An Empirical Evaluation of the Approximation of Subjective Logic Operators Using Monte Carlo Simulations
Abstract
In this paper we analyze the use of subjective logic as a framework for performing approximate transformations over probability distribution functions. As for any approximation, we evaluate subjective logic in terms of computational efficiency and bias. However, while the computational cost may be easily estimated, the bias of subjective logic operators have not yet been investigated. In order to evaluate this bias, we propose an experimental protocol that exploits Monte Carlo simulations and their properties to assess the distance between the result produced by subjective logic operators and the true result of the corresponding transformation over probability distributions. This protocol allows a modeler to get an estimate of the degree of approximation she must be ready to accept as a trade-off for the computational efficiency and the interpretability of the subjective logic framework. Concretely, we apply our method to the relevant case study of the subjective logic operator for binomial multiplication and fusion, and we study empirically their degree of approximation.
keywords:
subjective logic , Monte Carlo simulation , Beta distributions , binomial product , subjective logic fusion1 Introduction
Subjective logic (SL) [4] defines a framework for expressing uncertain probabilistic statements in the form of subjective opinions. A subjective opinion allows a modeler to state probabilities over a set of alternative events along with a measure of the global uncertainty of such modeling. Subjective opinions thus integrate a form of first-order uncertainty, relative to the distribution of probability mass over events, and a form of second-order uncertainty, due to the incertitude in distributing the probability mass. Subjective opinions provide a simple, clean and interpretable way to encode and manipulate uncertainty; as such, they constitute a useful modelling tool in sensitive scenarios in which statistical models can not be inferred from data, but must be built relying on the domain knowledge or the intuition of experts. In this fashion, SL has been extensively adopted to model uncertainty in several fields such as trust modeling, biomedical data analysis or forensics analysis [4].
From a purely statistical point of view, subjective opinions can be seen as an alternative representation for standard probability distribution functions (pdfs), such as Beta pdfs or Dirichlet pdfs. Indeed, under certain assumptions, it is possible to define a unique mapping between subjective opinions and probability distribution functions [4]. This means that subjective opinions may be interpreted as a re-parametrization of standard distributions from the statistical literature.
SL also defines several operators over subjective opinions. These operators allow to carry out transformations over subjective opinions in a very efficient way. With respect to the underlying probability distributions, SL operators provide an extremely quick approximation of operations over probability distributions that would be otherwise very difficult or impossible to evaluate analytically.
Thus, beyond its original application, SL may also be seen as an effective statistical tool to compute approximate probability distributions generated by the transformations encoded into the SL operators. However, while the efficiency of SL operators may be easily evaluated, estimates about their bias are lacking. This shortcoming may limit the adoption of SL in favor of other better-studied approaches, such as Monte Carlo (MC) simulations. Modern probabilistic programming languages [2] provide a versatile language in which operations over probability distributions may be easily defined and evaluated using pre-coded inference algorithms. While being computationally more expensive, these techniques provide comforting guarantees on the convergence of the algorithms as a function of the number of sampling iterations. These guarantees, contrasting the lack of formal bounds of SL operators, may be a strong argument for many researchers to overlook SL and the related set of operators.
In this paper, we propose a protocol to address numerically the problem of characterizing the approximation of SL operators by offering an empirical analysis of their bias with respect to MC simulations. SL operators and MC simulations are taken as two distinct frameworks to approximate operations over pdfs, each one with its strenghts and limitations. Our analysis defines a quantitative comparison in which SL operators and MC simulations are contrasted in terms of the trade-off between computational efficiency and bias. More specifically, our approach allows to answer the question: What amount of approximation should we be ready to accept in exchange for the computational efficiency of subjective logic?
To show the usefulness of our protocol, we consider the specific case of binomial multiplication and fusion. Binomial multiplication is a simple SL operator that returns the approximation of the product of two Beta pdfs. Computing the product of independent Beta pdfs is a non-trivial problem [1] with relevant applications in fields such as reliability analysis and operations research [10]. Binomial multiplication in SL may then be seen as a simple and effective algorithm to compute an approximate solution to the problem of multiplying together two Beta pdfs. Fusion is a SL operator used for merging the opinions of different agents. This operator has been studied and applied in the context of second-order Bayesian networks [6]. For both operators, we compare the approximation obtained using SL to moment-matching approximation and kernel-density approximation produced via MC simulations. In this way, we are able to get an understanding of the amount of approximation that we should be ready to accept if we want to work in the framework of SL.
The rest of the paper is organized as follows. Section 2 reviews the basics of subjective logic and Section 3 presents the main aspects of computational statistics relevant to this work. Section 4 describes the computational complexity of SL approximations and MC approximations, while Section 5 discusses the bias of the same techniques. Section 6 proposes a grounded framework for evaluating the degree of approximation of SL operators in relation to MC simulations. Section 7 makes this framework concrete by applying it to the case study of the product of Beta pdfs, and it presents a set of empirical simulations to validate our approach; similarly, Section 8 applies our framework to another case study, the fusion of Beta pdfs, and it validates our methodology via empirical simulations. Finally, Section 9 summarizes the results and discusses possible directions for future work. For convenience and reference, Table 1 summarizes the notation that will be used throughout this paper.
| Collection of mutually exclusive events | |
| Number of mutually exclusive events | |
| Random variables over | |
| Sample of a random variable | |
| Subjective logic opinion | |
| Belief (vector and scalar) | |
| Disbelief (scalar) | |
| Prior probability (vector, scalar) | |
| Uncertainty (scalar) | |
| Probability distribution function (pdf) of X | |
| -th moment of the pdf of X | |
| , | Expected value and variance of the pdf of X |
| Distance between the pdf of X and the pdf of Y | |
| Empirical pdf for X estimated from samples | |
| Number of samples | |
| Pdf underlying a subjective logic opinion | |
| Empirical pdf for X estimated via Monte Carlo (MC) sampling | |
| Empirical pdf for X estimated via MC and kernel density estimation (KDE) | |
| Empirical pdf for X estimated via MC and moment matching (MM) | |
| Empirical pdf for X estimated via MC and MM with a Gaussian approximation | |
| Empirical pdf for X estimated via MC and ad MM with a Beta approximation | |
| Pdf for X estimated via analytic MM with a Gaussian approximation | |
| Pdf for X estimated via analytic MM with a Beta approximation | |
| Space of probability distribution functions | |
| Space of subjective opinions | |
| Binary operator on the space of probability distribution functions | |
| Binary operator on the space of subjective logic opinions |
2 Subjective Logic
In this section, we present the fundamentals of SL. We start with a formalization of subjective opinions and we show how they may be mapped to probability distributions.
Subjective opinions
Let be a discrete collection of mutually exclusive and exhaustive events. A subjective opinion is a triple:
| (1) |
such that
| (2) |
where , with , is the belief vector expressing the probability mass that the modeler places on each event in , is the uncertainty scalar quantifying the uncertainty of the modeler in its definition of , and is the prior vector encoding a prior probability distribution over the events in . This subjective opinion is called a multinomial opinion.
Notice that the constraint in Equation 2 limits the degrees of freedom of and to and, consequently, defines a -dimensional simplex on which subjective opinions may be represented.
The limit-case multinomial opinion is the binomial opinion for . In this case and the subjective opinion in Equation 1 may be re-written for simplicity as:
| (3) |
such that
| (4) |
where is the belief scalar expressing the probability of , is the disbelief scalar expressing the probability of , is the uncertainty scalar and is a scalar expressing the prior probability of .
