Adversarial YOLO: Defense Human Detection Patch Attacks
via Detecting Adversarial Patches
Abstract
The security of object detection systems has attracted increasing attention, especially when facing adversarial patch attacks. Since patch attacks change the pixels in a restricted area on objects, they are easy to implement in the physical world, especially for attacking human detection systems. The existing defenses against patch attacks are mostly applied for image classification problems and have difficulty resisting human detection attacks. Towards this critical issue, we propose an efficient and effective plug-in defense component on the YOLO detection system, which we name Ad-YOLO. The main idea is to add a patch class on the YOLO architecture, which has a negligible inference increment. Thus, Ad-YOLO is expected to directly detect both the objects of interest and adversarial patches. To the best of our knowledge, our approach is the first defense strategy against human detection attacks.
We investigate Ad-YOLO’s performance on the YOLOv2 baseline. To improve the ability of Ad-YOLO to detect variety patches, we first use an adversarial training process to develop a patch dataset based on the Inria dataset, which we name Inria-Patch. Then, we train Ad-YOLO by a combination of Pascal VOC, Inria, and Inria-Patch datasets. With a slight drop of mAP on VOC 2007 test set, Ad-YOLO achieves AP of persons, which highly outperforms AP for YOLOv2 when facing white-box patch attacks. Furthermore, compared with YOLOv2, the results facing a physical-world attack are also included to demonstrate Ad-YOLO’s excellent generalization ability.
1 Introduction
Patch attacks have been recognized as a very practical means to threaten computer vision systems. Unlike the traditional strategy, patch attacks only change the pixels in the restricted area and are not imperceptible, which is close to the effect of graffiti or stickers in form. Therefore, it is more realistic in physical-world attacks. At present, many carefully crafted adversarial patches have achieved remarkable results in the fields of image classification [5], face recognition [12] and object detection [2, 14, 6].
Compared with rich work on patch attacks, considerable attention for patch defenses has been devoted to image classification and cannot be transferred to object detection due to the large computational cost [15, 10] or the lack of prior knowledge about the patch [16]. In addition, there are some image preprocessing methods for mitigating adversarial noise for patch attacks, such as image denoising DW [4], LGS [9] and partial occlusion MR [8], but the drawback is the accuracy decrease on the original examples. Besides, most of these defenses are designed to resist patch attacks in the digital space and are ineffective to defend against physical-world attacks.
This paper focuses on patch defenses for objection detection, especially human detection systems. We first conjecture that a qualified defense should have the following characteristics:
-
•
Timeliness: the method shows good real-time performance against patch attacks.
-
•
Detectability: the method cannot affect the detector to recognize persons without attacks.
-
•
Robustness: the method is resilient to white-box patch attacks and shows generalization to different scenarios and persons.
To achieve the above three properties, we establish an efficient and effective plug-in defense component on the YOLO detection system, which we name Ad-YOLO, that enhances the resilience against patch attacks. Specifically, observing that the object detection model YOLOv2 has a high ability for detecting two types of objects with overlapping regions, we add a new category of adversarial patch to YOLOv2. Therefore, we first develop a patch dataset by an adversarial training process based on the Inria dataset, which we name Inria-Patch, and train Ad-YOLO by a combination of Pascal VOC, Inria, and Inria-Patch datasets. With our defense method, Ad-YOLO is expected to directly detect adversarial patches and persons at the same time when facing with a physical-world attack.
