An Architectural Error Metric for CNN-Oriented Approximate Multipliers
Abstract
As a potential alternative for implementing the large number of multiplications in convolutional neural networks (CNNs), approximate multipliers (AMs) promise both high hardware efficiency and accuracy. However, the characterization of accuracy and design of appropriate AMs are critical to an AM-based CNN (AM-CNN). In this work, the generation and propagation of errors in an AM-CNN are analyzed by considering the CNN architecture. Based on this analysis, a novel AM error metric is proposed to evaluate the accuracy degradation of an AM-CNN, denoted as the architectural mean error (AME). The effectiveness of the AME is assessed in VGG and ResNet on CIFAR-10, CIFAR-100, and ImageNet datasets. Experimental results show that AME exhibits a strong correlation with the accuracy of AM-CNNs, outperforming the other AM error metrics. To predict the accuracy of AM-CNNs, quadratic regression models are constructed based on the AME; the predictions show an average of 3% deviation from the ground-truth values. Compared with a GPU-based simulation, the AME-based prediction is about faster.
Index Terms:
approximate multiplier, convolutional neural network, error metric, error propagationI Introduction
With the development of artificial intelligence, the number of parameters and arithmetic operations of neural networks increases rapidly. How to deploy large-scale neural network applications to hardware platforms with limited resources and power consumption has become a crucial issue. Leveraging the error tolerance inherent in convolutional neural networks (CNNs), approximate computing has emerged as a promising technique to enhance the efficiency of CNN accelerators [1, 2]. As multiplication dominates the computations in CNNs, a direct and effective approach for approximate computing in CNNs is utilizing approximate multipliers (AMs) [3, 4, 5, 6, 7]. In this case, the key question is how to select or design appropriate AMs for a CNN under a certain accuracy constraint.
In general, the accuracy of an AM-based CNN (AM-CNN) is assessed through simulations using frameworks such as TFApprox [8], ProxSim [9], AdaPT [10], and ApproxTrain [11]. In these frameworks, approximate multiplication is implemented by accessing the look up table (LUT) containing the products of all possible input combinations. Based on this, the 2D convolution operation in the TensorFlow or PyTorch framework is modified to support simulations for AM-CNNs. However, simulations provide only accuracy, lacking the capacity to guide the AM selection or design. Moreover, even using state-of-the-art simulation approaches, the search for the optimal AM in a large design space is still time-consuming.
An alternative approach to evaluating the accuracy of an AM-CNN involves accuracy prediction. This method disregards the specific hardware structure of the AM and focuses solely on its error characteristics. For example, treating the errors introduced by AMs as noise [12, 13, 14], or representing an AM by its error metrics [15, 16, 17, 18]. By modeling the impact of the AM error characteristics on the AM-CNN accuracy, guidance can be provided for CNN-oriented AM selection and design. However, although offering theoretical insights, many existing accuracy prediction methods for AM-CNN have limited practical applicability. The main challenges are as follows.
-
•
CNNs generally contain numerous multiplications and nonlinear functions, making the error propagation process within AM-CNNs difficult to mathematically model. Consequently, current accuracy prediction methods for AM-CNNs are often rather complex.
-
•
A universally accepted and efficient method to characterize the error characteristics of a CNN-oriented AM is lacking. Specifically, there is no error metric for AMs that can adequately captures their impacts on the accuracy of AM-CNNs.
In this work, we linearly model the process of error generation and propagation within AM-CNNs. Based on this model, a novel AM error metric denoted as the architectural mean error (AME) is proposed to evaluate the accuracy degradation of an AM-CNN. The experimental results show that the AME exhibits a strong correlation with the accuracy of AM-CNNs, and the AME-based quadratic regression models can predict the accuracy of AM-CNNs with an average of 3% deviation. Given an AM-CNN, computing the AME involves only a few matrix operations, making the AME-based accuracy prediction about faster than a GPU-based simulation.
The novel contributions of this work are as follows.
-
•
A linear model is developed to fit the error generation and propagation process within an AM-CNN.
-
•
An architectural error metric is proposed for AM to evaluate the accuracy degradation of AM-CNNs.
-
•
Quadratic regression models are trained based on the AME to predict the accuracy of AM-CNNs.
-
•
The effectiveness of the proposed AME is verified by using it to accelerate the selection process of the Pareto-optimal AMs for CNN applications.
The rest of the paper is organized as follows. Section II introduces the studies related to this work. Section III shows the definitions of the error metrics and outlines our motivation. Section IV describes the process for deriving the proposed AME. Section V presents the experimental results for evaluating the effectiveness of AME. Section VI provides application cases of AME. Section VII discusses the characteristics of AME. Finally, Section VIII concludes the paper.
II Related Work
To explore the relationship between the error metrics of an AM and the accuracy of the corresponding AM-CNN, various approaches have been explored in state-of-the-art researches.
Ansari et al. [15] trained two-class classifiers to categorize AMs based on whether they degrade the accuracy of AM-CNNs. These classifiers take various AM error metrics as inputs; these metrics are subsequently ranked based on their significance in achieving a high classification accuracy. The experimental results highlighted two critical AM error metrics, the variance of error (VarE) and the root-mean-square error (RMSE). However, this study only analyzed a small-scale CNN (i.e., the LeNet-5) on small datasets such as MNIST and SVHN. In addition, the classification accuracy of the constructed AM classifiers is pretty low, e.g., the highest accuracy is below 86%.
Similarly, [16] trained not only classifiers but also regressors to predict the AM-CNN accuracy based on AM error metrics. More complex CNNs such as VGG and ResNet, are involved in this study. By performing a dropout feature ranking, [16] finally summarized three important AM error metrics, the mean error (ME), the mean error distance (MED), and the error rate (ER). Although high accuracy is achieved, the classifiers and regressors constructed in [16] are generally complex and require a large number of samples for the training process. Moreover, this study lacks a mathematical explanation for the effectiveness of these metrics.
Kim et al. [17] analyzed the error generation and propagation process in an AM-CNN, demonstrating that AMs with low values of variance of relative error (VarRE) are unlikely to lead to accuracy degradation in AM-CNNs. However, in the experiments, fixed-point multiplications are utilized in the inference of the considered CNN models, which is far more accurate than the commonly used designs. Thus, the error effects of the AMs on the AM-CNNs cannot be effectively illustrated. Also, only three AMs are tested to verify the analyses, the applicability of the conclusions to arbitrary AMs has not been demonstrated.
