An empirical approach to model selection: weak lensing and intrinsic alignments
Abstract
In cosmology, we routinely choose between models to describe our data, and can incur biases due to insufficient models or lose constraining power with overly complex models. In this paper we propose an empirical approach to model selection that explicitly balances parameter bias against model complexity. Our method uses synthetic data to calibrate the relation between bias and the difference between models. This allows us to interpret values obtained from real data (even if catalogues are blinded) and choose a model accordingly. We apply our method to the problem of intrinsic alignments – one of the most significant weak lensing systematics, and a major contributor to the error budget in modern lensing surveys. Specifically, we consider the example of the Dark Energy Survey Year 3 (DES Y3), and compare the commonly used nonlinear alignment (NLA) and tidal alignment & tidal torque (TATT) models. The models are calibrated against bias in the plane. Once noise is accounted for, we find that it is possible to set a threshold that guarantees an analysis using NLA is unbiased at some specified level and confidence level. By contrast, we find that theoretically defined thresholds (based on, e.g., values for ) tend to be overly optimistic, and do not reliably rule out cosmological biases up to . Considering the real DES Y3 cosmic shear results, based on the reported difference in from NLA and TATT analyses, we find a roughly chance that were NLA to be the fiducial model, the results would be biased (in the plane) by more than . More broadly, the method we propose here is simple and general, and requires a relatively low level of resources. We foresee applications to future analyses as a model selection tool in many contexts.
keywords:
methods: statistical – cosmology: observations – cosmological parameters – gravitational lensing: weak1 Introduction
Modern cosmology is an increasingly high-dimensional problem. Although the standard cosmological model itself is relatively simple, containing only five or six free parameters, it cannot, in general, be constrained in isolation. One must rely on measurements on real data, which can contain any number of additional features resulting from non-cosmological processes. It is necessary to include models for such systematics in any cosmological inference, and to marginalise over their parameters. Contemporary weak lensing analyses (see, e.g., Heymans et al. 2013; Dark Energy Survey Collaboration 2016; Jee et al. 2016; Hildebrandt et al. 2017; Troxel et al. 2018; Hikage et al. 2019; Hamana et al. 2020; Asgari et al. 2021; Loureiro et al. 2022; Amon et al. 2022; Secco, Samuroff et al. 2022; Doux et al. 2022) typically have around free parameters, the majority of which are related to measurement uncertainties. This picture is unlikely to change in the coming years. Indeed, as we move into the era of Stage IV surveys (Ivezić et al. 2019; Spergel et al. 2015; Laureijs et al. 2011), the unprecedented statistical power of these new data sets carries an increasing sensitivity to systematics.
Some systematic uncertainties can be modelled pretty accurately given our prior knowledge of their nature; for instance PSF modelling error (Jarvis et al., 2021) and shear measurement biases (Heymans et al., 2006; Bridle et al., 2010; Mandelbaum et al., 2015). In most cases, however, there is a relative lack of prior knowledge about the magnitude and/or scale dependence of the effects being modelled. Some examples include the impact of baryonic feedback (Osato et al., 2015; Chen et al., 2022; Tröster et al., 2022), nonlinear structure formation (and the impact of neutrinos on it; Saito et al. 2008; Bird et al. 2012; Mead et al. 2021; Knabenhans et al. 2021) and galaxy bias (Desjacques et al., 2018; Simon & Hilbert, 2018; Pandey et al., 2020). Here, there is clearly an argument for using the most sophisticated (physically motivated) model available. This is the safest way to avoid bias due to model insufficiency. That said, extra free parameters do potentially carry a cost in terms of constraining power. They can also worsen projection effects, which complicate the interpretation of projected parameter constraints (see Joachimi et al. 2021a; Krause et al. 2021). The ideal approach, then, would be to select a model that balances the two: complex enough to avoid bias, but not more complex than is needed to describe the data.
Model selection methods are widely used in cosmology, often seeking to answer the question of whether introducing new parameters to cosmological models is justified by the data. Some of the most common tools for this are tests, the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), the Deviance Information Criterion (DIC) and Bayes ratios (see e.g. Liddle et al. 2006a; Liddle 2007; Trotta 2007, 2008; Kerscher & Weller 2019). A characteristic of how all these statistics have been used is that they are interpreted using threshold statistical values, derived in terms of the theoretical properties of the model, e.g. the Jeffreys scale for Bayes ratios. They have also been most commonly applied to compare how well cosmological models fit the data post-analysis, rather than actively being used to select elements of the analysis in the blinded stages. By contrast, the process for choosing the fiducial model for an analysis typically does not make use of model comparison statistics at all. Rather, we tend to rely on generating and analysing simulations (either analytic or numerical) containing various forms of unmodelled systematics (e.g., Krause et al. 2017, 2021; Joachimi et al. 2021a). This approach works, but does heavily depend on the ability to create realistic mocks. It is also important to notice that any model selection method will typically have a number of subjective choices built into them, e.g., whether to compare data vectors or perform likelihood inference, and what cutoff to use for decision-making. This is also true, to an extent, for the method we will present in this paper. That said, our method has the feature that the decision-making happens in well-defined places and has a well-defined interpretation connected to parameter biases (e.g. selecting a tolerable bias level and a confidence interval), as we will see in the following sections.
One of the most significant sources of systematic uncertainty in weak lensing is an effect known as intrinsic alignment (IA; Troxel & Ishak 2015; Joachimi et al. 2015; Kirk et al. 2015; Kiessling et al. 2015). IAs are coherent galaxy shape alignments that are not purely due to lensing, but rather to the interactions with the local and large-scale gravitational field. Although in essence an astrophysical effect, IA correlations appear on much the same angular scales as cosmological ones, and it can be very difficult to disentangle the two. They are not universal, in the sense that they depend significantly on the particular galaxy sample (colour, luminosity, satellite fraction and redshift distribution; e.g. Johnston et al. 2019), and also the details of the shape measurement (Singh & Mandelbaum, 2016). To add to the problem, unlike, for example, photometric redshift error or shear bias, one cannot easily derive tight priors on IAs using simulations or external data. Some physically-motivated IA models that have been developed in the last two decades include the linear alignment (LA) model (Catelan et al., 2001; Hirata & Seljak, 2004, 2010) which, as the name suggests, assumes a linear relationship between galaxy shapes and the local tidal field; an empirical modification of this, known as the nonlinear alignment model (NLA; Hirata et al. 2007; Bridle & King 2007), which is now one of the most common IA models in contemporary weak lensing; and in recent years, the tidal alignment and tidal torquing model (TATT; Blazek et al. 2015; Blazek et al. 2019), which has provided a slightly more complex alternative to NLA. Based on perturbation theory, TATT includes additional terms that are quadratic in the tidal field, intended to encapsulate the processes driving IAs in spiral galaxies, and also additional terms that are designed to enable better IA modelling on smaller (but still 2-halo) scales.
In this paper we propose a new model selection method, which uses the real data. The general idea is to run two competing models on the blinded data, and compare them using statistical metrics. Here we explore two convenient metrics: the difference in the best per degree of freedom, , and the Bayes ratio . We show that, for the method we are proposing, is a very useful metric to perform model selection ( is less so, for reasons discussed in Section 5.2 and Appendix C). To allow us to interpret the , we use simulated data to calibrate its relation to biases in parameter space due to model insufficiency. It is this process, of running a set of simulations and measuring parameter bias as a function of observable metrics that we refer to as “calibrating the bias-metric relation" in the following sections. The full details on how to perform this calibration are outlined in Section 4. This approach can, in principle, be applied to any type of data and/or systematics. However, in what follows, we apply it the specific scenario of choosing an intrinsic alignment model for a cosmic shear analysis.
The paper is structured as follows: we describe the theoretical modelling of the cosmic shear two-point data vector in Section 2. In Section 3 we describe how the synthetic cosmic shear data is generated, including the choice of IA scenarios. The ingredients and steps for the model selection method are described in Section 4. Our results when applying our method to the problem of IAs in the Dark Energy Survey Year 3 (DES Y3) are presented in Section 5. Finally, in Section 6 we summarise our findings and their significance in the context of the field.
2 Theory & Modelling
We carry out our analysis in the context of the flat CDM cosmological model. The cosmological parameters are , where is the density parameter for matter, and the equivalent for baryons; is the dimensionless Hubble constant; and are the amplitude and slope of the primordial curvature power spectrum at a scale of Mpc-1 respectively; and is the neutrino mass density parameter. We assume three degenerate massive neutrino species, following Krause et al. (2021). We discuss the nuisance parameters of our analysis in the following sections. Prior choices are further described in Appendix A.
2.1 Modelling Cosmic Shear
The impact of gravitational lensing along a particular line of sight is determined by two quantities, known as convergence and shear. The convergence term of the weak lensing transformation describes how much a galaxy on a particular line of sight is distorted due to intervening large scale structure. It is defined as the weighted mass overdensity , integrated along the line of sight to the distance of the source :
| (1) |
where is the angular position at which the source is observed. The kernel , defined in Eq. (5), is sensitive to the relative distances of the source and the lens. It is this geometrical term that makes cosmic shear sensitive to the expansion history of the Universe.
The two-point cosmic shear correlations are obtained by decomposing into - and -mode components (Crittenden et al., 2002; Schneider et al., 2002). For two redshift bins and , they can be written in terms of the convergence power spectrum at an angular wavenumber as
| (2) | ||||
| (3) |
where the functions are calculated from Legendre polynomials and averaged over angular bins (see Eqs. 19 and 20 in Krause et al. 2021).
Assuming the Limber approximation (Limber, 1953; LoVerde & Afshordi, 2008), the 2D convergence power spectrum is related to the 3D matter power spectrum as:
| (4) |
where is the nonlinear matter power spectrum and the lensing weight is:
| (5) |
with the source galaxy redshift distribution normalised to integrate to 1, and the horizon distance. We follow Krause et al. (2021), and model using a combination of CAMB (Lewis et al., 2000) for the linear part, and HaloFit (Takahashi et al., 2012) for nonlinear modifications. In theory, the power spectra of convergence, , and cosmological shear, , are the same, and can be modelled fairly simply as described in Eq. (4). In practice, however, measurements are sensitive not only to the pure cosmological shear, but also to additional correlations due to, e.g., intrinsic alignments. In the presence of IAs, the convergence spectra in Eqs. (2) and (3) are replaced by , the calculation of which we come to in Section 2.2.
2.2 Modelling Intrinsic Alignments
In general terms, the impact of intrinsic alignments (IAs) can be thought of as adding a coherent additional component to each galaxy’s shape. That is, the observed ellipticity is , or the sum of a shear due to cosmological lensing, an IA-induced shear, and a random shape noise component. Although the latter is typically dominant for any single galaxy, it cancels when the ellipticity is averaged across a large population of galaxies. At the level of angular correlation functions, one has:
| (6) |
The first term, , is the auto-correlation of cosmological lensing, and is defined in Eq. (4). The intrinsic-intrinsic contribution is referred to as the II term, and arises from galaxies that are spatially close to one another. The intrinsic-shear cross-correlation is known as the GI term, and emerges from the fact that galaxies at different distances along the same line of sight can either be lensed by, or experience gravitational tidal interaction with, the same large scale structure.
Again assuming the Limber approximation, the angular power spectra can be written as
| (7) |
and
| (8) |
Given Eqs. (4), (7) and (8), we have the ingredients to use Eqs. (2) and (3) to predict the observable . Note that the GI and II power spectra are model dependent. Indeed, how one calculates them is a significant analysis choice in any cosmic shear analysis. In the sections below we describe the two model choices explored in this work.
2.2.1 TATT Model
The tidal alignment and tidal torque model (TATT; Blazek et al. 2019) is based on nonlinear perturbation theory, which is used to expand the field of intrinsic galaxy shapes in terms of the tidal field and the matter overdensity . Whereas is a scalar at all points in space, and are matrices, defining an ellipsoid in 3D space. Although in principle the expansion could be extended to any order, our implementation includes terms up to quadratic in the tidal field:
| (9) |
where and are free parameters. This leads to the power spectra:
| (10) |
| (11) |
| (12) |
The various subscripts to the power spectra indicate correlations between different order terms in the expansion of . They can all be calculated to one-loop order as integrals of the linear matter power spectrum over (see Blazek et al. 2019 for the full definitions). As can be seen here, the TATT model predicts both - and -mode II contributions. These are propagated to separate - and -mode angular power spectra, which enter in Eqs. (2) and (3). The amplitudes are defined, by convention, as:
| (13) |
| (14) |
The pivot redshift and the constant are fixed to values of and . Again, this is a convention, such that and are roughly of the order of for a typical population of source galaxies. The power law term in and adds some flexibility to capture possible redshift evolution beyond what is already encoded in the model. Our implementation of the TATT model then has five free parameters: , which we allow to vary with wide flat priors , . This choice of uniformative priors is motivated by the fact that IAs are very sensitive to the properties of the galaxy population, making it very difficult to derive informative priors, and resulting in a lack of directly transferable constraints in the literature for the TATT model parameters. Although intended to match up with different alignment mechanisms, in practice and capture any correlations that scale linearly and quadratically with the tidal field. The third amplitude is designed to capture the fact that galaxies over-sample densely populated regions (i.e., one cannot sample the field uniformly throughout the Universe).
