Adversarial Memory Networks for Action Prediction
Abstract
Action prediction aims to infer the forthcoming human action with partially-observed videos, which is a challenging task due to the limited information underlying early observations. Existing methods mainly adopt a reconstruction strategy to handle this task, expecting to learn a single mapping function from partial observations to full videos to facilitate the prediction process. In this study, we propose adversarial memory networks (AMemNet) to generate the “full video” feature conditioning on a partial video query from two new aspects. Firstly, a key-value structured memory generator is designed to memorize different partial videos as key memories and dynamically write full videos in value memories with gating mechanism and querying attention. Secondly, we develop a class-aware discriminator to guide the memory generator to deliver not only realistic but also discriminative full video features upon adversarial training. The final prediction result of AMemNet is given by late fusion over RGB and optical flow streams. Extensive experimental results on two benchmark video datasets, UCF-101 and HMDB51, are provided to demonstrate the effectiveness of the proposed AMemNet model over state-of-the-art methods.
1 Introduction
Action prediction is a highly practical research topic that could be used in many real-world applications such as video surveillance, autonomous navigation, human-computer interaction, etc. Different from action recognition, which recognizes the human action category upon a complete video, action prediction aims to understand the human activity at an early stage – using a partially-observed video before an entire action execution. Typically, action prediction methods [32, 2, 22, 4, 46, 50] assume that a portion of consecutive frames from the beginning is given, considered as a partial video. The challenges mainly arise from the limited information in the early progress of videos, leading to the incomplete temporal context and a lack of discriminative cues for recognizing actions. Thus, the key problem of solving action prediction lies in: how to enhance the discriminative information for a partial video?
In recent years, many research efforts centering on the above question have been made for the action prediction task. Pioneering works [32, 2, 21] mainly handle partial videos by relying on hand-crafted features, dictionary learning, and designing temporally-structured classifiers. More recently, deep convolutional neural networks (CNNs), especially those pre-trained on large-scale video benchmarks (e.g., Sports-1M [18] and Kinetics [19]), have been widely adopted to predict actions. The pre-trained CNNs, to some extent, compensate for the incomplete temporal context and empower reconstructing full video representations from the partial ones. Along this line, existing methods [22, 34, 46, 23] focus on designing models to continuously improve the reconstruction performance, yet without considering the “malnutrition” nature (i.e., the limited temporal cues) of incomplete videos. Particularly, it will be more straightforward to learn what “nutrients” (e.g., the missing temporal cues or reconstruction bases) a partial video may need for recognizing actions, compared with mapping it to an entire video. Moreover, it is also challenging to handle various partial videos by resorting to a single model.
In this study, we propose a novel adversarial memory networks (AMemNet) model to address the above challenges. The proposed AMemNet leverages augmented memory networks to explicitly learn and store full video features to enrich incomplete ones. Specifically, we treat a partial video as a query and the corresponding full video as its memory. The “full video” is generated with relevant memory slots fetched by the query of partial videos. We summarize the contribution of this work in two aspects.
Firstly, a memory-augmented generator model is designed for generating full-video features conditioning on partial-video queries. We adopt a key-value memory network architecture [28, 49] for action prediction, where the key memory slots are used for capturing similar partial videos and the value memory slots are extracted from full training videos. The memory writing process is implemented by gating mechanism and attention weights. The input/forget gates enable AMemNet to dynamically update video memories attended by different queries and thus memorize the variation between different video progress.
Secondly, a class-aware discriminator model is developed to guide the memory generator with adversarial training, which not only employs an adversarial loss to encourage generating realistic full video features, but also imposes a classification loss on training the network. By this means, the discriminator network could further push the generator to deliver discriminative full-video features.
The proposed AMemNet obtains prediction results by employing a late fusion strategy over two streams (i.e., RGB and optical flow) following [35, 43]. Extensive experiments on two benchmark datasets, UCF101 and HMDB51, are conducted to show the effectiveness of AMemNet compared with state-of-the-art methods, where our approach surprisingly achieves over accuracy by only observing of the beginning video frames on the UCF101 dataset. A detailed ablation study compared with several competitive baselines is also presented.
2 Related Work
Action Recognition targets at recognizing the label of human action in a given video, which is one of the core tasks for video understanding. Previous works have extensively studied this research problem from several aspects, including hand-crafted features (e.g., spatio-temporal interest points [8, 31], poselet key-frames [30, 27]), and dense trajectory [42], 3D convolutional neural networks [17, 39, 14], recurrent neural networks (RNN) based methods [29, 9], and many recent deep CNN based methods such as temporal linear encoding networks [7], non-local neural networks [45], etc. Among existing methods, the two-stream architecture [35, 10, 43] forms a landmark [3], which mainly employ deep CNNs on the RGB and optical flow streams for exploiting the spatial-temporal information inside videos. In this work, we also adopt the two-stream structure as it naturally provides the complimentary information for the action prediction task – the RGB stream contributes more on the early observation and the optical flow leads the following progress.
Action Prediction has attracted lots of research efforts [22, 34, 46, 23, 4, 50] in recent years, which tries to predict action labels upon the early progress of videos and thus falls into a special case of video-based action recognition. Previous works [32, 2, 26, 21] solve this task via hand-crafted features, and recent works [22, 34, 46, 23, 5, 20, 13, 4, 50] mainly rely on pre-trained deep CNN models for encoding videos, such as the 3D convolutional networks in [22, 23, 46], deep CNNs in [34, 4], and two-stream CNNs in [5, 20, 13, 50]. Among these works, the most common way for predicting actions is to design deep neural networks model for reconstructing full videos from the partial ones, such as deep sequential context networks [22], the RBF Kernelized RNN [34], progressive teacher-student learning networks [46], adversarial action prediction networks [23], etc. Moreover, some other interesting methods include the LSTM based ones [33, 20, 47], part-activated deep reinforcement learning [4], residual learning [13, 50], motion prediction [1], asynchronous activity anticipation [51], etc.
The memory augmented LSTM (Mem-LSTM) [20] model and adversarial action prediction networks (AAPNet) [23] share some similar ideas to our approach. However, several essential differences between the proposed AMemNet and Mem-LSTM/AAPnet could be summarized. First, memory networks play distinct roles in Mem-LSTM [20] and AMemNet. Mem-LSTM formulates action labels as video memories and adopts the memory network as a nearest-neighbor classifier. Differently, the proposed AMemNet develops a key-value memory architecture as a generator model and learns value memory slots from full videos as reconstruction bases for a generation purpose. Second, the generator models used in AAPNet [23] and AMemNet are different. AAPNet [23] employs a variational-GAN model, whereas AMemNet develops the memory-augmented generator to explicitly provide auxiliary information to generate full-video features for testing videos.
Memory Networks, i.e., Memory-Augmented Neural Networks [48, 12], generally consist of two components: 1) a memory matrix and 2) a neural network controller, where the memory matrix is used for storing the information as memory slots and the neural network controller is generally designed for addressing, reading and writing memories. Several representative memory network architectures include end-to-end memory networks [37], Key-Value memory networks [28, 49], neural tuning machines [12, 44], recurrent memory networks [40, 38], etc. The memory networks work well in practice for its flexibility in saving the auxiliary knowledge and its ability in memorizing the long-term temporal information. The proposed AMemNet shares the same memory architecture with [28, 49] and employs the memory writing methods provided in [12], which, however, is designed with different purposes compared with these methods. The memory module in AMemNet is tailored for solving the action prediction problem.
3 Methodology
3.1 Problem Setup
Given a set of training videos , where denotes one video sample and refers to its action category label, action prediction aims to infer by only observing the beginning sequential frames of instead of using the entire video. Let be the observation ratio and be the length (i.e., the total number of frames) of , a partial video is defined as that is a subsequence of the full video containing from the first frame to the -th frame. We employ a set of observation ratios to mimic the partial observations at different progress levels and define as the -th progress level observation of , . By this means, the training set is augmented as times of the original one, i.e., . Following the existing work [22, 4, 50], we set and increase from to with a fixed step of .
We propose to solve the action prediction problem with memory networks. The partial video is formulated as a query to “retrieve” its lost information from a memory block learned from all the full training videos. To encode video memories, we build a training set as , where indicates the full video of , i.e., . Different from previous works [22, 20, 23], which require the progress level during the training process, the proposed AMemNet is “progress-free”. Hence, for convenience, we omit the subscript of the partial video when no confusion occurs, and always denote as a triplet of partial observation, full observation, and action category of the same video sample throughout the paper.
Following [35, 43], we train the proposed AMemNet model on the RGB frames and optical flows, respectively, and employ a late fusion mechanism to exploit the spatial-temporal information in a two-stream framework. Each stream employs the same network architecture with its own trainable weights. We refer to / as two modalities, and omit the subscripts (/) when it is unnecessary.