III Analysis of Error Metrics
III-A Error Metric Definitions
Errors introduced by AMs are propagated and accumulated in an AM-CNN, causing feature changes and thus affecting the accuracy. Both the output errors of an AM and the accumulated errors in the AM-CNN can be characterized by error metrics. To distinguish these two types of errors, we denote the former as and the latter as ; they are given by
| (1) | ||||
where and are the approximate and the corresponding accurate multiplication results, respectively; and are the approximate and the corresponding accurate output features of a neuron, respectively. Also, to evaluate the relative deviation from the accurate value, the relative errors ( and ) are defined. They are given by
| (2) | ||||
By calculating the probability (), mean (), variance (), and other measurements of errors and relative errors, various error metrics are obtained. Table I shows the definitions of some common AM error metrics, where and are the total numbers of errors and relative errors, respectively. The error metrics for AM-CNNs are defined similarly, with and in Table I replaced by and , respectively, while retaining the same metric names.
| Metric | Description | Formula |
|---|---|---|
| ER | Error rate. | |
| ME | Mean error. | |
| MRE | Mean relative error. | |
| MED | Mean error distance. | |
| MRED | Mean relative error distance. | |
| VarE | Variance of error. | |
| VarRE | Variance of relative error. | |
| VarED | Variance of error distance. | |
| VarRED | Variance of relative error distance. | |
| MSE | Mean-square error. | |
| RMSE | Root-mean-square error. | |
| WCE | Worst-case error. | |
| WCRE | Worst-case relative error. |
To enhance hardware efficiency, the data in CNN is commonly quantized to a lower bit width, such as 8-bit [1]. For an AM with inputs of low bit width, its error metrics can be evaluated through traversing all possible input combinations. For example, the mean error (ME) of an unsigned AM can be calculated as follows
| (3) |
where is the joint probability mass function of the inputs, and is the for . To simplify the expression, (3) can be transformed to
| (4) |
where is the Frobenius inner product operation (i.e., the element-wise inner product of two matrices); and are two matrices containing the and for all possible , respectively. As contains all possible output errors of an AM, it can be referred to as the error matrix of the AM.
III-B Motivation: Error Metrics and Accuracy of AM-CNNs
Given an AM-based application, it is feasible to estimate the output error metrics of the application based on the error metrics of the employed AMs. This approach requires analyzing and modeling the error generation and propagation process within the application [19, 20]. As the quality of an AM-CNN is generally evaluated by the degradation of accuracy (e.g., classification accuracy) rather than the output error, our focus shifts to the error metrics associated with the output features of the last approximate NN layer.
Since each CNN layer outputs multiple features, individually analyzing the impact of changes in each feature on accuracy is less meaningful. Hence, we employ the error statistics across all output features of a layer as the error metrics of the layer, e.g., the ME of a layer is given by
| (5) |
where is the total number of test cases; , , and denote the height, width and channel number of the output feature maps of this layer, respectively.
We conducted experiments to assess the correlation between the accuracy and the error metrics of the last approximate layer for AM-CNNs. The experiments cover thousands of AM-CNNs given in Section V. Table II reports the Pearson correlation coefficients (PCCs), calculated as per (6), for various configurations of AM-based VGG-16 and ResNet-18 on the CIFAR-10 dataset.
| (6) |
where is the set of classification accuracy of AM-CNNs, and represents the set of error metrics corresponding to these AM-CNNs. Note that, unlike other non-negative metrics, the values of ME and mean relative error (MRE) can be either positive or negative. This characteristic leads to conflicting correlations between these values and the AM-CNN accuracy. For example, both higher negative ME and lower positive ME (i.e., MEs closer to 0) can indicate smaller errors and are generally associated with higher AM-CNN accuracy. Hence, the PCCs for positive and negative values of ME and MRE are calculated separately, as shown in Table II.
| Metric | VGG-16 | ResNet-18 |
|---|---|---|
| ER | 0.046 | 0.511 |
| ME | -0.844 0.696 a | -0.955 0.854 a |
| MRE | -0.743 0.310 a | -0.906 0.780 a |
| MED | -0.566 | -0.761 |
| MRED | -0.505 | -0.597 |
| VarE | -0.488 | -0.771 |
| VarRE | -0.465 | -0.426 |
| VarED | -0.487 | -0.741 |
| VarRED | -0.465 | -0.426 |
| MSE | -0.483 | -0.705 |
| RMSE | -0.583 | -0.780 |
| WCE | -0.615 | -0.852 |
| WCRE | -0.509 | -0.513 |
| aPCC for positive values PCC for negative values. | ||
It can be seen that the ME, essentially revealing the error expectation for the last approximate layer, exhibits the strongest correlation with the AM-CNN accuracy. Hence, we propose to construct a new AM error metric to estimate the error expectation of the last approximate layer. This metric, presented in the form of (4), should have a strong correlation with the AM-CNN accuracy.
IV Proposed Architectural Error Metric
This section first constructs a linear model based on two assumptions to fit the error generation and propagation process in an AM-CNN. A novel AM error metric is then proposed, which contains the information pertaining to both the CNN architecture and the AM error characteristics.
IV-A Error Generation
As one of the fundamental and computationally intensive components in CNNs, the convolutional layer typically accounts for the majority of computations. Therefore, designing AM-CNN generally involves approximating the convolutional layer [4, 5, 6, 7]. The calculation for an output feature () of the convolutional layer is expressed as
| (7) |
where is the total number of weights in a filter, is the th input activation, is the weight for , and is the bias. According to (1), the corresponding approximate output feature () of the layer with multiplications implemented by the same type of AMs can be described as
| (8) |
and the error of this output feature is given by
| (9) |
The expectation of can be obtained as
| (10) |
Given (5), the error expectation of this layer is calculated as
| (11) |
Assumption 1: can be estimated as per the data distribution. During the entire convolution process, each weight multiplies with almost every input activation in the same channel. Moreover, there is a certain correlation between different channels. Hence, can be estimated as
| (12) |
where and are two row vectors, contains the probabilities () for all possible values of , while contains the frequencies () for all possible values of ; and is the AM error matrix as in (4). For the case of using unsigned AM, there are , and . Note that for an AM-CNN without weight fine-tuning (e.g., retraining), is fixed and the same as that of the original exact CNN model, while is determined by the input activation distribution of this layer.
