An efficient aggregation method for the symbolic representation of temporal data
Abstract
Abstract: Symbolic representations are a useful tool for the dimension reduction of temporal data, allowing for the efficient storage of and information retrieval from time series. They can also enhance the training of machine learning algorithms on time series data through noise reduction and reduced sensitivity to hyperparameters. The adaptive Brownian bridge-based aggregation (ABBA) method is one such effective and robust symbolic representation, demonstrated to accurately capture important trends and shapes in time series. However, in its current form the method struggles to process very large time series. Here we present a new variant of the ABBA method, called fABBA. This variant utilizes a new aggregation approach tailored to the piecewise representation of time series. By replacing the k-means clustering used in ABBA with a sorting-based aggregation technique, and thereby avoiding repeated sum-of-squares error computations, the computational complexity is significantly reduced. In contrast to the original method, the new approach does not require the number of time series symbols to be specified in advance. Through extensive tests we demonstrate that the new method significantly outperforms ABBA with a considerable reduction in runtime while also outperforming the popular SAX and 1d-SAX representations in terms of reconstruction accuracy. We further demonstrate that fABBA can compress other data types such as images.
Keywords: Knowledge representation, Symbolic aggregation, Time series mining, Data compression
1 Introduction
Time series are a ubiquitous data type in many areas including finance, meteorology, traffic, and astronomy. The problem of extracting knowledge from temporal data has attracted a lot of attention in recent years. Important data mining tasks are query-by-content, clustering, classification, segmentation, forecasting, anomaly detection, and motif discovery; see [17] for a survey. Common problems related to these tasks are that time series data are typically noisy and of high dimension, and that it may be difficult to define similarity measures that are effective for a particular application. For example, two noisy time series may be of different lengths and their values may range over different scales, but still their “shapes” might be perceived as similar [5, 17]. To address such problems, many high-level representations of time series have been proposed, including numerical transforms (e.g., based on the discrete Fourier transform [29, 49], discrete wavelet transform [4, 49], singular value decomposition [30], or piecewise linear representations [9, 27, 26]) and symbolic representations (such as SAX [32, 33], 1d-SAX [35], many other SAX variants [45, 40, 6, 53, 51, 42, 31, 18]).
In this paper, we focus on a recent symbolic representation called adaptive Brownian bridge-based symbolic aggregation (ABBA) [15] and propose an accelerated version called fABBA. The new method serves the same purpose as ABBA, i.e., it is dimension and noise reducing whilst preserving the essential shape of the time series. However, fABBA uses a new sorting-based aggregation procedure whose computational complexity is considerably lower than ABBA (which is based on k-means). We provide an analysis of the representation accuracy of fABBA which goes beyond the analysis available for ABBA and demonstrate that the computed symbolic strings are very accurate representations of the original time series. We also demonstrate that fABBA can be applied to other data types such as images. Python code implementing the new method and reproducing all experiments in this paper is available at
The rest of this paper is organized as follows. In Section 2 we briefly review the original ABBA approach and motivate the need for a faster algorithm. Section 3 presents the new method, including the sorting-based aggregation approach. A theoretical discussion of the expected reconstruction accuracy and computational complexity is provided in Section 4. Section 5 contains several numerical tests comparing the new method with other well-established algorithms for symbolic time series representation. We conclude in Section 6 with some ideas for follow-on research.
2 Overview of ABBA and motivation
Review
ABBA is a symbolic representation of time series based on an adaptive polygonal chain approximation and a mean-based clustering algorithm. Formally, we consider the problem of aggregating a time series into a symbolic representation , , where each is an element of an alphabet of symbols. The notation is also summarized in Table 1. The ABBA method consists of two steps, compression and digitization, which we review below.
| time series | |
|---|---|
| after compression | |
| after digitization | |
| inverse-digitization | |
| quantization | |
| inverse-compression |
The ABBA compression step computes an adaptive piecewise linear continuous approximation of . Given a compression tolerance tol, the method adaptively selects indices so that the time series is approximated by a polygonal chain going through the points for . This gives rise to a partition of into pieces , each of integer length in the time direction. The criterion for the partitioning is that the squared Euclidean distance of the values in from the straight polygonal line is bounded by . More precisely, starting with and given an index , we find the largest possible such that and
| (1) |
Each linear piece of the resulting polygonal chain is described by a tuple , where is the increment in value. The whole polygonal chain can be recovered exactly from the first value and the tuple sequence
| (2) |
The ABBA digitization step assigns the tuples in (2) into clusters . Before doing so, the tuple lengths and increments are separately normalized by their standard deviations and , respectively. A further scaling parameter scl is used to assign different weight (“importance”) to the length of each piece in relation to its increment value. Hence, one effectively clusters the scaled tuples
| (3) |
If , then clustering is performed on the increments alone, while if , the lengths and increments are clustered with equal weight.
In the original ABBA method [15] the cluster assignment is performed using k-means [34], by iteratively aiming to minimize the within-cluster-sum-of-squares
| (4) |
with each 2d cluster center corresponding to the mean of the scaled tuples associated with the cluster .
Given a partitioning of the tuples into clusters , the unscaled cluster centers
are then used to define the maximal cluster variances in the length and increment directions as
respectively. Here, denotes the number of tuples in cluster . The aim is to seek the smallest number of clusters such that
| (5) |
with a tolerance . Once the optimal has been found, each cluster is assigned a symbol , respectively. Finally, each tuple in the sequence (2) is replaced by the symbol of the cluster it belongs to, resulting in the symbolic representation .
Discussion
The final step of the ABBA digitization procedure just outlined, namely the determination of the required number of clusters , requires repeated runs of the k-means algorithm. This algorithm partitions the set of time series pieces into the specified number of clusters by minimizing the sum-of-squares error (SSE) between each point and its nearest cluster center. Choosing the right number of clusters and performing repeated SSE calculations is found to be a major computational bottleneck of ABBA, in particular when the number of pieces and the final parameter turn out to be large (say, with in the hundreds and or above). While there are other approaches to estimate the “right” number of clusters, such as silhouette coefficients [41], these still require a clustering to be computed first and hence are of high computational complexity.
While there are a large number of alternative clustering methods available (such as STING [48], BIRCH [54], CLIQUE [1], WaveCluster [44], DenClue [23], spectral clustering [50], Gaussian mixture model [12, 20, 7], DBSCAN [19] and HDBSCAN [8], to name just a few of the more commonly used), many of these are inappropriate for time series data and/or require difficult parameter choices. For example, the density-based DBSCAN algorithm is not appropriate for time series pieces because there is no reason to expect that similar pieces would aggregate in regions of high density.
3 Method
In Section 3.1 below we introduce a new sorting-based aggregation approach for time series pieces. This approach addresses the above-mentioned problems with ABBA as it does not require an a-priori specification of the number of clusters and significantly reduces computational complexity by using early stopping conditions. The use of this approach within ABBA is discussed in Section 3.2.
3.1 Sorting-based aggregation
We start off with data points in , obtained as in (3) but sorted in one of the following two ways.
-
•
Binned and lexicographically sorted: if and then we require that . Here, and refer to the first and second coordinate of , respectively. This form of lexicographic sorting is meaningful if the first components () take on only a small number of distinct values. This can be achieved by assigning the ’s into a small number of bins depending on . Within ABBA this condition is naturally satisfied as each corresponds to the scaled length of a piece , which is an integer.
-
•
Sorted by norm: if then necessarily , where corresponds to a norm. In all our numerical tests we assume that this is the norm for (Euclidean norm) or (Manhattan norm).
These sorting conditions are essential for the efficiency of our aggregation algorithm in various ways. First, it is clear that two data points and with a small distance
| (6) |
must also have similar norm values since
| (7) |
Hence, a small distance between norm values is a necessary condition for the closeness of data points. While it is not a sufficient condition, norm-sorted points with adjacent indices are more likely to be close in distance than without sorting, facilitating the efficient assignment of nearby points into clusters. Moreover, the imposed sorting can be used to stop searching for data points near a given point prematurely without traversing all of the remaining points.
Indeed with lexicographic sorting, if and (the minimum bin width around ), then we know that is closest to among all points . On the other hand, if for some and , then for all . As a consequence, we can stop searching through the bins for points near as soon as the first component is large enough. Also within a bin, if but , we know that for all the following indices .
Similarly, when the data is sorted by norm, then from (7) we know that when for some index , we have for all . Hence, we can terminate the search for points near as soon as reaches this index .
