AI-Generated Image Quality Assessment Based on Task-Specific Prompt and Multi-Granularity Similarity
Abstract
Recently, AI-generated images (AIGIs) created by given prompts (initial prompts) have garnered widespread attention. Nevertheless, due to technical nonproficiency, they often suffer from poor perception quality and Text-to-Image misalignment. Therefore, assessing the perception quality and alignment quality of AIGIs is crucial to improving the generative model’s performance. Existing assessment methods overly rely on the initial prompts in the task prompt design and use the same prompts to guide both perceptual and alignment quality evaluation, overlooking the distinctions between the two tasks. To address this limitation, we propose a novel quality assessment method for AIGIs named TSP-MGS, which designs task-specific prompts and measures multi-granularity similarity between AIGIs and the prompts. Specifically, task-specific prompts are first constructed to describe perception and alignment quality degrees separately, and the initial prompt is introduced for detailed quality perception. Then, the coarse-grained similarity between AIGIs and task-specific prompts is calculated, which facilitates holistic quality awareness. In addition, to improve the understanding of AIGI details, the fine-grained similarity between the image and the initial prompt is measured. Finally, precise quality prediction is acquired by integrating the multi-granularity similarities. Experiments on the commonly used AGIQA-1K and AGIQA-3K benchmarks demonstrate the superiority of the proposed TSP-MGS.
1 Introduction









Artificial Intelligence-Generated Content (AIGC), especially AI-generated images (AIGIs), attracts wide attention across various fields due to its flexibility and convenience. Recent advancements in Text-to-Image (T2I) generation models, such as Generative Adversarial Networks (GANs) [63, 55], regression-based models [4, 32], and diffusion-based models [66, 17], allow diverse AI-generated images to be available. However, the quality of AI-generated images is inconsistent due to the instability of generation techniques, limiting the broader applications of these images. Therefore, developing effective quality assessment models is essential for improving the generation model’s capabilities and selecting high-quality AI-generated images.
Over recent decades, general-purpose image quality assessment (IQA) methods have made substantial progress, which primarily focus on images degraded by artificial distortions [36, 18, 21], such as compression, noise, and blurring, as well as images captured in the wild [10, 13, 6, 60]. They evaluate perception quality based on the distortion properties extracted from global images or local image patches [25, 15, 11, 34, 54]. However, degradations of AIGIs are unique [70, 19], making these methods inapplicable. Specifically, AIGIs usually do not align with the initial prompts due to the poor prompt comprehension of generative models, as shown in Fig. 1(a). Additionally, AIGIs often exhibit low perception quality for the limited generation capabilities of generative models, as illustrated in Fig. 1(b). Therefore, an effective method is required to evaluate both the alignment and perception quality of AIGIs.
To this end, advanced AIGC image quality assessment (AIGCIQA) methods have been proposed over the last few years and can be broadly categorized into three types. The first type [53, 51, 16, 19] evaluates human preference for AIGIs but falls short in proving a thorough understanding of quality. The second type [28, 5, 7] employs vision-language models (VLMs), such as CLIP [31], to evaluate the alignment and perception quality of AIGIs. They construct task prompts based on the initial prompts and use the same task prompts to guide the above evaluation learning. However, such task prompts tend to favor alignment quality prediction, which reduces the model’s effectiveness in predicting perception quality. The third type [30, 56] introduces an additional single-modal image encoder to boost perception quality evaluation while using VLMs for alignment quality assessment. Although this design is effective, it increases the model’s complexity.
To address the above challenges, we propose an advanced AIGCIQA method named TSP-MGS. To resolve task ambiguity caused by shared task prompts, we design task-specific prompts for alignment and perception quality predictions to describe the quality degree, which enhances the model’s perception of the two tasks. Considering that initial prompts provide rich descriptions of AIGI details, we introduce them to guide the model’s detail awareness. The above methods only consider the coarse-grained similarity between AIGIs and prompts, neglecting the important detail distortions. To address this, we present the multi-granularity similarity measurement for a comprehensive quality evaluation. Specifically, the sentence-level (coarse-grained) similarity between AIGIs and their task-specific prompts is measured to capture overall quality-aware representations. Then, the word-level (fine-grained) similarity between AIGIs and their initial prompts is calculated to learn detailed quality-aware representations. By integrating the coarse-grained and fine-grained similarities, we achieve precise quality prediction of AIGIs.
The main contributions of this paper are summarized as follows:
-
•
We design task-specific prompts to describe alignment and perception quality degree, improving the model’s awareness of each task.
-
•
We compute multi-granularity similarities between AIGIs and their prompts, promoting holistic and detailed awareness of quality representation.
-
•
Integrating the task-specific prompts and the multi-granularity similarity, we propose an effective AIGCIQA method named TSP-MGS, which achieves state-of-the-art quality predictions on AGIQA-1K and AGIQA-3K benchmarks.
2 Related Work
This section reviews representative general-purpose IQA methods and existing artificial intelligence-generated content IQA methods.
2.1 General-Purpose Image Quality Assessment
General-purpose IQA methods typically evaluate synthetically or authentically distorted images [36, 18, 21, 10, 13, 6, 60], with an important part of reliable degradation-aware feature extraction.
Traditional IQA methods [25, 33, 8, 65, 50] often leverage hand-crafted features extracted from the spatial or transform domains to characterize distortions. However, these features are limited in capturing complex distortions, such as mixed distortions and authentic distortions, which significantly impair the performance of traditional methods. Convolutional neural network (CNN)-based IQA methods [15, 40, 67, 27, 59, 9] improve the ability to assess complex distortions by leveraging the automatic feature extraction capabilities of CNN models. Moreover, they demonstrate superior adaptability to diverse distortions and have better generalization capacity. However, they fall short in combining contextual information, which is crucial for accurate quality assessment. In contrast, Vision Transformer (ViT)-based IQA methods [72, 11, 57, 42, 37] address this limitation by using self-attention mechanisms that enable the model to build long-range dependency among image patches.
VLMs aim to model image-text correlations to facilitate zero-shot visual recognition [64]. Owing to the utilization of contrastive learning [31] and pre-training on diverse image-text datasets [31, 58, 20], VLMs exhibit excellent generalization capability and transferability, which has made them widely applicable in vision tasks, such as image classification [31, 58], segmentation [52, 24], and detection [71, 20]. Inspired by this, the exploration of applying VLMs to IQA is attracting increased attention. Current researches focus on designing suitable textual descriptions [43, 69] and constructing datasets with quality description [47, 48]. Multimodal IQA methods reduce the model’s reliance on extensive manual annotations and provide more intuitive explanations of image quality, enhancing users’ understanding of image distortions.
2.2 AIGC Image Quality Assessment
AIGIs [70, 19] are generated based on their initial prompts, however, limitations in the text comprehension or image generation of generative models often result in T2I misalignment or poor perception quality. Consequently, existing AIGCIQA methods are primarily designed to address these two challenges.
