[1]\fnmYang \surQian
[1]\orgdivInformation and Computer Sciences Department, \orgnameUniversity of Hawai’i at Mānoa, \orgaddress\cityHawai’i, \countryUSA 2]\orgdivStanford School of Medicine, \orgnameStanford University, \orgaddress\cityCalifornia, \countryUSA
Advancing Human Action Recognition with Foundation Models trained on Unlabeled Public Videos
Abstract
The increasing variety and quantity of tagged multimedia content on a variety of online platforms offer a unique opportunity to advance the field of human action recognition. In this study, we utilize 283,582 unique, unlabeled TikTok video clips, categorized into 386 hashtags, to train a domain-specific foundation model for action recognition. We employ VideoMAE V2, an advanced model integrating Masked Autoencoders (MAE) with Vision Transformers (ViT), pre-trained on this diverse collection of unstructured videos. Our model, fine-tuned on established action recognition benchmarks such as UCF101 and HMDB51, achieves state-of-the-art results: 99.05% on UCF101, 86.08% on HMDB51, 85.51% on Kinetics-400, and 74.27% on Something-Something V2 using the ViT-giant backbone. These results highlight the potential of using unstructured and unlabeled videos as a valuable source of diverse and dynamic content for training foundation models. Our investigation confirms that while initial increases in pre-training data volume significantly enhance model performance, the gains diminish as the dataset size continues to expand. Our findings emphasize two critical axioms in self-supervised learning for computer vision: (1) additional pre-training data can yield diminishing benefits for some datasets and (2) quality is more important than quantity in self-supervised learning, especially when building foundation models.
keywords:
Self-Supervised Learning, Action Recognition, Vision Transformers, TikTok Video Pre-training1 Introduction
Action recognition is a fundamental computer vision task that involves identifying and classifying human actions within video sequences. This technology is critically important in various applications, including security systems, interactive gaming, and healthcare monitoring. As social media platforms have grown, TikTok has become a prominent source of diverse human action videos. In response, we have developed a specialized foundation model trained on a carefully curated set of 283,582 TikTok video clips. This dataset, known as TikTokActions, represents a wide array of human activities and is designed to reflect real-world scenarios and cultural diversities. It includes unique, non-standard human actions, filling gaps in existing action recognition datasets and expanding the variety of human activities that current models can recognize.
Contrasting with the Kinetics dataset[1], which also sources user-generated content but from YouTube, our TikTokActions dataset is composed exclusively of TikTok videos. These are characterized by their dynamic and spontaneous nature, often featuring rapid transitions and creative interactions that are less common in YouTube’s typically longer and more structured videos. This difference provides unique training challenges, enhancing the ability of models to interpret a broad spectrum of human actions in unpredictable environments.
We conducted a series of rigorous experiments to evaluate the efficacy of the TikTokActions dataset for pre-training computer vision models on action-related tasks. Using the advanced VideoMAE V2 model equipped with ViT-base and ViT-giant backbones[2], we explored the dataset’s capabilities. The ViT-base provided a baseline for comparison against other models with similar architectures, while the ViT-giant was used to assess the maximum potential of our dataset. Subsequent fine-tuning on well-known datasets such as UCF101[3], HMDB51[4], Kinetics[1], and Something-Something V2[5] revealed that models pre-trained on TikTokActions often performed comparably to, or even better than, those trained solely on these traditional benchmarks or those pre-trained on significantly larger datasets, where enhancements tend to be incremental.
Additionally, we investigated the relationship between the number of pre-training videos and model performance on downstream tasks. By training VideoMAE V2[2] on increasing subsets of our collection, from 1,000 videos up to 6,000, we observed that performance remained robust, suggesting that massive datasets are not always essential for effective pre-training. This discovery emphasizes the efficiency of using online, unlabeled videos as a source for pre-training, challenging the prevailing reliance on large-scale video datasets for optimal model performance. Prior to deploying such methodologies in practical applications, we urge the research community to consider the ethical implications of using publicly available data for training deep learning models, particularly in terms of data scraping and privacy concerns.
2 Related Work
2.1 Human Action Recognition Datasets
The evolution of action recognition research has been significantly shaped by the development and availability of benchmark datasets, which guide and validate advancements in computer vision methodologies. The UCF101[3] dataset, known for its diverse array of human actions, has been instrumental in pioneering research within this domain. Likewise, the HMDB-51[4] dataset, despite its smaller scale, offers a rich variety of human actions captured under realistic conditions, providing essential challenges for model evaluation.
Introduced in 2017, the Kinetics Human Action Video dataset [1] became a cornerstone in this field with over 400 distinct human action classes derived from YouTube videos. It set a new benchmark, catalyzing further research and development in action recognition technologies. Similarly, AVA [6] provides densely labeled video segments that allow for action localization in addition to recognition, offering a deeper understanding of context and action dynamics.
Emerging datasets such as Ego4D [7], which focuses on first-person video analysis, and HowTo100M [8], which leverages instructional videos for action recognition, reflect the diversifying sources and modalities being explored. EPIC-Kitchens [9], ActivityNet [10], and THUMOS [11] offer further variations in complexity and scenarios, pushing the envelope on what models can understand and predict.
Recent datasets have addressed limitations of earlier collections. The Something-Something dataset [5] focuses on human-object interactions within everyday scenarios, offering a unique perspective that highlights the complexity of routine human activities. Moments in Time [12] and Multi-Moment Dataset [13] extend this by providing large-scale resources for temporal action understanding, capturing short videos that encompass a wide range of activities. The recent Tencent-MVSE dataset [14], another substantial contribution, is designed for multi-modal video similarity evaluation, adding another layer of complexity to action recognition tasks.
Building upon the diversity and scope of existing datasets, the TikTokActions dataset is meticulously designed to capture the rapidly evolving landscape of social media-driven human interactions. Unlike traditional datasets, which often focus on pre-defined, standard action categories, TikTokActions delves into a broader spectrum of spontaneous and culturally varied human behaviors, which are inherently more aligned with contemporary social media trends. This alignment is critical as platforms like TikTok foster unique user-generated content that is not only highly dynamic but also reflective of current societal norms and interactions.
In direct comparison to the Kinetics dataset, which largely aggregates content from YouTube, TikTokActions offers an array of actions driven by the unique constraints and creativity of TikTok’s platform, such as shorter video lengths and a more diverse global user base. This distinction is significant as it introduces new challenges in action recognition, particularly in recognizing quick, context-driven actions that are less prevalent in the typically longer-form content of YouTube.
To substantiate the dataset’s novelty and utility, we conducted a thorough analysis of the action categories present in TikTokActions compared to those in Kinetics and other major benchmarks. Our findings reveal that TikTokActions includes a higher proportion of non-standard actions, such as specific dance moves, challenge-based activities, and regional cultural expressions, which are underrepresented in other datasets. This inclusion not only enhances the dataset’s coverage of real-world scenarios but also provides a more granular understanding of human actions within the digitally connected world.
