Adjusting inverse regression for predictors with clustered distribution
Abstract
A major family of sufficient dimension reduction (SDR) methods, called inverse regression, commonly require the distribution of the predictor to have a linear and a degenerate for the desired reduced predictor . In this paper, we adjust the first- and second-order inverse regression methods by modeling and under the mixture model assumption on , which allows these terms to convey more complex patterns and is most suitable when has a clustered sample distribution. The proposed SDR methods build a natural path between inverse regression and the localized SDR methods, and in particular inherit the advantages of both; that is, they are -consistent, efficiently implementable, directly adjustable under the high-dimensional settings, and fully recovering the desired reduced predictor. These findings are illustrated by simulation studies and a real data example at the end, which also suggest the effectiveness of the proposed methods for non-clustered data.
doi:
10.1214/154957804100000000keywords:
and
1 Introduction
Sufficient dimension reduction (SDR) has attracted intensive research interest in the recent years due to the need of high-dimensional statistical data analysis. Usually, SDR assumes that the predictor affects the response through a lower-dimensional , that is,
| (1) |
where means independence; and the research interest of SDR is to find the qualified as the subsequent predictor in a model-free manner, i.e. without parametric assumptions on . For identifiability, Cook (1998) introduced the central subspace, denoted by , as the parameter of interest, whose arbitrary basis matrix satisfies (1) with minimal number of columns. This space is unique under fairly general conditions (Yin, Li and Cook, 2008).
When the research interest is focused on regression analysis, SDR is adjusted to find that only preserves the information about regression, i.e. being measurable with respect to . Similar to , the unique parameter of interest in this scenario is called the central mean subspace and denoted by (Cook and Li, 2002). For ease of presentation, we do not distinguish the two parameters and unless otherwise specified, and call both the central SDR subspace uniformly. Let be the dimension of the central SDR subspace and be its arbitrary basis matrix.
In the literature, a major family of estimators for the central SDR subspace is called inverse regression, which includes the ordinary least squares (OLS; Li and Duan, 1989) and principal Hessian directions (pHd; Li, 1992) that estimate , and sliced inverse regression (SIR; Li, 1991), sliced average variance estimator (SAVE; Cook and Weisberg, 1991), and directional regression (DR; Li and Wang, 2007) that estimate , etc. A common feature of the inverse regression methods is that they first use the moments of to construct a matrix-valued parameter , whose columns fall in the central SDR subspace under certain parametric assumptions of , and then use an estimate of to recover the central SDR subspace. Suppose has zero mean and covariance matrix . The forms of for OLS, SIR, and SAVE are, respectively,
| (2) |
where denotes for any matrix . Clearly, is readily estimable when is discrete with limited number of outcomes. To ease the estimation for continuous (except for OLS), the slicing technic is commonly applied to replace a univariate in with , being a fixed integer and being the th quantile of ; the case of multivariate follows similarly. Because the moments of can be estimated by the sample moments within each slice , a consistent estimator of , denoted by , can be readily constructed. The central SDR subspace is then estimated by the linear span of the leading left singular vectors of .
Despite their popularity in applications, the inverse regression methods are also commonly criticized for the aforementioned parametric assumptions on . For example, the first-order inverse regression methods, i.e. OLS and SIR that only involve or its average , require the linearity condition
| (3) |
where is the projection matrix onto the column space of under the inner product . The second-order inverse regression methods that additionally involve , e.g. pHd, SAVE, and directional regression, require both the linearity condition (3) and the constant variance condition
| (4) |
Since both conditions adopt simple parametric forms on the moments of , they can be violated in practice. Moreover, as the central SDR subspace is unknown, both (3) and (4) are often strengthened to that they hold for any . The strengthened linearity condition requires to be elliptically distributed (Li, 1991), and, together with the strengthened constant variance condition, must have a multivariate normal distribution (Cook and Weisberg, 1991). Hall and Li (1993) justified the approximate satisfaction of (3) for general as grows, but their theory is developed for diverging , and, more importantly, it is built in a Bayesian sense that follows a continuous prior distribution on . In the literature of high-dimensional SDR (Chen, Zou and Cook, 2010; Lin, Zhao and Liu, 2016; Zeng, Mai and Zhang, 2022), sparsity is commonly assumed on the central SDR subspace so that only has a few nonzero rows. Thus, Hall and Li’s result is often inapplicable.
To enhance the applicability of inverse regression, multiple methods have been proposed to relax the linearity condition (3). Li and Dong (2009) and Dong and Li (2010) allow to lie in a general finite-dimensional functional space, and they reformulate the inverse regression methods accordingly as minimizing certain objective functions. However, the non-convexity of the objective functions may complicate the implementation, and, unlike the connection between the linearity condition and the ellipticity of , the relaxed linearity condition is lack of interpretability. Another effort specified for SIR can be found in Guan, Xie and Zhu (2017), which assumes to follow a mixture of skew-elliptical distributions with identical shape parameters up to multiplicative scalars. Guan, Xie and Zhu’s method can be easily implemented once the mixture model of is consistently fitted.
In a certain sense, the minimum average variance estimator (MAVE; Xia et al., 2002), a state-of-the-art SDR method that estimates the central mean subspace by local linear regression, can also be regarded as relaxing the linearity condition (3) for OLS. Recall that OLS is commonly used to estimate the coefficients, i.e. the one-dimensional , of the linear model of . Thus, the linearity condition (3) on can be regarded as a surrogate to the assumption of linear for SDR estimation. As MAVE adopts and fits a linear in each local neighborhood of , it equivalently adopts the linearity condition in these neighborhoods, which only requires the first-order Taylor expansion of and thus is fairly general.
Following the same spirit as MAVE, the aggregate dimension reduction (ADR; Wang et al., 2020) conducts SIR in the local neighborhoods of and thus also relaxes the linearity condition. Recently, the idea of localization was also studied in Fertl and Bura (2022), who proposed both the cumulative covariance estimator (CVE) to recover and the enemble CVE (eCVE) to recover . For convenience, we call MAVE, ADR, CVE, eCVE, and other SDR methods based on localized estimation uniformly the MAVE-type methods. By the nature of localized estimation, these methods share the common limitation that they quickly lose consistency as grows.
Generally, the conjugate between the parametric assumptions on , i.e. (3) and (4), and the parametric assumptions on can be formulated under the unified SDR framework proposed in Ma and Zhu (2012). In the population level, each SDR method in this framework solves the estimating equation
| (5) |
for certain and , where and are the working models for and , respectively. Ma and Zhu (2012) justified a double-robust property that, as long as either or truly specifies the corresponding regression function when is fixed at , any minimal solution to (5) must be included in the central SDR subspace. Up to asymptotically negligible errors, (5) incorporates a large family of SDR methods. For example, with and the linearity condition (3), one can take linear and force to be zero, and solving (5) delivers OLS if is and delivers SIR if it is .
The double-robustness property for (5) illuminates the tradeoff for general SDR methods: if we choose to avoid parametric assumptions or nonparametric estimation on , then we must adopt those on instead. In principle, like the rich literature for modeling , numerous assumptions can be adopted on to represent different balances between parsimoniousness and flexibility. Nonetheless, under the unified framework (5), only the two extremes have been widely studied in the SDR literature: the most aggressive parametric models (3) and (4) in inverse regression, and the most conservative nonparametric model in MAVE. Although a compromise between the two was discussed by Li and Dong (2009) and Dong and Li (2010) as mentioned above, there is lack of parametric learning of that specifies easily interpretable conditional moments and is often satisfied in practice.
In this paper, we adjust both the first- and second-order inverse regression methods by approximating the distribution of with mixture models, where we allow each mixture component to differ in either center or shape but it must satisfy the linearity condition (3) and the constant variance condition (4). The mixture model approximation has been widely used in applications to fit generally unknown distributions (Lindsay, 1995; Everitt, 2013), especially those with clustered sample support, and it permits estimating each of and by one of multiple commonly seen parametric models chosen in a data-driven manner. As supported by numerical studies, the proposed methods also have a consistent sample performance under more complex settings, for example, if has a unimodal but curved sample support. Compared with the MAVE-type methods, our approach is more robust to the dimensionality and in particular effective under the high-dimensional settings. Compared with Guan, Xie and Zhu (2017), it allows the mixture components to have different shapes and is applicable for all the second-order inverse regression methods. It also alleviates the issue of non-exhaustive recovery of the central SDR subspace that persists in OLS and SIR, in a similar fashion to MAVE and ADR that capture the local patterns of data.
The rest of the paper is organized as follows. Throughout the theoretical development, we assume to be continuous and follow a mixture model, under which the parametric forms of the moments of are studied in Section . We adjust SIR in Section , and further modify it towards sparsity under the high-dimensional settings in Section 4. Section 5 is devoted for the adjustment of SAVE. The simulation studies are presented in Section 6, where we evaluate the performance of the proposed methods under various settings, including the cases where does not follow a mixture model. A real data example is investigated in Section 7. The adjustment for OLS is omitted for its similarity to SIR. The adjustments of other second-order inverse regression methods, as well as the detailed implementation and complementery simulation studies, are deferred to the Appendix. R code for implementing the proposed methods can be downloaded at https://github.com/Yan-Guo1120/IRMN. For convenience, we focus on continuous whose sample slices have an equal size, and we regard the dimension of the central SDR subspace as known a priori. The generality of the latter is briefly justified in Section 2, given the consistent estimation of discussed in Sections 3 and 5.
2 Preliminaries on mixture models
We first clarify the notations. Suppose . For any matrix , let be the column space of and let be the vector that stacks the columns of together. Like in (2), sometimes we also denote itself by . We expand in (3) to for any positive definite matrix , and, with being the identity matrix, we denote by . For a set of matrices with equal number of rows, we denote the ensemble matrix by .
