Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models
Abstract
Recently, Large language models (LLMs) with in-context learning have demonstrated remarkable potential in handling neural machine translation. However, existing evidence shows that LLMs are prompt-sensitive and it is sub-optimal to apply the fixed prompt to any input for downstream machine translation tasks. To address this issue, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM’s embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Rather than using other embedding models for semantic demonstration retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM to build better input representation for retrieving more semantic-related translation demonstrations. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences. Finally, extensive experiments on the proposed diplomatic Chinese-English parallel dataset and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP.
Introduction
Neural Machine Translation (NMT) (Bahdanau, Cho, and Bengio 2015), the core of which lies in the encoder-decoder architecture, aims to translate texts in the source language into the target language automatically. NMT is a challenging task since it involves translating text among different languages and requires semantic alignment between languages (Fan et al. 2021; Costa-jussà et al. 2022; Yuan et al. 2023). Even so, it has made remarkable progress in recent years, especially with the emergence of large language models (LLMs) like ChatGPT & GPT-4 (Ouyang et al. 2022), GLM (Du et al. 2022), Llama (Touvron et al. 2023; Dubey et al. 2024), etc. Benefiting from the increasing scale of parameters and training corpus, these LLMs have gained a universal ability to handle various NLP tasks via in-context learning (ICL) (Brown et al. 2020) or prompt engineering (Chen et al. 2023), which is the process of structuring input text with exemplars and human-written instructions for LLMs, rather than conducting costly task-specific fine-tuning. Unsurprisingly, LLMs with ICL or prompting techniques have shown outstanding potential in machine translation (Zhang, Haddow, and Birch 2023a; Zhu et al. 2024; Zhang et al. 2023) by constructing elaborate instruction or prompts with different prompting strategies.
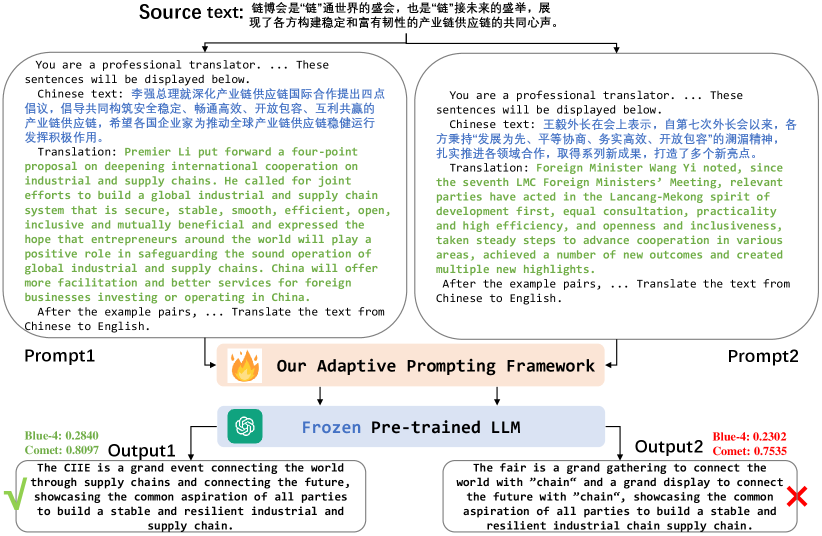
Pioneering work (Zhang, Haddow, and Birch 2023a) conducted a systematic study on prompting strategies for machine translation with the testbed GLM-130B (Zeng et al. 2022), including zero-shot prompting and few-shot prompting. Coincidentally, another work (Zhang et al. 2023) evaluated 15 publicly available language models on machine translation tasks with zero-shot prompting and few-shot learning. (Zhu et al. 2024) explored the multilingual translation capabilities of eight popular LLMs, including ChatGPT and GPT-4. Although all these existing works have shown promising translation performance under the settings of both zero-shot prompting and few-shot ICL, they found that the prompt examples matter the translation performance, which means that LLMs are prompt-sensitive. Using suboptimal examples or instructions can degenerate translation. For example, as shown in Figure 1, the LLM with prompt 1 which is more related to the input text can generate a better translation result than the LLM with prompt 2 according to the BLEU and Comet. In terms of semantic consistency, we can also observe that the translation quality of the LLM with prompt 1 is higher than the LLM with prompt 2. Therefore, selecting suitable adaptive translation demonstrations to elicit the translation capability of an LLM is crucial for high-quality machine translation under in-context learning.
Choosing suitable translation demonstrations for different input text is challenging and nontrivial. To address this issue, we propose an Adaptive Few-Shot Prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM’s embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. The retrieval top-k translation demonstrations will be filled into the handcrafted instruction prompt template which is used for various source sentences uniformly. These translation demonstrations are crucial in eliciting the translation capability of an LLM to generate more semantic-consistent target sentences with current input source sentences. M3-Embedding (Chen et al. 2024) shows that conducting semantic retrieval with a combination of different retrieval functionalities can achieve better retrieval performance by improving the discrimination of embeddings. Inspired by this, we construct a demonstration retrieval module based on dense embedding, sparse embedding, and multi-vector embedding to build better input representation for retrieving more semantic-related translation demonstrations. The dense embedding, sparse embedding, and multi-vector embedding of a sentence are generated from deployed LLM which is also used for machine translation. Then, we use a constructed adaptive few-show prompt to obtain the translation result in the target language. There is output diversity in an LLM (Kirk et al. 2023) due to the probabilistic sampling. Different outputs can lead to different translation quality. To mitigate semantic bias caused by LLMs’ probabilistic sampling and ensure semantic-consistent translation, we force the deployed LLM to generate multiple output candidates in the target language and rerank these candidates by a rerank model based on a small language model (SLM). Since there is no available large-scale annotated corpus about the translation quality of different translation outputs and annotating such a corpus is costly, we train the rerank model at a lower cost with a self-supervision way by negative sampling with different text perturbation. With the rerank model, we can choose better translation results, ensuring better semantic consistency between source inputs and target outputs.
