AI Coach Assist: An Automated Approach for Call Recommendation in Contact Centers for Agent Coaching
Abstract
In recent years, the utilization of Artificial Intelligence (AI) in the contact center industry is on the rise. One area where AI can have a significant impact is in the coaching of contact center agents. By analyzing call transcripts using Natural Language Processing (NLP) techniques, it would be possible to quickly determine which calls are most relevant for coaching purposes. In this paper, we present “AI Coach Assist”, which leverages the pre-trained transformer-based language models to determine whether a given call is coachable or not based on the quality assurance (QA) questions asked by the contact center managers or supervisors. The system was trained and evaluated on a large dataset collected from real-world contact centers and provides an effective way to recommend calls to the contact center managers that are more likely to contain coachable moments. Our experimental findings demonstrate the potential of AI Coach Assist to improve the coaching process, resulting in enhancing the performance of contact center agents.
1 Introduction
AI has the potential to revolutionize many industries, including the contact center industry. With the growing demand for high-quality customer service, contact centers are constantly seeking ways to improve their processes and enhance their agents’ performance. One way to achieve this goal is by providing effective coaching and feedback to agents, which can help them identify areas of improvement and develop the necessary skills to provide exceptional customer service. As a common practice, contact center managers or supervisors manually select call recordings to listen in, and grade agents’ performance using a rubric that contains questions such as “did the agent greet the customer by name" or “did the agent properly resolve the customer issue" to score the call in order to verify if the agent is following the company’s preferred protocol. The grades given by the managers along with their comments are then shared with the agents to improve their performance. However, with the large volume of calls that contact centers receive, it is very challenging for managers or supervisors to determine which calls are most important for agent coaching. Thus, the traditional approaches to randomly select calls for agent coaching has the following limitations:
-
•
Time-consuming process: Coaching agents can be a time-consuming process, particularly for managers and supervisors who must manually review large numbers of calls to identify which calls are most relevant for coaching.
-
•
Inefficient use of resources: Without an efficient and effective process for determining which calls are most relevant for coaching, resources may be wasted on calls that are not critical for improving agent performance.
This is where NLP could be useful. By analyzing call transcripts using NLP models, it could be possible to recommend calls to the contact center managers/supervisors that are most relevant for coaching purposes. This will lead to an improved coaching experience by prioritizing the calls for analysis that are more likely to contain coachable moments, resulting in saving time for the contact center managers as well as improving agent performance, ultimately leading to better customer satisfaction. For the purpose of improving real-world contact centers, we present the AI Coach Assist system to assist contact center managers or supervisors by suggesting calls that could be more useful for agent coaching.
In this paper, we explore the concept of our proposed AI Coach Assist system, which leverages the advantage of fine-tuning a pre-trained transformer-based language model Devlin et al. (2019); Sanh et al. (2019); Liu et al. (2019); Lan et al. (2020); Zhong et al. (2022). Moreover, we provide a detailed overview of its development process (implementation and preparation of a balanced dataset to avoid biases), as well as our experimental findings. In addition, we demonstrate how it could be productionized in real-world contact centers to assist managers/supervisors. Note that our model does not automate the scoring of employee performance or replace human review. Instead, our model is intended to help contact center supervisors by recommending calls for coaching their employees instead of the traditional random sampling of calls.
2 Related Work
The significant performance gain achieved via leveraging transformer-based language models Vaswani et al. (2017); Devlin et al. (2019); Liu et al. (2019); Lan et al. (2020) in a wide range of NLP tasks in recent years has also led to the use of transformer-based models in the contact center industry Laskar et al. (2022b, c, a); Khasanova et al. (2022). The successful deployment of these models in industries has helped many organizations to enhance their processes, resulting in improved customer satisfaction. In recent years, several studies Fu et al. (2022a, b) have explored the potential of AI-powered call analysis (e.g., entity recognition, sentiment analysis, etc.), along with providing real-time assistance to contact center agents.
