An ECM algorithm for Skewed Multivariate Variance Gamma Distribution in Normal Mean-Variance Representation
Abstract: Normal mean-variance mixture distributions are widely applied to simplify a model’s implementation and improve their computational efficiency under the Maximum Likelihood (ML) approach. Especially for distributions with normal mean-variance mixtures representation such as the multivariate skewed variance gamma (MSVG) distribution, it utilises the expectation-conditional-maximisation (ECM) algorithm to iteratively obtain the ML estimates. To facilitate application to financial time series, the mean is further extended to include autoregressive terms. Techniques are proposed to deal with the unbounded density for small shape parameter and to speed up the convergence. Simulation studies are conducted to demonstrate the applicability of this model and examine estimation properties. Finally, the MSVG model is applied to analyse the returns of five daily closing price market indices and standard errors for the estimated parameters are computed using Louis’s method.
Keywords: EM algorithm, maximum likelihood estimation, multivariate skewed variance gamma distribution, normal mean-variance representation, unbounded likelihood.
1 Introduction
Variance Gamma (VG) distribution has been widely used to model financial time series data, particularly the log-price increment (return) which has the characteristics of having high concentration of data points around the center with occasional extreme values. Some key properties includes finite moments of all orders and a member of the family of elliptical distributions in the symmetric case. See Madan and Seneta, (1990) for more details of the properties of the VG distribution and its financial applications. However, its applicability is still limited by its rather complicated density. To estimate the model parameters Madan and Seneta, (1987) applied the ML approach using characteristic function from a Chebyshev polynomial expansion. Madan and Seneta, (1990) and Tjetjep and Seneta, (2006) used the method of moments to estimate the parameters for the VG and skewed VG models respectively. Finlay and Seneta, (2008) compared the performance of various estimation methods for data with long range of dependence, namely the methods of moments, product-density maximum likelihood, minimum , and the empirical characteristic function. They showed that the performance of product-density maximum likelihood estimator is better than the method of moments and minimum estimators in terms of goodness-of-fit. McNeil et al., (2005) (§3.2.4) applied the Expectation-Maximisation (EM) algorithm to generalised hyperbolic (GH) distribution which nests VG distribution as a special case. However, they did not address the main challenge in estimation when the density is unbounded at the center, a feature of some financial time series. Fung and Seneta, (2010) adopted a Bayesian approach with diffuse priors as a proxy for ML approach to estimate the bivariate skewed VG and Student-t models. They implemented the models using the Bayesian software WinBUGS, and compared their goodness-of-fit performances with simulated and real data sets. We propose to use EM algorithm under the ML approach to estimate parameters of the VG model directly. Our proposed method not only provides improved accuracy but also handles the problem of unbounded density.
It is well known that the VG distribution has normal mean-variance mixtures representation in which the data follow a normal distribution condition on some mixing parameters which have a gamma distribution. Large values of the mixing parameters correspond to the normal distributions having relatively larger variances to accommodate outliers. Hence outlier diagnosis can be performed using these mixing parameters (Choy and Smith,, 1997). More importantly, the conditional normal data distribution greatly simplifies the parameter estimation based on standard results. However, the mixing parameters are not observed. In case with missing data, ML estimation becomes very challenging as the marginal likelihood function involves high dimensional integration. Dempster et al., (1977) showed that the EM algorithm can be used to find the ML estimates for univariate Student-t distribution with fixed degrees of freedom in normal mean-variance mixture representation. Dempster, Laird and Rubin (1980) extended these results to the regression case. Meng and Rubin, (1993) improved the EM algorithm to Expectation/Conditional Maximisation (ECM) algorithm which simplifies the maximisation step by utilising some standard results of normal distribution when conditioned on some mixing parameters. Moreover, the ECM algorithm still possesses desirable properties from the EM algorithm. Meng, (1994) considered a variation of the ECM algorithm called multicycle ECM (MCECM) which inserts extra E-steps after each update of parameters. Liu and Rubin, (1994) advanced the ECM algorithm to Expectation/Conditional Maximisation Either (ECME) by maximising the actual likelihood rather than the conditional/constrained expected likelihood. Liu and Rubin, (1995) applied the MCECM and ECME algorithms to obtain the ML estimates for multivariate Student-t distribution with incomplete data. They also found that the ECME algorithm converges much more efficiently than the EM and ECM algorithms in terms of computational time. Hu and Kercheval, (2008) used the MCECM algorithm with the Student-t distribution for portfolio credit risk measurement.
We adopt the ECM algorithms for VG distribution and extend it to multivariate skewed VG (MSVG) distribution because univariate symmetric VG distribution fails to account for the dynamics of cross-correlated time series with asymmetric tails. For example, the returns of daily price for stocks in related industries are cross-correlated across stocks, serially correlated over time and possibly right or left tailed. We further include autoregressive (AR) terms in the means to allow for autocorrelation. This generalised model called MSVG AR can describe many essential features of financial time series. However this model, as well as its estimation methodologies that can cope with various computational difficulties in ML implementation, is still relatively scarce in the literature. For the ECM algorithms, these computational difficulties include accurately calculating the ML estimates with unbounded likelihood while maintaining computational efficiency.
To deal with these technical issues and evaluate the performance ECM algorithms, we perform three simulation studies. Firstly, as the two ECM type algorithms, namely the MCECM and ECME algorithms, have a trade-off between computational efficiency and performance, we derive a method we call the hybrid ECM (HECM) to improve the efficiency whilst also maintaining good performance. We compare the efficiency of these three algorithms through simulated data. Secondly, we propose to bound the density within a certain range around the centre should it become unbounded when the shape parameter is small and observations are close to the mean. We show that the proposed technique improves computational efficiency and performance of the HECM algorithm. Lastly, we analyse the performance of the algorithm for different MSVG distributions with high or low levels of shape and skew parameters. Results are promising. We then apply the HECM estimator to fit the MSVG model to multiple stock market indices. To assess the significance of parameter estimates, standard errors are also evaluated using Louis’s method (Louis,, 1982). Results show that the MSVG AR model provides good fit to the data and reveals high correlation between some pairs of indices. We then fit a bivariate model to a pair of highly correlated market indices. The contour plot of fitted density reveals that the bivariate model captures the high concentration of observations in the center and heavy outliers on the edge. Results facilitate portfolio setting based on a basket of market indices.
In summary, our proposed HECM estimator is new in the literature of VG models and forms a useful toolkit to its implementation with all important technical issues clearly addressed. We also showcase its efficiency and demonstrate its applicability through real examples. Nevertheless the techniques provided in HECM estimation including the way to handle unbounded density can be generalised to other distributions with normal mean-variance mixtures representation. The structure of the paper is as follows. Section 2 introduces the MSVG distribution and some of its key properties. Section 3 presents the ECM algorithms for estimating the model parameters and the calculation of their standard errors by computing the information matrix through Louis’s formula. We also propose some techniques to address the technical issues in the ECM algorithms. Section 4 describes the simulation studies to assess the performance of proposed techniques in handling these technical issues. Section 5 implements the HECM algorithm to real data. Finally, a brief conclusion with discussion is given in Section 6.