Having only two degrees of freedom, binomial opinions in the form belong to a two-dimensional simplex and may be visualized together with in a barycentric coordinate system111See http://folk.uio.no/josang/sl/BV.html for an illustration..
Mapping of subjective opinions
In order to ground SL, a mapping has been defined between multinomial opinions and Dirichlet pdfs and between binomial opinions and Beta pdfs.
Given a mapping constant , it is possible to define a unique mapping from opinions to pdfs. Let be a multinomial opinion with ; can be mapped to a Dirichlet pdf with distribution , where the vector of parameters is defined as:
| (5) |
For binomial opinions, specifically, given a mapping constant , it is possible to define a unique mapping from opinions to pdfs. Let be a binomial opinion with ; can be mapped to a Beta pdf with distribution , where and are parameters defined as:
| (6) |
Notice that, for reasons of consistency, is usually fixed to [4]. We then have a mapping from opinion to pdf :
Vice versa, given a mapping constant and a fixed prior distribution , it is possible to define a unique mapping from pdfs to opinions. Let be a Dirichlet pdf with distribution with ; can be mapped to a multinomial opinion , where the parameters are computed as:
| (7) |
Again, for a binomial opinion, given a mapping constant and a fixed prior distribution , it is possible to define a unique mapping from pdfs to opinions. Let be a Beta pdf with distribution with ; can be mapped to a binomial opinion , where the parameters are computed as:
| (8) |
For reasons of consistency, is usually fixed to [4]. Given a prior distribution , this generates the mapping from pdf to opinion :
Subjective opinion operators
SL defines several operators over subjective opinions, such as addition, product or fusion [4]. In general, these operators are computed over the parameters of subjective opinions. Let and be two subjective opinions and let be a generic operator over the space of subjective opinions . Then, resulting from the application of the operator to and is given as:
| (9) |
where are operator-specific functions returning the values of belief, uncertainty and prior for the opinion .
Subjective opinion operators for evaluating operations over pdfs
When properly defined, SL operators can be used to approximate operations over probability distribution functions. Suppose we are given two pdfs, and , and we want to compute a generic operation over them, over the space of probability distributions . Computing this operation over probability distributions may be very complex. However, if we have an SL operator that approximates , we may find a workaround computing by projecting the two distribution onto the opinions and , computing the resulting opinion , and then mapping the result back onto a probability distribution function . In this way, the resulting pdf provides an easy-to-compute approximation of the real pdf (see Figure 1).
3 Computational Statistics
In this section, we review some elements of computational statistics that are relevant to our work. We describe how sampling is used in MC simulations; we show how unbiased estimators can be built via MC integration; we discuss how unbiased estimators can be used to build moment-matching approximation; we show how pdfs may be reconstructed through kernel density estimation; and, finally, we bring these parts together to show how MC simulations may be used to compute the product of pdfs via moment-matching or kernel-density estimation.
Monte Carlo sampling
MC simulations are stochastic numerical algorithms designed to find approximate solutions through repeated random sampling. This paradigm has been applied in many areas of research to solve problems whose exact analytical solution is impossible or too difficult to derive. In statistics, MC simulations are widely used to evaluate probability distributions whose analytical form can not be explicitly expressed. Let be a random variable with a probability distribution on the support ; let us also assume that the analytical form of is unknown but that we can sample realizations of the random variable ; then, MC simulations allow us to draw a large number of independent samples and use them to (i) compute useful empirical statistical descriptors of the probability distribution , or, eventually, (ii) reconstruct the approximate shape of the probability distribution .
Monte Carlo integration
In order to compute useful empirical statistical descriptors of the probability distribution , MC simulations rely on integration and on the law of large numbers. Let be a statistics of the probability distribution that can be computed from a function applied to the samples . The statistics is then defined as:
| (10) |
By the law of large numbers, an estimator of can be computed using samples of as:
| (11) |
It is immediate to see that using Equation 11 and choosing an appropriate function we can directly estimate useful statistics of the distribution , such as moments and quantiles. Thus, through a MC simulation we can sample points from and compute informative estimator statistics .
Moment-matching approximation
A probability distribution is completely characterized by the collection of all its moments; if we know the parametric form of the function from which we are sampling from, but we ignore the exact value of its parameters, we can compute an estimate by setting the moments to the estimated values . In several scenarios of interest it may actually be possible to compute analytically the value of few lower moments of interest (such as, mean and variance); this approach is well-known and it has been used in the study of SL operators as well (see, for instance, [7]). In general, though, MC simulation and integration provide an empirical and robust way to compute estimators of the -th moments of a probability distribution , even when no exact analytical formula for computing the moments of interest is available.
Kernel density estimation
Beyond computing statistics, it is possible to use samples generated in a MC simulation to reconstruct the actual probability distribution . A standard approach to reconstruct a continuous function from a set of finite points is kernel density estimation (KDE). Any function may be expressed as a convolution with a kernel function :
| (12) |
Practically, it is possible to get an empirical approximation using only a finite set of points :
| (13) |
where the kernel is a symmetric function, like a triangular function or a Gaussian, and denotes the width of the kernel; empirical rules are available to select an optimal value for this parameter in relation to the number of samples available [11]. Thus, using the same MC simulation procedure to sample points from it is possible also to estimate an approximate probability distribution .
Monte Carlo simulation for evaluating operations over pdfs
Suppose we are given two probability distributions, and , and suppose we want to compute the distribution determined by the application of operation , that is, . If the pdf can not be computed analytically, MC simulations may be used to sample from and to estimate a pdf that approximates . As a first solution, we could rely on the samples obtained by sampling from and to estimate the moments and then instantiate a moment-matching approximation (see Figure 2). Alternatively, we could use the same samples from to perform a kernel-density estimation and compute the KDE approximation (see Figure 3). Notice that, differently from the SL approximation , we decorate the approximations computed via MC simulations and with a hat to underline that they are empirical statistics.
4 Computational Complexity
In this section, we discuss and compare the computational complexity of SL operators and MC simulations. We will evaluate the computational complexity using the notation as the time complexity of running a given algorithm as a function of its input.
Subjective logic
SL operators are defined to be extremely efficient. Indeed, given two opinions and and the generic operator , the computation of usually requires only a limited number of function evaluations, as shown in Equation 9. The number of evaluations is , where is the number of events over which the opinions are defined. Thus, the overall complexity is : it depends only on the number of events considered, and it is independent of the actual form of the mapped distributions. This makes SL operators an attractive choice especially when working in lower dimensions.
Monte Carlo simulation
The MC approach is, by definition, computationally intensive. The computational complexity of a MC simulation scales as a function of the number of samples that must be produced. Each iteration requires random sampling and the execution of all the operations necessary to sample from . Overall, the computational complexity of the MC simulation is .
If we are using MC simulations to estimate a moment-matching approximation , MC integration allows us to compute statistics from the samples generated during the MC simulation with no additional overall computational complexity.
However, if we want to estimate the actual pdf via KDE we have to take into account an increase in the overall computational complexity from the linear order to the quadratic order . Computing the pdf is then a significantly computationally expensive procedure.
It is evident that, taking into account computational complexity only, SL operators dominate MC simulations, with or without KDE, especially considering that the number of samples in a MC simulation is required to grow large in order to return reliable results even in low dimensions.
5 Bias
In this section, we start analyzing the degree of approximation of SL operators and MC simulations. We will evaluate the degree of approximation in terms of bias of the estimator , that is, as the expected value of the difference between the true distribution and the estimated approximation: .
