Addressing Over-Smoothing in Graph Neural Networks via Deep Supervision
Abstract
Learning useful node and graph representations with graph neural networks (GNNs) is a challenging task. It is known that deep GNNs suffer from over-smoothing where, as the number of layers increases, node representations become nearly indistinguishable and model performance on the downstream task degrades significantly. To address this problem, we propose deeply-supervised GNNs (DSGNNs), i.e., GNNs enhanced with deep supervision where representations learned at all layers are used for training. We show empirically that DSGNNs are resilient to over-smoothing and can outperform competitive benchmarks on node and graph property prediction problems.
1 Introduction
We live in a connected world and generate vast amounts of graph-structured or network data. Reasoning with graph-structured data has many important applications such as traffic speed prediction, product recommendation, and drug discovery (Zhou et al., 2020a; Gaudelet et al., 2021). Graph neural networks (GNNs), first introduced by Scarselli et al. (2009), have emerged as the dominant solution for graph representation learning, which is the first step in building predictive models for graph-structured data.
One of the most important applications of GNNs is that of node property prediction, as in semi-supervised classification of papers (nodes) in a citation network (see, e.g., Kipf and Welling, 2017). Another exciting and popular application of GNNs is that of graph property prediction, as in, for example, graph classification and regression. In this setting, we are given a set of graphs and corresponding labels, one for each graph, and the goal is to learn a mapping from the graph to its label. In both problems, node and graph property prediction, the labels can be binary, multi-class, multi-label, or continuous.
Even though GNNs have been shown to be a powerful tool for graph representation learning, they are limited in depth, that is the number of GNN layers. Indeed, deep GNNs suffer from the problem of over-smoothing where, as the number of layers increases, the node representations become nearly indistinguishable and model performance on the downstream task deteriorates significantly.
Previous work has analyzed and quantified the over-smoothing problem (Liu et al., 2020; Zhao and Akoglu, 2020; Chen et al., 2020) as well as proposed methodologies to address it explicitly (Li et al., 2018; Zhao and Akoglu, 2020; Xu et al., 2018b). Some of the most recent approaches have mainly focused on forcing diversity on latent node representations via normalization (see, e.g, Zhou et al., 2020b; Zhao and Akoglu, 2020). However, while these approaches have tackled the over-smoothing problem in node-property prediction tasks with reasonable success, they have largely overlooked the graph-property prediction problem.
In this paper we show that over-smoothing is also a critical problem in graph-property prediction and propose a different approach to overcome it. In particular, our method trains predictors using node/graph representations from all layers, each contributing to the loss function equally, therefore encouraging the GNN to learn discriminative features at all GNN depths. Inspired by the work of Lee et al. (2015), we name our approach deeply-supervised graph neural networks (DSGNNs).
Compared to approaches such as those by Liu et al. (2020), our method only requires a small number of additional parameters that grow linearly (instead of quadratically) with the number of GNN layers. Furthermore, our approach can be combined with previously proposed methods such as normalization (Zhao and Akoglu, 2020) easily and we explore the effectiveness of this combination empirically. Finally, our approach is suitable for tackling both graph and node property prediction problems.
In summary, our contributions are the following,
-
•
We propose the use of deep supervision for training GNNs, which encourages learning of discriminative features at all GNN layers. We refer to these types of methods as deeply-supervised graph neural networks (DSGNNs);
-
•
DSGNNs can be used to tackle both node and graph-level property prediction tasks;
-
•
DSGNNs are general and can be combined with any state-of-the-art GNN adding only a small number of additional parameters that grows linearly with the number of hidden layers and not the size of the graph;
-
•
and we show that DSGNNs are resilient to the over-smoothing problem in deep networks and can outperform competing methods on challenging datasets.
2 Related Work
GNNs have received a lot of attention over the last few years with several extensions and improvements on the original model of Scarselli et al. (2009) including attention mechanisms (Veličković et al., 2018) and scalability to large graphs (Hamilton et al., 2017; Klicpera et al., 2018; Chiang et al., 2019; Zeng et al., 2019). While a comprehensive introduction to graph representation learning can be found in Hamilton (2020), below we discuss previous work on graph property prediction and over-smoothing in GNNs focused on the node property prediction problem.
2.1 Graph Property Prediction
A common approach for graph property prediction is to first learn node representations using any of many existing GNNs (Kipf and Welling, 2017; Hamilton et al., 2017; Veličković et al., 2018; Xu et al., 2018a) and then aggregate the node representations to output a graph-level representation. Aggregation is performed using a readout (also known as pooling) function applied to the node representations output at the last GNN layer. A major issue is the readout function’s ability to handle isomorphic graphs. It should be invariant to such permutations. Robustness for isomorphic graphs can be achieved via readout functions invariant to the node order such as the sum, mean or max.
Several more sophisticated readout functions have also been proposed. For example, Lee et al. (2019) proposed weighted average readout using self-attention (SAGPool). Zhang et al. (2018) proposed a pooling layer (SortPool) that sorts nodes based on their structural role in the graph; sorting the nodes makes them invariant to node order such that representations can be learnt using D convolutional layers.
Gao and Ji (2019) combine pooling with graph coarsening to train hierarchical graph neural networks. Similarly, Ying et al. (2018) proposed differentiable pooling (DiffPool) where the pooling layer learns a soft assignment vector for each node to a cluster. Each cluster is represented by a single super-node and collectively all super-nodes represent a coarse version of the graph; representations for each super-node are learnt using a graph convolutional layer. These hierarchical methods coarsen the graph by reducing the graph’s nodes at each convolutional layer down to a single node whose representation is used as input to a classifier.