3.2 Adversarial Memory Networks (AMemNet)
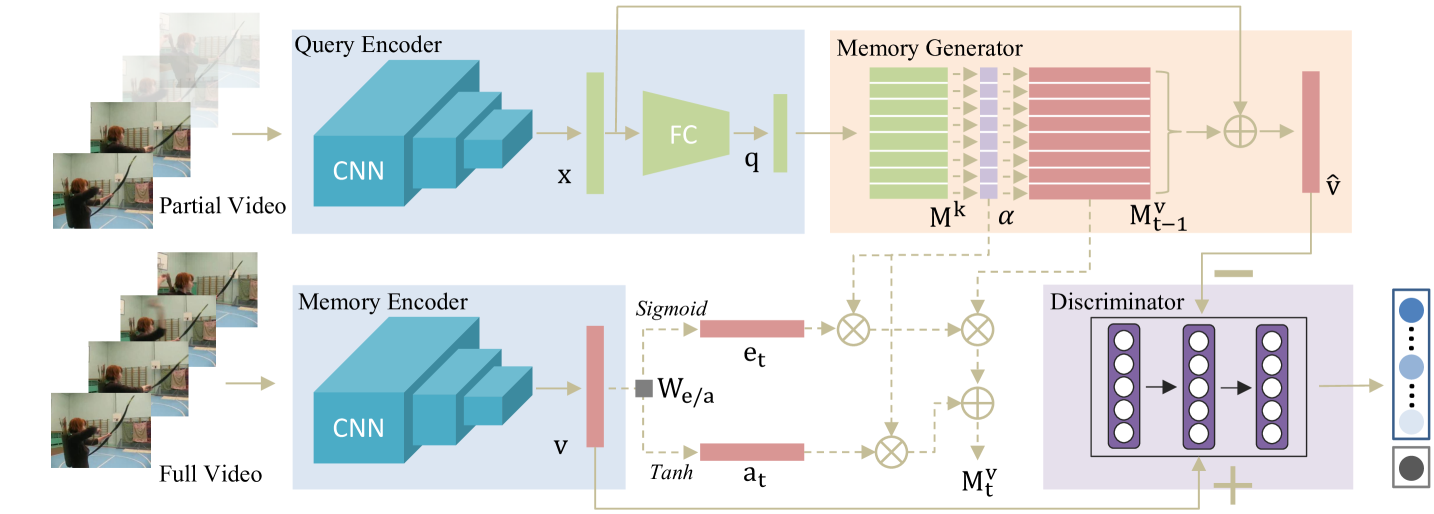
Fig. 1 shows the network architecture of the proposed AMemNet model. Overall, our model consists of three components: 1) query/memory encoder; 2) memory generator, and 3) discriminator. The encoder network is used to vectorize the given partial/full video as feature representations, the memory generator is learned to generate a full video representation conditioning on the partial video query, and the discriminator is trained to distinguish between fake and real full video representations and also deliver the prediction scores over all the categories. During the training process, the value memories are continuously updated by full videos with erase/add vectors that work as input/forget gates. We show the details of each component in the following.
3.2.1 Query/Memory Encoder
Given a partial video and its corresponding full video , we employ deep convolution neural networks (CNN) as an encoding model to obtain feature representations as follows: and , where and are the encoded representations for and , respectively, is the feature dimension, and parameterizes the CNN model. Following [5, 50], we instantiate with the pre-trained TSN model [43] for its robust and competitive performance on action recognition.
The proposed AMemNet model utilizes the partial video feature as a query to fetch relevant memories, which are learned from full training videos, to generate its full video feature . Hence, it is natural to directly utilize as the memory encoder for learning memory representations of full videos . On the other hand, to facilitate the querying process, we further encode the partial video representation in a lower-dimensional embedding space by
| (1) |
where denotes the query vector, refers to the dimension of query embeddings, and is given by fully-connected networks. By using Eq. (1), the query encoder is formulated by concatenating on top of . In this work, the memory and query encoder share the same CNN weights, and freeze with the pre-trained TSN model to avoid overfitting. Thus, the encoding component of AMemNet is mainly parameterized by .
3.2.2 Memory Generator
We adopt the key-value memory network architecture [28, 49] and develop it as a generator model by
| (2) |
where denotes the memory generator and represents the generated full video representation. Particularly, includes two memory blocks, termed as a key memory matrix and a value memory matrix , where is the number of memory slots in each memory block. The memory slot, in essence, is one row in /, learned with query and full video memory during the training process. The benefits of using such a key-value structure lies in separating the learning process for different purposes – could focus on memorizing different queries of partial videos and is trained to distill useful information from full videos for generation. To generate , our memory generator conducts the following three steps in a sequence.
1) Memory Addressing. The key memory matrix of provides sufficient flexibility to store similar queries (partial videos) for addressing the relevant value memory slots in with querying attentions. The addressing process is computed by
| (3) |
where denotes the soft attention weights over all the memory slots, refers to its -th row, and is a similarity score function, which could be given by the cosine similarity or norm . Notably, Eq. (3) enables an end-to-end differentiable property [37, 28] of our memory networks, optimizing the key slots with backpropagation gradients.
2) Memory Writing. The value memory matrix of memorizes full videos for the generation purpose, where the memory slots attended by a partial video query are written with its full video representation . Specifically, updates the value memory matrix with gate mechanism and attentions following [12, 28]. Let be the current training step and be the value memory matrix in the last step, is obtained by
| (4) | ||||
| (5) | ||||
| (6) | ||||
| (7) |
where and represent the erase vector and add vector, respectively, denotes the element-wise multiplication, and is computed by Eq (3) with (, ) arriving at the -th training step. In Eqs. (4) and (5), the erase vector and add vector work as input and forget gates in the LSTM model [15], implemented by two linear projection matrices111We omit all the bias vectors to simplify notations. and , respectively. The decides the forgetting degree of memory slots in , while computes the update in . By using query attentions , Eqs. (6) and (7) will mainly update the most attended () memory slots and leave the ones () that are irrelevant to the query nearly unchanged.
3) Memory Reading. After updating the value memory matrix , generates the full video representation by reading memory slots from in the following way:
| (8) |
which adds a skip-connection between the partial video feature and the memory output. Notably, Eq. (8) enables to memorize the residual between a partial video and its corresponding entire one.
3.2.3 Discriminator
The discriminator network is designed with two purposes as 1) predicting the true action category label given the real/generated (/) full video representation, and 2) distinguishing the real full video representation and the fake one . Inspired by [6, 23], we build the discriminator in a composition way: , where works as a classifier to predict probability scores over action classes, and follows the same definition in the GAN model [11] to infer the probability of the given sample being real. The discriminator in our model is formulated as fully-connected networks parameterized by .
3.3 Objective Function
The main goal of this work is to deliver realistic full-video representations for partial videos to predict their correct action classes. To this end, three loss functions are jointly employed for training the proposed AMemNet model.
Adversarial Loss. Given a partial video feature and its real full video representation , we compute the adversarial loss by
| (9) |
The discriminator tries to differentiate from the real one by maximizing , while, on the contrary, the memory generator aims to fool by minimizing . By using Eq. (9), we could employ to push towards generating realistic full video features.
Reconstruction Loss. The adversarial loss encourages our model to generate video features approaching the real feature distribution of full videos, yet without considering the reconstruction error at an instance level, which might miss some useful information for recovering from . In light of this, we define a reconstruction loss as
| (10) |
which calculates the squared Euclidean distance between the generated feature and its corresponding full video feature . Eq. (10) further guides the memory generator by bridging the gap between and .
Classification Loss. It is important for to generate discriminative representations for predicting different action classes. Thus, it is natural to impose a classification loss on training the memory generator as follows:
| (11) | ||||
| (12) |
where indicates the one-hot vector of an action label over classes and computes the cross-entropy between two probability distributions. Let be the output of , we have .
Different from [23], which only employs the classification loss in training the discriminator model with full videos, we employ Eq. (11) and Eq. (12) to train the discriminator and the memory generator alternatively. The benefit lies in: a high-quality classifier is first obtained by minimizing with real full videos and then is leveraged to “teach” for generating representations to lower . By this means, could learn the discriminative information from .
Final Objective. By summarizing Eq. (9) to Eq. (12), the final objective function of the proposed AMemNet model is given by
| (13) | ||||
| (14) |
where includes all the trainable parameters for generating from , parametrizes the discriminator, and and are the trade-off parameters balancing different loss functions. To proceed with the training procedure, we optimize and by alternatively solving Eq. (13) and Eq. (14) while fixing the other.
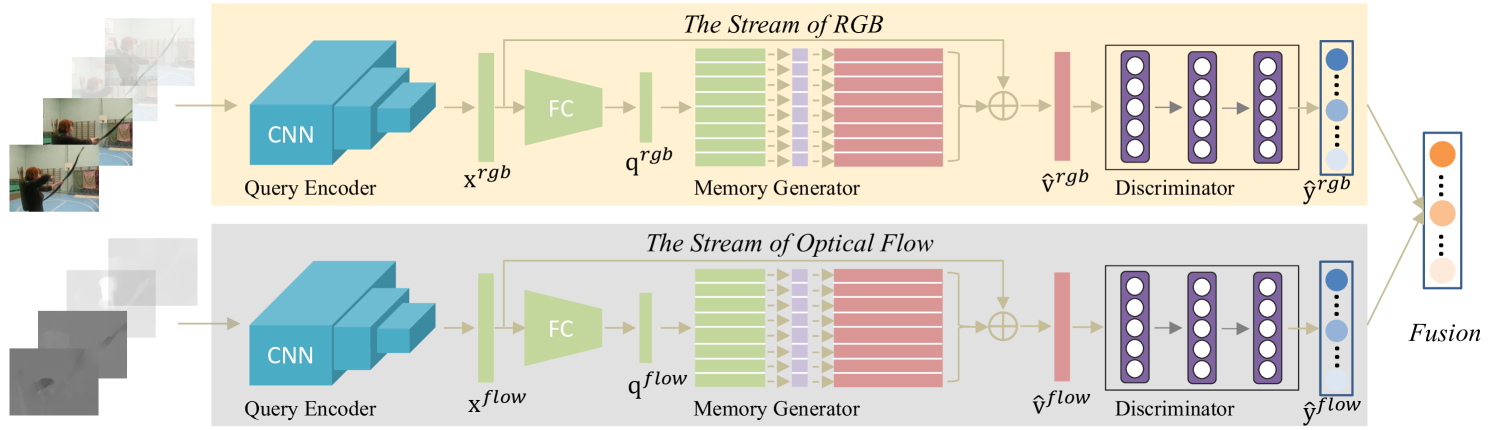
3.4 Two-Stream Fusion for Action Prediction
After training the proposed AMemNet model via Eq. (13) and Eq. (14), we freeze the model weights and suppress the memory writing operations in Eq. (4)-(7) for testing AMemNet. Particularly, given a partial video feature , we predict its action label by
| (15) |
where denotes the probability distribution over action classes for .
As shown in Fig 2, we adopt a two-stream framework [35, 43] to exploit the spatial and temporal information of given videos, where we first test AMemNet on each stream (i.e., RGB frames and optical flow) individually, and then fuse the prediction scores to obtain the final result. Given and , we obtain the prediction results and by using Eq. (15) with and , respectively. The final prediction result is given by
| (16) |
where is the fusion weight for integrating the scores given by the stream of spatial RGB frames and the stream of temporal optical flow images.
