AFE-CNN: 3D Skeleton-based Action Recognition with Action Feature Enhancement
Abstract
Existing 3D skeleton-based action recognition approaches reach impressive performance by encoding handcrafted action features to image format and decoding by CNNs. However, such methods are limited in two ways: a) the handcrafted action features are difficult to handle challenging actions, and b) they generally require complex CNN models to improve action recognition accuracy, which usually occur heavy computational burden. To overcome these limitations, we introduce a novel AFE-CNN, which devotes to enhance the features of 3D skeleton-based actions to adapt to challenging actions. We propose feature enhance modules from key joint, bone vector, key frame and temporal perspectives, thus the AFE-CNN is more robust to camera views and body sizes variation, and significantly improve the recognition accuracy on challenging actions. Moreover, our AFE-CNN adopts a light-weight CNN model to decode images with action feature enhanced, which ensures a much lower computational burden than the state-of-the-art methods. We evaluate the AFE-CNN on three benchmark skeleton-based action datasets: NTU RGB+D, NTU RGB+D 120, and UTKinect-Action3D, with extensive experimental results demonstrate our outstanding performance of AFE-CNN.
keywords:
3D Skeleton, Action Recognition, Feature Enhance, Attention1 Introduction
Human action recognition task can be roughly processed as two steps: 1) action features extraction and 2) action classification, wherein the quality of action features largely impact the action classification accuracy. Early works [1, 2, 3, 4, 5] extract action features from RGB videos, which however suffer from background noise and illumination changes. Recently, depth camera (e.g., Kinect sensor) emerges as a powerful tool to acquire 3D skeleton data. Compared with RGB videos, 3D skeleton data are more robust to background noise and illumination changes, and can effectively avoid cluttered backgrounds and irrelevant objects. As a result, significant efforts have been devoted in recent year to the 3D skeleton-based human action recognition task.
Existing works using 3D skeleton data apply conventional classifiers, e.g., k-Nearest Neighbor [6], Support Vector Machine [7], which can easily recognize actions by feeding raw skeletons. However, these conventional methods [8, 9] cannot adapt to challenging actions such as human-to-human interaction, human-to-object interaction and are infeasible to apply on large scale datasets [10]. To overcome these short comes, recent efforts [11, 12, 13, 14, 15] adopt deep learning-based methods (e.g., recurrent neural network (RNN) [16], long short term memory (LSTM) [14], graph convolutional network (GCN) [17] and convolutional neural network (CNN) [11]) to recognize actions. Amongst deep models, RNN, LSTM, and GCN-based models naturally suffer from increasing model complexity (e.g., a large number of input features) and computational burden to improve action recognition accuracy. Moreover, they are easily trapped in overfitting problems and cannot directly learn high-level features with spatio-temporal information [10].
On the contrary, CNN-based methods encode high-level features and spatio-temporal information in an image, which can effectively reduce model overfitting and represent 3D skeleton data in a more comprehensive way. The core of developing CNN-based action recognition models is to effectively encode features from 3D skeleton data so as to improve the recognition accuracy [18]. Existing approaches to CNN-based action recognition adopt handcrafting approaches [19, 20, 10, 21, 22, 23, 18] to encode features to images. Specifically, these handcrafting approaches focus on compressing more features (e.g., skeleton motion [22], joint angles [10]) in one image and employee a state-of-the-art CNN architecture to decode features and recognize actions. However, such handcrafted images are difficult to handle challenging data which consist various of camera views, body sizes and marginally different actions (e.g., writing and typing).
In this paper, we propose the AFE-CNN: a learning-based action feature enhance model to enhance features of 3D skeleton-based actions for better encoding of actions to image format. Specifically, compared with handcrafted action feature-based images, our AFE-CNN utilizes learning-based methods to enhance features of 3D skeleton-based actions from key joints and bone vectors perspectives, which makes the action recognition model more robust to various camera views and body sizes. Then, a light-weight four-stream CNN model is deployed to learn comprehensive information in action feature-enhanced images and recognize actions. Notably, our designed action feature enhance modules can effectively improve model generalization on challenging actions (e.g., reading, writing). Furthermore, our AFE-CNN emphasizes key frames in skeleton sequences by a frame attention module, and we also embed temporal information in transformed images for enhancing the temporal information. Finally, we train our AFE-CNN end to end and achieves 86.2% on cross-subject metric and 92.2% on cross-view metric on the benchmark dataset NTU-RGB+D. Furthermore, our AFE-CNN not only achieves outstanding performance, but also very low computational costs, e.g., it costs 3.5ms for one forward inference. Our main contributions are summarized as three folds:
-
1.
We propose a novel learning-based model to enhance the features of 3D skeleton-based actions, which achieves the state-of-the-art performance on three benchmark datasets for the action recognition task.
-
2.
We design action feature enhance modules to adapt to various camera views and body sizes, thus significantly improves the recognition accuracy of our proposed model on challenging actions.
-
3.
Our AFE-CNN adopts a light-weight CNN architecture to alleviate the computation burden and can largely reduce computing time.
2 Related Works
The most relevant works to our studies can be roughly classified into two categories. First category contains deep learning-based approaches for 3D skeleton-based action recognition, and the second category contains the action features via visual representation approaches for 3D skeleton-based action recognition.
2.1 Deep Learning-based Action Recognition
To recognize an action, it generally requires spatio-temporal information in a 3D skeleton sequence. Therefore, RNN and LSTM network can demonstrate their advantages on spatio-temporal information processing. Liao et al. [16] encoded the spatio-temporal information from streamed 3D skeleton data, wherein a novel hybrid RNN architecture decode them to recognize actions. To reduce the effect on irrelevant joints, Liu et al. [24] designed a global context-aware attention LSTM to selectively learn the spatio-temporal information from most relevant joints. In [25], Si et al. novelty combined a spatial reasoning network and a temporal stack learning network to learn the spatial structural information and temporal information of skeleton sequences. With the similar idea of combining networks, Zhang et al. [26] combined two streams LSTM networks, one is to decode spatio-temporal information in skeleton sequence, another is to transform viewpoints to address various of camera views.
From the perspective of 3D skeleton structure, the key joints are connected with each other by bone links, which contain rich spatial information. Hence, the GCN-based model shows another way of thinking to represent spatio-temporal information in a 3D skeleton sequence. Li et al. [27] adopted a ”two stream” strategy and proposed an action-structural graph convolution network to capture actional links and structural links, which can learn both spatial and temporal features for action recognition. To capture variation of spatio-temporal information in 3D skeleton data, Gao et al. [28] utilized spatio-temporal modeling of 3D skeleton data and applied optimization on consecutive frames for efficient spatio-temporal data representation. In [29], Papadopoulos et al. adopted two novel GCN-based models to capture vertex features and short/long-term temporal features for action recognition. However, such GCN-based methods generally have a low computational efficiency due to their complex network structures.
2.2 Action Features via Visual Representation
Generally, a 3D skeleton sequence can be easily encoded into one image and further decoded by a CNN-based model, thus the recent CNN-based works mostly make effort on exploring features in 3D skeleton data and represent them by images. Kim et al. [19] directly transformed frame-wise 3D coordinates of joints to images and decoded them by using a residual temporal CNN model. In [20], Li et al. manually transform raw 3D skeleton data to images by utilizing joint reference and projection, and employed a pre-trained VGG-19 model for end to end training. Despite the success on utilizing high level features, representing low-level features (e.g., joint angles, motion direction and magnitude) are also considered as an effective approach to improve the accuracy of 3D skeleton-based action recognition. Kim et al. [10] represented the features by using the spatial correlations of joints and temporal dynamics of 3D skeleton, and achieved remarkable performance. To eliminate the effect of camera view variations, Liu et al. [23] presented an skeleton feature enhanced method for view invariant action recognition, to further improve the performance, the skeleton motion enhancement methods are also applied. In [18], Li et al. separated the skeleton into several body parts and mapped them to images via a scale invariant transformation approach to eliminate the effect of different body sizes. Combining GCN and CNN is also a novel approach to explore spatio-temporal information in 3D skeleton data. Zhang et al. [30] developed an simple yet effective GCN-based model to enhance the joint feature by introducing semantics of joints and hierarchically exploit their relationship, and used CNN model to explore correlation across frames.
