Adaptive stimulus design for dynamic recurrent neural network models
Abstract
We present a theoretical application of an optimal experiment design (OED) methodology to the development of mathematical models to describe the stimulus-response relationship of sensory neurons. Although there are a few related studies in the computational neuroscience literature on this topic, most of them are either involving non-linear static maps or simple linear filters cascaded to a static non-linearity. Although the linear filters might be appropriate to demonstrate some aspects of neural processes, the high level of non-linearity in the nature of the stimulus-response data may render them inadequate. In addition, modelling by a static non-linear input - output map may mask important dynamical (time-dependent) features in the response data. Due to all those facts a non-linear continuous time dynamic recurrent neural network that models the excitatory and inhibitory membrane potential dynamics is preferred. The main goal of this research is to estimate the parametric details of this model from the available stimulus-response data. In order to design an efficient estimator an optimal experiment design scheme is proposed which computes a pre-shaped stimulus to maximize a certain measure of Fisher Information Matrix. This measure depends on the estimated values of the parameters in the current step and the optimal stimuli are used in a maximum likelihood estimation procedure to find an estimate of the network parameters. This process works as a loop until a reasonable convergence occurs. The response data is discontinuous as it is composed of the neural spiking instants which is assumed to obey the Poisson statistical distribution. Thus the likelihood functions depend on the Poisson statistics. The model considered in this research has universal approximation capability and thus can be used in the modelling of any non-linear processes. In order to validate the approach and evaluate its performance, a comparison with another approach on estimation based on randomly generated stimuli is also presented.
keywords:
Optimal Design, Sensory Neurons, Recurrent Neural Network, Excitatory Neuron, Inhibitory Neuron, Maximum Likelihood Estimation1 Introduction
Optimal experiment design (OED) or shortly optimal design [1] is a sub-field of optimal control theory which concentrates design of an optimal control law aiming at the maximization of the information content in the response of a dynamical system related to its parameters. The statistical advantage brought by information maximization helps the researchers to generate the best input to their target plant/system that can be used in a system identification experiment producing estimates with minimum variance [2]. With the utilization of mathematical models in theoretical neuroscience research, the application of optimal experiment design in adaptive stimuli generation should be beneficial as it is expected to have better evaluations of the model specific parameters from the collected stimulus-response data. Though these benefits, the optimal experiment design have not found its place among theoretical or computational neuroscience research due to the nature of the models. As the stimulus-response relationship is naturally quite non-linear, computational complexity of the optimization algorithms utilized for an optimal experiment design will typically be very high and thus OED has not gained enough attraction during the past decades. However, thanks to the today’s computational powers of new microprocessors, it will be much easier to talk about a real optimal experiment design in neuroscience research ([3],[4]). In the past decades, some researchers had stimulated their models by Gaussian white noise stimuli [5], [6] and performed an estimation of input-output relationships of their model ([7] [8] and [9]). This algorithmically simpler approach is theoretically proven to be efficient in the estimation of models based on linear filters and their cascades. However, in [10], it is suggested that white noise stimuli may not be successful as a stimuli in the parametric identification of non-linear response models due to high level of parameter confounding (refer to [11] for a detailed description of the confounding phenomenon in non-linear models).
Concerning the applications of optimal experiment design to biological neural network models, there exist a limited amount of research. One such example is [12] where a static non-linear input output mapping is utilized as a neural stimulus-response model. The optimal design of the stimuli is performed by the maximization of the D-Optimal metric of the Fisher Information Matrix (FIM) [13] which reflects a minimization of the variance of the total parametric error of the model network. In the last research,the parameter estimation is based on the Maximum A Posteriori (MAP) Estimation methodology [14] which is linked to the Maximum Likelihood Estimation (ML) [15] approach. Two other successful mainly experimental work on applications of optimal experiment design to adaptive data collection are [16] and [17]. The experimental works successfully proven the efficiency of optimal designs for certain models in theoretical neuroscience. However, none of those studies explore fully dynamical non-linear models explicitly. Because of this deficiency, this research will concentrate on an application of the optimal experiment design to a fully dynamical non-linear model. The final goal is almost similar to that of [12].
The proposed model is a continuous time dynamical recurrent neural network (CTRNN) [18] in general and it also represents the excitatory and inhibitory behaviours [19] of the realistic biological neurons. Like in that of [20] and its derivatives, the CTRNN describes the dynamics of the membrane potentials of the constituent neurons. However, the channel activation dynamics is not directly represented. Instead it constitutes, a more generic model which can be applied to a network having any number of neurons. The dynamic properties of the neuron membrane is represented by time constants and the synaptic excitation and inhibition are represented as network weights (scalar gains). Though not the same, a similar excitatory-inhibitory structure is utilized in numerous studies such as [21, 22, 23]. As there isn’t sufficient amount of research on the application of OED to dynamical neural network models, it will be convenient to start with a basic network model having two neurons representing the average of excitatory and inhibitory populations respectively. The final goal is to estimate the time constants and weight parameters. The optimal experiment design will be performed by maximizing a certain metric of the FIM. The FIM is a function of stimulus input and network parameters. As the true network parameters are not known in the actual problem, the Information Matrix should depend on the estimated values of the parameters in the current step. An optimization on a time dependent variable like stimulus will not be easy and often its parametrization is required. In auditory neuroscience point of view, that can be done by representing the stimuli by a sum of phased cosine elements. If periodic stimulation is allowed, these can be formed as harmonics based on a base stimulation frequency. The optimally designed stimulus will be the driving force of a joint maximum likelihood estimation (JMLE) process which involves all the recorded response data. Unfortunately, the recorded response data will not be continuous. The reason for this is that, in vivo measurements of the membrane potentials are often very difficult and dangerous as the direct manipulation with the neuron in vivo may trigger the death of a neuron. Thus, in the real experimental set-up, the peaks of the membrane potentials are collected as firing instants. As a result, one will only have a neural spike train with the exact neural spiking times (timings of the membrane potential peaks) but no other data. This outcome prevents one to apply traditional parameter estimation techniques such as minimum mean square estimation (MMSE) as it will require continuous firing rate (is based on the membrane potential) data. Researches like [24], suggests that the neural spiking profile of sensory neurons obey the famous inhomogeneous Poisson distribution [25]. Under this assumption, the Fisher Information Matrix [12] and Likelihood functions [26, 27] can be derived based on Poisson statistical distribution. The optimization of a certain measure of Fisher Information Matrix and the Likelihood can be performed by readily available packages such as MATLAB® Optimization Toolbox (like well known fmincon algorithm).
There are certain challenges in this research. First of all, the limited availability of similar studies lead to the fact that this work is one of the first contributions on the applications of optimal experiment design to the dynamical neural network modelling. Secondly, we will most probably not be able to have a reasonable estimate just from a single spiking response data set as we do not have a continuous response data. This is also demonstrated in the related kernel density estimation research such as [28, 29, 30, 31]. From these sources, one will easily note that repeated trials and superimposed spike sequences are required to obtain a meaningfully accurate firing rate information from the neural response data. In a real experiment environment, repeating the trials with the same stimulus profile will not be appropriate as the repeated responses of the same stimulus are found to be attenuated. Because of this issue, a new stimulus should be designed each time based on the currently estimated parameters of the model and then it should be used in an updated estimation. These updated parameters are used in the next step to generate the new optimal stimulus. As a result one will have a new stimulus in each step and thus the risk of response attenuation is largely reduced. In a maximum likelihood estimation, the likelihood function will depend on the whole spiking data obtained throughout the experiment (or simulation). The parallel processing capabilities of MATLAB® (i.e. parfor) on multiple processor/core computers will help in resolving of those issues.
2 Models & Methods
2.1 Continuous Time Recurrent Neural Networks
The continuous time recurrent neural networks have a similar structure to that of the discrete time counterparts that are often met in artificial intelligence studies. In Figure 1, one can see a general continuous time network that may have any number of neurons.