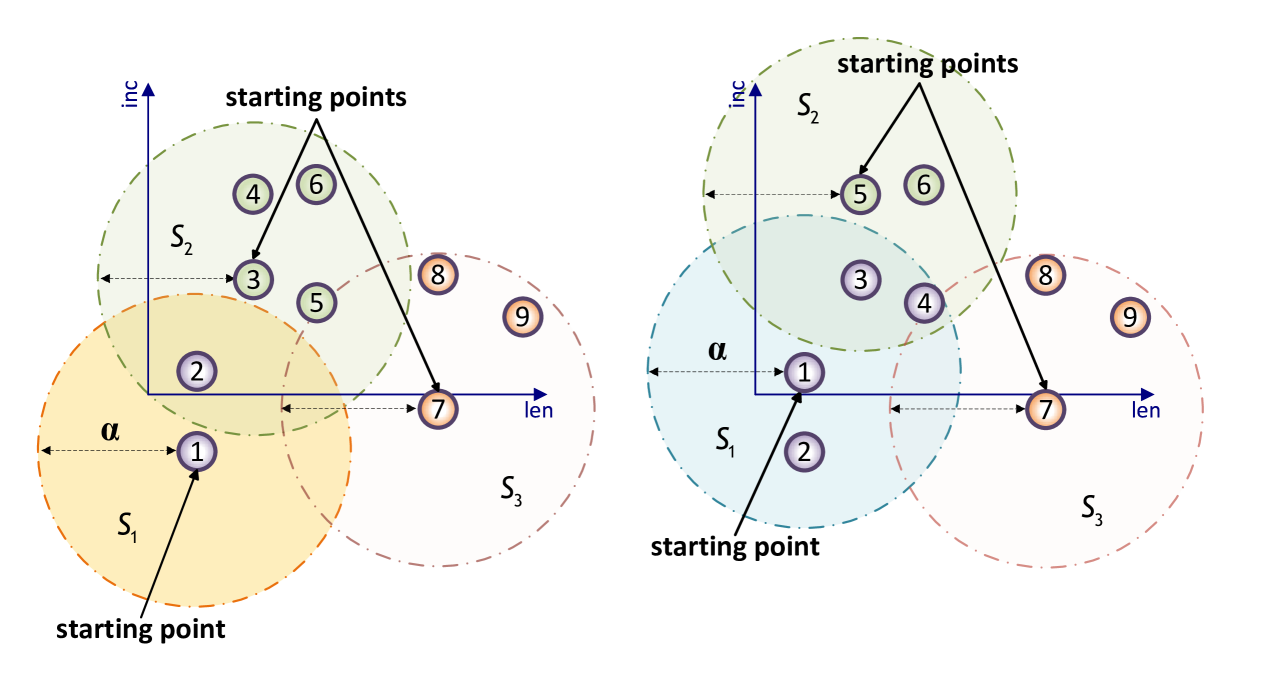
With these termination conditions for the search in place, we now propose our aggregation approach in Algorithm 1. It assumes the data points to be sorted in one of the two ways described above, and requires a hyperparameter for controlling the group size. Hereforth, we term “group” is used instead of “cluster” in order to clearly distinguish this approach from other clustering methods. We will discuss the role of the parameter in Section 4.1 and in the numerical experiments, Section 5.5. Starting with the first sorted point, which is considered the starting point of the first group, the algorithm traverses points in the sorted order and assigns them to the current group if the distance to the starting point does not exceed . A visual illustration of Algorithm 1 is shown in Figure 1.
We emphasize that the starting points are fixed while the groups are being formed, hence they do not necessarily correspond to the mean centers of each group (as would be the case, e.g., in k-means). This is a crucial property of this algorithm as the mean center of a group is only known once the group is fully formed. By using this concept of starting points we avoid repeated center calculations, resulting in significantly reduced computational complexity (see the analysis in Section 4.2). As the points are traversed in sorted order, we use the early stopping conditions for the search whenever applicable. Only when all points have been assigned to a group, the centers are computed as the mean of all data points associated with a group (Step 6 in Algorithm 1).
Label all of them as “unassigned”. 2. For let be the first unassigned point and set .
(The point is the starting point of a new group.)
If there are no unassigned points left, go to Step 6. 3. Compute 4. If , • assign to the same group as • increase 5. If or termination condition is satisfied, go to Step 2. Otherwise go to Step 3. 6. For each computed group, compute the group center as the mean of all its points.
3.2 fABBA
The fABBA method for computing a symbolic representation of a time series follows the same compression phase as the original ABBA method described in Section 2. That is, given a tolerance tol, we compute the same polygonal chain approximation as in (1), resulting in the same tuple sequence (2), and the same sequence of scaled points as in (3).
The fABBA digitization then proceeds using Algorithm 1 described in Section 3 to assign the points to groups , each represented by a symbol in , resulting in the symbolic representation
Each group has an associated group center corresponding to the mean of all points associated with that group. These mean centers can be used to reconstruct an approximation of the time series from its symbolic representation.
4 Analysis and discussion
We now analyze the quality of the groups returned by Algorithm 1 (Section 4.1) and discuss its time complexity (Section 4.2). We also discuss the viability of alternative clustering methods (Section 4.3).
4.1 Clustering quality
Throughout this section we assume that the points are already scaled and sorted by their Euclidean norm. Recall that in Algorithm 1 we effectively use a starting point as a “temporary” group center when computing the distances in Step 3. By construction, all points in a group, say, , satisfy
| (8) |
So, upon replacing the temporary group center by the true group mean in Step 6 of the algorithm,
and using that the mean minimizes the sum of squares on the left-hand side of (8), we obtain
| (9) |
This is a variance-based cluster condition similar to the one used in the ABBA method; see also (5).
We now analyze how the use of starting points as “temporary” group centers affects the WCSS defined in (4). The WCSS is a measure for the coherence of the groups. The smaller its value, the more tightly packed are points within each group. In order to make the analysis tractable, we assume that both grouping approaches—measuring distance from a starting point versus measuring distance from the true group mean—lead to the same groupings. For clarity we denote by the within-cluster-sum-of-squares as defined in (4) using the group means as the centers, while uses the starting points. It turns out that both of these quantities cannot be arbitrarily large. Indeed, let be aggregated into with associated starting points . Then
Similarly, it can easily be shown that
Consider each mean as an additional element of a the group , which is also the starting point of that group . Hence, we are effectively grouping points into groups and so the bound follows from the bound for when is replaced by .
Both of these bounds are only attained with worst-case point distributions. In practice, the measured and are usually smaller than these bounds suggest. This has to do with the fact that, in expectation, each term in will usually be smaller than the worst-case value . Indeed, let us assume that the points in a group follow a uniform random distribution in the disk with center 0. (The latter assumption is without loss of generality as the distances within a group are shift-independent.) Then the distance of a random point from the origin is a probability variable, say . Since the area of the disk is , the distance to the origin has a cumulative distribution function
and a probability density . Hence, the expected is
which is a factor of two smaller than the worst-case.
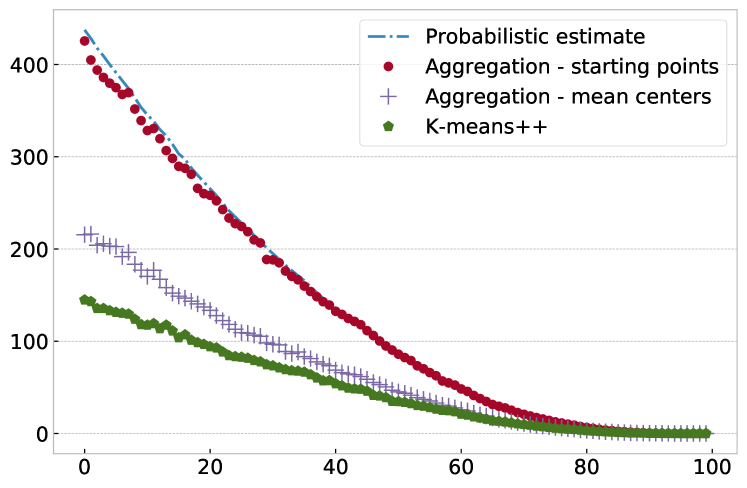
Let us illustrate the above with an experiment on synthetic data using data points chosen as 10 separated isotropic Gaussian blobs each with 100 points. We run Algorithm 1 on this data for various values of , measuring the obtained as a function of the number of groups . For each grouping we then compute the mean centers of each group and compute the corresponding as well. Both curves are shown in Figure 2, together with the probabilistic estimate just derived. We find that the matches the probabilistic estimate very well, while is smaller. Note that is the actual WCSS achieved by Algorithm 1 after Step 6 has been completed and all starting points are replaced by group means. We also show the WCSS achieved by k-means++ [3] with the cluster parameter chosen equal to the number of groups. (K-means++ is a derivative of k-means with an improved initialization using randomized seeding.) As expected, k-means++ achieves an even smaller WCSS as its objective is the minimization of exactly that quantity. However, it is striking to see that all three WCSS values are rather close to each other, with the aggregation-based algorithm achieving values which are just a moderate multiple of k-means++, while not actually performing any WCSS calculations. (Note that the WCSS is a “squared” quantity. So if two WCSS values differ by a factor of, say 2, in the units of distance this would only be a factor of .) We will demonstrate in Section 5 that the tiny worsening of WCSS incurred with Algorithm 1 is barely noticeable in the reconstruction of compressed time series.
4.2 Computational complexity
Let us turn our attention to the computational complexity of Algorithm 1, which is dominated by two operations involving the data: (i) the initial sorting of data points in Step 1 and (ii) the distance calculations in Step 3. For the sorting operation we can assume that an algorithm with worst-case and average runtime complexity has been used, such as introsort [38].