For this work we use the DES Y3 implementation of TATT, within CosmoSIS v1.6111https://bitbucket.org/joezuntz/cosmosis/wiki/Home; des-y3 branch of cosmosis-standard-library (Zuntz et al., 2015). The power spectra in Equations (10)-(12) (with the exception of the nonlinear matter power spectrum ) are generated using FAST-PT v2.1222https://github.com/JoeMcEwen/FAST-PT (McEwen et al., 2016; Fang et al., 2017).
2.2.2 NLA Model
Although chronologically older and more commonly used, the nonlinear alignment model (NLA; Bridle & King 2007) is a subspace of TATT. Built on the assumption that galaxy shapes align linearly with the background tidal field, it predicts:
| (15) |
with the amplitude as defined in Eq. (13) in our implementation. The NLA model as implemented here differs from its predecessor, the linear alignment model (Catelan et al., 2001; Hirata & Seljak, 2004, 2010), by the fact that in the above equations is the full nonlinear matter power spectrum (in our case generated using HaloFit), not the linear version. Unlike the original formulation, our implementation of NLA also includes a power law redshift dependence in to capture any additional evolution beyond the basic model (as in Eq. (13) above). In total, our implementation of the NLA model has two free parameters, and , which we vary with the priors given in Section 2.2.1.
2.3 Other Nuisance Parameters & Scale Cuts
Both the TATT and NLA pipelines include free parameters for redshift error and residual shear bias. We adopt the same modelling as Krause et al. (2021), giving us one and one parameter per redshift bin, or a total of eight nuisance parameters. Note however, that these parameters are prior dominated for Y3 cosmic shear-only chains, and so add relatively little to the effective dimensionality. For details about the priors see Appendix A and Table 2. We also adopt the fiducial DES Y3 cosmic shear scale cuts (see Krause et al. 2021 for an explanation of how these were derived).
3 Creating and analysing the cosmic shear data vector
In this section we describe how we generate mock data. This is necessary to calibrate the relation between bias in cosmological parameters and statistical metrics used for model comparison, which is central to our method for model selection. Essentially we wish to create an ensemble of data vectors that span a useful range of bias in cosmological parameters and (or ), allowing us to map out the relation between the two. In Section 3.1 we focus on how to simulate the cosmological lensing terms (which depend on cosmology, not the IA model). Then in Section 3.2 we describe the IA terms (IA model-dependent). We explain how we incorporate noise into our analyses, and why it is necessary, in Section 3.3. Finally, we describe our sampler choices in Section 3.4, and in particular an approximation using importance sampling that we use to accelerate the analysis of the noisy data vectors.
3.1 Generating Mock Data
For a given set of input parameters, we generate a noiseless DES Y3-like cosmic shear data vector, , using the theory pipeline described in Section 2. We assume the fiducial Y3 redshift distributions, as presented in Myles, Alarcon et al. (2021). In all data vectors, the same input flat CDM cosmology is used . This corresponds to , , where . We choose these to match the marginalised mean values from the DES Y1 pt chain used to generate IA samples (see Section 3.2 below). Note, however, that the exact values are not expected to affect our results. We also fix all the redshift and shear calibration nuisance parameters to zero when generating data vectors.
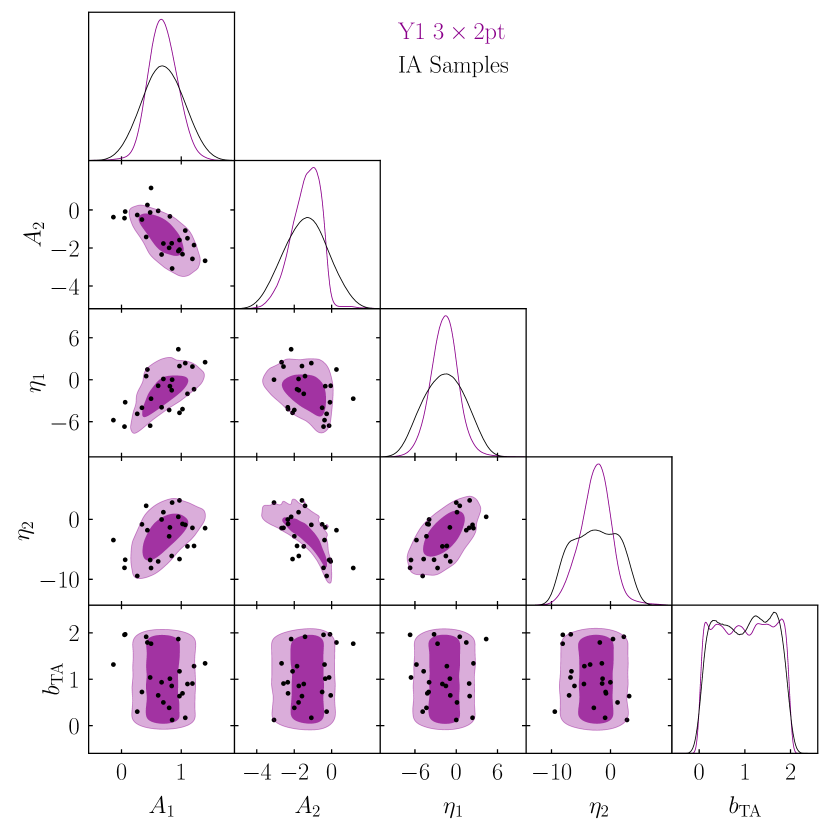
3.2 Choosing IA Scenarios
When constructing simulated data vectors, it is important to remember that IA model parameters are not independent. The total GI+II intrinsic alignment component in a scenario with, e.g., is very different from one with . As a consequence, it is possible for two sets of input IA parameters to give similar cosmological bias (when analysed with NLA), but quite different values. Specific combinations of TATT parameter values may enhance or cancel out cosmological parameter bias, and so it is useful to sample the 5D TATT parameter space rather than scaling up individual parameters to explore the potential for cosmological parameter bias due to model insufficiency. Therefore, instead of a single mock data vector, we generate a set of 21 data vectors, all with the same cosmology, but with different possible IA scenarios. The number of mock data vectors is an analysis choice. The more we generate, the better we cover the IA parameter space, but it also increases computational costs. We verified that 21 was a sufficient number of scenarios to have samples presenting low, medium and high bias in cosmological parameters, while still being reasonable in terms of computational cost (i.e. the chains to run).
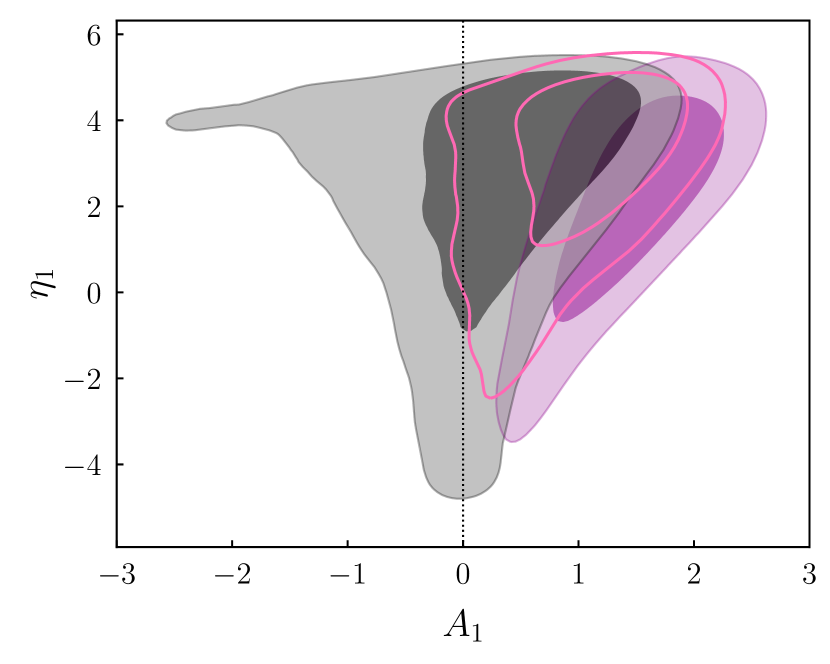
To do this, we follow the recipe set out in Section 2 of DeRose et al. (2019). Starting with the posterior from the DES Y1 pt TATT analysis (the purple contours in Figure 1; Samuroff et al. 2019), we evaluate the covariance matrix of the TATT parameters, and perform an eigenvalue decomposition. We then use Latin Hypercube sampling to generate samples, which are roughly evenly distributed in dimensional space. Finally, we use the eigenvalues/vectors to rotate and normalise those samples into the parameter space. The results are shown in Figure 1. The idea is that this provides a slightly broader coverage than could be obtained simply by drawing points from the joint posterior, while maintaining the correlations between parameters. In this way, we can cover a range of marginal cases, which are pessimistic, but still consistent with the data; this is useful, since for our purposes it is more important to span the range of plausible TATT model parameters than to preserve the statistics of the Y1 posterior exactly.
3.3 Adding Noise
Since real measurements unavoidably include an (unknown) noise realisation, the calibration of the bias-metric relation is inherently a probabilistic problem (we will return to this point in Section 5; see the discussion there for details). For this reason, it is important that our simulations capture all sources of scatter in the data.
For each of our 21 IA scenarios, defined by a set of input TATT parameter values , we have a set of noisy data vectors , where noise realisation is drawn from the covariance matrix, and is assumed to be independent of . We use the final DES Y3 covariance matrix, which is analytic and includes a Gaussian shape noise and cosmic variance contribution, as well as higher order non-Gaussian and super-sample terms (Friedrich et al., 2021). In total we generate 50 noise realisations, which we apply to each data vector. This gives us a collection of 21 noiseless data vectors, and noisy ones.
