[1,2]\fnmMouad \surELAARABI
1]\orgdivNantes Université, \orgnameEcole Centrale Nantes, CNRS, GeM, UMR 6183, \orgaddress\cityNantes, \postcode44321, \countryFrance
2]\orgdivNantes Université, \orgnameIRT Jules Verne, \orgaddress\cityBouguenais, \postcode44340, \countryFrance
Adaptive parameters identification for nonlinear dynamics using deep permutation invariant networks
Abstract
The promising outcomes of dynamical system identification techniques, such as SINDy [1], highlight their advantages in providing qualitative interpretability and extrapolation compared to non-interpretable deep neural networks [2]. These techniques suffer from parameter updating in real-time use cases, especially when the system parameters are likely to change during or between processes. Recently, the OASIS [3] framework introduced a data-driven technique to address the limitations of real-time dynamical system parameters updating, yielding interesting results. Nevertheless, we show in this work that superior performance can be achieved using more advanced model architectures.
We present an innovative encoding approach, based mainly on the use of Set Encoding methods of sequence data, which give accurate adaptive model identification for complex dynamic systems, with variable input time series length. Two Set Encoding methods are used: the first is Deep Set [4], and the second is Set Transformer [5]. Comparing Set Transformer to OASIS framework on Lotka-Volterra for real-time local dynamical system identification and time series forecasting, we find that the Set Transformer architecture is well adapted to learning relationships within data sets. We then compare the two Set Encoding methods based on the Lorenz system for online global dynamical system identification. Finally, we trained a Deep Set model to perform identification and characterization of abnormalities for 1D heat-transfer problem.
keywords:
data-driven dynamical system identification, neural networks, deep permutation invariant networks, online parameter updating, sparse regression1 Introduction
Exploring dynamic systems through differential equations is intriguing, providing valuable insights into variable interactions and system behavior. These insights can be useful for many tasks, such as monitoring and controlling industrial processes. However, this could be a challenging undertaking due to their inherent complexity (such as variability of parameters and representativeness of the model). The direct construction of these equations from theoretical principles is a significant challenge and may be sensitive to changes in the parameters or modeling hypotheses, leading researchers to rely on alternative methods such as analyzing empirical data through simulations or experiments. This process involves generating datasets and conducting meticulous analyses using appropriate methods, offering valuable insights about the intrinsic interactions between variables and enhancing the understanding of physical system dynamics.
While machine learning methods offer a potential solution, they suffer from issues such as a lack of interpretability, as the trained model is a black box and generally requires extensive training data for high accuracy, which is not always readily available. These methods may also struggle to generalize for unseen data [2]. On the other hand, model discovery methods [6, 7] aims to identify the true governing equation through empirical data, providing insights into the interactions between the data, which could be applied to a wide range of engineering tasks.
| Abbreviation | Definition |
| CAE | Computer-Aided Engineering |
| DMD | Dynamic Mode Decomposition |
| DMDc | Dynamic Mode Decomposition with control |
| DNN | Deep Neural Network |
| EQL | EQuation Learning |
| ISAB | Induced Self-Attention Block |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| MAB | Multi-head Attention Block |
| MAPE | Mean Absolute Percentage Error |
| MLP | MultiLayer Perceptron |
| MPC | Model Predictive Control |
| NSODE | Neural Symbolic Ordinary Differential Equation |
| OASIS | Operable Adaptive Sparse Identification of Systems |
| OASIS-P | Online Adaptive Sparse Identification of Systems for Fault Prognosis |
| ODE | Ordinary Differential Equation |
| PINN | Physics Informed Neural Network |
| PINN-SR | Physics Informed Neural Network with Sparse Regression |
| PDE | Partial Differential Equation |
| PMA | Pooling by Multihead Attention |
| PySR | Python Symbolic Regression |
| SAB | Self-Attention Block |
| SENDI | Set Encoding for Nonlinear Dynamics Identification |
| SGA-PDE | Symbolic Genetic Algorithm for discovering open-form Partial Differential Equations |
| SINDYc | Sparse Identification of Nonlinear Dynamics with Control |
| SINDy | Sparse Identification of Nonlinear Dynamics |
| SR3 | Sparse Relaxed Regularized Regression |
| rFF | row-wise FeedForward |
| sMAPE | symmetric Mean Absolute Percentage Error |
| \botrule |
1.1 Background and motivations
In this work, we focus on dynamic system identification methods [8] that have demonstrated excellent results. SINDy [1] (Please refer to Tab. 1 for abbreviations), based on sparse regression, aims to extract the dynamical links within data. The main idea is to select a few optimal candidate functions from pre-defined over-complete dictionaries, which could be defined based on prior knowledge about the physical laws governing the process and effectively describe the dynamics. This is achieved by using a sparse regression method [9, 10, 11]. On the other hand, PDE Net, proposed by [12], aims to identify PDE equations by discretizing the PDE using forward Euler in time and finite difference in space. This method introduces a different approach mainly based on a succession of symbolic neural networks that aim to link multiple candidates using the EQuation Learning (EQL) architecture [13] and select the best ones using learnable convolutional kernels . Other methods use a different approach, SGA-PDE [14] proposes the use of symbolic mathematics tree representation with classical and differential operators to represent the PDE and a genetic algorithm to find the best representation tree. In the same context, PySR [15] introduces a Python library for symbolic regression based on multi-population evolutionary algorithm. This library is particularly well-suited for identifying ODEs, but has limited capabilities in identifying PDEs. This limitation arises from the fact that PySR’s operators are restricted to basic algebraic operators. In contrast, SGA-PDE [14] extends this capability by incorporating differential operators.
These methods offer high potential as the identified parameters can be transferred and used within traditional CAE simulation software finite elements. Additionally, they can be coupled with DNN such as PINN [16] to identify and simulate the dynamics simultaneously as proposed by [17].
Nevertheless, these methods are not pertinent (inference time, adaptability, and leveraging new data to enhance accuracy…) in cases of online identification, where abrupt changes may occur during the process. In such scenarios, the model needs to rapidly adjust to these changes. SINDy-Model Predictive Control (MPC) [18] demonstrates that a combination of SINDy with control [19], built on classical SINDy and DMDc [20], allows for better control of the system dynamics after a change. This method compared SINDYc, DMDc, and a DNN, revealing that the combination of SINDYc with DMDc yields interesting results. Moreover [21] suggests an adaptive model for abrupt changes based on SINDy. This method involves two processes: the first detects the changes, while the second identifies and then modifies, adds, or removes parameters from the dynamic system.
These methods present significant potential but have limitations when the identification time is crucial. A slight delay in identification can lead to substantial changes, such as in process systems prognosis [22]. Developing an accurate dynamics identification model using limited data is not viable and may take a considerably long time, hindering its use for interactive applications. Therefore, using SINDYc or abrupt-SINDy online for real applications is challenging.
Recently, [23] presented a sequence to sequence Transformer [24] architecture to train a general model to perform symbolic regression identification, with faster inference time. This technique is then generalized to ODE identifications, as presented in ODEFormer [25] and NSODE [26]. They introduced a transformer-based method to identify ODEs structure and parameters, utilizing Symbolic Regression techniques. While the first method targets univariate ODEs, the second extends to multivariate ODEs. These methods focus on training a general model to conduct forward identification of symbolic representations of ODEs based on time series observations. ODEFormer [25] exhibits promising results compared to alternative methods. However, this approach is limited when a partial or full knowledge of the dynamics terms are available. Also these methods necessitate an embedding step and an additional fine-tuning step to refine the identified ODE parameters, posing challenges for real-world applications. Hence, the high complexity of the architecture may pose limitations, especially with long time series. Finally, since the model output uses natural language, it would be challenging to couple these methods with other deep learning methods, such as PINNSR [17].
In the same context, OASIS [3] has presented a framework that integrates both the strengths of SINDy for identifying the dynamics parameters and a DNN trained offline with parameters identified by SINDy. The latter is subsequently used online to provide parameter predictions for predictive control. OASIS has also been applied for fault real-time prognosis and demonstrated interesting and accurate results [22]. The trained neural network uses a single time frame input which cannot handle information about sequence data. Additionally, classical neural network architectures may fail to encode the interactions between data, and therefore struggle to capture the dynamical system, especially with complex systems.
1.2 Paper contributions
We introduce a deep learning architecture for evolving online dynamics identification based on Set Encoding. Our goal is to enhance the encoding of interactions within data, leading to improved prediction accuracy of system parameters. We employ two distinct architectures Deep Set [4] and Set Transformer [5].
These methods use two different encoding techniques, that can learn both simple pairwise relationships and higher-order links between set data, which can be applied to diverse datasets, making it suitable for a wide range of applications including supervised (our work) and unsupervised learning.
In this work, we are particularly interested in applying this technique to sequential data, notably time series. Our main focus is to combine these methods with SINDy to provide an identification framework of the dynamics parameters of a fixed ODE for online use cases such as time series forecasting.
The problem addressed in this article is defined in Eq. 1:
| (1) |
where is a pre-defined search library based on knowledge about the dynamical system, is a vector containing the variables of the dynamical system, represents the parameters of the dynamical system to be calculated. The main goal is to train the Set Encoding methods represented as to predict the matrix, thereby identifying the dynamics system.
The main contributions of the study are to :
-
•
Propose an appropriate approach to encode and decode to effectively learn the interactions between data, which provide accurate predictions of dynamics parameters. This architecture can handle sequential data with variable sizes, offering enhanced predictions compared to single-time point predictions.
-
•
Illustrate that integrating physics loss in offline learning contributes to a better convergence and generalization of the model.
-
•
Demonstrate that these methods can provide robust predictions with data containing noise.
-
•
Provide accurate predictions (after offline training) with an inference time of milliseconds, making it suitable for real-time applications.
This article is structured as follows: the section 2 will be dedicated to a brief presentation of related works such as SINDYc which will be used in the following sections, and the OASIS framework along with its training method. Then, in section 3, we introduce the two set encoding architectures and discuss their use for online dynamics identification. Section 4 will focus on comparing OASIS and set encoding for local dynamics identification using the Lotka-Volterra system, followed by a comparison of the two set encoding architectures for global dynamics identification using the Lorenz system, then using Deep Set for 1D heat-transfer identification and characterization. Finally, a conclusion of this work and areas for improvement are given.
2 Related works
In this section, we briefly introduce SINDYc (Sec. 2.1) and OASIS (Sec. 2.2). SINDYc is utilized to generate training data for comparing OASIS and our methods in the first application with the Lotka-Volterra system (Sec. 4.2), as well as for comparing the two Set Encoding methods presented in Sec.3 for the second application with the Lorenz system (Sec. 4.3).
2.1 SINDYc
SINDYc [19] method allows the identification of parameters of a dynamical system with control variables. Drawing upon prior knowledge of the system’s dynamic behavior, a set of candidate functions, referred to as the search space or library denoted by , is defined. These functions can collectively represent the dynamical system. The underlying idea is primarily based on the notion that an identified system should encompass a limited and concise set of functions. This approach can be applied to various dynamic systems (ODE and PDE), as well as to dynamic systems with control variables (Eq. 2), which are external variables.
| (2) |
Where is a matrix with state variables with time snapshots, is the time derivative of , usually approximated using total variation regularized derivatives [27], and are the control variables with time snapshots, and are the initial conditions. The equation identified by SINDYc is defined as :
| (3) |
whereas is a coefficient matrix representing the selected functions from the search library , which is defined by multiple functions (Eq. 4) usually using partial knowledge of the physics, for example, the library function could be defined as:
| (4) |
To identify the dynamical system while avoiding overfitting, the matrix must be sparse, implying that the less significant coefficients need to be equal to zero. This is achieved by solving the LASSO optimization problem (Eq. 5) defined as :
| (5) |
where the first term represents the residual error and the second term is a regularizer applied to the coefficients matrix or the parameters of the ODE/PDE, and is a weight parameter that imposes regularization. The larger it is, the stronger the regularization becomes, leading to the elimination of more terms from the search library while potentially reducing the accuracy. Other methods could be used such as Sparse Relaxed Regularized Regression (SR3) [11], or thresholded least squares that use the norm 0 to eliminate less significant coefficients [1, 28, 10].
Despite all the advantages of SINDYc, this method is restricted in cases where system parameters tend to vary during the process, or whenever the system must be identified online based on sensor data. While abrupt-SINDy[21] presents a method to address this issue, it has drawbacks, notably the quantity of data required for identification and the computational cost, which can be significant for real-time cases. In this study we will focus on using SINDy and SINDYc as offline identification methods to generate some datasets, which are then used to train Deep Neural Networks to perform the approximation of parameters online.
2.2 OASIS
The OASIS framework is primarily based on SINDYc but unlike the latter, it favors the use of offline trained DNN through results from SINDYc, making it more suitable for real-time parameter identification cases.
The dynamical system (Eq. 2) is a set of measured or generated time series. Then, the set is divided into multiple sub domains (Fig. 1. a), which are further used for offline identification through SINDYc (Eq. 3) using an identical search library (Fig. 1. b).
