Aesthetic Quality Assessment for Group photograph
Abstract
Image aesthetic quality assessment has got much attention in recent years, but not many works have been done on a specific genre of photos: Group photograph. In this work, we designed a set of high-level features based on the experience and principles of group photography: Opened-eye, Gaze, Smile, Occluded faces, Face Orientation, Facial blur, Character center. Then we combined them and 83 generic aesthetic features to build two aesthetic assessment models. We also constructed a large dataset of group photographs - GPD- annotated with the aesthetic score. The experimental result shows that our features perform well for categorizing professional photos and snapshots and predicting the distinction of multiple group photographs of diverse human states under the same scene.
keywords:
Image aesthetic quality assessment, group photograph, machine learning, feature design, dataset1 Introduction
With the rapid growth of image applications, the traditional image quality evaluation no longer satisfies the practical need. Thus the image aesthetic quality assessment (IAQA) was born. IAQA uses the computer simulation of human perception and cognition of beauty to automatically assess the ”beauty” of images (i.e., Computer evaluation of image aesthetic quality) [Jin et al., 2018c]. It mainly responds to the aesthetic stimuli formed by the image under the influence of aesthetic elements such as composition, color, luminance, and depth of field.
In daily life, we often encounter a situation where we need to take group photographs for souvenirs. So how to estimate the aesthetic values of a group photograph and further provide a guidance system for real-time group photo shooting will become meaningful. The current methods of IAQA mainly focus on the effects of composition, color, light and shadow, depth of field, and other components on the aesthetics of the entire image, which can classify the professional photographs and snapshots, as shown in Figure1(a). Nevertheless, when evaluating the aesthetics of group photographs, people are not only concerned with the above factors but also focus on the state of the person in the image, such as whether someone’s eyes closed, does not look at the camera, the face is blocked, does not smile and other factors. If these factors are not taken into account in the aesthetic quality assessment of group photography, the evaluation will not be accurate. An example is shown in Figure 1(b), the two images assessed by the general method have similar ratings. However, when considering the criteria for group photography, it is clear that we are more satisfied with the first one.

Therefore, we propose a method to assess the aesthetic quality of the group photograph. Firstly, we extracted the texture, brightness, low depth of field, color, and other features commonly used in IAQA. Moreover, we designed seven specific features that conform to group photography experience and principles, such as whether the face in the photo is occluded, whether someone closes their eyes, whether they smile or not. We then constructed a dataset (GPD) specifically for group photography aesthetic quality assessment. It contains a total of 1000 pictures, which are selected from the network, the existing IAQA dataset, and photos taken by ourselves. Finally, with the extracted features, we trained a classifier and a regression model on the GPD-dataset, which are used to classify photos into good and bad categories and predict aesthetic scores, respectively.
To summarize, our main contributions in this paper are as follows:
-
1.
We design 7 new features related to group photography as the standard for aesthetic assessment.
-
2.
We build GPD dataset annotated with the aesthetic score, and develop an online annotation system to collect users’ aesthetic evaluation of photographs.
-
3.
We propose a classifier and a regression model trained by our features, which outperform existing methods in in group photo aesthetic evaluation.
2 Related works
Early research on IAQA focused on low-level visual features and then training classifiers or regressors to evaluate image aesthetics [Luo & Tang, 2008, Datta et al., 2006, Yan Ke et al., 2006, Tong et al., 2005]. In 2004, Microsoft Asia Research Institute and Tsinghua University [Tong et al., 2005] jointly proposed a method that can automatically distinguish the photographs taken by professional photographers from those taken by customers. This work is considered as the earliest research on IAQA. They used a 21-class, a total of 846-dimensional low-level global features to learn the classification model to classify the test images aesthetically. In 2006, Datta et al. [2006] began to use local features for aesthetic assessment, combining the low-level features such as color, texture, shape, picture size and high-level features such as depth of field, tripartite rule, regional contrast and so on which are usually used for image retrieval, and then trained the SVM classifier for the binary classification of image aesthetic quality. Yan Ke et al. [2006] proposed using global edge distribution, color distribution, hue counting, contrast, and brightness to represent the image. Based on these features, the naive Bayesian classifier is trained. All the above works are aesthetic evaluations that are unrelated to content. Since 2010, some aesthetic assessment research related to content has appeared [Jin et al., 2010, Wei Luo et al., 2011, Tang et al., 2013]. In 2014, with the emergence of AVA [Murray et al., 2012], a large-scale aesthetic analysis dataset, significant progress had been made in the automatic aesthetic analysis by using deep learning technology [Jin et al., 2018b, Talebi & Milanfar, 2018, Jin et al., 2016, Kong et al., 2016, Lu et al., 2014]. The classification accuracy rate of ILGNet-Inc.V4 proposed by [Jin et al., 2018b, Talebi & Milanfar, 2018, Jin et al., 2016] ranked first in the world on the ava dataset. In recent years, researchers have mainly studied the problem of IAQA from different tasks. In order to solve the problem of the need for subjective labeling when the image database is established, Ning Ma Ma et al. [2019] proposed a deep attractiveness rank net (DARN) model to learn aesthetic scores. Tian et al. [2015] proposed a query-based aesthetic assessment deep learning model that makes different aesthetic evaluations based on different styles of images. Kim et al. [2018] considers not only objective factors but also subjective factors of user reviews for aesthetic assessment. Schwarz et al. [2018] extended the one-dimensional score to a multi-dimensional aesthetic space score. Ma et al. [2017] proposed an A-Lamp CNN architecture to learn the fine-grained and the overall layout aesthetic assessment simultaneously. In addition, in terms of the prediction of image aesthetic distribution, jinxing et al. Jin et al. [2018a] proposed the method that predicts image aesthetic distribution, opening the direction of aesthetic prediction in the era of deep learning. There are also some research results in the aesthetic assessment of faces and portraits [Redi et al., 2015, Xue et al., 2013, Li et al., 2010]. In the study of group photo images, Rawat et al. [2018] proposed the spring-electric model, which recommended the appropriate station and the proportion of the characters to the photograph. However, they did not evaluate the aesthetic quality from the perspective of the subject. To our best knowledge, there are currently no research on the aesthetic assessment of group photography.
