-Divergence Loss Function for Neural Density Ratio Estimation
Abstract
Density ratio estimation (DRE) is a fundamental machine learning technique for capturing relationships between two probability distributions. State-of-the-art DRE methods estimate the density ratio using neural networks trained with loss functions derived from variational representations of -divergences. However, existing methods face optimization challenges, such as overfitting due to lower-unbounded loss functions, biased mini-batch gradients, vanishing training loss gradients, and high sample requirements for Kullback–Leibler (KL) divergence loss functions. To address these issues, we focus on -divergence, which provides a suitable variational representation of -divergence. Subsequently, a novel loss function for DRE, the -divergence loss function (-Div), is derived. -Div is concise but offers stable and effective optimization for DRE. The boundedness of -divergence provides the potential for successful DRE with data exhibiting high KL-divergence. Our numerical experiments demonstrate the effectiveness of -Div in optimization. However, the experiments also show that the proposed loss function offers no significant advantage over the KL-divergence loss function in terms of RMSE for DRE. This indicates that the accuracy of DRE is primarily determined by the amount of KL-divergence in the data and is less dependent on -divergence.
1 Introduction
Density ratio estimation (DRE), a fundamental technique in various machine learning domains, estimates the density ratio between two probability densities using two sample sets drawn separately from and . Several machine learning methods, including generative modeling [9, 23, 35], mutual information estimation and representation learning [3, 11], energy-based modeling [10], and covariate shift and domain adaptation [29, 12], involve problems where DRE is applicable. Given its potential to enhance a wide range of machine learning methods, the development of effective DRE techniques has garnered significant attention.
Recently, neural network-based methods for DRE have achieved state-of-the-art results. These methods train neural networks as density ratio functions using loss functions derived from variational representations of -divergences [22], which are equivalent to density-ratio matching under Bregman divergence [34]. The optimal function for a variational representation of -divergence, through the Legendre transform, corresponds to the density ratio.
However, existing neural network methods suffer from several issues. First, an overfitting phenomenon, termed train-loss hacking by Kato and Teshima [14], occurs during optimization when lower-unbounded loss functions are used. Second, the gradients of loss functions over mini-batch samples provide biased estimates of the full gradient when using standard loss functions derived directly from the variational representation of -divergence [3]. Third, loss function gradients can vanish when the estimated probability ratios approach zero or infinity [2]. Finally, optimization with a Kullback–Leibler (KL) divergence loss function often fails on high KL-divergence data because the sample requirement for optimization increases exponentially with the true amount of KL-divergence [26, 31, 19].
To address these problems, this study focuses on -divergence, a subgroup of -divergences, which has a sample complexity independent of its ground truth value. We then present a Gibbs density representation for a variational form of the divergence to obtain unbiased mini-batch gradients, from which we derive a novel loss function for DRE, referred to as the -divergence loss function (-Div). Despite its simplicity, -Div offers stable and effective optimization for DRE.
Furthermore, this study provides technical justifications for the proposed loss function. -Div has a sample complexity that is independent of the ground truth value of -divergence and provides unbiased mini-batch gradients of training losses. Additionally, choosing within the interval ensures that -Div remains lower-bounded, preventing train-loss hacking during optimization. By selecting from this interval, we also avoid vanishing gradients in neural networks when they reach extreme local minima. We empirically validate our approach through numerical experiments using toy datasets, which demonstrate the stability and efficiency of the proposed loss function during optimization.
However, we observe that the root mean squared error (RMSE) of the estimated density ratios increases significantly for data with higher KL-divergence when using the proposed loss function. The same phenomenon is observed with the KL-divergence loss function. These results suggest that the accuracy of DRE is primarily determined by the magnitude of KL-divergence inherent in the data, rather than by the specific choice of in the -divergence loss function. This observation highlights a fundamental limitation shared across different -divergence-based DRE methods, emphasizing the need to consider the intrinsic KL-divergence of data when evaluating and interpreting DRE performance.
The key contributions of this study are as follows: First, we propose a novel loss function for DRE, termed -Div, providing a concise solution to instability and biased gradient issues present in existing -divergence-based loss functions. Second, technical justifications and theoretical insights supporting the proposed -Div loss function are presented. Third, we empirically confirm the stability and efficiency of the proposed method through numerical experiments. Finally, our empirical results reveal that the accuracy of DRE, measured by RMSE, is primarily influenced by the magnitude of KL-divergence inherent in the data, rather than by the specific choice of in the -divergence loss function.
2 Problem Setup
Problem definition. and are probability distributions on with unknown probability densities and , respectively. We assume almost everywhere , ensuring that the density ratio is well-defined on their common support.
The goal of DRE is to accurately estimate from given i.i.d. samples and .
Additional notation. denotes the expectation under the distribution : , where is a measurable function over . denotes the empirical expectation of : . The variables in a function or the superscript variable “” of can be omitted when unnecessary and instead represented as or . denotes the indicator function: if “cond” is true, and 0 otherwise. Similarly, notations and are defined. is written for .
3 DRE via -divergence variational representations and its major problems
In this section, we introduce DRE using -divergence variational representations and -divergence loss functions. First, we review the definition of -divergences. Next, we identify four major issues with existing -divergence loss functions: the overfitting problem with lower-unbounded loss functions, biased mini-batch gradients, vanishing training loss gradients, and high sample requirements for Kullback–Leibler (KL) divergence loss functions.
3.1 DRE via -divergence variational representation
First, we review the definition of -divergences.
Definition 3.1 (-divergence).
The -divergence between two probability measures and , which is induced by a convex function satisfying , is defined as .
Many divergences are specific cases obtained by selecting a suitable generator function . For example, corresponds to KL-divergence.
Then, we derive the variational representations of -divergences using the Legendre transform of the convex conjugate of a twice differentiable convex function , [21]:
| (1) |
where the supremum is taken over all measurable functions with and . The maximum value is achieved at .
By replacing with a neural network model , the optimal function for Equation (1) is trained through back-propagation using an -divergence loss function, such that
| (2) |
where is a real-valued function, the superscript variable “” can be omitted when unnecessary and instead represented as . As shown in Table 2, we list pairs of convex functions and the corresponding loss functions in Equation (2) for several -divergences.
3.2 Train-loss hacking problem
When -divergence loss functions , as defined in Equation (2), are not lower-bounded, overfitting can occur during optimization. For example, we observe the case of the Pearson loss function, , as follows. Since the term is not lower-bounded, it can approach negative infinity, causing the entire loss function to diverge to negative infinity as for . Consequently, when for some . As shown in Table 2, both the KL-divergence and Pearson loss functions are not lower-bounded, and hence, are prone to overfitting during optimization. This phenomenon is referred to as train-loss hacking by Kato and Teshima [14].
3.3 Biased gradient problem
Neural network parameters are updated using the accumulated gradients from each mini-batch. It is desirable for these gradients to be unbiased, i.e., holds. However, the equality between and requires the uniform integrability of , i.e., . The uniform integrability condition is typically violated when the loss function exhibits heavy-tailed behavior, which often occurs for the standard -divergence loss functions derived solely from Equation (2). Consequently, the standard loss functions frequently result in biased gradients.
To illustrate this, consider employing the KL-divergence loss function for optimizing a shift parameter of , where and . Intuitively, in the above example, biased gradients occur because the KL-divergence loss gradients contain terms inversely proportional to the estimated density ratios, making their expectation diverge. Specifically, the loss function is obtained as , and the gradient is expressed as . Then, we have and . Consequently, we generally observe that .
To mitigate this issue, Belghazi et al. [3] introduced a bias-reduction method for stochastic gradients in KL-divergence loss functions.