By providing detailed statistics on the distribution of these categories, along with examples in our supplementary materials, we demonstrate the unique value of TikTokActions in filling the existing gaps within the field of action recognition. This detailed comparison and analysis affirm that TikTokActions is not just an addition to the plethora of action recognition datasets but a necessary evolution to keep pace with the changing dynamics of human activity in the digital age.
2.2 Computer Vision Foundation Models
Foundation models in computer vision have revolutionized the way we approach diverse tasks across modalities, offering scalable solutions that extend from image to video understanding. The Florence model [15], Specifically, encapsulates the progression of foundation models, adeptly offering transitions from broad scene outlines to detailed object-centric views and from static imagery to dynamic video sequences. Additionally, its effectiveness spans various modalities, from RGB imagery to textual data, establishing new standards in tasks like classification, object detection, retrieval, and particularly in action recognition.
Significant advancements have also been seen with the introduction of VideoMAE V2 [2]. This self-supervised pre-training methodology stands out for its ability to train on datasets exceeding 1 million videos. With its innovative dual masking strategy and progressive training approach, VideoMAE V2 sets new standards in action recognition. Empirical evaluations demonstrate its superior performance across multiple benchmarks, emphasizing its effectiveness in real-world scenarios.
Further developments include ViViT [16] and TimeSformer [17], which adapt transformer architectures specifically for video, offering improvements in handling the temporal dynamics of action sequences. These models demonstrate the potential of transformers in capturing complex, time-related patterns in video data.
The Quo Vadis model [18] introduced a new approach by integrating the Kinetics dataset to set a performance benchmark, inspiring subsequent models to focus on improving temporal understanding and action recognition capabilities. Similarly, Temporal Relational Reasoning in videos [19] provided insights into the importance of temporal dynamics, influencing how subsequent models like Non-local Neural Networks [20] handle long-range dependencies within video sequences.
A Closer Look at Spatiotemporal Convolutions [21] further explored the convolutional network architectures, focusing on how variations in spatial and temporal modules affect performance on action recognition tasks. This study paved the way for more specialized models like the Video Action Transformer Network [22], which introduced an approach to directly model relationships between actions and corresponding contextual features in videos.
Furthermore, 2D CNNs such as TSN [23], TSM [24], TANet [25], and TDN [26] have been influential by effectively incorporating temporal information, a critical aspect of video understanding.
The use of 3D CNNs such as I3D [18], R(2+1)D [21], ARTNet [27], and Slow-Fast [28] has further pushed the envelope in spatial-temporal feature integration, enhancing model performance on complex video tasks.
In the domain of transformers, advancements have continued with models such as MViT [29] and Video Swin Transformer [30] which have introduced ways to integrate spatial and temporal features more effectively, pushing the boundaries of action recognition performance. Additionally, UniFormer [31] integrates local and global interactions more efficiently, which is crucial for detailed action understanding in videos.
The diversity of foundation models extends to multi-modal approaches, where models like Perceiver IO [32] and Data2Vec [33] have been developed to handle various inputs ranging from text to video, showing flexibility and robustness in learning from heterogeneous data sources.
In the context of enhancing action recognition, SlowFast Networks [28] and X3D [34] introduce novel architectural choices that optimize the processing of temporal variations and the physical intensity of actions. These developments underscore the trend towards more specialized and efficient models that are not only capable of high performance but also adaptability across different action recognition scenarios.
Our TikTokActions dataset, with its focus on spontaneous and diverse user-generated content, provides a rich testing ground for these advanced models. By evaluating these models on our dataset, we aim to explore how well they can adapt to and interpret the nuanced, quick-transition actions typical of content found on modern social media platforms. The insights gained can help tailor these foundation models to better handle real-world variability and complexity in human actions.
In our efforts to push the frontiers of action recognition further, we also draw upon the extensive research documented in the Multi-dataset Training of Transformers [35], which explores the robustness gained from training across varied video datasets. Such approaches are crucial as they contribute to the generalization capabilities of models, preparing them for deployment in diverse, unstructured environments.
3 Dataset Construction
3.1 Video Collection Overview
To support our experimentation exploring the utility of unlabeled public data for pre-training foundation models for human action recognition, we curated an extensive collection of TikTok videos. This collection, consisting of over 280,000 video clips from 386 hashtags, captures a wide spectrum of human actions across various scenarios. The videos span diverse categories, from dance movements and fitness exercises to hand gestures and daily activities. Unlike traditional datasets like Kinetics, our collection uniquely incorporates elements of pop culture, memes, and rapid trend evolution, providing dynamic content that significantly boosts the model’s ability to understand and generalize from real-world, culturally relevant scenarios.
3.2 Video Selection Methodology
To curate a diverse and relevant set of videos from TikTok, we initially examined several well-known action recognition datasets, including UCF101[3], HMDB51[4], and Google DeepMind Kinetics[1]. These datasets helped us to understand the broad categories of human actions typically represented in research. We identified four primary categories: dance, sports, fitness, and kinetics.
Building upon these categories, we explored TikTok to identify relevant hashtags that capture a wide array of human actions within these domains. Our selection was strategically guided by six principles designed to ensure a comprehensive and culturally relevant collection: generalization, specification, noun substitution, noun-verb order, hashtag consolidation, and social/cultural relevance. These principles helped ensure that the videos not only cover a broad spectrum of actions but also include dynamic and culturally significant content such as memes, pop culture trends, and unique challenges—elements that are distinctly prevalent on TikTok.
The social/cultural relevance was particularly important, allowing us to incorporate an additional category that includes a wide variety of actions originating from distinct social and cultural contexts, such as viral dance challenges and fitness trends. Popularity and engagement levels also played a crucial role in our selection process; we set a minimum threshold of 5 million views per hashtag to ensure that the content is not only relevant but also resonates widely with users, reflecting substantial public engagement and visibility. This approach allows us to harness rich, culturally nuanced content that can aid in training models to better understand and interpret human actions in real-world contexts.