3 Aesthetic Factors for Group photography
In this section, we will discuss the extraction of features for representing the aesthetic quality of a group photograph. We extract two major groups of features: group photographic features conformed to the group photographic rules and low-level generic aesthetic features proposed in [Datta et al., 2006, Wu et al., 2019, Machajdik & Hanbury, 2010]. These features are combined to obtain better estimates of the aesthetic scores. The following subsections explain each group of features.
3.1 Group Photography Features
When people assess group photographs, they usually pay more attention to the facial information and position of the person in the image. Therefore, we utilize proven face recognition tools Face++ [2019] and BaiduAI [2019] to extract face-related information and perform further feature design based on this information.
Assuming faces are detected in a group photograph, the detected face sequence is represented as follows:
| (1) |
where represents the facial information of the ith person, which includes: The coordinates of the top-left point of the facial box (); The height and width of the facial box (); Confidence () of different eye states ( broken into 6 states, detailed in section 3.1.1); The gaze direction of the left and right eyes (); The value of the smile (); Rotation angle of the head (); The occlusion degree of seven regions of the face (,detailed in section 3.1.2); The position coordinates of the person in the photograph (); The degree of blur of the face ().

3.1.1 Open-eyed
Eyes are the windows to one’s soul. When we shoot portraits, we tend to focus on people’s eyes, and so do group photos. If someone’s eyes are closed or obscured in a group picture, the beauty of that will be greatly decreased. Therefore, we consider the eyes states of each person in the photo, which including: Eye opening without glasses ; Eye opening with ordinary glasses ; Wearing sunglasses ; Covered eye ; Eye closing without glasses and eye closing with ordinary glasses . We use Face++ [2019] to predict the confidence of each status of the left and right eye, respectively, which are {}. The equals 100. We select the state of the maximum of six confidences as the condition of the eye. If the condition of eyes belongs to one of these three states (), we judge the person is open-eyed and thus formulate that as:
| (2) |
| (3) |
| (4) |
where and represent the final state prediction of the left and right eyes, respectively. and are the confidence of 6 states corresponding to the left and right eyes. is the mapping between confidence and corresponding status. We further calculate the proportion of people whose open-eyed. Based on the experience for group photograph assessment, we found the proportion has a non-linearity relationship with the evaluation result. i.e., when all the people open their eyes, the assessment is high. Once someone closes their eyes, the evaluation of the image falls into the bad category, and then gradually decrease with the number of close-eyed people. Thus we fit the formula (5), where is the proportion and is the final feature of open-eyed.
| (5) |
3.1.2 Occluded Faces
In group photography, the most basic requirement is that everyone’s face is not occluded. If someone is masked, no matter how splendid the color, composition, light and shadow of the photo is, the photo will be discarded without hesitation. Hence, whether the face is occluded or not is another crucial criterion for judging the quality of the group photograph.
We use the method provided by BaiduAI [2019] to obtain the information about occluded faces in the photograph. The face is segmented into seven regions (see Figure 2. (a)): the left and right eye, the left and right cheek, mouth, jaw, and nose. An occlusion degree will be calculated of each region, which is a floating-point number in the range [0, 1], where 1 means that the region is completely occluded. When the occlusion degree of any region exceeds the recommendation threshold provided in BaiduAI, we judge that the person’s face is occluded. We define the occluded face as:
| (6) |
where indicates whether the face of the ith person is occluded, and 1 denotes occlusion. The and are the value of the occlusion degree and threshold of each region. Then we calculate the proportion of the number of un-occluded people defined as (). Same as , the proportion and evaluation also satisfies the nonlinearity relationship. The is the occluded faces feature, and the formula is described as follows.
| (7) |
3.1.3 Face Orientation
A word that photographers often say during photography is ”Looking at the camera”. If a person in viewfinder looks at the camera, but the head tilted, the photo is not a high-quality image. Therefore, we get the yaw angle of head as , where [-180,180]. When [-30,30], it is considered that facing the camera. We record whether the character is facing the camera as , which equals means yes. Same as above, the proportion of the number of people without head-tilted to the total number of people is calculated. This proportion also fits a non-linear relationship. is the face orientation feature. The formula is as follows.
| (8) |
| (9) |
3.1.4 Gaze
For formal group photography, everyone’s focus on the lens is an important criterion. So we designed a feature to represent the proportion of people looking at the camera. There are three prerequisites before estimating gaze: eyes open, facing the camera, eyes are not occlusion. We utilize the information detected by face++ to calculate the direction of the gaze. The gaze estimation process is as follows:
-
1.