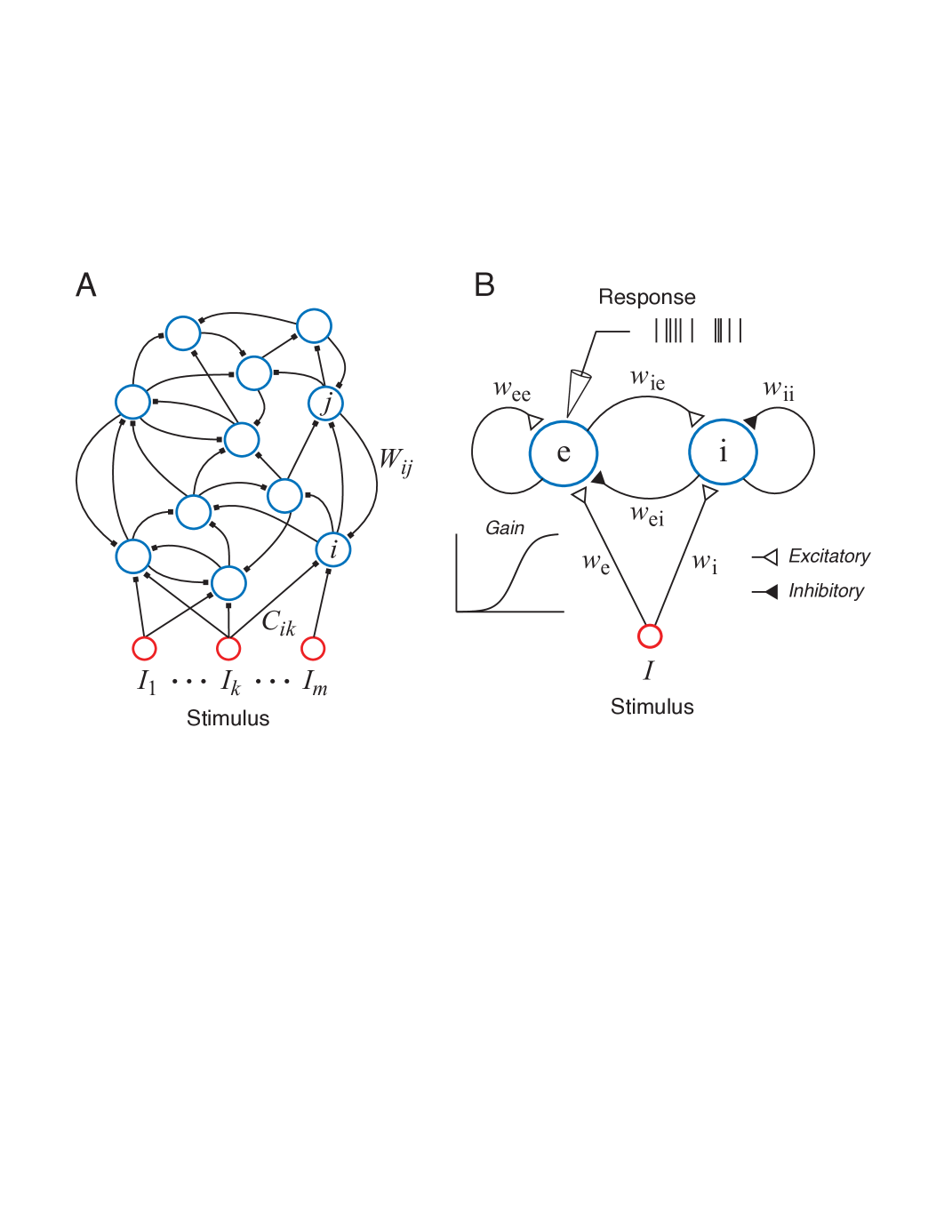
The mathematical representation of this generic model can be written as shown below [18]:
| (1) |
where is the time constant, is the membrane potential of the neuron, is the synaptic connection weight between the and neurons is the connection weight from input to the neuron and is the input. The term is a membrane potential dependent function which acts as a variable gain on the synaptic inputs to from the neuron to the one. It can be shown by a logistic sigmoid function which can be shown as:
| (2) |
where is the maximum rate at which the neuron can fire, is a soft threshold parameter of the neuron and is a slope constant. This is the only source of non-linearity in (1). In addition it also models the activation-inactivation behaviour in more specific models of the neuron (like [20]). The work by [32] shows that (2) gives a relationship between the firing rate and membrane potential of the neuron. In sensory nervous system, some of neurons have excitatory synaptic connections while some have inhibitory ones. This fact is reflected to the model in (1) by assigning negative values to the weight parameters which are originating from neurons with inhibitory synaptic connections. In the introduction of this research, it is stated that it would be convenient to apply the theory to a basic network first of all due to the lack of related research and computational complexity. So a basic excitatory and inhibitory continuous time recurrent dynamical network can be written as shown in the following:
| (3) | |||||
| (4) |
where the subscripts and stands for excitatory and inhibitory neurons respectively. Starting from now on, we will have a single stimulus and it will be represented by the term which will be generated by the optimal design algorithm. In addition in order to suit the model equations to the estimation theory formalism the time constant may be moved to the right hand side as shown below:
| (5) |
where and are the reciprocals of the time constants and . They are taken to the right for easier manipulations of the equations. Note that this equation is written in matrix form to be conformed to the formal non-linear system forms. A descriptive illustration related to (5) is presented in Figure 1b. It should also be noted that, in (4) and (5) the weights are all assumed as positive coefficients and they have signs in the equation. So negative signs indicate that originating neuron is inhibitory (tend to hyper-polarize the other neurons in the network).
2.2 Inhomogeneous Poisson spike model
The theoretical response of the network in (4) will be the firing rate of the excitatory neuron as . In the actual environment, the neural spiking due to the firing rate is available instead. While introducing this research, it is stated that this spiking events conform to an inhomogeneous Poisson process which is defined below:
| (6) |
where
| (7) |
is the mean number of spikes based on the firing rate which varies with time, and indicates the cumulative total number of spikes up to time , so that is the number of spikes within the time interval . In other words, the probability of having number of spikes in the interval is given by the Poisson distribution above.
Consider a spike train in the time interval (here so and become and ). Here the spike train is described by a list of the time stamps for the spikes. The probability density function for a given spiking train can be derived from the inhomogeneous Poisson process [26, 27]. The result reads:
| (8) |
This probability density describes how likely a particular spike train is generated by the inhomogeneous Poisson process with the rate function . Of course, this rate function depends implicitly on the network parameters and the stimulus used.
2.3 Maximum Likelihood Methods and Parameter Estimation
The network parameters to be estimated are listed below as a vector:
| (9) |
which includes the time constants and all the connection weights in the E-I network. Our maximum-likelihood estimation of the network parameters is based on the likelihood function given by (8), which takes the individual spike timings into account. It is well known from estimation theory is that maximum likelihood estimation is asymptotically efficient, i.e., reaching the Cramér-Rao bound in the limit of large data size.
To extend the likelihood function in (8) to the situation where there are multiple spike trains elicited by multiple stimuli, consider a sequence of stimuli. Suppose the -th stimulus () elicits a spike trains with a total of spikes in the time window , and the spike timings are given by . By (8), the likelihood function for the spike train is
| (10) |
where is the firing rate in response to the -th stimulus. Note that the rate function depends implicitly on the network parameters and on the stimulus parameters. The left-hand side of (10) emphasizes the dependence on network parameters , which is convenient for parameter estimation. The dependence on the stimulus parameters will be discussed in the next section.
We assume that the responses to different stimuli are independent, which is a reasonable assumption when the inter-stimulus intervals are sufficiently large. Under this assumption, the overall likelihood function for the collection of all spike trains can be written as
| (11) |
By taking natural logarithm, we obtain the log likelihood function:
| (12) |
Maximum-likelihood estimation of the parameter set is given formally by
| (13) |
Numerical issues related to this optimization problem will be discussed in Sections 2.5 and 2.6. In addition, some discussion on the local maxima problems is provided in Section 3.3.
2.4 Objective function of optimal design of stimuli
The optimal design method generates the stimuli by maximizing a utility function, or an objective function. The basic idea is that these stimuli are designed so as to elicit responses that are most informative about the network parameters. In optimal design method, the utility function depends on the stimulus parameters , but typically also on the model parameters . An intuitive explanation of the dependence on the model parameter is best illustrated with an example. Suppose we want to estimate a Gaussian tuning curve model with unknown parameters although we may have some idea about the sensible ranges of these parameters. To estimate the height of the tuning curve accurately, we should place a probing stimulus around the likely location of the peak. To estimate the width, the probing stimulus should go to where the tuning curve is likely to have the steepest slope. For the baseline, we should go for the lowest response. This simple example illustrates two facts: first, optimal design depends on our knowledge of possible parameter values; second, the elicited responses in an optimally design experiment are expected to vary over a wide dynamic range as different parameters are estimated.
Once the utility function is chosen, the optimally designed stimulus may be written formally as:
| (14) |
where the network parameters can be obtained by maximum-likelihood estimation from the existing spike data as described in the preceding section. Here the stimulus is specified by vector , which is a set of parameters rather than the actual stimulus itself. Direct computation of the actual time-varying stimulus is not easy because no closed analytical form of the objective function is available and furthermore the computation of the optimal control input generally requires a backward integration or recursion. Instead of struggling with this difficulty, one can restrict the stimulus to a well known natural form such as sum of phased cosines as shown below:
| (15) |
where is the amplitude, is the frequency of the -th Fourier component, and is the phase of the component. We choose a base frequency and set the frequencies of all other components as the harmonics: for . Now the stimulus parameters can be summarized by the stimulus parameter vector:
| (16) |
We sometimes refer to as the stimulus, with it understood that it really means a set of parameters that uniquely specify the actual stimulus .
Some popular choices of the objective function are based on the Fisher information matrix, which is generally defined as:
| (17) |
where is the probability distribution of the response to a given stimulus . One should here note that, the term is different from the terms in (8) and in (10). The latter two are derived from the spiking likelihood function presented in [26, 27] whereas the definition is derived from (6). However only the related results are provided in this text in order to save space. In (17), represents the weighted average over all possible responses to all available sets of stimuli . This average is calculated based on the response probability distribution . Stimulus variable can be represented by a group of parameters such as the Fourier series parameters in (15) which are and . The frequency parameter may or may not be fixed depending on the requirements or computational burden.
The Fisher information matrix reflects the amount of information contained in the noisy response about the model parameters , assuming a generative model given by the conditional probability . So the stimulus designed by maximizing a certain measure of the Fisher information matrix (17) is expected to decrease the error of the estimation of the parameters .
The utility function can be chosen as a scalar function of the Fisher information matrix . One theoretically well founded popular choice is the D-optimal design:
| (18) |
although the determinant of the Fisher information matrix is not always easy to optimize. The A-optimal design is based on the trace of the Fisher information matrix and is easier to optimize:
| (19) |
Another alternative is the E-optimal design where the objective function is the smallest eigenvalue of the Fisher information matrix. In this paper the A-optimality measure of the information matrix is preferred. There is an obvious reason for this preference. As the computational complexity of the optimization algorithms are expected to be high, the necessity of numerical derivative computation should be avoided as much as possible. Since it is not easy to evaluate the derivatives of the eigenvalues and determinants by any means other than numerical approximations it will be convenient to apply a criterion like A-optimality which has a direct relationship like the sums of the diagonal elements.
In the beginning of this section we mentioned that an optimally design stimulus is expected to depend on which parameter is supposed to be estimated. Since a scalar utility function in (18) or (19) depends on all the parameters , optimizing a single scalar function is sufficient to recover all the parameters. When a sequence of stimuli are generated by optimal design, the stimuli may sometimes alternate spontaneously as if the optimization is performed with respect to each of the parameters one by one [12].
In our network model, the recorded spike train has an inhomogeneous Poisson distribution with the rate function . We write this rate as to emphasize that it is a time-varying function that depends on both the stimulus and the network parameters . For a small time window of duration and centered at time , the Fisher information matrix entry in (17) is reduced to:
| (20) |
Since the Poisson rate function varies with time, the A-optimal utility function in (19) should be modified by including integration over time:
| (21) |
Here the time window is ignored because it is a constant coefficient that does not affect the result of the optimization.
For convenience, we can also define the objective function with respect to a single parameter as follows:
| (22) |
The objective function in (21) is identical to .