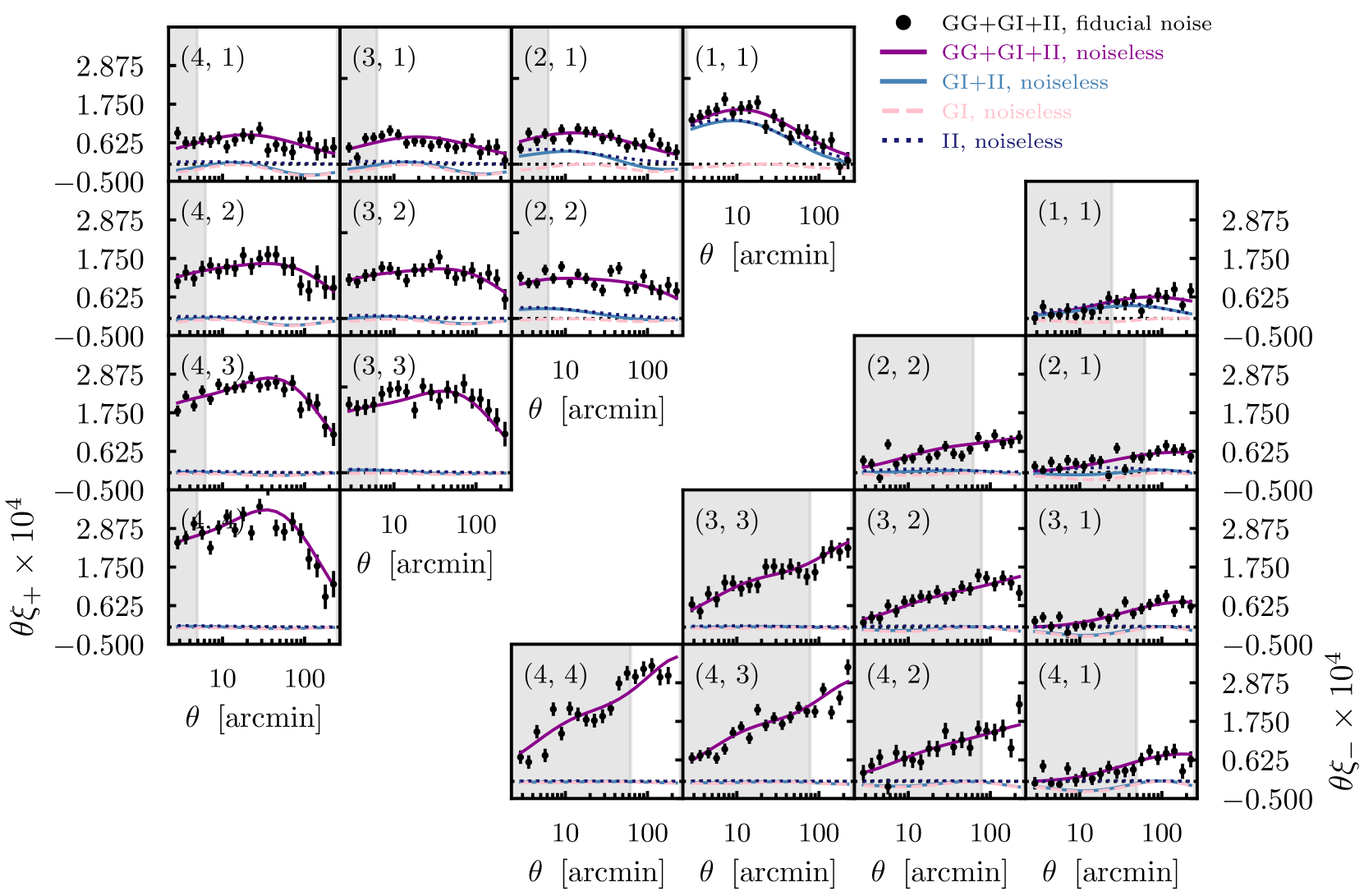
For testing, however, it is convenient to arbitrarily choose a single fixed noise realisation, which we refer to as fiducial noise. Figure 2 shows an example DES Y3-like data vector, generated using the setup described above, with the fiducial noise realisation added. For this particular example, the input TATT parameters are the mean values from the Y1 posteriors in Figure 1. For reference, we also show the noiseless version (purple solid), as well as the separate (again, noiseless) IA contributions. Since the IA signal in the lowest bin () seems to dominate, one could reasonably ask whether we could simply focus on this part of the data vector for model selection. We ultimately decide against this for a few reasons. First, although the IA signal is strongest in bin , we can see there is also non-negligible signal in the surrounding bins (e.g. and ). Indeed, during the DES Y3 analysis, a range of IA mitigation techniques were explored, including dropping the lowest auto bin correlations. For moderate TATT scenarios, it was found that this could not reliably eliminate cosmology biases, suggesting the IA contamination is not confined to the data vector. Additionally, the degree to which the low redshift II contribution dominates the IA signal is somewhat dependent on the input TATT parameters, and so the strength of this assumption varies in parameter space.
3.4 Choice of Sampler
3.4.1 Nested Sampling
To sample the cosmic shear likelihood, we use the PolyChord nested sampling algorithm (Handley et al., 2015), which generates estimates for the multidimensional posterior and the evidence for a given model simultaneously. This matches the DES Y3 choice, and has been validated in terms of both evidence and the contour size compared with a long monte carlo chain (Lemos, Weaverdyck et al., 2022). We briefly explored the possibility of using MultiNest (Feroz et al., 2019), which is conceptually similar, but significantly faster. Ultimately, however, we found that MultiNest underestimates the width of the posteriors in all cases we tested (both NLA and TATT; see Appendix D). It also gives inaccurate evidence values (Lemos, Weaverdyck et al., 2022), which tend to skew towards preferring NLA. For these reasons, we did not pursue this.
To obtain estimates for the best , we use oversampled chains (i.e., output with the number of points as saved in the standard chains). This approach has been tested in the Y3 cosmic shear setup, and shown to give comparable results to running a likelihood maximiser (Secco, Samuroff et al., 2022). All sampling, as well as the modelling steps described in Section 2, are carried out using CosmoSIS.
3.4.2 Importance Sampling
To assess the impact of data vector noise, in addition to nested sampling we also make use of importance sampling (IS; Neal 1998; Tokdar & Kass 2010 see also Lewis & Bridle 2002; Padilla et al. 2019 for cosmology-specific applications). For each IA scenario , we wish to estimate the shape and position of the posterior, as well as the best fit and evidence. Running full chains for every combination of noise and IA scenario would be expensive, and IS provides a fast approximation.
Say one wants to estimate the characteristics of a distribution , over parameter . One can estimate the mean of the function under as:
| (16) |
This can be rewritten in terms of a second distribution :
| (17) | |||
| (18) |
where we have redefined the ratio of distributions as a weight . The second line follows as a Monte Carlo estimate for the first, and the sum runs over values of drawn from . The equations above make no assumptions about Gaussianity, or about the nature of the distributions. To work well, however, it does require to be non-zero over the range of for which we wish to estimate , and it works better in cases where the number of samples is large. Functionally, it also requires (a) that one has, or can generate, samples from , and (b) that for any given , one can evaluate both and .
For our application, is a reference posterior obtained from running a chain on the noiseless data vector . As before, we use the oversampled PolyChord output for this. The target distribution is the posterior we are trying to estimate, conditioned on a noisy data vector . With this setup, we can estimate for each noise realisation by simply iterating through the samples from and assigning each a weight equal to the ratio of the two posteriors.
In addition to the target posterior for each model, we also estimate the best . For this, we create a high density pool of samples by merging all of our oversampled PolyChord chains (21 IA samples), in addition to a small number of additional chains run with a Y1 like covariance matrix. This gives us over a million points in parameter space per model. For each noisy data vector, we re-evaluate the likelihood at each point, and select the maximum. Given an estimate for the best from IS, and assuming a Gaussian likelihood, the Bayesian evidence can then be estimated as (see Section 3 Joachimi et al. 2021b):
| (19) |
where index indicates a noise realisation, and and are the evidence and best obtained from a fiducial reference chain, which in our case are our noiseless chains.
To test the performance of our IS setup, we ran five additional PolyChord chains at different noise realisations, once in the low bias regime and again in the intermediate () bias regime. We verified that in all cases, our IS setup recovered the best as well as the shape and mean of the posteriors with a comparable level precision to a full chain. Our implementation is a slight modification of the code discussed in Weaverdyck, Alves et al. (2022), and will be available on release of that paper.
4 Model Selection
In this section, we define the components of our model selection method. In essence, we are proposing to calibrate the observed value of model comparison statistics against the probability of cosmological parameter bias. These quantities can be computed using noisy simulated data, but first they must be properly defined. To this end, we define how we quantify cosmological parameter bias in Section 4.1. The metrics that we tested in search of a useful bias–metric relation are discussed in Section 4.2. In Section 4.3 we make considerations regarding unconverged samples. We summarize our model selection method in Section 4.4.
4.1 Significance Level of Cosmological Parameter Biases
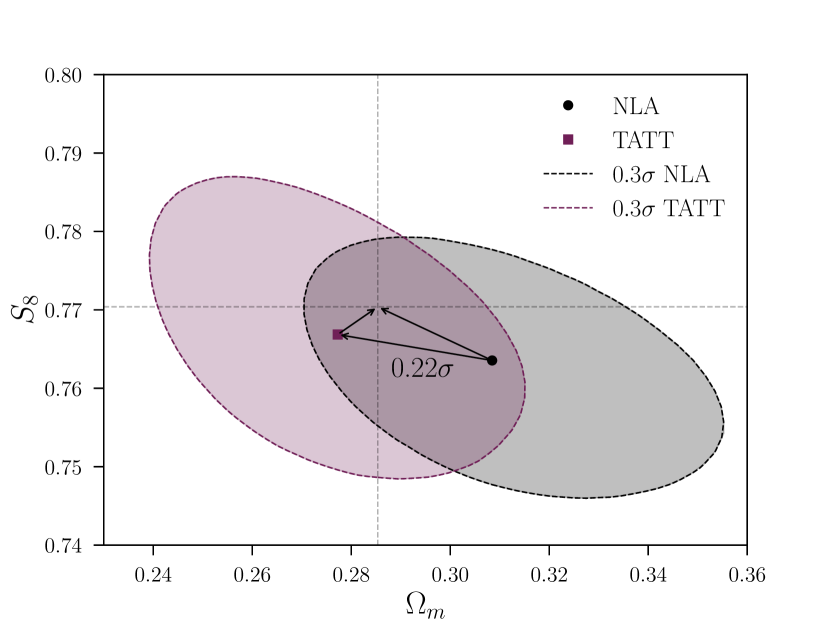
Now that we have a set of noisy data vectors, the next step is to fit them with all parameters free. We analyse each data vector twice, fitting to our full set of cosmological and nuisance parameters, but in one case using TATT, and in the other NLA. We then define bias as the distance between the peak of the marginalised posteriors in the plane. Figure 3 illustrates this for a particular simulated data vector. In brief, the algorithm works by evaluating the Euclidean distance between the peaks of the two posteriors, and in space. It then sequentially computes the confidence ellipses of at different levels, and finds a value of that minimises the distance between the ellipse and the peak of . Note that this is the same recipe used in Krause et al. (2021). The choice of and as the parameters of interest comes simply from the fact that these are the cosmological parameters best constrained by DES. One could conceivably use a more complicated separation metric that is sensitive to the full parameter space, along the lines of those used for assessing tensions between data sets (e.g. Lemos, Raveri, Campos et al. 2021). For our purposes, however, we follow Krause et al. (2021) and consider the simpler 2D metric to be sufficient.
We use noisy simulated data, as described in Section 3.3 – this is an important feature of our analysis, and it is necessary to allow us to meaningfully interpret our statistical metrics. Therefore, the relative separation of the two posteriors is a more useful quantity than the distance from the input values of and . The value shown in Figure 3 is assessed relative to the TATT posterior. This found to be more stable than assessing it relative to the NLA posterior, particularly in relatively extreme IA scenarios where the NLA posteriors are significantly shifted and can be distorted by prior edge effects.
Finally, it is implicit in the above that marginalised TATT constraints represent correct results by which to measure bias. That is, when we refer to bias, we are in fact talking about bias in the cosmological model when assuming the NLA model, with respect to what we find when assuming the TATT model. Although this is clearly reasonable (since our data were created using TATT), marginal contours can be subject to projection effects. Indeed, since some of the TATT parameters are relatively poorly constrained by shear-shear analysis alone, the two IA models cannot be assumed to experience projection effects to the same degree. We test this in Appendix A, and find projection offsets between TATT and NLA at the level of . This is well below the threshold of used for this work, and is thus unlikely to significantly affect our results.
4.2 Model Comparison Statistics
We investigate two commonly used test statistics, the difference and the Bayes ratio. We show in Section 5 that the former is more robust against noise than the latter, and is therefore a more useful metric for the method we are proposing.
4.2.1 Difference Tests
When dealing with nested models (i.e., where one model is a subspace of the other, as in the case with NLA and TATT), the difference in the best that can be achieved by each model on the same data is a convenient statistic for model selection (Steiger et al., 1985; Rigdon, 1999; Schermelleh-Engel et al., 2003; Andrae et al., 2010).
The difference metric is defined as the difference in the best values of the parameter fits when assuming the two IA models, divided by the difference in their numbers of degrees of freedom ():
| (20) |
where s indicates the smaller model (the one with fewer free parameters and therefore more degrees of freedom; NLA in our example), and l denotes the model with more parameters, larger, and so fewer degrees of freedom (TATT in our case)333Note that it is this quantity, weighted by the difference in , that we refer to as throughout the paper, and not the simple difference. This allows us to briefly compare with theoretical cut-offs in Section 5.1. For practical purposes, however, this is not strictly necessary – one could just as easily calibrate the raw difference.. Note that the point estimate to use for the “best " here is somewhat subjective. For a given chain, we use the value closest to the peak of the multidimensional posterior. One could also use the maximum likelihood, although in practice this tends to be a slightly noisier quantity.