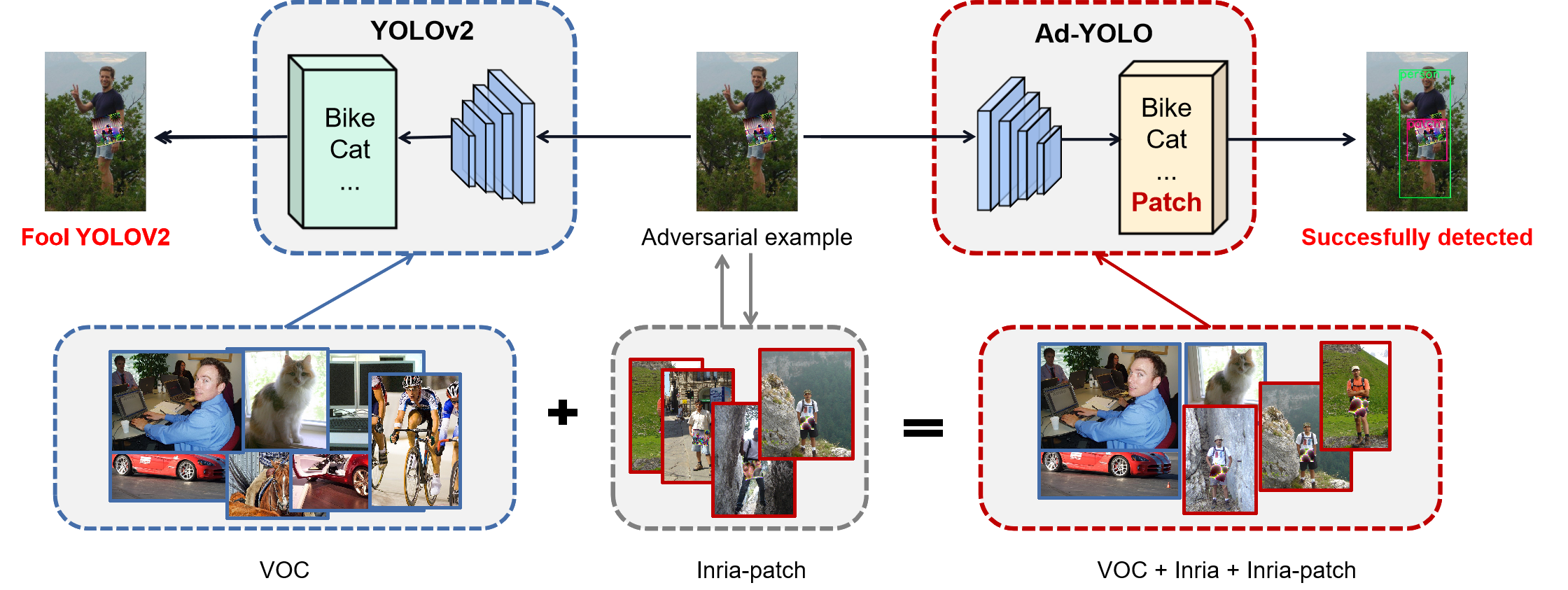
We demonstrate the performance of Ad-YOLO in detectability and robustness with a series of experiments. The results indicate that Ad-YOLO can only reduce the mAP on VOC 2007 test set from to , the AP of persons on Inria test set from to , but exhibit AP of patch on Inria-Patch dataset. This means that Ad-YOLO can both detect persons and adversarial patches with the same level and remarkable precision. In addition, when facing white-box patch attacks, Ad-YOLO can also achieve AP of persons, which highly outperforms AP for YOLOv2. Furthermore, compared with YOLOv2, the results facing a physical-world attack are also included to demonstrate Ad-YOLO’s excellent generalization ability. Figure 1 demonstrates the performance of YOLOv2 and Ad-YOLO when facing with a physical-world attack in a human detection system.


Our main contributions can be summarized as follows:
-
•
We propose a defense model called Ad-YOLO against patch attacks in a human detection system, which adds the patch category to the YOLOv2 model and maintains high detection capability both on persons and adversarial patches.
-
•
We develop a patch dataset named Inria-Patch containing 200 adversarial patches with diversity and adversariality.
-
•
We provide a comprehensive analysis for generalization of Ad-YOLO to different scenarios and persons. In addition, We examine the performance of Ad-YOLO against white-box patch attacks and physical-world attacks.
2 Related work
Most published defenses against patch attacks focus on image classification. [10] proposed the first certified defense against patch attacks based on interval bound propagation and two training strategies to speed up the approach while trading-off efficiency and robustness. In [16], PatchGuard was proposed to use convolutional networks with small receptive fields that impose a bound on the number of features corrupted by an adversarial patch. However, the premise is to have a priori knowledge of the size of the patch, which is unrealistic in physical-world attacks. In [15], rectangular occlusion attacks (ROA), coupled with adversarial training, were proposed to achieve high robustness against several prominent examples of physical-world attacks, but it is too computationally expensive for object detection systems.
