11email: trtikm@gmail.com
September 30, 2025
Anonymous On-line Communication Between Program Analyses
Abstract
We propose a light-weight client-server model of communication between existing implementations of different program analyses. The communication is on-line and anonymous which means that all analyses simultaneously analyse the same program and an analysis does not know what other analyses participate in the communication. The anonymity and model’s strong emphasis on independence of analyses allow to preserve almost everything in existing implementations. An analysis only has to add an implementation of a proposed communication protocol, determine places in its code where information from others would help, and then check whether there is no communication scenario, which would corrupt its result. We demonstrate functionality and effectiveness of the proposed communication model in a detailed case study with three analyses: two abstract interpreters and the classic symbolic execution. Results of the evaluation on SV-COMP benchmarks show impressive improvements in computed invariants and increased counts of successfully analysed benchmarks.
Keywords:
Communication, program analysis, anonymous, online, Apron, Box, Polka, Symbolic execution.1 Introduction
Our experience with several program analysis tools suggests that a piece of information provided to an analysis at a right place may (substantially) improve its result. Although it is usually not difficult to identify such places (e.g. evaluation of highly over-approximated program operators, like bit-operators, pointer arithmetic, etc.) a problem is where to get the information. The additional information may be known to another program analysis.
We propose a light-weight communication model allowing a program analysis to issue a query to other analyses (analysing the same program in the same time) for an additional information which might hopefully push it towards to a better result. The communication is in the style client-server. The server mediates the communication between individual analyses (clients). Each client performs his work on his own private data (like internal program representation, memory model, etc.). Nevertheless, the communication itself has to be performed in term all clients understand. Client’s query thus typically begins with a conversion of his internal data to common terms, and it ends by the opposite conversion.
The proposed communication model is based on the following key features which together distinguishes our work from previous approaches in the field:
-
•
Independence of clients: Each client implements his communication protocol without consideration of other clients. This implies that in order to add a new client into the communication, implementations of all former clients remain exactly the same, i.e. no line of code has to be changed, added, or removed. Also, if we have clients with their communication code already established, then code of no client has to be changed in order to run any of their possible combinations.
-
•
Asynchronous execution of clients: The communication model casts no requirements for synchronization of computational steps of clients. It means that some clients may perform forward analysis, other backward, and even speed in which different clients explore their internal program representations may differ.
-
•
Reuse of current implementations: The model attempts to preserve both algorithms and related data structures of analyses which clients perform. So, there is no need for their re-implementations. A client only has to add an implementation of the communication protocol, determine places in its code where to use information from others, and check that there is no communication scenario which would corrupt his results.
An important part of the paper is also the case study, which represents the first instance of the proposed communication model. There are three clients in the case study. Two of them perform “intervals” and “polyhedrons” abstract interpretations [7] and the third is the classic symbolic execution [16]. The description of the case study in this paper serves as a detailed example. It is meant to be used as guide for building other instances of the model. The evaluation of the case study was performed on SV-COMP [26] benchmarks for five combinations of clients. Results of individual combination were compared per client in terms of strengthened invariants (for abstract interpreters) and impact of the communication on success/fail termination states (for all clients). Although results of individual configurations are quite impressive for themselves, we further observed that each configuration can actually bring as not negligible improvements over others. This opens a new (originally unexpected) application of the approach: Given clients and a program to be analysed, we build as many combinations from all as possible (we are only limited by resources, like number of computers, threads, time, etc.) and we analyse the program for each of them. Then we merge all results.
We explain the communication model in Sec. 2. We first describe common terms in which the communication is performed and then we present communication protocols for clients and the server. The case study is presented in Sec. 3. It starts with a description of all three clients and the rest is dedicated to a detailed evaluation.
2 Communication model
A client is a program analysis tool or a program analysis inside a tool which is able to communicate with other clients during analysis of a given program. A server is a program utility mediating the communication between clients. A client can only communicate with the server and has no information about other clients, except their count. Data exchanged between the server and a client are received in exactly the same order as they are sent. There is a time-out for whole the communication common to all clients and the server. There is a single program analysed by all clients.