In the limit that the additional parameters in the larger model have no impact on the quality of the fit, the metric is exactly zero: . Very small values can therefore be taken as evidence that the smaller model is sufficient, given the data. In practice, however, this is an unlikely outcome, as extra parameters will typically allow the model more flexibility. Under the null hypothesis that the two models and both adequately fit the data, the value of the numerator is -distributed with degrees of freedom, and the expectation value is (Wilks, 1938). One can interpret larger using the corresponding p-values to quantify the degree to which the data appear to favour the larger model. As we will discuss in Section 5, however, for our purposes it is more useful to focus on the observed relation between and parameter bias than on formal statistical thresholds. That is, we propose to use as an empirical tool, which requires calibration using simulated likelihood analyses for any given problem. This way, we are also free from other assumptions behind the standard use of the metric – for example, it formally requires nested models whereas an empirical calibration would not. Note that our approach here is functionally similar, but motivated slightly differently, to the calibration of Posterior Predictive Distribution (PPD) values for internal consistency testing, as implemented in Doux, Baxter et al. (2021).
In principle, is prior-independent. In Bayesian inference, however, the prior typically controls the regions of parameter space that can be explored, and so restrict the values of that can be attained. In practice, this is only an issue if the likelihood peaks outside the prior bounds (which is, in any case, usually a red flag).
One other point to remember is that, although in an ideal case with well-constrained parameters one extra parameter constitutes one fewer degree of freedom, in practice this is often not true. In such cases, one can calculate the effective degrees of freedom (see Raveri & Hu 2019). With the fiducial DES Y3 cosmic shear setup (minus the shear ratios), the effective degrees of freedom for TATT and NLA are 222 and 224 respectively, giving (compared with from simple parameter counting; see Secco, Samuroff et al. 2022 Table III).
In Section 5, we also briefly consider two other likelihood-based metrics: the Akaike Information Criterion (AIC; Akaike 1973) and the Bayesian Information Criterion (BIC; Schwarz 1978). Although these statistics have very different theoretical underpinnings (see Liddle 2007), they are similar in form, and can be conveniently reformulated as thresholds in . As with value cut-offs, however, they are seen to be relatively under-cautious in separating high- and low-bias scenarios (see Section 5 and Figure 4).
4.2.2 Bayes Ratio
The Bayesian evidence ratio, or Bayes ratio (Jeffreys, 1961; Kass & Raftery, 1995), is a slightly more complicated alternative to . It is defined as the probability of measuring a data vector assuming a given model , divided by the probability of measuring the same data for a second model :
| (21) |
Here, is the Bayesian evidence, which can be obtained marginalising over all the model parameters :
| (22) |
where is the likelihood, and is the prior, both assuming a particular model. The Bayes ratio is typically interpreted using the Jeffreys scale (Jeffreys, 1961), which defines ranges of values that match up to labels (e.g., “strong evidence", “substantial evidence", etc.).
Note that and are not independent from one another (indeed the latter approximates the former under certain assumptions; see Bishop 2006; Marshall et al. 2006). It is important, then, to be careful when seeking to combine information from the two.
Evidence ratios have been widely used in cosmology, both for comparing different data sets under the same model (i.e., as a tension metric; Marshall et al. 2006; Lemos, Raveri, Campos et al. 2021), and for model comparison on the same data (Liddle, Mukherjee & Parkinson, 2006a; Kilbinger et al.,, 2010; Secco, Samuroff et al., 2022). It is worth bearing in mind that the formulation in the two contexts is slightly different. In the former case there is explicit prior dependence, which motivates the use of statistics such as Suspiciousness (see e.g. Lemos, Raveri, Campos et al. 2021 Section 4.2). The version commonly used for model selection, on the other hand, should be independent of the choice of priors, at least in the limit that (a) the models are nested and (b) the priors on the extra parameters are wide compared with the likelihood.
Since cosmological analyses involve a large number of free parameters, computing the Bayesian evidence requires integrating a probability distribution over a high number of dimensions. A common way to calculate it is while producing the posterior distributions, using nested sampling (Skilling, 2006). The precision required from the sampler in order to compute reliable Bayesian evidences, however, often makes the sampling time very long. We choose to use the PolyChord nested sampling algorithm in this work (Handley et al., 2015) – although see Appendix D, where we consider the feasibility of using MultiNest (Feroz et al., 2019) as a slightly faster alternative.
4.2.3 Bias Probability
The above quantities give us the basic tools for our model comparison. There is, however, a piece missing. As we mention in Section 3.3, the calibration is inherently probabilistic. The model comparison metrics (both and ), as well as the offset between the NLA and TATT best fits, are somewhat sensitive to noise, and we do not know the true noise realisation in the data. We thus define a bias probability for a particular bias tolerance :
| (23) |
In words, is the probability of the bias in – being greater than , if the observed from the data is below some threshold (which is to be determined empirically based on the adopted and ).
It is estimated by plotting the distribution of all of our noisy data vectors in the bias plane, and, for a particular , evaluating the fraction of points that lie both above and below (i.e., in the lower right quadrant of Figure 4). In practice, one starts by defining the tolerance and the desired bias confidence . For example, one might require the bias to be smaller than at confidence. Given those numbers, we can then iteratively evaluate Eq. (23) with different thresholds until the required is achieved.
4.3 Dealing with Unphysical Values and Unconverged IA Samples
It is also worth briefly remarking that in our analysis we found about 50 (out of 1050) data points for which , and so . Given that NLA and TATT are nested models, these points are unphysical (a more flexible model should always be able to produce a better or as-good fit). We conclude that they are an artefact of the sampling method; although we tested the robustness of our IS setup, and found it can reproduce the best fit from chains to reasonable precision, some level of sampling noise is still present. Given this logic, it is reasonable to assume that if we were to find in real data, there would likely be some follow-up investigation and the chains would be rerun. This is particularly true if the is an integral part of the analysis plan, as it is in our method. We thus choose to discard these points. It is worth bearing in mind, however, that this may or may not be a reasonable decision in other setups, depending on the models being compared and the details of the analysis.
Also note that, although our results are based on 21 IA samples, we did initially draw 25 scenarios (see Section 3.2). Of these 25, we found four to be so extreme that the NLA PolyChord chains failed to converge in the noiseless case. These resulted in highly distorted and often bimodal contours in the plane, making it difficult to obtain meaningful estimates for the bias. Given this, and also for the reasoning discussed above, we choose to omit these samples from our analysis. This leaves us with a total of 21 IA samples.
4.4 The Recommended Method for Model Selection
Given all the definitions set out in the sections above, we now follow the recipe outlined below, in order to map and calibrate the bias-metric relation. These steps are, in essence, our method; when written out in this form, it can be very easily generalised to other model selection problems beyond our particular example of IA in cosmic shear.
-
1.
Sample IA scenarios: Draw about parameter samples from either a posterior from a previous analysis or from some reasonable priors using the method described in Section 3.2 (we used 21 drawn from DES Y1 TATT posteriors).
-
2.
Generate data vectors: Generate a simulated noiseless data vector for each IA scenario drawn in the previous step. Other model parameters (e.g., cosmological and nuisance parameters) should be fixed to some fiducial values. See Section 3.1.
-
3.
Analyse noiseless data vectors: There are two chains per data vector, one corresponding to model , and the other to . Again, we compared the TATT and NLA IA models using PolyChord to compute statistics. These choices might vary under different applications. Details on the sampling can be found in Section 3.4.1.
-
4.
Compute parameter bias and plot out the bias-metric relation: Demonstrate that the noiseless data vectors show a clear correlation between the test statistic (e.g., or Bayes factor) and parameter bias, as described in Section 4.1.
-
5.
Generate noise realisations: For each data vector, generate noise realisations using the covariance matrix, as explained in Section 3.3. In our case, that gives a total of noisy data vectors.
-
6.
Analyse noisy data vectors: As discussed above, we choose to use importance sampling to give a fast approximation for the noisy posteriors. For all noise realisations (50) and IA scenarios (21), for both IA models (2) 2100 total, estimate the posterior, the NLA-TATT bias and the model test statistics. See Section 3.4.2.
-
7.
Calculate probability: Plot out the bias-metric relation. Use the quantities computed in the previous step to calculate the probability of bias greater than some pre-defined threshold (see Section 4.2.3).
-
8.
Run analyses on blinded data: Run a full chain on the real data in order to evaluate the observed model statistic. This can then be interpreted in terms of bias probability using the results of the above step. See Section 5.
Note that, to obtain an accurate calibration of the value, all aspects of the modelling should be as close to the final fiducial analysis setup as possible. For an estimate of the computational resources required to employ the proposed method, see Appendix E.
5 Results
Now we have outlined the details of our method in Section 4.4, we will now consider a specific application. As discussed earlier, we choose to focus on the problem of deciding between two intrinsic alignment models for a cosmic shear analysis: NLA and TATT. Although these models are nested, the method does not assume this. Indeed, the only requirement is the ability to generate mock data to calibrate the chosen test statistics; therefore it is quite general and can be applied to a variety of model selection problems.
In Section 5.1 we discuss the results from our PolyChord chains on noiseless data vectors, and the basic trends. Section 5.2 then discusses the more complete probabilistic calibration, which properly factors in the impact of noise. We also compare our empirical results against theoretically derived thresholds. Section 5.3 looks at how far bias can be inferred from NLA fits alone, without explicit model comparison. Lastly, Section 5.4 considers the wider outlook for lensing cosmology.
5.1 The Noiseless Case
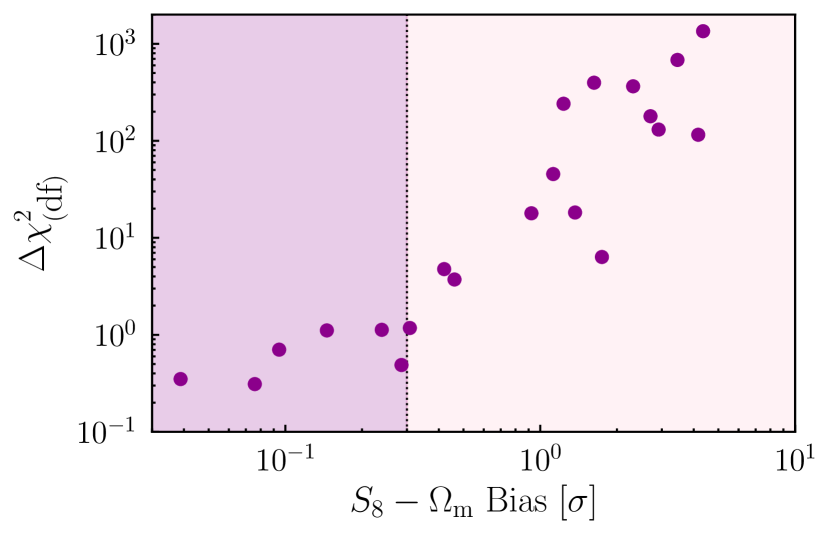
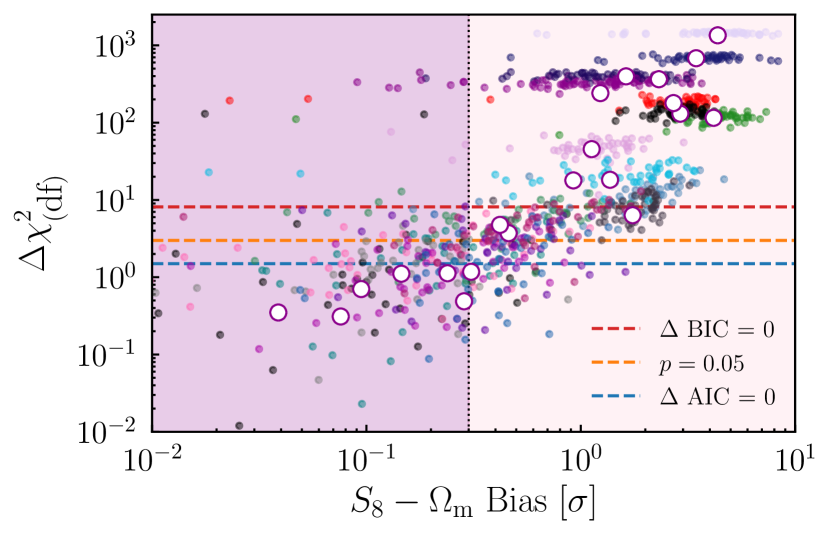
Considering first the noiseless case, Figure 4 shows the relation between bias in the plane and the NLA-TATT . Each point results from running two chains on the same noiseless simulated data vector, first using NLA, and then using TATT. As defined in Eq. (20), large values of indicate statistical preference for the larger model (i.e., TATT). We see a relatively tight relation between bias and , going from when bias is small to relatively large values at the high bias end: low bias small difference, high bias large difference. Interestingly, the relation appears to have the form (approximately) of a double power law, with a steep slope in the high bias regime, switching to a somewhat shallower function below . It is worth stressing, however, that this relation is empirical. We do not have a particular expectation for its shape, and it is likely that the details depend on the analysis choices and survey setup. Note that even without data vector noise, this relation presents some scatter. This arises both from sampler noise, and from the fact that this is a complex high dimensional problem, for which two sets of IA values that produce biases of a similar magnitude will not necessarily produce identical values. The vertical dotted line marks the bias threshold adopted by DES (Krause et al., 2021), which we adopt as our fiducial tolerance (see Section 5.2 below). Although we cannot use this noiseless result for any empirical method because real data will always contain noise, confirming that these quantities clearly correlate is a necessary first step in our method, and important to check before incurring the expense of further calculations. We will see in the next section that the correlation between and bias holds (with some additional scatter) when we proceed to the noisy case.