2.2 Over-smoothing in Node-Property Prediction
Li et al. (2018) focus on semi-supervised node classification in a setting with low label rates. They identify the over-smoothing problem as a consequence of the neighborhood aggregation step in GNNs; they show that the latter is equivalent to repeated application of Laplacian smoothing leading to over-smoothing. They propose a solution that increases the number of training examples using a random walk-based procedure to identify similar nodes. The expanded set of labeled examples is used to train a Graph Convolutional Network (GCN, Kipf and Welling, 2017). The subset of nodes that the GCN model predicts most confidently are then added to the training set and the model is further fine-tuned; they refer to the latter process as self-training. This approach is not suitable for the graph property prediction setting where node-level labels are not available and the graphs are too small for this scheme to be effective.
Liu et al. (2020) propose Deep Adaptive Graph Neural Networks (DAGNNs) for training deep GNNs by separating feature transformation from propagation. DAGNN uses a Multi-layer Perceptron (MLP) for feature transformation and smoothing via powers of the adjacency matrix for propagation similarly to Klicpera et al. (2019) and Wu et al. (2019). However, the cost of their propagation operation increases quadratically as a function of the number of nodes in the graph hence DAGNNs do not scale well to large graphs. Furthermore, DAGNN’s ability to combine local and global neighborhood information is of limited use in the graph property prediction setting where the graphs are small and the distinction between local and global node neighborhoods is difficult to make.
Zhao and Akoglu (2020) also analyze the over-smoothing problem and quantify it by measuring the row and column-wise similarity of learnt node representations. They introduce a normalization layer called PairNorm that during training forces these representations to remain distinct across node clusters. They show that generally, the normalization layer reduces the effects of over-smoothing for deep GNNs. To evaluate their approach, they identify the Missing Features (MF) setting such that when test node features are missing then GNNs with PairNorm substantially outperform GNNs without it. PairNorm is a general normalisation layer and it can be used with any graph GNN architecture including ours introduced in Section 4. It is applicable to both node and graph-level representation learning tasks.
Zhou et al. (2020b) also adopt group normalisation (Wu and He, 2018) in neural networks to the graph domain. They show their approach tackles over-smoothing better than PairNorm. Group normalisation is most suited to node classification tasks and requires clustering nodes into groups posed as part of the learning problem. The number of groups is difficult to determine and must be tuned as a hyper-parameter.
Finally, in an approach closely related to ours, Xu et al. (2018b) propose jumping knowledge networks (JKNets) that make use of jump connections wiring the outputs of the hidden graph convolutional layers directly to the output layer. These vectors are combined and used as input to a classification or regression layer. JKNets combine learnt node representations aggregated over different size neighborhoods in order to alleviate the problem of over-smoothing. We propose a different approach that, instead of combining hidden representations across layers, introduces a classification or regression layer attached to the output of each hidden graph convolutional layer.
3 Graph Neural Networks
Let a graph be represented as the tuple where is the set of nodes and the set of edges. The graph has nodes. We assume that each node is also associated with an attribute vector and let represent the attribute vectors for all nodes in the graph. Let represent the graph adjacency matrix; here we assume that is a symmetric and binary matrix such that , where if there is an edge between nodes and , i.e., , and otherwise. Also, let represent the diagonal degree matrix such that .
Typical GNNs learn node representations via a neighborhood aggregation function. Assuming a GNN with layers, we define such a neighborhood aggregation function centred on node at layer as follows,
| (1) |
where is the set of node ’s neighbors in the graph, is an aggregation function, is a linear transformation that could be the identity function, and is a non-linear function applied element-wise. Let the representations for all nodes at the -th layer with output dimension ; we set . and . A common aggregation function that calculates the weighted average of the node features where the weights are a deterministic function of the node degrees is as proposed by Kipf and Welling (2017). Here represents the twice normalized adjacency matrix with self loops given by where is the degree matrix for and is the identity matrix. Substituting this aggregation function in Equation 1, specifying to be a linear projection with weights and defining the matrix such that , gives rise to the graph convolutional layer of Kipf and Welling (2017),
| (2) |
where, as before, is a non-linear function, typically the element-wise rectified linear unit (ReLU) activation (Nair and Hinton, 2010). Many other aggregation functions have been proposed, most notably the sampled mean aggregator in GraphSAGE (Hamilton et al., 2017) and the attention-based weighted mean aggregator in graph attention networks (GAT Veličković et al., 2018). In our work, we employ GAT-based graph convolutional layers, as they have been shown by Dwivedi et al. (2020) to be more expressive than the graph convolutional network (GCN) architecture of Kipf and Welling (2017). In this case we make with
| (3) |
for , where , as before, is the set of node ’s neighbors; and are trainable weight vector and matrix respectively and is the concatenation operation.
3.1 Node Property Prediction
Equation 2 is a realization of Equation 1 and constitutes the so-called spatial graph convolutional layer. More than one such layers can be stacked together to define GNNs. When paired with a task-specific loss function, these GNNs can be used to learn node representations in a semi-supervised setting using full-batch gradient descent. For example, in semi-supervised node classification, it is customary to use the row-wise softmax function at the output layer along with the cross-entropy loss over the training (labeled) nodes.
3.2 Graph Property Prediction
In the graph property prediction setting, we are given a set of graphs and corresponding properties (labels) . The goal is to learn a function that maps a graph to its properties. The standard approach is to first learn node representations using a -layer GNN followed by a readout function that outputs a graph-level vector representation. This graph-level representation can be used as input to a classifier or regressor. The readout function for a graph is generally defined as,
| (4) |
where such that is the dimensionality of the graph-level representation vectors. Note that Equation 4 aggregates representations from all nodes in the graph.
