Analogical Concept Memory for
Architectures Implementing the Common Model of Cognition
Abstract
Architectures that implement the Common Model of Cognition - Soar, ACT-R, and Sigma - have a prominent place in research on cognitive modeling as well as on designing complex intelligent agents. In this paper, we explore how computational models of analogical processing can be brought into these architectures to enable concept acquisition from examples obtained interactively. We propose a new analogical concept memory for Soar that augments its current system of declarative long-term memories. We frame the problem of concept learning as embedded within the larger context of interactive task learning (ITL) and embodied language processing (ELP). We demonstrate that the analogical learning methods implemented in the proposed memory can quickly learn a diverse types of novel concepts that are useful not only in recognition of a concept in the environment but also in action selection. Our approach has been instantiated in an implemented cognitive system Aileen and evaluated on a simulated robotic domain.
keywords:
cognitive architectures , common model of cognition , intelligent agents , concept representation and acquisition , interactive learning , analogical reasoning and generalization , interactive task learning1 Introduction
The recent proposal for the common model of cognition (CMC; Laird et al. 2017) identifies the central themes in the past years of research in three cognitive architectures - Soar (Laird, 2012), ACT-R (Anderson, 2009), and Sigma (Rosenbloom et al., 2016). These architectures have been prominent not only in cognitive modeling but also in designing complex intelligent agents. CMC architectures aim to implement a set of domain-general computational processes which operate over domain-specific knowledge to produce effective task behavior. Early research in CMC architectures studied procedural knowledge - the knowledge of how to perform tasks, often expressed as if-else rules. It explored the computational underpinnings of a general purpose decision making process that can apply hand-engineered procedural knowledge to perform a wide-range of tasks. Later research studied various ways in which procedural knowledge can be learned and optimized.
While CMC architectures have been applied widely, Hinrichs and Forbus (2017) note that reasoning in them focuses exclusively on problem solving, decision making, and behavior. Further, they argue that a distinctive and arguably signature feature of human intelligence is being able to build complex conceptual structures of the world. In the CMC terminology, the knowledge of concepts is declarative knowledge - the knowledge of what. An example of declarative knowledge is the final goal state of the tower-of-hanoi puzzle. In contrast, procedural knowledge in tower-of-hanoi are the set of rules that guide action selection in service of achieving the goal state. CMC architectures agree that conceptual structures are useful for intelligent behavior. To solve tower-of-hanoi, understanding the goal state is critical. However, there is limited understanding of how declarative knowledge about the world is acquired in CMC architectures. In this paper, we study the questions of declarative concept representation, acquisition, and usage in task performance in a prominent CMC architecture - Soar. As it is similar to ACT-R and Sigma in the organization of computation and information, our findings can be generalized to those architectures as well.
1.1 Declarative long-Term memories in Soar
In the past two decades, algorithmic research in Soar has augmented the architecture with decalartive long-term memories (dLTMs). Soar has two - semantic (Derbinsky et al., 2010) and episodic (Derbinsky and Laird, 2009) - that serve distinct cognitive functions following the hypotheses about organization of memory in humans (Tulving and Craik, 2005). Semantic memory enables enriching what is currently observed in the world with what is known generally about it. For example, if a dog is observed in the environment, for certain types of tasks it may be useful to elaborate that it is a type of a mammal. Episodic memory gives an agent a personal history which can later be recalled to establish reference to shared experience with a collaborator, to aid in decision-making by predicting the outcome of possible courses of action, to aid in reasoning by creating an internal model of the environment, and by keeping track of progress on long-term goals. The history is also useful in deliberate reflection about past events to improve behavior through other types of learning such as reinforcement learning or explanation-based learning. Using dLTMs in Soar agents has enable reasoning complexity that wasn’t possible earlier (Xu and Laird, 2010; Mohan and Laird, 2014; Kirk and Laird, 2014; Mininger and Laird, 2018).
However, a crucial question remains unanswered - how is general world knowledge in semantic memory acquired? We posit that this knowledge is acquired in two distinctive ways. Kirk and Laird (2014, 2019) explore the view that semantic knowledge is acquired through interactive instruction when natural language describes relevant declarative knowledge. An example concept is the goal of tower-of-hanoi a small block is on a medium block and a large block is below the medium block. Here, the trainer provides the definition of the concept declaratively which is later operationalized so that it can be applied to recognize the existence of a tower and in applying actions while solving tower-of-hanoi. In this paper, we explore an alternative view that that this knowledge is acquired through examples demonstrated as a part of instruction. We augment Soar dLTMs with a new concept memory that aims at acquiring general knowledge about the world by collecting and analyzing similar experiences, functionally bridging episodic and semantic memories.
1.2 Algorithms for analogical processing
To design the concept memory, we leverage the computational processes that underlie analogical reasoning and generalization in the Companions cognitive architecture - the Structure Mapping Engine (SME; Forbus et al. 2017) and the Sequential Analogical Generalization Engine (SAGE; McLure et al. 2015). Analogical matching, retrieval, and generalization is the foundation of the Companions Cognitive architecture. In Why we are so smart?, Gentner claims that what makes human cognition superior to other animals is “First, relational concepts are critical to higher-order cognition, but relational concepts are both non-obvious in initial learning and elusive in memory retrieval. Second, analogy is the mechanism by which relational knowledge is revealed. Third, language serves both to invite learning relational concepts and to provide cognitive stability once they are learned” (Gentner, 2003). Gentner’s observations provide a compelling case for exploring analogical processing as a basis for concept learning. Our approach builds on the analogical concept learning work done in Companions (Hinrichs and Forbus, 2017). Previous analogical learning work includes spatial prepositions Lockwood (2009), spatial concepts (McLure et al., 2015), physical reasoning problems (Klenk et al., 2011), and activity recognition (Chen et al., 2019). This diversity of reasoning tasks motivates our use of analogical processing to develop an architectural concept memory. Adding to this line of research, our work shows that you can learn a variety of conceptual knowledge within a single system. Furthermore, that such a system can be applied to not only learn how to recognize the concepts but also acting on them in the environment within an interactive task learning session.
1.3 Concept formation and its interaction with complex cognitive phenomenon
Our design exploration of an architectural concept memory is motivated by the interactive task learning problem (ITL; Gluck and Laird 2019) in embodied agents. ITL agents rely on natural interaction modalities such as embodied dialog to learn new tasks. Conceptual knowledge, language, and task performance are inextricably tied - language is a medium through which conceptual knowledge about the world is communicated and learned. Task performance is aided by the conceptual knowledge about the world. Consequently, embodied language processing (ELP) for ITL provides a set of functional requirements that an architectural concept memory must address. Embedding concept learning within the ITL and ELP contexts is a significant step forward from previous explorations in concept formation. Prior approaches have studied concept formation independently of how they will be used in a complex cognitive system, often focusing on the problems of recognizing the existence of a concept in input data and organizing concepts into a similarity-based hierarchy. We study concept formation within the context of higher-order cognitive phenomenon. We posit that concepts are learned through interactions with an interactive trainer who structures a learner’s experience. The input from the trainer help group concrete experiences together and a generalization process distills common elements to form a concept definition.
1.4 Theoretical Commitments, Claims, and Contributions
Our work is implemented in Soar and consequently, brings to bear the theoretical postulates the architecture implements. More specifically, we build upon the following theoretical commitments:
-
1.
Diverse representation of knowledge: In the past decade, the CMC architectures have adopted the view that architectures for general intelligence implement diverse methods for knowledge representation and reasoning. This view has been very productive in not only studying an increasing variety of problems but also in integrating advances in AI algorithmic research in the CMC framework. We contribute to this view by exploring how algorithms for analogical processing can be integrated into a CMC architecture.