3.2.1 Generalization/Using the umbrella terms
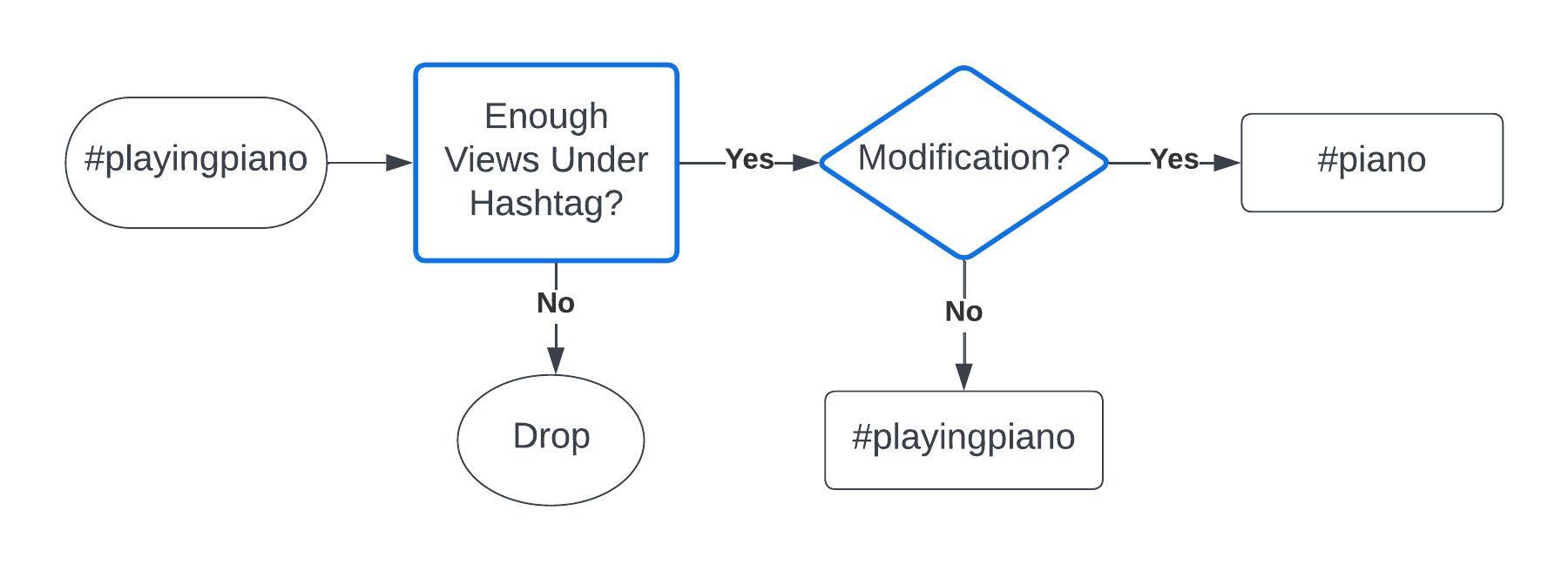
When comparing the hashtags we generated with those used by TikTok users, we observed that hashtags related to specific actions can often be represented in a very broad or inclusive manner on the platform. For instance, the hashtag #basketball can serve as an umbrella term encompassing a wide array of hashtags, such as #playingbasketball, #dunking, #dribbling.
3.2.2 Specification
There are situations where specificity is crucial. For instance, within the broader classification of Ballroom Dance, distinct dance styles such as Waltz, Quickstep, and Tango exist. Instead of solely using the hashtag #ballroomdance, we include specific hashtags, including #chacha, #salsa, #tango, and #waltz, to ensure our datasets encompass pertinent human actions inherent to distinct dance styles.
3.2.3 Noun Substitution
While gathering short TikTok videos, we observed that a more effective approach for identifying the desired content is to employ a single noun instead of an entire verb phrase. For instance, the use of the hashtag #piano suffices to compile a more extensive collection(see Table 1) of short videos instead of using #pianoplaying.
| Hashtags | Number of Views |
|---|---|
| #piano | 44.4 Billion |
| #playingpiano | 29.4 Million |
3.2.4 Noun-Verb Order
We noticed a preference among users for using noun phrases over verb phrases when describing their activities. For example, TikTok users frequently use hashtags like #shoerepair instead of verb phrases like #repairingshoes.
3.2.5 Hashtag Consolidation
When composing the hashtag list, we streamlined similar hashtags into a single one if they denote the same type of human action, prioritizing those with higher views on TikTok. For example, we retain #cuttingcakes and remove similar hashtags like #cutfruit, #applecutting, and #breadcutting.
3.2.6 Social/cultural Considerations
Culturally and socially relevant hashtags were included when crafting the hashtag list. For instance, the ”flower challenge” originated as a dance challenge on TikTok initiated by a K-pop star, and TikTok users subsequently adopted the hashtag #flowerchallenge when sharing their dance videos.
In Figure 1, we show an example flowchart of the hashtag selection and modification process. Our final and complete list of hashtags along with video numbers is in Appendix A.
3.3 Video Collection and Processing
We curated a comprehensive video collection using the official TikTok research API, focusing on approximately 900 videos per hashtag from a set of hashtags identified through our selection process. Each video and its metadata were processed to facilitate model training, using tools such as PySceneDetect and YOLO v8[36]. This processing resulted in a JSON file for each video, which included metadata capturing attributes like title, duration, and scene distribution, as analyzed by PySceneDetect.
3.3.1 PySceneDetect and YOLOv8 Processing
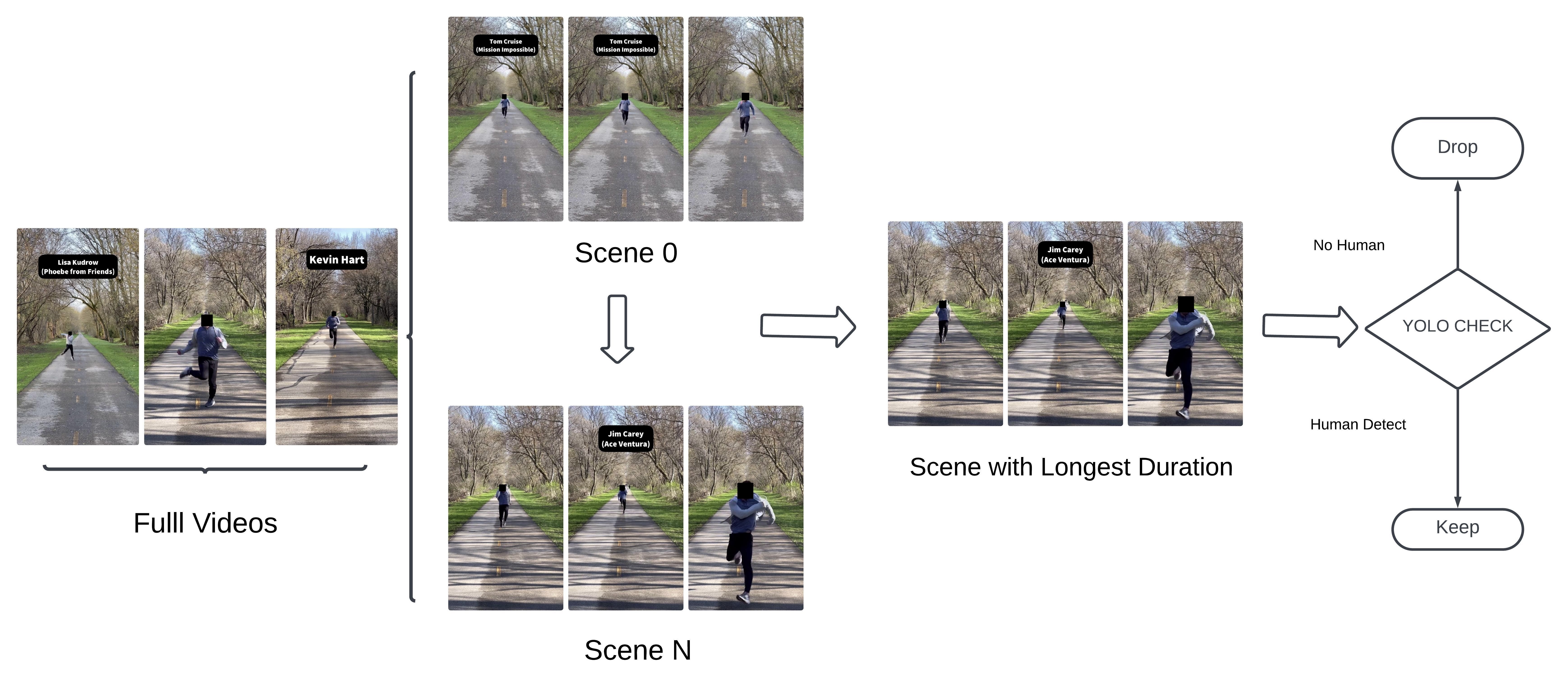
Our processing approach began with PySceneDetect, used to analyze the scene composition of each video. This tool helped identify distinct scenes within the videos, enabling us to focus on the longest scene clips, hypothesized to have the highest likelihood of containing significant human action.