The number of total distance calculations can be counted as follows. For each unassigned point , Step 4 is guaranteed to include at least this point itself in a group, so the outer loop over all unassigned pieces (beginning with Step 2) will end after at most iterations. (The trivial distance does not need to be computed.) In the worst case, with the early termination condition never invoked and no groups of size larger than one being formed, each will be compared to all with indices . In total, distance calculations are required in this case. On the other hand, if the sorting is perfect so that points belonging to the same group have consecutive indices, and if early termination conditions are always invoked exactly before a new group is formed, every point in a group will be involved in exactly one nontrivial distance calculation , leading to linear complexity .
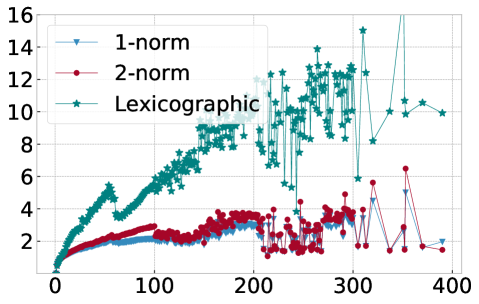
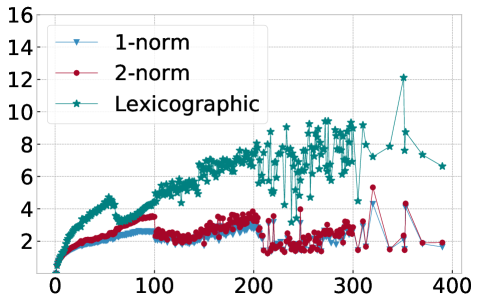
In Section 5 we will demonstrate in a comparison involving a large number of time series, that for points arising from the ABBA compression step the average number of distance calculations per point is indeed very small, in some cases as small as just 2 and rarely above 10, in particular, when Euclidean norm sorting is used. (See Figure 10 which shows an almost bounded number of the average distance calculations as the number of pieces increases.) In practice this means that Algorithm 1, and hence the digitization phase of fABBA, is dominated by the cost for the initial sorting in Step 1. As a consequence, fABBA outperforms the original ABBA implementation based on k-means++ significantly.
4.3 Comparison with other clustering methods
One might wonder whether the use of other clustering algorithms might be more appropriate. We argue that in the context of fABBA the WCSS criterion is indeed the correct objective function, advocating distance-based clustering methods like k-means and Algorithm 1. This is justified by the observation that the error of the ABBA reconstruction can be modelled as a Brownian bridge (see the analysis in [15, Section 5], which we do not repeat here) and the overall error is controlled by the total cluster variance, which coincides with the WCSS up to a constant factor.
Nevertheless, we provide here for completeness a comparison of the digitization performance obtained with other clustering algorithms, namely k-means++, spectral clustering, Gaussian mixture model (GMM), DBSCAN, and HDBSCAN. To this end we sample 100 time series of length 5000 from a standard normal distribution and then measure the mean squared error (MSE) and dynamic time warping (DTW) distance [43] of the reconstruction, digitization runtime, and the number of distinct symbols used. For the computation of DTW distances we use the implementation in the tslearn library [46] with all default options. For HDBSCAN we use the open-source software [37, 36]. The remaining algorithms are implemented in scikit-learn [39]. All algorithms are executed through the Cython compiler for a fair runtime comparison.
The number of distinct symbols for the symbolic representation is not a user-specified parameter for Algorithm 1, DBSCAN and HDBSCAN, but we must specify for the other clustering algorithms (k-means++, spectral clustering, GMM). Therefore, we first run fABBA with (digitization) and (aggregation) and use the number of generated groups as the cluster parameter for k-means++, spectral clustering, and GMM (weights are initialized using k-means). For DBSCAN, we use all default options for the parameters except for setting identical to and specifying . For HDBSCAN we use , and to achieve roughly the same number of symbols as used by the other algorithms.
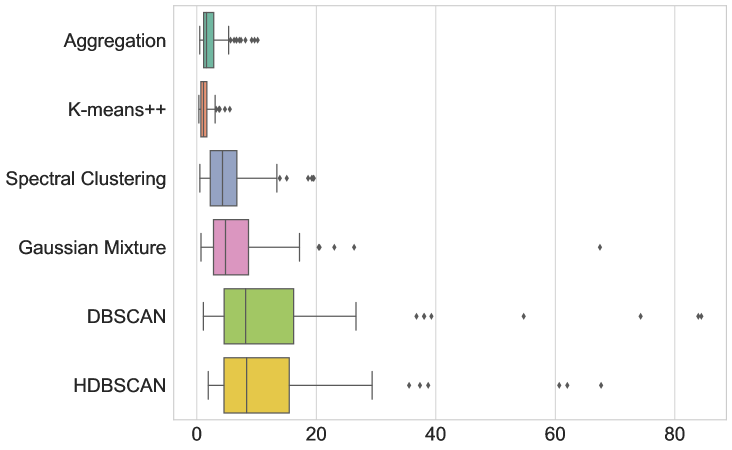
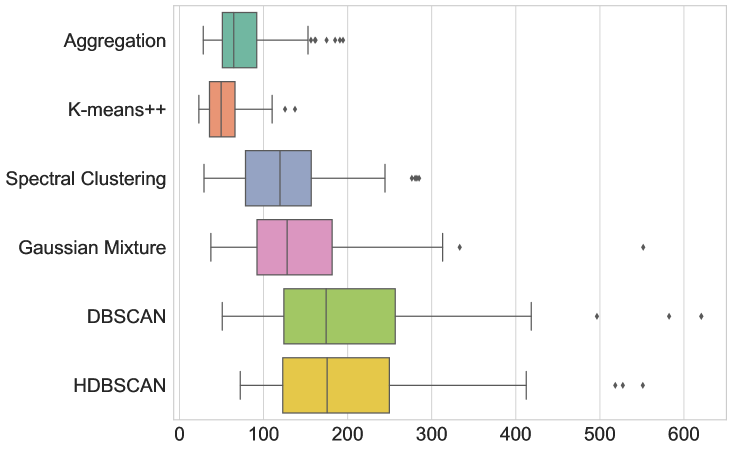
The results are given in Figure 3 and Table LABEL:table:com_other_clusterings. In terms of average runtime, our new aggregation Algorithm 1 is the fasted (51.215 ms), closely followed only by DBSCAN (59.057 ms). The box-and-whiskers plots in Figure 3 depict the distributions of the four metrics, with each box showing the first quartile , median, and third quartile , while the whiskers extend to points that lie within the 1.5 interquartile range of and . Observations that fall outside this range are displayed separately. We see that k-means++ is the only method that outperforms Algorithm 1 in terms of MSE and DTW error, but only by a small margin and at the cost of being almost 8 times slower. Therefore, Algorithm 1 indeed seems to be the most appropriate method to use in this test.
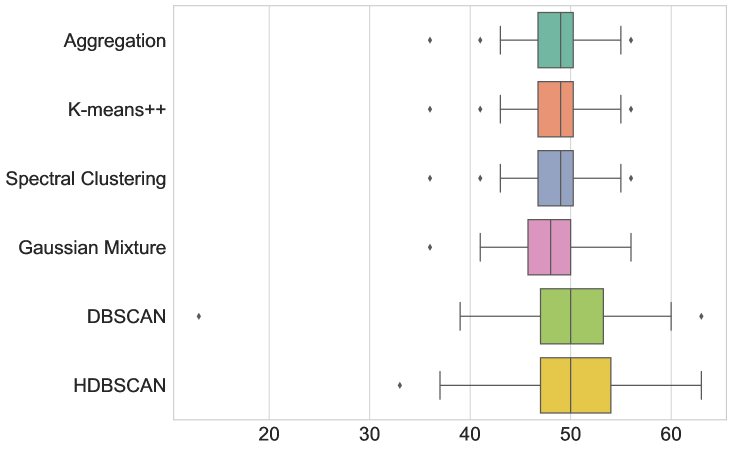
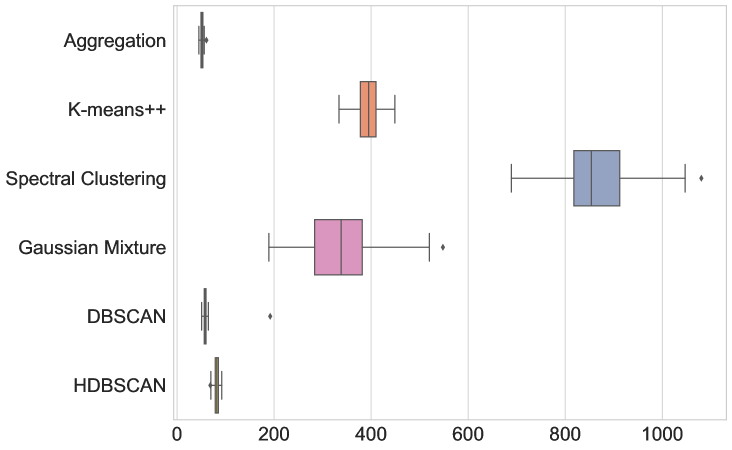
| Metric | Aggregation | K-means++ | Spectral clustering | GMM | DBSCAN | HDBSCAN |
|---|---|---|---|---|---|---|
| MSE | 2.480 | 1.394 | 5.313 | 7.079 | 13.027 | 11.943 |
| DTW | 77.448 | 54.208 | 124.034 | 144.755 | 200.429 | 196.246 |
| # Symbols | 48.550 | 48.550 | 48.550 | 47.660 | 49.640 | 50.170 |
| Runtime (ms) | 51.215 | 394.925 | 869.471 | 341.255 | 59.057 | 81.773 |
5 Numerical tests
In this section we evaluate and compare the performance of fABBA with the help of well-established metrics and performance profiles. The source code for reproducing our experiments is available on GitHub222https://github.com/nla-group/fABBA. All experiments were run on a compute server with two Intel Xeon Silver 4114 2.2G CPUs, a total of 20 cores, and 1.5 TB RAM. All code is executed in a single thread.