Besides, Language evolves throughout time. To better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences about the question answers with Chinese foreign-ministry spokesman and foreign journalists. These parallel sentences have very high semantic consistency since they are diplomatically oriented and have been rigorously vetted and proofread. Extensive experiments on our proposed diplomatic Chinese-English parallel dataset and United Nations Parallel Corpus (Chinese-English part) show that the effectiveness and superiority of our AFSP.
The main contributions of this work are concluded as follows: First, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. Second, in our AFSP, rather than using other embedding models for semantic retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM itself to build better input representation for retrieving more semantic-related translation demonstrations. Third, to recognize better translation results, we build a rerank model trained in a self-supervision way with negative sampling, ensuring better semantic consistency between source inputs and target outputs and mitigating semantic bias caused by LLMs’ probabilistic sampling. Finally, we construct a high-quality diplomatic Chinese-English parallel dataset and extensive experiments on it and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP quantitatively and qualitatively.
Related work
The emergence of LLMs has shown outstanding potential in the field of machine translation. Unlike traditional neural machine translation methods (Bahdanau, Cho, and Bengio 2014; Sennrich, Haddow, and Birch 2015; Wang et al. 2022) which need to be trained with a large-scale machine translation dataset, LLMs were trained on general large-scale corpus and could effectively finish downstream machine translation tasks via prompt engineering or in-context learning without extra model tuning. Current research evaluating and improving the machine translation capabilities of LLMs can be included in two lines. The first line focuses on comprehensive evaluations of LLMs under various translation scenarios, including multilingual translation (Jiao et al. 2023; Hendy et al. 2023), document-level translation (Wang et al. 2023; Hendy et al. 2023), low-resource translation (Jiao et al. 2023; Bawden and Yvon 2023), etc. Another line focuses on designing novel mechanisms to improve the machine translation capabilities of LLMs, including the design of prompt templates (Zhang, Haddow, and Birch 2023b; Jiao et al. 2023), demonstration selection for in-context learning (Zhang, Haddow, and Birch 2023b; Vilar et al. 2022; García et al. 2023; Yao et al. 2023; Merx et al. 2024; Jiang and Zhang 2024a), self-refinement (Feng et al. 2024b, a), agentic workflow (Wu et al. 2024; Guo et al. 2024), etc.
Among these research lines, the most relevant to our work is the demonstration selection. (Vilar et al. 2022) investigated various strategies for choosing translation examples for few-shot prompting. (García et al. 2023) outperformed the best-performing system on the WMT’21 English-Chinese news translation task by only using five random examples of English-Chinese parallel data at inference. Both these two works found that example quality is the most important factor, but random sampling will influence their performances. (Yao et al. 2023) proposed a low-resource LLM prompting technique In-Context Sampling (ICS) to produce confident predictions by optimizing the construction of multiple ICL prompt inputs. Leveraging a novel corpus derived from a Mambai language manual and additional sentences translated by a native speaker, (Merx et al. 2024) examine the efficacy of few-shot prompting for machine translation (MT) in the low-resource context by prompting with the strategic selection of parallel sentences and dictionary entries, enhancing translation accuracy.
Different from them, our AFSP automatically selects suitable translation demonstrations for various source input sentences to elicit the translation capability of an LLM for better machine translation. Rather than using other embedding models for semantic demonstration retrieval, our AFSP first deploys a translation demonstration retrieval module based on the deployed LLM’s embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates with an SLM which is trained in a self-supervised way.
Adaptive Few-shot Prompting (AFSP)
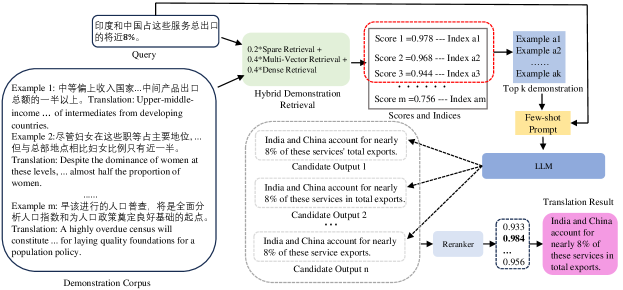
We introduce our Adaptive Few-Shot Prompting framework, which first adaptively retrieves suitable demonstrations to fill into the placeholder in the prompt template from the demonstration corpus and then sorts the multiple candidate sampled outputs generated by the deployed LLM to obtain final translation result. In this work, except for the demonstration placeholder, we use fixed prompt words in the prompt template for general task description. The overview of the inference phase in our AFSP framework is shown in Figure 2. AFSP relies on three key components: a translation demonstration corpus, a hybrid demonstration retrieval module based on the deployed LLM-driven embedding, and a re-ranker module. The translation demonstration corpus aims to provide high-quality parallel translation pairs. The retrieval module takes charge of selecting suitable demonstrations to fill into the prompt template for each input source text. The hybrid demonstration retrieval module is train-free and produces a relevance score based on multiple types of embedding ways for each input source and the text in the demonstration corpus by the deployed LLM for machine translation, rather than using third-party embedding models. With the retrieval demonstrations, we fill the demonstrations into a predefined few-shot prompt and enter it into an LLM for multiple candidate output generation. Finally, we deploy a re-ranker module, which is a small language model (SLM) trained in a self-supervised manner, to sort the generated candidate outputs and obtain the final translation result.
| You are a professional translator. I will give you one or more examples of text fragments, where the first one is in and the second one is the translation of the first fragment into . These sentences will be displayed below. |
| 1. text: |
| translation: |
| 2. text: |
| translation: |
| 3. text: |
| translation: |
| … |
| k. text: |
| translation: |
| After the example pairs, I will provide a/an sentence and I would like you to translate it into . Please provide only the translation result without any additional comments, formatting, or chat content. Translate the text from to . |
Prompt template and Demonstration Corpus
In AFSP, as shown in Table 1, we only use a fixed prompt template with variable placeholders inspired from prior works (Jiang and Zhang 2024b; Agarwal et al. 2024). We do not focus on the diversified design of prompt templates in this work and achieve adaptive prompts for different source text by filling suitable demonstrations according to the retrieved results from the demonstration corpus. Demonstration corpus can be any high-quality parallel translation corpus. In practice, it can be expanded with extra parallel translation corpus. For the sake of simplicity, we simply use the training set from specific translation tasks as the demonstration sources to build the demonstration corpus. For example, we use the training part in the UN Open Corpus v1.0 (Chinese and English versions) as the demonstration corpus when conducting Chinese-English bilingual translation. Similarly, we also use the training subset of our newly constructed Diplomatic corpus as the demonstration corpus when conducting machine translation on its test set.
