An Online Learning Approach to Dynamic Pricing and Capacity Sizing in Service Systems
Abstract
We study a dynamic pricing and capacity sizing problem in a queue, where the service provider’s objective is to obtain the optimal service fee and service capacity so as to maximize the cumulative expected profit (the service revenue minus the staffing cost and delay penalty). Due to the complex nature of the queueing dynamics, such a problem has no analytic solution so that previous research often resorts to heavy-traffic analysis where both the arrival rate and service rate are sent to infinity. In this work we propose an online learning framework designed for solving this problem which does not require the system’s scale to increase. Our framework is dubbed Gradient-based Online Learning in Queue (GOLiQ). GOLiQ organizes the time horizon into successive operational cycles and prescribes an efficient procedure to obtain improved pricing and staffing policies in each cycle using data collected in previous cycles. Data here include the number of customer arrivals, waiting times, and the server’s busy times. The ingenuity of this approach lies in its online nature, which allows the service provider do better by interacting with the environment. Effectiveness of GOLiQ is substantiated by (i) theoretical results including the algorithm convergence and regret analysis (with a logarithmic regret bound), and (ii) engineering confirmation via simulation experiments of a variety of representative queues.
Keywords: online learning in queues; service systems; capacity planning; staffing; pricing in service systems
1 Introduction
1.1 Problem Statement and Methodology
1.1.1 Pricing and capacity sizing in queue
We study a service queueing model where the service provider manages congestion and revenue by dynamically adjusting the price and service capacity. Specifically, we consider a queue, in which the demand for service is per unit of time when each customer is charged by a service fee ; the cost for providing service capacity is ; and a holding cost incurs per job per unit of time. By choosing the appropriate service fee and capacity , the service provider aims to maximize the net profit, which is the service fee minus the staffing cost and penalty of congestion, i.e.,
| (1) |
where is the steady-state queue length under service rate and price .
Problems in this framework have a long history, see for example Kumar and Randhawa (2010), Lee and Ward (2014), Lee and Ward (2019), Maglaras and Zeevi (2003), Nair et al. (2016), Kim and Randhawa (2018) and the references therein. Due to the complex nature of the queueing dynamics, exact analysis is challenging and often unavailable (computation of the optimal dynamic pricing and staffing rules is not straightforward even for the Markovian queue (Ata and Shneorson, 2006)). Therefore, researchers resort to heavy-traffic analysis to approximately obtain performance evaluation and optimization results. Commonly adopted heavy-traffic regimes require sending the arrival rate and service capacity (service rate or number of servers) to . Although heavy-traffic analysis provides satisfactory results for large-scale queueing systems, approximation formulas based on heavy-traffic limits often become inaccurate as the system scale decreases.
1.1.2 An online learning method
In this paper we propose an online learning framework designed for solving Problem (1). According to our online learning algorithm, the queue will be operated in successive cycles, where in each cycle the service provider’s decisions on the service fee and service capacity , deemed the best by far, are obtained using the system’s data collected in previous operational cycles. Data hereby include (i) the number of customers who join for service, (ii) customers’ waiting times, and (iii) the server’s busy time, all of which are easy to collect. Newly generated data, which represent the response from the (random and complex) environment to the present operational decisions, will be used to obtain improved pricing and staffing policies in the next cycle. In this way the service provider can dynamically interact with the environment so that the operational decisions can evolve and eventually approach the optimal solution.
At the beginning of each cycle , the service provider’s decisions will be computed and enforced throughout the cycle. At the heart of our procedure for computing is to obtain a sufficiently accurate estimator for the gradient of the objective function of (1), using past experience. Specifically, our online algorithm will update according to
where is the updating step size for cycle . We call this algorithm Gradient-based Online Learning in Queue (GOLiQ).
Besides showing that, under our online learning scheme, the decisions in cycle , will converge to the optimal solutions as increases, we quantify the effectiveness of GOLiQ by computing the regret - the cumulative loss of profit due to the suboptimality of , namely, the maximum profit under the (unknown) optimal strategy minus the expected profit earned under the online algorithm over time. When GOLiQ’s hyperparameters are chosen optimally, we show that our regret bound is logarithmic so that the service provider, with any initial pricing and staffing policy , will quickly learn the optimal solutions without losing much profit in the learning process.
1.2 Advantages, Challenges and Contributions
In what follows, we first discusses the general advantages of the online learning approach by contrasting with heavy-traffic methods; we next explain the key challenges we face in the development of online learning algorithms for queueing systems.
1.2.1 Online learning vs. heavy-traffic method.
First, heavy-traffic solutions are derived from approximating models which arise as the system scale approaches infinity, so the fidelity of the solutions is sensitive to the system scale. Unlike heavy-traffic methods, online learning approaches do not require any asymptotic scaling, so they can treat service systems at any scale (small or large). Second, heavy-traffic approaches usually require the knowledge of certain distributional information apriori (e.g., moments and distribution functions of service times), which serve as critical input parameters for the heavy-traffic models. On the other hand, online learning methods require information of this kind to a lesser extent. Although certain distribution information can help fine-tune parameters of online algorithms, it is less crucial to algorithm design and implementation. So in this sense, the dependence on the distributional information is weaker than that of heavy-traffic analysis. Last, online learning is advantageous when the underlining problem focuses on performance optimization in the long run. Heavy-traffic analysis gives approximate solutions that are static, and in a longer time frame, the performance discrepancy (relative to the true optimal reward) should grow linearly as time increases. But online learning is a dynamic evolution, and its data-driven nature enables it to constantly produce improved solutions which will eventually reach optimality. In addition, heavy-traffic solutions require the establishment of heavy-traffic limit theorems and careful analysis of the dynamics of the limit processes (e.g., fluid and diffusion). Both steps can be quite sophisticated in general. See Remarks 11 and 12 for more detailed discussions; also see Section 6.3 for numerical evidence.
1.2.2 Challenges of online learning in queueing systems.
Online learning in queues is by no means an easy extension of online learning in other domains; its theoretical development has to account for the unique features in queueing systems. A crucial step is to develop effective ways to control the nonstationary error that arises at the beginning of every cycle due to the policy update. Towards this, we develop a new regret analysis framework for the transient queueing performance that not only helps establish desired regret bounds for the specific online algorithm, but may also be used to develop online learning method for other queueing models (see Section 4). Another challenge we have to address here is to devise a convenient gradient estimator for the online learning algorithm (essentially, an estimator for the gradient of ). The estimator should have a negligible bias to warrant a quick convergence of the algorithm, and at the same time, its computation (using previous data) should be sufficiently straightforward to ensure the ease of implementation (The detailed gradient estimator of GOLiQ for the system is given in Section 5).
1.2.3 Main Contributions
We summarize our contributions below.
-
•
To the best of our knowledge, the present work is the first to develop an online learning framework for joint pricing and staffing in a queueing system with logarithmic regret bound in the total number of customers served (Theorem 3). Due to the complex nature of queueing systems, previous research often resorts to asymptotic heavy-traffic analysis to approximately solve for desired operational decisions. The ingenuity of our online learning method lies in the ability to obtain the optimal solutions without needing the system scale (e.g., arrival rate and service rate) to grow large. The other appeal of our method is its robustness, especially in its weaker dependence on the distributions of service and arrival times.
-
•
A critical step in the regret analysis is the treatment of the transient system dynamics, because when improved operational decisions are obtained and implemented at the beginning of a new period, the queueing performance will shift away from previously established steady-state level. Towards this, we develop a new way to treat and bound the transient queueing performance in the regret analysis of our online learning algorithm (Theorem 1). Bounding the transient error also guarantees convergence of the SGD iteration (Theorem 2). Comparing to previous literature (e.g., the regret bound is in Huh et al. (2009)), our analysis of the regret due to nonstationarity gives a much tighter logarithmic bound. In addition, the regret analysis in the present paper may be extended to other queueing systems which share similar properties to .
-
•
Supplementing the theoretical results of our regret bound, we evaluate the practical effectiveness of our method by conducting comprehensive numerical experiments. Our simulations draw the following two main conclusions. First, our method is robust in several dimensions: (i) GOLiQ exhibits convincing performance for queues having representative arrival and service distributions; (ii) GOLiQ remains effective even when certain theoretical assumptions are relaxed. Furthermore, in order to clearly highlight the advantages of our online learning approach relative to the previous results of heavy-traffic limits, we provide a careful performance comparison of these two methods. We show that GOLiQ is more effective in any one of the following three cases: the system scale is not too large, staffing cost is high, or service times are more variable.
1.3 Organization of the paper
In Section 2, we review the related literature. In Section 3, we introduce the model assumptions and provide an outline of our online learning algorithm. In Section 4, we conduct the regret analysis for GOLiQ by separately treating the regret of nonstationarity - the part of regret arising from the transient system dynamics, and the regret of suboptimality - the part originating from the errors due to suboptimal pricing and staffing decisions. In Section 5, we give the detailed description of GOLiQ and establish a logarithmic regret bound by appropriately selecting our algorithm parameters. In Section 6 we conduct numerical experiments to confirm the effectiveness and robustness of GOLiQ. We conclude in Section 7. In the e-companion, we give all technical proofs and provide additional numerical examples.
2 Related Literature
The present paper is related to the following three streams of literature.
Pricing and capacity sizing in queues.
There is a rich literature on pricing and capacity sizing in service systems under different settings. Maglaras and Zeevi (2003) studies pricing and capacity sizing problem in a processor sharing queue motivated by internet applications; Kumar and Randhawa (2010) considers a single-server system with nonlinear delay costs; Nair et al. (2016) studies and systems with network effect among customers; Kim and Randhawa (2018) considers a dynamic pricing problem in a single-server system. The specific problem (1) we consider here is most closely related to Lee and Ward (2014), i.e., joint pricing and capacity sizing for the queue. Later, the authors extend their results to the model with customer abandonment in Lee and Ward (2019). As there is usually no closed-form solution for the optimal strategy or equilibrium, asymptotic analysis is adopted under large-market assumptions. In detail, their analysis is rooted in a deterministic static planning problem which requires both the service capacity and the demand rate to scale to infinity. Most of the papers conclude that heavy-traffic regime is economically optimal. (There are some exceptions where heavy-traffic regime is not optimal, for example, Kumar and Randhawa (2010) shows that agent is forced to decrease its utilization if the delay cost is concave.) Our algorithm is motivated by the pricing and capacity sizing problem for service systems, however, as explained previously, our methodology is very different from the asymptotic analysis used in these papers.
Reinforcement learning for queueing systems.
Our paper is also related to a small but growing literature on reinforcement learning (RL) for queueing systems. Dai and Gluzman (2021) studies an actor-critic algorithm for queueing networks. Liu et al. (2019) and Shah et al. (2020) develop RL techniques to treat the unboundedness of the state space of queueing systems. Jia et al. (2021) studies a price-based revenue management problem in an queue with a discrete price space; their methodology draws from the multi-armed bandit framework (with each price treated as an “arm”). Krishnasamy et al. (2021) develops bandit methods for scheduling problem in a multi-server queue with unknown service rates. Our work draws distinction from the above-mentioned literature in two dimensions. First, we are the first to develop an online learning method for joint pricing and capacity sizing in queue. In addition, our method applies to settings of continuous decision variables. Comparing to the more general RL literature, our algorithm design and regret analysis take advantage of the specific queueing system structure so as to establish tight regret bounds and more accurate control of the convergence rate. In some sense, the algorithm developed in the present paper may be viewed as a version of the policy gradient method, a special class of RL methods (Sutton and Barto, 2018), see Remark 2 for detailed discussions.
Stochastic gradient decent algorithms.
In general, our algorithm falls into the broad class of stochastic gradient descent (SGD) methods. There are some early papers on SGD algorithms for steady-state performance of queues (see Fu (1990), Chong and Ramadge (1993), L’Ecuyer et al. (1994), L’Ecuyer and Glynn (1994) and the references therein). In particular, these papers have established convergence results of SGD algorithms for capacity sizing problems with a variety of gradient estimating designs. In this paper, we consider a more general setting in which the price is also optimized jointly with the service capacity. Besides, in order to establish theoretical bounds for the regret, we conduct a careful analysis on the convergence rate of the algorithm and provide an explicit guidance for the optimal choice of algorithm parameters, which is not discussed in this early literature. Our algorithm design and analysis are also related to the online learning methods in recent inventory management literature (Burnetas and Smith, 2000; Huh et al., 2009; Huh and Rusmevichientong, 2013; Zhang et al., 2020; Yuan et al., 2021). Among these papers, our work is perhaps most closely related to Huh et al. (2009) where the authors develop an SGD based learning method for an inventory model with a bounded replenishment lead time. Still, due to the unique natures of queueing models, we develop a new regret analysis framework as we shall explain with details in Section 1.2.3.
3 Problem Setting and Algorithm Outline
In Section 3.1 we describe the queueing model and technical assumptions. In Section 3.2, we provide a general outline of GOLiQ. Finally, in Section 3.3 we conduct preliminary analysis of the queueing performance under GOLiQ.
3.1 Model and Assumptions
We study a queueing system having customer arrivals according to a renewal process with generally distributed interarrival times (the first ), independent and identically distributed (i.i.d.) service times following a general distribution (the second ), and a single server that provides service under the first-in-first-out (FIFO) discipline. Each customer upon joining the queue is charged by the service provider a fee . The demand arrival rate (per time unit) depends on the service fee and is denoted as . To maintain a service rate , the service provider continuously incurs a staffing cost at a rate per time unit.
For and , the service provider’s goal is to determine the optimal service fee and service capacity with the objective of maximizing the steady-state expected profit (1), or equivalently minimizing the objective function as follows
| (2) |
We shall impose the following assumptions on the above service system throughout the paper.