Generally speaking, the spatio-temporal information in 3D skeleton data can be easily encoded in image format and effectively decoded by CNN-based models. However, the existing approaches using handcrafted action feature images are difficult to handle challenging actions and generally require a large scale CNN model to decode spatio-temporal information in image patterns. Therefore, it is highly desirable to develop a more efficient method to encode action features that can be decoded by a light-weight CNN model for reducing computational burden.
3 Methodology
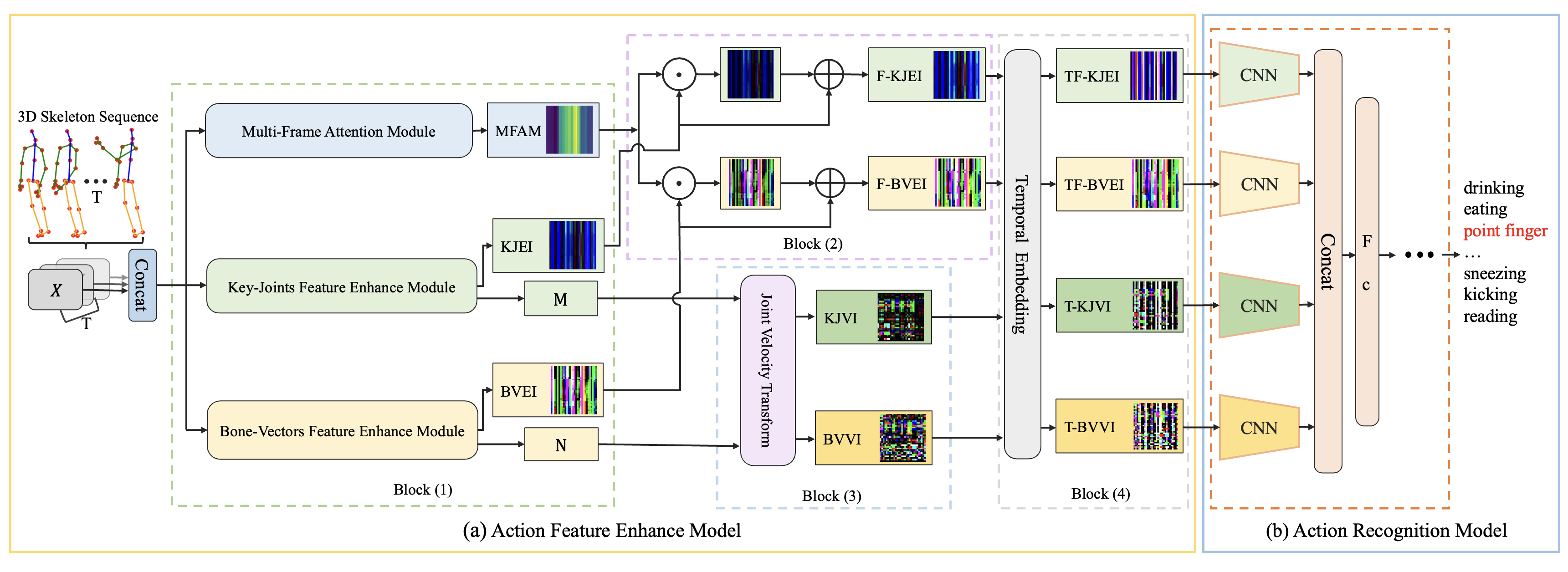
3.1 Model Overview
As shown in Fig 1, our AFE-CNN contains two main models: Action Feature Enhance model and Action Recognition model. In the Action Feature Enhance model, there are four blocks: 1) Skeleton Sequence Image Transform block; 2) Multi-Frame enhance block; 3) Skeleton Motion Velocity Image Transform block and 4) Temporal Embedding block.
In Block 1, the input is 3D skeleton sequences and the outputs contain two parts. The first part has three images, namely Multi-Frame Attention Map (MFAM), Key-Joints Feature Enhance Image (KJEI) and Bone-Vectors Feature Enhance Image (BVEI). Specifically, MFAM is calculated from skeleton frames through the Multi-Frame Attention Module. KJEI specifies key joints of 3D skeleton sequences which is produced by the Key-Joints Feature Enhance Module. BVEI specifies bone vectors of 3D skeleton sequences through a Bone-Vectors Feature Enhance Module. The second part contains two matrices, namely and , where represents the enhanced key joints by the Key-Joints Feature Enhance Module, and represents the enhanced bone vectors from the skeleton sequence by the Bone-Vectors Feature Enhance Module. In Block 2, the inputs are MFAM, KJEI and BVEI from block 1 and the outputs are two new images, namely the frame-enhanced KJEI (F-KJEI) and the frame-enhanced BVEI (F-BVEI). In Block 3, the inputs are and . The outputs are two images, namely Key-Joints Motion Velocity Image (KJVI) and Bone-Vectors Motion Velocity Image (BVVI), which are generated by the joint velocity transform model. In Block 4, the Temporal Embedding module takes four images from blocks 2 and 3 as the inputs and generates four feature enhanced action-transformed images, namely temporal frame-enhanced KJEI (TF-KJEI), temporal frame-enhanced BVEI (TF-BVEI), temporal-enhanced KJVI (T-KJVI), and temporal-enhanced BVVI (T-BVVI), which include the temporal information of the skeleton sequence. The action recognition model consists of four light-weight convolutional neural networks and several fully connected layers. The inputs are the four enhanced action-transformed images, i.e., TF-KJEI, TF-BVEI, T-KJVI, and T-BVVI from Block 4 and the output is the action label.
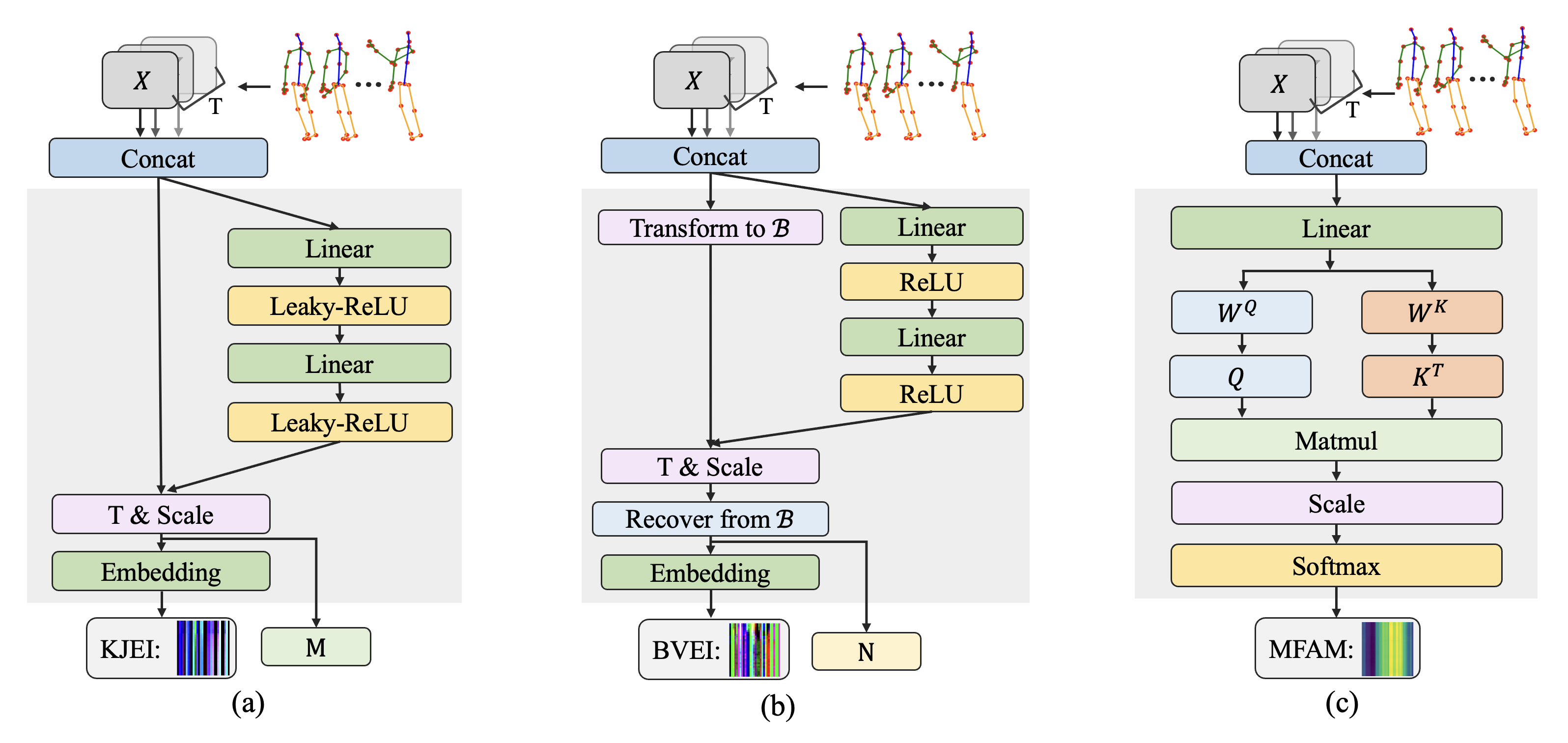
3.2 Action Feature Enhance Model
In this section, we will discuss the details about five modules in the action feature enhance model.