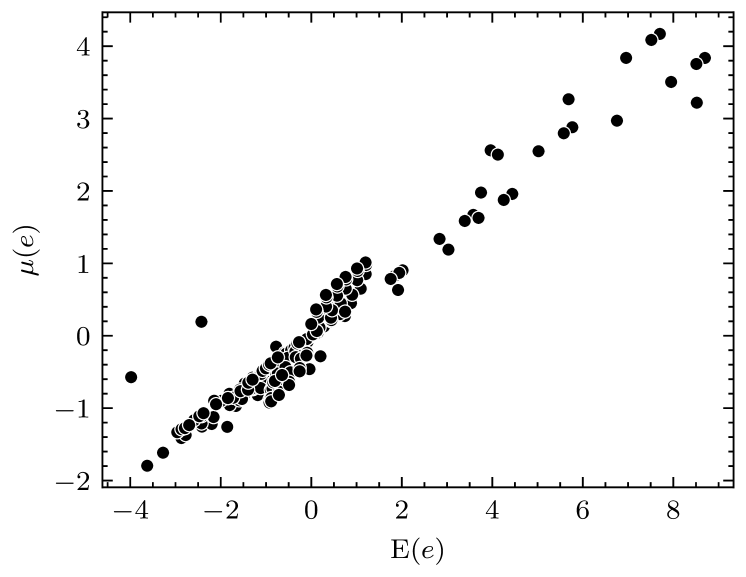
Approaches similar to this assumption (i.e., predicting the error based on the data distribution) have been utilized in previous works, yielding good results [5, 6]. To further verify the feasibility of this assumption, experiments were conducted to compare the estimated by using (12) with the measured by using (5). These experiments were conducted on the last convolutional layer of VGG-16 using the CIFAR-10 dataset, involving hundreds of AMs given in Section V. The experimental results are presented in Fig. 1. It demonstrates that, despite a numerical deviation, the estimated exhibits an extremely strong correlation with the measured (with a PCC exceeding 0.99). This result is sufficient for error estimation as we prioritizes the difference between the errors caused by different AMs, over the exact error values.
IV-B Error Propagation
In an AM-CNN, only the first approximate layer and the layers before it have accurate inputs, while all the other layers are influenced by the output errors of their previous approximate layers. An output feature of the AM-based convolutional layer with inaccurate inputs is given by
| (13) |
where is the input error for the th input activation. The error of this output feature is calculated as
| (14) |
The expectation of is given by
| (15) |
It can be seen that the error of this output feature is derived from two mutually independent sources, i.e., the input errors () and the AM output errors ().
Assumption 2: can be fitted as a linear combination of the error expectations of the input and AM. Denote this layer as layer , and the (defined in (11)) corresponding to this layer and the previous layer as and , respectively. The is fitted as
| (16) |
where is the error propagation factor for layer . The last term of (16) is equal to (10), which is the error expectation under accurate inputs.
Then, the is given by
| (17) |
where denotes the intrinsic error expectation of layer , which can be estimated by using (12).
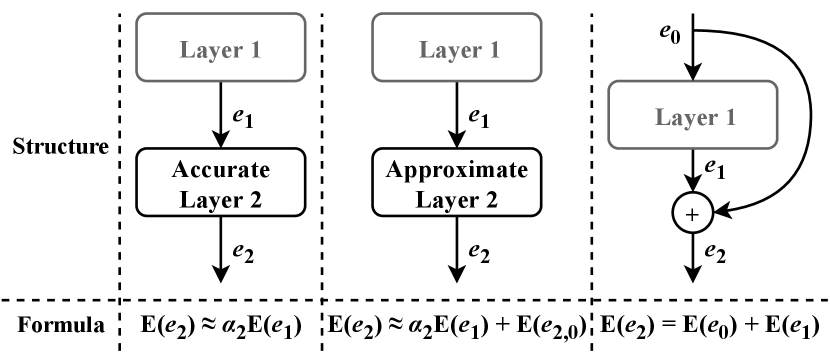
By extending (17), the linear error propagation model can be obtained, as shown in Fig. 2. The accurate layer in Fig. 2 can be a convolutional layer or a batch normalization layer, while the approximate layer is an AM-based convolutional layer. Although this model is somewhat oversimplified, it is efficient enough. Our goal is to develop a more efficient method for evaluating the accuracy of AM-CNNs than traditional simulations. Under this premise, any complex error propagation model that makes the error estimation process slower than simulation is meaningless. Details of employing this model to fit the error propagation within various CNN layers are as follows.
IV-B1 Convolutional Layer
Based on (17), the error propagation process within an exact or approximate convolutional layers can be linearly fitted by choosing an appropriate error propagation factor . The quantifies the impact of the input errors on the output errors for a layer; however, it is hard to obtain the corresponding mathematical formula. According to (15), when , the error primarily propagates from an input to the output through multiplication by the fixed weight (). Therefore, it is feasible to treat as a constant for a pretrained CNN layer and approximate it by empirical values obtained in experiments. Specifically, for a layer, after measuring the mean values of the input, output, and intrinsic errors separately on a given dataset, can be calculated based on the formulas in Fig. 2. Moreover, several principles can be applied to obtain a better , as follows.
-
•
is expected to be independent of the AM, and depends solely on the CNN. However, since this is an idealized approximate model, the actual measured may vary slightly depending on the AM used.
-
•
A suitable AM for measuring should degrade the accuracy of the corresponding AM-CNN by 2% to 10%.
-
•
The absolute value of valid is usually less than 10, and more often close to 1.
-
•
To take into account AMs with various error characteristics, it is better to measure the for multiple typical AMs and then take the average.
IV-B2 Nonlinear Layer
Nonlinear operations in CNNs typically involve the ReLU activation function and pooling. A shared characteristic of these operations is the ability to selectively extract specific significant features while leaving their values unchanged. Specifically, ReLU extracts features with positive values, while max pooling extracts features with relatively high values. Therefore, when focusing exclusively on the error expectation corresponding to the significant features, nonlinear layers can be ignored. For example, if we only count the errors on the positive features when measuring the error propagation factor , the ReLU activation function can be ignored.
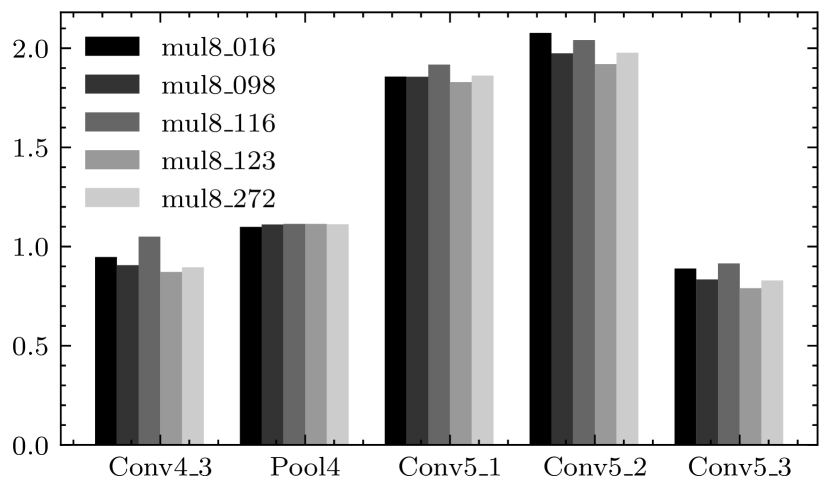
A verification of the above discussion is shown in Fig. 3. We measured the of a max pooling layer (denoted as Pool4), which is the ratio of the mean values of the input and output errors. This measurement focus on the errors on positive features, and the resultant is close to 1. Hence, the error expectations for the input and output features of the layer are identical, allowing to discard the impacts of this layer on error propagation.