-
2.
Deliberate access of conceptual knowledge: Following CMC architectures, we assume that declarative, conceptual knowledge is accessed through deliberation over when and how to use that knowledge. The architectures incorporates well-defined interfaces i.e. buffers in working memory that contain information as well as an operation the declarative memory must execute on the information. Upon reasoning, information may be stored, accessed, or projected (described in further detail in Section 4).
-
3.
Impasse-driven processing and learning: Our approach leverages impasse in Soar, a meta-cognitive signal that can variably indicate uncertainty or failure in reasoning. Our approach uses impasses (and the corresponding state stack) to identify and pursue opportunities to learn.
-
4.
A benevolent interactive trainer: We assume existence of an intelligent trainer that adopts a collaborative goal with the learning system that it learns correct definitions of concepts. Upon being prompted, the trainer provides correct information to the learner to base its concept learning upon.
Based on these theoretical commitments, our paper contributes an integrative account of a complex cognitive phenomenon - interactive concept learning. Specifically, this paper:
-
1.
defines the concept formation problem within larger cognitive phenomenon of ELP and ITL;
-
2.
identifies a desiderata for an architectural concept memory;
-
3.
implements a concept memory for Soar agents using the models of analogical processing;
-
4.
introduces a novel process - curriculum of guided participation - for interactive concept learning;
-
5.
introduces a novel framework for evaluating interactive concept formation.
Our implementation is a functional (and not an architectural) integration of analogical processing in Soar’s declarative long-term memory systems. It characterizes how an analogical concept memory can be interfaced with the current mechanisms. Through experiments and system demonstration, we show that an analogical concept memory leads to competent behavior in ITL. It supports learning of diverse types of concepts useful in ITL. Learned concept representations support recognition during ELP as well as action based on those concepts during task performance. The concepts are from few examples provided interactively.
2 Preliminaries - The AILEEN Cognitive System
Aileen is a cognitive system that learns new concepts through interactive experiences (linguistic and situational) with a trainer in a simulated world. A system diagram is shown in Figure 1. Aileen lives in a simulated robotic world built in Webots111https://www.cyberbotics.com/. The world contains a table-top on which various simple objects can be placed. A simulated camera above the table captures top-down visual information. Aileen is engaged in a continuous perceive-decide-act loop with the world. A trainer can set up a scene in the simulated world by placing simple objects on the scene and providing instructions to the agent. Aileen is designed in Soar which has been integrated with a deep learning-based vision module and an analogical concept memory. It is related to Rosie, a cognitive system that has demonstrated interactive, flexible learning on a variety of tasks (Mohan et al., 2012, 2014; Mohan and Laird, 2014; Kirk and Laird, 2014; Mininger and Laird, 2018), and implements a similar organization of knowledge.
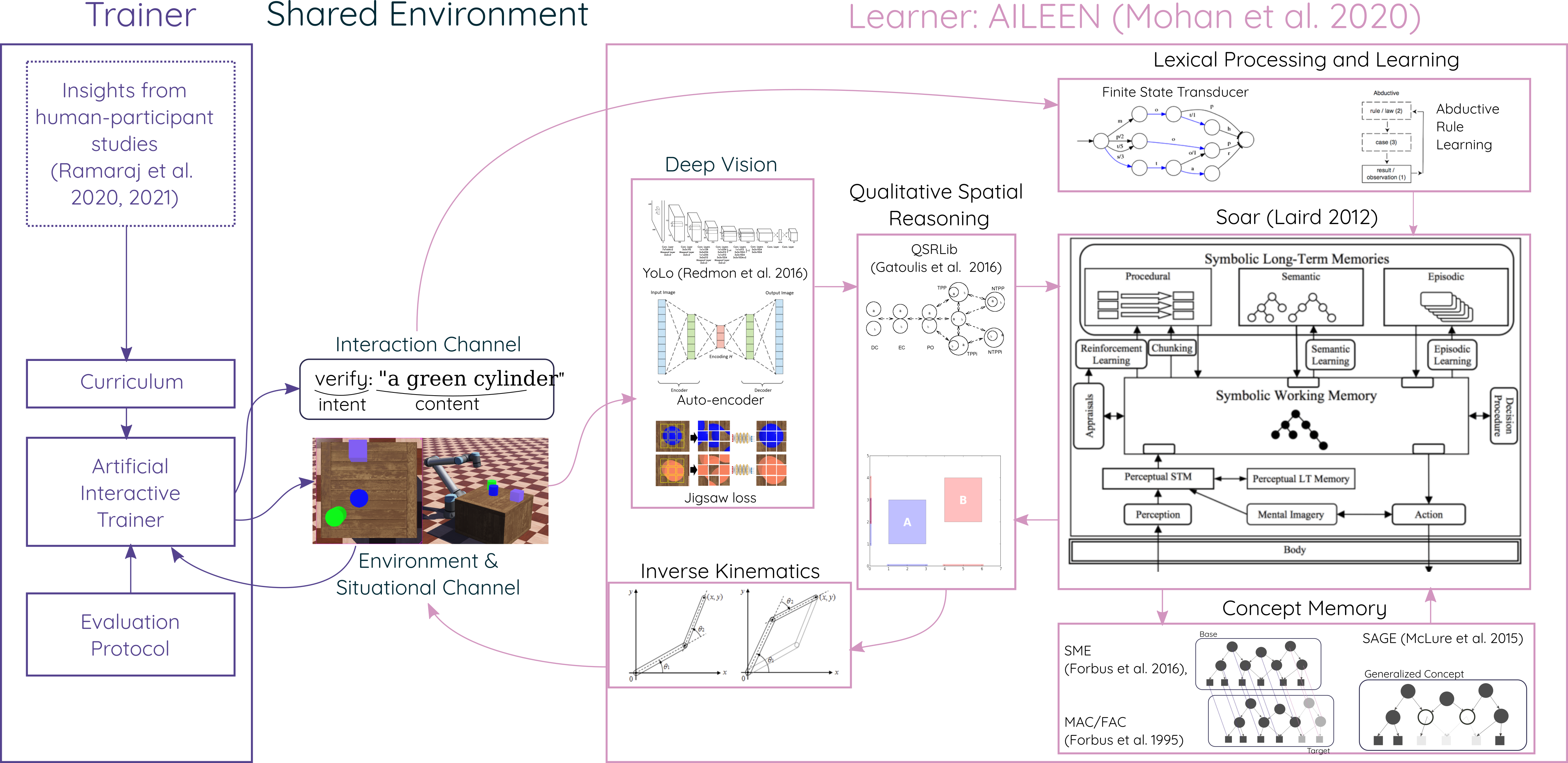
Visual Module
The visual module processes the image taken from the simulated camera. It produces output in two channels: object detections as bounding boxes whose centroids are localized on the table-top and two perceptual symbols or percepts corresponding to the object’s shape and color each. The module is built using a deep learning framework - You Only Look Once (YoLo: Redmon et al. (2016)). YoLo is pre-trained with supervision from the ground truth in the simulator ( images). It is detects four shapes (error rate ) - box (percept - CVBox), cone (CVCone), ball (CVSphere), and cylinder (CVCylinder).