Assumption 1.
Demand rate, staffing cost, and uniform stability
-
The arrival rate is continuously differentiable and non-increasing in .
-
The staffing cost is continuously differentiable and non-decreasing in .
-
The lower bounds and satisfy that so that the system is uniformly stable for all feasible choices of the pair .
Part of Assumption 1 is commonly used in the literature of SGD methods for queueing models to ensure that the steady-state mean waiting time is differentiable with respect to model parameters (see Chong and Ramadge (1993), Fu (1990), L’Ecuyer et al. (1994), L’Ecuyer and Glynn (1994), also see Theorem 3.2 of Glasserman (1992)). In the our numerical experiments (see Section 11.1), we show that our online algorithm remains effective when this assumption is relaxed.
We do not require full knowledge of service and inter-arrival time distributions. But in order to develop explicit bounds for the part of the regret due to the nonstationarity of the queueing processes, we require both distributions to be light-tailed. Specifically, since the actual service and interarrival times are subject to our pricing and staffing decisions, we model the interarrival and service times by two scaled random sequences and , where and are two independent i.i.d. sequences of random variables having unit means, i.e., . We make the following assumptions on and .
Assumption 2.
Light-tailed service and interarrival times
There exists a sufficiently small constant such that the moment-generating functions
In addition, there exist constants , and such that
| (3) |
where and are the cummulant generating functions of and .
Note that as . Suppose and are smooth around 0, then we have and by Taylor’s expansion. This implies that, for any , we can make small enough, such that and . To obtain the bound in (3), we can simply take . Hence, a sufficient condition that warrants (3) is to require that and be smooth around 0, which is true for many distributions of and considered in common queueing models. Assumption 2 will be used in our proofs to build an explicit bound for the regret of nonstationarity.
Finally, in order to warrant the convergence of our online learning algorithm, we require a convex structure for the problem in (2), which is common in the SGD literature; see Broadie et al. (2011), Kushner and Yin (2003) and the references therein.
Let and . Let denote the gradient of a function and denote the Euclidean norm.
Assumption 3.
Convexity and smoothness
There exist finite positive constants and such that for all
-
;
-
.
Remark 1.
Our simulation experiments show that our algorithm works effectively for some representative queues with conditions in Assumption 3 relaxed; see Section 6 and Section 11 in the Supplement Material. In addition, we later provide some sufficient conditions for Assumption 3 in the special case of queues in Section 12.
3.2 Outline of GOLiQ
In general, an SGD algorithm for a minimization problem over a compact set relies on updating the decision variable via the recursion
where is the step size, is a random estimator for , is the decision variable by step , and the projection operator restricts the updated decision in . For problem (2), we let represent the service capacity and price at step , We define
| (4) |
where is the -algebra including all events in the first iterations. Intuitively, measures the bias of the gradient estimator and measures its variability. As we shall see later, and play important roles in designing the algorithm and establishing desired regret bounds.
The standard SGD algorithm iterates in discrete step . In our setting, however, the queueing system and objective function are defined in continuous time (in particular, is the steady-state queue length observed in continuous time). To facilitate the regret analysis, we first transform the objective function into an expression of customer waiting times that are observed in discrete time. By Little’s law, we can rewrite the objective function as, for all ,
| (5) |
where is the steady-state waiting time under . In each cycle , our algorithm adopts the average of observed customer waiting times to estimate , where denotes the number of customers that enter service in cycle (we refer to as the cycle length or sample size of cycle ). But any finite will introduce a bias to our gradient estimate . To mitigate the bias due to the transient performance of the queueing process, we shall let the cycle length be increasing in (in this way the transient bias will vanish eventually). We give the outline of the algorithm below.
Outline of GOLiQ:
-
0.
Input: and for , initial policy .
For ,
-
1.
In the cycle, operate the queue under policy until customers enter service.
-
2.
Collect and use the data (e.g., customer delays) to build an estimator for .
-
3.
Update .
Remark 2 (Exploration vs. exploitation).
The online nature of this algorithm makes it possible to obtain improved decisions by learning from past experience, which is in the spirit of the essential ideas of reinforcement learning where an agent (hereby the service provider) aims to tradeoff between exploration (Step 1) and exploitation (Steps 2 and 3). Effectiveness of the algorithms lies in properly choosing the algorithm parameters and devising an efficient gradient estimator . For example, if is too small, we are unable to generate sufficient data (we do not have much to exploit in order for devising a better policy); if is too large, we incur a higher profit loss due to suboptimality of the policy in use (we do not explore enough for seeking potentially better policies). In particular, GOLiQ may be viewed as a special case of the policy gradient (PG) algorithm (the general idea of PG is to estimate the policy parameters using the gradient of the value function learned via continuous interaction with the system, see for example Sutton and Barto (2018)). To put this into perspective, the policy in the present paper is specified by a pair of parameters , and in each iteration, we update the policy parameters using an estimated policy gradient learned from data of the queueing model. In the subsequent sections, we give detailed regret analysis that can be used to establish optimal algorithm parameters (Section 4) and develop an efficient gradient estimator (Section 5).
3.3 System Dynamics under GOLiQ
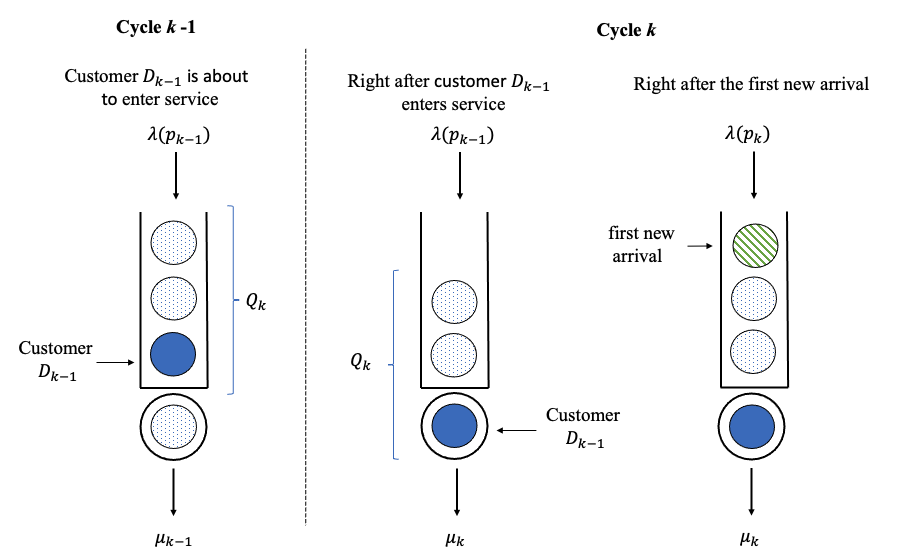
We explain explicitly the dynamic of the queueing system under GOLiQ, with the system starting empty. We first define notations for relevant performance functions. For , let be the length of cycle in the units of time, and let be the total number of customers who enter service in cycle . For , let be the waiting time of the customer that enters service in cycle . We define . We use the two i.i.d. random sequences and to construct the service and inter-arrival times in cycle , . In particular, corresponds to the service time of the customer , and corresponds to the inter-arrival time between customers and in cycle . Let . Last, we use to denote the number of existing customers (those who arrive in previous cycles) at the beginning of cycle in , with . We will have for , as we shall explain soon, according to our updating procedure. The detailed dynamics of the queueing system in cycle is summarized as follows:
-
•
Updating the control policy. In cycle , we adopt the pricing and staffing policy . The service time of customer in cycle is for . Cycle ends as soon as a total number of (of which the value is to be determined later) customers have entered service. So, customer will receive service in cycle (with service time ) and the queue leftover consists of at least one customer, i.e., for a new cycle , which begins under a new policy as follows:
-
–
Service rate. The service rate is updated to immediately as the new cycle begins, so that all existing customers will undergo service times with rate .
-
–
Service fee. The price remains at the beginning of cycle and evolves to immediately after the first new customer arrives in the new cycle; we charge this customer with (because its interarrival time is modulated by ) and all subsequent customers in cycle with .
-
–
-
•
Leftovers from previous cycles. For , at the beginning of cycle , there are customers waiting in queue indexed by from 1 to . The customer who just enters service is indexed by 0. We update the price from to right after the first new customer (indexed by ) arrives in a new cycle. As a consequence, the prices charged to customers are not yet updated to . Denote by and as the price and arrival rate for customer in cycle , respectively, for . The corresponding interarrival time is . In case , some queueing leftover are customers from earlier cycles. So here . In addition, in case , part of will continue to remain in cycle and we will have, for example, .
-
•
New arrivals. We denote interarrival times for new customers in cycle by for if . (As will soon become clear, the case is a rare event with a negligible probability under appropriate algorithm settings, see Remark 3.)
-
•
Customer delay. Customers’ waiting times in cycle are characterized by the recursions
(6) where .
-
•
Server’s busy time. The age of the server’s busy time observed by customer upon arrival, which is the length of time the server has been busy since the last idleness, is given by the recursions
(7) where the indicator is 1 if occurs and is 0 otherwise.
We provide explanations for (6) and (7). First, recursion (6) simply follows from Lindley’s equation. Next, recursion (7) follows from the fact that, for customer , if the queue is empty upon its arrival, the observed busy time is simply 0 by definition; otherwise, the server must have been busy since the arrival of the previous customer and therefore, the observed busy time by customer should extend that of customer by an additional inter-arrival time. As we shall see later, both the delay and busy time observed by customers will be important ingredients (i.e., data) for building the gradient estimator of the online learning algorithm.
Remark 3 (Clearance of the leftover ).
As explained above, is random and unbounded, while in our algorithm design, the cycle length is deterministic. So it is indeed possible the remaining queue content may not be all cleared in cycle (i.e., ). We will see later in the regret analysis that our choice of leads to a small probability of uncleared leftovers and thus the impact of the rare event is negligible.
In Figure 1, we further illustrate how the service price and service rate are updated by showing the ordering of all relative events as a new cycle begins. We emphasize that (i) the service rate is updated to immediately when a new cycle begins, which is triggered as soon as the last one of customers enters service; and (ii) the service price is updated to only after the first external arrival occurs in the new cycle (we honor our previous prices for all customers who arrive in the previous cycle).
We end this section by providing a uniform boundedness result for all relevant queueing functions. This result below will be used in the next sections to establish desired regret bounds. The proof follows from a stochastic ordering approach and is given in Section 8.1.
4 Regret Analysis
The online learning approach described in Section 3.2 is a data-driven method, it should contunue to generate improved solutions that will eventually converge to the true optimal solution as the server’s experience accumulates (by serving more and more customers). The performance of GOLiQ is measured by the so-called regret, which can be interpreted as the cost to pay, over the time or the number of samples, for the algorithm to learn the optimal policy. In this section, we give a formal definition of the regret and conduct the regret analysis for our online learning algorithm.
The expected net cost of the queueing system incurred in cycle is
| (8) |
where the summation is in case . The total regret accumulated in the first cycles is
| (9) |
is regret in cycle (the expected system cost in cycle minus the optimal cost).
Remark 4.
Following Huh et al. (2009) and Jia et al. (2021), our regret defined in (9) is computed by accumulating the difference between the steady-state maximum profit under and the expected profit earned under GOLiQ. However, one may find such a definition to be somewhat too demanding; it appears to be more reasonable if we were to benchmark with the nonstationary dynamics under , rather than the steady-state performance. Nevertheless, our numerical studies confirm that the nuance of the two aforementioned regret definitions is negligible. See Section 11.5.
Separation of regret.
To treat the total regret defined in (9), we separate it into two parts: regret of nonstationarity which quantifies the error due to the system’s transient performance, and regret of suboptimality which accounts for the suboptimality error due to the present policy. In detail, we write
| (10) |
so that
| (11) |
Intuitively, measures the performance error due to transient queueing dynamics (regret of nonstationarity), while accounts for the suboptimality error of control parameters (regret of suboptimality).
In what follows, we will analyze the two terms and separately. To treat , we develop in Section 4.1 a new framework to analyze the transient queueing behavior using the coupling technique (Theorem 1). The development of the theoretical bound for is given in Section 4.2 (Theorem 2). Results in these sections provide convenient conditions that facilitate the convergence and regret bound analysis of our GOLiQ algorithm for GI/GI/1 queues (which is to be given in Section 5). The roadmap of the theoretical analysis is depicted in Figure 2.
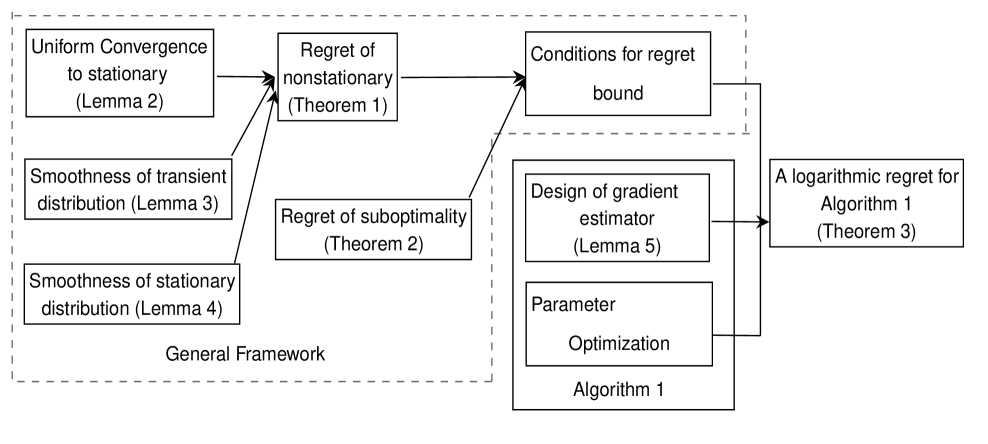
4.1 Regret of Nonstationarity
In this part, we analyze the transient queueing dynamics, base on which we develop a theoretical upper bound for . As we shall see later in Section 5, this analysis is also essential to bounding the bias and variance of the gradient estimators for GOLiQ.