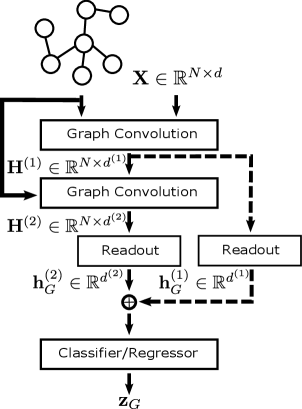
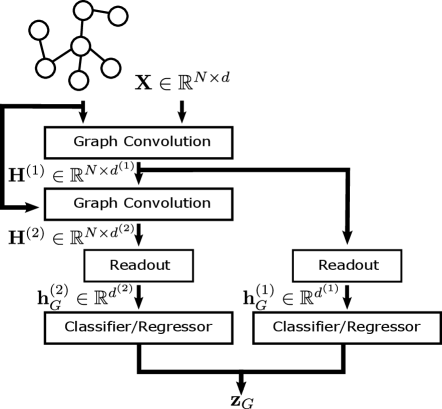
Figure 1 (left) shows a diagram of the standard GNN architecture with optional jump connections; for node property prediction tasks the architecture is the same but with the Readout layers removed. Jump connections can be applied at the node level, i.e., concatenate node representations output from each convolutional layer, or at the graph-level as shown in Figure 1. Furthermore, we include a multi-layer Perceptron (MLP) as the classifier/regressor so that the network can be trained end-to-end using stochastic gradient descent. The MLP is optional when using the standard architecture but necessary when employing jump connections. Given a suitable loss function such as the cross-entropy for classification or the root mean squared error (RMSE) for regression, we can train predictive models in a supervised setting for graph-level tasks and semi-supervised setting for node-level tasks.
4 Deeply-supervised Graph Neural Networks
Deeply-supervised nets (DSNs, Lee et al., 2015) were proposed as a solution to several problems in training deep neural networks. By using companion objective functions attached to the output of each hidden layer, DSNs tackle the issue of vanishing gradients. Furthermore, in standard neural networks with shallow architectures, deep supervision operates as a regularizer of the loss at the last hidden layer. Lastly, and more importantly, for deep networks, it encourages the estimation of discriminative features at all network layers (Lee et al., 2015). Therefore, inspired by this work, we introduce deeply supervised graph neural networks (DSGNNs), i.e., graph neural network architectures trained with deep supervision. Thus, we hypothesize that DSGNNs are resilient to over-smoothing and test this hypothesis by evaluating and analyzing their performance in training shallow and deep networks in Section 5.
Once we have defined node-level representations, as described in Section 3, our first step to construct and train DSGNNs is to compute graph-level representations at each layer using , where is obtained using the recurrent relation in Equation 2. As before, is a readout (or pooling) function. Simple examples of readout functions are the mean and the maximum of the features across all the nodes in the graph. This is followed by a linear layer and (potentially) a non-linearity that computes the output for each layer, . For example, can be the softmax function or the identity function for classification or regression, respectively. Finally, given a loss function over our true and predicted outputs we learn all model parameters by optimizing the average loss function across all layers.
4.1 Graph Classification with a 2-Layer Network
As an illustrative example, here we consider a graph classification problem with classes using a -layer GAT model as shown in Figure 1 (right). See Section A.1 in the Appendix for an example of the node classification setting.
(i) Layer-dependent graph features: We first compute, for each graph, layer-dependent graph features as:
| (5) | |||
| (6) |
where the activations are element-wise and the readouts operate across rows.
(ii) Layer-dependent outputs: We then compute the outputs for each layer as:
| (7) |
where we note the new parameters , which are different from the previous weight matrices .
(iii) Layer-dependent losses: We now compute the cross-entropy loss for each layer:
| (8) |
where is the set of training graphs, is the predicted probability for class and graph , and is the corresponding ground truth label.
(iv) Total loss: The DSGNN loss is the mean of the losses of all predictive layers, for , we have:
| (9) |
where each of the individual losses are given by Equation 8. We estimate the model parameters using gradient-based optimization so as to minimize the total loss in Equation 9. Unlike Lee et al. (2015), we do not decay the contribution of the surrogate losses as a function of the training epoch. Consequently, at prediction time we average the outputs from all classifiers and then apply the softmax function to make a single prediction for each input graph.
4.2 Advantages of Deep Supervision
As mentioned before, over-smoothing leads to node representations with low discriminative power at the last GNN layer. This hinders the deep GNN’s ability to perform well on predictive tasks. DSGNNs circumvent this issue as the learned node representations from all hidden layers inform the final decision. The distributed loss encourages node representations learned at all hidden layers to be discriminative such that network predictions do not rely only on the discriminative power of the last layer’s representations.
Furthermore, deep supervision increases the number of model parameters linearly to the number of MLP layers. Consider a classification model with hidden layers, dimensional graph-level representations, and a single layer MLP. If the number of classes is , then a DSGNN model requires parameters more than a standard GNN.
5 Empirical Evaluation
We aim to empirically evaluate the performance of DSGNNs on a number of challenging graph and node classification and regression tasks. We investigate empirically if the addition of deep supervision provides an advantage over the standard GNN and JKNet (Xu et al., 2018b) architectures shown in Figure 1.