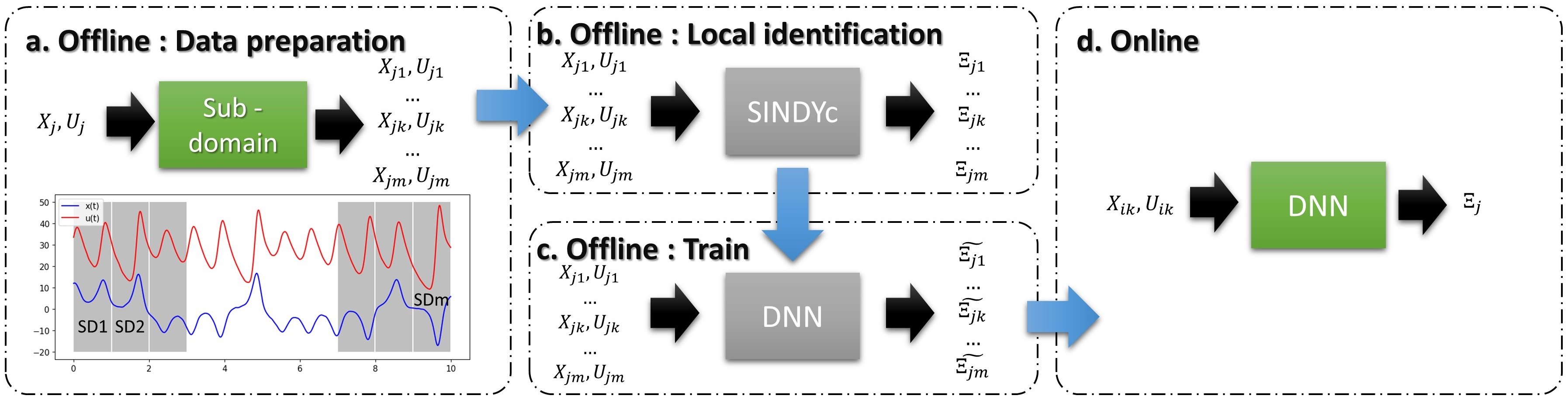
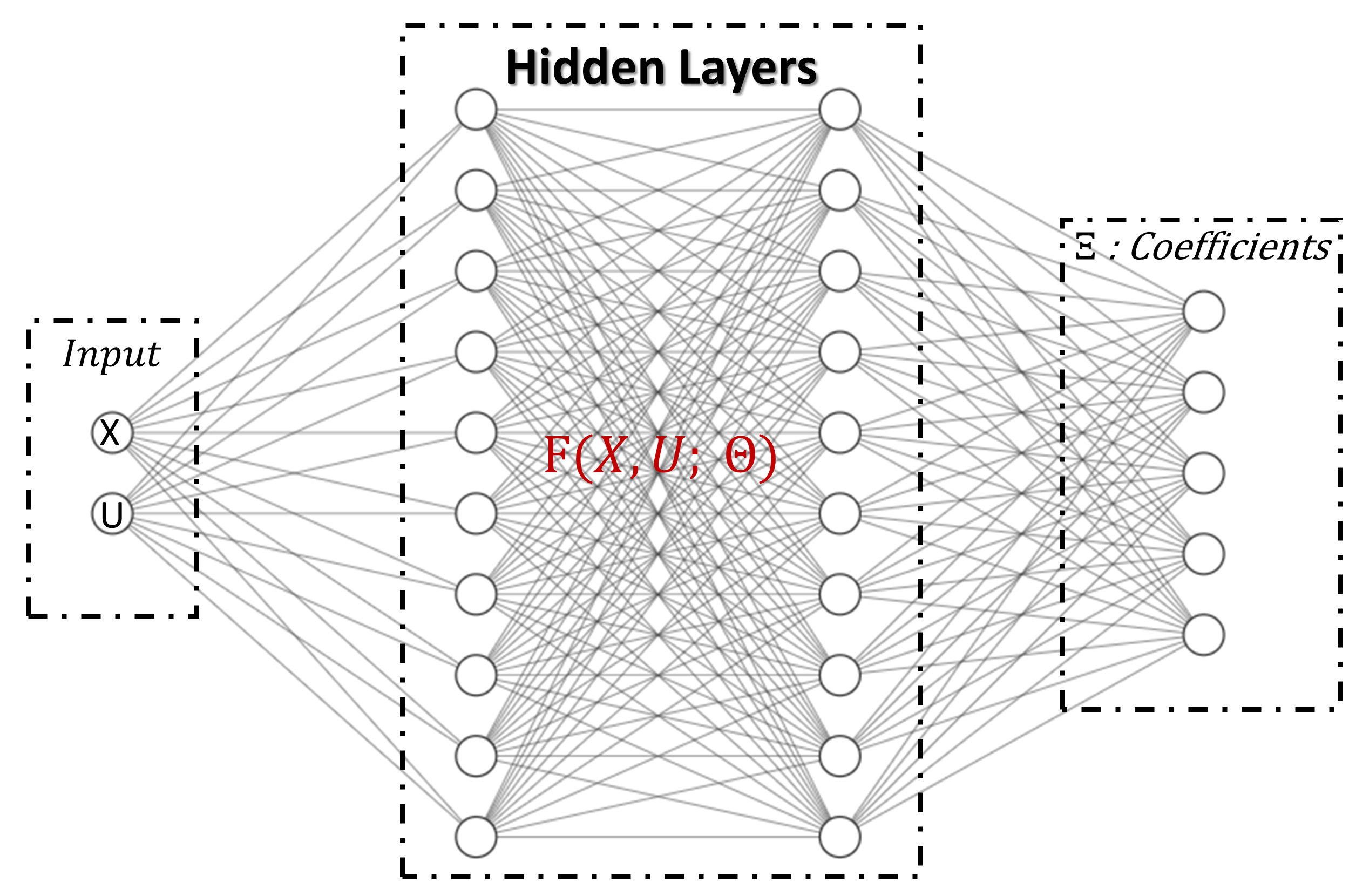
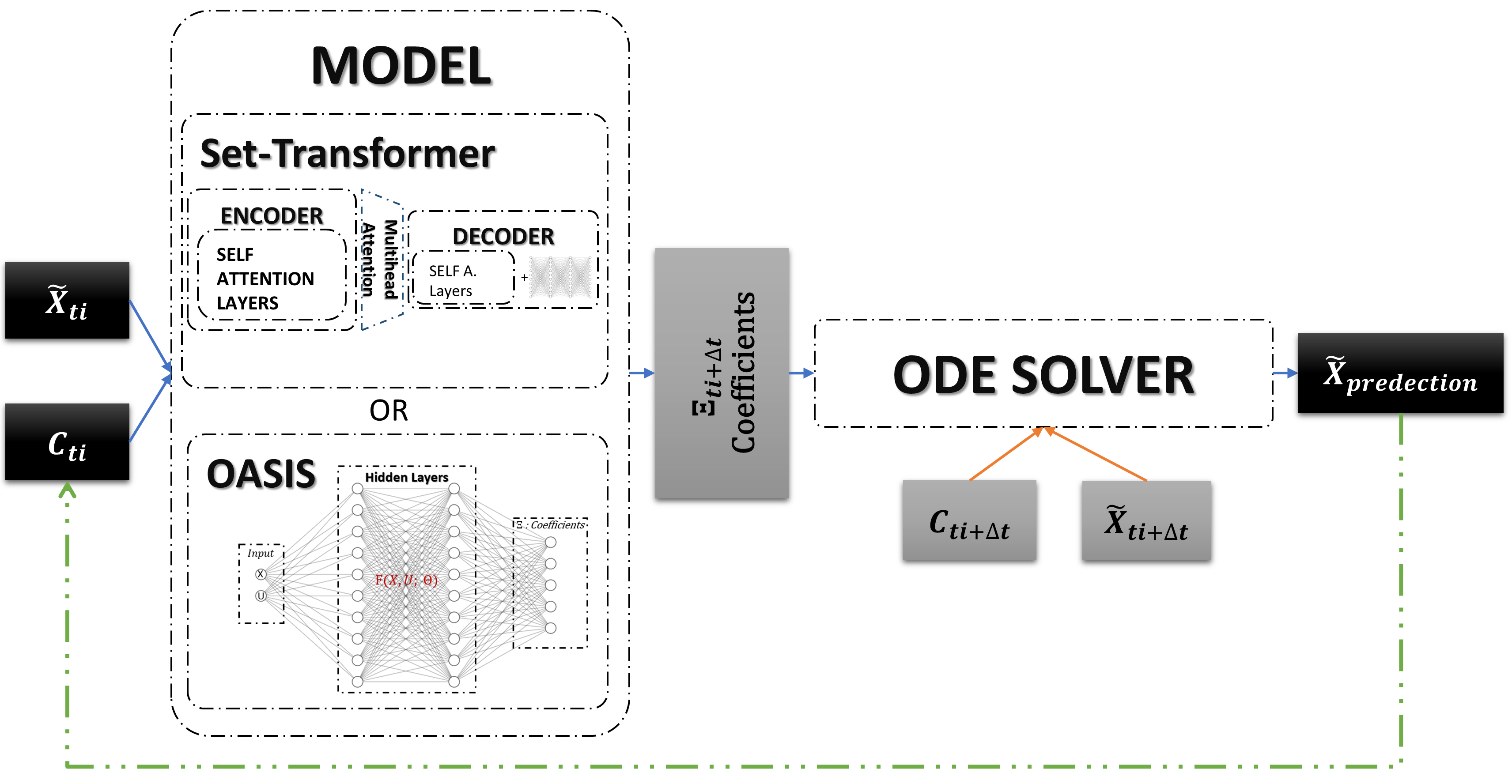
This dataset is then utilized for training the DNN (Fig. 2) model (Fig. 1. c), where the input comprises state and control variables and the output corresponds to the predicted . The training process involves leveraging the information contained in the datasets, enabling the model to learn and capture the underlying patterns and relationships within the data, allowing accurate and online identification (Fig. 1. d). This is achieved by minimizing the error between the predictions of the DNN and the true coefficients (Eq. 6).
| (6) |
Here, is the output prediction of the DNN (Fig. 2), and denotes its trainable parameters. Additionally, it is important to include regularization terms to mitigate overfitting problems, where represents the trainable variables of the DNN.
The trained model is then employed in real-time for online identification of the dynamical system (Eq. 2) coefficients , enabling accurate extrapolation or prediction of optimal control parameters.
Because the DNN inputs are the current states of the system and controller , the OASIS framework does not aim to identify the global dynamics; this means the primary goal is not to identify the true and global coefficients of the governing ODE, but rather a local dynamic system limited to a small time range, and that provides limited extrapolation or prediction of optimal control parameters. This approach is motivated by the fact that accurate identification of the global dynamics is not straightforward and not always feasible [22].
In seeking to identify a valid local dynamics within a limited time interval, frequent model updates are necessary, which can lead to computational issues. To address this concern, the strategy of OASIS-P [22] aims at choosing an optimal frequency for model updating, minimizing the identification error and consequently the extrapolation error.
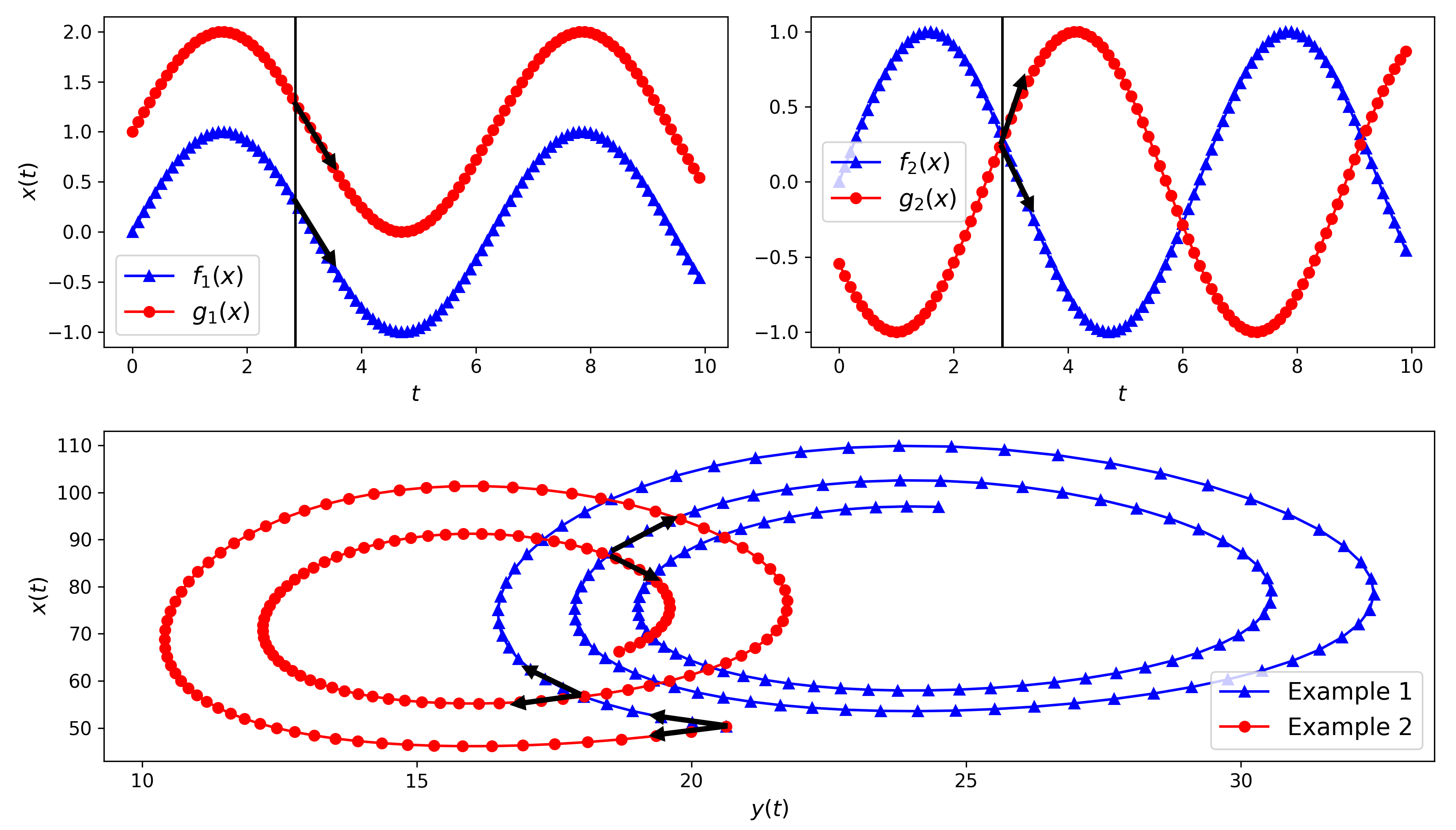
The fact that the networks use only a single state to predict the parameters defining the local system behaviors poses a potential restriction whenever the dynamics cannot be captured from a single time frame but require a longer observation window. This approach is expected to yield accurate predictions (example in Fig. 3 top left). However, the limitation is attributed to the non-uniqueness of the solution with a single state, as demonstrated by the example in Fig. 3 top right where the intersection of the two time series may introduce confusion during the model training process. The Fig. 3 bottom presents two examples of the Lokta-Volterra dynamics with similar initial conditions and control variables but with small changes in the dynamics parameters. The black arrows show cases where the model inputs are similar ( and ) for the two examples (example 1 in blue and example 2 in red), but the dynamics differ. This aligns with the model’s inadequate capacity to capture temporal information effectively, resulting in less accurate predictions. The following section will present a more suitable architecture capable of effectively encoding temporal information, thereby providing better predictions.
3 Invariant Deep Learning model for Nonlinear Dynamics Identification
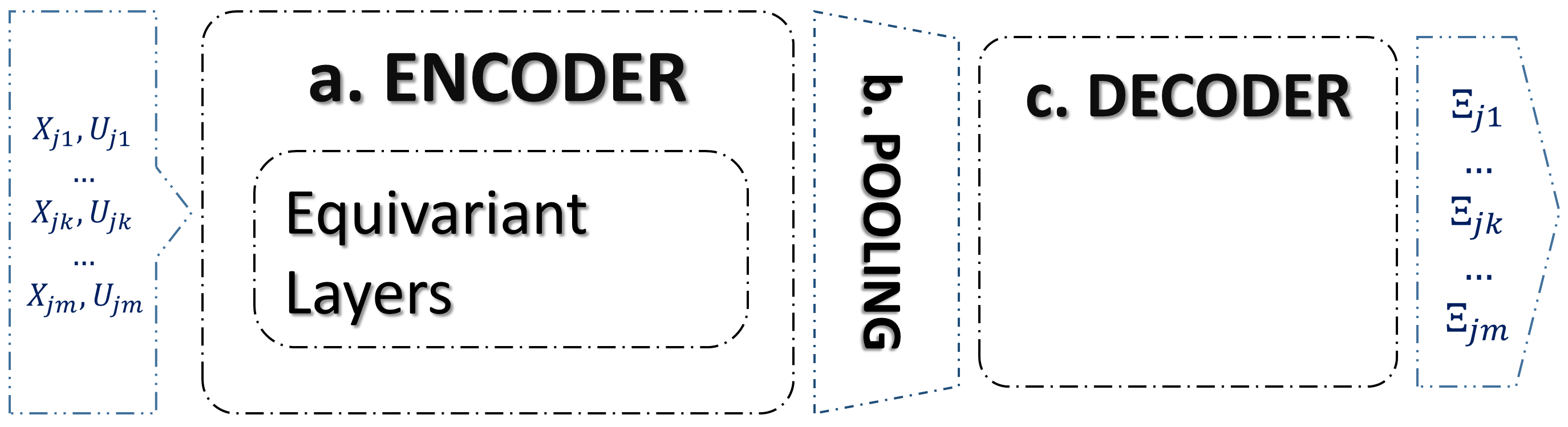
In this section the proposed architecture is founded on a concept termed Set Encoding. In contrast to classical neural network models (Fig. 2), where the primary goal is to learn a function connecting a fixed-dimensional input tensor to its corresponding output value, set encoding (Fig. 4) could be used to establish links between input data sets with variable shapes (variable time series length and variable time steps ) and their corresponding labels, while maintaining permutation invariance. This objective is realized by encoding input data sets through equivariant layers (Fig. 4 a), followed by pooling steps to attain permutation-invariant properties (Fig. 4 b). Subsequently, the information is decoded (Fig. 4 c) to yield the appropriate outputs.
