Analyzing the Granularity and Cost of Annotation in Clinical Sequence Labeling
Abstract
Well-annotated datasets, as shown in recent top studies, are becoming more important for researchers than ever before in supervised machine learning (ML). However, the dataset annotation process and its related human labor costs remain overlooked. In this work, we analyze the relationship between the annotation granularity and ML performance in sequence labeling, using clinical records from nursing shift-change handover. We first study a model derived from textual language features alone, without additional information based on nursing knowledge. We find that this sequence tagger performs well in most categories under this granularity. Then, we further include the additional manual annotations by a nurse, and find the sequence tagging performance remaining nearly the same. Finally, we give a guideline and reference to the community arguing it is not necessity and even not recommended to annotate in detailed granularity because of a low Return on Investment. Therefore we recommend emphasizing other features, like textual knowledge, for researchers and practitioners as a cost-effective source for increasing the sequence labeling performance.
Index Terms:
Data processing; Electronic medical records; Health information management; Neural networks; Supervised learning; Text analysisI Introduction
Natural Language Processing (NLP) techniques can derive a wide range of applications in medical and health practice. Specifically, in order to understand the clinical records well, we need deep understanding of the textual contents [10, 15]. This yields the necessity for addressing downstream tasks under the concept of sequence labeling, which is our main focus on the clinical handover.
However, most commonly used and state-of-the-art NLP models are mostly supervised learning algorithms, which means the performance of the model is highly dependent on the quality and amount of labeled training data [12]. A well-annotated, high-quality dataset is regarded as the default prerequisite before researchers start to show their magic [7, 9]. Therefore, we argue that the analysis of the process of creating such annotated datasets is highly overlooked.
This work studies the process to automatically annotate clinical handover. In this process, we train a model using a labeled handover dataset such that the model can annotate future clinical records (i.e. identify which part is patient introduction and which part is the appointment information with a doctor).
In order to thoroughly study the data annotation process, the work mainly focuses on the relationship between the granularity of annotations and sequence labeling performance. Specifically, we try to answer “Is the cost of additional expert annotation worth it?” Hence, we try different granularity levels when annotating and/or labeling the tags in a clinical handover dataset in order to analyze the difference in terms of the sequence labeling performance. We also study the “return on investment” when detailing the granularity against the performance gain of the model. This is because of the nature of (clinical)text annotation — the high cost of human labor resources.
In the end, we quantitatively formulate the human labor cost against the performance gain, estimate the market value of the annotation process, give conclusions, and argument on to what extent should future researchers devote their time and money into detailing the annotation granularity of their datasets. This is an important contribution to the community, as we test the feasibility of devoting more time and money on more detailed annotations to increase the task performance. Our outcomes will guide future research of the community, especially given that research related to data annotation are usually very costly [7, 9].
II Dataset
In this paper, the synthetic dataset created and released by Suominen et al.[16] is used. This dataset is created in five steps: 1. Create a patient profile. 2. Collaborate with a registered nurse (RN) to create a synthetic but realistic nursing handover dataset. 3. Create a structured handover form. 4. Create a written, structured document with the form in the third step and written, free-form text documents. 5. Create spoken, free-form text documents.
There are three groups of textual features already annotated in the dataset, namely, syntactic, semantic and statistical features. The syntactic features are about general characteristics of the word itself, including the “Lemma”, “Named Entity Recognition”, “Part of Speech” tags, and so on. The semantic features are closely related to the semantic meaning of the word, which includes information about the top candidates the word is retrieved with, and the top mappings in the Unified Medical Language System. The statistical features are more about the positioning of the word, for example, the location of the word in a document.
We also introduce the additional annotation by the nurse to later draw comparison before and after this annotation is adopted. During annotation, an Australian registered nurse will manually annotate key points to better describe the patient case. Words are colored to represent different high-level categories. Here is a fraction of what the dataset looks like:
Ken Harris, 71 yrs old under Dr Gregor, complained of chest pain. ECG was done and was reviewed by the team. He was also given some anginine.
For example, “Harris” is colored blue representing its label (manually by the nurse) ‘PatientIntroduction’. Importantly, the task is to see how better the sequence labeling performance becomes (or whether it will become) with and without the expert annotation, to infer a finer level ground truth label. In other words, we evaluate how much better the model becomes (or whether it will become) after the nurse telling it that “Harris” belongs to ‘PatientIntroduction’ than using purely textual features to infer its (finer level) ground truth: ‘PatientIntroduction_LastName’.