Subjective logic
The bias of SL operators is dependent on the definition of the specific operator, and a generic theoretical treatment is not possible. Moreover, an analytic study of the bias is not always available for all possible SL operators. In Section 7 we will consider the case study of the binomial operator for subjective logic and we will analyze more in detail its specific bias.
Monte Carlo simulation
MC simulations are known to provide asymptotically unbiased estimators. If we estimate a statistics of the pdf using a MC integration as in Equation 11, then is an asymptotically unbiased estimator, that is, in the limit of infinite samples, it converges to the true quantity it approximates:
| (14) |
where we made explicit the dependence of on the number of samples .
If we use MC integration to estimate the moments for a moment-matching approximation , the MC simulation provides us with unbiased estimators of the moments; this means that, by increasing the number of samples generated in a MC simulation, we can get arbitrarily close to the true value of the estimated quantity. However, notice that while the estimated moments are asymptotically unbiased, the is biased; this bias is due to the limited set of moments used to approximate .
If we use a MC simulation to estimate the true pdf directly via KDE, the empirical pdf is biased. In this case, it is known that the width parameter of KDE regulates the trade-off between bias and variance. In general, the bias can be shown to be proportional to the width of the kernel :
| (15) |
under the constraint that can not be reduced to zero, for statistical and computational reasons [11]. When using a Gaussian kernel, the widely-adopted Silverman rule suggests the adoption of a kernel width of the following size:
| (16) |
where is the empirical standard deviation computed from the samples:
| (17) |
where is the empirical mean. It follows, then, that the bias of the KDE approximation is proportional to:
| (18) |
As said, this bias can never be reduced to zero. However, in specific computational setting, this bias may be bounded by finding an optimal trade-off between the number of samples and the empirical standard deviation .
In particular, if the domain of is a discrete domain, as in the case of multinomial opinions and Dirichlet pdfs which underlie subjective opinions, then the empirical standard deviation may be bounded and it may be possible to estimate the magnitude of the bias as a function of the number of samples .
In summary, from the point of view of approximation, MC simulations represents a safer choice than SL operators, as they are grounded in solid theory and they allow us to quantify and to control the bias. The lack of any bound for SL operators may be seen as an obstacle in adopting them when working in critical domains where precise approximations are required. In the next section, we will introduce our protocol to solve this problem and estimate the degree of approximation of SL operators.
6 Computational Evaluation of the Degree of Approximation of Subjective Logic Operators
In this section we present a framework to evaluate the bias of an SL operator. We start by discussing how MC approximations may be related to SL approximation using a distance measure; then, we define what precise distance measure we will use and how it relates to bias.
Relating subjective logic approximation and Monte Carlo approximations via a distance measure
In the previous sections we illustrated two methodologies for finding an approximation of the pdf , one based on SL operators () and one relying on MC simulations (). Figure 4 merges the graphs in Figure 1, 2 and 3 to illustrate the alternative computational paths that are offered to compute an approximation of ; starting from the distributions , the upper path represents the SL approach to finding an approximation of , while the lower paths represent MC approaches to finding an approximation of the same quantity .
Now, approximate methods trade off precision in the results for simplicity in computation. In order to make a grounded decision on which approximation path in Figure 4 to use, it is necessary to quantify the trade-off between computational complexity and bias. As discussed in Section 4 and 5, in the case of KDE approximation via MC simulations, both complexity and bias are known. However, in the case of SL operators, we may easily derive their computational complexity, but we have no simple way of evaluating their bias. Exploiting the properties of MC integration and the idea of distance between pdfs, it is possible to assess the degree of approximation of SL operators in a computational fashion by relating them to MC simulations.
A simple way to evaluate how well a pdf approximates another pdf is to estimate the distance between them, , where is a measure of distance or divergence between pdfs [8]. The degree of approximation of could then be obtained by measuring the distance from the true pdf :
| (19) |
However, since the true pdf is taken to be unknown or hard to compute, it is challenging to get a direct estimate of these quantities. Since we can not rely directly on , we can instead exploit MC simulations and its properties.
From Equation 15 in Section 5, we know that the KDE estimation is biased and we know how to evaluate it. Moreover, from Equation 18 in Section 5, we see that this bias depends on the number of samples and the standard deviation . Now, if the domain of is a discrete domain, as in the case of multinomial opinions and Dirichlet pdfs, then the empirical standard deviation may be bounded and it may be possible to estimate the magnitude of the bias as a function of the number of samples . It may be possible to select a number of samples that shrinks the bias to a negligible quantity; in such case, we can then accept the KDE estimation as a close approximation of the true pdf :
| (20) |
We underline that this approximation holds only under the assumption that, for an increasing number of samples , the bias of the estimate tends, if not to zero, to a quantity whose order of magnitude is negligible with respect to further analysis; in other words, the validity of the approximation in Equation 20 is conditional on the pdf we are considering, the analysis we will be carrying out, and the number of samples we can produce (for an example of an evaluation of these conditions, see the application to the case study of the product of Beta pdfs in Section 7 and Section 7.1).
The approximation in Equation 20 is extremely useful because it means that while we can not evaluate absolute distances with respect to the true distribution , we can still evaluate the relative distance between the KDE approximation and the SL approximation, and use it as a proxy for the distance between the SL approximation and the true distribution :
| (21) |
Thus, given only a finite set of samples we can obtain an empirical statistic of the distance as:
| (22) |
If the condition in Equation 20 holds, we expect the distance to be orders of magnitudes greater than ; this would indeed confirm that the bias of is negligible and that the computation of (using a finite number of samples) provides a good estimate of the degree of approximation of the SL approximation.
Relating distance measure to bias
So far, we have discussed distance measures in abstract terms. The quantity may indeed be computed using different pdf distance, such as -divergences or integral probability metrics [13].
In this paper, we will rely on computing a simple integral distance, defined as:
| (23) |
This distance is the same as the total variation distance except for the scaling constant:
| (24) |
The constant rescales the distance on the interval . However, in order to get an absolute evaluation of how the mass of the two distributions and overlaps, we drop the scaling constant.
The choice of an integral distance is justified for three reasons. First, from a conceptual point of view, an integral distance allows us to get a complete picture of the difference between two pdfs. While measures based on the evaluation of a limited set of synthetic statistics such as moments would provide us with a rough evaluation of the difference between two distributions, an integral distance provides a more precise way to assess the distribution of the mass of probability, taking into account, for instance, the potential presence of multiple modes or how mass subtly distributes on the tails.
Second, from a computational point of view, the integral distance allows us, once again, to exploit MC integration. Recall that we want to get an estimation of through the approximation . Now, if we reconstruct via KDE, we can estimate the integral distance via MC integration over the domain of the events as:
| (25) |
Third, from a theoretical point of view, the integral in Equation 25 is related to the bias:
| (26) | ||||
| (27) | ||||
| (28) |
Thus, using the integral distance we can obtain an estimation of the distance as well as an upper bound on the bias of . Notice that the absolute value in the integral distance provides a more honest evaluation of the absolute difference between pdfs, avoiding an averaging effect in absence of the absolute value operator.
Figure 5 summarizes our overall framework to evaluate the degree of approximation of the SL approximation as the integral distance , under the assumption that . This approach is generic and it is not tied to the SL approximation. If the condition in Equation 20 can be guaranteed, the same approach may be used to get an estimation of the distance between the true pdf and other potential approximation. For instance, Figure 5 shows our methodology applied also to the problem of estimating the distance from the true pdf of the moment-matching approximation by computing the distance .
