An Elementary Method For Fast Modular Exponentiation With Factored Modulus
Abstract.
We present a fast algorithm for modular exponentiation when the factorization of the modulus is known. Let be positive integers and suppose factors canonically as . Choose integer parameters for . Then we can compute the modular exponentiation in steps (i.e., modular operations). We go on to analyze this algorithm mathematically and programmatically, showing significant asymptotic improvement in specific cases. Specifically, for an infinite family of we achieve a complexity of steps, much faster than the Repeated Squaring Algorithm, which has complexity . Additionally, we extend our algorithm to matrices and hence general linear recurrences. The complexity is similar; with the same setup we can exponentiate matrices in in less than steps. This improves Fiduccia’s algorithm and the results of Bostan and Mori in the case of . We prove analogous results for ring extensions.
1. Introduction
An important problem at the intersection of cryptography and number theory is the Modular Exponentiation Problem. This is the problem of computing for positive integers . It happens that solving for in the equation , called the Discrete Logarithm Problem (DLP), is computationally hard. This makes modular exponentiation useful in many cryptosystems, most notably the RSA public key cryptosystem and the Diffie-Hellman key exchange. The standard algorithm to solve the Modular Exponentiation Problem is the Repeated Squaring Algorithm, which runs in steps (in this paper, a step is a modular multiplication). To our knowledge, there are no existing significant asymptotic improvements to this algorithm.
In this paper, we present an efficient algorithm to solve the Modular Exponentiation Problem when the factorization of the modulus is known. Such a situation is potentially practically useful, as modular exponentiation is generally performed for encryption and thus the user has the freedom of choosing and knowings its factorization. In the 1984 paper [1], Bach proves the existence of a Hensel lifting type algorithm that can lift solutions to the discrete logarithm from modulo to modulo in polynomial time. One can intuit that in a similar way, there exists a speedup to modular exponentiation when the factorization of the modulus has some prime power in it; this is what our algorithm provides. The algorithm is quite elementary: it hinges on the binomial theorem and the clever recursive computation of inverses and binomial coefficients. It also depends on a set of parameters: If can be factored as , we choose for each an integer parameter . We then compute in steps (again, steps are modular multiplications). We additionally provide an memory algorithm for memory-sensitive scenarios, where we define memory to mean the memory of an integer modulo , or bits. For general we make asymptotic improvements as measured by specific metrics. For a certain infinite family of we achieve a complexity of . Furthermore, our algorithm profits from the development of other fast algorithms. For example, if one were to discover a faster modular exponentiation algorithm, we could use this as the modExp function in our algorithm. This, in turn, makes our algorithm faster than the default one.
In section 2 of this paper, we lay out some preliminary results that our algorithm and analysis require. In section 3, we present the algorithm with pseudocode. In section 4, we mathematically analyze our algorithm. Because its complexity depends on number-theoretic properties of , we require results from analytic number theory to estimate the “average” complexity. We discuss families of for which we make significant improvements. Then, in section 5, we present an version of our algorithm for matrices, linear recurrences, and ring extensions. Finally, in section 6, we test our algorithm for prime powers against Python’s built-in function to show our algorithm does practically. A Python implementation of the algorithm and programmatical analysis for it can be found at [2].
2. Preliminaries
The complexity of our algorithm depends on the number-theoretic properties of the modulus, so we will need multiple preliminary definitions to continue with this analysis. In general, we use the variable for a prime. We denote the canonical decomposition as . By convention, we let denote the least residue of modulo . We let denote the -adic valuation of , and we use this notation interchangeably with . We let be the Riemann Zeta Function and let denote Euler’s Totient Function. Additionally, we let denote Chebyshev’s Function. We must define the radical of an integer because this is intimately related to the optimal complexity that our algorithm may achieve:
Definition 2.1.
If , define the radical of as .
A useful notation that will assist our analysis is the following:
Definition 2.2.
Let , and define the multiset . We define , and set .
Our algorithm hinges on the following theorem, due to Euler:
Theorem 2.3.
(Euler) Let be relatively prime positive integers. Then .
Another result due to Euler which we need to use in our analysis is the Euler Product formula:
Theorem 2.4.