III Method
In this section, we introduce the architecture of the trained model, namely Embeddings + Bidirectional Long Short-Term Memory (BiLSTM) + Conditional Random Field (CRF). Lastly, evaluation methods of the model performance and annotation cost are introduced.
III-A Embeddings
In this work, multiple embeddings of different levels (word embeddings and document embeddings) are stacked up.
Word Embeddings. The GloVe embedding is a global log-bilinear regression model [13]. The GloVe model property is necessary to generate linear directions of meaning, and the proposed global log-bilinear regression models are appropriate to do so. In this work, GloVe embedding is used as a part of stacked embedding to build up the language model for the sequence labeling task.
Character Embedding specifically points to the neural architectures that Lample et al. proposed in 2016 [11]. It resolves the problem that good sequence labeling, especially named entity recognition systems heavily rely on hand-crafted features as well as domain-specific features to learn effectively from the available supervised and small training corpora.
State-of-the-art embeddings including BERT-embeddings [5], ELMo-embeddings [14] and Flair-embeddings [1] are also adopted.
BERT enables the tasks without abundant training resources to benefit from the architecture, such as this work on Synthetic Nursing Handover Dataset, with a limited amount of training set of only 100 clinical records.
The word vectors of ELMo embedding are learned from the internal states in a deep bi-directional language model (BiLM) trained from a large corpus. The vectors are derived from a BiLSTM trained with a coupled language model based on a large text corpus. This is the reason why ELMo embedding is used in this paper.
Flair embedding [1], is a novel embedding pre-trained on a large unlabeled corpora, capturing word meanings in the surrounding context. This makes the model able to produce different embeddings for polysemous words based on their usage.
Document Embeddings. We further use Transformer Document Embeddings, which encodes the whole text piece into a representation.
Transformer Document Embeddings uses the power of transformer, which is already shown in the elaboration of BERT model [5].We use the robust pre-trained BERT transformer to embed each piece of clinical record into a single representation.
Stack Embeddings. Stack embedding is one of the most important steps used in this project. This means different word embeddings are stacked together to give a more robust embedding performance.
For example, we want a combination of the classical embeddings and advanced embeddings. What we do is to use the stack embedding feature to concatenate the two vector representations of the same token, as shown below in Equation (1).
| (1) |
III-B Long Short-Term Memory & Conditional Random Field
This section introduces the overall architecture of the BiLSTM + CRF part in this work. This is to simulate the state-of-the-art performance of current sequence labeling practice. The work mainly focuses on the comparison under the same architecture, rather than the architecture itself.
The Long Short-Term Memory network is a Recurrent Neural Network (RNN) with special architecture. Furthermore, the Bidirectional Long Short-Term Memory model is introduced [8]. Rather than using a single hidden state , which only takes context from the past, the model presents each sequence both forward and backward to two separate hidden states to capture past and future information respectively. The final output of the model is the concatenation of two hidden states.
CRF is a model used for sequence labeling, which has all the advantages of Maximum entropy Markov models, while also solved the problem of label bias [3]. The advantage of CRF is that it can be generalized easily to other kinds of stochastic context-free grammars that are significant in classification tasks in natural language processing, such as the task in this work.
In this work, the BiLSTM + CRF pipeline is used, giving the best performances [6].
III-C Evaluation Methods
This section introduces metrics used in our work to measure the model performance and cost, namely confusion matrix, micro and macro-averaged scores for performance evaluation and return on investment (ROI) for annotation cost estimation.
Confusion Matrix
The confusion matrix used in this work is a standard version, consisting of the 2x2 grid with True Positive (TP), False Positive (FP), False Negative (FN) and True Negative (TN). We also use the four derived metrics, namely accuracy, precision, recall and F-1 score which are given as follows: Accuracy = (TP+TN)/(TP+TN+FP+FN), Precision = (TP)/(TP+FP), Recall=(TP)/(TP+FN), =2 (Precision Recall)/(Precision+Recall).
Macro- and Micro-averaged Evaluation
To generalize the evaluation above to a wider range of tasks, especially to multi-class classification, we introduce micro and macro-averaged evaluation.
