Adaptive DropBlock Enhanced Generative Adversarial Networks for Hyperspectral Image Classification
Abstract
In recent years, hyperspectral image (HSI) classification based on generative adversarial networks (GAN) has achieved great progress. GAN-based classification methods can mitigate the limited training sample dilemma to some extent. However, several studies have pointed out that existing GAN-based HSI classification methods are heavily affected by the imbalanced training data problem. The discriminator in GAN always contradicts itself and tries to associate fake labels to the minority-class samples, and thus impair the classification performance. Another critical issue is the mode collapse in GAN-based methods. The generator is only capable of producing samples within a narrow scope of the data space, which severely hinders the advancement of GAN-based HSI classification methods. In this paper, we proposed an Adaptive DropBlock-enhanced Generative Adversarial Networks (ADGAN) for HSI classification. First, to solve the imbalanced training data problem, we adjust the discriminator to be a single classifier, and it will not contradict itself. Second, an adaptive DropBlock (AdapDrop) is proposed as a regularization method employed in the generator and discriminator to alleviate the mode collapse issue. The AdapDrop generated drop masks with adaptive shapes instead of a fixed size region, and it alleviates the limitations of DropBlock in dealing with ground objects with various shapes. Experimental results on three HSI datasets demonstrated that the proposed ADGAN achieved superior performance over state-of-the-art GAN-based methods. Our codes are available at https://github.com/summitgao/HC_ADGAN
Index Terms:
deep learning, generative adversarial network (GAN), hyperspectral image (HSI) classification, adaptive dropblockI Introduction
Benifiting from the advancement of earth observation programs, hyperspectral sensors have received great attention over the past few years. A great number of hyperspectral images (HSI) captured by spaceborne or airborne sensors are available [1]. These images have high spectral resolutions and abundant spatial information, which brings opportunities to a wide variety of applications, such as urban development [2], land cover change monitoring [3], environmental pollution monitoring [4] and resource management [5]. Among these applications, classification has become one of the most critical topics in the hyperspectral application community.
Hyperspectral images classification aims to assign a distinct label to each pixel vector so that it is well defined by a given class. Plenty of methods have been proposed to solve the problem. In the early days of HSI classification, researchers mainly focused on spectral information [6] [7] [8]. However, the same object in different locations may exhibit different spectral features, while different objects may emerge with similar spectral features [9]. It is commonly difficult to classify such objects by using spectral features alone. To solve the problem, many studies combined spectral features with spatial features to establish spectral-spatial models for HSI classification. Benediktsson et al. [2] proposed a classification method based on mathematical morphology profiles, which uses both the spatial and spectral features for classification. Fauvel et al. [10] established a framework that fused the morphological information and the original hyperspectral image. Li et al. [11] presented a classification framework that integrates the local binary patters (LBP), global Gabor features and spectral features. In [12], spatial-spectral information was transposed into a sparse model for classification. Pan et al. [13] developed the hierarchical guidance filtering to obtain a set of spectral-spatial features from different scales, and then an ensemble model is established to utilize these features simultaneously. Besides these techniques, morphological kernel [14] [15], edge-preserving filter [16], extinction profile [17] and superpixel segmentation [18] are also employed to explore spectral and spatial information for HSI classification. The combination of spectral and spatial information improves the classification performance [19] [20] [21] [22]. Although these techniques have achieved excellent performance, they are mainly based on hand-crafted descriptors. However, most hand-crafted descriptors heavily depend on prior knowledge to obtain optimal parameters, which limits the applicability of these methods in various scenarios. Robust feature extraction is widely acknowledged as a critical step in HSI classification.
Deep learning has become the most impactful developments in artificial intelligence and big data analysis over the past few years. It has been demonstrated that deep models are capable of extracting the invariant and discriminant features efficiently in computer vision and natural language processing tasks [23] [24] [25] [26]. Inspired by these flourishing tehniques, deep models have been designed to classify HSIs. Chen et al. [27] first presented a deep learning-based HSI classification method, and employed a stacked autoencoder (SAE) as a classifier. In [28], the deep belief network (DBN) is introduced for spectral-spatial information exploration. Pan et al. [29] proposed a vertex component analysis network (VCANet), which takes the physical characteristics of HSIs into account. VCANet is capable to exploit discriminative features when training samples are limited.
Recently, convolutional neural networks (CNNs) have been widely used in HSI classification. CNNs make use of regional connections to extract contextual features, and have shown outstanding classification performance. In [30], spectral features are extracted via one-dimensional CNN, and spatial features are exploited via two-dimensional CNN. Then spectral and spatial features are combined for classification. Chen et al. [31] developed a 3D-CNN HSI classification model, in which regularization is used in the training procedure to mitigate the overfitting problem. Zhong et al. [32] presented an end-to-end CNNs that take the 3D cube as input data. Residual learning is introduced to solve the exploding gradient problem. In [33], Gabor filters are combined with convolutional filters to alleviate the overfitting problem in CNN training. Inspired by the inception module [34], Gong et al. [35] proposed a CNNs with multiscale convolution. The multiscale filter banks enrich the representation power of the deep model. Ma et al. [36] designed an end-to-end deconvolution network with skip architecture for spatial and spectral feature extraction. The network is capable to recover the lost information in the pooling operation of the CNN via unpooling and deconvolution layers.
CNN-based methods have achieved tremendous progress in HSI classification. However, the performance of these techniques heavily depends on the number of training samples. Commonly, it is a challenging task to collect lots of training samples from HSIs. This problem can be alleviated by data augmentation. Cropping, horizontal flipping, generative model are typical data augmentation techniques. Recently, the generative model has drawn a lot of attention, since it is able to generate high-quality samples to alleviate the overfitting problem. Goodfellow et al. [37] designed the generative adversarial network (GAN), which is comprised of a generator and a discriminator . The generator captures the data distribution while judges that whether a sample comes from or from the training data. The generator can be considered as a regularization method that can effectively alleviate the overfitting problem to a great extent.
Researchers have made efforts to design GAN-based models to alleviate the limited high-quality sample problem. Zhan et al. [38] proposed a semisupervised framework based on 1D-GAN. After that, Zhu et al. [39] proposed a 3D-GAN for HSI classification. The spatial information is taken into consideration, and a softmax classifier is employed in the discriminator to auxiliary classification. Feng et al. [40] proposed a multiclass GAN for HSI classification. Two generators are designed in multiclass GAN to generate hyperspectral image patches, and a discriminator is devised to output multiclass probabilities. Zhong et al. [41] integrated GAN and conditional random field (CRF) together, where dense CRFs impose graph constraints on the discriminators of GAN to refine the classification results.