Given a program written in a certain programming language, a concrete program state is an element of the concrete semantics of the language, an abstract state space is any subset of a client’s interpretation (e.g. abstraction or generalisation) of the semantics of the language, and an abstract program state is an element of an abstract state space.
Let us suppose a client receives an information from other clients (via the server) that “at address 1234 there is stored an integer greater than zero”. This information is useless for the client until it is coupled with the following:
-
1.
An actual value of the instruction counter.
-
2.
A set of program paths (from the program’s entry to the actual instruction counter) for which the information was inferred.
-
3.
A meaning of the address 1234 in order to map it into a particular address in client’s representation of program’s memory.
Points 1. and 2. are discussed in Sec. 2.1, the point 3. in Sec. 2.2, and a concrete structure of the received information in Sec. 2.3. The communication is described in Sec. 2.3 and 2.4 as client’s and server’s communication protocols.
2.1 Canonical program
Given a program written in a certain programming language, a canonical program is a model of program’s instruction counter designed and used by clients for purposes of their communication. Before start of the communication each client must have his copy of the canonical program.
There is a program representation which is very popular among clients: a control-flow graph. We present a “default” recipe how clients may build a canonical program from a control-flow graph of an elected client. Clients may later separate the resulting implementation into a stand-alone utility program.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
We assume in the recipe that the input control-flow graph satisfies the following properties (which might require some pre- and/or post-processes of a raw control-flow graph produced by the client):
-
•
The instruction counter is modeled by nodes and edges represent possible transitions of the counter during execution of the program.
-
•
Each sub-program is represented by a separate component with a single entry node and a single exit node.
-
•
The control-flow graph is coupled with a set of all edges representing calls of sub-programs. Let us denote it “set of calls”.
-
•
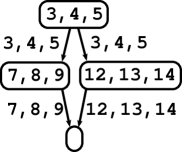
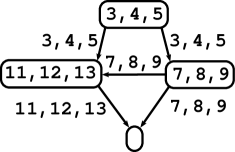
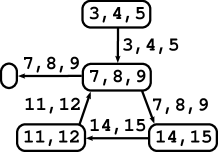
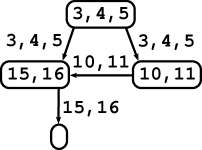
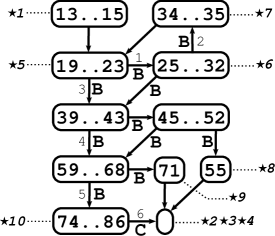
The control-flow graph was constructed on a syntactically reshaped version of the original program, where each lexical token was put into a separate line. For C programs there are tools available for this functionality including computation of the back-mapping of lines to the original program [22, 23]. This reshaping is used to achieve one-to-one mapping between program lines and indices of lexical tokens (since these indices may not be directly available to a client). In Fig. 1 (a) there are five C samples with tokens indexed. In the reshaped program these indices are equal to program lines.
-
•
The control-flow graph is coupled with a “back-mapping” to the reshaped source code of the analysed program, which maps each edge to a set of all those program lines (i.e. lexical tokens) s.t. an effect of the code at those lines is associated with the edge. It does not imply that index of every program’s token must appear in the range of the back-mapping. Typically, indices of tokens whose purpose is captured by the shape of the control-flow graph (e.g. semicolons, some brackets, keywords like if, else, for, etc.) must not appear in the back-mapping. Such conventions are dependent on agreement of clients. We require the back-mapping has the following property: If two edges have non-empty intersection of their sets of lines, then the edges have the same head node. Back-mappings for all 5 samples of Fig. 1 (a) are depicted in Fig. 1 (b)-(f) as labels of edges. Please, ignore labels of nodes. A code associated with an edge may consist of one or more statements (e.g. a sequence of assignments, whole if-then-else statement, or even several loops). This level of details is given by the input control-flow graph. Of course, more detailed control-flow graphs are preferable. For sample 1 we present at Fig. 1 (b) a detailed version (left) and a coarse one (right).
The recipe proceeds in the following three steps:
-
1.
Discard all labels of all nodes and edges of the control-flow graph.
-
2.
Label each edge in the set of calls as call edge and label each edge with an out-degree greater then 1 as branching edge.
-
3.
