs (M) | SI-SNR | ESTOI | PESQ | DNSMOS | ||
| OVRL | SIG | BAK | |||||||
| Noisy | - | - | - | 5.366 | 0.625 | 1.391 | 2.147 | 2.918 | 2.340 |
| GTCRN | Vanilla | 23.67 | 33.83 | 13.552 | 0.727 | 2.130 | 2.838 | 3.124 | 3.992 |
| Adaptive | 117.36 | 37.16 | 14.296 | 0.747 | 2.292 | 2.887 | 3.172 | 4.013 | |
| LiSenNet | Vanilla | 36.78 | 55.77 | 14.352 | 0.742 | 2.244 | 2.897 | 3.180 | 4.018 |
| Adaptive | 198.94 | 60.61 | 15.003 | 0.759 | 2.369 | 2.963 | 3.240 | 4.045 | |
| DPCRN-light | Vanilla | 80.78 | 194.57 | 14.431 | 0.752 | 2.313 | 2.910 | 3.197 | 4.018 |
| Adaptive | 410.21 | 198.79 | 15.147 | 0.765 | 2.427 | 2.964 | 3.246 | 4.040 | |
| DPCRN-middle | Vanilla | 300.81 | 734.31 | 15.569 | 0.775 | 2.521 | 2.997 | 3.281 | 4.047 |
| Adaptive | 1440.29 | 740.37 | 15.948 | 0.782 | 2.582 | 3.030 | 3.311 | 4.059 | |
| DPCRN-large | Vanilla | 787.15 | 1716.93 | 15.952 | 0.784 | 2.605 | 3.020 | 3.304 | 4.051 |
| Adaptive | 2455.01 | 1723.76 | 16.139 | 0.787 | 2.621 | 3.040 | 3.324 | 4.054 | |
| DCCRN | Vanilla | 3671.05 | 5601.27 | 14.870 | 0.768 | 2.458 | 2.989 | 3.273 | 4.043 |
| Adaptive | 22449.07 | 5564.01 | 15.208 | 0.777 | 2.526 | 3.027 | 3.309 | 4.053 | |
VI-A3 Generalization capability of adaptive convolution
We replace the vanilla convolutions with the adaptive convolutions in various CNN-based models of different structures and scales to evaluate the generalization capability of adaptive convolution. The results, as shown in Table III, demonstrate that adaptive convolution significantly improves the performance across all metrics, particularly in lightweight models. Beyond the improvements observed in DPCRN-light, adaptive convolution introduces approximately a 0.16 PESQ gain and a 0.05 DNSMOS-OVRL gain in GTCRN, as well as a PESQ gain exceeding 0.12 and a DNSMOS-OVRL gain over 0.06 in LiSenNet. These substantial improvements can be attributed to adaptive convolution’s ability to expand the originally limited parameter space of lightweight models, thereby significantly enhancing their representation capacity.
However, as the model size increases, the improvements introduced by adaptive convolution become less pronounced. For DPCRN-middle, it achieves approximately a 0.06 PESQ gain and a 0.03 DNSMOS-OVRL gain. While still significant, these improvements are relatively smaller compared to those observed in lightweight models. For DPCRN-large, the improvements are minimal, with only about a 0.2 dB SI-SNR gain, a 0.02 PESQ gain, and a 0.02 DNSMOS-OVRL gain. The diminishing improvement can be attributed to the extensive parameter space inherent in larger models. Specifically, the convolutional kernels in such models already include filters capable of adapting to diverse spectral features, reducing the benefit of additional candidate kernels. Moreover, the exponential increase in parameters introduced by adaptive convolution may make training more challenging, further limiting its effectiveness in larger models.
For larger DCCRN model, however, the improvements introduced by adaptive convolution are more pronounced and comparable to those observed in DPCRN-middle. This can be attributed to DCCRN’s relatively lower baseline performance, which suggests a smaller effective parameter space. As a result, adaptive convolution yields more significant gains in this context. Moreover, since convolution operations account for over 97% of DCCRN’s MACs, the proposed strategy, which focuses on optimizing CNNs, becomes even more effective.