2 Multivariate Skewed Variance Gamma Model
While univariate VG models has been considered in many times in the literature, MSVG models are in fact more applicable because they reveal the dependence between different components and allows asymmetric tail behavior. Let be a set of -dimensional multivariate observations following a MSVG distribution with the probability density function (pdf) given by:
| (1) |
where is the location parameter, is a positive definite symmetric scale matrix, is the skewness parameter, is the shape parameter, is the gamma function and is the modified Bessel function of the second kind with index (see Gradshteyn and Ryzhik,, 2007, §9.6). Based on this parametrisation, decreasing the shape parameter will increase the probability around as well as the tail probabilities at the expense of probability in the intermediate range. See Fung and Seneta, (2007) for more information about the shape parameter and the tail behavior which is of power-modified exponential-type.
The MSVG distribution has a normal mean-variance mixtures representation given by:
| (2) |
where is a Gamma distribution with shape parameters , rate parameter and pdf:
The mean and variance of a MSVG random vector are given by:
| (3) |
respectively. , The pdf in (1) as is given by:
where . This shows that the pdf at is unbounded when . This is an important property of the MSVG distribution to be addressed in the next section.
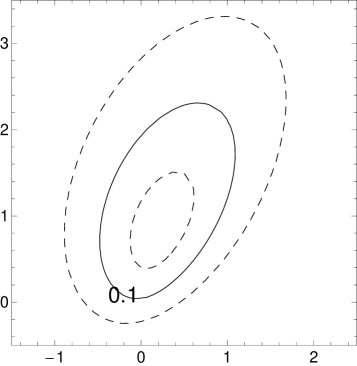
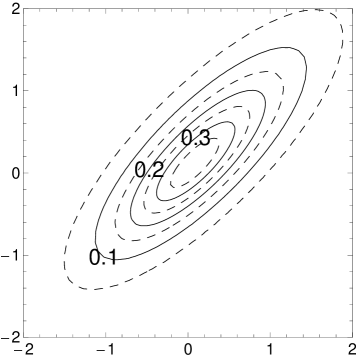
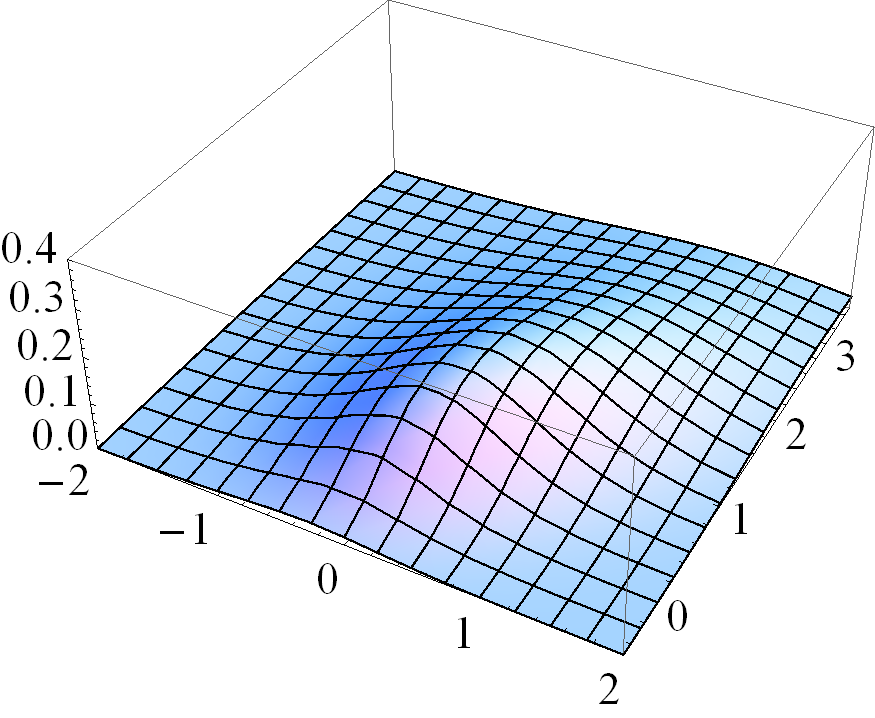
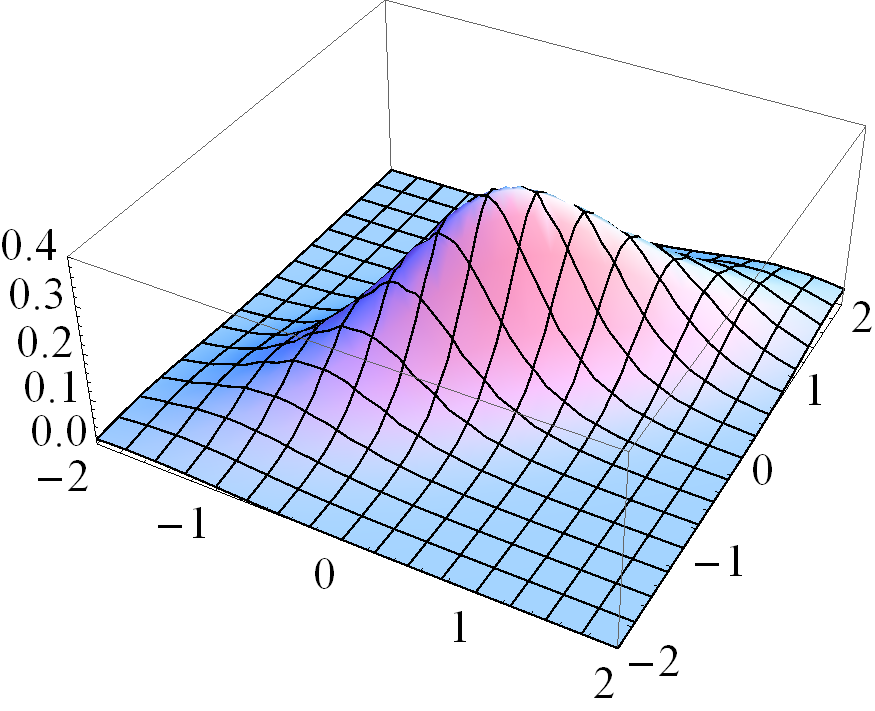
Figure 1 gives four pairs of contour and three dimensional plots for various cases of the MSVG distribution. The first pair of plots is based on parameters
Based on the distribution for the first pair of plots, three other pairs of plots demonstrate the changes in pdf when the shape parameter decreases to , the skewness parameter increases to , and the correlation coefficient in increases to 0.8, respectively, while keeping other parameters fixed. Note that the density for the case with small is unbounded.