For multi-classification tasks, there are generally multiple categories, with each instance belonging to one of them. For a certain class , we denote the metrics as follows: : True positive for class , where the instance belongs to and is actually classified as . We give the definition in a similar manner for , and . On top of the four definitions, we can give the definition of and for each class same as above.
We further introduce the micro- and macro-averaged evaluation. Assume there are total classes in the task, for micro-averaged, we give a representation of Micro-Precision, then Micro-Recall and Micro- can be derived in the same manner:
| (2) |
In addition to the analysis per class, we further have evaluation across all classes using the arithmetic mean, which is known as macro-averaged as follows (we give macro-averaged precision as an example):
| (3) |
The metrics cover both the overall performance (macro-averaged, the majority classes and those classes with very few occurrences) and performance overall samples (micro-averaged, emphasizing the importance of those dominant majority classes).
III-D Annotation Cost Evaluation
Return on Investment
Return on Investment (ROI) is a financial metric that is widely used to measure the probability of gaining a return from an investment [2]. We use ROI to directly calculate the cost for annotation in this work.
Annotation Cost Rate
According to a scaled and normalized estimation standard on “Scale”, a data platform for AI, the annotation cost for English-language transcription is US$ 0.08 per token [4].
These are the core cost evaluation formula for this work.
IV Result
The result analysis is organized by comparing the model without nursing knowledge and the model with nursing knowledge (i.e. before and after the additional annotation).
IV-A Annotation without Nursing Knowledge
We first look into the model without using the additional manual annotation under the supervision of a registered nurse. The model is studied using pure syntactical, semantic, and statistical knowledge of the clinical trial record.
By first drawing the confusion matrix, we observe that the model is good at identifying classes with a large amount of instances.
| Category | # Words | TN | FP | FN | TP |
|---|---|---|---|---|---|
| … | … | … | … | … | … |
| E. NA | 3152 | 3574 | 1004 | 395 | 2757 |
| (1) NA | 3152 | 3680 | 898 | 408 | 2744 |
| F. PatientIntroduction | 2221 | 82587 | 225 | 889 | 1329 |
| (1) Gender | 544 | 7040 | 146 | 178 | 366 |
| (2) Ageinyears | 281 | 7442 | 7 | 1 | 280 |
| … | … | … | … | … | … |
There are two levels of sequence tagging, for instance, ’PatientIntroduction’ (macro) and ’PatientIntroduction_Gender’ (micro) (see Table I).
By analyzing micro-averaged score, it can be observed that on this multi-class sequence labeling task, the accuracy of the model is extremely high, reaching 0.999 in some classes. It can also be argued that it is right because there are only a few instances in some classes, that the F-1 scores for them are low.
From the micro-averaged scores, we argue that the model without additional annotation has a mediocre ability to distinguish text contents regarding ‘Future’ of the patients, ‘Medication’ used, and ‘MyShift’ describing the daily life of the patients. But its performance is poor in describing ‘Appointment/Procedure’ which refers to a medical appointment with doctors.
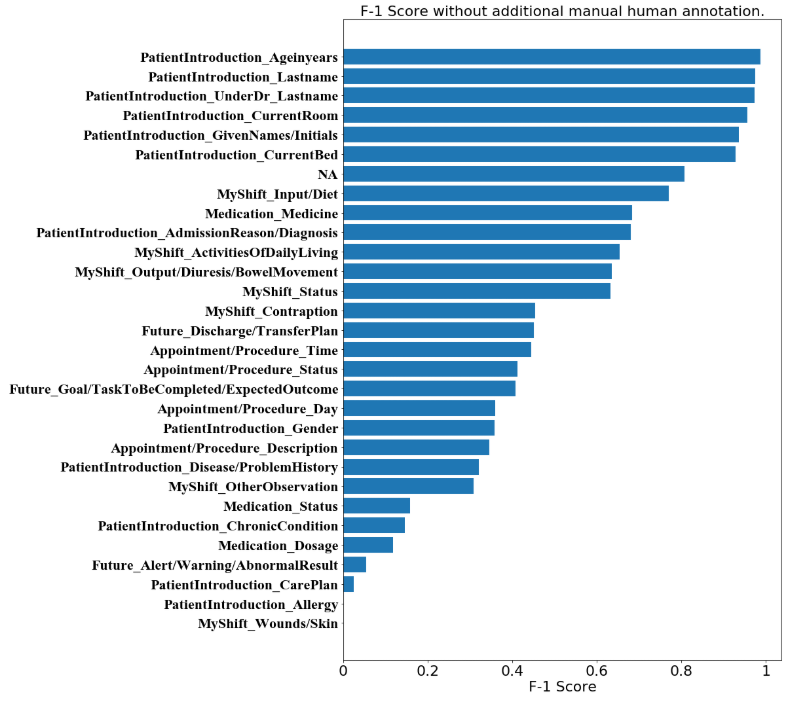
We then present a straightforward visualization of the F-1 score distribution among all sub-categories in Figure 1. From the distribution, we argue that the model without nursing-knowledge-based annotation has an outstanding ability in predicting tags for tokens about the patient introduction, as well as tokens without significant meanings (the ‘NA’ tags).