4 Experiments
4.1 Experimental Setting
Datasets. Two benchmark video datasets, UCF101 [36] and HMDB51 [24], are used in the experiment. The UCF101 dataset consists of videos from human actions covering a wide range of human activities, and the HMDB51 dataset collects video clips from movies and web videos over action categories. We follow the standard training/testing splits on these two datasets following [43, 23]. We test the proposed AMemNet model over three splits and report the average prediction result for each dataset. We employ the preprocessed RGB frames and optical flow images provided in [10].
Implementation Details. The proposed AMemNet is built on top of temporal segment networks (TSN) [43], where we adopt the BN-Inception network [16] as its backbone and employ the pre-trained model on the Kinetics dataset [19]. The same data augmentation strategy (e.g., cropping and jittering) as provided in [43] is employed for encoding all the partial and full videos as feature representations. We formulate as fully-connected networks of two layers, where the middle layer has hidden states and the final query embedding size is set as . The batch normalization and LealyRelu are both used in . We employ memory slots for the key and value memory matrices, hence we have and . All the memory matrices and gating parameters in are randomly initialized. We implement the discriminator network by one fully-connected layer, where the softmax and sigmoid activation function are used for and , respectively.
For each training step, we first employ the Adam optimizer with a learning rate of to update with Eq. (13) twice, and then optimize once by solving Eq. (14) with the SGD optimizer of learning rate and momentum rate. We set the batch size as . For all the datasets, we set to strengthen the impact of on the memory generator for encouraging discriminative representations, and set to avoid overemphasizing the reconstruction of each video sample to lead the overfitting issue. The fusion weight is fixed as for all the datasets following [43]. All the codes in this work were implemented by Pytorch and ran with Titan X GPUs.
Compared Methods. We compare our approach with three different kinds of methods as follows. 1) Single-stream methods: Integral BoW (IBoW) [32], mixture segments sparse coding (MSSC) [2], multiple temporal scales SVM (MTSSVM) [21], deep sequential context networks (DeepSCN) [22], part-activated deep reinforcement learning (PA-DRL) [4], and progressive teacher-student learning (PTSL) [46]. 2) Two-stream methods: memory augmented LSTM (Mem-LSTM) [20], temporal sequence learning (TSL) [5], residual generator network with Kalman filter (RGN-KF) [50], and adversarial action prediction networks (AAPNet) [23]. We implemented the AAPNet with the same pre-trained TSN features as our approach and posted the authors’ reported results for the other single/two-stream methods. 