For colors, each detected region containing an object is cropped from the image, and a -means clustering is applied all color pixel values within the crop. Next, two weighted heuristics are applied that selects the cluster that likely comprises the detected shape among any background pixels and/or neighboring objects. The first heuristic selects the cluster with the maximum number of pixels. The second heuristic selects the cluster with the centroid that is closest to the image center of the cropped region. The relative weighted importance of each of these heuristics is then trained using a simple grid search over and : , where , is the set clusters, denotes the ratio between the number of pixels in each cluster and the the number of pixels in the image crop, and is the Euclidean distance between the centroid of the cluster and the image center normalized by the cropped image width. The average RGB value for all pixels included in the cluster with the highest score is calculated and compared with the preset list of color values. The color label associated with the color value that has the smallest Euclidean distance to the average RGB value is selected. The module can recognize colors (error rate ): CVGreen, CVBlue, CVRed, CVYellow, and CVPurple. Note that the percepts are named so to be readable for system designers - the agent does not rely on the percept symbol strings for any reasoning.
Spatial Processing Module
The spatial processing module uses QSRLib (Gatsoulis et al., 2016) to process the bounding boxes and centroids generated by the visual module to generate a qualitative description of the spatial configuration of objects. For every pair of objects, the module extracts qualitative descriptions using two spatial calculi (qsrs): cardinal direction (CDC) and region connection (RCC8). Additionally, the spatial processing module can also convert a set of calculi into regions and sample points from them. This enables Aileen to identify locations in continuous space that satisfy qualitative spatial constraints when planning actions.
World representation, Intrinsic & Extrinsic Behaviors
The outputs of the visual module and the spatial module are collected into an object-oriented relational representation of the current state of the world. Each detected object is asserted and represented with attributes that indicated its color and shape visual properties and is assigned a unique identifier. Qualitative relationships extracted by the spatial processing module are represented as as binary relation between relevant objects. The set of objects that exist on the scene and qualitative relationships between them capture the current state of the world and are written to Soar’s working memory graph.
Interactive and learning behaviors in Aileen are driven by its procedural knowledge encoded as rules in Soar and similarly to Rosie (Mohan et al., 2012) consists of knowledge for:
- 1.
-
2.
Comprehension: Aileen implements the Indexical Model of comprehension (Mohan et al., 2014) to process language by grounding it in the world and domain knowledge. This model formulates language understanding as a search process. It interprets linguistic symbols and their associated semantics as cues to search the current environment as well as domain knowledge. Formulating language comprehension in this fashion integrates naturally with interaction and learning where ambiguities and failures in the search process drive interaction and learning.
-
3.
External task execution: Aileen has been programmed with primitive actions that enable it to manipulate its environment: point(o), pick-up(o), and place([x, y, z]). Following Mohan and Laird (2014), each primitive action has a proposal rule that encodes its pre-conditions, a model that captures state changes expected to occur when the action is applied, and an application rule. Additionally, given a task goal, Aileen can use iterative-deepening search to plan a sequence of primitive actions to achieve the goal and execute the task in the world.
-
4.
Learning: Learning in Aileen is the focus of this paper and is significantly different from Rosie. Rosie uses an interactive variation of explanation-based learning (Mohan and Laird, 2014) to learn representation and execution of tasks. Aileen uses analogical reasoning and generalization to learn diverse concepts including those relevant to task performance (Sections 3 and 4). A crucial distinction is that EBL requires a complete domain theory to correctly generalize observed examples while analogical reasoning and generalization can operate with partial domain theory by leveraging statistical information in observed examples.
The ongoing ITL research in Soar demonstrates the strength of this organization of knowledge in hybrid cognitive systems. Our conjecture is that an ideal concept memory in an architecture must support complex, integrated, intelligent behavior such as ELP and ITL.
Using Conceptual Knowledge in Aileen
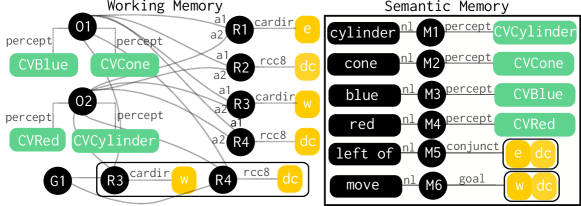
Consider the world in Figure 1 and the corresponding working memory graph in Figure 2. Semantic memory stores concept definitions corresponding to various words used to interact with Aileen. Maps (M1, M2, M3, M4, M5, M6) - in semantic memory (shown in Figure 2) - associate words (cylinder) to their conceptual definition (percept CVCylinder). Maps provide bi-directional access to the association between words and concept definitions. The semantic memory can be queried with a word to retrieve its concept definition. The semantic memory can also we queried with a concept definition to access the word that describes it.
Phrases (1) blue cone left of red cylinder and (2) move blue cone right of red cylinder can be understood via indexical comprehension (details by as follows:
-
1.
Parse the linguistic input into semantic components. Both (1) and (2) have two references to objects: {or1: obj-ref{property:blue, property:cone}} and {or2: obj-ref {property:red, property: cylinder}}. Additionally, (1) has a reference to a spatial relationship: {rel1: {rel-name: left of, argument1: or1, argument2: or2}}. (2) has a reference to an action: {act1: {act-name: move, argument1: or1, argument2: or2, relation: left of} }. For this paper, we assume that the knowledge for this step is pre-encoded.
-
2.
Create a goal for grounding each reference. The goal of processing an object reference is to find a set of objects that satisfy the properties specified. It starts with first resolving properties. The process queries semantic memory for a percept that corresponds to various properties in the parse. If the knowledge in Figure 2 is assumed, property blue resolves to percept CVBlue, cone to CVCone, red to CVRed, and cylinder to CVCylinder. Using these percepts, Aileen queries its scene to resolve object references. For or1, it finds an object that has both CVBlue and CVCone in its description. Let or1 resolve to o1 and or2 to o2 where o1 and o1 are identifiers of objects visible on the scene. The goal of processing a relation reference is to find a set of spatial calculi that correspond to the name specified. If knowledge in Figure 2 is assumed, rel1 in (1) is resolved to a conjunction of qsrs e(a1,a2)dc(a1,a2) i.e, object mapping to a1 should be east (in CDC) of a2 and they should be disconnected. Similarly, act1 in (2) resolves to a task goal which is a conjunction of qsrs w(a1,a2)dc(a1,a2)
-
3.
Compose all references: Use semantic constraints to resolve the full input. For (1) and (2) a1 is matched to to ar1 and consequently to o1. Similarly, a2 is resolved to o2 via ar2.
Tasks are represented in Aileen as goals that it must achieve in its environment. Upon being asked to execute a task, move blue cone right of red cylinder, indexical comprehesion determines the desired goal state as w(a1,a2)dc(a1,a2). Now, Aileen must execute a sequence of actions to achieve this desired goal state in its environment. Leveraging standard pre-conditions and effects of actions, Aileen can simulate the results of applying plausible actions in any state. Through an iterative deepening search conducted over actions, Aileen can generate and execute a plan that will achieve a desired goal state in the environment.
3 The Interactive Concept Learning Problem
With an understanding of how indexical comprehension connects language with perceptions and actions and how tasks are executed, we can begin to define the concept learning problem. Our main question is this - where does the conceptual knowledge in semantic memory (in Figure 2) come from? We study how this knowledge is acquired through interactions with an intelligent trainer who demonstrates relevant concepts by structuring the learner’s environment. In Soar, episodic memory stores contextual experiences while the semantic memory stores general, context-independent facts. Our approach uses supervision from an intelligent trainer to group contextual experiences together. An analogical generalization process distills the common elements in grouped contextual experience. This process can be seen as mediating knowledge in Soar’s episodic and semantic memories.