A crude bound. Roughly speaking, since the parameters and functions , are all bounded, the regret is in the same order as the transient bias of the waiting time process, i.e.,
Here we use to denote the steady-state waiting time of the queue with parameter . Under the uniform stability condition (Assumption 1), it is not difficult to show that there exist positive constants and , independent of and such that
Then, as a direct consequence, we have
An analogue of the above bound is given by Huh et al. (2009) (Lemma 11) in an inventory model.
An improved bound. In the rest of this subsection, we will conduct a more delicate analysis on the transient performance of the queueing system, and our analysis will render a (tighter) sub-linear bound (of which the exact order depends on the concrete algorithm, as we shall see later).
Theorem 1.
Remark 5.
As will become clear later in Section 5, we obtain a bound for Algorithm 1 by validating Condition (b) in Theorem 1 with , which is much tighter than the crude bound. This bound for is critical to achieving an overall logarithmic regret bound in the total number of served customers. An explicit expression of constant is given in (8.5).
4.1.1 Roadmap of the proof of Theorem 1
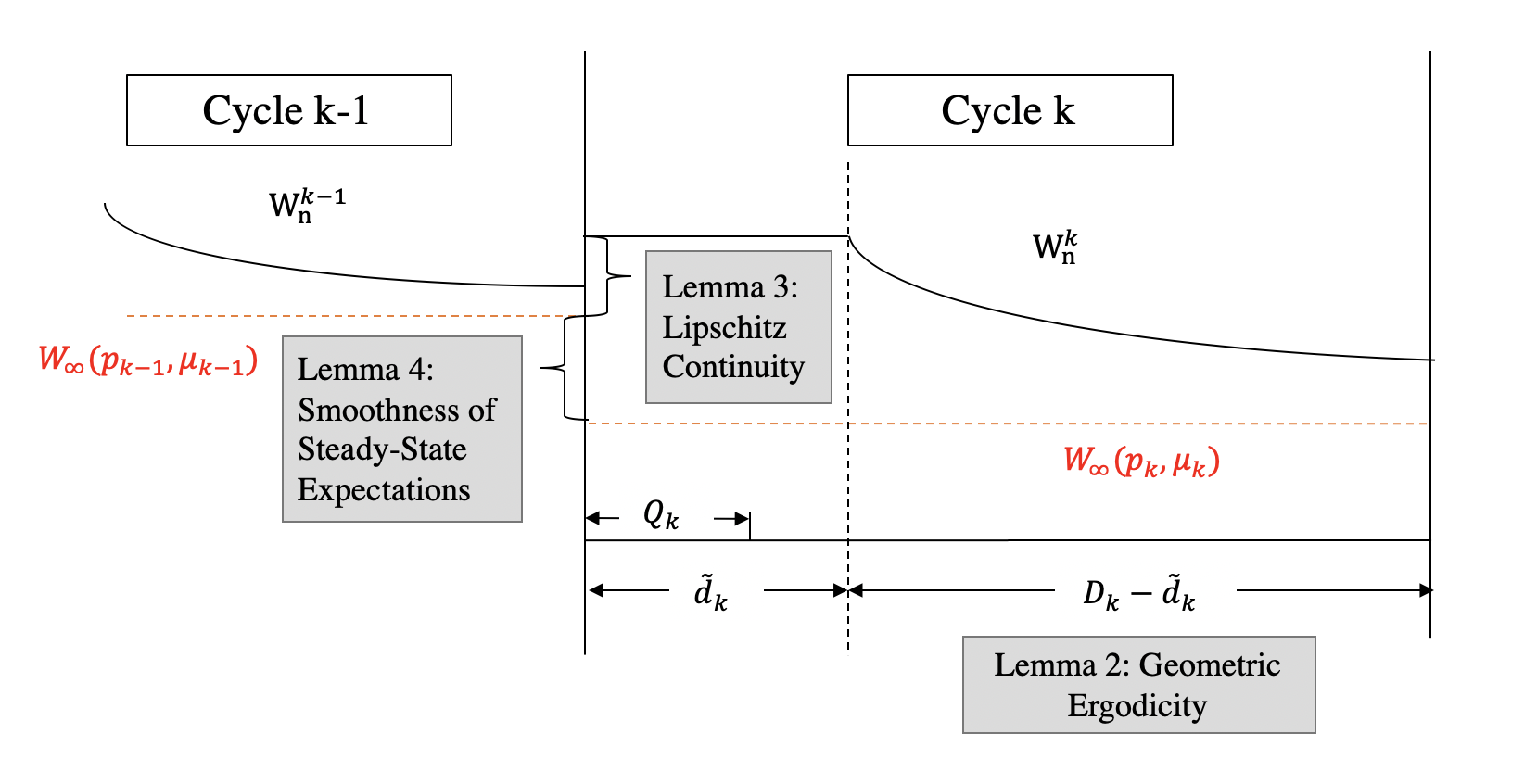
Our point of departure in proving Theorem 1 is to decompose into three terms. We shall split each cycle into a warm-up period consisting the first customers and the near-stationary period consisting of all remaining customers, where are as defined in Assumption 2. The three parts are: transient error in the near-stationary period (), transient error in the warm-up period () and the remaining error (). The detailed separation is given below
The term is a function in and equals to the steady-state expected waiting time under parameter . To prove , it suffices to show that for . Below we explain the main ideas of our treatment to , and :
-
•
: We will first show that, after serving customers, with a sufficiently high probability, all existing customers have left the system and follows the dynamic of a GI/GI/1 queue with arrival rate and service rate . Then, we show that , for , will converge exponentially fast to the steady state (Lemma 2). Hence is close to for , warranting a small transient error .
-
•
: Note that the customers in the warm-up period include those leftovers from previous periods, and their arrival rates are different from . To control the impact of such difference between and , we first establish almost sure Lipschitz continuity of waiting times (for queues having customer-heterogeneous arrival rates) with respect to the arrival rate sequence and the initial state (Lemma 3). As a consequence, we can prove that taking advantage of the fact that the initial state is close to the steady-state . Then, we show that the steady-state distribution is smooth in the parameter (Lemma 4), i.e., , which completes the analysis for .
- •
Also see in Figure 3 for a graphical illustration.
Following the above roadmap, we next give detailed analysis for by establishing three lemmas (Lemmas 2–4). We believe that these results are not only essential to the transient analysis in the present paper, but may also be of independent interest for theoretic studies of other queueing models.
Bounding . We first establish the rate at which waiting times converge to their steady state distributions. For two given sequences and , we say two queues with the same parameter are synchronously coupled if their waiting times and satisfy
i.e., the two systems share the same sequences of service and interarrival times. The proof of Lemma 2 is given in Section 8.
Lemma 2.
Exponential loss of memory of initial state Suppose two queues with parameter are synchronously coupled with initial waiting times and , respectively. Then, for the two positive constants and defined in Assumption 2 and any , we have, conditional on and ,
In order to bound , at the beginning of each cycle , given , we couple with that is independently drawn from the steady-state waiting time distribution . The sequence is defined as
Then, by definition, conditional on , for all , and therefore,
As we will show in the proof of Corollary 1, is coupled with except on a set of negligible set, with . As a result, we can use Lemma 2 to construct a bound on for .
Corollary 1.
Under the conditions of Theorem 1, there exists a constant independent of and , such that for all and ,
| (13) |
As a direct consequence, we have .
Bounding . We first show that the waiting times of a queueing model having customer-heterogeneous arrival rates are Lipschitz continuous with respect to the rates and the initial state almost surely.
Lemma 3.
(Lipschitz continuity) Consider two waiting time sequences and for with initial values and respectively. Let and be the corresponding sequences of service and arrival rates, respectively, i.e.,
Suppose there exist two constants such that
Then we have, for all ,
where and are the corresponding observed busy periods. In particular, and satisfy the recursion (7) defined in Section 3.3 with any given initial values of and .
As discussed above, controlling also involves bounding the difference between the mean steady-state waiting times in two consecutive cycles. Hence, we next establish a uniform high-order smoothness result for the steady-state waiting times with respect to the model parameter .
Lemma 4.
Smoothness in and Suppose for . Let be the steady-state waiting time of the GI/GI/1 queue under parameter , respectively. Then, the steady-state waiting times can be coupled such that, there exists a constant independent of satisfying that, for all ,
where a closed-form expression of constant is given in (31).
We adopt a “coupling from the past” (CFTP) approach in the proof of Lemma 4 (see Section 8). Roughly speaking, CFTP is a synchronous coupling starting from infinite past. In the proof of Lemma 4, we shall explicitly explain how to construct the CFTP.
Now we are ready to analyze . Essentially, we shall compare in the warm-up period with . For each cycle , recall that we have already coupled with a stationary sequence in cycle , we then extend the sequence to cycle in the sense that
Then, conditional on , . So we have
Bounding the first term by Lemma 3 and the second term by Lemma 4 yields the following bound on .
Corollary 2.
Bounding . We complete our analysis on the regret of nonstationarity by showing that . The proof of Corollary 3 below basically follows from Lemma 1 and Lemma 2 with some similar argument as used in the proof of Corollary 2.
Corollary 3.
Under the conditions of Theorem 1, .
Finishing the Proof of Theorem 1. Then, Theorem 1 follows immediately from Corollaries 1 to 3. A complete proof of Theorem 1, including the proofs of Corollaries 1 to 3, is given in Section 8.5 of e-companion. In particular, we provide an explicit expression of the constant in terms of the model parameters in (8.5).
Remark 6.
We advocate that Theorem 1 may apply to other queueing models (its scope is beyond the queue), as long as one can verify three conditions for the designated model: (i) uniform boundedness for the rate of convergence to the steady state, i.e., Lemma 2, (ii) path-wise Liptschize continuity, i.e., Lemma 3, and (iii) smoothness of the stationary distributions in the control variables, i.e., Lemma 4.
4.2 Regret of Suboptimality
To bound the regret of suboptimality , we need to control the rate at which converges to . This depends largely on the effectiveness of the estimator for . In our algorithm, such effectiveness is measured by the bias and variance . The following result shows that, if and can be appropriately bounded, then, will converge to rapidly and hence can be properly bounded.
Theorem 2.
Regret of suboptimality Suppose Assumptions 3 holds. If there exists a constant such that the following conditions hold for all ,
-
,
-
,
-
,
where is a constant, and is the step size, then, there exists a constant with an explicit expression given in (34), such that for all ,
| (15) |
and as a consequence,
| (16) |
Remark 7 (Selecting the “optimal” ).
The above expression (16) indicates a trade-off in the selection of the parameter . On the one hand, increasing the sample size reduces the bias for the gradient estimator, and hence leads to a smaller value of . On the other hand, a larger makes the system operate under a sub-optimal decision for a longer time. To this end, one may choose an optimal order (in ) for by minimizing the order of the regret as in (16).
Our proof of Theorem 2 follows an inductive approach as used in Broadie et al. (2011). Let . According to the SGD iteration , we have
Then, by Assumption 3 and the definition of by (4), we derive the following recursive inequality for :
and we prove (15) by induction. The full proof is given in Section 8.7 of the e-companion.
In Section 5, we apply Theorem 2 to treat our online learning algorithm (Algorithm 1) by verifying that Conditions (a)–(c) are satisfied. Because in Theorem 2, Conditions (a)–(c) are stated explicitly in terms of the step size , bias and variance of the gradient estimator, these conditions may serve as useful building blocks for the design and analysis of online learning algorithms in other queueing models as well.
5 GOLiQ for the Queue
In this section, we provide a concrete GOLiQ algorithm that solves the optimal pricing and capacity sizing problem (1) for a queueing system. We show that the gradient can be estimated “directly” from past experience (i.e., data of delay and busy times generated under the present policy). Applying the regret analysis developed in Section 4, we provide a theoretic upper bound for the overall regret in Theorem 3.
5.1 A Gradient Estimator
Following the algorithm framework outlined in Section 3.2, we now develop a detailed gradient estimator . Regarding the objective function in (5), it suffices to construct estimators for the partial derivatives
| (17) |
Following the infinitesimal perturbation analysis (IPA) approach (see, for example, Glasserman (1992)), we next show that the partial derivatives in (17) can be expressed in terms of the steady-state distributions and of the waiting time process and observed busy period process , of which the dynamics are characterized by (6)–(7).
Lemma 5.
Suppose Assumptions 1 and 2 holds. Then, for any , are differentiable in and . Besides,
| (18) | ||||
Proof of Lemma 5.
To prove Equation (18), it suffices to work with the partial derivatives of the steady-state expectation . We follow the IPA analysis in Glasserman (1992) and Chen (2014).