Hybrid Demonstration Retrieval
As claimed in the pioneering works (Zhang, Haddow, and Birch 2023a; Zhang et al. 2023; Zhu et al. 2024), the number, quality, and semantic similarity of prompt examples matter the translation performance. Therefore, it is crucial to adaptively retrieve high-quality and highly semantic similar demonstrations for different input texts to achieve better LLM prompting for better eliciting the translation capability of an LLM. To achieve this goal, superior embedding-based semantic representation is essential. (Chen et al. 2024) shows that a combination of different embedding-based retrieval functionalities can improve the discrimination of embedding-based semantic representation. Inspired by them, we build an embedding-based hybrid demonstration retrieval module for demonstration retrieval in a training-free way by utilizing the embedding matrix of the deployed LLM that conducts machine translation. The retrieval results are sorted by a weighted combination of relevance scores based on dense embedding, sparse embedding, and multi-vector embedding. The reason we use the deployed LLM as the embedding generator rather than other embedding models is that LLM is pre-trained with large-scale general corpus and can represent text accurately.
Formally, given a query text in the source language, the demonstration retrieval module can retrieve translation demonstration from the corpus based on the hybrid relevance score of and : . Here, denotes the retrieval function based on the hybrid relevance score. For the text , dense embedding, sparse embedding, and multi-vector embedding can be formalized separately as follows: 1) dense embedding : the text is first transformed into the embedding vectors based on the embedding layer in the LLM. Then, we obtain by conducting max pooling on and normalization: . 2) sparse embedding : the embedding vector is also used to estimate the importance of each token to facilitate lexical representation. For each token within the text , the token weight is calculated as , where is rectified linear unit and . is the dimension size of the embedding and is a projection matrix mapping token embedding into a float number as its importance. It is only initialized by Gaussian initialization since we found Gaussian initialization is enough to make the model work fine without any model training. 3) multi-vector embedding : it is an extension of dense embedding by utilizing the entire output embeddings for text representation: , where is a projection matrix initialized by Gaussian initialization.
With the above three embeddings with different granularities, we can calculate three relevance scores for multi-granularity retrieval. For dense retrieval, given a text and source demonstration , we can compute the relevance score by the inner product between the two embeddings and as follows: . For sparse retrieval, we can compute by the joint importance of the co-existed tokens (denoted as ) as follows: . For multi-vector retrieval, we can compute by late interaction as follows: , where and are the lengths of text and source demonstration .
Based on the above three relevance scores, we conduct the demonstration retrieval in a hybrid process according to which can be defined as follows:
| (1) |
where , , and are three hyper-parameters to adjust the weights of three retrieval functionality.
Result Re-ranking
There is output diversity in an LLM (Kirk et al. 2023) due to the probabilistic sampling. The different outputs may have different semantic biases, which will influence the final translation performance. To mitigate this issue, we force the deployed LLM to generate multiple output candidates in the target language and rerank these candidates by a re-ranker model based on a small language model (SLM). The re-ranker takes charge of scoring the output candidates. However, training this re-ranker is challenging since there is available large-scale annotated corpus about the translation quality of different translation outputs and annotating such a corpus is costly. Therefore, we design a self-supervised training method to train such a re-ranker at a low cost by conducting negative sampling with different text perturbations.
Negative Sampling
Formally, given the parallel translation corpus where and are the texts in the source language and the target language respectively. To construct a dataset to train the re-ranker, we can disturb the by multiple degeneration operation set including converting to the parallel text (), back translation (), inserting source text (), spelling mistake (), repeated translation (), synonym replacement (). and are the degenerated text and corresponding quality score, respectively. We define the quality score of the original target text as 1. Assuming that contains a null operation that means we just copy the original text into and all possible combinations of the degeneration operation in , for each possible combination , we can obtain the degenerated text and calculate its score as follows:
| (2) | ||||
where represents the degeneration function with the degenration operation combination and is the number of degeration operations in . In this way, we can generate a large-scale dataset from the parallel translation corpus to train the re-ranker in a self-supervised manner.
Re-ranker and Learning Objectives
We deploy BERT (Devlin et al. 2019) as the backbone of the SLM in the Re-ranker. For Chinese-English translation, we use Bert-large-cased111https://huggingface.co/google-bert/bert-large-cased while we use Bert-based-Chinese222https://huggingface.co/google-bert/bert-base-chinese as the SLM for English-Chinese translation. Given a degenerated text and its quality score , the re-ranker takes the degenerated text as input and predicts a quality assessment score as close to the annotated score as possible. The re-ranker calculates the quality assessment score by applying a Linear layer to map the output encoding of [CLS] token into 1-D float number followed by the function to normalize the output to between 0 and 1. To optimize the re-ranker, we adopted Mean Squared Error as its objective function to enable the re-ranker to predict quality assessment scores. Therefore, the re-ranker and its learning objective can be modeled as follows:
| E | (3) | |||
Experiments
Experiment Settings
Datasets
To validate the effectiveness of the proposed AFSP, we first crawled a high-quality parallel Chinese-English dataset named Diplomatic corpus from the China Diplomatic website333https://www.fmprc.gov.cn/. The Diplomatic corpus consists of speeches made by spokespersons during routine press conferences, including questions posed by journalists and responses from Chinese spokespersons on a range of diplomatic issues. There are some advantages in the Diplomatic corpus. The first is accessibility. All data is publicly available on the China Diplomatic website and can be easily found online. The second is high quality. All bilingual materials are translated by professional translators from specialized institutions, ensuring superior quality. The third is language complexity. The Diplomatic corpus contains certain political terminology and specialized terms, which may pose challenges for the LLM in the context of China’s political landscape. The final one is recency. All texts are recorded from 2022 to 2023 which can reflect the latest advances in language. Besides, we also use a Chinese-English subset from the UN Open Corpus v1.0 as the second testbed, which can show the universality of the proposed AFSP. We use UN to denote this subset. The UN Parallel Corpus is a parallel corpus that includes official UN documents and statements from meetings. The content covers various fields such as politics, economics, culture, and technology. This corpus records texts written and manually translated from 1990 to 2014, aligned at the sentence level. We randomly selected 120,000 entries as the data for evaluation. The statistics for both two datasets are shown in Table 2. For both two datasets Diplomatic and UN, we randomly selected 500 parallel translation pairs to serve as the test set for evaluating AFSP. The remaining pairs are used as the demonstration corpus for adaptive demonstration retrieval.