Once the longest scenes were identified, the YOLOv8[36] model was employed to detect human figures in these segments. The primary goal of this processing was to ensure accurate identification of videos containing human subjects, vital for the training of our models.
During the frame extraction phase, we used the ffprobe tool to determine the total frame count of each video clip. Due to the large number of frames in many videos, we applied subsampling for efficiency. Typically, a fixed number of frames (usually 10) were extracted at regular intervals throughout the video.
The extracted frames were then processed using the YOLOv8[36] model to detect human presence. Frames that included at least one ”person” label were counted towards the total number of frames containing humans for that particular video.
Post-processing included applying a threshold for human presence; videos needed to exceed a pre-defined frame threshold with human detections to qualify. Videos that did not meet this threshold were subject to further review. This systematic approach helped compile aggregated statistics on the human presence in our video collection, ensuring the quality of content used for model training. The entire process, from video selection to frame extraction and human detection, was documented to maintain transparency and reproducibility. Figure 2 illustrates the process of clip extraction from the raw videos sourced from TikTok.
4 Performance on Benchmarks
In the domain of human action recognition, benchmarking performance is essential to understand the efficacy of a model. This section evaluates the performance of our model, initially pre-trained on the entire collection of 283,582 unlabeled TikTok video clips using VideoMAE V2[2]. We employed both the ViT-base and ViT-giant backbones for pre-training to assess the impact of model capacity. Subsequently, the model was fine-tuned on Kinetics-400 (K400). Following this, the model underwent further fine-tuning on UCF-101[3] and HMDB51[4], adopting a transfer learning approach akin to the experimental setups used in VideoMAE V2 studies. Additionally, we extended our evaluation to include the Something-Something V2[5] dataset, assessing the model’s adaptability and performance across varied action recognition contexts.
4.1 Pre-training on VideoMAE V2
VideoMAE V2[2] is a state-of-the-art masked autoencoding framework, notable for its flexibility in backbone selection, ranging from base to billion-level configurations. We opted for both the ViT-base and ViT-giant backbones. The ViT-base was used to provide a baseline comparison with other models using similarly sized backbones, while the ViT-giant was employed to explore the maximum potential of the dataset, aiming to achieve the highest possible accuracy. The generalization capability of VideoMAE V2 pre-trained ViTs[37] as video foundation models has been demonstrated across multiple downstream tasks, highlighting its robustness and adaptability.
Our training was conducted on 8 NVIDIA A100 40GB GPUs, utilizing the full set of 283,582 unlabeled TikTok videos. The pre-training on the ViT-base backbone, which ran for 800 epochs and lasted for 20 days, provided a comprehensive base for developing a robust model capable of understanding a wide array of human actions. The ViT-giant backbone was pre-trained under similar conditions, running for 1200 epochs over 30 days, to push the performance boundaries further.
4.2 Fine-Tuning on Established Datasets
After initial pre-training, the model underwent two distinct paths of fine-tuning. The first path involved direct fine-tuning on the Kinetics-400 and Something-Something V2 datasets to assess immediate applicability to broad action recognition tasks. The results of this direct fine-tuning are detailed in Table 2 and Table 3. The second path involved using the model fine-tuned on Kinetics-400 as an intermediary for transfer learning on UCF-101 and HMDB51, leveraging robust pre-training on TikTok videos. The outcomes of this transfer learning process are presented in Table 4.
| method | pre-train data | data size | epoch | ViT-B | ViT-g |
|---|---|---|---|---|---|
| MAE-ST [feichtenhofer2022masked] | Kinetics400 | 0.24M | 1600 | 81.3 | - |
| VideoMAE V1 [38] | Kinetics400 | 0.24M | 1600 | 81.5 | - |
| VideoMAE V2 [2] | UnlabeledHybrid | 1.35M | 1200 | 81.5 | 87.2 |
| VideoMAE V2 | TikTok | 0.28M | 800 | 81.1 | - |
| VideoMAE V2 | TikTok | 0.28M | 1200 | - | 85.51 |
| method | pre-train data | data size | epoch | ViT-B | ViT-g |
|---|---|---|---|---|---|
| MAE-ST [feichtenhofer2022masked] | Kinetics400 | 0.24M | 1600 | 70.8 | - |
| VideoMAE V1 [38] | Sth-Sth V2 | 0.17M | 2400 | 70.8 | - |
| VideoMAE V2 [2] | UnlabeledHybrid | 1.35M | 1200 | 71.2 | 77.0 |
| VideoMAE V2 | TikTok | 0.28M | 800 | 69.2 | - |
| VideoMAE V2 | TikTok | 0.28M | 1200 | - | 74.27 |
| Dataset | ViT-b Top-1 (%) | ViT-g Top-1 (%) |
|---|---|---|
| HMDB-51[4] | 83.9 | 86.08 |
| UCF-101[3] | 97.5 | 99.05 |
Observations on data scaling. We studied the influence of pre-training data size on the performance of VideoMAE V2. In this experiment, we pre-trained the video models with ViT-B and ViT-g backbones on our TikTok dataset, which contains approximately 0.28M videos. The fine-tuning accuracy is detailed in Table 2 for Kinetics-400 and Table 3 for Something-Something V2. Despite using approximately five times fewer pre-training samples compared to the UnlabeledHybrid dataset (1.35M videos), our model achieved comparable results. Specifically, the ViT-B backbone pre-trained on TikTok data achieved 81.1% on Kinetics-400, which is only 0.4% lower than the 81.5% achieved using the much larger UnlabeledHybrid dataset. Similarly, for Something-Something V2, the ViT-B backbone pre-trained on TikTok data achieved 69.2%, compared to 71.2% with the UnlabeledHybrid dataset, showing a difference of 2%. These small differences highlight the efficacy of our foundation model on TikTok videos, which did not include any information from the original fine-tuned dataset.