Given , we define and rewrite the recursion (6) as
Define the derivative process , then by chain rule, we have
and obtain a recursion . Let . Then, it is straightforward to see that satisfies the recursion given in (7) as the observed busy period , i.e.,
Under the assumption that the queueing system is stable, the limit should be equal in distribution to . Therefore, we formally derive
| (19) |
The above heuristics can be made rigorous by verifying exchanges of limits using the results in Glasserman (1992), and we refer the readers to Section 8.9 for detailed explanations. Using (19), we can derive the partial derivative of the steady-state waiting time with respect to price as below:
Now we turn to . Let , it is easy to check that . Then, following steps similar to those for (19), we have
Therefore,
and hence,
Finally, plugging the expressions of the two partial derivatives into yields (18). ∎
5.2 GOLiQ: A Version
Utilizing results in Lemma 5, we are ready to design a version of the GOLiQ algorithm, where we estimate the terms and in the partial derivatives (18) using the finite-sample averages of and observed in each cycle . The formal description of the algorithm is given in Algorithm 1.
Remark 8 (On the queueing leftover).
We elaborate more on our treatment of , the existing queue content at the beginning of cycle . First, the content of includes customer arrivals in cycle and possibly even earlier cycles. Second, it is also possible to have . Nevertheless, these above cases do not affect the implementation of Algorithm 1 (note that Algorithm 1 gives a gradient estimator using samples without specifying any of the above events). Of course, the event does play a role in our theoretic regret analysis, but it is a rare event with a negligible probability (in fact, we show that the probability will be suppressed to , also see Remark 3.
Selecting the “optimal” hyperparameters.
The effectiveness of Algorithm 1 largely hinges upon carefully selecting the three hyperparameters: (i) the warm-up time , (ii) the learning step size , and (iii) the exploration sample size . Except for which has no bearing on the theoretical order of the regret, both the other two parameters and will play critical roles in our regret analysis. We next give the forms of the two parameters. First, The step size satisfies
| (20) |
where is the convexity bound specified in Assumption 3. Next, the sample size satisfies
| (21) |
for any warm-up parameter , where and are the constants specified in Assumption 2, and the explicit formula of is given in (36).
The above-mentioned forms of and are obtained from our detailed regret analysis where we show that the structure of (20) and (21) “minimizes” the order of the overall regret (in the sense of maximizing and as in Theorems 1 and 2). Although the theoretical bounds of parameters , and are imposed to facilitate our regret analysis, our numerical experiments show that GOLiQ remains effective even when the theoretical bounds are relaxed, confirming the robustness of GOLiQ to these hyperparameters; see Section 9 for details. Next, we show that Algorithm 1 has a regret bound of with being the cumulative number of customers served by cycle . We do so by verifying that our choices of and (along with the corresponding and ), will satisfy the conditions in Theorem 1 and Theorem 2.
Theorem 3.
Remark 9 (On the logarithmic regret bound (23)).
Below we provide some additional discussions on the regret bound (23):
-
On the constant . The explicit expression for the constant , although complicated, is given by (38). It involves error bound corresponding to the transient behavior of the queueing system, the bias and variance of the gradient estimator, moment bounds on the queue length and other model parameters. One can verify that is decreasing in the convergence rate coefficient and increasing in the moment bounds of the queue length .
-
On the first logarithmic term. Consider an SGD algorithm in that an unbiased gradient estimator with a bounded variance can be evaluated using a single data point (i.e., , ), it has been proved the scaled error converges in distribution to a non-zero random variable (Theorem 2.1 in Chapter 10 of Kushner and Yin (2003)). Hence, the convergence rate for that any SGD-based algorithm can achieve is at best (yielding a cumulative regret of order ), which is exactly the rate of convergence established by our online algorithm (taking in Theorem 3). In this sense, GOLiQ is already achieving an “optimal” convergence rate. We point out that, due to the nonstationary error of the queueing system, our gradient estimator is obtained using an increasing number of data points in order to guarantee a reasonably small bias.
-
On the second logarithmic term. In order to control the regret of nonstationarity, the queueing system need to be operated in each cycle for a duration of order . Because the queueing performance converges to its steady state exponentially fast, this inevitably introduces an extra logarithmic term in our regret bound (which explains the “square” in ). The question that remains open is whether this bound is optimal. We conjecture that the answer is yes but admit that a rigorous treatment of a lower regret bound can be quite challenging. For example, establishing a lower regret bound requires a lower bound on the convergence rate of a queue, which by itself is an open question. We leave this question to future research.
Remark 10 (Controlling the length of cycle ).
We use (the number of customers served in cycle ), instead of the clock time , to control and measure the regret bound. The benefit of using (rather ) as the cycle length is that it facilitates the technical analysis, because is directly related to the number of samples used to estimate our gradient estimator. In fact, using instead of has no bearing on the order of the regret bound. To see this, note that the arrival rate is assumed to fall into a compact set . Therefore, since is the total units of clock time elapsed after cycle , we have for all .
6 Numerical Experiments
To confirm the practical effectiveness of our online learning method, we conduct numerical experiments to visualize the algorithm convergence, benchmark the outcomes with known exact optimal solutions, estimate the true regret and compare it to the theoretical upper bounds. Our base example is an queue, having Poisson arrivals with rate , and exponential service times with rate . In our optimization, we consider a commonly used logistic demand function (Besbes and Zeevi, 2015)
| (24) |
where is the system scale (also referred to as the market size). We also consider the following convex cost function for the service rate
| (25) |
See the top left panel of Figure 4 for in (24). In particular, the optimal pricing and staffing problem in (1) now becomes
| (26) |
In light of the closed-form steady-state formulas of the queue, we can obtain the exact values of the optimal solutions and the corresponding objective value , with which we are able to benchmark the solutions from our online optimization algorithm.
We first consider two one-dimensional online optimization problems in Section 6.1. We next treat the two-dimensional pricing and staffing problem in Section 6.2. In Section 6.3, we compare our results to previously established asymptotic heavy-traffic solutions in Lee and Ward (2014). Additional numerical experiments are provided in the e-companion: In Section 9 we investigate the robustness of GOLiQ to the hyperparameters. In Section 10 we benchmark the performance of GOLiQ to other online learning methods. Section 11 includes more experiments regarding the relaxation of uniform stability and GOLiQ’s performance in queues having other inter-arrival and service time distributions.
6.1 One-Dimensional Online Optimizations
Algorithm 1 covers special cases where there is only one decision variable. For example, if the service capacity (service fee ) is an exogenous parameter and the only decision is the service fee (service capacity ), then one can simply fix () throughout the learning process. The theoretical regret bound (as in Theorem 3) for these one-dimensional cases remains unchanged.
6.1.1 Online optimal pricing with a fixed service capacity
Motivated by revenue management problems in revenue generating service system, our first example focuses on the one-dimensional optimization of price with service rate held fixed. In this case we can simply omit the term in (26). Fixing the other model parameters as , and , we first obtain the exact optimal price (top right panel of Figure 4). According to Algorithm 1 and Theorem 3, we set the step size and cycle length .
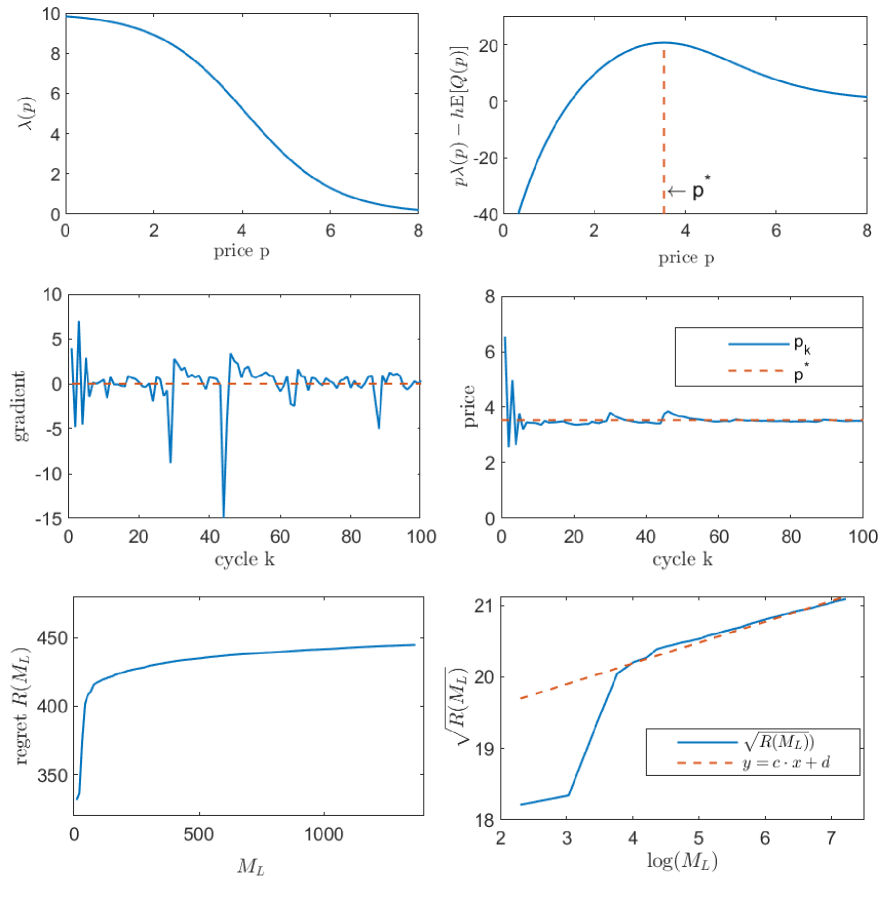
In Figure 4, we give the sample paths of the gradient and price as functions of the number of cycles , and the mean regret (estimated by averaging 500 independent sample paths) as a function of the cumulative number of service completions . We observe that although the objective function is not convex in , the pricing decision quickly converges to the optimal value , and the regret grows as a logarithmic function of . In particular, a simple linear regression for the pair (bottom right panel) verifies our regret bound given in Theorem 3.
6.1.2 Online optimal staffing problem with an exogenous arrival rate
Motivated by conventional service systems where customers are served based on good wills (e.g., hospitals), we next solve an online optimal staffing problem, with the objective of minimizing the combination of the steady-state queue length (or equivalently the delay) and the staffing cost, with the arrival rate (or equivalently, the price ) held fixed. Namely, we omit the term in (26). Fixing , , and , we obtain the exact optimal service capacity (top right panel of Figure 5). Also by Algorithm 1 and Theorem 3, we set the step size and cycle length with initial service rate .
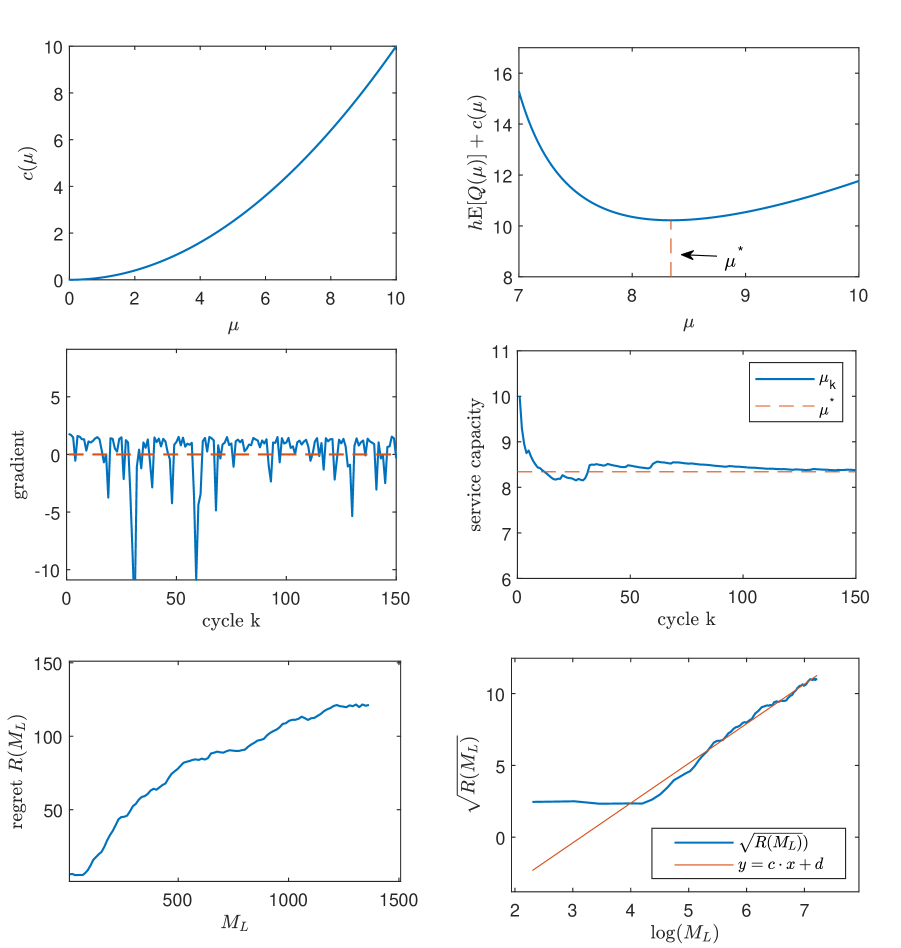
In Figure 5, we again give sample paths of the gradient and service capacity , and estimation of the regret. As the number of cycles increases, our stage- staffing decision quickly converges to (bottom right panel) and the regret also grows as a logarithmic function of (bottom left panel).
6.2 Joint Pricing and Staffing Problem
We next consider a joint staffing and pricing problem having the objective function in (26), with the logistic demand function in (24) and parameters , , and . The optimal price and service rate are given as benchmarks (top right panel in Figure 6).