| Dataset | Language | #Sent. | #Word | #Average. |
| Diplomatic | English | 5.528K | 415K | 75.20 |
| Chinese | 5.528K | 316K | 57.29 | |
| UN | English | 120K | 3,500K | 29.11 |
| Chinese | 120K | 3,220K | 26.75 |
| ChatGLM3-6B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero-shot | 18.89 | 50.57 | 21.23 | 10.25 | 21.13 | 42.76 | 88.07 | 22.69 | 54.64 | 59.91 | 31.99 | 50.93 | 66.50 | 81.47 |
| Few-shot | 20.27 | 51.73 | 20.54 | 10.28 | 20.46 | 43.81 | 88.22 | 23.61 | 55.70 | 60.84 | 33.05 | 51.63 | 67.06 | 81.39 |
| KNN Few-shot | 20.22 | 51.77 | 20.77 | 10.36 | 20.68 | 43.90 | 88.33 | 22.93 | 55.14 | 60.40 | 32.50 | 51.13 | 66.69 | 81.25 |
| AFSP w/o rerank (Ours) | 25.92 | 56.80 | 22.47 | 11.39 | 22.40 | 48.58 | 88.99 | 28.14 | 59.29 | 63.83 | 37.32 | 54.94 | 69.34 | 82.32 |
| AFSP (Ours) | 27.36 | 58.22 | 22.92 | 11.52 | 22.85 | 49.78 | 89.12 | 29.17 | 60.01 | 64.02 | 37.64 | 55.15 | 69.68 | 82.74 |
| InternLM2-7B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero-shot | 20.60 | 52.32 | 22.41 | 11.14 | 22.25 | 44.49 | 88.42 | 23.36 | 56.06 | 60.43 | 32.62 | 51.16 | 67.72 | 81.92 |
| Few-shot | 24.45 | 55.69 | 22.66 | 11.64 | 22.51 | 47.21 | 89.01 | 24.15 | 57.06 | 61.40 | 33.81 | 52.24 | 68.48 | 81.66 |
| KNN Few-shot | 24.91 | 56.28 | 22.81 | 11.71 | 22.64 | 47.61 | 88.95 | 24.73 | 57.42 | 61.68 | 34.33 | 52.63 | 68.66 | 81.94 |
| AFSP w/o rerank (Ours) | 30.72 | 60.78 | 22.86 | 11.92 | 22.72 | 52.28 | 89.52 | 30.10 | 61.24 | 64.98 | 39.34 | 56.28 | 71.01 | 82.53 |
| AFSP (Ours) | 31.75 | 61.34 | 22.86 | 11.93 | 22.71 | 52.85 | 89.62 | 31.28 | 61.90 | 64.87 | 39.66 | 56.09 | 70.87 | 82.74 |
| Llama3-8B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero-shot | 10.72 | 37.16 | 17.44 | 8.12 | 17.22 | 32.02 | 84.57 | 24.03 | 56.68 | 60.91 | 33.55 | 51.66 | 68.21 | 82.27 |
| Few-shot | 15.53 | 45.71 | 18.51 | 8.83 | 18.33 | 38.97 | 86.22 | 25.66 | 57.98 | 62.40 | 35.18 | 53.13 | 68.83 | 82.81 |
| KNN Few-shot | 16.51 | 46.81 | 18.69 | 8.98 | 18.54 | 39.90 | 86.52 | 25.32 | 57.58 | 62.27 | 35.07 | 52.99 | 68.41 | 82.76 |
| AFSP w/o rerank (Ours) | 26.34 | 55.55 | 19.81 | 9.56 | 19.60 | 47.95 | 87.96 | 30.71 | 61.46 | 65.72 | 40.24 | 57.10 | 71.10 | 83.29 |
| AFSP (Ours) | 27.67 | 56.71 | 19.86 | 9.87 | 19.65 | 49.05 | 88.41 | 31.02 | 61.48 | 65.73 | 40.25 | 56.97 | 70.98 | 83.34 |
| Chatgpt-3.5-turbo-0125 | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero-shot | 22.96 | 54.90 | 22.34 | 11.13 | 22.22 | 46.54 | 89.13 | 27.66 | 59.92 | 64.11 | 37.29 | 55.47 | 70.65 | 83.24 |
| Few-shot | 24.57 | 56.73 | 22.33 | 11.17 | 22.18 | 48.18 | 89.51 | 28.12 | 60.54 | 64.55 | 37.71 | 55.98 | 70.96 | 83.43 |
| KNN Few-shot | 25.63 | 57.83 | 22.42 | 11.38 | 22.33 | 49.09 | 89.49 | 28.34 | 60.49 | 64.53 | 37.91 | 56.00 | 70.89 | 83.45 |
| AFSP w/o rerank (Ours) | 30.26 | 62.10 | 23.47 | 11.73 | 23.36 | 52.93 | 89.94 | 31.29 | 62.46 | 66.42 | 40.75 | 58.00 | 72.12 | 83.86 |
| AFSP (Ours) | 32.30 | 63.53 | 23.26 | 11.69 | 23.26 | 54.31 | 90.32 | 32.30 | 63.19 | 66.93 | 41.440 | 58.67 | 72.46 | 83.95 |
| ChatGLM3-6B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero Few-shot | 18.89 | 52.89 | 42.15 | 17.93 | 41.72 | 45.21 | 86.94 | 21.46 | 58.02 | 59.99 | 34.20 | 53.20 | 64.11 | 83.64 |
| Few-shot | 19.05 | 52.62 | 42.14 | 17.62 | 41.64 | 45.07 | 86.33 | 21.75 | 58.21 | 59.43 | 34.57 | 52.82 | 65.25 | 82.46 |
| KNN Few-shot | 18.80 | 52.29 | 41.63 | 17.50 | 41.24 | 44.89 | 86.56 | 22.74 | 59.01 | 60.07 | 35.33 | 53.46 | 65.12 | 83.08 |
| AFSP w/o rerank (Ours) | 24.84 | 57.28 | 42.83 | 18.34 | 42.45 | 50.15 | 87.99 | 29.35 | 63.44 | 64.59 | 41.67 | 58.22 | 69.00 | 84.55 |