Observations on model scaling. We also explored how different model capacities affect performance. The fine-tuning results for models pre-trained with ViT-B and ViT-g backbones are presented in Table 2 and Table 3. The ViT-g model, representing a billion-level parameter architecture, consistently demonstrated improved performance over the ViT-B model. For example, the ViT-g backbone pre-trained on TikTok data achieved 85.51% on Kinetics-400, compared to 81.1% for the ViT-B backbone, showing an improvement of 4.41%. Similarly, for Something-Something V2, compared to the ViT-B backbone, there is an improvement of 5.07%. These results suggest that increasing model capacity can further boost performance, validating the potential of large-scale pre-training on diverse video datasets like those from TikTok.
Observations on transfer learning. We further evaluated the performance of our pre-trained models by using Kinetics-400 fine-tuned models for transfer learning on HMDB-51 and UCF-101 datasets. The results are summarized in Table 4. The ViT-B model achieved 83.9% on HMDB-51 and 97.5% on UCF-101, while the ViT-g model achieved 86.08% on HMDB-51 and 99.05% on UCF-101.
Overall, our findings highlight the significant potential of using large, unlabeled video collections from platforms like TikTok for advancing human action recognition tasks. This approach capitalizes on the rich, varied nature of content available on social media, which, when used for pre-training, enhances the model’s ability to generalize across different datasets and action recognition scenarios. The robust performance observed across both direct fine-tuning and transfer learning paths underscores the value of TikTok videos in training models for complex action recognition challenges. The TikTok dataset, which is unlabeled and lacks ground truth annotations, still produced promising results, demonstrating the model’s capacity to learn effectively from unstructured video content.
5 Dataset Size vs. Fine-Tuning Efficacy
To investigate the impact of pre-training data size on downstream model performance, we varied the size of the pre-training data from 1,000 to 6,000 videos, randomly selected from the TikTokActions dataset. Each data size level was used to pre-train the model in three independent runs to measure variance. Following pre-training, these models were fine-tuned on the UCF-101[3] dataset. The primary metric for evaluating model performance was the accuracy observed on the test set of UCF-101, allowing us to draw conclusions about the relationship between pre-training data size and fine-tuning effectiveness.
From the result in Figure 3, the volume of pre-trained data from the TikTokActions dataset was incrementally increased, and we observed a positive correlation with the Top-1 accuracy, particularly notable as the volume grew from 1,000 to 3,000 videos. However, subsequent increases in data volume yielded a reduced rate of improvement in Top-1 accuracy, indicating diminishing returns despite the larger dataset sizes. The Top-5 accuracy continued to show slight improvements, but the incremental benefit also appeared to diminish as the dataset size expanded beyond 3,000 videos. These findings suggest an asymptotic behavior in the benefit derived from increasing the volume of pre-training data for our models.
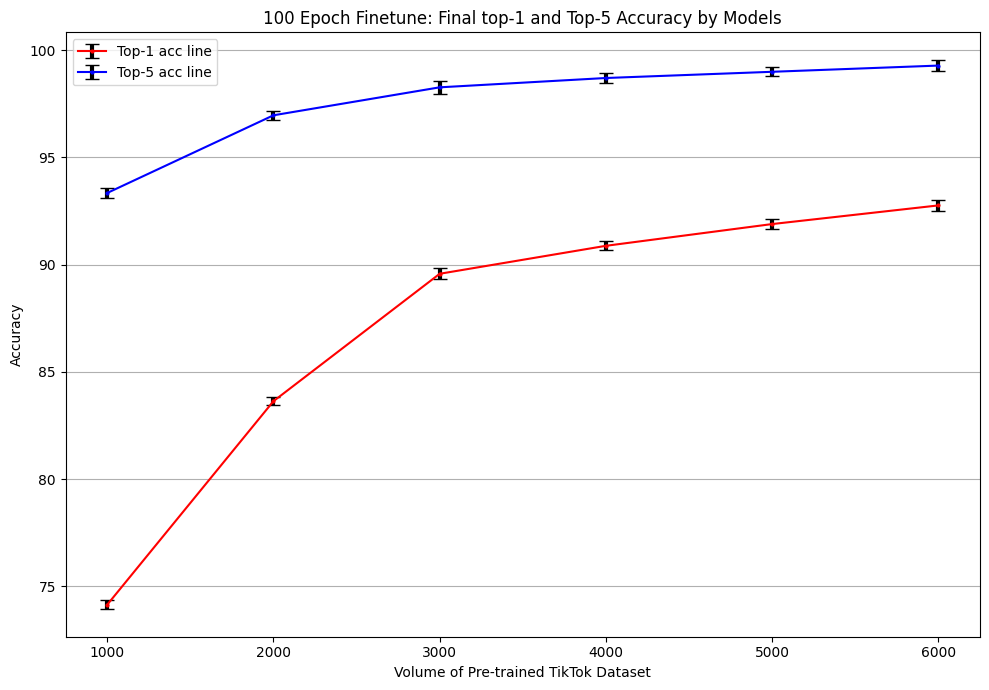
6 Dataset Size vs. Fine-Tuning Efficacy
We conducted further experiments to demonstrate the efficacy of the collection in pre-training models for action recognition. We used a targeted subset of 6,900 high-quality clips sourced from 73 TikTok hashtags. From Figure 4, we can see the pre-trained model achieved a top-1 accuracy of 94.35% and a top-5 accuracy of 99.35% when fine-tuning on the UCF101[3]. This is remarkably close to the performance of models pre-trained on the UCF101 dataset itself (8155 from 101 classes), which exhibited a top-1 accuracy of 94.50% and a top-5 accuracy of 99.64%. The comparable accuracies highlight the mined dataset’s quality and its potential to serve as a substantial pre-training resource, even with fewer and more focused training samples. The model trained from scratch, without the benefit of such a rich dataset, performed significantly poorer, reinforcing the value of pre-training on high-quality, domain-specific data. This outcome attests to the robustness and generalization capabilities of models pre-trained on the curated dataset.