3) Baselines: We also compare AMemNet with temporal segment networks (TSN) [43]. Specifically, we test the TSN model pre-trained on the UCF101/HMDB51 dataset as baseline results, and finetune the TSN model pre-trained on the Kinetics dataset for UCF101 and HMDB51, respectively. Moreover, we train a k-nearest neighbors (KNN) classifier with the Kinetics pre-trained TSN features, termed as TSN+KNN, and report its best performance by selecting from . For a fair comparison, we follow the same testing setting in previous works [22, 4, 50] by evenly dividing all the videos into 10 progresses, i.e., as described in Section 3.1. However, it is worth noting that, the proposed AMemNet does not require any progress label in both training and testing.
4.2 Prediction Performance
UCF101 Dataset. Table 1 summarizes the prediction accuracy of the proposed AMemNet and 13 compared methods on the UCF101 dataset. Overall, AMemNet consistently outperforms all the competitors over different observation ratios with a significant improvement. Impressively, the proposed AMemNet achieves around accuracy when only video is observed, which fully validates the effectiveness of applying AMemNet for early action prediction. This is mainly benefited from the rich key-value structured memories learned from full-video features guided by the adversarial training.
The single-stream methods mainly explore the temporal information by using hand-crafted features (e.g., spatio-temporal interest points (STIP) [8], dense trajectory) like in IBoW [32], MSSC [2], and MTSSVM [21], or by utilizing 3D convolutional networks (e.g., C3D [39]) like in DeepSCN [22] and PTSL [46]. Differently, the two-stream methods deploy the convolutional neural networks on two pathways to capture the spatial information of RGB images and the temporal characteristics of optic flows, respectively. On the one hand, the two-stream methods could better exploit the spatial-temporal information inside videos than using one single stream. The proposed AMemNet inherits the merits from this two-stream architecture, and thus performs better than the single-stream methods that even employ a more powerful CNN encoder, e.g., the 3D ResNeXt-101 [14] used in PTSL [46] is much deeper than BN-Inception in the proposed AMemNet. On the other hand, compared with two-stream methods, especially the AAPNet [23] implemented with the same backbone as our model, the consistent improvement of AMemNet over AAPNet shows the effectiveness of using the memory generator to deliver “full” video features in early progress.