In addition, some work is based on preprocessing input images to mitigate adversarial noise but cannot be transplanted to object detection. In [4], the proposed digital watermarking (DW) exploited important pixels that affect the gradient of the loss and mask them out in the image. In [9], local gradient smoothing (LGS) was based on the empirical observation that the image gradients tend to be large within these adversarial patches. However, the above two methods significantly reduce the accuracy of unattacked images and are easily broken by white-box attacks. The minority report (MR) [8] proposed a defense against patch attacks based on partially occluding the image around each candidate patch location, but this defense only detects the presence of an attack, rather than recovering the correct prediction.
As far as we know, patch defenses have not been rigorously explored in object detection systems. In [11], Saha et al. proposed a defense algorithm by regularizing the model to limit the influence of image regions outside the bounding boxes of the detected objects. This method is only applicable when the patch does not occlude the object in digital space, which is different from the scenario discussed in this paper. For defenses against physical-world attacks, Wu, Tong et al. [15] made an attempt on the image classification. Due to the huge amount of computational cost, it is difficult to incorporate into the object detection.
3 Methodology
3.1 Attack Method
Generally speaking, there are currently two main solutions to patch attacks in human detection systems. The difference is whether we put the patch in the background [14] or on the objects of interest [6]. Considering that environmental factors are difficult to control in actual scenarios, the method of placing patches on the object is more in line with the needs of the application. Therefore, we use the method proposed in [14] to attack the object detection model YOLOv2.
First, we review the one-stage detection system YOLOv2 architecture. YOLOv2 divides a single frame image into multiple grids, and predicts bounding boxes for each grid cell. Assuming that there are classes to be identified, each bounding box can be written as an dimensional vector, as shown below:
| (1) |
where and represent the center of the bounding box. and represent the width and height predicted relative to the whole image. is the confidence score that represents the intersection over union (IOU) between the predicted box and any ground truth box, and conditional class probabilities are conditioned on the grid cell containing an object.
To attack the above model, the method [14] considers the following mathematical formulation of finding an adversarial patch:
| (2) |
where is a distribution over samples, ia s distribution over patch transformations, and is a patch application function that transforms the patch with and applies the result to the image by masking the appropriate pixels. The loss function consists of three parts, as shown below:
| (3) |
The first item here is non-printable fraction denoted as that represents how well the colours in the patch can be represented by a common printer. The second item, , is the total variation value of the image, which makes the patch color transition smooth and more natural. The third represents the probability that the detector will detect a person, and we want this value to be as small as possible. We assume that people happen to be , then, there are three choices for , namely, , and . In [14], experiments are conducted on these three loss functions, and it is found that has the strongest attack effect. In this paper, we set to generate patches.
The attack proposed in [14] can generate a rectangular patch, which can be printed out and taped to people’s chest during the attack. Thus, the accuracy of the detector in identifying a person can be greatly reduced, making the detector unable to identify the presence of a person, as shown in Figure 1(a). This type of attack in the physical world is inexpensive and highly threatening, so it is imperative to formulate corresponding defense strategies.
3.2 Adversarial YOLO
Motivated by the fact that object detection model YOLOv2 can recognize overlapping objects, in this paper, we develop an Ad-YOLO model that can recognize adversarial patches as a new category and restore the original object information. Additionally, to achieve better defense, we construct a new dataset, Inria-Patch, to assist in training the Ad-YOLO model.
3.2.1 Framework
Figure 2 provides an overview of our defense framework. From the structure of the neural network, Ad-YOLO retains all layers of YOLOv2 except for the last layer by adding a “patch” category. Therefore, Ad-YOLO is expected to recognize the objects and patches from the input image at the same time, see the right part of Figure 2.
As we introduced, YOLOv2 divides an input image into preselected areas, with each area predicts anchor boxes. Each anchor box is a vector with dimension , as shown in (1). We then arrange the anchor boxes in order, and thus each preselected area would output a vector with dimension . Ultimately, the output of YOLOv2 can be expressed as a tensor of . For Ad-YOLO, we only add the patch category in the last layer of YOLOv2, so the length of each anchor box vector becomes , and the corresponding final output becomes a tensor with dimension .
We write as the loss function of Ad-YOLO, which inherits the full form of YOLOv2 loss function and add the loss for the conditional patch class probability. We assume that the adversarial patches we generate to train Ad-YOLO are . Then, our method can be expressed as:
| (4) |
where is a distribution over samples, and as shown below:
| (5) |
is a patch application function mentioned in (2), is the new label formed after the addition of a patch category to the ground true label of input image .
