Adaptive Privacy Composition for Accuracy-first Mechanisms
Abstract
In many practical applications of differential privacy, practitioners seek to provide the best privacy guarantees subject to a target level of accuracy. A recent line of work by [12, 21] has developed such accuracy-first mechanisms by leveraging the idea of noise reduction that adds correlated noise to the sufficient statistic in a private computation and produces a sequence of increasingly accurate answers. A major advantage of noise reduction mechanisms is that the analysts only pay the privacy cost of the least noisy or most accurate answer released. Despite this appealing property in isolation, there has not been a systematic study on how to use them in conjunction with other differentially private mechanisms. A fundamental challenge is that the privacy guarantee for noise reduction mechanisms is (necessarily) formulated as ex-post privacy that bounds the privacy loss as a function of the released outcome. Furthermore, there has yet to be any study on how ex-post private mechanisms compose, which allows us to track the accumulated privacy over several mechanisms. We develop privacy filters [17, 7, 22] that allow an analyst to adaptively switch between differentially private and ex-post private mechanisms subject to an overall differential privacy guarantee.
1 Introduction
Although differential privacy has been recognized by the research community as the de-facto standard to ensure the privacy of a sensitive dataset while still allowing useful insights, it has yet to become widely applied in practice despite its promise to ensure formal privacy guarantees. There are notable applications of differential privacy, including the U.S. Census [1], yet few would argue that differential privacy has become quite standard in practice.
One common objection to differential privacy is that it injects noise and can cause spurious results for data analyses. A recent line of work in differential privacy has focused on developing accuracy-first mechanisms that aim to ensure a target accuracy guarantee while achieving the best privacy guarantee [12, 21]. In particular, these accuracy-first mechanisms do not ensure a predetermined level of privacy, but instead provide ex-post privacy, which allows the resulting privacy loss to depend on the outcome of the mechanism. This is in contrast to the prevalent paradigm of differential privacy that fixes the scale of privacy noise in advance and hopes the result is accurate. With accuracy-first mechanisms, practitioners instead specify the levels of accuracy that would ensure useful data analyses and then aim to achieve such utility with the strongest privacy guarantee.
However, one of the limitations of this line of work is that it is not clear how ex-post privacy mechanisms compose, so if we combine multiple ex-post privacy mechanisms, what is the overall privacy guarantee? Composition is one of the key properties of differential privacy (when used in a privacy-first manner), so it is important to develop a composition theory for ex-post privacy mechanisms. Moreover, how do we analyze the privacy guarantee when we compose ex-post privacy mechanisms with differentially private mechanisms?
Our work seeks to answer these questions by connecting with another line work in differential privacy on fully adaptive privacy composition. Traditional differential privacy composition results would require the analyst to fix privacy loss parameters, which is then inversely proportional to the scale of noise, for each analysis in advance, prior to any interaction. Knowing that there will be noise, the data scientist may want to select different levels of noise for different analyses, subject to some overall privacy budget. Privacy filters and odometers, introduced in [17], provide a way to bound the overall privacy guarantee despite adaptively selected privacy loss parameters. There have since been other works that have improved on the privacy loss bounds in this adaptive setting, to the point of matching (including constants) what one achieves in a nonadaptive setting [7, 22].
A natural next step would then be to allow an analyst some overall privacy loss budget to interact with the dataset and the analyst can then determine the accuracy metric they want to set with each new query. As a motivating example, consider some accuracy metric of % relative error to different counts with some overall privacy loss parameters , so that the entire interaction will be -differentially private. The first true count might be very large, so the amount of noise that needs to be added to ensure the target % relative error can be huge, and hence very little of the privacy budget should be used for that query, allowing for potentially more results to be returned than an approach that sets an a priori noise level.
A baseline approach to add relative noise would be to add a large amount of noise and then check if the noisy count is within some tolerance based on the scale of noise added, then if the noisy count is deemed good enough we stop, otherwise we scale the privacy loss up by some factor and repeat. We refer to this approach as the doubling approach (see Section 7.1 for more details), which was also used in [12]. The primary issue with this approach is that the accumulated privacy loss needs to combine the privacy loss each time we add noise, even though we are only interested in the outcome when we stopped. Noise reduction mechanisms from [12, 21] show how it is possible to only pay for the privacy of the last noise addition. However, it is not clear how the privacy loss will accumulate over several noise reduction mechanisms, since each one ensures ex-post privacy, not differential privacy.
We make the following contributions in this work:
-
•
We present a general (basic) composition result for ex-post privacy mechanisms that can be used to create a privacy filter when an analyst can select arbitrary ex-post privacy mechanisms and (concentrated) differentially private mechanisms.
-
•
We develop a unified privacy filter that combines noise reduction mechanisms — specifically the Brownian Mechanism [21] — with traditional (concentrated) differentially private mechanisms.
-
•
We apply our results to the task of releasing counts from a dataset subject to a relative error bound comparing the unified privacy filter and the baseline doubling approach, which uses the privacy filters from [22].
Our main technical contribution is in the unified privacy filter for noise reduction mechanisms and differentially private mechanisms. Prior work [21] showed that the privacy loss of the Brownian noise reduction can be written in terms of a scaled Brownian motion at the time where the noise reduction was stopped. We present a new analysis for the ex-post privacy guarantee of the Brownian mechanism that considers a reverse time martingale, based on a scaled standard Brownian motion. Composition bounds for differential privacy consider a forward time martingale and apply a concentration bound, such as Azuma’s inequality [6], so we show how we can construct a forward time martingale from the stopped Brownian motions, despite the stopping times being adaptive, not predictable, at each time. See Figure 1 for a sketch of how we combine reverse time martingales into an overall forward time filtration.