In the literature, the mixture model has been widely employed to approximate unknown distributions (Lindsay, 1995; Everitt, 2013), both clustered and non-clustered, as it provides a wide range of choices to balance between the estimation efficiency and the modeling flexibility, especially for the local patterns of data. Application fields include, for example, astronomy, bioinformatics, ecology, and economics (Marin, Mengersen and Robert, 2005, Subsection 1.1). Given a parametric family of probability density functions on , a mixture model for means
| (6) |
where is an unknown integer, each mixture component is generated from , is a latent variable that follows a multinomial distribution with support and probabilities , and are mutually independent. For the identifiability of (6), we require each to be positive and each to be distinct, as well as additional regularity conditions on . The latter can be found in Titterington, Smith and Makov (1985), details omitted. As a special case, when is the family of multivariate normal distributions, (6) becomes a mixture multivariate normal distribution with being , the mean and the covariance matrix of the th mixture component. Here, we allow ’s to differ.
For the most flexibility of the mixture model (6), one can allow the number of mixture components to be relatively large or even diverge with in practice, so that it can “facilitate much more careful description of complex systems” (Marin, Mengersen and Robert, 2005, Subsection 1.2.3), including those distributions who convey non-clustered sample supports. An extreme case is the kernel density estimation that uses an average of multivariate normal distributions to approximate a general distribution, which can be regarded as a mixture multivariate normal distribution mentioned above but with . For simplicity, we set to be fixed as grows throughout the theoretical development, by which (6) is a parametric analogue of kernel density estimation, with each mixture component being a “global” neighborhood of . The setting of non-clustered approximated by mixture model will be investigated numerically in Section .
Given that truly specifies the distributions of the mixture components, the consistency of the mixture model (6) hinges on the true determination of . This can be achieved by multiple methods, such as the Bayesian information criterion (BIC; Zhao, Hautamaki and Fränti, 2008), the integrated completed likelihood (Biernacki, Celeux and Govaert, 2000), the sequential testing procedure (McLachlan, Lee and Rathnayake, 2019a), and the recently proposed method based on data augmentation (Luo, 2022). In the presence of these estimators, we regard as known a priori throughout the theoretical study to ease the presentation. The generality of doing so is justified in the following lemma, which shows that the asymptotic properties of any statistic that involves will be invariant if is replaced with its arbitrary consistent estimator . The same invariance property also holds for using the true value of the dimension of the central SDR subspace in place of its consistent estimator, which justifies the generality of assuming known mentioned at the end of the Introduction.
Lemma 1.
Suppose is a consistent estimator of in the sense that . For any statistic that involves , let be constructed in the same way as but with replaced by . Then we have for any , that is, is asymptotically equivalent to .
Proof.
For any and , we have
The second equation above is due to whenever . Thus, we have . This completes the proof. ∎
Given , the marginal density of is up to the unknown ’s, which generates a maximal likelihood approach to estimate these parameters using the EM algorithm; see Cai, Ma and Zhang (2019) and McLachlan, Lee and Rathnayake (2019b) for the relative literature. Hereafter, we treat the estimators and as granted, and assume their -consistency and asymptotic normality whenever needed. The same applies to and defined above, where and for general parametric family can be derived by appropriate transformations of .
To connect the mixture model (6) with a parametric model on the moments of , we assume that the linearity condition and the constant variance condition holds for each mixture component; that is, for ,
| (7) | |||
| (8) |
Referring to the discussion about (3) and (4) in the Introduction, this includes but is not limited to the cases where each mixture component of is multivariate normal. For clarification, hereafter we call (3) the overall linearity condition and call (7) the mixture component-wise linearity condition whenever necessary, and likewise call (4) and (8) the overall and the mixture component-wise constant variance conditions, respectively. Because is latent, we next provide two useful derivations of (7). For each , let be , which is a known function up to ’s, and let be for any . Generally, differs from unless in the extreme case . The latter is not assumed in this article. The estimators and are readily derived from the mixture model fit.
Lemma 2.
Suppose follows a mixture model that satisfies (7). For , let be . We have
| (9) | |||
| (10) |
From the proof of Lemma 2, in can be replaced with the indicator , so (9) resembles the mixture component-wise linearity condition (7) for a single mixture component of . Similarly, (10) is an ensemble of (7) across all the mixture components of .
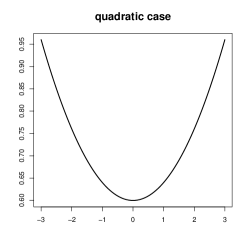
Depending on how is distributed, that is, how is associated with , the functional form of in (10) can be approximated by various parametric models. In this sense, (10) relaxes the overall linearity condition (3) to numerous parametric models, among which the most appropriate is automatically chosen by the data. For example, if the mixture components of are well separate, then each is close to a Bernoulli distribution and thus is nearly a linear spline of . This is illustrated by in the upper-left and upper-middle panels of Figure 1, where is a balanced mixture of and , with and in the former and both equal to in the latter. In the other extreme, if ’s are degenerate, which occurs if the mixture components of are identical along the directions in , then reduces to satisfy the overall linearity condition (3). When ’s are continuously distributed, conveys other forms, such as a quadratic function if we change and in the upper-left panel to , as depicted in the upper-right panel of Figure 1.
Similar to (7), the mixture component-wise constant variance condition (8) can also be modified in two directions towards practical use, with the aid of and , respectively.





Lemma 3.
Proof.
Same as in (10), the functional form of in (12) can be approximated by various commonly seen parametric models. This is illustrated in the lower panels of Figure 1, where we again set to be a balanced mixture of and , with being , , and , respectively. The resulting approximates to a piecewise constant function and a trigonometric function in the first two cases. In the third case, is degenerate, and, by (12), is exactly a quadratic function. As mentioned below Lemma 2, the overall linearity condition (3) is satisfied for in this case. A relative discussion about the inverse regression methods under linear and quadratic , but with elliptically distributed , can be found in Luo (2018).
Compared with the general parametric families of discussed in Li and Dong (2009) and Dong and Li (2010), the proposed parametric form (10) has a clear interpretation; that is, it is most suitable to use if the sample distribution of conveys a clustered pattern. In addition, because we model by averaging a few linear functions of , the result is relatively robust to the outliers of . The functional form of is also relaxed in our work, whereas it is fixed as a constant in Dong and Li (2010).
Recall that the MAVE-type methods adopt the linearity condition in the local neighborhoods of , and that each mixture component in the mixture model (6) can be regarded as a global neighborhood of . Since we adopt the linearity condition and the constant variance condition for each mixture component of , a corresponding modification of the inverse regression methods will naturally serve as a bridge, or a compromise, that connects inverse regression with the MAVE-type methods. This modification will also inherit the advantages of both sides, including the -consistency and the exhaustive recovery of the central SDR subspace, etc., as seen next.
3 Adjusting SIR for under mixture model
Based on the discussions in Section 2, there are two intuitive strategies for adjusting inverse regression for that follows a mixture model. First, one can conduct inverse regression on each mixture component of using (9) and (11), and then merge the SDR results. Second, one can construct and solve an appropriate estimation equation (5) with the aid of the functional forms (10) for and (12) for . Because these two strategies use the terms and , respectively, which characterize the “global” neighborhoods of and , they can be parallelized with MAVE and its refined version (Xia et al., 2002). We start with adjusting SIR in this section, and discuss both strategies sequentially.
To formulate the first strategy, we first parametrize the SDR result specified for an individual mixture component of as the conditional central subspace on , which is the unique subspace of that satisfies
| (13) |
with minimal dimension. Denote this space by . For a general non-latent variable , the space spanned by the union of ’s, denoted by , is called the partial central subspace in Chiaromonte, Cook and Li (2002). Naturally, the first strategy aims to estimate , so it recovers if
| (14) |
Because is the latent variable constructed for the convenience of modeling the distribution of , we can naturally assume that is uninformative to given . Intuitively, this means that the term can be removed from (13), by which becomes identical to . The only issue is that the support of can be a proper subset of the support of , under which may only capture a local pattern of and becomes a proper subspace of . Nonetheless, since the supports of for must together cover the support of , the union of ’s must span the entire . This reasoning is rigorized in the following lemma, which justifies (14) and thus justifies the consistency of the first strategy.
Lemma 4.
Suppose . Then the coincidence between and in (14) always holds. In addition, if the support of coincides with the support of for some , then further coincides with specified for the th mixture component of .
Proof.
Since , clearly satisfies (13) for each . Since is by definition the intersection of all the subspaces of that satisfy (13) (Chiaromonte, Cook and Li, 2002), it must be a subspace of . Thus, we have
| (15) |
Conversely, let be an arbitrary basis matrix of . By definition, satisfies (13) for each , which means that, for any ,
| (16) |
Since , we have . Thus, (16) implies
| (17) |
which means that is invariant as varies and thus equal to . Hence, (17) implies , which, by the arbitrariness of , means . By the definition of , we have . Together with (15), we have (14). Suppose the support of is identical to the support of . Then, for any , coincides with in terms of the same functional form and the same domain. The proof of thus follows the same as above.
The coincidence between the overall support of and that specified for an individual mixture component occurs, for example, if has a mixture multivariate normal distribution. However, such coincidence should be often unreliable in practice, as the clustered pattern of determines that each of its individual mixture components is likely clouded within a specific region of the support of . Thus, we recommend using the ensemble as a conservative choice rather than using an individual , although the former means more parameters to estimate.
To recover by conducting SIR within the mixture components of , we first formulate the slicing technic in SIR mentioned in the Introduction by replacing in (2) with , which generates
| (18) |
that again spans a subspace of under the overall linearity condition (3). In light of (9) that reformulates the mixture component-wise linearity condition (7), we incorporate the grouping information for the th mixture component, i.e. , into (18) and merge the results across all the mixture components. These deliver
| (19) |
whose linear span is employed to recover . Because is constructed under the mixture model (6), we call any method that recovers , M in the subscript for the mixture model. As seen in the next theorem, the consistency of in the population level is immediately implied by Lemma 2, under the mixture component-wise linearity condition (7).
Theorem 1.
Suppose follows a mixture model that satisfies (7). Then is always a subspace of . In addition, if, for any , there exists and such that , then is identical to .
Proof.