We implemented111We will release the source code upon publication acceptance the standard GNN, JKNet, and DSGNN architectures using PyTorch and the Deep Graph Library (DGL, Wang et al., 2019). The version of the datasets we use is that available via DGL222https://github.com/dmlc/dgl and DGL-LifeSci333https://github.com/awslabs/dgl-lifesci. All experiments were run on a workstation with GB of RAM, Nvidia Telsa P100 GPU, and Intel Xeon processor.
| Model | ESOL | Lipophilicity | Enzymes |
|---|---|---|---|
| RMSE | Accuracy | ||
| GNN | 0.726 (0.063) [6] | 0.618(0.033) [8] | 64.1(6.8) [2] |
| JKNet | 0.728 (0.074) [8] | 0.633 (0.035) [10] | 65.7 (5.8) [2] |
| DSGNN | 0.694 (0.065) [16] | 0.594 (0.033) [16] | 63.3 (7.7) [2] |
| Model | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Accuracy | |||
| GNN | 82.6 (0.6) [2] | 71.1 (00.6) [2] | 77.2 (0.5) [9] |
| JKNet | 81.4 (0.6) [3] | 68.5 (0.4) [2] | 76.9 (0.9) [11] |
| DSGNN | 81.1 (1.0) [4] | 69.9 (0.4) [3] | 77.5 (0.5) [12] |
| GNN-PN | 77.9 (0.4) [2] | 68.0 (0.7) [3] | 75.5 (00.7) [15] |
| DSGNN-PN | 73.1 (0.8) [7] | 59.4 (1.6) [2] | 75.9 (00.5) [7] |
| Model | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Accuracy | |||
| GNN | 77.5 (0.8) [10] | 62.8 (0.7) [2] | 76.8 (0.7) [9] |
| JKNet | 74.9 (1.0) [15] | 61.8 (0.8) [2] | 76.4 (0.7) [9] |
| DSGNN | 76.8 (0.8) [11] | 61.0 (1.0) [2] | 0.771 (0.4) [10] |
| GNN-PN | 75.8 (0.4) [6] | 62.1 (0.6) [4] | 75.0 (0.7) [15] |
| DSGNN-PN | 73.5 (0.9) [15] | 52.8 (1.2) [9] | 74.7 (0.9) [25] |
5.1 Datasets and Experimental Set-up
DSGNN is a general architecture such that it can use any combination of graph convolutional and readout layers. We focus the empirical evaluation on a small number of representative methods. For graph convolutions we use graph attention networks (GAT, Veličković et al., 2018) with multi-head attention We average or concatenate the outputs of the attention heads (we treat this operation as a hyper-parameter) and use the resulting node vectors as input to the next layer.
For DSGNN and JKNet, the last GAT layer is followed by a fully connected layer with an activation suitable for the downstream task, e.g., softmax for classification. The linear layer is necessary to map the GAT layer representations to the correct dimension for the downstream task. So, a DSGNN or JKNet model with layers comprises of GAT layers and one linear layer. For a standard GNN model, the last layer is also GAT following Veličković et al. (2018) such that a -layer model comprises of GAT layers.
We used the evaluation protocol proposed by Errica et al. (2019) and present results for six benchmark datasets. Of these, three are graph tasks and three are node tasks. We include detailed dataset statistics in Table 4 in the Appendix.
5.1.1 Graph Property Prediction
The graph property prediction datasets are from biochemistry where graphs represent molecules. The task is to predict molecular properties. We base our empirical evaluation on three datasets which are ESOL from Delaney (2004), Lipophilicity from Gaulton et al. (2017) and Enzymes from Schomburg et al. (2004). Enzymes is a graph classification task whereas ESOL and Lipophilicity are regression tasks. We use -fold cross validation and repeat each experiment times. We optimize the root mean square error (RMSE) for regression and the cross-entropy loss for classification.
For all architectures, we set all hidden layers to size with attention heads (total features). All layers are followed with a activation (Nair and Hinton, 2010) except the last one; the last layer either uses activation or no activation for classification and regression tasks respectively. We varied model depth in the range . For readout, we use the non-parametric max function. We perform grid search for learning rate: {, , } and weight decay: {, }. We use batch size and train for a maximum epochs using mini-batch SGD with momentum set to .
5.1.2 Node Property Prediction
The node classification datasets are the citation networks Cora, Citeseer and Pubmed from Sen et al. (2008). The task for all datasets is semi-supervised node classification in a regime with few labeled nodes. We used the splits from Yang et al. (2016) and performance on the validation set for hyper-parameter selection. We repeat each experiment times. We optimize the cross-entropy loss and use accuracy for model selection and performance comparison.
We set all hidden layers to size with attention heads (total features) and (Clevert et al., 2015) activation for all GAT layers. We varied model depth in the range . We performed grid search for the initial learning rate: {}, weight decay: {}, and dropout (both feature and attention): {}. We trained all models using the Adam optimiser (Kingma and Ba, 2014) for a maximum epochs and decayed the learning rate by a factor of every epochs.
 |
 |
 |
5.2 Results
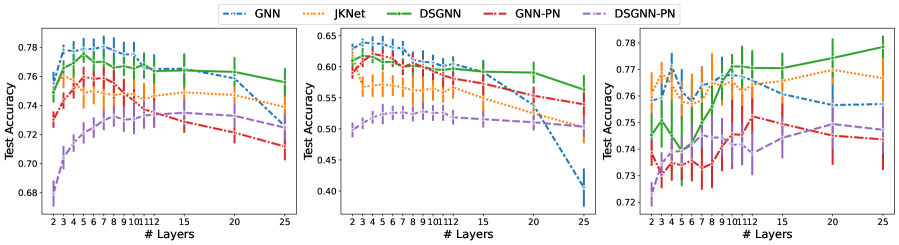
Tables 1 and 2 show the performance for each architecture and for the all datasets. Also shown for each model is the number of layers required to achieve the best performance. For each dataset, model selection across model depth is based on validation set performance and the tables report performance on the test set for the selected models.