To develop our ideas further, we focus on learning three kinds of concepts. These concepts are crucial for ELP and ITL. Visual concepts correspond to perceptual attributes of objects and include colors and shapes. They provide meaning to nouns and adjectives in the linguistic input. Spatial concepts correspond to configuration of objects and provide grounding to prepositional phrases in the linguistic input. Action concepts correspond to temporal changes in object configurations and provide grounding to verb phrases.
3.1 A Curriculum of Guided Participation
We introduce a novel interactive process for training Aileen to recognize and use novel concepts - guided participation. Guided participation sequences and presents lessons - conjoint stimuli (world and language) - to Aileen. A lesson consists of a scenario setup in Aileen’s world and an interaction with Aileen. A scenario can be a static scene when training visual and spatial concepts or a sequence of scenes when training an action concept. An interaction has a linguistic component (content) and a non-linguistic component (signal). The signal component of instruction guides reasoning in Aileen and determines how it processes and responds to the content. Currently, Aileen can interpret and process the following types of signals:
-
1.
inform: Aileen performs active learning. It uses all its available knowledge to process the content through indexical comprehension (Section 3). If failures occur, Aileen creates a learning goal for itself. In this goal, it uses the current scenario to generate a concrete example of the concept described in the content. This example is sent to its concept memory. If no failure occurs, Aileen does not learn from the example. Aileen learning is deliberate; it evaluates the applicability of its current knowledge in processing the linguistic content. It learns only when the current knowledge isn’t applicable, and consequently, Aileen accumulates the minimum number of examples necessary to correctly comprehend the content.
-
2.
verify: Aileen analyzes the content through indexical comprehension and determines if the content refers to specific objects, spatial relationships, or actions in the accompanying scenario. If Aileen lacks knowledge to complete verification, Aileen indicates a failure to the instructor.
-
3.
react: This signal is defined only when the linguistic content contains a reference to an action. Aileen uses its knowledge to produce an action instantiation. Upon instantiation, Aileen determines a goal state in the environment and then plans, a sequence of actions to achieve the goal state. This sequence of actions is executed in the environment.
Incorporating these variations in how Aileen responds to the linguistic content in a lesson enables flexible interactive learning. A trainer can evaluate the current state of knowledge in Aileen by assigning it verify and react lessons. While the verify lesson tests if Aileen can recognize a concept in the world, the react lesson tests if Aileen can use a known concept to guide its own behavior in the environment. Observations of failures helps the trainer in structuring inform lessons that guide Aileen’s learning. In an inform lesson, Aileen evaluates its own learning and only adds examples when necessary. Such learning strategy distributes the onus of learning between both participants. Lessons can be structured in a flexible, reactive way in real human-robot training scenarios.
| Current world scene | Episodic trace | |||
|---|---|---|---|---|
| objects | relations | T0 | T1 | T2 |
| (isa o1 CVBlue) | (e o1 o2) | (H T0 (dc o1 o2)) | (H T1 (held O1)) | (H T2 (w o1 o2)) |
| (isa o1 CVCone) | (dc o1 o2) | (H T0 (e o1 o2)) | ... | ... |
| (isa o2 CVRed) | (w o2 o1) | ... | ... | (final T2 T1) |
| (isa o2 CVCyl) | (dc o2 o1) | (isa T0 start) | (after T1 T0) | (after T2 T1) |
3.2 Desiderata for a Concept Memory
We extend the concept memory desiderata originally proposed by (Langley, 1987) to enable embedding it within larger reasoning tasks, in this case ELP and ITL:
-
D0
Is (a) architecturally integrated and (b) uses relational representations.
-
D1
Can represent and learn a diverse types of concepts. In particular, for Aileen, the concept memory must be able to learn visual concepts, spatial concepts, and action concepts.
-
D2
Learn from exemplars acquired through experience in the environment. Aileen is taught through lessons that have two stimuli - a scenario and linguistic content that describes it.
-
D3
Enable incremental accumulation of knowledge. Interactive learning is a distinctive learning approach in which behavior is intertwined with learning. It has been previously argued that interleaving behavior and learning splits the onus of learning between the instructor and the learner such that the instructor can observe the learner’s behavior and provide more examples/instruction if necessary.
-
D4
Learn from little supervision as realistically humans cannot provide a lot of examples.
-
D5
Facilitate diverse reasoning over definitions of concepts.
-
(a)
Evaluate existence of a concept in the current environment, including its typicality. This enables recognizing a concept in the environment.
-
(b)
Envision a concept by instantiating it in the current environment. This enables action in the environment.
-
(c)
Evaluate the quality of concept definitions. This enables active learning - if the quality of a concept is poor, more examples can be added to improve it.
-
(a)
4 Concept Memory
Concept learning in Aileen begins with a failure during indexical comprehension in an inform lesson. Assume that Aileen does not know the meaning of red, i.e, it does not know that red implies the percept CVRed in the object description. When attempting to ground the phrase red cylinder in our example, Indexical comprehension will fail when it tries to look-up the meaning of the word red in its semantic memory. As in Rosie, a failure (or an impasse) in Aileen is an opportunity to learn. Learning occurs through interactions with a novel concept memory in addition to Soar’s semantic memory. Similarly to Soar’s dLTM, the concept memory is accessed by placing commands in a working memory buffer (a specific sub-graph). The concept memory interface has commands: create, store, query, and project. Of these, store and query are common with other Soar dLTMs. create and project are novel and explained in the following sections.
| Term | Definition | |
|---|---|---|
| Similarity | The score representing the quality of an analogical match, degree of overlap | |
| Correspondence | A one-to-one alignment between the compared representations | |
| Candidate Inference | Inferences resulting from the correspondences of the analogy | |
| Threshold | Definition | Value |
| Assimilation | Score required to include a new example into a generalization instead of storing it as an example | 0.01 |
| Probability | Only facts exceeding this value are considered part of the concept. | 0.6 |
| Match | Score required to consider that an inference is applicable in a given scene | 0.75 |
Aileen’s concept memory is built on two models of cognitive processes: SME (Forbus et al., 2017) and SAGE (McLure et al., 2015) and can learn visual, spatial, and action concepts (desiderata D0). Below we describe how each function of concept memory is built with these models. The current implementation of the memory represents knowledge as predicate calculus statements or facts, we have implemented methods that automatically converts Soar’s object-oriented graph description to a list of facts when needed. Example translations from Soar’s working memory graph to predicate calculus statements are shown in Table 1. Visual and spatial learning requires generating facts from the current scene. Examples for action learning are provided through a demonstration which is automatically encoded in Soar’s episodic memory. An episodic trace of facts is extracted from the episodic memory (shown in Table 1). We will rely on examples in Table 1 for illustrating the operation of the concept memory in the remainder of this section. We have summarized various terms and parameters used in analogical processing in Table 2.
4.1 Creation and Storage
When Aileen identifies a new concept in linguistic content (word red), it creates a new symbol RRed. This new symbol in incorporated in a map in Soar’s semantic memory and is passed on to the concept memory for creation of a new concept via the create command. The concept memory creates a new reasoning symbol as well as a new generalization context (shown in Figure 3). A generalization context is an accumulation of concrete experiences with a concept. Each generalization context is a set of individual examples and generalizations.
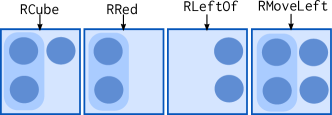
| Facts | P |
|---|---|
| (isa (GenEntFn 0 RRedMt) RRed) | 1.0 |
| (isa (GenEntFn 0 RRedMt) CVRed) | 1.0 |
| (isa (GenEntFn 0 RRedMt) CVCube) | 0.5 |
| (isa (GenEntFn 0 RRedMt) CVCylinder) | 0.5 |
[table]
After creating a new concept, Soar stores an example in the concept memory. The command {store: [(isa o2 CVRed) (isa o2 CVCylinder) (isa o2 RRed)], concept: RRed} stores that the object o2 in the world is an example of the concept RRed. This example A is stored in the RRed generalization context as is - as a set of facts. Assume that at a later time, Soar sends another example B of RRed concept through the command {store: [(isa o3 CVRed) (isa o3 CVCube) (isa o3 RRed)], concept: RRed}. The concept memory adds the new example to the RRed generalization context by these two computational steps:
-
1.