5.1 Comparison with k-means++
To further the findings in Section 4.3 we perform a direct comparison of Algorithm 1 with k-means++ [3] on a different dataset. We use the Shape sets, a dataset containing eight benchmarks corresponding to different shapes that are generally difficult to cluster. The benchmarks are referred to as (1) Aggregation, (2) Compound, (3) Pathbased, (4) Spiral, (5) D31, (6) R15, (7) Jain, and (8) Flame.
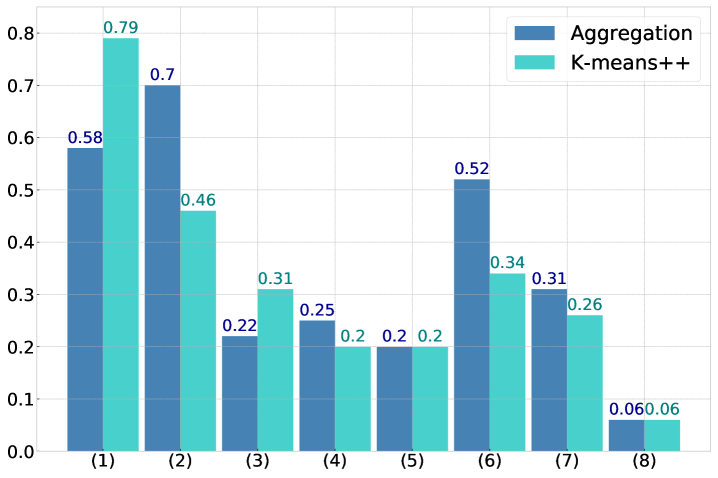
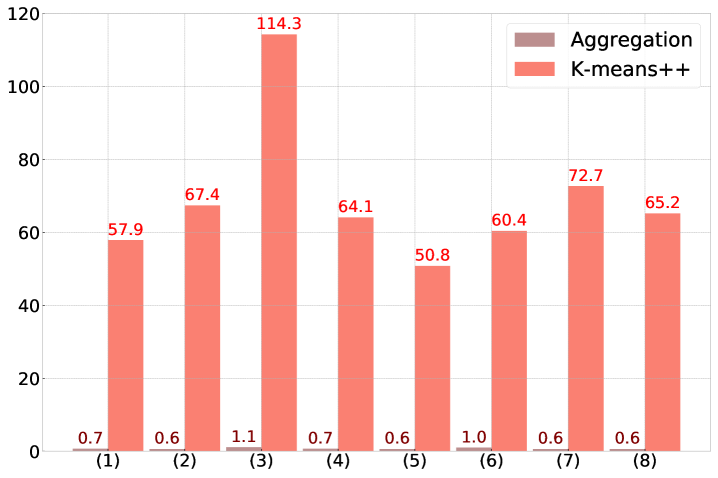
The test is conducted by first normalizing each dataset and then running Algorithm 1 using the tolerance . Afterwards k-means++ is run using the same number of clusters as determined by Algorithm 1. The number of data points in each benchmark and the number of (predicted) labels are listed in Table LABEL:table:clusteringbenchmark. Note that this comparison is not primarily about the accuracy of identifying clusters “correctly”. The grouping in Algorithm 1 is controlled by the parameter and the variance-based criterion (9), not by a criterion for cluster quality. Nevertheless, when comparing the adjusted Rand indices [24] of the obtained clusters in Figure 4 (a), Algorithm 1 is surprisingly competitive with k-means++: on four of the eight benchmarks Algorithm 1 outperforms k-means++ and on two other benchmarks the adjusted Rand indices are almost identical. The main take-away from this test, however, is that the runtime of Algorithm 1 with the same number of clusters is significantly reduced, by factors well above 50, in comparison to k-means++. See Figure 4 (b).
| ID | Dataset | # points | Labels | Alg. 1 groups | Reference |
|---|---|---|---|---|---|
| (1) | Aggregation | 788 | 7 | 6 | [22] |
| (2) | Compound | 399 | 6 | 8 | [52] |
| (3) | Pathbased | 300 | 3 | 8 | [10] |
| (4) | Spiral | 312 | 3 | 8 | [10] |
| (5) | D31 | 3100 | 31 | 7 | [47] |
| (6) | R15 | 600 | 15 | 8 | [47] |
| (7) | Jain | 373 | 2 | 6 | [25] |
| (8) | Flame | 240 | 2 | 8 | [21] |
5.2 Performance profiles
Performance profiles are an effective and widely used tool for evaluating the performance of a set of algorithms on a large set of test problems [14]. They can be used to compare quantities like runtime, number of function evaluations, number of iterations, or the memory used.
Let represent a set of problems and let be a set of algorithms. Let be a performance measurement of algorithm run on problem , assuming that a smaller value of is better. For any problem , let be the best performance of an algorithm on problem and define the performance ratio as
| (10) |
We set if solver fails on problem . We define
| (11) |
where . The performance profile of solver is
| (12) |
In other words, is the empirical probability that the performance ratio for solver and each problem is within a factor of the best possible ratio. The function is the cumulative distribution function of the performance ratio. Its graph, the performance profile, reveals several performance characteristics in a convenient way. In particular, solvers with fast increasing performance profile are preferable, provided the problem set is suitably large and representative of problems that are likely to occur in applications.
5.3 Reconstruction performance
We perform experiments running the SAX, 1d-SAX, ABBA, and fABBA methods on the 201,161 time series included in the UCR 2018 Archive [11]. All of the four methods fall in the class of numerical transforms, are based on piecewise polynomial approximation, and hence are rather easily comparable. Our selection of symbolic representations is guided by the public availability of Python implementations, e.g., within the tslearn library [46]. We follow the experimental design in [15, Section 6] to allow for a direct comparison. Each original time series is first processed by the fABBA compression with the initial tolerance , returning the number of pieces required to approximate to that accuracy. The compression rate is defined as
| (13) |
If the compression rate turns out to be larger than 0.2, we increase the tolerance tol in steps of 0.05 and rerun the fABBA compression until . If this cannot be achieved even with a tolerance of , we consider the time series as too noisy for symbolic compression and exclude it from the test. (In other words, if the compression is almost as long as the original time series, there is no point using any symbolic representation.) The numbers of time series finally included in the test are listed in Table 4.
| tol | 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | 0.30 | 0.35 | 0.40 | 0.45 | 0.50 |
|---|---|---|---|---|---|---|---|---|---|---|
| Num | 108,928 | 4,352 | 2,425 | 2,531 | 2,913 | 2,311 | 1,546 | 1,184 | 993 | 730 |
After the compression phase we run the fABBA digitization using 2-norm sorting with the scaling parameter , corresponding to unweighted 2d clustering. The digitization rate is
| (14) |
where is the number of symbols assigned by fABBA. This is then followed by running SAX, 1d-SAX, and ABBA () with the same number of pieces and symbols . Finally, we reconstruct the time series from their symbolic representations and measure the distance to the original time series in the Euclidean norm and DTW distance. We also measure the Euclidean and DTW distance of the differenced time series (effectively ignoring errors in representing linear trends).
