After: Active Learning Based Fine-Tuning Framework for Speech Emotion Recognition
Abstract
Speech emotion recognition (SER) has drawn increasing attention for its applications in human-machine interaction. However, existing SER methods ignore the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance. Moreover, they require much time to fine-tune on each specific speech dataset, restricting their effectiveness in real-world scenes with large-scale noisy data. To address these issues, we propose an active learning (AL) based Fine-Tuning framework for SER that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training and the downstream task. Then, AL methods are used to iteratively select a subset of the most informative and diverse samples for fine-tuning, reducing time consumption. Experiments demonstrate that using only 20%pt. samples improves 8.45%pt. accuracy and reduces 79%pt. time consumption.
Index Terms— Speech Emotion Recognition, Large-scale Pre-trained Model, Fine-Tuning, Active Learning
1 Introduction
The language of tones is the oldest and most universal of all our means of communication [1]. Speech emotion recognition (SER) aims to identify emotional states conveyed in vocal expressions as an essential topic in tone analysis. It has attracted much attention in both the industrial and academic communities, such as medical surveillance systems [2], psychological treatments [3, 4], and intelligent virtual voice assistants [5].
Emerging SER methods are broadly classified into Classic Machine Learning-based methods and Deep Learning-based methods [6]. The former methods [7, 8, 9] typically consist of three main components: feature extraction, feature selection, and emotion recognition. However, selecting and designing features for specific corpora is time-consuming [10], and they always need better generalization on unseen datasets [11]. Deep learning-based methods can address these issues by automatically extracting more abstract features to improve generalization [12, 13, 14], benefiting from various neural network architectures such as convolutional neural networks (CNN) [15] and Transformers [16]. With the development of pre-trained language models [17] and the availability of large-scale datasets, various pre-trained automatic speech recognition (ASR) models, such as wav2vec 2.0 [18], HuBERT [19] and Data2vec [20], have been proposed. These ASR models use speech’s acoustic and linguistic properties to provide more robust and context-aware representations for speech signals. Xia et al. [21] proved that fine-tuning SER datasets on wav2vec 2.0 [22] obtained state-of-the-art (SOTA) performance on IEMOCAP [23]. This finding inspired researchers to explore new fine-tuning strategies on ASR models, which has become a new paradigm for SER. For example, Ren et al. [24] proposed a self-distillation SER model for fine-tuning wav2vec 2.0 and obtained SOTA performance on the DEMoS dataset [25]. Alef et al. [26] fine-tuned wav2vec 2.0 by jointly optimizing the SER and ASR tasks and achieving SOTA performance in Portuguese datasets.
Although the above methods have achieved great success, several issues still need to be solved. 1) current methods seldom consider the information gap between the pre-trained ASR and downstream SER task. For example, wav2vec 2.0 [18] adopts a masked learning objective to predict missing frames from the remaining context, while the downstream SER [15, 27] task aims to minimize cross-entropy loss between predicted and referenced emotion labels for speech signals. Suchin et al. [28] proved that the information gap would decrease the performance of downstream tasks. To solve it, Pseudo-TAPT [29] first uses K-means to obtain pseudo-labels of speech signals and uses supervised TAPT [28] to continually pre-train. However, K-means is sensitive to the initial value, making Pseudo-TAPT unstable and computationally expensive. 2) current methods only fine-tune and validate the performance on a specific speech dataset. For example, Xia et al. [21] used IEMOCAP, leading to over-fitting and poor generalization for unseen datasets. Real-world scenes contain much heterogeneous and noisy data, which hinders the application of these SER methods. 3) pre-trained ASR models often contain millions of parameters, such as wav2vec 2.0 contains 317 million parameters, which is time-consumption for real-world and large-scale datasets.
To alleviate the above issues, we propose an active learning-based fine-tuning framework for SER (After), which can be easily applied to noisy and heterogeneous real-world scenes. Specifically, we first propose an unsupervised task adaptation pre-training (TAPT) method [28] to reduce the information gap between the pre-trained and downstream SER task, where the pre-trained model can understand the semantic information of the SER task. Then, we created a large-scale heterogeneous and noisy dataset to simulate real-world scenes. Furthermore, we propose AL strategies with clustering-based initialization to iteratively select a smaller, more informative, and diverse subset of samples for fine-tuning, which can efficiently eliminate noise and outliers, improve generalization, and reduce the time-consuming. Experimental results demonstrate the effectiveness and better generalization of After in noisy real-world scenes. Specifically, by fine-tuning only on 20% pt. of the labeled samples, After can improve the unweighted accuracy by 8.45%pt. compared to SOTA methods and reduce time consumption by 79% pt. compared to the fastest baseline.