For each , we have
which, by (9), means . This implies . The second statement of the theorem is straightforward, so its proof is omitted. ∎
Referring to the generality of the mixture model discussed in Section 2, we regard as building a path that connects SIR and ADR. In one extreme, it coincides with SIR if has only one mixture component or more generally if both and are invariant across different mixture components of ; the coincidence in the latter case is readily implied by (9), under which is a list of identical copies of (18). In the other extreme, if we let diverge with , then the mixture components will resemble the local neighborhoods of and thus will essentially resemble ADR. Generally, depending on the underlying distribution of , will provide a data-driven balance between the estimation efficiency and the reliability of SDR results.
Similarly to the exhaustiveness of ADR, an important advantage of over SIR is that its exhaustiveness is more general, as justified in Theorem 1. In particular, it can detect symmetric associations between and , which cannot be captured by SIR. To see this, suppose follows a symmetric mixture model with respect to the origin, and
| (20) |
where is a random error. Then can clearly detect as long as is asymmetric with respect to zero for at least one mixture component, which occurs if one of ’s has nonzero first entry. Figure 2 illustrates this with being a balanced mixture of and . In general, the asymmetry of is satisfied for at least one mixture component of if ’s differ along the directions in , in which case the multiplicative weight in disturbs any symmetric pattern between and into asymmetry. Since ’s are regulated to differ from each other, with a sufficiently large and assuming a continuous prior distribution for (Hall and Li, 1993), the exhaustiveness of is satisfied with probability one in a Bayesian sense.

Related to this, another advantage of over SIR is that it allows more flexibility in choosing the number of slices . When implementing SIR in practice, researchers need to address the tradeoff in selecting : while a small means better estimation accuracy due to less number of parameters, it elevates the risk of non-exhaustive recovery of , as SIR can only recover up to directions. By contrast, can recover up to directions, relieving the freedom of choosing a coarse slicing to enhance the estimation accuracy. This advantage is crucial when is discrete or categorical with a small number of categories, in which case must also be small and the issue of non-exhaustiveness is less worrisome for . The same advantage is also enjoyed by ADR, i.e. the localized SIR, which sets automatically. Again, this complies with the connection between and ADR discussed below Theorem 1.
To implement in the sample level, we can replace , , and in with , , and mentioned in Section 2, and replace the population mean in with the sample mean. The resulting is -consistent and asymptotically normal. By Luo and Li (2016), this permits using the ladle estimator on to determine the dimension of , given the identity between and discussed above. When the sample size is limited compared with the dimension or the number of mixture components , we also recommend using the predictor augmentation estimator (PAE; Luo and Li, 2021) to determine , which does not require the asymptotic normality of . As discussed above Lemma 1 in Section 2, these estimators permit us to safely assume to be known throughout the theoretical study. Given , we use its first left singular vectors to span an -consistent estimator of . The proofs of these results are simple, so they are omitted. The details about the implementation of is deferred to Appendix B.
When the dimension of is large, the estimation bias in the clustering stage, especially in estimating , will adversely affect . One way to address this issue is to impose additional constraints on the distribution of ; see Section 4 later. Alternatively, observe that follows a mixture model in . The low dimensionality of makes its estimation more accurate than that of , i.e. regardless of the dimension of , given a consistent initial estimator of . As can be rewritten as , the enhanced estimation power can also be understood as benefited from targeting at the conditional mean of , which is intuitively smoother than itself. In addition, (10) implies that can be estimated by linearly regressing on , which does not involve ’s and thus is robust to the dimension of .
Based on these observations, we now turn to the second strategy of estimating mentioned in the beginning of this section, which serves as a refinement of . Namely, we use (10) to construct an appropriate estimating equation (5) for . The consistency of this approach is endorsed by Ma and Zhu (2012), as in (5) needs to be truly specified only when coincides with .
Assume that is known a priori, where in practice we can replace with a consistent estimator such as . Let
| (21) |
By (10), coincides with . We explain later why using instead of the argument in . To measure the relative “importance” of an outcome to the SDR estimation, we introduce
| (22) |
This term is best interpretable when follows a mixture normal distribution: by Stein’s Lemma, it can rewritten as a weighted average of the derivative of the regression function with respect to , i.e.
| (23) |
which reveals the strength of the point-wise effect of on regressing .
We now plug and into (5), with set at zero as permitted by the double-robust property. To avoid obscures caused by dimensionality (Ma and Zhu, 2013), we rewrite (5) as minimizing the magnitude of its left-hand side over all the -dimensional subspaces of ; that is, we minimize
| (24) |
where denotes the Frobenius norm of a matrix and transforms any vector to the diagonal matrix with being the diagonal. Same as for , in will be replaced with , the explanation for using instead of deferred to later. Clearly, the minimum value of is zero, and can be reached by . Following Ma and Zhu (2012), under fairly general conditions, the intersection of all the minimizers of also minimizes , which means that it is the unique minimizer of of the smallest dimension, and it is always a subspace of under the mixture component-wise linearity condition (7). We call any method that recovers this space , R in the subscript for refined.
Similar to , the exhaustiveness of depends on the variability of the association between and across different mixture components of . In the special case that the ’s are identical to each other, the following theorem justifies a sufficient condition for the exhaustiveness of .
Theorem 2.
Suppose follows a mixture model that has identical ’s and satisfies (7). If has rank , then exhaustively recovers .
Proof.
For any such that is a proper subspace of , suppose is -dimensional, is of full column rank, is a basis of , and, without loss of generality, for some semi-orthogonal . We have for , which, by (21), means
where . Since is invariant of , as is . Denote the former by and the latter by , and write as . We then have
Because is invertible, must be nonzero. Hence, if is invertible, which is the condition adopted in this theorem, then is always nonzero, and, as , must also be nonzero for any that spans a proper subspace of . Thus, exhaustively recovers . This completes the proof. ∎
The exhaustiveness condition in Theorem 2 essentially requires that, for any direction in , the association between and is asymmetric in at least one mixture component of . Again, this will be likely to hold in a Bayesian sense if the number of mixture components is sufficiently large in the mixture model of , and it will be trivially true if we let diverge with , e.g. in the scenario of approximating non-clustered distribution of by the mixture model. Same as , depending on the complexity of , builds a path from SIR that adopts the aggressive parametric assumption on to the fully nonparametric SDR methods, i.e. of MAVE-type, that require the weakest assumption on . In one extreme that is degenerate, will also be degenerate and will reduce to a linear , which together imply the identity between and SIR. In the other extreme that is identical to , the integrand in (24) would resemble the efficient score for homoscedastic data (Luo, Li and Yin, 2014), had in the integrand been replaced with and been consistently estimated instead of being misspecified at zero.
The concern behind the use of instead of the argument in and is as follows. If we replace with the argument in both in and , then the unique minimizer of (24) of smallest dimension, if exists, will still fall in . However, the corresponding exhaustiveness will require stronger assumptions. For example, this space will be trivially zero-dimensional in Model (20), whereas still recovers the one-dimensional . For this reason, we decide not to do so when constructing .
To implement , we assume its exhaustiveness as well as the exhaustiveness of , and we start with estimating by rewriting this term as and running a kernel regression of on , where denotes the result of . By plugging ’s, ’s, and the estimates of ’s into (24), we have that consistently estimates . is then the unique minimizer of , which is -consistent and asymptotically normal. Referring to the discussions above, it can outperform in the sample level, which is analogous to the relative effectiveness of the refined MAVE with respect to MAVE (Xia et al., 2002). For continuity of the context, we leave the detailed form of and the algorithm for its minimization to Appendix B.
As mentioned in the Introduction, when follows a mixture skew-elliptical distribution, Guan, Xie and Zhu (2017) proposed the generalized Stein’s Lemma based method (StI) to consistently recover . Due to the violation of the mixture component-wise linearity condition (7), both and are theoretically inconsistent under Guan, Xie and Zhu’s settings. Nonetheless, while StI requires identical ’s up to multiplicative scalars and uses the average of SDR results across different mixture components, we allow ’s to vary freely and we collect the information for SDR from all the mixture components to form the final result. Therefore, our approaches are sometimes exclusively useful and are more likely to recover exhaustively. As seen next, our approaches can also be extended to the high-dimensional settings, as well as to the second-order inverse regression methods.
4 An extension towards the high-dimensional sparse settings
In the literature, SIR has been widely studied under the high-dimensional settings, with the aid of the sparsity assumption on that only a few rows of are nonzero. Representative works include Chen, Zou and Cook (2010), Li (2007), Lin, Zhao and Liu (2019), and Tan et al. (2018), etc. A common strategy employed in these works is to reformulate SIR as a least squares method and then incorporate penalty functions. Accordingly, the overall linearity condition (3) is commonly adopted, which, as mentioned in the Introduction, can be restrictive in practice due to the sparsity assumption.
We now modify and towards sparsity under the high-dimensional settings. For the applicability of existing clustering analysis, here we follow Cai, Ma and Zhang (2019) to assume that has a mixture multivariate normal distribution with the number of mixture components known a priori and all ’s identical to some invertible , and that
| (25) |
under which the consistent estimators ’s, , and ’s have been derived in Cai, Ma and Zhang (2019). Given the mixture model fit, we modify and following the spirit of Tan et al. (2018) for its computational efficiency.
Following Tan et al. (2018), we change the parametrization in SDR to and further extend the parameter space to the set of -dimensional positive semi-definite matrices, denoted by . Let
| (26) |
and be its estimator using ’s and ’s. We minimize
| (27) |
over , where is a tuning parameter, and denote the trace and the spectral norm of a matrix, respectively, and for any matrix .
Because (27) is a convex minimization problem, it has the unique minimizer, which we denote by . By simple algebra, must be on the boundary of the constraints in (27), and must have the form for some with being semi-orthogonal. We estimate by , and call this estimator the sparse or simply due to the natural bond between and defined in (19). Its consistency is justified in the following theorem, where we use
| (28) |
to measure the distance between and .
Theorem 3.
Let under the sparsity assumption (25), let be the number of nonzero rows of under the sparse SDR assumption, and let be the th largest eigenvalue of . Under the regularity conditions (C1)-(C3) (see Appendix A), if , , , and , then we have
| (29) |
Proof.