The optimization of the D-optimal criterion in (18) is not affected by parameter rescaling, or changing the units of parameters. For example, changing the unit of parameter 1 (say, from msec-1 to sec-1) is equivalent to rescaling the parameter by a constant coefficient: . The effect of this transformation is equivalent to a rescaling of the determinant of the Fisher information matrix by a constant, namely, , which does not affect the location of the maximum of (18). By contrast, the criterion function in (19) or (21) are affected by parameter rescaling. A parameter with a smaller unit would tend to have larger derivative value and therefore contribute more to (21) than a parameter with a large unit. To alleviate this problem, we use one by one to generate the stimuli. That is, stimulus 1 is generated by maximizing , and stimulus 2 is generated by maximizing , and so on. Once the 8th stimulus is generated by maximizing , we go back and use to generate the next stimulus, and so on. Finally, an alternative way to get rid of scale dependence is to introduce logarithm and use as the criterion, which, however, may become degenerate when approaches 0.
2.5 Gradient Computation
As just explained in the previous section about the computational issues in this research, the gradient computation decreases the computation durations considerably. The main issue with this fact is the lack of closed form expressions like in the case of static non-linear mappings as the model. In researches such as [33], [2] and [34] the gradients are computed as a self contained differential equation which is formed by taking the derivatives of the model equations (3) and (4) from both sides.
Compiling all the information in this section one can write the gradient of the Fisher Information Measure (i.e. the Fisher Information Matrix with a certain optimality criterion such as A-Optimality). In the beginning of this section, it is stated that the sensitivity levels of the firing rate w.r.to different network parameters are different and thus it would be convenient to maximize the fisher information for a single parameter at a time.
The optimization as expressed in (14) the optimal design problem is converted into a parameter optimization problem to optimize the amplitudes ’s and ’s of the stimulus. For the sake of simplicity and modularity in programming, these equations can be written using their shorthand notations.
Let
| (23) |
We write the state of the network as a vector:
and we need derivatives such as . Here, the idea is to use these derivatives as variables that can be solved directly from differential equations derived from the original dynamical equations in (5).
For the optimal design, one can write the following:
| (24) |
where and are the derivatives of the gain functions and respectively, and the matrices derivatives are defined in the usual manner:
| (25) |
and
| (26) |
In the evaluation of the Fisher Information Matrix and the gradients in estimation one will need the derivatives with respect to the parameters .
It follows from the original dynamical equation in (5) that
| (28) |
where and the last term refers to the extra components resulting from the chain rule of differentiation. These extra terms are presented in Table 1.
| Parameter | Extra term in Equation (28) | |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 |
The maximization of the Fisher Information Measure in trace form requires its gradients and they involve second order cross derivatives of the membrane potentials with respect to parameters and stimulus parameters .
Taking derivative of (27) with respect to , we find:
| (29) |
where , , and
| (30) |
which is compatible with (26). The last term is specified in Table 2
| Parameter | Extra term in Equation (29) | |
|---|---|---|
| 1 | ||
| 1 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 | ||
| 8 |
To compute the gradients needed for optimizing the objective function based on Fisher Information or for performing maximum-likelihood estimation, we need to evaluate the derivatives of the mean firing rate with respect to the network parameters in (9) or the stimulus parameters in (23). The first and the second order derivatives are:
| (31) |
| (32) |
| (33) |
These formulas are expressed in terms of the derivatives , and , which are regarded as dynamical variables that can be solved from the three differential equations (27)–(29). Here the initial conditions were always assumed to be the equilibrium state. The initial values of the derivatives can be set to zero as recommended in [2].
The gradient of the Fisher Information Measure in (21) with respect to the stimulus parameters can be written as
| (34) | |||||
| (35) |
which the last expression is written in terms of the derivatives that are already evaluated by equations (31)–(33). If the Fisher Information is computed with respect to one parameter at a time as shown in (22), one rewrite the above by removing the summation as:
| (36) | |||||
| (37) |
2.6 Other Numerical Issues Related to Optimization
Up to this point, the theoretical grounds of this research are presented. In order to achieve the results one needs two separate maximization algorithms targeting (13) and (14). Optimization algorithms have varieties in certain aspects. One of these classifications is the gradient requirements. The global optimization algorithms such as genetic algorithms (MATLAB® ga), simulated annealing (MATLAB® simulannealbnd) and pattern search (MATLAB® patternsearch) do not require gradient computations. However due to their stochastic nature, they do a lot of computations which increase the computation duration drastically. In addition, that stochastic nature leads to different results at the end of different runs. Disabling this randomness, might have adverse effects on the optimization performance and their ability of finding a global optimum solution. In order not to be trapped in these issues we will stick to gradient based optimization routines such as constrained interior-point gradient descent. MATLAB® provides these algorithms through its optimization toolbox. Interior point and similar methods are available in fmincon function. We can write the following facts about the optimization algorithm:
-
1.
MATLAB®’s fmincon allows the user to set constraints on the solution.In the optimal design the stimulus amplitudes will have an upper bound (numerical details will be discussed Section 3.2. The stimulus amplitude is expected to tend to the upper bound. The parameter estimation process will also be benefited from similar bounds as they are assigned to be positive in (5). In addition assignment of bounds on parameters will aid in prevention of overstimulation of the model.
-
2.
fmincon and similar algorithms are local optimizers. In order to find a good optimum, the algorithms are often repeated with multiple initial guesses and the best one is chosen according to the value of the objective and gradient value at the termination point. This is especially important in the optimal design part as Fisher Information measure in (21) may have lots of local minima. The same factors do exist for likelihood function (12) however as the number of samples increases the likelihood function tend to converge to the same optimum for different initial guesses. See Section 3.3 for a detailed discussion of this issue.
-
3.
The local optimization algorithms need the gradient of the objective functions. In MATLAB®’s fmincon and other similar packages have the ability to compute the gradients numerically. However this capability may not be an advantage in this sort of complicated problems for two main reasons. First of all, numerical gradient computation increases the risk of singularities in the solution. Secondly, the computational duration increases dramatically. It is often noted that, the numerical differentiation in fmincon at least doubles the computational duration. This is unacceptable in the context of this research.
-
4.
Longer simulation times due to the computational complexity of the overall problem can be eliminated to a certain extent (about the 5 times shorter duration) by utilizing the MATLAB®’s parallel computation facilities (such as replacing standard for loops by parfor loops).
-
5.
The MATLAB® version used in this research is R2013b and the fmincon version included in this package has the interior-point method of constrained non-linear optimization by default. This is not the only method available in fmincon and it can always be modified by changing the algorithm option. However, the interior-point method appears to be the most efficient among all available options.
2.7 Procedural Information
In this section, we will summarize the overall procedure to give an insight about how the optimal design and parameter estimation algorithm works together in a automatized loop. Before giving a start, it is worth to discuss the initial parameter problem. In the beginning of an experiment (or simulation in our case), one usually has no idea about the true or approximate values of the network parameter vector . However, the optimal design always needs a current estimate. Thus one should assign a randomly chosen initial parameter vector. A good rule to get that value is to draw one sample from a parametric subspace of which members are uniformly distributed between the lower and upper bounds of the parameters. One can find the details about the parametric bounds in Table 3 Setting a parametric bound on the stimulus amplitude coefficients ( in (15)) might be critical. Too large amplitudes may lead to instabilities or very large responses which may break the optimal design procedures. Because of this fact, an upper bound on ’s will most often required. A few number of initial simulations will be required to determine a nominal value for those bounds. If no instabilities are detected one will be fine with the decided value of the bounds on (which is termed as ) and can continue the optimization with these bounds. Mostly, the optimization procedure will fail when the assigned value of the bounds are too large.
The algorithmic details of the overall process are summarized as shown below:
-
1.
Set
-
2.
Generate a random parameter vector from a uniform distribution between and (from Table 3).
-
3.
Set
-
4.
Set
-
5.
Optimize based on to generate stimulus
-
6.
Using the stimulus perform a maximum likelihood estimation to find a new estimate of and replace by the new estimate.
-
7.
Set and go to Step 5 . If set
-
8.
If stop and report the result as otherwise go to Step 4
3 Results
In this section, we will summarize the functional and numerical details of the combined optimal design - parameter estimation algorithm and present the results in comparison with the random stimuli tests. This section is divided into several sections discussing the numerical details of an example application, statistical properties of the optimal stimuli, accuracy of the parameter estimation and parameter confounding phenomenon.
3.1 Details of the example problem
This section is devoted to the detailed presentation of the simulation set-up. An numerical example will be presented which will demonstrate our optimal design approach. In the example application, the algorithms presented in Sections 2.3 and 2.4 are applied to probe an EI network.
In order to verify the performance of the parameter estimation we have to compare the estimates with their true values. So we will need a set of reference values of the model parameters in (5). These are shown in Table 3.
| Parameter | () | () | (k) | (k) | (mVs) | (mVs) | (mVs) | (mVs) |
|---|---|---|---|---|---|---|---|---|
| True value | ||||||||
| Lower bound | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Upper bound | 100 | 100 | 2 | 2 | 3 | 3 | 3 | 3 |
| Mean (OED) | ||||||||
| STD (OED) | ||||||||
| Mean (RAND) | ||||||||
| STD (RAND) |
Our model in (5) has two more important components which are the gain functions and . These are obtained by setting in (2) by either ’’ or ’’. So one has additional parameters which have direct effect on the neural model behaviour. This research targeted the estimation of the network parameters only. Because of that, the parameters of the gain functions are kept as fixed and they have the values .