For the overall macro-averaged score of the model without nursing-knowledge-based annotation, the model performs well in terms of macro-averaged accuracy, which reaches beyond 0.95. On the other hand, it gives a mediocre performance on precision, recall, and F-1 score, with scores near 0.55.
IV-B Annotation with Nursing Knowledge
Similarly, we first draw the confusion matrix of the model trained with nursing knowledge. From the new confusion matrix table, we observe that the four metrics do not seem to differ from those for the model without nursing-knowledge-based annotation. However, it can be observed that the number of predicted labels has changed. In ‘Appointment/Procedure’, ‘ClinicianLastname’, ‘ClinicianTitle’ and ‘Hospital’ no longer exist, as well as ‘RiskManagement’ under ‘MyShift’ and ‘Allergy’ under ‘PatientIntroduction’. This is not a surprise as these sub-categories were already predicted poorly before adding further manual annotation from the nurse.
In terms of micro-averaged evaluation scores, the model after adding additional manual annotation is, surprisingly, no much difference to that before adding additional annotations. This is an interesting finding that is against our intuitive idea. This is because adding additional annotation by nursing knowledge means telling the model which high-level category the token belongs to. The model only needs to distinguish the sub-category within the range of the high-level category. However, according to the experiment result, we cannot observe a substantial difference or performance increase except for some minor substantial changes in categories with very few sample sizes, where fluctuation is more likely to occur.
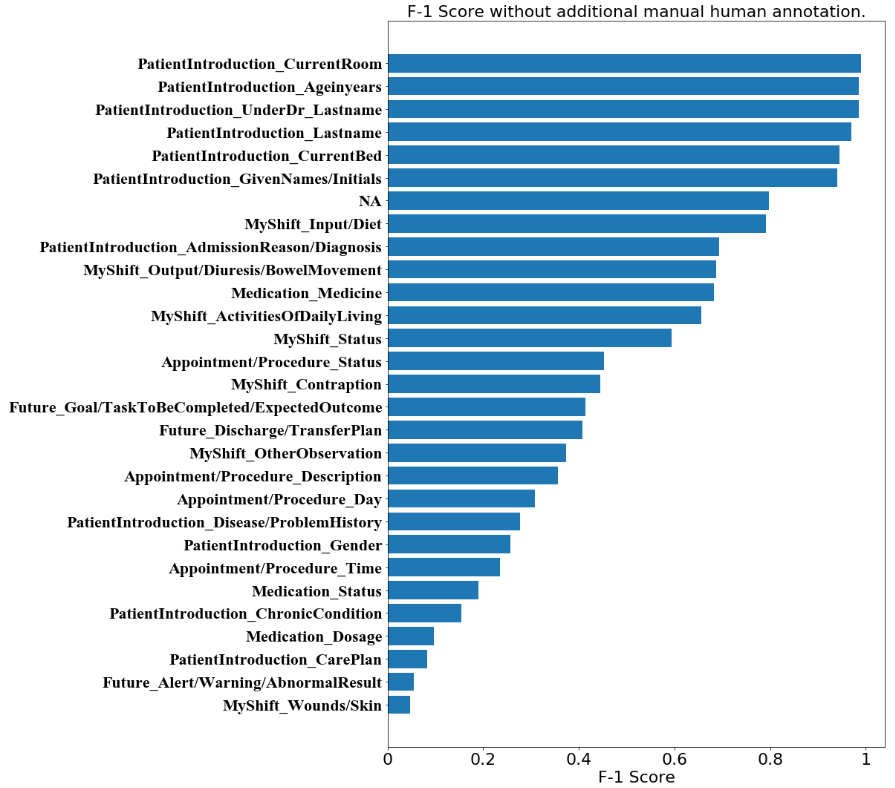
In the sub-categories which remain at the same level, we specifically point out that some of them are consistently distinguished well. This includes ‘Input/Diet’ and ‘NA’ which reaches a F-1 score near 0.8. This also includes ‘Ageinyears’, ‘CurrentBed’, ‘CurrentRoom’, ‘GivenNames/Initials’, ‘Lastname’ and ‘UnderDr_Lastname’, which reaches F-1 scores near or over 0.95 which are outstanding. It can be argued that the model with the stacking of the state-of-the-art embeddings has a good ability to distinguish the tags about names, genders etc. Sub-categories with more than 0.9 F-1 score are mainly under the ‘PatientIntroduction’ category.