5.2.1 Graph Regression and Classification
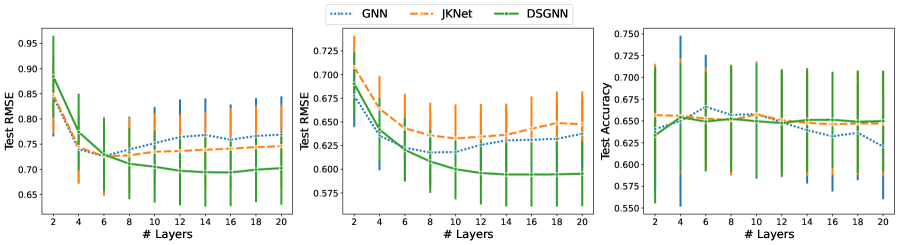
We see in Table 1 that for ESOL and Lipophilicity, models enhanced with deep supervision achieved the best outcome. In addition, DSGNN performs best at a much larger depth than the other architectures. On the graph classification dataset (Enzymes), all models perform similarly with JKNet having a small advantage. For graph classification, all architectures performed best using only convolutional layers.
Figure 2 shows the performance of each architecture as a function of model depth. For the regression datasets, all architectures benefit from increasing depth up to a point. For GNN models with more than and layers for ESOL (left) and Lipophilicity (middle) datasets respectively performance starts decreasing. Similarly for JKNet for models with more than and layers for ESOL and Lipophilicity respectively. On the other hand, with the exception of the Enzymes dataset, DSGNN performance continues to improve for up to layers for both datasets before it flattens out. Our evidence suggests that for graph-level tasks DSGNNs can exploit larger model depth to achieve improved performance when compared to standard GNNs and JKNets.
5.2.2 Node Classification
Table 2 shows that the standard GNN architecture outperformed the others in two of the three node classification datasets, namely Cora and Citeseer. DSGNN demonstrated a small advantage on the larger Pubmed dataset. As previously reported in the literature, shallow architectures perform best on these citation networks. We observe the same since for the smaller Cora and Citeseer all architectures performed best with to layers. Only on Pubmed all architectures benefited from increased model depth. We attribute this to the graph’s larger size where more graph convolutional layers allow for information from larger neighborhoods to inform the inferred node representations.
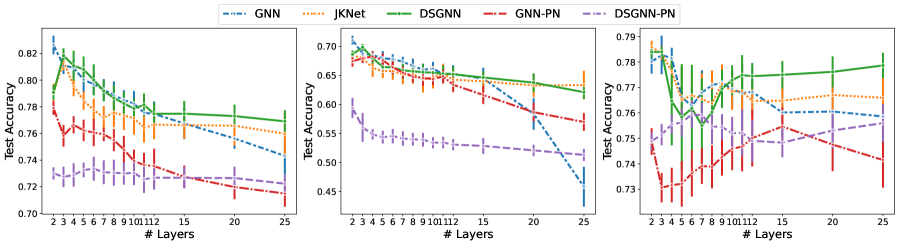
It can be seen in Figure 3 that for the smaller Cora and Citeseer, for all models performance degrades as model depth increases. As we noted earlier, this performance degradation has been attributed to the over-smoothing problem in GNNs. In our experiments, DSGNN demonstrated consistently higher resilience to over-smoothing than competing methods. Table 5 in the Appendix shows the performance of all architectures with layers and clearly indicates that DSGNN outperforms the standard GNN and JKNet for Cora and Pubmed. JKNet is best for Citeseer with DSGNN a close second. As expected DSGNN and JKNet are more resilient to over-smoothing as compared to the standard GNN with more than layers. For all datasets and especially Citeseer, performance for the standard GNN degrades substantially as a function of model depth.
Lastly, we note that for all datasets the addition of pair normalization (PairNorm, Zhao and Akoglu, 2020) to the standard GNN hurts performance. This finding is consistent with the results in Zhao and Akoglu (2020). However, as we will see in Section 5.2.3, PairNorm can be beneficial in the missing feature setting. Table 1 shows that the performance of GNN with PN drops by approximately on Cora and Citeseer respectively. DSGNN with PairNorm is the worst performing architecture across all node classification datasets. Consequently, we do not recommend the combination of deep supervision and PairNorm.
5.2.3 Node Classification with Missing Features
Zhao and Akoglu (2020) introduced the missing features setting for the node classification task and demonstrated that GNNs with PairNorm achieve the best results and for deeper models. In the missing features setting, a proportion of nodes in the validation and test sets have their feature vectors zeroed. This setting simulates the missing data scenario common in real-world applications. The missing data proportion can vary from where all nodes have known attributes and where all nodes in the validation and test sets have missing attributes. Here we consider the performance of standard GNN, JKNet, and DSGNN for the latter setting only.
Table 3 and Figure 4 show the performance of the three architectures in the missing features setting. We note that in comparison to the results in Table 2 and excluding Citeseer, all models achieved their best performance at larger depth. Interestingly and in contrast to Zhao and Akoglu (2020), we found that the standard GNN architecture performed best for the smaller Cora and Citeseer graphs. We attribute the standard GNN’s good performance to our use of a model with high capacity ( attention heads and -dimensional embeddings for each head) as well as careful tuning of relevant hyper-parameters. Zhao and Akoglu (2020) use a simpler model, e.g., one attention head, and do not tune important hyper-parameters such as learning rate, dropout and weight decay.