Some methods [53, 51, 16] focus on learning human preference for AIGIs. However, they lack thorough quality perception. Other methods focus on predicting quality scores. Peng et al. [28] evaluated the alignment quality by employing the CLIP to measure the similarity between AIGIs and their prompts. Then, they transformed the measured similarity into precise quality scores. Fang et al. [5] mixed image features and prompt features derived from hybrid text encoders, enhance the model’s text comprehension capabilities and quality assessment performance. These methods manually design prompts, leading to limited flexibility. To handle this limitation, Fu et al. [7] introduced learnable visual and textual prompts. Nevertheless, these methods emphasize alignment quality prediction but ignore perception quality.
To this end, Yang et al. [56] adopted an image encoder to extract perception degradation features and a VLMs to learn semantic-aware features. Then, they fused these features using a designed cross-attention module to achieve a comprehensive quality assessment. Unlike this, Yu et al. [62] extracted and fused multi-layer perception degradation features of the image, and they integrated the perception scores and alignment scores during the regression stage. Although these methods consider perception and alignment features simultaneously, an additional image encoder is needed for perception feature extraction, increasing the model’s complexity while ignoring the extra information provided by text prompts.
3 Method
In this section, we first illustrate the overall framework of the proposed method and briefly review CLIP [31]. Then, we detail text prompt construction, multi-granularity similarity measurement, and quality regression.
3.1 Overall Framework
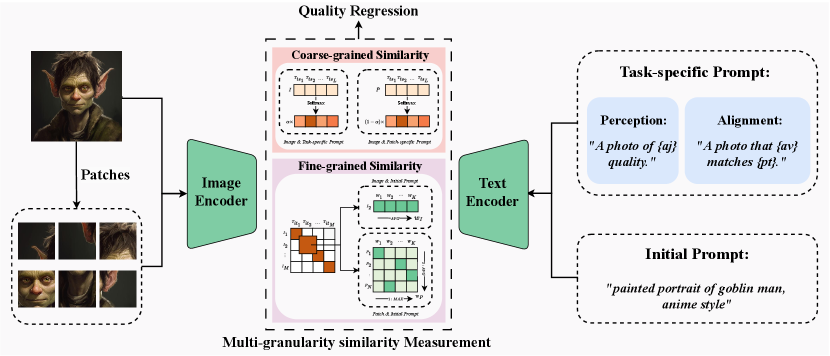
The overall framework of our method is illustrated in Fig. 2. It adopts the CLIP [31] as the baseline, which consists of an image encoder , a text encoder , and the cosine similarity measurement. Given an image and the corresponding prompt , the image feature and prompt feature can be formulated as
| (1) |
Then, cosine similarity is calculated to measure the matching degree between and , which can be expressed as
| (2) |
where is the vector dot-product and means the norm.
| Explanation | Notation |
| Image feature | |
| Patch feature | , indexes the patch |
| Word feature | , indexes the word of the initial prompt |
| Task-specific prompt feature | , indexes the quality level of the image |
The proposed method consists of three main steps: (1) feature extraction. It uses the resized AIGI and patches as the inputs of the image encoder, with the output features denoted as and , respectively. Besides, the task-specific prompt and initial prompt are used as the input of the text encoder, with their features represented as and , respectively; (2) multi-granularity similarity measurement. The coarse-grained similarity between the task-specific prompt and the image, as well as between the task-specific prompt and the patches is calculated. This enables a holistic quality perception. Moreover, the fine-grained similarity between the initial prompt and the image, as well as the initial prompt and the patches is measured. This provides a detailed quality understanding; (3) quality regression. It predicts an accurate AIGI quality by integrating the multi-granularity similarities.
3.2 Text Prompt
As shown in Fig. 1, alignment quality and perception quality of an AIGI do not strictly exhibit a positive correlation, demonstrating that using the same prompt for both quality evaluations may lead to ambiguous semantic guidance. To this end, we construct task-specific prompts to enhance the model’s task-aware ability for alignment and perception quality evaluation.
Task-Specific Prompt
For alignment quality evaluation, we adopt an alignment-specific prompt to describe the alignment degree between AIGI and its initial prompt [28], denoted as
where adv is in .
For perception quality evaluation, we adopt a perception-specific prompt to describe the degree of visual quality. Inspired by [43, 69], we employ and compare two different text descriptions, which are shown as follows
where ant is antonym description, which is one of [43], adj means adjective description selected from [69].
Task-specific prompts, i.e., alignment-specific and perception-specific prompts, guide the model to form an overall quality identification of AIGIs. To further be aware of detailed image quality, we also include initial prompts as the input of the text encoder, denoted as .
3.3 Multi-granularity Similarity
We measure the coarse-grained similarity, shown in Fig. 3, between AIGIs and task-specific prompts (sentence level) to improve the model’s perception of the overall quality level. In addition, we calculate the fine-grained similarity, shown in Fig. 4, between AIGIs and the initial prompt to enhance the awareness of detailed quality. In the following, we present definite similarity measurements.
For ease of understanding, we briefly describe the notations in Tab. 1.
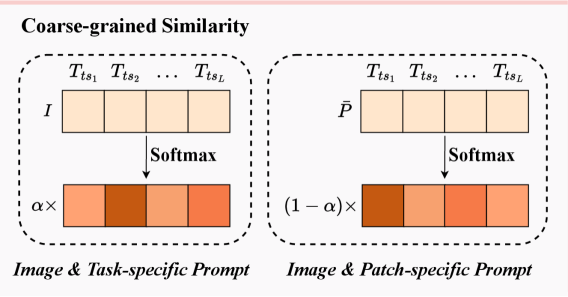
Coarse-grained Similarity
We can calculate the coarse-grained similarity between and using Eq. 2 and convert it into a probability value by the Softmax function
| (3) |
Similarly, we can compute the coarse-grained similarity between patches and and convert it into a probability value following Eq. 3. Notably, we utilize average patch feature of for measurement.
Coarse-grained similarity evaluates the degree of alignment quality between an AIGI and quality-level descriptions, which provides an intuitive quality understanding. Additionally, we perform similarity measurements from both image and image patch perspectives, enhancing prediction accuracy and reliability.