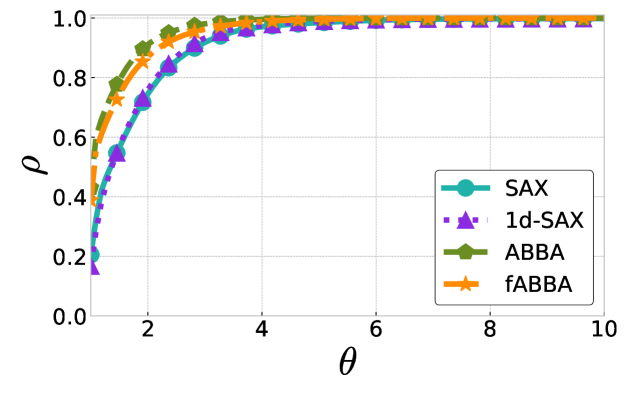
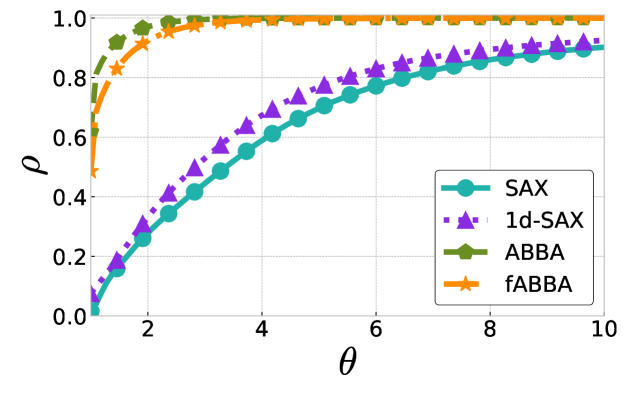
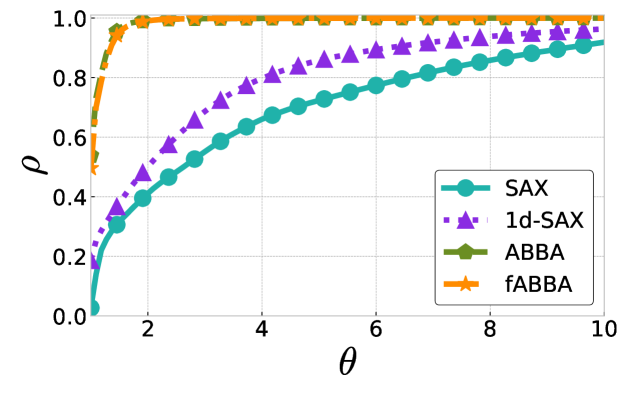
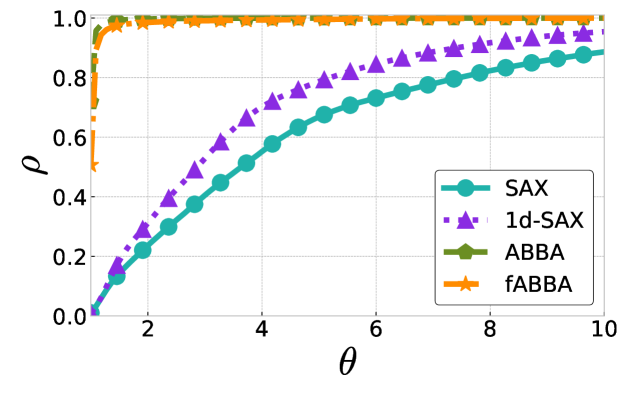
The performance profiles for the parameter choices and are shown in Figure 5 and Figure 6, respectively. The mean values of the compression rate for and 0.5 are approximately 0.896 and 0.615, respectively. The performance profiles reveal that ABBA and fABBA consistently achieve similar reconstruction accuracy in all four distance metrics and lead to significantly more accurate reconstructions than SAX and 1d-SAX. The only exception is with the Euclidean distance metric, in which case all four algorithms have similar reconstruction performance; see Figure 6(a).
For illustration, some examples of reconstructions for and are shown in Figure 7 and 8, respectively. The fABBA reconstruction closely follows that of ABBA and both representations capture the essential shape features of the time series.
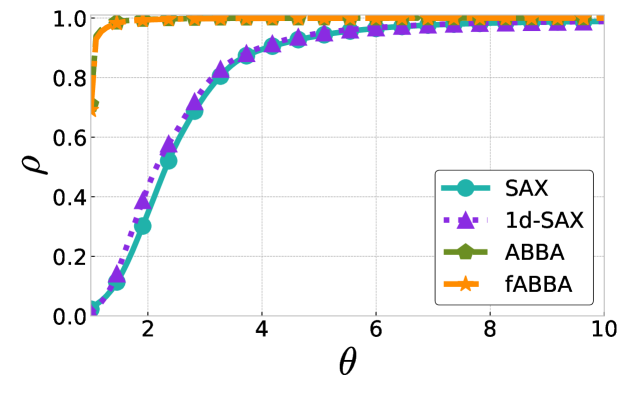
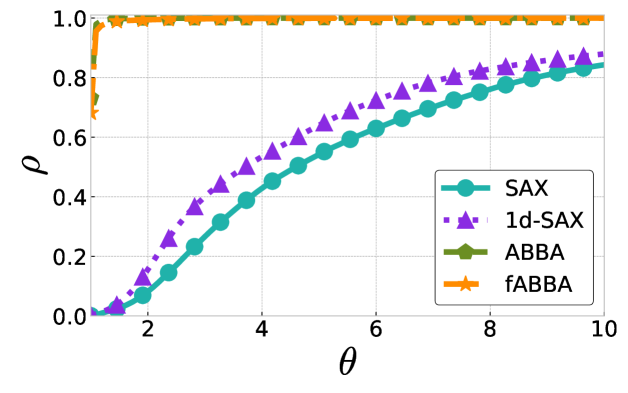
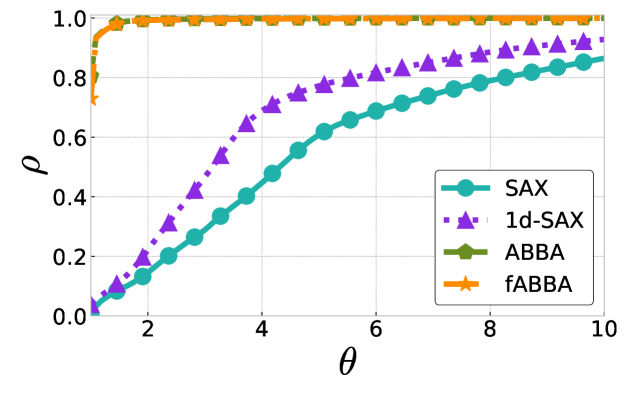
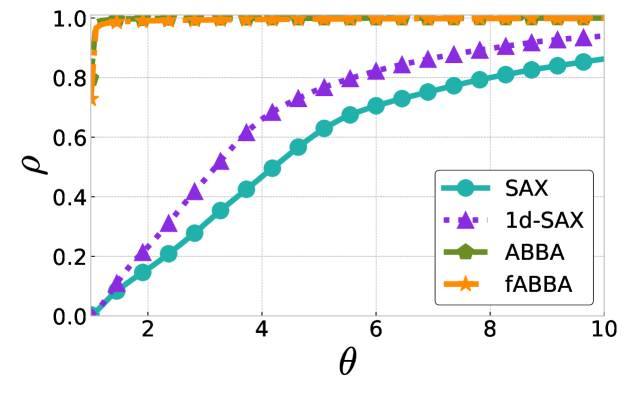
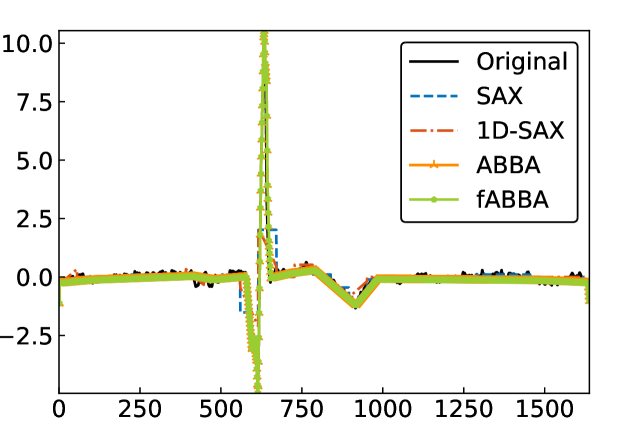
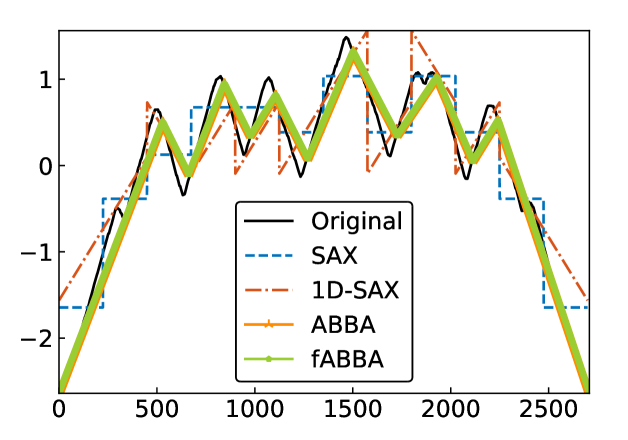
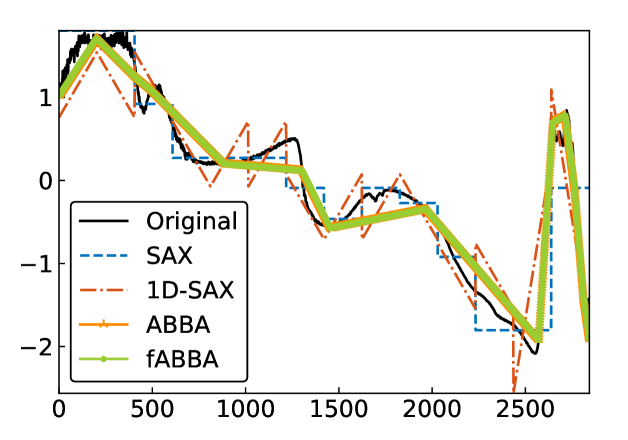
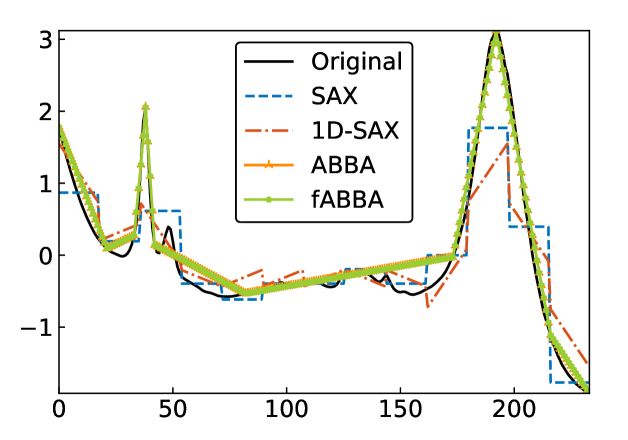
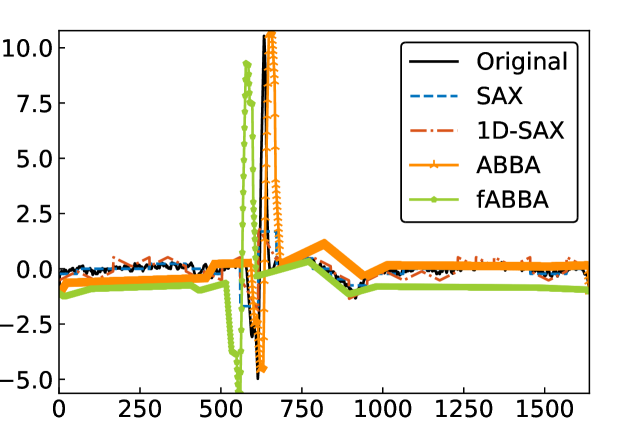
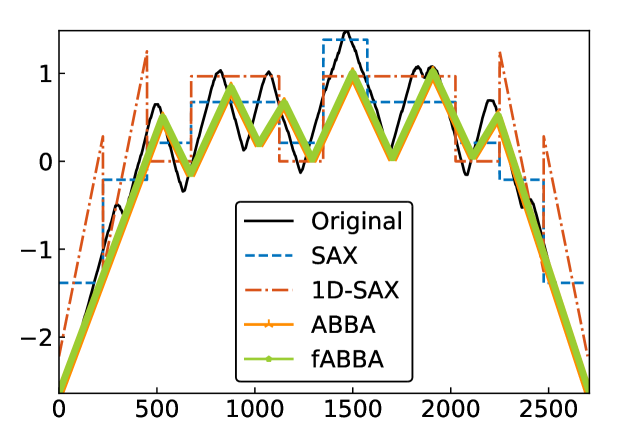
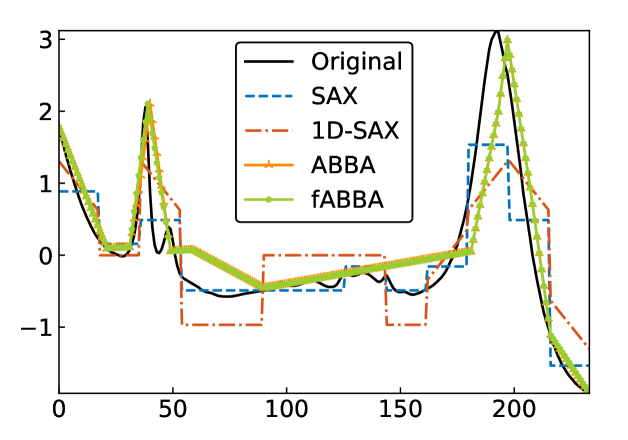