From the above description, it can be concluded that Ad-YOLO has two advantages. On the one hand, Ad-YOLO inherits the reference effectiveness of YOLOv2 and satisfies the requirement on timeliness to defend against a physical-world attacks. On the other hand, Ad-YOLO can also be regarded as a model for detecting attacks in a sense.
3.2.2 Inria-Patch Dataset

In order to improve the training effect of Ad-YOLO, we constructed a patch dataset that containing patches with diversity and adversariality. The former ensures the generalization for Ad-YOLO, while the latter guarantees a good defense effect. To this end, we explore adversarial training for a trial.
Adversarial training [3, 13, 7] is one of the most commonly used methods to improve the robustness of the model against adversarial attacks, and it is a process of training a neural network on a mixture of clean data and adversarial examples. In general, the purpose of adversarial training is to obtain an enhanced neural network, which is the starting point from the perspective of defense. Here, we examine this method from an attack perspective.
Adversarial training based on patch attacks can be expressed as
| (6) |
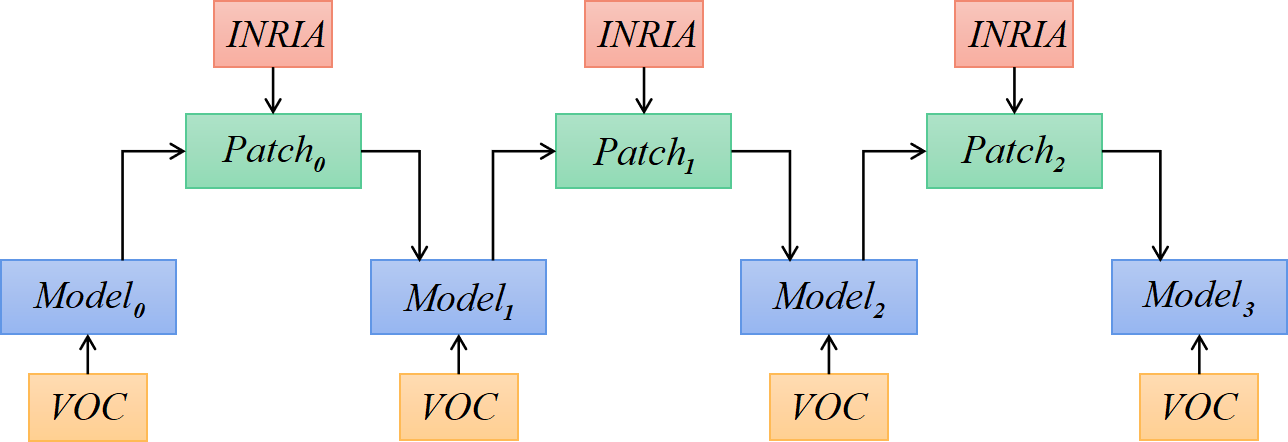
The can obtain adversarial training models, and can generate adversarial patches based on the trained models. In the process of alternating iterations, we generate four models and obtain multiple adversarial patches during the training of each model, some of which are shown in Figure 3. In the figure, we can see that the patches generated from different models vary greatly, while the patches generated by the same model have relatively small differences. The AP of each patch for attacks written in the lower-left corner indicates that all patches have good attack performance.
4 Experiments
4.1 Setup
Dataset We leverage both the 2007+2012 [1] Pascal VOC dataset and the YOLOv2 model for the human detection task. In the construction of the Inria-Patch dataset, we first train the YOLOv2 neural network on VOC 2007+2012 training set and name it and then, use the attack [14] to generate adversarial patches on the Inria dataset, denoted as . Next, are randomly added to the Inria dataset to retrain YOLOv2 with VOC 2007+2012 training set, and we obtain the new model . We carry out a total of three cycles and obtain a series of models: , , , . For the abpve four models, many more adversarial patches can be generated with the same attack method. Figure 4 shows the process for constructing the Inria-Patch dataset. For each model, five attacks with different initial values are performed, and there are a total of 20 attacks to generate adversarial patches. In the training process of each attack, 10 patches are taken out at the same step length interval, and 200 patches are obtained in total. Some patches are shown in Figure 3. Among these patches, 160 patches are used to train Ad-YOLO, which form the dataset P0, and the remaining 40 patches form the dataset P1. For convenience, we list some simple notations, as shown in Table 1.