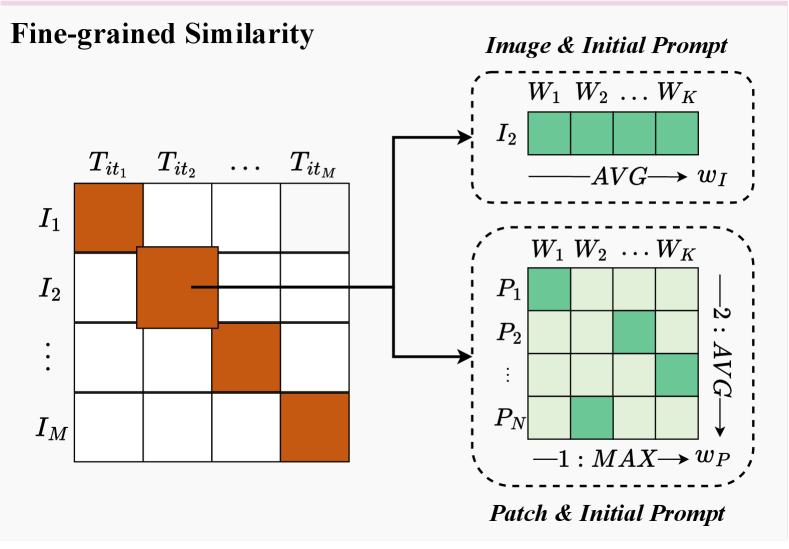
Fine-grained Similarity
Coarse-grained similarity computes the matching degree between an image and a sentence, focusing on general similarity. To account for finer details, we introduce the fine-grained similarity measurement between AIGI and its initial prompt. The initial prompt contains keywords used for image generation, by calculating the similarities between the image and these words, we can achieve a delicate awareness of image quality and content. To this end, we calculate the fine-grained similarity between and and average similarities, which is formalized as follows
| (4) |
Similarly, we can compute the mean fine-grained similarity between and following Eq. 4. Simultaneously considering the coarse-grained and fine-grained similarity, we achieve a holistic and detailed quality perception of AIGI, facilitating valid quality prediction.
3.4 Quality Regression
Here, we integrate and transform the above measurements into a quality score. First, and represent the probability that an AIGI belongs to the -th quality level, thus, they are converted into quality scores with the following formula
| (5) |
where .
and indicate how well an AIGI matches the initial prompt, suggesting how good the detailed quality is. We convert them into quality scores with the following formula
| (6) |
The final quality score of an AIGI is obtained by integrating and , which is formalized as follows
| (7) |
where is the weight used to balance and .
Mean Absolute Error (MAE) is used as the loss function to fine-tune our model, which is shown as follows
| (8) |
where is the subjective quality score.
4 Experiments
This section briefly describes the AIGCIQA datasets, the metrics for performance evaluation, and the details of the implementation. Additionally, it provides a detailed analysis of the experimental results to offer insights into the proposed method.
4.1 Datasets and Evaluation Criteria
AIGCIQA Datasets
The proposed method is validated on two commonly used AIGCIQA datasets, including AGIQA-1K [70], and AGIQA-3K [19]. The AGIQA-1K dataset contains 1080 images generated by two T2I models and each image is assigned a Mean Opinion Score (MOS) of quality. The AGIQA-3K dataset includes 2982 images generated by six T2I models, where MOS for both quality and alignment are provided.
Evaluation Criteria
Spearman Rank Correlation Coefficient (SRCC) and Pearson Linear Correlation Coefficient (PLCC), defined as Eq. 9 and Eq. 10, are commonly employed as evaluation metrics for quality assessment. They measure the ranking ability and fitting ability of a prediction model respectively.
| (9) |
| (10) |
where is the rank difference of the subjective quality score and the predicted score .
| Method | SRCC | PLCC | |
| ResNet50 [12] | CVPR’16 | 0.6365 | 0.7323 |
| MGQA [45] | VCIP’21 | 0.6011 | 0.6760 |
| CLIPIQA [43] | AAAI’23 | 0.8227 | 0.8411 |
| IP-IQA [30] | ICME’24 | 0.8401 | 0.8922 |
| IPCE [28] | CVPRW’24 | 0.8535 | 0.8792 |
| MoE-AGIQA-v1 [56] | CVPRW’24 | 0.8530 | 0.8877 |
| MoE-AGIQA-v2 [56] | CVPRW’24 | 0.8501 | 0.8922 |
| TSP-MGS | – | 0.8567 | 0.8846 |
| Method | Perception | ||
| SRCC | PLCC | ||
| CNNIQA [15] | CVPR’14 | 0.7478 | 0.8469 |
| DBCNN [67] | TCSVT’20 | 0.8207 | 0.8759 |
| HyperIQA [40] | CVPR’20 | 0.8355 | 0.8903 |
| CLIPIQA [43] | AAAI’23 | 0.8426 | 0.8053 |
| IP-IQA [30] | ICME’24 | 0.8634 | 0.9116 |
| IPCE [28] | CVPRW’24 | 0.8841 | 0.9246 |
| MoE-AGIQA-v1 [56] | CVPRW’24 | 0.8758 | 0.9294 |
| MoE-AGIQA-v2 [56] | CVPRW’24 | 0.8746 | 0.9014 |
| TSP-MGS | – | 0.8901 | 0.9270 |
| Method | Alignment | ||
| SRCC | PLCC | ||
| CLIP [31] | ICML’21 | 0.5972 | 0.6839 |
| ImageReward [53] | NIPS’23 | 0.7298 | 0.7862 |
| HPS [51] | ICCV’23 | 0.6623 | 0.7008 |
| PickScore [16] | NIPS’23 | 0.7320 | 0.7791 |
| StairReward [19] | TCSVT’24 | 0.7472 | 0.8529 |
| IPCE [28] | CVPRW’24 | 0.7697 | 0.8725 |
| TSP-MGS | – | 0.7734 | 0.8773 |
4.2 Implementation Details
All experiments are performed on a PC equipped with an NVIDIA GeForce 4090 GPU, using PyTorch 1.12.0 and CUDA 11.3. We load the ViT-B/32 as the backbone of our method, where input images are with size . We employ the AdamW optimizer with a learning rate of 5e-6 and a weight decay of 5e-4. The model is trained for 20 epochs, with a cosine annealing learning rate scheduler applied to gradually reduce the learning rate every 5 epochs. Besides, we set the batch size to 16.
To ensure the reproducibility of experiments and fairness in comparison, we adopt the dataset split strategy from the IPCE [28] to divide each AIGCIQA dataset into training and testing sets in a 4:1 ratio. All experiments are conducted 10 times, and the average results are reported.
4.3 Benchmark Results
We compare the proposed method with existing deep learning (DL)-based AIGCIQA methods to highlight its superiority.
AGIQA-1K
We compare our method with SOTA DL-based methods, including ResNet50 [12], MGQA [45], CLIPIQA [43], IP-IQA [30], IPCE [28], and MoE-AGIQA-v1/v2 [56], on the AIGC-1K dataset. Tab. 2 presents the SRCC and PLCC results, with the performance of the comparison methods sourced from existing work. It can be seen that multi-modal AIGCIQA methods [43, 30, 28, 56] outperform single-modal ones [12, 45] by a considerable margin, indicating that prompts contribute to the AIGI quality perception. As a multi-modal method, TSP-MGS achieves a 0.8567 SRCC, surpassing other methods. In addition, it obtains a 0.8846 PLCC, the second-best result marginally lower than the best 0.8922.