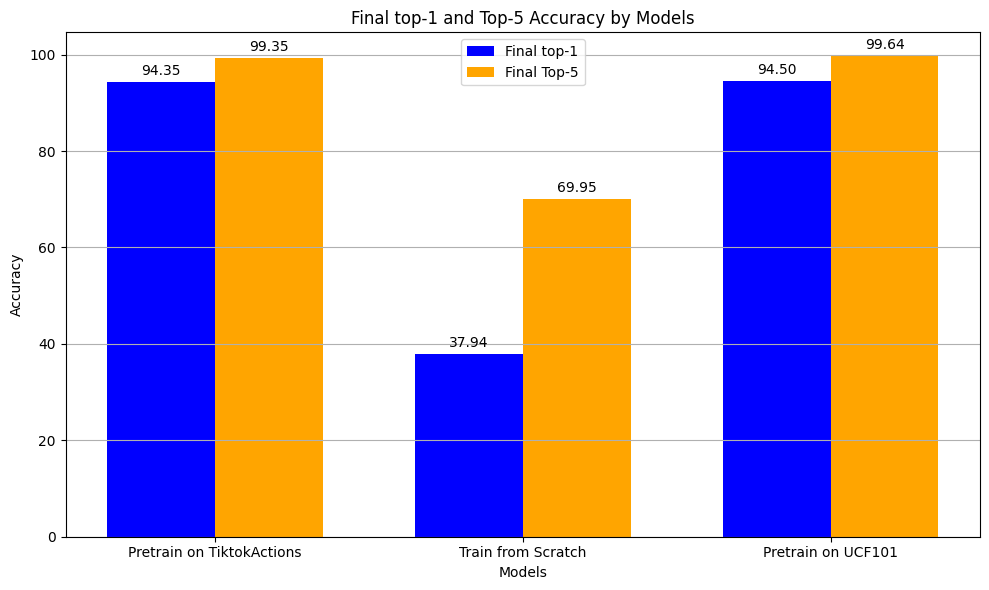
7 Discussion
The curation of TikTok videos for enhancing human action recognition models provides a unique contribution to the field, especially by incorporating a variety of distinct yet non-traditional human actions. These actions, sourced from the TikTok platform, were carefully selected to complement the more conventional actions typically found in established datasets like UCF101[3] and HMDB51[4]. This approach not only diversifies the types of human actions available for model training but also qualitatively enriches the dataset, thereby challenging and extending the adaptability of action recognition algorithms.
Integrating these unique and diverse actions from TikTok, we have expanded the range of actions that machine learning models can recognize, addressing the dynamic nature of human actions in digital media where new and unconventional actions frequently emerge. This strategy highlights the value of leveraging culturally rich and dynamic user-generated content as a training resource in an era dominated by digital media.
Furthermore, our findings challenge the conventional wisdom that larger datasets always yield better pre-training results. The competitive performance of our models, initially pre-trained on a curated subset of TikTok videos and subsequently fine-tuned on Kinetics-400[1] (K400) and Something-Something V2(Sth-Sth)[5], suggests that a well-curated, smaller dataset can sometimes outperform a larger, more generic one. This observation encourages a shift towards more efficient dataset compilation and model training paradigms, emphasizing data quality over quantity.
Looking ahead, exploring the potential of using the full breadth of the TikTok video collection for pre-training could further enhance model performance and generalization across various tasks. Additionally, integrating these videos with other datasets, such as Kinetics-400 and Something-Something, could provide deeper insights into the unique characteristics and potential synergies between different types of video content.
An emerging area of interest is the application of weekly self-supervised learning techniques, which involve regular, unsupervised updates to the model based on new data inflows. Such techniques could significantly boost the adaptability and accuracy of models trained with dynamic, culturally relevant content from platforms like TikTok.
8 Ethics
This study has been approved under the University of Hawaii Institutional Review Board (IRB) under protocol number 2024-00396. Furthermore, this research adheres to strict ethical guidelines regarding the use of online video data, specifically videos collected from TikTok. All videos were legally accessed via the TikTok Research API, and our data collection process is in full compliance with the TikTok Research API Terms of Service. Importantly, only those videos where the user granted explicit download permission were included in our training process. Equally as importantly, we deleted all of the data after model training as an additional layer of security.
We place a high priority on user privacy. To protect individual privacy, we have implemented face obfuscation techniques in the video clips included in our paper. Moreover, in line with the terms of service, we do not distribute any TikTok user content directly. Instead, we focus on training a foundation model, which we only use to identify action patterns, not personal biometric features.
Genderal Ethical Considerations for Online Video Research: The use of online video data poses unique challenges and ethical considerations, particularly regarding privacy, informed consent, and the potential risks associated with the use of such data. Our study emphasizes the importance of adhering to ethical principles that safeguard participant interests. We have made significant efforts to minimize potential harm by anonymizing the data and not sharing the curated dataset. We recommend that researchers adhere to such privacy protections.
Furthermore, we advocate for the inclusion of clearer guidelines in the terms of service on video platforms, which would allow users of the platforms to explicitly exclude their videos from research use. This approach does not replace the need for informed consent but is a step towards enhancing ethical practices in online video research. We aim to foster a transparent and informed discussion about the use of online video data in computational research.
We also argue that the use of the models plays a critical role in deciding the ethical standards that are required. Predicting human actions such as running, swimming, or playing piano from videos is a common task that is unlikely to lead to harm, especially given how common action recognition computer vision research is. By contrast, if the AI were used to predict sensitive properties about the end user such as mental health diagnoses, income, political party, or anything else along those lines, then the standard for explicit consent and ethical practices would rise to a much higher level [39].
Acknowledgements
This work was made possible by a multitude of supporters and funding sources. We thank the National Science Foundation for their generous support through the CyberTraining grant (Award No. 2118222) under the HI-DSI project. The technical assistance and advanced computing resources provided by the University of Hawaii Information Technology Services–Cyberinfrastructure, partially funded by NSF CC* awards #2201428 and #2232862 (Koa), have been invaluable. The development and acceleration of cloud computing through JetStream2 have significantly contributed to our research; we acknowledge David Y. Hancock, Jeremy Fischer, John Michael Lowe, Winona Snapp-Childs, Marlon Pierce, Suresh Marru, J. Eric Coulter, Matthew Vaughn, Brian Beck, Nirav Merchant, Edwin Skidmore, and Gwen Jacobs for this computational infrastructure (DOI: 10.1145/3437359.3465565). The AWS Cloud Credit for Research program has also played a crucial role in providing computational resources for our work. We used ChatGPT to edit the grammar of our manuscript and to re-phrase sentences that were originally worded unclearly. However, all contents in this manuscript are original ideas and analyses conducted by the authors.
Appendix A Sample Clips
In the appendix, we will present additional insights into our dataset, specifically focusing on visual and statistical aspects. This includes select screenshots of our video clips, which exemplify the diversity and context of the actions captured within our dataset. Alongside these visuals, we will include the figure, which provides the number distributions of videos for each hashtag. Furthermore, we will present the distribution of video durations, offering a comprehensive view of the temporal characteristics of our clips. These elements combined will give a more complete picture of the dataset’s richness.