IV-B3 Batch Normalization Layer
The batch normalization layer normalizes its inputs as
| (18) |
where and are the mean and variance of the batch of inputs, respectively; is a small constant utilized to prevent division by zero; and are the scaling and offset factors, respectively. It is noteworthy that these parameters (, , , , ) are determined during CNN construction and training, and remain fixed during inference. Therefore, for a batch normalization layer with inaccurate inputs, the calculation during the inference process is as follows.
| (19) |
Thus, the output error of the batch normalization layer is given by
| (20) |
(20) illustrates that during the inference process, the input error of a batch normalization layer is propagated linearly to the output. This is consistent with the proposed error propagation model for exact convolutional layer, and therefore can also be represented by the leftmost column of Fig. 2.
IV-B4 Residual Layer
According to the linearity of the expectation, the error expectations are added in the residual layer implemented by addition, as shown in the rightmost column of Fig. 2.
IV-C The Architectural Mean Error
Based on the proposed linear model, the error expectation of the last approximate layer can be recursively estimated. An example is presented below to explain this in detail.
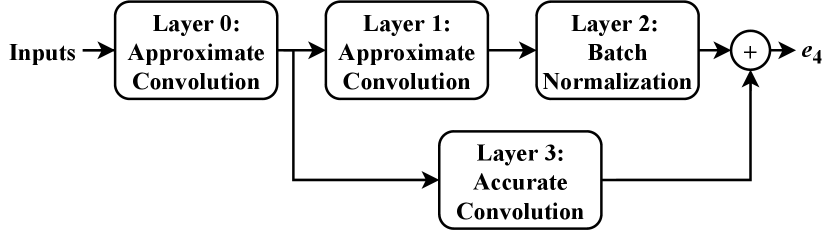
Fig. 4 shows a typical part of an AM-CNN. Based on the proposed error propagation model (Fig. 2), when the inputs to this part are accurate, the can be fitted as
| (21) | ||||
By using (12), can be further estimated as
| (22) | ||||
where is the architectural matrix for layer , which is AM-independent and only depends on the original exact CNN.
Typically, for an AM-CNN containing approximate layers, the error expectation of the last approximate layer is
| (23) |
In the case where all approximate layers use the same type of AMs, (23) can be transformed to
| (24) |
As (24) has the same form as (4), we consider it as a new AM error metric, referred to as the architectural mean error (AME). AME contains two aspects of information that are crucial to the AM-CNN accuracy, i.e., the CNN architecture () and the AM error characteristics (). These two elements are mutually independent, thus can be obtained separately.
Note that (23) is feasible to guide layer-wise approximation. However, to reduce the search space size in this work, we prefer to employ the AME to facilitate the selection or design of a single appropriate AM. This is consistent with the scenario of arithmetic circuit reuse in resource-constrained hardware platforms.
V Experiments
In this section, the effectiveness of the proposed AME is evaluated by the experiments illustrated in Fig. 5. The pretrained CNN models include VGG-16 on CIFAR-10 and ImageNet, ResNet-18 on CIFAR-10 and CIFAR-100, ResNet-34 on CIFAR-10 and CIFAR-100, and ResNet-50 on ImageNet. We focus on the unsigned AM because it is one of the most commonly used AM configurations in AM-CNNs [4, 16].
The AM library contains four categories of unsigned AMs, with a total of 1,481 AMs.
When constructing an AM-CNN, all the multipliers in the convolutional layers of a pretrained CNN model are replaced with the same type of AMs selected from the AM library. To prevent unexpected accuracy degradations, the other arithmetic operations and the convolutional layers with the kernel size equal to 1 in ResNet remain accurate. To enable the multiplications to be performed by using unsigned multipliers, the input activations and weights of the convolutional layers were quantized to 8-bit unsigned integers.
| CNN | Dataset | VarE [15] | RMSE [15] | VarRE [17] | ME [16] | MED [16] | ER [16] | AME | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Neg | Pos | Neg | Pos | |||||||
| VGG-16 | CIFAR-10 | -0.177 | -0.168 | -0.353 | 0.224 | -0.279 | -0.268 | -0.634 | 0.840 | -0.770 |
| VGG-16 | ImageNet | -0.016 | -0.143 | -0.093 | 0.118 | 0.124 | -0.129 | -0.383 | 0.919 | -0.863 |
| ResNet-18 | CIFAR-10 | 0.051 | 0.026 | -0.384 | 0.123 | -0.894 | -0.186 | -0.384 | 0.838 | -0.898 |
| ResNet-18 | CIFAR-100 | 0.121 | 0.123 | -0.260 | 0.302 | -0.912 | -0.318 | -0.461 | 0.908 | -0.910 |
| ResNet-34 | CIFAR-10 | 0.089 | 0.016 | -0.258 | 0.577 | -0.745 | -0.554 | -0.452 | 0.853 | -0.791 |
| ResNet-34 | CIFAR-100 | 0.150 | 0.177 | -0.072 | 0.209 | -0.887 | -0.315 | -0.510 | 0.937 | -0.743 |
| ResNet-50 | ImageNet | -0.036 | -0.022 | -0.065 | 0.136 | -0.015 | -0.107 | -0.438 | 0.873 | -0.837 |
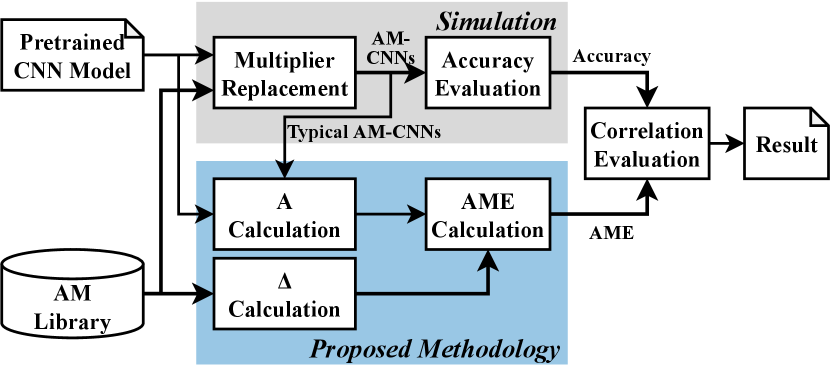
Fig. 6 shows the calculation process of the architectural matrix . Specifically, 2 to 5 typical AM-CNNs corresponding to each pretrained CNN model are selected, and the error propagation factor is estimated using the method described in Section IV-B1. and were obtained by conducting data statistics on the pretrained CNN model using a dataset comprising images sampled from the training dataset. In this work, we sampled 10,000 images for CIFAR-10 and CIFAR-100, and 1,280 images for ImageNet.