Although these GAN-based models have achieved satisfying performance over their contemporary baselines, there still exist two drawbacks over HSI classification, which are urgently needed to be solved.
The first challenge is imbalanced training data. The accuracy of classification is likely to deteriorate when available training samples are not uniformly distributed among different classes. However, the imbalanced training data problem is fundamental in HSIs, since objects with different sizes present in a typical scene [42]. In Zhu’s work [39], auxiliary classifier GAN (ACGAN) [43] is employed for HSI classification. In ACGAN, the discriminator has two outputs: one to discriminate real and fake samples, and the other to classify samples. It seems that ACGAN is capable of producing samples of a specific class. In practice, it is observed that two loss functions of the discriminator turnout to be flawed when generating the minority-class samples. The reason for this phenomenon is that when minority-class samples are passed to the discriminator, they are likely to be assigned the fake label. Therefore, the discriminator intends to associate fake label to the minority-class samples. At this point, the generators produce samples that look real but not represent the minority class. The quality of generated samples is deteriorated, and hence the classification performance is impaired.
Another critical issue is mode collapse. The generator fools the discriminator by only producing data from the same data mode [44]. It leads to a weak generator that can generate samples within a narrow scope of the data space. Therefore, the generated samples are too similar for the model to learn the true data distribution, and the model can hardly learn the full data distribution. The model collapse can be considered as a consequence of overfitting to the feedback of the discriminator. In a disparate line of work, DropBlock [45] was designed in CNNs to alleviate overfitting. In DropBlock, features in a square mask from one feature map are dropped together during training. It is demonstrated that DropBlock can learn more spatially distributed representations. However, when dealing with objects with various shapes, the fixed square masks are inflexible. We argue that if irregularly shaped masks are taken into account, the mode collapse problem can be alleviated.
To tackle the aforementioned limitations of GAN-based classification methods, we established an Adaptive Dropblock-enhanced Generative Adversarial Networks (ADGAN) for HSI classification. On the one hand, considering the contradiction between the loss functions of the discriminator in ACGAN, the discriminator in ADGAN is adjusted to be one single output that returns either the specific class label or the fake label. The generator is trained to avoid the fake label and match the desired class labels. Since the discriminator is now defined as one single objective, it will not contradict itself. On the other hand, we propose adaptive DropBlock (AdapDrop) as a regularization method used in the generator and the discriminator. Instead of dropping a fixed size region, the AdapDrop generated drop masks with adaptive shapes, relaxing the limitations of DropBlock in dealing with objects with various shapes.
To validate the effectiveness of the proposed method, extensive experiments are conducted on three datasets. Experimental results demonstrate that the proposed ADGAN yields better performance than state-of-the-art GAN-based methods. In summary, the our contributions are threefold:
-
•
We develop a novel GAN-based HSI classification model that contains a single output in discriminator. The contradictions in ACGAN when dealing with minority-class samples are mitigated.
-
•
For the purpose of alleviating the mode collapse problem, we propose the AdapDrop for regularization. The AdapDrop generates masks with adaptive shapes, which can boost the classification performance.
-
•
We conducted extensive experiments on three well-known hyperspectral datasets under the condition of limited training samples to validate the effectiveness of the proposed method. The experimental results achieve competitive results compared with other state-of-the-art classification methods.
The rest of this paper is organized as follows. In Section II, the basic concepts of ACGAN and DropBlock are briefly reviewed. The scheme of the proposed method and its components are introduced in Section III. Experimental results and analysis are presented in Section IV. Finally, conclusions are drawn in Section V.
II Background
II-A Generative Adversarial Networks
In recent years, GANs provide a solution to estimate input data distribution, and correspondingly generate synthetic samples [37]. GAN is comprised of two parts, the generator and the discriminator . The generator attempts to learn the distribution of real data, and generate data that subjects to this distribution. The discriminator judges whether the input is real or fake.The generator takes a random noise vector as input, and outputs an image . The discriminator receives a real image or a synthesized image from as inputs, and outputs a probability distribution . The discriminator is trained to maximize the log-likelihood it assigns to the correct source as follows:
| (1) |
The generator is trained to minimize the following likelihood:
| (2) |
When training GAN, an alternating optimization technique is employed. Specifically, is optimized by maximizing with fixed in one iteration. After that, is optimized with minimizing with fixed. In such adversarial training, the discriminator and the generator promote each other. After many iterations, captures the distribution of real data. At the same time, the capability of to distinguish real data and fake data is enhanced.
II-B Auxiliary Classifier GANs
In naive GAN, the discriminator only judges whether the input samples are real or fake. Therefore, they are not suitable for multiclass image classification. To tackle the limitations of naive GAN, Odena et al. [43] proposed auxiliary classifier GAN (ACGAN). In ACGAN, the discriminator is a softmax classifier that can output multiclass label probabilities.
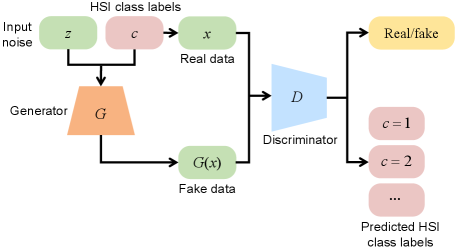
The architecture of ACGAN employed in [39] is illustrated in Fig. 1. The generator accepts the class label as input. The real data with the corresponding label and the data generated by are regarded as the input of . The discriminator has two outputs: one to discriminate the real and fake data, and the other to classify input in terms of its class . The loss function of ACGAN is comprised of two parts: the log-likelihood of the right source of input and the log-likelihood of the right class labels . The and are computed as:
| (3) |
| (4) |
During training, the generator is optimized to maximize , and the discriminator is optimized to maximize . Therefore, the generator can be conditioned to draw a sample of the desired class.
II-C DropBlock
Most current deep models are inclined to suffer from over-parameterization, and therefore give rise to overfitting problem. In this regard, regularization methods are harnessed to mitigate this issue. To date, dropout [46] is a widely used regularization method and has been proved to be rather effective for fully connected layers. However, features in convolutional layers are highly spatially correlated. Dropout becomes less effective since it does not take image spatial information into account.
Recently, Ghisasi et al. [45] proposed DropBlock, which is particularly effective to regularize the convolutional layers. Rather than dropping out random units, DropBlock drops contiguous regions from a feature map in convolutional layer. It can be considered as a form of structured dropout. It is demonstrated that employing DropBlock in convolutional layers and skip connections effectively improve the classification performance.