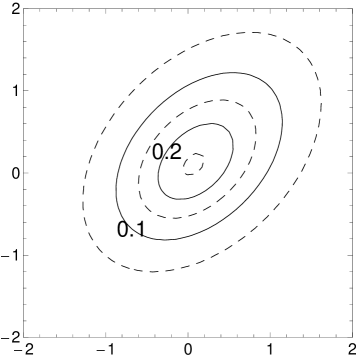
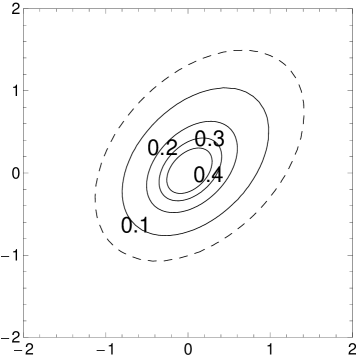
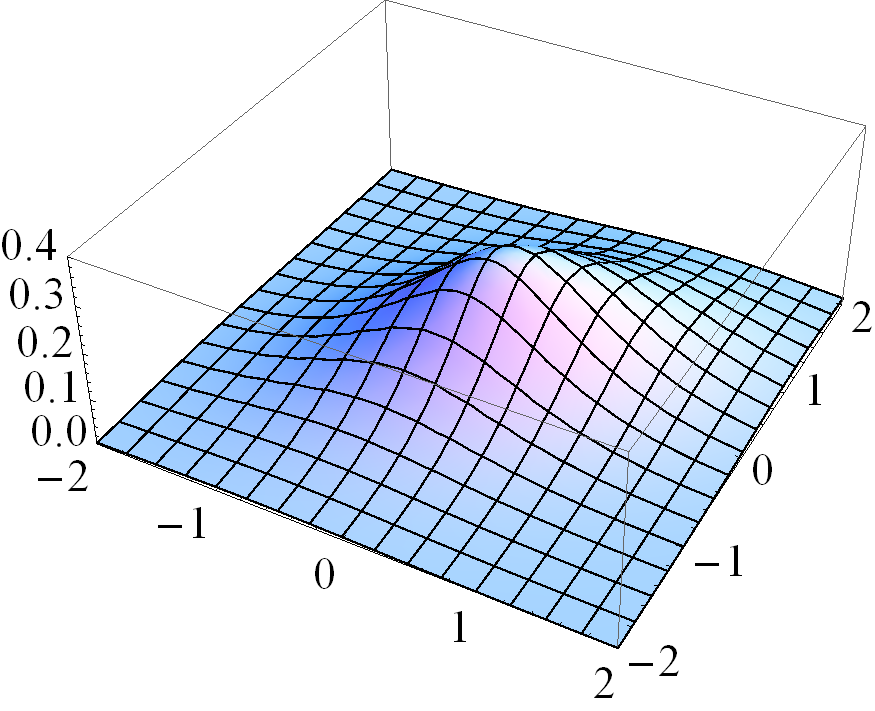
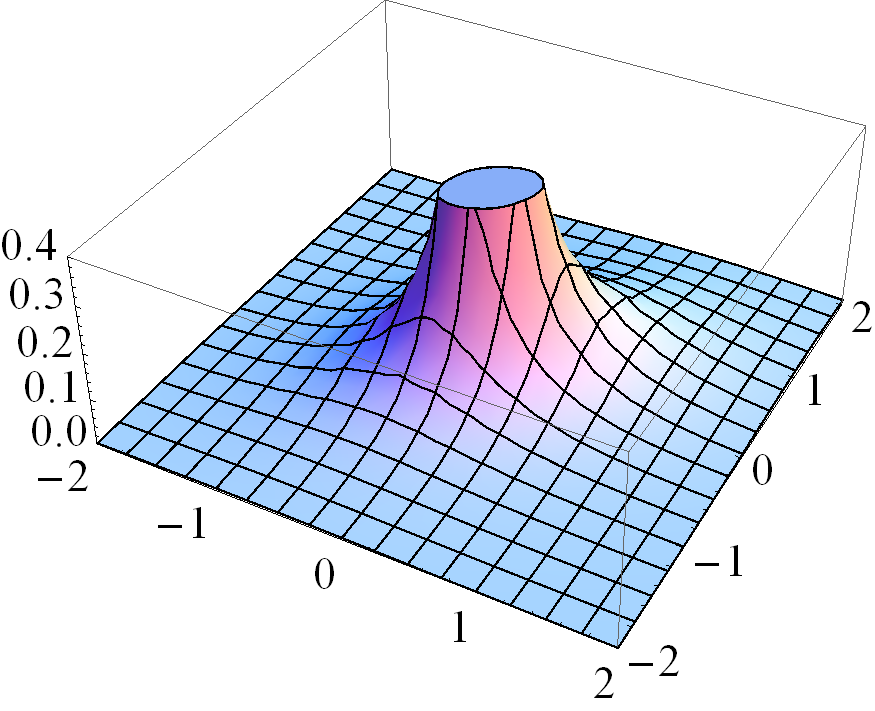
3 ECM Algorithm
In the likelihood approach, maximising the complicated density in (1) can be computationally intensive. We propose the ECM algorithm in the likelihood approach because the normal mean-variance mixtures representation in (2) can greatly simplify the maximisation procedures in the M-step of the algorithm. Then we extend the algorithm to incorporate an AR(1) term and discuss some technical issues involving small .
3.1 Basic algorithm
The ML estimates for parameters in the parameter space maximises the log-likelihood
where is the pdf of MSVG distribution in (1). Using the normal mean-variance mixtures representation of the MSVG distribution in (2), we consider to be unobserved and to be the complete data where . The complete data density can be represented as a product of conditional normal densities given the unobserved mixing parameters and the gamma densities of the mixing parameters, that is,
This is essentially a state space model with normals as the structural distributions, as the state or missing parameters, and gamma as the mixing distribution. Due to the mixing structure, the complete-data log-likelihood function can be factorised into two distinct functions as follows:
| (4) |
where the log-likelihood of the conditional normal distributions is given by:
| (5) |
for some constant and the log-likelihood of the conditional gamma distributions is given by:
| (6) |
Hence, condition on , the estimation of all parameters can be separated in two blocks: the conditional maximisation (CM) of from the conditional normals log-likelihood function and the CM of from the gamma log-likelihood function. The mixing parameter is first estimated by the conditional expectation given the observed-data . The procedures are described as below:
E-step for :
To derive the conditional expectations of the
’s given the observed-data and parameters ,
we need the conditional posterior distribution of given by:
| (7) |
which corresponds to the pdf of a generalised inverse Gaussian distribution (Embrechts,, 1983). Using this posterior distribution, we can calculate the following conditional expectations:
| (8) | ||||
| (9) | ||||
| (10) |
where which is approximated using the central difference formula
| (11) |
where we let .
CM-step for :
Given the mixing parameters , the ML estimate of can be obtained by maximising in (5) with respect to .