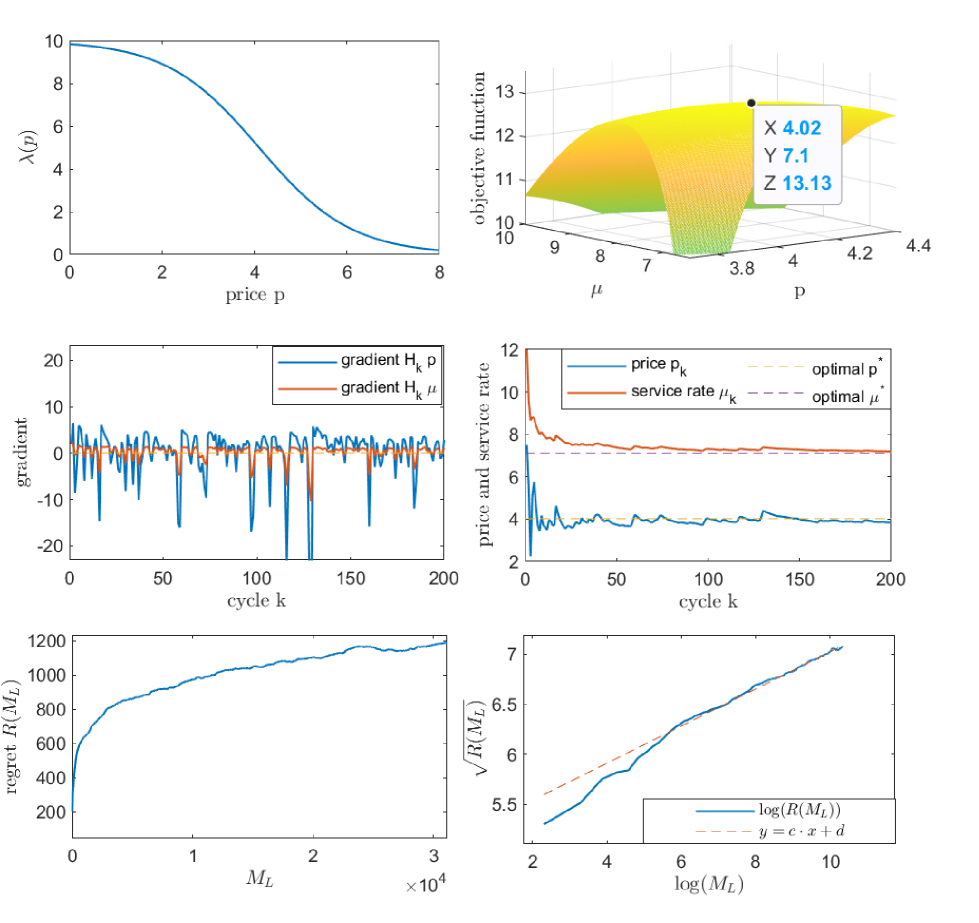
In Figure 6, we show that and converge quickly to their corresponding optimal target levels and (although the objective is not always convex when ). And similar to the one-dimensional cases, the regret grows as a logarithmic function of (bottom left panel).
6.3 Comparison to Heavy-Traffic Methods
In this subsection, we provide numerical analysis to contrast the performance of GOLiQ to that of the heavy-traffic approach in Lee and Ward (2014). In Lee and Ward (2014), the objective is to find the optimal decisions and for the optimization problem (1) with a linear staffing cost Because this problem is not amenable to analytic treatments (due to the complex queueing dynamics), the authors resort to the heavy-traffic approximation by constructing a sequence of queues indexed by a scaling factor , where the model has an arrival rate which grows to infinity as increases. The authors propose an asymptotically optimal solution
| (27) |
where , and and are defined in Assumption 2, and solves a deterministic static planning problem:
| (28) |
We remark that the solution in Lee and Ward (2014) requires the precise knowledge of the second moments of service and arrival times (e.g., the term in (27)), but such information is not needed in GOLiQ.
Experiment settings.
We consider an model with a phase-type service-time distribution, and a logit demand in (24) where the base demand rate has and the market size plays the role of the scaling factor. We fix the delay cost throughout this experiment. To quantify the regret, we obtain the exact optimal policy using the Pollaczek-Khinchine formula for the queue-length function
| (29) |
where is the squared coefficient of variation (SCV) for the service time. We next describe the detailed settings for comparing GOLiQ to heavy-traffic solution in Lee and Ward (2014), dubbed LW. In order to benchmark the regret of our GOLiQ to that of LW, we continue to consider a dynamic environment where the number of cycles increases. In the cycle,
-
•
the LW policy remains fixed at as in (27) (it does not evolve with );
-
•
our online learning policy is dynamically updated according to GOLiQ (Algorithm 1).
Because the LW policy is an approximation, it will yield a linear regret as increases. But LW’s linear regret should not be too steep when is large enough. In contrast, although GOLiQ is guaranteed to generate a sublinear regret, it is expected to have a larger reget increment at the earlier “exploration” stage, because it is learning without the supervision of the fluid or diffusion limits (as in the LW approach). Nevertheless, we expect that GOLiQ will eventually outperform the LW method (exhibiting a lower regret level) when is sufficiently large. We next numerically study how soon GOLiQ surpasses LW and the impact of the following three parameters:
-
(i)
staffing cost ;
-
(ii)
service-time SCV ;
-
(iii)
market size (i.e., system scale).
We intentionally set the initial decision of GOLiQ far from the optimal solution in the experiment.
Experiment results.
In Figure 7, we report results of regret for both GOLiQ and LW. For the three factors , and , we change one at a time (with the other two held fixed). In Panels (a)-(c), we vary the staffing cost from 0.5 to 2. In Panels (d)-(f), we vary the service-time SCV from 0.1 to 10. Here the cases , 1, and 10 are achieved by considering Erlang, exponential, and hyperexponential service-time distributions. In Panels (g)-(i), we vary the system scale from 1 to 25. In all of the cases, we use hyper-parameter and . Monte-Carlo estimates of the regret curves are obtained by averaging 100 independent runs.
We can see from Figure 7 that, in all cases, GOLiQ will eventually establish a lower regret level than the LW policy. Varying these three factors clearly has an significant impact on how soon GOLiQ outperforms LW.
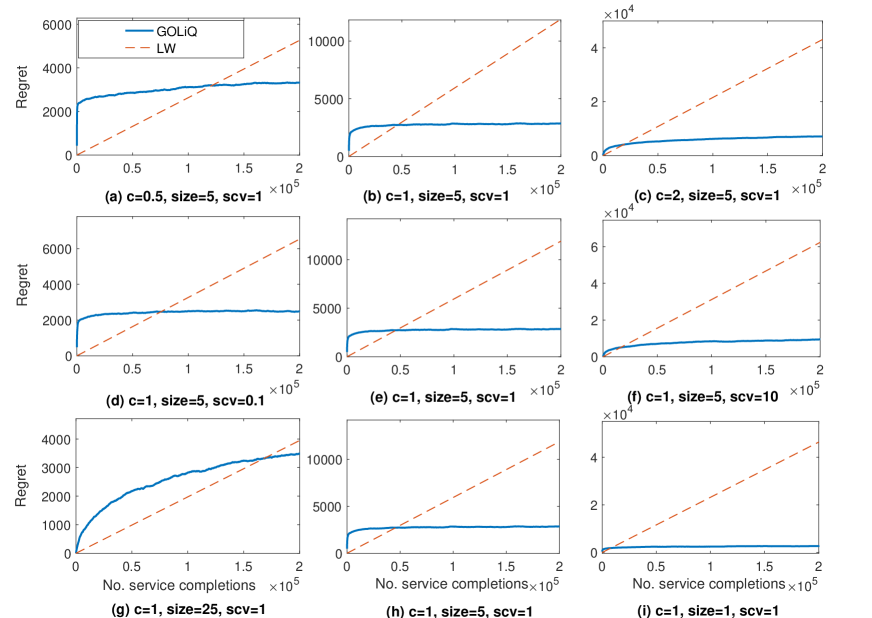
Our findings are summarized below:
-
•
Staffing cost : Figure 7 shows that GOLiQ intends to outperform LW when is relatively large. We provide our explanations below. First, a larger staffing cost will induce a smaller , which leads to a longer waiting queue. On the other hand, note that the LW solution is primarily based on solving the deterministic static problem (28); and unlike the stochastic revenue optimization problem (1), the objective function of (28) overlooks the queue-length holding cost. This explains why GOLiQ gains its advantage over LW as increases. See Panels (a)-(c) of Figure 7.
-
•
Service SCV : When the service-time SCV is smaller, the LW method intends to work better, because the basic idea of LW stems from solutions of a fluid model (where the service times are assumed deterministic). On the other hand, when is larger, the system becomes more variable so that our learning-based algorithm begins to excel (because GOLiQ takes into account real-time information dynamically). See Panels (d)-(f) of Figure 7.
-
•
Market size : When is small, LW loses its advantages because it arises from the large-scale limit of the queue which requires to be sufficiently large. While the performance of our GOLiQ is robust to the system scale. See Panels (g)-(i).
-
•
Performance in the long run: GOLiQ is a more effective approach in the long run, because the LW solution remains static and its error grows linearly as time increases.
Remark 11 (Different philosophies: online learning vs. heavy traffic).
We emphasize that online learning and heavy-traffic analysis are two methodologies developed based on distinct philosophies. First, when the system size is large, heavy-traffic models are able to produce high-fidelity solutions, but they require more prior knowledge of the system as inputs. On the other hand, online learning requires less prior understanding of the system, because the data-driven nature allows it to dynamically evolve and improve (whereas heavy-traffic solutions are static). Second, the notions of asymptotic optimality are different. As an approximate method, heavy-traffic analysis is said to be asymptotically optimal in the sense that as the system size grows large, its solution will become close to the true optimal solution. On the other hand, the solution of the online learning method will converge to the true optimal solution as the server’s experience accumulates (by serving more and more customers).
7 Conclusion
In this paper we develop an online learning framework designed for dynamic pricing and staffing in queueing systems. The ingenuity of this approach lies in its online nature, which allows the service provider to continuously obtain improved pricing and staffing policies by interacting with the environment. The environment here is interpreted as everything beyond the service provider’s knowledge, which is the composition of the random external demand process and the complex internal queueing dynamics. The proposed algorithm organizes the time horizon into successive operational cycles, and prescribes an efficient way to update the service provider’s policy in each cycle using data collected in previous cycles. Data include the number of customer arrivals, waiting times, and the server’s busy times.
A key appeal of the online learning approach is its insensitivity to the scale of the queueing system, as opposed to the heavy-traffic analysis, which requires the system to be in large scale (with the arrival and service rate both approaching infinity). Effectiveness of our online learning algorithm is substantiated by (i) theoretical results including the algorithm convergence and regret analysis, and (ii) engineering confirmation via simulation experiments of a variety of representative queues. Theoretical analysis of the regret bound in the present paper may shed lights on the design of efficient online learning algorithms (e.g., bounding gradient estimation error and controlling proper learning rate) for more general queueing systems.
There are several venues for future research. One natural extension would be to develop new regret analyses that do not require the uniform stability condition. Another interesting and promising direction is to develop an online learning method without assuming the knowledge of the arrival rate function , where the learner (hereby the service provider), during the interactions with the environment, will have to resolve the tension between obtaining an accurate estimation of the demand function and optimizing returns over time. A third dimension is to extend the methodology to more general model settings (e.g., queues having customer abandonment and multiple servers), which will make the framework more practical for service systems such as call centers and healthcare. In this regard, results in the present paper may serve as useful foundations; in particular, Theorems 1 and 2 will help construct desired regret bounds as long as their associated conditions can be verified. Doing so usually requires two main steps in a new queueing model: (i) proving a new ergodicity (or rate of convergence to stationarity) result that can be used to bound the regret of nonstationarity; (ii) designing a new gradient estimator which is easily computed from data (here a good gradient estimator should have small bias and variance subject to conditions in Theorem 2).
References
- Abate et al. (1995) Abate, J., G. L. Choudhury, and W. Whitt (1995). Exponential approximations for tail probabilities in queues, i: waiting times. Operations Research 43(5), 885–901.
- Asmussen (2003) Asmussen, S. (2003). Applied Probability and Queues. Springer.
- Ata and Shneorson (2006) Ata, B. and S. Shneorson (2006). Dynamic control of an M/M/1 service system with adjustable arrival and service rates. Management Science 52, 1778–1791.
- Besbes and Zeevi (2015) Besbes, O. and A. Zeevi (2015). On the (surprising) sufficiency of linear models for dynamic pricing with demand learning. Management Science 61(4), 1211–1224.
- Blanchet and Chen (2015) Blanchet, J. and X. Chen (2015). Steady-state simulation of reflected Brownian motion and related stochastic networks. Annals of Applied Probability 25, 3209–3250.
- Broadie et al. (2011) Broadie, M., D. Cicek, and A. Zeevi (2011). General bounds and finite-time improvement for the kiefer-wolfowitz stochastic approximation algorithm. Operations Research 59(5), 1211–1224.
- Burnetas and Smith (2000) Burnetas, A. N. and C. E. Smith (2000). Adaptive ordering and pricing for perishable products. Operations Research 43(3), 436–443.
- Chen (2014) Chen, X. (2014). Exact gradient simulation for stochastic fluid networks in steady state. Winter Simulation Conference (WSC) 2015(586-594).
- Chong and Ramadge (1993) Chong, E. K. P. and P. J. Ramadge (1993). Optimization of queues using an infnitesimal perturbation analysis-based stochastic algorithm with general update times. SIAM Journal on Control and Optimization 31, 698–732.
- Dai and Gluzman (2021) Dai, J. G. and M. Gluzman (2021). Queueing network controls via deep reinforcement learning. Stochastic Systems.
- Fu (1990) Fu, M. C. (1990). Convergence of a stochastic approximation algorithm for the GI/G/1 queue using infinitesimal perturbation analysis. Journal of Optimization Theory and Applications 65, 149–160.