| Dataset | I0, I1 | Inria training set and test set |
| P0, P1 | 160 and 40 adversarial patches | |
| I*-P* | Randomly add patch P* on I* | |
| Model | YOLOv2 trained on Pascal VOC | |
| Adversarial training models, |
Implementation details. In the training of the above models, the Adam optimizer is used with a learning rate of 0.01. In the training of adversarial patches, the default optimizer is Adam, and the learning rate is initialized as 0.03 and decays by a factor of 0.1 every 50 epochs.
| class | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table |
| YOLOv2 | 83.18 | 80.53 | 73.61 | 66.86 | 51.12 | 76.19 | 83.33 | 81.86 | 56.64 | 68.88 | 73.97 |
| Ad-YOLO | 82.31 | 79.36 | 71.05 | 68.82 | 50.19 | 76.40 | 81.44 | 83.50 | 53.42 | 68.13 | 72.82 |
| dog | horse | mbike | person | plant | sheep | sofa | train | tv | mAP | ||
| 79.31 | 78.19 | 78.52 | 78.70 | 51.20 | 70.59 | 74.06 | 82.31 | 72.02 | 73.05 | ||
| 78.18 | 76.14 | 77.93 | 77.67 | 48.90 | 68.76 | 73.94 | 85.98 | 71.98 | 72.35 |
All of our experiments are conducted on a computer cluster with 2 Intel Xeon E5-2650 v4 CPU cores, 128 GB RAM, and 8 NVIDIA Tesla V100 16 GB GPUs. Training each and our Ad-YOLO requires four GPUs for four days, and training each patch requires one GPU for one day.
4.2 Object detection
We first conduct a series of analyses on the performance of Ad-YOLO for object detection. Table 2 demonstrates the mAP and per-class AP for YOLOv2 () and Ad-YOLO on VOC 2007 test set. One can observe that variations in AP with each category introduced by Ad-YOLO are moderate. In the average sense, Ad-YOLO scores , with a negligible decrease of from YOLOv2.
Next, we check the effectiveness of Ad-YOLO for detecting persons on I1. As shown in Figure 6, Ad-YOLO reduces AP from for YOLOv2 to , thus resulting in a decrease. In addition, patch detection for Ad-YOLO is measured on the I1-P1 dataset, and the AP reaches .
Then, we seek to demonstrate the generalization of Ad-YOLO to unseen adversarial patches or persons. To this end, we evaluate a broader set of combinations of adversarial patches dataset with Inria dataset and study the effect of changing factors that are seen or unseen on the results. Table 3 shows the comparison of Ad-YOLO’AP in 4 combination cases. Specifically, Case I0-P0 is the result of the training process of Ad-YOLO and the performance is slightly better the other cases. The case I1-P0 reflects our Ad-YOLO’s generalization to detect persons under seen patch attacks. In this case, Ad-YOLO achieves relatively good results, with AP reaching . When facing attacks of unknown adversarial patches, in case I0-P1, Ad-YOLO can still defend the attack, and the identification accuracy of the persons reaches . In the case I1-P1, the attacks and scenarios Ad-YOLO faces are both unknown, and Ad-YOLO can also successfully defend against patch attacks in this case, reaching , which is the lowest value in the four cases but meets its most difficult objective conditions.
Figure 5 is the display of defense in the case I1-P1. Our Ad-YOLO can simultaneously identify person and patch information under various circumstances. However, as shown in Figure 5(c), when a patch overlaps with others, Ad-YOLO may fail to detect patch information but does not affect human detection. The better results are also shown in Figure 5(b) and Figure 5(c) when the patch does not overlap in the case of one or more than one person. In Figure 5(d) shows a more complicated scenarios with more people and overlapping relationship. We can see all persons are successfully detected.
| Combination form | AP |
| Training case: I0-P0 | 79.70% |
| Test case1: I1-P0 | 78.70% |
| Test case2: I0-P1 | 78.63% |
| Test case3: I1-P1 | 77.82% |




To summarize, Ad-YOLO matches the property of detectability that a qualified defense should have. On one hand, Ad-YOLO shows a powerful strength in detecting persons on the Inria dataset without severe impact on mAP for Pascal VOC dataset. On the other hand, Ad-YOLO shows good generalization to different scenes and persons.