III Methodology
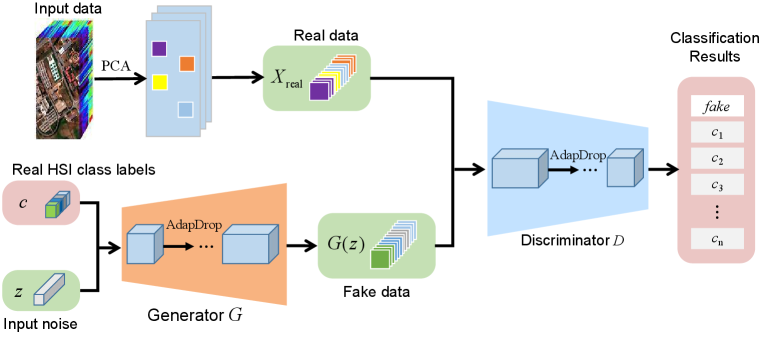
III-A Framework of the Proposed ADGAN
The framework of the proposed ADGAN is illustrated in Fig. 2. The input hyperspectral image contains hundreds of bands, and there is a lot of redundancy among these spectral bands. It is rather difficult to obtian a robust generator , since the generator can hardly imitate the real data when high redundancy exists. Therefore, the number of spectral bands of the input HSI is reduced to three components by PCA [47]. The spectral information can be condensed to a suitable scale by PCA. This operation is a non-trivial step since PCA can not only dramatically reduce the computational complexity, but also contribute to training a robust generator .
From Fig. 2, it can be observed that the input of the generator include both noise and class labels . The discriminator receives the image patches with labels and some fake patches . It should be noted that in the proposed ADGAN, the discriminator has only one single output that returns either a specific class or the label. Then, the generator is trained to generate image patches that match the desired class label. To this end, the discriminator is trained to maximize the log-likelihood as follows:
| (5) |
The generator is trained to maximize the log-likelihood as follows:
| (6) |
The first term of encourages the discriminator to assign true label for real sample, and the second term expects to assign label to the generated samples. On the contrary, the generator expects to draw a sample of the desired class. By adversarial learning, the generator captures the real data distribution of the desired class.
As mentioned before, the discriminator in Zhu’s work [39] has two outputs, one to discriminate the real and fake data, and the other to classify the input in term of its class . In the training phase, the generator aims to draw images belonging to class . Therefore, the parameters of generator are optimized to maximize the superposition of two components. The first is the log-likelihood of generating an image that the discriminator considers real. The second component is the log-likelihood of generating an image that the discriminator considers it to be class . However, there exists a contradiction between two components when dealing with the minority-class. Specifically, when a generated minority-class image is fed into the discriminator, it is likely to be judged as a fake image since the minority-class images are scarce in the training set. To optimize its loss function, the discriminator prefers to associate label to the minority-class images. Then, the two components of generator will contradict each other, and two components can hardly be optimized at once. This phenomenon deteriorates the quality of generated images, which severely limits the performance of GAN-based approaches for HSI classification. To solve this problem, we proposed the ADGAN that alleviates the contradiction in ACGAN, and achieves the balance in training samples to some extent.
In the proposed ADGAN, the discriminator has one output that returns either a specific class or the label, as shown in Fig. 2. The discriminator is trained to associate the real samples with their class label . Meanwhile, also tries to associate the samples generated by with the label. On the contrary, the generator is trained to avoid the label and match the generated samples to the desired class. By doing so, the balance of training samples can be balanced to some extent. Besides, since the discriminator in ADGAN is now defined as one single objective rather than a combination of two objectives, it will not contradict itself.
In ADGAN, the network extracts the spectral and spatial feature simultaneously. The input hyperspectral data is condensed by PCA, and only three components are reserved. Through PCA, an optimal representation of the input HSI is achieved, and the computational burden is also dramatically reduced. From Fig. 2, we can observe that the generator accepts random Gaussian noise as input. The noise is transformed to the same size as the real input data with three bands in the spectral domain. After that, the discriminator accepts the generated fake samples togehter with the real samples as input. The output of indicates the probability that the input sample belongs to class or fake. After many iterations, both and achieve optimized results. Specifically, can generate fake data that subject to the distribution of real data, while can hardly discriminate it. The competition between both networks can promote the HSI classification performance. The key idea of ADGAN lies in restoring the balance of dataset, and through the design of novel adversarial objective functions, the contradiction in ACGAN can be alleviated.
III-B Structured Dropout with Attention Mechanism: Adaptive DropBlock
In the proposed ADGAN, and are both in the form of convolutional networks. Pooling layers are replaced with strided convolutions. In addition, batch normalization is employed in both the and . To further improve the classification performance, we proposed Adaptive DropBlock as the regularization method to enhance the spatially correlated feature representations.
Deep neural networks generally suffer from over-parameterization, and thus give rise to the overfitting problem. Regularization methods, such as batch normalization and dropout, are harnessed to mitigate the problem. In this paper, the proposed ADGAN is comprised of two convolutional networks, which makes it more complex to regularize.
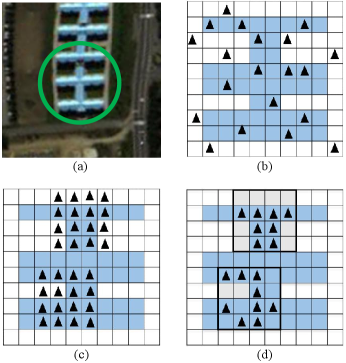
Many regularization methods have been proposed to alleviate the overfitting problem, such as DropBlock [45], DropPath [48], and DropConnect [49]. DropBlock is one of the most commonly used regularization methods in CNNs. It operates on the feature maps, and then the units in a random contiguous region of feature maps are dropped together. As DropBlock discards features in a correlated area, the remaining semantic information will be used to fit the training data. However, DropBlock backfires when it drops overmuch information in the feature map, since it drops the whole blocks with fixed shape, which may contain essential features for training, as illustrated in Fig. 3.
To mitigate the drawback of DropBlock, we propose Adaptive DropBlock (AdapDrop), which is a structured regularization method with attention mechanism. AdapDrop first randomly selects some blocks in the feature map. Then it produces adaptive mask with irregular shapes in the selected blocks by dropping the top th percentile elements. The top th percentile elements are chosen according to the values in the feature map. Due to the continuity of image pixel values, the neighboring pixels in the feature map have similar values. Hence, when we drop the top th percentile elements, it is usually expressed as an irregular shape according to the spatial characteristics of the target object, such as the roof of a building, lawn garden, etc. Therefore, the AdapDrop effectively remove maximally activated regions and encourage the network to consider less prominent features.