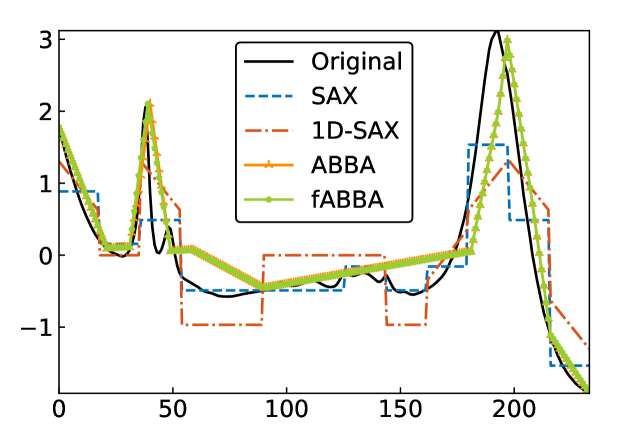
5.4 Runtime performance
In Figure 9 we compare the digitization runtime of fABBA and ABBA with 2-norm sorting and scaling parameter for all problems considered in the previous section. This is done using a histogram of the ratio
for each time series. We find that fABBA is always faster than ABBA and the speedup factor can be as large as with a mode of .
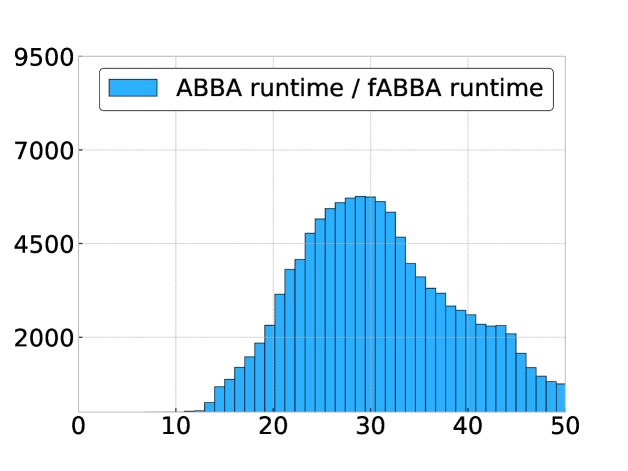
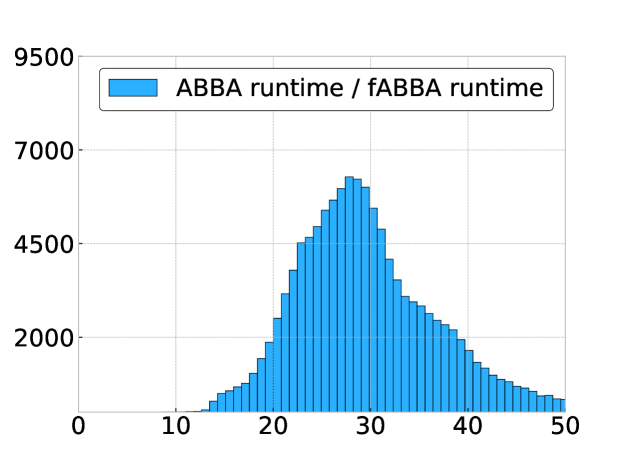
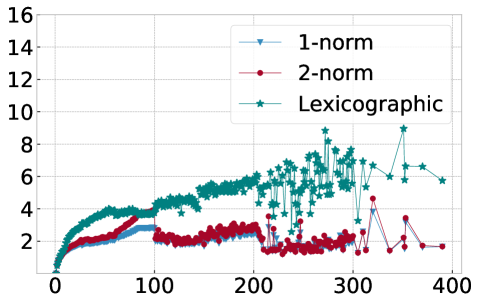
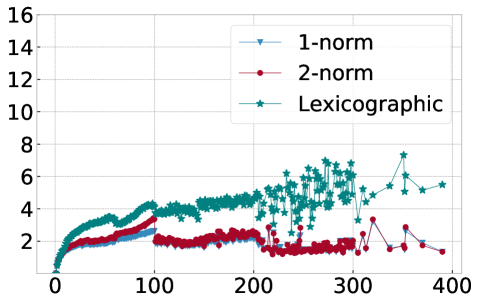
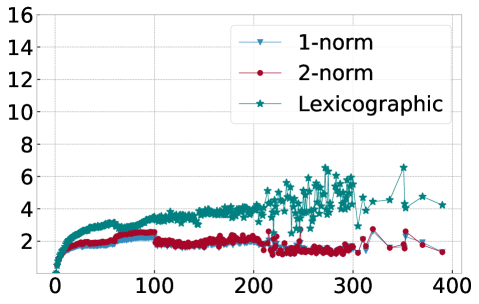
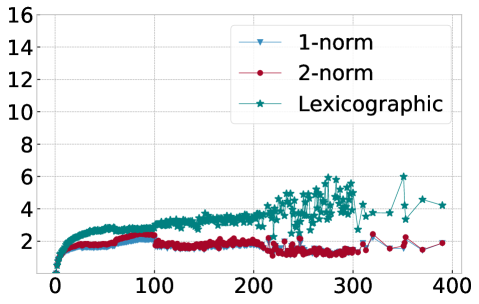
In order to explain this speedup from the viewpoint of Algorithm 1, we visualize in Figure 10 the average number of distance calculations depending on the number of pieces and when different sorting methods are used, namely lexicographic sorting and 1- and 2-norm sorting. We find that in particular for norm sorting, the number of average distance calculations can be as small as and it hardly ever exceeds . As a consequence, the computational cost of the aggregation is roughly linear in the number of pieces . With the number of pieces scaling linearly with the length of the original time series , the aggregation phase is of linear complexity in , and the overall complexity of Algorithm 1 is dominated by operations for the initial sorting.