In addition to these studies, several commercial solutions have been developed that offer AI-powered call analysis and AI assistance for agents in contact centers. Some of these solutions also offer real-time feedback to agents during calls111https://cloud.google.com/solutions/contact-center, accessed in Feb 2023.222https://cresta.com/product/agent-assist/, accessed in Feb 2023.333https://www.five9.com/products/capabilities/agent-assist, accessed in Feb 2023, allowing them to adjust their behavior and improve their performance in real-time. However, to the best of our knowledge, there is no prior commercial application that assists contact center managers by suggesting calls that could be the most useful to coach agents.
One potential approach for this purpose could be the use of automatic call recommendation, where calls are analyzed using NLP techniques and suggested to the contact center managers based on various factors, such as agents’ behavior, issue resolution, customer satisfaction, sales success, etc. These suggested calls can then be analyzed by the managers for coaching purposes to provide relevant feedback to agents. In this regard, we propose AI Coach Assist, a system that leverages the transformer architecture to effectively analyze the full call transcripts in contact centers and recommends contact center managers with calls that are more likely to contain coachable moments for a given query. In the following section, we describe how we construct a dataset, which we denote as QA Scorecard, to train and evaluate our proposed AI Coach Assist system.
| Split | Total Samples | Not Coachable | Coachable | Avg. Question Length | Avg. Transcript Length |
|---|---|---|---|---|---|
| Training | 12065 | 6521 | 5544 | 9.77 | 659.53 |
| Validation | 1653 | 891 | 762 | 9.62 | 664.55 |
| Test | 3435 | 1855 | 1580 | 9.77 | 727.77 |
| Question Type | Example Question |
|---|---|
| Account Verification | Did the agent verify the customer’s email address? |
| Addressing Customer | Did the agent use the customer’s name appropriately? |
| Behavioral | Did the agent show proper empathy statements? |
| Closing | Did the agent properly end the call? |
| Providing Complete Information | Did the agent mention the payment terms in detail? |
| Customer Identification | Did the agent verify the customer’s information? |
| Customer Satisfaction | Was the customer happy? |
| Greeting | Did the agent properly greet the customer? |
| Information Collection | Did the agent collect all necessary information from the customer? |
| Issue Identification | Could the agent properly identify the issue? |
| Issue Resolution | Could the agent resolve the issue? |
3 The QA Scorecard Dataset
We collected our data from real-world contact centers. The dataset consists of customer-agent call conversation transcripts generated using Automatic Speech Recognition (ASR) systems, along with annotations indicating whether a call is coachable or not. The process of annotating the dataset was carefully designed and implemented, as the annotations were performed by real-world contact center managers and supervisors who analyzed the whole conversation/transcript. In this way, we ensure the high quality of the dataset.
The data annotation works as follows, the managers/supervisors assign a score to the call based on the performance of the agent for a particular question. We consider a call as coachable for a particular question if the call achieves less than 50% scores, otherwise, we consider the call for that particular question as not coachable. The dataset was collected over a period of one year and includes a diverse range of call types from different industries, with a variety of customer interactions, reflecting the real-world complexities of the contact center industry. The resulting dataset consists of a large number of call transcripts and annotations, providing a robust representation of real-world customer-agent interactions.
Note that a total of 58 questions are curated, which are distributed among training, validation, and test sets. While constructing the training, validation, and test splits, we observe that the class distribution (whether coachable or not coachable) for many question-transcript pairs was imbalanced. Thus, to ensure an unbiased dataset (as well as to avoid model overfitting), for each question, we ensured that the ratio between coachable and not coachable classes (or vice-versa) to be at most 1:2. In Table 1, we describe the distribution of our dataset based on our training, validation, and test set. Meanwhile, to evaluate the performance of AI Coach Assist based on the type of the questions, we also categorize the questions into 11 types using human annotators. We show the question types with example questions for each type in Table 2.