3.4 Vanishing gradient problem
The vanishing gradient problem is a well-known issue in optimizing GANs [2]. We suggest that this problem occurs when the following two conditions are met: (i) the loss function results in minimal updates of model parameters, and (ii) updating the model parameters leads to negligible changes in the model’s outputs. Thus, the problem emerges when the following equation holds:
| (3) |
where denotes a zero vector of the same dimension as the model gradient.
In Equation (3), condition (i) describes the loss function’s gradient vanishing, while condition (ii) ensures that the vanishing gradient condition persists. Specifically, the following three observations clarify their relationship: First, condition (i) does not necessarily imply condition (ii); Second, condition (i) alone does not guarantee its own persistence; Third, condition (ii) ensures the continued validity of condition (i).
To illustrate the first observation, consider the KL-divergence loss. Because its gradient is obtained as as shown in Table 2, (i) reduces to . Then, (i) does not ensure (ii). To understand the second and third observations, note that (ii) is both necessary and sufficient for preventing updates to the model parameters. Thus, if condition (ii) does not hold, the model’s predictions may change, potentially leading to the breakdown of condition (i). On the other hand, if condition (ii) holds, the model updates do not alter the outputs, leaving the gradient condition (i) unchanged, thereby causing the vanishing gradient problem to persist.
Consider the scenario where estimated density ratios become extremely small or large, fulfilling sufficient conditions for Equation (3) to hold. Table 2 presents the gradient formulas for the divergence loss functions (as provided in Table 2) along with their asymptotic behavior of the loss gradients as or . These results demonstrate that major -divergence loss functions satisfy the conditions for Equation (3), showing that , where and are constants, as or . In summary, all the divergence loss functions in Tables 2 and 2 can experience vanishing gradients when the estimated density ratio approaches extremal estimates.
3.5 Sample size requirement problem for KL-divergence
The sample complexity of the KL-divergence is , which implies that
| (4) |
where represents an arbitrary KL-divergence estimator for a sample size using a variational representation of the divergence, and represents the true value of KL-divergence [26, 31, 19]. That is, when using KL-divergence loss functions, the sample size of the training data must increase exponentially as the true amount of KL-divergence increases in order to sufficiently train a neural network. To address this issue, existing methods divide the estimation of high divergence values into multiple smaller divergence estimations [28].
| Name | convex function |
|
|||||
|---|---|---|---|---|---|---|---|
| KL | No | ||||||
| Pearson | No | ||||||
| Squared Hellinger | Yes | ||||||
| GAN |
|
|
Yes |
| Name | ||||||
|---|---|---|---|---|---|---|
| KL | * | |||||
| Pearson | * | |||||
| Squared Hellinger |
|
* | ||||
| GAN |
|
|
||||
4 DRE using a neural network with an -divergence loss
In this section, we derive our loss function from a variational representation of -divergence and present the training and prediction methods using this loss function. The exact claims and proofs for all theorems are deferred to Section C in the Appendix.
4.1 Derivation of our loss function for DRE
Here, we define -divergence (Amari’s -divergence), which is a subgroup of -divergence, as [1]:
| (5) |
where . From Equation (5), Hellinger divergence is obtained when , and when .
Then, we obtain the following variational representation of -divergence :
Theorem 4.1.
A variational representation of -divergence is given as
| (6) |
where the supremum is taken over all measurable functions satisfying and . The maximum value is achieved at .
From the right-hand side of Equation (6), we obtain a standard -divergence loss function as
| (7) |
Because and are generally observed when , the standard -divergence loss function with has biased gradients.
To obtain unbiased gradients for any , we rewrite the terms and of the equation in Gibbs density form. Then, we have another variational representation of -divergence.
Theorem 4.2.
A variational representation of -divergence is given as
| (8) |
where the supremum is taken over all measurable function satisfying and . The equality holds for satisfying .
Subsequently, we obtain our loss function for DRE, called -Divergence loss function (-Div).
Definition 4.3 (-Div).
-Divergence loss is defined as:
| (9) |
The superscript “” is dropped when unnecessary and instead expressed as .
4.2 Training and predicting with -Div
We train a neural network with -Div as described in Algorithm 1. In practice, neural networks rarely achieve the global optimum in Equation (8). The following theorem suggests that normalizing the estimated values, , improves the optimization of the neural networks.
Theorem 4.4.
For a fixed function , let be the optimal scalar value for the following infimum:
| (10) |
Then, satisfies . That is, .
5 Theoretical results for the proposed loss function
In this section, we provide theoretical results that justify our approach with -Div. The exact claims and proofs for all the theorems are deferred to Section C.3 in the Appendix.
5.1 Addressing the train-loss hacking problem
-Div avoids the train-loss hacking problem when is within . Table 3 summarizes the lower-boundedness status of -Div for each case: , , or . -Div is lower-bounded when , whereas it is not lower-bounded when or . Thus, selecting from the interval (0, 1) effectively prevents the train-loss hacking problem.
5.2 Unbiasedness of gradients
By rewriting in the Gibbs density form , we mitigate the heavy-tailed behavior that often breaks uniform integrability in the standard -divergence loss functions. Hence, we present Theorem 5.1, which guarantees the unbiasedness of -Div’s gradients.
Theorem 5.1 (Informal statement).
Let be a function such that the map is differentiable for all and for -almost every . Under some regularity conditions, including the local Lipschitz continuity of , we have
| (11) |
In Section 6.2, we empirically confirm that this unbiasedness is crucial for stable and effective optimization, as it prevents gradient estimates from drifting in the presence of heavy-tailed data.
5.3 Addressing gradient vanishing problem
| Intervals of | |||||
|---|---|---|---|---|---|
| (as ) | lower-unbounded | ||||
| (as ) | lower-unbounded | ||||
| lower-bounded |
| Intervals of | ||||
|---|---|---|---|---|
When is within , -Div avoids the gradient vanishing issue during training. Below, we describe why gradient vanishing does not occur in this case.
First, we obtain the gradients of the standard -divergence loss in Equation (7) and -Div:
| (12) | ||||
| (13) |
Next, consider the case where the estimated probability ratios, and , are either nearly zero or very large for some point . Because equations such that and follow from the assumption that for all , the behavior of under certain regularity conditions for , as or , is summarized in Table 4.
In all cases except for -Div with , vanishing of the loss gradients is observed, such that or . This implies that, during optimization, neural networks may remain stuck at extreme local minima when their density ratio estimations are either or . However, this issue is avoided when is within the interval . Additionally, choosing within the interval mitigates numerical instability arising from large differences in gradient values of the loss function for and , which is represented as in Table 4.
5.4 Sample size requirements for optimizing -divergence
We present the exact upper bound on the sample size required for minimizing -Div in Theorem 5.2, which corresponds to Equation (4) for KL-divergence loss functions. The sample size requirement for minimizing -Div is upper-bounded depending on the value of . Intuitively, this property arises from the boundedness of Amari’s -divergence: .
Theorem 5.2.
Let and . Subsequently, let
| (14) |
Then,
| (15) |
holds, where
and , , , , and .
Unfortunately, despite the sample requirement stated in Equation (15), we empirically find that the estimation accuracy for -Div and KL-divergence loss functions is roughly the same as that of KL-divergence loss functions in downstream tasks of DRE, including KL-divergence estimation, as discussed in Section 6.3.
6 Experiments
We evaluated the performance of our approach using synthetic datasets. First, we assessed the stability of the proposed loss function due to its lower-boundedness for within . Second, we validated the effectiveness of our approach in addressing the biased gradient issue in the training losses. Finally, we examined the -divergence loss function for DRE using high KL-divergence data. Details on the experimental settings and neural network training are provided in Section D in the Appendix.