Determine the center of the circle: .
-
2.
Determine the radius: .
-
3.
Calculating the average gaze: .
-
4.
Calculating the gaze junction point coordinates: .
Where and are the landmarks of the left and right eyeball center, and are the width and height of the rectangle of face, respectively. The gaze direction vector of the left and right eye are recorded as and . We use the face landmarks to define a rectangular range (see Figure 2.(b)), If the gaze junction point falls within the range, it is judged that the people is looking at the lens. It is defined as follow,
| (10) |
where represents the coordinates of the gaze junction of the ith person in the frame, and is the rectangular range of the ith person, means looking at the camera. Then we take the ratio of the people looking at the lens, and the ratio also meets the nonlinear relationship with the assessment. is the gaze feature.
| (11) |
3.1.5 Facial blur
Whether the face is clear or not is essential to the quality of a photograph. Therefore, we obtain the blur degree of face by Face++. We employ the recommended threshold (generally is 50) as the threshold. If the blur degree greater than the threshold, we consider the person’s face was not captured clearly. It can be formalization as:
| (12) |
where indicates whether the face of the ith person in the photograph is blurred or not. Then we calculated the percentage of the number of people whose facial blur degree exceeded the threshold as . The higher the percentage, the higher the quality. is facial blur feature.
| (13) |
3.1.6 Smile
Smile plays a vital role in the emotional expression of group photography. Through observation, we found that a large proportion of people smiling in group photograph is often attractive and easier to remember than no smile in group photograph. We use to represent the degree of smile. There is a threshold for the degree of smile provided by Face++. We count the number of people with a smile formulated as , which the degree of smile greater than the threshold. Then we take the ratio of the number of people with smile as the smile feature , which is defined as:
| (14) |
| (15) |
3.1.7 Character center
Through observation and experience, we found that in a good group photo, the positions of the people are usually horizontally centered and uniformly arranged, particularly the formal group photos. Therefore, the horizontal position of people is also positively correlated to the quality of group photograph.We sequentially detect the horizontal x-axis coordinate of the center of each person’s face, represented as , and then average the x-axis coordinates, which is represented by define as:
| (16) |
Next, we compute the relative position of the character center and the picture. We formulate that as , where is the width of the frame. We divided the photograph evenly into five parts. If is in the range of 0.4 to 0.6, it means that is located in the center of the photograph, i.e., the people position is horizontally centered. We call the character center feature.
| (17) |
3.2 Generic Aesthetic Features
In addition to group photographic features, we selected 83 features from the generic aesthetic features mentioned in [Datta et al., 2006, Wu et al., 2019, Machajdik & Hanbury, 2010], such as exposure, saturation and texture based on wavelet transform, as aesthetic features to evaluate group photography aesthetics. These features can be divided into four categories: color, local, texture, and composition. The above features are not the focus of this paper, so briefly described in Table 1.
| Category | Short Name | # | Description |
|---|---|---|---|
| color | Brightness, Hue, Saturation | f8-f13 | mean brightness, saturation, and hue of the image and the center of the picture [Datta et al., 2006]. |
| Emotion | f52-f54 | emotional measure based on brightness and saturation[Machajdik & Hanbury, 2010]. | |
| Colorfulness | f55 | colorfulness measured, using the Earth Mover’s Distance (EMD) between the histogram of an image and the histogram having a uniform color distribution [Machajdik & Hanbury, 2010]. | |
| Color | f56-f71 | amount of black, silver, gray, white, maroon, red, purple, fuchsia, green, lime, olive, yellow, navy, water blue [Wu et al., 2019]. | |
| regional | Disconnected Region | f28 | image segmentation, based on K-means, number of disconnected regions in the image Datta et al. [2006]. |
| Local HSV | f29-f43 | average H, S and V values for each of the top 5 connected regions [Datta et al., 2006]. | |
| Ratio | f44-f48 | the size ratio of the top 5 connected regions with respect to the image. [Datta et al., 2006] | |
| texture | Wavelet textures | f14-f25 | after three-level wavelet transform, wavelet textures for each channel (Hue, Saturation, Brightness) and each level (1-3), sum of all levels for each channel [Datta et al., 2006]. |
| GLCM | f72-f83 | features based on the GLCM: contrast, correlation, homogeneity, energy for Hue, Saturation and Brightness channel [Machajdik & Hanbury, 2010]. | |
| composition | Image size | f26-f27 | Image size, sum of the length and width; image proportion, ratio of the length and width. Datta et al. [2006] |
| Low Depth of Field (DOF) | f49-f51 | low depth of field indicator; ratio of wavelet coefficients of inner rectangle vs. whole image (for Hue, Saturation and Brightness channel) [Datta et al., 2006]. | |
| Dynamics | f84-f89 | absolute angles, relative angles, and lengths of static (horizontal, vertical) and dynamic (oblique) lines [Machajdik & Hanbury, 2010]. | |
| Level of Detail | f90 | number of segments after waterfall segmentation [Machajdik & Hanbury, 2010]. |
4 Group photography Dataset
The datasets related to photography aesthetics include AVA [Murray et al., 2012], AADB [Kong et al., 2016]. AVA included 250,000 images, each with the corresponding aesthetic classification and rating labels. AADB contains 10,000 images, which has more balanced distribution of professional photograph and snapshot. Each image is annotated with score and eleven attributes. Nevertheless, there is no dataset for aesthetic evaluation of group photography at present. To this end, we collected a group photography dataset GPD by ourselves, which consists of three parts: group photographs shot by ourselves, selected from the existing aesthetic photography dataset, and obtained through internet. GPD contains a total of 1000 group photographs, and each image has been scored. Samples of GPD is shown in Figure 3.