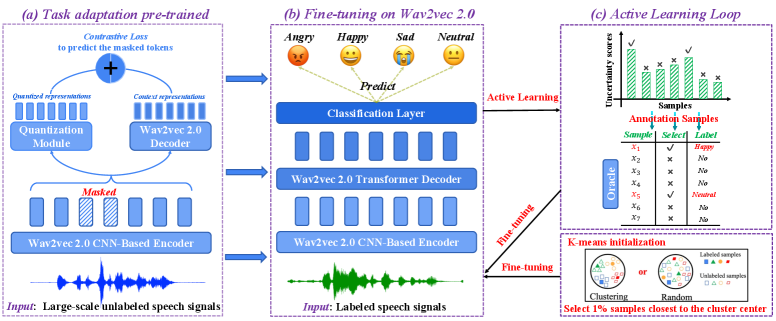
2 Methodology
The overall framework is shown in Figure 1, where After contains three main components: a task adaptation pre-trained module, an active learning-based fine-tuning module and an emotion classification module. First, we will formally give the task definition of SER and subsequently introduce each component of After in detail.
2.1 Task Formulation
Given speech datasets = where represents the -th speech signal and represents its corresponding emotion label. We aim to fine-tune a pre-trained automatic speech recognition model , such as wav2vec 2.0 [29], on labeled speech datasets to obtain accurately predicted emotion labels for all speech signals.
2.2 Task Adaptation Pre-training (TAPT)
Here we introduce our TAPT component in detail. To better leverage pre-trained prior knowledge for the benefit of downstream tasks, Gururangan et al. [28] continue training the pre-trained model RoBERTa [30] on downstream datasets via the same loss of the pre-training task (reconstruct the masked tokens [17]) and significantly improved the performance on text classification. Inspired by their work, we added an extra step to After by continuing the wav2vec 2.0 training speech recognition model on downstream SER’s training datasets while keeping the same loss function with wav2vec 2.0 unchanged. By conducting this process, we bridge the information gap between the pre-trained ASR task and the target SER task, which we have preliminarily confirmed helps according to our experiments in Section 3.2.
As shown in Figure 1 (a), the wav2vec 2.0 model (), with pre-trained weights , consists of three sub-modules: the feature encoder module, the transformer module and the quantization module. Specifically, we use a CNN-based encoder to encode the -th input unlabeled speech signals into low-dimensional vectors as . Then, we randomly mask 15%pt. features (following BERT [17]) of the speech vectors and decode them with two decoders to obtain quantized and context representations, where the quantization decoder can decode continuous speech vectors into discrete code word from phonemes codebooks 111A quantized codebook refers to a set of predetermined values or codewords used to represent a continuous signal in a discrete form [18]. as and wav2vec 2.0 decoder (transformer layers) can use self-attention to decode continuous speech vectors into context-aware representations . Then, we design contrastive loss [18] (cl) to minimize the differences between quantized and context representations as
| (1) |
where the temperature hyperparameter is set to 0.1, and with representing the transposition of a vector. Eq. (1) can help to obtain better quantized and context representations because two decoders can provide highly heterogeneous contexts for each speech signal [31].
To minimize the information gap between the pre-trained model and downstream SER task, following BERT [17], we first randomly mask 15%pt. tokens of each speech signal and then use reconstruction loss on the corrupted downstream SER dataset to generate tokens for reconstructing the original data, which can be formulated as
| (2) |
where is the number of masked tokens, and are the ground-truth and predicted token probability of the -th masked token.
Finally, we combine contrastive loss and reconstruction loss for the TAPT process as
| (3) |
Although Pseudo-TAPT [29] also adopts TAPT, they spent much time using K-means to extract frame-level emotional pseudo labels and continually pre-train their model in a supervised manner. However, K-means is sensitive to the initial value and outliers [32], making Pseudo-TAPT unstable and computationally expensive.