We visualize the F-1 score distribution for the model after additional manual annotation. It can be observed that the distribution is no distinct difference to that before the additional annotation. This is both in terms of the absolute values of each sub-category and in terms of the placing among the sub-categories. We observe that most sub-categories under ‘PatientIntroduction’ have the highest F-1 scores in both Figures 1 and 2, with ‘NA’ following them in the 7th place. Sub-categories without many instances are those with the lowest F-1 scores. This is reasonable due to insufficient learning by the deep language model.
In terms of macro-averaged score, the model, which includes additional manual annotation does not seem to perform differently from that without the additional manual annotation as well. This is also against the intuitive idea from people that “adding high-level tag annotation does help the model to classify sub-tags better”. The macro-averaged accuracy, macro-averaged recall, and macro-averaged F-1 score all remain within a 1% range of fluctuation, while macro-averaged precision increases by 2%, which is also hard to be argued as a substantial increase given the amount of cost paid into the additional annotation.
IV-C Visualized Comparison and Cost Analysis
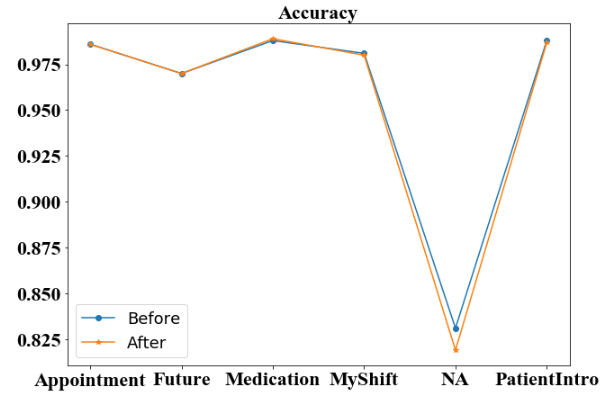
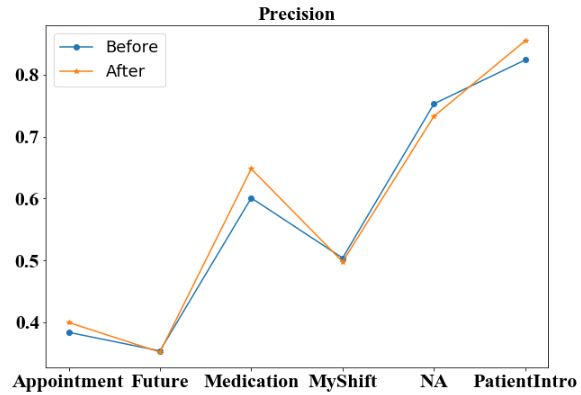
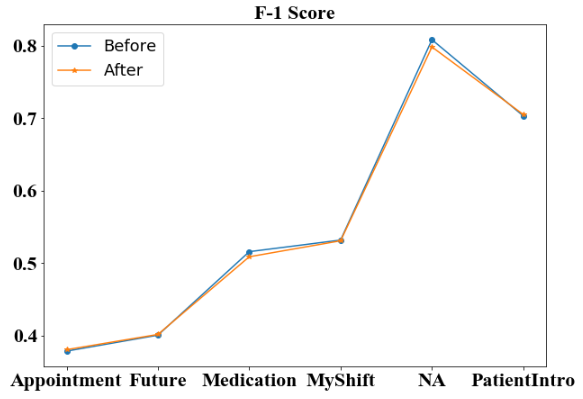
We first compare the four metrics of high-level categories before and after additional annotation. For three of the four micro-averaged metrics: accuracy (Figure 3), recall (Figure 5) and F-1 score (Figure 6), the additional annotation does not bring any substantial changes to the performance in most of the 6 high-level categories. However, the additional annotation does yield a worse accuracy score on ‘NA’ tag and a large drop in ‘Medication’ category from 0.453 to 0.419. But for micro-averaged precision (Figure 4), there are noticeable performance increases in 3 of the 6 categories. Specifically, the micro-averaged precision for ‘Medication’ class receives a nearly 5% boost, from 0.601 to 0.648.