After equating each component of the partial derivatives of to zero, we obtain the following estimates:
| (12) | ||||
| (13) | ||||
| (14) |
where the complete data sufficient statistics are
| (15) |
CM-step for :
Given the mixing parameters ,
the ML estimate of can be obtained by numerically maximising in (6) with respect to
using Newton-Raphson (NR) algorithm where the derivatives is given by:
| (16) | ||||
| (17) |
where is the digamma function and . This ECM algorithm is the MCECM algorithm. In summary, the algorithm involves the following steps:
Initialisation step: Choose suitable starting values for the parameters. If the data is roughly symmetric around the mean, then it is recommended to choose starting values where and denote the sample mean and sample variance-covariance matrix of respectively.
At the -th iteration with current estimates ,
E-step 1: Calculate and for in (8) and (9), respectively, using . Calculate also the sufficient statistics , and in (15).
E-step 2: Calculate and for in (8) and (10) respectively using the updated estimates . Calculate also the sufficient statistics and in (15).
CM-step 2: Update the estimate to using the derivatives in (16) and (17) for the NR procedure and the sufficient statistics.
Stopping rule: Repeat the procedures until the relative increment of log-likelihood function is smaller than the tolerance level .
Alternatively, the ECME algorithm update the estimate to in CM-step 2 by maximising directly the actual log-likelihood which is the sum of log pdfs in (1) for . This procedure is implemented using the optimize function specified in R which is a combination of golden section search and successive parabolic interpolation.
3.2 Algorithm with AR term
Suppose now our observed-data is . The MSVG distribution for where with AR mean function of order 1 (without loss of generosity) can be represented hierarchically as follows:
| (18) |
where , and is a matrix with all eigenvalues less than 1 in modulus. Because of the dependency structure, we maximise the conditional likelihood function for given expressed by:
So the conditional log-likelihood is given by:
where the log-likelihood of the conditional normal distribution is given by:
| (19) |
for some constant and is given in equation (6).
E-step for :
This step is similar to the E-step in Section 3.1. Just replace
with
.
CM-step for :
Similarly condition on , the ML estimates of
can be obtained by maximising in (19) with respect to .
This gives us a close form solution as follows:
| (20) | ||||
| (21) |
where (20) as a generalisation of (12) and (13) can be further generalised to include higher order AR terms in the mean function. Then the complete data sufficient statistics are given by (15) with the addition of
| (22) |
CM-step for :
This step is the same as in Section 3.1.
In summary, the layout of the MCECM and ECME algorithms are similar to those for the MSVG model in Section 3.1 except that we update and instead of and adjust the E-step accordingly.
3.3 Adjustment to ECM algorithm
3.3.1 Adjustment for small
Numerical problems may occur when dealing with since the pdf in (1) at is unbounded for such . To handle such case, we can show that as ,
So for and , and are unbounded for data points at the mean respectively. As these expected values are numerically unstable to calculate, we propose to bound the pdf around by a bound such that if
| (23) |
where is a small fixed constant, then we compute the expected values and in (9) and (10) with replacing . The region in (23) will be called the delta region. We will analyse the optimal choices of in a simulation study in the next section.
Another problem may occur when estimating . Suppose that for some , then . Now consider the CM-step for , needs to be calculated before calculating . For the term of the first summation for calculating in (14), we get that
which leads to diverging to infinity since does not converge to zero. To solve this problem, we insert an extra E-step to update and after updating . This adjustment makes the term of the first summation in to be
for some finite constant matrix resulting in a more numerically stable estimate for . Thus adding an additional E-step to update after updating and before updating improves the numerical stability and convergence of the algorithm.
3.3.2 Hybrid ECM algorithm
Meng and Rubin, (1993), Liu and Rubin, (1994) together showed that the MCECM and ECME algorithm always increase the log-likelihood monotonically. However, problems might occur when dealing with multimodel log-likelihood such as the MSVG log-likelihood when .
In the MCECM algorithm, is estimated by numerically maximising the log-likelihood of the conditional gamma mixing density using NR algorithm with derivatives (16) and (17). The ECME algorithm which numerically maximises the actual log-likelihood of the MSVG distribution with pdf (1), is computationally less efficient than the MCECM algorithm despite less iterations are required for convergence. However, the ECME algorithm is more stable than the MCECM algorithm since the CM-step for maximises the actual log-likelihood, hence avoiding the missing data in CM-step 2.
In light of this, we propose an algorithm which combines the efficiency of the MCECM algorithm while maintaining the performance of the ECME algorithm. We call this the hybrid ECM (HECM) algorithm. Essentially it starts with the MCECM algorithm and repeats until either the relative increment of log-likelihood is smaller than which stops the algorithm, reverts back to the previous estimates and performs the ECME algorithm.
For the univariate skew VG model, the performance of the HECM algorithm can be improved by replacing the estimate for in (12) with the estimate for such that it maximizes the actual log-likelihood .
The two adjustments using density bound and extra E-step as well as the hybrid procedures balance computational efficiency, and accuracy of the ML estimation.
3.4 Observed Information Matrix
Letting be the complete data, Louis, (1982) expressed the observed information matrix in terms of the conditional expectation of the derivatives of complete data log-likelihood and with respect to conditional distribution which depends on :
| (24) |
In the context of MSVG model, is given by (4). The first derivatives of complete data log-likelihood can be expressed as
where and are the vectorisation and half-vectorisation operators respectively, is the matrix of 1’s, be a conformable identity matrix, and
Calculating the conditional expectations in equation (24) requires the second order derivatives which can be obtained using vector differentiation, and the following conditional expectations
where we let and which is approximated using central difference formula.
The asymptotic covariance matrix of can be approximated by the inverse of the observed information matrix . This gives us a way to approximate the standard error of
| (25) |
4 Simulation Study
We perform three simulation studies: firstly, to compare the efficiency of the MCECM, ECME and HECM algorithms with the extra E-step mentioned in Section 3.3.1; secondly, to analyse the optimal choices of on increasing the dimension of MSVG distribution; and lastly, to assess the performance of HECM algorithm for different levels of shape and skewness parameters. We use the statistical program called R to generate random samples from the MSVG distribution each of sample size and estimate the parameters for each sample. We set the true parameters to be
for the bivariate base model and use initial values recommended in Section 3.1, that is . To improve convergence, we multiply the data by . Thus we have the scaled parameters as , and for , and respectively. The results are then rescaled back and for each random sample, we calculate the log-likelihood to assess the model fit.