AGIQA-3K
We compare our method with CNNIQA [15], DBCNN [67], HyperIQA [40], CLIPIQA [43], IP-IQA [30], IPCE [28], and MoE-AGIQA-v1/v2 [56] on the perception quality evaluation, and with VLM-based methods CLIP [31], ImageReward [53], HPS [51], PickScore [16], StairReward [19], and IPCE [28] on the alignment quality evaluation. The results are presented in Tab. 3 and Tab. 4, respectively, where the performance of the comparison methods is sourced from existing work.
As the results reported in Tab. 3, the methods [30, 28, 56] concentrated on degradation learning of AIGIs achieve better performance in perception quality predictions. Our method achieves the highest SRCC value of 0.8901 and the second-highest PLCC value of 0.9270, demonstrating its effectiveness in perceptual quality assessment. Tab. 4 illustrates that all methods are weak in alignment quality prediction. However, our method shows superiority by achieving the best prediction performance with a 0.7734 SRCC and 0.8773 PLCC.
In conclusion, our method demonstrates robust performance in assessing perception and alignment quality on the AGIQA-1K and AGIQA-3K datasets, validating its effectiveness in addressing the complexities of AIGI.
| Task prompt | P | Perception | Alignment | |||
| SRCC | PLCC | SRCC | PLCC | |||
| ✓ | 0.8766 | 0.9177 | 0.7127 | 0.8304 | ||
| ✓ | 0.8891 | 0.9254 | 0.7089 | 0.8401 | ||
| ✓ | ✓ | 0.8868 | 0.9229 | 0.7045 | 0.8341 | |
| ✓ | 0.8780 | 0.9190 | 0.7128 | 0.8406 | ||
| ✓ | 0.8901 | 0.9270 | 0.7129 | 0.8384 | ||
| ✓ | ✓ | 0.8893 | 0.9266 | 0.7115 | 0.8406 | |
| ✓ | 0.8817 | 0.9214 | 0.7734 | 0.8773 | ||
| ✓ | 0.8884 | 0.9245 | 0.7544 | 0.8668 | ||
| ✓ | ✓ | 0.8868 | 0.9257 | 0.7618 | 0.8729 | |
4.4 Ablation Study
To verify the effectiveness of each designed module of the proposed method, we perform ablation experiments on the AGIQA-3K dataset, which are detailed as follows.
Text Prompt
Here, we validate the effectiveness of task-specific prompts and initial prompts. First, we discuss the effects of different task-specific prompts , , and . To be more persuasive, we compare the experimental results for each combination of task-specific prompts with the image encoder inputs and P, as shown in Tab. 5. The best SRCC and PLCC are highlighted in red. For perception quality evaluation, , which emphasizes visual degradation levels as detailed in Sec. 3.2, boosts the model’s prediction results. For alignment quality evaluation, further highlights the T2I correspondence degrees, leading to better predictions than the others. In addition, perception quality predictions based on image patches are generally better than those based on resized images, and alignment quality predictions using resized images are better than those using image patches. In summary, appropriately designing text descriptions for specific tasks enables the model to capture more relevant features. Moreover, an overall understanding of AIGIs benefits alignment quality evaluation, in which local detail perception promotes perception quality prediction.
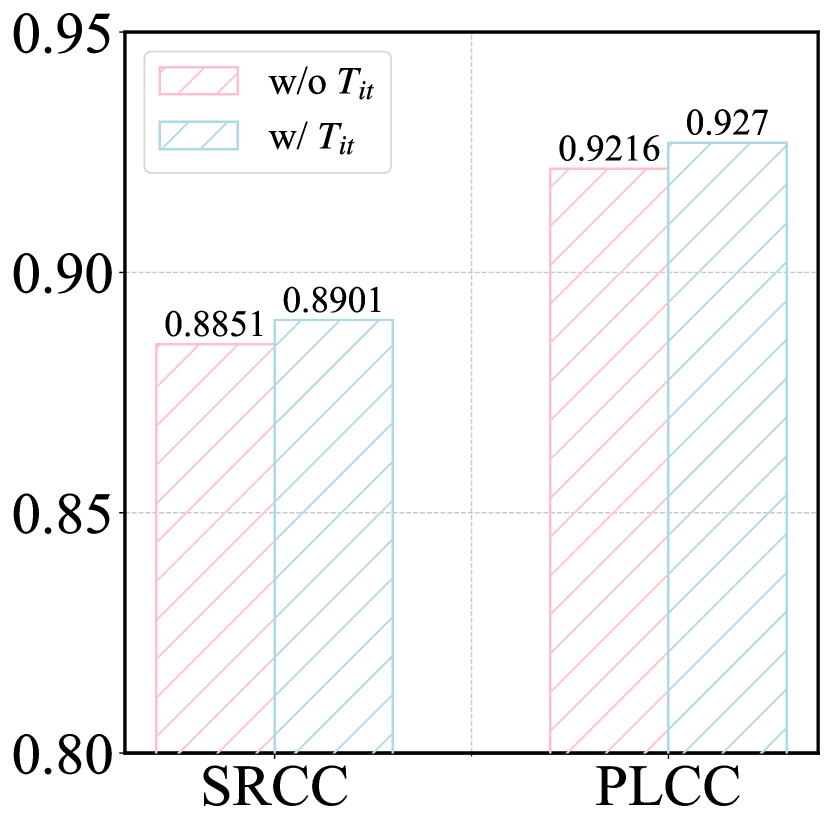
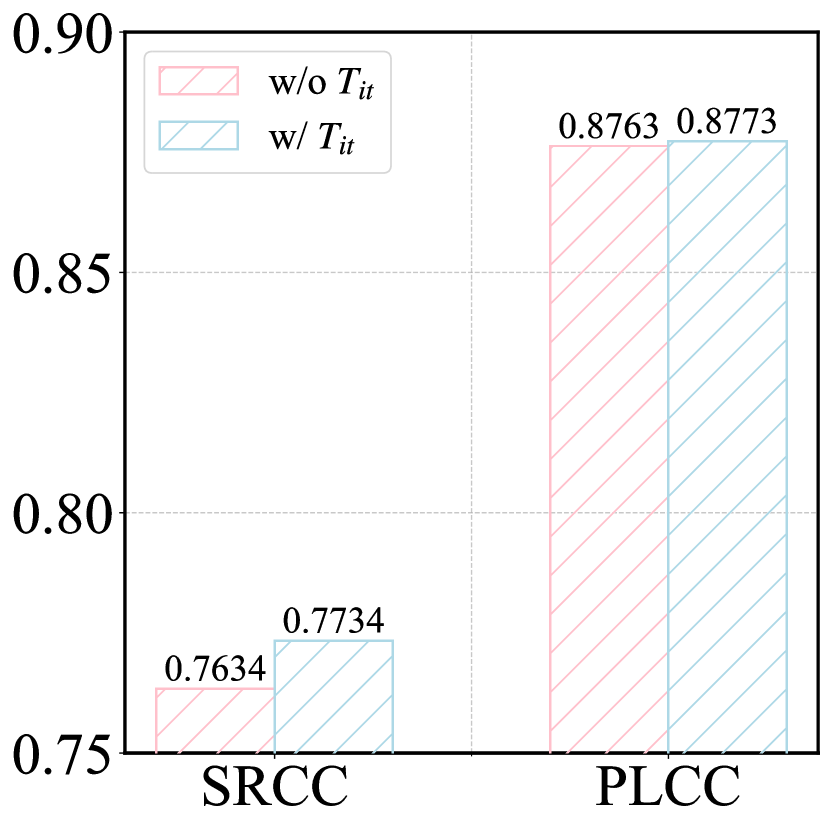
Additionally, we validate the effectiveness of the initial prompts, with results shown in Fig. 5. It can be observed that excluding the initial prompts leads to reduced performance in both alignment quality and perception quality prediction. This indicates that enhancing the model’s understanding of the relationship between AIGIs and prompt words can improve its ability to perceive image degradation.