(Euler) Let be a multiplicative function, i.e., is true when . Then
In particular, we have the following Euler Product for :
To acquire precise asymptotics for specific sums, we need the following asymptotics:
Theorem 2.5.
(Stirling’s Approximation)
Theorem 2.6.
(Chebyshev)
To approximate average order summations, we will need Abel’s summation formula, referred to as partial summation:
Theorem 2.7.
(Abel) Let be a sequence of complex numbers. Define . Fix real numbers and let be a continuously differentiable function on . Then
We compare our algorithm to the standard repeated squaring method for modular exponentiation (there is no general asymptotic improvement to this method, as far as we know). We may compute in steps by this method. By Euler’s theorem, we can reduce this to which is considered .
For a ring , we let denote the general linear group over . We will need the well-known fact that . We will also need the following theorem due to Lagrange:
Theorem 2.8.
(Lagrange) Let be a group of order . Then for every , is the identity.
To compute the order of general linear groups over , we must first compute the order of . We do this with the following lemma:
Lemma 2.9.
For a prime and a we have
Proof.
We proceed by induction on , with trivial. Notice the natural ring homomorphism given by . This induces the surjection . Hence . Since there are choices for each entry of a matrix in the kernel of , the size of the kernel is , and we have the desired result. ∎
This allows us to prove the following important lemma:
Lemma 2.10.
If is the canonical factorization of some ,
Proof.
By the Chinese Remainder Theorem, we have the ring isomorphism
and thus there is a corresponding isomorphism
This implies the desired result by Lemma 2.9. ∎
Remark 2.11.
It follows from Lemma 2.10 that we may compute in steps, which is insignificant.
We use standard convention (from [3]) for the asymptotic notations , and . We use and rather unconventionally: provided there is a function such that for sufficiently large . We use a similar definition for .
3. The Algorithm
Our main theorem is the following:
Theorem 3.1.
Let be a positive integer with known factorization and let be positive integers such that . For each , choose an integer parameter . With , we may compute in
steps.
First, we need a definition that will simplify our calculation of modular inverses.
Definition 3.2.
For some and , define to be the inverse pair of modulo , where and . Define the inverse pair of as .
Example 1.
Let us compute the inverse pair of modulo as an example. We have . Then, . So the inverse pair of modulo is . Observe also that .
Notice that always exists because is clearly invertible modulo . Intuitively, inverse pairs are inverses equipped with an extra parameter that allows for computation of fractions with denominator not necessarily relatively prime to .
Consider the following lemma that allows for recursive computation of modular inverses.
Lemma 3.3.
If all of are invertible modulo ,
Proof.
Note . Working in ,
as desired. ∎
We now extend this result from a recursive computation of modular inverses to a recursive computation of inverse pairs.
Lemma 3.4.
We may linearly compute given the inverse pairs .
Proof.
We claim that the following formula holds:
Note that by definition, so that
Suppose , so that and are relatively prime. Decompose via the division algorithm. We wish to show that
Note that
so we wish to show that
which is obvious. There are no inversion issues as by the Euclidean Algorithm, and as . ∎
We are now equipped to prove Theorem 3.1. The algorithm is as follows.
Proof.
First, define and . Decompose with the division algorithm. Then,
Now, can be computed with the standard Repeated Squaring Algorithm. The complexity of this is . By the division algorithm, , so this is . For computation of the second term, first notice that by Euler’s theorem, so there exists some integer with . Now, we expand using the binomial theorem:
Let . Only the first terms need to be computed, as all the later terms are modulo . This is because for a prime ,
so for all , and thus and .
Additionally, we can linearly compute the terms with the identity
Notice that in our binomial recursion, the one inverse we need to calculate is the inverse of . Using Lemma 3.4, because we are performing a linear computation, we can compute the inverse pairs of through modulo in time and space. This is the only time we use more than memory in this algorithm. From here, we can use our identity to compute to in time and space. This is the final aspect of our calculation, and we may now recover . It is now clear that the number of steps is and the space complexity is . Because and
this concludes the proof of our main theorem. ∎
Example 2.