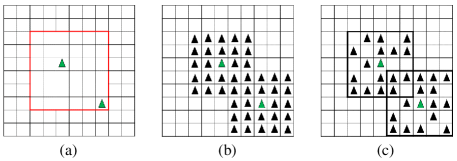
The three phases of AdapDrop is shown in Fig. 4. An adaptive mask is applied to the feature map and scale the output. The AdapDrop algorithm is shown in Algorithm 1. It has three parameters, which are , , and . is the size of the mask block, and denotes the top th percentile elements in the mask block will be dropped. controls the number of features to drop, and the computation of can be found in [45]. The current feature map is first normalized, and a new feature map is generated. A set of pixels are sampled with the Bernoulli distribution. For each position , create a spatial square block centered at . The size of the block is . In each block, the top th percentile elements are set to be zero, and the rest elements are set to be one. Next, apply the mask and scale the output as:
| (7) |
The denotes the number of elements in the masks, and denotes the number of one in the masks.
III-C Implementation Details of the Proposed ADGAN
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x5.png)
Table I shows the implementation details of the proposed ADGAN. The generator and discriminator are CNNs with five convolutional layers. The size of the input noise is . The generator converts the inputs to fake samples with the size of . In the generator , the AdapDrop is employed in the second convolutional layer, while the AdapDrop is employed in the forth transposed convolutional layer in the discriminator .
IV Experimental Results and Analysis
In this section, we first describe the datasets used in our experiments. Then, an exhaustive investigation of several important parameters of the AdapDrop is presented. Besides, We tested the impact of different regularization methods on classification results in the network. Next, the comparisons with five closely related HSI classifiers are provided After that, we compared the running time of different classification methods. Finally, we visualized the generated samples to show the advantage of ADGAN.

IV-A Datasets Description
To evaluate the performance of the ADGAN on HSI classification, three representative HSI datasets are used, including the Salinas, Indian Pines, and Pavia University datasets.
-
1.
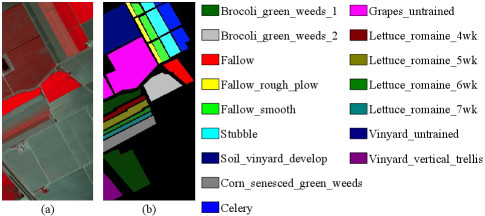
The Salinas dataset was captured by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor. The size of the image is 512217 pixels. The dataset is comprised of 204 spectral bands. Some low signal-to-noise ratio (SNR) bands are removed. The dataset has a high spatial resolution of 3.7m per pixel. The false-color composite image (bands 50, 170, 190) and the corresponding ground reference map are illustrated in Fig. 5.
-
2.
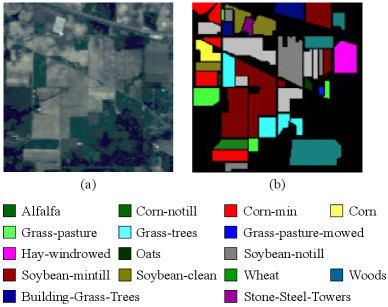
The Indian Pines dataset is a mixed vegetation site in Northwestern Indiana, and it was collected by the AVIRIS sensor. The size of the dataset is 145145 pixels. It is comprised of 220 spectral bands in the wavelength range of 0.4-2.5 m. The false-color composite image and the ground reference map are shown in Fig. 6. It should be noted that the water absorption bands are removed in our implementations.
-
3.
The Pavia University dataset was acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) in northern Italy in 2001. The dataset convers nine urban land-cover types. The size of the dataset is 610340 pixels, and the resolution of the image is 1.3m per pixel. The dataset is comprised of 103 spectral bands in the wavelength range from 430 to 860 nm. Fig. 7 illustrates the dataset and the corresponding ground reference map.
For all three datasets, the labeled samples were split into two parts: the training set and the test set. Because of the relatively higher computational complexity of the GANs, we try to control the number of training samples to ensure stable experimental results. After numerous experiments, we found that randomly selecting 300 training samples on the Salinas dataset, 1000 training samples on the Indian Pines dataset, and 1000 training samples on the Pavia University dataset can ensure stable results. For the Salinas dataset, the number of training and test samples for each class are listed in Table. II. For the Indian Pines and Pavia University dataset, sample distribution is listed in Table. III and IV, respectively. The training set adjusts the parameters during the training process by testing the classification accuracies and the losses of the temporary model generated during training. The network with the lowest loss is selected for testing. In the test process, all the test samples in the dataset are used to estimate the capability of the trained network. Three evaluation criteria, including overall accuracy (OA), average accuracy (AA), and Kappa coefficient () are presented for all test samples.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x11.png)
IV-B Parameter Analysis
IV-B1 Analysis of
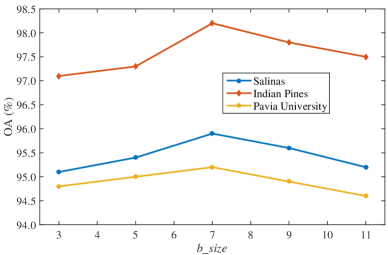
The size of block in AdapDrop is an important parameter that affects the classification accuracy. The contextual information in classification is sensitive to neighborhood noise. Fig. 8 shows the classification performance on three datasets under different . In our implementations, the varies from 3 to 11. We can observe that when increases from 3 to 7, the classification accuracy improves since more contextual information is taken into account. However, when the larger block size is selected, continuous blank areas affect the robust training of the network. When , the best accuracy is achieved. Therefore, is set to 7 in the following experiments.
IV-B2 Analysis of
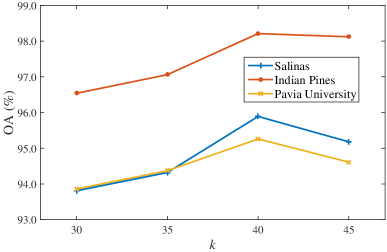
The parameter denotes that the top th percentile elements in the mask block will be dropped, and it is a critical parameter in AdapDrop. We evaluate the classification performance by take = 30, 35, 40, and 45, respectively. Fig. 9 illustrates the influence of on classification accuracy on three datasets. It can be seen that when , the OA achieves the best performance. When smaller is selected, the dropped features can hardly achieve the goal of mitigating overfitting. When it gets bigger, the network dropped too much features, and the network inclines to learn incorrect representations provided by the irrelevant background. Therefore, is chosen as 40 in our following experiments.