In this section, we explore the applicability of two set encoding methods for online and adaptative dynamics identification, utilizing variable shapes of time series. The first method, Deep Set, is based on a DNN (Fig. 2) architecture, while the second method, Set Transformer, is built upon a transformers architecture [24].
3.1 Deep Set
The Deep Set architecture (Fig. 5) can be divided into three transformations. The first step involves encoding the inputs into a latent space through a series of layers with non-linear activation functions (Eq. 8). In our cases the input is a set of and , where , , and represent respectively the number of state variables, control variables, and the time series length. This transformation can be made permutation-equivariant by employing suitable layers. This implies that the output remains equivariant to permutations of set elements. This objective can be accomplished by defining the neural network layers as in Eq. 7, as demonstrated by [4].
| (7) |
Following this encoding, a pooling transformation is applied (such as max, mean, sum, etc.) with respect to the time dimension which yields a set of latent variables , as defined in Eq. 8 :
| (8) |
where in represents the number of encoded features. This operation enables the model to manage inputs of variable shapes, thereby achieving an invariant-type (Eq. 9) encoding.
| (9) |
The final step involves decoding the latent vector to obtain the desired output. In this application, we will only utilize the invariant property.
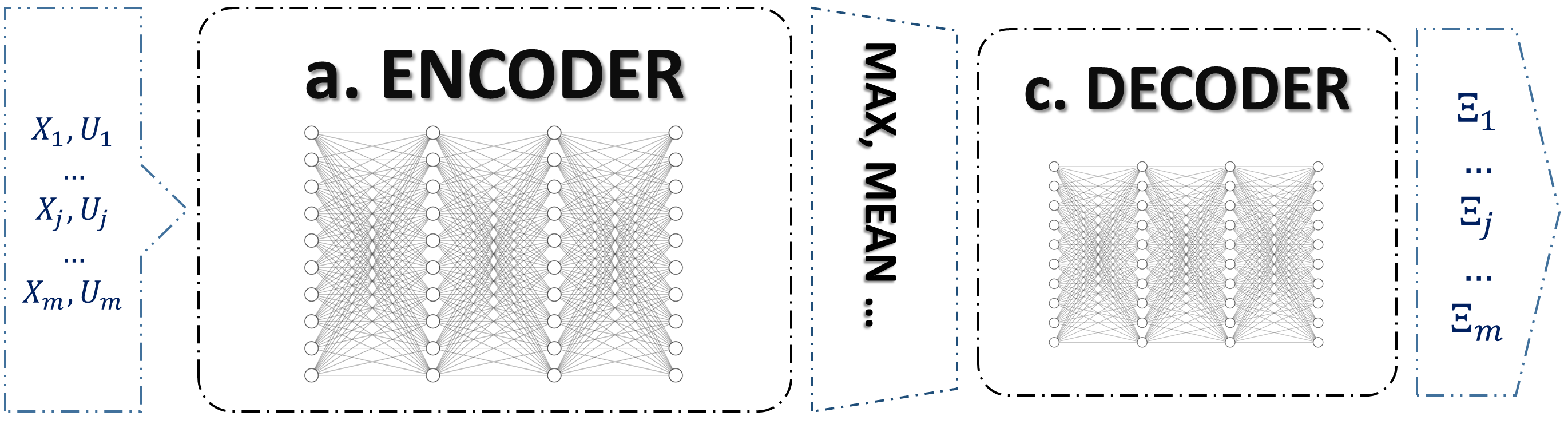
3.2 Set Transformer
The architecture of set transformer (Fig. 6), is based on transformer model [24]. The motivation behind the use of this architecture lies in its ability to encode links and pairwise interactions among the elements of sets through the attention mechanism. The architecture is primarily built on layers called self attention layers, constructed to be permutation-equivariant.
The attention mechanism can be defined by the Eq. 10 :
| (10) |
Where is a matrix of sets with the same dimension , and and , referred to as Keys and Values, are two matrices of sets with the same number of sets. The dimension of is the same as that of , while has a different dimension . The initial part of the equation, , measures the similarity between the two sets of matrices, where usually denotes the softmax function applied to the product to convert it into a probability distribution. The result of this product represents a weight matrix, which is used to assign different importance to the elements of the matrix .
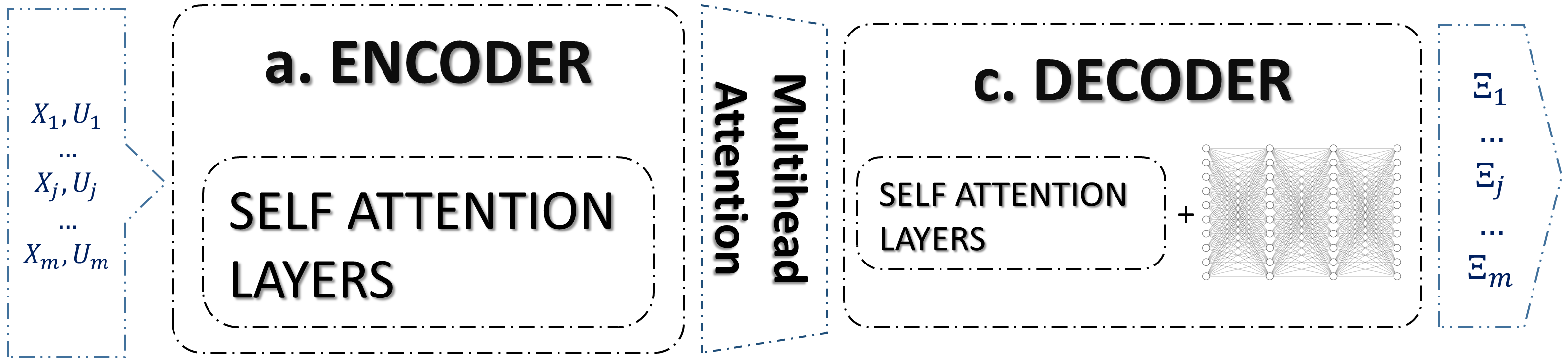
Utilizing this mechanism empowers the model to capture relevant patterns and dependencies in the data. To achieve this objective, the mechanism is extended to Multi-head Attention (Eq. 11) defined by three transformations.
| (11) |
The initial step involves projecting the , , and matrices to a higher dimension and using learnable parameters . Subsequently, the attention mechanism is applied to the resulting projections, referred to as Head Attentions . These Head Attentions are then concatenated and multiplied by a trainable variable matrix . In this application, it was considered that , and .
The Set Transformer proposes set operation blocks, utilizing a Multi-Head Attention mechanism to encode the data and subsequently aggregate and decode the encoded features. The data is encoded through Multihead Attention Blocks (MAB) and Set-Attention Blocks (SAB). Given two input sets matrices , MAB is defined as:
| (12) |
The is the layer normalization [29], and represents a row-wise feed forward neural network without activation functions. The SAB block is defined as :
| (13) |
Where the Keys and Queries are identical, employing the self-attention mechanism to capture interactions between input features. The encoding is then defined by a succession of SAB blocks (Eq. 14).
| (14) |
The output of the latter is determined by the function , where . This output is subsequently aggregated through the PMA (Pooling Multihead Attention) block defined as :
| (15) |
Where is a trainable matrix, with being the desired output features (1 in our case). This allows for an aggregation based on the importance of set elements rather than equal importance (as in the cases of max, mean, etc., aggregation). Following this transformation, a SAB is applied to better capture the connections between the output features (Eq. 15).
Considering the quadratic time complexity of the Set Attention Block (SAB) as , where represents the number of sets, [5] introduced an improved version named Induced Set Attention Block (ISAB). The ISAB offers reduced computational complexity while preserving the same performance.
The architectures of both models are more complex compared to OASIS, which may raise concerns, particularly regarding overfitting problems. We address these concerns in some examples in the next section. The selection of hyperparameters can be managed using classical testing and validation approaches, which we have employed in this work. In the following section, we demonstrate that this complexity offers significant advantages through three different applications. Additionally, we provide solutions and perspectives to mitigate potential overfitting issues.
4 Results
4.1 Tests cases
To demonstrate the advantages of Set Encoding methods, we present three test cases with three different systems. In the section 4.2 we present a comparison of OASIS framework and Set Transformer for online nonlinear dynamics identification. The Lotka–Volterra [30] (Eq. 16) system is used to compare these two methods.
| (16) |
First, we generate a dataset with various initial conditions and control variables. We then divide the time domain into multiple sub domains, and SINDYc is subsequently employed to identify the local dynamics model for each sub domains. Both methods are then trained to capture the local dynamics using time series and their corresponding identified local SINDYc mode.
While OASIS methods are limited to online local system identification, Set Encoding methods could also be applied in global non-linear dynamics identification. In the section 4.3 we compare the two Set Encoding. These methods can handle variable input sizes, which means capturing the true dynamics through a sequence of data is possible. Furthermore, it can capture the interactions between input data, all of which help enhance the identification process. To study the usefulness of these methods, Set Transformer and Deep Set are compared for the Lorenz system (Eq. 17).
| (17) |
Monitoring and control of industrial processes are generally based on fixing the theoretical parameters of the process and material properties. However, these parameters can change during the process. Therefore, it is important to use sensor data to identify these parameters in real-time. If any deviations are detected, control systems can be used to correct the process by adjusting the parameters, thereby improving its performance.
To address these challenges, Set Encoders can be applied for industrial process monitoring. For example, in the thermo-stamping process, a thin composite plate is heated to make it less rigid before being formed using a specific mold. Using real-time sensor data, the Set Encoder can approximate the material properties during the heating step, which helps, for example, to ensure the temperature is homogeneous throughout the depth of the plate to avoid defects during forming. In this application, we begin with a preliminary study of 1D heating using synthetic data before applying it to real data of the heating step in the thermo-stamping process in future work.
In 4.4, we will study the 1D heat-transfer problem (PDE example) using a Deep Set model. We will train the model to approximate diffusivity and to characterize an abnormality defined as a local decrease in diffusivity, using noisy data. The equation is given by (Eq. 18):
| (18) |
4.2 Application 1 : local model identifications (OASIS vs Set Transformer)
4.2.1 Data generation
The Lotka–Volterra system (Eq. 16) is used to compare these two methods. Where, and respectively represent the populations of prey and predators. is a control variable that limits the rate of increase or decrease of the predators. The parameters , , , and represent respectively the rates of increase or decrease of prey and predators, as well as the effect of predators on prey (and vice versa). An example of a solution of Eq. 16 is given in Fig. 7.
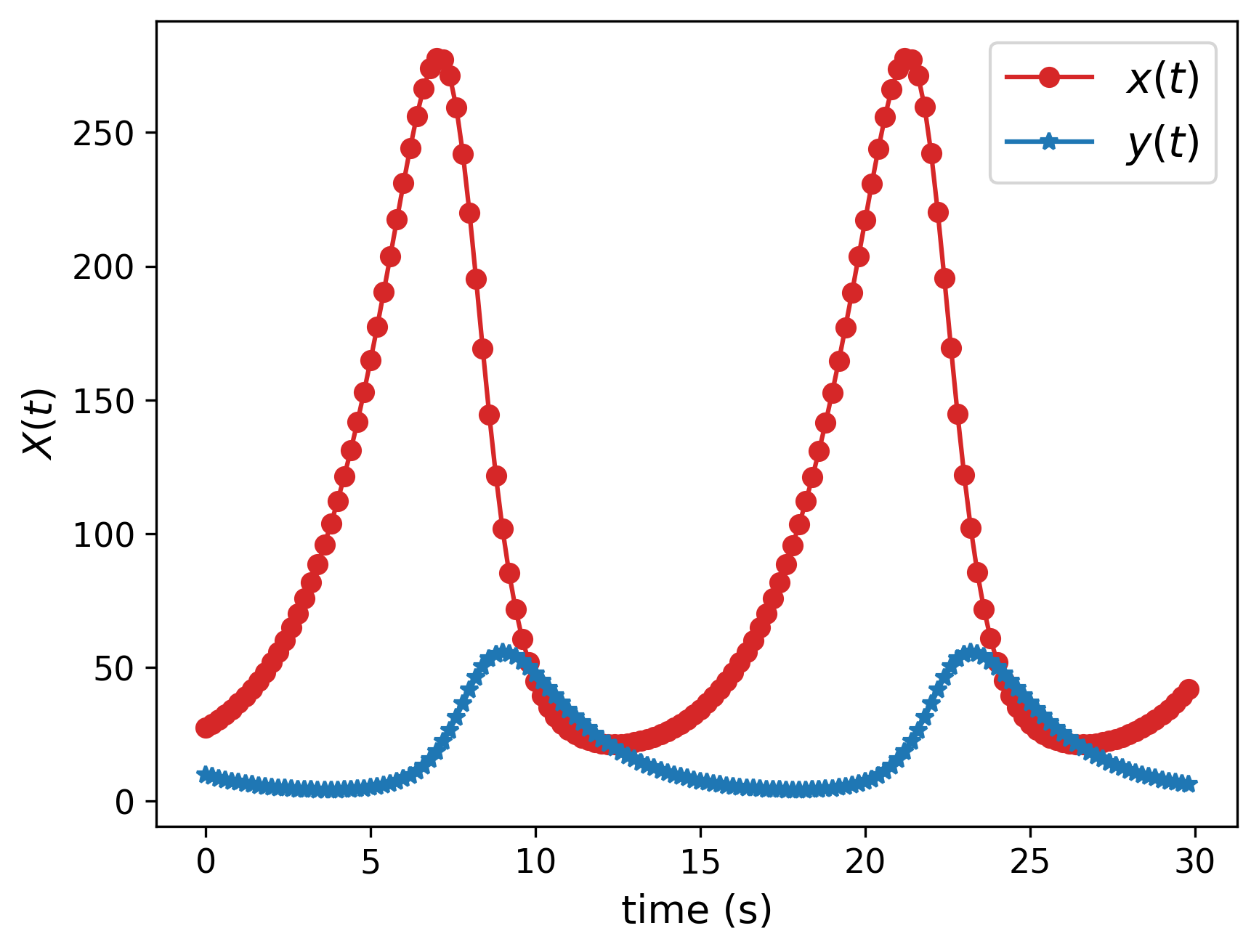
The dataset is generated through various combinations of control variable () and initial conditions and , using the Sobol [31, 32] sampling method as given in Tab. 2. The data generation is performed using the LSODA [32] method from the SciPy Python package. In this comparison (Fig. 8), 278 datasets are generated, of which 166 will be used for model training, and 112 will be employed for model validation to mitigate overfitting issues, and a test set to compare the two methods.