We present the details of the algorithm in the special case of , , , and (so ). Our goal is to compute . We let , so that
Notice that , so we let . Compute via the standard modExp algorithm. Now compute
by the Binomial Theorem. We can recursively compute the coefficients modulo by the method outlined above. Thus we may compute each term for . Finally, compute .
Example 3.
As a particular case, let us compute . Decompose . Compute . Write . Notice is an integer by Euler. Then
Therefore, .
Notice that this algorithm is space, which is not always ideal. For more memory-sensitive scenarios, we may compute inverses directly rather than recursively. This gives rise to the following theorem:
Theorem 3.5.
Let be a positive integer with known factorization and let be positive integers such that . For each , choose an integer parameter . With , we may compute in
steps and memory.
Proof.
Identical to Theorem 3.1, except instead of recursively computing inverse pairs, compute the modular inverses with standard inversion algorithms: . If, for example, we use the Extended Euclidean Algorithm then calculating the inverses of to has complexity We do not give pseudocode for this algorithm, instead see [2]. ∎
3.1. Pseudocode
Define to be the standard Repeated Squaring Algorithm for computing . We use the integer division notation . The pseudocode builds up to our algorithm, , , , , . Here and are positive integers, as usual. and are equal sized arrays, is an array of primes and is an array of positive integers. also has the same length as and , and is an array of non-negative integer parameters such that for all . We store the inverse pairs in a 2-dimensional array . This algorithm computes modulo .
4. Mathematical Analysis
It’s important to optimally choose the parameters . For general , the optimal choice is of the form for all . This is due to the following theorem:
Theorem 4.1.
In other words, for general we expect to be . The choice of is then clear. Let us proceed with some analysis of this choice.
By some metrics, we make asymptotic improvement to the standard repeated squaring methods with (i.e., ). But by other metrics, we may not. First, let us sweep the term under the rug (we can do so due to Theorem 4.1). If we just compute or , we get . However, the sum is not , and is not even for any .
Theorem 4.2.
For any , we have that
Proof.
By the simple estimate that for , we have that
Note that, by Stirling’s approximation,
and
Swapping the order of the summation, we may rewrite this sum as
Thus, applying Merten’s first theorem and Chebyshev’s asymptotics for , we have that
Therefore,
On the other hand, , so that
Therefore,
as desired. ∎
Theorem 4.3.
For any and , we have that
Proof.
Notice that is multiplicative, and for prime and . Therefore, the Dirichlet Series of is
This expression simplifies to
Thus
by the Euler product for . Sending on the real axis, the product tends to infinity. Because , . Let and suppose for the sake of contradiction that . For we have that, by partial summation,
Note that because the first term on the RHS vanishes. Thus is on the order of
To arrive at the desired contradiction, we must show that this integral is . In order to do this, we induct on (we may assume is an integer). For , the result is obvious. For higher , we may integrate by parts. Set and . Then
which implies the result by the induction hypothesis, as both terms are . ∎
In fact, there is a more precise estimate than Theorem 4.3.
Theorem 4.4.
[5] For any we have that
By the metric given by Theorem 4.2, we make an improvement “on average” to the repeated squaring method. However, by Theorem 4.3, we “expect” (very loosely), so that we “expect”
. By this metric, we do make asymptotic improvement to the repeated squaring method.
Nonetheless, it is particularly fruitful to work with smooth rather than general . We have the following corollary of Theorem 3.1:
Corollary 4.5.
Let be a positive integer with known factorization such that all primes have the same bit length as an integer , and all are such that . Let be positive integers such that . We may then compute in steps.
Proof.
The idea is to use Theorem 3.1 and set for some , and choose such that for all . In other words, take , for example. Then , and
Notice that
so we may choose on the order of (as is necessary and sufficient). With this choice, we compute in
steps. Note that
so that our modular exponentiation can be completed in steps. ∎
Remark 4.6.
This shows that in general it is best to choose all as . When faced with the problem of optimizing these parameters, we can hence choose a relatively strong upper bound. On the other hand, it seems very difficult to compute the exactly optimal multiset . Note that this is important because a smart choice of can make for a big performance boost (see Figure 3). If one could better understand the constant factors at play, then, modifying the above calculations, they could theoretically find the optimal choice of .