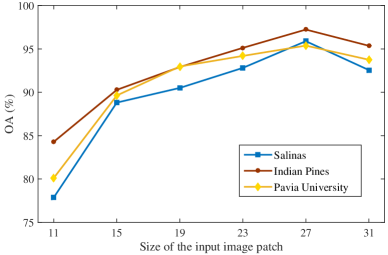
IV-B3 Analysis of the size of the patch
The size of the input image patch is an important parameter. As illustrated in 10, the input image patches are set to 11, 15, 19, 23, 27, and 31, respectively. It can be observed that the classification accuracy sharply increases when the patch size ranges from 11 to 27 on three datasets. When patch size grows larger than 27, the classification accuracy tends to decrease. It is owing to the reason that larger image patch takes pixels of different classes into account, and hence some negative effects are incurred. In the meanwhile, the valuable spatial information is not exploited effectively when the patch size is rather small. Therefore, the extracted features are not representative of the central pixel. Therefore, in our implementations, the input image patch size is set to 27 27 pixels on three datasets.
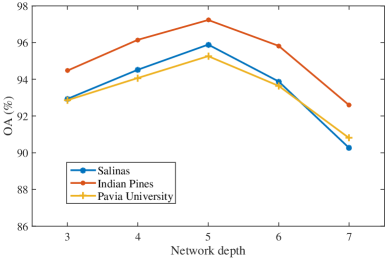
IV-B4 Analysis of network depth
It is widely acknowledged that the network depth of current deep learning-based methods is getting deeper and deeper. However, when training samples are relatively limited, the parameters in deeper models can hardly be optimized, and the model is unable to work well. As illustrated in Fig. 11, when the network depth is set to 5, the best performance is obtained on three datasets. It is reasonable that deeper architectures may suffer from the exploding gradients problem. Specifically, error gradients accumulate quickly and thus result in an unstable network. Hence, the network depth is set to be 5.
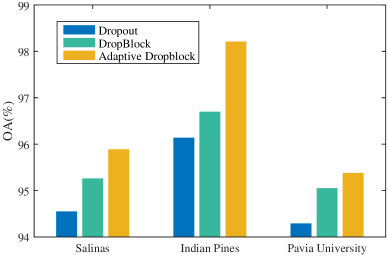
IV-C Comparison with Different Regularization Methods
In this subsection, we empirically investigate the effectiveness of the proposed AdapDrop for HSI classification. Dropout and DropBlock are employed for comparison in extensive experiments. As shown in Fig. 12, the proposed AdapDrop has a superior performance compared with Dropout and DropBlock. Among these methods, Dropout is less effective since it randomly drop separate pixels in the feature map, and the dropped information can be easily retrieved through neighborhood pixels. DropBlock removes the entire blocks, and the network’s learning capabilities may be affected. The proposed AdapDrop removes highly informative regions in the feature map, and the network can effectively learn robust featuresof the ground objects in HSI classification.
IV-D Classification Results on Three Datasets
In order to verify the effectiveness of the proposed ADGAN, we compare it with five closely related methods such as the random forest (RF) [6], contextual SVM (CSVM) [50], CNN with extinction profiles (EP-CNN) [51], spectral-spatial ResNet (SS-ResNet) [52], and 3D-ACGAN [39]. In order to ensure a fair comparison, all the methods use default parameters, and the same proportion of training sets. All the experimental results are obtained by running 10 times independently with a random division for training and test sets.
RF investigate a random forest of binary classifiers as a means of increasing diversity of hierarchical classifiers. The is set to be 20, and one hundred trees are grown for each experiment. For CSVM, both local spectral and spatial information in a reproducing kernel Hillbert space are jointly exploited. A neighborhood of 99 pixels is employed, and default parameters of SVM are used as mentioned in [50]. EP-CNN fuses the hyperspectral and light detection and ranging-derived data using extinction profiles and deep learning. A neighborhood with the size of 2727 pixels is considered. and are employed as described in [51]. The SS-ResNet combines spatial and spectral information, and it takes advantage of residual learning. A neighbor hood with the size of 1111 is employed. In addition, 300 epochs and the Adam optimizer are used. For 3D-ACGAN, the source code provided by Prof. Chen is used and default parameters are chosen as mentioned in [39]. Specifically, 6464 neighborhood of each pixel is used, and the input images are normalized into the range [-0.5, 0.5]. The size of mini-batch is 100, and the Adam optimizer is employed. For data preprocessing, 3 components are utilized as the inputs. The generator and discriminator are designed with 5 convolutional layers. The size of the input noise is 10011, and the generator converts the inputs to fake samples with the size of 64643. In order to fairly compare the proposed ADGAN with 3D-ACGAN, both methods have similar architectures except for the output of the discriminator.
Both visual and quantitative analyses are provided in our experiments. For visual analysis, the classification maps generated by different methods are illustrated in figure form. For quantitative analysis, the classification maps are illustrated in tabular form.