| Variable | Range |
|---|---|
| : Control variable | [-1; 5] |
| : Initial condition | [5; 50] |
| : Initial condition | [5; 15] |
| : Time interval | [0; 30] |
| \botrule |
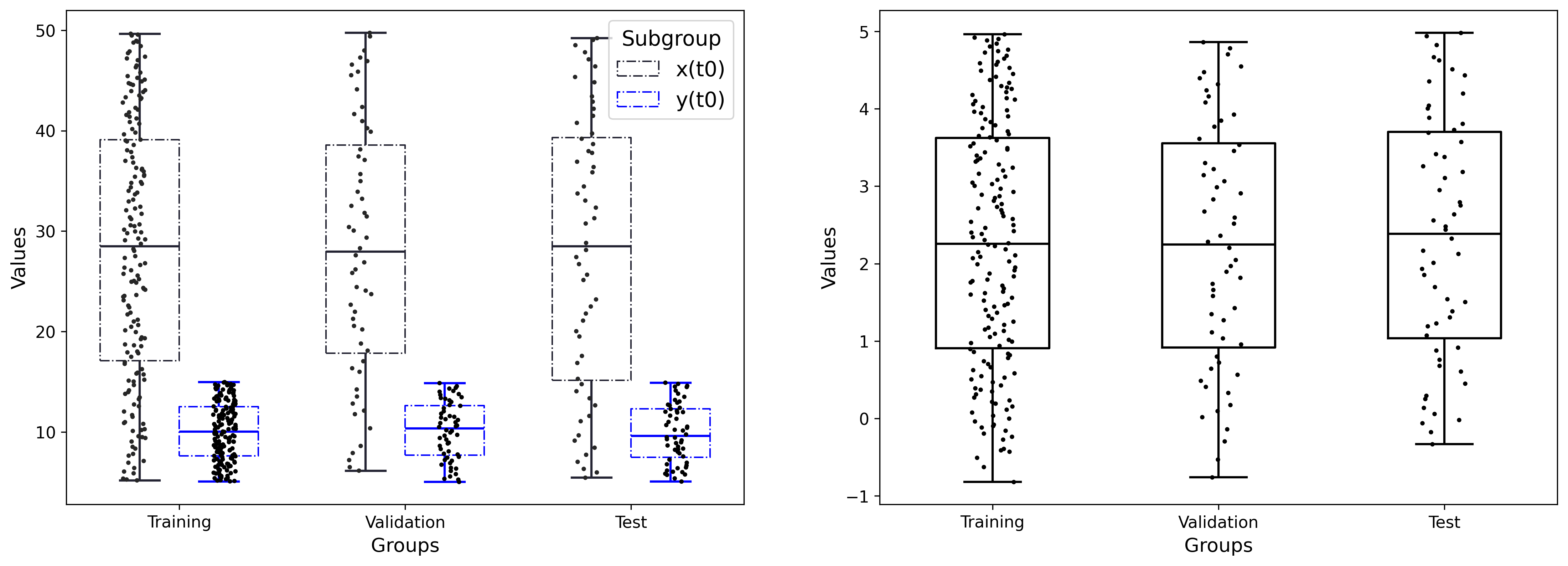
Each dataset is divided into several sub domains over time. SINDYc is then used to identify the local model of the different sub domains, which may be different from the global dynamics but can be used within a short time interval. In this case, we assume that there is no initial information about the search library. The identification is performed using the PySINDy Python package [33]. We use a base of polynomials of degree 3 defined as :
| (19) | ||||
where is the search library, where represents the control variables, and is a sparse tensor representing the parameters to be fitted.
4.2.2 Training process and Criteria for comparison
Given the utility and significance of these methods in real-time control and defect detection, it is crucial to evaluate their extrapolation capabilities. For a fair comparison, both methods underwent training on the same dataset and were then assessed and validated using a separate portion designated for validation. The Tab. 3 summarizes the training process for both methods. The error function is defined as a sum of three parts, the first one represents the difference between the true and predicted parameters, the second part represents local dynamic loss by calculating the difference between the known derivative of and and where is know, the final term represents the regularization, contributing to the effective generalization of models. Both methods are trained using identical optimizer and a fixed number of epochs, incorporating variable learning rates during the training process. A noteworthy distinction pertains to the input of the two models. The first maps a single time step to , whereas the Set Transformer encodes a temporal series of variable length. We also train the models to predict the dynamics of the subsequent sub domain based on the current sub domain’s time series and control variable as defined in Eq. 20 :
| (20) |
Where is the time snapshots, for OASIS framework and . Which will help in achieving better results for extrapolation.
| Set Transformer | OASIS | |
| Optimizer | Adam | |
| Loss function | = | |
| Learning rate | ||
| Epochs | [2000, 2000, 4000, 2000, 2000, 2000, 2000] | |
| Input Shape | : | |
| Output Shape | : | |
| \botrule | ||
To ensure fairness and balance in the comparison, we used hyper-parameters tunning for training both methods, varying hyper-parameters like hidden layers, neurons per layer, regularization coefficient , and activation functions. We then select the best architecture by assessing performance through validation error.
4.2.3 Comparison and Conclusion
The test set is not utilized during the training process; instead, the validation portion is employed solely for selecting the best model during training. We also employ two models for each method to predict the coefficients of and , which we believe will facilitate the training process.
The models are then compared based on their ability to capture local dynamics and extrapolate (Fig. 10) for a limited time range. This process is summarized in Fig. 9. The input of Set Transformer is a sequence, while the input of OASIS is a single point in time, first the models are used to identify the local dynamics which corresponds to the local dynamics of the following sub domain for the test dataset. It is then used with initial values and control value to extrapolate using ’LSODA’ as ODE-Solver, the output of the solver is a times series , and corresponds to the time sub domain windows, which is then compared to the ground truth (simulation data) using MAPE (Eq. 21 and Eq. 22).
| (21) |
| (22) |
This metric is usually used to measure the prediction accuracy. It quantifies the average percentage deviation between the predicted solution and the ground truth, providing a measure of how well the predictions align with the actual outcomes. Based on the analysis by [34] of time series forecasting evaluation, MAPE is a suitable metric in the absence of outliers and intermittence. We also utilize sMAPE, which is more suitable in the presence of outliers. This metric quantifies the percentage difference between predicted and actual values, with adjustments made to ensure equal treatment of both small and large values in the evaluation process (see Appendix A.1).
The two models are trained using fixed sub domain windows (sequences of 10 time points referred to as ), as explained in sections 4.2.2 and 4.2.1, and then compared using the test dataset, with 3 different sub domain windows 10, 15 and 20, to evaluate the ability of the models to generalize and to capture the local dynamics.
Applying the same logic as explained earlier, we compute the Total MAPE for each dataset (Eq. 23) and Eq. 24).
| (23) |
| (24) |
This metric is then used to compare the two methods. Based on [34] MAPE is not a suitable metric in the presence of outliers. To ensure a fair comparison we first, eliminate outlier results using the normal Z-score (or Six Sigma rules). This means that if the MAPE of a dataset performs significantly better or worse compared to others, it will not be included in the comparison of the two methods. Then we calculate the average of and over all test datasets for and respectively. In addition, we calculate the median and the 90th percentile. This will provide a more comprehensive understanding of the accuracy of the model.
We conduct the same comparison without eliminating outlier results, using the sMAPE metric, which is more suitable in the presence of outliers (see Appendix A.1).
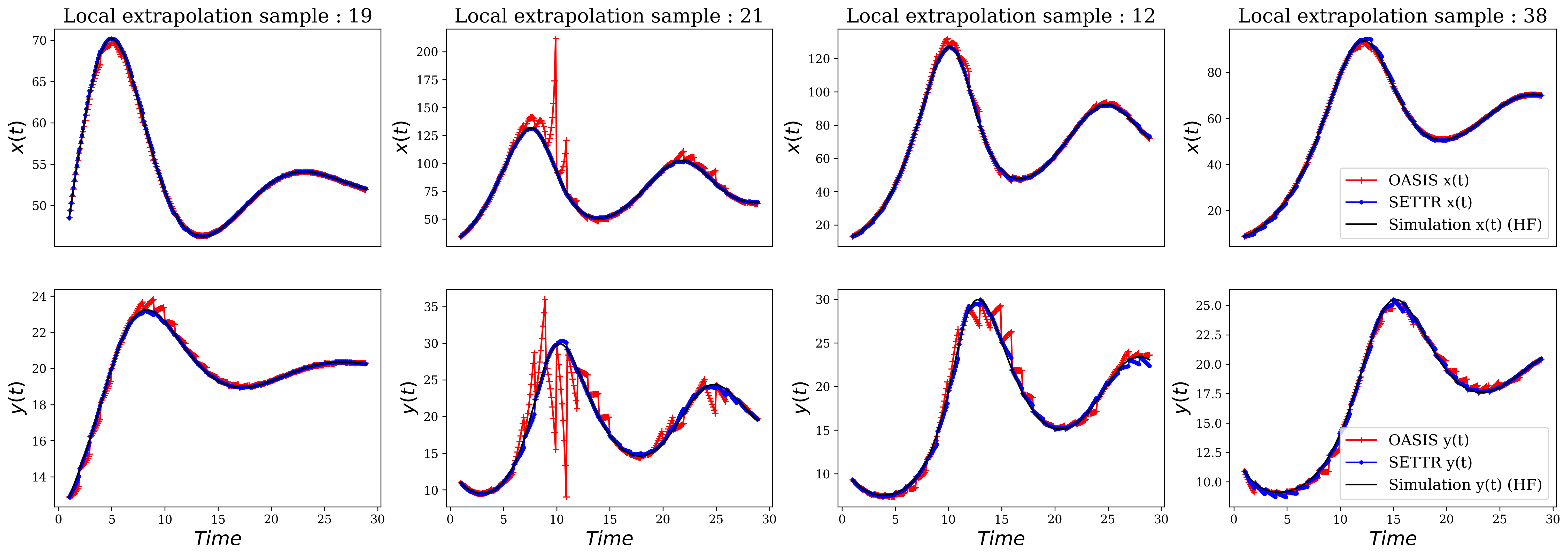
During these tests, we observed that OASIS and Set Transformer may fail to predict the local dynamics, which can result in divergence. In some cases, this divergence is acceptable (Samples 11 and 21 in Fig. 10), but we also found that it is possible for the model to completely fail to capture the dynamics, leading to infinite divergences. In this case, the dataset is not included in the comparison using the MAPE metric. To represent this, we added the divergence metric to highlight the model’s ability to avoid complete divergences.
The results are presented in Tabs. 4, 5 and 6 which correspond to the 3 sub domains windows sizes as previously explained (, and ), with four different extrapolation windows. This means that based on one sub domain window, we try to extrapolate for larger windows. We refer to these as extrapolation windows.
The primary attention lies in the divergence difference between the Set Transformer and OASIS frameworks, which increases with larger sub domain windows with 40-55% of infinite divergences. In contrast, Set Transformer remains stable with significantly lower divergence percentages. This phenomenon is understandable because the set encoding architecture attempts to encode all time series data to generate predictions. Additionally, as the quantity of data increases, so does the accuracy. We can also see that both models give very acceptable results for small extrapolation windows, this could be highly related to the training process of the two models, where we focus on predicting only the next sub domain dynamics. While the average of MAPE remains good for large extrapolation windows (). The inaccuracy, or the 90th percentile represents the maximum MAPE error observed in 90% of the test sets, increases significantly for OASIS, while it increases reasonably for Set Transformer maintaining acceptable extrapolation.
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 0.43 | 1.01 | 0.76 | 3.75 | 5.36 | 44.64 | |
| 0.67 | 1.90 | 1.07 | 3.27 | 5.36 | 44.64 | ||
| 2 | 1.35 | 2.35 | 3.63 | 9.73 | 5.36 | 42.86 | |
| 3.65 | 6.31 | 17.01 | 21.60 | 5.36 | 42.86 | ||
| 3 | 1.93 | 3.21 | 4.21 | 10.28 | 7.14 | 41.07 | |
| 3.28 | 6.24 | 11.06 | 19.00 | 7.14 | 41.07 | ||
| 4 | 4.09 | 5.44 | 12.20 | 15.40 | 3.57 | 39.29 | |
| 5.34 | 8.45 | 18.76 | 24.83 | 3.57 | 39.29 | ||
| \botrule | |||||||
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 1.00 | 0.83 | 1.54 | 1.22 | 7.14 | 51.79 | |
| 0.88 | 2.92 | 1.50 | 4.63 | 7.14 | 51.79 | ||
| 2 | 2.41 | 2.81 | 3.86 | 5.12 | 7.14 | 51.79 | |
| 2.26 | 5.49 | 2.75 | 8.98 | 7.14 | 51.79 | ||
| 3 | 3.49 | 5.11 | 5.84 | 11.79 | 5.36 | 44.64 | |
| 2.88 | 7.83 | 5.56 | 19.44 | 5.36 | 44.64 | ||
| 4 | 6.24 | 8.09 | 14.70 | 22.14 | 3.57 | 44.64 | |
| 5.20 | 11.80 | 16.38 | 38.38 | 3.57 | 44.64 | ||
| \botrule | |||||||
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 2.42 | 1.09 | 3.99 | 1.84 | 7.14 | 55.36 | |
| 1.03 | 3.89 | 1.78 | 6.15 | 7.14 | 55.36 | ||
| 2 | 5.10 | 4.41 | 8.79 | 9.15 | 7.14 | 50.00 | |
| 2.08 | 7.14 | 3.79 | 11.86 | 7.14 | 50.00 | ||
| 3 | 9.90 | 10.17 | 15.92 | 23.57 | 7.14 | 44.64 | |
| 6.51 | 14.75 | 16.66 | 39.65 | 7.14 | 44.64 | ||
| 4 | 9.28 | 10.25 | 14.16 | 24.59 | 3.57 | 53.57 | |
| 4.46 | 8.95 | 9.60 | 23.78 | 3.57 | 53.57 | ||
| \botrule | |||||||
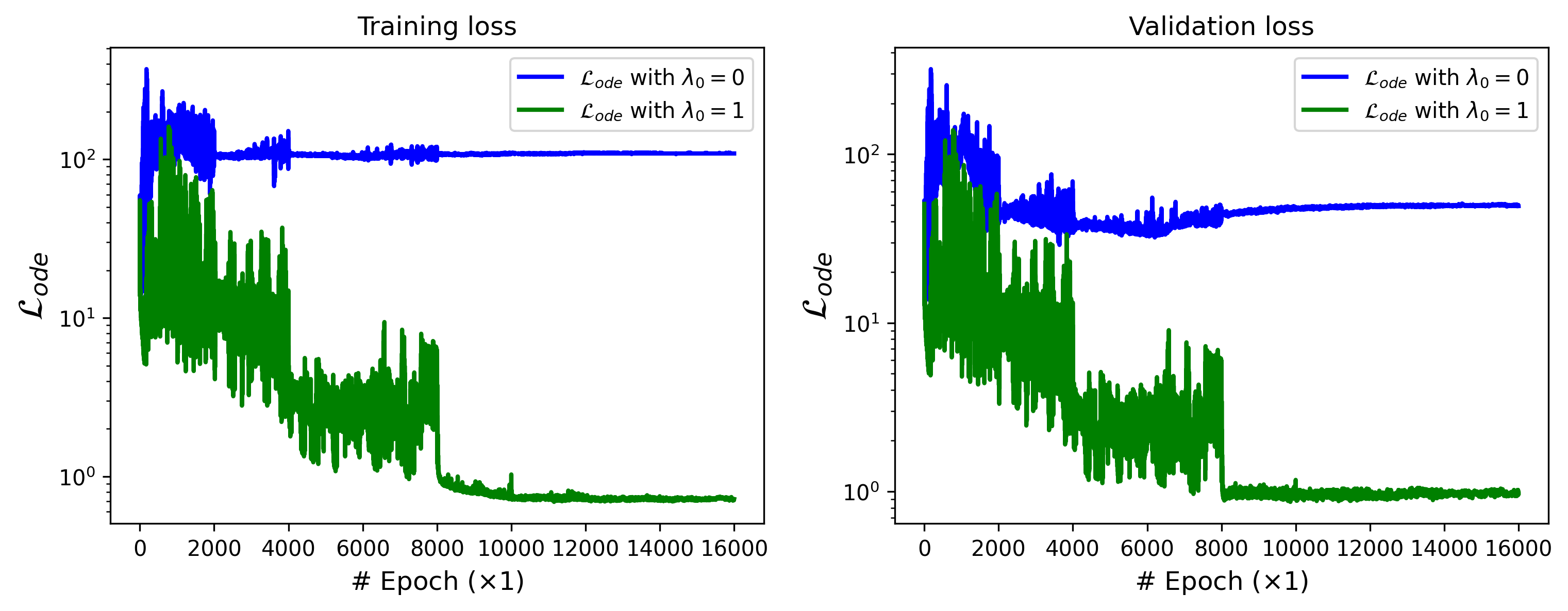
On the other hand, we concluded that adding the ODE loss as given in Tab. 3 significantly improves the results, especially in cases where the dynamics terms are unknown or only partially known, as well as in cases where the goal is to identify local dynamics valid for short time windows. The Fig. 11 represents the ODE loss for training and validation using the Set Transformer method with the same architecture. When is used with , and when indicates that the ODE loss is not used, we can easily observe the difference in convergence. This difference can be explained by the fact that assigns weighted attention to each coefficient. This means that if the contribution of a coefficient is significant, its loss will also be significant compared to other coefficients, and vice versa.