In other words, when has large exponents relative to its prime factors, our algorithm makes large improvements (as in the case where the exponents are on the order of ). In particular, our algorithm does well for prime powers. We have the following cororollary:
Cororollary 4.7.
Let where . Let be positive integers such that . We may then compute in steps.
Proof.
This trivially follows from Corollary 4.5 with . ∎
This is quite impressive as, if we pick on the order of , we may modular exponentiate modulo in the same number of steps (asymptotically) as modulo . Furthermore, because each operation (modular multiplication or addition) can be taken to be , we have the following result:
Corollary 4.8.
Let the modulus be a positive integer with known factorization such that all primes have the same bit length as an integer , and all are such that . If the standard modular exponentiation algorithm takes time, our algorithm for the same values takes time, for some constant and given unit of time.
Proof.
For convenience, denote simply as . The standard algorithm takes steps and hence time. Our algorithm takes steps and hence time. Then, if is the time it takes our algorithm to run and is the time for the standard algorithm to run, we have for some constants that
Hence , so we obtain the desired result by taking the appropriate . ∎
Remark 4.9.
One may think that for such smooth , a CRT-type approach may also be fast. However, it is well-known (see e.g. [6]) that CRT is , where the moduli have bit length . Hence this is a non-issue.
5. General Modular Exponentiation
We may extend the ideas of our method to prove a more general theorem about matrix modular exponentiation, which translates over to linear recurrences. In this section, a step is a matrix multiplication.
Theorem 5.1.
Let be the canonical factorization of some . Choose parameters for each . Let . Let and . Then we may compute in steps.
Proof.
Remark 5.2.
A near-identical result holds for the special linear group instead. This is less practically useful but still important to note.
This asymptotic may be slightly difficult to work with, but a trivial corollary is the following:
Corollary 5.3.
Let be the canonical factorization of some . Choose parameters for each . Let . Let and . Then we may compute in steps.
Proof.
This follows from Theorem 5.1 and the obvious estimate . Indeed, the double sum is upper-bounded by and so the result follows. ∎
Remark 5.4.
With , we get Theorem 3.1 for prime powers. Also, this shows we can modular exponentiate matrices of size in the same complexity as natural numbers.
Another corollary is that we may quickly compute the residue of large elements of a linear recurrent sequence modulo prime powers:
Corollary 5.5.
Let be the canonical factorization of some . Choose parameters for each . Let be a sequence of elements of related with a linear recurrence relation of degree :
Suppose that . Given sufficient initial terms, we may compute any element in steps.
Proof.
Linear recurrence relations of order can be represented as matrix powers. In particular, the respective matrices are in , so the result follows immediately by Theorem 5.1. One must make sure that the matrix produced has determinant invertible in (and hence in ). This determinant has magnitude , so we require . This condition is met, so we are done. ∎
Remark 5.6.
This shows that we may compute the th Fibonacci number modulo in the same number of steps as we perform a modular exponentiation modulo . For example, modulo we may do it in steps.
Fiduccia [7] and, more recently, Bostan and Mori [8] provide the state-of-the-art results for this problem in the case of a sequences over a general ring. The amount of steps taken is on the order of , where is the number of operations to multiply two polynomials in the ring. We achieve a stronger bound for the case where the ring is . Our bound does not depend on because of the reduction we make modulo . In order to reduce in the same manner modulo for the bounds given by Fiduccia and by Bostan and Mori, the best possible reduction is by . By Lemma 2.10, . If is the exponent for matrix multiplication, we take under steps of the same complexity as the steps taken by Fiduccia. Therefore Fiduccia’s algorithm is better as a function of , but we are better as a function of . It is often the case that , so we make significant improvement. Indeed, the key optimization that Fiduccia makes (involving the characteristic polynomial) only affects the complexity as a function of .
We can also apply our algorithm to ring extensions:
Theorem 5.7.
Let be a prime and and be natural numbers. Consider a finite ring extension . Consider the corresponding field extension . We can exponentiate in in steps, where each step is an operation in .
