Adaptive Identification with Guaranteed Performance Under Saturated-Observation and Non-Persistent Excitation
Abstract
This paper investigates adaptive identification and prediction problems for stochastic dynamical systems with saturated output observations, which arise from various fields in engineering and social systems, but up to now still lack comprehensive theoretical studies including guarantees for the estimation performance needed in practical applications. With this impetus, the paper has made the following main contributions: (i) To introduce an adaptive two-step quasi-Newton algorithm to improve the performance of the identification, which is applicable to a typical class of nonlinear stochastic systems with outputs observed under possibly varying saturation. (ii) To establish the global convergence of both the parameter estimators and adaptive predictors and to prove the asymptotic normality, under the weakest possible non-persistent excitation condition, which can be applied to stochastic feedback systems with general non-stationary and correlated system signals or data. (iii) To establish useful probabilistic estimation error bounds for any given finite length of data, using either martingale inequalities or Monte Carlo experiments. A numerical example is also provided to illustrate the performance of the proposed identification algorithm.
Asymptotic normality, convergence, non-PE condition, stochastic systems, saturated observations.
1 Introduction
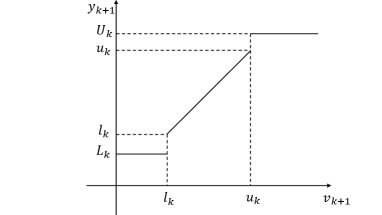
Identifying the input-output relationship and predicting the future behavior of dynamical systems based on observation data are fundamental problems in various fields including control systems, signal processes, machine learning, etc. This paper considers identification and prediction problems for stochastic dynamical systems with saturated output observation data. Here, by saturated output observations, we mean that the observations for the output are produced through the following mechanism: at each time, the noise-corrupted output can be observed precisely only when its value lies in a certain range, however, when the output value exceeds this range, its observation becomes saturated, leading to imprecise information. The relationship between the system output and its observation is illustrated in Fig.1, where and represent the system output and its observation respectively, the interval is the precise observation range, when the system output exceeds this range, the only possible observation is a constant, either or . Note that if we take , then the saturation function will become the ReLu function widely used in machine learning; and if we take , the saturation function will turn to be a binary-valued function widely used in classification problems([mc1943], [gs1990]).
Saturated output observations in stochastic dynamical systems exist widely in various fields including engineering ([sj2004][hf2009]), economics ([tj1958]-[cm2013]), and social systems[judical]. We only mention several examples in three different application areas. The first example is from control engineering ([sj2004]), where represents the sensor observation of the system output, which can be considered as a saturated output observation since it becomes saturated if the output is too large to exceed the observation range of the available sensors. The second example is from economics ([tj1958]), where is interpreted as an index of the consumer’s intensity of desire to purchase a durable, is the true purchase which can be regarded as a saturated observation, since the intensity can be observed only if it exceeds a certain threshold where the true purchase takes place; The third example is from sentencing ([judical]), where is the pronounced penalty and can also be regarded as a saturated observation since it is constrained within the statutory range of penalty according to the related basic criminal facts.
Since the emergence of saturation changes the structure of the original systems and may degrade system performance, providing a theoretical analysis for the performance guarantee of the identification algorithm is one of the most important issues addressed in this paper. Compared with the unsaturated case of observations, the key challenge of the current saturated case is the inherent nonlinearity in the observations of the underlying stochastic dynamical systems. In the past several decades, various identification methods with saturated observations have been studied intensively with both asymptotic and non-asymptotic results, on which we give a brief review separately in the following:
First, most of the existing theoretical results are asymptotic in nature, where the number of observations needs to increase unboundedly or at least to be sufficiently large. For example, the least absolute deviation methods were considered in [PJ1984], and the strong consistency and asymptotic normality of the estimators were proven for independent signals satisfying the usual persistent excitation (PE) condition where the condition number of the information matrix is bounded. Besides, the maximum likelihood (ML) method was considered in [ly1992], where consistency and asymptotic efficiency were established for independent or non-random signals satisfying a stronger PE condition. Moreover, a two-stage procedure based on ML was proposed in [hj1976] to deal with two coupled models with saturated observations. Furthermore, the empirical measure approach was employed in [ZG2003]-[YG2007], where strong consistency and asymptotic efficiency were established under periodic signals with binary-valued observations. Such observations were also considered in [GZ2013], where a strongly consistent recursive projection algorithm was given under a condition stronger than the usual PE condition.
Second, there are also a number of non-asymptotic estimation results in the literature. Despite the importance of the asymptotic estimation results as mentioned above, non-asymptotic results appear to be more practical, because one usually only has a finite number of data available for identification in practice. However, obtaining non-asymptotic identification results, which are usually given under high probability, is quite challenging especially when the structure comes to nonlinear. Most of the existing results are established under assumptions that the system data are independently and identically distributed (i.i.d), e.g., the analysis of the stochastic gradient descent methods in [kv2019],[dc2021]. For the dependent data case, an online Newton method was proposed in [po2021], where a probabilistic error bound was given for linear stochastic dynamical systems where the usual PE condition is satisfied.