Based on this comparison, we can see the importance of using Set Encoding for local dynamics identification, which could be utilized for extrapolation, as demonstrated in the example above, or for other use cases such as predictive control. We demonstrated that OASIS may fail to capture the local dynamic, resulting in inaccurate results and divergence, while Set Transformer remains stable and leverages all available data to predict the local dynamics. These results could be improved by using variable sub domain windows during the training process, which would provide the Set Transformer method the ability to generate more accurate results and enhance extrapolation capabilities. This approach is demonstrated in the next example, where we aim to identify the global dynamics using an expanding time window. Furthermore, using this approach with noisy data is going to be challenging, which is related to the high sensitivity of SINDy to noise [35]. Additionally, in this case, we only aim to identify a local dynamic, which means that the identification process is more challenging. Moreover, in extrapolation use cases, it is essential to update the model frequently to obtain accurate results. Using the predictions of Set Transformer (or OASIS) and then an ODE solver to extrapolate poses two challenges. The first one is related to the training process, which involves the generation of training data and using SINDy for the identification of local dynamics with noisy data, which is challenging. Furthermore, even slight noise in the initial conditions may lead to inaccurate extrapolation or complete divergence.
4.3 Application 2 : Global model identifications (Deep Set vs Set Transformer)
4.3.1 Data generation
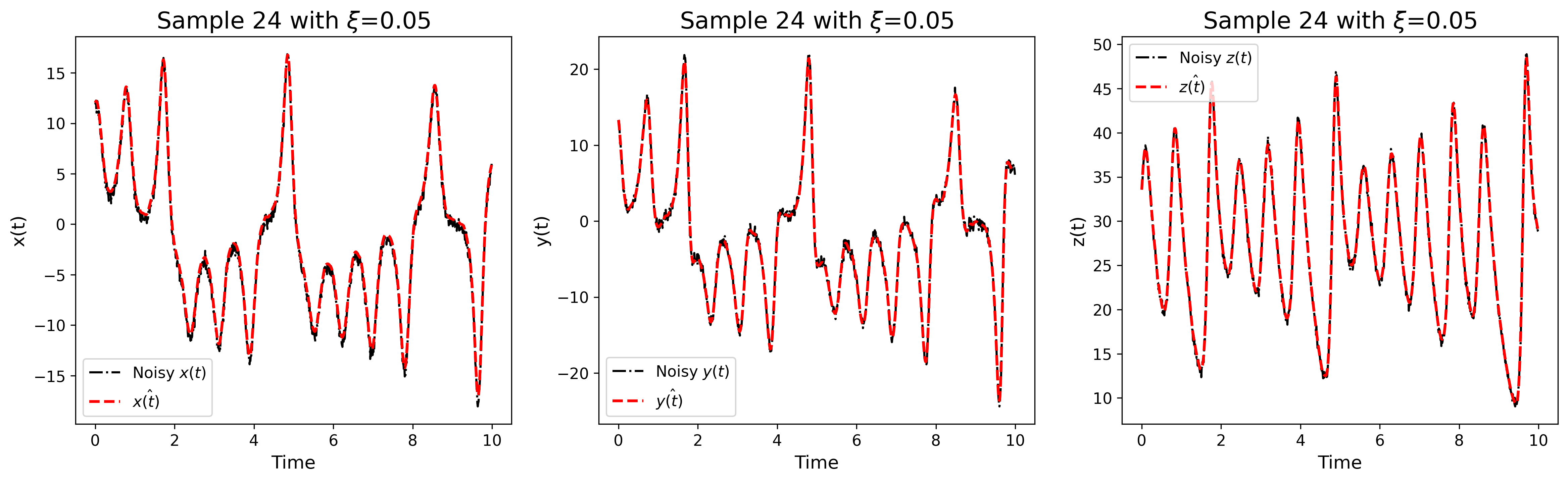
We generate a dataset of 1024 Lorenz systems with variables parameters , and initial conditions as described in Tab. 7 using LSODA [32] methods implemented in SciPy Python package. The parameters and initial conditions are sampled using the Sobol [31, 32] method implemented in the SciPy Python package. As the number of possible combinations of parameters and initials conditions is large and taking into consideration the chaotic behavior of the Lorenz system, we use 70% data to train the model and the remaining 30% for validation and testing.
| Variables | Range |
|---|---|
| variations | [8; 12] |
| variations | [20; 35] |
| variations | [0; 4] |
| variations | [-5; 5] |
| variations | [4; 50] |
| variations | [5; 15] |
| train and validation | [0, 10[ |
| test | [0, 20[ |
| \botrule |
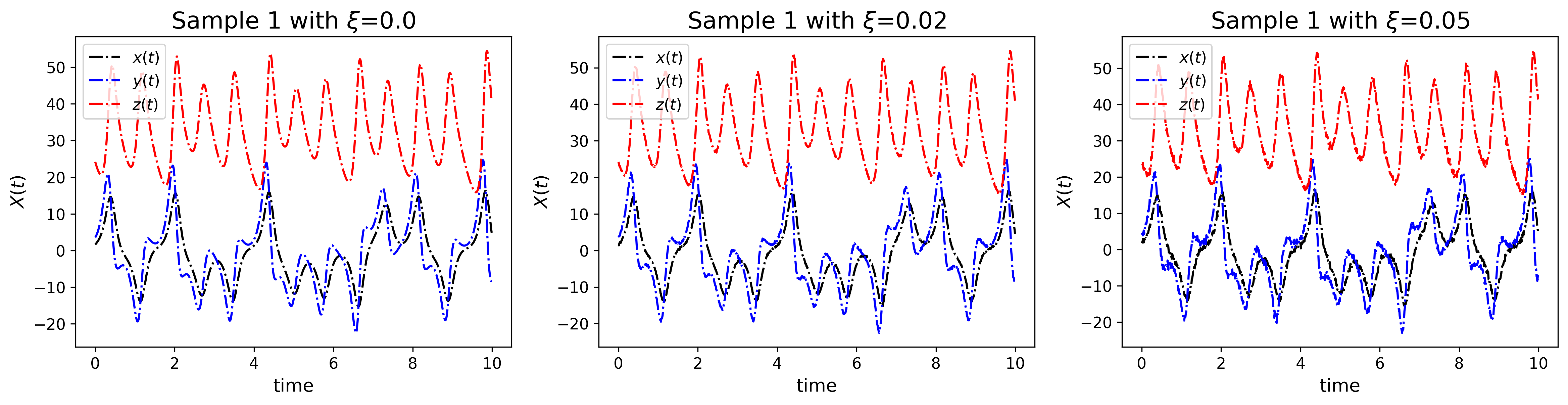
To study the robustness of the models concerning data quality, we generate 3 datasets with three levels of Gaussian noise. as described in Eq. 25 :
| (25) |
Fig. 12 shows an example with three levels of noise. Using the same parameters and initial conditions, we then compute the approximation of the derivative with respect to time using total variation method [27] for noisy data and central difference (Eq. 26) for clean data.
| (26) |
Afterwards, we compute , which represents the approximation of the integral of using the cumulative trapezoidal integration method (Eq. 27) (with the SciPy Python package).
| (27) |
This approach contributes to noise reduction in the data (Fig. 13), it will also enable the models to learn effective denoising techniques (further explanations are given in section 4.3.2). PySINDy (Python package) is then used to compute the approximation of the parameters for each dataset. In this application we assume that the ODE search library is known and well defined, our main focus is on calculating the parameters . The identification process is defined as in Eq. 28 .
| (28) |
4.3.2 Train process and criteria of comparison
We implement a consistent training regime for both models (Deeps Set and Set Transformer), employing varied architectures for both methods. Following this, we conduct a comparison of the optimal architecture configurations for each method. A core principle underlying the utilization of Set Encoding models is the integration of adaptability, enabling predictions that dynamically adjust to an increasing volume of data over time. We employ a sliding window approach with increasing widths. Through this approach, the models are designed to adaptively incorporate new information for updating predictions of Lorenz parameters.
| Deep Set | Set Transformer | |
| Optimizer | Adam | |
| Loss function | ||
| Learning rate | ||
| Epochs | [400, 400, 400, 400, 400] | |
| Input Shape | ||
| Output Shape | ||
| \botrule | ||
The model inputs are , which represent the noisy data, we added the time dimension, which will be encoded during the pooling phase. This will enable the model to better comprehend the dynamic while increasing input size, and hold good accuracy with variables times steps . The output is defined as . The training process is summarized in Tab. 8. We employ the Adam [36] optimizer for training both models, with a step decay learning rate. The loss function comprises two components. The first part represents the loss associated with parameters loss where and denote the fitted parameters using SINDy (Eq. 28) based on denoised data and the predicted parameters. Note here that may differ from , the true parameters vector. The second part represents the loss associated with the ODE loss utilizing denoised variables, in this study, we fix to 1. Training both methods to predict denoised parameters enables the model to additionally learn denoising techniques while processing noisy input data. Both methods are trained and validated on the same dataset. The best model will be selected based on its accuracy in validation; subsequently, the best model instances are chosen for a comparative analysis between the two models, for more details see appendix A.4.
The comparison of instances of the two models will be based on their ability to deliver accurate and stable predictions, while considering the variability in both the quality and quantity of data. Note here that we trained individual instances to predict each parameter of the Lorenz systems, which helps the models converge faster.
4.3.3 Comparison and discussion
The instances comparison are based on three features :
-
1.
Accuracy : the accuracy of selected instances is assessed using -score metric [37] defined as :
(29) which measures how well the predicted values match the actual values. In our context, it quantifies the precision of predicting Lorenz parameters. The closer the score is to 1, the better the accuracy. It is important to note that our comparison involves evaluating the model predictions against the true Lorenz parameters, and not the fitted SINDy parameters . We assess the instances’ capability to provide accurate predictions with variable input sizes, we employ the weighted average of defined as :
(30) which assigns more importance to predictions with fewer data points, where . This study is based on an expanding window approach, with two windows utilized: one for interpolation study where , and another for extrapolation where , which is never used during training or validation.
Results of are presented in Fig. 14. The overall performance of both methods is good for both interpolation and extrapolation (). The accuracy drops for extrapolation, which is related to new Lorenz patterns unseen during the training process. It is also related to the time dimension used during training, limited to . In interpolation, Method Deep Set yields slightly better results, while in extrapolation, Method Set Transformer tends to be more stable (results do not change much). An exception is the prediction of , for which the accuracy drops for both methods. This can be explained by the data generation process (Eq. 28), where we can observe that the prediction of is based on , whereas for the prediction of and , it is based directly on and , respectively, which are the input of the models, making it easier to learn. Furthermore, in extrapolation, Set Transformer performs better in the prediction of , while in interpolation, Deep Set was slightly better.
We can also observe that for both interpolation and extrapolation, both methods demonstrate very good robustness to different noise levels. We present the with respect to the quantity of data in appendix A.2 (Fig. 18, 19 and 20).
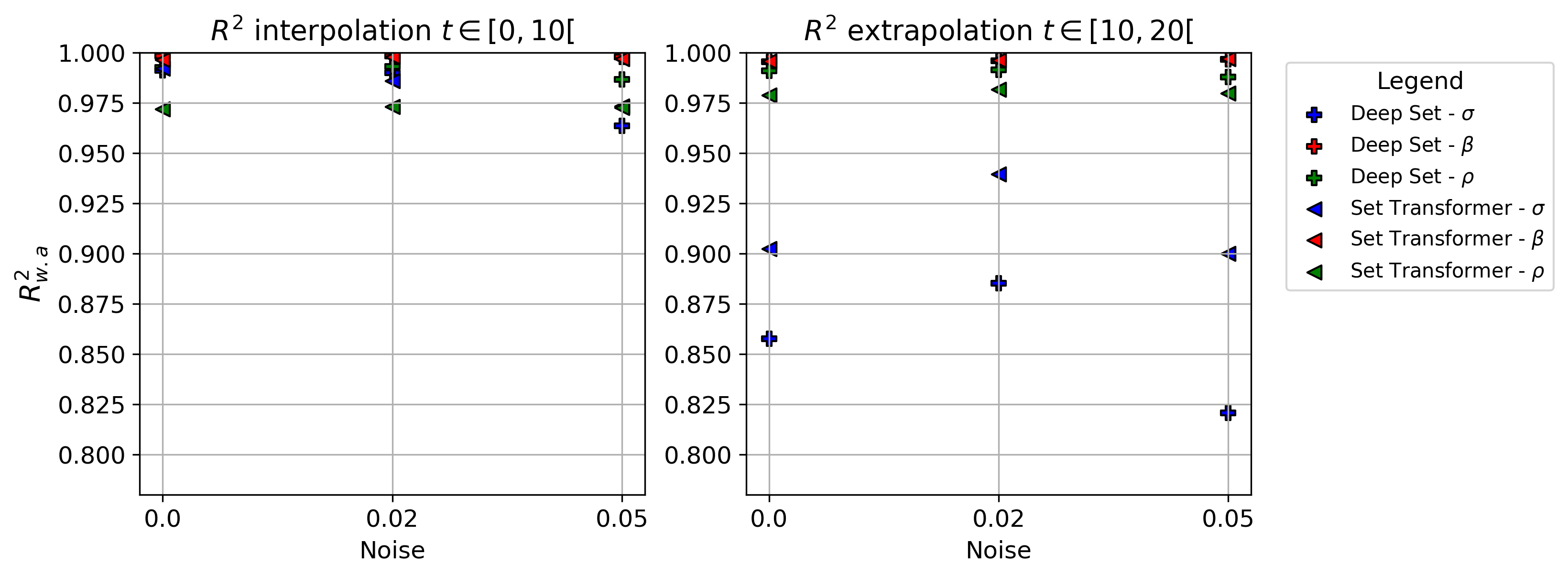
Figure 14: Accuracy results using metric for Deep Set and Set Transformer instances for , and . On the left interpolation results for , and on the right extrapolation results for . -
2.