In Table 1, we refer to AMemNet-RGB and AMemNet-Flow as the single-stream result by using AMemNet on RGB frames and flow images, respectively. Two interesting observations could be drawn: 1) The RGB contributes more than the flow at the beginning, as the still images encapsulating scenes and objects could provide key clues for recognizing the actions with few frames. 2) The late fusion naturally fits action prediction by integrating the complimentary information between two streams over time.
HMDB51 Dataset. Table 2 reports the prediction results of our approach and TSN [43] on the HMDB51 dataset, which, compared with UCF101, is a more challenging dataset for predicting actions due to the large motion variations rather than static cues across different categories [24]. As can be seen, the flow result of AMemNet exceeds AMemNet-RGB around accuracy after more progress being observed (e.g., ). However, even under this case, the proposed AMemNet still consistently improves AMemNet-Flow by incorporating RGB results along with different progresses. Moreover, the clear improvements of AMemNet over TSN indicate that the full video memories learned by our memory generator could well enhance the discriminability of video representations in early progress.
4.3 Model Discussion
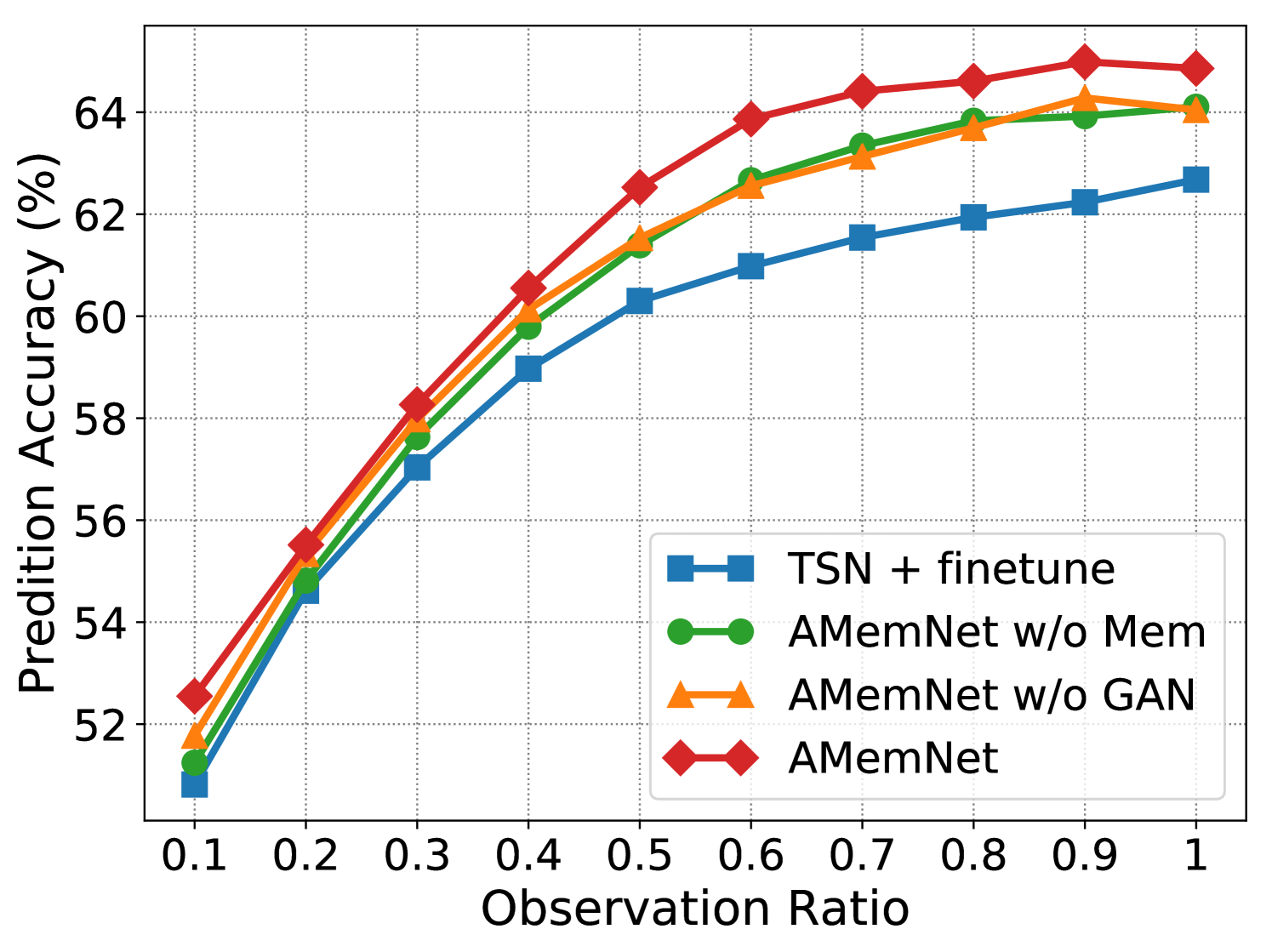
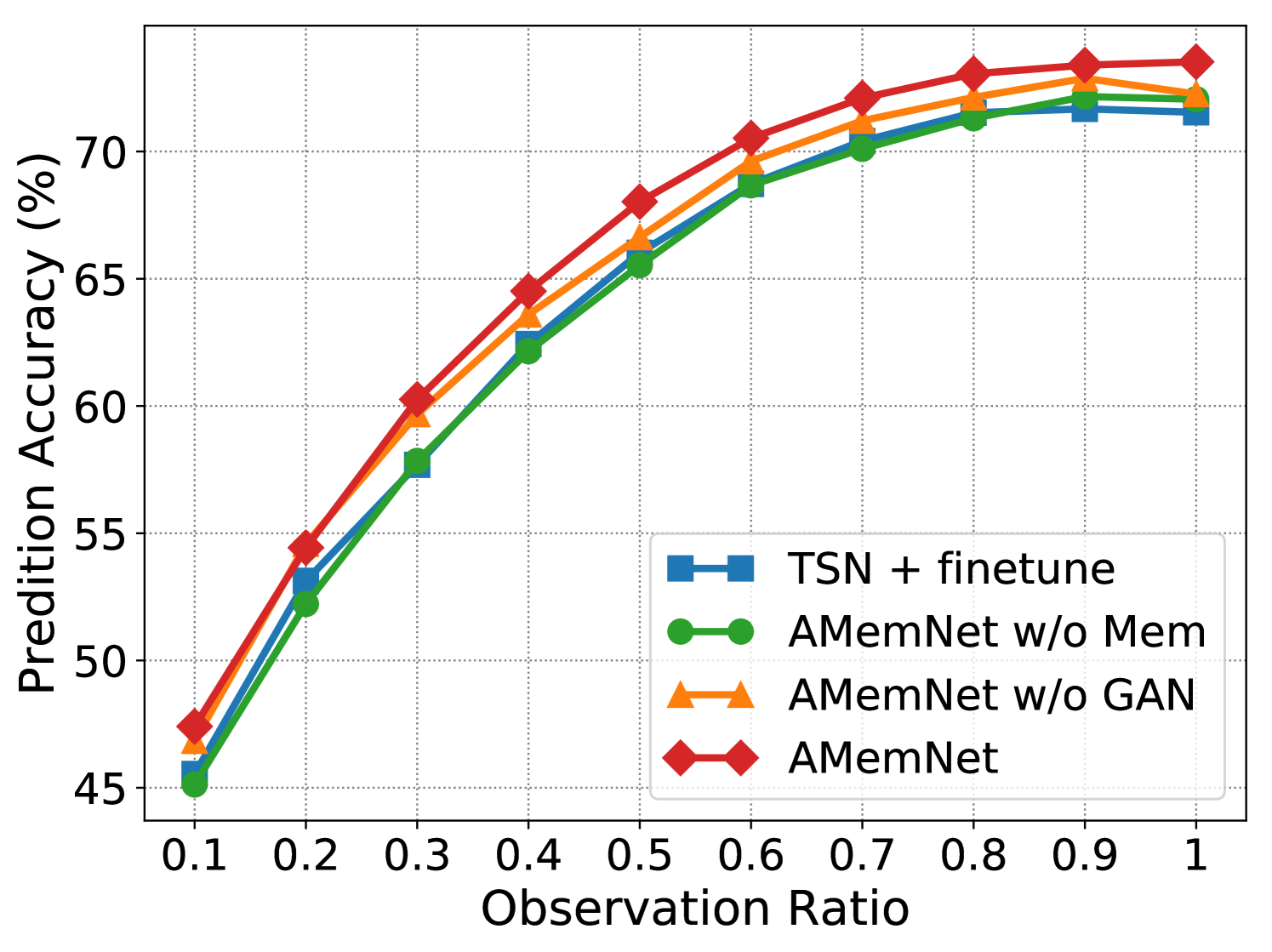
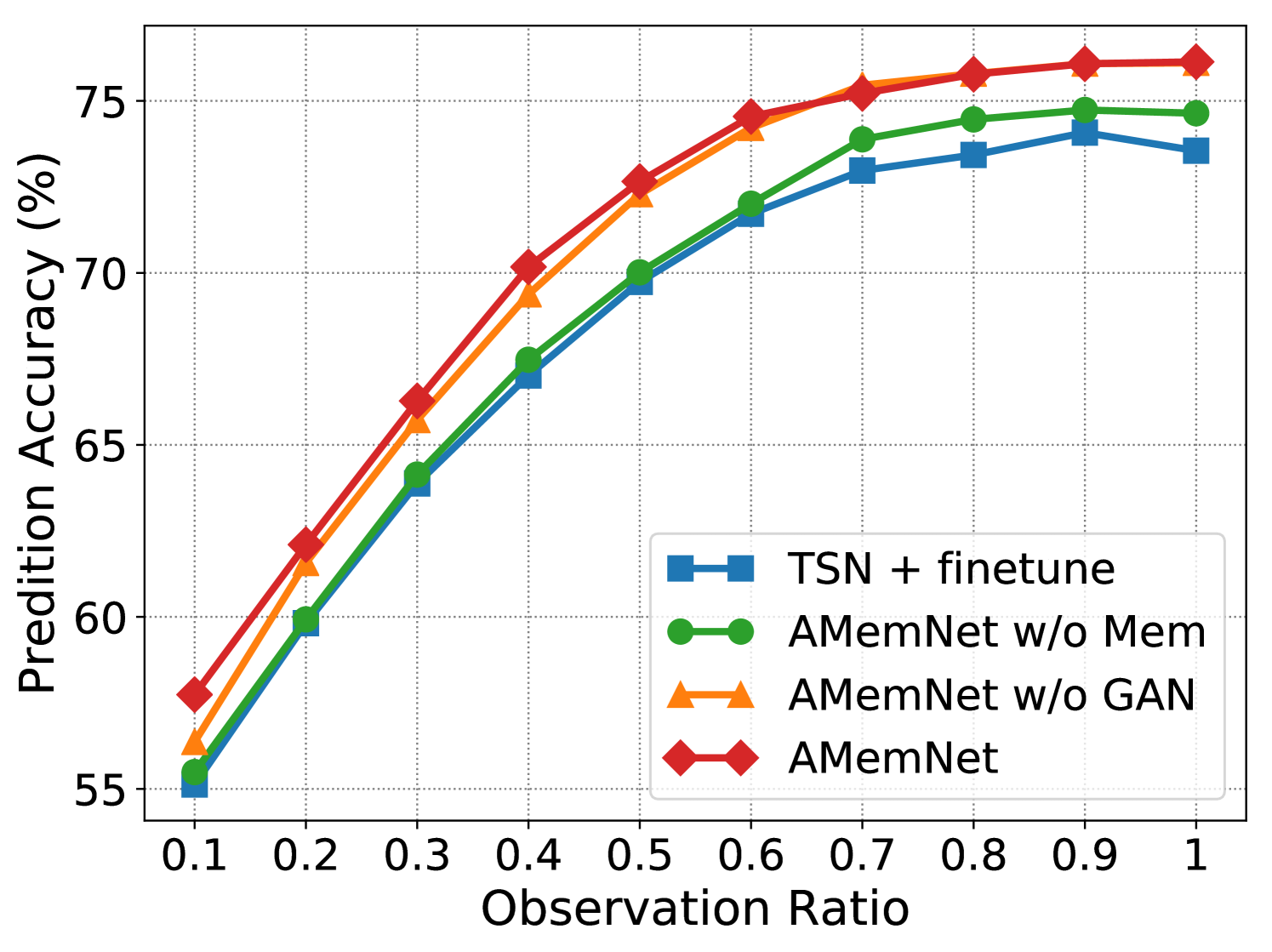
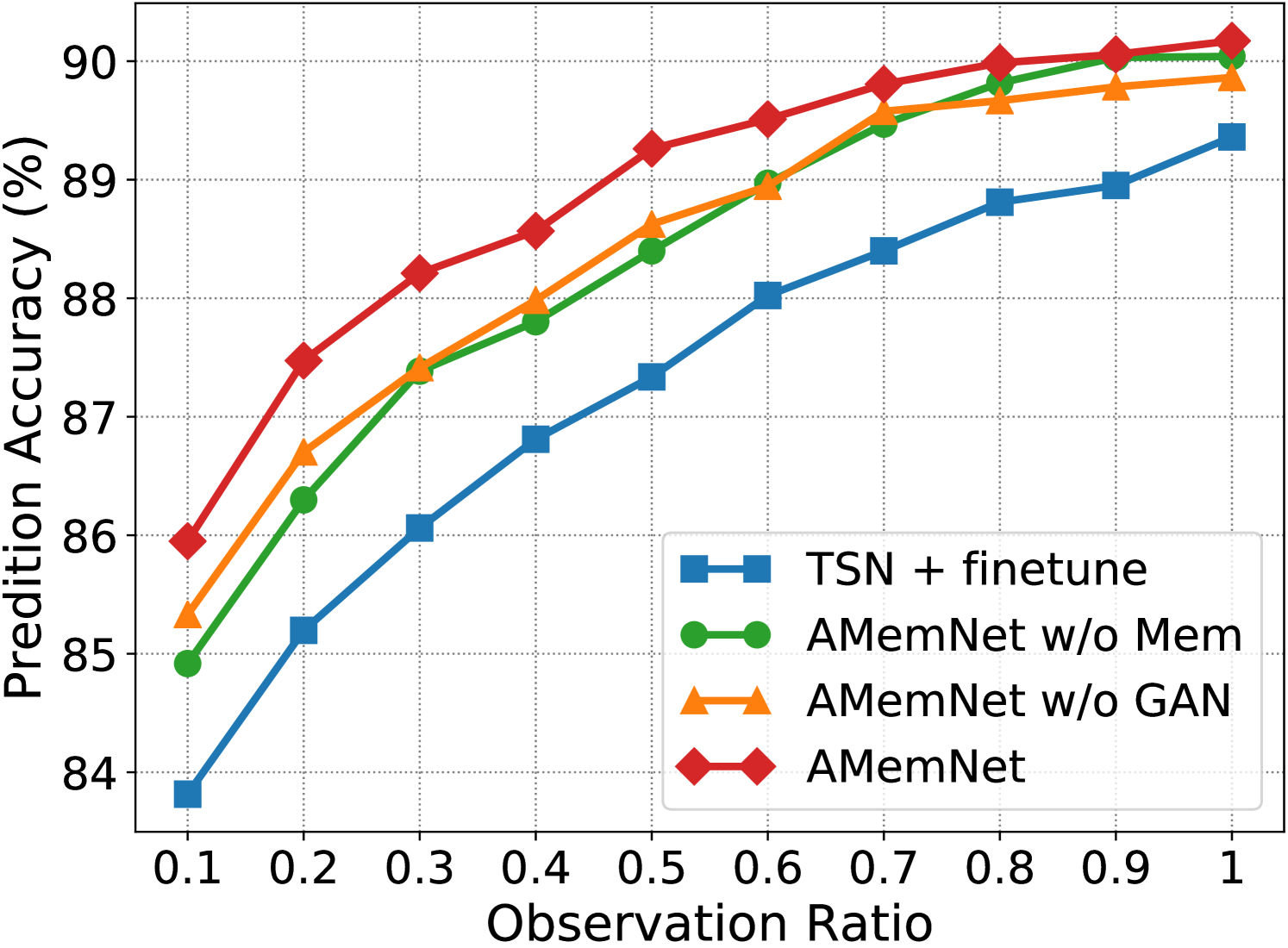
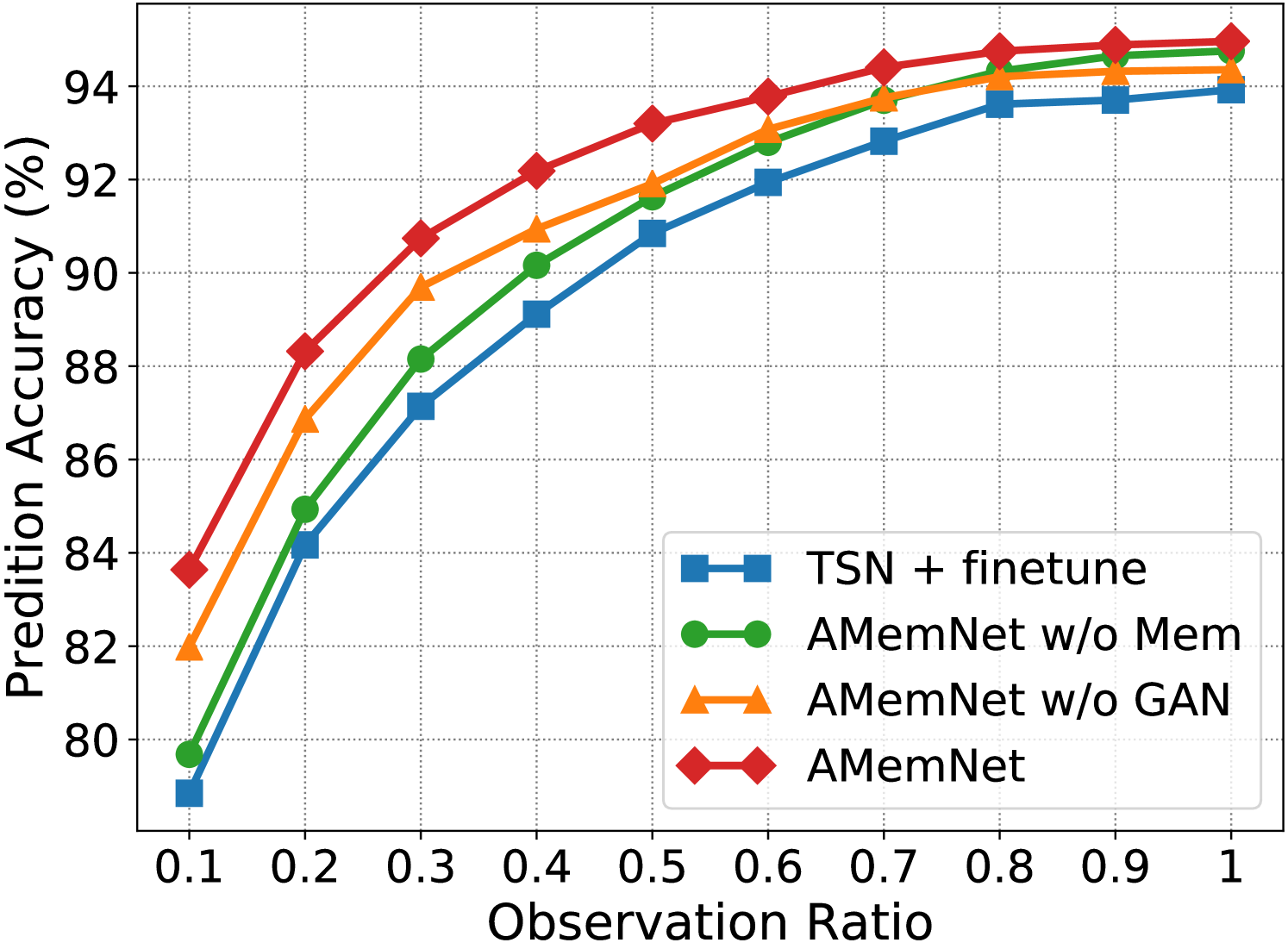
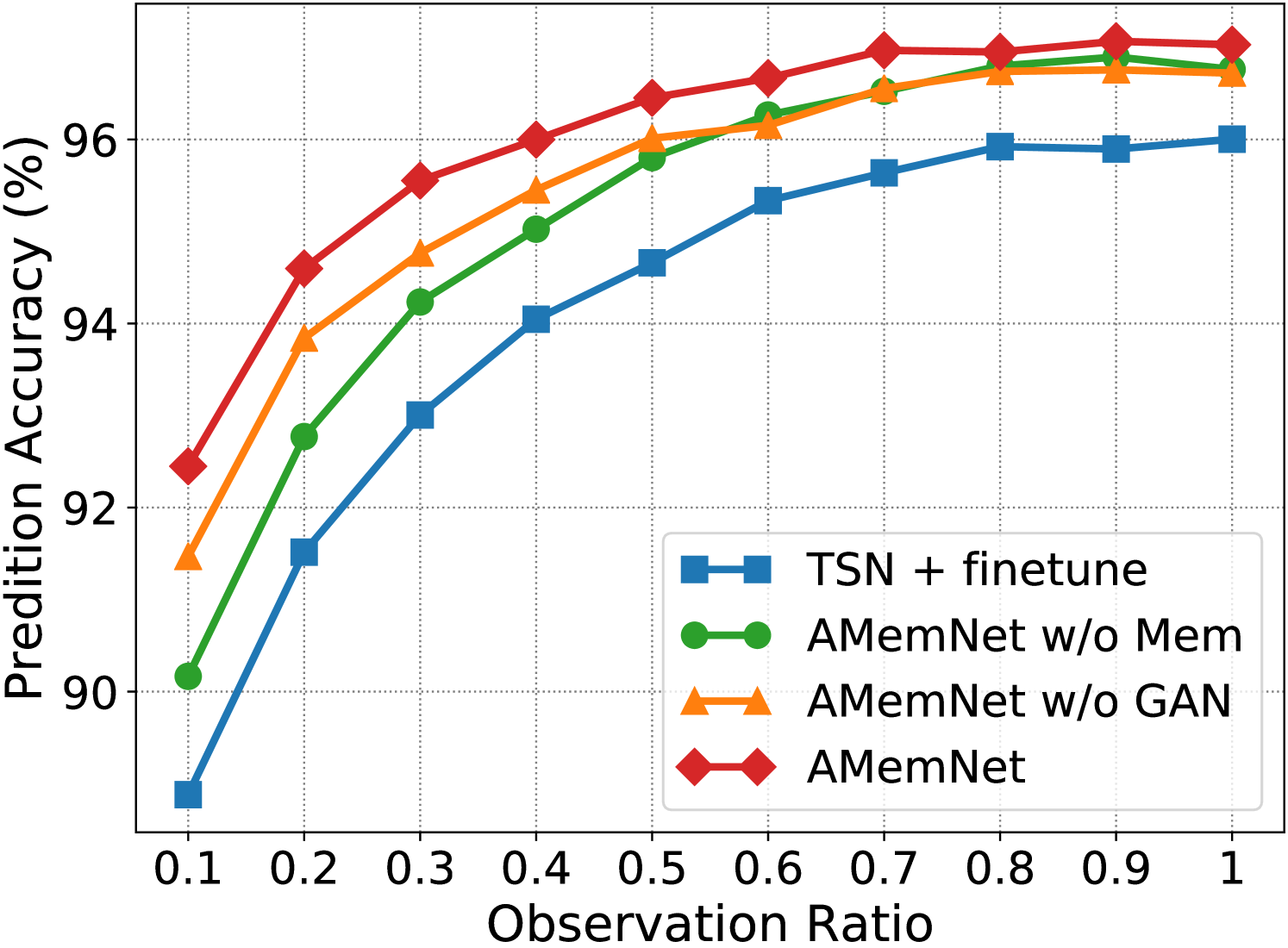
Ablation Study. Fig. 3 shows the ablation study of the proposed AMemNet model on the UCF101 dataset222 More ablation study results and parameter analyses on the UCF101 and HMDB51 datasets are provided in the supplementary material. in terms of RGB, Flow and fusion, respectively, where we test all the methods by different observation ratios. We adopt TSN + finetune as a sanity check for our approach and implement two strong ablated models to discuss the impact of two main components of AMemNet as follows. 1) AMemNet w/o Mem refers to our model by discarding the memory generator, i.e., . Instead, we use the same generator network as in AAPNet [23] for generating full video features with AMemNet w/o Mem. 2) AMemNet w/o GAN is developed without the adversarial training and is trained by only using a classification loss.
As shown in Fig 3, AMemNet improves all the above methods with a clear margin on different cases, which strongly supports the motivation of this work. It is worth noting that, for the early progress (i.e., the observation ratio ), AMemNet w/o GAN clearly boots the performance over AMemNet w/o Mem. This demonstrates the effectiveness of using memory networks to compensate for the limited information in incomplete videos. As observing more progress, the GAN model will lead the generating process since it has sufficient information given by the partial videos, where AMemNet w/o Mem improves over AMemNet w/o GAN after on the UCF101 dataset.