4 Our Proposed Approach
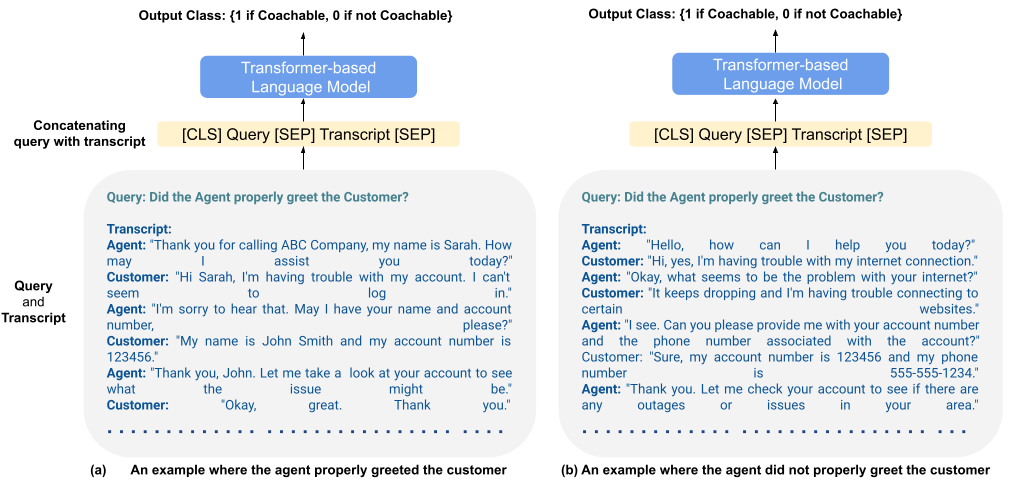
We treat the AI Coach Assist model as a text classification model that combines the query/question given by the contact center manager or supervisor with the call transcript to predict whether a given call is coachable or not. Due to the recent success of fine-tuning pre-trained transformer models for text classification Devlin et al. (2019); Liu et al. (2019); Lan et al. (2020), we also leverage the pre-trained language models based on the transformer architecture for this task.
As we are doing text classification instead of generation, we give input data to the pre-trained language model as follows (see Figure 1): at first, we create a text sequence by concatenating the question and the call transcript. Then, this concatenated text sequence is given as input to the language model to learn the contextual relationship between the sentences. The pre-trained transformer language model is fine-tuned to output a probability score for each input sequence, indicating the likelihood that the call is coachable or not, for the given question. Whether a question-transcript pair is coachable or not coachable is determined based on the probability score of the class having the higher score.
Since our objective is to build the AI Coach Assist system for real-world contact centers, we consider the following two cases while selecting the pre-trained language models:
(i) Utilize a model to ensure high efficiency:
We choose DistilBERT Sanh et al. (2019) for this scenario. DistilBERT is a distilled version of BERT Devlin et al. (2019), designed to be smaller and faster while retaining a similar level of performance. Despite its smaller size, DistilBERT has been shown to perform similarly to BERT on many NLP tasks, making it a suitable alternative for many NLP applications. This makes it a popular choice for real-world scenarios where computational resources are limited but the preference is to deploy a fast and optimize model in production.
(ii) Utilize a model to ensure higher accuracy:
For this purpose, we leverage the DialogLED model Zhong et al. (2022), which was pre-trained on long dialog conversations, having more similarities with our customer-agent conversation dataset. Though in comparison to DistilBERT, the DialogLED model may require higher computational resources for production deployment, it fulfills our criteria of using a model that may provide higher accuracy for being pre-trained on long dialog conversations, mimicking the customer-agent conversations in the real world. In addition, DialogLED can also process long text sequences, contrary to the 512-token limit of most transformer-based models Devlin et al. (2019); Sanh et al. (2019); Liu et al. (2019); Lan et al. (2020). This makes DialogLED a suitable choice to build the AI Coach Assist system since the average length of the transcripts in our QA scorecard dataset is longer than 512 words.
5 Experiments
In this section, we first present the experimental settings and the implementation details of our proposed model. Then we discuss our experimental findings in detail.