In summary, almost all of the existing identification results for stochastic dynamical systems with saturated observations need at least the usual PE condition on the system data, and actually, most need i.i.d assumptions. Though these idealized conditions are convenient for theoretical investigation, they are hardly satisfied or verified for general stochastic dynamical systems with feedback signals (see, e.g. [1412020]). This inevitably brings challenges for establishing an identification theory on either asymptotic or non-asymptotic results with saturated observations under more general (non-PE) signal conditions.
Fortunately, there is a great deal of research on adaptive identification for linear or nonlinear stochastic dynamical systems with uncensored or unsaturated observations in the area of adaptive control, where the system data used can include those generated from stochastic feedback control systems. By adaptive identification, we mean that the identification algorithm is constructed recursively, where the parameter estimates are updated online based on both the current estimate and the new observation, and thus the iteration instance depends on the time of the data observed. In comparison with offline algorithms such as those widely used in statistics and machine learning where the iteration instance is the number of search steps in numerical optimization ([yy2015],[sm2018]), the adaptive algorithm has at least two advantages: one is that the algorithm can be updated conveniently when new data come in without restoring the old data, and another is that general non-stationary and correlated data can be handled conveniently due to the structure of the adaptive algorithm. In fact, extensive investigations have been conducted in adaptive identification in the area of control systems for the design of adaptive control laws, where the system data are generated from feedback systems that are far from stationary and hard to be analyzed [g1995]. Many adaptive identification methods have been introduced in the existing literature where the convergence has also been analyzed under certain non-PE conditions (see e.g. [cg1991]-[lw1982]). Among these methods, we mention that Shadab et al. [ss2023] considered the first-order gradient estimator for linear regression models with some finite-time parameter estimation techniques, where the PE condition is replaced with a condition enforced to the determinant of an extended regressor matrix. Ljung [Lj1977] established a convergence theory via the celebrated ordinary differential equation (ODE) method which can be applied to a wide class of adaptive algorithms, where the conditions for regressors are replaced by some stability conditions for the corresponding ODE. Lai and Wei [lw1982] considered the classical least squares algorithm for linear stochastic regression models, and established successfully the strong consistency under the weakest possible non-PE condition. Of course, these results are established for the traditional non-saturated observation case.
The first paper that establishes the strong consistency of estimators for stochastic regression models under general non-PE conditions for a special class of saturated observations (binary-valued observations) appears to be [ZZ2022], where a single-step adaptive quasi-Newton-type algorithm was proposed and analyzed. The non-PE condition used in [ZZ2022] is similar to the weakest possible signal condition for a stochastic linear regression model with uncensored observations (see [lw1982]), which can be applied to non-stationary stochastic dynamical systems with feedback control. However, there are still some unresolved fundamental problems, for instance, a) How should a globally convergent estimation algorithm be designed for stochastic systems under general saturated observations and non-PE conditions? b) What is the asymptotic distribution of the estimation error under non-PE conditions? c) How to get a useful and computable probabilistic estimation error bound under non-PE conditions when the length of data is finite?
The main purpose of this paper is to solve these problems by introducing an adaptive two-step quasi-Newton-type identification algorithm, refining the stochastic Lyapunov function approach, and applying some martingale inequalities and convergence theorems. Besides, the Monte Carlo method is also found quite useful in computing the estimation error bound. The key feature of the current adaptive two-step quasi-Newton (TSQN) identification algorithm compared to the adaptive single-step quasi-Newton method is that the TSQN algorithm has improved performance under non-PE conditions. The main reasons behind this fact are as follows: (i) The scalar adaptation gain of the single-step quasi-Newton method is constructed by using only the fixed given a priori information about the parameter set, whereas the scalar adaptation gain of the current TSQN algorithm is designed by using the online information to have it improved adaptively. (ii) A regularization factor is also introduced in the TSQN algorithm, which can be taken as a “noise variance” estimate to improve the adaptation algorithm further. To be specific, the main contributions of this paper can be summarized as follows:
-
•
A new two-step quasi-Newton-type adaptive identification algorithm is proposed for stochastic dynamical systems with saturated observations. The first step is to produce consistent parameter estimates based on the available “worst case” information, which is then used to construct the adaptation gains in the second step for improving the performance of the adaptive identification.
-
•
Asymptotic results on the proposed new identification algorithm, including strong consistency and asymptotic normality, are established for stochastic dynamical systems with saturated observations under quite general non-PE conditions. The optimality of adaptive prediction or regrets is also established without resorting to any excitation conditions. This paper appears to be the first for adapted identification of stochastic systems with guaranteed performance under both saturated observations and general non-PE conditions.