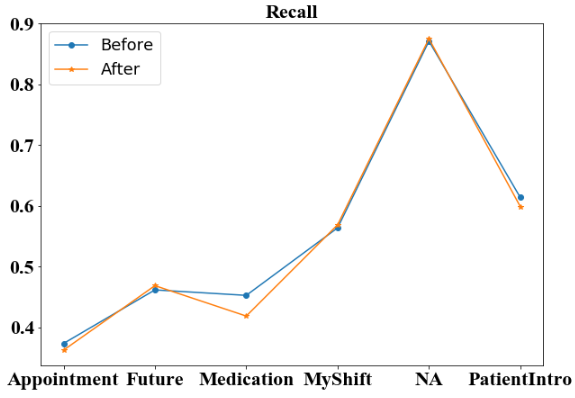
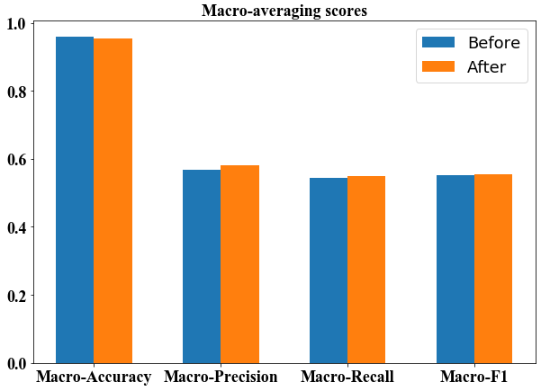
We then compare the macro-averaged scores before and after additional annotation. From the bar plot (Figure 7) we observe that the macro-averaged accuracy of the two models are both high above 0.9, with the ’After’ model even being lower. For the macro-averaged precision score, the ’After’ model increases for around 1%, still remaining at a level around 0.55-0.60. For the macro-averaged recall, and macro-averaged F-1 score, we observe that the model before and after additional annotation does not provide any additional information, and both remain at the level around 0.55–0.60.
We finally estimate the human labor annotation cost by a quantitative analysis. The statistical figures on the Synthetic Nursing Handover Dataset show that the training set and validation set has 8487 tokens annotated in total, while the test set has 7730 tokens annotated. This annotation work is all done by a human Australian registered nurse, where we yield that . According to the sequence labeling result above, we have and , thus . According to the parameters calculated above, and the formula for human labor cost rate and return on investment (Equation 4),
| (4) |
Thus, we have which is an extremely small ROI rate. This means that the return for our additional annotation is small enough to be omitted. The estimated pay to the nurse for annotating the dataset is US, where the source of the 0.08 rate is mentioned in Section III-D. We further calculate that if we want the F-1 score for the model to increase 1%, we have to pay US. This is not a decent amount of human labor cost in terms of the increase of sequence labeling performance, thus we argue that the additional nursing-knowledge-based annotation in the task is costly, and researchers should not include this kind of additional work when processing their own datasets in medical NLP; instead, we encourage investigating more frugal approaches to use the human time where it is needed the most and developing better NLP workflows to harvest the potential of smaller annotated resources.
V Discussion
In this work, we researched into the dataset annotation process, which is vital for most of the machine learning and deep learning tasks. We specifically focused on the annotation granularity and related performance changes and human labor costs. First, we found that using only syntactic, semantic, and statistical annotation features of the text corpus with well-designed embeddings can yield a good performance in categories with a large amount of instances in the sequence labeling task. Second, we added knowledge-based annotations by an Australian registered nurse into consideration, and found that the text labeling performance remained nearly the same. This is the most surprising finding that is against people’s intuitive ideas. This means that adding specialized human knowledge — even carefully quality-controlled expert annotations — does not always yield a performance gain in sequence labeling tasks. Third, we formulated the cost of annotation in terms of human labor cost, and derived the conclusion that doing the manual annotation on clinical records is extremely costly in terms of the performance gain of the model. Future researchers in the clinical NLP should not — without careful consideration of the anticipated ROI — spend their time and money investing in dataset annotation in a more detailed granularity.