3.2.1 Key-Joints Feature Enhance Module
Generally, actions with subtle limb motion differences could only cause pixel-level differences among their action-transformed images. For instance, the transformed image of “writing” is slightly different from the counterpart of “typing”, since the limb motion differences only reflect by their fingers. As a result, such subtle motion differences could not be picked up by CNN-based models, leading a sub-optimal performance in action recognition. To enlarge the differences among the transformed images of actions, we propose a Key-Joints Feature Enhance Module that uses the key-joints of given skeleton sequences to enhance features of transformed images.
Let denote the skeleton frames in a given skeleton sequence, where is a matrix with size that represents 3D coordinates of joints in frame , and is the number of frames in the skeleton sequence. As shown in Fig 2 (a), the firstly passes a concatenation step to form a tensor. This tensor then passes two fully connected layers with leakyReLU [31] activation function and outputs a scale matrix . In the parallel, the tensor is transformed to a matrix of size , which is treated as a 3-channel image of size sized 3-channel image: . Finally, the scaled joints matrix is calculated by:
| (1) |
Thereafter, the is fed to an Embedding layer for linear transformation, where the embedding layer is a weight matrix, to produce the key-joints feature enhanced image , which is referred to as KJEI.
3.2.2 Bone-Vectors Feature Enhance Module
Having captured key-joints features through our Key-Joints Feature Enhance Module, we further include a Bone-Vectors Feature Enhance Module to enhance the transformed images using bone vector features. The bone vectors contain more details of human actions that could not be captured by less ideal camera views, e.g., the ones taken by cameras from the back-side. A camera standing behind humans can only film the human back, and information about human hands motion and gestures cannot be captured. Fortunately, the bone vectors can provide integral human body maps to fill the losing motion information. We now introduce our Bone-Vectors Feature Enhance Module that includes bone vectors of humans to enhance the transformed images of actions.
Let denotes the 3D coordinate of -th joint and denotes the bone vector formed by the -th joint and -th joint, which can also be represented as , and calculated as follows:
| (2) |
where , with and indicating and , respectively. For each , bone vector is calculated and concatenated to form based on the formula below:
| (3) |
where is the -th frame in the skeleton sequence; is obtained by concatenating the corresponding vectors . As such, the bone vector matrices of frames is defined as .
As shown in Fig 2 (b), the passes similar steps to the ones in Fig 2 (a) except for the “transform to B” step which outputs a matrix for scaling scales bone vector lengths. This scaled bone vector collection is converted into a matrix of size : with 3 channels, and the scaled bone matrix is calculated by:
| (4) |
After that, the scaled bone matrix is manipulated to recover the key joints position by:
| (5) |
where is the root joint position. Finally, we fed to the embedding layer which is a weight matrix to produce the bone-vectors feature enhanced image , which is also referred to as BVEI.
3.2.3 Multi-Frame Attention Module (MFAM)
Generally, the label of an action depends on a series of key skeleton frames, which means every single frame in an action sequence should have different weights in classifying an action. For example, giving an action sequence that denotes the action of “drinking”, it is essentially the “drink” frames that decide the action’s label instead of “picking up the cup”. Inspired by self-attention mechanism in Transformer module [32], we specify different importance scores of skeleton frames to emphasize key frames for CNN-based action classification. We now introduce our Multi-Frame Attention Module that devices the self-attention mechanism to yield different weights for skeleton-transformed images.
From Fig 2 (c), the is firstly fed to a fully connected layer, then it splits to two branches: the left branch is used for providing query matrix and the right branch for providing key matrix . We compute the dot products of and transpose of key matrix , then divide the dot products by , where denotes the dimension of key matrix. Formally,
| (6) |
where is the output multi-frame attention map.
Thereafter, as shown in Fig 1, we multiply the multi-frame attention map with key-joints feature enhanced image . To prevent loss information, we add itself after multiplication, and the final key-joint attention feature image is computed by:
| (7) |
where is the element-wise product and is the attention operator in our Multi-Frame Attention Module. Similarly, the bone-vector attention feature image is obtained by:
| (8) |
3.2.4 Joint Velocity Image Transform Module
Inspired by two-stream architecture [1], which utilizes optical flow fields to complement the original stream. We propose a Skeleton Moving Velocity Transform module to calculate moving velocity of each key joint as another action feature representation stream. Given a key joint position as , a -joints skeleton is denoted as . The moving velocity of each key joint between two frames is computed by:
| (9) |
where denotes the time difference between two consecutive frames and is the frame index. As shown in Fig 1, we fed the scaled joints matrix and the scaled bone matrix into the transform module, which outputs image matrices. Thereafter, they are transformed to a sized image matrix by linear transformation, which named key joint velocity image (KJV) and bone vectors velocity image (BVV), respectively.
3.2.5 Temporal Embedding Module(TE)
It is well-acknowledged that recognizing an action is highly dependent on the timing when the key poses happen [33]. For example, standing and sitting are two timely opposite actions, and one can be regarded as the reversed time sequence of another action. A 3D skeleton-based action recognition task generally transforms a skeleton sequence into an action feature image, and the temporal information is represented as the relative position of the pixels and embed in action feature image. However, conventional CNN model is considered to be spatial-agnostic [34], which makes it difficult to find the temporal information of an action-transformed image. To address this problem, we propose a Temporal Embedding (TE) module to enhance the temporal information in the action-transformed images.
Inspired by ViT [35], we provide a dimensional relative positional embedding as temporal information for action-transformed images. Here, we regard each column of an action-transformed image as the corresponding key frame pose, and we utilize the relative distance between columns to encode the spatial information. As shown in Fig 1, we add a learned dimensional positional embedding to all action-transformed images to enhance the temporal features. To this end, these images will be fed to our Four-Stream CNN model.
3.3 Action Recognition Model
In this section, we will discuss the details of CNN models used in our action recognition model and our training strategy.