(a)
Shooting by ourselves: Our research team used mobile phones and SLR cameras to take some group photographs. During the photography, the subjects constantly changed position and their expression. Most of the time, the photographer was in the status of continuous shooting, and deliberately took some photographs under the condition of out of focus, overexposure, not following the composition, and blurring caused by shaking the hands. The photographs taken by ourselves are mostly image pairs, i.e., multiple photos of different states are taken in the same scene. This is for better explain the inaccuracy of traditional method evaluating the group photographs. This section contains a total of 600 images.
(b)
Selected from the existing dataset: We selected part of the group photographs from the AVA and AADB datasets. The sources of these images are mostly social networking sites such as Flickr and DPChallenge. Most of the photographs were shot and uploaded by amateur photographers. We selected the group photographs among them, but the aesthetic quality of these is not high, and there are photographic problems such as blurring and overexposure. So this partition balances the distribution of quality in GPD, making GPD more robust. This section contains a total of 224 images.
(c)
Download from the Internet: We selected group photos from image sites such as Baidu Pictures, Petal.com. This partition includes 74 images, all of which are formal group photographs. They are taken by professional photographers and have high aesthetic quality. The photographs in this partition are more attractive than the previous two.
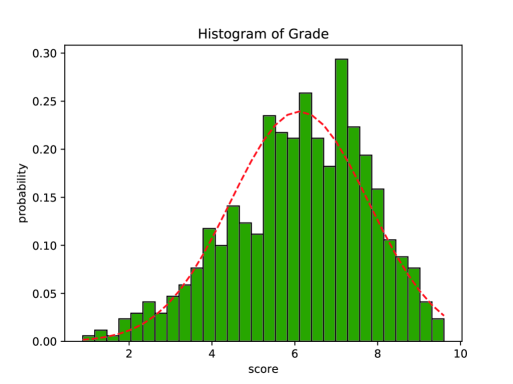
To obtain the aesthetic annotations of the group photograph, we designed an online annotation tool, which can rate the group photograph that appears randomly - made the assessment based on the first impression - on the website by users. The scores range from 1 to10. We give tips on the website for scoring, ”please pay attention to the following factors when scoring: face occlusion, eyes closed, gaze, smile, and general aesthetic factors such as lighting, composition, color, and picture clarity.” In the end, each photograph is assessed by 5 to 20 people, and the average score of each image is taken as its ground truth label. In addition, the website has an image upload model, so users can voluntarily upload their own group photographs for the GPD. Figure 4 shows the probability distribution of GPD.
In GPD dataset, there are two kinds of annotation for each image, one is that the binary value represents the quality of the image, which is used for classifier training, and the other is the score, which is used for regression training. The binary label is obtained by binarizing the score label with 6 (the median value of the aesthetics label in the dataset) as the dividing line
5 Aesthetic Quality Assessment for Group Photograph
In order to verify the effectiveness of our proposed group photo aesthetic features, we proposed a method whose system flow as in Figure 5. We first construct a group photo dataset, including the image and the label (ground truth), and then perform image preprocessing on all images. On the processed image, we extract the group photograph features and generic aesthetic features, and store them into a vector. After feature extraction, the dataset is divided into a training and test set to training a classifier and a regression. The classifier classifies the photo into two categories: good or bad. The regressor evaluates the image aesthetics with a score of 1 to 10, and finally uses the trained classifier and regression to predict the photo in the test set. We compared the results with the test set label to estimate the accuracy of the classifier and regressor.
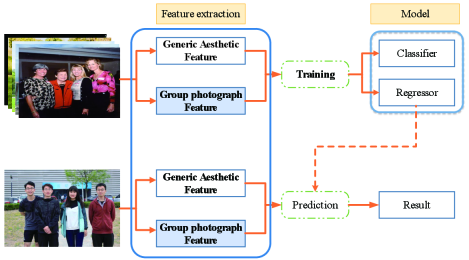
Before generic aesthetic features extraction, we preprocess all the images. The processes include: Adjusting the image size to 128 *128 pixels, which can not only retain enough image information but also meet the efficiency of calculation; Converting RGB color space into HSV and LUV color space, some features need to be extracted from these two color spaces; The K-means is used to segment the image according to chromaticity in the LUV color space; The Waterfall segmentation [Marcotegui & Beucher, 2005] is used to segment the image into continuous regions in the HSV color space. On the basis of these image preprocessing, the features are extracted according to the description in Table 1.