SME performs an analogical match between the two examples. The result of analogical matching has two components: a correspondence set and a similarity score. A correspondence set contains alignment of each fact in one example with at most one fact from other. The similarity score indicates the degree of overlap between the two representations. In the two examples A and B, there are two corresponding facts: (isa o2 CVRed) aligns with (isa o3 CVRed) and (isa o2 RRed) aligns with (isa o3 RRed). If the similarity score exceeds an assimilation threshold (Table 2), SAGE continues to the next step to create a generalization.
-
2.
SAGE assimilates the two examples A and B into a generalization (e.g. Figure 3). It :
-
(a)
Uses the correspondence to create abstract entities. In the two examples provided, (isa o2 RRed) aligns with (isa o3 RRed) and (isa o2 CVRed) with (isa o3 CVRed). Therefore, identifiers o2 and o3 can be replaced with an abstract entity (GenEntFn 0 RRedMt).
-
(b)
Maintains a probability that a fact belongs in the generalization. Because (isa (GenEntFN 0 RRedMT) RRed) and (isa (GenEntFn 0 RRedMT) CVRed) are common in both examples, they are assigned a probability of . Other facts are not in the correspondences and appear in of the examples in the generalization resulting in a probability of . Each time a new example is added to this generalization, the probabilities will be updated the reflect the number of examples for which the facts were aligned with each other.
-
(a)
Upon storage in a generalization context, a generalization becomes available for matching and possible assimilation with future examples enabling incremental (D3), example-driven (D2) learning.
4.2 Query
During indexical comprehension, Aileen evaluates if a known concept exists in the current world through the query command. Assume that in an example scene with two objects, indexical comprehension attempts to find the one that is referred to by red through {query: {scene: [(isa o4 CVRed) (isa o4 CVBox) (isa o5 CVGreen) (isa o2 CVCylinder)], pattern: (isa ?o RRed)}}. In response to this command, the concept memory evaluates if it has enough evidence in the generalization context for RRed to infer (isa o2 RRed). The concept memory performs this inference through the following computations.
-
1.
SME generates a set of candidate inferences. It matches the scene with the generalization in Figure 3 (right). This match results in a correspondence between the facts (isa o4 CVRed) in scene) and (isa (GenEntFn 0 RRedMt) CVRed), which aligns o4 with (GenEntFn 0 RRedMt). Other facts that have arguments that align, but are not in the correspondences, are added to the set of candidate inferences. In our example, a candidate inference would be (isa o4 RRed).
-
2.
AILEEN filters the candidate inferences based on the pattern in the query command. It removes all inferences that do not fit the pattern. If the list has an element, further support is calculated.
-
3.
AILEEN evaluates the support for inference by comparing the similarity score of the match to the match threshold. That is, the more facts in the generalization that participate in the analogical match then it is more likely that the inference is valid.
Through queries to the concept memory and resultant analogical inferences, the working memory graph (of the world in Figure 4) is enhanced. This enhanced working memory graph supports indexical comprehension in Section 3. Note that the internal concept symbols in blue (such as RBlue) are generalization contexts in the concept memory that accumulate examples from training. Consequently, the ‘meaning’ of the world blue will evolve as more examples are accumulated.
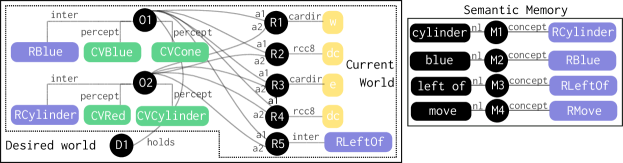
(H (:skolem (GenEntFn 0 0 rMoveMt)) (held O1)
(after (:skolem (GenEntFn 0 0 rMoveMt)) T0)
4.3 Projection
In ITL, simply recognizing that an action has been demonstrated is insufficient, the agent must also be able to perform the action if directed (desiderata D5). One of the advantages of analogical generalization is that the same mechanism is used for recognition and projection. Consider the example scene Figure 1 in which the trainer asks Aileen to move the blue cone to the right of the red cylinder using the react signal. Assume that Aileen has previously seen some other examples of this action that are stored in concept memory as episodic traces (an example is shown in 1).
During indexical comprehension, Aileen performs queries to identify the blue cone, O1, and red cylinder, O2. Similarly, it maps the verb and the related preposition to RMove and RRightOf. To act, Aileen uses its concept memory to project the action through the command {project: {trace: [(H T0 (dc o1 o2)) (H T0 (e o1 o2)) (isa AileenStartTime T0) ...], concept: RMove}. A summary is shown in Figure 5 starting at T0. In response, the concept memory performs the following computations:
-
1.
SME generates a set of candidate inferences. SME to matches the current scene expressed as a trace against the generalization context of the action RMove. SME generates all the candidate inferences that symbolically describe the next states of the action concept.
-
2.
Aileen filters the candidate inferences to determine which apply in the immediate next state (shown in Figure 5). For example, the trace in the project command contains episode T0 as the AileenStartTime. The filter computation will select facts that are expected to be held in (t) and that the (after (t) T0) holds.
This retrieval is accepted by Aileen to be next desired state it must try to achieve in the environment.
5 Evaluation
In this section, we evaluate how the proposed concept memory address the desiderata outlined in section 3.2. As per desiderata D0, the concept memory can be integrated into a CMC architecture through its interfaces (defined in section 4) and SME & SAGE support inference and learning over relational representations (in Table 1). For the remaining desiderata, we conducted a set of empirical experiments and demonstrations.
-
H1
As per D1, can the concept memory learn a diverse types of concepts? Our hypothesis is that because SME & SAGE operate over relational, structured representations, the concept memory designed with these algorithms can learn a variety of concepts. We designed our experiments to study how Aileen learns visual, spatial, and action concepts.
-
H2
As per D2, D3, & D4, can the concepts be learned incrementally through limited, situated experience? Aileen can learn from a curriculum of guided participation that incrementally introduces a variety of concepts through a conjoint stimuli of scene information with language. We designed our learning experiments to reflect how a human-like teaching (Ramaraj et al., 2021) would unfold and report our observations about the memory’s performance especially focusing on the number of examples needed to learn from.
-
H3
As per D5, does the concept memory support diverse reasoning? The representations acquired by the concept memory not only support recognition of a concept on the scene, it also guides action selection as well as identifying opportunities to learn.
Method
We performed separate learning experiments for visual, spatial, and action concepts (D1). We leverage the lessons of guided participation in the design of our experimental trials. Each trial is a sequence of inform lessons. In an inform lesson, a concept is randomly selected from a pre-determined set and shown to Aileen accompanied with linguistic content describing the concept (D2). The lesson is simplified, i.e, there are no distractor objects (examples are shown in Figures 6, 7, & 8). The lesson is presented to Aileen and we record the number of store requests it makes to the concept memory. Recall that Aileen learns actively; i.e, it deliberately evaluates if it can understand the linguistic content with its current knowledge and stores examples only when necessary. The number of store requests made highlight the impact of such active learning.