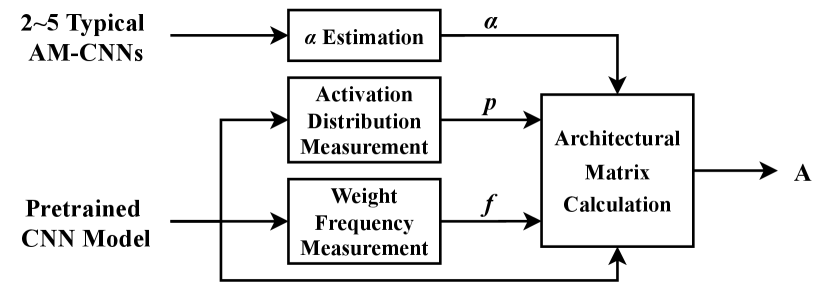
The error matrix of an AM was obtained through traversing all possible input combinations and recording the output errors. Specifically, if the LUT of the AM is known, only one subtraction from the LUT of the exact multiplier is required to obtain the .
The experiments were conducted on Intel Xeon Gold 6226R CPU and NVIDIA GTX 3090 GPU. The AM-CNN simulations were based on the TFApprox [8], which is a TensorFlow-based framework that supports GPU-based simulation.
V-A Correlation Evaluation
By using (6), the PCC was calculated to evaluate the correlation between the AME and the accuracy of AM-CNNs. In addition, several AM error metrics that have been proved to be important to the AM-CNN accuracy from recent studies were considered for comparison. The evaluation included only AM-CNNs with less than 30% accuracy degradation, as those exceeding this threshold are commonly unacceptable.
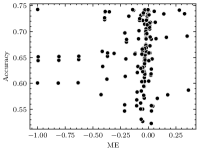
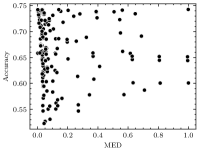
Table III shows the PCCs between the AM-CNN accuracy and the AM error metrics. Overall, the correlation between the accuracy and the AME is quite strong, especially for the negative AME. The positive ME performs slightly better than positive AME in two applications (ResNet-18 on CIFAR-100 and ResNet-34 on CIFAR-100); however, it performs poorly in other applications, especially for those with complex dataset (i.e., ImageNet). Therefore, AME is shown to be a generic AM error metric that strongly correlates with the AM-CNN accuracy. The universality of AME arise from the information it contains about the CNN architecture.
Furthermore, using AME as the input, we trained regression models to predict the accuracy of AM-CNNs with less than 30% accuracy degradation. The ME, MED, and ER that perform relatively well in Table III were considered for comparison. In the training, the quadratic regression algorithm was utilized, which makes the model simpler than most state-of-the-art learning-based designs [27, 15, 28, 16]. The evaluation metric of the regression model is the mean absolute percentage error (MAPE), given by
| (25) |
where is the number of samples, and are the predicted and actual accuracy of the th AM-CNN, respectively.
| CNN | Dataset | ME | MED | ER | AME |
|---|---|---|---|---|---|
| VGG-16 | CIFAR-10 | 6.242 | 6.230 | 5.267 | 1.950 |
| VGG-16 | ImageNet | 11.76 | 11.36 | 9.345 | 6.331 |
| ResNet-18 | CIFAR-10 | 5.336 | 6.391 | 8.330 | 3.498 |
| ResNet-18 | CIFAR-100 | 5.965 | 6.710 | 7.274 | 3.287 |
| ResNet-34 | CIFAR-10 | 5.445 | 6.190 | 7.286 | 4.848 |
| ResNet-34 | CIFAR-100 | 6.524 | 5.564 | 8.443 | 3.706 |
| ResNet-50 | ImageNet | 7.790 | 7.835 | 7.444 | 3.539 |
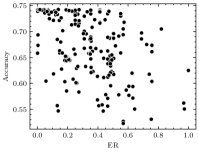
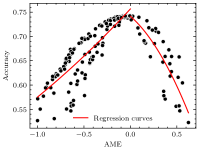
Table IV shows the MAPEs of the obtained regression models. It can be seen that the AME-based models exhibit high prediction accuracy, outperforming other models in all applications. Taking the ResNet-50 on ImageNet as an example, Fig. 7 more intuitively demonstrates the performance of AME in the accuracy prediction. Compared to other metrics (ME, MED, and ER), the relationship between AME and accuracy is clearer, allowing it to be effectively modeled with quadratic regression curves111Due to the differing correlations between positive and negative AME and accuracy, two separate regression curves were employed to handle positive and negative AME respectively, as shown in Fig. 7(d)..
V-B Time Requirements
We compare the time requirement of the AME-based prediction with that of the TFApprox-based simulation.
Taking the VGG-16 on ImageNet as an example, without considering parallelism, Table V presents the average time consumed by an AM-CNN on each major step of AME evaluation. It shows that calculating is the most time-consuming step, which includes the layer-wise data statistics for the pretrained CNN model and typical AM-CNNs. Specifically, it takes 1,702 seconds to measure the error propagation factors () of all layers in an AM-CNN, and this measurement was performed on four AM-CNNs to determine credible . In addition, it takes 3628 seconds to obtain the input activation distributions and weight frequencies for all convolutional layers in the pretrained CNN model.
| Step | Time/s |
|---|---|
| Calculation | |
| Calculation | |
| AME Calculation |
However, the calculation only needs to be performed once for a CNN model. After determining the , only two steps are required to obtain the AME of an AM, i.e., calculating the followed by a Frobenius inner product of and . Therefore, when the architecture of the CNN is given, the required time for the AME-based prediction is on the order of s. Table VI shows the speedup of AME-based predictions compared to TFApprox-based simulations in various applications. The geometric mean speedup over these applications is about .
| CNN | Dataset |
|
|
Speedup | ||||
|---|---|---|---|---|---|---|---|---|
| VGG-16 | CIFAR-10 | |||||||
| VGG-16 | ImageNet | |||||||
| ResNet-18 | CIFARa | |||||||
| ResNet-34 | CIFARa | |||||||
| ResNet-50 | ImageNet | |||||||
| aCIFAR-10 or CIFAR-100. | ||||||||
VI Application of the Proposed AME
A typical application of the proposed AME is to expedite the AM selection process for CNN applications. As an example, we used AME to select the Pareto-optimal AMs from the EvoApprox8b library [21] for CNN-based image classification applications.