3.3.1 Four-Stream CNN
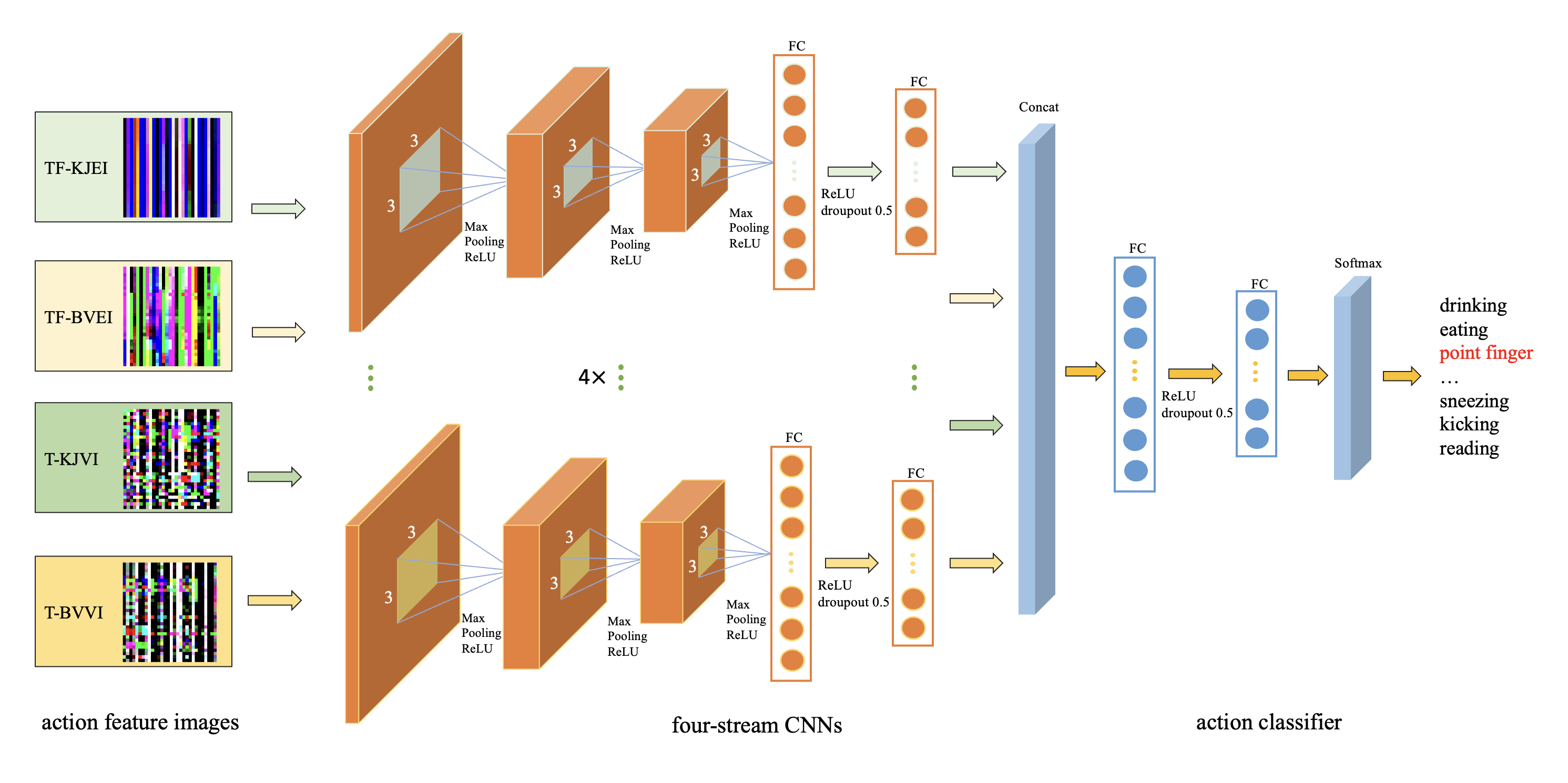
To obtain more discriminate features from action-transformed images, we propose a four-stream CNN-based action recognition model. Our four-stream CNN model is a modified version of a lightweight CNN model which is proposed by Caetano et al. [36]. This lightweight CNN contains three convolution layers which have similar structure to VGG Net [37], and followed by two fully connected layers. Here, we modified their convolution layers with different padding size and different dimension of fully connected layers. The kernel size for each convolution layer is with a stride of 2. After each convolution layer, we adopt a max pooling and a LeakyReLU [31] layer. For each action-transformed image, we employ a CNN model to extract the action feature vector, then, we concatenate these four action feature vectors and fed the consolidated one to a two layers fully connected networks for action recognition.
3.3.2 Model Optimization
With a skeleton-based action recognition dataset, our CNN-based action recognition architecture is trained uniformly by using categorical cross-entropy loss function:
| (10) |
where is the number of action categories, denotes the true value which is either or , and is the Softmax probability for action category.
Compared with conventional hand-craft action-transformed image action recognition methods, our proposed methods do not require any manually action feature extraction. Moreover, compared with using large-scale CNN model, we do not need any pre-trained models to improve the performance of action recognition.
4 Experiments and Discussion
We implement our experiments in PyTorch framework with single GeForce RTX 3090 GPU. We train our model with Adam optimizer by using the initial learning rate at 0.001, the shrink factor of 0.1 after 20 epochs. Due to different size of datasets, we set a batch size of 64 for both NTU RGB+D [38] and NTU RGB+D 120 [39], and a batch size of 8 for UTKinect-Action3D [40].
4.1 Datasets
NTU RGB+D: This dataset is recorded by Kinect v2 sensors and each skeleton is depicted by 3D locations of 25 body joints. In details, it contains 56,880 3D skeleton sequences with 40 different human subjects and covers 60 daily action categories, which including single person actions, human-objective interactions, and human-human interactions. It is a challenge dataset due to its large scale, diverse action categories and various of camera views. We evaluate our method on this dataset by using two official evaluation metrics: cross-subject (subjects with 20 specific IDs are for training and the remaining for testing) and cross-view (samples from camera 1 for testing while the samples from camera 2 and 3 for training).
NTU RGB+D 120: This dataset is the extended version of the NTU RGB+D by adding another 60 challenging action categories. Compared with NTU RGB+D, this dataset is more challenge due to more subjects and increased variations of view points. In details, it contains totally 114,480 3D skeleton sequences with 106 subjects which performers in a wide range of age distribution. These samples are captured from 155 different camera views and recorded in 32 different scenes. This dataset provides two evaluation metrics: cross-subject (subjects with 53 specific IDs are for training and remaining for testing) and cross-setup (samples with even collection setup IDs for training while remaining of odd setup IDs for testing).
UTKinect-Action3D: Compared with NTU RGB+D and NTU RGB+D 120, this dataset is significantly smaller. It has 200 3D skeleton sequences of 10 daily human-object interactive action categories. Each skeleton is recorded as 20 body joints. Due to its small-scale, we utilize the cross-subject (half of the subjects for training and the remaining subjects for testing) as the evaluation metric to prevent potential risk of model overfitting.
4.2 Experiment Results
Here, we compare our AFE-CNN with several SOTA 3D skeleton action recognition methods on NTU RGB+D, NTU RGB+D 120 and UTKinect-Action3D respectively.
4.3 Results on NTU RGB+D
| Methods | Architecture | Accuracy (%) | |
|---|---|---|---|
| CrossSubject | CrossView | ||
| PAM+PTF [8] | PAM | 68.2 | 76.3 |