2.3 Active Learning (AL) based Fine-tuning
After the TAPT process, we obtain the model with as the weight initialization for the AL process (cf. Line 1 of Algorithm 1). A typical AL setup starts by treating as a pool of unlabeled data and performs iterations of sample selection. Specifically, in the -th iteration, samples = are selected using a given acquisition function . For example, we adopt Entropy [33] as to measure the uncertainty of the samples and select the most uncertain samples. These selected samples are then labeled and added to the -th training dataset , with which a model is fine-tuned for SER.
One primary goal of After is to explore whether AL strategies can reduce the number of annotation samples, as labeling large-scale datasets is the most laborious part of SER. Thus, for simplicity, we adopt five of the most well-known and influential AL strategies for evaluation, including Entropy [33], Least Confidence [34], Margin Confidence [34], ALPs [35] and BatchBald [36]. These methods use different criteria to help select the most uncertain and informative samples from . For example, we can adopt entropy to measure the uncertainty of as
| (4) |
where is the number of emotional classes and represents the predicted probability of for the -th emotion.
And we select the number of most uncertainty samples for annotation and add them to the training dataset . Traditional AL methods use random initialization, while we found that the AL methods are sensitive to initialized samples and easily select redundant samples or outliers in each AL iteration with a bad initialization. Thus, instead of directly using AL methods, we propose a clustering-based initialization for all AL methods (we use K-means in this study) and obtain better performance (details about K-means are given in Sec 3.2). Please note that, as shown in Algorithm 1, clustering-based initialization is only applied in the initialization process once, and the subsequent AL loop does not need a K-means process.
2.4 Emotion Recognition Classifier
As shown in Figure. 1 (b), we add a task-specific classification layer with additional parameters for emotion recognition on the top of wav2vec 2.0. We fine-tune the classification model in each AL iteration with all labeled samples in (cf. Lines 6-10 of Algorithm 1). We use the cross-entropy loss for the emotion recognition classifier:
| (5) |
where is the number of emotion classes, is the number of slected samples at -th iteration, is the -th predicted label, and is the -th ground-truth of -th class.
| Datasets | Characteristics | |
|---|---|---|
| Number of Samples | Ratio of Four Labels | |
| IEMOCAP [23] (English) | 10,038 | 2.5 : 1.2 : 2.4 : 1.0 |
| EMODB [37] (German) | 408 | 3.1 : 1.3 : 1.0 : 1.1 |
| SHEMO [38] (English) | 2,737 | 5.3 : 5.1 : 2.2 : 1.0 |
| RAVDESS [39] (English) | 672 | 2.0 : 1.0 : 2.0 : 2.0 |
| EMov-DB [40] (English) | 3,038 | 1.4 : 1.0 : 0.0 : 0.0 |
| CREMA-D [41] (English) | 4,900 | 1.0 : 1.7 : 1.0 : 1.0 |
| Merged Dataset | 21,793 | 1.5 : 1.4 : 1.0 : 1.5 |
3 Experiments and Discussions
3.1 Experimental Settings
3.1.1 Datasets
We first evaluated the performance of all baselines using the widely used benchmark dataset, IEMOCAP [23]. IEMOCAP is a multimodal database commonly employed for evaluating SER performance. There are five conversation sessions in IEMOCAP, each with a female and a male actor attempting to act in improvised and scripted scenarios. It consists of 10,039 speech utterances, with all audio signals sampled at 16kHz with a 16 bits resolution. To ensure a fair comparison with previous works, we merge the “excited” class into the “happy” class, resulting in four considered emotions: neutral, happy, angry, and sad. Following Chen et al. [29], we adopted a 5-fold cross-validation approach, where each IEMOCAP session was held out as the test set. We randomly selected 10%pt. data from the remaining four sessions as our validation dataset and the rest as our training dataset.