EvoApprox8b contains 500 unsigned AMs. This experiment aims to pick out the AMs optimized for the area222Areas of AMs in this experiment were determined through synthesis using Synopsys Design Compiler with 28nm CMOS technology. of the AM and the accuracy of the corresponding AM-CNN. To avoid time-consuming simulations, we utilized the AME instead of AM-CNN accuracy as an optimization objective. In other words, for AMs with the same area, the one with the lowest absolute value of AME is selected.
As the AM-CNN accuracy predicted based on AME slightly deviates from the actual value, we introduced an iterative search method to prevent missing the real Pareto-optimal AMs, as shown in Algorithm 1. Specifically, at each iteration, the Pareto-optimal AM set with respect to area and AME is obtained, these AMs are recorded and removed from the library. This process is repeated until the iteration number reaches the preset threshold. Finally, a pseudo Pareto-optimal AM set is constructed by merging the AM sets obtained in all iterations. Thus, a larger iteration number is likely to result in more AMs. The Pareto-optimal set search step (line 3) in Algorithm 1 is a multi-objective optimization problem, for which a traversal-based method was utilized in this experiment. Since the searching method does not affect the experimental results, its details are omitted.
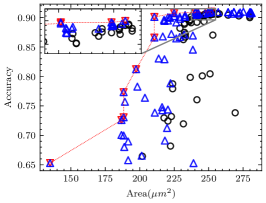
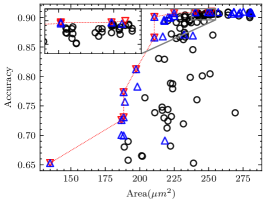
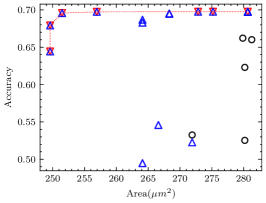
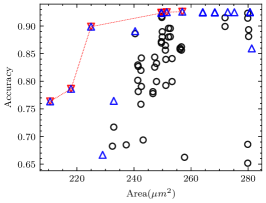
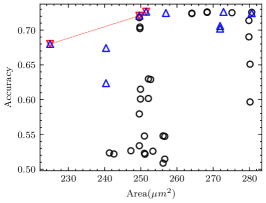
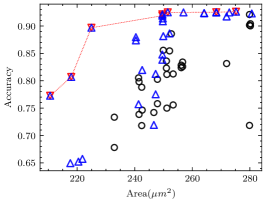
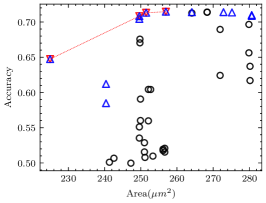
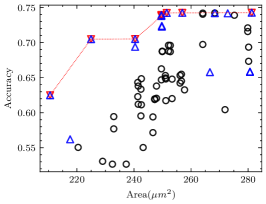
For each CNN application in the experiment, we measured the minimum number of iterations required to ensure that the pseudo Pareto-optimal AM set encompasses all real Pareto-optimal AMs with accuracy degradation not exceeding 30%, as shown in Table VII. As observed, for applications other than VGG-16 on CIFAR-10, 2 iterations suffice to ensure no real Pareto-optimal AM is missed. In fact, VGG-16 on CIFAR-10 has the best error tolerance among these applications, many AMs do not cause a significant accuracy degradation, as shown in Fig. 8(a). In this case, the deviation of AME-based prediction has a relatively significant impact. However, as shown in Fig. 8(b), after 3 iterations, we have covered all real Pareto-optimal AMs except the one with the largest area and the highest AM-CNN accuracy. This is adequate for AM-CNN designs where minimizing area is the primary optimization objective. Moreover, since the time required to compute an AME is on the order of s, the supplementary time overhead incurred by multiple iterations is negligible.

| CNN | Dataset |
|
Proportion | ||
|---|---|---|---|---|---|
| VGG-16 | CIFAR-10 | 6 | 12/80 | ||
| VGG-16 | ImageNet | 2 | 7/15 | ||
| ResNet-18 | CIFAR-10 | 2 | 7/19 | ||
| ResNet-18 | CIFAR-100 | 1 | 3/10 | ||
| ResNet-34 | CIFAR-10 | 2 | 8/31 | ||
| ResNet-34 | CIFAR-100 | 2 | 4/12 | ||
| ResNet-50 | ImageNet | 2 | 8/17 |
The proportion of the real Pareto-optimal AMs in the final pseudo Pareto-optimal AM set was also recorded, as shown in Table VII. Fig. 8 provides a more intuitive representation of the experimental results. It shows that the real Pareto-optimal AMs are encompassed within the pseudo Pareto-optimal AMs selected based on AME. To distinguish the real Pareto-optimal AMs, subsequent simulations can be performed within a much less number of AMs. This is much faster than searching directly in the library containing hundreds of AMs.
Take the VGG-16 on ImageNet as an example. According to Table V and Table VI, the total time spent evaluating the AMEs corresponding to 500 AMs is about seconds, which is comparable to the time spent simulating the accuracy of 9 AM-CNNs ( seconds). Hence, the initial AM selection based on AME, followed by simulation and filtering, results in a total time requirement approximately equivalent to performing simulations of AM-CNNs. This approach is roughly 21 faster than the traditional method of simulating 500 AM-CNNs. It is anticipated that as the number of AMs in the library grows, the speedup ratio will likewise increase.
This experiment illustrates that, given a search space, AME-based selection can quickly prune it, thereby speeding up the search for the Pareto-optimal AMs for CNN applications.
Furthermore, AME has the potential to facilitate the automated design of CNN-oriented AM. In contrast to selecting pre-existing generic AM from a library, automated design aims to generate the optimal hardware for AMs under specific constraints. [29, 28, 30]. The process of automated design typically includes circuit coding, design space construction, and design space search. For example, the AMs of EvoApprox8b are automated designed through a Cartesian genetic programming (CGP)-based methodology [29]. Specifically, a candidate AM is represented as a fixed-sized 2D Cartesian grid of nodes interconnected by a feed-forward network, where each node represents a 2-input Boolean function (e.g., AND, OR). Consequently, a candidate solution can be represented by a netlist that records the node connections. After determining candidate netlists (i.e., the design space), a multi-objective evolutionary algorithm was executed to search for the Pareto-optimal AM set with respect to error metrics and hardware costs.
It is noteworthy that the error metric used as the optimization objective during the design space search process determines the error characteristics of the AM obtained. When utilizing an application-independent AM error metric, such as the mean relative error distance (MRED) [29], the resulting AMs are also application-independent. However, when utilizing an AM error metric that incorporates the data distribution of a specific CNN application [30], the obtained AMs tend to maintain a high accuracy for the corresponding AM-CNNs. As the proposed AME demonstrates a strong correlation with the AM-CNN accuracy and can be efficiently evaluated, it holds significant potential to serve as an optimization objective in the automated design of AMs for CNN applications.