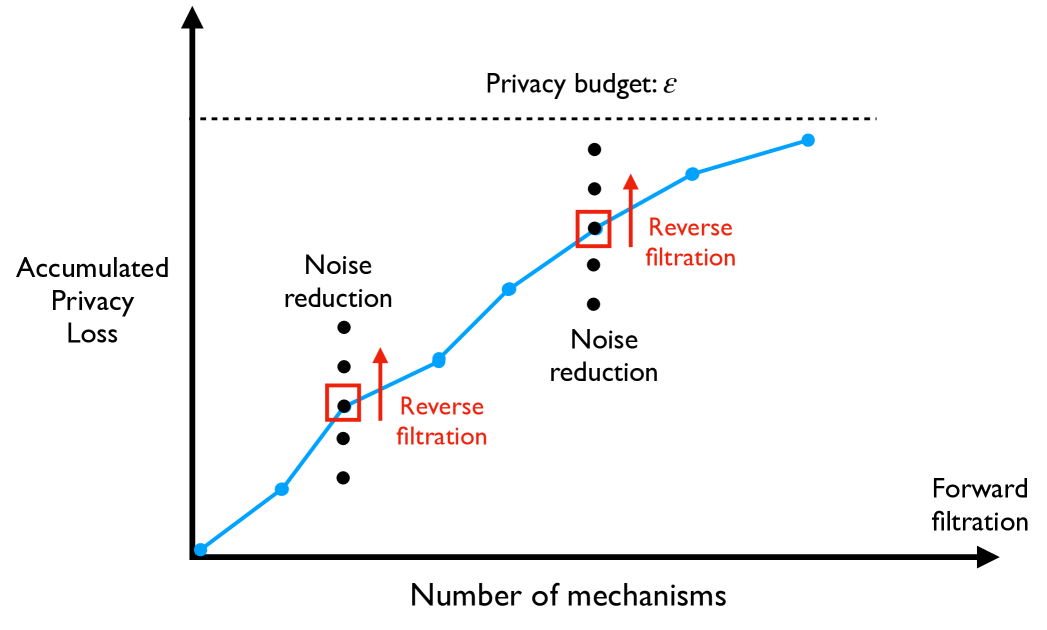
As a running example, we consider the problem of releasing as many counts as possible subject to the constraint that each noisy count should have no more than a target relative error and that some overall privacy loss budget is preserved. A recent application of differential privacy for releasing Wikipedia usage data111https://www.tmlt.io/resources/publishing-wikipedia-usage-data-with-strong-privacy-guarantees considered relative accuracy as a top utility metric, demonstrating the importance of returning private counts subject to relative accuracy constraints. There have been other works that have considered adding relative noise subject to differential privacy. In particular, iReduct [23] was developed to release a batch of queries subject to a relative error bound. The primary difference between that work and our setting here is that we do not want to fix the number of queries in advance and we want to allow the queries to be selected in an adaptive way. Xiao et al. [23] consider a batch of queries and initially adds a lot of noise to each count and iteratively checks whether the noisy counts are good enough. The counts that should have smaller noise are then identified and a Laplace based noise reduction algorithm is used to decrease the noise on the identified set. They continue in this way until either all counts are good enough or a target privacy loss is exhausted. There are two scenarios that might arise: (1) all counts satisfy the relative error condition and we should have tried more counts because some privacy loss budget remains, (2) the procedure stopped before some results had a target relative error, so we should have selected fewer queries. In either case, selecting the number of queries becomes a parameter that the data analyst would need to select in advance, which would be difficult to do a priori. In our setting, no such parameter arises. Furthermore, they add up the privacy loss parameters for each count to see if it is below a target privacy loss bound at each step (based on the -general sensitivity), however we show that adding up the privacy loss parameters can be significantly improved on. Other works have modified the definition of differential privacy to accommodate relative error, e.g. [20].
2 Preliminaries
We start with some basic definitions from differential privacy, beginning with the standard definition from Dwork et al. [5, 4]. We first need to define what we mean by neighboring datasets, which can mean adding or removing one record to a dataset or changing an entry in a dataset. We will leave the neighboring relation arbitrary, and write to be neighbors as .
Definition 2.1.
An algorithm is -differentially private if, for any measurable set and any neighboring inputs ,
| (1) |
If , we say is -DP or simply pure DP.
The classical pure DP mechanism is the Laplace mechanism, which adds noise to a statistic following a Laplace distribution.
Definition 2.2 (Laplace Mechanism).
Given a statistic , the Laplace Mechanism with privacy parameter returns .
In order to ensure enough noise is added to a statistic to ensure privacy, it is important to know the statistic’s sensitivity which we define as the following where the max is over all possible neighboring datasets
Lemma 2.1 (Dwork et al. [5]).
Given , the Laplace mechanism with privacy parameter is -DP.
A central actor in our analysis will be the privacy loss of an algorithm, which will be a random variable that depends on the outcomes of the algorithm under a particular dataset.
Definition 2.3 (Privacy Loss).
Let be an algorithm and fix neighbors in . Let and be the respective densities of and on the space with respect to some reference measure. Then, the privacy loss between and evaluated at point is:
Further, we refer to the privacy loss random variable to be . When the algorithm and the neighboring datasets are clear from context, we drop them from the privacy loss, i.e. and .
2.1 Zero-concentrated DP
Many existing privacy composition analyses leverage a variant of DP called (approximate) zero-concentrated DP (zCDP), introduced by Bun and Steinke [2]. Recall that the Rényi Divergence of order between two distributions and on the same domain is written as the following where and are the respective probability mass/density functions,
Since we study fully adaptive privacy composition (where privacy parameters can be chosen adaptively), we will use the following conditional extension of approximate zCDP, in which the zCDP parameters of a mechanism can depend on prior outcomes.
Definition 2.4 (Approximate zCDP [22]).
Suppose with outputs in a measurable space . Suppose . We say the algorithm satisfies conditional -approximate -zCDP if, for all and any neighboring datasets , there exist probability transition kernels such that the conditional outputs are distributed according to the following mixture distributions:
where for all , and , .
The classical mechanism for zCDP is the Gaussian mechanism, similar to how the Laplace mechanism is the typical mechanism for pure DP.
Definition 2.5 (Gaussian Mechanism).
Given a statistic , the Gaussian Mechanism with privacy parameter returns .
We then have the following result, which ensures privacy that scales with the sensitivity of statistic .
Lemma 2.2 (Bun and Steinke [2]).
Given , the Gaussian mechanism with privacy parameter is -zCDP.
The following results establish the relationship between zCDP and DP and the composition of zCDP.
Lemma 2.3 (Bun and Steinke [2]).
If is -DP, then is also -approximate -zCDP. If is -approximate -zCDP, then is also -DP for .
Lemma 2.4 (Bun and Steinke [2]).
If is -approximate -zCDP and is -approximate -zCDP in its first coordinate, then where is -approximate -zCDP.
2.2 Concurrent composition
We will use concurrent composition for differential privacy, introduced by [18] and with subsequent work in [13, 19], in our analysis, which we define next. We first define an interactive system.
Definition 2.6.
An interactive system is a randomized algorithm with input an interactive history with a query . The output of is denoted .
Note that an interactive system may also consist of an input dataset that the queries are evaluated on, which will then induce an interactive system. In particular, we will consider two neighboring datasets and , which will then induce interactive systems corresponding to input data for and . We will use the concurrent composition definition from [13].
Definition 2.7 (Concurrent Composition).