However, on the larger Pubmed dataset, DSGNN with layers achieves the highest test accuracy. A DSGNN model with layers as shown in Figure 4 and Table 6 in the Appendix achieves the highest test accuracy even when compared to the -layer DSGNN model; the latter was selected for inclusion in Table 3 because it achieved the highest validation accuracy that we used for model selection across model depth. We provide additional analysis of DSGNN’s ability to learn more discriminative node representations and alleviate over-smoothing in the Appendix Section A.3.2. We conclude that DSGNN is the more robust architecture to the over-smoothing problem in the missing feature setting and especially for larger graphs.
6 Conclusion
We introduced deeply-supervised graph neural networks (DSGNNs) and demonstrated their effectiveness in training high performing models for graph and node property prediction problems. DSGNNs are GNNs enhanced with deep supervision that introduce companion losses attached to the hidden layers guiding the learning algorithm to learn discriminative features at all model depths.
DSGNNs overcome the over-smoothing problem in deep models achieving competitive performance when compared with standard GNNs enhanced with PairNorm and jump connections. We provided empirical evidence supporting this for both graph and node property prediction and in the missing feature setting. We found that combining deep supervision with PairNorm degrades model performance. DSGNNs are more resilient to the over-smoothing problem achieving substantially higher accuracy for deep models. In future work, we plan to investigate the application of DSGNNs on larger graphs where we expect deep supervision will be beneficial.
References
- Chen et al. (2020) Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 3438–3445, 2020.
- Chiang et al. (2019) Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 257–266, 2019.
- Clevert et al. (2015) Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
- Delaney (2004) John S Delaney. ESOL: estimating aqueous solubility directly from molecular structure. Journal of chemical information and computer sciences, 44(3):1000–1005, 2004.
- Dwivedi et al. (2020) Vijay Prakash Dwivedi, Chaitanya K Joshi, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Benchmarking graph neural networks. arXiv preprint arXiv:2003.00982, 2020.
- Errica et al. (2019) Federico Errica, Marco Podda, Davide Bacciu, and Alessio Micheli. A fair comparison of graph neural networks for graph classification. arXiv preprint arXiv:1912.09893, 2019.
- Gao and Ji (2019) Hongyang Gao and Shuiwang Ji. Graph u-nets. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2083–2092. PMLR, 09–15 Jun 2019. URL http://proceedings.mlr.press/v97/gao19a.html.
- Gaudelet et al. (2021) Thomas Gaudelet, Ben Day, Arian R Jamasb, Jyothish Soman, Cristian Regep, Gertrude Liu, Jeremy B R Hayter, Richard Vickers, Charles Roberts, Jian Tang, David Roblin, Tom L Blundell, Michael M Bronstein, and Jake P Taylor-King. Utilizing graph machine learning within drug discovery and development. Briefings in Bioinformatics, 22(6), 05 2021. ISSN 1477-4054. doi: 10.1093/bib/bbab159. URL https://doi.org/10.1093/bib/bbab159. bbab159.
- Gaulton et al. (2017) Anna Gaulton, Anne Hersey, Michał Nowotka, A Patricia Bento, Jon Chambers, David Mendez, Prudence Mutowo, Francis Atkinson, Louisa J Bellis, Elena Cibrián-Uhalte, et al. The ChEMBL database in 2017. Nucleic acids research, 45(D1):D945–D954, 2017.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pages 1024–1034, 2017.
- Hamilton (2020) William L. Hamilton. Graph representation learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 14(3):1–159, 2020.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. In International Conference on Learning Representations, 2017.
- Klicpera et al. (2018) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Combining neural networks with personalized pagerank for classification on graphs. In International Conference on Learning Representations, 2018.
- Klicpera et al. (2019) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. Combining neural networks with personalized pagerank for classification on graphs. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=H1gL-2A9Ym.
- Lee et al. (2015) Chen-Yu Lee, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. Deeply-Supervised Nets. In Guy Lebanon and S. V. N. Vishwanathan, editors, Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, volume 38 of Proceedings of Machine Learning Research, pages 562–570, San Diego, California, USA, 09–12 May 2015. PMLR. URL http://proceedings.mlr.press/v38/lee15a.html.
- Lee et al. (2019) Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-attention graph pooling. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 3734–3743. PMLR, 09–15 Jun 2019. URL http://proceedings.mlr.press/v97/lee19c.html.
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. URL https://ojs.aaai.org/index.php/AAAI/article/view/11604.
- Liu et al. (2020) Meng Liu, Hongyang Gao, and Shuiwang Ji. Towards deeper graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, page 338–348, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450379984. doi: 10.1145/3394486.3403076. URL https://doi.org/10.1145/3394486.3403076.
- Nair and Hinton (2010) Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
- Scarselli et al. (2009) Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2009. doi: 10.1109/TNN.2008.2005605.
- Schomburg et al. (2004) Ida Schomburg, Antje Chang, Christian Ebeling, Marion Gremse, Christian Heldt, Gregor Huhn, and Dietmar Schomburg. BRENDA, the enzyme database: updates and major new developments. Nucleic acids research, 32(suppl_1):D431–D433, 2004.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(86):2579–2605, 2008. URL http://jmlr.org/papers/v9/vandermaaten08a.html.
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks. In International Conference on Learning Representations, 2018.