| AFSP (Ours) | 24.61 | 57.60 | 42.80 | 18.34 | 42.44 | 50.52 | 88.24 | 29.07 | 64.49 | 65.08 | 41.75 | 58.39 | 69.64 | 84.87 |
| InternLM2-7B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero Few-shot | 17.32 | 50.31 | 37.36 | 17.82 | 36.81 | 43.49 | 86.30 | 25.48 | 61.86 | 63.52 | 38.68 | 56.96 | 67.23 | 84.71 |
| Few-shot | 17.85 | 51.53 | 41.13 | 18.39 | 40.70 | 44.43 | 86.70 | 25.76 | 62.65 | 63.49 | 38.81 | 57.00 | 68.35 | 83.92 |
| KNN Few-shot | 17.80 | 51.27 | 39.45 | 18.16 | 39.04 | 44.30 | 86.58 | 26.30 | 62.61 | 63.95 | 39.27 | 57.28 | 68.02 | 84.45 |
| AFSP w/o rerank (Ours) | 26.21 | 58.49 | 40.45 | 19.17 | 40.13 | 51.59 | 88.34 | 31.28 | 61.90 | 64.87 | 39.66 | 56.09 | 72.84 | 86.12 |
| AFSP (Ours) | 26.10 | 58.76 | 40.46 | 19.27 | 40.13 | 51.75 | 88.91 | 33.98 | 67.37 | 68.63 | 46.27 | 62.47 | 71.93 | 86.50 |
| Llama3-8B | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero Few-shot | 8.85 | 35.40 | 34.21 | 15.43 | 33.66 | 30.26 | 81.12 | 18.60 | 55.35 | 58.18 | 32.07 | 51.08 | 63.92 | 83.38 |
| Few-shot | 13.11 | 44.47 | 34.05 | 15.30 | 33.39 | 38.42 | 83.41 | 21.91 | 58.12 | 60.77 | 35.13 | 53.67 | 65.88 | 84.25 |
| KNN Few-shot | 12.64 | 43.78 | 29.44 | 15.04 | 28.89 | 37.87 | 83.47 | 21.72 | 57.58 | 60.66 | 35.14 | 53.60 | 65.73 | 84.28 |
| AFSP w/o rerank (Ours) | 22.74 | 53.99 | 33.11 | 16.46 | 32.54 | 47.79 | 86.51 | 30.11 | 63.94 | 66.75 | 44.22 | 60.69 | 71.31 | 86.26 |
| AFSP (Ours) | 23.62 | 54.53 | 34.26 | 16.90 | 33.84 | 48.45 | 87.21 | 31.03 | 64.88 | 67.06 | 44.94 | 60.95 | 71.68 | 86.24 |
| Chatgpt-3.5-turbo-0125 | ||||||||||||||
| Methods | English-to-Chinese | Chinese-to-English | ||||||||||||
| BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | BLUE-4 | METEOR | ROUGE-1 | ROUGE-2 | ROUGE-L | CHRF | COMET-Kiwi | |
| Zero Few-shot | 20.04 | 52.94 | 31.96 | 17.48 | 31.51 | 46.28 | 87.10 | 24.49 | 61.31 | 63.27 | 37.99 | 56.90 | 67.80 | 85.43 |
| Few-shot | 21.29 | 55.39 | 42.96 | 18.62 | 42.51 | 47.93 | 87.88 | 27.04 | 63.92 | 65.33 | 40.59 | 58.91 | 69.65 | 85.90 |
| KNN Few-shot | 20.27 | 53.80 | 35.09 | 17.95 | 34.66 | 47.05 | 87.51 | 27.10 | 63.13 | 64.90 | 40.59 | 58.65 | 69.30 | 85.85 |
| AFSP w/o rerank (Ours) | 28.41 | 61.09 | 40.71 | 18.98 | 40.33 | 53.92 | 89.10 | 32.74 | 66.86 | 68.85 | 46.24 | 63.14 | 72.99 | 86.91 |
| AFSP (Ours) | 29.06 | 62.00 | 42.40 | 19.05 | 42.00 | 54.59 | 89.48 | 34.09 | 67.48 | 69.28 | 46.96 | 63.65 | 73.32 | 87.34 |
Metrics
To conduct a comprehensive assessment of translation quality, we employed the most commonly used BLEU (Papineni et al. 2002), METEOR (Banerjee and Lavie 2005), ROUGE-1, ROUGE-2, ROUGE-L (Lin 2004), CHRF (Popović 2015), and COMET-Kiwi(Rei et al. 2022) as evaluation metrics. Besides, we also evaluate our AFSP by conducting a human evaluation of fluency, accuracy, and consistency of style.
Implementation Details
We evaluate AFSP on three open-source LLMs, ChatGLM3-6B, InternLM2-7B, and Llama3-8B, as well as one closed-source LLM ChatGPT-3.5-turbo-0125 by comparing with three baselines, Zero-shot (Jiang and Zhang 2024a), Few-shot (Jiang and Zhang 2024a), kNN-based few-shot (Nori et al. 2023) in both Chinese-to-English and English-to-Chinese translation directions. The , , and are set to 0.4, 0.4, 0.2 for the computation of the final relevance score in hybrid demonstration retrieval. The shot for few-shot prompts is set to 3 due to the limited GPU memory of NVIDIA RTX 3090. For the closed-source ChatGPT-3.5-turbo-0125, we deploy ChatGLM3-6B as the embedding model for hybrid demonstration retrieval. We conduct top-30 sampling for ChatGLM3-6B, InternLM2-7B, and Llama3-8B and top-5 sampling for ChatGPT-3.5-turbo-0125 due to cost considerations.