Most existing methods are inadequate for real-world applications and susceptible to noise due to their heavy reliance on fine-tuning models using specific small-scale datasets. To address this issue, we conducted additional experiments by creating a larger training dataset. We achieved this by merging various datasets from different sources to simulate the noisy environments encountered in real-world scenarios. As shown in Table 1, we manually controlled the number of instances for each of the four labels in the Merged dataset to maintain label balance. Please note that EMODB is a German dataset that can help improve the noise of the merge dataset. To explore whether the Merged dataset could improve performance on a single dataset, such as IEMOCAP, we also employed a 5-fold cross-validation approach by leaving each IEMOCAP session out as the test set, randomly selected 10%pt. dataset from the remaining Merged dataset as our validation dataset, leaving the rest for training purposes. Please note that we only employed the training data for both the TAPT and AL-based fine-tuning processes to prevent data leakage during evaluation. Furthermore, the training procedures were conducted from scratch separately for the IEMOCAP and Merged datasets.
3.1.2 Baselines
We compared various algorithms, including SOTA SER baselines and widely used AL methods. For SER methods, we selected the recently best-performing approaches: GLAM [42], LSSED [43], RH-emo [44], Light [15], Pseudo-TAPT [29], and w2v2-L-r-12 [45]. In terms of AL methods, we opted for the most efficient ones for our framework, which are: Entropy [33], Least Confidence [34], Margin Confidence [34], wav2vec 2.0 & clustering, ALPs [35], and BatchBald [36].
3.1.3 Implementation details
All experiments used the same learning rate with the Adam optimizer. Our implementation of wav2vec 2.0 was based on the Hugging Face framework. The window length of the audio is set to 20 ms. We fine-tuned the model in a few-shot manner, which proposes longer fine-tuning, more evaluation steps during training, and early stopping with 20 epochs based on validation loss. To have a fair comparison with the previous studies, we employed either off-the-shelf software packages or utilized the code provided by the respective authors. Each model was executed ten times, and the average performance across these runs was considered the final result. The choices of (hyper)parameters follow default if provided or tuned if not. Following He et al. [46], we evaluated the models using weighted accuracy (WA) and unweighted accuracy (UA) [47] in speaker-independent settings. Please note that we did not require the data to be labeled by actual annotators. Instead, we used the ground-truth labels available in the training dataset. Specifically, we masked the labels and only revealed them when the AL methods determined that the samples should be labeled, which is a common trick used by AL researchers to test out their ideas [33]. However, it is worth mentioning that human annotators would be responsible for labelling the data in a real-world scenario.
3.2 Active Learning Strategies Selection for After
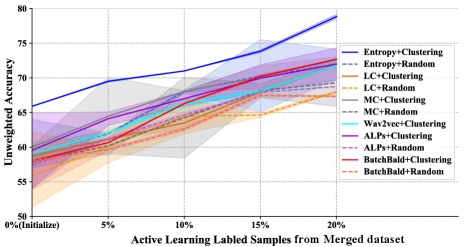
As shown in Figure 1 (c), After incorporates an AL strategy for sample selection. To identify the most suitable AL method for After, we combined it with multiple well-known AL methods and evaluated their performance. Furthermore, we found that AL methods are sensitive to initialization, with most AL methods randomly selecting 1%pt. samples for initialization [48]. Unlike them, we propose a novel clustering-based (K-means) initialization method to improve the performance of SER. Specifically, we first extract sample representations of training data from the wav2vec 2.0 CNN-based encoder. Then, we employed K-means on the training data and selected 1%pt. samples closest to the cluster centres as our initialized samples. Please note that we used elbow method [49] to determine the number of clusters for K-means automatically, and we used the Euclidean distance to measure the distance between sample representations.
Figure 2 demonstrates that the clustering-based initialization outperforms the random initialization for all AL methods. The initial set of samples can well influence the selection order of samples in each iteration of AL, and an effective initialization can significantly enhance the performance and stability of AL methods. Figure 2 illustrates that Entropy+Clustering is the most effective AL strategy for After on the Merge dataset. Although we only show the diagram for UA due to space constraints, the diagram for WA is similar to UA. Therefore, Entropy+Clustering is selected as the primary AL method for After. And we recommend using Entropy+Clustering, the simplest yet most efficient strategy for real-world applications.
