5pt
0.84(0.08,0.93) ©20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Analysis of Visual Reasoning on One-Stage Object Detection
Abstract
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 [1] on COCO [2] in terms of mAP while still running in real-time.
Index Terms— object detection, one-stage object detection, visual reasoning
1 Introduction
Object detection aims to classify and localize objects of interest in a given image. It has attracted great attention of the community because of its close ties with other computer vision applications. Many traditional methods have been proposed to solve object detection problem before the major breakthrough in deep learning area. These methods [3, 4, 5, 6, 7] were built on handcrafted feature representations. Inevitable dependency on handcrafted features limited the performance of traditional approaches. The great impact of the AlexNet [8] has put a new complexion on the object detection approaches and then deep learning based methods have completely dominated literature. Deep learning based detectors can be divided into two categories: two-stage object detectors and one-stage object detectors. Two-stage detectors have low inference speeds due to the intermediate layer used to propose possible object regions. Region proposal layer extracts regions of objects in the first stage. In the second stage, these proposed regions are used for classification and bounding box regression. On the other hand, one-stage detectors could predict all the bounding boxes and class probabilities in a single pass with high inference speeds. This makes one-stage detectors more suitable for real-time applications.
Recent one-stage object detectors [9, 10, 1, 11, 12] achieve good performance on datasets such as MS COCO [2] and PASCAL VOC [13]. However, they lack of ability to consider possible relations between image regions. The current one-stage detectors treat each image region separately. They are unaware of distinct image regions due to small receptive fields when image size is considered. They depend solely on high-quality local convolutional features to detect objects successfully. However, this is not the way how human visual system works. Humans have an ability of reasoning to carry out visual tasks with the help of acquired knowledge. Many methods [14, 15, 16, 17, 18] have been proposed to mimic human reasoning ability in object detection. On the other hand, these methods are mostly complicated and uses two-stage detection architectures. Thus, they are not applicable for real-time applications.
In this paper, we propose a new approach to incorporate visual reasoning into one-stage object detection. Different from ViT-YOLO [18], we integrate multi-head attention based reasoning layer on top of the neck instead of the backbone. By this way, reasoning information about the relationships between different image regions can be extracted by using more meaningful, fine-grained and enhanced feature maps.
This paper’s contributions can be summarized as follows:
-
•
We present that one-stage object detection can be improved by visual reasoning. A new architecture is proposed that can extract semantic relations between image regions to predict bounding boxes and class probabilities.
-
•
We analyze the effect of using only reasoning features on object detection performance. We demonstrate that fusing backbone output only-convolutional and reasoning features achieves the best performance improvement over the baseline model while still running in real-time.
-
•
We analyze the effect of utilizing reasoning on average precision improvement for each object category.

2 Approach
The general structure of the proposed method is shown in Figure 1. Firstly, convolutional features are extracted by the Darknet-53 [1] backbone. Like YOLOv3, proposed method produces bounding box predictions at 3 different scales. Feature maps from different layers of the backbone are collected and concatenated after the necessary upsampling operations by FPN [19] like neck. Then, the semantic relationships between image regions are extracted in the reasoning layer. At the final stage, class probabilities and bounding boxes are predicted by the YOLO head.
2.1 Reasoning Layer
As a reasoning layer, transformer encoder-like [20] model is used. The architecture of the reasoning layer is shown in Figure 2. All of the sub-layers of the reasoning layer are explained in detail in the following subsections.