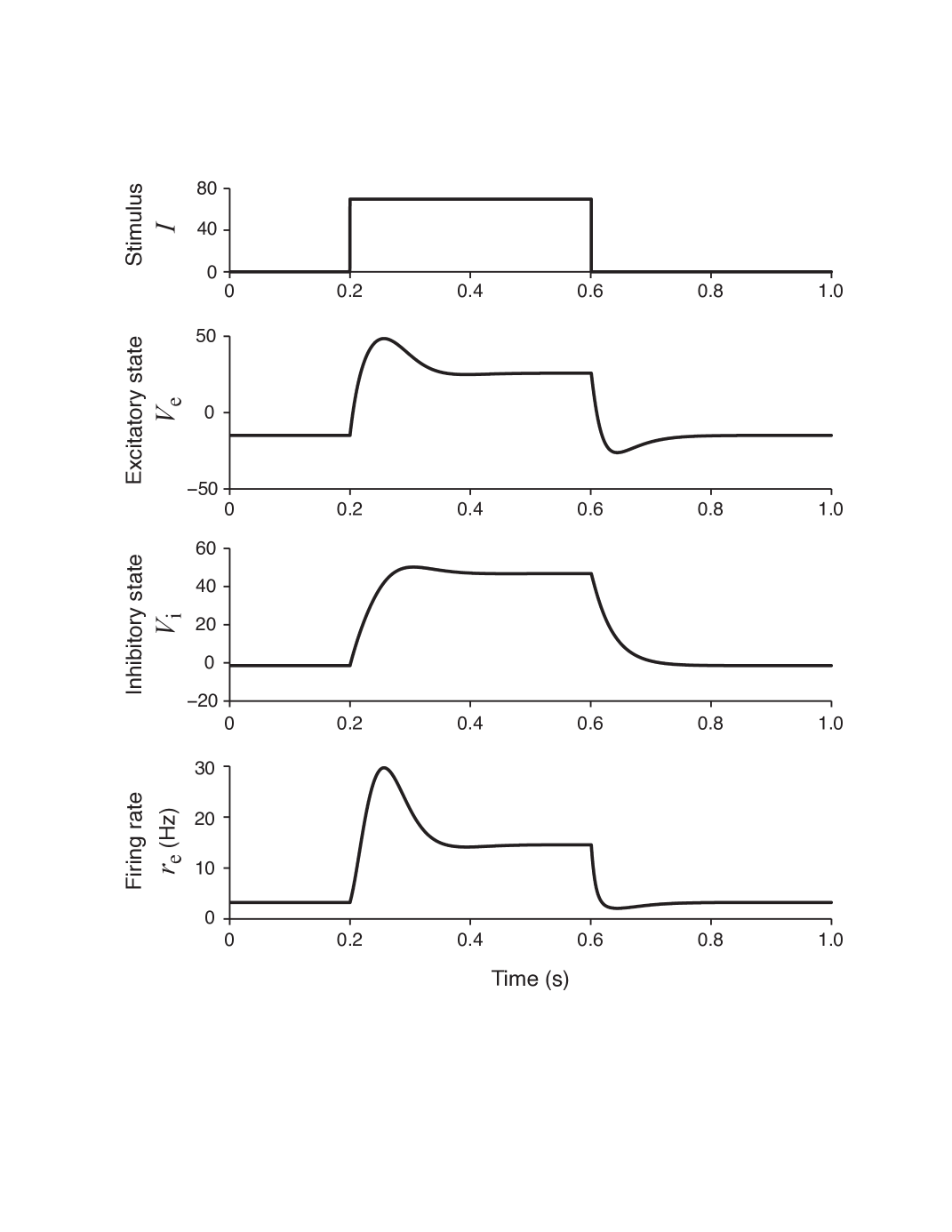
This set of parameters (gain functions and Table 3) allows the network to have a unique equilibrium state for each stationary input. To demonstrate the excitatory and inhibitory characteristics of our model, we can stimulate the model with a square wave (pulse) stimulus as shown in Figure 2A. The resultant excitatory and inhibitory neural membrane potential responses ( and ) are shown in Figure 2B and Figure 2C. It can be said that, the network has shown both transient and sustained responses. In Figure 2D, the excitatory firing rate response which is related to excitatory potential as is shown. The response is slightly delayed which leads to the depolarization of excitatory unit until ms. This delay is also responsible from the subsequent re-polarization and plateau formation in the membrane potential of excitatory neuron. The firing rate is higher during excitation and lower in subsequent plateau and repolarization phases (Figure 2D).
The optimisation of the stimuli requires that the maximum power level in a single stimulus is bounded. This is a precaution to protect the model from potential instabilities due to over-stimulation. In addition, if applied in a real environment the experiment subject will also be protected from such over-stimulations. As the amplitude parameter is assumed positive, assigning an upper bound defined as should be enough. This is applied to all stimulus amplitudes (i.e. ). In this research, a fixed setting of A is chosen. The lower bound is obviously . For the phase , no lower or upper bounds are necessary as the cosine function itself has already been bounded as . The frequencies of the stimulus components are harmonics of a base frequency . Since we have a simulation time of seconds, we have a reasonable choice of Hz which is in fact equal to . So we have chosen an integer relationship between the stimulation frequency and simulation time. The number of stimulus components is chosen as which is found to be reasonable concerning speed and performance balance. These are reasonable choices specifically for this research because utmost importance is first given to computational performance. The first few simulations showed that choosing at a higher setting then leads to longer simulation durations which are not desirable. In addition there seems no significant advantage of a larger setting for . For the base frequency , few different values other than Hz are tried ( Hz, Hz, Hz) but the optimization worked best at the mentioned frequency.
It is well known that optimization algorithms such as fmincon requires an initial guess of the optimum solution. A suitable choice for the initial guesses can be their assignment from a set of initial conditions generated randomly between the optimization bounds. In the optimization of stimuli, the initial amplitudes can be uniformly distributed between and phases can be uniformly distributed between . Although we do not have any constraints on the phase parameter, we limit the initial phase values to a safe assumed range. In the analysis of the optimal phase results we will wrap the resultant phase values to a range using modulo function. Thus assuming an initial range in the same interval will be meaningful.
We follow a similar strategy for the parameter estimation based on maximum likelihood method. The multiple initial guesses will be chosen from a set of values uniformly distributed between the lower and upper bounds defined in Table 3.
In Section 2.3, one recall from (11) that the likelihood estimation should produce better results when the number of samples (i.e. in (11)) increases. Because of this fact, the likelihood function is based on data having all spikes generated since the beginning of the simulation. The number of repeats determines . If simulation is repeated times ( iterations), one will have an value of due to the fact that each iteration has optimal designs sub-steps (with respect to each parameter . Read Section 2.4). So, if one has 15 iterations , which means likelihood has samples. This also means that optimal design and subsequent parameter estimation will also be repeated times.
3.2 Statistics of optimally designed stimuli
Having all necessary information from Section 3.1, one can perform an optimal design and obtain a sample optimal stimulus and associated neural responses Figure 3. It is noted that the optimal stimulus in Figure 3 top panel has a periodic variation as it is modelled as a phased cosines form (as it is equivalent to real valued Fourier series).
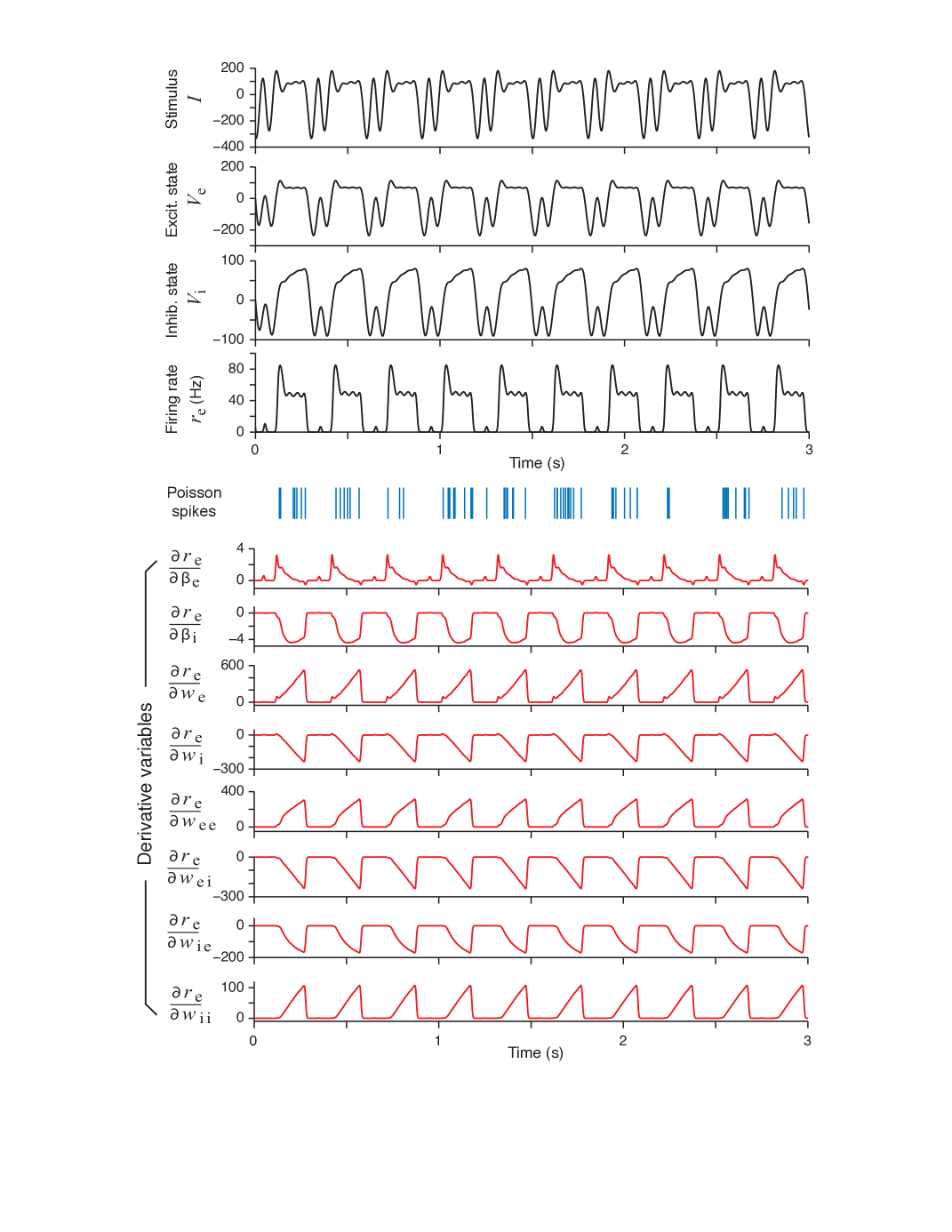
In addition to the fundamental responses, the second half of Figure 3 displays the variation of the parametric sensitivity derivatives which are generated by integrating (28) and then substituting to (31). The variation of the sensitivity derivatives support the idea of optimization of the Fisher Information Metric with respect to a single parameter (see (22)) as the sensitivity (or gradient) of the Fisher Information Metric in (22) with respect to a single parameter varies widely from parameter to parameter. . It appears that, the weight parameters have a very high sensitivity which are more than times that of the parameters. Also some of the parameters affecting the behaviour of inhibitory (I) unit and also the E-I interconnection weights have a reverse behaviour. This fact appears as a negative values variation of the sensitivity derivatives. Self inhibition coefficient does not show this behaviour as it represent an inhibitory effect on the inhibitory neuron potential (which favours excitation).