4.1 Efficiency across algorithms
To illustrate that the three algorithms, MCECM, ECME, and HECM provide good estimates, we perform the simulation above with replications using the bivariate base model and compare their relative performance. In Table 1 below, the average of parameter estimates, log-likelihoods, number of iterations for convergence over replications, and the total computational times are presented. For each algorithm, we generate the same set of simulated data using the same seed to eliminate the effect of sampling errors in the comparison.
| true | MCECM | ECME | HECM | |
| 0 | 0.0072 | 0.0072 | 0.0072 | |
| 0 | 0.0069 | 0.0069 | 0.0069 | |
| 1 | 0.9959 | 0.9959 | 0.9959 | |
| 0.4 | 0.3973 | 0.3973 | 0.3973 | |
| 1 | 0.9914 | 0.9914 | 0.9914 | |
| 0.2 | 0.2067 | 0.2067 | 0.2068 | |
| 0.3 | 0.3062 | 0.3062 | 0.3062 | |
| 2.5 | 2.5699 | 2.5709 | 2.5710 | |
| loglik | 2713.41 | 2713.41 | 2713.41 | |
| conv.iter | 75.6 | 31.8 | 76.6 | |
| time (hr) | 8.1 | 16.4 | 9.1 |
All estimates obtained are reasonably close to the true value which supports the validity of these algorithms. As expected, MCECM algorithm is the most efficient in terms of computation time whereas ECME algorithm converges the fastest in terms of the number of iterations. However the ECME and HECM algorithms provide slightly better model fits when comparing more digits of the averaged log-likelihood. Overall HECM algorithm is preferred as it provides better model fit than the MCECM algorithm and runs faster than the ECME algorithm. Hence HECM algorithm will be adopted in all subsequent analyses.
4.2 Efficiency across for small shape parameter
In this simulation study, we analyse the behavior of estimates for different levels of as defined in Section 3.3.1. We begin the simulation study with bivariate skewed VG distribution with parameters as in Table 1 but with as the true shape parameter. The shape parameter is chosen to satisfy the condition for unbounded density. We repeat the experiment for different levels of but we do not report average log-likelihood because it can be estimated to be as large as possible by reducing the value of . For each level, we repeat the estimation procedure times. Generally from the results of the experiment as shown in Table 2, the further away the is from the range (1e-5,1e-3), the further away are the estimates from their true values. Hence, an optimal range of is from 1e-5 to 1e-3.
This experiment is repeated for dimension with . The results for these experiments are given in Tables 3.
| levels | |||||||||
| true | 1e-300 | 1e-100 | 1e-50 | 1e-10 | 1e-7 | 1e-5 | 1e-4 | 1e-3 | |
| 0 | 0.0040 | 0.0040 | 0.0040 | 0.0040 | 0.0040 | 0.0040 | 0.0040 | 0.0039 | |
| 0 | 0.0058 | 0.0058 | 0.0058 | 0.0058 | 0.0058 | 0.0058 | 0.0058 | 0.0056 | |
| 1 | 1.2118 | 1.0600 | 1.0434 | 1.0111 | 1.0043 | 0.9997 | 0.9961 | 0.9916 | |
| 0.4 | 0.4880 | 0.4251 | 0.4184 | 0.4054 | 0.4027 | 0.4009 | 0.3994 | 0.3976 | |
| 1 | 1.2149 | 1.0607 | 1.0438 | 1.0116 | 1.0049 | 1.0003 | 0.9967 | 0.9921 | |
| 0.2 | 0.1939 | 0.1910 | 0.1932 | 0.1952 | 0.1952 | 0.1953 | 0.1951 | 0.1950 | |
| 0.3 | 0.2904 | 0.2861 | 0.2894 | 0.2925 | 0.2925 | 0.2925 | 0.2923 | 0.2921 | |
| 0.6 | 0.3300 | 0.4421 | 0.4964 | 0.5771 | 0.5885 | 0.5965 | 0.6010 | 0.6053 | |
| Estimate in bold is closest to the true value. | |||||||||
| levels | ||||||||
| true | 1e-7 | 1e-6 | 1e-5 | 1e-4 | 1e-3 | 1e-2 | 1e-1 | |
| 0 | -0.0019 | -0.0019 | -0.0019 | -0.0019 | -0.0019 | -0.0018 | 0.0013 | |
| 0 | -0.0024 | -0.0024 | -0.0024 | -0.0024 | -0.0024 | -0.0022 | -0.0020 | |
| 0 | -0.0012 | -0.0012 | -0.0012 | -0.0012 | -0.0012 | -0.0011 | -0.0015 | |
| 1 | 1.0092 | 1.0070 | 1.0049 | 1.0026 | 0.9989 | 0.9952 | 0.9889 | |
| 0.4 | 0.4020 | 0.4012 | 0.4003 | 0.3994 | 0.3980 | 0.3966 | 0.3942 | |
| 0.3 | 0.3019 | 0.3013 | 0.3007 | 0.3000 | 0.2989 | 0.2978 | 0.2960 | |
| 1 | 1.0094 | 1.0073 | 1.0051 | 1.0029 | 0.9992 | 0.9956 | 0.9893 | |
| 0.2 | 0.2007 | 0.2003 | 0.1999 | 0.1995 | 0.1988 | 0.1981 | 0.1969 | |
| 1 | 1.0128 | 1.0107 | 1.0086 | 1.0064 | 1.0027 | 0.9991 | 0.9926 | |
| 0.2 | 0.2012 | 0.2012 | 0.2012 | 0.2012 | 0.2010 | 0.2007 | 0.1999 | |
| 0.3 | 0.3026 | 0.3026 | 0.3026 | 0.3026 | 0.3025 | 0.3019 | 0.3013 | |
| 0.4 | 0.4018 | 0.4018 | 0.4018 | 0.4018 | 0.4016 | 0.4010 | 0.4009 | |
| 1 | 0.9512 | 0.9602 | 0.9696 | 0.9795 | 0.9912 | 1.0013 | 1.0225 | |
| Estimate in bold is closest to the true value. | ||||||||
On increasing the dimension, the optimal ranges for is (1e-5,1e-1). As for the subsequent simulation experiment, we implement within the optimal ranges for dimension 2 to 3. As results show that the optimal range only increases slowly with , we apply the optimum range for to the five dimensional MSVG model in the real data analysis.
For the univariate case, we use the modified HECM algorithm as mentioned in Section 3.3.2. The results are presented below in Table 4. Due to the modification, it is not possible to directly compare the algorithm for high dimensional cases. As the level gets bigger, and increases towards the true value. However, increases away from the true value. Since the optimal range is not clear for the univariate case, we suggest any in the range (1e-10,1e-3).
| levels | ||||||||
|---|---|---|---|---|---|---|---|---|
| true | 1e-300 | 1e-100 | 1e-50 | 1e-20 | 1e-10 | 1e-5 | 1e-3 | |
| 0 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| 1 | 0.8564 | 0.8564 | 0.8564 | 0.8564 | 0.8663 | 0.8862 | 0.9148 | |
| 0.2 | 0.1878 | 0.1878 | 0.1878 | 0.1878 | 0.1885 | 0.1907 | 0.1952 | |
| 0.3 | 0.3102 | 0.3102 | 0.3102 | 0.3102 | 0.3111 | 0.3137 | 0.3267 | |
4.3 Effects of shape and skewness parameters
In this simulation study, we study the performance of HECM algorithm for various levels of skewness parameter when the shape parameter is and which indicates large and small value respectively according to the condition . We consider the same bivariate base model as described at the start of Section 4 except that the true skewness parameters are = (0.2,0.2), (0.5,0.5), (0.7,0.7), (1,1), (2,2) and (0.5,2). We report the averaged iteration in which the algorithm switches from MCECM to ECME algorithm as denoted by switch iter, the averaged iteration when the algorithm converges by conv iter, and the total time it takes to run the algorithm.