In addition to the results presented in this section, we conducted two additional experiments: a comparison of -Div with existing DRE methods, and experiments using real-world data. These additional experiments are reported in Section E in the Appendix.
6.1 Experiments on the Stability of Optimization for Different Values of
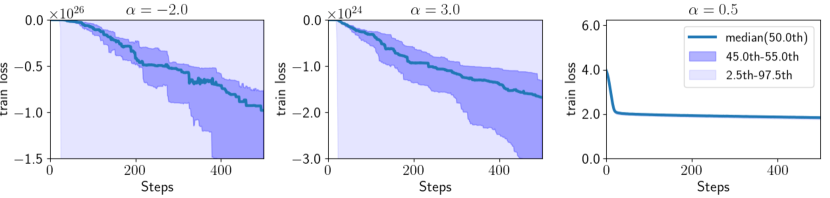
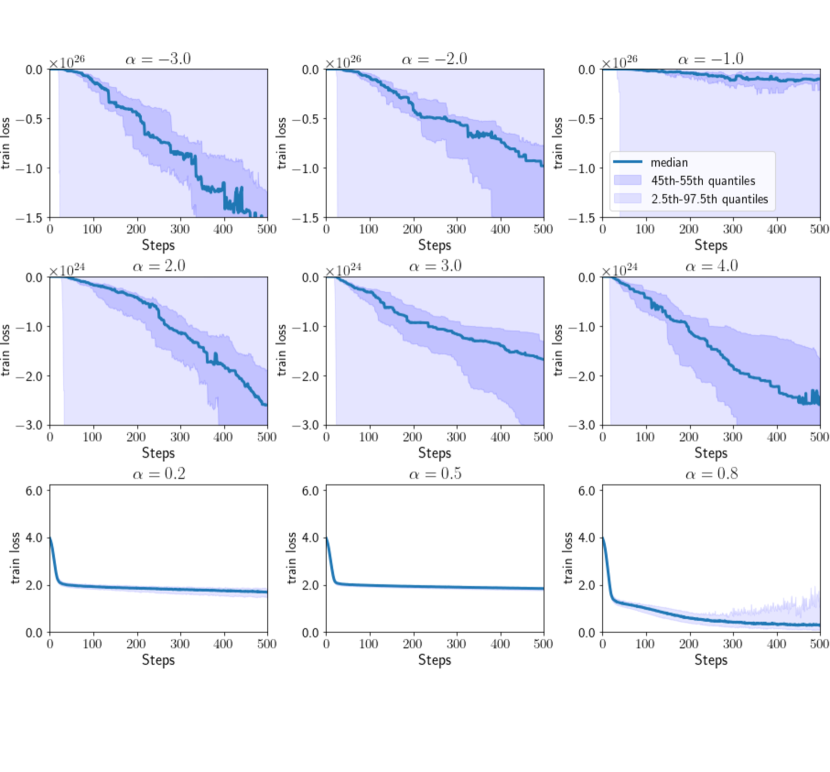
We empirically confirmed the stability of optimization using -Div, as discussed in Section 5.1. This includes addressing the potential divergence of training losses for and , and observing the stability of optimization when is within . Subsequently, we conducted experiments using synthetic datasets to examine the behavior of training losses during optimization across different values of at each learning step.
Experimental Setup. First, we generated 100 training datasets from two 5-dimensional normal distributions, and , where , and denotes the -dimensional identity matrix. The covariance matrix is defined as , and for . Subsequently, we trained neural networks using the synthetic datasets by optimizing -Div for , and , while measuring training losses at each learning step. For each value of , 100 trials were performed. Finally, we reported the median of the training losses at each learning step, along with the ranges between the 45th and 55th percentiles and between the 2.5th and 97.5th percentiles.
Results. Figure 2 presents the training losses of -Div across the learning steps for , and . Results for other values of are provided in Section D.1 in the Appendix. The figures on the left () and in the center () show that the training losses diverged to negative infinity when or . In contrast, the figure on the right () demonstrates that the training losses successfully converged. These results highlight the stability of -Div’s optimization when is within the interval , as discussed in Section 5.1.
6.2 Experiments on the Improvement of Optimization Efficiency by Removing Gradient Bias
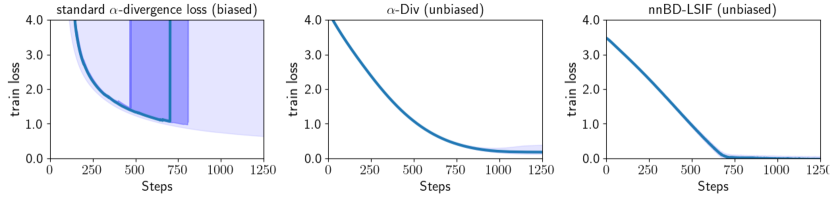
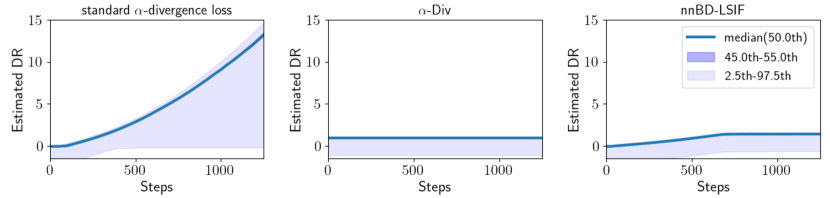
Unbiased gradients of loss functions are expected to optimize neural network parameters more effectively than biased gradients, since they update the parameters in ideal directions at each iteration. We empirically compared the efficiency of minimizing training losses between the proposed loss function and the standard -divergence loss function derived from Equation (12), which highlighted the effectiveness of the unbiased gradients of the proposed loss function. Additionally, we observed that the estimated density ratios using the standard -divergence loss function diverged to large positive values, suggesting that the gradients of the standard -divergence loss function vanished. In contrast, -Div exhibited stable estimation. This finding aligns with the discussion in Section 5.3.
Experimental Setup. We first generated 100 training datasets from two normal distributions, and , where denotes the 5-dimensional identity matrix. The means were set as and . We then trained neural networks using three different loss functions: the standard -divergence loss function defined in Equation (12), -Div, and deep direct DRE (D3RE) [14]. Training losses were measured at each learning step. D3RE addresses train-loss hacking issues associated with Bregman divergence loss functions, as described in Section 3.4, by mitigating the lower-unboundedness of loss functions. Specifically, for D3RE, we employed the neural network-based Bregman divergence Least Squares Importance Fitting (nnBD-LSIF) loss function, which ensures unbiased gradients and stable optimization. The hyperparameter for nnBD-LSIF was set to . For both the standard -divergence loss and -Div, we used . Finally, we reported the median training losses at each learning step, along with ranges between the 45th and 55th percentiles and between the 2.5th and 97.5th percentiles.
Results.
The top row in Figure 2 illustrates the training losses at each learning step for each loss function. The center and right panels show that -Div and nnBD-LSIF are more effective at minimizing training losses compared to the standard -divergence loss function. These findings indicate that the unbiased gradient of -Div, like nnBD-LSIF, leads to more efficient neural network optimization than the biased gradient of the standard -divergence loss function. These results highlight the ineffectiveness in optimization of the standard -divergence loss function inherent in its biased gradients and -Div successfully mitigates this issue.