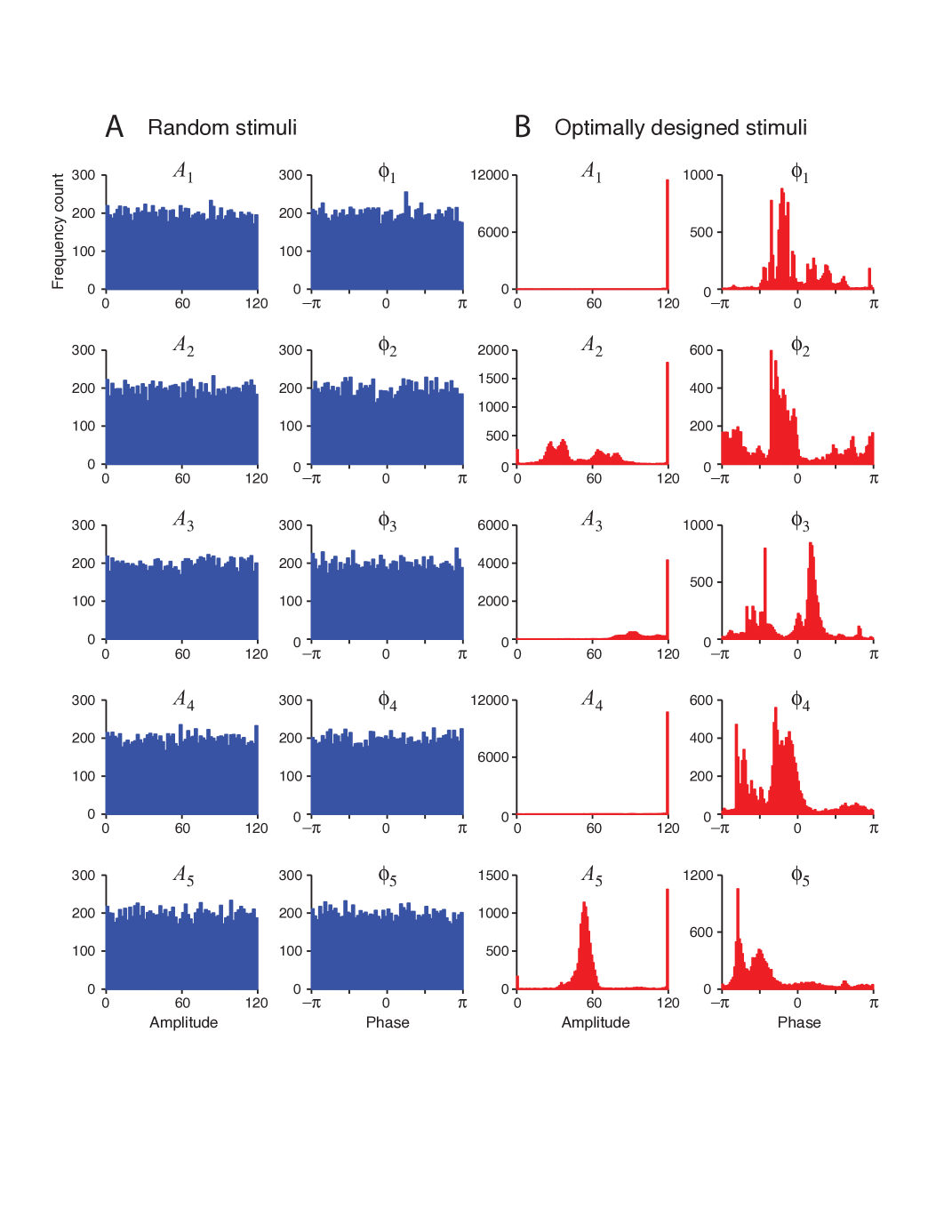
One of the most distinguishing result related to optimal design is the statistics of the optimal stimuli (i.e. the amplitudes and phases ). This analysis can be performed by generating the histograms of and from available data as shown in Figure 4. The Figure 4A shows the flat uniform distribution of the random stimuli amplitudes and phases. This is expected as the stimuli is generated directly from a uniform distribution. Concerning the optimal stimuli, the histograms shown in Figure 4B reveals that optimal design has a tendency to maximize the amplitude of the stimuli towards the upper bound. This reassures that optimal design tends to maximize the stimulus power which is expected increase the efficiency of the parameter estimation process and it distinguishes optimal stimuli from their randomly generated counterparts.
The results mentioned above coincide the findings of [35]. Here, what happens is related to the topological boundary property [36] associated with the optimal design results. It is found in [35] that, maximum firing rate response is always lies on the topological boundary of the collection of all allowable stimuli provided that the neurons have increasing gain functions and convergent synaptic connections between layers. Another interpretation of this result can be expressed as follows: The maximum and minimum responses of each individual neuron should arise from the stimulus boundary (from all available sets of stimuli) and the entire boundary of the pattern of responses elicited in a particular layer should also a result of the stimulation in the boundary level. This result is valid regardless of the neuron being feed-forward or recurrent. For recurrent neural networks we assume that the network is stable. Some mathematical proofs related to the stated results are also presented in [35]. In Figure 4B, the amplitudes of the Fourier stimulus components are collected at the boundary level which is . This is the topological boundary of the set of stimuli defined by (15).
Given a dataset consisting of stimulus-response pairs, we can always use maximum-likelihood estimation to fit a model to the data to recover the parameters. Maximum-likelihood estimation is known to be asymptotically efficient in the limit of large data size, in the sense that the estimation is asymptotically unbiased (i..e, average of the estimates approaches the true value) and has minimal variance (i.e., the variance of the estimates approaches the Cramér-Rao lower bound).
We found that maximum likelihood obtained from the optimally design stimuli was always much better than that obtained from the random stimuli (see Figure 5). It also reveals that, the likelihood value increases as the number of stimuli increases. For any given number of stimuli, the optimally designed stimuli always yielded much greater likelihood value than the random stimuli. The minimum difference between the likelihood values (the minimum from the optimal design and the maximum from the random stimuli based test) was typically about two times greater than the standard deviation of either estimates except for the case with samples . Even in this case, this violation appear only on one sample. In addition, it can be easily deduced from the box diagram in Figure 5 that the difference between th and th percentiles (st and rd quartiles) yield a value which is larger than three times the standard deviation of either estimate. The standard deviations of the maximum likelihood values are also larger in the random stimuli based tests. Those results are certain evidences of the superiority of an optimal design over the random stimuli based tests. The difference between the maximum values of the two likelihoods (from optimal and random stimuli) becomes more significant as the number of samples increases.
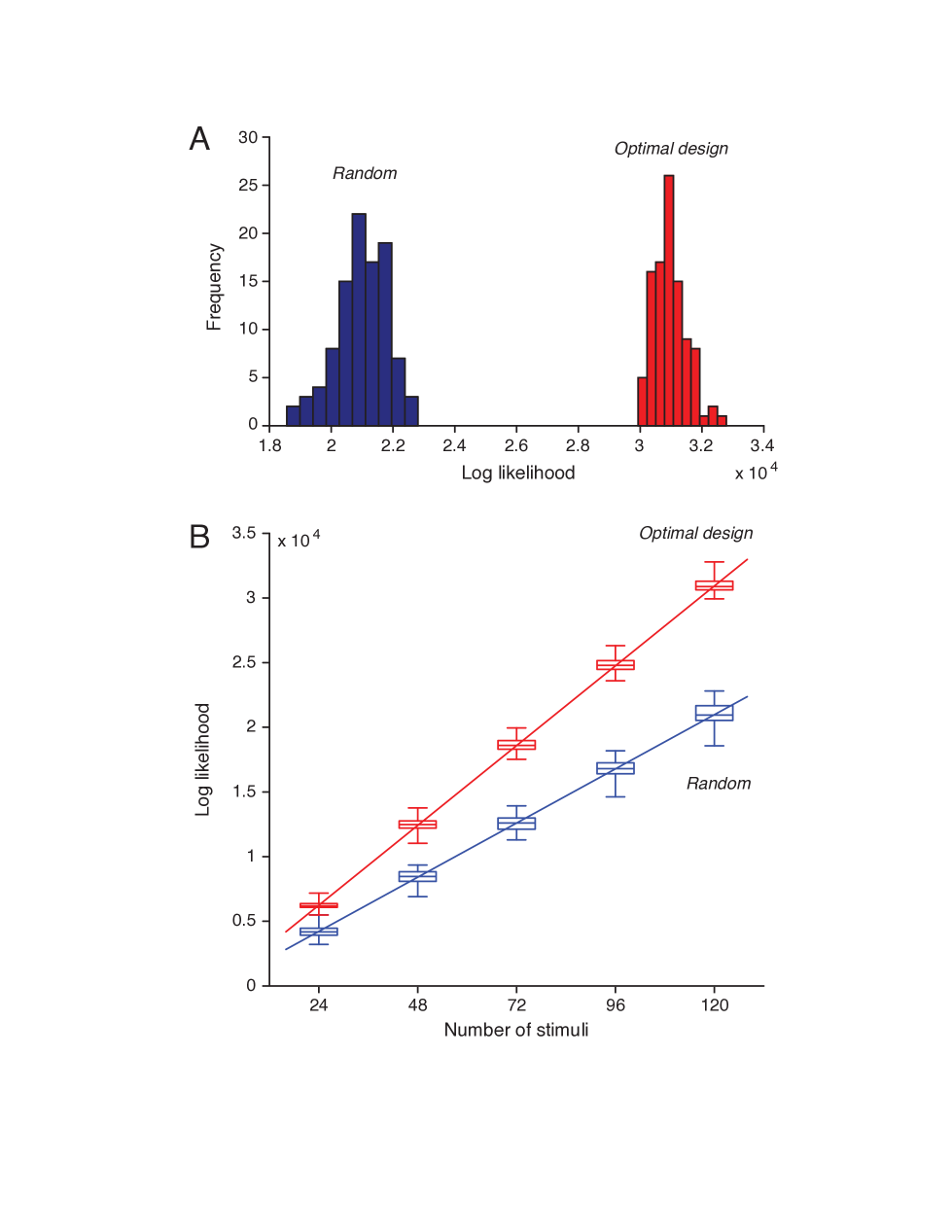
It would also be convenient to stress the fact that the greater the likelihood, the better the fitting of the data to the model. This fact is demonstrated by two regression lines imposed on the box diagram Figure 5. One of those lines correspond to the optimal design and the other correspond to the random stimuli based tests. Both regression lines path through the origin point (0, 0) approximately. This means that the ratio of the log likelihood values in the two cases is approximately a constant, regardless of the number of stimuli. The regression lines are represented by equations for optimal and for the random stimuli. So the two lines have a slope ratio of approximately . The significance of this number can be explained by a simple example. If one desires to attain the same level of likelihood with optimally designed stimuli, the required number of random stimuli to be generated is equal to a value about .