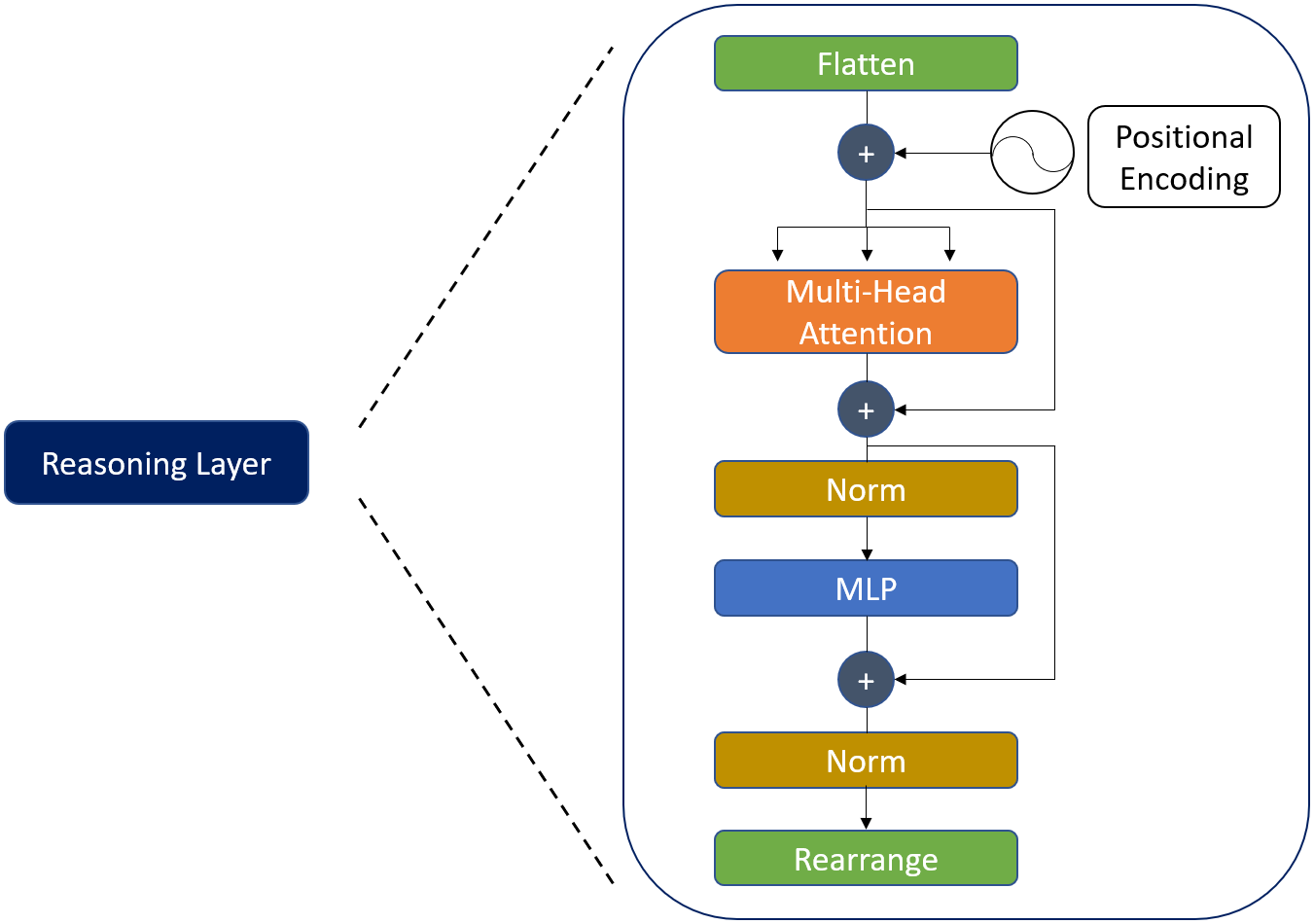
2.1.1 Flatten
The multi-head attention layer expects a sequence as an input. In Flatten, grid is converted to a sequence and fed to multi-head attention layer in this form.
2.1.2 Positional Encoding
By its nature, the multi-head attention layer is unaware of order in sequence. However, information about positions of the grid regions is valuable. To model order of image regions, fixed sinusoidal positional encoding [21] is used:
| (1) |
| (2) |
where i is the position of the grid region in the sequence, j is the feature depth index, and dfeature is the same with the feature depth. Generated values by sine and cosine functions are concatenated pairwise and added to convolutional feature embedding of the grid region.
2.1.3 Multi-Head Attention
Multi-head attention is the main layer where reasoning between grid cells, i.e. image regions, takes place. Reasoning between different regions of the input sequence is modeled by using self-attention which is based on three main concepts: query, key and value. In high level abstraction, query of a single grid cell in the sequence searches potential relationships and tries to associate this cell with other cells, i.e. image regions, in the sequence through keys. The comparison between query and key pairs gives us the attention weight for the value. Interaction between attention weights and values determines how much focus to place other parts of the sequence while representing the current cell.
In the self-attention, the query, key and value matrices are calculated by multiplying the input sequence X with 3 different weight matrices: , and :
| (3) |
| (4) |
| (5) |
To compare query and key matrices, the scaled dot-product attention is used [20]:
| (6) |
Each grid cell, i.e. image region, is encoded by taking a summation of attention weighted value matrix columns. The attention weights tell where to look in the value matrix. In other words, they tell which parts of the image are valuable, informative and relevant while encoding the current grid.
The self-attention mechanism was further improved by a multi-headed manner [20]. In the multi-head attention, self-attention computation is performed for a defined number of heads in parallel. The major superiority of multi-head over a single head is that it enables the model to work on different relationship subspaces. Each head has a different query, key and value matrices since each of these sets are obtained by using separate and randomly initialized weight matrices. The attention in head i is calculated as:
| (7) |
Then, attentions are concatenated and transformed using a weight matrix :
| (8) |
2.1.4 Skip Connections
There are two skip connections in the reasoning layer. Backpropagation is improved as stated in ResNet [22] paper and original information is propagated to the following layers by residual skip connections.
2.1.5 Normalization
2.1.6 MLP
Output of the multi-head attention is fed to multilayer perceptron (MLP) after normalization. MLP layer is composed of two linear layers and ReLU non-linearity in between:
| (9) |
2.1.7 Rearrange
Rearrange is the last sublayer of the reasoning layer where sequence is converted back to the grid format which detection head expects.