Inference time : Both trained models could be used directly for online applications. This is because the inference time is in the order of a few milliseconds on AuthenticAMD AMD EPYC 9474F@3.6Ghz 48-Core Processor, making these models more suitable for applications like the extrapolation of state variables [22] or online control [3]. These methods also can dynamically use new data to enhance the accuracy of the prediction or to reevaluate the prediction in case of changes in the system dynamics.
-
3.
Training : Based on the comparison of both methods, we observed that the implementation of Deep Set is easier compared to Set Transformer. Deep Set relies on simple dense layers, resulting in fewer hyperparameters, thus facilitating hyperparameter tuning. More details about the instance selection are provided in Appendix A.4.
4.4 Application 3: Characterizing Abnormalities in 1D Heat-Transfer Using Deep Set Model
4.4.1 Data generation
For this application we aim to train a Deep Set model to approximate online the diffusivity value from temperature data, we also challenge the model to characterize a local decrease of diffusivity. We start by generating a dataset using finite difference methods (implicit Euler method) with different diffusivity values . The 1D heating equation is defined as in Eq. 18 in this case is space-dependent. The initial temperature value is , , and the heat flux is defined as function as follow (Eq. 31) :
| (31) |
Where , which simply means that we impose a regularization to stop the heating if . The is defined as in Fig. 15, this function could be simplified as three characteristics, which is the normal diffusivity value, which presents the center of abnormality and which is simply the ratio between normal and abnormal diffusivity. The function defined as (Eq. 32), where and are two values that help define :
| (32) |
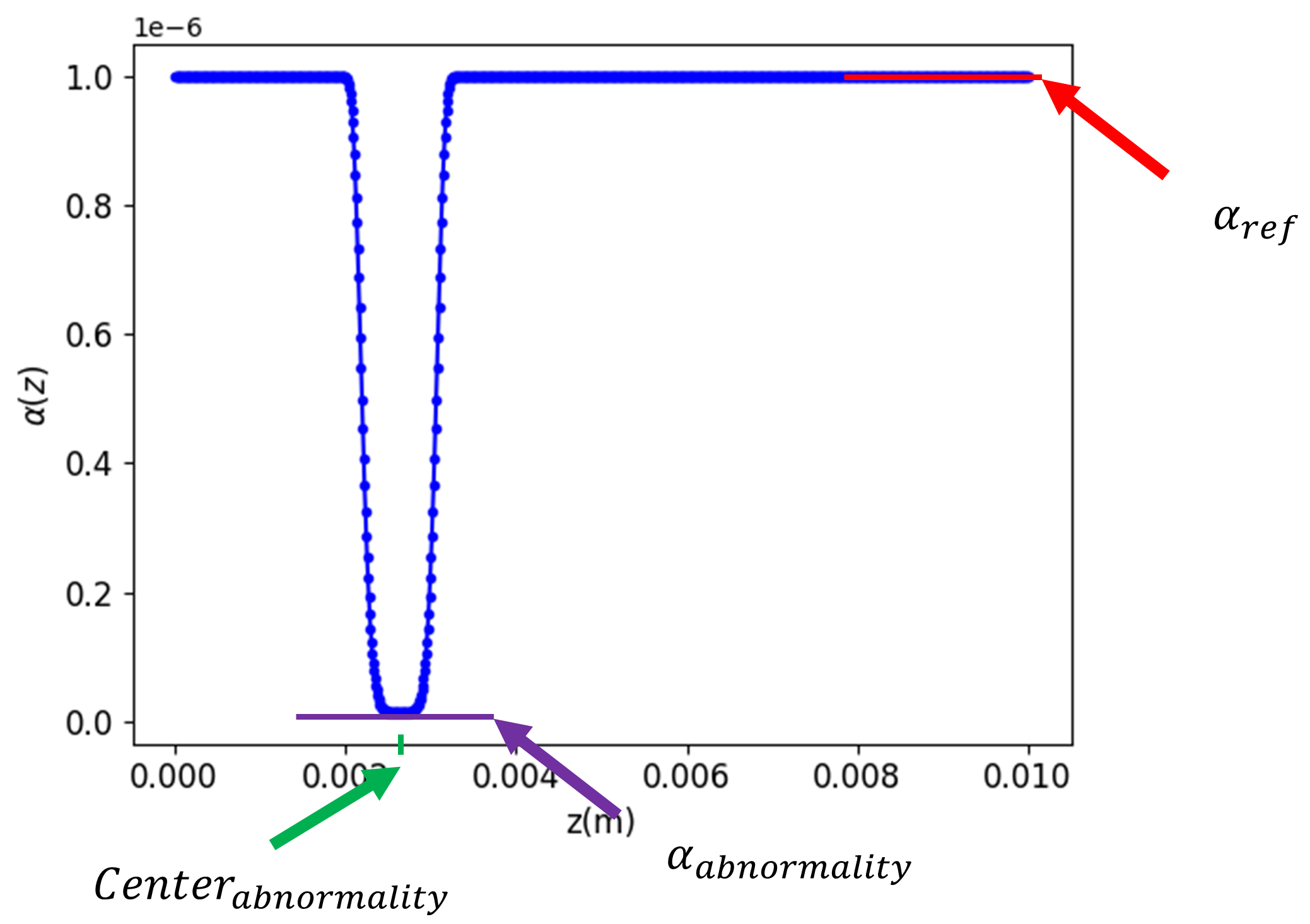
We generate datasets with different combinations of the three characteristics defined previously, where , where of this dataset is used for training and for validation, we also generate separately a test datasets to evaluate the performance of the model, the distribution of training, validation and test characteristics is defined as follows (Tab. 9) :
| Variables | Range | Distribution |
|---|---|---|
| [] | ||
| [] | ||
| [] | Sobol | |
| Time | [] | - |
| \botrule |
4.4.2 Training process
Using these datasets, we train a Deep Set model, where the input combines a time series of temperature at two positions and and the corresponding time (Example in Fig. 16), where . In this study we limited the model input temperature information to only two positions, the input which corresponds to the dataset is defined as (Eq. 33) :
| (33) |
Thus the model input and output could be defined as , where are the trainable parameters of Deep Set model. The details about the used architecture are given in A.5. We used a time-expanding window, which gives the model a flexible approximation of the characteristics using available information, which is improving as new data is available. The loss function is defined as (Eq. 34):
| (34) |
, which is composed of four losses: , , and , which correspond to the losses of each characteristic and the regularization of the model which helps avoid overfitting problems, in this application we found that gives better generalization.
We also study the model robustness to noise, for that we tested the model for four noise levels defined as (Eq.35) where and :
| (35) |
4.4.3 Results and discussion
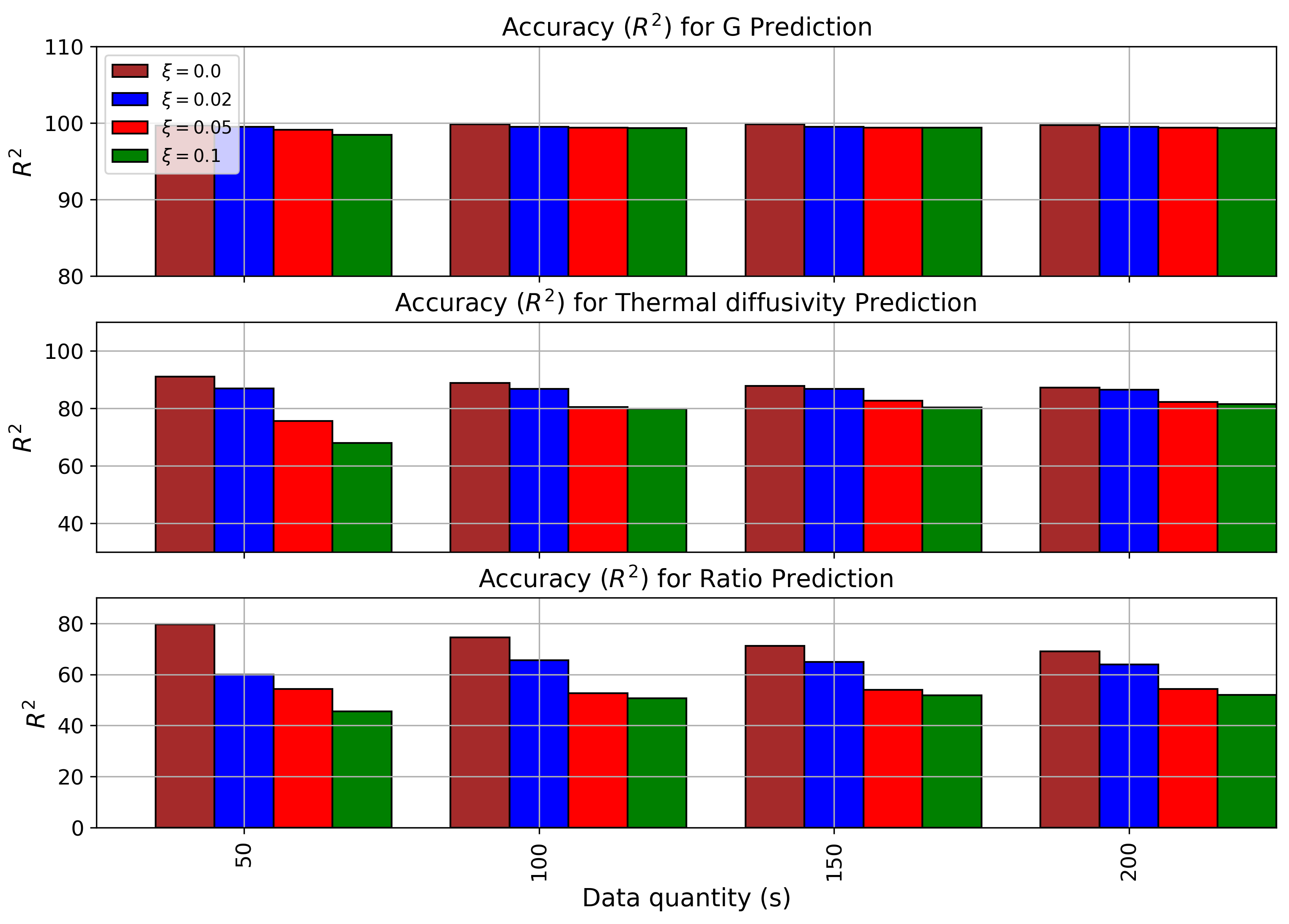
We trained different models for the four different noise levels , we then select the best model based on the loss of the validation datasets, the selected models are then tested using the test datasets. The selected model architecture is given in appendix A.5. We assess the model accuracy with respect to the quantity data and robustness to noise using the metrics (Eq. 29), we also use the same temperature position used for the training and validation, the results are :
-
•
Accuracy and robustness : We use the same accuracy assessment as in application 4.3 :
(36) , for this application we test the models for different data quantities where and data quantities .
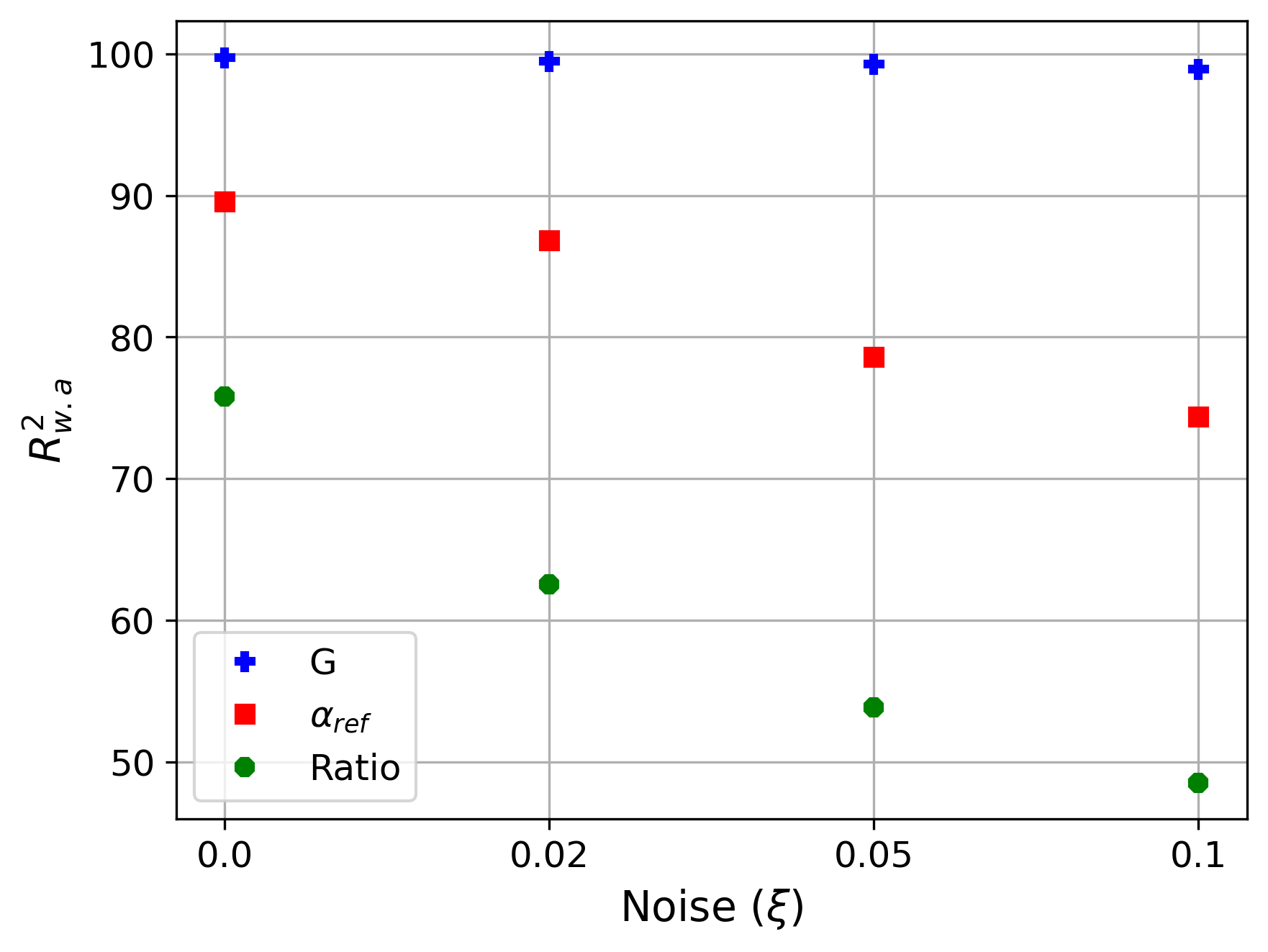
Figure 17: Accuracy results using metric for Deep Set for abnormalities characterization : , and , for 4 different noise levels from to From these results (Fig. 17, and. 21), we can see that the model can easily predict the of abnormality and remains stable with respect to noise, also the accuracy of the prediction of is good and decreases reasonably with the increase of noise, we believe that this is related to confusion related to the added noise which makes the precision of diffusivity very difficult, this is also related to the fact that the range of diffusivity is small while the noise levels represent a higher related to noise (for ) which confuse the training of the model. Finally, the prediction of the is acceptable for low noise levels but decreases as the noise level increases. We believe that this is related to the lack of information (only two temperature positions) and the confusion caused by the noise level. We also believe that increasing the number of datasets will improve the model accuracy. More details on the accuracy of the model with respect to data quantity are given in appendix A.3.