Suppose are interactive systems. The concurrent composition of them is an interactive system with query domain and response domain . An adversary is a (possibly randomized) query algorithm . The interaction between and is a stochastic process that runs as follows. first computes a pair , sends a query to and gets the response . In the -th step, calculates the next pair based on the history, sends the -th query to and receives . There is no communication or interaction between the interactive systems. Each system can only see its own interaction with . Let denote the random variable recording the transcript of the interaction.
We will be interested in how much the distribution of the transcript of interaction changes for interactive systems with neighboring inputs. We will say is -DP if for all neighboring datasets , we have for any outcome set of transcripts , we have for
We then have the following result from [13].
Theorem 1.
This result is very powerful because we can consider the privacy of each interactive system separately and still be able to provide a differential privacy guarantee for the more complex setting that allows an analyst to interweave queries to different interactive systems.
3 Privacy Filters
In order for us to reason about the overall privacy loss of an interaction with a sensitive dataset, we will use the framework of privacy filters, introduced in [17]. Privacy filters allow an analyst to adaptively select privacy parameters as a function of previous outcomes until some stopping time that determines whether a target privacy budget has been exhausted. To denote that privacy parameters may depend on previous outcomes, we will write to mean the privacy parameter selected at round that could depend on the previous outcomes , and similarly for . We now state the definition of privacy filters in the context of approximate zCDP mechanisms.
Definition 3.1 (Privacy Filter).
Let be an adaptive sequence of algorithms such that, for all , is -approximate -zCDP for all . Let and be fixed privacy parameters. Then, a function is an -privacy filter if
-
1.
for all , is a stopping time with respect to the natural filtration generated by , and
-
2.
the algorithm is -differentially private where .
Whitehouse et al. [22] showed that we can use composition bounds from traditional differential privacy (which required setting privacy parameters for the interaction prior to any interaction) in the more adaptive setting, where privacy parameters can be set before each query.
Theorem 2.
Suppose is a sequence of algorithms such that, for any , is -approximate -zCDP for all . Let and , be fixed privacy parameters. Consider the function given by
Then, the algorithm is -DP, where . In other words, is an -privacy filter.
4 Ex-post Private Mechanisms
Although privacy filters allow a lot of flexibility to a data analyst in how they interact with a sensitive dataset while still guaranteeing a fixed privacy budget, there are some algorithms that ensure a bound on privacy that is adapted to the dataset. Ex-post private mechanisms define privacy loss as a probabilistic bound which can depend on the algorithm’s outcomes, so some outcomes might contain more information about an individual than others [12, 21]. Note that ex-post private mechanisms do not have any fixed a priori bound on the privacy loss, so by default they cannot be composed in a similar way to differentially private mechanisms.
Definition 4.1.
Let be an algorithm and a function. We say is -ex-post private for all if, for any neighboring inputs , we have for all .
We next define a single noise reduction mechanism, which will interactively apply sub-mechanisms and stop at some time , which can be random. Each iterate will use a privacy parameter from an increasing sequence of privacy parameters and the overall privacy will only depend on the last privacy parameter , despite releasing noisy values with parameters for . Noise reduction algorithms will allow us to form ex-post private mechanisms because the privacy loss will only depend on the final outcome. We will write to be any algorithm mapping databases to sequences of outputs in , with intermediate mechanisms written as for the -th element of the sequence and for the first elements. Let be a probability measure on , for each let be a probability measure on , and let be a probability measure on . We assume that the law of on is equivalent to , the law of on is equivalent to , and the law of on is equivalent to for every and every . Furthermore, we will write to be the privacy loss of , be the privacy loss of , and to be the privacy loss of the sequence of mechanisms . We then define noise reduction mechanisms more formally.
Definition 4.2 (Noise Reduction Mechanism).
Let be a mechanism mapping sequences of outcomes and be any neighboring datasets. We say is a noise reduction mechanism if for any ,
We will assume there is a fixed grid of time values . We will typically think of the time values as being inversely proportional to the noise we add, i.e. where . An analyst will not have a particular stopping time set in advance and will instead want to stop interacting with the dataset as a function of the noisy answers that have been released. It might also be the case that the analyst wants to stop based on the outcome and the privatized dataset, but for now we consider stopping times that can only depend on the noisy outcomes or possibly some public information, not the underlying dataset.
Definition 4.3 (Stopping Function).
Let be a noise reduction mechanism. For , let be the filtration given by . A function is called a stopping function if for any , is a stopping time with respect to . Note that this property does not depend on the choice of measures , and .
We now recall the noise reduction mechanism with Brownian noise [21].
Definition 4.4 (Brownian Noise Reduction).
Let be a function and be a sequence of time values. Let be a standard -dimensional Brownian motion and be a stopping function. The Brownian mechanism associated with , time values , and stopping function is the algorithm given by
We then have the following result.
Lemma 4.1 (Whitehouse et al. [21]).
The Brownian Noise Reduction mechanism BM is a noise reduction algorithm for a constant stopping function . Furthermore, we have for any stopping function , the noise reduction property still holds, i.e.
5 General Composition of Ex-post Private Mechanisms
We start with a simple result that states that ex-post mechanisms compose by just adding up the ex-post privacy functions. We will write and . Further, we will denote as the privacy loss bound for algorithm conditioned on the outcomes of .
Lemma 5.1.
Fix a sequence . Let there be a probability measure on for each and the product measure on . Consider mechanisms for where each is -ex-post private for all prior outcomes . Then the overall mechanism is -ex-post private with respect to the product measure.
Proof.
We consider neighboring inputs and write the privacy loss random variable for in terms of the privacy losses of each for
Because each mechanism is -ex post private, we have and hence
Hence, we have , as desired. ∎
For general ex-post private mechanisms, this basic composition cannot be improved. We can simply pick to be the same as the privacy loss at each round with independently selected mechanisms at each round . We now show how we can obtain a privacy filter from a sequence of ex-post mechanisms as long as each selected ex-post privacy mechanism selected at each round cannot exceed the remaining privacy budget. We will write to denote the parameter selected as a function of prior outcomes from .
Lemma 5.2.
Let and be fixed privacy parameters. Let be a sequence of -ex-post private conditioned on prior outcomes where for all we have
Consider the function where
Then the algorithm is -DP where
Proof.
We follow a similar analysis in [22] where they created a filter for probabilistic DP mechanisms, that is the privacy loss of each mechanism can be bounded with high probability. We will write the corresponding privacy loss variables of to be and for the full sequence of algorithms , the privacy loss is denoted as .