Additionally, the training losses for the standard -divergence loss function diverged to positive infinity after 400 steps (the top panel in the left column), and the estimated density ratio diverged during optimization (the bottom panel in the left column). As shown in Table 4, the divergence of both the standard -divergence loss function and the estimated density ratio when , that is and with , imply that . Consequently, these results demonstrate that the vanishing gradient issue in the standard -divergence loss function occurs when the estimated density ratio becomes very large when . In contrast, -Div avoids this instability by maintaining stable gradients, which aligns with the discussion in Section 5.3.
6.3 Experiments on the Estimation Accuracy Using High KL-Divergence Data
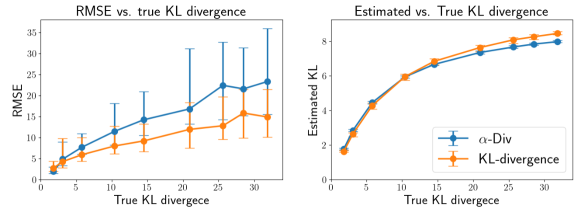
In Section 3.5, we examined the -divergence loss function, hypothesizing that its boundedness could address sample size issues in high KL-divergence data. Theorem 5.2, based on this boundedness, suggests that -Div can be minimized regardless of the true KL-divergence, indicating its potential for effective DRE with high KL-divergence data. To validate this hypothesis, we assessed DRE and KL-divergence estimation accuracy using both -Div and a KL-divergence loss function.
However, we observed that the RMSE of DRE using -Div increased significantly with higher KL-divergence, similar to the KL-divergence loss function.
Additionally, both methods yielded nearly identical KL-divergence estimations. These findings suggest that the accuracy of DRE and KL-divergence estimation is primarily influenced by the true amount of KL-divergence in the data rather than the -divergence.
Experimental Setup. We generated 100 training and 100 test datasets, each containing 10,000 samples. The datasets were drawn from two normal distributions, and , where and , with denoting the 3-dimensional identity matrix. The values of were set to 1.0, 1.1, 1.2, 1.4, 1.6, 2.0, 2.5, and 3.0. Correspondingly, the ground truth KL-divergence values of the datasets were 31.8, 25.6, 21.0, 14.5, 10.4, 5.8, 3.1, and 1.8 nats111A ’nat’ is a unit of information measured using the natural logarithm (base ), reflecting the increasing values. The true density ratios of the test datasets are known for this experimental setup. We trained neural networks on the training datasets by optimizing both -Div with and the KL-divergence loss function. After training, we measured the root mean squared error (RMSE) of the estimated density ratios using the test datasets. Additionally, we estimated the KL-divergence of the test datasets based on the estimated density ratios using a plug-in estimator. Finally, we reported the median RMSE of the DRE and the estimated KL-divergence, along with the interquartile range (25th to 75th percentiles), for both the KL-divergence loss function and -Div.
Results. Figure 3 shows the experimental results. The -axis represents the true KL-divergence values of the test datasets, while the y-axes of the graphs display the RMSE (left) and estimated KL-divergence (right) for the test datasets. We empirically observed that the RMSE for DRE using -Div increased significantly as the KL-divergence of the datasets increased. A similar trend was observed for the KL-divergence loss function. Additionally, the KL-divergence estimation results were nearly identical between both methods. These findings indicate that the accuracy of DRE and KL-divergence estimation is primarily determined by the magnitude of KL-divergence in the data and is less influenced by -divergence. Therefore, we conclude that the approach discussed in Section 5.4 offers no advantage over the KL-divergence loss function in terms of the RMSE for DRE with high KL-divergence data. However, we believe that these empirical findings contribute to a deeper understanding of the accuracy of downstream tasks in DRE using -divergence loss functions.
7 Conclusion
This study introduced a novel loss function for DRE, -Div, which is both concise and provides stable, efficient optimization. We offered technical justifications and demonstrated its effectiveness through numerical experiments. The empirical results confirmed the efficiency of the proposed loss function. However, experiments with high KL-divergence data revealed that the -divergence loss function did not offer a significant advantage over the KL-divergence loss function in terms of RMSE for DRE. These findings contribute to a deeper understanding of the accuracy of downstream tasks in DRE when using -divergence loss functions.
References
- Amari and Nagaoka [2000] Shun-ichi Amari and Hiroshi Nagaoka. Methods of information geometry, volume 191. American Mathematical Soc., 2000.
- Arjovsky and Bottou [2017] Martin Arjovsky and Léon Bottou. Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862, 2017.
- Belghazi et al. [2018] Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. Mutual information neural estimation. In International conference on machine learning, pages 531–540. PMLR, 2018.
- Bingham and Mannila [2001] Ella Bingham and Heikki Mannila. Random projection in dimensionality reduction: applications to image and text data. In Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, pages 245–250, 2001.
- Birrell et al. [2021] Jeremiah Birrell, Paul Dupuis, Markos A Katsoulakis, Luc Rey-Bellet, and Jie Wang. Variational representations and neural network estimation of rényi divergences. SIAM Journal on Mathematics of Data Science, 3(4):1093–1116, 2021.
- Blitzer et al. [2007] John Blitzer, Mark Dredze, and Fernando Pereira. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th annual meeting of the association of computational linguistics, pages 440–447, 2007.
- Cai et al. [2020] Likun Cai, Yanjie Chen, Ning Cai, Wei Cheng, and Hao Wang. Utilizing amari-alpha divergence to stabilize the training of generative adversarial networks. Entropy, 22(4):410, 2020.
- Choi et al. [2022] Kristy Choi, Chenlin Meng, Yang Song, and Stefano Ermon. Density ratio estimation via infinitesimal classification. In International Conference on Artificial Intelligence and Statistics, pages 2552–2573. PMLR, 2022.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- Gutmann and Hyvärinen [2010] Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 297–304. JMLR Workshop and Conference Proceedings, 2010.
- Hjelm et al. [2018] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670, 2018.
- Huang et al. [2006] Jiayuan Huang, Arthur Gretton, Karsten Borgwardt, Bernhard Schölkopf, and Alex Smola. Correcting sample selection bias by unlabeled data. Advances in neural information processing systems, 19, 2006.
- Kanamori et al. [2009] Takafumi Kanamori, Shohei Hido, and Masashi Sugiyama. A least-squares approach to direct importance estimation. The Journal of Machine Learning Research, 10:1391–1445, 2009.
- Kato and Teshima [2021] Masahiro Kato and Takeshi Teshima. Non-negative bregman divergence minimization for deep direct density ratio estimation. In International Conference on Machine Learning, pages 5320–5333. PMLR, 2021.
- Kato et al. [2019] Masahiro Kato, Takeshi Teshima, and Junya Honda. Learning from positive and unlabeled data with a selection bias. In International conference on learning representations, 2019.
- Ke et al. [2017] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30, 2017.
- Kingma [2014] Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kwon and Baek [2024] Euijoon Kwon and Yongjoo Baek. -divergence improves the entropy production estimation via machine learning. Physical Review E, 109(1):014143, 2024.
- McAllester and Stratos [2020] David McAllester and Karl Stratos. Formal limitations on the measurement of mutual information. In International Conference on Artificial Intelligence and Statistics, pages 875–884. PMLR, 2020.
- Menon and Ong [2016] Aditya Menon and Cheng Soon Ong. Linking losses for density ratio and class-probability estimation. In International Conference on Machine Learning, pages 304–313. PMLR, 2016.
- Nguyen et al. [2007] XuanLong Nguyen, Martin J Wainwright, and Michael Jordan. Estimating divergence functionals and the likelihood ratio by penalized convex risk minimization. Advances in neural information processing systems, 20, 2007.
- Nguyen et al. [2010] XuanLong Nguyen, Martin J Wainwright, and Michael I Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory, 56(11):5847–5861, 2010.