- Glasserman (1992) Glasserman, P. (1992). Stationary waiting time derivatives. Queueing Systems 12, 369–390.
- Huh et al. (2009) Huh, W. T., G. Janakiraman, J. A. Muckstadt, and P. Rusmevichientong (2009). An adaptive algorithm for finding the optimal base-stock policy in lost sales inventory system with censored demand. Mathematics of Operations Research 34(2), 397–416.
- Huh and Rusmevichientong (2013) Huh, W. T. and P. Rusmevichientong (2013). Online sequential optimization with biased gradients: Theory and applications to censored demand. INFORMS Journal on Computing 26(150-159).
- Jia et al. (2021) Jia, H., C. Shi, and S. Shen (2021). Online learning and pricing for service systems with reusable resources. Working paper.
- Kella and Ramasubramanian (2012) Kella, O. and S. Ramasubramanian (2012). Asymptotic irrelevance of initial conditions for Skorokhod refection mapping on the nonnegative orthant. Mathematics of Operations Research 37, 301–312.
- Kim and Randhawa (2018) Kim, J. and R. S. Randhawa (2018). the value of dynamic pricing in large queueing systems. Operations Research 66(2), 409–425.
- Krishnasamy et al. (2021) Krishnasamy, S., R. Sen, R. Johari, and S. Shakkottai (2021). Learning unknown service rates in queues: A multiarmed bandit approach. Operations Research 69(1), 315–330.
- Kumar and Randhawa (2010) Kumar, S. and R. S. Randhawa (2010). Exploiting market size in service systems. Manufacturing Service Oper. Management 12(3), 511–526.
- Kushner and Yin (2003) Kushner, H. J. and G. G. Yin (2003). Stochastic Approximation and Recursive Algorithms and Applications. Springer.
- L’Ecuyer et al. (1994) L’Ecuyer, P., N. Giroux, and P. W. Glynn (1994). Stochastic optimization by simulation: numerical experiments with the M/M/1 queue in steady-state. Management Science 40(10), 1245–1261.
- L’Ecuyer and Glynn (1994) L’Ecuyer, P. and P. W. Glynn (1994). Stochastic optimization by simulation: convergence proofs for the GI/GI/1 queue in steady state. Management Science 40(11), 1562–1578.
- Lee and Ward (2014) Lee, C. and A. R. Ward (2014). Optimal pricing and capacity sizing for the GI/GI/1 queue. Operations Research Letters 42, 527–531.
- Lee and Ward (2019) Lee, C. and A. R. Ward (2019). Pricing and capacity sizing of a service facility: Customer abandonment effects. Production and Operations Management 28(8), 2031–2043.
- Liu et al. (2019) Liu, B., Q. Xie, and E. H. Modiano (2019). Reinforcement learning for optimal control of queueing systems. In Proceedings of Allerton Conference.
- Maglaras and Zeevi (2003) Maglaras, C. and A. Zeevi (2003). Pricing and capacity sizing for systems with shared resources: approximate solutions and scaling relations. Management Science 49(8), 1018–1038.
- Nair et al. (2016) Nair, J., A. Wierman, and B. Zwart (2016). Provisioning of large-scale systems: the interplay between network effects and strategic behavior in the user base. Management Science 62(6), 1830–1841.
- Nakayama et al. (2004) Nakayama, M. K., P. Shahabuddin, and K. Sigman (2004). On finite exponential moments for branching processes and busy periods for queues. Journal of Applied Probability 41(A), 273–280.
- Shah et al. (2020) Shah, D., Q. Xie, and Z. Xu (2020). Stable reinforcement learning with unbounded state space. Working paper.
- Sutton and Barto (2018) Sutton, R. S. and A. G. Barto (2018). Reinforcement Learning: An Introduction (2nd ed.). The MIT Press.
- Yuan et al. (2021) Yuan, H., Q. Luo, and C. Shi (2021). Marrying stochastic gradient descent with bandits: Learning algorithms for inventory systems with fixed costs. Management Science.
- Zhang et al. (2020) Zhang, H., X. Chao, and C. Shi (2020). Closing the gap: A learning algorithm for lost-sales inventory systems with lead times. Management Science 66(5), 1962–1980.
SUPPLEMENTARY MATERIAL
This Supplementary Material provides supplementary materials to the main paper. In Section 8, we give all the technical proofs omitted from the main paper. In Section 9, we test the robustness of GOLiQ with respect to key algorithmic hyperparameters. In Section 10, we compare GOLiQ to the online learning method in Huh et al. (2009). In Section 11, we report additional numerical studies. To facilitate readability, we formally summarize all notations in Table 1 including all model parameters and functions, algorithmic hyperparameters, and constants in the regret analysis.
8 Proofs
8.1 Proof of Lemma 1
Let be the queue length when customer in cycle leaves the system. Then . The proof follows a stochastic ordering argument for models. Let , and be the waiting times, observed busy periods, and queue length process in a queue with stationary control parameter and , and with steady-state initial state, i.e., , and . Let’s call this system the dominating system. Then, for all ,
i.e., the arrival process in the dominating queue is the upper envelope process (UEP) for all possible arrival processes corresponding to any control sequence . Similarly, the service process in the dominating queue is the lower envelope process (LEP) for all possible service processes corresponding to any control sequence. As a consequence, since and ,
Under Assumption 2, the moment generating function of the random variable exists around the origin. Following Blanchet and Chen (2015), under Assumption 1, this condition can further imply that there exists a constant such that (See the Remark on p.3222 in Blanchet and Chen (2015)) Then, following Theorem 1 of Abate et al. (1995), there exists a constant such that . As a consequence, is finite for , and so are for all . Given that the moments of waiting times are finite, we can conclude that and are finite for all , applying Theorem 10.4.3 in Asmussen (2003). Finally, the moments of the observed busy period are finite following Proposition 4.2 in Nakayama et al. (2004). Therefore, we choose
and this closes our proof.
8.2 Proof of Lemma 2
For , define stopping times . For a fixed pair of inter-arrival and service time sequences, the consequent waiting time sequence in a single-server queue is monotone in its initial state . Without loss of generality, assume . Then, for all and therefore, . As the two queues are coupled with the same arrival and service time sequences, we will have for all . Therefore, we can conclude for all . For , we have following Kella and Ramasubramanian (2012).
For simplicity of notation, we write . For , define a random walk with . (Recall that and are the sequences of service and inter-arrival times.) By Lindley recursion, . Then, for any ,
where the second inequality holds as given that and that . Recall that and . Therefore,
Following Chebyshev’s Inequality, we have
where the last inequality follows from Assumption 2. On the other hand, let be an exponentially tilted probability measure with respect to , such that the likelihood ratio . Then,
In summary, we have , . So, we can conclude
8.3 Proof of Lemma 3
Define two auxiliary random walks:
Then, for any , we could express and as
Let and . Note that following the above notation, for each , is the waiting time of customer and as a consequence, should be understood as the inter-arrival time between customers and , and as the service time of customer .
Case 1: If and , i.e., both and hit zero before , we have
So, in this case
Recall that (and ) is the age of the server’s busy time observed by customer upon arrival. By definition, and therefore,
The second equation holds as the server has just served customers (indexed from to ) in the current busy cycle when customer enters service. Then,
Following a similar argument, we have
Therefore, in this case, we have
Case 2: If or , we can inductively derive that
In detail, it suffices to show that, for all ,
| (30) |
Without loss of generality, we assume . By definition, and hence for all . Then,
If , we have
On the other hand, if , we have So,
This closes the proof of (30).
As a result of (30), if , we can conclude the system (associated with ) was kept busy from time 0 until customer enters service. As a consequence, as , we have
Therefore,
and hence we can also conclude
8.4 Proof of Lemma 4
By the inequality that for , we have
It suffices to prove that there exist two constant such that for ,
Without loss of generality, assume . We now construct two stationary sequences that are coupled “from the past”. Let and be two i.i.d sequences corresponding to the service and inter-arrival times. For each , we define a random walk:
It is clear that is a random walk with negative drift for . Define
It is known in literature (see, for example, Blanchet and Chen (2015)) that is a stationary waiting time process of a queue, starting from , with parameter . In particular, the dynamics of satisfies that
with being the service time of customer and being the inter-arrival time between customer and . For a fixed sequence of , we have
As , we have . Besides, let , we have
As a consequence, we have
Note that is the service time of customer in the system with parameter . By the definition of , customer enters service immediately upon the arrival and the queue remains busy by arrival of customer . Therefore, the summation of service times on the right hand side equals to the time between the arrival of customer and the departure of customer , which equals to the observed busy period at the arrival of customer plus its waiting time, i.e.,
Therefore, for each ,
Following Lemma 1, . Let and we conclude, for ,
The bound for follows a similar argument and therefore we only provide a sketch of the proof. Without loss of generality, we assume and consider two stationary waiting time process that are coupled from past with the same sequence in a similar way as we introduced previously. Then, we have , and therefore,
As a consequence, we can take
| (31) |
8.5 Full Proof of Theorem 1
Proof of Corollary 1.
For any ,
Given that , by definition, is synchronously coupled with for . Note that given , and are independent of for . As a consequence, by Lemma 2, the conditional expectation
Therefore,
By Lemma 1 and Assumption 2, we have
As a consequence, we have
On the other hand,
Again, by Lemma 1, As ,
In summary, we have, for ,
As a direct consequence,
∎
Proof of Corollary 2.
Recall that by (6), for each cycle ,
Define
Then, in the case , we have for all . As a consequence, we have
For the second term, by Lemma 1, we have, for ,
For the first term, by definition, is a waiting time sequence with service and arrival rates and is a sequence with rates or . As a consequence, by applying Lemma 3, we have
By Lemma 1, we have that and , where and are the observed busy period and waiting time in a stationary queue with rate as defined in Lemma 1. On the other hand, under Condition (b) of Theorem 1,
Therefore,
Finally, by Corollary 1, we have
In summary, we can conclude
where the second inequality follows from Lemma 4. As a direct consequence, as .
∎
Proof of Corollary 3.
Note that by Lemma 1,
So it suffices to show that
Given and , is the time for the -th customer to enter service. Let be the inter-service time between the -th and the -th customers in cycle . Then, and for each ,
Therefore,
As a consequence,
Following Corollary 1 and Lemma 4, for , the first term
As to the second term, by definition, the customers 1 to arrive to the system while customer is waiting in the system, and therefore,
Here, is bounded since we assume that is light-tailed (Assumption 2). For the simplicity of notation, we just assume that for the same in Lemma 1. Then,
Finally,
Therefore, . ∎
Finishing the proof of Theorem 1.
First, by Corollary 1, we have
By Corollary 2,
Following the proof of Corollary 3, we have
Therefore, we can conclude that , with
| (32) |
Let be the upper bound of the regret in the first cycle. Here the constant since the decision region is bounded and by condition (a), is also bounded. Finally, we conclude that
with . ∎
8.6 Convergence Rate of Observed Busy Period
As an analogue of Lemma 2, we prove a uniform convergence rate for the observed busy period , which will be used to bound and of the gradient estimator (18) that involves terms of .
Lemma 6.
Let and be the observed busy period of the two queueing systems coupled as in Lemma 2, with and .
-
1.
.
-
2.
There exists a constant such that for all and .
8.7 Proof of Theorem 2
The proof follows an induction-based approach similar to Broadie et al. (2011). For simplicity of notation, we write . Let be the filtration up to cycle , i.e. including all events in the first cycles. Since ,
Note that
The second last inequality follows from and the Holder Inequality, the last inequality follows from .
Let and recall that . Then, we obtain the recursion
By Condition (b) and (c), we have
Because step size , for large enough, . Let . Then, for , . By Condition (a), , and by the induction assumption , for , we have
Then, we have as long as
| (33) |
To check (33), note that, and . Besides, for . Then, for ,
Let
| (34) |
Then we have for all , and we can conclude by induction, for all ,
By Assumption 3, there exists such that
As a consequence,
Note that equals to the arrival time of customer plus its waiting time. Therefore,
and we can conclude
8.8 Proof of Theorem 3
(i) For each , note that , let’s denote by
Then,
Following (18),
where and . Note that , and are bounded. Let , then
where the last equality follows from and and and are stationary versions of the waiting times and observed busy periods that are synchronously coupled with and respectively. Therefore, the bias
Following a similar argument as in the proof of Corollary 1, we have, for ,
For the observed busy period , following a similar analysis and Lemma 6, we have
where
| (35) |
If we choose
with
| (36) |
then
As a consequence,
Therefore, we can conclude that
On the other hand, as , and are bounded, . Recall that . Then,
By Lemma 1, we have
where and are defined as in Lemma 1. Note that by definition, and are stationary, we have
Therefore, is uniformly bounded. Given that , we have with
| (37) |
(ii) According to the update rule, we immediately got
(iii) We have just proved that the conditions of Theorem 1 are satisfied with . Therefore, with the expression of given in (8.5). Besides, conditions of Theorem 2 are satisfied with and . In particular, given that with . Therefore,
As a consequence, the total regret
The last inequality uses . Since , the relaxation from to will not change the order of the regret bound. In addition, we can find a closed-expression for as
| (38) |
8.9 Details in the Proof of Lemma 5
We first give a rigorous proof of (19) in derivation of the partial derivation . To better explain the proof, we adopt the notions in Glasserman (1992). We will take derivative with respective to the parameter . With a slight abuse of notation, we redefine and so that . And then, the Lindley recursion becomes
Note that the function is increasing and convex in and . In addition, the derivative process is denote as . Define such that
The stationary versions of the waiting time and derivative process are denoted as and . Then we can check Conditions (B1) to (B3) on page 377 of Glasserman (1992):
-
(B1)
For each , the sequence
is stationary and ergodic, as we can extend the i.i.d. sequences and to .