- Wang et al. (2019) Minjie Wang, Da Zheng, Zihao Ye, Quan Gan, Mufei Li, Xiang Song, Jinjing Zhou, Chao Ma, Lingfan Yu, Yu Gai, Tianjun Xiao, Tong He, George Karypis, Jinyang Li, and Zheng Zhang. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv preprint arXiv:1909.01315, 2019.
- Wu et al. (2019) Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International Conference on Machine Learning, pages 6861–6871, 2019.
- Wu and He (2018) Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018.
- Xu et al. (2018a) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations, 2018a.
- Xu et al. (2018b) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 5453–5462. PMLR, 10–15 Jul 2018b. URL http://proceedings.mlr.press/v80/xu18c.html.
- Yang et al. (2016) Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In International conference on machine learning, pages 40–48. PMLR, 2016.
- Ying et al. (2018) Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical graph representation learning with differentiable pooling. In Advances in neural information processing systems, pages 4800–4810, 2018.
- Zeng et al. (2019) Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. Graphsaint: Graph sampling based inductive learning method. In International Conference on Learning Representations, 2019.
- Zhang et al. (2018) Muhan Zhang, Zhicheng Cui, Marion Neumann, and Yixin Chen. An end-to-end deep learning architecture for graph classification. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. URL https://ojs.aaai.org/index.php/AAAI/article/view/11782.
- Zhao and Akoglu (2020) Lingxiao Zhao and Leman Akoglu. Pairnorm: Tackling oversmoothing in GNNs. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rkecl1rtwB.
- Zhou et al. (2020a) Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications. AI Open, 1:57–81, 2020a.
- Zhou et al. (2020b) Kaixiong Zhou, Xiao Huang, Yuening Li, Daochen Zha, Rui Chen, and Xia Hu. Towards deeper graph neural networks with differentiable group normalization. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 4917–4928. Curran Associates, Inc., 2020b. URL https://proceedings.neurips.cc/paper/2020/file/33dd6dba1d56e826aac1cbf23cdcca87-Paper.pdf.
Appendix A Appendix
A.1 Deep Supervision for Node Classification
In Section 4 we extended graph neural networks with deep supervision focused on the graph property prediction setting. Here, we explain how deep supervision can be applied for node property prediction with a focus on classification tasks.
We are given a graph represented as the tuple where is the set of nodes and the set of edges. The graph has nodes. We assume that each node is also associated with an attribute vector and let represent the attribute vectors for all nodes in the graph. A subset of nodes, , has known labels. Each label represents one of classes using a one-hot vector representation such that . The node property prediction task is to learn a function that maps node representations to class probabilities.
Consider the case of a -layer GNN with GAT [Veličković et al., 2018] layers and one attention head. The node representations output by each of the GAT layers are given by,
| (10) | |||
| (11) |
where the activations are element-wise, are the attention weights given by Equation 3, and are trainable layer weights.
Let each GAT layer be followed by a linear layer with activation calculating class probabilities for all nodes in the graph such that,
| (12) |
where are the class probabilities for all nodes as predicted by the th layer, and are the layer’s trainable weights.
Now we can compute layer-dependent losses as:
| (13) |
For a standard GNN, in order to estimate the weights , we optimize the cross-entropy loss calculated over the set of nodes with known labels only using .
Deep supervision adds a linear layer corresponding to each GAT layer in the model such that, in our example, the model makes two predictions for each node, and . We now estimate the weights {}, and optimize the mean loss that for our example is given by,
| (14) |
A.2 Datasets
| Name | Graphs | Nodes | Classes | Node features | # train/val/test |
|---|---|---|---|---|---|
| Enzymes | 600 | 33 (avg) | 6 | 18 | - |
| ESOL | 1144 | 13 (avg) | Regr. | 74 | - |
| Lipophilicity | 4200 | 27 (avg) | Regr. | 74 | - |
| Cora | 1 | 2708 | 7 | 1433 | 140/500/1000 |
| Citeseer | 1 | 3327 | 6 | 3703 | 120/500/1000 |
| Pubmed | 1 | 19717 | 3 | 500 | 60/500/1000 |
Table 4 gives detailed information about the datasets we used for the empirical evaluation of the different architectures.
Cora, Citeseer, and Pubmed are citation networks where the goal is to predict the subject of a paper. Edges represent citation relationships. We treat these graphs as undirected as it is common in the GNN literature. The datasets have known train/val/test splits from Yang et al. [2016]. Training sets are small with the number of labeled nodes equal to ( for each of classes), ( for each of classes), and ( for each of classes) for Cora, Citeseer, and Pubmed respectively.
Enzymes is a graph classification dataset where the goal is to predict enzyme class as it relates to the reactions catalyzed. ESOL is a regression dataset where the goal is to predict molecular solubility. Lastly, Lipophilicity is a regression dataset where the goal is to predict the octanol/water distribution coefficient for a large number of compounds.