In addition to the , we also consider the Bayes Ratio as a potential model comparison metric; while the former presents a clear relation to the bias (as seen in Figure 4), we find the latter be a relatively weak indicator, with additional intrinsic scatter. This can be seen in Appendix C, and in particular Figure 11. We also note that and are correlated. In principle one could seek to combine them, but naively treating them as independent metrics is almost certainly double-counting information. Therefore, here we focus on the results using . For further discussion of the Bayes ratio see Appendix C.
5.2 Noise & Probabilistic Calibration
In Figure 5 we illustrate the impact of data vector noise in the bias- plane. We show the same 21 noiseless samples discussed above, but now overlain with multiple different noise realisations, as approximated using importance sampling. As we can see, noise introduces scatter in the bias- relation. While this noise is considerably less than in the case of the Bayes factor (for which we show in Appendix C that the scatter due to noise is so large that the relation with bias is extremely weak), it is still non-negligible.
For comparison, we show the cut-offs implied by some standard model selection metrics: BIC, AIC and a value significance threshold444Assuming that the TATT model has 2 additional effective degrees of freedom compared with NLA. Note that this value was calculated for the DES Y3 shear-only (no shear ratio) case in Secco, Samuroff et al. (2022). It is thus valid for our particular case, but would not necessarily hold under changes to the data vector or analysis choices. of (see Section 4.2.1 for definitions). Unfortunately, in the presence of noise, we see that all three cut-offs are relatively weak indicators of bias – i.e., they still favour the simpler model even when significant amount of bias has been introduced in the cosmological parameters. Even in the case of AIC, which is the strictest of the three, there are a problematic fraction of noise realisations where the observable metric favours NLA, and yet NLA is biased by (see the points in the lower right hand corner of Figure 5). This illustrates a key motivation for adopting an empirical calibration. Theoretical limits imposed using, e.g., values are not designed to optimise the quantities we care most about (i.e., parameter biases). For a given analysis, it is impossible to know from first principles what level of bias is excluded for a given statistical metric cut-off without some form of calibration.
These observations have important consequences for our method. Since the exact noise realisation in any real data set is unknown, one cannot simply run a single set of IA samples (as in Figure 4), and perform a 1:1 bias- mapping. Nor, as we can see from Figure 5, can we simply fall back on theoretical cut-offs to reliably guard against model bias. Instead, we must consider the problem as a probabilistic one, and factor in the uncertainty from noise.
5.2.1 Probabilistic Interpretation
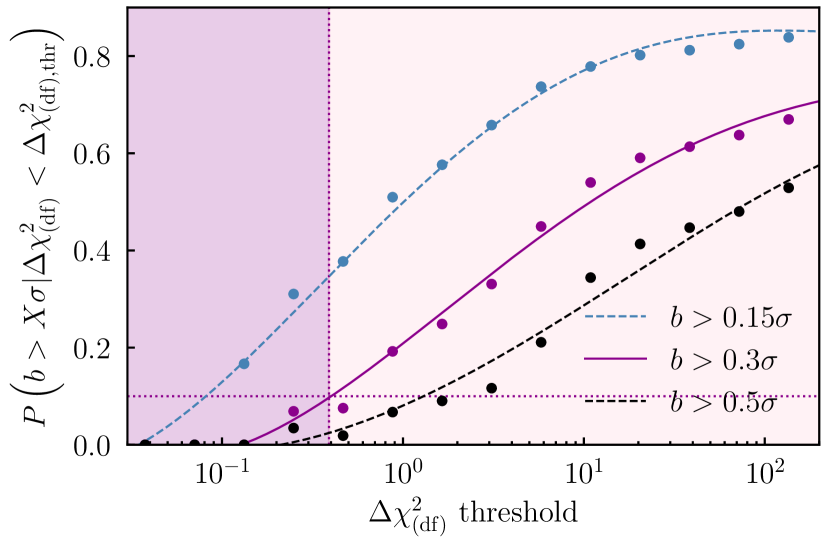
To interpret our results in a quantitative way, we use Eq. (23) and calculate the bias probability . This quantity should be interpreted as the conditional likelihood that, if in the real data one finds a value below some limit (a horizontal line in Figure 5), then the analysis using NLA will still in fact be biased by or more.
Figure 6 shows three curves corresponding to chosen bias thresholds of , , and . Each point is calculated using Eq. (23) and the curves are obtained by fitting a fifth order polynomial to the points. We tested the stability of these smoothed fits, and found that they are robust to doubling the number of noise realisations in Figure 5 (from 50 per IA sample to 100). This result provides a powerful tool, which can be used to interpret results from real data. For instance, say we were to run NLA and TATT chains on a blinded Y3 data vector, and find . With the aid of Figure 6, we could say that the chance of the NLA run being biased by more than in is about . The probability of exceeding a threshold is about , and the chance of bias greater than is about . In practice, the bias tolerance is an analysis choice. As discussed previously, DES Y3 chose a value of by which to judge simulated chains. The exact number, however, is somewhat subjective, and the most convenient value may depend on how well sampled the low bias end of the bias- relation is. As one might expect, the lower the bias threshold , the stronger the requirement on the (i.e., the stronger the data needs to favour NLA) in order to keep the bias probability low.
To understand how our results depend on various analysis choices, it is perhaps useful to think of the process in Section 4.4 as a series of transformations between different distributions. The points in Figure 5, which determine the final threshold, can be thought of as the convolution of two parts: an initial distribution of noiseless points (the open points in Figure 5 and the filled in Figure 4) and a second distribution conditioned on each one (where the tilde denotes noisy values of and bias). In the first case, , we start with a distribution in IA parameter space , which we choose. The samples from are mapped onto a distribution of noiseless data vectors, which are then transformed (via running chains) into samples in the final bias- space: . Both mapping steps are dependent on the survey analysis choices (choice of power spectrum, , covariance matrix, etc.). This is not a problem, as long as these choices match the ones that will be applied on real data. It is, however, likely these choices have an impact on the observed bias- correlation. It is clear from this that also depends to an extent on the choice of . We can see that behaves analogously to a prior, restricting the range of possibilities in the subsequent steps. However, given that the purple points in Figure 4 show a relatively tight correlation and cover a broad range of bias relatively uniformly, we do not expect the details to change things considerably.
The other part of the final sampling of points is the noise distribution . We obtain this for a particular IA sample by sampling noise realisations, and so transforming . This process is again dependent on the covariance matrix, but not on the choice of (at least, not directly).
The end result of the above is that, by convolving to get to , we are able to map out the relationship between a quantity we can measure (the noisy ) and the one we are interested in (parameter bias ).
5.2.2 Bias Tolerance Implications
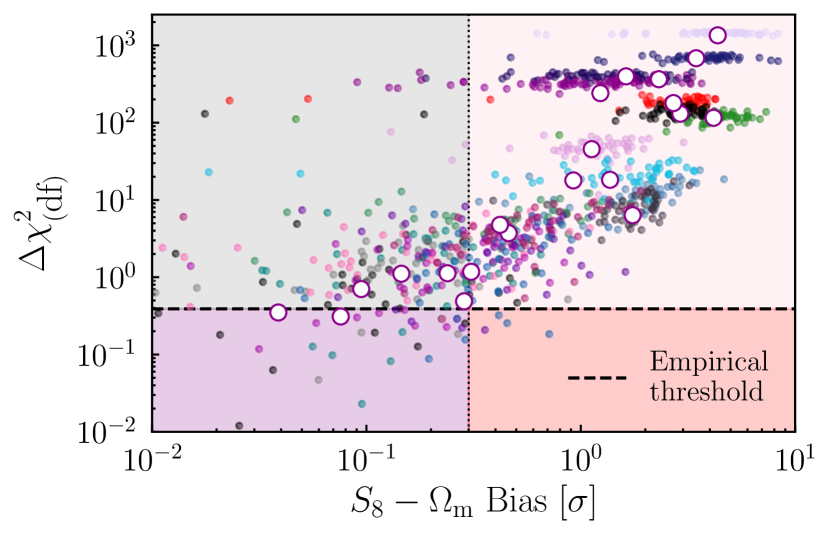
We further illustrate our results by taking a concrete example. For our DES Y3 setup, we choose a bias tolerance of , and a bias probability of (). Using Figure 6, this gives us (reading across where the horizontal dashed line meets the purple curve), which is shown in Figure 7 (the horizontal line labelled “empirical threshold"). With the bias and thresholds fixed, the four shaded regions in Figure 7 distinguish the following possible scenarios: (a) NLA is sufficient (i.e., the bias is below our limit) and chooses NLA (i.e., ; purple); (b) NLA is sufficient and chooses TATT (grey); (c) NLA is insufficient and chooses TATT (pink); (d) NLA is insufficient and chooses NLA (red). As we discussed previously, case (d) is the most dangerous, for obvious reasons. Scenario (b) is not ideal (since we may end up with a model that is more complicated than strictly necessary), but does not result in cosmological parameter biases. The different scenarios can be better understood with the help of a confusion matrix, shown in Table 1.
| Model preferred by Bias | ||||
| NLA | TATT | Total | ||
| Model preferred | TATT | |||
| by | NLA | |||
| Total | ||||
The columns here represent the model preference according to the amount of bias, and the rows represent the model preference according to the . Since we are effectively using as an empirical proxy for bias, we treat the classification according to the latter (i.e., does using NLA cause cosmological parameter biases for a particular data vector exceeding ?) as the truth and the label according to the former (i.e., is below ?) as the prediction (in machine learning language).
We see that in our samples, the cosmological parameter bias indicates that NLA should be preferred about of the time, while TATT should be preferred . In other words, NLA introduces a bias smaller than our threshold in of the cases. Note that this fraction is somewhat dependent on our particular choices. A different choice of posteriors in Figure 1, for example, could change this fraction. We do not, however, expect this to affect the validity of the method.
When it comes to the performance of in identifying the correct model, we see that it favours TATT in of the cases, and NLA in only . We can see that our method is quite conservative, in the sense that there is a non-negligible false positive rate. That is, it prefers TATT over NLA in of cases, even though NLA would not introduce bias to the model above the threshold. Reassuringly, however, we also see that our method is is highly effective in ruling out real bias. The strongest feature of our approach, perhaps, is the fact that it is very unlikely to select NLA if it is, in fact, introducing biases to the analysis. We can see this by the very small population of points in the lower right of the matrix (and the red shaded quadrant in Figure 7): this happens in only of cases. Put another way, if the calibrated favours TATT, there is a roughly chance () that NLA would, in reality, have been fine. Conversely, if it prefers NLA, there is () that NLA is insufficient. Therefore, even though the end result is somewhat cautious (in that there is a moderate false positive rate for TATT), on the positive side we can be confident that if NLA is in fact preferred by the data, it is very unlikely that it will introduce biases to the analysis. As a remark, however, it is important to acknowledge that a possible conclusion from these results is that simply using the most general model is the cheapest alternative from the perspective of computational resources. It is not obvious that this will always be the case, however, given the dependence on analysis setup and other factors.
It is also worth noticing that although the above discussion applied for our specific choices, we can control the conservatism to a significant degree through our analysis choices. We chose a specific bias tolerance and probability that we considered realistic. By changing these values (for example, allowing a bias probability of , or ) one can effectively shift the position of the cross in Figure 7, and trade off false positives for false negatives. This is another advantage of the method: it makes the level of conservatism explicit (and indeed quantifiable), and allows one to adjust that level as preferred. This is much less true when using alternative approaches to model selection.