Define the events
Using Bayes rule, we have that
where the last inequality follows from how we defined the stopping function . Now, we show that . Define the modified privacy loss random variables by
Likewise, define the modified privacy parameter random variables and in an identical manner. Then, we can bound in the following manner:
∎
Remark 1.
With ex-post privacy, we are not trying to ensure differential privacy of each intermediate outcome. Recall that DP is closed under post-processing, so that any post processing function of a DP outcome is also DP with the same parameter. Our privacy analysis depends on getting actual outcomes from an ex-post private mechanism, rather than a post-processed value of it. However, the full transcript of ex-post private mechanisms will ensure DP due to setting a privacy budget.
We now consider combining zCDP mechanisms with mechanisms that satisfy ex-post privacy. We consider a sequence of mechanisms where each mechanism may depend on the previous outcomes. At each round, an analyst will use either an ex-post private mechanism or an approximate zCDP mechanism, in either case the privacy parameters may depend on the previous results as well.
Definition 5.1 (Approximate zCDP and Ex-post Private Sequence).
Consider a sequence of mechanisms , where . The sequence is called a sequence of approximate zCDP and ex-post private mechanisms if for each round , the analyst will select to be -approximate -zCDP given previous outcomes for , or the analyst will select to be -ex-post private conditioned on for . In rounds where zCDP is selected, we will simply write , while in rounds where an ex-post private mechanism is selected, we will set .
We now state a composition result that allows an analyst to combine ex-post private and zCDP mechanisms adaptively, while still ensuring a target level of privacy. Because we have two different interactive systems that are differentially private, one that uses only zCDP mechanisms and the other that only uses ex-post private mechanisms, we can then use concurrent composition to allow for the interaction for the sequence described in Definition 5.1.
Theorem 3.
Let . Let be a sequence of approximate zCDP and ex-post private mechanisms. As we did in Lemma 5.2, we will require that the ex-post private mechanisms that are selected at each round have ex-post privacy functions that do not exceed the remaining budget from . Consider the following function as the following for any sequence of outcomes
where is the stopping rule given in Theorem 2 with privacy parameters and is the stopping rule given in Lemma 5.2 with privacy parameters . Then, the algorithm is -DP, where
Proof.
We will separate out the approximate zCDP mechanisms, from the ex-post private mechanisms to form two separate interactive systems. In this case, the parameters that are selected can only depend on the outcomes from the respective interactive system, e.g. can only depend on prior outcomes to mechanisms for . From Theorem 2, we know that is -DP. We denote to be the privacy loss random variable for the ex-post private mechanism at round . We will also write the stopping time for the ex-post private mechanisms as . From Lemma 5.2, we know that is -DP.
From Theorem 1, we know that the concurrent composition, which allows for both and to interact arbitrarily, will still be -DP. ∎
Although we are able to leverage advanced composition bounds from traditional differential privacy for the mechanisms that are approximate zCDP, we are simply adding up the ex-post privacy guarantees, which seems wasteful. Next, we consider how we can improve on this composition bound for certain ex-post private mechanisms.
6 Brownian Noise Reduction Mechanisms
We now consider composing specific types of ex-post private mechanisms, specifically the Brownian Noise Reduction mechanism. From Theorem 3.4 in [21], we can decompose the privacy loss as an uncentered Brownian motion, even when the stopping time is adaptively selected.
Theorem 4 (Whitehouse et al. [21]).
Let BM be the Brownian noise reduction mechanism associated with time values and a function . All reference measures generated by the mechanism are those generated by the Brownian motion without shift (starting at ). For neighbors and stopping function , the privacy loss between and is given by
Suppose has -sensitivity at most . Then, letting , we have the following where is a standard, univariate Brownian motion.
This decomposition of the privacy loss will be very useful in analyzing the overall privacy loss of a combination of Brownian noise reduction mechanisms.
6.1 Backward Brownian Motion Martingale
We now present a key result for our analysis of composing Brownian noise reduction mechanisms. Although in [21], the ex-post privacy proof of the Brownian mechanism applied Ville’s inequality [for proof, cf. 8, Lemma 1] to the (unscaled) standard Brownian motion , it turns out that the scaled standard Brownian motion forms a backward martingale [cf. 16, Exercise 2.16] and this fact is crucial to our analysis.
Lemma 6.1 (Backward martingale).
Let be a standard Brownian motion. Define the reverse filtration , meaning that if . For every real , the process
is a nonnegative (reverse) martingale with respect to the filtration . Further, at any , , almost surely, and for any stopping time with respect to (equality holds with some restrictions). In short, is an “e-value” for any stopping time — an e-value is a nonnegative random variable with expectation at most one.
Let be independent, standard Brownian motions, with corresponding backward martingales and (internal to each Brownian motion) filtrations as defined in the previous lemma. Select time values . Let a Brownian noise reduction mechanism be run using and stopped at . Then as per the previous lemma. Based on outputs from the , we choose time values . Now run the second Brownian noise reduction using , stopping at time . Since are independent, we still have that . Let be the updated filtration, based on which we choose time values . Because is independent of the earlier two, at the next step, we still have . Proceeding in this fashion, it is clear that the product of the stopped e-values where
| (2) |
is itself a (forward) nonnegative supermartingale with respect to the filtration , with initial value . Applying the Gaussian mixture method [cf. 9, Proposition 5], we get that for any and with ,
This then provides an alternate way to prove Theorem 3.6 in Whitehouse et al. [21].
Theorem 5.
Let be a sequence of stopping functions, as in Definition 4.3, and a sequence of time values . Let denote a Brownian noise reduction with statistic that can be adaptively selected based on outcomes of previous Brownian noise reductions and has -sensitivity 1. We then have, for any ,
In other words, is -ex post private.
Remark 2.
We note here that the stopping time of each Brownian noise reduction is with respect to where . From the point of view of the analyst, is random (being fixed, but unknown, is the same as being a realization from some random mechanism). In fact, extends with , which would reveal but the analyst only has access to for which she pays.
Remark 3.
For the multivariate case we have where each coordinate is an independent Brownian motion, and we will write the filtration to be the natural reverse filtration corresponding to the Brownian motion for index . We then define . From Lemma 6.1, we have the following for all , , and
We then consider the full -dimensional Brownian motion so that with a unit vector we have
6.2 Privacy Filters with Brownian Noise Reduction Mechanisms
Given Lemma 6.1 and the decomposition of the privacy loss for the Brownian mechanism given in Theorem 4, we will be able to get tighter composition bounds of multiple Brownian noise reduction mechanisms rather than resorting to a general ex-post privacy composition in Lemma 5.2. It will be important to only use time values with the Brownian noise reduction mechanisms that cannot exceed the remaining privacy loss budget, similar to how in Lemma 5.2 we did not want to select an ex-post private mechanism whose privacy loss could exceed the remaining privacy budget. We then make the following condition on the time values that are used for each Brownian noise reduction given prior outcomes from the earlier Brownian noise reductions with time values and stopping functions for and overall budget
| (3) |
Lemma 6.2.