| TSRJI [11] | CNN | 73.3 | 80.3 |
| ImageGen+VGG-19 [20] | CNN | 75.2 | 82.1 |
| ResTCN [19] | CNN | 74.3 | 83.1 |
| Skelemotion [22] | CNN | 76.5 | 84.7 |
| MTLN [41] | CNN | 79.6 | 84.8 |
| SPMF+ResNet [21] | CNN | 78.9 | 86.2 |
| Synthesized CNN [23] | CNN | 80.0 | 87.2 |
| MTCNN+RotClips [15] | CNN | 81.1 | 87.4 |
| ST-GCN [17] | GCN | 81.5 | 88.3 |
| VA-LSTM [42] | LSTM | 80.7 | 88.8 |
| PoT2I+Inception-v3 [10] | CNN | 83.8 | 90.3 |
| 3scale ResNet152 [18] | CNN | 84.6 | 90.9 |
| AFE-CNN (Ours) | CNN | 86.2 | 92.2 |
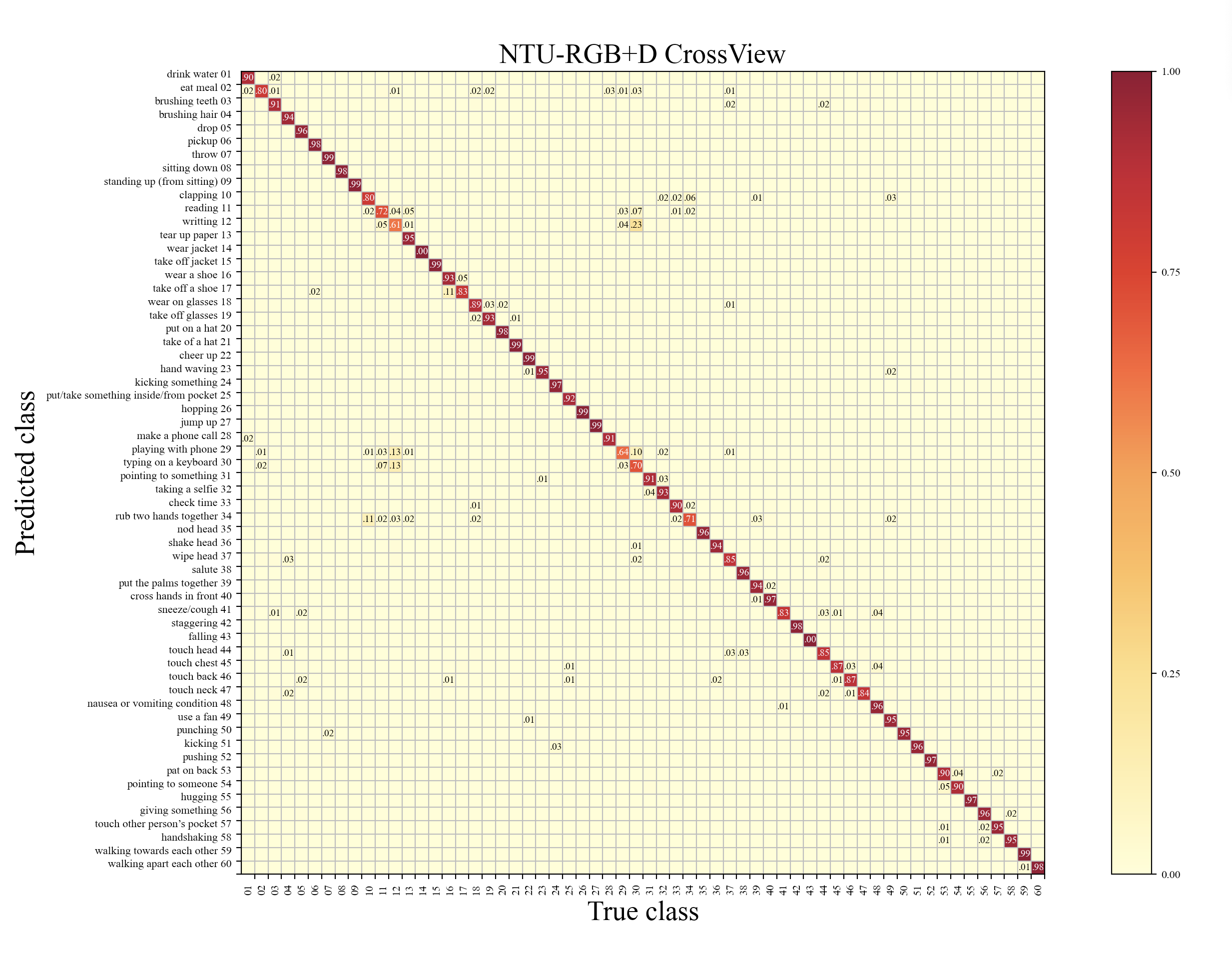
From the results shown in Table 1, our AFE-CNN achieves the highest accuracy on both cross-subject (86.2%) and cross-view (92.2%) evaluation metrics. Accordingly, the corresponding confusion matrix of NTU-RGB+D results under cross-subject metric and cross-view metric are depicted in Fig 5 and Fig 4 respectively. It can be observed that there is a large gap of accuracy between deep learning-based methods (e.g.,MTLN [41],ResTCN [19]) and traditional machine learning-based methods (e.g., TSRJI [11] and PAM+PTF [8]). Because the traditional machine learning-based methods are hard to handle large-scale action dataset, therefore, the most of 3D skeleton-based action recognition methods are developed with deep learning-based architectures (e.g., CNN, LSTM, GCN).
In these deep learning-based approaches, the LSTM-based and GCN-based architecture achieve applaud performance (e.g., ST-GCN [17], VA-LSTM [42]) due to they are expert on spatio-temporal information processing. However, compared with CNN-based methods, the LSTM-based and GCN-based methods consume more computing time due to their complex network structure.
For CNN-based architecture, few of methods directly feed raw coordinate data to a CNN model (e.g., TCN [19]), and the most of methods first transform different levels of action features (e.g., high-level action features [20, 15], low-level action features [11, 10, 18, 41], motion features [22, 21, 23]) to image format as inputs for CNN models. To further improve action recognition accuracy, several methods [18, 10, 21] employee large scale CNN model (e.g., ResNet, Inception-v3) to extract more spatio-temporal information in large size action feature images. Although these approaches significantly improve the performance thanks to the benefits of large scale CNNs feature extraction in image classification, they load more computation burden which largely increase computing time. Moreover, the hand-crafted action features are difficult to handle challenging data with various of camera views, body sizes, and they have become the bottleneck to further improve the performance. In contrast to these methods, our AFE-CNN outperforms all handcrafted action feature image approaches and only requires light-weight CNN models.
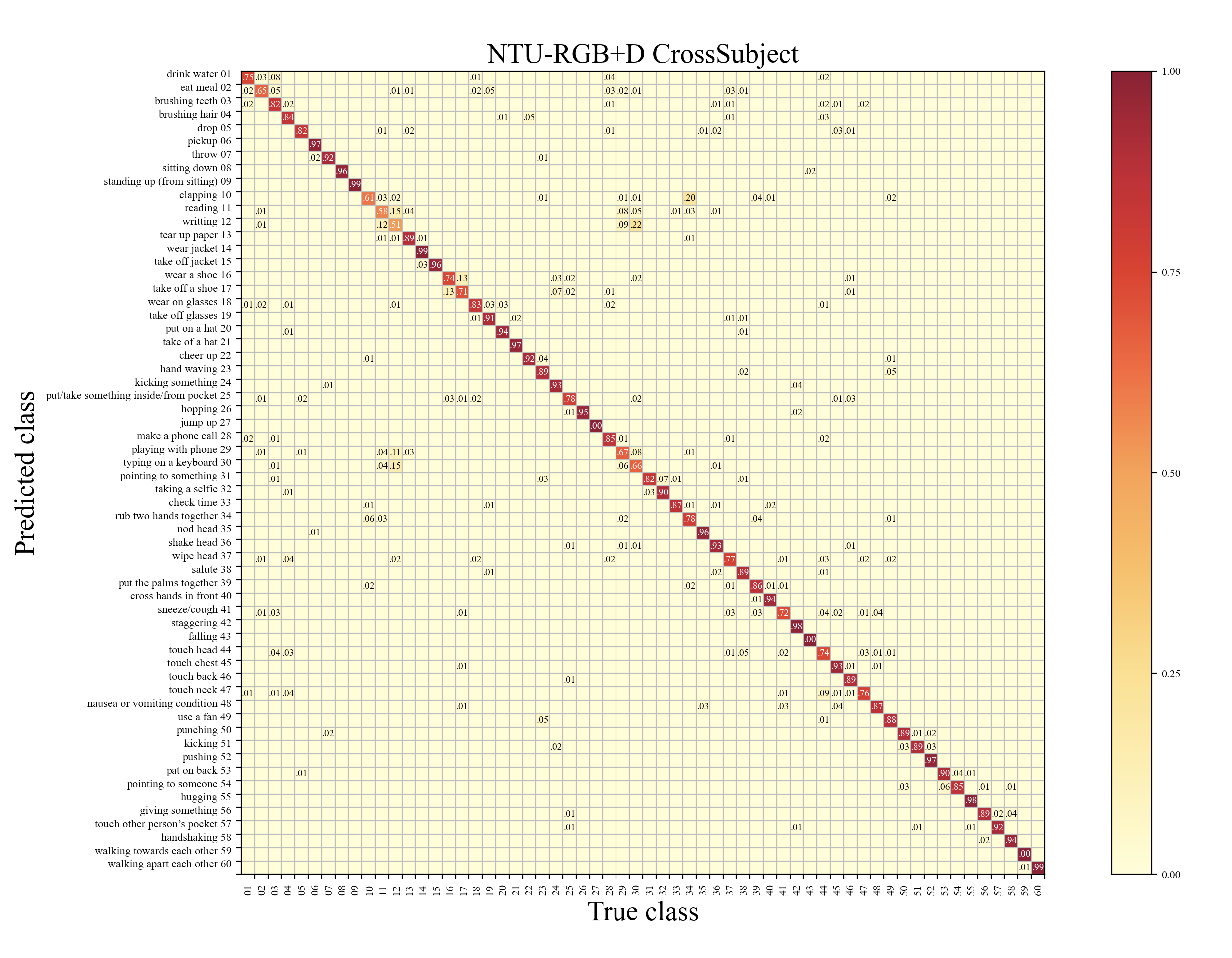
4.4 Results on NTU RGB+D 120
| Methods | Architecture | Accuracy (%) | |
|---|---|---|---|
| CrossSubject | CrossSetup | ||
| MTLN [41] | CNN | 58.4 | 57.9 |
| MTCNN+RotClips [15] | CNN | 62.2 | 61.8 |
| TSRJI [11] | CNN | 67.9 | 62.8 |
| Synthesized CNN [23] | CNN | 60.3 | 63.2 |
| GCA-LSTM [24] | LSTM | 61.2 | 63.3 |
| Skelemotion [22] | CNN | 67.7 | 66.9 |
| Logsig-RNN [16] | RNN | 68.3 | 67.2 |
| Gimme Signals [43] | CNN | 70.8 | 71.6 |
| ST-GCN [17] | GCN | 70.7 | 73.2 |
| AS-GCN [27] | GCN | 77.7 | 78.9 |
| GVFE+DH-TCN [29] | GCN | 78.3 | 79.8 |
| SR-TSL [25] | LSTM | 74.1 | 79.9 |
| SGCN [30] | GCN | 79.2 | 81.5 |
| AFE-CNN (Ours) | CNN | 80.4 | 81.6 |
As shown in Table 2, our AFE-CNN outperforms than other methods on both cross-subject (80.2%) and cross-setup (81.6%). In this dataset, some methods utilize RNN-based[16] and LSTM-based[24, 25] methods and achieve promising results, and the best LSTM-based [25] method reaches 79.9% accuracy on cross-setup metric. In addition, the GCN-based [27, 29, 30] action recognition approaches achieve applaud performance due to GCNs are specialize on finding spatio-temporal information in raw 3D skeleton sequence. But they still suffer from a high computational burden. Compared with GCN and LSTM-based methods, our AFE-CNN achieves high accuracy of action recognition while ensuring a low computational burden.