IV-D1 Results on the Salinas Dataset
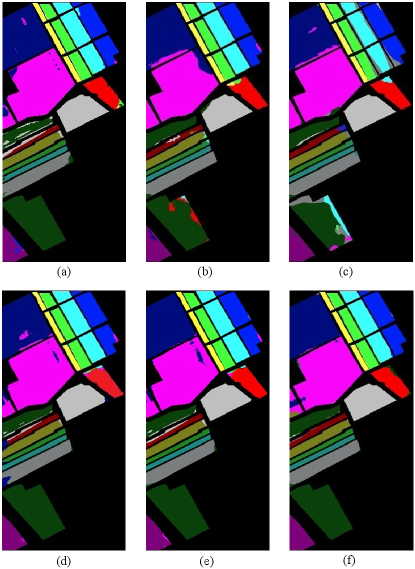
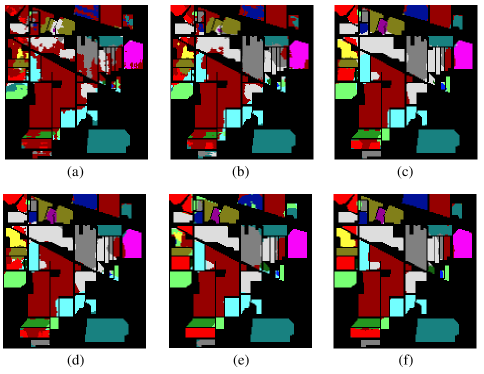
Table V lists the corresponding evaluation criteria of six algorithms. The first 16 rows illustrate the results of each class, and the last 3 rows show the OA, AA and Kappa coefficients. The best classification results are emphasized by bolding. As shown in Table V, deep learning-based methods, EP-CNN, SS-ResNet, 3D-ACGAN and ADGAN, are superior to RF and CSVM because of the hierarchical nonlinear feature extraction. Compared with EP-CNN and SS-ResNet, 3D-ACGAN improves the classification performance with the assistance of generated samples. Among the six methods, ADGAN achieves the best classification results in most cases since it not only generated high-quality samples but also alleviated the drawback of ACGAN as mentioned before. Additionally, compared with other methods, ADGAN improves at least 1.11% in OA, 0.79% in AA and 0.41% in Kappa. Fig. 13 shows the classification maps of different methods on the Salinas dataset. As illustrated in Fig. 13(a)-(d), RF, CSVM, EP-CNN and SS-ResNet misclassify many samples at the boundary of different classes. Compare with these methods, 3D-ACGAN achieves better classification result on majority classes because of data augmentation. Compared with 3D-ACGAN, the proposed ADGAN performs better in minority classes, for example Lettuce_romaine_4wk, Lettuce_romaine_6wk, Lettuce_romaine_7wk. It is demonstrated that the proposed ADGAN achieves the best performance on the Salinas dataset.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x19.png)
IV-D2 Results on the Indian Pines dataset
The statistical classification results on the Indian Pines dataset are summarized in Table VI, and Fig. 14 illustrates the classification results of different methods. As can be observed from Table VI, SS-ResNet, 3D-ACGAN and ADGAN are superior to RF, CSVM and EP-CNN by introducing attention mechanism or extra generated training samples. For minority classes, such as Alfalfa, Grass-pasture-mowed, Oats and Stone-Steel-Towers, the classification performance of the proposed ADGAN is better than 3D-ACGAN. It is demonstrated that ADGAN has better classification performance when handling minority class samples on this dataset. Among all these methods, ADGAN obtains the best statistical results in terms of the OA, AA and Kappa. As shown in Fig. 14(a)-(d), many samples belonging to the Soybean-clean and Building-Grass-Trees are falsely assigned the neighboring labels by RF, CSVM, EP-CNN and SS-ResNet. Compared with them, ADGAN achieves better region uniformity in the Soybean-notill class. Moreover, ADGAN obtains better performance in boundary pixel classification of the Stone-Steel-Towers, which is limited in training set. It is evident that the proposed ADGAN obtains the best performance on the Indian Pines dataset.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x20.png)
IV-D3 Results on the Pavia University dataset

![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x22.png)
The quantitative criteria of different methods on the Pavia University dataset are shown in Table VII. The corresponding classification maps on the dataset are illustrated in Fig. 15. As can be observed in Table VII, the Gravel and Self-Blocking Bricks classes are misclassified by RF, CSVM, EP-CNN and SS-ResNet. Compared with these methods, 3D-ACGAN and ADGAN obviously improve the classification performance by generating high-quality training samples. When handling the minority classes, such as Painted metal sheets, Bitumen and Shadows, the proposed ADGAN performs better than 3D-ACGAN. From visual comparisons, the proposed ADGAN obtains the best classification results. The proposed ADGAN surpasses 3D-ACGAN by 1.13%, 1.20% and 1.25% in terms of OA, AA and Kappa. As shown in Fig. 15(a)-(d), there are many noisy scattered points in the Bare soil and Gravel in the classification results by RF, CSVM, EP-CNN and SS-ResNet. Compared to them, 3D-ACGAN and ADGAN provide better results with little noise. It should be noted that, when handling the minority classes, such as Bitumen and Shadows, ADGAN performs better and is the closest to the ground truth map. The experimental results on this dataset demonstrate that the ADGAN exhibits good classification performance by capturing the intrinsic inter-class discriminative features.
From visual comparisons, the classification results by the proposed ADGAN are less noisy than the other methods. The quantitative criteria in Tables V - VII are consistent with the visual comparisons. It should be noted that deep learning-based methods generally perform better than shallow architectures. Especially, the GAN-based methods indeed obtain better classification results when the training samples are limited. The proposed ADGAN is capable to achieve better classification accuracy than 3D-ACGAN in minority class classification owing to the newly designed discriminator and AdapDrop.
IV-E Investigation on Running Time
Table VIII lists the running time of different classification methods on three datasets. Compared with RF and CSVM, deep learning-based methods cost more training time because of the construction of deep network. 3D-ACGAN and ADGAN are time-consuming on the training time because adversarial learning needs more time to converge. For the test time, the proposed ADGAN has obvious advantage than EP-CNN and SS-ResNet because of the simpler network structure of the discriminator. Furthermore, we can observe that ADGAN has competitive performance compared with 3D-ACGAN in test time. It means that the proposed ADGAN is capable of real-time applications.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/x23.png)
IV-F Visualization of Adversarial Samples
In the visualization experiment, some representative fake samples generated by the 3D-ACGAN and the proposed ADGAN on the Salinas dataset are illustrated in Fig. 16. As can be observed, the proposed ADGAN can generate high-quality samples which have similar structures compared with the real image samples. On the contrary, 3D-ACGAN sometimes fails to generate good samples for the minority class and collapse towards learning the basic structures of the real samples. As mentioned before, because of the self-contradiction in 3D-ACGAN’s discriminator, the generator prefers to generate samples belonging to the majority class. Therefore, the performance of 3D-ACGAN in generating minority class samples is affected. The proposed ADGAN models the classification task and the discrimination task into one single objective. Hence, the mode collapse issue can be alleviated to some extent. The proposed ADGAN is superior in adversarial learning when aiming at the generation of minority class samples, and can be employed to improve the HSI classification accuracy.

V Conclusions and Future Work
In this paper, an adaptive DropBlock-enhanced framework for HSI classification is proposed. The proposed ADGAN can effectively alleviate the following two problems: 1) the imbalanced training data in HSI, and 2) the mode collapse problem in GAN-based classification methods. First, the discriminator is adjusted to be a single output that returns either the fake label or the specific class label. The discriminator will not contradict itself when training samples are imbalanced. Second, AdapDrop is proposed as a regularization method to mitigate the mode collapse problem. Instead of dropping a fixed size region, the proposed AdapDrop generates drop masks with adaptive shapes, which can better deal with ground objects with various shapes. To evaluate the proposed framework, extensive experiments are performed on three hyperspectral datasets. The results show that the proposed ADGAN can achieve better performance compared with the state-of-the-art baselines.
In the future, we plan to extend our work in two directions. First, several self-attention networks will be investigated to improve classification performance. In addition, more regularization techniques will be explored to alleviate the mode collapse problem, and therefore further enhance the classification performance.
Acknowledgement
We would like to thank Prof. Y. Chen for sharing the source code of 3D-ACGAN. We would also like to thank the Associate Editor and all the reviewers for their valuable comments and suggestions, which have significantly improved the quality of the paper.