However, the work has limitations in the following aspects. First, the work is very specific in the field of medical NLP, and even specifically for the sequence labeling tasks in the field. Out of the strict attitude to this work, we point out that it cannot be guaranteed that the same conclusion regarding the relationship between classification result and human labor cost can be generalized to other fields of NLP, say, semantics parsing or social media analysis. Second, due to the black-box nature of deep learning, we cannot provide a solid explanation of why the detailed expert annotations cannot help the sequence tagger to perform better. However, we can try to control other variables, like try using more and less complex models to study the impact of the underlying embedding complexity and network architecture as future works.
One of the most important contributions of this work is the advice and guideline to the medical NLP researchers in the community. According to our work, we recommend that future researchers and practitioners emphasize the linguistic as opposed to medical knowledge as a cost-effective source for increasing the sequence labeling performance with additional expert-annotation in a specific field when designing, developing, and using expert-annotated human language technologies and related data resources. Although capturing medical knowledge is valuable, expert annotations of this kind are hard and costly to obtain and modify as NLP systems call for revisions and extensions [7, 9]. Hence, we advocate the community to focus more on the pure textual language features. This is because the extra gain from domain-specific knowledge may become marginal as a better textual language feature is extracted from general corpus, especially given the extremely high labor cost for domain-specific knowledge.
References
- [1] A. Akbik, D. Blythe, and R. Vollgraf, “Contextual string embeddings for sequence labeling,” in Proceedings of the 27th International Conference on Computational Linguistics, 2018, pp. 1638–1649.
- [2] A. Beattie, “How to calculate return on investment (roi),” Jun 2020. [Online]. Available: https://www.investopedia.com/articles/basics/10/guide-to-calculating-roi.asp
- [3] L. Bottou, “Une approche theorique de l’apprentissage connexionniste et applications a la reconnaissance de la parole,” Ph.D. dissertation, 1991.
- [4] S. contributors, “Pricing: Accelerate the development of your ai applications.” [Online]. Available: https://scale.com/pricing
- [5] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [6] C. Ee Kin, “Medium.” [Online]. Available: https://becominghuman.ai/my-solution-to-achieve-top-1-in-a-novel-data-science-nlp-competition-db8db2ee356a
- [7] E. Hovy and J. Lavid, “Towards a ’science’ of corpus annotation: A new methodological challenge for corpus linguistics,” International Journal of Translation Studies, vol. 22, pp. 13–36, 01 2010.
- [8] Z. Huang, W. Xu, and K. Yu, “Bidirectional lstm-crf models for sequence tagging,” arXiv preprint arXiv:1508.01991, 2015.
- [9] M. Johnson, P. Anderson, M. Dras, and M. Steedman, “Predicting accuracy on large datasets from smaller pilot data,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Melbourne, Australia: Association for Computational Linguistics, Jul. 2018, pp. 450–455. [Online]. Available: https://www.aclweb.org/anthology/P18-2072
- [10] K. Kreimeyer, M. Foster, A. Pandey, N. Arya, G. Halford, S. F. Jones, R. Forshee, M. Walderhaug, and T. Botsis, “Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review,” Journal of Biomedical Informatics, vol. 73, pp. 14 – 29, 2017. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1532046417301685
- [11] G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” arXiv preprint arXiv:1603.01360, 2016.
- [12] R. Mitkov, C. Orasan, and R. Evans, “The importance of annotated corpora for nlp: the cases of anaphora resolution and clause splitting,” in Proceedings of Corpora and NLP: Reflecting on Methodology Workshop. Citeseer, 1999, pp. 1–10.
- [13] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
- [14] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” arXiv preprint arXiv:1802.05365, 2018.
- [15] I. Spasic and G. Nenadic, “Clinical text data in machine learning: Systematic review,” JMIR Med Inform, vol. 8, no. 3, p. e17984, Mar 2020. [Online]. Available: http://medinform.jmir.org/2020/3/e17984/
- [16] H. Suominen, L. Zhou, L. Hanlen, and G. Ferraro, “Benchmarking clinical speech recognition and information extraction: new data, methods, and evaluations,” JMIR medical informatics, vol. 3, no. 2, p. e19, 2015.