Let and consider a sequence of each with statistic with sensitivity , stopping function , and time values which can be adaptively selected and satisfies (3). Consider the function where contains all possible outcome streams from as the following for any sequence of outcomes :
Then, for , is -DP, where
Proof.
We use the decomposition of the privacy loss at round for Brownian noise reduction in Theorem 4 that is stopped at time value to get the following with the natural filtration generated by . Recall that we have for the Brownian motion used in the Brownian noise reduction
From Lemma 6.1 we have for all and with time value
We then form the following process,
Hence, with fixed time values for we have for all
We then replace with an adaptive stopping time functions , rather than fixing them in advance, in which case we rename as . We know from Lemma 6.1 that is still an e-value for any . We then apply the optional stopping theorem to conclude that with the stopping time that . By the definition of our stopping time, so that , we have for all
We then set to get
We then have a high probability bound on the overall privacy loss, which then implies differential privacy. ∎
One approach to defining a privacy filter for both approximate zCDP and Brownian noise reduction mechanisms would be to use concurrent composition, as we did in Lemma 5.2. However, this would require us to set separate privacy budgets for approximate zCDP mechanisms and Brownian noise reduction, which is an extra (nuissance) parameter to set.
We now show how we can combine Brownian noise reduction and approximate zCDP mechanisms with a single privacy budget. We will need a similar condition on the time values selected at each round for the Brownian noise reduction mechanisms as in (3). Note that at each round either an approximate zCDP or Brownian noise reduction mechanism will be selected. Given prior outcomes and previously selected zCDP parameters — noting that at round where BM is selected we have or if a zCDP mechanism is selected we simply set and — we have the following condition on and the time values if we select a BM at round and have overall budget ,
| (4) |
Theorem 6.
Let and . Let be a sequence of approximate zCDP and ex-post private mechanisms where each ex-post private mechanism at round is a Brownian Mechanism with an adaptively chosen stopping function , a statistic with -sensitivity equal to 1, and time values that satisfy the condition in (4). Consider the function as the following for any sequence of outcomes :
Then for , the algorithm is -DP, where the stopping function is
Proof.
We will show that is -approximate -zCDP and then use Lemma 2.3 to obtain a DP guarantee stopping at as defined in the theorem statement.
We follow a similar analysis to the proof of Theorem 1 in [22]. Let and denote the joint distributions of with inputs and , respectively. We overload notation and write and for the likelihood of under input and respectively. We similarly write and for the corresponding conditional densities.
For any we have
When then show that the two likelihoods can be decomposed as weighted mixtures of and , as well as and , respectively such that the mixture weights on and are at least , and for all ,
| (5) |
By our assumption of approximate zCDP at each step , we can write the conditional likelihoods of and as the following convex combinations:
such that for all and all prior outcomes , we have both
| (6) | |||
| (7) |
Note that at each round, we either select an approximate zCDP mechanism or select a Brownian noise reduction, and in the latter case and , which then means and at those rounds . We will write the distribution for any prefix of outcomes from and similarly we will write the distribution for the prefix of outcomes from . We can then write these likelihood as a convex combination of likelihoods, using the fact that for all .
| (8) | ||||
| (9) |
For any fixed and , consider the following filtration where , with , .
We will first consider the Brownian noise reduction mechanisms with time values to be stopped at fixed rounds , although not every round will have a Brownian noise reduction mechanism selected with Brownian motion . We will write out the privacy loss for the Brownian noise reduction mechanisms stopped at rounds as where from Theorem 4 we have,
We will add the noise reduction outcomes to the filtration, so that . From Lemma 6.1, we know for all
We then replace with an adaptive stopping time functions with corresponding stopping times , rather than fixing them in advance, in which case we rename as and the same inequality still holds with the filtration . Note that we will call so that .
At rounds where a Brownian noise reduction mechanism is not selected, we simply have and . We also consider the modified privacy losses for the approximate zCDP mechanisms where
Due to mechanisms being zCDP, we then have for any
Because at each round , the mechanism selected is either approximate zCDP or a Brownian noise reduction with a stopping function, we can write the privacy loss at each round as the sum so that for all we have
| (10) | ||||
| (11) |
We know that is a supermartingale with respect to . From the optional stopping theorem, we have
This will ensure (5) holds. Although for rounds where we select a Brownian noise reduction we have and , we still need to show that for rounds where approximate zCDP mechanisms were selected the original distributions and can be written as weighted mixtures including and , respectively. This follows from the same analysis as in [22], so that for all outcomes where we have
and similarly for . As is argued in [22], it suffices to show that the two likelihoods of the stopped process and can be decomposed as weighted mixtures of and as well as and , respectively such that the weights on and are at least . Note that from our stopping rule, we haven for all
We then still need to convert to DP, which we do with the stopping rule and the conversion lemma between approximate zCDP and DP in Lemma 2.3. ∎
7 Application: Bounding Relative Error
Our motivating application will be returning as many counts as possible subject to each count being within relative error, i.e. if is the true count and is the noisy count, we require . It is common for practitioners to be able to tolerate some relative error to some statistics and would like to not be shown counts that are outside a certain accuracy. Typically, DP requires adding a predetermined standard deviation to counts, but it would be advantageous to be able to add large noise to large counts so that more counts could be returned subject to an overall privacy budget.
7.1 Doubling Method
A simple baseline approach would be to use the “doubling method”, as presented in [12]. This approach uses differentially private mechanisms and checks whether each outcome satisfies some condition, in which case you stop, or the analyst continues with a larger privacy loss parameter. The downside of this approach is that the analyst needs to pay for the accrued privacy loss of all the rejected values. However, handling composition in this case turns out to be straightforward given Theorem 2, due to [22]. We then compare the ‘doubling method” against using Brownian noise reduction and applying Theorem 6.
We now present the doubling method formally. We take privacy loss parameters , where . Similar to the argument in Claim B.1 in [12], we use the factor because the privacy loss will depend on the sum of square of privacy loss parameters, i.e. up to some iterate , in Theorem 2 as is the zCDP parameter. This means that if is the privacy loss parameter that the algorithm would have halted at, then we might overshoot it by . Further, the overall sum of square privacy losses will be no more than . Hence, we refer to the doubling method as doubling the square of the privacy loss parameter.