2.2 Reasoner Configurations
Two different network configurations are trained and tested on COCO [2] dataset. In the first configuration, only reasoning features are fed to the detection head. In the second configuration, backbone output convolutional features are concatenated with reasoning features. Then, this new feature set is fused in 1x1 convolutional layer and fed to the detection head. Details related with network configurations are given in the following subsections.
2.2.1 YOLOv3-Reasoner1
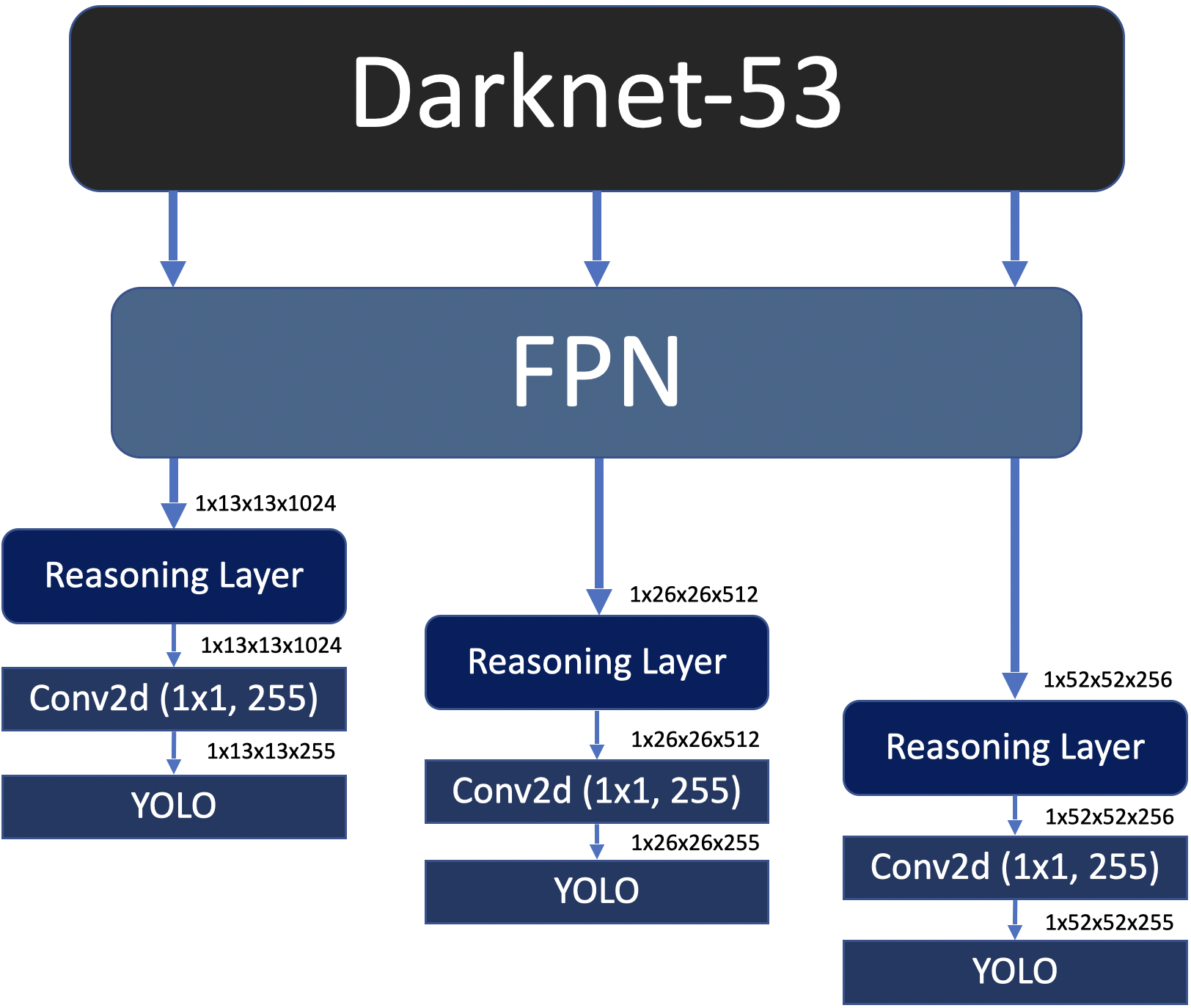
FPN output is directly fed to the reasoning layer in this configuration. Number of heads are chosen 16, 8 and 4 for each scale respectively so that embedding size for each head has become 64. The reasoning layer output is fed to 1x1 convolutional layer. The whole architecture of YOLOv3-Reasoner1 is shown in Figure 4.