5.1 Implementation
For the DialogLED model, we adopt the DialogLED-base444https://huggingface.co/MingZhong/DialogLED-base-16384 model from the HuggingFace library Wolf et al. (2020). Specifically, we used the LEDForSequenceClassification which adds a classification head on top of the LED (Longformer-Encoder-Decoder) model Beltagy et al. (2020). We ran our experiments in GCP555https://console.cloud.google.com/ on an n1-standard-32 machine with 4 Nvidia T4 GPUs. A total of epochs were run, with the training batch size set to 666Larger batch size leads to Out of GPU Memory errors., and the maximum sequence length set to . The learning rate was set to . For the DistilBERT model, we leverage its base model from HuggingFace777https://huggingface.co/distilbert-base-cased. We also set the learning rate for DistilBERT to and ran 3 epochs with the training batch size set to 16 while the maximum sequence length set to . Note that for both models, these hyperparameters were tuned based on the performance in the validation set. The best-performing method in the validation set was then used for evaluation on the test set.
5.2 Results & Discussions
In this section, we first present the results of our base models. Then we conduct some ablation tests and also compare our proposed models with some classical machine learning baselines to further validate the effectiveness of our approach. Finally, we study the advantages and limitations of our model based on various question types.
| Model | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|
| DialogLED | 67.92 | 63.72 | 65.76 | 70.52 |
| DistilBERT | 62.53 | 58.39 | 60.39 | 66.25 |
| Model | Precision | Accuracy |
|---|---|---|
| DialogLED | 67.92 | 70.52 |
| - without query | 57.76 | 62.83 |
| - reduced sequence length = 512 | 66.01 | 67.52 |
| - reduced sequence length = 256 | 63.15 | 63.64 |
| DistilBERT | 62.53 | 66.25 |
| - without query | 59.32 | 61.22 |
5.2.1 Performance of the Base Models
In this section, we compare the performance of using DialogLED and DistilBERT as the base model for the AI Coach Assist system. Though we consider precision and accuracy as the main criteria for the production deployment of this system, for this performance evaluation we also consider recall and f1 in addition to precision and accuracy.
We observe from our results given in Table 3 that the DialogLED model outperforms its counterpart DistilBERT model in terms of all metrics (precision, recall, f1, and accuracy). The DialogLED-based model also ensures scores above 60 in all 4 metrics. Moreover, in terms of accuracy and f1, it achieves a score of 70.52 and 65.76, respectively. Meanwhile, both models achieve comparatively lower recall scores, noticeably the DistilBERT model achieves a recall score even below 60. However, in our criteria for production deployment, a highly precise model is more important, with both DialogLED and DistilBERT achieving higher precision scores (67.92 and 62.53, respectively) in comparison to their recall scores (63.72 and 58.39, respectively).
The superior performance using DialogLED over DistilBERT in all these metrics demonstrates the effectiveness of fine-tuning a language model for contact center telephone transcripts that is pre-trained on dialog conversations. Moreover, since customer-agent conversations can also be quite long and may not fit within the 512 tokens limit of DistilBERT-like models (as shown in Table 1), the ability of DialogLED to process input text of larger size may also help it to achieve better performance. In the following section, we conduct some ablation studies to further investigate the effectiveness of our models.
| Model | Precision | Accuracy |
|---|---|---|
| TF-IDF + SVM | 57.9 | 57.7 |
| TF-IDF + Decision Tree | 58.0 | 60.8 |
| TF-IDF + Random Forest | 59.3 | 60.1 |
| TF-IDF + Naïve Bayes | 52.5 | 53.3 |
| DialogLED | 67.9 | 70.5 |
| DistilBERT | 62.5 | 66.3 |
5.2.2 Ablation Studies
In this section, we conduct some ablation studies to investigate our approach of concatenating the query and the transcript as input for our transformer-based language models (DialogLED/DistilBERT), as well as how the sequence length impacts the overall performance of DialogLED. We show the results from our ablation study in Table 4.
For our first ablation test, we remove the query from the input text to better study the relationship between the query and the transcript. We find that for both models the accuracy is dropped by a great margin if the query is removed. The removal of the query from the input text leads to an accuracy drop of 10.90% for DialogLED and 8.03% for DistilBERT. In terms of precision, the performance is deteriorated by 14.96% and 5.13%, for DialogLED and DistilBERT, respectively. These findings demonstrate that the model learns to predict the coachable and not coachable moments in transcripts for the given query based on the concatenated representation of the query and the transcript.