Additionally, to measure generality and correctness, we test Aileen knowledge after every inform lesson through two exams: generality and specificity (examples are shown in Figures 6, 7, & 8). Both exams are made up of verify lessons that are randomly selected at the beginning of the trial. As Aileen learns, the scores on these test demonstrate how well Aileen can apply what it has learned until now. In the generality lessons, Aileen is asked to verify if the concept in the linguistic input exists on the scene. If Aileen returns with a success status, it is given a score of and otherwise. In the specificity exam, Aileen is asked to verify the existence of a concept, however, the scenario does not contain the concept that is referred to in the linguistic content. If Aileen returns with a failed status, it is given a score of and otherwise. Both types of exam lessons have distractor objects introduced on the scene to evaluate if existence of noise impacts the application of conceptual knowledge.
Results
Figure 6 illustrates visual concept learning. Aileen begins without any knowledge of any concept. As two concepts (green and cone) are introduced in the first lesson, it provides several store commands to its concept memory (shown in blue bars). The number of commands reduce as the training progresses demonstrating that the learning is active and opportunistic (D5 c). As is expected, the score on the generality exam is very low in the beginning because Aileen doesn’t know any concepts. However, this score grows very quickly with training eventually reaching perfect performance at lesson . The score on the specificity exam starts at , this is to be expected as well. This is because if a concept is unknown, Aileen cannot recognize it on the scene. However, as the trial progress we see that this score doesn’t drop. This indicates that conceptual knowledge of one concept doesn’t bleed into others. Note that the exams have distractor objects while learning occurred without any distractors - good scores on these exams demonstrate the strength of relational representations implemented in Aileen. Finally, Aileen learns from very few examples indicated that such learning systems can learn online with human trainers (D3, D4).
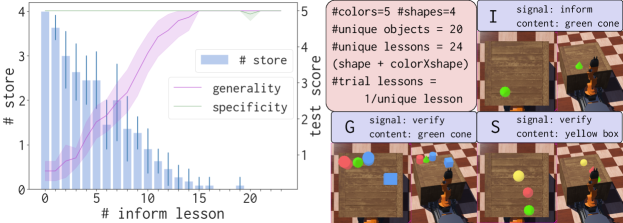
Figure 7 illustrates spatial concept learning (commenced after all visual concepts are already known). Spatial relationships are defined between two objects each of which can be possible in the domain. Concrete examples include irrelevant information (e.g., left of” does not depend on visual properties of the objects). Despite this large complex learning space, learning is quick and spatial concepts can be learned with few examples. These results demonstrate the strength of analogical generalization over relational representations. An interesting observation is that generality scores do not converge to as in visual concept learning. A further analysis revealed that in noisy scenes when the trainer places several distractors on the scene, sometimes the objects move because they are placed too close and the environment has physics built into it. The movement causes objects to move from the intended configuration leading to apparent error in Aileen’s performance. This is a problem with our experimental framework. The learning itself is robust as demonstrated by number of store commands in the trial which reduce to at the end.
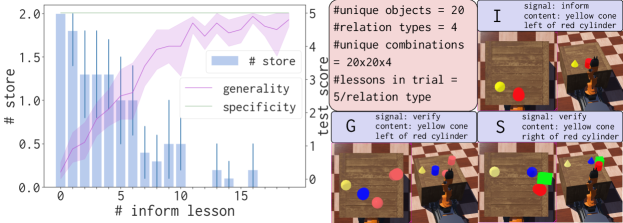
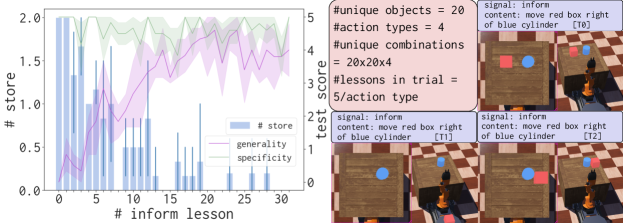
Figure 8 illustrates action learning (commenced after all visual and spatial concepts have been learned). Actions are generated through the template move ¡object reference 1¿ ¡relation¿ ¡object reference 2¿. Similarly to spatial concepts, the learning space is very large and complex. When Aileen asks, it is provided a demonstration of action performance as shown in Figure 8 (T0, T1, T2). Aileen stores the demonstration trace in its episodic memory. For storing an example in the concept memory, information in Soar’s episodic memory is translated into an episodic trace as shown Table 1. Similarly to visual and spatial learning, inform lessons with simplified scene are used to teach a concept. Exams made up of positive and negative verify lessons are used to evaluate learning. As we see in Figure 8, Aileen can quickly learn action concepts. Errors towards the later part of the experimental trial occur for the same reason we identified in spatial learning.
Task Demonstration
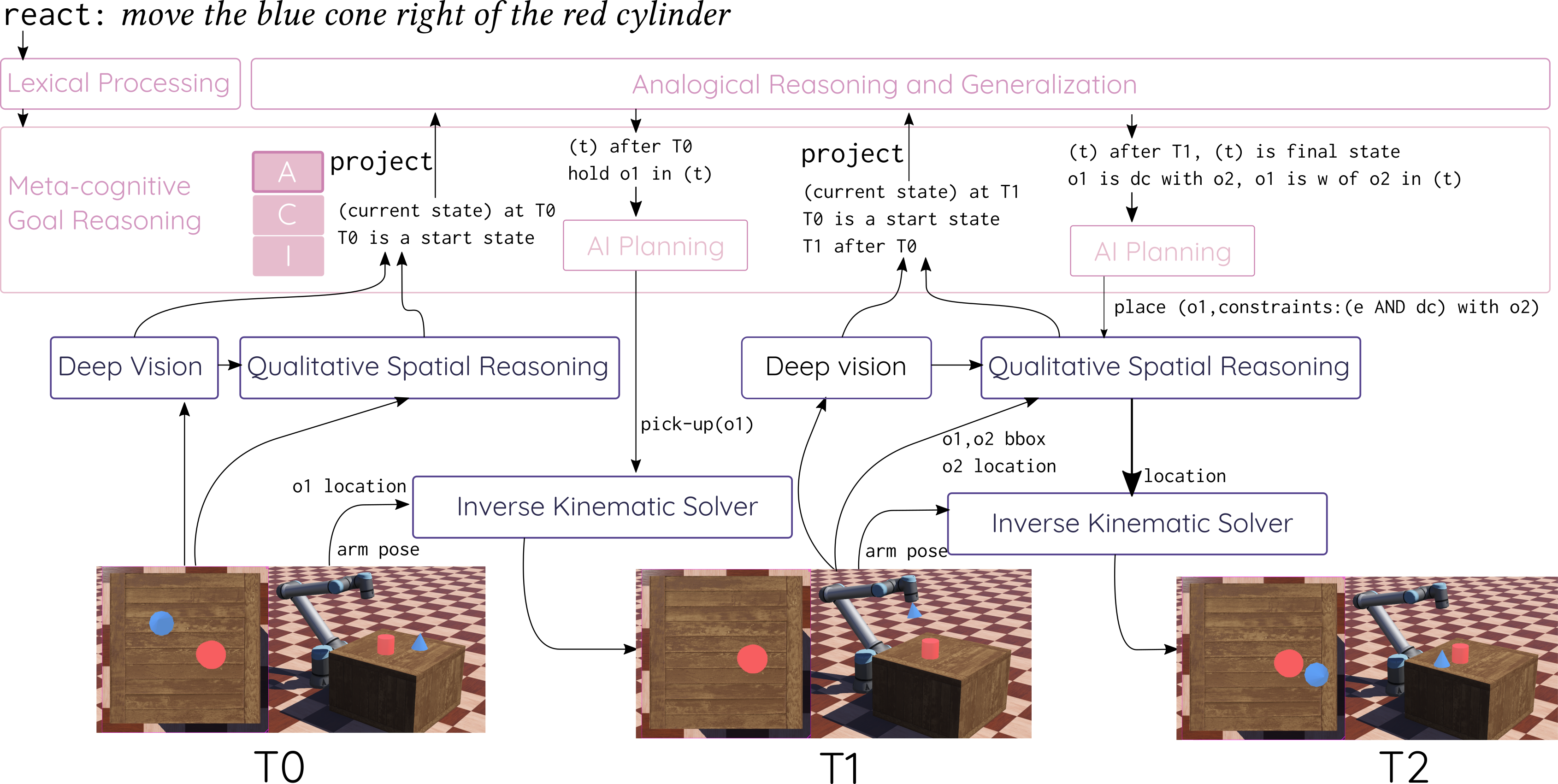
After visual, spatial, and action concepts were taught, we used a react lesson to see if Aileen could perform the actions when asked. Consider the time T0 in Figure 9 when Aileen is asked to move the blue cone right of the red cylinder. It can successfully use methods of analogical processing to guide action planning through the concept memory interface. First, it uses its visual concepts during indexical comprehension to resolve blue cone to (O1) and the red cylinder to (O2). It maps the verb move to a known action trace indexed by RMove. Then, it projects this action in the future. As described in Section 4.3, the concept memory returns with a set of predicates that have to be true in the next state (holds(O1)). Aileen plans using its pre-encoded actions models and iterative deepening search. The search results in pick-up(O1) where O1. After executing a pick-up action, Aileen invokes projection again to determine if RMove requires more steps. In this case, it does, and the candidate inferences specify that O1 should be located to the w of O2 and they should be topologically disjoint. Further, these candidate inferences indicate that this is the last step in the action, and therefore Aileen marks the action as completed after executing it.