VI-B Experimental Results for AdaptCRN
| Model | Para. (K) | MACs (M) | SI-SNR | ESTOI | PESQ | DNSMOS | ||
| OVRL | SIG | BAK | ||||||
| Noisy | - | - | 5.366 | 0.625 | 1.391 | 2.147 | 2.918 | 2.340 |
| AdaptCRN | 134.51 | 37.92 | 14.892 | 0.759 | 2.387 | 2.939 | 3.219 | 4.037 |
| w/o Adaptive convolution | 29.44 | 33.67 | 13.826 | 0.736 | 2.192 | 2.872 | 3.158 | 4.008 |
| w/o Joint channel attention | 124.68 | 37.30 | 14.718 | 0.756 | 2.352 | 2.925 | 3.207 | 4.031 |
| w/o Joint multi-layer kernel attention | 169.21 | 40.31 | 14.803 | 0.759 | 2.386 | 2.939 | 3.221 | 4.036 |
| w/o Dynamic range compression | 134.51 | 37.92 | 14.695 | 0.755 | 2.342 | 2.929 | 3.211 | 4.031 |
| DW(8)-PW(8)-skip-PW(8) | 134.51 | 37.13 | 14.672 | 0.755 | 2.358 | 2.931 | 3.212 | 4.034 |
| DW(8)-PW(8) | 112.88 | 30.32 | 14.551 | 0.754 | 2.343 | 2.926 | 3.207 | 4.031 |
| DW(8)-PW(64) | 255.00 | 31.52 | 14.826 | 0.759 | 2.390 | 0.942 | 3.221 | 4.039 |
| Model | Para. (K) | MACs (M) | SI-SNR | ESTOI | PESQ | DNSMOS | ||
| OVRL | SIG | BAK | ||||||
| Noisy | - | - | 5.366 | 0.625 | 1.391 | 2.147 | 2.918 | 2.340 |
| DPCRN-light [10] | 80.78 | 194.57 | 14.431 | 0.752 | 2.313 | 2.910 | 3.197 | 4.018 |
| GTCRN [7] | 23.67 | 33.83 | 13.552 | 0.727 | 2.130 | 2.838 | 3.124 | 3.992 |
| LiSenNet [16] | 36.78 | 55.77 | 14.352 | 0.742 | 2.244 | 2.897 | 3.180 | 4.018 |
| AdaptCRN | 134.51 | 37.92 | 14.892 | 0.759 | 2.387 | 2.939 | 3.219 | 4.037 |
| Model | Para. (K) | MACs (M) | SI-SNR | STOI | PESQ |
| Noisy | - | - | 8.45 | 0.921 | 1.97 |
| DeepFilterNet [12] | 1780 | 350 | 16.63 | 0.942 | 2.81 |
| GTCRN [7] | 24 | 34 | 18.83 | 0.940 | 2.87 |
| ULCNet [15] | 688 | 98 | 17.20 | - | 2.87 |
| FSPEN [14] | 79 | 89 | - | 0.942 | 2.97 |
| LiSenNet [16] | 37 | 56 | - | 0.937 | 2.95 |
| AdaptCRN | 135 | 38 | 18.82 | 0.940 | 2.98 |
The model is trained without PESQ loss.
VI-B1 Ablation study results for AdaptCRN
We evaluate the effectiveness of the proposed structures in AdaptCRN through ablation experiments by selectively removing specific modules. The results, summarized in Table IV, highlight the pivotal role of adaptive convolution in enhancing model performance. With an increase in computational complexity of less than 5M MACs, adaptive convolution delivers significant improvements, including nearly 1 dB in SI-SNR, 0.02 in ESTOI, 0.19 in PESQ, and over 0.06 in DNSMOS-OVRL. In the proposed model, we utilize adaptive convolution with , as this configuration provides a favorable balance between performance gains and parameter amount. Due to the extremely low parameter count of the basic model, the additional parameters introduced by adaptive convolution remain within an acceptable range for real-time applications.