Experiment Result
Main Results
Table 3 and Table 4 show the performance of our AFSP and baselines on different translation datasets and different LLMs. Compared to baselines, our AFSP demonstrates superior performance by always generating higher-quality translation according to various metrics. For instance, when Llama-3-8B translates from Chinese to English on the UN, our ASFP achieves significant improvements over KNN Few-shot with 9.31 improvement in BLEU-4, 7.3 improvement in METEOR, 7.35 improvement in ROUGE-L, and 1.96 improvement in COMET-Kiwi. Other models also show significant metric improvements in translation across different datasets and LLMs, highlighting the effectiveness of our AFSP method.
| Method | Fluency | Accuracy | Style | Fluency | Accuracy | Style |
| Chinese-to-English | English-to-Chinese | |||||
| Zero-shot | 0.1428 | 0.2071 | 0.2 | 0.1428 | 0.1214 | 0.1428 |
| Few-shot | 0.25714 | 0.2571 | 0.2714 | 0.1428 | 0.25 | 0.1714 |
| KNN Few-shot | 0.2714 | 0.2285 | 0.1928 | 0.1785 | 0.1428 | 0.15 |
| ASFP (Ours) | 0.32857 | 0.3071 | 0.3071 | 0.5357 | 0.4857 | 0.5357 |
Human Evaluation
To further validate the effectiveness of the AFSP, we also conducted a human evaluation of both two datasets and two translation directions to compare AFSP with baselines. For each translation direction, we randomly selected 5 examples from each dataset. Participants judged the options based on fluency, accuracy, and style retention by selecting the sentence they deemed best. We tested the translation results generated by Llama3-8B and invited 14 teachers or students fluent in English or Chinese to participate in the evaluation for each translation direction. To avoid bias, the output order was randomized. The evaluation results in Table 5 demonstrate that our AFSP outperforms all baselines in fluency, semantic accuracy, and style consistency.
| Embedding | BGE-M3 | E5-Large | BGE-large | BCE | ChatGLM3-6B |
| Chinese-to-English | |||||
| BLUE-4 | 27.31 | 26.39 | 22.91 | 27.99 | 29.17 |
| METEOR | 58.69 | 58.00 | 54.88 | 59.15 | 60.02 |
| ROUGE-1 | 63.42 | 62.83 | 60.19 | 63.79 | 64.02 |
| ROUGE-2 | 36.57 | 35.73 | 32.34 | 37.14 | 37.65 |
| ROUGE-L | 54.45 | 53.80 | 50.87 | 54.90 | 55.15 |
| CHRF | 69.00 | 68.54 | 66.47 | 69.30 | 69.68 |
| COMET-Kiwi | 82.18 | 82.90 | 81.16 | 82.29 | 82.74 |
| English-to-Chinese | |||||
| BLUE-4 | 23.61 | 24.12 | 20.29 | 24.74 | 27.37 |
| METEOR | 54.85 | 55.06 | 51.80 | 55.59 | 58.23 |
| ROUGE-1 | 21.46 | 21.95 | 20.61 | 21.80 | 22.92 |
| ROUGE-2 | 10.76 | 10.90 | 10.40 | 10.81 | 11.53 |
| ROUGE-L | 21.39 | 21.86 | 20.53 | 21.69 | 22.85 |
| CHRF | 46.65 | 46.97 | 43.92 | 47.53 | 49.78 |
| COMET-Kiwi | 88.73 | 88.69 | 88.29 | 88.85 | 89.12 |
The Choice of Embedding Model
In our hybrid demonstration retrieval, we use the embedding model in the deployed LLM to compute relevance scores. To show the effectiveness of using the embedding model of the deployed LLM model, we conduct an ablation study on various embedding models including BGE-M3, E5-Large, BGE-large, and BCE. The results in Table 6 show using the embedding model of the deployed LLM model is a better choice than using third-party embedding models.
| // | 0.2/0.4/0.4 | 0.3/0.3/0.4 | 0.4/0.3/0.3 | 0.25/0.25/0.5 | 0.25/0.35/0.4 | 0.35/0.35/0.3 | 0.4/0.4/0.2 |
| Chinese-to-English | |||||||
| BLUE-4 | 27.77 | 27.85 | 27.90 | 27.87 | 27.75 | 27.86 | 28.14 |
| METEOR | 58.90 | 58.99 | 59.02 | 58.97 | 58.95 | 58.99 | 59.29 |
| ROUGE-1 | 63.54 | 63.67 | 63.70 | 63.65 | 63.63 | 63.67 | 63.83 |
| ROUGE-2 | 36.97 | 37.03 | 37.10 | 37.10 | 37.05 | 37.08 | 37.32 |
| ROUGE-L | 54.65 | 54.70 | 54.79 | 54.75 | 54.71 | 54.79 | 54.94 |
| CHRF | 69.06 | 69.16 | 69.19 | 69.08 | 69.16 | 69.13 | 69.68 |
| COMET-Kiwi | 82.30 | 82.33 | 82.38 | 82.36 | 82.31 | 82.37 | 82.32 |
| English-to-Chinese | |||||||
| BLUE-4 | 25.82 | 25.69 | 25.87 | 25.72 | 25.63 | 25.72 | 25.92 |
| METEOR | 56.65 | 56.54 | 56.64 | 56.59 | 56.52 | 56.59 | 56.80 |
| ROUGE-1 | 22.15 | 22.21 | 22.44 | 22.35 | 22.24 | 22.16 | 22.47 |
| ROUGE-2 | 11.32 | 11.21 | 11.36 | 11.24 | 11.08 | 11.23 | 11.39 |
| ROUGE-L | 22.10 | 22.14 | 22.36 | 22.28 | 22.16 | 22.08 | 22.40 |
| CHRF | 48.46 | 48.33 | 48.44 | 48.40 | 48.31 | 48.41 | 49.78 |
| COMET-Kiwi | 88.98 | 88.94 | 88.99 | 88.97 | 88.95 | 88.99 | 88.99 |
Ablation on Weights of Hybrid Demonstration Retrieval
The hybrid demonstration retrieval uses multiple retrieval functions to compute relevance scores. To investigate the influence of different weights , , and , we conduct experiments with ChatGLM3-6B on the Diplomatic Corpus by setting different , , and . The results in Table 7 show that , , and are set to 0.4, 0.4, and 0.2 can achieve the best performance on most of the metrics.