Label each node by a set of indices of program’s lexical tokens. We compute node’s label as the union of values of the back-mapping function for each out-edge from the node.
Observe that labels of exit nodes of all sub-programs are necessarily empty. Now we can define meaning of a node of a canonical program:
A statement that the instruction counter is at a certain node of a canonical program means that the instruction counter is at the position in the source code s.t. all lines of an instruction to be executed next belong to the label of the node.
Canonical programs for all five samples of Fig. 1 (a) are depicted in Fig. 1 (b)-(f) (please ignore labels of edges; labels of branching edges are omitted).
In the remainder of the paper we use the term node as a representation of a concrete value of the instructions counter in a canonical program. Similarly, we use the term edge for a possible transition of the counter between nodes. Finally, we distinguish two kinds of edges: call and branching, with obvious meanings.
2.1.1 Mapping between canonical and internal program representation
Another important purpose of labels of canonical program’s nodes is to allow individual clients to build a mapping between nodes of the canonical program and their own internal program representations (on which analyses are actually performed). A construction of such mapping requires that all clients build their internal program representations from the reshaped program instead of the original one. Not all nodes of the canonical program has to appear in the mapping. Nevertheless, a client should attempt to establish the mapping for as much nodes as possible, since he may issue communication queries (or provide a useful information to others) only at nodes with the mapping.
Since labels of nodes of a canonical program partition all tokens of the program (possibly expect some auxiliary tokens as mentioned above), clients may store only incomplete information about program lines in their internal program representations. This information may differ from client to client. For example, given a C statement a=0; one client may identify it only by the line of its first token, i.e. the line of a, another by the line of the last token, i.e. of 0 (or even of ;), and another by the line of the root operator, i.e. of =. Moreover, client may perform several equivalent program transformations, e.g. code optimisations. Consider for example a client which first translates a C program to LLVM assembly with several optimisations enabled, and then he builds his internal program representation from the optimised assembly. Such transformation typically reduce information about program lines.
It is very difficult (or impossible) to provide a general algorithm for construction of such mapping, since internal program representation of a client may be arbitrary. Here we provide a “default” recipe for construction of the mapping for clients whose internal program representation has a form of a control-flow graph in which nodes model the instruction counter:
Let be an edge of an internal program representation s.t. there is a source code line associated with the edge, and let be a node of the canonical program containing the line in its label. We extend the mapping in any of the following three cases:
-
1.
If in-degrees of both and are zeros, then link with .
-
2.
If is an exit node and has a successor with the empty label and with the out-degree 0, then link with the successor of .
-
3.
If all successor edges of have lines associated and all the lines belong to the label of a single successors node of the node and , then link with .
(a)
 (b)
(c)
(b)
(c)
We demonstrate an application of the recipe in an example depicted in Fig. 2.1.1.
2.1.2 Context
A filter is a set of kinds of edges of a canonical program (remember that we distinguish only two kinds of edges in this presentation). A context is a list of edges of a canonical program s.t. each edge has a kind which belongs to a given filter. For example, any context constructed for the filter may contain only call edges.
A context constructed for a certain filter represents a set of program paths starting at the program’s entry node. A path belongs to the set if and only if the context is equal to a list of edges constructed from the path s.t. each edge with a kind belonging to the filter is preserved and any other is removed.
A context coupled with a node represents the set of its paths restricted to those terminating at the node.
We demonstrate of a meaning of a pair “node,context” on example canonical program in Fig 2.1.1 (b) constructed for the C function in Fig 2.1.1 (a). We consider several contexts coupled with the same node labeled by {13..15}. We list the contexts in the following table together with their creation filters and with description of set of paths they represent:
| Context | Filter | Descritption |
|---|---|---|
| All paths reaching the node. | ||
| {call} | All possible paths to the node performing 4 recursive calls btree_contains74. | |
| {call, branching} | The path looping twice in the while17 loop, then taking false branches of both if37 and if57 (without evaluation of ==51) and then applying the recusrice call btree_contains74. |
Since client’s mapping between a canonical program and an internal program representation may be only partial, it may be impossible for the client to create some contexts. For example, if the tail node of some branching edge is not mapped, then the client cannot create a context for a filter with branching edges kind representing program paths passing only through that edge. Therefore, properties of client’s analysis (like call-sensitivity or path-sensitivity) may not always be reflected in the communication through contexts due to incompleteness of the mapping.