Proof.
A nice example of this theorem is that we provide fast modular exponentiation for Gaussian Integers modulo prime powers! This case is also related to Theorem 5.1 due to the bijection .
6. Programmatical Analysis
In this section, we test only integer modular exponentiation of our algorithm, as we prove that the generalizations have similar complexities.
Let us begin by testing our algorithm for . We will test against Python’s built-in function. We will iterate over primes , and choose randomly in a small interval around . In particular, we choose uniformly at random in the interval . We choose randomly (such that ) as well. We choose randomly in the interval . We choose for simplicity. We then compare the runtime for computation of via our method () and Python’s built-in function () over iterations.
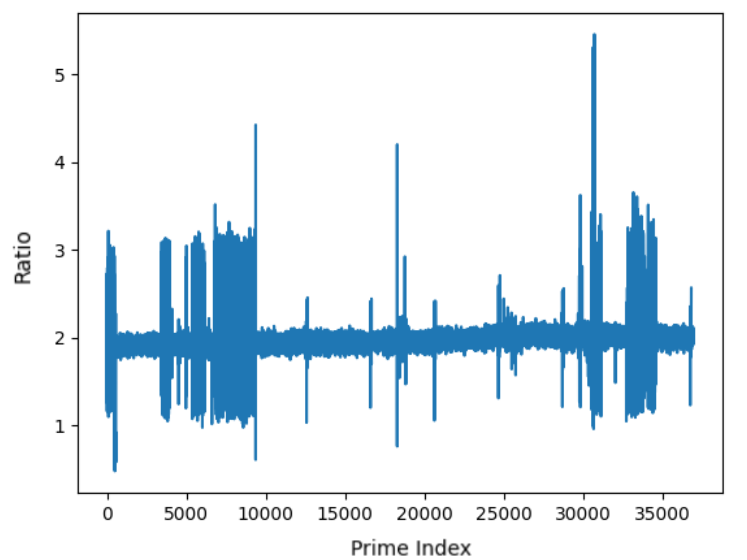
In Figure 1 we iterate over , plotting versus the respective ratio .
In Figure 2 we iterate over , plotting versus the respective ratio .
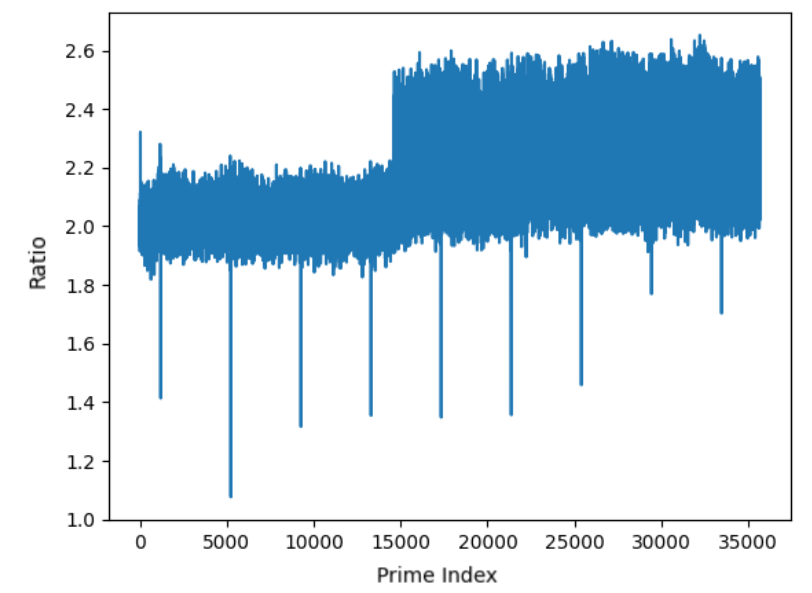
As seen in the figures, there is a high variance in the ratio over small primes, whereas it steadies out for larger primes. The large jump in the second figure at about is likely because Python has different optimizations for smaller calls of the function. We still do not have an explanation for the random jumps in data. Nonetheless, a basic implementation of our algorithm makes significant improvements to the highly optimized function.