5.3 A Simpler Approach: How Much Can We Tell From A Single Model?
It is also worth taking a moment to consider a related question: if the true IA scenario is extreme enough to give significant cosmological biases, would there be clear red flags from NLA alone, assuming that no fits were carried out with TATT? If this were the case, it would provide a simpler route – instead of performing empirical calibration using simulations, we could simply run one model on the data, and interpret results to see if a more sophisticated model is needed. Considering our 21 IA scenarios with a fixed noise realisation, we find that around of cases with bias have values that appear entirely consistent with being drawn from the corresponding distribution555Where the NLA value here is calculated by assuming is drawn from a distribution with 224 degrees of freedom (see Secco, Samuroff et al. 2022). The null hypothesis in this case is that the NLA model is adequate to describe the data, and so small values would indicate model insufficiency., . A similar picture is seen when we consider a single high bias IA scenario with alternative noise realisations – computing values for each realisation, the majority are above 0.05, even in the presence of bias . In other words, even in cases where NLA is significantly biased, it is not necessarily obvious from considering the uncalibrated value of alone. In contrast, the method we propose, using , can correctly identify the need to use TATT to achieve sufficiently unbiased results of the time (see the confusion matrix in Section 5.2).
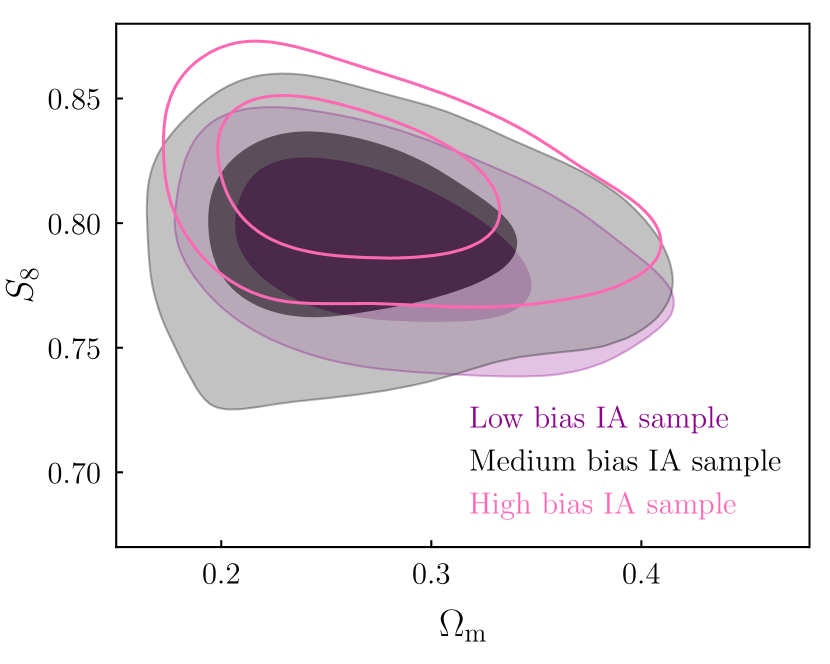
Likewise, although extreme biases do tend to distort the shape of the posteriors, this is not always true in more moderate (but still significantly biased) cases. Figure 8 shows the NLA posteriors in a few different IA scenarios, spanning the range from almost no bias (purple shaded), to (pink, open contours). For reference we also show the posteriors from TATT fits to the same data vectors in Appendix B. Taken in isolation, none of these show clear signs of problems with the model. It is also interesting that IA mismodelling bias does not always translate into significantly non-zero values for the inferred NLA parameters. In the medium bias case, for example, and are both consistent with zero to . Here there is a relatively strong degeneracy between and , allowing both combined with low , but also a stronger IA amplitude with a larger . In projection, this results in broad contours on both parameters (notice the black contours in the upper panel of Figure 8 are slightly wider than the others, with a more prominent asymmetry at high/low ).
5.4 Intrinsic alignment modelling & wider implications for weak lensing
The results discussed so far have a number of direct implications for the question of intrinsic alignment model selection. Primarily, we have shown that it is possible to perform empirical model selection with lensing data. There is a clear relation between cosmological parameter bias and , which allows one to define a threshold that can then be applied to the real data. That said, the failure of conventional statistical metrics (e.g., values) to identify scenarios with significant cosmological parameter biases is notable, and should be kept in mind when trying to understand statistics derived from any single run on real data. The properly calibrated model statistics, however, provide an alternative to the model selection exercises used in previous analyses, which have tended to rely on either simulated analyses (Secco, Samuroff et al. 2022 Section A3), or arguments based on direct-detection studies (Hikage et al. 2019; Joachimi et al. 2021a, Sections 5.4 and 2.4 respectively). The empirical method is arguably an advance on both; first of all, it avoids questions about what constitutes an “extreme" model, which tend to arise in the simulation-based approach. Since the current best constraints on TATT model parameters are relatively weak, it is relatively easy to select an IA scenario that is both consistent with observations, and which would cause significant bias in an NLA analysis (note that this is still true in light of the most recent DES Y3 results Secco, Samuroff et al. 2022; Amon et al. 2022; DES Collaboration 2022). Our empirical approach also avoids the uncertainties that are inherent in extrapolating observations based on direct IA measurements on one very specific type of galaxies to weak lensing measurements on another population entirely.
Although the empirical approach has various strengths, is worth reiterating that data vector noise is a significant source of scatter in the bias- relation. For this reason it is important to accurately simulate the noise properties of the particular data set. While this is in principle simple, given an accurate covariance matrix, it does mean the model selection exercise needs to be repeated for any new data set or changes to the analysis. It also means it is crucial to have a fast and accurate way of estimating posteriors for a large number of noise realisations, such as the IS framework used here.
It is also interesting, finally, to consider how our findings relate to the real Y3 results. Although comparing with the full pt results is difficult, for the reasons given above, Secco, Samuroff et al. (2022) (Section VIIB and Table III) present a comparison of IA models without shear ratios, an analysis configuration that matches ours. Specifically, comparing the 2 parameter NLA model with 5 parameter TATT, they find and . Interpreted with the help of Figure 6, this puts the risk of NLA being biased by at somewhere around , meaning runs using NLA on Y3 were more likely than not to be unbiased to within the threshold.
6 Conclusions
In this paper, we explore the idea that model selection for cosmological analyses could be performed a posteriori, being informed by the blinded data themselves. Our goal is to select a model that is sufficient to describe the data, resulting in unbiased parameter constraints at some specified tolerance level. We chose to focus on a specific problem: how best to decide on an intrinsic alignment model for a cosmic shear analysis. This is an important question, and one that has been the subject of much discussion within the weak lensing community in recent years. That said, the basic concept behind our method is much more general, and could be applied in a variety of different contexts; in principle it requires only that the data (including its noise) can be readily simulated.
Using simulated noisy DES Y3 weak lensing data, we tested the method, and identified statistical tools with which to implement it. The main conclusions of our study are as follows:
-
•
We showed a clear relation between the difference between two models, and model insufficiency bias on cosmological parameters. This relation was seen to extend across a wide range of biases, from low to high, allowing one to define an empirical threshold in order to ensure bias is below an acceptable level.
-
•
We tested a number of common -based metrics such as AIC, BIC and pre-defined value cutoffs. These were seen to be generally under-cautious, favouring the simpler model even in the presence of parameter biases. This result motivates us to use an empirical calibration. Similarly, when trying to interpret the goodness of fit statistic from a single model, a standard cutoff is not reliable to rule out significant biases.
-
•
In addition to maximum likelihood-based statistics, we also consider the Bayes factor as a model selection tool. Although useful in the extreme cases, it was seen to be only weakly discriminating for cosmological parameter biases in the range . We therefore recommend it be used with caution, ideally in conjunction with other model selection metrics.
-
•
Noise is seen to have a potentially significant impact on both the cosmological bias, and the , for any given input IA scenario. At high bias, the picture is relatively stable; noise cannot, in general, cause model selection metrics to prefer the simpler model in a case where adopting that model induces large cosmological parameter biases. The reverse is, however, possible. Due to noise, one can end up in scenario with small cosmological parameter bias, but with selection metrics favouring the more complex model. In this regard, our method tends to err on the side of caution.
Although our qualitative findings are general, it is worth bearing in mind that the details are specific to the DES Y3 cosmic shear only setup. Factors such as choice of two-point statistics, covariance and scale cuts could very easily have an impact, as could modelling choices (baryonic treatment, power spectrum, cosmological model etc) and the choice of sampler. It is therefore important that the simulated analyses used to derive a threshold are as close as possible (and ideally identical) to the real setup that will be applied to the blinded data.
Model selection is an important topic in cosmology, and in science more generally. It is quite common to have a set of models under consideration, with little prior knowledge about the values of their parameters; what level of complexity is sufficient to describe the data, given its precision, depends on the unknown true model and its unknown parameter values. Given these circumstances, arguably the most cautious approach would be to use the most flexible model, which is more likely to be unbiased. This paper sets out an alternative method, which allows information in the data to inform model selection. Although applicable in similar situations to Bayesian Model Averaging (BAM; Liddle et al., 2006b; Vardanyan et al., 2011), i.e., where there is not enough prior information to justify choosing one model over another, our approach has the advantage of simplicity, and maintains the idea of a fiducial model, which is often useful for practical purposes. It also avoids the prior dependence of methods such as BAM, which is well documented in the literature. Given its generality, simplicity, and the relatively low level of resources required, we foresee applications of the empirical method discussed in this paper to future analyses as a model selection tool in many contexts.
Data Availability
All simulated data vectors, PolyChord chains and Importance Sampling noise samples used in this work are publicly available at https://github.com/AndresaCampos/empirical_model_selection.
Acknowledgements
We thank Scott Dodelson, Sukhdeep Singh, Lucas Secco, Alex Amon, Judit Prat and Agnès Ferté for useful discussions contributing to this work. Many thanks also to Jessie Muir, Noah Weaverdyck, Otávio Alves, Shivam Pandey, and Cyrille Doux for support with code, in particular with setting up the importance sampling pipeline used in this paper. Contour plots were made using the GetDist package (Lewis, 2019).
Andresa Campos thanks the support from the U.S. Department of Energy grant DE-SC0010118 and the NSF AI Institute: Physics of the Future, NSF PHY-2020295. Simon Samuroff is partially supported by NSF grant AST-2206563. RM is supported in part by the Department of Energy grant DE-SC0010118 and in part by a grant from the Simons Foundation (Simons Investigator in Astrophysics, Award ID 620789).