| True | |||||||
| true | |||||||
| 0 | -0.0081 | -0.0129 | -0.0149 | -0.0176 | -0.0246 | -0.0071 | |
| 0 | -0.0095 | -0.0143 | -0.0162 | -0.0186 | -0.0244 | -0.0292 | |
| 1 | 0.9960 | 0.9942 | 0.9927 | 0.9903 | 0.9779 | 0.9951 | |
| 0.4 | 0.3985 | 0.3963 | 0.3947 | 0.3921 | 0.3790 | 0.3932 | |
| 1 | 0.9952 | 0.9931 | 0.9915 | 0.9888 | 0.9759 | 0.9727 | |
| 0.2061 | 0.5108 | 0.7128 | 1.0154 | 2.0221 | 0.5050 | ||
| 0.2084 | 0.5131 | 0.7150 | 1.0173 | 2.0229 | 2.0277 | ||
| 3 | 3.1006 | 3.0856 | 3.0785 | 3.0699 | 3.0477 | 3.0535 | |
| switch.iter | 99.31 | 105.34 | 111.89 | 125.73 | 241.16 | 192.61 | |
| conv.iter | 99.31 | 105.34 | 111.89 | 125.73 | 241.16 | 192.61 | |
| time (hr) | 11.5 | 12.1 | 12.3 | 22.8 | 41.2 | 34.2 | |
Table 5 shows that all estimates are very close to their true values. On increasing the level of skewness, the biases of parameters , and tend to increase gradually while the bias for decreases gradually. The number of iterations to switch and converge and hence the computation time also increase accordingly. This also applies for the unequal skewness case. Moreover, there is no reliance of ECME algorithm as the parameter is chosen so that . Indeed the simulation with larger skewness needs more iterations for the algorithm to converge. The results when is presented in Table 6.
| True | |||||||
| true | |||||||
| 0 | 0.0043 | 0.0083 | 0.0108 | 0.0136 | 0.0212 | 0.0052 | |
| 0 | 0.0042 | 0.0082 | 0.0110 | 0.0138 | 0.0213 | 0.0213 | |
| 1 | 0.9995 | 1.0054 | 1.0114 | 1.0220 | 1.0573 | 1.0175 | |
| 0.4 | 0.4006 | 0.4061 | 0.4124 | 0.4226 | 0.4391 | 0.4167 | |
| 1 | 0.9990 | 1.0044 | 1.0111 | 1.0217 | 1.0540 | 1.0558 | |
| 0.1950 | 0.4904 | 0.6876 | 0.9845 | 2.0337 | 0.5007 | ||
| 0.1943 | 0.4897 | 0.6866 | 0.9835 | 2.0328 | 2.0028 | ||
| 0.6 | 0.5968 | 0.5961 | 0.5957 | 0.5945 | 0.5946 | 0.5940 | |
| switch.iter | 26.8 | 27.6 | 28.1 | 23.7 | 23.2 | 26.5 | |
| conv.iter | 28.4 | 28.0 | 28.5 | 24.5 | 23.2 | 26.5 | |
| time (hr) | 4.9 | 3.5 | 3.7 | 6.7 | 5.8 | 6.6 | |
The parameter estimates using HECM algorithm and optimal to deal with unbounded density are reasonably accurate. This justifies the choice of for . Surprisingly the algorithm roughly needs around the same number of iterations for each skewness level. In comparison with the results in Table 5 for larger , the algorithm requires significantly less iterations. Eventually, the HECM algorithm switch to ECME to obtain parameter estimates. This justifies our proposed HECM algorithm instead of relying solely on MCECM.
In summary, the proposed HECM algorithm gives good parameter estimates for the MSVG distribution even when its shape parameter is small and skewness is heavy.
5 Real Data Analysis
To illustrate the applicability of HECM algorithm using the MSVG AR model, we consider the returns of five daily closing price indices, namely, Deutscher Aktien (DAX), Standard & Poors 500 (S&P 500), Financial Times Stock Exchange 100 (FTSE 100), All Ordinaries (AORD) and Cotation Assiste en Continu 40 (CAC) from 1st January 2004 to 31st December 2012 with tolerance level of . After filtering the data with missing closing prices, we obtain the data size of . Plots of the five time series are given in Figure 2. As the summary statistics in Table 7 show that the data exhibit considerable skewness and kurtosis, we begin our analyses with the MSVG model adopting a constant mean. To assess the model fit, we use the Akaike information criterion with a correction for finite sample size (AICc) given by:
where denotes the number of model parameters. Model with the lowest AICc value is preferred as it demonstrates the best model fit after accounting for model complicity.
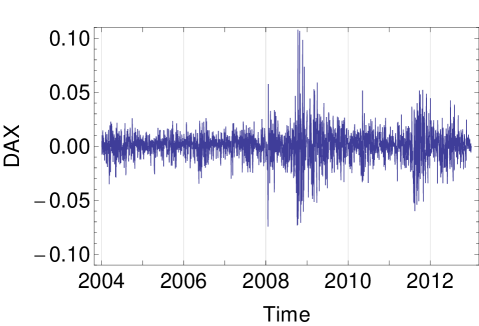
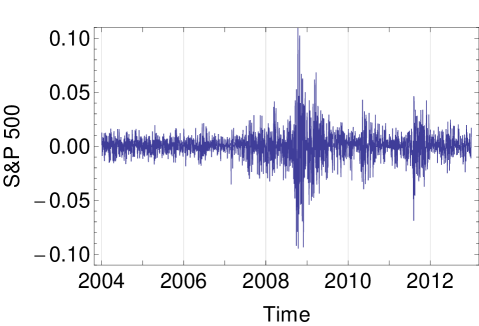
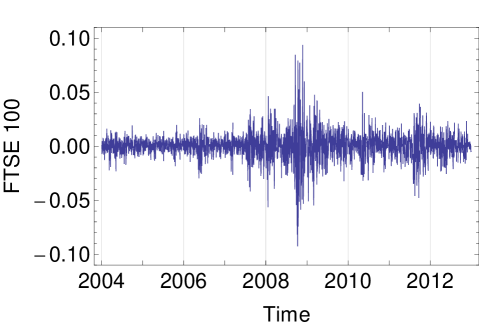
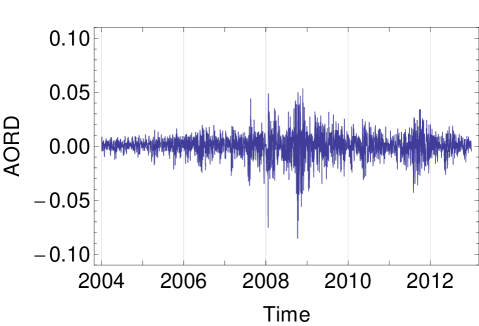
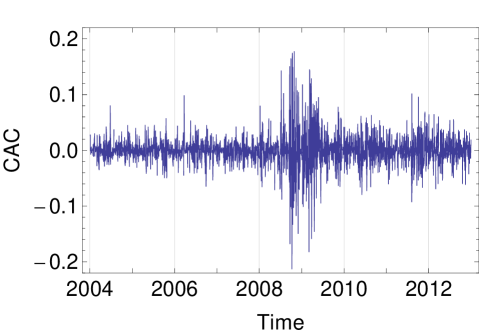
| DAX | S&P 500 | FTSE 100 | AORD | CAC | |
| mean† | 0.2901 | 0.1096 | 0.1223 | 0.1587 | 0.1755 |
| sd | 0.0146 | 0.0136 | 0.0127 | 0.0114 | 0.0287 |
| max | 0.1080 | 0.1096 | 0.0938 | 0.0540 | 0.1778 |
| min | 0.0774 | 0.0947 | 0.0926 | 0.1049 | 0.2133 |
| skewness | 0.0208 | 0.2939 | 0.0946 | 0.7291 | 0.1524 |
| kurtosis | 9.4529 | 12.9395 | 11.0138 | 10.4846 | 11.7483 |
| The reported means are multiplied by 1000. | |||||
The results for the estimated parameters and their standard errors are given in Table 8 .