The below figure shows how the problem of optimizing is important.
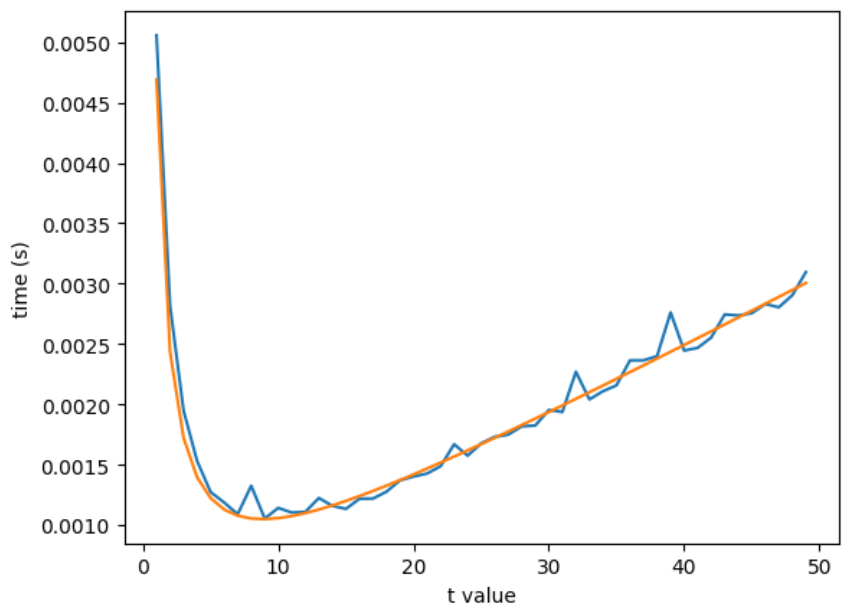
For a specific choice of computing with and (chosen arbitrarily), we vary the choice of over the set . We plot this against the runtime for computation to create the blue curve. As seen in the figure, the optimal value of yields a time approximately times faster than . The orange curve demonstrates how the graph follows a curve of the form , as indicated by Corollary 4.5. The value is .
Recall that we achieve a complexity of for an infinite family of , by Corollary 4.5. We aim to show this empirically. Because the complexity of the repeated squaring algorithm is , if we graph the ratio of the runtime of python’s built-in modular exponentiation function to ours, we expect to see . With and , we anticipate a graph of the form .
The setup is as follows. Let be the first prime greater than . For we let and . Pick for simplicity. Then, is in the desired family. For each , we compute the ratio and plot it against .
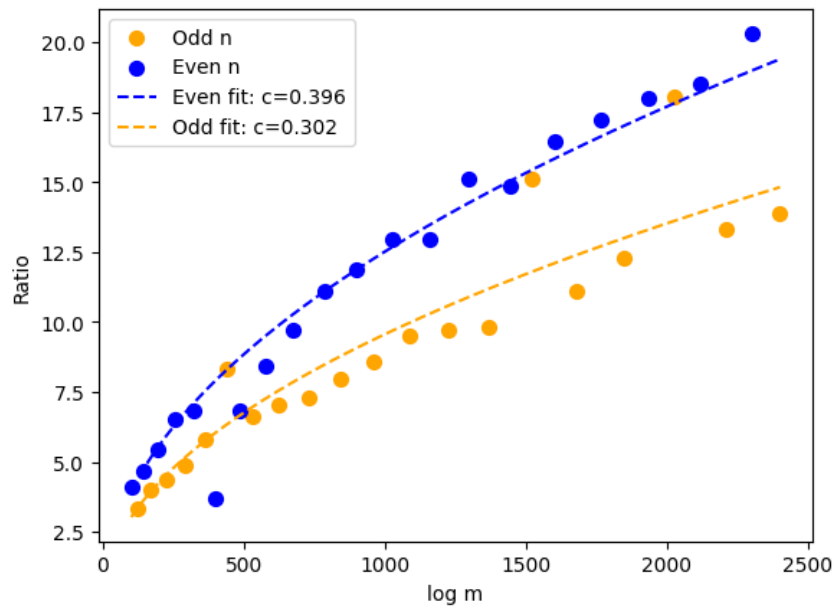
The desired curve appears. Interestingly, the ratio for even is on average percent higher than for odd . The curves fit quite well: the values for even and odd are and percent respectively.