For our other ablation test, we reduce the input sequence length from our DialogLED model. We find that reducing the input sequence length from 1024 to 512 and 256 leads to a huge drop in accuracy (dropped by 4.71% and 9.76%, respectively) and precision (dropped by 2.81% and 7.02%, respectively). This demonstrates the effectiveness of using the DialogLED model which can process longer input sequences.
Moreover, we observe that when the size of the input sequence length for DialogLED is 512 (same as DistilBERT), it still outperforms DistilBERT in terms of both accuracy and precision. This further gives an implication that the utilization of a model that is pre-trained on conversational data is more helpful to improve the performance of the Ai Coach Assist system.
5.2.3 Performance against other Baselines
In this section, we compare our proposed models for the AI Coach Assist system: DialogLED and DistilBERT, with some baseline models to further study their effectiveness. Below, we describe the baseline models that we use for comparisons:
TF-IDF with Classical Machine Learning Models as Baselines: We use TF-IDF as keyword-based features for some classical machine learning models, such as Support Vector Machine (SVM) Hearst et al. (1998), Random Forest Ho (1995), Decision Tree Rokach and Maimon (2005), and Naïve Bayes Webb et al. (2010), as our baseline models for comparisons. We show our experimental results in Table 5 to observe that both of our proposed models (the DialogLED model which obtains the highest accuracy and the DistilBERT model which ensures high efficiency) for AI Coach Assist outperform all TF-IDF feature-based classical machine learning approaches. On Average, the DistilBERT model and the DialogLED model outperform the baseline models by 8.97% and 12.48% in terms of precision, while 16.20% and 17.78% in terms of accuracy, respectively.
5.2.4 Performance based on Question Types
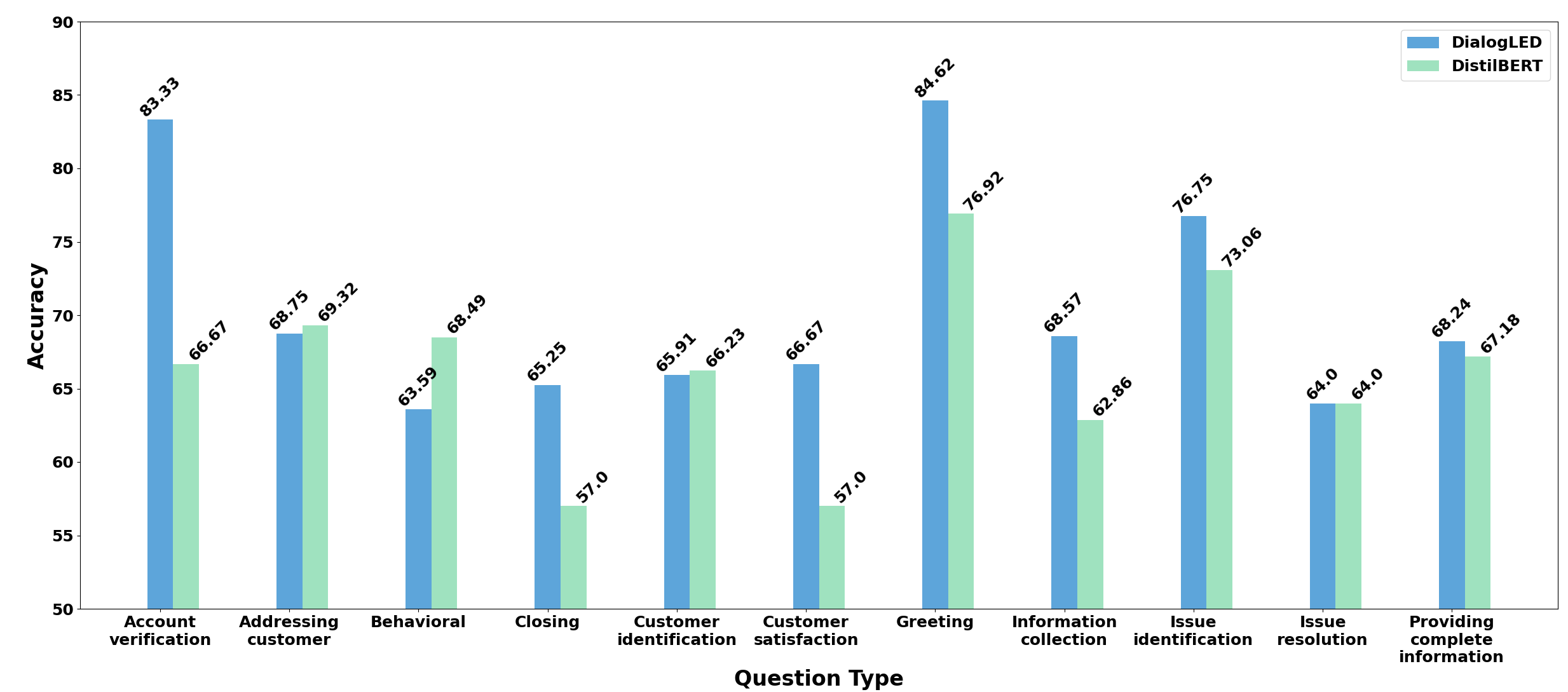
In this section, we conduct an in-depth analysis of the proposed models for AI Coach Assist: DialogLED and DistilBERT. For our analysis, we investigate their performance in different question types. In Figure 2, we show their accuracy on each question type. We observe that for most question types, DialogLED outperforms DistilBERT (the only exceptions are the following question types: Addressing Customer, Behavioural, and Customer Identification). Among the questions where DialogLED outperforms DistilBERT (7 out of 11), the highest performance gains are in question types that are of Greeting and Account Verification. For Greeting, it achieves the best accuracy with a score of 84.62, while for Account Verification, the accuracy is 83.33. Meanwhile, even though the DialogLED model achieves an accuracy of at least 60 for all question types, the DistilBERT model achieves quite low scores for some question types (e.g., only 57% scores for Closing type and Customer Satisfaction type questions). For the DialogLED model, it finds the Behavioral and the Issue Resolution type questions most challenging, as its accuracy drops below 70. Among these two question types, the Behavioral question type achieves the lowest accuracy score of 63.59, followed by Issue Resolution, with an accuracy of 64.0.