- Nowozin et al. [2016] Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-gan: Training generative neural samplers using variational divergence minimization. Advances in neural information processing systems, 29, 2016.
- Paszke et al. [2017] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- Pedregosa et al. [2011] Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python. the Journal of machine Learning research, 12:2825–2830, 2011.
- Poole et al. [2019] Ben Poole, Sherjil Ozair, Aaron Van Den Oord, Alex Alemi, and George Tucker. On variational bounds of mutual information. In International Conference on Machine Learning, pages 5171–5180. PMLR, 2019.
- Ragab et al. [2023] Mohamed Ragab, Emadeldeen Eldele, Wee Ling Tan, Chuan-Sheng Foo, Zhenghua Chen, Min Wu, Chee-Keong Kwoh, and Xiaoli Li. Adatime: A benchmarking suite for domain adaptation on time series data. ACM Transactions on Knowledge Discovery from Data, 17(8):1–18, 2023.
- Rhodes et al. [2020] Benjamin Rhodes, Kai Xu, and Michael U Gutmann. Telescoping density-ratio estimation. Advances in neural information processing systems, 33:4905–4916, 2020.
- Shimodaira [2000] Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of statistical planning and inference, 90(2):227–244, 2000.
- Shiryaev [1995] Albert Nikolaevich Shiryaev. Probability, 1995.
- Song and Ermon [2019] Jiaming Song and Stefano Ermon. Understanding the limitations of variational mutual information estimators. arXiv preprint arXiv:1910.06222, 2019.
- Sugiyama et al. [2007a] Masashi Sugiyama, Matthias Krauledat, and Klaus-Robert Müller. Covariate shift adaptation by importance weighted cross validation. Journal of Machine Learning Research, 8(5), 2007a.
- Sugiyama et al. [2007b] Masashi Sugiyama, Shinichi Nakajima, Hisashi Kashima, Paul Buenau, and Motoaki Kawanabe. Direct importance estimation with model selection and its application to covariate shift adaptation. Advances in neural information processing systems, 20, 2007b.
- Sugiyama et al. [2012] Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori. Density-ratio matching under the bregman divergence: a unified framework of density-ratio estimation. Annals of the Institute of Statistical Mathematics, 64:1009–1044, 2012.
- Uehara et al. [2016] Masatoshi Uehara, Issei Sato, Masahiro Suzuki, Kotaro Nakayama, and Yutaka Matsuo. Generative adversarial nets from a density ratio estimation perspective. arXiv preprint arXiv:1610.02920, 2016.
Appendix A Organization of the Supplementary Document
The organization of this supplementary document is as follows: Section B reviews prior work in DRE using -divergence optimization. Section C presents the theorems and proofs cited in this study. Section D provides details of the numerical experiments conducted. Finally, Section E presents additional experimental results.
Appendix B Related Work
Nguyen et al. [22] proposed DRE using variational representations of -divergences. Sugiyama et al. [34] introduced density-ratio matching under the Bregman divergence, a general framework that unifies various methods for DRE. As noted by Sugiyama et al. [34], density-ratio matching under the Bregman divergence is equivalent to DRE using variational representations of -divergences. Kato and Teshima [14] proposed a correction method for Bregman divergence loss functions s, in which the loss functions diverge to negative infinity, as discussed in Section 3.2. For estimation in scenarios with high KL-divergence data, Rhodes et al. [28] proposed a method that divides the high KL-divergence estimation into multiple smaller divergence estimations. Choi et al. [8] further developed a continuous decomposition approach by introducing an auxiliary variable for transforming the data distribution. DRE using variational representations of -divergences has also been studied from the perspective of classification-based modeling. Menon and Ong [20] demonstrated that DRE via -divergence optimization can be represented as a binary classification problem. Kato et al. [15] proposed using the risk functions in PU learning for DRE.
Lastly, we review prior studies on DRE focusing on -divergence loss functions. Birrell et al. [5] derived an -divergence loss function from Rényi’s -divergence, while Cai et al. [7] employed a standard variational representation of Amari’s -divergence with or . Kwon and Baek [18] presented essentially the same -divergence loss function proposed in this study, utilizing the Gibbs density expression to measure entropy in thermodynamics. In contrast, we propose the loss function to address the biased gradient problem.
Appendix C Proofs
In this section, we present the theorems and the proofs referenced in this study. First, we define -Div within a probabilistic theoretical framework. Following that, we provide the theorems and the proofs cited throughout the study.
Capital, small and bold letters.
Random variables are denoted by capital letters. For example, . Small letters are used for values of the random variables corresponding to the capital letters; denotes a value of the random variable . Bold letters and represent sets of random variables and their values.
C.1 Definition of -Div
Definition C.1 (-Divergence loss).
Let denote i.i.d. random variables drawn from , and let denote i.i.d. random variables drawn from . Then, the -Divergence loss is defined as follows:
| (17) |
where is a measurable function over such that .
C.2 Proofs for Section 4
In this section, we provide the theorems and the proofs referenced in Section 4.
Theorem C.2.
A variational representation of -divergence is given as
| (18) |
where the supremum is taken over all measurable functions with and . The maximum value is achieved at .
Proof of Theorem C.2.
Let for , then
| (19) |
Note that, the Legendre transform of is obtained as
| (20) |
and for the Legendre transforms of functions, it holds that
| (21) |
Here, denotes the Legendre transform of .
By differentiating , we obtain
| (23) |
Thus,
| (24) |
| (25) |
In addition, from Equations (24) and (25), we observe that is equivalent to . Similarly, is equivalent to .
This completes the proof. ∎
Theorem C.3 (Theorem 4.2 in Section 4 restated).
The -divergence is represented as
| (26) |
where the supremum is taken over all measurable functions with and . The equality holds for satisfying
| (27) |
proof of Theorem 4.2.
Substituting into in Equation (18), we have
| (28) |
Finally, from Theorem 4.1, the equality for Equation (28) holds if and only if
| (29) |
This completes the proof. ∎
Lemma C.4.
For a measurable function with and , let
| (30) |
Then the optimal function for is obtained as , -almost everywhere.
proof of Lemma C.4.
First, note that it follows from Jensen’s inequality that
| (31) |
for and with , and equality holds when .
Substitute , , , and into Equation (31), we obtain
and is minimized when , -almost everywhere. Therefore, is achieved at , -almost everywhere. Thus, we obtain , -almost everywhere.
This completes the proof. ∎
Lemma C.5.
For a measurable function with and , let
| (32) | ||||
| (33) |
and let
| (34) | ||||
| (35) |
where the infima of Equations (34) and (35) are considered over measurable functions with and .
proof of Lemma C.5.
Let .
First, it follows from Lemma C.4 that
| (37) |
Next, we obtain
| (38) |
Let . Note that,
| (39) |
Then, we have
| (40) |
From Theorem C.3, we have
| (41) |
Then, we observe that
That is, the following sequence is uniformly integrable for :
Thus, from the property of the Lebesgue integral (Shiryaev, P188, Theorem 4), we have
| (43) |
Here, we have
| (44) |
This completes the proof. ∎
C.3 Proofs for Section 5
In this section, we provide the theorems and the proofs referenced to in Section 5.
Theorem C.7 (Theorem 5.1 in Section 5 restated).
Let be a function such that the map is differentiable for all and for -almost every . Assume for a point , it holds that and , and there exists a compact neighborhood of , denoted by , and a constant value , such that .
Then,
| (47) |
proof of Theorem C.7.
We now consider the values, as , of the following two integrals:
| (48) |
and
| (49) |
Note that it follows from the intermediate value theorem that
| (50) |
Integrating the term on the left-hand side of Equation (51) with respect to , we have
| (52) |
Considering the supremum for in Equation (52), we obtain
| (53) |
since is compact.