7.2 Experiments
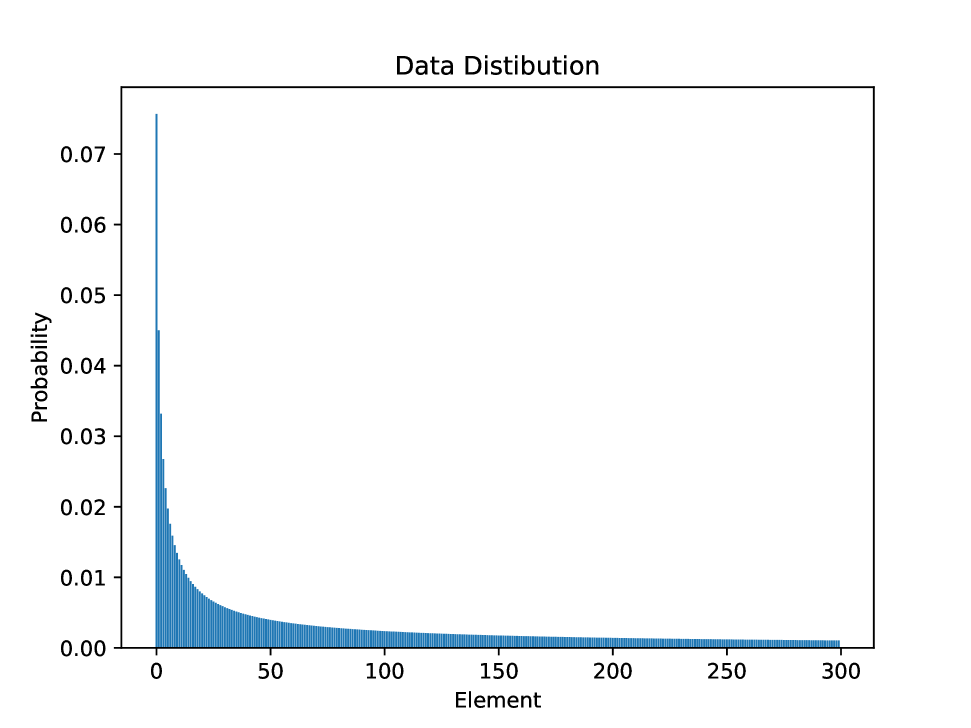
We perform experiments to return as many results subject to a relative error tolerance and a privacy budget . We will generate synthetic data from a Zipf distribution, i.e. from a density for and . We will set a max value of the distribution to be and . We will assume that a user can modify each count by at most 1, so that the -sensitivity is 300 and -sensitivity is 1. See Figure 2 for the data distribution we used.
In our experiments, we will want to first find the top count and then try to add the least amount of noise to it, while still achieving the target relative error, which we set to be . To find the top count, we apply the Exponential Mechanism [14] by adding Gumbel noise with scale to each sensitivity 1 count (all 300 elements’ counts, even if they are zero in the data) and take the element with the top noisy count. From [3], we know that the Exponential Mechanism with parameter is -zCDP, which we will use in our composition bounds. For the Exponential Mechanism, we select a fixed parameter .
After we have selected a top element via the Exponential Mechanism, we then need to add some noise to it in order to return its count. Whether we use the doubling method and apply Theorem 2 for composition or the Brownian noise reduction mechanism and apply Theorem 6 for composition, we need a stopping condition. Note that we cannot use the true count to determine when to stop, but we can use the noisy count and the privacy loss parameter that was used. Hence we use the following condition based on the noisy count and the corresponding privacy loss parameter at iterate :
Note that for Brownian noise reduction mechanism at round , we use time values . We also set an overall privacy budget of . To determine when to stop, we will simply consider the sum of squared privacy parameters and stop if it is more than roughly 2.705, which corresponds to the overall privacy budget of with . If the noisy value from the largest privacy loss parameter does not satisfy the condition above, we discard the result.
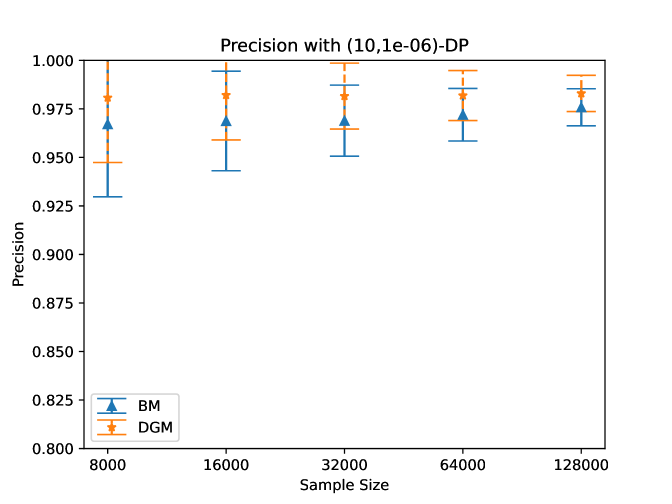
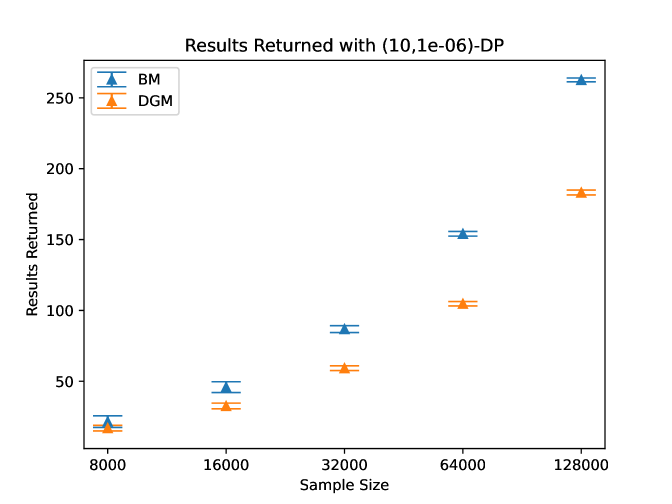
We pick the smallest privacy parameter squared to be for each in both the noise reduction and the doubling method and the largest value will change as we update the remaining sum of square privacy loss terms that have been used. We then set 1000 equally spaced parameters in noise reduction to select between and the largest value for the square of the privacy loss parameter. We then vary the sample size of the data in and see how many results are returned and of those returned, how many satisfy the actual relative error, which we refer to as precision. Note that if 0 results are returned, then we consider the precision to be 1. Our results are given in Figure 3 where we give the empirical average and standard deviation over 1000 trials for each sample size.