| Demonstration number | 1 | 2 | 3 | 1 | 2 | 3 |
| Chinese-to-English | English-to-Chinese | |||||
| BLUE | 26.71 | 27.66 | 29.17 | 24.24 | 25.98 | 27.37 |
| METEOR | 58.13 | 58.91 | 60.02 | 55.23 | 56.91 | 58.23 |
| ROUGE-1 | 62.00 | 63.63 | 64.02 | 22.16 | 22.04 | 22.92 |
| ROUGE-L | 54.07 | 54.72 | 55.15 | 22.05 | 21.95 | 22.85 |
| CHRF | 68.71 | 69.13 | 69.68 | 47.23 | 47.84 | 49.78 |
| COMET-Kiwi | 81.77 | 82.34 | 82.74 | 88.79 | 88.92 | 89.12 |
The Number of Translation Demonstrations
We verify the effects of different numbers of demonstrations for few-shot prompting by using the Diplomatic Corpus dataset on ChatGLM3-6B. The results in Table 8 show the best translation performance can be achieved when the number of demonstrations is 3.
Conclusion
In this work, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus based on hybrid demonstration retrieval. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel sentences. Extensive experiments on the proposed Diplomatic dataset and UN show the effectiveness and superiority of our AFSP.
References
- Agarwal et al. (2024) Agarwal, R.; Singh, A.; Zhang, L. M.; Bohnet, B.; Chan, S.; Anand, A.; Abbas, Z.; Nova, A.; Co-Reyes, J. D.; Chu, E.; Behbahani, F. M. P.; Faust, A.; and Larochelle, H. 2024. Many-Shot In-Context Learning. ArXiv, abs/2404.11018.
- Bahdanau, Cho, and Bengio (2014) Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural Machine Translation by Jointly Learning to Align and Translate. CoRR, abs/1409.0473.
- Bahdanau, Cho, and Bengio (2015) Bahdanau, D.; Cho, K. H.; and Bengio, Y. 2015. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015.
- Banerjee and Lavie (2005) Banerjee, S.; and Lavie, A. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In IEEvaluation@ACL.
- Bawden and Yvon (2023) Bawden, R.; and Yvon, F. 2023. Investigating the Translation Performance of a Large Multilingual Language Model: the Case of BLOOM. In European Association for Machine Translation Conferences/Workshops.
- Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901.
- Chen et al. (2023) Chen, B.; Zhang, Z.; Langrené, N.; and Zhu, S. 2023. Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review. arXiv preprint arXiv:2310.14735.
- Chen et al. (2024) Chen, J.; Xiao, S.; Zhang, P.; Luo, K.; Lian, D.; and Liu, Z. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216.
- Costa-jussà et al. (2022) Costa-jussà, M. R.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; Maillard, J.; et al. 2022. No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672.
- Devlin et al. (2019) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Burstein, J.; Doran, C.; and Solorio, T., eds., Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. Minneapolis, Minnesota: Association for Computational Linguistics.
- Du et al. (2022) Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; and Tang, J. 2022. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 320–335.
- Dubey et al. (2024) Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783.
- Fan et al. (2021) Fan, A.; Bhosale, S.; Schwenk, H.; Ma, Z.; El-Kishky, A.; Goyal, S.; Baines, M.; Celebi, O.; Wenzek, G.; Chaudhary, V.; et al. 2021. Beyond english-centric multilingual machine translation. Journal of Machine Learning Research, 22(107): 1–48.
- Feng et al. (2024a) Feng, Z.; Chen, R.; Zhang, Y.; Meng, Z.; and Liu, Z. 2024a. Ladder: A Model-Agnostic Framework Boosting LLM-based Machine Translation to the Next Level. arXiv preprint arXiv:2406.15741.
- Feng et al. (2024b) Feng, Z.; Zhang, Y.; Li, H.; Wu, B.; Liao, J.; Liu, W.; Lang, J.; Feng, Y.; Wu, J.; and Liu, Z. 2024b. TEaR: Improving LLM-based Machine Translation with Systematic Self-Refinement.
- García et al. (2023) García, X.; Bansal, Y.; Cherry, C.; Foster, G. F.; Krikun, M.; Feng, F.; Johnson, M.; and Firat, O. 2023. The unreasonable effectiveness of few-shot learning for machine translation. ArXiv, abs/2302.01398.
- Guo et al. (2024) Guo, S.; Zhang, S.; Ma, Z.; Zhang, M.; and Feng, Y. 2024. SiLLM: Large Language Models for Simultaneous Machine Translation. ArXiv, abs/2402.13036.
- Hendy et al. (2023) Hendy, A.; Abdelrehim, M. G.; Sharaf, A.; Raunak, V.; Gabr, M.; Matsushita, H.; Kim, Y. J.; Afify, M.; and Awadalla, H. H. 2023. How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. ArXiv, abs/2302.09210.
- Jiang and Zhang (2024a) Jiang, Z.; and Zhang, Z. 2024a. Can ChatGPT Rival Neural Machine Translation? A Comparative Study. arXiv preprint arXiv:2401.05176.
- Jiang and Zhang (2024b) Jiang, Z.; and Zhang, Z. 2024b. Convergences and Divergences between Automatic Assessment and Human Evaluation: Insights from Comparing ChatGPT-Generated Translation and Neural Machine Translation.