Therefore, the following set is uniformly integrable for :
| (54) |
Similarly, for Equation (49), we have
| (55) |
Therefore, the following set is uniformly integrable for :
| (56) |
Thus, the Lebesgue integral and are exchangeable for the set in Equation (56). Then, we have
| (57) |
Similarly, we obtain
| (58) |
This completes the proof. ∎
Theorem C.8.
Assume . Let . Subsequently, let
| (60) |
Then, it holds that as ,
| (61) |
where
| (62) |
and
| (63) | ||||
| (64) | ||||
| (65) | ||||
| (66) |
proof of Theorem C.8.
First, note that
| (67) |
On the other hand, from Lemma C.5, we obtain
Subtracting Equation (LABEL:D_alpha_represented_as_exp) from Equation (67), we have
| (69) |
Let . Then are independent and identically distributed variables whose means and variances are as follows:
| (70) |
and
| (71) |
Similarly, let . Then are independent and identically distributed variables whose means and variances are as follows:
| (72) |
and
| (73) |
Now, we consider an asymptotical distribution of the following term:
| (74) |
By the central limit theorem, we observe that as ,
| (75) |
and
| (76) |
This completes the proof. ∎
Appendix D Details of the experiments in Section 6
In this section, we provide details of the hyperparameter settings used in the experiments described in Section 6.
D.1 Details of the experiments in Section 6.1
In this section, we provide details of the experiments reported in Section 6.1.
D.1.1 Datasets.
We generated the following 100 train datasets. and where , and denotes the -dimensional identity matrix, and with , and for . The size of each dataset was 5000.
D.1.2 Experimental Procedure.
Neural networks were trained using the synthetic datasets by optimizing -Div for , and while measuring the training losses for each learning step. For each value of , 100 trials were conducted. Finally, we reported the median, ranging between the 45th and 55th quartiles, and between the 2.5th and 97.5th quartiles of the training losses at each learning step.
D.1.3 Neural Network Architecture, Optimization Algorithm, and Hyperparameters.
A 5-layer perceptron with ReLU activation was used, with each hidden layer comprising 100 nodes. For optimization, the learning rate was set to 0.001, the batch size to 2500, and the number of epochs to 250. The models for DRE were implemented using the PyTorch library [24] in Python. Training was conducted with the Adam optimizer [17] in PyTorch and an NVIDIA T4 GPU.
D.1.4 Results.
Figure 4 presents the training losses of -Div across learning steps for , and . The upper (, and ) and middle ( and ) figures in Figure 4show that the training losses diverged to large negative values when or . In contrast, the bottom figure (, and ) Figure 2, the training losses of -Div converged, illustrating the stability of optimization with -Div when .
D.2 Details of the experiments in Section 6.2
In this section, we provide details about the experiments reported in Section 6.2.
D.2.1 Datasets.
We first generated 100 training datasets, each with a total size of samples. Each dataset was drawn from two normal distributions: and where denotes the -dimensional identity matrix, and and .
D.2.2 Experimental Procedure.
We trained neural networks using the training datasets, optimizing both -Div and the standard -divergence loss function defined in Equation (7) with , as well as nnBD-LSIF, while measuring the training losses at each learning step. We conducted 100 trials and reported the median training losses, along with the ranges between the 45th and 55th percentiles, and between the 2.5th and 97.5th percentiles, at each learning step.
Loss functions used in the experiments.
We used -Div, the standard -divergence loss function, and the non-negative Bregman divergence least-squares importance fitting (nnBD-LSIF) loss function [14] to train neural networks. The standard -divergence loss function, presented in Equation (7), exhibits a biased gradient when .
nnBD-LSIF is an unbounded Bregman divergence loss function obtained from the deep direct DRE (D3RE) method proposed by Kato and Teshima [14], which is defined as
| (83) |
where if otherwise , and is positive constant. Note that, nnBD-LSIF has an unbiased gradient. The optimization efficiency of nnBD-LSIF was observed to confirm the effectiveness of an unbiased gradient of an -divergence loss function as well as -Div.
D.2.3 Neural Network Architecture, Optimization Algorithm, and Hyperparameters.
We used a 4-layer perceptron with ReLU activation, in which each hidden layer contained 100 nodes. For optimization, we set the learning rate to 0.00005, the batch size to 2500, and the number of epochs to 1000. We implemented all models for DRE using the PyTorch library [24] in Python. Training was performed with the Adam optimizer [17] in PyTorch, utilizing an NVIDIA T4 GPU.
D.3 Details of the experiments in Section 6.3
In this section, we provide details of the experiments reported in Section 6.3.
D.3.1 Datasets.
Initially, we created 100 train and test datasets, each with a size of 10,000. Each dataset is generated from two normal distributions and where denotes the -dimensional identity matrix and values were , 1.1, 1.2, 1.4, 1.6, 2.0, 2.5, or 3.0, and and . In the aforementioned setting, the ground truth KL-divergence amounts of the datasets is obtained as
| (84) |
From Equation (84), we see that the ground truth KL-divergence amounts of the datasets were 31.8, 25.6, 21.0, 14.5, 10.4, 10.4, 5.8, 3.1, and 1.8, which correspond to the ascending values, such that .
D.3.2 Experimental Procedure.
We trained neural networks using the training datasets by optimizing both -Div with and a KL-divergence loss function. Details of the KL-divergence loss function used in the experiments are provided in the following paragraph. Training was halted if the validation losses, measured using the validation datasets, did not improve during an entire epoch. After training the neural networks, we measured the root mean squared error (RMSE) of the estimated density ratios using the test datasets. We estimated the KL-divergence of the test datasets for each trial using the estimated density ratios and the plug-in estimation method, which is detailed below. A total of 100 trials were conducted. Finally, we reported the median RMSE of the DRE and the estimated KL-divergence, along with the interquartile range (25th to 75th percentiles), for each KL-divergence loss function and -Div.
KL-divergence loss function.
A standard KL-divergence loss function is obtained as
| (85) |
In our pre-experiment, the standard KL-divergence loss function exhibited poor optimization performance, which we attributed to its biased gradients. However, we found that applying the Gibbs density transformation, as described in Section 4.1, improved optimization performance for the KL-divergence loss function. Therefore, we used the following KL-divergence loss function, in our experiments:
| (86) |
Plug-in KL-divergence estimation method using the estimated density ratios.
The KL-divergence of the test datasets was estimated by estimated predicted density ratios for the test datasets using plug-in estimation, such that
| (87) |
where .
D.3.3 Neural Network Architecture, Optimization Algorithm, and Hyperparameters.
The same neural network architecture, optimization algorithm, and hyperparameters were used for both -Div and the KL-divergence loss function. A 4-layer perceptron with ReLU activation was employed, with each hidden layer consisting of 256 nodes. For optimization with the -Div loss function, the value of was set to 0.5, the learning rate to 0.00005, and the batch size to 256. Early stopping was applied with a patience of 32 epochs, and the maximum number of epochs was set to 5000. For optimization using the KL-divergence loss function, the learning rate was 0.00001, with a batch size of 256. Early stopping was applied with a patience of 2 epochs, and the maximum number of epochs was 5000. All models for both D3RE and -Div were implemented using PyTorch library [24] in Python. The neural networks were trained with the Adam optimizer [17] in PyTorch on an NVIDIA T4 GPU.
Appendix E Additional Experiments
E.1 Comparison with Existing DRE Methods
We empirically compared the proposed DRE method with existing DRE methods in terms of DRE task accuracy. This experiment followed the setup described in Kato and Teshima [14].