References
- [1] B. Tu, X. Zhang, X. Kang, J. Wang and J. A. Benediktsson, “Spatial density peak clustering for hyperspectral image classification with noisy labels,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 7, pp. 5085–5097, Jul. 2019.
- [2] J. A. Benediktsson, J. A. Palmason and J. R. Sveinsson, “Classification of hyperspectral data from urban areas based on extended morphological profiles,” IEEE Trans. Geosci. Remote Sens., vol. 43, no. 3, pp. 480–491, Mar. 2005.
- [3] Q. Wang, Z. Yuan, and X. Li, “GETNET: A general end-to-end two-dimensional CNN framework for hyperspectral image change detection,” IEEE Tran. Geosci. Remote Sens., vol. 57, no. 1, pp. 3–13, Jan. 2019.
- [4] P. Arellano, K. Tansey, H. Balzter and D. S. Boyd, “Detecting the effects of hydrocarbon pollution in the Amazon forest using hyperspectral satellite images,” Environmental Pollution, vol. 205, pp. 225–239, 2015.
- [5] Q. Wang, Y. Gu and D. Tuia, “Discriminative multiple kernel learning for hyperspectral image classification,” IEEE Tran. Geosci. Remote Sens., vol. 54, no. 7, pp. 3912–3927, Jul. 2016.
- [6] J. Ham, Y. Chen, M. M. Crawford, and J. Ghosh, “Investigation of the random forest framework for classification of hyperspectral data,” IEEE Trans. Geosci. Remote Sens. , vol. 43, no. 3, pp. 492–501, Mar. 2005.
- [7] F. Ratle, G. Camps-Valls, and J. Weston, “Semisupervised neural networks for efficient hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 48, no. 5, pp. 2271–2282, May 2010.
- [8] M. Fauvel, J. Chanussot, and J. A. Benediktsson, “Evaluation of kernels for multiclass classification of hyperspectral remote sensing data,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process., May 2006, DOI: 10.1109/ICASSP.2006.1660467
- [9] H. Zhang, Y. Li, Y. Jiang, P. Wang, Q. Shen and C. Shen, “Hyperspectral classification based on lightweight 3-D-CNN With transfer learning,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 8, pp. 5813–5828, Aug. 2019.
- [10] M. Fauvel, J. A. Benediktsson, J. Chanussot and J. R. Sveinsson, “Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles,” IEEE Trans. Geosci. Remote Sens., vol. 46, no. 11, pp. 3804–3814, Nov. 2008.
- [11] W. Li, C. Chen, H. Su and Q. Du, “Local binary patterns and extreme learning machine for hyperspectral imagery classification,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 7, pp. 3681–3693, Jul. 2015.
- [12] J. Zou, W. Li, and Q. Du, “Sparse representation-based nearest neighbor classifiers for hyperspectral imagery,” IEEE Geosci. Remote Sens. Lett., vol. 12, no. 12, pp. 2418–2422, Dec. 2015.
- [13] B. Pan, Z. Shi and X. Xu, “Hierarchical guidance filtering-based ensemble classification for hyperspectral images,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 7, pp. 4177–4189, Jul. 2017.
- [14] L. Fang, S. Li, W. Duan, J. Ren, and J. A. Benediktsson, “Classification of hyperspectral images by exploiting spectral-spatial information of superpixel via multiple kernels,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 12, pp. 6663–6674, Dec. 2015.
- [15] M. Fauvel, J. Chanussot, and J. A. Benediktsson, “A spatial-spectral kernel-based approach for the classification of remote-sensing images,” Pattern Recognit., vol. 45, no. 1, pp. 381–392, 2012.
- [16] X. Kang, S. Li, and J. A. Benediktsson, “Spectral-spatial hyperspectral image classification with edge-preserving filtering,” IEEE Trans. Geosci. Remote Sens., vol. 52, no. 5, pp. 2666–2677, May 2014.
- [17] L. Fang, N. He, S. Li, P. Ghamisi, and J. A. Benediktsson, “Extinction profiles fusion for hyperspectral images classification,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 3, pp. 1803–1815, Mar. 2018.
- [18] S. Li, T. Lu, L. Fang, X. Jia, and J. A. Benediktsson,“Probabilistic fusion of pixel-level and superpixel-level hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 12, pp. 7416–7430, Dec. 2016.
- [19] Y. Zhong, A. Ma, and L. Zhang, “An adaptive memetic fuzzy clustering algorithm with spatial information for remote sensing imagery,” IEEE J. Sel. Topics Appl. Earth Observat. Remote Sens., vol. 7, no. 4, pp. 1235–1248, Apr. 2014.
- [20] Y. Y. Tang, Y. Lu, and H. Yuan, “Hyperspectral image classification based on three-dimensional scattering wavelet transform,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 5, pp. 2467–2480, May 2015.
- [21] W. Li and Q. Du, “Collaborative representation for hyperspectral anomaly detection,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 3, pp. 1463–1474, Mar. 2015.
- [22] C. Chen, W. Li, E. W. Tramel, M. Cui, S. Prasad, and J. E. Fowler, “Spectral-spatial preprocessing using multihypothesis prediction for noise-robust hyperspectral image classification,” IEEE J. Sel. Topics Appl. Earth Observat. Remote Sens., vol. 7, no. 4, pp. 1047–1059, Apr. 2014.
- [23] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst., 2012, pp. 1097–1105.
- [24] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., Jun. 2014, pp. 580–587.
- [25] G. Hinton et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal Process. Mag., vol. 29, no. 6, pp. 82–97, Nov. 2012.
- [26] K. Yao, G. Zweig, M.-Y. Hwang, Y. Shi, and D. Yu, “Recurrent neural networks for language understanding,” in Proc. Interspeech., 2013, pp. 2524–2528.
- [27] Y. Chen, Z. Lin, X. Zhao, G. Wang, and Y. Gu, “Deep learning-based classification of hyperspectral data,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 7, no. 6, pp. 2094–2107, Jun. 2014.
- [28] Y. Chen, X. Zhao, and X. Jia, “Spectral–spatial classification of hyperspectral data based on deep belief network,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 8, no. 6, pp. 2381–2392, Jun. 2015.
- [29] B. Pan, Z. Shi and X. Xu, “R-VCANet: A new deep-learning-based hyperspectral image classification method,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 10, no. 5, pp. 1975–1986, May 2017.
- [30] H. Zhang, Y. Li, Y. Zhang, and Q. Shen, “Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network,” Remote Sens. Lett., vol. 8, no. 5, pp. 438–447, May 2017.