4.3 Defense against patch attacks
The second battery of experiments seek to demonstrate the defense of Ad-YOLO against white-box attacks together with physical-world attacks, and the results show that Ad-YOLO meets the requirement for robustness.
4.3.1 White-box attacks
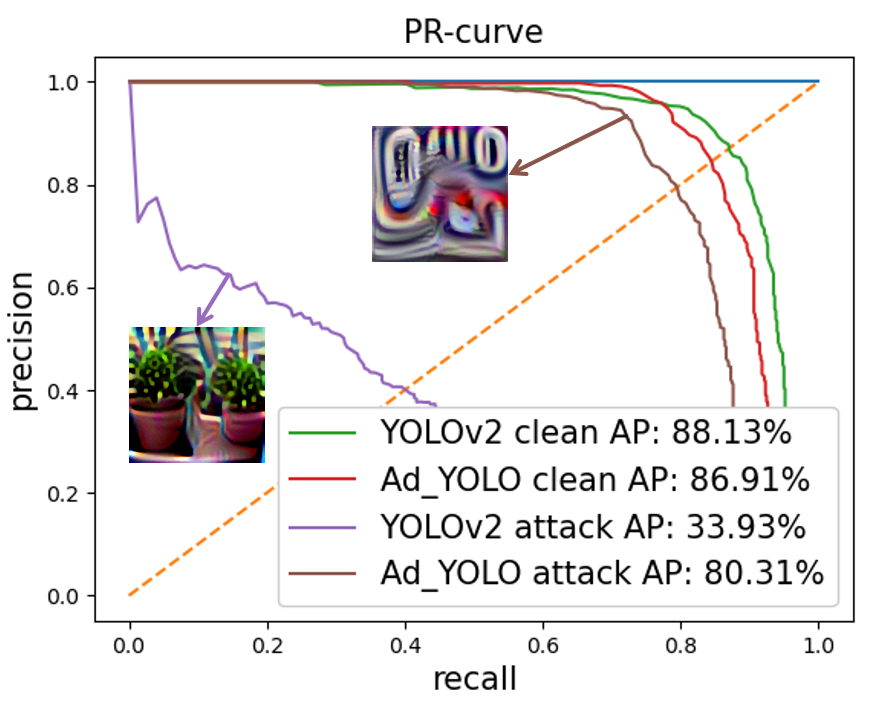
Here, we evaluate white-box patch attacks on Ad-YOLO. First, we leverage the same attack method [14] to generate adversarial patches against YOLOv2 and Ad-YOLO. Then, we use generated patches to attack the two models. Figure 6 shows the performance of Ad-YOLO and YOLOv2 against white-box attacks. As we can see from the figure, two patches are considerably different due to the distinct structure of the two models, and both attacks hinder the detection of the corresponding model (YOLOv2’AP decreases from to , Ad-YOLO’AP decreases from to ), However, Ad-YOLO shows a particularly better defense, a increase in AP for human detection.
4.3.2 Physical-World attacks






We evaluate Ad-YOLO against physical-world attacks. In these attacks, adversarial patches are printed and designed to be placed on people’s chests. We choose different scenes to further demonstrate the defense effects. Specifically, we design 2 different scenes to compare the original detector () with Ad-YOLO against physical-world attacks, and we use the identical adversarial patches randomly selected in P1.
Figure 7 shows that the adversarial patches successfully attacked the original detector but failed to fool Ad-YOLO. When attacked, our Ad-YOLO could not only successfully defend against the patch attack but also recognize the patch information.
4.4 Comparison with adversarial training models
Adversarial training approach is one of the most widely used defense method to effectively reinforce the model’s robustness to resist the adversarial attacks of white-box in classification problems, but it is rarely used in object detection problems. This part compares and shows the outstanding points of our Ad-YOLO and adversarial training method in object detection problems. In the process of developing the patch dataset, we obtain a series of adversarial train models and corresponding adversarial patches generated by white-box attacks.
| Model | Clean accuracy on P0 | White-box attack |
| Ad-YOLO | 86.58% | 80.31% |
Table 4 presents the results comparing the effectiveness of Ad-YOLO on P0 dataset and against white-box attacks to adversarial training models. In line with expectations, adversarial training models can improve the robustness to resist adversarial attack, while the clean AP decreases. However, the effect and cost of upgrading are obviously much worse than that of classification, it shows about increase in white-box attacks but with decrease in clean AP. In addition, we can see that the best performance in terms of adversarial robustness in adversarial training models is achieved by when facing the white-box attack, but the result AP is still far worse than Ad-YOLO with AP . Our Ad-YOLO has increased robustness by around but at the cost of clean AP decrease. On the basis of such a significant improvement, the drop of clean AP of Ad-YOLO is negligible compared to the original model ().