E.1.1 Existing -Divergence Loss Functions for Comparison.
The proposed method was compared with the Kullback–Leibler importance estimation procedure (KLIEP) [33], unconstrained least-squares importance fitting (uLSIF) [13], and deep direct DRE (D3RE) [14]. The densratio library in R was used for KLIEP and uLSIF. 222The URL: https://cran.r-project.org/web/packages/densratio/index.html. For D3RE, the non-negative Bregman divergence least-squares importance fitting (nnBD-LSIF) loss function was employed.
E.1.2 Datasets.
For each , and , 100 datasets were generated, comprising training and test sets drawn from two -dimensional normal distributions and , where denotes the -dimensional identity matrix, , and .
E.1.3 Experimental Procedure.
Model parameters were trained using the training datasets, and density ratios for the test datasets were estimated. The mean squared error (MSE) of the estimated density ratios for the test datasets was calculated based on the true density ratios. Finally, the mean and standard deviation of the MSE for each method were reported.
E.1.4 Neural Network Architecture, Optimization Algorithm, and Hyperparameters.
For both D3RE and -Div, a 3-layer perceptron with 100 hidden units per layer was used, consistent with the neural network structure employed in Kato and Teshima [14]. For D3RE, the learning rate was set to 0.00005, the batch size to 128, and the number of epochs to 250 for each data dimension. The hyperparameter was set to 2.0. For -Div, the learning rate was set to 0.0001, the batch size to 128, and the value of to 0.5 for each data dimension. The number of epochs was set to 40 for data dimensions of 10, 50 for dimensions of 20, 30, and 50, and 60 for a dimension of 100. The PyTorch library [24] in Python was used to implement all models for both D3RE and -Div. The Adam optimizer [17] in PyTorch, along with an NVIDIA T4 GPU, was used for training the neural networks.
Results.
| Data dimensions () | |||||
|---|---|---|---|---|---|
| Model | |||||
| KLIEP | 2.141(0.392) | 2.072(0.660) | 2.005(0.569) | 1.887(0.450) | 1.797(0.419) |
| uLSIF | 1.482(0.381) | 1.590(0.562) | 1.655(0.578) | 1.715(0.446) | 1.668(0.420) |
| D3RE | 1.111(0.314) | 1.127(0.413) | 1.219(0.458) | 1.222(0.305) | 1.369(0.355) |
| -Div | 0.173(0.072) | 0.278(0.113) | 0.479(0.259) | 0.665(0.194) | 1.118(0.314) |
Table 5 summarizes the results for each method across different data dimensions. Six cases where the MSE for KLIEP exceeded 1000 were excluded. For all data dimensions, -Div consistently demonstrated superior accuracy compared to the other methods, achieving the lowest MSE values. However, it is important to note that the prediction accuracy of -Div significantly decreased as the data dimensions increased. The curse of dimensionality in DRE was also observed in experiments with real-world data, which will be reported in the next section.
E.2 Experiments Using Real-World Data
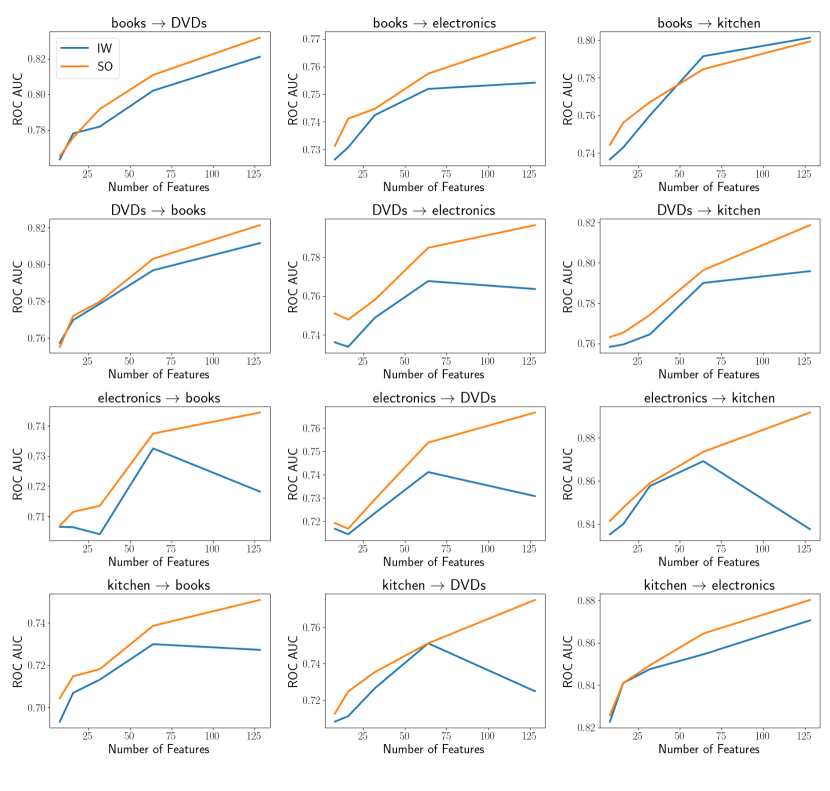
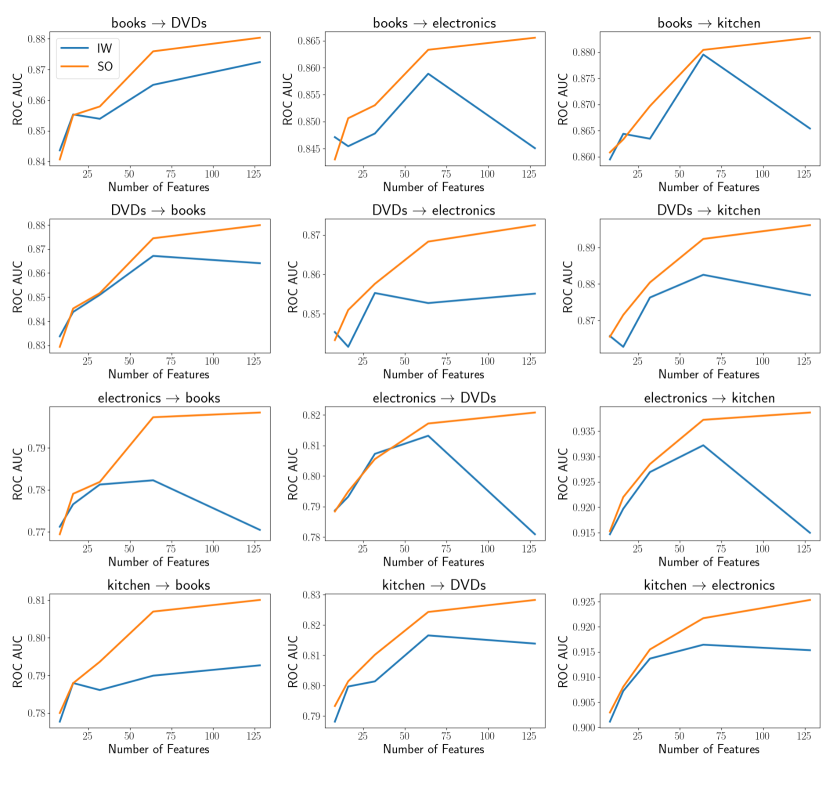
We conducted numerical experiments with real-world data to highlight important considerations in applying the proposed method. Specifically, we conducted experiments on Domain Adaptation (DA) for classification models using the Importance Weighting (IW) method [29]. The IW method builds a prediction model for a target domain using data from a source domain, while adjusting the distribution of source domain features to match the target domain features by employing the density ratio between the source and target domains as sample weights.