6 Usage in Real World Contact Centers
In this section, we discuss how the AI Coach Assist system can be used in real-world contact centers. Since determining the calls that are coachable is not required in real-time, rather they are required after the call is over, the inference speed of the model may not be an issue in this regard. Moreover, for contact centers where the computing resource is not a problem, our DialogLED-based model could be used, as it achieves better accuracy than its DistilBERT counterpart. Since the size of the trained DialogLED model is 648 MB, the DistilBERT model which takes only 263 MB could be used in scenarios where the computing resource is limited.
We also prototype our proposed system for usage in a real contact center. Since directly predicting a score to a call might impact the evaluation of agent performance in contact centers, as such metrics could be used by managers for performance evaluation of agents, in our prototype we rather recommend a list of calls to the managers that are highly likely to contain coachable moments for a particular question type. Thus, instead of using those calls for a direct performance evaluation of agents, the managers still require to listen to the conversation or read the ASR-generated transcript. More particularly, using our proposed AI Coach Assist, we help the managers with a list of calls that they may use to manually grade agent performance, contrary to the existing methods of random call selection. In this way, the proposed prototype of AI Coach Assist may not cause any ethical concerns.
7 Conclusion
In this paper, we presented AI Coach Assist, a transformer-based pairwise sentence classification model that combines the query/question given by the contact center manager or supervisor with the call transcript to determine which calls are most relevant for coaching purposes. The evaluation results demonstrate the potential of AI Coach Assist to transform the way contact centers coach their agents, providing an efficient and effective method that recommends calls that are the most relevant for coaching purposes. This will help to improve the coaching process and enhance the performance of contact center agents, leading to better customer satisfaction. Note that our model is intended to help contact center supervisors to be more effective in coaching their employees by improving over the random sampling of calls. The model does not automate the evaluation of employee performance by replacing human review.