7 Case Study: Product of Beta Distributions
In this section, we show how our framework may be applied to the problem of computing the product of Beta distributions. We first recall the definition of a Beta distribution and the definition of the product of Beta distributions; we then introduce the SL operator for binomial multiplication and we discuss how it can be used for approximating the distribution of the random variable given by the product of two independent random variables with Beta distributions; we work out the computational complexity of binomial multiplication and show the lack of generic estimate of its degree of approximation; to solve this problem, we apply our framework to get an evaluation of the degree of approximation of binomial multiplication; finally, we run an extensive set of empirical simulations to validate our theoretical results.
Beta pdf
Let be a random variable on the support ; we say that follows a Beta distribution with parameters and when its probability density function has the following form:
| (29) |
where is the Beta function.
Product of Beta pdfs
Let and be two independent Beta random variables with associated pdfs and . Let us define a third random variable as the product of the two Beta random variables . The probability density function of does not follow a Beta distribution anymore, and its precise analytical form can not be easily expressed using elementary functions [9]. An analytical solution to the evaluation of the pdf of the product of two Beta distributions has been offered in [10]222This paper actually presents the more generic solution to the problem of multiplying two general Beta distribution, which subsume the multiplication of two simple Beta distributions as defined above.:
| (30) |
where is the Lauricella D hyper-geometric series. While this formula provides an elegant solution to the problem of finding the pdf of the product of two Beta pdfs, its straightforward evaluation is challenging as the Lauricella function requires the computation of factorial products and series.
Other analytical approaches to evaluate the product of two or more Beta distributions have been proposed, including methods relying on high-order functions, such as the Meijer G-function or Fox’s H function, or modeling the pdf of the product using an infinite mixture of simpler distributions [14, 1]. These approaches also present computational challenges, despite more efficient solutions have been investigated [14, 1].
Finally, common approaches rely on MC simulations to sample points from the probability distribution of and to compute statistics of the pdf by matching the moments or the quantiles of [9], as we reviewed in Section 3. Notice that when considering the product of two independent random variables , it is straightforward to compute the mean and the variance of analytically as:
| (31) |
Thus, if we were to perform a moment-matching approximation considering only the first two moments, we could instantiate such an approximation without running any MC simulation with a constant computational complexity of .
Subjective logic binomial multiplication
An alternative solution to compute the product of Beta distributions is based on the use of the SL operator for binomial multiplication. Given two binomial opinions and defined on different domains, the binomial opinion resulting from the multiplication is computed as [4]:
| (32) |
Practically, a binomial product operator allows us to evaluate the combination of two opinions over two different facts. In the domain of probability distributions, the multiplication of opinions translates into the multiplication of the mapped pdfs .
Approximating the product of Beta pdfs
Now, assume we are interested in computing the product , where and are two independent Beta random variables. Since an analytic solution is hard to compute, we may decide to rely either on the SL approximation or on a MC approximation.
Concerning moment-matching approximations we may consider a Gaussian pdf and a Beta pdf. Using a Gaussian pdf is a choice motivated by the simplicity and the ubiquity of this distribution; however, this is clearly a naive choice, as a Gaussian pdf has an unbounded support, is symmetrical and it assumes that all the statistical moments greater than the second are zero. Using a Beta distribution is a more prudent choice: even if it is known that the product of two Betas is not, in general, a Beta distribution, a Beta pdf still fits the right support and it may have other moments different from zero. In order to evaluate the parameters of our Gaussian and Beta approximation, we may rely on MC simulations or on an analytic evaluation. If we opt for MC simulations, we can use MC integration to estimate the mean and the variance of ; the Gaussian approximation is then instantiated as , while the Beta approximation is defined as , thus guaranteeing that , and have the same mean and variance. If we rely on an analytic approach, we can easily compute the mean and the variance of using Equation 31; as before, the Gaussian approximation is then instantiated as , while the Beta approximation is defined as
Figure 6 provides a concrete instantiation of the diagram in Figure 4, in which the generic operators and have been substituted with multiplication and the generic moment-matching approximation has been replaced by the empirical Gaussian approximation , the empirical Beta approximation , the analytic Gaussian approximation , and the analytic Beta approximation .
As discussed earlier, choosing which path to take, whether to follow the SL approximation path in upper part of the graph or opt for one of the MC approximations in the lower part, requires evaluating the trade-off between computational complexity and degree of approximation of the different approaches. As these parameters are known in the case of MC simulations, we will review here the computational complexity and the approximation of the binomial multiplication.
Computational complexity of the binomial product operator
Binomial multiplication is extremely efficient. Given two binomial opinions and it is possible to compute their product through a fixed and finite number of arithmetic operations. Independently from the actual form of the mapped distributions, the product is always computed in the same amount of time. As such, the computational complexity of these SL operators is constant .
Approximation of the binomial operator
The original paper that introduced the SL operator for binomial multiplication [5] proposed a first qualitative analysis of the degree of approximation of this operator. In particular, it considered the specific instance of the multiplication of two Beta pdfs of the form ; the pdf of and reduces to a uniform distribution over , which is taken to be a worst-case scenario with maximal variance and entropy. The analytical solution to this particular case was then computed and graphically compared to the pdf associated with product . This study provided a clear visual appraisal of the difference between the exact pdf and the SL-approximated pdf, but no quantitative estimation were provided for more general cases.
Relating the binomial multiplication and Monte Carlo approximations
In order to compute a numerical estimation of the degree of approximation of the SL operator for binomial multiplication we want to rely on the framework described in Section 6.
The basic condition expressed in Equation 20 requires the bias of to be bounded and negligible. Recall that this bias, using a Gaussian kernel with width computed using the Silverman rule, is , where
| (33) |
Now, notice that on our bounded support we can expect the difference to, be at most, in the order of . This implies that, in the worst case, the order of magnitude of may be estimated as:
| (34) |
| (35) |
Consequently, relying on Silverman rule in Equation 16, the order of magnitude of largest kernel width may be bounded as:
| (36) |
| (37) |
As such, from Equation 18, the bias will be proportional to this upper bound:
| (38) |
Thus, for instance, if we were to run our MC simulation sampling samples, then we can expect the bias of to be in the order of . This analysis on the bias allows us to consider the bias negligible if we are comparing it with quantities, such as , order of magnitude greater than . If this condition is met, then we can estimate the degree of approximation of binomial multiplication adopting the framework illustrated in Figure 5 and instantiated for this specific SL operator as in Figure 7.
7.1 Empirical Evaluation
In this section we describe our experimental simulations for the evaluation of the degree of approximation of the binomial product. We will first offer a qualitative analysis of the SL approximation and the approximation generated via MC simulation ; then, we will provide a quantitative statistical assessment of the distance ; next, we will analyze a specific study case concerning the worst-case scenario of the product of two degenerate Beta random variables; finally, we will assess quantitatively the degree of approximation in the product of multiple opinions.
In our simulations starting in the domain of subjective logic, opinions are sampled randomly. The parameters , and must be sampled from a simplex defined by the constraint ; therefore we sample them from a Dirichlet distribution with , which guarantees a uniform sampling over the simplex. The parameter , instead, is sampled from a uniform distribution . In the simulations starting in the domain of probability distributions, Beta distributions are sampled randomly; both parameters and are drawn from a uniform pdf on a bounded domain, .
All the simulations are carried out using the WebPPL probabilistic programming language [3] and the scripts are available online333https://github.com/FMZennaro/SLMC/BinomialProduct.