Before group photograph feature extraction, we utilized Face++ to detect and save the information of facial recognition, the state of the person’s eyes, the smile degree, the rotation angle of face, the degree of facial blur and the landmarks of face in each image from the GPD. We applied Baidu AI’s face detection tool to detect and save the face occlusion of the person. Based on these information, the group photograph features are calculated according to Section 3.1.
6 Experiments
This section shows the effectiveness of our proposed features, and comparison of the performances of our method with other methods, in the specific genre: group photography. Firstly, we used the random forest to obtain the importance of each feature to analyze their impact on assessment. Secondly, we applied k-fold cross validation (k = 10) to split GPD into train set and test set, then trained a classifier using support vector machine (SVM) and a regression model using random forest regression (RF). Finally, we report the performance of this method compared with other methods based on deep learning.
6.1 Importance of features
Before evaluating the importance of features, all 90 features were normalized by the Z-score standardization method, i.e., using conversion function : . We used the Gini-based Random Forest [Breiman, 2017] to analyze the respective importance ranking of all features for the model. The top 33 features which importance greater than 0.011 are shown in Figure 6.
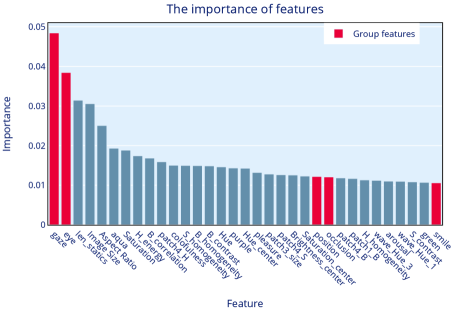
It can be seen that there are 5 group photograph features in the ranks. Among them, the importance of gaze features and opened-eyes features is much higher than other, indicating that the eyes state is important in the group photo evaluation. The importance of the central position of the character, face occlusion, and smile also exceeded the average value, which also played a positive role in the model. The two features of facial blur and face orientation do not appear in top33, because the feature extraction of facial blur depends on the image resolution. If the image itself is low-resolution, the face also blur. The estimation of face orientation is challenging which affected by the light direction, shooting angle, etc., so it is not accurate. The length of the static line is the third important feature, which demonstrates that the feature of horizontal line composition are positive for group photo aesthetic assessment. The three features of brightness, saturation and hue in the center of the image are as same as our hypothesis that the group photography should satisfy the central composition rule. We also found that emotional features (PAD), Pleasure and Arousal has some influence, Pleasure reflects the degree of the people’s love for images, The Arousal reflects the level of neurophysiological activation, dominance reflects people’s anger and fear, and there is no direct relationship with the evaluation of group photos, which is basically consistent with our hypothesis.
6.2 Classifier
Through the feature importance analysis based on random forest, it can be concluded that not all features are effective for group photo assessment. So, as same as [Machajdik & Hanbury, 2010], we used two feature selection methods (filter-based and wrapper-based) to filter out the useless features: one is based on the accuracy of single feature classification and the other is recursive feature elimination (RFE) - a feature selection method based on wrapper. We used the sklearn-svm package [Pedregosa et al., 2011] to train the classification model using the standard RBF kernel (), and use 10-fold cross-validation to ensure the fairness of the experiment. The average AUC of 10-fold cross-validation was adopted as the quality measure of the classifier. AUC is defined as Area under the ROC Curve.
Because the average score of GPD is 6.05, we employed 6 as the boundary to divide the group image into two categories: good and bad. The ROC curve of the model trained by each group photo feature is shown in Figure 7(a), which performance is similar to the importance ranking. The AUC of the gaze feature is 0.73 and the AUC of the opened-eye feature is 0.68. It also shows that the two features are effective for group photo assessment, and the effect of facial blur feature is not ideal, which is due to the challenge of the face recognition in low-quality images.
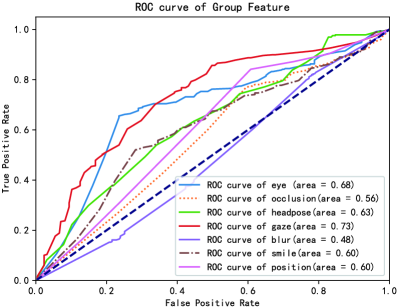
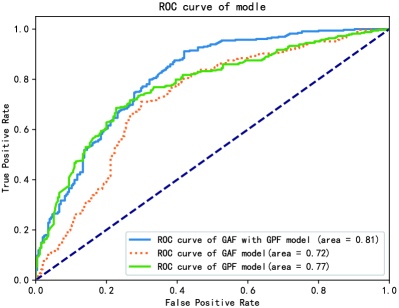
Figure 7 (b) shows the ROC and AUC of three models built on the combination of group photograph features (GPF) and generic aesthetic features (GAF). Among them, the features applied in the GAF&GPF model are 20 features selected from all features by the above two feature selection methods, the features used in the GAF model are selected from the generic aesthetic features, and the features used in the GPF model only contain group photo features. The selected feature set is shown in Table 2. It can be seen that the GAF&GPF model completely wraps the GAF model, and the AUC value reached 0.81. The AUC of the GPF model is larger than the GAF model, but smaller than the GAF&GPF model, which indicates that GAF combined with GPF can make the evaluation performance to the best. Table 3 compares the three models from four measurements: accuracy, precision, recall and F1. We found that the model trained by the combination of the generic aesthetic features and group photo features is better than the other two models in each measurement.