We also evaluated our approach on real data from Reddit comments from https://github.com/heyyjudes/differentially-private-set-union/tree/ea7b39285dace35cc9e9029692802759f3e1c8e8/data. This data consists of comments from Reddit authors. To find the most frequent words from distinct authors, we take the set of all distinct words contributed by each author, which can be arbitrarily large and form the resulting histogram which has -sensitivity 1 yet unbounded -sensitivity. To get a domain of words to select from, we take the top-1000 words from this histogram. We note that this step should also be done with DP, but will not impact the relative performance between using the Brownian noise reduction and the Doubling Gaussian Method.
We then follow the same approach as on the synthetic data, using the Exponential Mechanism with , minimum privacy parameter , relative error , and overall -DP guarantee. In 1000 trials, the Brownian noise reduction precision (proportion of results that had noisy counts within 1% of the true count) was on average 97% (with minimum 92%) while the Doubling Gaussian Method precision was on average 98% (with minimum 93.5%). Furthermore, the number of results returned by the Brownian noise reduction in 1000 trials was on average 152 (with minimum 151), while the number of results returned by the Doubling Gaussian method was on average 109 (with minimum 108).
8 Conclusion
We have presented a way to combine approximate zCDP mechanisms and ex-post private mechanisms while achieving an overall differential privacy guarantee, allowing for more general and flexible types of interactions between an analyst and a sensitive dataset. Furthermore, we showed how this type of composition can be used to provide overall privacy guarantees subject to outcomes satisfying strict accuracy requirements, like relative error. We hope that that this will help extend the practicality of private data analysis by allowing the release of counts with relative error bounds subject to an overall privacy bound.
There are several open questions with this line of work. In particular, we leave open the problem of showing ex-post privacy composition that improves over basic composition for certain mechanisms. Although we only studied the Brownian noise reduction, we conjecture that Laplace noise reduction mechanisms [11] compose in a similar way, achieving privacy loss that depends on a sum of squared realized privacy loss parameters. Furthermore, we leave open the problem of improving computational run time of the noise reduction mechanisms. In particular, if we are only interested in the last iterate of the Brownian noise reduction with a particular stopping function, can we simply sample from a distribution in one-shot to arrive at that value, rather than iteratively checking lots of intermediate noisy values, which seems wasteful. Lastly, we hope that this will lead to future work in designing new ex-post private mechanisms based on some of the primitives of differential privacy, specifically the Exponential Mechanism.
9 Acknowledgements
We would like to thank Adrian Rivera Cardoso and Saikrishna Badrinarayanan for helpful comments. This work was done while G.S. was a visiting scholar at LinkedIn. ZSW was supported in part by the NSF awards 2120667 and 2232693 and a Cisco Research Grant. AR was supported by NSF DMS-2310718.
References
- Abowd et al. [2022] J. M. Abowd, R. Ashmead, R. Cumings-Menon, S. Garfinkel, M. Heineck, C. Heiss, R. Johns, D. Kifer, P. Leclerc, A. Machanavajjhala, B. Moran, W. Sexton, M. Spence, and P. Zhuravlev. The 2020 census disclosure avoidance system topdown algorithm, 2022. arXiv: 2204.08986.
- Bun and Steinke [2016] M. Bun and T. Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography, pages 635–658. Springer Berlin Heidelberg, 2016. ISBN 978-3-662-53641-4. URL https://link.springer.com/chapter/10.1007/978-3-662-53641-4_24.
- Cesar and Rogers [2021] M. Cesar and R. Rogers. Bounding, concentrating, and truncating: Unifying privacy loss composition for data analytics. In Proceedings of the 32nd International Conference on Algorithmic Learning Theory, volume 132 of Proceedings of Machine Learning Research, pages 421–457. PMLR, 16–19 Mar 2021. URL https://proceedings.mlr.press/v132/cesar21a.html.
- Dwork et al. [2006a] C. Dwork, K. Kenthapadi, F. McSherry, I. Mironov, and M. Naor. Our data, ourselves: Privacy via distributed noise generation. In Advances in Cryptology - EUROCRYPT 2006, pages 486–503. Springer Berlin Heidelberg, 2006a. ISBN 978-3-540-34547-3. URL https://www.iacr.org/archive/eurocrypt2006/40040493/40040493.pdf.
- Dwork et al. [2006b] C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Third Conference on Theory of Cryptography, TCC’06, page 265–284. Springer-Verlag, 2006b. ISBN 3540327312. doi: 10.1007/11681878˙14. URL https://doi.org/10.1007/11681878_14.
- Dwork et al. [2010] C. Dwork, G. N. Rothblum, and S. P. Vadhan. Boosting and differential privacy. In 51st Annual Symposium on Foundations of Computer Science, pages 51–60, 2010.
- Feldman and Zrnic [2021] V. Feldman and T. Zrnic. Individual privacy accounting via a rényi filter. In Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=PBctz6_47ug.
- Howard et al. [2020] S. R. Howard, A. Ramdas, J. McAuliffe, and J. Sekhon. Time-uniform Chernoff bounds via nonnegative supermartingales. Probability Surveys, 17:257 – 317, 2020.
- Howard et al. [2021] S. R. Howard, A. Ramdas, J. McAuliffe, and J. Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences. The Annals of Statistics, 49(2):1055 – 1080, 2021.
- Kairouz et al. [2017] P. Kairouz, S. Oh, and P. Viswanath. The composition theorem for differential privacy. IEEE Transactions on Information Theory, 63(6):4037–4049, 2017. doi: 10.1109/TIT.2017.2685505. URL https://doi.org/10.1109/TIT.2017.2685505.
- Koufogiannis et al. [2017] F. Koufogiannis, S. Han, and G. J. Pappas. Gradual release of sensitive data under differential privacy. Journal of Privacy and Confidentiality, 7(2), 2017.
- Ligett et al. [2017] K. Ligett, S. Neel, A. Roth, B. Waggoner, and S. Z. Wu. Accuracy first: Selecting a differential privacy level for accuracy constrained erm. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf.
- Lyu [2022] X. Lyu. Composition theorems for interactive differential privacy. In Advances in Neural Information Processing Systems, volume 35, pages 9700–9712. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/3f52b555967a95ee850fcecbd29ee52d-Paper-Conference.pdf.
- McSherry and Talwar [2007] F. McSherry and K. Talwar. Mechanism design via differential privacy. In 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), pages 94–103, 2007. doi: 10.1109/FOCS.2007.66. URL http://dx.doi.org/10.1109/FOCS.2007.66.