Moreover, it can be seen that there is a large gap of accuracy between CNN-based methods and GCN-based methods (e.g., Gimme Signals [43] and GVFE+DH-TCN [29]). This verifies the CNN-based model is hard to handle more challenging dataset due to the limitations of hand-craft features transformed images (e.g., more various of camera views, body sizes and marginally different actions). However, our AFE-CNN can effectively enhance the action features of challenging actions that enables a light-weight CNN model to achieve outstanding performance.
4.5 Results on UTKinect-Action3D
| Methods | Architecture | Accuracy (%) |
|---|---|---|
| MLSTM+Weight Fusion [12] | RNN | 96.0 |
| GFT [13] | GCN | 96.0 |
| ST-LSTM [14] | LSTM | 97.0 |
| PAM+PTF [8] | PAM | 97.0 |
| Lie Group [9] | SVM | 97.1 |
| PoT2I+Inception-v3 [10] | CNN | 98.5 |
| GR-GCN [28] | GCN | 98.5 |
| GCA-LSTM [24] | LSTM | 99.0 |
| MTCNN+RotClips [15] | CNN | 99.0 |
| Multi-Stream CNN [44] | CNN | 99.0 |
| AFE-CNN (Ours) | CNN | 99.0 |
From the results shown in Table 3, our AFE-CNN achieves the accuracy of 99.0% in this dataset and several methods [24, 15, 44] also achieve the same result. Accordingly, the corresponding confusion matrix of this dataset as shown in Fig 6, where some walk and wave action samples are misclassified to each other. In this small-scale dataset, some traditional machine learning-based methods [8, 9] even achieve comparable performance compared with other deep learning-based methods. The CNN-based methods [10, 15, 44] generally have an applaud performance while the GCN-based [13, 28] methods have a lower accuracy. In these CNN-based methods, only PoT2I+Inception-v3 [10] adopts a single CNN architecture, which cannot decode more action features and cause the action recognition accuracy less 0.5% than other CNN-based methods. Although our AFE-CNN utilize a light-weight CNN model, our four-streams CNN architecture ensure that more action features are encoded and decoded, therefore, our AFE-CNN also can achieve a promising performance in small-scale dataset.
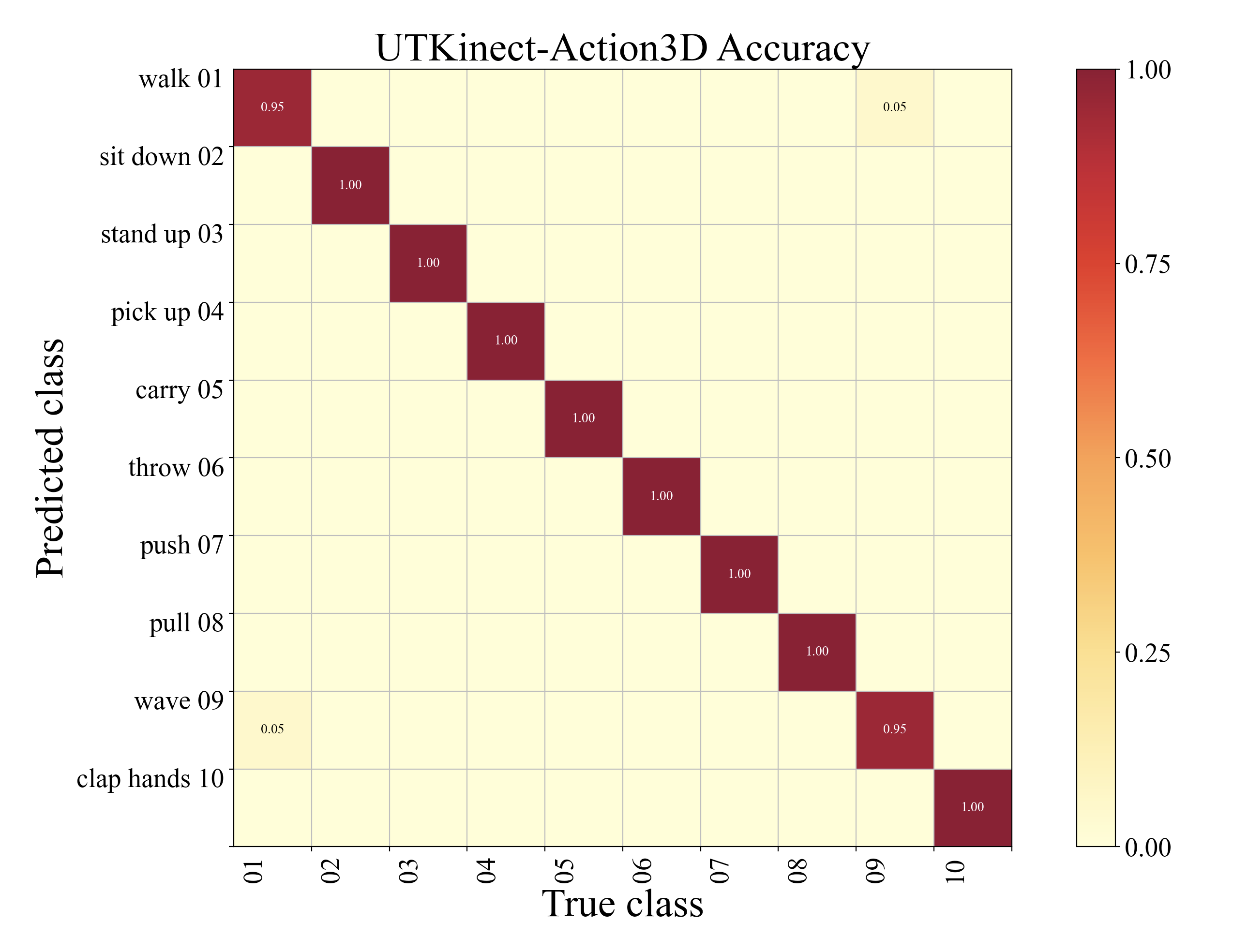
4.6 Ablation Study
In this section, we carry out several ablation studies on NTU-RGB+D dataset to validate the contribution of key modules of AFE-CNN.
4.6.1 Ablation study on multi-frame attention and temporal embedding module
To verify the contributions made by our multi-frame attention module and temporal embedding module, we train the AFE-CNN with and without them and compare the results on the perspective of cross-subject and cross-view metrics.
| Methods | Accuracy (%) | |
|---|---|---|
| CrossSubject | CrossView | |
| AFE-CNN | 84.9 | 90.1 |
| AFE-CNN+MFAM | 85.7 | 91.3 |
| AFE-CNN+MFAM+TE | 86.2 | 92.2 |
As shown in Table 4, we can observe that the temporal embedding module could improve accuracy on cross-subject and cross-view metrics by 0.5% and 0.9% respectively. This means the temporal embedding module can effectively enhance the temporal information in action feature images and improves the performance of AFE-CNN. For multi-frame attention module, it improves the accuracy on cross-subject metric by 0.8% and the accuracy on cross-view metric by 1.2%, both of them are higher than temporal embedding module, which means multi-frame attention module contributes more than the temporal embedding module in AFE-CNN.