2.2.2 YOLOv3-Reasoner2
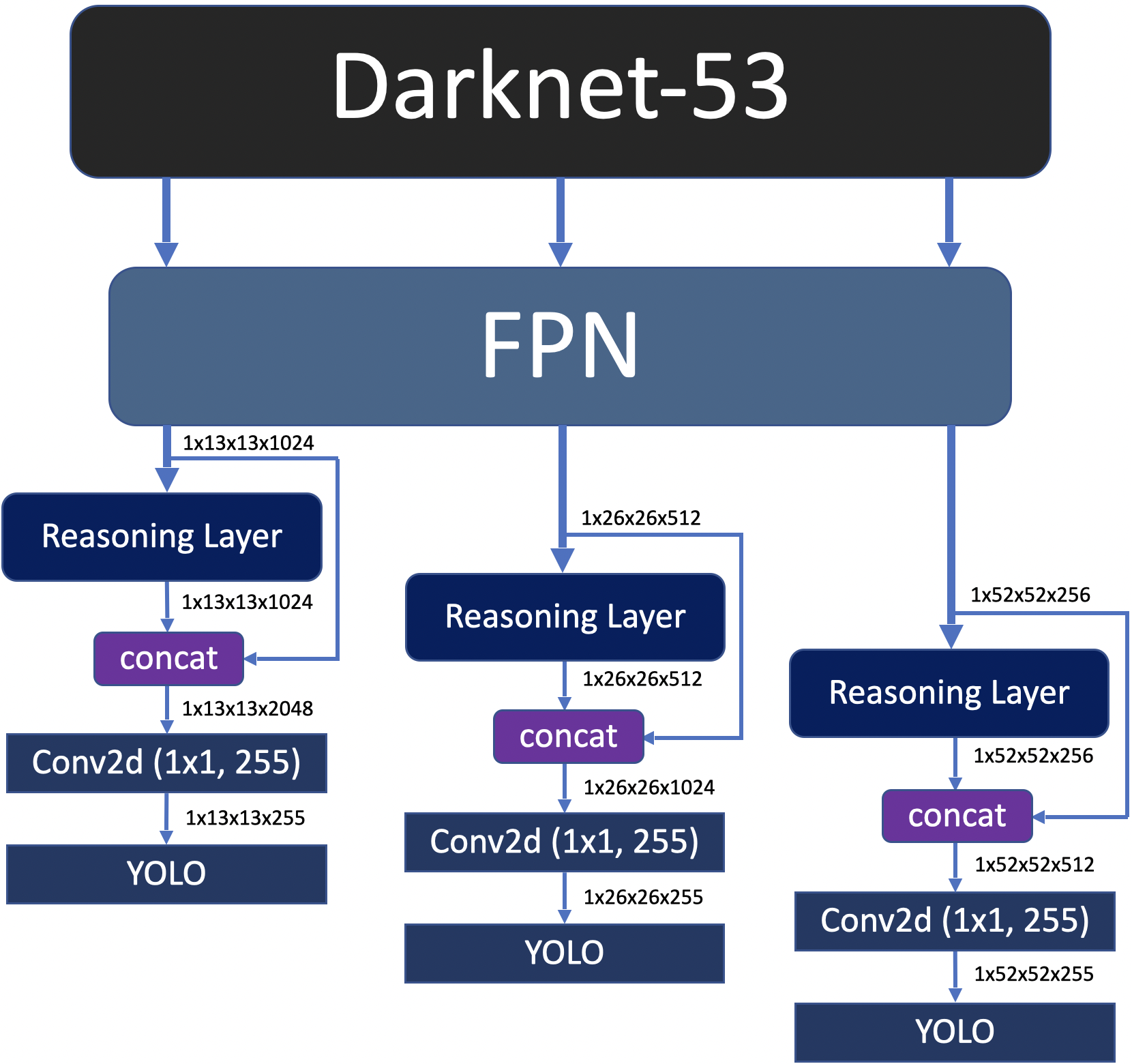
In this configuration, output of the reasoning layer is concatenated with FPN output through a shortcut connection. Then, the output of the concatenation layer is fed to the 1x1 convolutional layer in order to fuse the information which is composed of reasoning and original only-convolutional features. There is a possibility that some parts of the convolutional features have been weakened in the reasoning layer. Our concatenation strategy ensures the reusability of the original convolutional features. The architecture of YOLOv3-Reasoner2 is shown in Figure 5.
3 Experiments
In this section, we evaluate our reasoner networks. Firstly, dataset and evaluation metrics are introduced. Then, implementation details are given. Finally, quantitative and qualitative evaluation results are given.
3.1 Dataset and Evaluation
Experiments are performed on the MS COCO [2] dataset. The 2017 configuration of the dataset consists of 118K training and 5K validation images from 80 different object categories. As an evaluation metric, mean average precision (mAP) at IoU (Intersection over Union) = .5 is used as it is in the original YOLOv3 paper [1].