| estimate | standard error | |
| 1.40 | 0.054 | |
| Corr | ||
| AICc | 69422 | |
| conv iter | 41 | |
| time (sec) | 91 |
The model is then extended to include an AR(1) term in the mean to describe the autocorrelation of the five return series. Similarly, results for the estimated parameters and their standard errors are given in Table 9:
| estimate | standard error | |
| 1.45 | 0.057 | |
| Corr | ||
| AICc | 70866 | |
| conv iter | 50 | |
| time (sec) | 111 |
The two sets of model parameters are not directly comparable. However the estimates of and correlation matrices are very similar while are some what similar. The standard error for the estimate in MSVG AR model suggests that only the second column has all parameters being significant. Since the second column of the matrix has relatively larger values, all five stocks are strongly lag-one cross-correlated with S&P 500. It is not surprising to know that the returns in S&P 500 has the most impact on each of the five returns the next day because S&P 500 has been shown to be a strong predictor for a number of market indices. This is due to its large market share and its minimal real time difference with lag-one return of other markets. Comparing the AICc of the two models, the MSVG AR model provides better model fit which is further illustrated in the histogram of residuals in Figure 3 after filtering out the AR(1) term. Fitted marginal pdfs with as the mean of the MSVG model are added to the figure to facilitate comparison. Overall the two MSVG models provide good fits to the data despite occasionally, the peaks of the histogram and fitted pdf around the means does not match exactly possibly due to the rather strong assumption of a common shape parameter across all components. This is a limitation of the MSVG distribution.
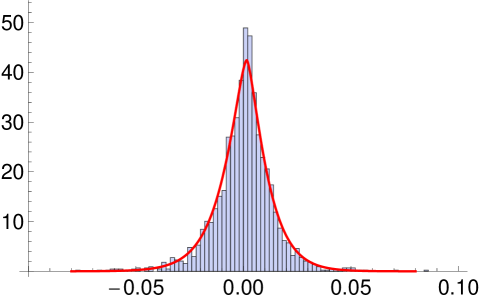
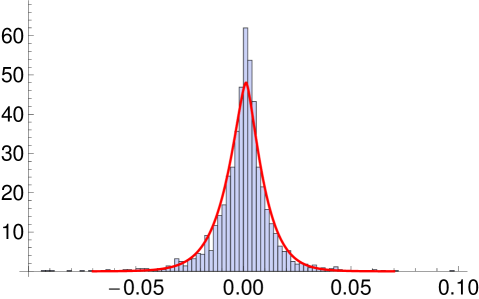
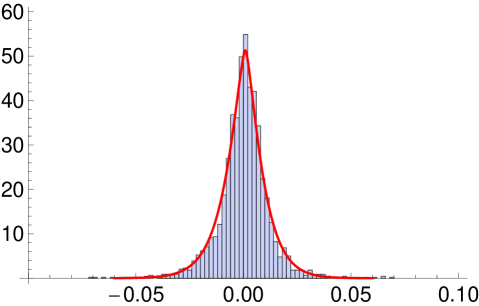
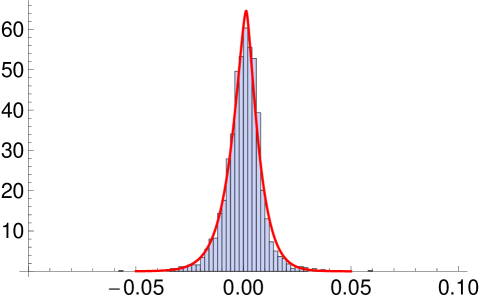
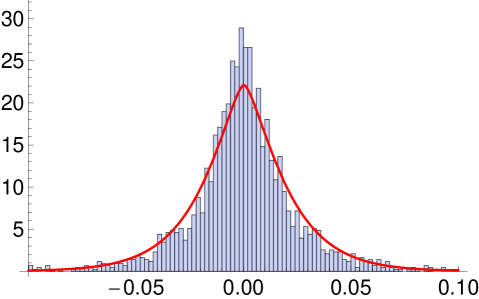
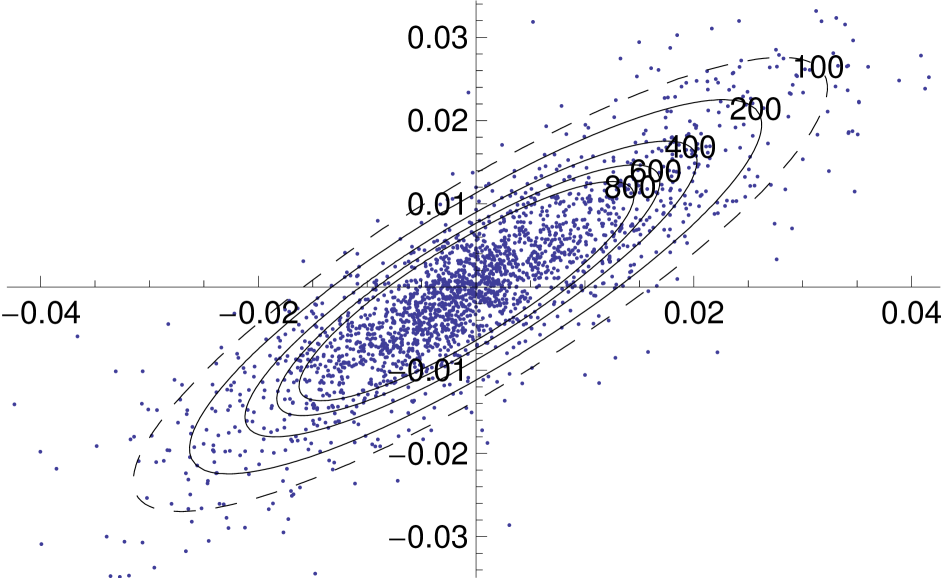
From the correlation matrices of the two models, the pair of market indices DAX and FTSE 100 are highly correlation (), possibly due to the strong competitiveness of the German and UK markets as they are the major stock markets in Europe. This gives rise to similar cross-correlation for both DAX and FTSE 100 with the other stocks. The model fit of the MSVG AR model for DAX and FTSE 100 bivariate return data is displayed in the contour plot in Figure 4. Since the parameter estimates are quite similar to the five dimensional empirical study, we omit reporting these results. Overall the model captures the strong correlation between the two stocks, giving a good overall fit to the DAX and FTSE 100 data set.