In Figure 5, we present the extensive diversity of the TikTokActions dataset, which captures a wide range of human activities tagged across multiple domains such as fitness, sports, and dance. The collection features a variety of video types that include full-body human actions, clips focusing on hand movements, and scenarios involving multiple individuals. The presence of such varied content provides a rich learning ground for self-supervised learning models to extract and learn a comprehensive set of features from human actions, gestures, and interactions, aiding in the enhancement of action recognition capabilities.

Appendix B Dataset Composition
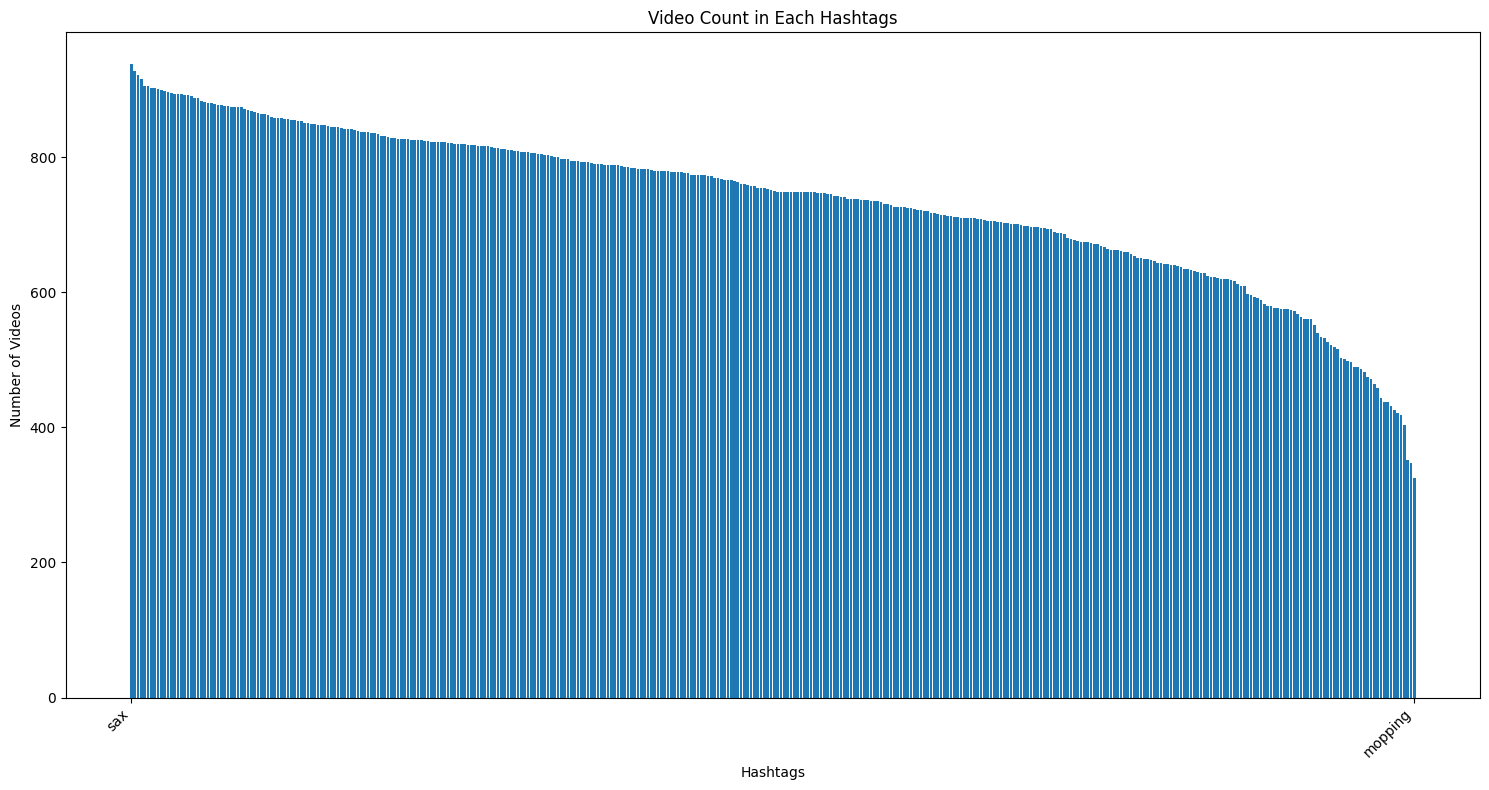
Our dataset offers a diverse array of video counts across different hashtags. Figure 6 illustrates the distribution of videos across various hashtags, indicating the prevalence of certain actions within our dataset. On average, each hashtag is associated with approximately 735 videos. The ’sax’ category stands out with the maximum count of 938 videos, while the ’mopping’ category has the minimum, with 325 videos.
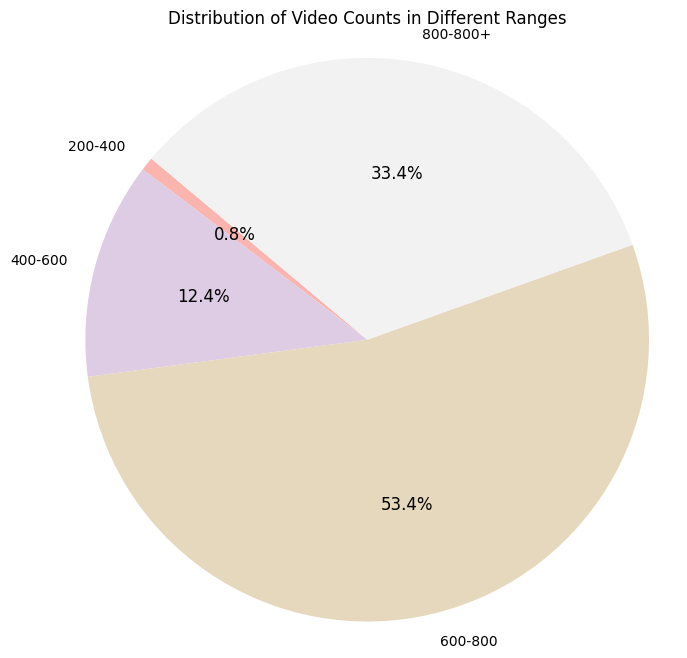
Conversely, Figure 7 displays a pie chart that categorizes the dataset into four video count ranges: 200-400, 400-600, 600-800, and 800+ videos per category. It is noteworthy that a significant portion, 53.4%, of the hashtags have a video count that falls within the 600-800 range.
Appendix C Dataset Duration
In the composition of the TikTokActions dataset, a key focus was on ensuring that each video clip is sufficiently long to capture a complete action, while also maintaining a manageable length for analysis. To this end, we established a minimum clip duration of 3.5 seconds, ensuring each clip is long enough to encompass a full action. Simultaneously, to avoid excessively long clips, which can complicate analysis and may contain extraneous information, we capped the maximum duration at 10 seconds. For videos exceeding this length, only the most relevant 10-second segment, typically featuring the most significant action, was selected. This methodology results in a dataset that is both comprehensive and tailored for efficient action recognition analysis.