- (B2)
-
(B3)
For all ,
According to the discussion on p.379 of Glasserman (1992), Condition (B3) holds for queues under the usual stability condition that . Below, we give a detailed verification of this condition under our model setting.
Recall that and by Assumption 1, . So there exists a constant , such that for all Let denote the support of and let . We first show by contradiction that . Since is the infimum of the support,Besides, if ,
On the other hand, we have
where the last inequality follows from the fact that and are independent in the queue. This is a contradiction, so we can conclude that . Next, we show that . Following a similar derivation, we can conclude
In addition, we have and following Lemma 1. As a consequence, we can prove (19) using the following Corollary 5.3 in Glasserman (1992):
Lemma 7 (Corollary 5.3 in Glasserman (1992)).
Suppose that is increasing and (jointly) convex, and that and are almost surely convex. Suppose (B1)-(B3) hold, for all in its range. Then, and
almost everywhere in the range of .
The derivation of follows a similar argument with .
9 Relaxing Theoretical Bounds of Hyperparameters
In this section, we conduct numerical experiments to investigate the robustness of GOLiQ’s performance to the two main hyperparameters: (i) cycle length , and (ii) step size . We follow two steps:
- •
-
•
Next, we test the algorithm’s performance while varying these hyperparameters; we especially consider values that violate their corresponding theoretical bounds.
9.1 Theoretical bounds for and
We follow Section 6.2 by considering the example having the objective function in (26) and demand function in (24), with , size and . In order to obtain the theoretic bounds for hyper-parameters, we set the region so that is strongly convex on .
Theoretical bound for .
Theoretical bound for .
To calculate the lower bounds of and specified in (21), we first estimate and . We set . First, according to the expression (36) and , we see that . Next, following (3), we select which gives the smallest theoretical lower bound.
Hence, (21) requires that and , which leads to a bound for the cycle length .
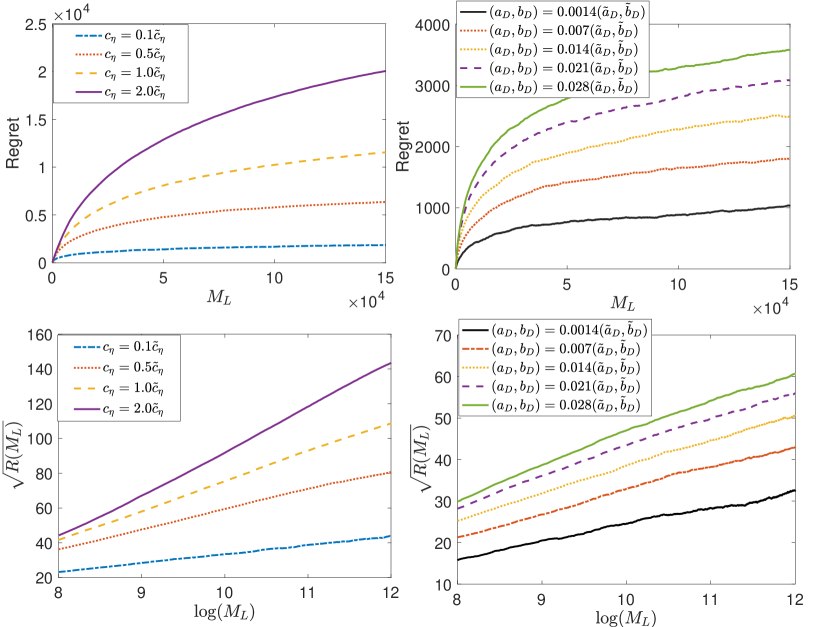
9.2 Robustness to the Theoretical Bounds
Recall that the theoretical bounds in (20) and (21) require that , and . We hereby test the criticality of these lower bounds , and by implementing GOLiQ with . Specifically, in our first experiments, we consider for the step-size , with (see left-hand panels of Figure 8); in our second experiment, we consider for the sample-size , with (see right-hand panels of Figure 8). In both experiments, we plot the average regret curves estimated by 500 independent runs.
Figure 8 reveals that GOLiQ continues to perform effectively even when the hyperparameters are chosen to be much smaller than their corresponding theoretical lower bounds. For , our algorithm generates a logarithm regret even when . (However, we discover that GOLiQ will fail to converge and yield a linear regret if we keep reducing (e.g., to ). For , all regret curves exhibit a logarithmic order (even when ). In summary, our numerical experiments show that the theoretical bounds for our hyperparameters do not seem to be too restrictive. In addition, the experiment in Section 6.3 serves as another piece of evidence supporting the robustness of GOLiQ. In Section 6.3, we apply GOLiQ with the same hyperparameters and for different settings with various , and (see Figure 7), and GOLiQ exhibits stable performance with similar logarithm regrets. Of course, we acknowledge that the specific selection of these hyperparameters in a practical setting will require further tuning in order to make the most efficient use of GOLiQ.
Remark 12 (Requirement of information: online learning vs. heavy traffic).
We provide our view on how online learning relies on the system information, and we treat heavy-traffic methods as a benchmark. First, online learning in general requires less prior information of the distributions than heavy-traffic methods do. For example, to solve the problem in the present study, the diffusion limit in Lee and Ward (2014) requires the knowledge of the exact values of the second moments of arrival and service times. On the other hand, even though the efficiency of GOLiQ is subject to constraints in terms of certain model parameters, the bounds of these constraints may be relaxed without needing to sacrifice much of the algorithm’s performance. Second, the required information (e.g., moments) serves as crucial input parameters for the heavy-traffic models, whereas the design and implementation of online learning algorithms do not immediately require the aforementioned information (even though it is still relevant to the tuning of hyperparameters). All that we require is that the constants in (20) and (21) are not too small. So as long as we follow the structure specified in (20)–(21), it will not be too difficult to find reasonably sound hyperparameters (e.g., by a trial-and-error search) even without precise information of parameters and as in Assumption 2. However, trial-and-error will be ineffective for heavy-traffic methods because precise information is needed (e.g., ). In this sense, online learning depends on the system information to a lesser extent.
10 Comparison With Online Learning Algorithm in Huh et al. (2009)
In order to highlight the novelty in the regret analysis of this work, we wish to provide a comparison to other existing online learning algorithms developed for queueing systems. Unfortunately, there exists no previous algorithm that aims to solve a similar (not to mention the same) problem as in this paper.
Huh et al. (2009) develops an online learning algorithm with the objective of finding the optimal base-stock policy for an inventory system with a non-zero replenishment lead time. At a glance, Huh et al. (2009) does not seem to be relevant to the present paper at all. Indeed, results in Huh et al. (2009) are by no means directly comparable to GOLiQ, because the two articles consider two different systems. Nevertheless, the fundamental idea in the regret analysis by Huh et al. (2009) may be used as a basis to devise a queueing-version algorithm.To understand why this is possible, we first discuss the similarities of our method and that in Huh et al. (2009); and we next explain their major distinctions.
Similarities.
First, Huh et al. (2009) analyzes the transient regret bound of an inventory system operated under a stationary base-stock policy, of which the main framework is analogous to that in the present work. Second, the heart of the online learning algorithm in Huh et al. (2009) is an SGD method. Last, the regret in Huh et al. (2009) is also defined using the steady-state performance as the benchmark.
Distinctions.
Nevertheless, we stress that GOLiQ is not a quick extension of the regret analysis in Huh et al. (2009). First, a queueing model, by its very nature, has completely different dynamics, problem structure, and research questions from inventory systems. For example, the state space of the queueing model here is unbounded, while the inventory system in Huh et al. (2009) is bounded. (The unbounded state space has made the analysis on transient error and gradient variance more challenging.) Next, our analysis of the “regret of nonstationarity” is a novelty; when establishing our regret bound, we examine more delicately the transient error at the beginning of the cycles, so as to render a smaller regret bound than the linear bound as in Huh et al. (2009). Also see Section 4.1 for additional discussions. In detail, different from the analysis in Huh et al. (2009), we further separate the transient error in each cycle into two parts, i.e., the ‘warm-up’ part and ‘near-stationary’ part, and deal with them using different coupling techniques: coupling from the previous cycle and coupling from infinite past for the ‘warm-up’ part and synchronous coupling in the same cycle for the ‘near-stationary’ part. Last, our novel theoretical analysis yields different “optimal” structure for the hyperparameters and .
According to their regret analysis, Huh et al. (2009) propose to choose the hyperparameters and which yield a regret bound in the order . However, we point out that the objective function in Huh et al. (2009) is convex while GOLiQ in the present paper is designed assuming a strongly convex objective function (Assumption 3). Therefore, to make a fair comparison between GOLiQ and the online learning algorithm proposed in Huh et al. (2009), we need to redo the regret analysis in Huh et al. (2009) under the strong convexity. This change, as we will show below, will yield a different set of hyperparameters.
Suppose we select and . Then, following Lemma 11 of Huh et al. (2009), (compared to in our analysis). Given that the objective function is strongly convex, Theorem 2 yields that for . As a result, the overall regret is
with . Consequently, the order of is minimized by setting
| (39) |
which yields an improved regret bound (as opposed to the previous regret under regular convexity).
We refer to Algorithm 1 with and selected according to (39) as GOLiQ-H. To compare GOLiQ with GOLiQ-H, we follow the setting in Section 6.2 by considering an queue, with and
In Figure 9, we plot the average regret curves (estimated by averaging 500 independent paths) for both GOLiQ and GOLiQ-H. The hyperparameters are and for GOLiQ, and and for GOLiQ-H. Unsurprisingly, Figure 9 confirms that GOLiQ is more effective than GOLiQ-H. This is consistent with our theoretical analysis because GOLiQ yields a logarithmic regret while GOLi-H has a regret bound of .
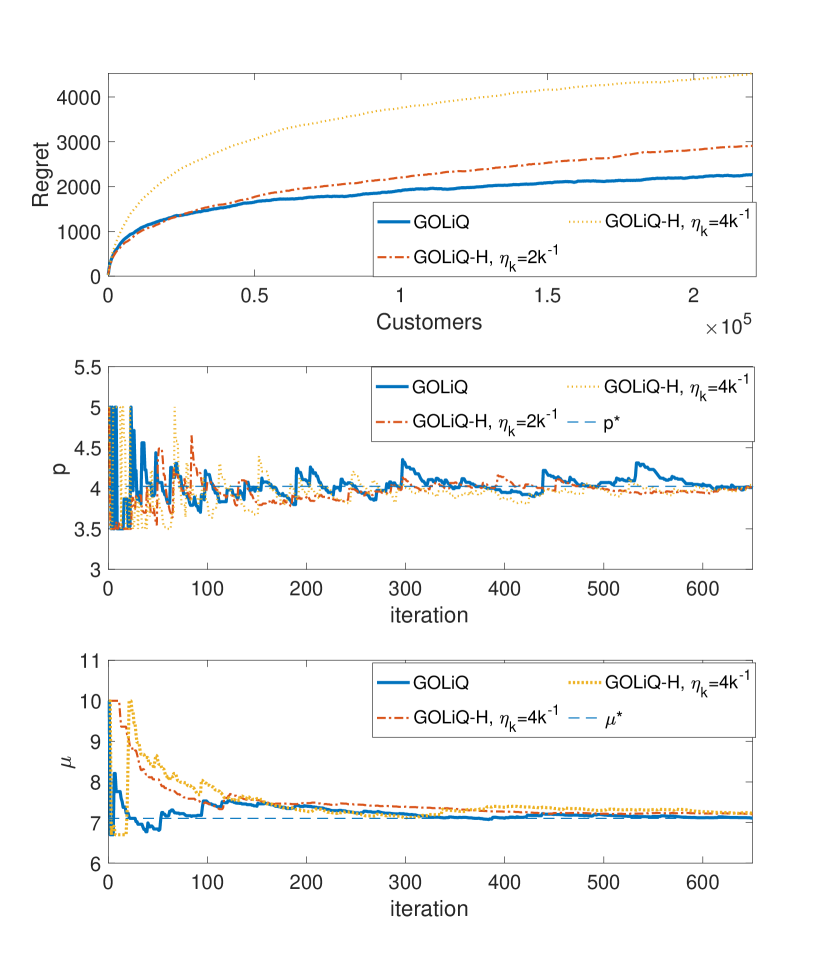
11 Additional Numerical Examples
In this section we conduct additional numerical experiments to confirm the practical effectiveness of our algorithm. In what follows, we first test the case where the uniform stability condition is relaxed; we next report the algorithm performance for queueing models with phase-type and lognormal distributions.