| # | GPF Model |
|
|
|
|
||||||||
| f1-f7 | * | * | * | ||||||||||
| f8-f13 | * | * | * | * | |||||||||
| f55 | * | * | |||||||||||
| f56-f71 | * | * | |||||||||||
| f28 | * | ||||||||||||
| f29-f43 | * | * | * | * | |||||||||
| f44-f48 | * | * | |||||||||||
| f14-f25 | * | * | |||||||||||
| f72-f83 | * | * | * | * | |||||||||
| f26-f27 | * | * | * | * | |||||||||
| f49-f51 | * | ||||||||||||
| f84-f89 | * |
| Models | Accuracy | Precision | Recall | F1 |
| GAF& GPF classifier | 0.7097 | 0.7968 | 0.7543 | 0.7285 |
| GAF classifier | 0.6573 | 0.5721 | 0.5969 | 0.5612 |
| GPF classifier | 0.6889 | 0.7878 | 0.6771 | 0.7025 |
6.3 regression model
We adopted random forest regression algorithm to train the regression model, through 10-fold cross verification to determine the parameters: the maximum depth is 5, and the number of basic learners is 130. Firstly, the random forest algorithm is used for feature selection. Like the training classifier, three different feature subsets are selected from the feature set which is shown in Table 2. Using these three feature sets to train three models on the GPD (20% randomly selected as the test set and 80% as the training set) for 100 times. We use the (coefficient of determination) to measure the regression. is always between 0 and 1, best score is 1, which is defined as:
| (18) |
where is the prediction score, is label (ground truth), is the average value of the test image label, and is the number of test images. Finally, Averaging the of 100 times to avoid the coincidence caused by random sampling from dataset, the comparison of the experimental results is shown in Table 4.
| Models | Maximum | Average |
|---|---|---|
| GAF & GPF Regressor | 0.563 | 0.415 |
| GPF Regressor | 0.529 | 0.372 |
| GAF Regressor | 0.379 | 0.241 |
The results show that the average of the GAF&GPF model reaches 0.415 and the Maximum reaches 0.563 in these 100 times trainings, which is not particularly high, but the best performance of the three models. It also shows that the group photo features and general aesthetic features are effective for group photo evaluation. The of GPF model is also higher than that of the model trained by generic aesthetic features, which proved that people pay more attention to the rules we proposed for group photography. General aesthetic features have relatively little impact on the assessment of the group photos.
6.4 Comparison
In order to verify that the generic aesthetic features cannot fit the image aesthetic assessment for group photos, and the other method cannot distinguish the photos of different people‘s status under the same scene, we preformed the following comparison. We have taken four groups of photos, where each group contains a standard group photo and three photos that do not conform to the group photography rules. They are divided into three categories: ”Looking away”, ”Occlusion” and ”Not in the center ”. Then we utilized four methods: NIMA-res [Talebi & Milanfar, 2018], NIMA-mobile [Talebi & Milanfar, 2018], Kong [Kong et al., 2016] and our regression model to evaluate them. The discrimination of the standard image and the other types is defined as , where and are the score of standard group photo and other types. We calculate the difference between other types and standard photos in each group to measure the discrimination of each model. Figure 8 shows the comparative experimental results.

Looking at Figure 8, taking the first row (a) as an example, the degree of differentiation using the deep learning method are very small or even negative which are 0.231, -0.097, -0.453, respectively. It shows that these methods only from the perspective of the general image to assess the photo, do not consider the people’s state. The of our regression model can reach 1.793, which makes a good distinction between standard group photo and “Looking away”. This is mainly because our assessment method is based on the constraint of people’s state, then combined with general features to assessment group photos. It can be found from the observation of column (c) that the face in first group, the third group and the fourth group have serious occlusion. Using our method to evaluate, the discrimination is close to 1. In the second group, the rightmost character is slightly obscured by objects, and the discrimination is 0.301. However, the discrimination of the deep learning method in the evaluation of such photos is small, all of which are floating up and down 0, and there is Irregular, which proved that the occlusion feature is also effective in group photo evaluation. From Figure 8, it can be seen that the discrimination (in the range of [1.4-2.3]) of column (a) is generally higher than that of column (b) and (c) (in the range of [0.3-1.7]). This fully corresponds our expectations, as well as the importance ranking of photo features, the impact of eye‘s state is greater than the face occlusion and the position of the person on the photo assessment. We also observed that when assess column (d), there’s a good chance that being negative , which indicates that the deep learning methods consider that the object on the side has a higher aesthetic score than the object on the center. The rule of thirds may be effective when assessment landscape photos, but it is not applicable in the group photos. It also demonstrated that the method based on deep learning relies on a large number of aesthetic photos, without professional knowledge, so it only learns some generic shooting rules and aesthetic features, and it is difficult to make a correct assessment of images in a specific field. On the whole, the discrimination of the assessment method based on deep learning is between -0.5 and 1. The assessment of group photos does not take into account the state of people, and can’t distinguish between good and bad photos when assess multiple group photos in the same scene, but the of our model is between 0.3 and 2.3, which can make a good discrimination of such photos.