The following table details the distribution of video durations within our dataset, post these adjustments:
| Duration Range (seconds) | Number of Videos |
|---|---|
| 3.5-5 | 30103 |
| 5-10 | 81356 |
| 10+ | 172123 |
References
- \bibcommenthead
- Kay et al. [2017] Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., Suleyman, M., Zisserman, A.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017) https://doi.org/10.48550/arXiv.1705.06950
- Wang et al. [2023] Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., Qiao, Y.: Videomae v2: Scaling video masked autoencoders with dual masking. arXiv preprint arXiv:2303.16727 (2023) https://doi.org/10.48550/arXiv.2303.16727 . CVPR 2023 camera-ready version
- Soomro et al. [2012] Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012) https://doi.org/10.48550/arXiv.1212.0402 . CRCV-TR-12-01
- Kuehne et al. [2011] Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: Hmdb: A large video database for human motion recognition. In: 2011 International Conference on Computer Vision, pp. 2556–2563 (2011). https://doi.org/10.1109/ICCV.2011.6126543
- Goyal et al. [2017] Goyal, R., Kahou, S.E., Michalski, V., Materzyńska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., Hoppe, F., Thurau, C., Bax, I., Memisevic, R.: The ”something something” video database for learning and evaluating visual common sense. arXiv preprint arXiv:1706.04261 (2017) https://doi.org/10.48550/arXiv.1706.04261
- Gu et al. [2018] Gu, C., Sun, C., Ross, D.A., Vondrick, C., Pantofaru, C., Li, Y., Vijayanarasimhan, S., Toderici, G., Ricco, S., Sukthankar, R., et al.: Ava: A video dataset of spatio-temporally localized atomic visual actions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6047–6056 (2018)
- Grauman et al. [2021] Grauman, K., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. arXiv preprint arXiv:2110.07058 (2021)
- Miech et al. [2019] Miech, A., et al.: Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2630–2640 (2019)
- Damen et al. [2018] Damen, D., et al.: Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 720–736 (2018)
- Heilbron et al. [2015] Heilbron, F.C., et al.: Activitynet: A large-scale video benchmark for human activity understanding. Proceedings of the IEEE conference on computer vision and pattern recognition, 961–970 (2015)
- Idrees et al. [2017] Idrees, H., et al.: The thumos challenge on action recognition for videos “in the wild”. Computer Vision and Image Understanding 155, 1–23 (2017)
- Monfort et al. [2019] Monfort, M., et al.: Moments in time dataset: One million videos for event understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence 42(2), 502–508 (2019)
- Monfort et al. [2021] Monfort, M., et al.: Multi-moment dataset: Learning multi-objective rewards and policy alignments from human video annotations. arXiv preprint arXiv:2106.06012 (2021)
- Liu et al. [2022] Liu, X., et al.: Tencent-mvse: A large-scale benchmark dataset for multi-modal video similarity evaluation. CVPR (2022)
- Yuan et al. [2021] Yuan, L., Chen, D., Chen, Y.-L., Codella, N., Dai, X., Gao, J., Hu, H., Huang, X., Li, B., Li, C., Liu, C., Liu, M., Liu, Z., Lu, Y., Shi, Y., Wang, L., Wang, J., Xiao, B., Xiao, Z., Yang, J., Zeng, M., Zhou, L., Zhang, P.: Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432 (2021) https://doi.org/10.48550/arXiv.2111.11432
- Arnab et al. [2021] Arnab, A., et al.: Vivit: A video vision transformer. Proceedings of the IEEE/CVF International Conference on Computer Vision, 6836–6846 (2021)
- Bertasius et al. [2021] Bertasius, G., et al.: Is space-time attention all you need for video understanding? arXiv preprint arXiv:2102.05095 (2021)
- Carreira and Zisserman [2017] Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4724–4733 (2017)
- Zhou et al. [2018] Zhou, B., Andonian, A., Oliva, A., Torralba, A.: Temporal relational reasoning in videos. Proceedings of the European Conference on Computer Vision (ECCV), 803–818 (2018)
- Wang et al. [2018] Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794–7803 (2018)
- Tran et al. [2018] Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6450–6459 (2018)
- Girdhar et al. [2019] Girdhar, R., Carreira, J., Doersch, C., Zisserman, A.: Video action transformer network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 244–253 (2019)
- Wang et al. [2016] Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Van Gool, L.: Temporal segment networks: Towards good practices for deep action recognition. In: European Conference on Computer Vision, pp. 20–36 (2016)
- Lin et al. [2019] Lin, J., Gan, C., Han, S.: Tsm: Temporal shift module for efficient video understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7083–7093 (2019)
- Liu et al. [2018] Liu, J., Shahroudy, A., Xu, D., Wang, G., Chichung, A.K.: Tanet: Robust 3d action recognition with temporal convolutional networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2018)
- Wang et al. [2021] Wang, L., Li, Z., Van Gool, L., Timofte, R.: Tdn: Temporal difference networks for efficient action recognition. arXiv preprint arXiv:2012.10071 (2021)
- Wang et al. [2018] Wang, L., Li, W., Li, W., Van Gool, L.: Appearance-and-relation networks for video classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1430–1439 (2018)
- Feichtenhofer et al. [2019] Feichtenhofer, C., et al.: Slowfast networks for video recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2019)
- Fan et al. [2021] Fan, H., et al.: Multiscale vision transformers. arXiv preprint arXiv:2104.11227 (2021)
- Liu et al. [2021] Liu, Z., et al.: Video swin transformer. arXiv preprint arXiv:2106.13230 (2021)
- Li et al. [2022] Li, H., et al.: Uniformer: Unifying convolution and self-attention for visual recognition. arXiv preprint arXiv:2201.09450 (2022)
- Jaegle et al. [2021] Jaegle, A., et al.: Perceiver io: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795 (2021)
- Baevski et al. [2022] Baevski, A., et al.: data2vec: A general framework for self-supervised learning in speech, vision and language. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
- Feichtenhofer et al. [2020] Feichtenhofer, C., et al.: X3d: Expanding architectures for efficient video recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
- Arnab et al. [2022] Arnab, A., et al.: Multi-dataset training of transformers for robust action recognition. In: Advances in Neural Information Processing Systems (2022)
- Reis et al. [2023] Reis, D., Kupec, J., Hong, J., Daoudi, A.: Real-time flying object detection with yolov8. arXiv preprint arXiv:2305.09972 (2023) https://doi.org/10.48550/arXiv.2305.09972
- Dosovitskiy et al. [2020] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) https://doi.org/10.48550/arXiv.2010.11929 . ICLR camera-ready version
- Tong et al. [2022] Tong, Z., Song, Y., Wang, J., Wang, L.: Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
- [39] Jaiswal, A., Shah, A., Harjadi, C., Windgassen, E., Washington, P.: Ethics of the use of social media as training data for ai models used for digital phenotyping. JMIR Research Protocols