References
- Akaike (1973) Akaike H., 1973, Proceedings of the Second International Symposium on Information Theory, Tsahkadsor, Armenia, USSR
- Amon et al. (2022) Amon A., et al., 2022, Phys. Rev. D, 105, 023514
- Andrae et al. (2010) Andrae R., Schulze-Hartung T., Melchior P., 2010, arXiv e-prints, p. arXiv:1012.3754
- Asgari et al. (2021) Asgari M., et al., 2021, A&A, 645, A104
- Bird et al. (2012) Bird S., Viel M., Haehnelt M. G., 2012, MNRAS, 420, 2551
- Bishop (2006) Bishop C. M., 2006, Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg
- Blazek et al. (2015) Blazek J., Vlah Z., Seljak U., 2015, J. Cosmology Astropart. Phys., 8, 015
- Blazek et al. (2019) Blazek J. A., MacCrann N., Troxel M. A., Fang X., 2019, Phys. Rev. D, 100, 103506
- Bridle & King (2007) Bridle S., King L., 2007, New Journal of Physics, 9, 444
- Bridle et al. (2010) Bridle S., et al., 2010, MNRAS, 405, 2044
- Catelan et al. (2001) Catelan P., Kamionkowski M., Blandford R. D., 2001, MNRAS, 320, L7
- Chen et al. (2022) Chen A., et al., 2022, arXiv e-prints, p. arXiv:2206.08591
- Crittenden et al. (2002) Crittenden R. G., Natarajan P., Pen U.-L., Theuns T., 2002, ApJ, 568, 20
- DES Collaboration (2022) DES Collaboration 2022, Phys. Rev. D, 105, 023520
- Dark Energy Survey Collaboration (2016) Dark Energy Survey Collaboration 2016, Phys. Rev. D, 94, 022001
- DeRose et al. (2019) DeRose J., et al., 2019, ApJ, 875, 69
- Desjacques et al. (2018) Desjacques V., Jeong D., Schmidt F., 2018, Phys. Rep., 733, 1
- Doux et al. (2021) Doux C., Baxter E., et al., 2021, MNRAS, 503, 2688
- Doux et al. (2022) Doux C., et al., 2022, MNRAS,
- Fang et al. (2017) Fang X., Blazek J. A., McEwen J. E., Hirata C. M., 2017, J. Cosmology Astropart. Phys., 2017, 030
- Feroz et al. (2019) Feroz F., Hobson M. P., Cameron E., Pettitt A. N., 2019, The Open Journal of Astrophysics, 2, 10
- Friedrich et al. (2021) Friedrich O., et al., 2021, MNRAS, 508, 3125
- Hamana et al. (2020) Hamana T., et al., 2020, PASJ, 72, 16
- Handley et al. (2015) Handley W. J., Hobson M. P., Lasenby A. N., 2015, MNRAS, 453, 4384
- Heymans et al. (2006) Heymans C., et al., 2006, MNRAS, 368, 1323
- Heymans et al. (2013) Heymans C., et al., 2013, MNRAS, 432, 2433
- Hikage et al. (2019) Hikage C., et al., 2019, PASJ, 71, 43
- Hildebrandt et al. (2017) Hildebrandt H., et al., 2017, MNRAS, 465, 1454
- Hirata & Seljak (2004) Hirata C. M., Seljak U., 2004, Phys. Rev. D, 70, 063526
- Hirata & Seljak (2010) Hirata C. M., Seljak U. c. v., 2010, Phys. Rev. D, 82, 049901
- Hirata et al. (2007) Hirata C. M., Mandelbaum R., Ishak M., Seljak U., Nichol R., Pimbblet K. A., Ross N. P., Wake D., 2007, MNRAS, 381, 1197
- Ivezić et al. (2019) Ivezić Ž., et al., 2019, ApJ, 873, 111
- Jarvis et al. (2021) Jarvis M., et al., 2021, MNRAS, 501, 1282
- Jee et al. (2016) Jee M. J., Tyson J. A., Hilbert S., Schneider M. D., Schmidt S., Wittman D., 2016, ApJ, 824, 77
- Jeffreys (1961) Jeffreys H., 1961, The theory of probability. OUP Oxford
- Joachimi et al. (2015) Joachimi B., et al., 2015, Space Sci. Rev., 193, 1
- Joachimi et al. (2021a) Joachimi B., et al., 2021a, A&A, 646, A129
- Joachimi et al. (2021b) Joachimi B., Köhlinger F., Handley W., Lemos P., 2021b, A&A, 647, L5
- Johnston et al. (2019) Johnston H., et al., 2019, A&A, 624, A30
- Kass & Raftery (1995) Kass R., Raftery A., 1995, Journal of the American Statistical Association, 90, 773
- Kerscher & Weller (2019) Kerscher M., Weller J., 2019, SciPost Phys. Lect. Notes, p. 9
- Kiessling et al. (2015) Kiessling A., et al., 2015, Space Sci. Rev., 193, 67
- Kilbinger et al. (2010) Kilbinger M., et al., 2010, MNRAS, 405, 2381
- Kirk et al. (2015) Kirk D., et al., 2015, Space Sci. Rev., 193, 139
- Knabenhans et al. (2021) Knabenhans M., et al., 2021, MNRAS, 505, 2840
- Krause et al. (2017) Krause E., et al., 2017, arXiv e-prints, p. arXiv:1706.09359
- Krause et al. (2021) Krause E., et al., 2021, arXiv e-prints, p. arXiv:2105.13548
- Laureijs et al. (2011) Laureijs R., et al., 2011, arXiv e-prints, p. arXiv:1110.3193
- Lemos et al. (2021) Lemos P., Raveri M., Campos A., et al., 2021, MNRAS, 505, 6179
- Lemos et al. (2022) Lemos P., Weaverdyck N., et al., 2022, MNRAS,
- Lewis (2019) Lewis A., 2019, arXiv e-prints, p. arXiv:1910.13970
- Lewis & Bridle (2002) Lewis A., Bridle S., 2002, Phys. Rev. D, 66, 103511
- Lewis et al. (2000) Lewis A., Challinor A., Lasenby A., 2000, ApJ, 538, 473
- Liddle (2007) Liddle A. R., 2007, MNRAS, 377, L74
- Liddle et al. (2006a) Liddle A., Mukherjee P., Parkinson D., 2006a, Astronomy & Geophysics, 47, 4.30
- Liddle et al. (2006b) Liddle A. R., Mukherjee P., Parkinson D., Wang Y., 2006b, Phys. Rev. D, 74, 123506
- Limber (1953) Limber D. N., 1953, ApJ, 117, 134
- LoVerde & Afshordi (2008) LoVerde M., Afshordi N., 2008, Phys. Rev. D, 78, 123506
- Loureiro et al. (2022) Loureiro A., et al., 2022, A&A, 665, A56
- Mandelbaum et al. (2015) Mandelbaum R., et al., 2015, MNRAS, 450, 2963
- Marshall et al. (2006) Marshall P., Rajguru N., Slosar A., 2006, Phys. Rev. D, 73, 067302
- McEwen et al. (2016) McEwen J. E., Fang X., Hirata C. M., Blazek J. A., 2016, J. Cosmology Astropart. Phys., 2016, 015
- Mead et al. (2021) Mead A. J., Brieden S., Tröster T., Heymans C., 2021, MNRAS, 502, 1401
- Myles et al. (2021) Myles J., Alarcon A., et al., 2021, MNRAS, 505, 4249
- Neal (1998) Neal R. M., 1998, arXiv e-prints, p. physics/9803008
- Osato et al. (2015) Osato K., Shirasaki M., Yoshida N., 2015, ApJ, 806, 186
- Padilla et al. (2019) Padilla L. E., Tellez L. O., Escamilla L. A., Vazquez J. A., 2019, arXiv e-prints, p. arXiv:1903.11127
- Pandey et al. (2020) Pandey S., et al., 2020, Phys. Rev. D, 102, 123522
- Raveri & Hu (2019) Raveri M., Hu W., 2019, Phys. Rev. D, 99, 043506
- Rigdon (1999) Rigdon E. E., 1999, Structural Equation Modeling: A Multidisciplinary Journal, 6, 219
- Saito et al. (2008) Saito S., Takada M., Taruya A., 2008, Phys. Rev. Lett., 100, 191301
- Samuroff et al. (2019) Samuroff S., et al., 2019, MNRAS, 489, 5453
- Sánchez et al. (2022) Sánchez C., Prat J., et al., 2022, Phys. Rev. D, 105, 083529
- Schermelleh-Engel et al. (2003) Schermelleh-Engel K., Moosbrugger H., Müller H., 2003, Methods of Psychological Research Online, 8, 23–74
- Schneider et al. (2002) Schneider P., van Waerbeke L., Mellier Y., 2002, A&A, 389, 729
- Schwarz (1978) Schwarz G., 1978, Annals of Statistics, 6, 461–464
- Secco et al. (2022) Secco L. F., Samuroff S., et al., 2022, Phys. Rev. D, 105, 023515
- Simon & Hilbert (2018) Simon P., Hilbert S., 2018, A&A, 613, A15
- Singh & Mandelbaum (2016) Singh S., Mandelbaum R., 2016, MNRAS, 457, 2301
- Skilling (2006) Skilling J., 2006, Bayesian Anal., 1, 833
- Spergel et al. (2015) Spergel D., et al., 2015, arXiv e-prints, p. arXiv:1503.03757
- Steiger et al. (1985) Steiger J., Shapiro A., Browne M., 1985, Psychometrika, 50, 253
- Takahashi et al. (2012) Takahashi R., Sato M., Nishimichi T., Taruya A., Oguri M., 2012, ApJ, 761, 152
- Tokdar & Kass (2010) Tokdar S. T., Kass R. E., 2010, WIREs Computational Statistics, 2, 54
- Tröster et al. (2022) Tröster T., et al., 2022, A&A, 660, A27
- Trotta (2007) Trotta R., 2007, MNRAS, 378, 72
- Trotta (2008) Trotta R., 2008, Contemporary Physics, 49, 71
- Troxel & Ishak (2015) Troxel M. A., Ishak M., 2015, Phys. Rep., 558, 1
- Troxel et al. (2018) Troxel M. A., et al., 2018, Phys. Rev. D, 98, 043528
- Vardanyan et al. (2011) Vardanyan M., Trotta R., Silk J., 2011, MNRAS, 413, L91
- Weaverdyck et al. (2022) Weaverdyck N., Alves O., et al., 2022, in prep
- Wilks (1938) Wilks S. S., 1938, The Annals of Mathematical Statistics, 9, 60
- Zuntz et al. (2015) Zuntz J., et al., 2015, Astronomy and Computing, 12, 45
Appendix A Parameters & Priors
Our setup matches the fiducial choices of the DES Y3 cosmic shear analysis. The only significant difference is that, for the sake of simplicity, we choose not to use the additional shear ratio likelihood included by Secco, Samuroff et al. (2022); Amon et al. (2022) (a similar decision was made for validating the analysis choices pre-unblinding; see Krause et al. 2021). As a result, our model space is slightly smaller, since we do not need to vary parameters for galaxy bias or lens photo error. The corresponding parameters and their priors are shown in Table 2. Note that these are almost identical to the priors used in the Y3 analysis, except for those on the shear calibration parameters, which have been shifted to match the input to the simulated data.
In a particular setup, one should expect some level of projection effects in the marginal parameter constraints (Krause et al., 2021). Since such offsets are artefacts of the way we choose to visualise our results (i.e., the global best fit is still accurate) it is not, in general, useful to think of them as a form of bias; our method does, however, rely on our ability to interpret differences in the 2D projected plane. It is thus helpful to try to quantify such effects in our case. In Figure 9 we show the results of our NLA and TATT analyses on an NLA-only data vector, with our fiducial noise realisation. That is, in this case, both the TATT and NLA models can reproduce the data exactly (up to noise). The offset between the best-fitting parameters when using the two models, shown in Figure 9, is at the level of . This effectively provides a floor to the bias in our analysis. Although we can occasionally find biases below this level due to noise (see Section 5 for discussion), we should consider all these cases as unbiased, at least to within the uncertainty due to projection effects. Note that this is consistent with the results of Krause et al. (2021), who performed a similar test using noiseless data (see their Figure 4).
Note that projection effects are complicated, and may be a function of (among other things) the choice of input parameters, noise realisation, priors and constraining power of the data. Although it is reassuring that our result matches that of Krause et al. (2021), there may still be some residual uncertainty in the size of the effect. This is not, however, necessarily a problem for our method. Indeed, variable projection effects would simply add an extra source of noise in the bias-metric relation, which would be factored into our results in the same way as, e.g., chain-to-chain sampler noise.
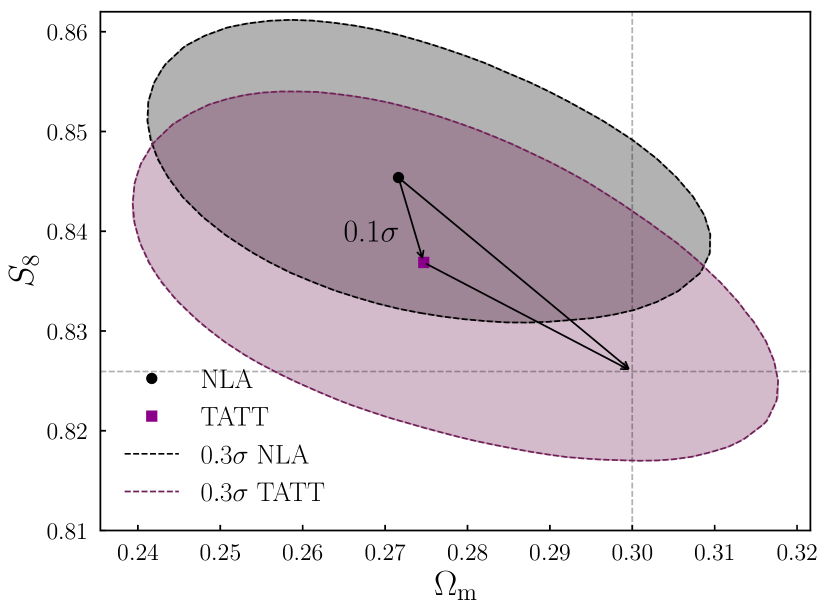
| Parameter | Fiducial Value | Prior |
| Cosmological Parameters | ||
| Calibration Parameters | ||
| Intrinsic Alignment Parameters * | ||
Appendix B NLA & TATT Posteriors
For completeness, in Figure 10 we show the TATT model posteriors for the IA scenarios discussed in Section 5 and Figure 8. In that section we discussed three sets of IA model parameters that were selected to give a range of severity of bias in NLA. Our results there showed that significant biases can be present in an NLA analysis without necessarily distorting the shape of the contours or giving a “bad" (interpreted in the conventional way, using statistically-motivated cut-offs). As expected, the cosmological parameter contours in Figure 10 (upper panel) are consistent with each other. Since the data vectors contain (the same) noise, they are offset from the input point slightly. Depending on the input scenario, the width also varies slightly, primarily due to the tail in space, which correlates with .