Another statistical comparison of the maximized likelihoods can be performed by Wilcoxon rank-sum tests [37, 38, 39]. When applied, one will be able to see the difference which is highly significant. Regardless of the number of samples the p-values remained at least times smaller than the widely accepted probability significance threshold of or .
The likelihood function provides an overall measure of how well a model fits the data. We have also tested the mean errors of individual parameters relative to their true values. The main finding is that, for each individual parameter, the error is typically smaller for the optimally designed stimuli than the error for the random stimuli. This result can be observed from the bar charts presented in Figure 6. The heights of the bars show the mean error levels for randomly and optimally generated stimuli respectively. One can get the benefits of the rank-sum test on the statistical properties of the parameter estimates. Computation of rank-sum p-values for each individual parameter corresponding to the case of samples yields:
| (39) |
The above result showed that for the differences are statistically significant for parameters. For different values one can refer to Figure 6. In this illustration, the statistical significance of the difference between optimal and random stimuli based tests are indicated as an asterisk placed above the bars. Any of the cases with asterisk means that, the associated sample size led to a result where optimal design is significantly better.
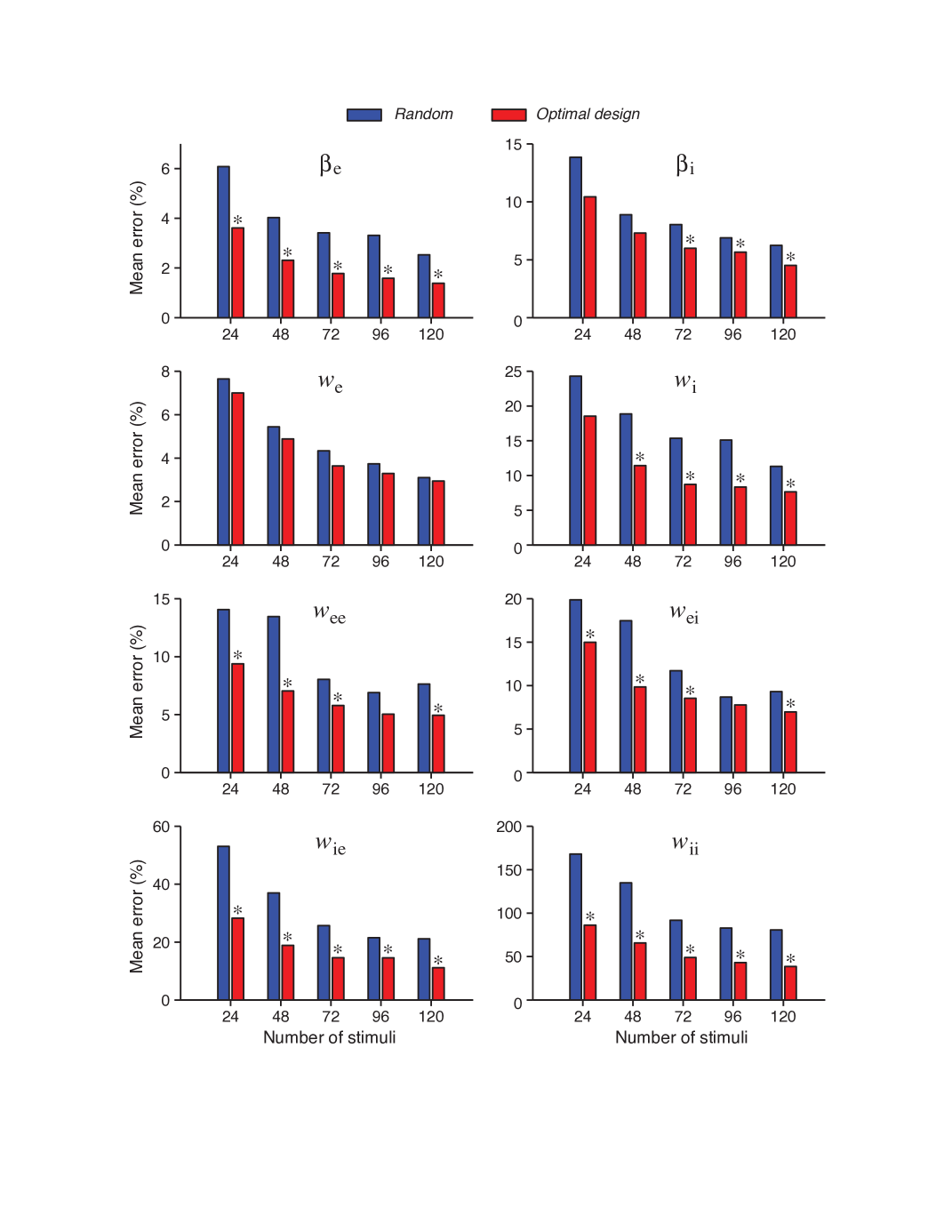
Here an interesting result is the statistical non-significance of the third parameter regardless of the sample size . This might be associated with the parameter confounding phenomenon that is discussed in Section 3.4.
For convenience, one can see the mean values and standard deviations of the estimates obtained from optimal and random stimuli in Table 3. These are obtained with samples. In general, mean values seem to be comparable for both stimuli however the standard deviations of estimates from optimal stimuli are smaller then that obtained from random stimuli. The mean values of parameters and are also closer to the true values when obtained from optimal stimuli.
3.3 Problem of local maxima during optimization
We need optimization in two places: maximum likelihood estimation of parameters, and optimal design of stimuli. Due to speed and computational complexity considerations one needs to utilize gradient base local optimizers such as MATLAB® fmincon. These algorithms often needs initial guesses and not all of the initial guesses will converge to a true value. This issue may especially appear in the cases where the objective function involves dynamical model (differential or difference equations). In such cases, the problem of multiple local maxima might occur in the objective function which often requires multiple initial guesses to be provided to the solver. So an analysis on this issue may reveal useful information.
Suppose there are repeats or starts from different initial values. Let be the probability of finding the “correct” solution in an individual run with random initial guess. Then in repeated runs, the probably that at least one run will lead to the “correct” solution is
| (40) |
The probability can be estimated from a pairwise test or directly from the values of the likelihood and Fisher Information Metric. In the test of the likelihood function, one can achieve the goal by starting the optimization from different initial guesses and checking the number of solutions which stay in an error bound for each individual parameter with respect to the solution leading to the highest likelihood value. In other words, to pass the test the following criterion should be satisfied for each individual parameter in (9):
| (41) |
where is the local optimum solution having the highest objective (likelihood) value and is the estimated value of . If the above is satisfied for all , this result is counted as one pass.
So for maximum likelihood estimation with , the data suggests a probability of and to get a correct rate we will only need repeats. This is a result obtained from multiple initial guesses per different stimuli configurations (total of occurrences). Here, we have a high probability of obtaining a global maxima and thus we may get rid of multiple initial guesses requirement in the estimation of .
For the optimal design part the problem is expected to be harder as the stimulus amplitudes tend to the upper bound . This should be due to the increasing level of response as the stimulus approaches the upper bound. It should also be remembered that, the Fisher Information measure is computed with respect to a single parameter as shown in (22). Thus it will here be convenient to analyse the respective Fisher Information metric as defined w.r.to each parameter . Like in the case of likelihood analysis, we do the analysis on samples (i.e. stimuli) separately for amplitudes and phases . The criterion for passing the test is similar to that of (41) after replacing by from (16) and by with being the stimulus parameter yielding the largest value of . Note that, since we do not have any concept of ”true stimulus parameters” we will use in the denominator of (41).
After doing the analysis for amplitudes , one can see that highest probability value is obtained for whereas the smallest value is obtained for as . The second and third smallest values are and having and respectively. The indices ,, and correspond to the ,, and . This means that the lowest probability values occur at the parameters , and . This result might be interesting as those three parameters have strong correlations at least with one other network parameter (see Section 3.4). The required number of repeats appears to be for the worst case ( for ).
For the phase parameters , different initial conditions lead to different values. This is an expected situation as fmincon or similar functions are local optimizers. In fact, the stochastic nature of the global optimizing routines such as the genetic algorithms or simulated annealing will also lead to a similar result when initial populations are provided after each run. Because of this outcome, the solution yielding the largest value of Fisher Information Metric among all runs with different initial conditions should be preferred in the actual application.
Modern parallel computing facilities will ease the implementation of optimization with multiple random guesses.