The symbolic actions generated through planning are incrementally transformed into concrete information required to actuate the robot. pick-up executed on a specific object can be directly executed using an inverse kinematics solver. place action is accompanied with qualitative constraints. For example, to place o1 to right of o2, it must be place in a location that is to the west and such that their bounding boxes are disconnected. Aileen uses QSRLib to sample a point that satisfies the constraint. Once a point is identified, the inverse kinematics solver can actuate the robot to achieve the specified configuration. The successive projection and their interaction with action planning is shown in Figure 9.
6 Related Work
Diverse disciplines in AI have proposed approaches for concept learning from examples however, not all approaches can be integrated in a CMC architecture. We use the desiderata defined in Section 3.2 to evaluate the utility of various concept learning approaches. The vast majority study the problem in isolation and consider only flat representations violating the desiderata D0. ML-based classification approaches are designed for limited types of concepts (such as object properties), violating desiderata D1, and require a large number of examples, violating desiderata D4, which are added in batch-mode, violating desiderata D3. On the other hand, while EBL and Inductive logic programming (Muggleton and De Raedt, 1994) can learn from few datapoints, they require fully-specified domain theory violating desiderata D2. Bayesian concept learning Tenenbaum (1999) uses propositional representations, violating D0, and each demonstration has focused on a single type of concept, violating D1.
There are a few cognitive systems’ approaches to the concept learning problem that aim toward the desiderata that we delineated in Section 3. In the late s - early s, there was a concerted effort to align machine learning and cognitive science around concept formation (Fisher, 1987). For example, Labyrinth (Thompson and Langley, 1991) creates clusters of examples, summary descriptions, and a hierarchical organization of concepts using a sequence of structure examples. COBWeb3 (Fisher, 1987) incorporates numeric attributes and provides a probabilistic definition differences between concepts. Building off these ideas, Trestle (MacLellan et al., 2015) learns concepts that include structural, relational, and numerical information. Our work can be seen as a significant step in advancing these research efforts. First, the proposed concept memory leverages the computational models of analogical processing that have been shown to emulate analogical reasoning in humans. Second, we place the concept learning problem within the larger problems of ELP and ITL in a cognitive architecture context. We demonstrate not only concept formation but also how learned concepts are applied for recognition, scene understanding, and action reasoning. By integrating with vision techniques, we demonstrate one way in which concept formation is tied to sensing.
Another thread of work in the cognitive system’s community that we build upon is that of analogical learning and problem-solving. Early analogical problem-solving systems include Cascade (VanLehn et al., 1991), Prodigy (Veloso et al., 1995), and Eureka (Jones and Langley, 2005). They typically used analogy in two ways: (1) as analogical search control knowledge where previous examples were used to guide the selection of which problem-solving operator to apply at any time, and (2) for the application of example-specific operators in new situations. Aileen differs in two important ways: (1) it relaxes the need for explicit goals further in its use of projection to specify the next subgoal of an action, and (2) it uses analogical generalization on top of analogical learning to remove extraneous knowledge from the concept.
7 Discussion, Conclusions, and Future Work
In this paper, we explored the design and evaluation of a novel concept memory for Soar (and other CMC cognitive architectures). The computations in the memory use models of analogical processing - SAGE and SME. This memory can be used to acquire new situated, concepts in interactive settings. The concepts learned are not only useful in ELP and recognition but also in task execution. While the results presented here are encouraging, the work described in this paper is only a small first step towards an architectural concept memory. We have only explored a functional integration of analogical processing in Soar. The memory has not be integrated into the architecture but is a separate module that Soar interacts with. There are significant differences between representations that Soar employs and those in the memory. For an efficient integration and a reactive performance that Soar has historically committed to, several engineering enhancements have to be made.
There are several avenues for extending this work. We are looking at three broad classes of research: disjunctive concepts, composable concepts, and expanded mixed-initiative learning. Disjunctive concepts arise from homographs (e.g., bow in musical instrument versus bow the part of a ship) as well as when the spatial calculi does not align with the concept or the functional aspects of the objects must be taken into account (e.g., a cup is under a teapot when it is under the spigot, while a saucer is under a cup when it is directly underneath). One of the promises of relational declarative representations of the form learned here is that they are composable. This isn’t fully exploited for learning actions with spatial relations in them. Our approach ends up with different concepts for move-left and move-above. A better solution would be to have these in the same generalization such that Aileen would be able to respond to the command to move cube below cylinder assuming it been taught a move action previously along with the concepts for below, cube, and cylinder. Another avenue is contextual application of concepts. For example, bigger box requires comparison between existing objects. Finally a cognitive system should learn not only from a structured curriculum designed by an instructor but also in a semi-supervised fashion while performing tasks. In our context this means adding additional examples to concepts when they were used as part of a successful execution. This also means, when there are false positives that lead to incorrect execution, revising the learned concepts based on this knowledge. One approach from analogical generalization focuses on exploiting these near-misses with SAGE (McLure et al., 2015).
Inducing general conceptual knowledge from observations is a crucial capability of generally intelligent agents. The capability supports a variety of intelligent behavior such as operation in partially observable scenarios (where conceptual knowledge elaborates what is not seen), in language understanding (including ELP), in commonsense reasoning, as well in task execution. Analogical processing enables robust incremental induction from few examples and has been demonstrated as a key cognitive capability in humans. This paper explores how analogical processing can be integrated into the Soar cognitive architecture which is capable of flexible and contextual decision making and has been widely used to design complex intelligent agents. This paper paves way for an exciting exploration of new kinds of intelligent behavior enabled by analogical processing.