- [31] Y. Chen, H. Jiang, C. Li, X. Jia, and P. Ghamisi, “Deep feature extraction and classification of hyperspectral images based on convolutional neural networks,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 10, pp. 6232–6251, Oct. 2016.
- [32] Z. Zhong, J. Li, Z. Luo, and M. Chapman, “Spectral-spatial residual network for hyperspectral image classification: A 3-D deep learning framework,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 2, pp. 847–858, Feb. 2018.
- [33] Y. Chen, L. Zhu, P. Ghamisi, X. Jia, G. Li, and L. Tang, “Hyperspectral images classification with Gabor filtering and convolutional neural network,” IEEE Geosci. Remote Sens. Lett., vol. 14, no. 12, pp. 2355–2359, Dec. 2017.
- [34] C. Szegedy et al. “Going deeper with convolutions,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., Jun. 2015, pp. 1–9.
- [35] Z. Gong, P. Zhong, Y. Yu, W. Hu and S. Li, “A CNN with multiscale convolution and diversified metric for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 6, pp. 3599–3618, Jun. 2019.
- [36] X. Ma, A. Fu, J. Wang, H. Wang and B. Yin, “Hyperspectral image classification based on deep deconvolution network with skip architecture ,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 8, pp. 4781–4791, Aug. 2018.
- [37] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, “Generative adversarial networks,” in Proc. Adv. Neural Inf. Process. Syst., 2014, pp. 2672–2680.
- [38] Y. Zhan, D. Hu, Y. Wang, and X. Yu, “Semisupervised hyperspectral image classification based on generative adversarial networks,” IEEE Trans. Geosci. Remote Sens. Lett., vol. 15, no. 2, pp. 212–216, Feb. 2018.
- [39] L. Zhu, Y. Chen, P. Ghamisi, and J. A. Benediktsson, “Generative adversarial networks for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 9, pp. 5046–5063, Sep. 2018.
- [40] J. Feng, H. Yu, L. Wang, X. Cao, X. Zhang and L. Jiao, “Classification of hyperspectral images based on multiclass spatial–spectral generative adversarial networks,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 8, pp. 5329–5343, Aug. 2019.
- [41] Z. Zhong, J. Li, D. A. Clausi and A. Wong, “Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification,” IEEE Trans. Cybern., DOI: 10.1109/TCYB.2019.2915094
- [42] J. Li, Q. Du, Y. Li and W. Li, “Hyperspectral image classification with imbalanced data based on orthogonal complement subspace projection,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 7, pp. 3838–3851, Jul. 2018.
- [43] A. Odena, C. Olah, and J. Shlens, “Conditional image synthesis with auxiliary classifier GANs,” in Proc. Int. Conf. Mach. Learn., 2017, pp. 2642–2651.
- [44] T. Chavdarova and F. Fleuret, “SGAN: An alternative training of generative adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 9407–9415.
- [45] G. Ghiasi, T. Lin, and Q. V. Le, “Dropblock: A regularization method for convolutional networks,” in Proc. Adv. Neural Inf. Process. Syst., 2018, pp. 10727–10737.
- [46] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” J. Mach. Learn. Res., vol. 15, no. 1, pp. 1929–1958, 2014.
- [47] G. Licciardi, P. R. Marpu, J. Chanussot, and J. A. Benediktsson, “Linear versus nonlinear PCA for the classification of hyperspectral data based on the extended morphological profiles,” IEEE Geosci. Remote Sens. Lett., vol. 9, no. 3, pp. 447–451, May 2011.
- [48] B. Zoph, V. Vasudevan, J. Shlens and Q. V. Le, “Learning Transferable Architectures for Scalable Image Recognition,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 8697–8710.
- [49] L. Wan, M. D. Zeiler, S. Zhang, Y. LeCun, and R. Fergus, “Regularization of neural networks using dropconnect,” in Proc. Int. Conf. Mach. Learn., 2013, pp. 1058–1066.
- [50] P. Gurram and H. Kwon, “Contextual SVM using Hilbert space embedding for hyperspectral classification,” IEEE Geosci. Remote Sens. Lett., vol. 10, no. 5, pp. 1031–1035, Sep. 2013.
- [51] P. Ghamisi, B. Höfle, and X. X. Zhu, “Hyperspectral and LiDAR data fusion using extinction profiles and deep convolutional neural network,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 10, no. 6, pp. 3011–3024, Jun. 2017.
- [52] J. M. Haut, M. E. Paoletti, J. Plaza, A. Plaza and J. Li, “Visual attention-driven hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 10, pp. 8065–8080, Oct. 2019.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/jjwang.jpg) |
Junjie Wang received the B. Sc. degree in computer science from Ocean University of China, Qingdao, China, in 2018. He is currently pursuing the M.Sc. degree in computer science and applied remote sensing with the School of Information Science and Technology, Ocean University of China, Qingdao, China. His current research interests include computer vision and remote sensing image processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/fgao.jpg) |
Feng Gao received the B. Sc degree in software engineering from Chongqing University, Chongqing, China, in 2008, and the Ph. D. degree in computer science and technology from Beihang University, Beijing, China, in 2015. He is currently an Associate Professor with the School of Information Science and Engineering, Ocean University of China. His research interests include remote sensing image analysis, pattern recognition and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/jydong.jpg) |
Junyu Dong received the B.Sc. and M.Sc. degrees from the Department of Applied Mathematics, Ocean University of China, Qingdao, China, in 1993 and 1999, respectively, and the Ph.D. degree in image processing from the Department of Computer Science, Heriot-Watt University, Edinburgh, United Kingdom, in 2003. He is currently a Professor and Vice Dean with the School of Information Science and Engineering, Ocean University of China. His research interests include visual information analysis and understanding, machine learning and underwater image processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3c4bc555-5402-4cc3-82ed-d9d3cf77d2f0/qiandu.jpg) |
Qian Du (Fellow, IEEE) received the Ph.D. degree in electrical engineering from the University of Maryland at Baltimore, Baltimore, MD, USA, in 2000. She is currently the Bobby Shackouls Professor with the Department of Electrical and Computer Engineering, Mississippi State University, Starkville, MS, USA. Her research interests include hyperspectral remote sensing image analysis and applications, pattern classification, data compression, and neural networks. Dr. Du served as a Co-Chair for the Data Fusion Technical Committee of the IEEE Geoscience and Remote Sensing Society (GRSS) from 2009 to 2013 and the Chair for the Remote Sensing and Mapping Technical Committee of the International Association for Pattern Recognition (IAPR) from 2010 to 2014. She currently serves as the Chief Editor of the IEEE Joural of Selected Topics in Applied Earth Observations and Remote Sensing. |