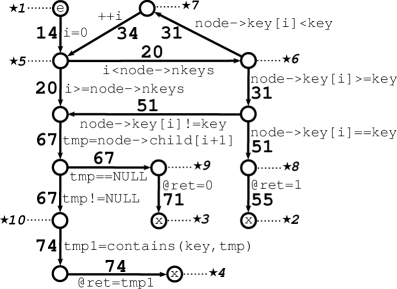
Let us return back to the example above. Now we try to translate the node (labeled by {13..15}) and all three contexts in the table to the internal program representation in Fig. 2.1.1 (c). The link allow as to move from the node of the canonical program to the corresponding node in the internal program representation. In this case we move to the entry node. Note that in case there is no link for the node then we could not continue with the example.
The first context can be translated without any loss of accuracy, i.e. the set of path represented by the context does not have to be extended. The reason is simple, the context represents all paths from the programs entry up to our translated entry node (including any number of recursive calls, etc.).
The second context can also be translated without a loss of accuracy. That is because links and uniquely map the edge 6 to the path consisting of two edges associated the line 74 and just one of then is the call edge. The call site is thus uniquely identified.
The third context contains edges, namely 3, 4, and 5, which cannot be translated to the internal program representation, since we do not have links for tail nodes of the edges 3 and 4. So, we have to reduce the context into . Now we can translate all edges: Edges 1 and 2 of the loop translate to edges with lines 20 and 31 in the corresponding loop (we used links , , and for the translation), and the edge 6 is translated the same way as for the second context. In terms of the canonical program (Fig. 2.1.1 (b)) the reduced context extend the set of paths over the original one (as described in the table) by those paths which go through the node labeled by {45..52}. Nevertheless, if we look into the internal program representation (Fig. 2.1.1 (c)), then both the original and the reduced context represent the same set of paths, because of the optimised shape of the program representation. Namely, there is only one possible path from the loop (left along the edge with the line 20) to the call site. Therefore, a reduction of a context does not necessary implied a loss of precision.
Now we look at the opposite direction. We consider the following path in the internal program representation expressed in term of lines labeling edges: [14,20,31,34,20,31,34,20,67,67,74]. We now translate this path to the canonical program in a form of a context constructed for a filter the filter {call, branching}. The edge 14 can be translated to the canonical program, since we have links and . Nevertheless, the corresponding edge is neither call nor branching edge in the canonical program. So, we skip it. Edges 20 and 31 can be translated to branching edges 1 and 2 respectively. We further skip both edges 34 for the same reason as for the edge 14. Next, the edge 20 and both edges 67 cannot be mapped because of lack of links between nodes. And the call edge 74 can be mapped to the call edge 6. Therefore, we end up with the context . This is the reduced context we discussed above. Observe that we were unable to reconstruct the more precise context due to lack of mapping between nodes.
Finally, observe that the exit node of the canonical program is mapped to three exit nodes of the internal program representation. So, if we want to translate a pair “the exit node, context” to the internal program representation, then we may get three translated pairs “node,context′”, “node,context′”, and “node,context′”, which are supposed to be considered together (as union).
Now we define a special form of context reduction using a filter. Given a context and a filter, a reduced context by the filter is constructed from the given context s.t. each edge whose kind does not belong to the intersection of the filter and the construction filter of the context is removed.
Multi-threading
Different threads may be distinguished through a context: A construct which causes a creation of a new thread can be modeled in a canonical program by an artificially introduced branching (e.g. by two parallel edges). Clients may decide to use special labels and filters for these edges. We do not introduce them, because they are not necessary in further presentation.
2.2 Canonical memory
Given a program written in a certain programming language, a canonical memory is a model of program’s memory designed and used by clients for purposes of their communication. Organisation of memory may differ significantly for different languages, consider for example C and Prolog. Here we provide a “default” canonical memory where we model only address space and dereferences of addresses (which is sufficient for purposes of communication). The model is thus very low-level.