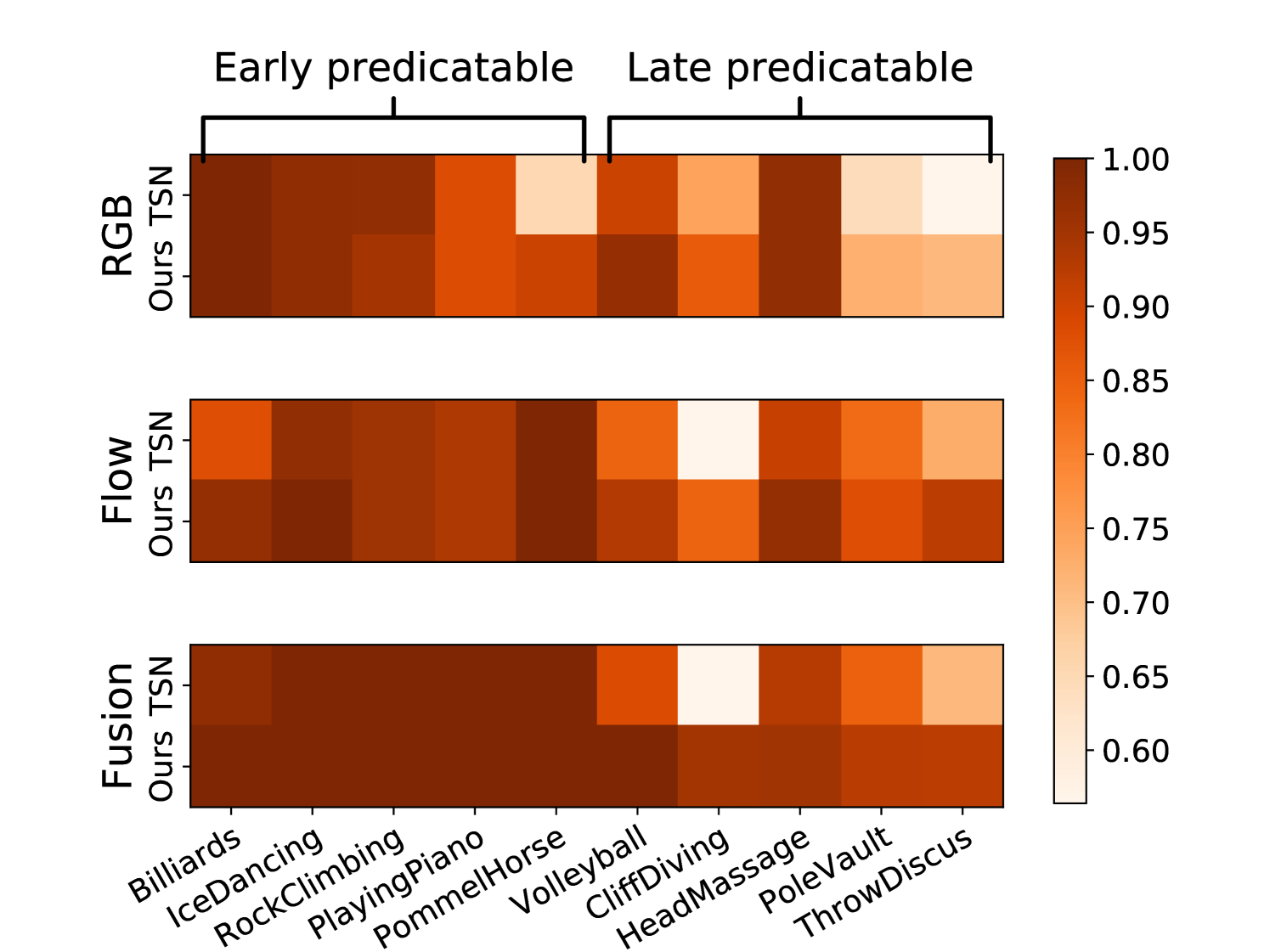
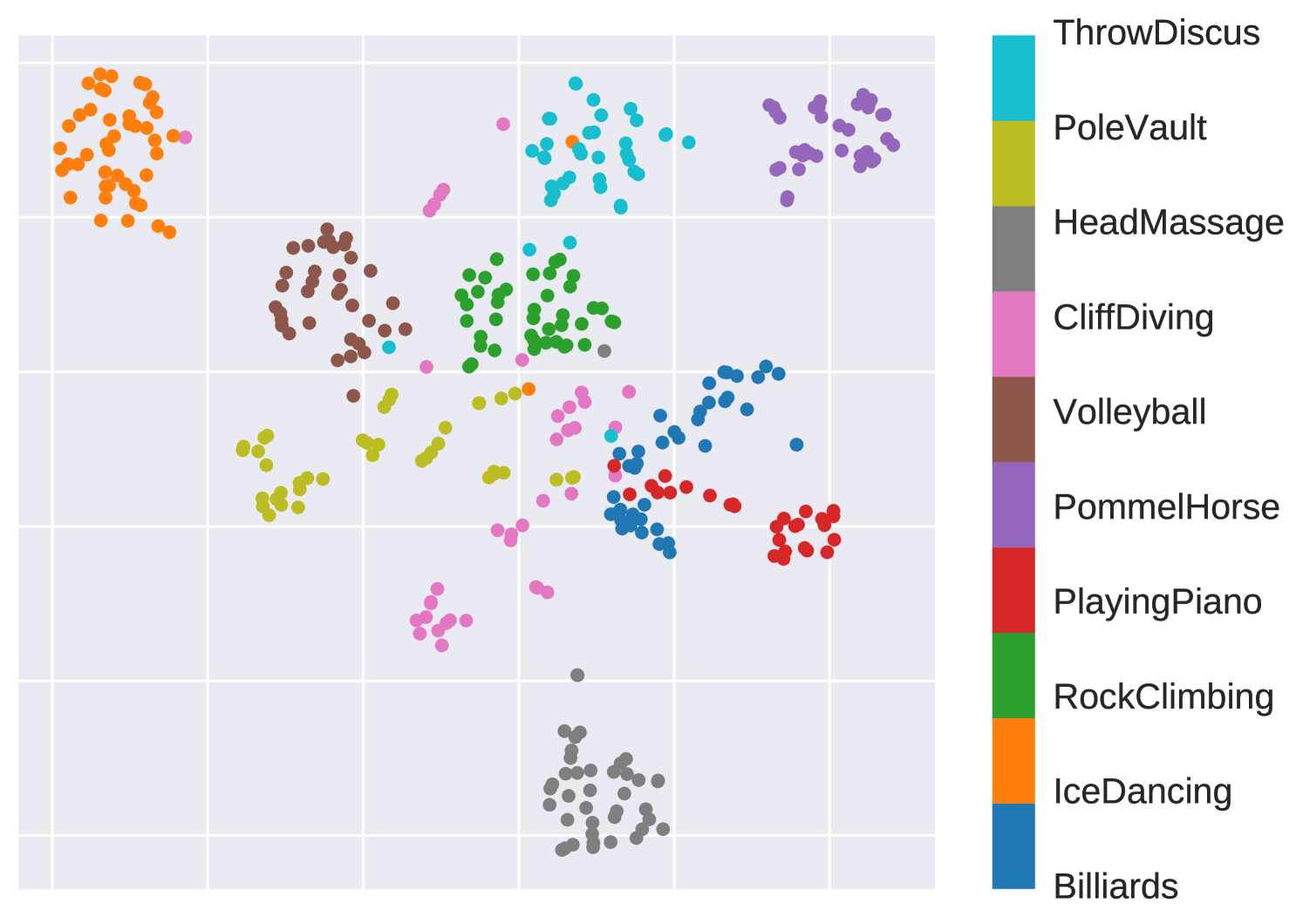
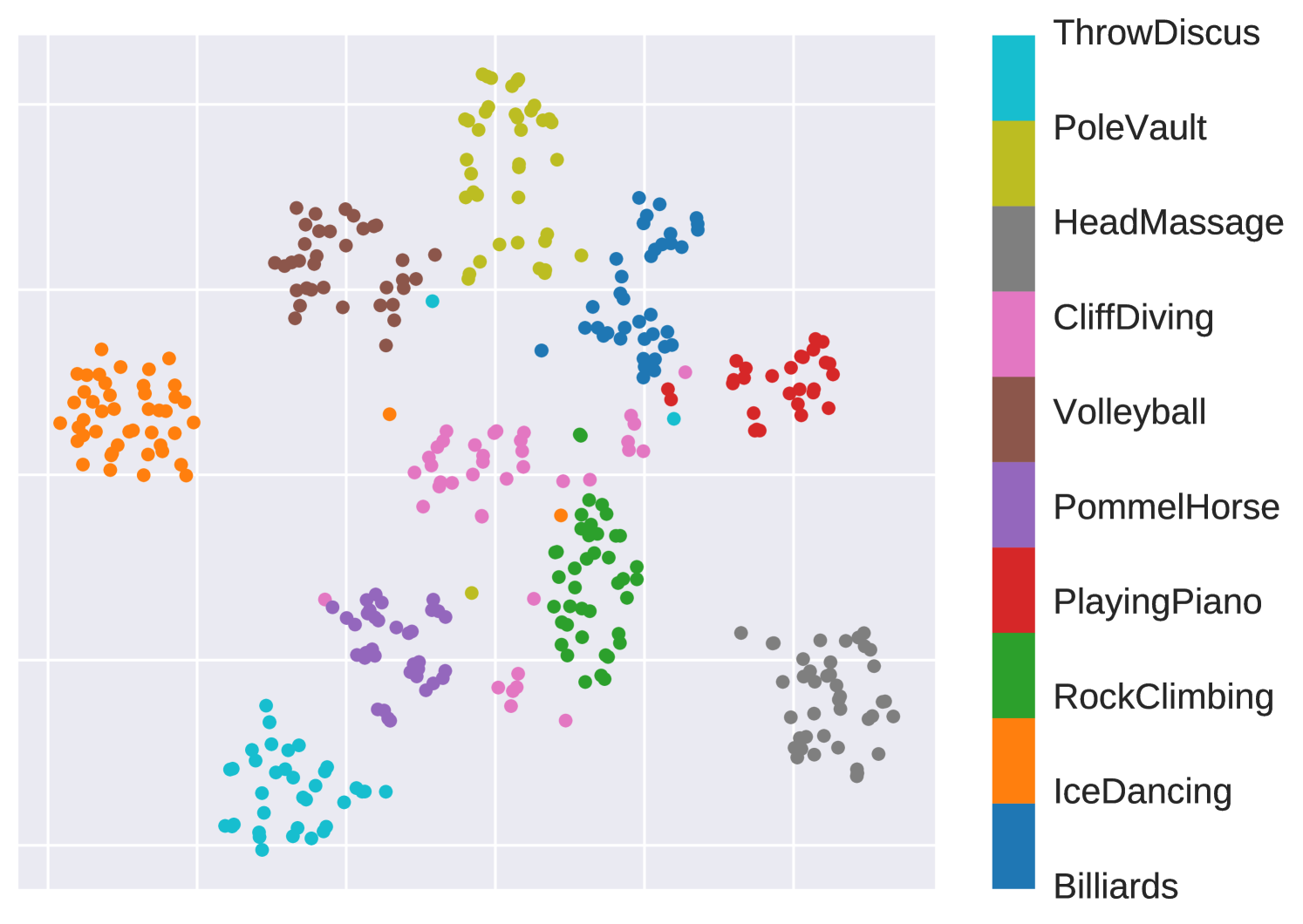
Early Predicable vs Late Predicable. In Fig. 4, we discuss the performance of AMemNet for action categories of different properties, e.g., predictability (the progress level required for recognizing an action), on the UCF101 dataset. We compare AMemNet and TSN [43] on the progress level video of 10 different categories in 4(a) and show the corresponding t-SNE [41] embeddings of TSN features and the generated full video features given by AMemNet in 4(b) and 4(c), respectively. Inspired by [22], we select 10 action categories from UCF101 and divide them into two groups as 1) the early predictable group including Billiards, IceDancing, RockClimbingIndoor, PlayingPiano, PommelHorse, and 2) the late predictable group including VolleyballSpiking, CliffDiving, HeadMassage, PoleVault, ThrowDiscus, where the early group usually could be predicted by given progress and the late group is selected as the non-early ones.