Theorem 3 can be proved by incorporating the theoretical results of Cai, Ma and Zhang (2019) into the proof of Theorem 1 in Tan et al. (2018). Hence, we only provide a sketch of the proof here for the case . Let . Under Condition (C1) in Appendix A of this article and Lemma 3.1, Lemma 3.2, and Theorem 3.1 in Cai, Ma and Zhang (2019), we have
Together with the sub-Gaussian condition of implied by its mixture multivariate normal distribution and Conditions (C2)-(C3) in Appendix A of this article, it is easy to modify the proofs of Lemma 1 and Proposition 1 in Tan et al. (2018) to derive
where for any matrix . Similarly, in our scenario, Lemma S1 in the supplementary material for Tan et al. (2018) can be modified to
| (30) |
where is defined in Equation (4) of Tan et al. (2018), , and the definitions of and can be found above Lemma S1 in the supplementary material for Tan et al. (2018); Lemma S5 in the supplementary material for Tan et al. (2018) can be modified to that the term be changed to ; Lemma S6 in the supplementary material for Tan et al. (2018) can be modified to that the convergence rate in its conclusion is ; the rest of the lemmas, including Lemma S2, Lemma S3, and Lemma S4, will still hold. Consequently, in the proof of Tan et al. (2018)’s Theorem 1 (see their supplementary material), the condition is needed to ensure (S25), and the term (which is a different term from defined above) is of order . A modification of equation (S29) in their proof then yields
| (31) |
where the definition of can be found below Lemma S1 in the supplementary material for Tan et al. (2018). By the subsequent logic flow of their proof, (30) and (4) together imply (29). This completes the proof. ∎
In Theorem 3, we allow divergence of both the number of variables of that are uniquely informative to and the dimension of . (29) suggests that the optimal value of is of order . In practice, we follow Tan et al. (2018) to suggest tuning by cross validation, details omitted.
To modify towards sparsity, we follow Theorem 2 to assume the equality of ’s, under which delivers the leading eigenvectors of in the population level with
| (32) |
Let be a consistent estimator of using ’s to replace ’s and using to replace . Similar to (27), we minimize
| (33) |
over , which again has the unique minimizer of the form for some that satisfies . We call the sparse or simply . Following a similar reasoning to Theorem 3, converges to at the same rate as . Because it does not involve , it can be more robust than against the estimation bias in fitting the mixture model of , caused by large or the non-normality of the mixture components, etc.
As mentioned above (25), the implementation of both and requires to be truly specified a priori in the clustering stage. Because there is lack of consistent estimators of under the high-dimensional settings in the existing literature, can be potentially underestimated in practice, causing inconsistency of and . Nonetheless, as these methods reduce to the sparse SIR proposed in Tan et al. (2018) when is forced to be one, which is the worst case scenario for estimating , they are still expected to outperform the existing sparse SIR if is underestimated to be some . To determine under the high-dimensional settings, which coincides with the rank of both and , we recommend applying the aforementioned PAE (Luo and Li, 2021) to either or , details omitted.
5 Adjusting SAVE for under mixture model
We now parallelize the two proposed strategies above to adjust SAVE for under the mixture model (6). The results can be developed similarly for the other second-order inverse regression methods, e.g. pHd and directional regression; see Appendix A for detail.
The first strategy amounts to conducting SAVE within each mixture component of and then taking the ensemble of the results. For , let be the th entry of , i.e. is one if and only if equals . For , we introduce
denoted by , whose ensemble over mimics SAVE for the th mixture component of . We recover by the column space of , and call the corresponding SDR method . When has only one mixture component, reduces to SAVE. Its general consistency is justified in the following theorem.
Theorem 4.
Proof.
By Theorem 4, the exhaustiveness of requires each informative direction of to be captured by SAVE in at least one mixture component of , so it is quite general (Li and Wang, 2007). The implementation of involves replacing the parameters of the mixture model in with the corresponding estimators in Section 2 and replacing the population moments with the sample moments. The resulting is -consistent and asymptotically normal, by which the ladle estimator (Luo and Li, 2016) can be applied again to determine . The leading left singular vectors of then span a -consistent estimator of . These results are straightforward, so we omit the details.
Under framework (5), SAVE can be reformulated by taking
with set at a constant for simplicity and , and set at zero because is zero, and also at zero due to the double-robust property. To adjust for the mixture model of , we apply the functional forms (10) for and (12) for , and we set at for each and then merge the estimating equations. For simplicity, one may also set at a constant as in SAVE. The resulting objective function is
where is defined in Lemma 3. Same as , there also exists the unique minimizer of with the smallest dimension, which is always a subspace of under the mixture component-wise linearity and constant variance conditions (7) and (8). The exhaustiveness of this space roughly follows that of SAVE, although is used instead of in .
Let be the estimator of using model fitting results in Section 2. We call the unique -dimensional minimizer of the refined or simply , whose -consistency can be easily proved. The implementation of is deferred to Appendix B. Again, the advantage of over comes from that the mixture components are embedded in the low dimensional rather than the ambient , much comparable with the advantage of the refined MAVE over MAVE.
6 Simulation studies
We now use simulation models to evaluate the effectiveness of the proposed methods. We will start with generating by some simple mixture multivariate normal models, under which we examine the performance of the proposed and . To better comprehend the applicability of and , we will then assess their robustness under more complex mixture model of and under the violation of the mixture model assumption itself. The adjusted sparse SIR, i.e. and , will be evaluated afterwards under the high-dimensional settings where , and the adjustments of SAVE will be assessed finally. The section is divided into four subsections in this order. A complementary simulation study is presented in Appendix C, where we evaluate how the estimation error in fitting the mixture model and how a hypothetical misspecification of impact the proposed SDR results.
6.1 Adjusted SIR for mixture normal
We first evaluate the performance of the proposed and in comparison of SIR and the MAVE-type methods, i.e. MAVE, ADR, and eCVE, in the case that follows a mixture multivariate normal distribution. The R packages meanMAVE and CVarE are used to implement MAVE and eCVE, respectively, where the tuning parameters are automatically selected. To implement ADR, we follow the suggestion in Wang et al. (2020) to set and characterize the local neighborhoods of by the -nearest neighbors with . To fit the mixture model in implementing and , we use the maximal likelihood estimation, with determined by BIC, both available from the R package mixtools. For SIR, , and , we set uniformly unless is discrete.
We apply these SDR methods to the following four models, where is an independent error with standard normal distribution. In the first three models, is a balanced mixture of two multivariate normal distributions, i.e. with , and we set and for some scalar for . Here, denotes the -dimensional square matrix whose th entry is , and we allow . The case of unbalanced is studied in Model and furthermore in Subsection 6.2 later.
In Models , is continuous and the central subspace is two-dimensional. The monotonicity or asymmetry between and varies in these models: while both and have monotone effects on in Model 1, the monotonicity only applies to in Model 2, and neither effects are asymmetric in Model 3. Consequently, these models are in favor of SIR from the most to the least, if we temporarily ignore the impact from the distribution of . By contrast, the asymmetry between and becomes stronger when specified for the individual mixture components in all the three models. The deviation between ’s also varies in these models, representing different degrees of separation between the mixture components of . In Model 4, consists of three unbalanced mixture components, and is binary with one-dimensional central subspace. The monotonicity between and in Model suggests that this model is in favor of SIR.
For each model, we set at , and generate independent copies. To measure the accuracy of an SDR estimator for each model, we use the sample mean and sample standard deviation of defined in (28). The performance of the aforementioned SDR methods under this measure are recorded in Table 1. For reference, if is randomly generated from the uniform distribution on the unit hyper-sphere , then is , which is for and for given .
From Table 1, SIR fails to capture the central subspace in Models . The MAVE-type methods have an uneven performance across the models. In particular, ADR fails to capture the local patterns of Model 3 where these patterns vary dramatically with the local neighborhoods of , MAVE fails to capture the non-continuous effect of in Model 1 and the effect of that falls out of the central mean subspace in Model 3, and eCVE shows a similar inconsistency to MAVE in Model 1. These comply with the intrinsic limitations of the corresponding SDR methods. By contrast, both and are consistent in all the models, and they mostly outperform SIR and the MAVE-type methods even when the latter are also consistent. Compared with , is generally a slight improvement.
| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| SIR | .908(.136) | .910(.128) | 1.08(.179) | .634(.127) |
| ADR | .611(.176) | .473(.138) | 1.31(.113) | .645(.189) |
| MAVE | .745(.229) | .223(.056) | .895(.278) | .326(.089) |
| eCVE | 1.42(.126) | .452(.128) | .609(.222) | 1.29(.226) |
| .590(.151) | .436(.094) | .553(.111) | .374(.105) | |
| .555(.146) | .402(.085) | .502(.109) | .338(.098) |
-
•
In each cell of Columns 2-5, is the sample mean (sample standard deviation) of for the corresponding SDR method, based on replications.
6.2 Robustness of adjusted SIR
We now evaluate the performance of and more carefully when the distribution of deviates from the simple balanced mixture multivariate normal distribution. These deviations include the case of unbalanced mixture components, the case of skewed distributions for the individual mixture components, and the case of non-clustered that violates the mixture model assumption itself.