-
•
Discussion : In this application we focused on the Deep Set architecture, nevertheless Set Transformer, which gives very good results for Lorenz chaotic systems, could also be applied to this application and is expected to give good results. Also, in this application, we did not add a physics loss simply because the approximation of in the PDE (Eq. 18) is not an easy task. Specifically, in this case where we use only two separated positions, the approximation of the second derivative with respect to space is challenging. This results in less robustness to noise compared to the second application. This problem will be addressed in a subsequent study where we will attempt to improve this method for application to PDE problems.
5 Conclusion and perspectives
In this paper, we presented a combination of two architectures of Set Encoding with the methods of SINDy and SINDYc. The Set Encoding methods are initially trained on a dataset generated by SINDy (or SINDYc) and subsequently employed in real-time to swiftly and accurately predict system dynamics parameters, which could be used for applications such as extrapolating state variables or system control. Our primary contribution lies in encoding variable-sized data sequences using an appropriate architecture, thereby enabling the model to better utilize all temporal information to enhance precision. Additionally, we propose a more suitable loss function. In application 1, we illustrate the need to incorporate the component in the loss function, which enhances the model training process. Our approach can be applied to local identification and global dynamics, as demonstrated in application 2 and 3. In the second application, we suggest a training approach on noisy data, demonstrating that both methods yield robust and stable results with different noise levels. However, this approach relies on datasets generated by SINDy, implying that accuracy is directly dependent on the precision of SINDy (or SINDYc). In the third application, we addressed a PDE example and showed that the model gives interesting results. Nevertheless, the generation of the training datasets is more challenging, especially when dealing with limited and noisy datasets in the context of partial differential equation (PDE) systems, where calculating derivatives in the presence of noise is particularly challenging.. To address this issue, an approach akin to PINN-SR [17] can be employed, extending our methodology to handle ODEs and PDEs with noisy and limited data quantities. In addition, the current Set Encoding architecture cannot handle cases where terms in differential equations are prone to deletion or addition in real-time applications. This implies that the models cannot activate or deactivate terms. To address this challenge, one can integrate a new decoding block with an appropriate activation function (such as a sigmoid function), which would be responsible for activating and deactivating dynamic system terms. Finally, we believe that a comparison between Deep Set and Set Transformer in online nonlinear dynamics identification is necessary to better understand the difference between these two methods. While Deep Set encodes data using classical neural network architecture, Set Transformer employs attention mechanisms, which enable better learning of interactions among input data. This has shown interesting results in many application fields. However, these advantages come with drawbacks such as increased training time and architectural complexity.
Appendix A Appendix
A.1 Using sMAPE metrics for comparison between OASIS and Set Transformer
We present the results based on the sMAPE metric (Eqs. 37, and 38). This metric is more suitable for evaluating the forecasting of time series with outliers. In this case, it is not necessary to eliminate outliers; we follow the same approach as that presented in section 4.2.2. According to the results presented in Tabs. 10, 11 and 12, we can see a close resemblance to the results presented using MAPE with outlier elimination.
| (37) |
| (38) |
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 0.47 | 1.23 | 1.11 | 3.58 | 5.36 | 44.64 | |
| 1.46 | 3.61 | 1.23 | 6.06 | 5.36 | 44.64 | ||
| 2 | 1.96 | 3.40 | 6.07 | 12.20 | 5.36 | 42.86 | |
| 4.45 | 6.44 | 18.69 | 19.46 | 5.36 | 42.86 | ||
| 3 | 2.31 | 4.23 | 5.78 | 13.59 | 7.14 | 41.07 | |
| 4.16 | 6.23 | 14.40 | 18.15 | 7.14 | 41.07 | ||
| 4 | 4.51 | 5.87 | 13.44 | 16.14 | 3.57 | 39.29 | |
| 6.85 | 9.07 | 24.34 | 21.02 | 3.57 | 39.29 | ||
| \botrule | |||||||
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 1.14 | 1.76 | 1.87 | 3.01 | 7.14 | 51.79 | |
| 1.84 | 4.62 | 1.81 | 8.41 | 7.14 | 51.79 | ||
| 2 | 2.69 | 3.78 | 5.07 | 10.55 | 7.14 | 51.79 | |
| 3.37 | 5.76 | 7.32 | 12.71 | 7.14 | 51.79 | ||
| 3 | 4.60 | 6.13 | 6.03 | 13.73 | 5.36 | 44.64 | |
| 3.71 | 8.48 | 9.53 | 20.58 | 5.36 | 44.64 | ||
| 4 | 7.40 | 9.56 | 14.88 | 24.25 | 3.57 | 44.64 | |
| 7.05 | 10.83 | 18.18 | 31.84 | 3.57 | 44.64 | ||
| \botrule | |||||||
| mean | 90% | divergence (%) | |||||
| SETTR | OASIS | SETTR | OASIS | SETTR | OASIS | ||
| 1 | 2.63 | 2.66 | 3.92 | 2.24 | 7.14 | 55.36 | |
| 2.79 | 5.81 | 2.05 | 7.52 | 7.14 | 55.36 | ||
| 2 | 6.21 | 7.35 | 11.32 | 24.77 | 7.14 | 50.00 | |
| 4.77 | 9.57 | 9.95 | 21.72 | 7.14 | 50.00 | ||
| 3 | 9.82 | 11.83 | 23.89 | 25.61 | 7.14 | 44.64 | |
| 7.08 | 12.76 | 18.22 | 33.02 | 7.14 | 44.64 | ||
| 4 | 9.88 | 12.51 | 16.45 | 35.09 | 3.57 | 53.57 | |
| 4.92 | 9.72 | 12.82 | 23.82 | 3.57 | 53.57 | ||
| \botrule | |||||||
A.2 Detailed accuracy results for the comparison between Deep Set and Set Transformer
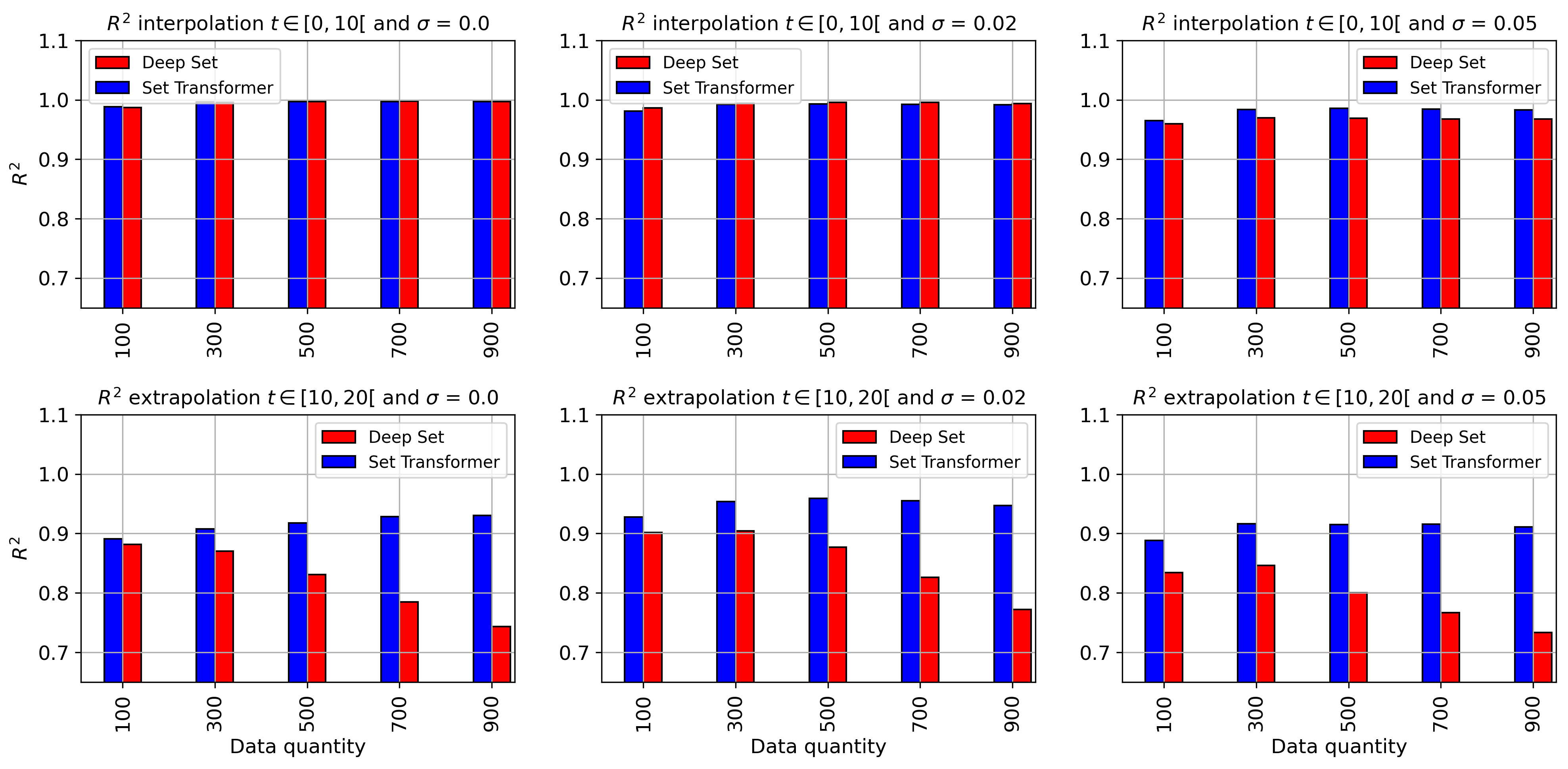
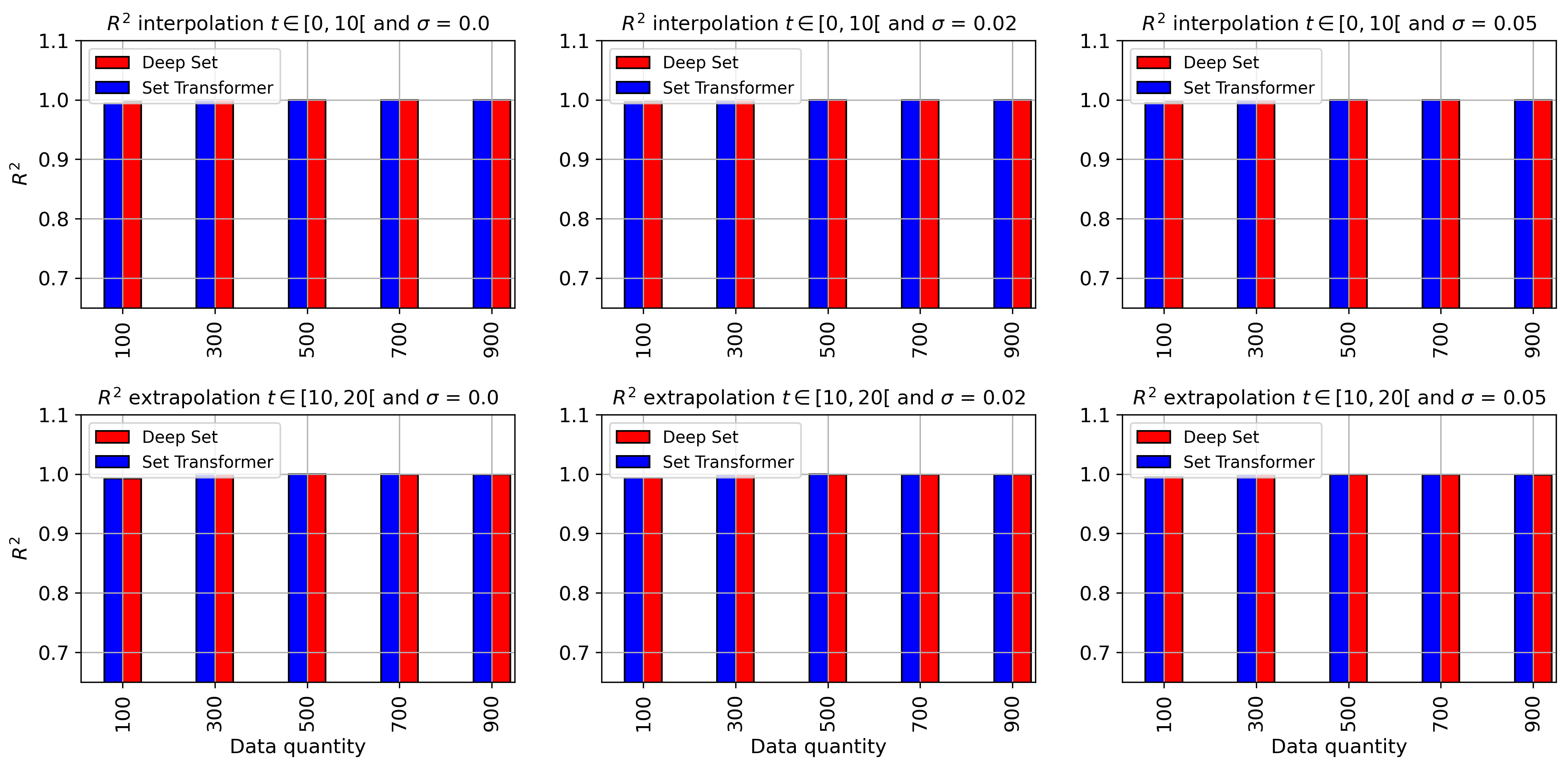
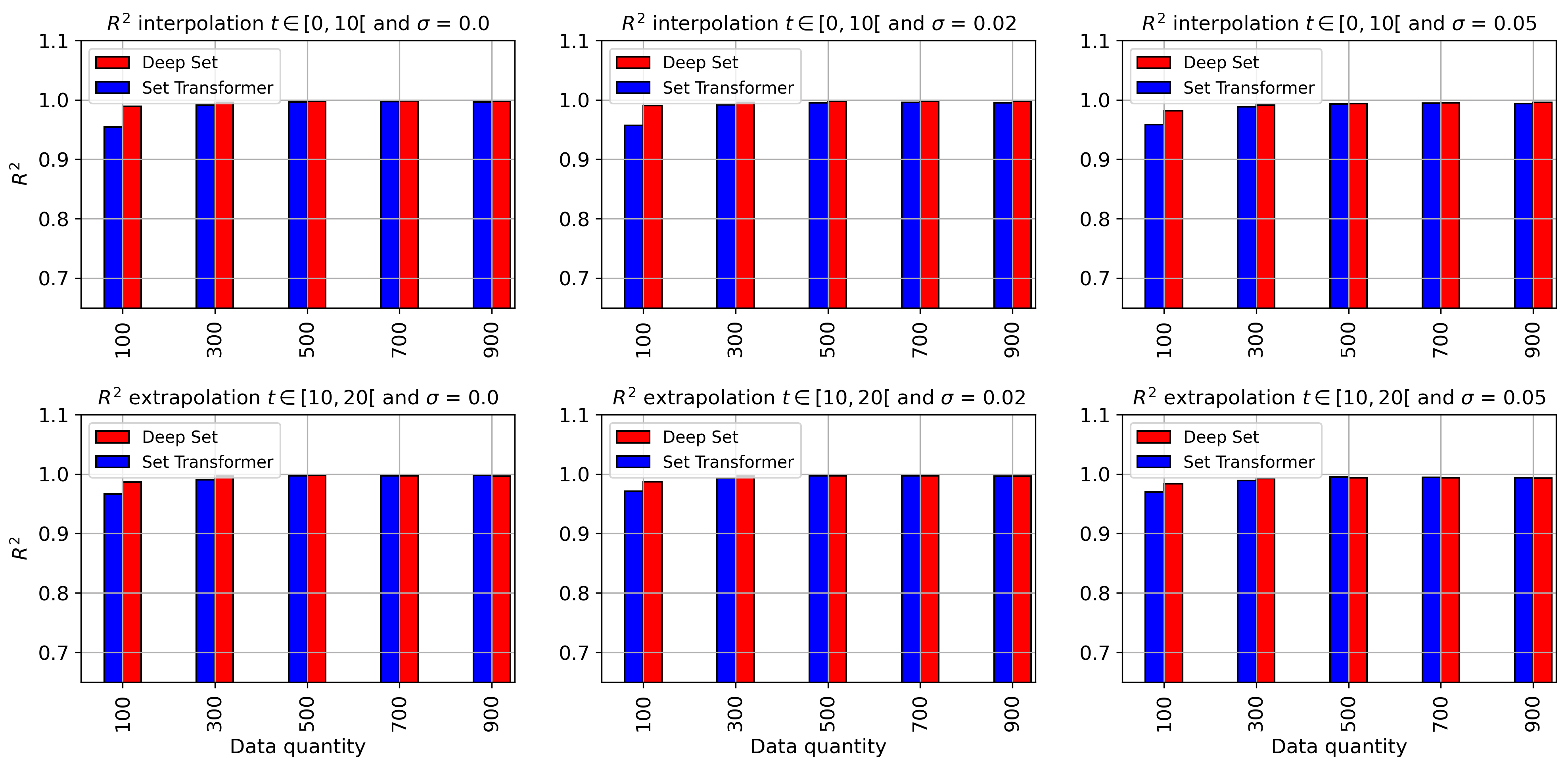
A.3 Detailed model accuracy with respect to data quantity and noise levels
A.4 Instance selection for the comparison between Deep Set and Set Transformer
The two Set Encoding methods are trained on different architectures independently, considering three levels of noise and three parameters of the Lorenz system (, , and ), with variable time windows. Simultaneously, they are validated on the validation dataset. A check-pointing process is used if the validation error (Tab. 8) reaches a new minimum to save an instance of the architecture. The same process is conducted with different architectures for both methods, and the best instances are selected for each method, noise level, and each parameter of the Lorenz system. These instances are then used to compare the two methods. The selected architectures are presented in Tabs. 13 and 14.