It is worth also briefly commenting here on the shapes of the TATT posteriors. It has been observed before that the TATT model can give rise to teardrop shaped, sometimes slightly bimodal contours in the plane (see for example Secco, Samuroff et al. 2022 Fig. 8 and Sánchez, Prat et al. 2022 Fig. 15). A significant tail to positive (or negative) tends to create a tail in , of the sort seen in grey contours in the bottom panel of Figure 10. Note however that the shape and asymmetry depends quite heavily on where the posteriors sit in parameter space (meaning the noise realisation as well as the “true" TATT parameters), and on the constraining power of the data (more constraining power tends to trim away some of the non Gaussian tails). It is not clear that we can use any sort of qualitative assessment based on the TATT posterior shape as an indicator for bias in simpler models.
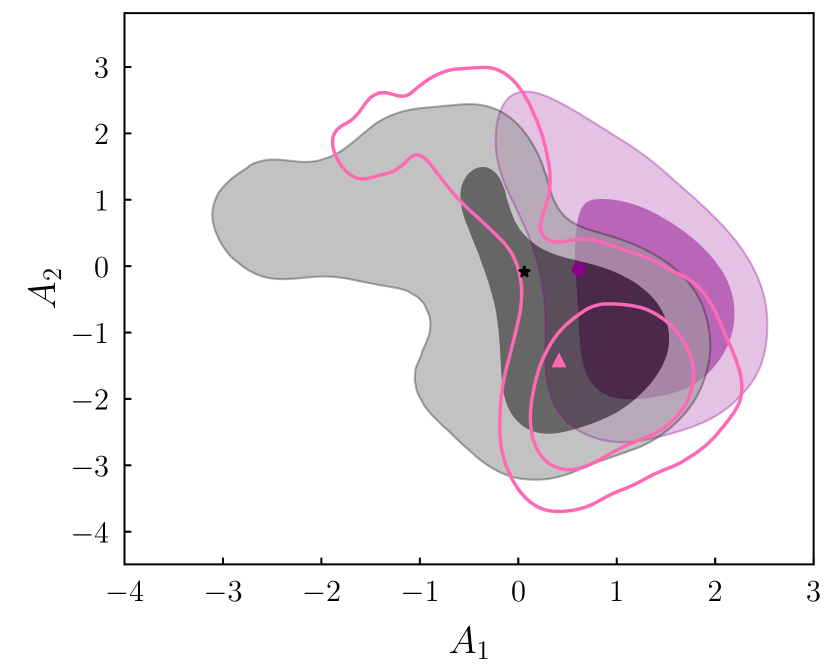
Appendix C Bayes Ratio
Although we ultimately choose to use the as our model comparison statistic, it is also useful to consider other commonly used alternatives. The Bayes ratio has become a popular tool in weak lensing cosmology in recent years, in part because it in principle contains more information than the likelihood. It is also readily available as the by-product of running a nested sampling algorithm to estimate posteriors.
In Figure 11 we show the same 21 IA scenarios as in Figures 4 and 6, but now using the Bayes factor as our model comparison statistic. In the top panel, the open points again show the noiseless case, with evidence values computed using PolyChord. As we can see, there is a weak correlation, with low bias scenarios tending to give somewhere between “substantial" and “barely worth mentioning" on the Jeffreys scale (the coloured bands). Interestingly, in none of our IA scenarios, not even in the regime that is functionally unbiased, do we see “strong" evidence for NLA.
The scattered points in the top panel of Figure 11 show the impact of noise, as estimated using importance sampling. Each colour represents an IA sample, with different points representing different noise realisations. Clearly is significantly more sensitive to noise than , as we can see by comparing Figures 11 and 6. We observe essentially two scenarios – when the bias in the plane is greater than , the Bayes Ratio can tells us that NLA is disfavoured relatively reliably. On the other hand, when the bias in the plane is smaller than , there is a considerable amount of scatter.
The bottom panel in Figure 11 shows the bias probability, conditioned on the Bayes ratio category. That is, given the data return in a particular class on the Jeffreys scale, is the probability that NLA is biased by more than . There is clearly at least some information here; if the Bayes factor actively favours TATT (), there is a high probability that NLA will be biased, even factoring in noise. Values within the “barely worth mentioning" category could essentially go either way. In the “substantial" category things look better, but even here there is chance of biases more than , and almost chance that NLA is biased by more than in the plane.
We can perhaps understand the relative noisiness in by considering Eq. (19). Assuming a Gaussian likelihood, the Bayes factor scales as ; any small perturbation in due to sampling noise will thus be magnified exponentially. We cannot say from this whether this is an inherent issue with the Bayes ratio, or only when estimated using our method of importance sampling. In the absence of an alternative fast method to estimate for many noise realisations, however, we recommend as a more robust metric to use with our method.
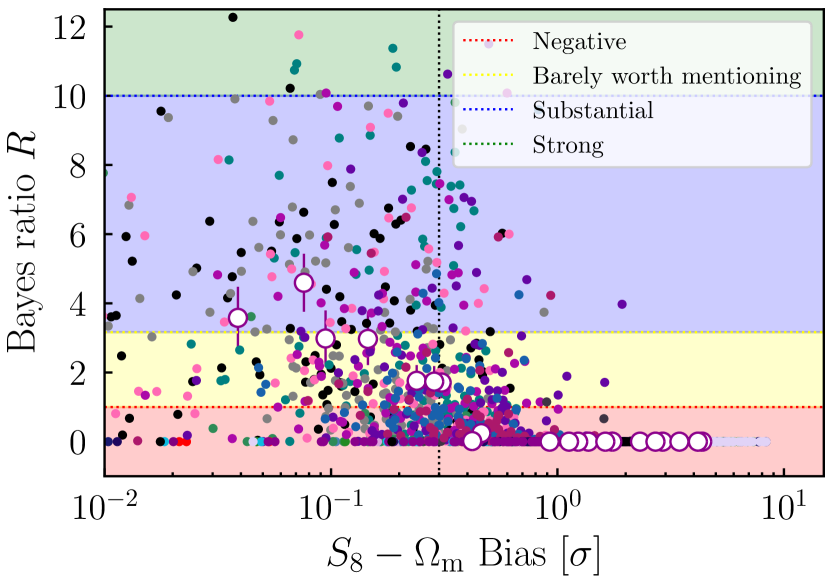
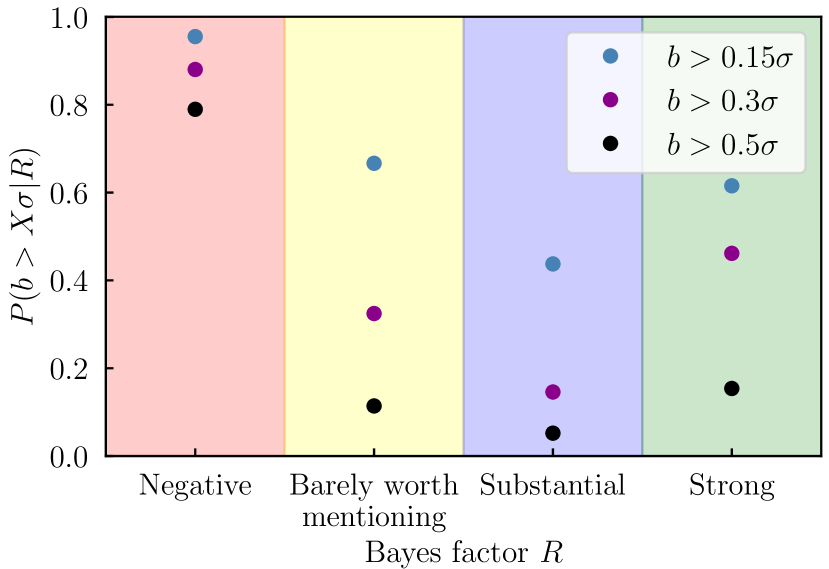
Appendix D Sampler Comparison
In this appendix we present a brief comparison of two commonly used nested sampling codes: PolyChord and MultiNest. Although a similar (albeit more extensive) exercise is discussed in Lemos, Weaverdyck et al. (2022), their analysis choices differ significantly from ours, and so it is worth revisiting the question. To this end, we re-analyse our 21 noise IA data vectors using MultiNest (500 live points, efficiency , tolerance). The results are then compared with our fiducial PolyChord run (500 live points, num_repeats, tolerance). We find:
-
•
The two samplers give consistent results for point estimates. That is, both can reliably locate the posterior mean, and the sampling around the peak is comparable, giving a similar level of noise in the best fit. As a result, the difference between NLA and TATT analyses is relatively insensitive to the choice of sampler.
-
•
MultiNest is seen to underestimate the width of the posteriors on cosmological parameters significantly. This is true in both models; combined with the previous point, it leads to a systematic overestimation of the bias for any given IA scenario. This can be seen in Figure 12, which shows the posteriors as estimated by both samplers for a particular IA scenario.
-
•
The Bayesian evidence estimates from MultiNest are low compared with PolyChord, as was shown in Lemos, Weaverdyck et al. (2022). Although this is true for both models, the overall result is to increase (i.e., push the Bayes ratio towards favouring NLA more strongly).
Given the observations listed above, we chose to use PolyChord as our fiducial sampler, despite the runtime advantage of MultiNest.
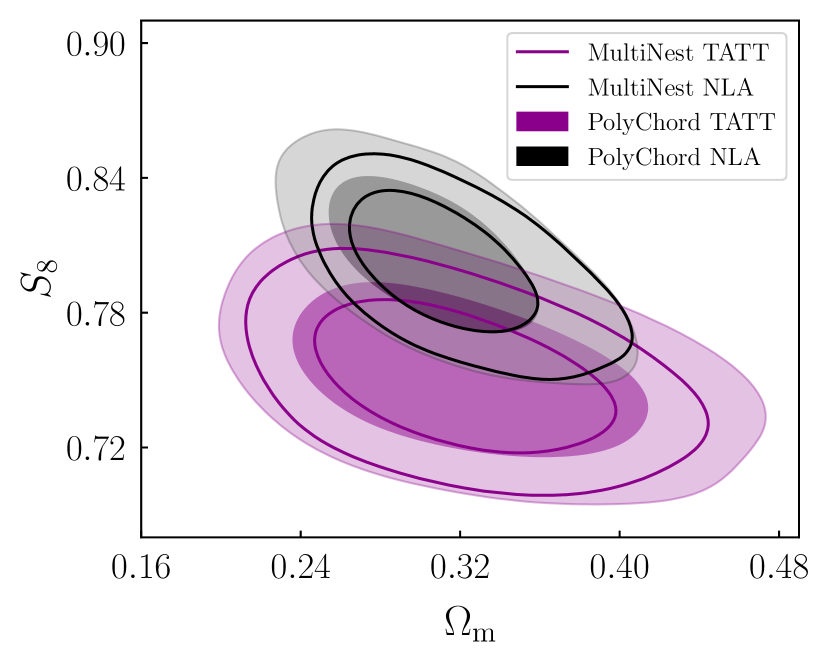
Appendix E Computational Resources
Here we describe the computational resources used for this paper. The aim is to provide an estimate of the computing power required to apply the method described in Section 4.4 to perform model selection. The exact amount of time/resources will naturally vary depending on the details of the analysis pipeline. In our particular case:
-
•
Generate 25 IA samples: less than 1 minute in 1 core.
-
•
Generate 25 IA datavectors: less than 1 minute per datavector in 1 core.
-
•
Run 25 NLA chains using PolyChord: around 22h per chain in 128 cores.
-
•
Run 25 TATT chains using PolyChord: around 28h per chain on 128 cores.
-
•
Generate 50 noise realisations, to be added to each one of the 25 data vectors: less than 1 minute in 1 core.
-
•
Generate importance sampling weights and the pool for 2550 noisy data vectors: around 6-12h on 128 cores.
-
•
Apply the weights to evaluate the NLA and TATT posteriors and compute the bias and best fit in each case: around 6-12h on 128 cores.