To generate an unbalanced mixture model for , we set in Models in Subsection 6.1 above to each of and , representing severe unbalance and mild unbalance between mixture components, respectively. The performance of the SDR methods are summarized in Table 2, in the same format as Table 1. Because similar phenomena to Table 1 can be observed, Table 2 again suggests the consistency of and when has a mixture multivariate normal distribution. However, when becomes smaller, the advantage of these methods over the existing SDR methods becomes less substantial, which can be anticipated in theory as a smaller can be regarded as a weaker clustered pattern of . Note that, for each model, the overall strength of SDR pattern differs when we change the distribution of . Thus, it is not meaningful to compare the performance of an individual SDR method in an individual model for different values of , i.e. across Table 1 and Table 2.
| Methods | Model 1 | Model 2 | Model 3 | |
|---|---|---|---|---|
| SIR | .729(.100) | .692(.140) | .937(.149) | |
| ADR | .572(.152) | .485(.126) | 1.15(.228) | |
| MAVE | .395(.109) | .211(.054) | .868(.283) | |
| eCVE | .503(.105) | .309(.055) | .702(.335) | |
| .461(.098) | .541(.131) | .458(.094) | ||
| .449(.106) | .531(.132) | .436(.100) | ||
| SIR | .713(.117) | .954(.255) | 1.36(.127) | |
| ADR | .586(.142) | .451(.109) | 1.23(.214) | |
| MAVE | .409(.102) | .218(.058) | .898(.263) | |
| eCVE | .841(.117) | .436(.045) | .594(.210) | |
| .503(.099) | .528(.133) | .481(.101) | ||
| .490(.097) | .498(.126) | .481(.098) |
-
•
The meanings of numbers in each cell follow those in Table 1.
Next, we add skewness to the mixture components of . As mentioned in Section 4, this case was studied in Guan, Xie and Zhu (2017), where StI was specifically proposed to recover . Because both and are theoretically inconsistent in this case due to the violation of the mixture component-wise linearity condition (7), we evaluate their sample-level effectiveness using SIR as a reference and using StI as the benchmark. For simplicity, we use three simulation models, i.e. Models (4.1), (4.3) and (4.5), in Guan, Xie and Zhu (2017):
where , , and is the same random error as in Subsection 6.1 above. For all the three models, is generated by , with
in the first two models, and with
in the third model. Here, denotes a multivariate skew normal distribution, with being the skewness parameter whose magnitude indicates the severity of skewness; see Guan, Xie and Zhu (2017) for more details. Roughly, the skewness is more severe for the mixture components of in Model (4.5) than in the other two models.
Same as Guan, Xie and Zhu (2017), we set . To permit a direct transfer of their simulation results, we also use instead of to measure the estimation error of a SDR method, which is a linear transformation of their working measure. The performance of all the SDR methods under is summarized in Table 3. From this table, the proposed and have a similar performance to StI in comparison of SIR for the first two models, and they are sub-optimal to StI but still substantially ourperform SIR for the third model, where again the skewness is more severe in the mixture components of . Overall, these suggest that both and are robust against mild skewness in the mixture components of if follows a mixture model, and is slightly better than in this context.
| Method | Model (4.1) | Model (4.3) | Model (4.5) |
|---|---|---|---|
| SIR | .156(.041) | .219(.112) | 1.20(.072) |
| .026(.012) | .050(.046) | .816(.201) | |
| .062(.044) | .078(.050) | .826(.232) | |
| StI | .026(.010) | .038(.022) | .168(.084) |
-
•
In each cell of Columns 2-4, is the sample mean (sample standard deviation) of for the corresponding SDR method, based on replications.
To evaluate the applicability of and for more complex data, we next generate such that it conveys a unimodal, continuous, but curved pattern. Namely, we first generate under , and, given , we generate in each of the following ways:
| (34) |
where is an independent error distributed as . The sample support of conveys a shape and a shape, respectively. For each case, we generate from Model 1, Model 2 and Model 4 in Subsection 6.1 above. The corresponding performance of SDR methods are summarized in Table 4, again measured by in (28). The results for Model 3 are omitted because is close to zero with a large probability under (34), which causes an intrinsic difficulty to recover its effect for this model. The similar phenomena in Table 4 to Table 1 suggest the robustness of both and against the violation of the mixture model assumption on , which means that these methods can have a wider application in practice.
| Methods | Model 1 | Model 2 | Model 4 | |
|---|---|---|---|---|
| V-shaped | SIR | .278(.059) | 1.14(.220) | 1.26(.099) |
| ADR | .654(.180) | .641(.231) | 1.01(.296) | |
| MAVE | .087(.019) | .064(.013) | 1.08(.358) | |
| eCVE | 1.41(.007) | 1.42(.010) | 1.33(.114) | |
| .292(.093) | .132(.112) | .357(.163) | ||
| .166(.109) | .115(.130) | .328(.185) | ||
| W-shaped | SIR | .317(.090) | .289(.067) | .196(.040) |
| ADR | .353(.096) | .310(.067) | .442(.110) | |
| MAVE | .076(.021) | .061(.013) | .372(.092) | |
| eCVE | 1.36(.243) | .328(.085) | .648(.395) | |
| .242(.102) | .236(.154) | .502(.178) | ||
| .151(.091) | .161(.079) | .495(.180) |
-
•
The meanings of numbers in each cell follow those in Table 1.
6.3 Adjusted high-dimensional sparse SIR
We now compare the proposed and with the sparse SIR proposed in Tan et al. (2018) under the high-dimensional settings, where is set at and is set at each of and . The ratio under the latter setting is the same as the simulation studies in Tan et al. (2018). The MAVE-type methods are omitted under these settings due to their theoretical inconsistency caused by localization.
To generate a high-dimensional mixture multivariate normal , we set with , and set both and to be . To set and , we follow Cai, Ma and Zhang (2019) to introduce a discriminant vector with the first ten entries being nonzero, and let and . The magnitude of controls the degree of separation between the two mixture components, which we set to be , , and sequentially. Note that with , the mixture pattern is rather weak along any direction of . Given , we generate from each of
| Model A: | ||||
| Model B: |
where is the same random error as in Subsection 6.1. Both models share the same one-dimensional . In Model A, the effect of on is only moderately asymmetric over all the observations, but it is more monotone if specified for each mixture component of . Both effects are monotone in Model B.
Because is continuous in both Model A and Model B, we still set the number of slices at five in implementing the sparse SIR and the proposed and . Again, as mentioned in Section 4, is assumed to be known when fitting the mixture multivariate normal distribution of in implementing the proposed methods. The accuracy of these SDR methods in estimating is summarized in Table 5, and their variable selection consistency, as measured by the true positive rate and the false positive rate, is summarized in Table 6, both based on independent runs.
| Model | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| A | SIR | .536(.169) | .641(.314) | 1.16(.039) | .712(.085) | .805(.069) | .992(.051) | |
| .342(.098) | .431(.087) | .487(.068) | .411(.197) | .686(.115) | .709(.102) | |||
| .236(.083) | .401(.095) | .420(.078) | .407(.122) | .569(.091) | .592(.103) | |||
| B | SIR | .665(.142) | .795(.115) | .973(.427) | .692(.086) | .846(.161) | .972(.061) | |
| .636(.357) | .570(.125) | .608(.220) | .620(.233) | .818(.111) | .832(.139) | |||
| .554(.407) | .569(.106) | .604(.185) | .586(.138) | .713(.104) | .704(.124) | |||
-
•
The meanings of numbers in each cell follow those in Table 1.
| Model | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| A | SIR | 1.00(.004) | 1.00(.017) | 1.00(.050) | 1.00(.032) | 1.00(.023) | 1.00(.024) | |
| 1.00(.002) | 1.00(.008) | 1.00(.012) | 1.00(.006) | 1.00(.021) | 1.00(.023) | |||
| 1.00(.001) | 1.00(.008) | 1.00(.008) | 1.00(.004) | 1.00(.011) | 1.00(.013) | |||
| B | SIR | 1.00(.021) | .976(.405) | .987(.031) | 1.00(.018) | 1.00(.039) | 1.00(.043) | |
| .933(.006) | .956(.198) | 1.00(.020) | 1.00(.011) | 1.00(.021) | 1.00(.024) | |||
| .940(.009) | .964(.186) | 1.00(.021) | 1.00(.007) | 1.00(.021) | 1.00(.021) | |||
-
•
In each cell of Columns 3-8, is the true(false) positive rate of the corresponding
-
•
sparse SDR method, based on replications.
From these two tables, both and are clearly more effective than the sparse SIR, except for Model B with where they are comparable. In both models, the sparse SIR quickly fails to recover as increases (although still consistent in variable selection), whereas and are much more robust against this change. The reason for the slightly compromised performance of and when increases, is that a larger makes the second mixture component of move towards the origin in Model A and leave the origin from the left in Model B, both leading to a vanishing signal of in this mixture component. When is , and still slightly outperform the sparse SIR, so they are useful even when the distribution of is only weakly clustered.
We next change to follow a V-shaped distribution, by first generating from and then generating as in the first case of (34) given . Same as above, we fix when approximating this distribution by a mixture multivariate normal distribution using Cai, Ma and Zhang’s method, for which a more complex non-clustered distribution such as W-shaped cannot be well approximated and thus is omitted. Based on independent runs, the performance of the sparse SDR methods for Model A and Model B is recorded in Table 7 and Table 8, in the same format as Table 5 and Table 6, respectively. Compared with Table 5 and Table 6, a less substantial but similar phenomenon can be observed, suggesting the usefulness of both and when has a curved and non-clustered distribution.
| Model | Method | |||
|---|---|---|---|---|
| model A | SIR | .625(.079) | .672(.068) | |
| .463(.078) | .502(.068) | |||
| .432(.089) | .499(.087) | |||
| model B | SIR | .614(.110) | .694(.088) | |
| .503(.108) | .545(.086) | |||
| .484(.106) | .510(.102) |
-
•
The meanings of numbers in each cell follow those in Table 1.
| Model | Method | |||
|---|---|---|---|---|
| model A | SIR | 1.00(.001) | 1.00(.001) | |
| 1.00(.001) | 1.00(.001) | |||
| 1.00(.001) | 1.00(.001) | |||
| model B | SIR | .987(.001) | 1.00(.001) | |
| 1.00(.004) | 1.00(.004) | |||
| 1.00(.004) | 1.00(.004) |
-
•
The meanings of numbers in each cell follow those in Table 6.
6.4 Adjusted SAVE under various settings
To illustrate the performance of the proposed and in comparison of SAVE and the MAVE-type methods, we generate by the following two models where is the same random error as in Subsection 6.1.
Similarly to the studies for the adjusted SIR, we first generate under the mixture model , where and we set for Model I and for Model II; we then generate under the V-shaped distribution and under the W-shaped distribution in the same way as in Subsection 6.2. Note that both and are theoretically consistent only in the first case.