4.6.2 Ablation study on Action Feature Enhance Modules
To verify the contributions of our key-joints feature enhance module and bone-vectors feature enhance module, we train the four-stream CNN-based action recognition model with and without these modules and compare their results on cross-subject and cross-view metrics.
| Methods | Accuracy (%) | |
|---|---|---|
| CrossSubject | CrossView | |
| AF-CNN | 79.2 | 84.0 |
| AF-CNN+KJFE | 82.9 | 89.1 |
| AF-CNN+BVFE | 83.8 | 88.2 |
| AF-CNN+KJFE+BVFE | 84.9 | 90.1 |
From the results shown in Table 5, we can observe that both of key-joints feature enhance module and bone-vectors feature enhance module can boost the performance of our CNN-based action recognition model. However, they show a different improvements on two evaluation metrics. The KJFE improves more on cross-view metrics (up to 89.1%) while BVFE improves more on cross-subject metric (up to 83.8%). This phenomenon is caused by two factors: one is the variations of camera views on two evaluation metrics, and the other is that the BVFE applies weights on bone vectors, which is more effective than key joints on some rare camera views. When combining KJFE and BVFE, we see significant performance improvements on both evaluation metrics.
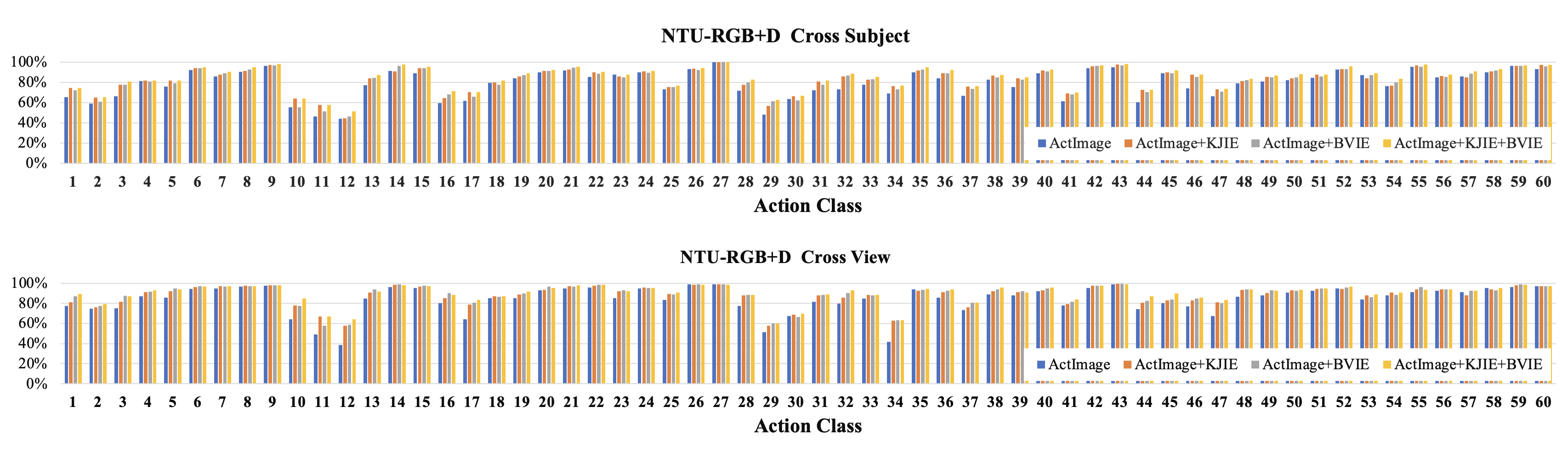
From the comparison of class by class action recognition accuracy as shown in Fig 7, we can find that our both KJFE and BVFE improve the action recognition accuracy on each action class. It is worth mentioning that on challenging action classes (e.g., class 11 reading and class 12 writing), our KJFE+BVFE improve the accuracy by 36.2% and 66.8% respectively on cross-view metric. For other action classes, our KJFE+BVFE remains high action recognition accuracy.
4.6.3 Ablation study on joint velocity transform module
| Methods | Accuracy (%) | |
|---|---|---|
| CrossSubject | CrossView | |
| AFE-CNN | 78.9 | 85.6 |
| AFE-CNN+JVTM | 86.2 | 92.2 |
Here we design an ablation study on the joint velocity transform module to analysis its contribution. As shown in Table 6, there is a large gap between whether the AFE-CNN uses the joint velocity transform module. For example, the JVTM improves the accuracy on cross-subject and cross view evaluation metrics by 7.3% and 6.6%, respectively. Thus, we believe that the joint velocity transform module plays a key role in achieving outstanding results in performing CNN-based action recognition task as it provides motion information which is critical to recognize actions.
4.7 Complexity measurement
In this section, we analysis the complexity of our AFE-CNN by measuring its computing time, floating-point operations per second (Flops) and further compare with several representative methods. It is noted that a comparison of processing time cannot be done fairly due to the diversity in use of frameworks (e.g., TensorFlow, PyTorch) and computing platforms (e.g., single GPU and multi-GPUs) are very diverse.
As shown in Table 7, our AFE-CNN only cost 3.5ms for one forward inference and only consumes 1.4GFlops, which are significantly lower than other methods. Compared with other methods [10, 21, 23] using handcrafted action feature images, our AFE-CNN can be fully executed on GPU. Since we adopt a light-weight CNN model as the back bone, our method can minimize the computing time. Although the GCN-based model has applaudable performance on 3D skeleton-based action recognition task, it costs more computing time due to its complex computational structure.
4.8 Visualization of Action Feature Images
To illustrate our action feature enhance mechanism, we visualize the action feature enhanced images and multi-frame attention maps of drink water and jump up actions. We further compare them with the action feature images without utilizing any proposed feature enhance module.

As shown in Fig 8, we can observe that the strips in action feature enhanced images are much more distinguishable than the images without being enhanced by our proposed feature enhance modules. Moreover, it is obviously that the TF-KJEI, TF-BVEI, T-KJVI, and T-BVVI encode different information in an action. Thus the CNN model can lead to outstanding performance thanks to the rich features in these action feature enhanced images. For MFAM, we can find that it successfully finds the key frames in an action sequence, where the yellow color indicates a stronger attention.
5 Conclusion
In this paper, we have proposed a novel learning-based action feature enhanced method for 3D skeleton-based action recognition, which namely AFE-CNN. Firstly, our AFE-CNN enhances the action features from key joint and bone vector perspectives to adapt to various camera views and body sizes. Secondly, the key frames of a skeleton sequence is enhanced by devicing a multi-frame attention module and a temporal embedding module to enhance temporal information. Thanks to the action feature enhance modules, our AFE-CNN effectively overcome the limitations of handcraft action features. The extensive experimental results demonstrate that our AFE-CNN achieves state-of-the-art performance on three benchmark datasets, and the recognition accuracy of challenging action classes is significantly improved. Notably, our AFE-CNN adopts light-weight CNN models so that the required computational load and computing time are extremely low. This makes it a good candidate technique for real-world applications.
References
- [1] K. Simonyan, A. Zisserman, Two-stream convolutional networks for action recognition in videos, in: Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, K. Weinberger (Eds.), Advances in Neural Information Processing Systems, Vol. 27, Curran Associates, Inc., 2014.
- [2] C. Feichtenhofer, A. Pinz, A. Zisserman, Convolutional two-stream network fusion for video action recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [3] L. Wang, Y. Qiao, X. Tang, Action recognition with trajectory-pooled deep-convolutional descriptors, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4305–4314.
- [4] Z. Zhang, S. Liu, S. Liu, L. Han, Y. Shao, W. Zhou, Human action recognition using salient region detection in complex scenes, in: The proceedings of the third international conference on communications, signal processing, and systems, Springer, 2015, pp. 565–572.
- [5] Y. Ye, Y. Tian, Embedding sequential information into spatiotemporal features for action recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2016.
- [6] V. Andersson, R. Dutra, R. Araújo, Anthropometric and human gait identification using skeleton data from kinect sensor, in: Proceedings of the 29th Annual ACM Symposium on Applied Computing, 2014, pp. 60–61.
- [7] D. Xu, X. Xiao, X. Wang, J. Wang, Human action recognition based on kinect and pso-svm by representing 3d skeletons as points in lie group, in: 2016 International Conference on Audio, Language and Image Processing (ICALIP), IEEE, 2016, pp. 568–573.
- [8] T. Huynh-The, C.-H. Hua, N. A. Tu, T. Hur, J. Bang, D. Kim, M. B. Amin, B. H. Kang, H. Seung, S.-Y. Shin, et al., Hierarchical topic modeling with pose-transition feature for action recognition using 3d skeleton data, Information Sciences 444 (2018) 20–35.