The results also indicate that joint channel attention contributes positively to the model’s performance with minimal increases in both parameters and computational complexity. Replacing the joint multi-layer kernel attention with independent kernel attention for each sub-layer results in negligible performance degradation but introduces over 30K additional parameters and slightly higher MACs, highlighting the efficiency of the joint multi-layer mechanism. Additionally, the dynamic range compression in the spectral compression module demonstrates a positive impact on performance.
Table IV further presents the model’s performance when the activation function between the two PW Conv layers in the adaptive block is removed (DW(8)-PW(8)-skip-PW(8)), where the numbers in parentheses (e.g., 8) denote , the number of candidate kernels. This modification results in some performance degradation but still outperforms a single PW Conv layer with (DW(8)-PW(8)). As analyzed in Section IV-C, the former configuration can be reparameterized into a single layer with 64 candidate kernels, showcasing the enhanced nonlinear representational capacity of adaptive convolution. Moreover, directly optimizing 64 independent kernels (DW(8)-PW(64)) achieves better performance compared to the reparameterized result, due to the lower-rank kernel space of the latter. This configuration even surpasses the original AdaptCRN, demonstrating adaptive convolution’s potential to significantly improve performance while lowering computational overhead, albeit with an increase in parameter amount, as discussed in Section IV-C and Section VI-A2.
VI-B2 Comparison with the baseline models
We evaluate our ultra-lightweight model, AdaptCRN, against DPCRN-light, GTCRN, and LiSenNet on DNS5 test set. As illustrated in Table V, AdaptCRN outperforms the baseline models across all metrics. AdaptCRN remains efficient with computational complexity fewer than 40M MACs, which is only slightly higher than GTCRN. While it does have more parameters compared to the baselines, it remains within acceptable limits for practical applications.
Furthermore, we conduct additional evaluations of AdaptCRN on the Voicebank+DEMAND dataset, using DeepFilterNet, GTCRN, ULCNet, FSPEN, and LiSenNet for comparison. Results for these models are sourced directly from their respective papers. Given the importance of PESQ as a metric in this evaluation, we ensure a fair comparison by using the results for LiSenNet trained without PESQ loss. As shown in Table VI, the results consistently highlight AdaptCRN’s competitive performance alongside lower computational complexity compared to other models.
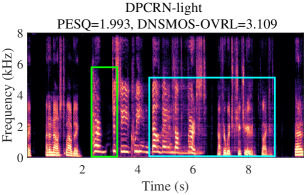
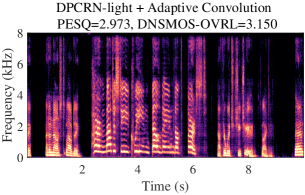
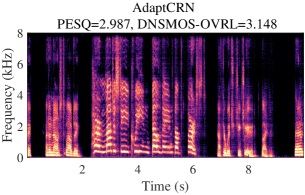
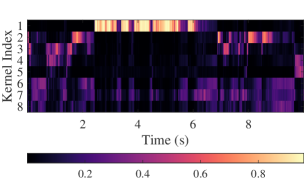
VI-C Visualization
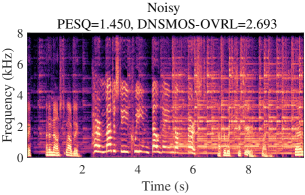
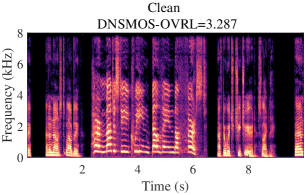
A typical audio sample from DNS5 test set is presented in Fig. 3, showcasing noisy and clean spectrograms, enhanced results from DPCRN-light, DPCRN-light integrated with adaptive convolution, and AdaptCRN. This sample poses challenges due to highly non-stationary noise and the presence of two speakers with distinct vocal characteristics, both of which should be preserved in single-channel SE task. The enhanced spectrogram of DPCRN-light exhibits noticeable distortion in one speaker’s voice (highlighted in the green box) and residual noise (highlighted in the blue box), which are effectively mitigated with the incorporation of adaptive convolution. AdaptCRN also achieves superior enhancement quality with ultra-low computational complexity, further highlighting the advantage of the propose methods. Additional audio samples are available at https://github.com/Dahan-Wang/Adaptive-Convolution-for-CNN-based-Speech-Enhancement-Models.