Image Input
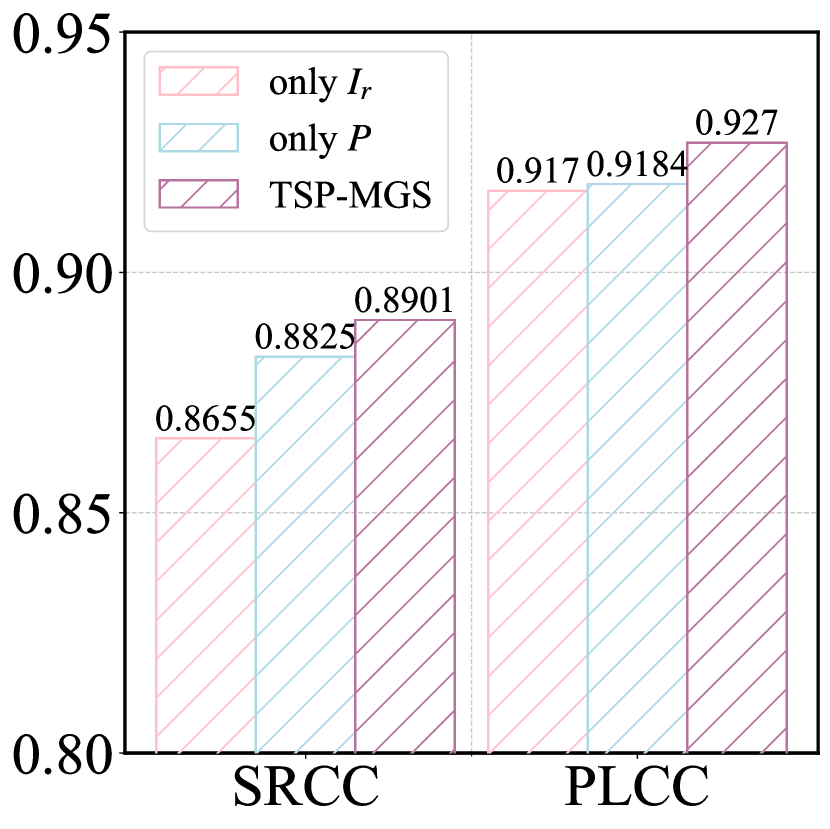
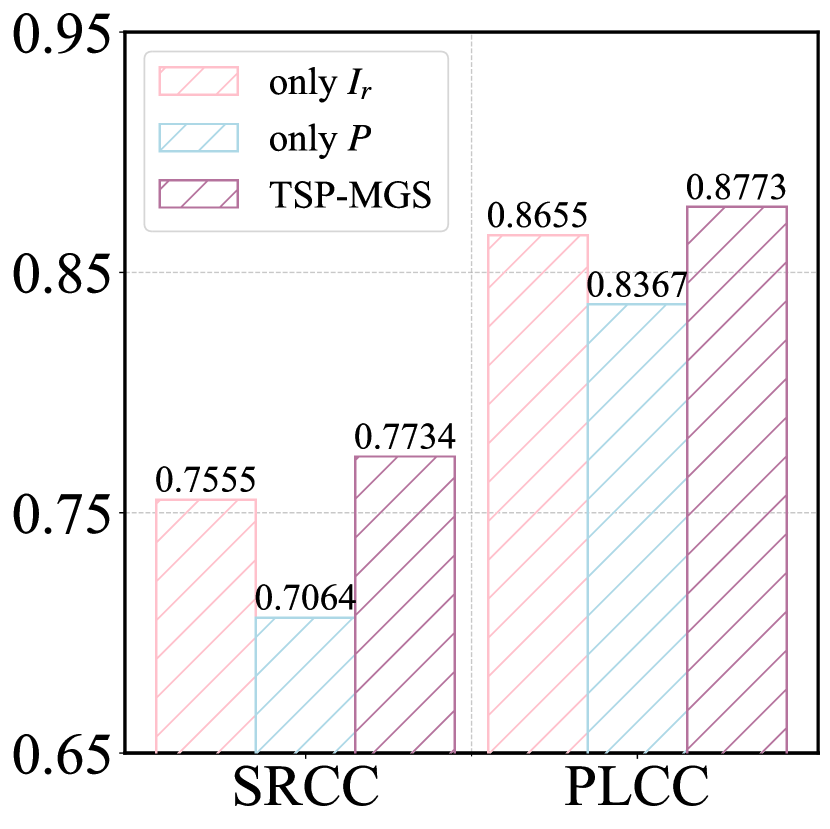
Following [28], we utilize the resized AIGI and its patches as inputs of the image encoder. Here, we analyze the model’s performance using only the resized AIGI (Only ), and only the image patches (Only ). Fig. 6 illustrates the experimental results. Perception quality evaluation based only on surpasses that based only on , demonstrating that more visual distortion details can be extracted from image patches. In contrast, alignment quality evaluation based only on outperforms that based only on , underscoring the importance of alignment between text and overall image. Moreover, utilizing and yields rich image and patch feature combinations, significantly enhancing the model’s performance in perception and alignment quality predictions.