7.1.1 Qualitative simulations
In the qualitative simulations we aim at getting a first intuitive feeling about the approximation of .
Protocol
In order to compare the SL approximation and the MC approximation we adopt the following protocol: (i) we sample two random opinions and ; (ii) we compute their product ; (iii) we project onto the distribution ; (iv) we project the opinions and onto the Beta distributions and ; (v) we re-create using MC simulation to draw samples from ; finally, (vi) we plot against numerically, without any smoothing or interpolation. On the side, (vii) we use the samples to estimate moments via MC integration and then instantiate the moment-matching approximations and ; (viii) we use Equation 31 to compute the analytic moment-matching approximations and ; (ix) we plot the moment-matching approximations against numerically.
Results
Figures 8 and 9 illustrates the difference between the SL binomial multiplication and the approximation of the true pdf plotted via MC. In some instances, seems to provide a very good approximation of , as shown in Figure 8. In other instances, as shown in Figure 9, this approximation is more coarse, especially when it comes to values of the support near the extremes.
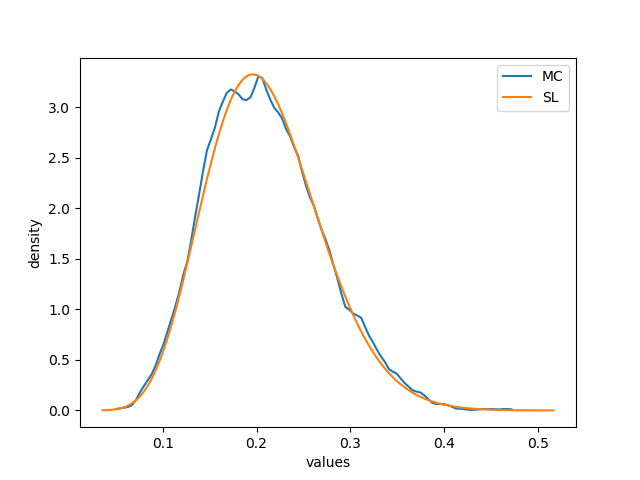
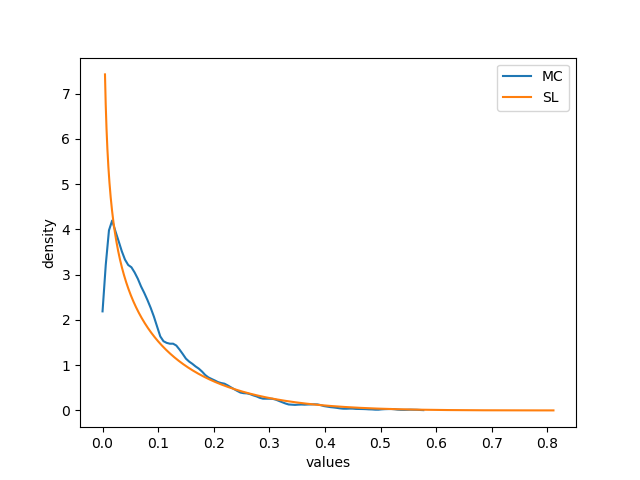
The discrepancy shown in Figure 9 may be theoretically imputed to a poor approximation of the MC simulation due to a limited number of samples. In order to confute this hypothesis, another identical simulation with a number of samples one order of magnitude larger was run. Figure 10 shows that this simulation returned the same qualitative result. This suggests that the gap between and may not be imputed to a poor MC approximation.
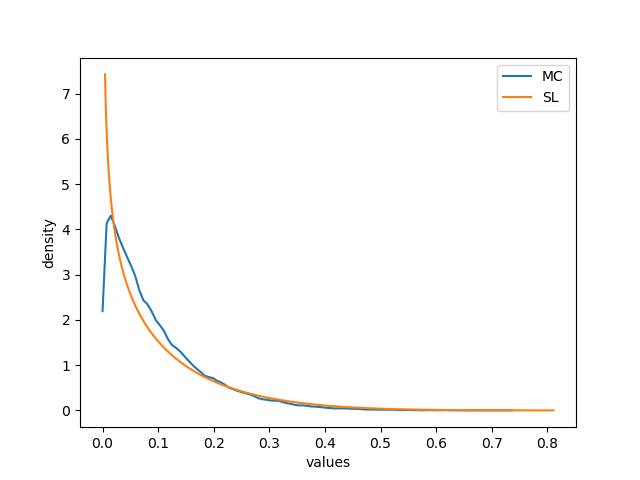
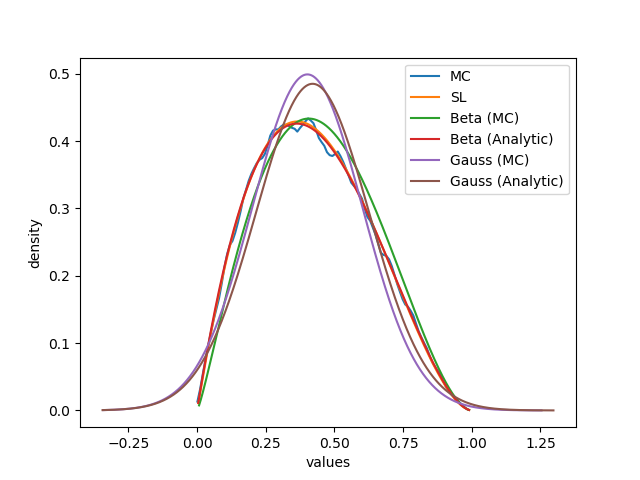
Figure 11 offers a visual comparison of the approximations offered by and contrasted now with the Gaussian , and the Beta , approximations. The analytic and empirical (via MC) approximations behave in a very similar fashion. Overall, the Gaussian approximations are the farthest from , while the Beta approximations follow very closely and ; in particular, the analytic Beta approximation almost overlap , because of a similar approach in evaluating the moments of .
Discussion
This analysis suggests that the SL approximation may provide a good and useful estimation of the true pdf ; indeed, follows very closely the shape which, in turn, is close to . Given that consists of a smooth Beta distribution, it is not surprising that the approximation suffers the worst near the boundaries where the MC estimate diverges from , as shown in Figure 9. The results also discourage the naive possibility of using a Gaussian approximation, since mismodels the true pdf by centering the mean but spreading probability mass too widely beyond the domain . Instead, a Beta approximation or provides an approximation qualitatively very close to and ; also, notice that the Beta approximation can be computed as cheaply as the SL approximation, with complexity , by evaluating its mean and variance analytically.
7.1.2 Quantitative simulations
Quantifying the gap between and that we observed in the qualitative study above is the aim of the quantitative simulations.
Protocol
The first part of our quantitative protocol is the same as the qualitative protocol: (i-a) we sample two random opinions and ; (ii-a) we compute their product ; (iii-a) we project onto the distribution ; (iv-a) we project the opinions and onto the Beta distributions and ; (v-a) we re-create using MC simulation to draw samples from . Then, instead of plotting our results, (vi-a) we use a KDE to explicitly estimate ; and, (vii-a) we compute via MC integration the area determined by the integral . On the side, we compute moment-matching approximations as before: (viii) we use the samples to estimate moments via MC integration and then instantiate and ; (ix) we use Equation 31 to compute the analytic approximations and ; (x) we compute via MC integration the area determined by the absolute difference between and each moment-matching approximation.