| Metric | AFTER (TAPT+ AL-based FT) | |||||
|---|---|---|---|---|---|---|
| 10% | 20% | 40% | 60% | 80% | 100% | |
| UA | 71.45 | 77.41 | 78.64 | 79.32 | 79.26 | 79.15 |
| WA | 69.01 | 74.32 | 75.48 | 76.03 | 75.92 | 75.94 |
| Time (mins) | 262.8 | 316.4 | 785.4 | 942.2 | 1182.6 | 1508.2 |
We analyzed the relationship between the ratio of labeled samples, performance, and time consumption of After. Results in Table 2 show that both performance and time consumption of After increased as the ratio of labeled samples increased. Our findings indicate that using 20%pt. labeled samples yielded a significant improvement in performance while reducing the time consumption by 79%pt. compared to fine-tuning on 100%pt. samples. Thus, we selected 20%pt. labeled samples as a trade-off between performance and time consumption for subsequent experiments.
| Methods | IEMOCAP | Merged Dataset | ||
|---|---|---|---|---|
| UA | WA | UA | WA | |
| GLAM [2022] | 74.01 | 72.98 | 71.38 | 69.28 |
| LSSED [2021] | 73.09 | 68.35 | 25.00 | 36.20 |
| RH-emo [2022] | 68.26 | 67.35 | 43.20 | 42.80 |
| Light [2022] | 70.76 | 70.23 | 69.28 | 71.38 |
| Pseudo-TAPT [2022] | 74.30 | 70.26 | 71.25 | 68.83 |
| w2v2-L-r-12 [2023] | 74.28 | 70.23 | 71.22 | 68.77 |
| After | ||||
3.3 Comparison with Best-performing Baselines
Table 3 displays the primary results of After and the baselines on two datasets regarding unweighted and weighted accuracy. After outperforms all baselines with only 20%pt. labeled samples for fine-tuning. Specifically, After improves UA and WA by 2.38%pt. and 0.36%pt. respectively, compared to the SOTA baseline (UA of Pesdo-TAPT and WA of GLAM), on the Merged dataset. And After improves UA and WA by 8.45%pt. and 4.12%pt. respectively, compared to SOTA baseline (UA of GLAM and WA of Light), on the Merged dataset.
LSSED [43] and RH-emo [44] achieved good results with the IEMOCAP but performed poorly with the Merged dataset. This discrepancy may be attributed to their limited denoising and domain transfer capabilities, preventing them from effectively handling the noise in the Merged dataset. On the other hand, GLAM [42] and Light [15] employed multi-scale feature representations and deep convolution blocks to capture high-level global data features. They are beneficial for filtering out noisy low-level features and enhancing performance on both datasets. Psedp-TAPT [29] improved model robustness by using K-means to capture higher-level frame emotion labels as pseudo labels for supervised TAPT. Although baselines can eliminate the noise of the dataset to a certain extent, they exhibited high time complexity during fine-tuning with large-scale datasets. They did not effectively bridge the gap between pre-training and the downstream SER task. In contrast, After uses unsupervised TAPT to mitigate the information gap between the source domain (ASR) and the target (SER) domain. Additionally, After selects a subset of the most informative and diverse samples for iterative fine-tuning, which has three advantages: Firstly, it reduces labour consumption for manually labelling large-scale SER samples; Secondly, by utilizing a smaller labeled dataset, After significantly reduces the overall time consumption (Figure 3), making it practical and feasible for real-world applications; Finally, the iterative fine-tuning process employed by After improves performance and stability by eliminating noise and outliers present in the selected samples, leading to enhanced overall model performance in SER tasks.
| Methods | Random Sampling | Entropy Sampling | ||||||
|---|---|---|---|---|---|---|---|---|
| FT | TAPT+FT | FT | After | |||||
| UA | WA | UA | WA | UA | WA | UA | WA | |
| 10%pt. | 50.82 | 48.96 | 70.21 | 68.85 | 68.21 | 66.32 | 71.45 | 69.01 |
| 20%pt. | 51.37 | 49.92 | 73.82 | 71.33 | 71.07 | 68.21 | 77.41 | 74.32 |
| 30%pt. | 52.37 | 50.18 | 74.49 | 71.89 | 72.35 | 69.21 | 78.20 | 75.16 |
| 40%pt. | 55.68 | 52.21 | 76.01 | 72.28 | 73.55 | 70.18 | 78.64 | 75.48 |
| 60%pt. | 60.39 | 59.32 | 77.21 | 74.58 | 74.28 | 71.35 | 79.32 | 76.03 |
| 80%pt. | 58.34 | 56.72 | 78.88 | 75.82 | 73.52 | 70.39 | 79.26 | 75.92 |
| 100%pt. | 57.21 | 54.12 | 78.21 | 75.36 | 73.89 | 70.89 | 79.15 | 75.94 |
3.4 Ablation Study for After
We performed an additional ablation study to evaluate the efficacy of After, as shown in Table 4. Specifically, we conducted fine-tuning (FT) and TAPT+FT on random sample selection and AL-based (Entropy) sample selection with varying ratios of labeled samples, ranging from 10%pt. to 100%pt..