3.4 Parameter confounding
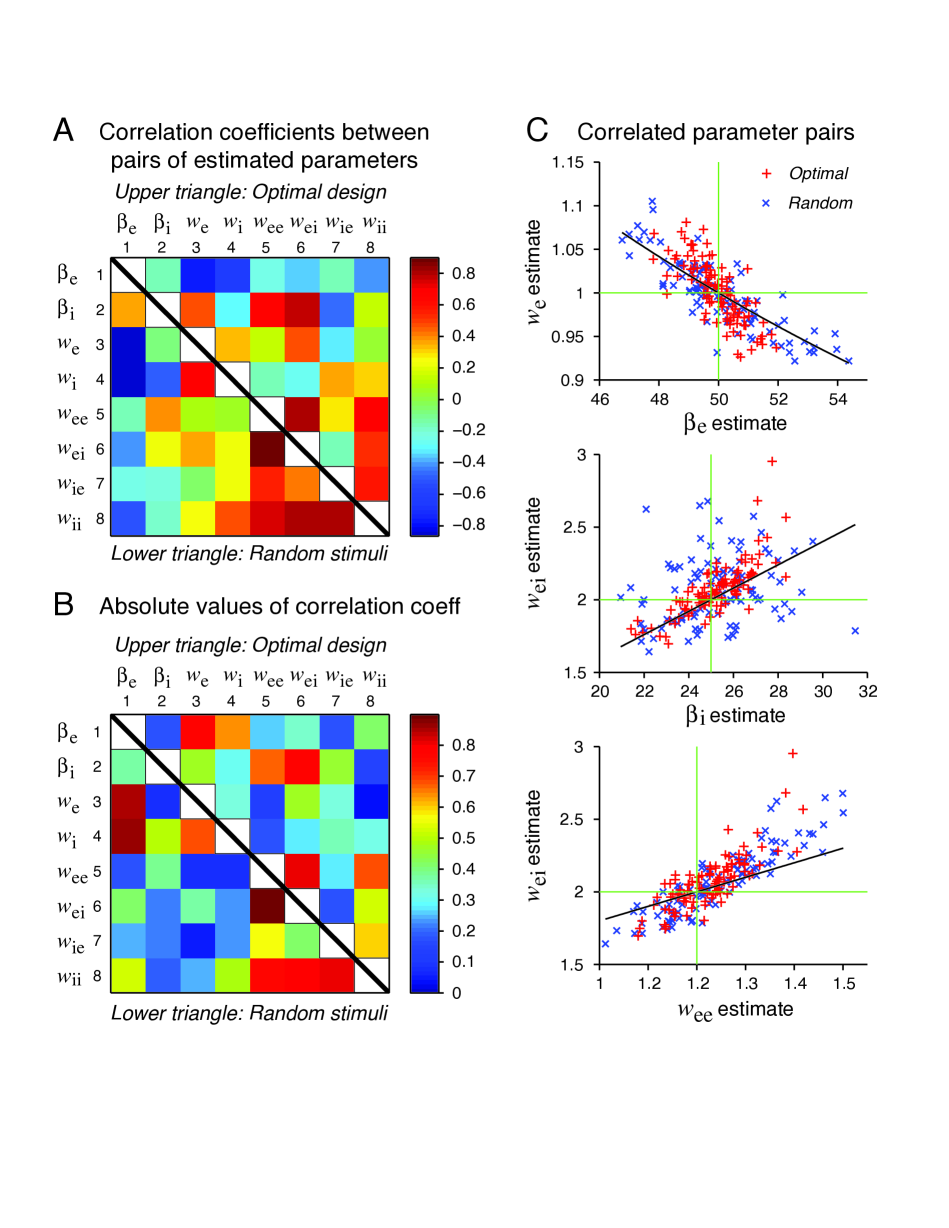
The errors of some parameters tend to be correlated (see Figure 7).
Parameter confounding may explain some of the correlations. The idea is that different parameter may compensate each other such that the network behaves in similar ways, even though the parameter values are different. It is known that in individual neurons, different ion channels may be regulated such that diverse configurations may lead to neurons with similar neuronal behaviours in their electrical activation patterns [40]. Similar kind of effect also exists at the network level [10].
Here we will consider the original dynamical equations and demonstrate how parameter confounding might arise. We first emphasize that different parameters in our model are distinct and there is no strict confounding at all. The confounding is approximate in nature.
From the correlation analysis on the optimal design data (Figures 7A and 7B), three pairs of parameters stand out with the strongest correlations. These pairs are , , and .
We will offer an intuitive heuristic explanation based on the idea of parameter confounding.
We here rewrite the dynamical equations for convenience as shown below:
| (42) | |||||
| (43) |
Example 1: Confounding of the parameter pair , .
The external stimulus drives the first equation (42) through the weight . If this product is the same, the drive would be the same, even though the individual parameters are different. For example, if is increased by 10% from its true value while is decreased by 10% from its true value, then the product stays the same, so that the external input provides the same drive to (42). Of course, any deviation from the true parameter values also leads to other differences elsewhere in the system. Therefore, the confounding relation is only approximate and not strict. This heuristic argument gives an empirical formula:
| (44) |
where and refer to the true values of these parameters, whereas and refer to the estimated values.
Example 2: Confounding of the parameter pair ).
These two parameters appear separately in different equations, namely, appearing only in (42) while appearing only in (43). To combine them, we need to consider the interaction of these two equations. To simplify the problem, we consider a linearised system around the equilibrium state:
| (45) | |||||
| (46) |
where and are the slopes of the gain functions, and and are extra terms that depend on the equilibrium state and other parameters. Note that appears in (45) only once, in the second term in the curly brackets. Since also satisfies (46), we solve for in terms of from (46) and find a solution of the form: where is a constant. Substitution into (45) shows that the parameter combination scales how strongly influences this equation. Thus we have a heuristic confounding relation:
| (47) |
Example 3: Confounding of the parameter pair .
These two parameters both appear in the curly brackets in (42). We have a heuristic confounding relation:
| (48) |
where and are the equilibrium states. If this equation is satisfied, we expect that the term in the curly brackets in (42) would be close to a constant (the right-hand side of (48)) whenever the state and are close to the equilibrium values. When the state variables vary freely, we expect this relation to hold only as a very crude approximation.
Simulation results show that these three confounding relation can qualitatively account for the data scattering. The random data follow the same pattern (see Figure 7C) although they appear to have more scattering compared to the optimal design based data. Although the confounding relations are not strictly valid, their offer useful approximate explanations that are based on intuitive argument and are supported by the data as shown in Figure 7.
The theoretical slopes are always smaller, suggesting that the heuristic theory only accounts for a portion of the correlation. It is likely that there are approximate confounding among more than those three pairs of parameters namely , , and .
4 Discussion
4.1 Summary of the results
The main results of this paper can be summarized as follows.
-
1.
We have implemented an optimal design algorithm for generating stimuli that can efficiently probe the E-I network, which describes the dynamic interaction between an excitatory neuronal population and an inhibitory neuronal population. The data has been used to model the auditory system etc.
-
2.
The dynamical network allows both transient and sustained response components (Figure 2)
-
3.
Derivatives are computed directly by differential equations derived from the original system (Figure 3)
-
4.
Optimally designed stimuli have patterns. The amplitude tend to be saturated, which can lead to faster search because only boundary values need to be checked (Figure 4)
-
5.
The optimally designed stimuli elicited responses that have more dynamic range (more variance in the histogram of amplitude of the stimulus waveform )
- 6.
-
7.
We studied parameter confounding which is thought to be a major source of the error (Figure 7).
-
8.
Significance of the results can readily lead to practical applications. For example in the modelling of the auditory networks known works all used stationary sound stimuli. However, it is beneficial to include time dependency as realistic neurons and their networks have several dynamic features.
4.2 Defence of this Research
Choice of the model:
The chosen model is an appropriate and simple model which has only two neurons with one being excitatory and one being inhibitory. This choice is reasonable in the context of this research as the availability of previous work targeting a similar goal is quite limited. In addition, the known ones mostly based on the static feed-forward network designs. In order to verify our optimal design strategy we have to start from a simpler model. The theoretical development and results of this work can very easily be adapted to alternative and/or more complicated models. Here the most critical parameter is the number of data generating neurons (neurons where the spiking events are recorded by electrode implantations) and the computational complexity. The former is a procedural aspect of the experiment whereas the latter is directly related to the instrumentation. In addition, the universal approximating nature of the CTRNN’s is an advantage on this manner.
Speed of computation:
In this work, we aim at investigation of the computational principles without trying the maximizing the computation speed. Right now on a single PC, having a Intel® Core™i7 processor with cores, the computational duration for optimization of a single stimulus is about minutes. Surely, this is an average value as the number of steps required to converge to an optimum depends on certain conditions such as the value of objective value, gradient, constraint violation and step size. A similar situation exist for the optimization of the likelihood. However in this case, the optimization times of the likelihood will vary due to its increasing size as all the historical spiking is taken into account (see (12)) leading to a function with gradually increasing complexity. Although that is not the only fact contributing to the computational times, the average duration of optimization tend to increase with the size of likelihood . An average value for the observed duration of likelihood optimization is minutes. As a result optimization of one stimulus and subsequent likelihood estimation requires a duration of about minutes. This is approximately one hour. So one complete run with a sample size of is completed in a duration about hours. Changing the value of the sample size will have a direct influence on the system computation time. For example, the duration of one complete run will reduce to a value about hours when . This is an expected situation as there will be a reduced number of the summation terms in the likelihood function. The reduction in the duration of the optimal design algorithm is only based on the reduction in the number of trials which is just equal to the sample size . So based on these findings, one will need a speed-up in order to adapt this work to an experiment. There are several ways to speed up the computation:
-
1.
Using a large time step: In this work we have integrated the equations using a time step of -millisecond or -seconds. This value may be increased to levels as high as -seconds. This modification will have a little contribution to the speed of computation. The benefits will most likely be from the optimal design part due to the manipulation of a single interval (no consideration of past/historical spike trains). However, the higher the time step the lower the accuracy of the estimates and the optimality of the stimuli. This main contributor to this fact is the spike generation algorithm where the accuracy of the locations of some spikes are lost when a coarse integration interval is applied.
-
2.
Using and/or developing streamlined optimization algorithms: This can be a subject of a new project on the same field. This development is expected to have a considerable contribution to the computation time without any trade-offs over performance.
-
3.
Generating the stimuli as a block rather than one by one: This is also a potential topic for a new project. This is expected to reduce the optimal design time without losing performance.
-
4.
Employment of larger cluster computing systems (or high performance computing systems (HPC)) having more than CPU cores: Though the most sophisticated and expensive solution, it is the best approach to cure the overall computational burdens and transform the theoretical only study to an experiment adaptable one.
-
5.
Porting the algorithms to a lower level programming language such as C/C++ or FORTRAN may help in speeding up the computation. If an efficient and stable numerical differentiation algorithm can be employed in this set-up, another optimality criterion such as D or E optimality can be used in the computation of the Fisher Information Metric which might help in reducing the number of steps (i.e and/or values).
-
6.
Knowing the fact that the optimal stimulus amplitudes tend to the upper boundary (remember from Figure 4B). All the amplitudes can be set to same value as and only is computed from optimization. This setting can be helpful for speeding up the optimization time during an actual experiment. However, it should be verified by simulation whether this choice is meaningful for an actual experiment. In this case, one may not need many repeats as only the statistics of the stimuli is required. This occurrence is quite common in the simulation results thus we do not expect a performance degradation when this change is applied to the stimuli characterization.
With the above adaptations, it is expected that we are within reach to reduce the computation time for each 3-second stimuli to less than 3 seconds. In addition one can has the following options which are related to tuning of the algorithms used in this research:
-
1.
The parameter related to the sample size might be reduced. That is an examined situation in this study. Optimal design seems to yield a better estimation performance with a reduced compared to random stimuli case with same . However, the former will lead to a slightly increased computational time. However, the trade-off is not very direct. For example, a random stimuli based simulation with samples requires a longer run than a simulation based on an optimally designed stimulus with samples. This is fairly a good trade-off.