Let . For each of SAVE, , and , we set . The MAVE-type methods are implemented in the same way as in Subsection . The results are summarized in Table 9. Clearly, both and are effective even when does not convey a clustered pattern, and they outperform both SAVE and the MAVE-type methods in most cases.
| Method | Model I | Model II | |||||
|---|---|---|---|---|---|---|---|
| MMN | V-shaped | W-shaped | MMN | V-shaped | W-shaped | ||
| SAVE | 1.40(.015) | 1.06(.342) | .267(.050) | .515(.114) | .249(.071) | .311(.092) | |
| ADR | .312(.071) | .398(.072) | .275(.079) | .620(.207) | .916(.314) | .403(.096) | |
| MAVE | .871(.625) | .129(.031) | .092(.028) | .371(.286) | .944(.344) | .408(.236) | |
| eCVE | .191(.208) | .353(.088) | .729(.425) | 1.14(.414) | 1.42(.009) | 1.38(.072) | |
| .347(.099) | .158(.055) | .532(.187) | .581(.166) | .103(.029) | .241(.186) | ||
| .334(.094) | .143(.028) | .514(.171) | .575(.160) | .106(.032) | .268(.129) | ||
-
•
“MMN” represents the case that is generated under the mixture multivariate normal distribution. The meanings of numbers in each cell follow those in Table 1.
6.5 A real data example
The MASSCOL2 data set, available at MINITAB (in catalogue STUDENT12), was collected in four-year colleges of Massachusetts in 1995, with the research interest on assessing how the academic strength of the incoming students of each college and the features of the college itself jointly affect the percentage of the freshman class that graduate. After removing missing values, observations are left in the data. Based on preliminary exploratory data analysis, we choose seven variables as the working predictor, including the percentage of the freshman class that were in the top of their high school graduating class (denoted by Top 25), the median SAT Math score (MSAT), the median SAT Verbal score (VSAT), the percentage of applicants accepted by each college (Accept), the percentage of enrolled students among all who were accepted (Enroll), the student/faculty ratio (SFRatio), and the out-of-state tuition (Tuition). The same predictor was also selected in Li and Dong (2009), who applied SDR to an earlier version of the data set. The response variable, which is the percentage of the freshman class that graduate, is labeled as WhoGrad in the data set. We next analyze this data set using the proposed and .
As suggested by BIC, the distribution of in this data set can be best approximated by the mixture multivariate normal distribution if we set the number of mixture components to be two or three. Here, we use three as a conservative choice. The dimension of for this data set is determined to be two. To choose for , we measure the performance of by the predictability of the corresponding reduced predictor, for which we calculate the out-of-sample based on the leave-one-out cross validation. In each training set, the regression function is fitted by kernel mean estimation using the R package npreg, with the bandwidth selected automatically from the R package npregbw. The resulting optimal choice of is two. Likewise, the optimal choice of for is three. We then apply and accordingly.
To illustrate the goodness of the mixture model fit for in this data set, we draw the scatter plots of the two-dimensional reduced predictors from and , in the upper-left and upper-right panels of Figure 3, respectively. The point type for each observation is determined by an independent multinomial random variable, with probability derived from the mixture model fit. The nature of clustering in these plots suggests the appropriateness of the mixture model and consequently the effectiveness of and for this data set. The latter is further supported by the aforementioned out-of-sample for the reduced predictor from these methods, which is for and is for . For reference, we also apply SIR, ADR, and eCVE to the data, and the out-of-sample for their reduced predictors are , , and , respectively. Roughly, this means that the variance of the error in the reduced data derived by is less than that by SIR, less than that by ADR, and less than that by eCVE. The out-of-sample for MAVE is , so MAVE performs equally well for this data set as the proposed SDR methods.




To visualize the effect of the reduced predictor from on the response, we draw the -dimensional scatter plot of the reduced data in the lower-left panel of Figure 3. Clearly, both components of the reduced predictor uniquely affect the response, and their effect interact with each other: the effect of the first component changes from moderately positive to dramatically positive as the second component grows, and the effect of the second component changes from monotone decreasing to monotone increasing as the first component grows. A similar pattern can be observed from the -dimensional scatter plot of the reduced data from , as depicted in the lower-right panel of Figure 3. To better interpret these, we report the coefficients of the working reduced predictor for each SDR method in Table 10, with each variable in the original predictor standardized to have the unit variance.
From Table 10, both and suggest that the median SAT Verbal score, the percentage of applicants accepted by each college, and the out-of-state tuition are the dominating variables in predicting the percentage of the freshman class that graduate, among which the out-of-state tuition seems to constantly contribute a positive effect. These may help the researchers comprehend the mechanism underlying the data set in the future investigation.
| direction 1 | direction 2 | direction 1 | direction 2 | ||
|---|---|---|---|---|---|
| Top 25 | .201 | -.014 | .193 | -.186 | |
| MSAT | -.197 | -.041 | -.076 | .330 | |
| VSAT | -.125 | -.516 | -.213 | -.726 | |
| Accept | -.193 | -.846 | -.189 | -.431 | |
| Enroll | .069 | .016 | .133 | .299 | |
| SFRatio | .223 | -.035 | .324 | -.027 | |
| Tuition | .901 | -.118 | .866 | .226 | |
7 Discussion
In the proposed work, we conduct SDR under the mixture model of , which relaxes the linearity and constant variance conditions commonly adopted in the inverse regression methods, and meanwhile provides a parametric analogue of the MAVE-type methods such as ADR. Complying with the wide applicability of mixture models in approximating unknown distributions, our numerical studies suggest the effectiveness of the proposed SDR methods for generally distributed predictors, even when the clustered pattern is not obvious.
One issue that is underrepresented in this article is the difficulty of fitting the mixture model. This includes a possibly high computational cost for implementing the maximal likelihood estimator, which is sensitive to the initial value, as well as the potential failure of recovering the mixture components with small proportions when the underlying mixture model is severely unbalanced. As mentioned in Section 4, under the high-dimensional settings, only the mixture multivariate normal distribution has been studied in the existing literature, with the number of mixture components assumed known, and with the homogeneity of ’s and the sparsity of ’s imposed for estimation consistency. These limitations may restrict the applicability of the proposed SDR methods, especially for large-dimensional data.
Finally, we speculate that the proposed strategy can be applied to adjust other SDR methods besides inverse regression. For example, we can assume a mixture model on instead of on , which will adjust the SDR methods that assume to have an elliptical contoured distribution or fall in the exponential family (Cook, 2007; Cook and Forzani, 2008). These extensions may further facilitate the applicability of SDR for data sets with large-dimensional and non-elliptically distributed predictor.
[Acknowledgments]
Appendix A Regularities and other adjusted SDR methods
In this Appendix, we include the adjustments of pHd and directional regression, as well as the regularity conditions (C1)-(C3) needed for Theorem 3 in the main text. The equations in this Appendix are labeled as (A.1), (A.2), etc.
A.1 Adjusted pHd and directional regression
The candidate matrix for pHd is . Thus, the first adjustment of pHd is to recover the central mean subspace by the column space of
| (A.1) |
A -consistent estimator can be constructed by plugging the mixture model fit and using the sample moments, whose leading left singular vectors span a -consistent estimator of , denoted by . In addition, define
where . The second adjustment of pHd is to minimize a sample-level , and the resulting minimizer spans a -consistent estimator of , denoted by .
Let be an independent copy of . The candidate matrix for directional regression is . The first adjustment of directional regression is to recover by the column space of
A -consistent estimator of can be constructed by plugging the mixture model fit and using the sample moments, whose leading left singular vectors span a -consistent estimator of , denoted by . In addition, we propose the following objective function
The second adjustment of directional regression is to minimize a sample-level , and the resulting minimizer spans a -consistent estimator of , denoted by . The minimization of both and requires iterative algorithms, which resemble those for implementing and discussed later in Appendix B and thus are omitted.
A.2 Regularity conditions for Theorem 3
(C1). The signal-to-noise ratio of the mixture multivariate normal distribution, defined as , satisfies , where is given in (C.24) in supplementary material for Cai, Ma and Zhang (2019).
(C2). has a bounded support. has a total variation of order , i.e.
where for any , and, for any , is the collection of all the -point partitions .
(C3). Define the -sparse minimal and maximal eigenvalues of as
where is the number of nonzero elements in for any . Assume that there exist constants such that .
Appendix B Algorithms for the proposed methods
In this Appendix, we elaborate the details in implementing , , , and .
B.1 Algorithms for and
Given , is readily derived by singular value decomposition. We list the detailed steps in Algorithm 1.
To implement , we fix at in and each involved in , where is an arbitrary orthonormal basis matrix of derived from . The estimators are then derived from the mixture model fit mentioned in Section 2, which deliver
Together with , we have
| (B.1) |
where denotes . To minimize , we propose an iterative algorithm as follows. Start with as the initial estimator of . In the th iteration, let be an orthonormal basis matrix of the most updated estimate of . We replace each in with , which changes into a quadratic function of that can be readily minimized, with the minimizer being the update . We repeat the iterations until a prefixed convergence threshold for defined in (28) of the main text is met. These are summarized as Algorithm 2.
B.2 Algorithms for and
Given , is readily derived by singular value decomposition. We list the detailed steps in Algorithm 3.
To implement , we fix at in each involved in , where is an arbitrary orthonormal basis matrix of derived from . The estimators are then derived from the mixture model fit mentioned in Section 2. We have,
| (B.2) |
where
To minimize , we propose an iterative algorithm as follows. Start with as the initial estimator of . In the th iteration, let be an orthonormal basis matrix of the most updated estimate of . We replace each in with , and replace each in with , which changes into a quadratic function of that can be readily minimized, with the minimizer being the update . We repeat the iterations until a prefixed convergence threshold for defined in (28) of the main text is met. These are summarized as Algorithm 4.