From Table 4, we have four interesting observations: (1) Fine-tuning with active learning significantly improves performance compared with random sampling (FT+Entropy vs FT+Random), regardless of the number of labeled samples. This result demonstrates that the AL-based fine-tuning strategy efficiently eliminates noise and outliers and selects the most informative and diverse samples for fine-tuning; (2) TAPT+FT outperforms FT on both random sampling and Entropy sampling, indicating that TAPT can effectively minimize the domain difference and significantly enhance the performance of the downstream SER task; (3) With the same number of labeled samples, After can obtain better results than TAPT+FT+Random on the Merged dataset. However, After with 20%pt. labeled samples performs worse than TAPT+FT+Random with 80%pt.100%pt. labeled samples. The reason is that TAPT+FT uses more labeled data for fine-tuning to prevent the model from overfitting and improve its robustness. In a fair comparison with the same size of the training data for fine-tuning, TAPT+FT+Random with 20%pt. labeled samples performs worse than After(20%pt.), demonstrating the effectiveness of After; (4) when 100%pt. sample is used, AL-based method significantly outperforms random sampling method (FT+Random vs FT+Entropy). The main reason is that Random-sampling is affected by noise data, and the model constantly corrects the classification boundary, making it difficult to improve the results. Entropy sampling avoids the effect of noisy data by selecting the most informative and diverse samples for FT in advance to fix the classification boundary properly.
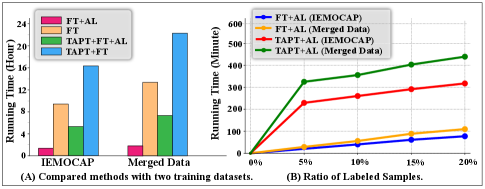
3.5 Time Consumption Comparison
Figure 3 (A) demonstrates that FT+AL with 20%pt. labeled samples significantly reduces the time consumption of FT (fine-tuning on all labeled samples). Compared to TAPT+FT, TAPT+FT+AL significantly decreases the time consumption with the main cost incurred by TAPT. Additionally, the relationship between time consumption and the ratio of labeled samples is shown in Figure 3 (B). AL-based fine-tuning exhibits a linear increase in time consumption with sample size from 1%pt.20%pt. (exponential growth from 30%pt.100%pt. in Table 2), indicating the efficiency of After and its potential to be applied in large-scale unlabeled real-world scenes.
4 Conclusion and Future Work
In this work, we investigated unsupervised TAPT and the AL-based fine-tuning strategy for improving the performance of SER. To extend SER for real-world applications, we constructed a large-scale noisy and heterogeneous dataset, and we used TAPT to minimize the information gap between the pre-trained and the target SER task. Experimental results indicated that After could dramatically improve performance and reduce time consumption. We plan to design more domain adaptation AL methods to solve the SER task in the future.
Acknowledgement
We would like to thank all the reviewers for their valuable suggestions, which helped us improve the quality of our manuscript. And Dongyuan Li acknowledges the support from the China Scholarship Council (CSC).
References
- [1] S. Blanton, “The voice and the emotions,” Quarterly Journal of Speech, vol. 1, no. 2, pp. 154–172, 1915.
- [2] C.Clavel, I.Vasilescu et al., “Feartype emotion recognition for audio-based vasilescusystems,” Speech Communication, vol. 50, no. 6, pp. 487–503, 2008.
- [3] N. Elsayed, Z. ElSayed et al., “Speech emotion recognition using supervised deep recurrent system for mental health monitoring,” CoRR, vol. abs/2208.12812, 2022.