In the future, we will study how to improve the performance on the question types where the model performs poorly. We will also study how to utilize other question-answering models Laskar et al. (2020, 2022d) or leverage generative large language models OpenAI (2023); Anil et al. (2023) that can point out the reason for a call being coachable and not coachable.
Limitations
As our models are trained on customer-agent conversations in English, they might not be suitable to be used in other domains, types of inputs (i.e written text), or languages. Moreover, as we demonstrated in the paper that the model has limitations in certain question types, the user needs to decide which question types to be used when deploying the system in production. Though the DialogLED model performs better, it requires higher computing resources. On the contrary, even though the DistilBERT model consumes lower memory, its performance is poorer than the DialogLED model.
Ethics Statement
-
•
Data Annotation: Since the calls are annotated by real-world contact center managers/supervisors, we did not require any additional compensation for this annotation. Rather, we develop a system where the managers/supervisors put their scores for different call conversations in their contact centers. To map the questions to different question types, Labelbox888https://labelbox.com/ was used for data annotation and the annotators were provided with adequate compensation (above minimum wages).
-
•
Privacy: There is a data retention policy available so that the call transcripts will not be used if the user does not give permission to use their call conversations for model training and evaluation. To protect user privacy, sensitive data such as personally identifiable information (e.g., credit card number, phone number) were removed while collecting the data.
-
•
Intended Use by Customers: Note that our model is intended to help contact center supervisors to be more effective in coaching their employees by improving over the random sampling of calls. The model does not automate the scoring of employee performance or replace human review.
-
•
Prevention of Potential Misuses: Below, we discuss some of the potential misuses of the system and our suggestions to mitigate them:
(i) Automatic Performance Reviews of Agents by Considering all Recommended Calls as Bad Calls: One potential misuse of the system could be the evaluation of agent performance by considering all recommended calls as bad calls without any manual review of the call. To mitigate this, we can do the following:
-
–
Contact center supervisors that use this system must be properly instructed that this system does not determine whether an agent performs badly in a certain call. Rather, the intention of the proposed system is to only suggest a set of calls to the managers (instead of randomly selecting calls) that they need to manually review to determine whether the agent requires coaching or not.
(ii) Considering Agents with More Recommended Calls as an Indicator to Poorer Agent Performance: Another potential misuse of the system is if contact center managers start considering that if more calls are recommended by our system for a particular agent, then the agent is more likely to perform poorly. To prevent this, we can do the following:
-
–
We may suggest some positive calls as well as negative calls to the managers. Here, positive calls are the ones that our system rates with a very high score and categorizes as not requiring any coaching. Whereas negative calls are the ones that our system rates with quite lower scores and classifies as coaching required. To avoid any misuse of the suggested calls, the proposed AI Coach Assist system should never reveal to the managers whether a call requires coaching or not. Rather it should only allow the managers to make the final decision on whether the call is a positive call or a negative call. Once the suggested calls are manually reviewed by the managers and categorized as positive by them, these calls can then be used to train other agents that require improvement in certain areas, whereas a call categorized as negative can be used to train a particular agent who did not perform well (i.e., requires coaching) in that specific call.
-
–
In addition, to avoid suggesting too many calls for the same agent, the system may suggest only a certain number of calls (not above a pre-defined limit) per agent to the managers.
(iii) Using Bad Questions For Model Development: In some contact centers, there may be questions that are used for evaluating agent performance which may contain any potential biases toward a specific race or gender. We can prevent this in the following way:
-
–
The system should only respond to a pre-selected set of questions that were used during the training phase of the model. Any questions that may pose any ethical concerns or potential biases should not be used while training the model such that these questions can also be automatically ignored during the inference phase.
-
–
-
•
License: We maintained the licensing requirements accordingly while using different tools (e.g., HuggingFace).
Acknowledgements
We appreciate the reviewers for their excellent review comments that helped us to improve the quality of this paper. We would also like to thank Shayna Gardiner and Elena Khasanova for reviewing the ethical concern of the proposed system.