VII Discussion
In this section, the rationale behind the effectiveness of the proposed AME is further discussed.
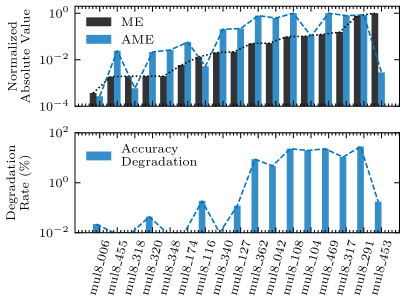
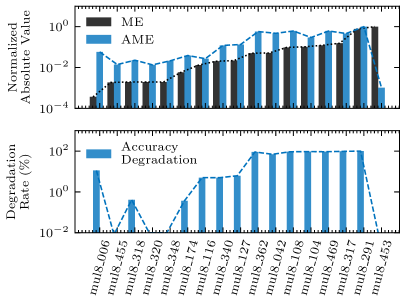
As per the experimental results shown in Section V-A, among the error metrics highlighted in existing researches (i.e., VarE [15], RMSE [15], VarRE [17], and ME [16]), ME shows the strongest correlation with the accuracy of AM-CNNs. Thus, ME is visually compared with AME, as shown in Fig. 9. Fig. 9 presents the values of ME, AME, and accuracy degradation in two CNN applications for AMs belonging to the union of the real Pareto-optimal AM sets obtained in Section VI. The AMs are listed in an ascending order of their absolute values of ME.
As observed in Fig. 9, AME has the following two superiorities over ME.
-
•
AME exhibits a trend closely aligned with the accuracy degradation of AM-CNNs. For example, the mul8_453 has the maximum absolute value of ME among these AMs; however, it only slightly degrades the accuracy of the two CNN applications. The AMEs corresponding to mul8_453 are significantly low. Hence, AME is more suitable to capture the impact of this AM on the accuracy of AM-CNNs.
-
•
AME varies depending on the application. For instance, the mul8_006 has the minimum absolute value of ME among these AMs, and it slightly degrades the accuracy of the VGG-16 on CIFAR-10. However, when applied to ResNet-50 on ImageNet, mul8_006 leads to an accuracy degradation of more than 10%. The AME of mul8_006 is low for VGG-16 on CIFAR-10, whereas it is much higher for ResNet-50 on ImageNet. In this case, AME can predict the accuracy degradation but ME cannot.
Compared to the calculation formula for ME (given by (4)), the formula for AME (given by (24)) replaces the data distribution matrix with the summation of architectural matrices . The matrix is application-independent, and generally represents a joint uniform distribution (i.e., all elements in are equal). In fact, most researches on AM error metrics are conducted under the assumption that the inputs of the AM follow a joint uniform distribution [15, 16, 17]. However, the inputs to the multipliers in the convolutional layer are not uniformly distributed. For example, Fig. 10 shows the data distributions of the last two convolutional layers in VGG-16 on CIFAR-10, where the weights and the input activations follow significantly disparate distributions. Hence, the ME calculated under the assumption of uniformly distributed inputs may not align with the actual application scenario. Some state-of-the-art researches have acknowledged this issue and measured data distributions from specific CNN applications to guide the design of CNN-oriented AMs [31, 30].
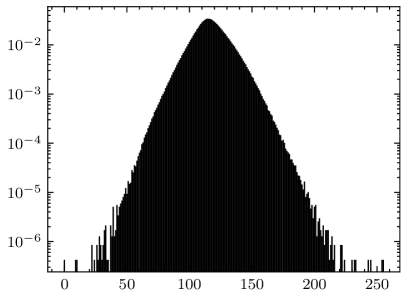
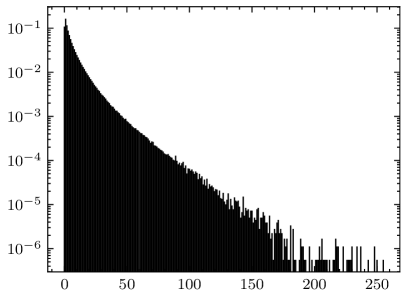
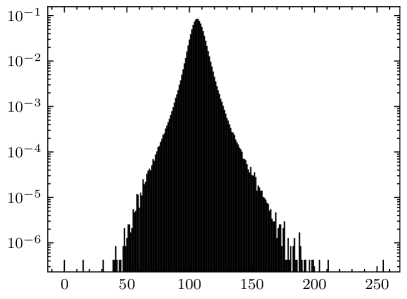
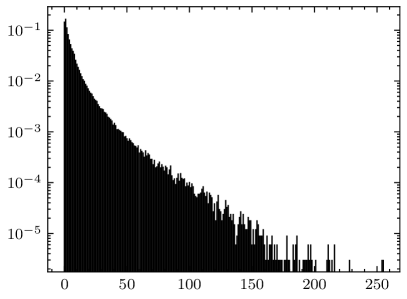
Comparing Fig. 10(a) with Fig. 10(c), and Fig. 10(b) with Fig. 10(d), it can be seen that even the data distributions of two adjacent layers can be different. According to (22), the architectural matrix of a layer can be viewed as the weighted data distribution of the layer, i.e., multiplied by a constant. Therefore, the summation of architectural matrices can be considered as a fusion of the data distributions of all approximate layers. This fusion is based on the proposed linear model for fitting the error propagation process in AM-CNNs. Consequently, AME contains more information about applications than traditional AM error metrics, thereby performing better in accuracy predictions for AM-CNNs.
VIII Conclusion
In this work, the error generation and propagation process within AM-CNNs is linearly modeled. Based on this model, a novel AM error metric, the architectural mean error (AME), is proposed to evaluate the accuracy degradation of an AM-CNN. The proposed AME involve the information of CNN architectures and AM error characteristics, thus exhibiting a strong correlation with the AM-CNN accuracy. Experimental results on various CNN models and datasets show that the AME can effectively predict AM-CNN accuracy with rapidity and high precision. Therefore, AME can be employed to facilitate the AM selection and design for CNN applications.
References
- [1] G. Armeniakos, G. Zervakis, D. Soudris, and J. Henkel, “Hardware approximate techniques for deep neural network accelerators: A survey,” ACM Comput. Surv., vol. 55, no. 4, pp. 1–36, 2022.
- [2] F. Guella, E. Valpreda, M. Caon, G. Masera, and M. Martina, “Marlin: A co-design methodology for approximate reconfigurable inference of neural networks at the edge,” IEEE Trans. Circuits Syst. I, Reg. Papers, 2024.