- [4] D. Li, J. You, K. Funakoshi, and M. Okumura, “A-TIP: attribute-aware text infilling via pre-trained language model,” in Proc. of COLING. International Committee on Computational Linguistics, 2022, pp. 5857–5869.
- [5] M.La.Mura and P.Lamberti, “Human-machine interaction personalization: A review on gender and emotion recognition through speech analysis,” in IEEE IoT, 2020, pp. 319–323.
- [6] BJ.Abbaschian, D.Sierra-Sosa, and A.Elmaghraby, “Deep learning techniques for speech emotion recognition, from databases to models,” Sensors, vol. 21, no. 4, pp. 1249–1258, 2021.
- [7] S. Gharsellaoui, S. Selouani, and M. S. Yakoub, “Linear discriminant differential evolution for feature selection in emotional speech recognition,” in Proc. of INTERSPEECH, 2019, pp. 3297–3301.
- [8] G. Paraskevopoulos, E. Tzinis et al., “Unsupervised low-rank representations for speech emotion recognition,” in Proc. of INTERSPEECH, 2019, pp. 939–943.
- [9] Y. Wang, D. Li, K. Funakoshi, and M. Okumura, “EMP: emotion-guided multi-modal fusion and contrastive learning for personality traits recognition,” in Proc. of ICMR, 2023, pp. 243–252.
- [10] M. M. H. E. Ayadi, M. S. Kamel, and F. Karray, “Survey on speech emotion recognition: Features, classification schemes, and databases,” Pattern Recognit., vol. 44, no. 3, pp. 572–587, 2011.
- [11] S. Padi, S. O. Sadjadi et al., “Improved speech emotion recognition using transfer learning and spectrogram augmentation,” in Proc. of ICMI, 2021, pp. 645–652.
- [12] Y. LeCun, Y. Bengio et al., “Deep learning,” Nat., vol. 521, no. 7553, pp. 436–444, 2015.
- [13] E. da Silva Morais, R. Hoory et al., “Speech emotion recognition using self-supervised features,” in Proc. of ICASSP. IEEE, 2022, pp. 6922–6926.
- [14] W. Chen, X. Xing et al., “Vesper: A compact and effective pretrained model for speech emotion recognition,” CoRR, vol. abs/2307.10757, 2023.
- [15] A.Aftab, A.Morsali, and et al., “A lightweight fully convolutional neural network for speech emotion recognition,” in Proc. of ICASSP, 2022, pp. 6912–6916.
- [16] A. Ghriss, B. Yang et al., “Sentiment-aware automatic speech recognition pre-training for enhanced speech emotion recognition,” in Proc. of ICASSP, 2022, pp. 7347–7351.
- [17] M. J.Devlin and et al., “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proc. of naacL-HLT, 2019, pp. 4171–4186.
- [18] A.Baevski, H.Zhou, and et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Proc. of NeurIPS, vol. 33, pp. 12 449–12 460, 2020.
- [19] C. A.Babu and et al., “Xls-r: Self-supervised cross-lingual speech representation learning at scale,” arXiv:2111.09296, 2021.
- [20] Alexei.B, Hsu.W, and et al., “Data2vec: A general framework for self-supervised learning in speech, vision and language,” arXiv:2202.03555, 2022.
- [21] Y. Xia, L. Chen et al., “Temporal context in speech emotion recognition,” in Proc. of INTERSPEECH, 2021, pp. 3370–3374.
- [22] S. Schneider, A. Baevski et al., “wav2vec: Unsupervised pre-training for speech recognition,” in Proc. of INTERSPEECH. ISCA, 2019, pp. 3465–3469.
- [23] M. C.Busso and et al., “IEMOCAP: interactive emotional dyadic motion capture database,” Lang. Resour. Evaluation, vol. 42, no. 4, pp. 335–359, 2008.
- [24] Z. Ren, T. T. Nguyen et al., “Fast yet effective speech emotion recognition with self-distillation,” CoRR, vol. abs/2210.14636, 2022.
- [25] E. Parada-Cabaleiro, G. Costantini et al., “Demos: an italian emotional speech corpus,” Lang. Resour. Evaluation, vol. 54, no. 2, pp. 341–383, 2020.