11.1 Violation of Uniform Stability
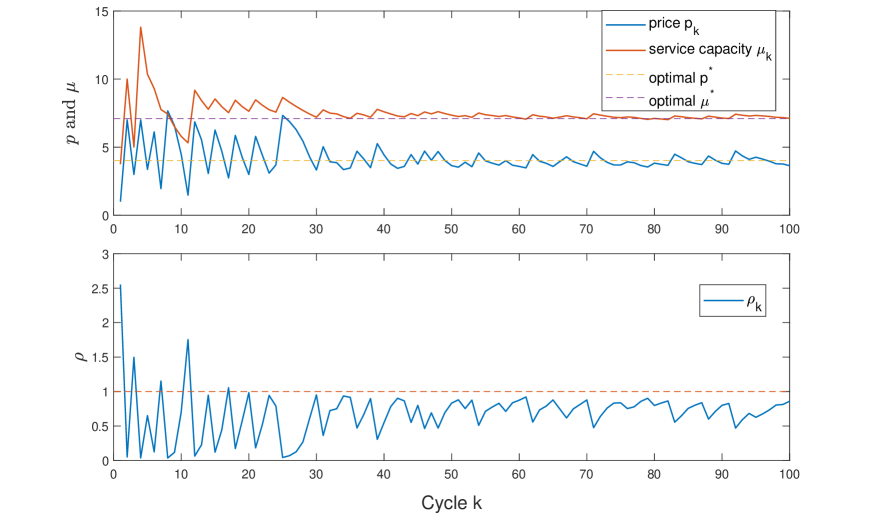
We extend the example considered in Section 6.2 with the uniform stability condition relaxed. Specifically, we begin with an initial setting of such that , which violates the stability condition. As shown in Figure 10, the pricing and staffing policies remain convergent to . Consistently, the resulting traffic intensity is quickly controlled to fall below 1; that is, the workload is kept in check despite of the unstable performance in the initial cycle.
11.2 with Phase-Type Service
To test the performance of our online learning algorithm for queues with non-exponential service times, we consider phase-type distributions: hyperexponential with phases () and Erlang with phases (). In Figure 11 we report the convergent sequence with service with service-time SCV (top panel), service with (middle panel), and service with (bottom panel). Other parameters include the step size , cycle length and initial condition and ().
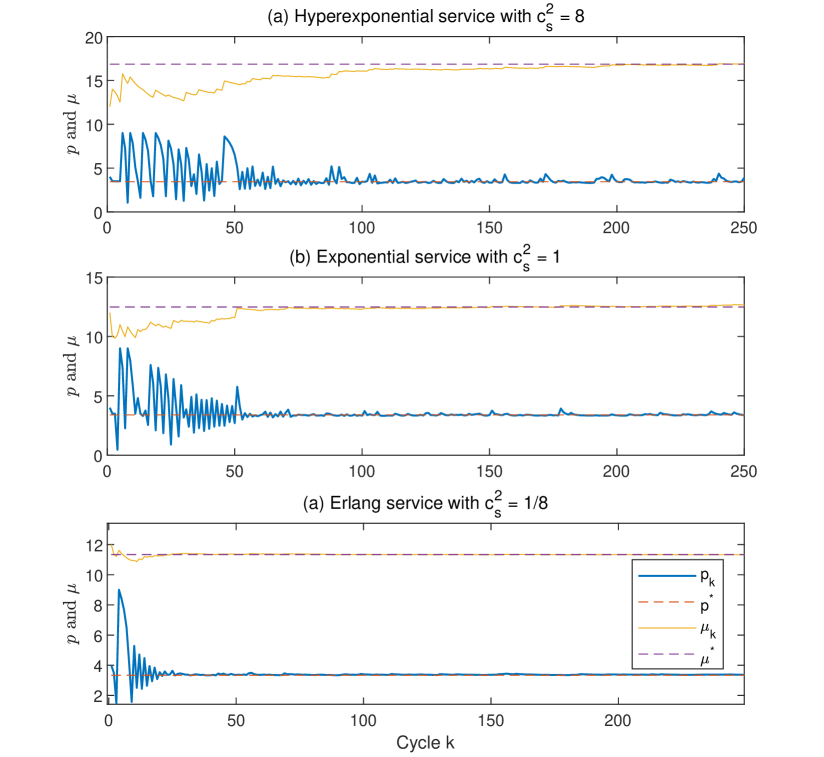
Figure 11 confirms that our algorithm remains effective. In addition, the convergence is faster as the CSV decreases. This is intuitive because a less variable service-time distribution yields a smaller for the gradient estimator.
11.3 Lognormal Service and Arrival
Next, we consider an queue with service and interarrival times following lognormal (LN) distributions. Our consideration here follows from the recent empirical confirmations of LN distributed service times in real service systems.
We let with being the SCV of the -distributed interarrival times. The other parameters remain the same as in Section 11.2. Because the exact optimal solutions are unavailable for this model, we are unable to provide an estimate of the regret as done in Figure 6, nor can we confirm the convex structure of the problem. Nevertheless, Figure 12 shows that our online algorithm continues to work well, despite the fact that LN is no longer a light-tail distribution (Assumption 2 does not hold in this case).
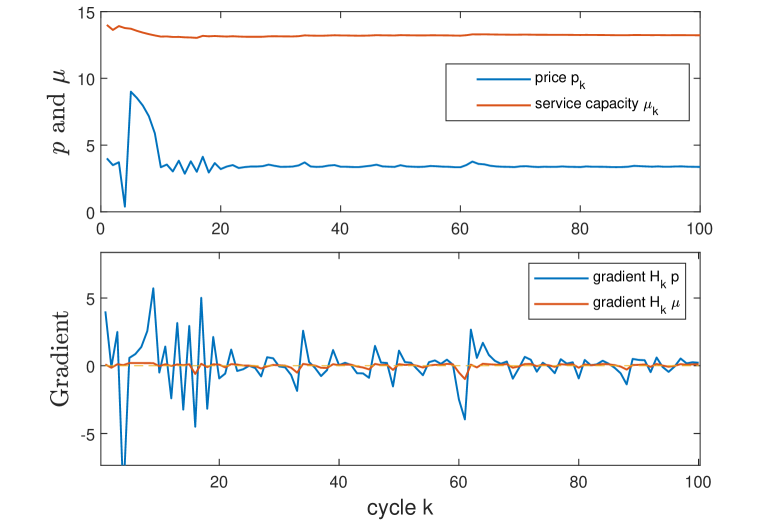
11.4 Extended Comparison of GOLiQ and Heavy-traffic Methods
Supplementing our investigations in Section 6.3, we provide additional numerical results. Recall that the heavy-traffic results in Lee and Ward (2014) are obtained by constructing a sequence of models indexed by , where the model has scaled arrival rate and service rate , so that both and grow to as increases. Lee and Ward (2014) develop asymptotic staffing and pricing solutions for the queue; they show that, as the scaling factor , the optimal price and service capacity , with .
We repeat our experiment in Section 6.2 with the scaling parameter for the arrival rate function (24). But we now focus on the optimal traffic intensity as varies. In Figure 13 we plot the optimal price and service rate as increases. In each experiment, we compute the optimal and using their average value in cycles 300–500 of Algorithm 1. Consistent with Lee and Ward (2014), Figure 13 shows that , and approach , and . On the other hand, when the scale is not very large, the heavy-traffic solutions can become inaccurate. For instance, when the optimal traffic is around 0.8, which is not close to 1.
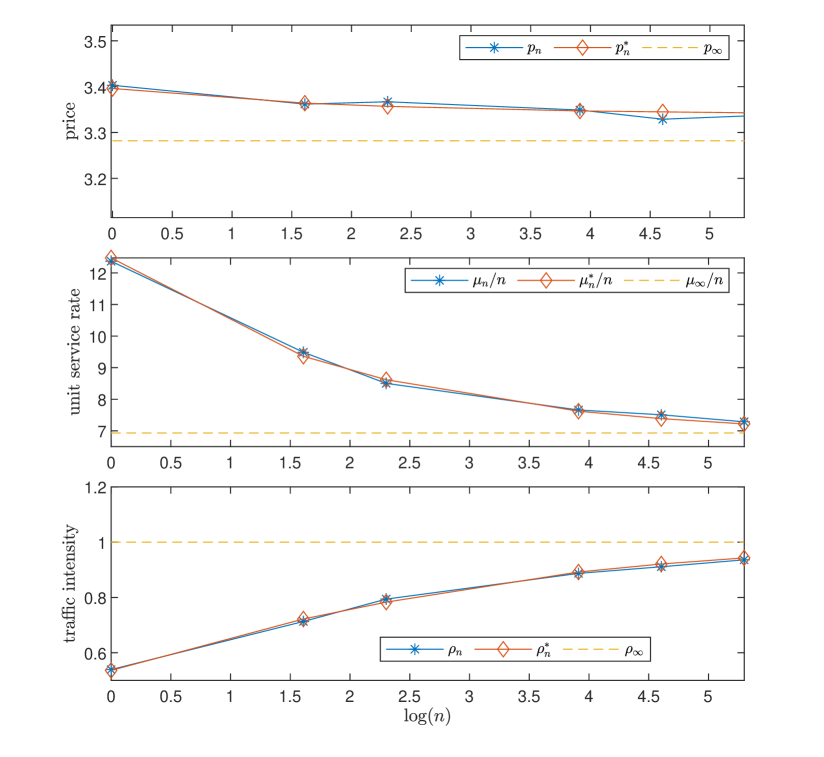
11.5 Alternative Definition of Regret
In this subsection, we attempt to rationalize our regret definition in (9). We consider a potential alternative to (9) which benchmarks the system revenue under GOLiQ with the nonstationary revenue under . Because the nonstationary queue length is intractable, we conduct additional numerical experiments to estimate the expected nonstationary regret via Monte-Carlo simulations.
Specifically, we simulate the regret in (10) under with the queueing system starting empty (of which the dynamics is nonstationary). We use the model in Section 6 having a logit demand function (24) with and a quadratic staffing cost in (25) with .
In Figure 14 we graph both versions of the regret under GOLiQ under the same experimental setting, with hyperparameters and . Figure 14 confirms that the these two versions of regret appear to be nearly indistinguishable. This is due to the geometric ergodicity of queue.
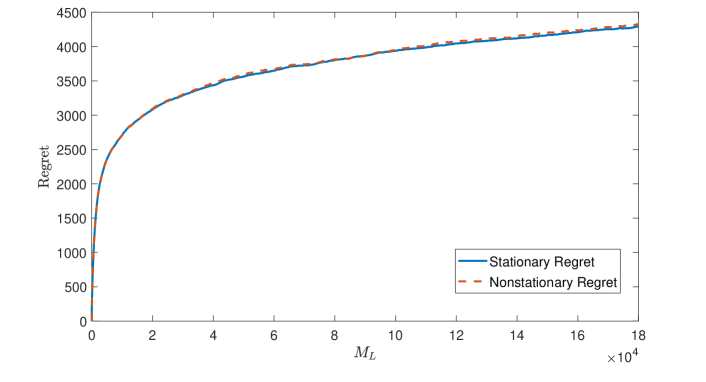
12 Additional discussion on Assumption 3
In this section, we provide some sufficient conditions for strong convexity in the case.
Lemma 8.
For queues, if is convex, , and in addition,
| (40) |
then is strongly convex in .
Proof of Lemma 8.
Recall that , and . Under condition (40), we have . Therefore, both and are convex, and it suffices to show that is strongly convex in and . For queues, Pollaczek-Khinchine formula yields that
with . For any given pair of , let be the Hessian matrix of . We next verify that is positively definite. By direct calculation, we have
with being the first and second order derivatives of . As a result, the determinant of Hessian matrix of is
To show that is positively definite, it suffices to show that , and are all positive. First, it is clear that
Next, we compute
Here, inequality (a) follows from that . Inequality (b) holds due to the facts that and that . The last inequality holds because . As a result, we have . Next, we verify that . Because , we have
Therefore,
Inequality (c) holds because is positive by (40). The last inequality follows from . This closes our proof. ∎
| Notation | Description | |
| Model parameters and functions | Feasible action space | |
| Staffing cost function | ||
| Objective (loss) function | ||
| Customer holding cost | ||
| Demand function | ||
| Service rate/capacity | ||
| Market size/ System scale in Section 6 | ||
| Service fee | ||
| Stationary queue length under | ||
| Service time of the customer in cycle | ||
| Interarrival time between and customers | ||
| Parameters of light-tail assumptions (Assumption 2) | ||
| Unscaled random “seeds” of interarrival and service times | ||
| Optimal decision fee and service rate | ||
| Algorithmic hyperparameters | Sample size (number of customers served) in cycle | |
| Step size or learning rate in cycle | ||
| Gradient estimator in cycle | ||
| Cumulative number of customers served by cycle | ||
| Queue content leftover from cycle | ||
| Delay of the customer in cycle | ||
| Warm up rate | ||
| () | Server’s busy time observed by customer in cycle | |
| Constants and bounds in regret analysis | Constants for in equation (21) | |
| Constant in Corollary 1 | ||
| Constant of stationary waiting times in Lemma 4 | ||
| Upper bounds for bias and Variance of | ||
| Constant for in equation (20) | ||
| Constants in Lemma 3 | ||
| Constant in Theorem 2 | ||
| Constant in the proof of Theorem 3 | ||
| Constant in the proof of Theorem 3 | ||
| Constant for the selection of (Theorem 3) | ||
| Constant of warm-up time (Theorem 1) | ||
| Constant of warm-up time (Theorem 1) | ||
| Stopping time of random walks (proof of Lemma 2) | ||
| Three terms of the regret of nonstationary | ||
| Bound of the cumulative regret (Theorem 3) | ||
| Constant for regret of nonstationary (proof of Theorem 1) | ||
| Constant in the proof of Theorem 1 | ||
| Constants for convexity and smoothness (Assumption 1) | ||
| Constant for (Theorem 1) | ||
| Constants for variance in Theorem 3 (37) | ||
| Constants for convergence rate of busy time in Lemma EC.1 | ||
| Bound in the proof of Theorem 3 (35) | ||
| Bound in the proof of Corollary 2 | ||
| Upper and lower bounds for | ||
| Uniform bound for queueing functions in Lemma 1 | ||
| Upper bound of the regret in the first cycle | ||
| Total regret during cycle | ||
| Regret of nonstationary/suboptimality in cycle | ||
| Cumulative/nonstationary/suboptimal regret by cycle | ||
| Length of cycle |