- [9] R. Vemulapalli, F. Arrate, R. Chellappa, Human action recognition by representing 3d skeletons as points in a lie group, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 588–595.
- [10] T. Huynh-The, C.-H. Hua, T.-T. Ngo, D.-S. Kim, Image representation of pose-transition feature for 3d skeleton-based action recognition, Information Sciences 513 (2020) 112–126.
-
[11]
C. Caetano, F. Brémond, W. R. Schwartz,
Skeleton image representation for 3d
action recognition based on tree structure and reference joints, CoRR
abs/1909.05704.
arXiv:1909.05704.
URL http://arxiv.org/abs/1909.05704 - [12] S. Zhang, Y. Yang, J. Xiao, X. Liu, Y. Yang, D. Xie, Y. Zhuang, Fusing geometric features for skeleton-based action recognition using multilayer lstm networks, IEEE Transactions on Multimedia 20 (9) (2018) 2330–2343.
- [13] J.-Y. Kao, A. Ortega, D. Tian, H. Mansour, A. Vetro, Graph based skeleton modeling for human activity analysis, in: 2019 IEEE International Conference on Image Processing (ICIP), IEEE, 2019, pp. 2025–2029.
- [14] J. Liu, A. Shahroudy, D. Xu, G. Wang, Spatio-temporal lstm with trust gates for 3d human action recognition, in: B. Leibe, J. Matas, N. Sebe, M. Welling (Eds.), Computer Vision – ECCV 2016, Springer International Publishing, Cham, 2016, pp. 816–833.
- [15] Q. Ke, M. Bennamoun, S. An, F. Sohel, F. Boussaid, Learning clip representations for skeleton-based 3d action recognition, IEEE Transactions on Image Processing 27 (6) (2018) 2842–2855.
-
[16]
S. Liao, T. J. Lyons, W. Yang, H. Ni,
Learning stochastic differential
equations using RNN with log signature features, CoRR abs/1908.08286.
arXiv:1908.08286.
URL http://arxiv.org/abs/1908.08286 - [17] S. Yan, Y. Xiong, D. Lin, Spatial temporal graph convolutional networks for skeleton-based action recognition, in: Thirty-second AAAI conference on artificial intelligence, 2018.
- [18] B. Li, Y. Dai, X. Cheng, H. Chen, Y. Lin, M. He, Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep cnn, in: 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), IEEE, 2017, pp. 601–604.
-
[19]
T. S. Kim, A. Reiter, Interpretable 3d
human action analysis with temporal convolutional networks, CoRR
abs/1704.04516.
arXiv:1704.04516.
URL http://arxiv.org/abs/1704.04516 - [20] C. Li, S. Sun, X. Min, W. Lin, B. Nie, X. Zhang, End-to-end learning of deep convolutional neural network for 3d human action recognition, in: 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), IEEE, 2017, pp. 609–612.
- [21] H.-H. Pham, L. Khoudour, A. Crouzil, P. Zegers, S. A. Velastin, Skeletal movement to color map: A novel representation for 3d action recognition with inception residual networks, in: 2018 25th IEEE International Conference on Image Processing (ICIP), 2018, pp. 3483–3487. doi:10.1109/ICIP.2018.8451404.
-
[22]
C. Caetano, J. Sena, F. Brémond, J. A. dos Santos, W. R. Schwartz,
Skelemotion: A new representation of
skeleton joint sequences based on motion information for 3d action
recognition, CoRR abs/1907.13025.
arXiv:1907.13025.
URL http://arxiv.org/abs/1907.13025 - [23] M. Liu, H. Liu, C. Chen, Enhanced skeleton visualization for view invariant human action recognition, Pattern Recognition 68 (2017) 346–362.
- [24] J. Liu, G. Wang, L.-Y. Duan, K. Abdiyeva, A. C. Kot, Skeleton-based human action recognition with global context-aware attention lstm networks, IEEE Transactions on Image Processing 27 (4) (2017) 1586–1599.
- [25] C. Si, Y. Jing, W. Wang, L. Wang, T. Tan, Skeleton-based action recognition with spatial reasoning and temporal stack learning, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018.
- [26] I. Lee, D. Kim, S. Kang, S. Lee, Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 1012–1020.
- [27] M. Li, S. Chen, X. Chen, Y. Zhang, Y. Wang, Q. Tian, Actional-structural graph convolutional networks for skeleton-based action recognition, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3595–3603.
- [28] X. Gao, W. Hu, J. Tang, J. Liu, Z. Guo, Optimized skeleton-based action recognition via sparsified graph regression, in: Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 601–610.
- [29] K. Papadopoulos, E. Ghorbel, D. Aouada, B. Ottersten, Vertex feature encoding and hierarchical temporal modeling in a spatial-temporal graph convolutional network for action recognition, arXiv preprint arXiv:1912.09745.
- [30] P. Zhang, C. Lan, W. Zeng, J. Xing, J. Xue, N. Zheng, Semantics-guided neural networks for efficient skeleton-based human action recognition, in: proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1112–1121.
-
[31]
K. He, X. Zhang, S. Ren, J. Sun, Delving
deep into rectifiers: Surpassing human-level performance on imagenet
classification, CoRR abs/1502.01852.
arXiv:1502.01852.
URL http://arxiv.org/abs/1502.01852 -
[32]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez,
L. Kaiser, I. Polosukhin, Attention is
all you need, CoRR abs/1706.03762.
arXiv:1706.03762.
URL http://arxiv.org/abs/1706.03762 -
[33]
P. P. San, P. Kakar, X.-L. Li, S. Krishnaswamy, J.-B. Yang, M. N. Nguyen,
Chapter
9 - deep learning for human activity recognition, in: H.-H. Hsu, C.-Y.
Chang, C.-H. Hsu (Eds.), Big Data Analytics for Sensor-Network Collected
Intelligence, Intelligent Data-Centric Systems, Academic Press, 2017, pp.
186–204.
doi:https://doi.org/10.1016/B978-0-12-809393-1.00009-X.
URL https://www.sciencedirect.com/science/article/pii/B978012809393100009X -
[34]
S. Sabour, N. Frosst, G. E. Hinton,
Dynamic routing between capsules,
CoRR abs/1710.09829.
arXiv:1710.09829.
URL http://arxiv.org/abs/1710.09829 -
[35]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai,
T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit,
N. Houlsby, An image is worth 16x16
words: Transformers for image recognition at scale, CoRR abs/2010.11929.
arXiv:2010.11929.
URL https://arxiv.org/abs/2010.11929 -
[36]
C. Caetano, J. Sena, F. Brémond, J. A. dos Santos, W. R. Schwartz,
Skelemotion: A new representation of
skeleton joint sequences based on motion information for 3d action
recognition, CoRR abs/1907.13025.
arXiv:1907.13025.
URL http://arxiv.org/abs/1907.13025 - [37] K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, CoRR abs/1409.1556.
- [38] A. Shahroudy, J. Liu, T.-T. Ng, G. Wang, Ntu rgb+d: A large scale dataset for 3d human activity analysis, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [39] J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y. Duan, A. C. Kot, Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding, IEEE Transactions on Pattern Analysis and Machine Intelligence 42 (10) (2020) 2684–2701. doi:10.1109/TPAMI.2019.2916873.
- [40] L. Xia, C. Chen, J. Aggarwal, View invariant human action recognition using histograms of 3d joints, in: Computer Vision and Pattern Recognition Workshops (CVPRW), 2012 IEEE Computer Society Conference on, IEEE, 2012, pp. 20–27.
- [41] Q. Ke, M. Bennamoun, S. An, F. Sohel, F. Boussaid, A new representation of skeleton sequences for 3d action recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [42] P. Zhang, C. Lan, J. Xing, W. Zeng, J. Xue, N. Zheng, View adaptive recurrent neural networks for high performance human action recognition from skeleton data, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 2117–2126.
- [43] R. Memmesheimer, N. Theisen, D. Paulus, Gimme signals: Discriminative signal encoding for multimodal activity recognition, in: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 10394–10401. doi:10.1109/IROS45743.2020.9341699.
- [44] M. Liu, C. Chen, H. Liu, 3d action recognition using data visualization and convolutional neural networks, in: 2017 IEEE International Conference on Multimedia and Expo (ICME), IEEE, 2017, pp. 925–930.