In these experiments, we used the Amazon review data [6] and employed two prediction algorithms: linear regression and gradient boosting. The hyperparameters for each algorithm were selected from a predefined set based on validation accuracy, using the Importance Weighted Cross Validation (IWCV) method [32] on the source domain data.
Through these experiments, we observed a decline in prediction accuracy on test data from the target domain as the data dimensionality increased. Specifically, there were instances where the accuracy worsened compared to models that did not use importance weighting—i.e., models trained solely on the source data. These phenomena are likely due to two issues in DRE: the degradation in density ratio estimation accuracy as dimensionality increases, as noted in Section E.1, and the negative impact of high KL-divergence on density ratio estimation, as observed in Section 6.3. It is important to note that the KL-divergence increases as the number of features increases (i.e., data dimensions), unless all features are fully independent.
E.2.1 Datasets.
The Amazon review dataset [6] includes text reviews and rating scores from four domains: books, DVDs, electronics, and kitchen appliances. The text reviews are one-hot encoded, and the rating scores are converted into binary labels. Twelve domain adaptation classification tasks were conducted, where each domain served once as the source domain and once as the target domain.
Notation.
and denote subsets of the original data for the source and target domains, respectively, for each feature dimension , where the columns of and are identical. and represent the objective variables in the source and target domains, respectively, which are binary labels assigned to each sample in the source and target domain data. and denote -dimensional feature tables used to estimate the density ratio , which is the ratio of the target domain density to the source domain density. indicates the number of columns (features) in the data .
E.2.2 Experimental Procedure.
Step 1. Creation of feature tables.
Many DA methods utilize feature embedding techniques to project high-dimensional data into a lower-dimensional feature space, facilitating the handling of distribution shifts between source and target domains [27]. However, our preliminary experiments revealed that model prediction accuracies were significantly influenced by the embedding procedures. To address these effects on DA task accuracies, we explored an embedding method with theoretical considerations detailed in the next section.
Specifically, we selected an identical set of columns from the original data of both the source and target domains for each feature dimension, , and , arranging the columns in ascending order of . Let and denote the subsets of the original data for the source and target domains, respectively, determined by these selected columns for each . We then generated a matrix from a normal distribution. Finally, by multiplying and , and and , we obtained the feature tables and , embedding the original source and target domain data into a -dimensional feature space. 333In our experiments, we utilized matrices generated from the normal distribution as embedding maps, which is equivalent to random projection [4]. However, the linearity of the map is not necessary for preserving the density ratios, as discussed in Section E.2.3. In contrast, linearity is a key requirement for the distance-preserving property of random projection.
Step 2. Estimation of importance weights.
Using the proposed loss function with and obtained from the previous step, we estimated the probability density ratio for each feature dimension , where . This ratio represents the density of the target domain relative to the source domain.
Step 3. Model construction.
We constructed the target model using the IW method. Specifically, we built a classification model using the training dataset , where the estimated density ratio served as the sample weights for the IW method. Additionally, we constructed a prediction model using only the source data, i.e., a model built without importance weighting.
Step 4. Verification of prediction accuracy
To evaluate the prediction accuracy of the models, we selected the ROC AUC score, as it measures the accuracy independent of the thresholds used for label determination. For the classification tasks in domain adaptation, we employed two classification methods, each representing a different algorithmic approach: LogisticRegression from the scikit-learn library [25] for linear classification, and LightGBM [16] for nonlinear classification.
The hyperparameter sets of both methods for evaluating the prediction accuracies on the target domains were selected using the IWCV method [32]. These hyperparameter sets were defined as all combinations of the values listed in Table 6 for LogisticRegression and Table 7 for LightGBM, respectively. Finally, the prediction accuracies on the target domain were assessed using the best model selected through IWCV, where the target domain data were used for the predictions.
| Hyperparameters | Values |
|---|---|
| l1_ratio (Elastic-Net mixing parameter) | 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0 |
| lambda (Inverse of regularization strength) | 0.0001, 0.001, 0.01, 0.05, 0.1, 0.25, 0.5, 0.75, 1, 1.5, 2, and 5 |
| Hyperparameters | Values |
|---|---|
| lambda_l1 ( regularization) | 0.0, 0.25, 0.5, 0.75, and 1.0 |
| lambda_l2 ( regularization) | 0.0, 0.0001, 0.001, 0.01, 0.1, 0.5, 1.0, 2.0, and 4.0 |
| num_leaves (Number of leaves in trees) | 64, 248, 1024, 2048, and 4096 |
| learning_rate (Learning rate) | 0.01, and 0.001 |
| feature_fraction (Ratio of featuresr used for modeling) | 0.4, 0.8, and 1.0 |
| Feature dimensions () | |||||
|---|---|---|---|---|---|
| Original data dimensions () | 500 | 700 | 900 | 1700 | 4600 |
E.2.3 Consideration of the Feature Embedding Method
Let denote a -class embedding map which maps the original data into the feature space with .
We now demonstrate that if is injective for both the source and target domain data, it preserves the density ratio between the target and source domain densities when it maps the original data into the embedded data.
To demonstrate this, we use the singular value decomposition (SVD) of the Jacobian matrix of , which gives
with
where and are orthogonal matrices in and , respectively, and for all . This gives the following relationship between the probability densities of the original and embedded data:
| (88) |
From Equation (88), the probability density ratio between the source and target domains of data embedded by is obtained as
Therefore, preserves the density ratio from the original data to the embedded data. Additionally, if is a matrix multiplication, its injectivity can be achieved for by reducing its dimensionality sufficiently. Reducing the dimensionality of can ensure the injectivity of .
We heuristically detected the injectivity of our embedding by observing the following: We identified the largest subset of columns in such that a significant increase in the KL-divergence between and was observed when a column is added to a partial subset of columns within it. Injectivity was assumed for columns within this subset.
Although our feature embedding procedure is based on heuristic observations and lacks rigorous theoretical analysis, we found it adequate for evaluating the performance of the proposed method in DRE downstream tasks with real-world data when the number of features increases.
The number of columns in the original data used in the experiments is listed in Table 8.
Neural Network Architecture, Optimization Algorithm, and Hyperparameters.
A 5-layer perceptron with ReLU activation was used, with each hidden layer consisting of 256 nodes. For optimization, the value of was set to 0.5, the learning rate to 0.0001, and the batch size to 128. Early stopping was applied with a patience of 1 epoch, and the maximum number of epochs was set to 5000. The PyTorch library [24] in Python served as the framework for model implementation. Training of the neural networks was carried out using the Adam optimizer [17] on an NVIDIA T4 GPU.
Results.
The results are shown in Figure 5 (LogisticRegression) and Figure 6 (LightGBM). The domain names at the origin of the arrows in the figure titles represent the source domains, and those at the tip indicate the target domains. The -axis of each figure shows the number of features, and the -axis represents the ROC AUC for the domain adaptation tasks. The orange line (SO) represents models trained using source-only data, i.e., models trained using source data without importance weighting, while the blue line (IW) represents models trained using source data with importance weighting.
Prediction accuracy for the models trained solely on the source data improved as the number of features increased, which is expected since more features typically lead to better accuracy. However, for both Logistic Regression and LightGBM, the performance of the IW method deteriorated as the number of features increased. A more significant decline in performance with increasing features was observed for most domain adaptation (DA) tasks, except for “books DVDs” and “kitchen DVDs”. These results suggest that the estimated density ratios caused the data distribution to deviate more from the target domain as the number of features increased. Consequently, the accuracy of the density ratio estimation (DRE) likely worsened with more features.