As expected, the proposed AMemNet mainly improves the TSN baseline over late predictable actions in Fig. 4(a), which again demonstrates the realistic of the full video features given by our memory generator. Moreover, as shown in Fig. 4(b) and 4(c), while TSN exhibits a good structured feature embeddings for early predictable classes, e.g., IceDancing and PommelHorse, its embeddings mixes up for the late predictable ones like PoleVault and CliffDiving. In contrast, AMemNet generates full video features that encourage a good cluster structure in the embedding space.
5 Conclusion
In this paper, we presented a novel two-stream adversarial memory networks (AMemNet) model for the action prediction task. A key-value structured memory generator was proposed to generate the full video feature conditioning on the partial video query, and a class-aware discriminator was developed to supervise the generator for delivering realistic and discriminative representations towards full videos through adversarial training. The proposed AMemNet adopts input and forget gates for updating the full video memories attended by different queries, which captures the long-term temporal variation across different video progresses. Experimental results on two benchmark datasets were provided to demonstrate the effectiveness of AMemNet for the action prediction problem compared with state-of-the-art methods.
References
- [1] Y. Cai, L. Huang, Y. Wang, T.-J. Cham, J. Cai, J. Yuan, J. Liu, X. Yang, Y. Zhu, X. Shen, D. Liu, J. Liu, and N. M. Thalmann. Learning progressive joint propagation for human motion prediction. In Computer Vision – ECCV 2020, pages 226–242, 2020.
- [2] Y. Cao, D. Barrett, A. Barbu, S. Narayanaswamy, H. Yu, A. Michaux, Y. Lin, S. Dickinson, J. Siskind, and S. Wang. Recognizing human activities from partially observed videos. In CVPR, 2013.
- [3] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and kinetics dataset. In CVPR, 2017.
- [4] L. Chen, J. Lu, Z. Song, and J. Zhou. Part-activated deep reinforcement learning for action prediction. In ECCV, September 2018.
- [5] S. Cho and H. Foroosh. A temporal sequence learning for action recognition and prediction. In WACV, pages 352–361, 2018.
- [6] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR, 2018.
- [7] A. Diba, V. Sharma, and L. Van Gool. Deep temporal linear encoding networks. In CVPR, July 2017.
- [8] P. Dollar, V. Rabaud, G. Cottrell, and S. Belongie. Behavior recognition via sparse spatio-temporal features. In VS-PETS, 2005.
- [9] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell. Long-term recurrent convolutional networks for visual recognition and description. In CVPR, June 2015.
- [10] C. Feichtenhofer, A. Pinz, and A. Zisserman. Convolutional two-stream network fusion for video action recognition. In CVPR, June 2016.
- [11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, pages 2672–2680. 2014.
- [12] A. Graves, G. Wayne, and I. Danihelka. Neural turing machines. CoRR, abs/1410.5401, 2014.
- [13] S. Guo, L. Qing, J. Miao, and L. Duan. Deep residual feature learning for action prediction. In IEEE International Conference on Multimedia Big Data, pages 1–6, 2018.
- [14] K. Hara, H. Kataoka, and Y. Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In CVPR, June 2018.
- [15] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, volume 37, pages 448–456, 2015.
- [17] S. Ji, W. Xu, M. Yang, and K. Yu. 3d convolutional neural networks for human action recognition. TPAMI, 2013.
- [18] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
- [19] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman. The kinetics human action video dataset. CoRR, abs/1705.06950, 2017.
- [20] Y. Kong, S. Gao, B. Sun, and Y. Fu. Action prediction from videos via memorizing hard-to-predict samples. In AAAI, 2018.
- [21] Y. Kong, D. Kit, and Y. Fu. A discriminative model with multiple temporal scales for action prediction. In ECCV, 2014.
- [22] Y. Kong, Z. Tao, and Y. Fu. Deep sequential context networks for action prediction. In CVPR, 2017.
- [23] Y. Kong, Z. Tao, and Y. Fu. Adversarial action prediction networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(3):539–553, 2020.
- [24] H. Kuhne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. Hmdb: A large video database for human motion recognition. In ICCV, 2011.
- [25] S. Lai, W. Zheng, J. Hu, and J. Zhang. Global-local temporal saliency action prediction. IEEE Transactions on Image Processing, 27(5):2272–2285, 2018.
- [26] T. Lan, T.-C. Chen, and S. Savarese. A hierarchical representation for future action prediction. In ECCV, 2014.
- [27] I. Laptev. On space-time interest points. IJCV, 64(2):107–123, 2005.
- [28] A. H. Miller, A. Fisch, J. Dodge, A. Karimi, A. Bordes, and J. Weston. Key-value memory networks for directly reading documents. In EMNLP, pages 1400–1409, 2016.
- [29] J. Y.-H. Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici. Beyond short snippets: Deep networks for video classification. In CVPR, 2015.
- [30] M. Raptis and L. Sigal. Poselet key-framing: A model for human activity recognition. In CVPR, 2013.
- [31] M. Ryoo and J. Aggarwal. Spatio-temporal relationship match: Video structure comparison for recognition of complex human activities. In ICCV, pages 1593–1600, 2009.
- [32] M. S. Ryoo. Human activity prediction: Early recognition of ongoing activities from streaming videos. In ICCV, 2011.
- [33] M. Sadegh Aliakbarian, F. Sadat Saleh, M. Salzmann, B. Fernando, L. Petersson, and L. Andersson. Encouraging lstms to anticipate actions very early. In ICCV, Oct 2017.
- [34] Y. Shi, B. Fernando, and R. Hartley. Action anticipation with rbf kernelized feature mapping rnn. In ECCV, September 2018.
- [35] K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, 2014.
- [36] K. Soomro, A. R. Zamir, and M. Shah. UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild. Technical report, CRCV-TR-12-01, 2012.
- [37] S. Sukhbaatar, a. szlam, J. Weston, and R. Fergus. End-to-end memory networks. In NeurIPS, pages 2440–2448. 2015.
- [38] Z. Tao, S. Li, Z. Wang, C. Fang, L. Yang, H. Zhao, and Y. Fu. Log2intent: Towards interpretable user modeling via recurrent semantics memory unit. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1055–1063, 2019.
- [39] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In ICCV, 2015.
- [40] K. M. Tran, A. Bisazza, and C. Monz. Recurrent memory networks for language modeling. In NAACL HLT, pages 321–331, 2016.
- [41] L. van der Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008.
- [42] H. Wang, A. Kläser, C. Schmid, and C.-L. Liu. Dense trajectories and motion boundary descriptors for action recognition. IJCV, 103(1):60–79, 2013.
- [43] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. V. Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, 2016.
- [44] Q. Wang, H. Yin, Z. Hu, D. Lian, H. Wang, and Z. Huang. Neural memory streaming recommender networks with adversarial training. In SIGKDD, pages 2467–2475, 2018.
- [45] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In CVPR, June 2018.
- [46] X. Wang, J.-F. Hu, J.-H. Lai, J. Zhang, and W.-S. Zheng. Progressive teacher-student learning for early action prediction. In CVPR, June 2019.
- [47] Y. Wang, L. Jiang, M.-H. Yang, L.-J. Li, M. Long, and L. Fei-Fei. Eidetic 3d lstm: A model for video prediction and beyond. In ICLR, 2019.
- [48] J. Weston, S. Chopra, and A. Bordes. Memory networks. CoRR, abs/1410.3916, 2014.
- [49] J. Zhang, X. Shi, I. King, and D. Yeung. Dynamic key-value memory networks for knowledge tracing. In WWW, pages 765–774, 2017.
- [50] H. Zhao and R. P. Wildes. Spatiotemporal feature residual propagation for action prediction. In ICCV, October 2019.