3.2 Implementation Details
Network configurations are trained for 100 epochs from scratch on the COCO dataset. Initial learning rate was set to 0.001. Adam optimizer is used with parameters set to = 0.9, = 0.999 and = 1e-08.
3.3 Quantitative Evaluation
In Table 1, comparison results of our reasoner networks and the baseline YOLOv3. Frame rate comparison results are obtained by using Quadro RTX 8000 GPU. YOLOv3-Reasoner2 configuration where both the backbone output only-convolutional and reasoning features are used together achieves the best result while still running in real-time.
| Model | #Param. | FPS | mAP |
|---|---|---|---|
| YOLOv3 | 61M | 51 | 26.18 |
| YOLOv3-Reasoner1 | 65M | 46 | 27.45 |
| YOLOv3-Reasoner2 | 66M | 45 | 28.68 |
3.4 Qualitative Evaluation
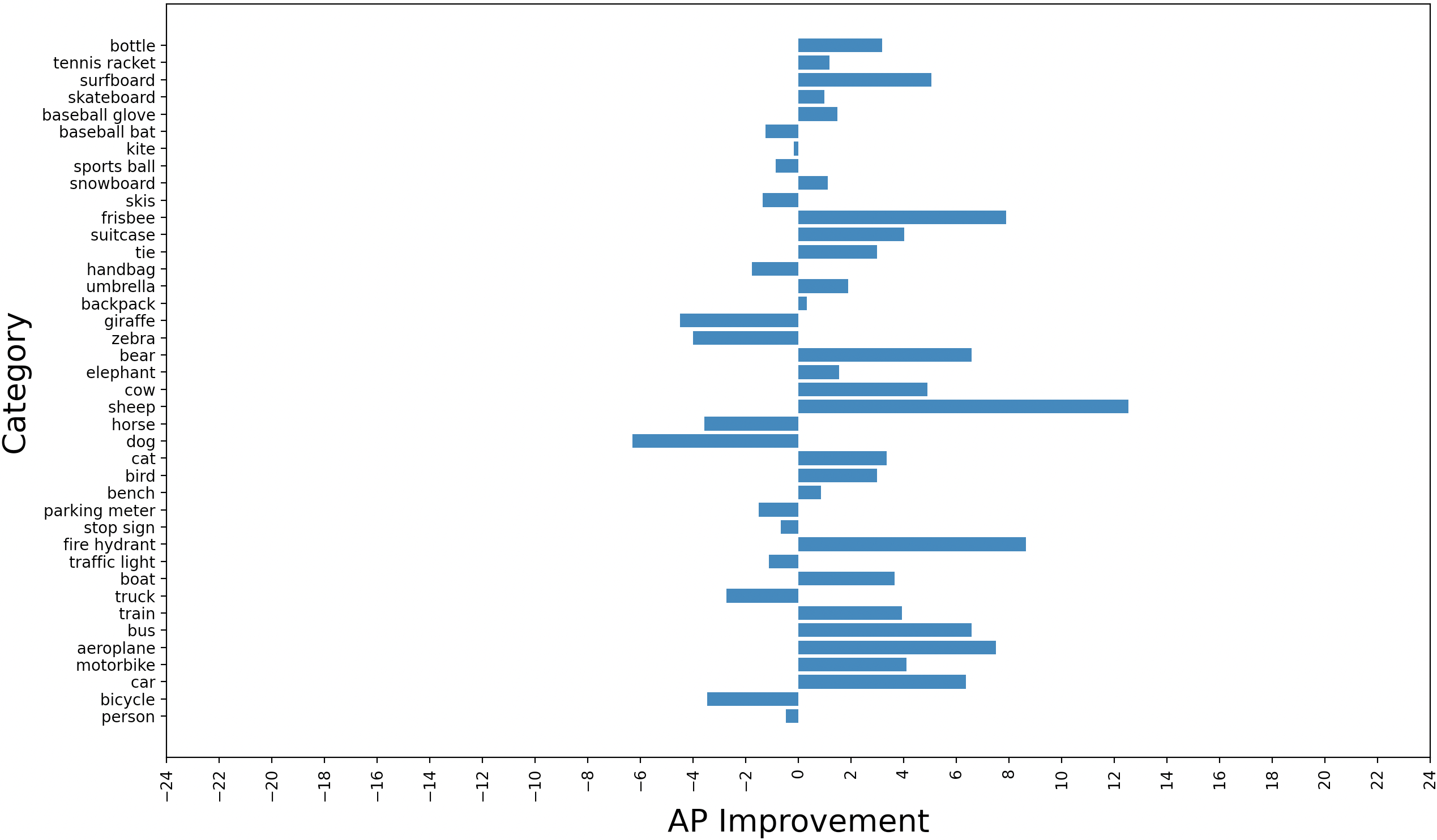
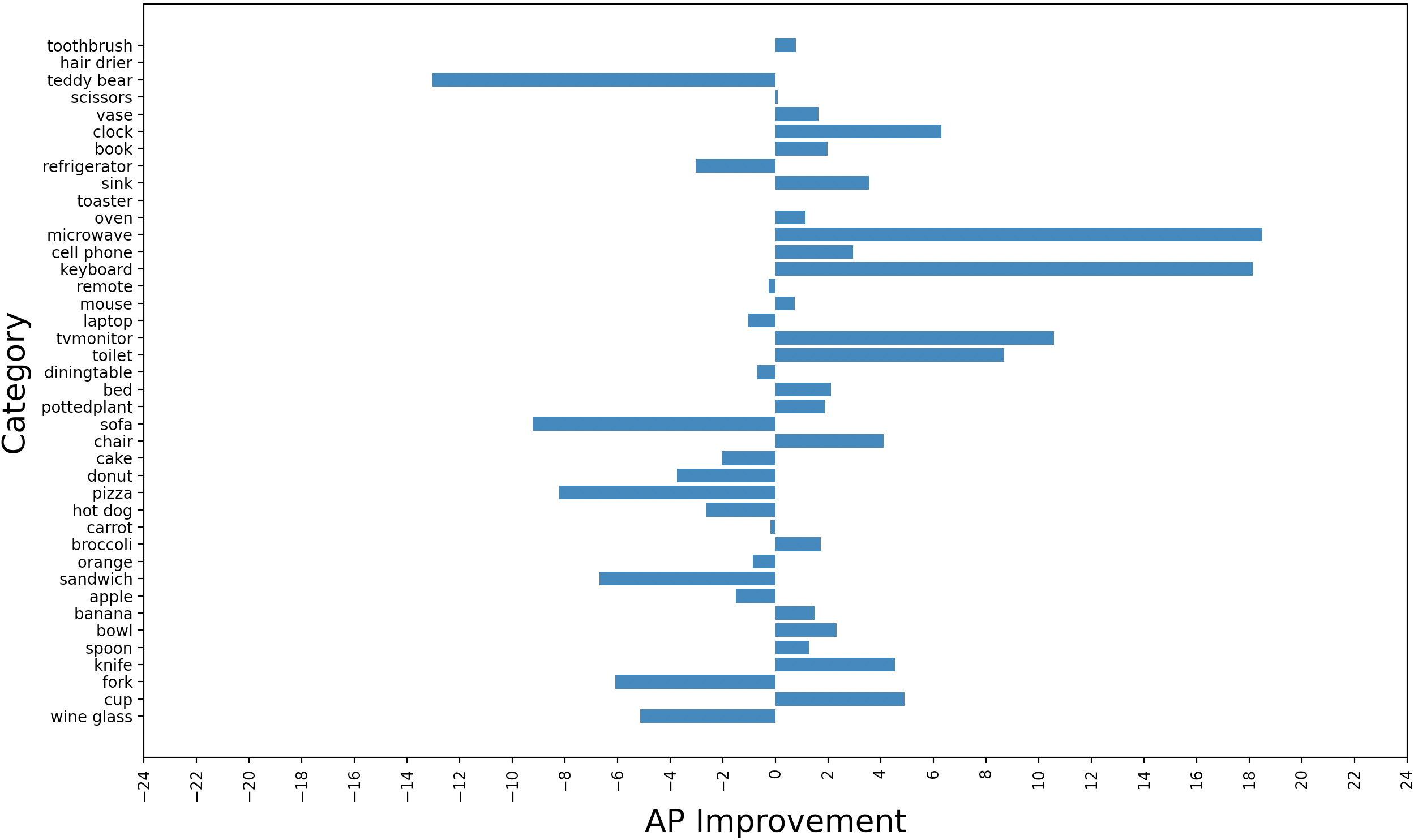
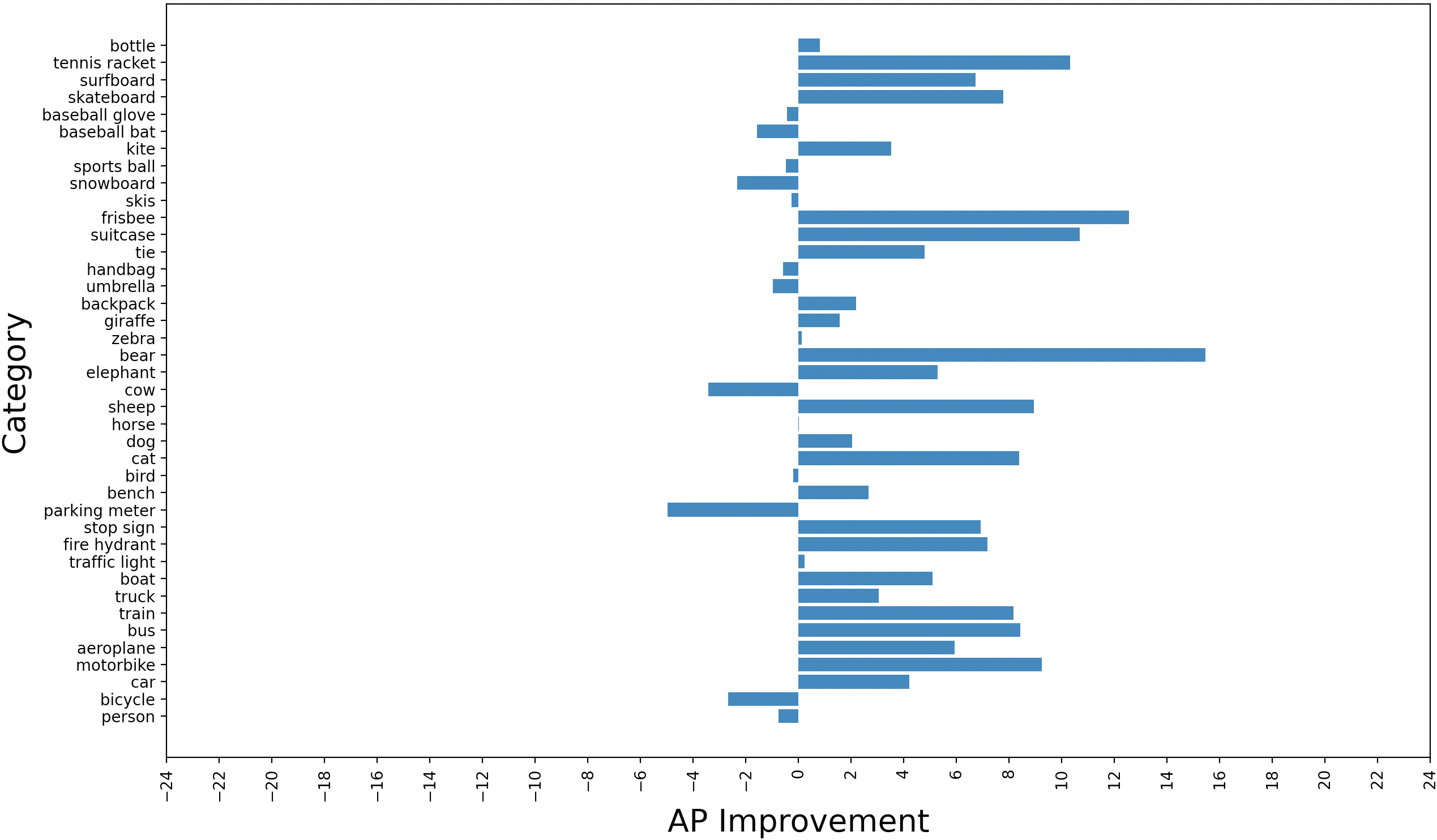
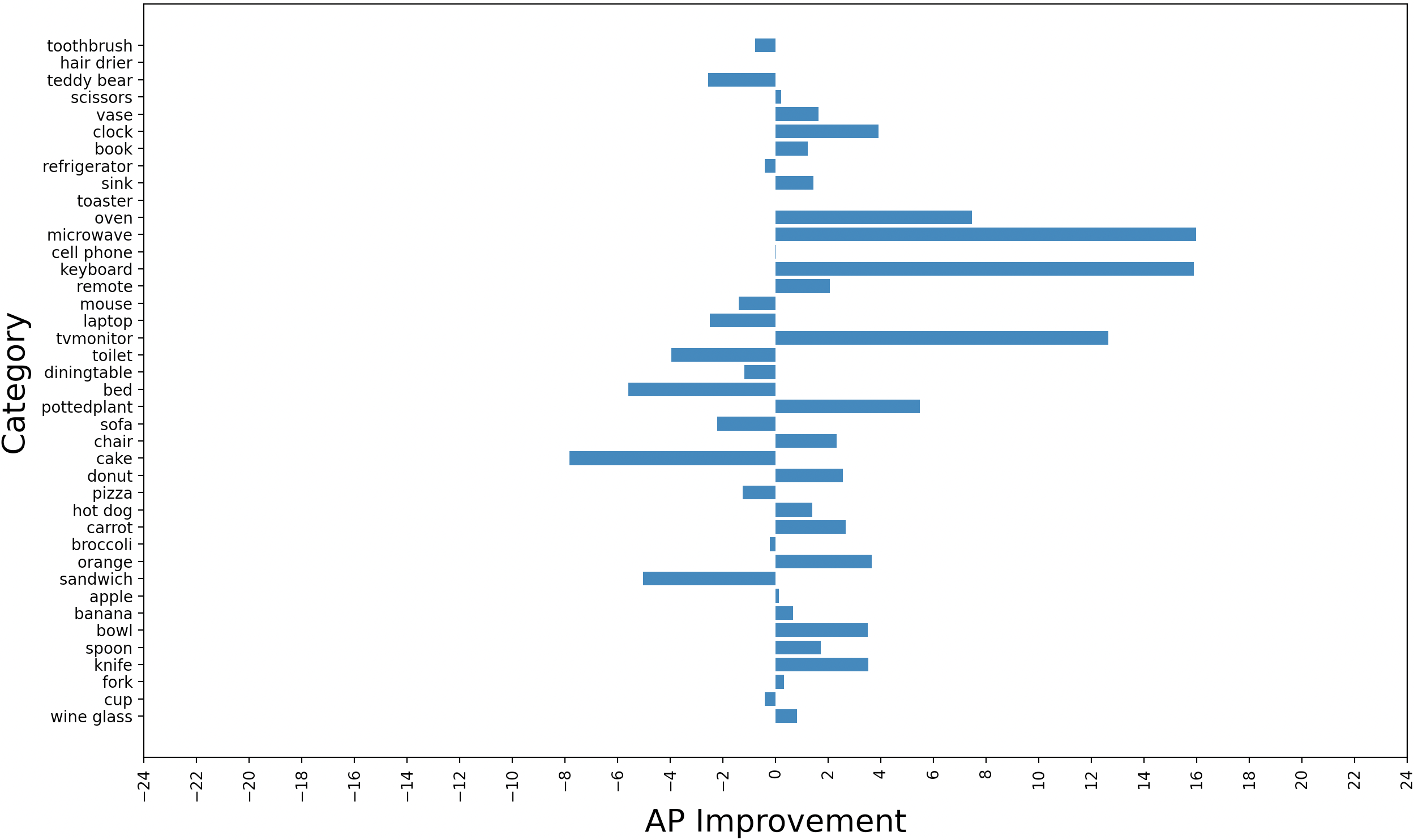
Differences in average precision for each category of the COCO dataset between the reasoner configurations and the baseline YOLOv3 are examined. Results are shown in Figure 3. The performance is improved on much of the categories. Improvements in YOLOv3-Reasoner2 