- Murtagh and Vadhan [2016] J. Murtagh and S. Vadhan. The complexity of computing the optimal composition of differential privacy. In Proceedings, Part I, of the 13th International Conference on Theory of Cryptography - Volume 9562, TCC 2016-A, pages 157–175. Springer-Verlag, 2016. ISBN 978-3-662-49095-2. doi: 10.1007/978-3-662-49096-9˙7. URL https://doi.org/10.1007/978-3-662-49096-9_7.
- Revuz and Yor [2013] D. Revuz and M. Yor. Continuous martingales and Brownian motion, volume 293. Springer Science & Business Media, 2013.
- Rogers et al. [2016] R. M. Rogers, A. Roth, J. Ullman, and S. P. Vadhan. Privacy odometers and filters: Pay-as-you-go composition. In Advances in Neural Information Processing Systems 29, pages 1921–1929, 2016. URL http://papers.nips.cc/paper/6170-privacy-odometers-and-filters-pay-as-you-go-composition.
- Vadhan and Wang [2021] S. Vadhan and T. Wang. Concurrent composition of differential privacy. In Theory of Cryptography, pages 582–604. Springer International Publishing, 2021. ISBN 978-3-030-90453-1.
- Vadhan and Zhang [2023] S. Vadhan and W. Zhang. Concurrent composition theorems for differential privacy. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, STOC ’23. ACM, June 2023. doi: 10.1145/3564246.3585241. URL http://dx.doi.org/10.1145/3564246.3585241.
- Wang et al. [2022] H. Wang, X. Peng, Y. Xiao, Z. Xu, and X. Chen. Differentially private data aggregating with relative error constraint, 2022. URL https://doi.org/10.1007/s40747-021-00550-3.
- Whitehouse et al. [2022] J. Whitehouse, A. Ramdas, S. Wu, and R. Rogers. Brownian noise reduction: Maximizing privacy subject to accuracy constraints. In Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=J-IZQLQZdYu.
- Whitehouse et al. [2023] J. Whitehouse, A. Ramdas, R. Rogers, and Z. S. Wu. Fully adaptive composition in differential privacy. In International Conference on Machine Learning. PMLR, 2023.
- Xiao et al. [2011] X. Xiao, G. Bender, M. Hay, and J. Gehrke. Ireduct: Differential privacy with reduced relative errors. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, SIGMOD ’11, page 229–240. Association for Computing Machinery, 2011. ISBN 9781450306614. doi: 10.1145/1989323.1989348. URL https://doi.org/10.1145/1989323.1989348.
Appendix A Noise Reduction Mechanisms
We provide a more general approach to handle both the Laplace and Brownian noise reduction mechanisms from [11, 12, 21]. Consider a discrete set of times with . We will allow the stopping time and the number of steps to be adaptive. We will handle the univariate case and note that the analysis extends to the multivariate case. We will write time functions to satisfy the following
Consider the noise reduction mechanisms where we have , where is either a standard Brownian motion or a Laplace process [11], and for we have
We will then write
We then consider the extended mechanism , where is a stopping function. Hence, takes values in where is a collection of all finite sequences of the type for and and for .
Let be the probability measure on this space generated by where is a point where . Note that might be a fake value that needs to be added to make the function equal zero. Let be the probability measure on this space generated by . We will then compute densities with respect to .
Let be a measurable set in . Let on which the last (smallest) -coordinate of every point is equal to . Then
By construction, is a function of . Therefore, for each , we have
where the set of paths is of the following form for a measurable subset of continuous functions on
The standard Brownian motion and the Laplace process both have independence of increments, so we have the following with as the density for
where the second equality follows from the fact that the law of a shifted process with independent increments on is equivalent to the law of the non-shifted process and its density is the ratio of the two densities evaluated at its left most point. We then conclude that
Therefore is absolutely continuous with respect to . To write the density (the Radon-Nikodym derivative), recall that the density is evaluated at some point . Let be the smallest -value in and be the corresponding space value. Then we have
Similarly, we consider so that the state space is . We will write to be the probability measure on this space generated by and to be the probability measure on this space generated by . We then compute densities with respect to .
Let now be a measurable subset of and let with the -coordinate equal to . Then we follow a similar argument to what we have above to show that
Hence, for we have
We then consider the privacy loss for both , denoted as , and , denoted as , under neighboring data and . We have
| (12) |
We then instantiate the Brownian noise reduction, in which case
Without loss of generality, consider the function so that we apply
We then use the Brownian motion to get the privacy loss
where is a standard Brownian motion for .
There is another noise reduction mechanism based on Laplace noise, originally from [11] and shown to be ex-post private in [12]. We first show that it is indeed a noise reduction mechanism with a stopping function and consider the resulting privacy loss random variable. We focus on the univariate case, yet the analysis extends to the multivariate case.
We construct a Markov process with such that, for each , has the Laplace distribution with parameter , which has density for . The process we construct has independent increments, i.e. for any the following differences are independent,
Hence, the process is Markovian. The idea of constructing such a process is that a Laplace random variable with parameter is a symmetric, infinitely divisible random variable without a Gaussian component whose Lévy measure has density
Let be an infinitely divisible random measure on with Lebesgue control measure and local Lévy density
| (13) |
We define , where . Then and for , is a symmetric, infinitely divisible random variable without a Gaussian component, whose Lévy measure has the density equal to
That is is a Laplace random variable with parameter and the resulting process has independent increments by construction. Note that the process has infinitely many jumps near . On an interval with , it is flat with probability .
We can then describe the Laplace noise reduction algorithm in a way similar to the Brownian Noise Reduction.
Definition A.1 (Laplace Noise Reduction).
Let be a function and a sequence of time values. Let be the Markov process described above independently in each coordinate and be a stopping function. The Laplace noise reduction associated with , time values , and stopping function is the algorithm given by
We then aim to prove the following
Lemma A.1.
The privacy loss for the Laplace noise reduction associated with , time values , and stopping function can be written as
Furthermore we have
Proof.
Because the Laplace process has independent increments, we get the same expression for the privacy loss as in (12) where we substitute the Laplace process for , which has the following density
We will again use for neighboring datasets with without loss of generality to get
Therefore, we have from (12)
∎
We now want to show a similar result that we had for the Brownian noise reduction mechanism in Lemma 6.1, but for the Laplace process. Instead of allowing general time step functions , we will simply look at time values so that
This form of the privacy loss for the Laplace noise reduction might be helpful in determining whether we can get a similar backward martingale as in the Brownian noise reduction case in Lemma 6.1. We leave the problem open to try to get a composition bound for Laplace noise reduction mechanisms that improves over simply adding up the ex-post privacy bounds as in Theorem 5.1.