7 Conclusion and future work
In this work, by analyzing the aesthetic features of group photography, we address the problem that the general method cannot accurately evaluate the group photograph, and introduce group photography features to facilitate investigation of this problem. Furthermore, we construct a group photography dataset (GPD), and built an online annotation tool for collecting the label of GPD. In the experiments, we validated that the proposed method can better evaluate group photography than previous methods that only considered generic features. However, our group photography scene is relatively single. Moreover, there is still a lot of space for improvement in the extraction of group photography features and generic aesthetic features in the future. To further improve the accuracy of the aesthetic evaluation of group photography, much work remains to be done.
Acknowledgments
This research was partially supported by National Natural Science Foundation of China [Grant No. 61771340,61602344] and Natural Science Foundation of Tianjin, China [Grant No. 18JCYBJC15300].
References
- BaiduAI [2019] BaiduAI (2019). Baidu ai open platform. https://ai.baidu.com/. Accessed 13 December 2019.
- Breiman [2017] Breiman, L. (2017). Classification and regression trees. Routledge.
- Datta et al. [2006] Datta, R., Joshi, D., Li, J., & Wang, J. Z. (2006). Studying aesthetics in photographic images using a computational approach. In A. Leonardis, H. Bischof, & A. Pinz (Eds.), Computer Vision – ECCV 2006 (pp. 288–301). Berlin, Heidelberg: Springer Berlin Heidelberg. doi:https://doi.org/10.1007/11744078_23.
- Face++ [2019] Face++ (2019). Face++ cognitive services web apis. https://www.faceplusplus.com/. Accessed 13 December 2019.
- Jin et al. [2016] Jin, X., Chi, J., Peng, S., Tian, Y., Ye, C., & Li, X. (2016). Deep image aesthetics classification using inception modules and fine-tuning connected layer. In 2016 8th International Conference on Wireless Communications Signal Processing (WCSP) (pp. 1–6). doi:10.1109/WCSP.2016.7752571.
- Jin et al. [2018a] Jin, X., Wu, L., Li, X., Chen, S., Peng, S., Chi, J., Ge, S., Song, C., & Zhao, G. (2018a). Predicting aesthetic score distribution through cumulative jensen-shannon divergence. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Jin et al. [2018b] Jin, X., Wu, L., Li, X., Zhang, X., Chi, J., Peng, S., Ge, S., Zhao, G., & Li, S. (2018b). Ilgnet: inception modules with connected local and global features for efficient image aesthetic quality classification using domain adaptation. IET Computer Vision, 13, 206–212. doi:10.1049/iet-cvi.2018.5249.
- Jin et al. [2010] Jin, X., Zhao, M., Chen, X., Zhao, Q., & Zhu, S.-C. (2010). Learning artistic lighting template from portrait photographs. In K. Daniilidis, P. Maragos, & N. Paragios (Eds.), Computer Vision – ECCV 2010 (pp. 101–114). Berlin, Heidelberg: Springer Berlin Heidelberg. doi:https://doi.org/10.1007/978-3-642-15561-1_8.
- Jin et al. [2018c] Jin, X., Zhou, B., Zou, D., Li, X., Sun, H., & Wu, L. (2018c). Image aesthetic quality assessment: A survey. Science & Technology Review, 36, 36–45. URL: http://www.kjdb.org/EN/abstract/article_14866.shtml. doi:10.3981/j.issn.1000-7857.2018.09.005.
- Kim et al. [2018] Kim, W., Choi, J., & Lee, J. (2018). Objectivity and subjectivity in aesthetic quality assessment of digital photographs. IEEE Transactions on Affective Computing, (pp. 1–1). doi:10.1109/TAFFC.2018.2809752.
- Kong et al. [2016] Kong, S., Shen, X., Lin, Z., Mech, R., & Fowlkes, C. (2016). Photo aesthetics ranking network with attributes and content adaptation. In B. Leibe, J. Matas, N. Sebe, & M. Welling (Eds.), Computer Vision – ECCV 2016 (pp. 662–679). Cham: Springer International Publishing. doi:https://doi.org/10.1007/978-3-319-46448-0_40.
- Li et al. [2010] Li, C., Gallagher, A., Loui, A. C., & Chen, T. (2010). Aesthetic quality assessment of consumer photos with faces. In 2010 IEEE International Conference on Image Processing (pp. 3221–3224). doi:10.1109/ICIP.2010.5651833.