5.5 Parameter study
We now perform a more exhaustive parameter study for fABBA in order to gain insights into its robustness with respect to the parameters. We consider three different initial sortings for Step 1 of Algorithm 1 and vary the parameter from . Table 5 displays the resulting average digitization rate , Euclidean (2-norm) and DTW distance between the reconstruction and the original time series, the total runtime for the digitization (in milliseconds), the number of distance calculations (denoted by dist), and the number of symbols used. We observe that when is increased, fewer symbols are used and the digitization is performed faster. On the other hand, and as expected, the reconstruction errors measured in the Euclidean and DTW distance become larger when is increased. Generally, there does not seem to be a significant difference in reconstruction accuracy for different norm sortings, but in view of distance calculations and runtime we recommend using 2-norm sorting as the default.
| 2-norm | DTW | Runtime (ms) | dist | # Symbols | |||
| Lexicographic sorting | 0.1 | 0.896 | 4.951 | 1.936 | 1.387 | 107.468 | 19.180 |
| 0.2 | 0.814 | 6.120 | 2.246 | 1.251 | 93.422 | 16.212 | |
| 0.3 | 0.740 | 7.584 | 2.712 | 1.144 | 85.810 | 13.887 | |
| 0.4 | 0.671 | 9.335 | 3.331 | 1.047 | 80.296 | 11.767 | |
| 0.5 | 0.615 | 11.107 | 4.063 | 0.976 | 70.762 | 10.246 | |
| 0.6 | 0.568 | 12.945 | 4.834 | 0.924 | 64.819 | 9.124 | |
| 0.7 | 0.528 | 14.808 | 5.625 | 0.881 | 60.609 | 8.205 | |
| 0.8 | 0.494 | 16.690 | 6.455 | 0.845 | 56.797 | 7.440 | |
| 0.9 | 0.463 | 18.547 | 7.341 | 0.814 | 53.241 | 6.806 | |
| 1-norm sorting | 0.1 | 0.896 | 4.945 | 1.935 | 1.479 | 45.485 | 19.214 |
| 0.2 | 0.815 | 6.143 | 2.256 | 1.336 | 50.729 | 16.279 | |
| 0.3 | 0.743 | 7.635 | 2.743 | 1.225 | 51.213 | 13.989 | |
| 0.4 | 0.676 | 9.374 | 3.362 | 1.128 | 48.072 | 11.967 | |
| 0.5 | 0.620 | 11.132 | 4.076 | 1.054 | 45.445 | 10.448 | |
| 0.6 | 0.572 | 13.023 | 4.884 | 0.996 | 43.271 | 9.281 | |
| 0.7 | 0.531 | 14.945 | 5.712 | 0.950 | 41.048 | 8.328 | |
| 0.8 | 0.495 | 16.911 | 6.633 | 0.911 | 38.915 | 7.531 | |
| 0.9 | 0.464 | 18.866 | 7.607 | 0.878 | 37.082 | 6.865 | |
| 2-norm sorting | 0.1 | 0.896 | 4.953 | 1.933 | 1.451 | 53.024 | 19.182 |
| 0.2 | 0.814 | 6.168 | 2.253 | 1.306 | 59.606 | 16.204 | |
| 0.3 | 0.740 | 7.693 | 2.747 | 1.192 | 59.985 | 13.864 | |
| 0.4 | 0.672 | 9.454 | 3.362 | 1.090 | 54.193 | 11.749 | |
| 0.5 | 0.615 | 11.289 | 4.120 | 1.015 | 50.184 | 10.226 | |
| 0.6 | 0.568 | 13.203 | 4.933 | 0.960 | 47.553 | 9.089 | |
| 0.7 | 0.527 | 15.145 | 5.769 | 0.914 | 44.832 | 8.154 | |
| 0.8 | 0.491 | 17.106 | 6.689 | 0.875 | 42.152 | 7.373 | |
| 0.9 | 0.460 | 19.039 | 7.640 | 0.843 | 39.983 | 6.722 |
5.6 Image compression
To demonstrate that fABBA can easily be applied to data not directly arising as time series, we discuss an application to image compression. This example also allows us to provide a different visual insight into fABBA’s reconstruction performance. Our approach is very simple: we select 12 images from the Stanford Dogs Dataset [13] and resize each image to pixels. We then reshape each RGB array into a univariate series (unfolded so that the values of the R channel come first, followed by the G and B channels) and then apply fABBA to compress this series. For the visualization of the reconstruction we simply reshape the reconstructed series into an RGB array of the original size. The results are presented in Figure 11 and Table LABEL:table:img_com, testing different compression tolerances tol while keeping the digitization tolerance fixed. We find that, even for the rather crude tolerance of , the essential features in each image are still recognizable despite the rather high compression rate (average ) and digitization rate (average ). This compressed lower-dimensional representation of images might be useful, e.g., for classification tasks, but this will be left for future work.




| Image ID | ||||||
|---|---|---|---|---|---|---|
| (1) | 0.085 | 0.132 | 0.222 | 0.061 | 0.518 | 0.020 |
| (2) | 0.032 | 0.405 | 0.050 | 0.306 | 0.147 | 0.135 |
| (3) | 0.219 | 0.042 | 0.295 | 0.031 | 0.364 | 0.024 |
| (4) | 0.701 | 0.012 | 0.808 | 0.009 | 0.897 | 0.006 |
| (5) | 0.333 | 0.048 | 0.410 | 0.038 | 0.533 | 0.026 |
| (6) | 0.315 | 0.041 | 0.385 | 0.034 | 0.548 | 0.021 |
| (7) | 0.443 | 0.013 | 0.468 | 0.011 | 0.493 | 0.009 |
| (8) | 0.037 | 0.519 | 0.103 | 0.232 | 0.329 | 0.061 |
| (9) | 0.065 | 0.316 | 0.170 | 0.129 | 0.424 | 0.039 |
| (10) | 0.283 | 0.081 | 0.444 | 0.040 | 0.685 | 0.016 |
| (11) | 0.089 | 0.081 | 0.113 | 0.079 | 0.157 | 0.072 |
| (12) | 0.306 | 0.058 | 0.381 | 0.046 | 0.539 | 0.028 |
| (13) | 0.032 | 0.658 | 0.053 | 0.451 | 0.153 | 0.157 |
| (14) | 0.037 | 0.250 | 0.222 | 0.053 | 0.397 | 0.025 |
| (15) | 0.295 | 0.035 | 0.373 | 0.032 | 0.473 | 0.025 |
| (16) | 0.034 | 0.482 | 0.084 | 0.219 | 0.392 | 0.031 |
| (17) | 0.014 | 0.828 | 0.038 | 0.473 | 0.204 | 0.113 |
| (18) | 0.133 | 0.108 | 0.197 | 0.082 | 0.342 | 0.046 |
| (19) | 0.403 | 0.023 | 0.445 | 0.022 | 0.557 | 0.022 |
| (20) | 0.072 | 0.192 | 0.093 | 0.164 | 0.147 | 0.128 |
| (21) | 0.006 | 0.876 | 0.008 | 0.789 | 0.019 | 0.456 |
| (22) | 0.170 | 0.088 | 0.233 | 0.071 | 0.397 | 0.037 |
| (23) | 0.128 | 0.101 | 0.216 | 0.074 | 0.534 | 0.025 |
| (24) | 0.181 | 0.056 | 0.208 | 0.047 | 0.257 | 0.038 |
| Average | 0.184 | 0.227 | 0.251 | 0.146 | 0.396 | 0.065 |
6 Discussion and future work
We have demonstrated that the fABBA method presented here achieves remarkable performance for the computation of symbolic time series representations. The fABBA representations are essentially as accurate as the ABBA representations, but the time needed for computing these representations is reduced by a significant factor (usually in the order of , sometimes as large as . The cause for this performance improvement lies in the small number of distance calculations that are required on average, the avoidance of the k-means algorithm, and the removal of the need to recompute clusterings for different values of .
In future work we aim to apply fABBA to other data mining tasks on time series like anomaly detection and motif discovery. In the context of time series forecasting, a combination of ABBA and LSTM has recently been demonstrated to reduce sensitivity to the LSTM hyperparameters and the initialization of random weights [16], and we believe that fABBA could simply replace ABBA in this context.
References
- [1] R. Agrawal, J. Gehrke, D. Gunopulos, and P. Raghavan. Automatic subspace clustering of high dimensional data for data mining applications. Proceedings of the ACM SIGMOD International Conference on Management of Data, 27:94–105, 1998.
- [2] S. Ahmad, A. Lavin, S. Purdy, and Z. Agha. Unsupervised real-time anomaly detection for streaming data. Neurocomputing, 262:134–147, 2017.
- [3] D. Arthur and S. Vassilvitskii. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, page 1027–1035, USA, 2007. SIAM.
- [4] I. Assent, M. Wichterich, R. Krieger, H. Kremer, and T. Seidl. Anticipatory DTW for efficient similarity search in time series databases. Proceedings of the VLDB Endowment, 2:826–837, 2009.