- [51] H. Zhao and R. P. Wildes. On diverse asynchronous activity anticipation. In Computer Vision – ECCV 2020, pages 781–799, 2020.
| Methods | Model Components | UCF101 | HMDB51 | ||||
|---|---|---|---|---|---|---|---|
| avg. | avg. | ||||||
| TSN + finetune | |||||||
| AMemNet w/o Mem | ✓ | ✓ | |||||
| AMemNet w/o GAN | ✓ | ✓ | |||||
| AMemNet w/o Res | ✓ | ✓ | |||||
| AMemNet (ours) | ✓ | ✓ | ✓ | ||||
Appendix A Supplementary Material
We provide 1) more ablation study results (Table 3-5 and Fig. 6) and 2) parameter analyses (Fig. 5(a) and Fig. 5(b)) in the supplementary material. Particularly, we report the averaged results over three splits of the UCF101 and HMDB51 datasets for ablation study, respectively, and mainly conduct the parameter analysis on split 1 of the HMDB51 dataset.
Ablation Study. The final objective function of the proposed AMemNet model is given by
where includes all the trainable parameters for generating from , parametrizes the discriminator, and are two trade-off parameters for balancing different terms.
Table 3 shows the overall comparison results between the proposed AMemNet and three ablated models and one baseline. Table 4 and Table 5 provide all the comparison results of each stream on the UCF101 and HMDB51 datasets, respectively. In the proposed AMemNet, the memory-augmented generator and the adversarial training loss play the key roles in generating full-video-like features, where contributes more on the early progress and leads the late progress. The reconstruction loss works as a “regularization” term for adversarial training, and thus AMemNet w/o Res presents a similar overall performance to our full model. As shown in Table 5, exhibits a more significant impact on the earlier progress (e.g., or ), since the videos in HMDB51 usually have a lager variance than UCF101. However, overemphasizing may lower the performance (see in Fig. 5(b)).
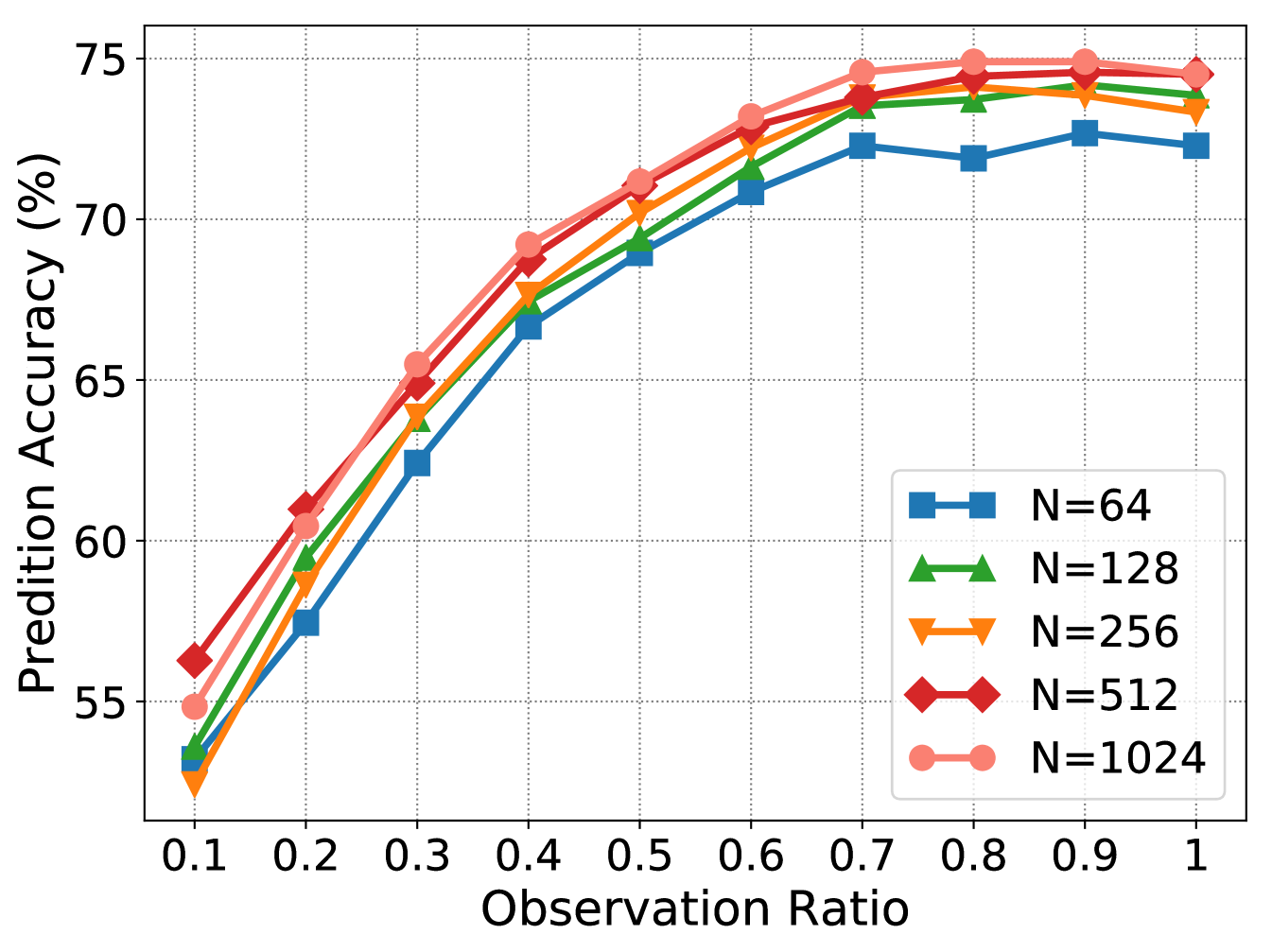
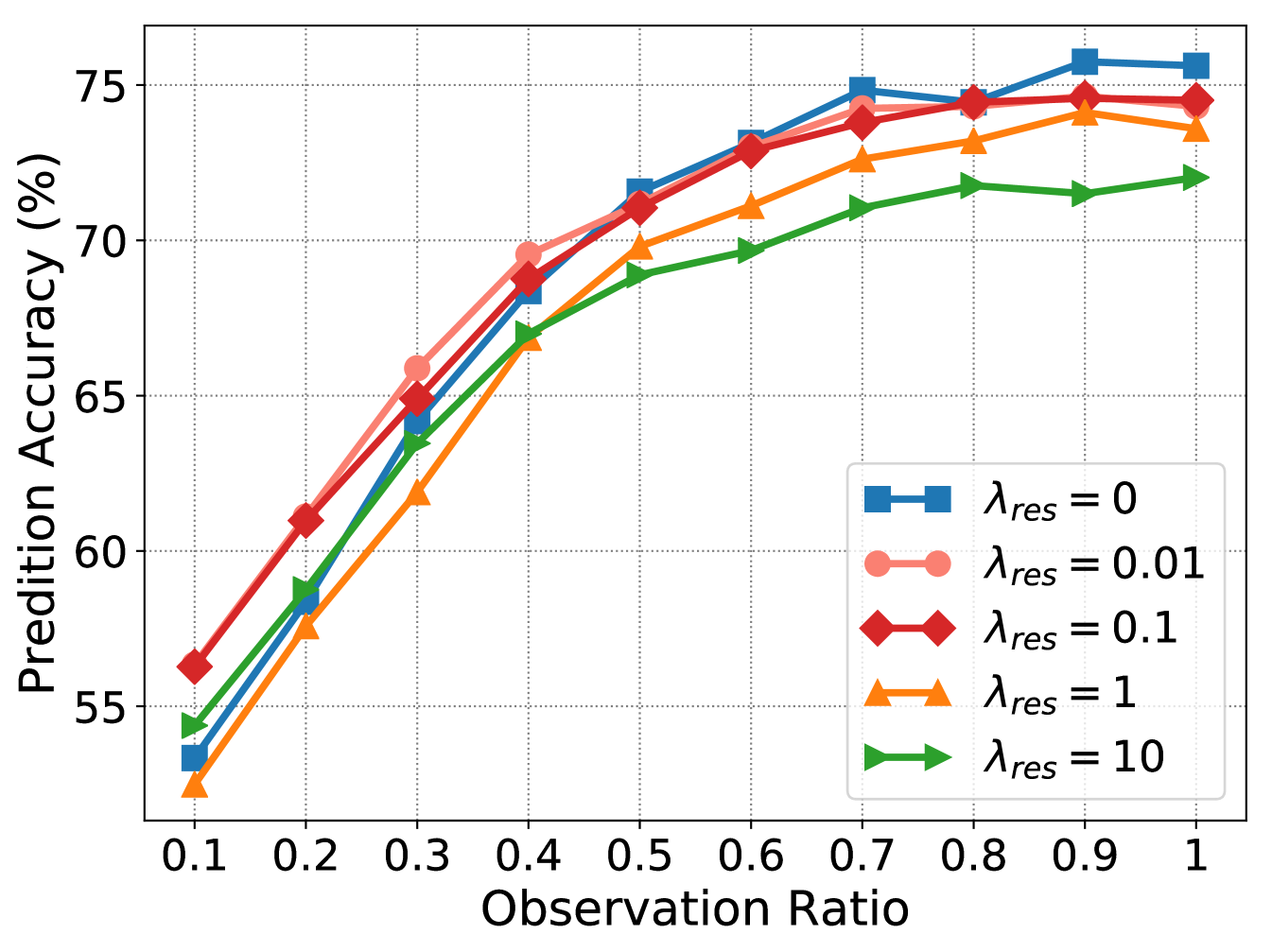
Parameter Analysis. In the experiment, we set the number of memory slots used in as by default. We study the impact of in Fig. 5(a), suggesting could lead to a stable prediction performance. We fix since the classification is the main goal for action prediction, and mainly tune in Fig. 5(b), which indicates a relatively small is useful for recovering the partial videos. We set as default.
| Method | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RGB | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet-RGB | |||||||||||
| Flow | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet-Flow | |||||||||||
| Fusion | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet (ours) |
| Method | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RGB | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet-RGB | |||||||||||
| Flow | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet-Flow | |||||||||||
| Fusion | TSN + finetune | ||||||||||
| AMemNet w/o Mem | |||||||||||
| AMemNet w/o GAN | |||||||||||
| AMemNet w/o Res | |||||||||||
| AMemNet (ours) |