For completeness, we also run a simulation starting in the domain of pdfs: (i-b) we sample two random Beta pdfs and ; (ii-b) we re-create using MC simulation to draw samples from ; (iii-b) we use a KDE to explicitly estimate ; (iv-b) we map the Beta distributions and onto the opinions and ; (v-b) we compute their product ; (vi-b) we project onto the distribution ; and, (vii-b) we compute via MC integration the area determined by the integral . As before, we also compute distances between and empirical (via MC) and analytical moment-matching approximations as explained in the steps (viii)-(x) above.
In order to get significant statistical result, we repeat each simulation times and we compute the mean and the standard deviation of the distance .
Notice that, since the pdf that we are trying to estimate is defined on a bounded interval, using a Gaussian kernel for KDE is a sub-optimal choice. The Gaussian kernel distributes the mass of probability over the entire real line, and thus we would inevitably spill part of the probability mass beyond the domain . To solve this problem we adopt the logit trick [12]: instead of applying a Gaussian KDE to estimate directly from the samples , we use a logit transform to project the sample onto the entire real line; we then apply a Gaussian KDE to the projected samples and rescale back the learned pdf to .
Refer to Figure 7 for the diagram of the experimental protocol for the quantitative simulations.
Results
Figure 12 shows the variation in the distances estimated as as a function of the number samples generated in the MC simulation. All the statistics are computed from repetitions and using uniformly sampled points on the support to perform MC integration.
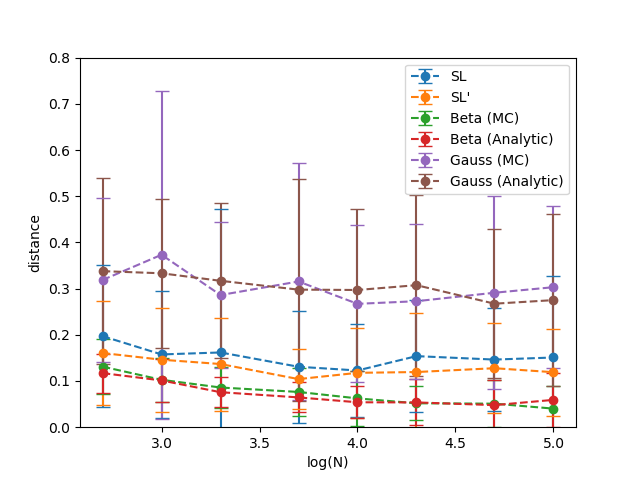
The stable trend of all the distances suggests that the MC simulations sampled enough points, for all the values of that we considered, to return a good approximation.
More importantly, recall that our whole analysis holds only if Equation 20 is satisfied. Using , we know from Equation 38 that the bias in evaluating is in the order of . Thus compared to the scale of the mean and variance error in our results, which are in the scale of , we can confirm that the bias is negligible. We can then state that does indeed provide a good estimate of .
Consistently with the previous experiments, the Gaussian approximations provides the worst approximation. Indeed, with distances and averaging around , we can expect one sixth of the probability mass of a Gaussian approximation not to overlap with the true distribution .
The Beta approximations and clearly offer a better solution. Even if the product of two Beta distributions is not a Beta distribution, it is clear from these results that the shape of is in general very close to a Beta pdf. Indeed, the expected value of and point out that of the mass of a Beta approximation and overlap with very limited variance.
The SL approximation also offers a good solution. The result of the simulation in which we started from opinions and the one in which we started from Beta pdfs are extremely close. This offers a confirmation of the robustness of the transformations between the domain of opinions and the domain of pdfs. Overall, the expected value of suggests that the typical overlap between the mass of and settles around , slightly worse than the Beta approximation. The high variance points to a strong case-by-case variability: in certain scenario may provide a model as good or better than or , but on other instances its quality may degrade further.
Discussion
The results of our quantitative analysis agree with the qualitative study. A Gaussian approximation or was shown to be a poor choice for modelling the product of two Beta distributions (and, for this reason, we will drop this approximation from the next simulations). Instead, the SL approximation and the Beta approximations or are both good approximations, assuming that we can accept a difference between the true pdf and the approximation up to of the probability density. With limited computational resources, seems to be, on average, the best bet.
7.1.3 Limit-case Study
In this limit-case study, we consider the worst-case scenario considered in [5]. This study provides a way to enrich the previous study and reconnect this paper to it.
Protocol
We quantitatively analyze the case in which both opinions and are degenerate Beta pdfs of the form with . To provide a quantitative analysis we follow the same protocol used in Section 7.1.2: first, we derive the MC approximation (using the KDE algorithm), the SL approximation , the empirical (via MC) Beta approximation and the analytic Beta approximation ; then, we compute the distance between the aforementioned distributions and the true pdf , whose exact form, , is given in [5].
Results
Table 2 shows the evaluation of the distance with respect to the true pdf , when performing MC simulations with points and using uniformly sampled points on the support to perform MC integration.
The results show that the difference between the approximations is about one order of magnitude from each other. The MC approximation is, as expected, very close to the true pdf , with a distance averaging around . This is higher than the theoretically computed value, likely due to the fact that we are evaluating a limit case; however, this difference is still small enough to allow us a comparison with the other approximations. The Beta approximations have a slightly higher distance around . Finally, the SL approximation has the highest distance at around , meaning that the probability mass of and overlap for about . All the results also show a high variance, which is caused by the difficulty in numerically approximating values near , where the true pdf diverges.
| KDE | 0.00871 0.01242 |
|---|---|
| SL | 0.20793 0.93301 |
| Beta (MC) | 0.03070 0.10018 |
| Beta (Analytic) | 0.03635 0.14617 |
Discussion
The results are consistent with our previous results obtained in the quantitative analysis in Section 7.1.2 and they confirm that the scenario considered in [5] with two degenerate Beta pdfs of the form and is indeed a hard case for SL approximation. The MC approximation performs better in modeling the true form of the pdf and, compared to it, the SL approximation is two orders of magnitude less precise in terms of integral distance. This simulation thus clearly highlights the cost in terms of accuracy that the computational simplicity of SL implies.
7.1.4 Multiple Products
In this last experimental section we consider the product of multiple opinions and we examine how approximation spread.
Protocol
We quantitatively evaluate the product of multiple opinions , … by randomly sampling opinions and then defining the product and . The following analysis adopts the same protocol used in the quantitative simulations in Section 7.1.2 in order to compute the SL approximation and the analytic Beta approximation , and then evaluate the integral distances , where now the final pdf over is given by the product of multiple opinions. Notice that, while the convergence properties of the MC simulation remains the same, we may expect the precision of the SL approximation and the Beta approximation to degrade over multiple products as successive approximations cumulate.
Results
Figure 13 shows the variation of the distance and as a function of the number of opinions that are multiplied together to determine . A slight increase in the degree of approximation may be observed as the number of factors increases from to .
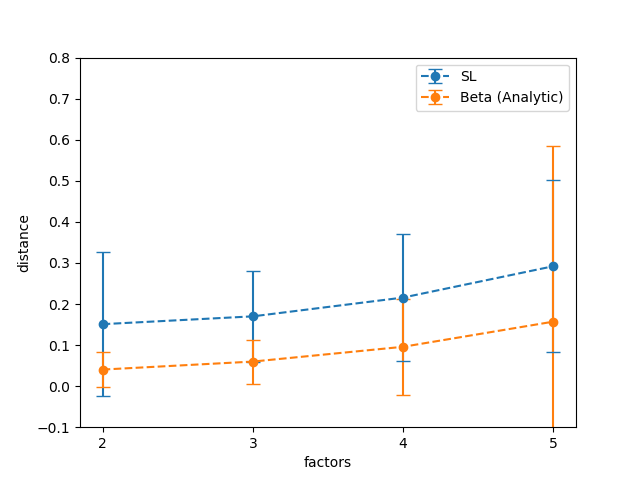
Discussion
The hypothesis that the degree of approximation of the SL operator and analytical Beta approximation degrades over multiple products because of the accumulation of approximation appears to be correct. As more factors are taken into consideration, both and slowly diverges from the true pdf . A modeler should be aware of these dynamics in case she were to use SL to approximate the product of multiple Beta random variables.