- Jiao et al. (2023) Jiao, W.; Wang, W.; tse Huang, J.; Wang, X.; and Tu, Z. 2023. Is ChatGPT A Good Translator? A Preliminary Study. ArXiv, abs/2301.08745.
- Kirk et al. (2023) Kirk, R.; Mediratta, I.; Nalmpantis, C.; Luketina, J.; Hambro, E.; Grefenstette, E.; and Raileanu, R. 2023. Understanding the effects of rlhf on llm generalisation and diversity. arXiv preprint arXiv:2310.06452.
- Lin (2004) Lin, C.-Y. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Annual Meeting of the Association for Computational Linguistics.
- Merx et al. (2024) Merx, R.; Mahmudi, A.; Langford, K.; de Araujo, L. A.; and Vylomova, E. 2024. Low-Resource Machine Translation through Retrieval-Augmented LLM Prompting: A Study on the Mambai Language. ArXiv, abs/2404.04809.
- Nori et al. (2023) Nori, H.; Lee, Y. T.; Zhang, S.; Carignan, D.; Edgar, R.; Fusi, N.; King, N.; Larson, J.; Li, Y.; Liu, W.; Luo, R.; McKinney, S. M.; Ness, R. O.; Poon, H.; Qin, T.; Usuyama, N.; White, C.; and Horvitz, E. 2023. Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine. arXiv:2311.16452.
- Ouyang et al. (2022) Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730–27744.
- Papineni et al. (2002) Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Annual Meeting of the Association for Computational Linguistics.
- Popović (2015) Popović, M. 2015. chrF: character n-gram F-score for automatic MT evaluation. In Bojar, O.; Chatterjee, R.; Federmann, C.; Haddow, B.; Hokamp, C.; Huck, M.; Logacheva, V.; and Pecina, P., eds., Proceedings of the Tenth Workshop on Statistical Machine Translation, 392–395. Lisbon, Portugal: Association for Computational Linguistics.
- Rei et al. (2022) Rei, R.; Treviso, M.; Guerreiro, N. M.; Zerva, C.; Farinha, A. C.; Maroti, C.; C. de Souza, J. G.; Glushkova, T.; Alves, D.; Coheur, L.; Lavie, A.; and Martins, A. F. T. 2022. CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task. In Koehn, P.; Barrault, L.; Bojar, O.; Bougares, F.; Chatterjee, R.; Costa-jussà, M. R.; Federmann, C.; Fishel, M.; Fraser, A.; Freitag, M.; Graham, Y.; Grundkiewicz, R.; Guzman, P.; Haddow, B.; Huck, M.; Jimeno Yepes, A.; Kocmi, T.; Martins, A.; Morishita, M.; Monz, C.; Nagata, M.; Nakazawa, T.; Negri, M.; Névéol, A.; Neves, M.; Popel, M.; Turchi, M.; and Zampieri, M., eds., Proceedings of the Seventh Conference on Machine Translation (WMT), 634–645. Abu Dhabi, United Arab Emirates (Hybrid): Association for Computational Linguistics.
- Sennrich, Haddow, and Birch (2015) Sennrich, R.; Haddow, B.; and Birch, A. 2015. Neural Machine Translation of Rare Words with Subword Units. ArXiv, abs/1508.07909.
- Touvron et al. (2023) Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vilar et al. (2022) Vilar, D.; Freitag, M.; Cherry, C.; Luo, J.; Ratnakar, V.; and Foster, G. F. 2022. Prompting PaLM for Translation: Assessing Strategies and Performance. ArXiv, abs/2211.09102.
- Wang et al. (2023) Wang, L.; Lyu, C.; Ji, T.; Zhang, Z.; Yu, D.; Shi, S.; and Tu, Z. 2023. Document-Level Machine Translation with Large Language Models. In Conference on Empirical Methods in Natural Language Processing.
- Wang et al. (2022) Wang, W.; Jiao, W.; Hao, Y.; Wang, X.; Shi, S.; Tu, Z.; and Lyu, M. R. 2022. Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation. In Annual Meeting of the Association for Computational Linguistics.
- Wu et al. (2024) Wu, M.; Yuan, Y.; Haffari, G.; and Wang, L. 2024. (Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts. ArXiv, abs/2405.11804.
- Yao et al. (2023) Yao, B.; Chen, G.; Zou, R.; Lu, Y.; Li, J.; Zhang, S.; Liu, S.; Hendler, J.; and Wang, D. 2023. More Samples or More Prompt Inputs? Exploring Effective In-Context Sampling for LLM Few-Shot Prompt Engineering. arXiv preprint arXiv:2311.09782.
- Yuan et al. (2023) Yuan, F.; Lu, Y.; Zhu, W.; Kong, L.; Li, L.; Qiao, Y.; and Xu, J. 2023. Lego-MT: Learning Detachable Models for Massively Multilingual Machine Translation. In Rogers, A.; Boyd-Graber, J.; and Okazaki, N., eds., Findings of the Association for Computational Linguistics: ACL 2023, 11518–11533. Toronto, Canada: Association for Computational Linguistics.
- Zeng et al. (2022) Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. 2022. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414.
- Zhang, Haddow, and Birch (2023a) Zhang, B.; Haddow, B.; and Birch, A. 2023a. Prompting large language model for machine translation: A case study. In International Conference on Machine Learning, 41092–41110. PMLR.
- Zhang, Haddow, and Birch (2023b) Zhang, B.; Haddow, B.; and Birch, A. 2023b. Prompting Large Language Model for Machine Translation: A Case Study. ArXiv, abs/2301.07069.
- Zhang et al. (2023) Zhang, X.; Rajabi, N.; Duh, K.; and Koehn, P. 2023. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with QLoRA. In Koehn, P.; Haddow, B.; Kocmi, T.; and Monz, C., eds., Proceedings of the Eighth Conference on Machine Translation, 468–481. Singapore: Association for Computational Linguistics.
- Zhu et al. (2024) Zhu, W.; Liu, H.; Dong, Q.; Xu, J.; Huang, S.; Kong, L.; Chen, J.; and Li, L. 2024. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. In Findings of the Association for Computational Linguistics: NAACL 2024, 2765–2781.