Appendix C Complementary simulation studies
In this Appendix, we present the complementary simulation studies to evaluate how the proposed and are impacted by the estimation error in fitting the mixture model of , as well as by hypothetical misspecification of the number of mixture components , under the conventional low-dimensional settings and assuming that the mixture model of holds. The misspecification of does not occur in the simulation studies of the main text due to the effectiveness of BIC, but it is possible in real data analyses and thus worth the investigation.
Generally, for an arbitrarily fixed working number of mixture components , the corresponding mixture model misspecifies the distribution of if , and it still correctly specifies the distribution if . Thus, the proposed SDR methods theoretically lose consistency if and are still consistent if . As an illustration, we set to be each of , , , and sequentially for all the models in Subsection 6.1 of the main text, and apply and in each case. Note that this procedure differs from the implementation of and in Subsection 6.1, as is forced to be a fixed value rather than being estimated by BIC. After repeating the procedure for times, the results are summarized in Table 11. When , both and reduce to SIR, so the result of SIR in Table 1 is used for this case.
| Methods | Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|---|
| SIR | .908(.136) | .910(.128) | 1.08(.179) | .634(.127) | |
| .590(.151) | .436(.094) | .553(.111) | .375(.058) | ||
| .555(.146) | .402(.088) | .502(.109) | .320(.076) | ||
| .698(.191) | .506(.154) | .608(.192) | .374(.105) | ||
| .642(.156) | .416(.128) | .545(.174) | .338(.098) | ||
| .801(.233) | .549(.188) | .636(.217) | .388(.104) | ||
| .689(.194) | .435(.163) | .590(.189) | .350(.095) | ||
| ADR | .611(.176) | .473(.138) | 1.31(.113) | .645(.189) | |
| MAVE | .745(.229) | .223(.056) | .895(.278) | .326(.089) | |
| eCVE | 1.42(.126) | .452(.128) | .609(.222) | 1.29(.226) |
-
•
The meanings of numbers in each cell follow those in Table 1.
Recall that is for Models and is for Model 4. Thus, Table 11 illustrates both the impact of overestimation of and the impact of underestimation of on the proposed methods for each model. Compared with both the benchmark and the worst case scenario, i.e. the proposed methods with truly specified and SIR, respectively, an overestimation of brings negligible additional bias to the proposed methods and makes them still comparable and sometimes outperform the MAVE-type methods. By contrast, an underestimate brings significant bias to the proposed methods (i.e. SIR) for all the four models. These comply with the theoretical anticipation above.
An interesting exception in Table 11 is the case of forced to be for Model 4, which suggests the effectiveness of the proposed methods even though is slightly underestimated. The reason is that the mixture of three multivariate normal distributions in this model can still be approximated by a mixture of two multivariate normal distributions to a good extent. To see this, we draw the scatter plot of , the sub-vector of that has the clustered pattern, in Figure 4. The point type of each observation is determined by an independent Bernoulli random variable, whose probability of success is derived from the mixture model fit with . The two fitted clusters are then formed by the observations that have the same point types. From Figure 4, each cluster conveys an approximate elliptical distribution, and, in particular, their loess fits of are approximately linear.





When is estimated by a consistent order-determination method, it may still be misspecified in practice. However, unlike the case of arbitrarily fixed above, an underestimation of in this case is plausibly a sign for severely overlapping mixture components in the data set; that is, two or more mixture components have similar distributions and thus can be regarded as one mixture component that approximately falls in the working parametric family (e.g. multivariate normal). Thus, the distribution of can still be approximated by the working mixture model, indicating the effectiveness of the proposed SDR methods. Together with the robustness of the proposed methods to the choice of discussed above, a misspecification of should not be worrisome in practice.
Next, we assess the impact of the estimation error of ’s, ’s, and ’s on the proposed and . To this end, we implement both SDR methods in the oracle scenario that the mixture model of is completely known for each model in Subsection 6.1 of the main text, and compare their performance (based on independent runs) with that in Table 1. The results are summarized in Table 12. Generally, the estimation error in fitting the mixture model of has a negligible impact on both of the proposed methods. A relative asymptotic study is deferred to future.
| Model 1 | Model 2 | Model 3 | Model 4 | |
|---|---|---|---|---|
| .590(.151) | .436(.094) | .553(.111) | .374(.105) | |
| .555(.146) | .402(.085) | .502(.109) | .338(.098) | |
| oracle- | .616(.158) | .469(.113) | .544(.128) | .401(.105) |
| oracle- | .538(.138) | .314(.064) | .476(.116) | .326(.078) |
-
•
The methods “oracle-” and “oracle-” refer to and with the mixture model of completely known, respectively. The meanings of numbers in each cell of Columns follow those in Table 1.
References
- Biernacki, Celeux and Govaert (2000) {barticle}[author] \bauthor\bsnmBiernacki, \bfnmChristophe\binitsC., \bauthor\bsnmCeleux, \bfnmGilles\binitsG. and \bauthor\bsnmGovaert, \bfnmGérard\binitsG. (\byear2000). \btitleAssessing a mixture model for clustering with the integrated completed likelihood. \bjournalIEEE transactions on pattern analysis and machine intelligence \bvolume22 \bpages719–725. \endbibitem
- Cai, Ma and Zhang (2019) {barticle}[author] \bauthor\bsnmCai, \bfnmT Tony\binitsT. T., \bauthor\bsnmMa, \bfnmJing\binitsJ. and \bauthor\bsnmZhang, \bfnmLinjun\binitsL. (\byear2019). \btitleCHIME: Clustering of high-dimensional Gaussian mixtures with EM algorithm and its optimality. \bjournalThe Annals of Statistics \bvolume47 \bpages1234–1267. \endbibitem
- Chen, Zou and Cook (2010) {barticle}[author] \bauthor\bsnmChen, \bfnmX.\binitsX., \bauthor\bsnmZou, \bfnmC.\binitsC. and \bauthor\bsnmCook, \bfnmR. D.\binitsR. D. (\byear2010). \btitleCoordinate-independent sparse suffcient dimension reduction and variable selection. \bjournalThe Annals of Statistics \bvolume6 \bpages3696–3723. \endbibitem
- Chiaromonte, Cook and Li (2002) {barticle}[author] \bauthor\bsnmChiaromonte, \bfnmFrancesca\binitsF., \bauthor\bsnmCook, \bfnmR Dennis\binitsR. D. and \bauthor\bsnmLi, \bfnmBing\binitsB. (\byear2002). \btitleSufficient dimension reduction in regressions with categorical predictors. \bjournalAnnals of Statistics \bpages475–497. \endbibitem
- Cook (1998) {bbook}[author] \bauthor\bsnmCook, \bfnmR. D.\binitsR. D. (\byear1998). \btitleRegression Graphics. \bpublisherWiley, New York. \endbibitem
- Cook (2007) {barticle}[author] \bauthor\bsnmCook, \bfnmR Dennis\binitsR. D. (\byear2007). \btitleFisher lecture: Dimension reduction in regression. \endbibitem
- Cook and Forzani (2008) {barticle}[author] \bauthor\bsnmCook, \bfnmR. Dennis\binitsR. D. and \bauthor\bsnmForzani, \bfnmLiliana\binitsL. (\byear2008). \btitlePrincipal Fitted Components for Dimension Reduction in Regression. \bjournalStatistical Science \bvolume23 \bpages485 – 501. \endbibitem
- Cook and Li (2002) {barticle}[author] \bauthor\bsnmCook, \bfnmR. D.\binitsR. D. and \bauthor\bsnmLi, \bfnmB.\binitsB. (\byear2002). \btitleDimension reduction for conditional mean in regression. \bjournalThe Annals of Statistics \bvolume30 \bpages455–474. \endbibitem
- Cook and Weisberg (1991) {barticle}[author] \bauthor\bsnmCook, \bfnmR. D.\binitsR. D. and \bauthor\bsnmWeisberg, \bfnmS.\binitsS. (\byear1991). \btitleDiscussion of “Sliced inverse regression for dimension reduction”. \bjournalJournal of the American Statistical Association \bvolume86 \bpages316–342. \endbibitem
- Dong and Li (2010) {barticle}[author] \bauthor\bsnmDong, \bfnmY.\binitsY. and \bauthor\bsnmLi, \bfnmB.\binitsB. (\byear2010). \btitleDimension reduction for non-elliptically distributed predictors: second-order methods. \bjournalBiometrika \bvolume97 \bpages279–294. \endbibitem
- Everitt (2013) {bbook}[author] \bauthor\bsnmEveritt, \bfnmBrian\binitsB. (\byear2013). \btitleFinite mixture distributions. \bpublisherSpringer Science & Business Media. \endbibitem
- Fertl and Bura (2022) {barticle}[author] \bauthor\bsnmFertl, \bfnmLukas\binitsL. and \bauthor\bsnmBura, \bfnmEfstathia\binitsE. (\byear2022). \btitleThe ensemble conditional variance estimator for sufficient dimension reduction. \bjournalElectronic Journal of Statistics \bvolume16 \bpages1595–1634. \endbibitem