8 Acknowledgements
The work presented in this paper was supported in part by the DARPA GAILA program under award number HR00111990056 and an AFOSR grant on Levels of Learning, a sub-contract from University of Michigan (PI: John Laird, FA9550-18-1-0180). The views, opinions and/or findings expressed are those of the authors’ and should not be interpreted as representing the official views or policies of the Department of Defense, AFOSR, or the U.S. Government.
References
- Anderson (2009) Anderson, J.R., 2009. How Can the Human Mind Occur in the Physical Universe? Oxford University Press.
- Chen et al. (2019) Chen, K., Rabkina, I., McLure, M.D., Forbus, K.D., 2019. Human-Like Sketch Object Recognition via Analogical Learning, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 1336–1343.
- Derbinsky and Laird (2009) Derbinsky, N., Laird, J.E., 2009. Efficiently Implementing Episodic Memory, in: International Conference on Case-Based Reasoning, Springer. pp. 403–417.
- Derbinsky et al. (2010) Derbinsky, N., Laird, J.E., Smith, B., 2010. Towards Efficiently Supporting Large Symbolic Declarative Memories, in: Proceedings of the 10th International Conference on Cognitive Modeling, Citeseer. pp. 49–54.
- Fisher (1987) Fisher, D.H., 1987. Knowledge Acquisition via Incremental Conceptual Clustering. Machine learning .
- Forbus et al. (2017) Forbus, K.D., Ferguson, R.W., Lovett, A., Gentner, D., 2017. Extending SME to Handle Large-Scale Cognitive Modeling. Cognitive Science 41, 1152–1201.
- Gatsoulis et al. (2016) Gatsoulis, Y., Alomari, M., Burbridge, C., Dondrup, C., Duckworth, P., Lightbody, P., Hanheide, M., Hawes, N., Hogg, D., Cohn, A., et al., 2016. QSRlib: A Software for Online Acquisition of QSRs from Video .
- Gentner (2003) Gentner, D., 2003. Why We’re So Smart? Language in Mind: Advances in the Study of Language and Thought .
- Gluck and Laird (2019) Gluck, K.A., Laird, J.E., 2019. Interactive Task Learning: Humans, Robots, and Agents Acquiring New Tasks Through Natural Interactions. volume 26. MIT Press.
- Hinrichs and Forbus (2017) Hinrichs, T.R., Forbus, K.D., 2017. Towards a Comprehensive Standard Model of Human-Like Minds, in: 2017 AAAI Fall Symposium Series.
- Jones and Langley (2005) Jones, R.M., Langley, P., 2005. A Constrained Architecture for Learning and Problem Solving. Computational Intelligence 21, 480–502.
- Kirk and Laird (2014) Kirk, J.R., Laird, J.E., 2014. Interactive Task Learning for Simple Games. Advances in Cognitive Systems .
- Kirk and Laird (2019) Kirk, J.R., Laird, J.E., 2019. Learning Hierarchical Symbolic Representations to Support Interactive Task Learning and Knowledge Transfer, in: Proceedings of the 28th International Joint Conference on Artificial Intelligence, AAAI Press. pp. 6095–6102.
- Klenk et al. (2011) Klenk, M., Forbus, K., Tomai, E., Kim, H., 2011. Using Analogical Model Formulation with Sketches to Solve Bennett Mechanical Comprehension Test problems. Journal of Experimental & Theoretical Artificial Intelligence 23, 299–327.
- Laird (2012) Laird, J.E., 2012. The Soar Cognitive Architecture.
- Laird et al. (2017) Laird, J.E., Lebiere, C., Rosenbloom, P.S., 2017. Toward a Common Computational Framework Across Artificial Intelligence, Cognitive Science, Neuroscience, and Robotics. AI Magazine 38, 13–26.
- Langley (1987) Langley, P., 1987. Machine Learning and Concept Formation. Machine Learning 2, 99–102.
- Lockwood (2009) Lockwood, K., 2009. Using Analogy to Model Spatial Language Use and Multimodal Knowledge Capture. Doctor of Philosophy .
- MacLellan et al. (2015) MacLellan, C.J., Harpstead, E., Aleven, V., Koedinger, K.R., 2015. Trestle: Incremental Learning in Structured Domains Using Partial Matching and Categorization, in: Proceedings of the 3rd Annual Conference on Advances in Cognitive Systems-ACS.
- McLure et al. (2015) McLure, M.D., Friedman, S.E., Forbus, K.D., 2015. Extending Analogical Generalization with Near-Misses, in: Twenty-Ninth AAAI Conference on Artificial Intelligence.
- Mininger and Laird (2018) Mininger, A., Laird, J.E., 2018. Interactively Learning a Blend of Goal-Based and Procedural Tasks, in: Thirty-Second AAAI Conference on Artificial Intelligence.
- Mohan and Laird (2014) Mohan, S., Laird, J., 2014. Learning Goal-Oriented Hierarchical Tasks from Situated Interactive Instruction, in: Twenty-Eighth AAAI Conference on Artificial Intelligence.
- Mohan et al. (2014) Mohan, S., Mininger, A., Laird, J., 2014. Towards an Indexical Model of Situated Language Comprehension for Cognitive Agents in Physical Worlds. Advances in Cognitive Systems .
- Mohan et al. (2012) Mohan, S., Mininger, A.H., Kirk, J.R., Laird, J.E., 2012. Acquiring Grounded Representations of Words with Situated Interactive Instruction. Advances in Cognitive Systems .
- Muggleton and De Raedt (1994) Muggleton, S., De Raedt, L., 1994. Inductive Logic Programming: Theory and Methods. The Journal of Logic Programming 19, 629–679.
- Ramaraj et al. (2021) Ramaraj, P., Ortiz, C.L., Klenk, M., Mohan, S., 2021. Unpacking Human Teachers’ Intentions For Natural Interactive Task Learning. arXiv:2102.06755.
- Redmon et al. (2016) Redmon, J., Divvala, S., Girshick, R., Farhadi, A., 2016. You Only Look Once: Unified, Real-Time Object Detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779–788.
- Rich et al. (2001) Rich, C., Sidner, C.L., Lesh, N., 2001. Collagen: Applying Collaborative Discourse Theory to Human-Computer Interaction. AI magazine 22, 15–15.
- Rosenbloom et al. (2016) Rosenbloom, P.S., Demski, A., Ustun, V., 2016. The Sigma Cognitive Architecture and System: Towards Functionally Elegant Grand Unification. Journal of Artificial General Intelligence 7, 1–103.
- Tenenbaum (1999) Tenenbaum, J.B., 1999. Bayesian Modeling of Human Concept Learning, in: Advances in neural information processing systems, pp. 59–68.
- Thompson and Langley (1991) Thompson, K., Langley, P., 1991. Concept Formation in Structured Domains, in: Concept Formation.
- Tulving and Craik (2005) Tulving, E., Craik, F.I., 2005. The Oxford Handbook of Memory. Oxford University Press.
- VanLehn et al. (1991) VanLehn, K., Jones, R.M., Chi, M., 1991. Modeling the Self-Explanation Effect with Cascade 3, in: Proceedings of the Thirteenth Annual Conference of the Cognitive Science Society, Lawrence Earlbaum Associates Hillsdale, NJ. pp. 137–142.
- Veloso et al. (1995) Veloso, M., Carbonell, J., Perez, A., Borrajo, D., Fink, E., Blythe, J., 1995. Integrating Planning and Learning: The Prodigy Architecture. Journal of Experimental & Theoretical Artificial Intelligence 7, 81–120.
- Xu and Laird (2010) Xu, J.Z., Laird, J.E., 2010. Instance-Based Online Learning of Deterministic Relational Action Models, in: Twenty-Fourth AAAI Conference on Artificial Intelligence.