References
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Beltagy et al. (2020) Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv:2004.05150.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Fu et al. (2022a) Xue-yong Fu, Cheng Chen, Md Tahmid Rahman Laskar, Shayna Gardiner, Pooja Hiranandani, and Shashi Bhushan Tn. 2022a. Entity-level sentiment analysis in contact center telephone conversations. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 484–491, Abu Dhabi, UAE. Association for Computational Linguistics.
- Fu et al. (2022b) Xue-Yong Fu, Cheng Chen, Md Tahmid Rahman Laskar, Shashi Bhushan Tn, and Simon Corston-Oliver. 2022b. An effective, performant named entity recognition system for noisy business telephone conversation transcripts. In Proceedings of the Eighth Workshop on Noisy User-generated Text (W-NUT 2022), pages 96–100, Gyeongju, Republic of Korea. Association for Computational Linguistics.
- Hearst et al. (1998) Marti A. Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf. 1998. Support vector machines. IEEE Intelligent Systems and their applications, 13(4):18–28.
- Ho (1995) Tin Kam Ho. 1995. Random decision forests. In Proceedings of 3rd international conference on document analysis and recognition, volume 1, pages 278–282. IEEE.
- Khasanova et al. (2022) Elena Khasanova, Pooja Hiranandani, Shayna Gardiner, Cheng Chen, Simon Corston-Oliver, and Xue-Yong Fu. 2022. Developing a production system for Purpose of Call detection in business phone conversations. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Track, pages 259–267, Hybrid: Seattle, Washington + Online. Association for Computational Linguistics.
- Lan et al. (2020) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. ALBERT: A lite BERT for self-supervised learning of language representations. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Laskar et al. (2022a) Md Tahmid Rahman Laskar, Cheng Chen, Xue-yong Fu, and Shashi Bhushan Tn. 2022a. Improving named entity recognition in telephone conversations via effective active learning with human in the loop. In Proceedings of the Fourth Workshop on Data Science with Human-in-the-Loop (Language Advances), pages 88–93, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
- Laskar et al. (2022b) Md Tahmid Rahman Laskar, Cheng Chen, Jonathan Johnston, Xue-Yong Fu, Shashi Bhushan TN, and Simon Corston-Oliver. 2022b. An auto encoder-based dimensionality reduction technique for efficient entity linking in business phone conversations. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3363–3367.
- Laskar et al. (2022c) Md Tahmid Rahman Laskar, Cheng Chen, Aliaksandr Martsinovich, Jonathan Johnston, Xue-Yong Fu, Shashi Bhushan Tn, and Simon Corston-Oliver. 2022c. BLINK with Elasticsearch for efficient entity linking in business conversations. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Track, pages 344–352, Hybrid: Seattle, Washington + Online. Association for Computational Linguistics.
- Laskar et al. (2022d) Md Tahmid Rahman Laskar, Enamul Hoque, and Jimmy Xiangji Huang. 2022d. Domain adaptation with pre-trained transformers for query-focused abstractive text summarization. Computational Linguistics, 48(2):279–320.
- Laskar et al. (2020) Md Tahmid Rahman Laskar, Xiangji Huang, and Enamul Hoque. 2020. Contextualized embeddings based transformer encoder for sentence similarity modeling in answer selection task. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 5505–5514.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Rokach and Maimon (2005) Lior Rokach and Oded Maimon. 2005. Decision trees. Data mining and knowledge discovery handbook, pages 165–192.
- Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR, abs/1910.01108.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008.
- Webb et al. (2010) Geoffrey I Webb, Eamonn Keogh, and Risto Miikkulainen. 2010. Naïve bayes. Encyclopedia of machine learning, 15:713–714.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45.
- Zhong et al. (2022) Ming Zhong, Yang Liu, Yichong Xu, Chenguang Zhu, and Michael Zeng. 2022. Dialoglm: Pre-trained model for long dialogue understanding and summarization. In Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022 Virtual Event, February 22 - March 1, 2022, pages 11765–11773. AAAI Press.