The frame-level kernel attention weights are visualized in Fig. 3(f), demonstrating the relationship between kernel allocation and speech spectral features. The visualization is derived from the third layer of the decoder in DPCRN-light with adaptive convolution, depicting the attention weights of 8 candidate kernels across frames. For clarity, the order of the kernels is manually adjusted during plotting. The results show that the first candidate kernel is predominantly activated during the utterance of the high-pitched speaker, while the segments from the other speaker with a lower pitch are primarily associated with the 2nd to 5th kernels. The 6th to 8th kernels appear to function mainly in pure noise segments. These findings indicate that the adaptive convolution assigns appropriate candidate kernels to each frame based on speech characteristics, effectively facilitating feature extraction and reconstruction.
VII Conclusion
In this paper, we propose adaptive convolution, an efficient and versatile convolutional module for CNN-based SE models. It is a frame-wise causal dynamic convolution that adjusts kernels based on spectral characteristics, akin to adaptive filtering. The adaptive convolution kernel is generated by assembling multiple parallel candidate kernels through frame-level attention weights derived from input features. We introduce several lightweight attention mechanisms to guide the kernel aggregation, which can be extended to a multi-head form for joint multi-layer kernel attention and joint channel attention. Moreover, we present AdaptCRN, an ultra-lightweight model that integrates adaptive convolution and several effective strategies. Experimental results and visualizations demonstrate that adaptive convolution can assign appropriate kernels to each frame based on speech characteristics, thereby significantly improving the performance of multiple CNN-based models with a negligible increase in computational complexity, especially for lightweight models. The results also show that AdaptCRN achieves competitive performance with several other SOTA lightweight models, even those with significantly higher computational cost, which further underscores the efficiency of adaptive convolution and the effectiveness of the proposed lightweight designs.
References
- [1] J. Benesty, S. Makino, and J. Chen, Speech enhancement. Springer Science & Business Media, 2006.
- [2] I. Cohen and B. Berdugo, “Speech enhancement for non-stationary noise environments,” Signal processing, vol. 81, no. 11, pp. 2403–2418, 2001.
- [3] D. Wang, Z. Hou, Y. Hu, C. Zhu, J. Lu, and J. Chen, “Incorporation of a modified temporal cepstrum smoothing in both signal-to-noise ratio and speech presence probability estimation for speech enhancement,” The Journal of the Acoustical Society of America, vol. 155, no. 6, pp. 3678–3689, 2024.
- [4] X. Hao, X. Su, R. Horaud, and X. Li, “Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6633–6637.
- [5] Z.-Q. Wang, S. Cornell, S. Choi, Y. Lee, B.-Y. Kim, and S. Watanabe, “TF-GridNet: Making time-frequency domain models great again for monaural speaker separation,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [6] H.-S. Choi, S. Park, J. H. Lee, H. Heo, D. Jeon, and K. Lee, “Real-time denoising and dereverberation wtih tiny recurrent U-Net,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 5789–5793.
- [7] X. Rong, T. Sun, X. Zhang, Y. Hu, C. Zhu, and J. Lu, “GTCRN: A speech enhancement model requiring ultralow computational resources,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 971–975.
- [8] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement.” in Interspeech, vol. 2018, 2018, pp. 3229–3233.
- [9] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang, and L. Xie, “DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement,” in Proc. Interspeech 2020, 2020, pp. 2472–2476.