Parameter
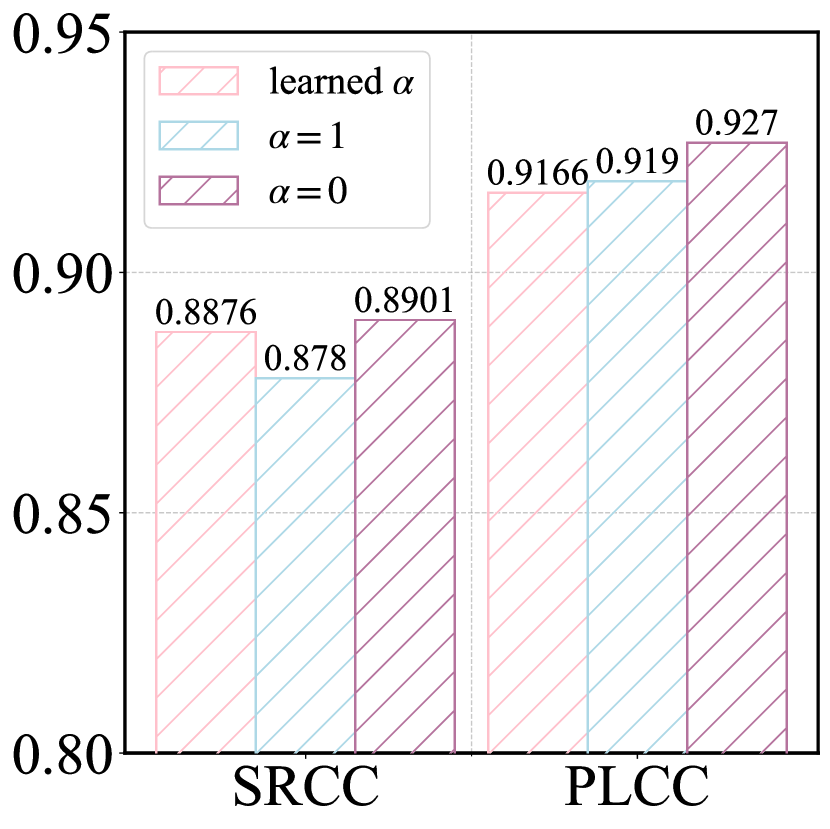
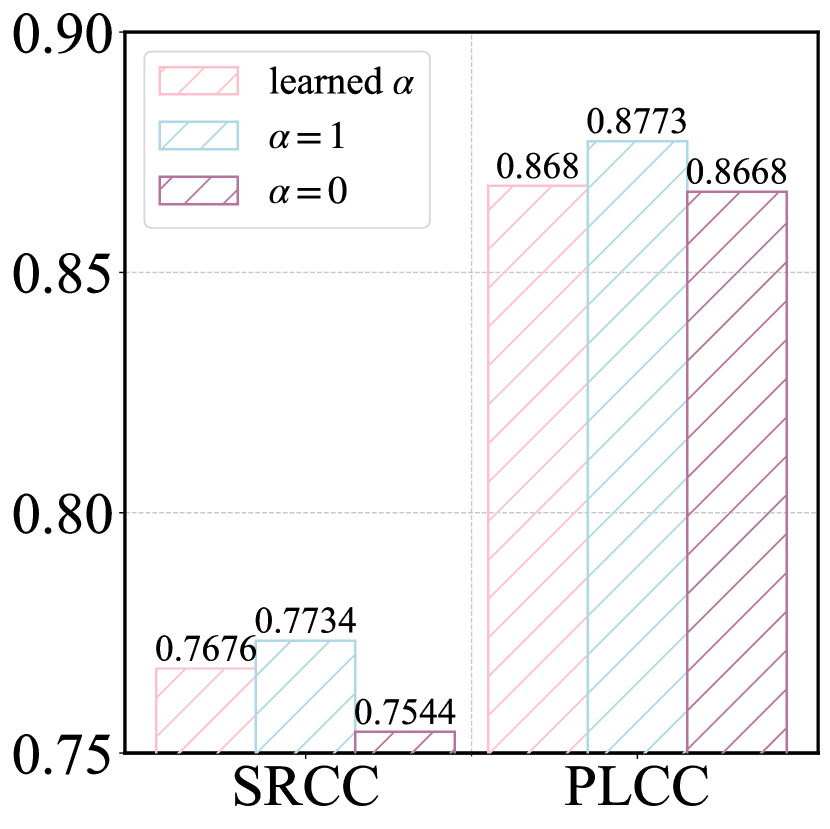
The parameter mentioned in Eq. 7 is used to balance and . Here, we discuss its impact on the perception and alignment quality evaluation, including , , and learned by the model. The results are shown in Fig. 7. For perceptual quality evaluation, the best prediction is achieved when setting , meaning that only coarse-grained similarity between image patches and perception-specific prompts is calculated. This highlights the importance of image details in perception quality prediction. For alignment quality evaluation, the optimal prediction is achieved when , where only the image is used in the coarse-grained similarity calculation. This emphasizes the importance of understanding the image content for alignment quality evaluation.
4.5 Visualization



To provide an intuitive observation, we present several AIGIs with subjective and predicted scores, shown in Fig. 8. Fig. 8(a) shows the accurately predicted samples covering a rich generated image content. The proposed TSP-MGS achieves precise perception and alignment quality predictions on these samples, demonstrating its effectiveness in handling complex AIGI quality evaluation. Fig. 8(b) shows the samples with failed predictions. These samples either have high alignment quality predictions but low perception predictions, or the reverse. The causes of the failures may be (1) AIGIs exhibiting rich textures but poor color, lighting, etc., which are often difficult for the model to capture. This leads to a deviation from a subjective score in the perception prediction, even when the predicted alignment quality is accurate. (2) Bias in the model’s understanding of the prompt or ambiguity arising from multiple meanings of words, failing alignment quality prediction. In summary, improving the model’s perception of non-structural distortions and promoting its correct understanding of prompts are crucial to improving the perception and alignment quality evaluation performance.
5 Conclusion
This paper introduces a novel quality assessment method for AIGIs, named TSP-MGS. It employs the CLIP model to measure the similarity between AIGI and the constructed prompts and transforms the similarity into a quality score. In summary, TSP-MGS has two innovations: (1) Considering the inconsistency between alignment and perception quality evaluation, task-specific prompts are constructed to guide each task learning, achieving holistic quality awareness. Moreover, the initial prompt used to generate the image is also introduced for a detailed quality perception. (2) Multi-granularity similarity between image and prompts is measured and integrated to enhance the model’s capabilities in intuitive quality understanding and detailed quality awareness. Experimental results on the AGIQA-1K and AGIQA-3K datasets validate the effectiveness of TSP-MGS in both alignment and perception quality assessment.
References
- Cheon et al. [2021] Manri Cheon, Sung-Jun Yoon, Byungyeon Kang, and Junwoo Lee. Perceptual image quality assessment with transformers. In CVPRW, pages 433–442, 2021.
- Deng et al. [2023] Xinchi Deng, Han Shi, Runhui Huang, Changlin Li, Hang Xu, Jianhua Han, James Kwok, Shen Zhao, Wei Zhang, and Xiaodan Liang. Growclip: Data-aware automatic model growing for large-scale contrastive language-image pre-training. In ICCV, pages 22121–22132, 2023.