-
•
Non-asymptotic error bounds for both parameter estimation and output prediction are also provided, when only a finite length of data is available, for stochastic dynamical systems with saturated observations and no PE conditions. Such bounds can be applied to sentencing computation problems based on practical judicial data [judical].
The remainder of this paper is organized as follows. Section 2 gives the problem formulation; The main results are stated in Section LABEL:ss3; Section LABEL:ss4 presents the proofs of the main results. A numerical example is provided in Section LABEL:ss5. Finally, we conclude the paper with some remarks in Section LABEL:ss6.
2 Problem Formulation
Let us consider the following piecewise linear regression model:
| (1) |
where is an unknown parameter vector to be estimated; , , represent the system output observation, stochastic regressor, and random noise at time , respectively. Besides, is a non-decreasing time-varying saturation function defined as follows:
| (2) |
where is the given precise observable range, and are the only observations when the output value exceeds this range.
2.1 Notations and Assumptions
Notations. By , we denote the Euclidean norm of vectors or matrices. The spectrum of a matrix is denoted by , where the maximum and minimum eigenvalues are denoted by and respectively. Besides, let denote the trace of the matrix , and by we mean the determinant of the matrix . Moreover, is the sequence of algebra together with that of conditional mathematical expectation operator , in the sequel we may employ the abbreviation to . Furthermore, a random variable belongs to if and a random sequence is called sequence if belongs to for all .
We need the following basic assumptions:
Assumption 1
The stochastic regressor is a bounded and adapted sequence, where is a non-decreasing sequence of algebras. Besides, the true parameter is an interior point of a known convex compact set .
By Assumption 1, we can find an almost surely bounded sequence such that
| (3) |
Assumption 2
The thresholds , , and are known adapted stochastic sequences, satisfying for any ,
| (4) |
where is a non-negative random variable, and
| (5) |
Remark 1
We note that the inequalities are determined by the non-decreasing nature of the saturation function used to characterize the saturated output observations as illustrated in Fig. 1, and that Assumption 2 will be automatically satisfied if and are bounded stochastic sequences. The conditions and are general assumptions that are used to guarantee the boundedness of the variances of the output prediction errors in the paper.
Assumption 3
The noise is an martingale difference sequence and there exists a constant , such that
| (6) |
Besides, the conditional expectation function , defined by , is known and differentiable with derivative denoted by . Further, there exist a random variable such that
| (7) |
| (8) |
where is a non-negative variable, is defined in .
Remark 2
It is worth to mention that under condition , the function in Assumption 3 is well-defined for any , and can be calculated given the conditional probability distribution of the noise . In Appendix LABEL:i, we have provided three typical examples to illustrate how to concretely calculate the function , which includes the classical linear stochastic regression models, models with binary-valued sensors, and censored regression models. Moreover, Assumption 3 can be easily verified if the noise is i.i.d Gaussian and if . Besides, when and , the system - will degenerate to linear stochastic regression models, and Assumption 3 will degenerate to the standard noise assumption for the strong consistency of the classical least squares ([lw1982]) since .
For simplicity of notation, denote
| (9) |
Under Assumption 3, and have upper bound and positive lower bound respectively, i.e.
| (10) |
2.2 Algorithm
Because of its “optimality” and fast convergence rate, the classical LS algorithm is one of the most basic and widely used ones in the adaptive estimation and adaptive control of linear stochastic systems. Inspired by the analysis of the LS recursive algorithm, we have introduced an adaptive quasi-Newton-type algorithm to estimate the parameters in linear stochastic regression models with binary-valued observations in [ZZ2022]. However, we find that a direct extension of the quasi-Newton algorithm introduced in [ZZ2022] from binary-valued observation to saturated observation does not give satisfactory performance, which motivates us to introduce a two-step quasi-Newton-type identification algorithm as described shortly.
At first, we introduce a suitable projection operator, to ensure the boundedness of the estimates while keeping other nice properties. For the linear space , we define a norm associated with a positive definite matrix as . A projection operator based on is defined as follows:
Definition 1
For the convex compact set defined in Assumption 1, the projection operator is defined as
| (11) |
We then introduce our new adaptive two-step quasi-Newton (TSQN) identification algorithm, where the gain matrix is constructed by using the gradient information of the quadratic loss function.
Step 1. Recursively calculate the preliminary estimate for :
| (12) | ||||
where and are defined as in , is the projection operator defined as in Definition 1, is defined in Assumption 3, the initial values and can be chosen arbitrarily in and with , respectively.
Step 2. Recursively define the accelerated estimate based on for :
| (13) | ||||
where can be any positive random process adapted to with , the initial values and can be chosen arbitrarily in and with , respectively.