- [5] V. Bettaiah and H. S. Ranganath. An analysis of time series representation methods: Data mining applications perspective. In Proceedings of the 2014 ACM Southeast Regional Conference, pages 1–6, USA, 2014. ACM.
- [6] A. Bondu, M. Boullé, and A. Cornuéjols. Symbolic representation of time series: A hierarchical coclustering formalization. In Advanced Analysis and Learning on Temporal Data, pages 3–16, Cham, 2016. Springer.
- [7] R. P. Browne and P. D. McNicholas. A mixture of generalized hyperbolic distributions. Canadian Journal of Statistics, 43:176–198, 2015.
- [8] R. J. G. B. Campello, D. Moulavi, and J. Sander. Density-based clustering based on hierarchical density estimates. In Advances in Knowledge Discovery and Data Mining, pages 160–172, Berlin, Heidelberg, 2013. Springer.
- [9] K. Chakrabarti, E. Keogh, S. Mehrotra, and M. Pazzani. Locally adaptive dimensionality reduction for indexing large time series databases. ACM Transactions on Database Systems, 27:188–228, 2002.
- [10] H. Chang and D.-Y. Yeung. Robust path-based spectral clustering. Pattern Recognition, 41:191–203, 2008.
- [11] H. A. Dau, E. Keogh, K. Kamgar, C.-C. M. Yeh, Y. Zhu, S. Gharghabi, C. A. Ratanamahatana, Yanping, B. Hu, N. Begum, A. Bagnall, A. Mueen, G. Batista, and Hexagon-ML. The UCR time series classification archive, 2018. https://www.cs.ucr.edu/~eamonn/time_series_data_2018/.
- [12] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B, 39(1):1–38, 1977.
- [13] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, USA, 2009. IEEE.
- [14] E. D. Dolan and J. J. Moré. Benchmarking optimization software with performance profiles. Mathematical Programming, 91:201–213, 2002.
- [15] S. Elsworth and S. Güttel. ABBA: Adaptive Brownian bridge-based symbolic aggregation of time series. Data Mining and Knowledge Discovery, 34:1175–1200, 2020.
- [16] S. Elsworth and S. Güttel. Time series forecasting using LSTM networks: A symbolic approach. Technical report, arXiv:2003.05672, 2020.
- [17] P. Esling and C. Agon. Time-series data mining. ACM Computing Surveys, 45(1), 2012.
- [18] B. Esmael, A. Arnaout, R. K. Fruhwirth, and G. Thonhauser. Multivariate time series classification by combining trend-based and value-based approximations. In Computational Science and Its Applications – ICCSA 2012, pages 392–403, Berlin, Heidelberg, 2012. Springer.
- [19] M. Ester, H.-P. Kriegel, J. Sander, and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, pages 226–231, USA, 1996. AAAI Press.
- [20] S. Frühwirth-Schnatter and S. Pyne. Bayesian inference for finite mixtures of univariate and multivariate skew-normal and skew-t distributions. Biostatistics, 11(2):317–336, 2010.
- [21] L. Fu and E. Medico. FLAME, a novel fuzzy clustering method for the analysis of DNA microarray data. BMC Bioinformatics, 8:1–15, 2007.
- [22] A. Gionis, H. Mannila, and P. Tsaparas. Clustering aggregation. ACM Transactions on Knowledge Discovery from Data, 1:4–es, 2007.
- [23] A. Hinneburg and D. A. Keim. An efficient approach to clustering in large multimedia databases with noise. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, pages 58–65, USA, 1998. AAAI Press.
- [24] L. Hubert and P. Arabie. Comparing partitions. Journal of Classification, 2:193–218, 1985.
- [25] A. K. Jain and M. H. C. Law. Data clustering: A user’s dilemma. In Pattern Recognition and Machine Intelligence, pages 1–10, Berlin, Heidelberg, 2005. Springer.
- [26] E. Keogh, K. Chakrabarti, M. Pazzani, and S. Mehrotra. Dimensionality reduction for fast similarity search in large time series databases. Knowledge and Information Systems, 3:263–286, 2001.
- [27] E. J. Keogh and M. J. Pazzani. An enhanced representation of time series which allows fast and accurate classification, clustering and relevance feedback. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, pages 239–243, USA, 1998. AAAI Press.
- [28] A. Khosla, N. Jayadevaprakash, B. Yao, and L. Fei-Fei. Novel dataset for fine-grained image categorization. In First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition, USA, 2011. IEEE.
- [29] M. Kontaki and A. Papadopoulos. Efficient similarity search in streaming time sequences. In Proceedings of the 16th International Conference on Scientific and Statistical Database Management, pages 63–72, USA, 2004. IEEE.
- [30] F. Korn, H. V. Jagadish, and C. Faloutsos. Efficiently supporting ad hoc queries in large datasets of time sequences. In Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 289–300, USA, 1997. ACM.
- [31] G. Li, L. Zhang, and L. Yang. TSX: A novel symbolic representation for financial time series. In Proceedings of the 12th Pacific Rim International Conference on Trends in Artificial Intelligence, pages 262–273, Berlin, Heidelberg, 2012. Springer.
- [32] J. Lin, E. Keogh, S. Lonardi, and B. Chiu. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, pages 2–11, USA, 2003. ACM.
- [33] J. Lin, E. Keogh, L. Wei, and S. Lonardi. Experiencing SAX: A novel symbolic representation of time series. Data Mining and Knowledge Discovery, 15:107–144, 2007.
- [34] S. P. Lloyd. Least squares quantization in PCM. IEEE Transactions on Information Theory, 28:129–137, 1982.
- [35] S. Malinowski, T. Guyet, R. Quiniou, and R. Tavenard. 1d-SAX: A novel symbolic representation for time series. In Advances in Intelligent Data Analysis XII, pages 273–284, Berlin, Heidelberg, 2013. Springer.
- [36] L. McInnes and J. Healy. Accelerated hierarchical density based clustering. In International Conference on Data Mining Workshops, pages 33–42, USA, 2017. IEEE.
- [37] L. McInnes, J. Healy, and S. Astels. hdbscan: Hierarchical density based clustering. The Journal of Open Source Software, 2:205, 2017.
- [38] D. R. Musser. Introspective sorting and selection algorithms. Software: Practice and Experience, 27:983–993, 1997.
- [39] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- [40] N. D. Pham, Q. L. Le, and T. K. Dang. HOT aSAX: A novel adaptive symbolic representation for time series discords discovery. In Proceedings of the Second International Conference on Intelligent Information and Database Systems: Part I, pages 113–121, Berlin, Heidelberg, 2010. Springer.
- [41] P. J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20:53–65, 1987.
- [42] H. Ruan, X. Hu, J. Xiao, and G. Zhang. Trsax—an improved time series symbolic representation for classification. ISA Transactions, 100:387–395, 2020.
- [43] H. Sakoe and S. Chiba. Dynamic programming algorithm optimization for spoken word recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 26(1):43–49, 1978.
- [44] G. Sheikholeslami, S. Chatterjee, and A. Zhang. Wavecluster: A eavelet-based clustering approach for spatial data in very large databases. The VLDB Journal, 8:289–304, 2000.
- [45] J. Shieh and E. Keogh. iSAX: Indexing and mining terabyte sized time series. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 623–631, USA, 2008. ACM.
- [46] R. Tavenard, J. Faouzi, G. Vandewiele, F. Divo, G. Androz, C. Holtz, M. Payne, R. Yurchak, M. Rußwurm, K. Kolar, and E. Woods. Tslearn, a machine learning toolkit for time series data. Journal of Machine Learning Research, 21:1–6, 2020.
- [47] C. Veenman, M. Reinders, and E. Backer. A maximum variance cluster algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24:1273–1280, 2002.
- [48] W. Wang, J. Yang, and R. R. Muntz. Sting: A statistical information grid approach to spatial data mining. In Proceedings of the 23rd International Conference on Very Large Data Bases, pages 186–195, USA, 1997. Morgan Kaufmann Publishers Inc.
- [49] Y.-L. Wu, D. Agrawal, and A. El Abbadi. A comparison of DFT and DWT based similarity search in time-series databases. In Proceedings of the Ninth International Conference on Information and Knowledge Management, pages 488–495, USA, 2000. ACM.
- [50] S. X. Yu and J. Shi. Multiclass spectral clustering. In Proceedings of the Ninth IEEE International Conference on Computer Vision, volume 2, page 313, USA, 2003. IEEE.
- [51] Y. Yu, Y. Zhu, D. Wan, H. Liu, and Q. Zhao. A novel symbolic aggregate approximation for time series. In Proceedings of the 13th International Conference on Ubiquitous Information Management and Communication, pages 805–822, Berlin, Heidelberg, 2019. Springer.
- [52] C. Zahn. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Transactions on Computers, C-20:68–86, 1971.
- [53] C. T. Zan and H. Yamana. An improved symbolic aggregate approximation distance measure based on its statistical features. In Proceedings of the 18th International Conference on Information Integration and Web-Based Applications and Services, pages 72–80, USA, 2016. ACM.
- [54] T. Zhang, R. Ramakrishnan, and M. Livny. BIRCH: An efficient data clustering method for very large databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 103–114, USA, 1996. ACM.