- Ding et al. [2022] Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. Image quality assessment: Unifying structure and texture similarity. IEEE TPAMI, 44(5):2567–2581, 2022.
- Ding et al. [2021] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. Cogview: Mastering text-to-image generation via transformers. NIPS, 34:19822–19835, 2021.
- Fang et al. [2024] Xi Fang, Weigang Wang, Xiaoxin Lv, and Jun Yan. Pcqa: A strong baseline for aigc quality assessment based on prompt condition. In CVPRW, pages 6167–6176, 2024.
- Fang et al. [2020] Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, and Zhou Wang. Perceptual quality assessment of smartphone photography. In CVPR, pages 3674–3683, 2020.
- Fu et al. [2024] Jun Fu, Wei Zhou, Qiuping Jiang, Hantao Liu, and Guangtao Zhai. Vision-language consistency guided multi-modal prompt learning for blind ai generated image quality assessment. IEEE Signal Processing Letters, 31:1820–1824, 2024.
- Gao et al. [2013] Xinbo Gao, Fei Gao, Dacheng Tao, and Xuelong Li. Universal blind image quality assessment metrics via natural scene statistics and multiple kernel learning. IEEE Transactions on Neural Networks and Learning Systems, 24(12):2013–2026, 2013.
- Gao et al. [2024] Yixuan Gao, Xiongkuo Min, Yucheng Zhu, Xiao-Ping Zhang, and Guangtao Zhai. Blind image quality assessment: A fuzzy neural network for opinion score distribution prediction. IEEE Transactions on Circuits and Systems for Video Technology, 34(3):1641–1655, 2024.
- Ghadiyaram and Bovik [2016] Deepti Ghadiyaram and Alan C. Bovik. Massive online crowdsourced study of subjective and objective picture quality. IEEE TIP, 25(1):372–387, 2016.
- Golestaneh et al. [2022] S. Alireza Golestaneh, Saba Dadsetan, and Kris M. Kitani. No-reference image quality assessment via transformers, relative ranking, and self-consistency. pages 3989–3999, 2022.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- Hosu et al. [2020] Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE TIP, 29:4041–4056, 2020.
- Jia et al. [2021] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- Kang et al. [2014] Le Kang, Peng Ye, Yi Li, and David Doermann. Convolutional neural networks for no-reference image quality assessment. In CVPR, pages 1733–1740, 2014.
- Kirstain et al. [2024] Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: an open dataset of user preferences for text-to-image generation. 2024.
- Kumari et al. [2023] Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. In CVPR, pages 1931–1941, 2023.
- Larson and Chandler [2010] Eric Cooper Larson and Damon Michael Chandler. Most apparent distortion: full-reference image quality assessment and the role of strategy. J. Electron. Imaging, 19(1):011006, 2010.
- Li et al. [2024] Chunyi Li, Zicheng Zhang, Haoning Wu, Wei Sun, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai, and Weisi Lin. Agiqa-3k: An open database for ai-generated image quality assessment. IEEE Transactions on Circuits and Systems for Video Technology, 34(8):6833–6846, 2024.
- Li et al. [2022] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In CVPR, pages 10955–10965, 2022.
- Lin et al. [2019] Hanhe Lin, Vlad Hosu, and Dietmar Saupe. Kadid-10k: A large-scale artificially distorted iqa database. In Int. Conf. Qual. Multimedia Exp., pages 1–3, 2019.
- Lin and Wang [2018] Kwan-Yee Lin and Guanxiang Wang. Hallucinated-iqa: No-reference image quality assessment via adversarial learning. In CVPR, pages 732–741, 2018.
- Liu et al. [2017] Xialei Liu, Joost Van De Weijer, and Andrew D. Bagdanov. Rankiqa: Learning from rankings for no-reference image quality assessment. In ICCV, pages 1040–1049, 2017.
- Luo et al. [2023] Huaishao Luo, Junwei Bao, Youzheng Wu, Xiaodong He, and Tianrui Li. Segclip: Patch aggregation with learnable centers for open-vocabulary semantic segmentation. In International Conference on Machine Learning, pages 23033–23044. PMLR, 2023.
- Mittal et al. [2012] Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain. IEEE TIP, 21(12):4695–4708, 2012.
- Moorthy and Bovik [2011] Anush Krishna Moorthy and Alan Conrad Bovik. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Transactions on Image Processing, 20(12):3350–3364, 2011.
- Pan et al. [2022] Zhaoqing Pan, Hao Zhang, Jianjun Lei, Yuming Fang, Xiao Shao, Nam Ling, and Sam Kwong. Dacnn: Blind image quality assessment via a distortion-aware convolutional neural network. IEEE Transactions on Circuits and Systems for Video Technology, 32(11):7518–7531, 2022.
- Peng et al. [2024] Fei Peng, Huiyuan Fu, Anlong Ming, Chuanming Wang, Huadong Ma, Shuai He, Zifei Dou, and Shu Chen. Aigc image quality assessment via image-prompt correspondence. In CVPRW, pages 6432–6441, 2024.
- Ponomarenko et al. [2013] Nikolay Ponomarenko, Oleg Ieremeiev, Vladimir Lukin, Karen Egiazarian, Lina Jin, Jaakko Astola, Benoit Vozel, Kacem Chehdi, Marco Carli, and Federica Battisti. Color image database tid2013: Peculiarities and preliminary results. In EUVIP, pages 106–111, 2013.
- Qu et al. [2024] Bowen Qu, Haohui Li, and Wei Gao. Bringing textual prompt to ai-generated image quality assessment. In ICME, pages 1–6, 2024.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In ICML. PMLR, pages 8821–8831, 2021.
- Saad et al. [2012] Michele A. Saad, Alan C. Bovik, and Christophe Charrier. Blind image quality assessment: A natural scene statistics approach in the dct domain. IEEE Transactions on Image Processing, 21(8):3339–3352, 2012.
- Saha et al. [2023] Avinab Saha, Sandeep Mishra, and Alan C. Bovik. Re-iqa: Unsupervised learning for image quality assessment in the wild. In CVPR, pages 5846–5855, 2023.
- Schuhmann et al. [2022] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Sheikh et al. [2006] Hamid R Sheikh, Muhammad F Sabir, and Alan C. Bovik. A statistical evaluation of recent full reference image quality assessment algorithms. TIP, 15(11):3440–3451, 2006.
- Shi et al. [2024] Jinsong Shi, Pan Gao, and Aljosa Smolic. Blind image quality assessment via transformer predicted error map and perceptual quality token. IEEE Transactions on Multimedia, 26:4641–4651, 2024.
- Shin et al. [2024] Nyeong-Ho Shin, Seon-Ho Lee, and Chang-Su Kim. Blind image quality assessment based on geometric order learning. In CVPR, pages 12799–12808, 2024.