-
2.
Another option to increase the computational performance might be the reduction of the cut-off points in the optimization algorithm such as the first order optimality measure (tolerance of the gradient) and the step-size. This will result in a faster computation but this approach may bring out questions on the accurate detection of the local minimums among which the best one is chosen (both in OED and likelihood optimization). For the fmincon algorithm in MATLAB the first order optimality tolerance and step-size might both be shifted from to . This tuning brings improvement in the computational duration about 10% without a considerable performance loss. However, if one has a HPC supported computational environment it is strongly recommended not to modify these settings.
Future Issues:
The above network is rather a simpler example to demonstrate the optimal design approach and its computational challenges. However more features can be brought to this research concerning efficiency and applicability to an actual experiment.
-
1.
Speed up issues: The tasks related to speed of computation discussed in Section 4.2 may be a separate project to be developed on top this research.
-
2.
Large number of neurons may be considered together with multiple stimulus inputs and response data collection from multiple neurons (both excitatory and inhibitory groups of neurons).
-
3.
More complex stimulus structures may be utilized. This can be achieved by increasing in (15) or considering different stimulus representations other than phase cosines.
-
4.
In this research, the primary goal was the estimation of the network weights and time constants . However, it will be interesting to test the methodology for its performance in estimation of firing thresholds and slopes. (i.e. the parameters and in (2))
-
5.
Some more realistic details like plasticity can be included to obtain a model describing the synaptic adaptation. Although it is expected to be a harder problem, the method takes fewer stimuli and should be faster.
-
6.
In this research, the optimal design process is performed by maximization of the Fisher Information Metric with respect to a single parameter which are individual elements of the main diagonal of the Fisher Information Matrix. This is at best close to A-Optimality measure of Optimal Design. However, it is stated in [41] that, D-Optimality brings an advantage that the optimization will be immune to the scales of the variables. On the contrary, it is also stated in the same source that this mentioned fact is not true for A- and E-Optimality criteria in general. The sensitivity to scaling of the variables lead to another issue that the confounding of the parameters brings certain problems about the bias and efficiency of the estimates. So it will be quite beneficial to see the results obtained from the same research with the optimal designs performed by D-Optimal and other measures of Fisher Information Metric such as E- and F-Optimality. As these will require a new set of computations it will be better to include them in a future study.
-
7.
Similar to the discussion in Article 6 above, the methodology of optimization in optimal designs and likelihood optimization should be considered. Current work involves evaluation of gradients for the sake of faster computation. However, this requires larger efforts in the preparation as one should develop a specific algorithm to compute the evolution of the gradients satisfactorily. This is also required for a speed-up. With the availability of a high performance computing system, other optimization methods such as simulated-annealing, genetic algorithms and pattern search might be employed instead of the local minimizers such as fmincon of MATLAB. These algorithms may help in searching for a better optimal stimulus.
-
8.
After a sufficiently fast simulation is obtained an experiment can be performed involving a living experimental subject. The mapping of the actual sound heard by the animal during the course of experiment to the optimally designed stimulus is a critical issue here and will also be a part of the future related research.
References
- [1] V. V. Fedorov, S. L. Leonov, Optimal Design for Nonlinear Response Models, Vol. 53, CRC Press Llc, 2013.
- [2] D. Telen, F. Logist, E. Van Derlinden, J. Van Impe, Approximate robust optimal experiment design in dynamic bioprocess models, in: Control & Automation (MED), 2012 20th Mediterranean Conference on, IEEE, 2012, pp. 157–162.
- [3] J. Benda, T. Gollisch, C. K. Machens, A. V. Herz, From response to stimulus: adaptive sampling in sensory physiology, Current Opinion in Neurobiology 17 (4) (2007) 430–436.
- [4] J. P. Newman, R. Zeller-Townson, M.-F. Fong, S. A. Desai, R. E. Gross, S. M. Potter, Closed-loop, multichannel experimentation using the open-source neurorighter electrophysiology platform, Frontiers in neural circuits 6.
- [5] L. Paninski, B. Lau, A. Reyes, Noise-driven adaptation: in vitro and mathematical analysis, Neurocomputing 52 (2003) 877–883.
- [6] P. Z. Marmarelis, V. Z. Marmarelis, Analysis of physiological systems: The white-noise approach, Plenum Press New York, 1978.
- [7] E. Chichilnisky, A simple white noise analysis of neuronal light responses, Network: Computation in Neural Systems 12 (2) (2001) 199–213.
- [8] L. Paninski, Maximum likelihood estimation of cascade point-process neural encoding models, Network: Computation in Neural Systems 15 (4) (2004) 243–262.
- [9] M. C.-K. Wu, S. V. David, J. L. Gallant, Complete functional characterization of sensory neurons by system identification, Annu. Rev. Neurosci. 29 (2006) 477–505.
- [10] C. DiMattina, K. Zhang, How to modify a neural network gradually without changing its input-output functionality, Neural computation 22 (1) (2010) 1–47.
- [11] C. DiMattina, K. Zhang, Adaptive stimulus optimization for sensory systems neuroscience, Frontiers in neural circuits 7.
- [12] C. DiMattina, K. Zhang, Active data collection for efficient estimation and comparison of nonlinear neural models, Neural computation 23 (9) (2011) 2242–2288.
- [13] F. Pukelsheim, Optimal design of experiments, Vol. 50 of SIAM Classics In Applied Mathematics, SIAM, 1993.
- [14] H. DeGroot Morris, Optimal statistical decisions, McGraw-Hill Company, New York, 1970.
- [15] I. J. Myung, Tutorial on maximum likelihood estimation, Journal of Mathematical Psychology 47 (1) (2003) 90–100.
- [16] D. Eyal, Adaptive on-line modeling in the auditory system: in vivo implementation of the optimal experimental design paradigm, Master’s thesis, Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD, USA (2012).
- [17] W. Tam, Adaptive modeling of marmoset inferior colliculus neurons in vivo, Ph.D. thesis, Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD, USA (2012).
- [18] R. D. Beer, On the dynamics of small continuous-time recurrent neural networks, Adaptive Behavior 3 (4) (1995) 469–509.
- [19] E. Ledoux, N. Brunel, Dynamics of networks of excitatory and inhibitory neurons in response to time-dependent inputs, Frontiers in computational neuroscience 5.
- [20] A. L. Hodgkin, A. F. Huxley, A quantitative description of membrane current and its application to conduction and excitation in nerve, The Journal of physiology 117 (4) (1952) 500.
- [21] K. E. Hancock, K. A. Davis, H. F. Voigt, Modeling inhibition of type ii units in the dorsal cochlear nucleus, Biological cybernetics 76 (6) (1997) 419–428.
- [22] K. E. Hancock, H. F. Voigt, Wideband inhibition of dorsal cochlear nucleus type iv units in cat: a computational model, Annals of biomedical engineering 27 (1) (1999) 73–87.
- [23] J. de la Rocha, C. Marchetti, M. Schiff, A. D. Reyes, Linking the response properties of cells in auditory cortex with network architecture: cotuning versus lateral inhibition, The Journal of Neuroscience 28 (37) (2008) 9151–9163.
- [24] M. N. Shadlen, W. T. Newsome, Noise, neural codes and cortical organization, Current opinion in neurobiology 4 (4) (1994) 569–579.
- [25] P. A. Lewis, G. S. Shedler, Simulation of nonhomogeneous poisson processes by thinning, Naval Research Logistics Quarterly 26 (3) (1979) 403–413.
- [26] U. T. Eden, Point process models for neural spike trains, Neural Signal Processing: Quantitative Analysis of Neural Activity (2008) 45–51.
- [27] E. N. Brown, R. Barbieri, V. Ventura, R. E. Kass, L. M. Frank, The time-rescaling theorem and its application to neural spike train data analysis, Neural computation 14 (2) (2002) 325–346.
- [28] M. Nawrot, A. Aertsen, S. Rotter, Single-trial estimation of neuronal firing rates: from single-neuron spike trains to population activity, Journal of neuroscience methods 94 (1) (1999) 81–92.
- [29] H. Shimazaki, S. Shinomoto, Kernel bandwidth optimization in spike rate estimation, Journal of computational neuroscience 29 (1-2) (2010) 171–182.
- [30] H. Shimazaki, S. Shinomoto, A method for selecting the bin size of a time histogram, Neural Computation 19 (6) (2007) 1503–1527.
- [31] S. Koyama, S. Shinomoto, Histogram bin width selection for time-dependent poisson processes, Journal of Physics A: Mathematical and General 37 (29) (2004) 7255.
- [32] K. D. Miller, F. Fumarola, Mathematical equivalence of two common forms of firing rate models of neural networks, Neural computation 24 (1) (2012) 25–31.
- [33] S. Flila, P. Dufour, H. Hammouri, M. Nadri, A combined closed loop optimal design of experiments and online identification control approach, in: Control Conference (CCC), 2010 29th Chinese, IEEE, 2010, pp. 1178–1183.
- [34] D. Telen, F. Logist, E. Van Derlinden, J. F. Van Impe, Robust optimal experiment design: A multi-objective approach, in: Mathematical Modelling, Vol. 7, 2012, pp. 689–694.
- [35] C. DiMattina, K. Zhang, How optimal stimuli for sensory neurons are constrained by network architecture, Neural computation 20 (3) (2008) 668–708.
- [36] B. Mendelson, Introduction to topology, Courier Corporation, 1990.
- [37] H. B. Mann, D. R. Whitney, et al., On a test of whether one of two random variables is stochastically larger than the other, The annals of mathematical statistics 18 (1) (1947) 50–60.
- [38] J. D. Gibbons, S. Chakraborti, Nonparametric statistical inference, Springer, 2011.
- [39] M. Hollander, D. A. Wolfe, E. Chicken, Nonparametric statistical methods, Vol. 751, John Wiley & Sons, 2013.
- [40] A. A. Prinz, D. Bucher, E. Marder, Similar network activity from disparate circuit parameters, Nature neuroscience 7 (12) (2004) 1345–1352.
- [41] L. A. Khinkis, L. Levasseur, H. Faessel, W. R. Greco, Optimal design for estimating parameters of the 4-parameter hill model, Nonlinearity in biology, toxicology, medicine 1 (3) (2003) 15401420390249925.