A.3 Additional Experimental Results
A.3.1 Deep Model Performance
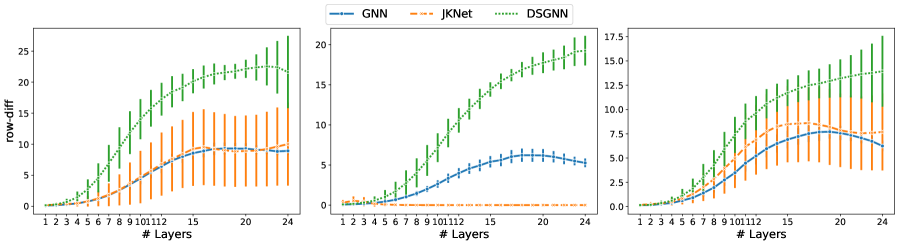
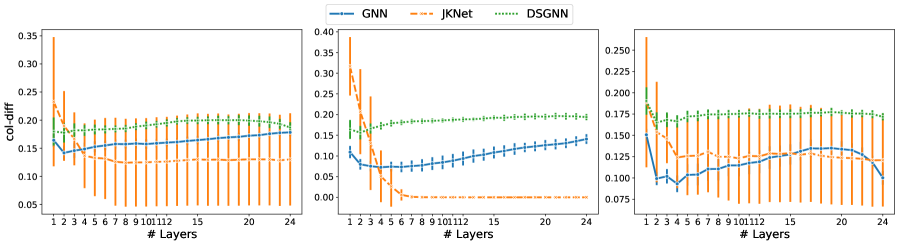
In Sections 5.2.2 and 5.2.3, we noted that for deep models with layers, DSGNNs demonstrate better resilience to the over-smoothing problem. Our conclusion holds for both the normal and missing feature settings as can be seen in Figures 2, 3 and 4.
Tables 5 and 6 focus on the node classification performance of models with layers. In the normal setting (Table 5), DSGNN outperforms the others on Cora and Pubmed by and respectively whereas it is second best to JKNet on Citeseer trailing by . In the missing feature setting (Table 6), DSGNN outperforms the second best model on all three datasets by , , and for Cora, Citeseer, and Pubmed respectively. In the missing features setting, DSGNN outperforms a standard GNN with PairNorm by , , and for Cora, Citeseer, and Pubmed respectively. This evidence supports our conclusion that enhancing GNNs with deep supervision as opposed to PairNorm or jump connections is a more suitable solution to the over-smoothing problem for deep GNNs.
| Model | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Accuracy | |||
| GNN | 74.3 1.3 | 45.8 3.3 | 75.9 0.9 |
| JKNet | 76.0 1.5 | 63.3 2.3 | 76.6 0.8 |
| DSGNN | 76.9 0.8 | 62.1 1.0 | 77.9 0.5 |
| GNN-PN | 71.5 0.9 | 57.0 1.4 | 75.6 0.7 |
| DSGNN-PN | 72.2 0.6 | 51.3 0.9 | 74.2 1.0 |
| Model | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Accuracy | |||
| GNN | 72.6 1.4 | 40.6 2.9 | 75.7 1.0 |
| JKNet | 73.9 1.5 | 50.3 2.4 | 76.7 0.9 |
| DSGNN | 75.6 0.9 | 56.3 2.2 | 77.9 0.4 |
| GNN-PN | 71.2 0.9 | 54.0 1.6 | 74.4 1.1 |
| DSGNN-PN | 72.5 0.8 | 50.3 1.4 | 74.7 0.9 |
A.3.2 Analysis of Learned Representations
We provide additional evidence that DSGNNs learn more discriminate node representations for all hidden graph convolutional layers leading to performance benefits outlined above. We focus on the node classification domain. We adopt the metrics suggested by Zhao and Akoglu [2020] for measuring how discriminate node representations and node features are.
Given a graph with nodes, let hold the -dimensional node representations output by the -th GAT layer. The row difference (row-diff) measures the average pairwise distance between the node representations (rows of ). The column difference (col-diff) measures the average pairwise distance between the -normalized columns of . The former measures node-wise over-smoothing and the latter feature-wise over-smoothing [Zhao and Akoglu, 2020].
We consider the row-diff and col-diff metrics for the deepest models we trained, those with layers of which are GAT. We calculate the two metrics for the node representations output by each of the GAT layers. Figures 5 and 6 show plots of the row-diff and col-diff metrics respectively. We note that for all datasets, DSGNN node representations are the most separable for the majority of layers. For all models, row-diff plateaus after the first few layers. We interpret this as a point of convergence for the learnt node representations such that adding more layers can only harm the model’s performance as indicated in Figure 3. We further demonstrate this point by visualising the node embeddings for Cora.
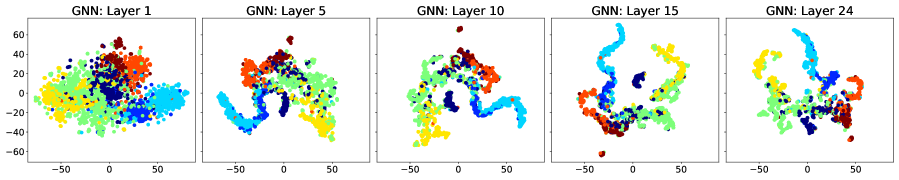
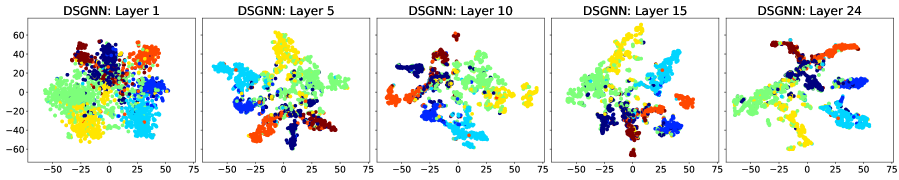
Figure 7 shows a visual representation of the learnt node embeddings for a subset of the GAT layers in the trained -layer models. We used t-SNE [van der Maaten and Hinton, 2008] to project the -dimensional node features to dimensions. We can see that all architectures learn clusters of nodes with similar labels. However, for the standard GNN and JKNet, these clusters remain the same for the -th layer and above. On the other hand, DSGNN continues to adapt the clusters for all layers as we would expect given the effect of the companion losses associated with each GAT layer.
 |
 |
 |
 |
 |