- Lu et al. [2014] Lu, X., Lin, Z., Jin, H., Yang, J., & Wang, J. Z. (2014). Rapid: Rating pictorial aesthetics using deep learning. In Proceedings of the 22nd ACM International Conference on Multimedia MM ’14 (p. 457–466). New York, NY, USA: Association for Computing Machinery. URL: https://doi.org/10.1145/2647868.2654927. doi:10.1145/2647868.2654927.
- Luo & Tang [2008] Luo, Y., & Tang, X. (2008). Photo and video quality evaluation: Focusing on the subject. In D. Forsyth, P. Torr, & A. Zisserman (Eds.), Computer Vision – ECCV 2008 (pp. 386–399). Berlin, Heidelberg: Springer Berlin Heidelberg. doi:https://doi.org/10.1007/978-3-540-88690-7_29.
- Ma et al. [2019] Ma, N., Volkov, A., Livshits, A., Pietrusinski, P., Hu, H., & Bolin, M. (2019). An universal image attractiveness ranking framework. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV) (pp. 657–665). doi:10.1109/WACV.2019.00075.
- Ma et al. [2017] Ma, S., Liu, J., & Wen Chen, C. (2017). A-lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4535–4544).
- Machajdik & Hanbury [2010] Machajdik, J., & Hanbury, A. (2010). Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM International Conference on Multimedia MM ’10 (p. 83–92). New York, NY, USA: Association for Computing Machinery. URL: https://doi.org/10.1145/1873951.1873965. doi:10.1145/1873951.1873965.
- Marcotegui & Beucher [2005] Marcotegui, B., & Beucher, S. (2005). Fast implementation of waterfall based on graphs. In C. Ronse, L. Najman, & E. Decencière (Eds.), Mathematical Morphology: 40 Years On (pp. 177–186). Dordrecht: Springer Netherlands. doi:https://doi.org/10.1007/1-4020-3443-1_16.
- Murray et al. [2012] Murray, N., Marchesotti, L., & Perronnin, F. (2012). Ava: A large-scale database for aesthetic visual analysis. In 2012 IEEE Conference on Computer Vision and Pattern Recognition (pp. 2408–2415). doi:10.1109/CVPR.2012.6247954.
- Pedregosa et al. [2011] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
- Rawat et al. [2018] Rawat, Y. S., Song, M., & Kankanhalli, M. S. (2018). A spring-electric graph model for socialized group photography. IEEE Transactions on Multimedia, 20, 754–766. doi:10.1109/TMM.2017.2750420.
- Redi et al. [2015] Redi, M., Rasiwasia, N., Aggarwal, G., & Jaimes, A. (2015). The beauty of capturing faces: Rating the quality of digital portraits. In 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG) (pp. 1–8). volume 1. doi:10.1109/FG.2015.7163086.
- Schwarz et al. [2018] Schwarz, K., Wieschollek, P., & Lensch, H. P. A. (2018). Will people like your image? learning the aesthetic space. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV) (pp. 2048–2057). doi:10.1109/WACV.2018.00226.
- Talebi & Milanfar [2018] Talebi, H., & Milanfar, P. (2018). Nima: Neural image assessment. IEEE Transactions on Image Processing, 27, 3998–4011. doi:10.1109/TIP.2018.2831899.
- Tang et al. [2013] Tang, X., Luo, W., & Wang, X. (2013). Content-based photo quality assessment. IEEE Transactions on Multimedia, 15, 1930–1943. doi:10.1109/TMM.2013.2269899.
- Tian et al. [2015] Tian, X., Dong, Z., Yang, K., & Mei, T. (2015). Query-dependent aesthetic model with deep learning for photo quality assessment. IEEE Transactions on Multimedia, 17, 2035–2048. doi:10.1109/TMM.2015.2479916.
- Tong et al. [2005] Tong, H., Li, M., Zhang, H.-J., He, J., & Zhang, C. (2005). Classification of digital photos taken by photographers or home users. In K. Aizawa, Y. Nakamura, & S. Satoh (Eds.), Advances in Multimedia Information Processing - PCM 2004 (pp. 198–205). Berlin, Heidelberg: Springer Berlin Heidelberg. doi:https://doi.org/10.1007/978-3-540-30541-5_25.
- Wei Luo et al. [2011] Wei Luo, Xiaogang Wang, & Tang, X. (2011). Content-based photo quality assessment. In 2011 International Conference on Computer Vision (pp. 2206–2213). doi:10.1109/ICCV.2011.6126498.
- Wu et al. [2019] Wu, Z., Kim, T., Li, Q., & Ma, X. (2019). Understanding and modeling user-perceived brand personality from mobile application uis. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems CHI ’19. New York, NY, USA: Association for Computing Machinery. URL: https://doi.org/10.1145/3290605.3300443. doi:10.1145/3290605.3300443.
- Xue et al. [2013] Xue, S., Tang, H., Tretter, D., Lin, Q., & Allebach, J. (2013). Feature design for aesthetic inference on photos with faces. In 2013 IEEE International Conference on Image Processing (pp. 2689–2693). doi:10.1109/ICIP.2013.6738554.
- Yan Ke et al. [2006] Yan Ke, Xiaoou Tang, & Feng Jing (2006). The design of high-level features for photo quality assessment. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06) (pp. 419–426). volume 1. doi:10.1109/CVPR.2006.303.