- [3] H. Jiang, F. J. H. Santiago, H. Mo, L. Liu, and J. Han, “Approximate arithmetic circuits: A survey, characterization, and recent applications,” Proc. IEEE, vol. 108, no. 12, pp. 2108–2135, 2020.
- [4] V. Mrazek, Z. Vasícek, L. Sekanina, M. A. Hanif, and M. Shafique, “ALWANN: Automatic layer-wise approximation of deep neural network accelerators without retraining,” in ICCAD, 2019, pp. 1–8.
- [5] Z.-G. Tasoulas, G. Zervakis, I. Anagnostopoulos, H. Amrouch, and J. Henkel, “Weight-oriented approximation for energy-efficient neural network inference accelerators,” IEEE Trans. Circuits Syst. I: Reg. Papers, vol. 67, no. 12, pp. 4670–4683, 2020.
- [6] G. Zervakis, O. Spantidi, I. Anagnostopoulos, H. Amrouch, and J. Henkel, “Control variate approximation for DNN accelerators,” in DAC, 2021, pp. 481–486.
- [7] O. Spantidi, G. Zervakis, I. Anagnostopoulos, H. Amrouch, and J. Henkel, “Positive/negative approximate multipliers for DNN accelerators,” in ICCAD, 2021, pp. 1–9.
- [8] F. Vaverka, V. Mrazek, Z. Vasicek, and L. Sekanina, “TFApprox: Towards a fast emulation of DNN approximate hardware accelerators on GPU,” in DATE, 2020, pp. 294–297.
- [9] C. De la Parra, A. Guntoro, and A. Kumar, “ProxSim: GPU-based simulation framework for cross-layer approximate DNN optimization,” in DATE, 2020, pp. 1193–1198.
- [10] D. Danopoulos, G. Zervakis, K. Siozios, D. Soudris, and J. Henkel, “Adapt: Fast emulation of approximate DNN accelerators in pytorch,” IEEE Trans. Comput. Aided Des. Integr. Circuits Syst., 2022.
- [11] J. Gong, H. Saadat, H. Gamaarachchi, H. Javaid, X. S. Hu, and S. Parameswaran, “ApproxTrain: Fast simulation of approximate multipliers for DNN training and inference,” IEEE Trans. Comput. Aided Des. Integr. Circuits Syst., 2023.
- [12] M. A. Hanif, R. Hafiz, and M. Shafique, “Error resilience analysis for systematically employing approximate computing in convolutional neural networks,” in DATE, 2018, pp. 913–916.
- [13] I. Hammad and K. El-Sankary, “Impact of approximate multipliers on VGG deep learning network,” IEEE Access, vol. 6, pp. 60 438–60 444, 2018.
- [14] C. De la Parra, A. Guntoro, and A. Kumar, “Efficient accuracy recovery in approximate neural networks by systematic error modelling,” in ASP-DAC, 2021, pp. 365–371.
- [15] M. S. Ansari, V. Mrazek, B. F. Cockburn, L. Sekanina, Z. Vasicek, and J. Han, “Improving the accuracy and hardware efficiency of neural networks using approximate multipliers,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 28, no. 2, pp. 317–328, 2019.
- [16] H. Mo, Y. Wu, H. Jiang, Z. Ma, F. Lombardi, J. Han, and L. Liu, “Learning the error features of approximate multipliers for neural network applications,” IEEE Trans. Comput., 2023.
- [17] M. S. Kim, A. A. Del Barrio, H. Kim, and N. Bagherzadeh, “The effects of approximate multiplication on convolutional neural networks,” IEEE Trans. Emerg. Top. Comput., vol. 10, no. 2, pp. 904–916, 2021.
- [18] O. Spantidi and I. Anagnostopoulos, “How much is too much error? analyzing the impact of approximate multipliers on DNNs,” in ISQED, 2022, pp. 1–6.
- [19] J. Castro-Godínez, S. Esser, M. Shafique, S. Pagani, and J. Henkel, “Compiler-driven error analysis for designing approximate accelerators,” in DATE, 2018, pp. 1027–1032.
- [20] M. Vaeztourshizi and M. Pedram, “Efficient error estimation for high-level design space exploration of approximate computing systems,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., 2023.
- [21] V. Mrazek, R. Hrbacek, Z. Vasicek, and L. Sekanina, “EvoApprox8b: Library of approximate adders and multipliers for circuit design and benchmarking of approximation methods,” in DATE, 2017, pp. 258–261.
- [22] S. Hashemi, R. I. Bahar, and S. Reda, “Drum: A dynamic range unbiased multiplier for approximate applications,” in ICCAD, 2015, pp. 418–425.
- [23] W. Liu, J. Xu, D. Wang, C. Wang, P. Montuschi, and F. Lombardi, “Design and evaluation of approximate logarithmic multipliers for low power error-tolerant applications,” IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 65, no. 9, pp. 2856–2868, 2018.
- [24] M. S. Ansari, B. F. Cockburn, and J. Han, “An improved logarithmic multiplier for energy-efficient neural computing,” IEEE Trans. Comput., vol. 70, no. 4, pp. 614–625, 2020.
- [25] A. G. M. Strollo, E. Napoli, D. De Caro, N. Petra, and G. Di Meo, “Comparison and extension of approximate 4-2 compressors for low-power approximate multipliers,” IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 67, no. 9, pp. 3021–3034, 2020.
- [26] L. Sayadi, S. Timarchi, and A. Sheikh-Akbari, “Two efficient approximate unsigned multipliers by developing new configuration for approximate 4:2 compressors,” IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 70, no. 4, pp. 1649–1659, 2023.
- [27] V. Mrazek, M. A. Hanif, Z. Vasicek, L. Sekanina, and M. Shafique, “autoAx: An automatic design space exploration and circuit building methodology utilizing libraries of approximate components,” in DAC, 2019, pp. 1–6.
- [28] S. Ullah, S. S. Sahoo, N. Ahmed, D. Chaudhury, and A. Kumar, “AppAxO: Designing application-specific approximate operators for fpga-based embedded systems,” ACM Trans. Embed. Comput. Syst., vol. 21, no. 3, pp. 1–31, 2022.
- [29] R. Hrbacek, V. Mrazek, and Z. Vasicek, “Automatic design of approximate circuits by means of multi-objective evolutionary algorithms,” in DTIS, 2016, pp. 1–6.
- [30] Z. Li, S. Zheng, J. Zhang, Y. Lu, J. Gao, J. Tao, and L. Wang, “Adaptable approximate multiplier design based on input distribution and polarity,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 30, no. 12, pp. 1813–1826, 2022.
- [31] C. Guo, L. Zhang, X. Zhou, W. Qian, and C. Zhuo, “A reconfigurable approximate multiplier for quantized CNN applications,” in ASP-DAC, 2020, pp. 235–240.