- Guan, Xie and Zhu (2017) {barticle}[author] \bauthor\bsnmGuan, \bfnmYu\binitsY., \bauthor\bsnmXie, \bfnmChuanlong\binitsC. and \bauthor\bsnmZhu, \bfnmLixing\binitsL. (\byear2017). \btitleSufficient dimension reduction with mixture multivariate skew-elliptical distributions. \bjournalStatistica Sinica \bpages335–355. \endbibitem
- Hall and Li (1993) {barticle}[author] \bauthor\bsnmHall, \bfnmP.\binitsP. and \bauthor\bsnmLi, \bfnmK. C.\binitsK. C. (\byear1993). \btitleOn almost linearity of low dimensional projections from high dimensional data. \bjournalThe Annals of Statistics \bvolume47 \bpages867–889. \endbibitem
- Li (1991) {barticle}[author] \bauthor\bsnmLi, \bfnmK. C.\binitsK. C. (\byear1991). \btitleSliced inverse regression for dimension reduction (with discussion). \bjournalJournal of the American Statistical Association \bvolume86 \bpages316–342. \endbibitem
- Li (1992) {barticle}[author] \bauthor\bsnmLi, \bfnmK.\binitsK. (\byear1992). \btitleOn principal Hessian directions for data visualization and dimension reduction: another application of Stein’s lemma. \bjournalJournal of the American Statistical Association \bvolume87 \bpages1025–1039. \endbibitem
- Li (2007) {barticle}[author] \bauthor\bsnmLi, \bfnmLexin\binitsL. (\byear2007). \btitleSparse sufficient dimension reduction. \bjournalBiometrika \bvolume94 \bpages603–613. \endbibitem
- Li and Dong (2009) {barticle}[author] \bauthor\bsnmLi, \bfnmB.\binitsB. and \bauthor\bsnmDong, \bfnmY.\binitsY. (\byear2009). \btitleDimension reduction for nonelliptically distributed predictors. \bjournalThe Annals of Statistics \bpages1272–1298. \endbibitem
- Li and Duan (1989) {barticle}[author] \bauthor\bsnmLi, \bfnmK. C.\binitsK. C. and \bauthor\bsnmDuan, \bfnmN.\binitsN. (\byear1989). \btitleRegression analysis under link violation. \bjournalThe Annals of Statistics \bpages1009–1052. \endbibitem
- Li and Wang (2007) {barticle}[author] \bauthor\bsnmLi, \bfnmB.\binitsB. and \bauthor\bsnmWang, \bfnmS.\binitsS. (\byear2007). \btitleOn directional regression for dimension reduction. \bjournalJournal of the American Statistical Association \bvolume35 \bpages2143–2172. \endbibitem
- Lin, Zhao and Liu (2016) {barticle}[author] \bauthor\bsnmLin, \bfnmQian\binitsQ., \bauthor\bsnmZhao, \bfnmZhigen\binitsZ. and \bauthor\bsnmLiu, \bfnmJun S\binitsJ. S. (\byear2016). \btitleSparse sliced inverse regression for high dimensional data. \bjournalarXiv preprint arXiv:1611.06655. \endbibitem
- Lin, Zhao and Liu (2019) {barticle}[author] \bauthor\bsnmLin, \bfnmQian\binitsQ., \bauthor\bsnmZhao, \bfnmZhigen\binitsZ. and \bauthor\bsnmLiu, \bfnmJun S\binitsJ. S. (\byear2019). \btitleSparse sliced inverse regression via lasso. \bjournalJournal of the American Statistical Association \bvolume114 \bpages1726–1739. \endbibitem
- Lindsay (1995) {binproceedings}[author] \bauthor\bsnmLindsay, \bfnmBruce G\binitsB. G. (\byear1995). \btitleMixture models: theory, geometry, and applications. \bpublisherIms. \endbibitem
- Luo (2018) {barticle}[author] \bauthor\bsnmLuo, \bfnmWei\binitsW. (\byear2018). \btitleOn the second-order inverse regression methods for a general type of elliptical predictors. \bjournalSTATISTICA SINICA \bvolume28 \bpages1415–1436. \endbibitem
- Luo (2022) {barticle}[author] \bauthor\bsnmLuo, \bfnmWei\binitsW. (\byear2022). \btitleDetermine the number of clusters by data augmentation. \bjournalElectronic Journal of Statistics \bvolume16 \bpages3910–3936. \endbibitem
- Luo, Li and Yin (2014) {barticle}[author] \bauthor\bsnmLuo, \bfnmW.\binitsW., \bauthor\bsnmLi, \bfnmB.\binitsB. and \bauthor\bsnmYin, \bfnmX.\binitsX. (\byear2014). \btitleOn efficient dimension reduction with respect to a statistical functional of interest. \bjournalThe Annals of Statistics \bvolume42 \bpages382–412. \endbibitem
- Luo and Li (2016) {barticle}[author] \bauthor\bsnmLuo, \bfnmW.\binitsW. and \bauthor\bsnmLi, \bfnmB.\binitsB. (\byear2016). \btitleCombining eigenvalues and variation of eigenvectors for order determination. \bjournalBiometrika \bvolume103 \bpages875–887. \endbibitem
- Luo and Li (2021) {barticle}[author] \bauthor\bsnmLuo, \bfnmWei\binitsW. and \bauthor\bsnmLi, \bfnmBing\binitsB. (\byear2021). \btitleOn order determination by predictor augmentation. \bjournalBiometrika \bvolume108 \bpages557-574. \endbibitem
- Ma and Zhu (2012) {barticle}[author] \bauthor\bsnmMa, \bfnmYanyuan\binitsY. and \bauthor\bsnmZhu, \bfnmLiping\binitsL. (\byear2012). \btitleA Semiparametric Approach to Dimension Reduction. \bjournalJournal of the American Statistical Association \bvolume107 \bpages168-179. \endbibitem
- Ma and Zhu (2013) {barticle}[author] \bauthor\bsnmMa, \bfnmY.\binitsY. and \bauthor\bsnmZhu, \bfnmL.\binitsL. (\byear2013). \btitleEfficient estimation in sufficient dimension reduction. \bjournalAnnals of statistics \bvolume41 \bpages250. \endbibitem
- Marin, Mengersen and Robert (2005) {barticle}[author] \bauthor\bsnmMarin, \bfnmJean-Michel\binitsJ.-M., \bauthor\bsnmMengersen, \bfnmKerrie\binitsK. and \bauthor\bsnmRobert, \bfnmChristian P\binitsC. P. (\byear2005). \btitleBayesian modelling and inference on mixtures of distributions. \bjournalHandbook of statistics \bvolume25 \bpages459–507. \endbibitem
- McLachlan, Lee and Rathnayake (2019a) {barticle}[author] \bauthor\bsnmMcLachlan, \bfnmGeoffrey J\binitsG. J., \bauthor\bsnmLee, \bfnmSharon X\binitsS. X. and \bauthor\bsnmRathnayake, \bfnmSuren I\binitsS. I. (\byear2019a). \btitleFinite mixture models. \bjournalAnnual review of statistics and its application \bvolume6 \bpages355–378. \endbibitem
- McLachlan, Lee and Rathnayake (2019b) {barticle}[author] \bauthor\bsnmMcLachlan, \bfnmGeoffrey J.\binitsG. J., \bauthor\bsnmLee, \bfnmSharon X.\binitsS. X. and \bauthor\bsnmRathnayake, \bfnmSuren I.\binitsS. I. (\byear2019b). \btitleFinite Mixture Models. \bjournalAnnual Review of Statistics and Its Application \bvolume6 \bpages355-378. \endbibitem
- Tan et al. (2018) {barticle}[author] \bauthor\bsnmTan, \bfnmKean Ming\binitsK. M., \bauthor\bsnmWang, \bfnmZhaoran\binitsZ., \bauthor\bsnmZhang, \bfnmTong\binitsT., \bauthor\bsnmLiu, \bfnmHan\binitsH. and \bauthor\bsnmCook, \bfnmR Dennis\binitsR. D. (\byear2018). \btitleA convex formulation for high-dimensional sparse sliced inverse regression. \bjournalBiometrika \bvolume105 \bpages769–782. \endbibitem
- Titterington, Smith and Makov (1985) {binproceedings}[author] \bauthor\bsnmTitterington, \bfnmD. Michael\binitsD. M., \bauthor\bsnmSmith, \bfnmAdrian F. M.\binitsA. F. M. and \bauthor\bsnmMakov, \bfnmUdi E.\binitsU. E. (\byear1985). \btitleStatistical analysis of finite mixture distributions. \bpublisherJohn Wiley & Sons. \endbibitem
- Wang et al. (2020) {barticle}[author] \bauthor\bsnmWang, \bfnmQin\binitsQ., \bauthor\bsnmYin, \bfnmXiangrong\binitsX., \bauthor\bsnmLi, \bfnmBing\binitsB. and \bauthor\bsnmTang, \bfnmZhihui\binitsZ. (\byear2020). \btitleOn aggregate dimension reduction. \bjournalStatistica Sinica \bvolume30 \bpages1027–1048. \endbibitem
- Xia et al. (2002) {barticle}[author] \bauthor\bsnmXia, \bfnmYingcun\binitsY., \bauthor\bsnmTong, \bfnmHowell\binitsH., \bauthor\bsnmLi, \bfnmWK\binitsW. and \bauthor\bsnmZhu, \bfnmLi-Xing\binitsL.-X. (\byear2002). \btitleAn adaptive estimation of dimension reduction space. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume64 \bpages363–410. \endbibitem
- Yin, Li and Cook (2008) {barticle}[author] \bauthor\bsnmYin, \bfnmX.\binitsX., \bauthor\bsnmLi, \bfnmB.\binitsB. and \bauthor\bsnmCook, \bfnmR. D.\binitsR. D. (\byear2008). \btitleSuccessive direction extraction for estimating the central subspace in a multiple-index regression. \bjournalJournal of Multivariate Analysis \bvolume99 \bpages1733–1757. \endbibitem
- Zeng, Mai and Zhang (2022) {barticle}[author] \bauthor\bsnmZeng, \bfnmJing\binitsJ., \bauthor\bsnmMai, \bfnmQing\binitsQ. and \bauthor\bsnmZhang, \bfnmXin\binitsX. (\byear2022). \btitleSubspace Estimation with Automatic Dimension and Variable Selection in Sufficient Dimension Reduction. \bjournalJournal of the American Statistical Association \bvolume0 \bpages1-13. \endbibitem
- Zhao, Hautamaki and Fränti (2008) {binproceedings}[author] \bauthor\bsnmZhao, \bfnmQinpei\binitsQ., \bauthor\bsnmHautamaki, \bfnmVille\binitsV. and \bauthor\bsnmFränti, \bfnmPasi\binitsP. (\byear2008). \btitleKnee point detection in BIC for detecting the number of clusters. In \bbooktitleAdvanced Concepts for Intelligent Vision Systems: 10th International Conference, ACIVS 2008, Juan-les-Pins, France, October 20-24, 2008. Proceedings 10 \bpages664–673. \bpublisherSpringer. \endbibitem