are much better than the YOLOv3-Reasoner1. It seems that usage of the fpn output convolutional and reasoning features together lowers the performance degrade in some of the categories.
4 Conclusion
The results and analysis indicate that visual reasoning is promising to advance one-stage object detection. Although direct usage of the reasoning features in detection head achieves better performance than the baseline, fusing only-convolutional and reasoning features gives the best result by ensuring the reusability of the original backbone output convolutional features. For future work, the idea behind the YOLOv3-Reasoner2 model could be applied to a more recent one-stage object detection architecture to indicate new state-of-the-art.
References
- [1] Joseph Redmon and Ali Farhadi, “Yolov3: An incremental improvement,” 2018.
- [2] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár, “Microsoft coco: Common objects in context,” 2015.
- [3] P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, 2001, vol. 1, pp. I–I.
- [4] P. Viola and M. Jones, “Robust real-time face detection,” in Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, 2001, vol. 2, pp. 747–747.
- [5] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), 2005, vol. 1, pp. 886–893 vol. 1.
- [6] Pedro Felzenszwalb, David McAllester, and Deva Ramanan, “A discriminatively trained, multiscale, deformable part model,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition, 2008, pp. 1–8.
- [7] Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester, and Deva Ramanan, “Object detection with discriminatively trained part-based models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1627–1645, 2010.
- [8] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, Eds. 2012, vol. 25, Curran Associates, Inc.
- [9] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, “You only look once: Unified, real-time object detection,” 2016.
- [10] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg, “Ssd: Single shot multibox detector,” Lecture Notes in Computer Science, p. 21–37, 2016.
- [11] Mingxing Tan, Ruoming Pang, and Quoc V. Le, “Efficientdet: Scalable and efficient object detection,” 2020.
- [12] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao, “Yolov4: Optimal speed and accuracy of object detection,” 2020.
- [13] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp. 303–338, June 2010.
- [14] Xinlei Chen and Abhinav Gupta, “Spatial memory for context reasoning in object detection,” 2017.
- [15] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen Wei, “Relation networks for object detection,” 2018.
- [16] Xinlei Chen, Li-Jia Li, Li Fei-Fei, and Abhinav Gupta, “Iterative visual reasoning beyond convolutions,” 2018.
- [17] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko, “End-to-end object detection with transformers,” 2020.
- [18] Zixiao Zhang, Xiaoqiang Lu, Guojin Cao, Yuting Yang, Licheng Jiao, and Fang Liu, “Vit-yolo:transformer-based yolo for object detection,” in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 2799–2808.
- [19] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie, “Feature pyramid networks for object detection,” 2017.
- [20] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” 2017.
- [21] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin, “Convolutional sequence to sequence learning,” 2017.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” 2015.
- [23] Sergey Ioffe and Christian Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” 2015.
- [24] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton, “Layer normalization,” 2016.