- Singh et al. [2022] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In CVPR, pages 15617–15629, 2022.
- Su et al. [2020] Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In CVPR, pages 3664–3673, 2020.
- Sun et al. [2022] Wei Sun, Huiyu Duan, Xiongkuo Min, Li Chen, and Guangtao Zhai. Blind quality assessment for in-the-wild images via hierarchical feature fusion strategy. In IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, pages 01–06, 2022.
- Wang et al. [2022] Jing Wang, Haotian Fan, Xiaoxia Hou, Yitian Xu, Tao Li, Xuechao Lu, and Lean Fu. Mstriq: No reference image quality assessment based on swin transformer with multi-stage fusion. In CVPRW, pages 1268–1277, 2022.
- Wang et al. [2023] Jianyi Wang, Kelvin C.K. Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. In AAAI, pages 2555–2563, 2023.
- Wang et al. [2024] Jiarui Wang, Huiyu Duan, Jing Liu, Shi Chen, Xiongkuo Min, and Guangtao Zhai. Aigciqa2023: A large-scale image quality assessment database for ai generated images: From the perspectives of quality, authenticity and correspondence. In CAAI International Conference on Artificial Intelligence, pages 46–57, 2024.
- Wang et al. [2021] Tao Wang, Wei Sun, Xiongkuo Min, Wei Lu, Zicheng Zhang, and Guangtao Zhai. A multi-dimensional aesthetic quality assessment model for mobile game images. In International Conference on Visual Communications and Image Processing, pages 1–5, 2021.
- Wang and Ma [2022] Zhihua Wang and Kede Ma. Active fine-tuning from gmad examples improves blind image quality assessment. IEEE TPAMI, 44(9):4577–4590, 2022.
- Wu et al. [2024a] Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, and Weisi Lin. Q-bench: A benchmark for general-purpose foundation models on low-level vision. In ICLR, 2024a.
- Wu et al. [2024b] Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Kaixin Xu, Chunyi Li, Jingwen Hou, Guangtao Zhai, Geng Xue, Wenxiu Sun, Qiong Yan, and Weisi Lin. Q-instruct: Improving low-level visual abilities for multi-modality foundation models. In CVPR, pages 25490–25500, 2024b.
- Wu et al. [2016] Qingbo Wu, Hongliang Li, Fanman Meng, King N. Ngan, Bing Luo, Chao Huang, and Bing Zeng. Blind image quality assessment based on multichannel feature fusion and label transfer. IEEE Transactions on Circuits and Systems for Video Technology, 26(3):425–440, 2016.
- Wu et al. [2018] Qingbo Wu, Hongliang Li, King N. Ngan, and Kede Ma. Blind image quality assessment using local consistency aware retriever and uncertainty aware evaluator. IEEE Transactions on Circuits and Systems for Video Technology, 28(9):2078–2089, 2018.
- Wu et al. [2023] Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. In IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023.
- Xu et al. [2022] Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In CVPR, pages 18113–18123, 2022.
- Xu et al. [2024a] Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: learning and evaluating human preferences for text-to-image generation. In NIPS, pages 15903–15935, 2024a.
- Xu et al. [2024b] Kangmin Xu, Liang Liao, Jing Xiao, Chaofeng Chen, Haoning Wu, Qiong Yan, and Weisi Lin. Boosting image quality assessment through efficient transformer adaptation with local feature enhancement. In CVPR, pages 2662–2672, 2024b.
- Xu et al. [2018] Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. Attngan: Finegrained text to image generation with attentional generative adversarial networks. In CVPR, pages 1316–1324, 2018.
- Yang et al. [2024] Junfeng Yang, Jing Fu, Wei Zhang, Wenzhi Cao, Limei Liu, and Han Peng. Moe-agiqa: Mixture-of-experts boosted visual perception-driven and semantic-aware quality assessment for ai-generated images. In CVPRW, pages 6395–6404, 2024.
- Yang et al. [2022] Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In CVPRW, pages 1190–1199, 2022.
- Yao et al. [2022] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. In International Conference on Learning Representations, 2022.
- Yao et al. [2023] Xiwen Yao, Qinglong Cao, Xiaoxu Feng, Gong Cheng, and Junwei Han. Learning to assess image quality like an observer. IEEE Transactions on Neural Networks and Learning Systems, 34(11):8324–8336, 2023.
- Ying et al. [2020] Zhenqiang Ying, Haoran Niu, Praful Gupta, Dhruv Mahajan, Deepti Ghadiyaram, and Alan C. Bovik. From patches to pictures (paq-2-piq): Mapping the perceptual space of picture quality. In CVPR, pages 3572–3582, 2020.
- You and Korhonen [2021] Junyong You and Jari Korhonen. Transformer for image quality assessment. In ICIP, pages 1389–1393, 2021.
- Yu et al. [2024] Zihao Yu, Fengbin Guan, Yiting Lu, Xin Li, and Zhibo Chen. Sf-iqa: Quality and similarity integration for ai generated image quality assessment. In CVPRW, pages 6692–6701, 2024.
- Zhang et al. [2017] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan: Text to photorealistic image synthesis with stacked generative adversarial networks. In ICCV, pages 5907–5915, 2017.
- Zhang et al. [2024] Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5625–5644, 2024.
- Zhang et al. [2015] Lin Zhang, Lei Zhang, and Alan C. Bovik. A feature-enriched completely blind image quality evaluator. IEEE Transactions on Image Processing, 24(8):2579–2591, 2015.
- Zhang et al. [2023a] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In CVPR, pages 3836–3847, 2023a.
- Zhang et al. [2020] Weixia Zhang, Kede Ma, Jia Yan, Dexiang Deng, and Zhou Wang. Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Transactions on Circuits and Systems for Video Technology, 30(1):36–47, 2020.
- Zhang et al. [2023b] Weixia Zhang, Dingquan Li, Chao Ma, Guangtao Zhai, Xiaokang Yang, and Kede Ma. Continual learning for blind image quality assessment. IEEE TPAMI, 45(3):2864–2878, 2023b.
- Zhang et al. [2023c] Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. Blind image quality assessment via vision-language correspondence: A multitask learning perspective. In CVPR, pages 14071–14081, 2023c.
- Zhang et al. [2023d] Zicheng Zhang, Chunyi Li, Wei Sun, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. A perceptual quality assessment exploration for aigc images. In Int. Conf. Multimedia and Expo. Worksh., pages 440–445, 2023d.
- Zhong et al. [2022] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, and Jianfeng Gao. Regionclip: Region-based language-image pretraining. In CVPR, pages 16772–16782, 2022.
- Zhu et al. [2021] Mengmeng Zhu, Guanqun Hou, Xinjia Chen, Jiaxing Xie, Haixian Lu, and Jun Che. Saliency-guided transformer network combined with local embedding for no-reference image quality assessment. pages 1953–1962, 2021.