8 Case Study: Fusion of Beta Distributions
In this section, we further showcase the versatility of our framework by applying it to yet another subjective logic operator. We first provide the definition of fusion of Beta distributions; we then introduce the SL operator for fusion and we discuss its approximation and complexity; finally, we apply our framework to the problem of getting an approximation of fusion and we run empirical simulations to validate our theoretical results.
Fusion of Beta pdfs
Let and be two independent Beta random variables with associated pdfs and . Let us define a third random variable as the fusion of the two Beta random variables [6]:
where and are realizations of the random variables and . As in the case of the product of Beta random variables, determining the shape of is a non-trivial problem. MC simulations offer a robust method to sample points from the probability distribution of and to estimate by moment-matching or kernel density estimation. Notice that, differently from the previous case study, we do not have an exact analytical solution for computing the first two moments of [6].
Subjective logic fusion
A SL operator may be instantiated to compute an approximate fusion over two binomial opinions. Given two binomial opinions and defined on the same domain and with the same prior , we define the binomial opinion resulting from the fusion as:
| (39) |
where
| (40) |
This formula expresses in the subjective logic formalism the moment-matching approximation of fusion defined in [6]. Practically, a fusion operator allows us to evaluate the aggregation of two different opinions on the same fact.
Approximating the product of Beta pdfs
Now, if we are interested in computing the fusion , where and are two independent Beta random variables, we may rely either on the SL approximation defined in Equation 39 or on approximations computed via MC simulations; as before we will consider the following approximations for the true pdf : a SL pdf , a KDE estimation , a Beta and a Gaussian moment-matching approximation , computed by evaluating mean and variance of via MC integration. Differently from before, we do not consider an exact analytical moment-matching approximation ( or ) because no exact analytical formula exists. Notice, also, that since we used the moment-matching approximation provided in [6] to define the SL operator in Equation 39, our results on the degree of approximation of the SL operator immediately extend to Operator 1 defined in [6].
Figure 14 provides the concrete instantiation of the diagram in Figure 4 for the SL operator of fusion and illustrates the alternative between the path of MC simulations and SL approximation.
Computational complexity of the fusion operator
Approximation of the binomial operator
The degree of approximation of the SL operator for fusion is equivalent to the approximation of the moment-matching solution on which it is defined; [6] offers an evaluation of this approximation within the wider context of belief propagation in second-order Bayesian networks. In the following paragraphs, we will instead aim at estimating, in a more directed way, the approximation of the SL operator via the computation of the distance .
Relating the binomial multiplication and Monte Carlo approximations
Following the approach described in the previous section, we will compute a numerical estimation of the degree of approximation of the SL operator for fusion relying on the framework described in Section 6.
Once again, we need to check that the basic condition expressed in Equation 20 requiring the bias of to be negligible is satisfied. Given that we will compute KDE using a Gaussian kernel with width defined by the Silverman rule (Equation 16), and given that the support of is bounded on , we can again expect the bias of our KDE estimator to be in the order of (Equation 38). Thus, the KDE bias may be considered negligible in the estimation of distances, if the distances we are considering are orders of magnitude greater than this bias. If this condition is met, then we can estimate the degree of approximation of fusion adopting the framework defined in Figure 5 and instantiated in Figure 15.
8.1 Empirical Evaluation
In this section we describe our experimental simulations for the evaluation of the degree of approximation of fusion. We will first provide a qualitative assessment of the SL approximation and the approximations generated via MC simulations; then, we will provide a quantitative statistical evaluation of the distance for the SL approximation and for Beta and Gaussian moment-matching approximations.
In our simulations we randomly generate opinion and pdfs using the same protocol defined in Section 7.1. These simulations are also run using the WebPPL probabilistic programming language [3] and the scripts are available online444https://github.com/FMZennaro/SLMC/Fusion.
8.1.1 Qualitative simulations
In the qualitative simulations we try to offer a first visual assessment of the quality of the approximation of .
Protocol
We follow the same protocol defined for the qualitative simulations in Section 7.1, just replacing the operations for binomial multiplication with the operations for fusion.
Results
Figures 16 and 17 offer a visual comparison of the approximations offered by and along with the Gaussian and the Beta moment-matching approximations computed via MC integration. While the pdf underlying the fusion of two random variables is not Beta distributed, both the SL approximation and the moment-matching approximation seem to offer a good coarse approximation of the true distribution ; both approximations match very well the true distribution within the support , but they may show problems modelling the behaviour of near the boundaries of the domain. As before, the Gaussian approximation offers the worst match, as its shape is not ideal to model a pdf on a bounded domain.
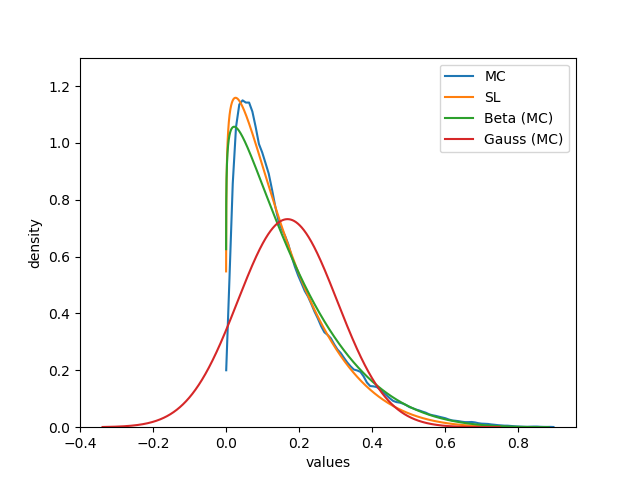
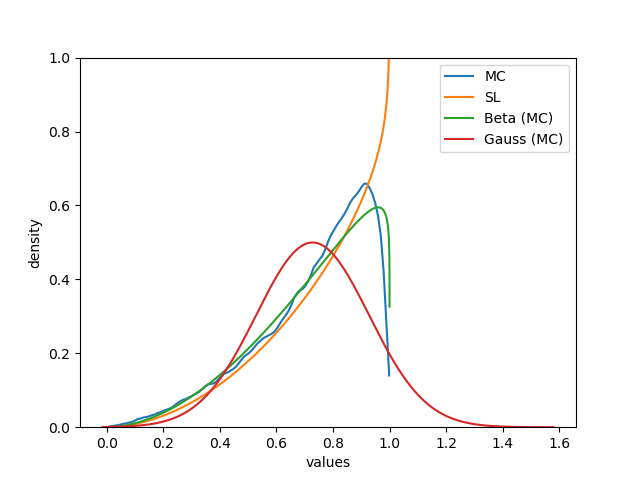
Discussion
This qualitative assessment suggests that the SL approximation may provide a good enough approximation of the true pdf at a very low computational cost. The Beta moment-matching approximation evaluated computing mean and variance via MC simulations seems to behave in a very similar fashion; however, in this case where no exact analytical moment-matching approximation is possible, the cost of evaluating corresponds to the cost of running the whole MC simulation. Last, the Gaussian moment-matching approximation constitutes a sub-optimal choice, as its fit is worse than the alternative approximations and its computational cost is equivalent to the Beta moment-matching approximation.