Ad-YOLO not only yields a significantly more robust detector, but also requires very little computing resources. As we know adversarial training methods need to alternate iterative training against attack patches and model parameters, this requires several times the computational cost of normal training and cannot be parallelized. Contrast with that, Ad-YOLO needs to be implemented to prepare the patch dataset which can be easily obtained by parallel training. Besides, compared with the normal training, the network structure and core training process of Ad-YOLO have no essential increase. Thus Ad-YOLO can performs great improvement in AP facing adversarial attacks (around increase), with negligible cost of clean AP ( decrease) and the same computational cost as normal training (significant advantages over adversarial training).
5 Conclusion
At present, most defenses against patch attacks are aimed at image classification, and there are few studies on objection detection models. We focus on the human detection in object detection system and propose a novel improved defense model Ad-YOLO and construed a Inria-Patch dataset with diversity and adversariality. Through the algorithm design and numerical experiments, Ad-YOLO meets the characteristics of Timeliness, Detectability and Defense. For timeliness, We add a category (patch class) on the YOLOv2 architecture at the network structure level, which has a negligible inference increment and very little extra training cost. For Detectability, the mAP results obtained by Ad-YOLO are almost the same as those of YOLOv2 ( to on VOC 2007 in Table 2, to on Inria in Figure 6). For Defense, Ad-YOLO can improve white-box defensive performance from to , it is significantly better than other contrast methods. Therefore, Ad-YOLO not only meets people’s needs for human detection, but also shows good defense effects against white-box attacks and physical-world attacks.
Acknowledgements
This work was supported in part by the Innovation Foundation of Qian Xuesen Laboratory of Space Technology, and in part by Beijing Nova Program of Science and Technology under Grant Z191100001119129.
References
- [1] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
- [2] Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1625–1634, 2018.
- [3] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In ICLR 2015 : International Conference on Learning Representations 2015, 2015.
- [4] Jamie Hayes. On visible adversarial perturbations & digital watermarking. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1597–1604, 2018.
- [5] Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial examples in the physical world. In ICLR (Workshop), 2017.
- [6] Mark Lee and J. Zico Kolter. On physical adversarial patches for object detection. arXiv preprint arXiv:1906.11897, 2019.
- [7] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In ICLR 2018 : International Conference on Learning Representations 2018, 2018.
- [8] Michael McCoyd, Won Park, Steven Chen, Neil Shah, Ryan Roggenkemper, Minjune Hwang, Jason Xinyu Liu, and David A. Wagner. Minority reports defense: Defending against adversarial patches. arXiv preprint arXiv:2004.13799, 2020.
- [9] Muzammal Naseer, Salman Khan, and Fatih Porikli. Local gradients smoothing: Defense against localized adversarial attacks. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1300–1307, 2019.
- [10] Aditi Raghunathan, Jacob Steinhardt, and Percy Liang. Certified defenses against adversarial examples. In ICLR 2018 : International Conference on Learning Representations 2018, 2018.
- [11] Aniruddha Saha, Akshayvarun Subramanya, Koninika Patil, and Hamed Pirsiavash. Role of spatial context in adversarial robustness for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 784–785, 2020.
- [12] Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K. Reiter. Adversarial generative nets: Neural network attacks on state-of-the-art face recognition. arXiv preprint arXiv:1801.00349, 2018.
- [13] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In ICLR 2014 : International Conference on Learning Representations (ICLR) 2014, 2014.
- [14] Simen Thys, Wiebe Van Ranst, and Toon Goedeme. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 49–55, 2019.
- [15] Tong Wu, Liang Tong, and Yevgeniy Vorobeychik. Defending against physically realizable attacks on image classification. In ICLR 2020 : Eighth International Conference on Learning Representations, 2020.
- [16] Chong Xiang, Arjun Nitin Bhagoji, Vikash Sehwag, and Prateek Mittal. Patchguard: Provable defense against adversarial patches using masks on small receptive fields. arXiv preprint arXiv:2005.10884, 2020.