- [10] X. Le, H. Chen, K. Chen, and J. Lu, “DPCRN: Dual-path convolution recurrent network for single channel speech enhancement,” in Proceedings of Interspeech 2021, 2021, pp. 2811–2815.
- [11] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 46–50.
- [12] H. Schröter, A. N. Escalante-B, T. Rosenkranz, and A. Maier, “DeepFilterNet: A low complexity speech enhancement framework for full-band audio based on deep filtering,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7407–7411.
- [13] H. Schröter, A. Maier, A. N. Escalante-B, and T. Rosenkranz, “DeepFilterNet2: Towards real-time speech enhancement on embedded devices for full-band audio,” in 2022 International Workshop on Acoustic Signal Enhancement (IWAENC). IEEE, 2022, pp. 1–5.
- [14] L. Yang, W. Liu, R. Meng, G. Lee, S. Baek, and H.-G. Moon, “FSPEN: an ultra-lightweight network for real time speech enahncment,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 671–10 675.
- [15] S. S. Shetu, S. Chakrabarty, O. Thiergart, and E. Mabande, “Ultra low complexity deep learning based noise suppression,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 466–470.
- [16] H. Yan, J. Zhang, C. Fan, Y. Zhou, and P. Liu, “LiSenNet: Lightweight sub-band and dual-path modeling for real-time speech enhancement,” arXiv preprint arXiv:2409.13285, 2024.
- [17] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [18] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [19] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A ConvNet for the 2020s,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 976–11 986.
- [20] X. Ma, X. Dai, Y. Bai, Y. Wang, and Y. Fu, “Rewrite the stars,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5694–5703.
- [21] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 030–11 039.
- [22] K. Han, Y. Wang, J. Guo, and E. Wu, “ParameterNet: Parameters are all you need for large-scale visual pretraining of mobile networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 751–15 761.
- [23] C. Li, A. Zhou, and A. Yao, “Omni-dimensional dynamic convolution,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=DmpCfq6Mg39
- [24] C. Li and A. Yao, “KernelWarehouse: Rethinking the design of dynamic convolution,” in International Conference on Machine Learning, 2024.
- [25] H. Su, V. Jampani, D. Sun, O. Gallo, E. Learned-Miller, and J. Kautz, “Pixel-adaptive convolutional neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 166–11 175.
- [26] C. Xu, B. Wu, Z. Wang, W. Zhan, P. Vajda, K. Keutzer, and M. Tomizuka, “Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16. Springer, 2020, pp. 1–19.
- [27] M. Xu, R. Ding, H. Zhao, and X. Qi, “PAconv: Position adaptive convolution with dynamic kernel assembling on point clouds,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3173–3182.
- [28] F. Gao, L. Wu, L. Zhao, T. Qin, X. Cheng, and T.-Y. Liu, “Efficient sequence learning with group recurrent networks,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018, pp. 799–808.
- [29] S.-W. Fu, C. Yu, T.-A. Hsieh, P. Plantinga, M. Ravanelli, X. Lu, and Y. Tsao, “Metricgan+: An improved version of metricgan for speech enhancement,” arXiv preprint arXiv:2104.03538, 2021.
- [30] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR–half-baked or well done?” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626–630.
- [31] H. Dubey, A. Aazami, V. Gopal, B. Naderi, S. Braun, R. Cutler, A. Ju, M. Zohourian, M. Tang, M. Golestaneh et al., “ICASSP 2023 deep noise suppression challenge,” IEEE Open Journal of Signal Processing, 2024.
- [32] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investigating RNN-based speech enhancement methods for noise-robust Text-to-Speech.” in SSW, 2016, pp. 146–152.
- [33] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752.
- [34] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE international conference on acoustics, speech and signal processing. IEEE, 2010, pp. 4214–4217.
- [35] J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2009–2022, 2016.
- [36] C. K. Reddy, V. Gopal, and R. Cutler, “DNSMOS p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 886–890.