6 Conclusion
The MCECM and ECME algorithms have been proposed to obtain the ML estimates of multivariate Student-t distribution (Liu and Rubin,, 1995). We advance the algorithms to HECM algorithm and demonstrate its applicability to the MSVG model with AR mean function. Our proposed HECM algorithm with two adjustments solves three technical issues in application.
Firstly, HECM algorithm improves the overall computational efficiency by combining the speed of MCECM algorithm at the start of iterations with the stability of ECME algorithm at latter iterations. Secondly, when the shape parameter is small and observations cluster closely to the mean, the problem of unbounded MSVG density leading to diverged estimates and can be resolved by capping the density within certain range of . We study the optimal choices of ranges for dimension . More studies are needed to verify the choices of for higher dimensions. Lastly, we add an extra E-step after updating but before updating to improve the stability of the estimate when the MSVG density is again unbounded.
The HECM algorithm is then applied to fit the MSVG model with an AR(1) mean structure to describe the dynamics in financial time series. To improve the model flexibility and predictability, the HECM algorithm can be easily extended to models with AR() terms. Moreover, the algorithm can be further enhanced to popular financial time series models such as GARCH models (Bollerslev,, 1986) and with leverage effect (Engle and Ng,, 1993). Some distribution families such as the multivariate skew Student-t distribution or multivariate skew generalised hyperbolic distribution which nests the MSVG distribution may be considered because they can be expressed in normal mean-variance mixtures representation. While these extensions improve the applicability of the algorithm, it is very challenging as there is no close-form solution for parameters in the mean function and hence more layers of iterations are required.
In summary, we show that the HECM algorithm improves the computation efficiency in the ML estimation for the complicated MSVG distribution in normal mean-variance mixtures representation. However, we also remark the limitation of the MSVG model with one shape parameter for all components. In practice, different time series may follow distributions with different shape parameters. Hence, to improve the model applicability, it is necessary to allow one shape parameter for each component resulting in a modified MSVG model, similar to the GARCH models in Choy et al., (2014).
Acknowledgments
I would like to thank John Ormerod for his helpful comments which leads to improvement of the paper.
References
- Bollerslev, (1986) Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. J. Econometrics, 31(3):307–327.
- Choy and Smith, (1997) Choy, S. and Smith, A. (1997). Hierarchical models with scale mixtures of normal distributions. Test, 6(1):205–221.
- Choy et al., (2014) Choy, S. T. B., Chen, C. W. S., and Lin, E. M. H. (2014). Bivariate asymmetric garch models with heavy tails and dynamic conditional correlations. Quantitative Finance, 14(7):1297–1313.
- Dempster et al., (1977) Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Statist. Soc. Ser. B, 39(1):1–38. With discussion.
- Embrechts, (1983) Embrechts, P. (1983). A property of the generalized inverse Gaussian distribution with some applications. J. Appl. Probab., 20(3):537–544.
- Engle and Ng, (1993) Engle, R. F. and Ng, V. K. (1993). Measuring and testing the impact of news on volatility. J. Finance, 48(5):1749–1778.
- Finlay and Seneta, (2008) Finlay, R. and Seneta, E. (2008). Stationary-increment variance-gamma and ”t” models: Simulation and parameter estimation. Int. Statist. Rev., 76(2):167–186.
- Fung and Seneta, (2007) Fung, T. and Seneta, E. (2007). Tailweight, quantiles and kurtosis: a study of competing distributions. Oper. Res. Lett., 35(4):448–454.
- Fung and Seneta, (2010) Fung, T. and Seneta, E. (2010). Modelling and estimation for bivariate financial returns. Int. Statist. Rev., 78(1):117–133.
- Gradshteyn and Ryzhik, (2007) Gradshteyn, I. S. and Ryzhik, I. M. (2007). Table of integrals, series, and products. Elsevier/Academic Press, Amsterdam, seventh edition. Translated from the Russian, Translation edited and with a preface by Alan Jeffrey and Daniel Zwillinger, With one CD-ROM (Windows, Macintosh and UNIX).
- Hu and Kercheval, (2008) Hu, W. and Kercheval, A. N. (2008). The skewed distribution for portfolio credit risk. In Econometrics and risk management, volume 22 of Adv. Econom., pages 55–83. Emerald/JAI, Bingley.
- Liu and Rubin, (1994) Liu, C. and Rubin, D. B. (1994). The ECME algorithm: a simple extension of EM and ECM with faster monotone convergence. Biometrika, 81(4):633–648.
- Liu and Rubin, (1995) Liu, C. and Rubin, D. B. (1995). ML estimation of the distribution using EM and its extensions, ECM and ECME. Statist. Sinica, 5(1):19–39.
- Louis, (1982) Louis, T. A. (1982). Finding the observed information matrix when using the EM algorithm. J. Roy. Statist. Soc. Ser. B, 44(2):226–233.
- Madan and Seneta, (1987) Madan, D. B. and Seneta, E. (1987). Chebyshev polynomial approximations and characteristic function estimation. J. Roy. Statist. Soc. Ser. B, 49(2):163–169.
- Madan and Seneta, (1990) Madan, D. B. and Seneta, E. (1990). The variance gamma (V.G.) model for share market returns. J. Bus., 63(4):511–524.
- McNeil et al., (2005) McNeil, A. J., Frey, R., and Embrechts, P. (2005). Quantitative risk management. Princeton Series in Finance. Princeton University Press, Princeton, NJ. Concepts, techniques and tools.
- Meng, (1994) Meng, X.-L. (1994). On the rate of convergence of the ECM algorithm. Ann. Statist., 22(1):326–339.
- Meng and Rubin, (1993) Meng, X.-L. and Rubin, D. B. (1993). Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika, 80(2):267–278.
- Tjetjep and Seneta, (2006) Tjetjep, A. and Seneta, E. (2006). Skewed normal variance-mean models for asset pricing and the method of moments. Int. Statist. Rev., 74(1):109–126.