- [26] G. AIS.Ferreira, “Domain specific wav2vec 2.0 fine-tuning for the se&r 2022 challenge,” CoRR, vol. abs/2207.14418, 2022.
- [27] M. Baruah and B. Banerjee, “Speech emotion recognition via generation using an attention-based variational recurrent neural network,” in Proc. of INTERSPEECH, 2022, pp. 4710–4714.
- [28] G.Suchin, M.Ana, and et al., “Don’t stop pretraining: Adapt language models to domains and tasks,” in Proc. of ACL, 2020, pp. 8342–8360.
- [29] L.Chen and A.Rudnicky, “Exploring wav2vec 2.0 fine-tuning for improved speech emotion recognition,” in Proc. of ICASSP, 2022.
- [30] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized BERT pretraining approach,” CoRR, vol. abs/1907.11692, 2019.
- [31] Y. You, T. Chen, Y. Sui, T. Chen, Z. Wang, and Y. Shen, “Graph contrastive learning with augmentations,” in Proc. of NeurIPS, 2020.
- [32] X. Zhang, Y. He et al., “A robust k-means clustering algorithm based on observation point mechanism,” Complex., vol. 2020, pp. 1–11, 2020.
- [33] R.Nicholas and M.Andrew, “Toward optimal active learning through monte carlo estimation of error reduction,” Proc. of ICML, vol. 2, pp. 441–448, 2001.
- [34] M.Dredze and K.Crammer, “Active learning with confidence,” in Proc. of ACL, 2008, pp. 233–236.
- [35] J. M.Yuan, H.Lin, “Cold-start active learning through self-supervised language modeling,” in Proc. of EMNLP, 2020, pp. 7935–7948.
- [36] A.Kirsch, Jv.Amersfoort, and Y.Gal, “Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning,” in Proc. of NeurIPS, 2019, pp. 7024–7035.
- [37] F.Burkhardt1, A.Paeschke, and et al., “A database of german emotional speech,” in Proc. of INTERSPEECH. ISCA, 2005, pp. 1517–1520.
- [38] M. OM.Nezami, PJ.Lou, “Shemo: a large-scale validated database for persian speech emotion detection,” Language Resources and Evaluation, vol. 53, no. 1, pp. 1–16, 2019.
- [39] SR.Livingstone and FA.Russo, “The ryerson audio-visual database of emotional speech and song,” PLOS ONE, vol. 13, no. 5, pp. 1–35, 05 2018.
- [40] A.Adaeze, T.Noé, and et al., “The emotional voices database: Towards controlling the emotion dimension in voice generation systems,” arXiv:1806.09514, 2018.
- [41] H.Cao, DG.Cooper, and et al., “CREMA-D: crowd-sourced emotional multimodal actors dataset,” IEEE Trans. Affect. Comput., vol. 5, no. 4, pp. 377–390, 2014.
- [42] W.Zhu and X.Li, “Speech emotion recognition with global-aware fusion on multi-scale feature representation,” in Proc. of ICASSP, 2022.
- [43] X. W.Fan and et al., “Lssed: A large-scale dataset and benchmark for speech emotion recognition,” in Proc. of ICASSP, 2021.
- [44] E.Guizzo, T.Weyde, and et al., “Learning speech emotion representations in the quaternion domain,” CoRR, vol. abs/2204.02385, 2022.
- [45] J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. W. Schuller, “Dawn of the transformer era in speech emotion recognition: Closing the valence gap,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–13, 2023.
- [46] Y. He, N. Minematsu, and D. Saito, “Multiple acoustic features speech emotion recognition using cross-attention transformer,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [47] A.Metallinou, S.Lee, and et al., “Decision level combination of multiple modalities for recognition of emotional expression,” in Proc. of ICASSP, 2010, pp. 2462–2465.
- [48] K. Margatina, G. Vernikos et al., “Active learning by acquiring contrastive examples,” in Proc. of EMNLP. Association for Computational Linguistics, 2021, pp. 650–663.
- [49] R. Sammouda and A. El-Zaart, “An optimized approach for prostate image segmentation using k-means clustering algorithm with elbow method,” Comput. Intell. Neurosci., vol. 2021, pp. 4 553 832:1–4 553 832:13, 2021.