A.4.1 Deep Set
The Deep Set model, as presented in section 3, can be summarized into three parts:
-
•
The first part is the encoding part, which takes as input the state variables of the Lorenz system and the time dimension . It projects these state variables into a higher dimension using a simple MLP. The architecture of this MLP is defined in (Tab. 13), where we have 5 layers with 320 perceptrons each and a ReLU activation function.
-
•
The second part consists of choosing a pooling function over the time dimension. In this application, we found that applying the absolute value function followed by mean aggregation gives better results. The output of the aggregation function is a timeless feature vector.
-
•
The last part consists of decoding the feature vector into the dynamics parameters. In this application, we used an MLP with the same architecture as for encoding.
| activation | Layers | Pooling | Trainable parameter count | |
|---|---|---|---|---|
| Encode | ReLU | 320 | ||
| Decode | ReLU | 320 | abs, mean | 927043 |
| \botrule |
A.4.2 Set Transformer
The Set Transformer architecture is more sophisticated compared to Deep Set, as it uses the attention mechanism, which means different encoding, pooling, and decoding approaches. Nevertheless, we can also summarize it as a three-part model:
-
•
As for the Deep Set, this part consists of encoding the Lorenz system variables. For that, we used ISAB (section 3.2), which performs an attention mechanism encoding within the time and the state variables of the Lorenz system. These variables are projected into a higher dimension , and then the attention mechanism is applied with respect to a trainable matrix called inducing points [5], with rows and columns. This means that ISAB will start by projecting the time snapshots into snapshots and then perform the attention mechanism with respect to the state variables of the Lorenz system. This method decreases the calculation time while providing similar results; more details are given in [5]. For the attention mechanism, we used attention heads (Tab. 13). In this part, we apply a feedforward neural network to the output of the attention mechanism, adding more nonlinearity. For this application, the feedforward neural network is simply an MLP with 2 layers, 45 perceptrons each, and a ReLU activation function.
-
•
The second part consists of applying pooling over the encoder feature vector, which is based on PMA, a Multi-Head Attention block that performs aggregation using the multi-head attention mechanism. For this, we used a pooling seed vector , where and .
-
•
Finally, we use an MLP with 2 layers, 40 perceptrons each, and a ReLU activation function, with a final layer of output dimension that corresponds to the 3 parameters of the Lorenz system.
| Attention blocks | rFF | Trainable parameter count | |
|---|---|---|---|
| Encode | ISAB() | rFF(45, 2, ReLU) | |
| Pooling | PAM() | rFF(40, 2, ReLU) | 1045733 |
| \botrule |
A.5 Deep Set Architecture for the Third Application
The selected architecture is defined in Tab. 15. As detailed in A.4, we selected the best model using the validation datasets and a checkpoint that saves instances when the validation loss reaches a new minimum. The selected architecture consists of three blocks. In the first block, we use an MLP with 5 layers, 256 perceptrons, and a GeLU activation function. For the second part, we use a sum aggregation function. The encoded vector is then decoded using three different MLPs with the same architecture as the encoder, each corresponding to one of the characteristics (, , and ).
| Activation | Layers | Pooling | Trainable Parameter Count | |
|---|---|---|---|---|
| Encode | GeLU | 2565 | ||
| Decode | GeLU | 32565 | sum | 1262083 |
| \botrule |
Declarations
-
•
Funding : The Jules Verne Institute of Research and Technology (IRT Jules Verne) (PhD PERFORM Program).
-
•
Conflict of interest : We affirm that there are no known conflicts of interest that have influenced this work.
-
•
Ethics approval and consent to participate : We confirm that this research complies with authors ethical standards. All authors consent to participate in the submitted work.
-
•
Data availability Not applicable.
-
•
Code availability Not applicable.
-
•
Author contributions Not applicable.
References
- \bibcommenthead
- Brunton et al. [2016] Brunton, S.L., Proctor, J.L., Kutz, J.N.: Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the national academy of sciences 113(15), 3932–3937 (2016)
- Rudin [2019] Rudin, C.: Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature machine intelligence 1(5), 206–215 (2019)
- Bhadriraju et al. [2020] Bhadriraju, B., Bangi, M.S.F., Narasingam, A., Kwon, J.S.-I.: Operable adaptive sparse identification of systems: Application to chemical processes. AIChE Journal 66(11), 16980 (2020)
- Zaheer et al. [2017] Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R.R., Smola, A.J.: Deep sets. Advances in neural information processing systems 30 (2017)
- Lee et al. [2019] Lee, J., Lee, Y., Kim, J., Kosiorek, A., Choi, S., Teh, Y.W.: Set transformer: A framework for attention-based permutation-invariant neural networks. In: International Conference on Machine Learning, pp. 3744–3753 (2019). PMLR
- Makke and Chawla [2024] Makke, N., Chawla, S.: Interpretable scientific discovery with symbolic regression: a review. Artificial Intelligence Review 57(1), 2 (2024)
- Lejeune et al. [2023] Lejeune, C., Mothe, J., Soubki, A., Teste, O.: Data driven discovery of systems of ordinary differential equations using nonconvex multitask learning. Machine Learning 112(5), 1523–1549 (2023)
- North et al. [2023] North, J.S., Wikle, C.K., Schliep, E.M.: A review of data-driven discovery for dynamic systems. International Statistical Review 91(3), 464–492 (2023)
- Tibshirani [1996] Tibshirani, R.: Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology 58(1), 267–288 (1996)
- Manucci et al. [2022] Manucci, M., Aguado, J.V., Borzacchiello, D.: Sparse data-driven quadrature rules via l p-quasi-norm minimization. Computational Methods in Applied Mathematics 22(2), 389–411 (2022)
- Zheng et al. [2018] Zheng, P., Askham, T., Brunton, S.L., Kutz, J.N., Aravkin, A.Y.: A unified framework for sparse relaxed regularized regression: Sr3. IEEE Access 7, 1404–1423 (2018)
- Long et al. [2019] Long, Z., Lu, Y., Dong, B.: Pde-net 2.0: Learning pdes from data with a numeric-symbolic hybrid deep network. Journal of Computational Physics 399, 108925 (2019)
- Martius and Lampert [2016] Martius, G., Lampert, C.H.: Extrapolation and learning equations. arXiv preprint arXiv:1610.02995 (2016)
- Chen et al. [2022] Chen, Y., Luo, Y., Liu, Q., Xu, H., Zhang, D.: Symbolic genetic algorithm for discovering open-form partial differential equations (sga-pde). Physical Review Research 4(2), 023174 (2022)
- Cranmer [2023] Cranmer, M.: Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582 (2023)
- Raissi et al. [2019] Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics 378, 686–707 (2019)
- Chen et al. [2021] Chen, Z., Liu, Y., Sun, H.: Physics-informed learning of governing equations from scarce data. Nature communications 12(1), 6136 (2021)
- Kaiser et al. [2018] Kaiser, E., Kutz, J.N., Brunton, S.L.: Sparse identification of nonlinear dynamics for model predictive control in the low-data limit. Proceedings of the Royal Society A 474(2219), 20180335 (2018)
- Brunton et al. [2016] Brunton, S.L., Proctor, J.L., Kutz, J.N.: Sparse identification of nonlinear dynamics with control (sindyc). IFAC-PapersOnLine 49(18), 710–715 (2016)
- Narasingam and Kwon [2017] Narasingam, A., Kwon, J.S.-I.: Development of local dynamic mode decomposition with control: Application to model predictive control of hydraulic fracturing. Computers & Chemical Engineering 106, 501–511 (2017)
- Quade et al. [2018] Quade, M., Abel, M., Nathan Kutz, J., Brunton, S.L.: Sparse identification of nonlinear dynamics for rapid model recovery. Chaos: An Interdisciplinary Journal of Nonlinear Science 28(6) (2018)
- Bhadriraju et al. [2021] Bhadriraju, B., Kwon, J.S.-I., Khan, F.: Oasis-p: Operable adaptive sparse identification of systems for fault prognosis of chemical processes. Journal of Process Control 107, 114–126 (2021)
- Kamienny et al. [2022] Kamienny, P.-A., d’Ascoli, S., Lample, G., Charton, F.: End-to-end symbolic regression with transformers. Advances in Neural Information Processing Systems 35, 10269–10281 (2022)
- Vaswani et al. [2017] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- d’Ascoli et al. [2023] d’Ascoli, S., Becker, S., Mathis, A., Schwaller, P., Kilbertus, N.: Odeformer: Symbolic regression of dynamical systems with transformers. arXiv preprint arXiv:2310.05573 (2023)
- Becker et al. [2023] Becker, S., Klein, M., Neitz, A., Parascandolo, G., Kilbertus, N.: Predicting ordinary differential equations with transformers. In: International Conference on Machine Learning, pp. 1978–2002 (2023). PMLR
- Chartrand [2011] Chartrand, R.: Numerical differentiation of noisy, nonsmooth data. International Scholarly Research Notices 2011 (2011)
- Rudy et al. [2017] Rudy, S.H., Brunton, S.L., Proctor, J.L., Kutz, J.N.: Data-driven discovery of partial differential equations. Science advances 3(4), 1602614 (2017)
- Ba et al. [2016] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
- Wangersky [1978] Wangersky, P.J.: Lotka-volterra population models. Annual Review of Ecology and Systematics 9(1), 189–218 (1978)
- Sobol [1967] Sobol, I.: The distribution of points in a cube and the accurate evaluation of integrals (in russian) zh. Vychisl. Mat. i Mater. Phys 7, 784–802 (1967)
- Virtanen et al. [2020] Virtanen, P., Gommers, R., Oliphant, T.E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., et al.: Scipy 1.0: fundamental algorithms for scientific computing in python. Nature methods 17(3), 261–272 (2020)
- de Silva et al. [2020] Silva, B.M., Champion, K., Quade, M., Loiseau, J.-C., Kutz, J.N., Brunton, S.L.: Pysindy: a python package for the sparse identification of nonlinear dynamics from data. arXiv preprint arXiv:2004.08424 (2020)
- Hewamalage et al. [2023] Hewamalage, H., Ackermann, K., Bergmeir, C.: Forecast evaluation for data scientists: common pitfalls and best practices. Data Mining and Knowledge Discovery 37(2), 788–832 (2023)
- Gelß et al. [2019] Gelß, P., Klus, S., Eisert, J., Schütte, C.: Multidimensional approximation of nonlinear dynamical systems. Journal of Computational and Nonlinear Dynamics 14(6), 061006 (2019)
- Kingma and Ba [2014] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- Chicco et al. [2021] Chicco, D., Warrens, M.J., Jurman, G.: The coefficient of determination r-squared is more informative than smape, mae, mape, mse and rmse in regression analysis evaluation. Peerj computer science 7, 623 (2021)
- O’Malley et al. [2019] O’Malley, T., Bursztein, E., Long, J., Chollet, F., Jin, H., Invernizzi, L., et al.: KerasTuner. https://github.com/keras-team/keras-tuner (2019)
- Fasel et al. [2021] Fasel, U., Kaiser, E., Kutz, J.N., Brunton, B.W., Brunton, S.L.: Sindy with control: A tutorial. In: 2021 60th IEEE Conference on Decision and Control (CDC), pp. 16–21 (2021). IEEE
- Proctor et al. [2016] Proctor, J.L., Brunton, S.L., Kutz, J.N.: Dynamic mode decomposition with control. SIAM Journal on Applied Dynamical Systems 15(1), 142–161 (2016)