One might notice three values of odd appear to fit on the curve for even . Those values are , , and . We do not know why this phenomenon occurs or why the ratio is higher in general for even .
Remark 6.1.
In Python, we have achieved computation time more than times faster than the built-in for specific large values of .
See [2] for the Python code used to create these graphs.
7. Conclusion
We presented a fast algorithm for modular exponentiation when the modulus is known. We also presented a variant of this algorithm which uses less memory. We analyzed this algorithm in the general case, then shifted our focus to the specific case where the modulus has large prime exponents. We showed particular interest in the case where the modulus is a prime power, and we analyzed this case programmatically, testing it against Python’s built-in function. We also presented a stronger version of our algorithm for matrix modular exponentiation, which applies to the computation of large terms in linear recurrent sequences modulo some .
This algorithm has potential practical use in cryptography. Fast modular exponentiation is vital in the fast encryption of classic algorithms such as RSA and the Diffie-Hellman Key Exchange. It is even used in quantum algorithms: modular exponentiation is the bottleneck of Shor’s algorithm. If one could construct a cryptosystem in which it is useful to have a known modulus with large prime exponents, our algorithm would be applicable to its encryption process. For example, a variant of Takagi’s cryptosystem [9] with larger exponents has such properties. Additionally, work has been done on using matrix exponentiation and linear recurrences for error-correcting codes. For example, Matsui’s 2012 paper [10] uses linear sequences for a decoding algorithm. It is quite possible that our algorithm is potentially useful for such an algorithm.
There are a couple of things that we wish to do with this work going forward. We’d like to find a framework for programmatically testing general moduli (not only prime powers). Additionally, we hope to to make further progress on the front of optimizing in practice. Furthermore, we want to come up with explanations for some of the phenomena that we see in the figures in section 5. Finally, we aim to implement further optimizations to our algorithm such as Montgomery Reduction.
8. Acknowledgments
We thank Dr. Simon Rubinstein-Salzedo for the useful discussion we had during the creation of this paper. We also thank Eva Goedhart and Nandita Sahajpal for awarding us the Lehmer Prize for this work at the 2023 West Coast Number Theory conference. We finally thank Dr. John Gorman from Jesuit High School Portland for inspiring this paper.
References
- [1] Eric Bach. Discrete Logarithms and Factoring. (UCB/CSD-84-186), Jun 1984.
- [2] Manu Isaacs and Anay Aggarwal. Algorithm for Fast Modular Exponentiation. https://github.com/misaacs3737/modExp/, 2023. Accessed: January 17, 2024.
- [3] Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms. Addison-Wesley, Reading, Mass., third edition, 1997.
- [4] Ivan Niven. Averages of Exponents in Factoring Integers. Proceedings of the American Mathematical Society, 22(2):356–360, 1969.
- [5] Olivier Robert and Gérald Tenenbaum. Sur la répartition du noyau d’un entier. Indagationes Mathematicae, 24(4):802–914, 2013. In memory of N.G. (Dick) de Bruijn (1918–2012).
- [6] Joris van der Hoeven. Fast Chinese Remaindering in Practice. In International Conference on Mathematical Aspects of Computer and Information Sciences, 2017.
- [7] Charles M. Fiduccia. An Efficient Formula for Linear Recurrences. SIAM Journal on Computing, 14(1):106–112, 1985.
- [8] Alin Bostan and Ryuhei Mori. A Simple and Fast Algorithm for Computing the -th Term of a Linearly Recurrent Sequence, 2020.
- [9] Tsuyoshi Takagi. Fast RSA-type cryptosystem modulo . In Advances in Cryptology—CRYPTO’98: 18th Annual International Cryptology Conference Santa Barbara, California, USA August 23–27, 1998 Proceedings 18, pages 318–326. Springer, 1998.
- [10] Hajime Matsui. Decoding a Class of Affine Variety Codes with Fast DFT, 2012.