8.1.2 Quantitative simulations
We now move to quantifying the gap between and observed in the above simulations.
Protocol
Results
Figure 18 presents the estimation of the distances as a function of the number samples generated in the MC simulation. These statistics are computed performing repetitions and using uniformly sampled points on the support for MC integration.
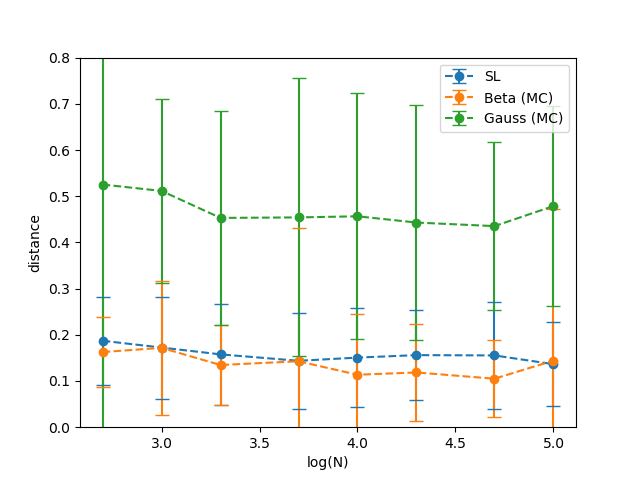
In general, as in the previous simulation, we can make two preliminary observation: (i) all the distances show a stable trend, thus suggesting that our MC results are approaching their asymptotic limit; (ii) the order of magnitude of the distances is significantly greater than the KDE bias (Equation 38), thus meaning that its bias is negligible with respect to the distances.
Confirming the previous qualitative investigation, the distance between the true pdf and the Gaussian approximation reaches values as high as , meaning that up to one fourth of the probability mass of does not to overlap with the true distribution .
The Beta approximation models the true pdf better, with a distance around , suggesting a good approximation in which of the mass of overlaps with .
Similarly, the SL approximation provides an equally good solution. The values of distance for are well within the range of the standard deviation of , suggesting that the degree of approximation of SL and Beta moment-matching are very close.
Discussion
The results of this analysis agree with the previous qualitative simulations. Moreover, even if these results are quantitatively different, they are qualitatively in line with our study of the binomial product operator. The quantitative difference between the approximation of the binomial product and the fusion may be likely ascribed to the fact that it is easier to model the product of independent random variables instead of an arbitrary operation like fusion. From a qualitative point of view, though, the Gaussian approximation ranks again last among the modeling options, while the SL approximation and the Beta approximations offer better solutions, at a computational cost that is constant (in the case of SL) or linear in the number of MC samples (in the case of Beta approximation).
9 Conclusion and Future Work
In this paper we studied the use of subjective logic as a framework for approximating operations over probability distributions. As in the case of any approximation, we considered SL operators from the perspective of the trade-off between the computational simplicity they guarantee and the precision they sacrifice. We proposed a protocol based on MC simulations to evaluate quantitatively this trade-off, estimating the distance between the SL approximation and a KDE estimation, under the assumption of a negligible bias between the KDE reconstruction and the true probability distribution.
We applied our protocol to the case study of the product and the fusion of two independent Beta distributions. The first case is relevant to fields like reliability analysis, while the second one is used in the field of subjective logic. In general, SL operators guarantee the preservation of the first moment, but do not strictly preserve higher moments or quantiles. To quantify the degree of approximation of the SL operators, we compared them with other standard approximations, such as moment-matching with a Gaussian pdf, moment-matching with a Beta pdf, and KDE via MC. Our simulations showed that, at the cost of accepting a difference between the SL approximation and the true pdf, SL offers a computationally efficient approximation. Both in the case of binomial products and in the case of fusion, the degree of approximation can be quantified in a mismatch between the SL approximation and the true pdf of up to of the probability mass. In general, KDE approximation and Beta approximation provided better estimation; KDE, however, has a computational cost that is quadratic in the number of samples generated via MC; moment-matching has a computational cost that can be constant and comparable to SL when moments of interest can be computed analytically, or, otherwise, linear in the number of samples generated via MC.
In summary, it is possible to enjoy the computational efficiency and the interpretability of SL if the modeling scenario allows room for approximations up to the amount estimated using our protocol. The recommendation is that, were SL operators to be used to model critical systems (as in the case of reliability analysis or when higher-order moments are critical), this divergence between the true pdf and the SL approximation that we highlighted should be factored in the analysis.
Further work will be developed for better characterizing the difference between true pdfs and SL approximations; in particular, understanding how the mass is differently allocated with respect to the overall shape of the pdf, whether, for instance, these differences are more accentuated near the mode (assuming one exists) or around the tail. According to the way in which probability mass is misplaced in SL approximations different forms of correction may be then considered.
Acknowledgment
The authors would like to express their gratitude to the anonymous reviewers who commented on the first version of this article and helped improving it.
References
- [1] CA Coelho and RP Alberto. On the distribution of the product of independent beta random variables–applications. Technical report, Technical report, CMA 12 Google Scholar, 2012.
- [2] Zoubin Ghahramani. Probabilistic machine learning and artificial intelligence. Nature, 521(7553):452, 2015.
- [3] Noah D Goodman and Andreas Stuhlmüller. The design and implementation of probabilistic programming languages, 2014.
- [4] A. Jøsang. Subjective Logic: A Formalism for Reasoning Under Uncertainty. Artificial Intelligence: Foundations, Theory, and Algorithms. Springer International Publishing, 2016.
- [5] Audun Jøsang and David McAnally. Multiplication and comultiplication of beliefs. International Journal of Approximate Reasoning, 38(1):19–51, 2005.
- [6] Lance Kaplan and Magdalena Ivanovska. Efficient belief propagation in second-order Bayesian networks for singly-connected graphs. International Journal of Approximate Reasoning, 93:132–152, 2018.
- [7] Lance M Kaplan, Murat Şensoy, Yuqing Tang, Supriyo Chakraborty, Chatschik Bisdikian, and Geeth de Mel. Reasoning under uncertainty: Variations of subjective logic deduction. In Information Fusion (FUSION), 2013 16th International Conference on, pages 1910–1917. IEEE, 2013.
- [8] David J.C. MacKay. Information theory, inference, and learning algorithms. Cambridge University Press, 2003.
- [9] TG Pham and N Turkkan. Reliability of a standby system with beta-distributed component lives. IEEE Transactions on Reliability, 43(1):71–75, 1994.
- [10] Thu Pham-Gia and Noyan Turkkan. The product and quotient of general beta distributions. Statistical Papers, 43(4):537–550, 2002.
- [11] Jose C. Principe. Information theoretic learning: Rényi’s entropy and kernel perspectives. Springer, 2010.
- [12] Cosma Shalizi. Advanced data analysis from an elementary point of view, 2013.
- [13] Bharath K Sriperumbudur, Kenji Fukumizu, Arthur Gretton, Bernhard Schölkopf, and Gert RG Lanckriet. On integral probability metrics,phi-divergences and binary classification. arXiv preprint arXiv:0901.2698, 2009.
- [14] Jen Tang and AK Gupta. On the distribution of the product of independent beta random variables. Statistics & Probability Letters, 2(3):165–168, 1984.