Addressing of program’s memory is based on the common segment-offset style. Given a program and an ordered list of all its identifiers referencing memory111Using the terminology of C language: All those which may be used as l-values. a segment is any integer between 0 and the number of identifiers in the list. The segment 0 is reserved for modeling of the standard invalid memory, represented by the NULL pointer in some languages. Other segments represent indices of identifiers in the list. We recommend to order identifiers in the list according to their token-indices (each identifier is also a lexical token), since there can be several identifiers with the same name. An offset is any non-negative integer.
A sequence of bytes starting at a given segment and offset can have any of the following type interpretations:
| i8, i16, i32, i64 | A signed 8,16,32,64-bit integer. |
|---|---|
| u8, u16, u32, u64 | An unsigned 8,16,32,64-bit integer. |
| f32, f64 | A 32,64-bit floating point number. |
| seg, off | A representation of addresses (pointers). |
A concrete encoding of these types is given either by the program’s deployment machine, or on a mutual agreement of clients. seg and off should be encoded as unsigned integers big enough to capture available address space. Data of composed types can be communicated with other clients only after their decomposition to elements of basic types above.
A dereference is a triple consisting of a segment expression, an offset expression, and a type. A segment expression is either a segment, or a dereference of the type seg. An offset expression is any integer expression over integer constants, interpreted functions for addition, multiplication, etc., and over dereferences of either any integer type or the type off. A dereference represents a type-interpreted values of bytes pointed to by its segment and offset expressions. A dereference is called basic if neither segment nor offset expression contains any dereference.
A value in the memory referenced by a program identifier is directly denoted by a basic dereference. A value stored in a non-leaked memory in the program’s heap can always be referenced by a finite sequence of dereferences starting with a certain program identifier. The sequence can always be expressed by nesting of dereferences inside segment and offset expressions of a non-basic dereference. Memory of a record on the top of the program’s call stack is directly read by basic dereferences. Memory of the records deeper in the stack is accessed via non-basic dereferences exactly the same way as the memory in the program’s heap.
|
||||||||||||||||||||
|
||||||||||||||||||||
| (c) |
Note that threads do not have to be considered here, since they may be distinguished through a context (see page 2.1.2). In Fig. 3 there is an example how a canonical memory is used.
2.3 Client’s side of the communication protocol
Client’s communication protocol is a specification of six functions. A client
has to implement each of them. The specifications are the following:
get_values(node,context,dereferences,self_call) -> formula
A client is queried for a superset of all concrete program states represented by all his abstract states related to the node and the context. In other words, the client is queries for an over-approximation of his current knowledge about program’s behaviour regarding the node and the context.
The passed dereferences can be used to determine what superset will be computed. Typically, knowledge in the abstract states about memory addressed by no dereference in dereferences is ignored. For example, let us suppose that program variables a and b are presented by basic dereferences (, , i32) and (, , i32) respectively, and . Then the client may ignore his knowledge about (, , i32) when computing an answer to the query. On the other hand, if client’s knowledge about a is expressed in a form of a constraint over several variables, like , then (, , i32) can be considered for the answer as well.
The superset is then encoded as a quantifier-free first order logic formula over dereferences in a standard format all client agreed on, e.g. SMT-LIB2 [25]. Any such formula may only contain interpreted symbols from theories of integers, Peano’s arithmetic, and reals. The only uninterpreted symbols are related to dereferences: A dereference with a segment expression , an offset expression , and a type is encoded as an application of a binary uninterpreted function to arguments and . It is not necessary to provide declarations of these uninterpreted functions, since all clients know their exact meanings. Returning back to the example above, client’s answer in SMT-LIB2 format may look like this: (< (+ (+ (DEREF_i32 2 0) (* 2 (DEREF_i32 3 0))) (- 6)) 0).
It is further highly recommended for clients to agree on additional syntactical restrictions for formulae. They should not restrict expressivity, they should ease decoding of answers. Clients may for example consider these: The formula is in DNF, right hand side of any (in)equality is always a numeric constant, distributive laws are applied where possible, constant expressions are simplified, no use of binary subtractions, etc. The last tree restrictions were applied in the example above.
If the client does not have established the mapping for the passed node, then he returns a simple tautology, e.g. (= 1 1).
The argument self_call is true if the client is the one who
initiated the query. Otherwise it is false.
get_coverage(node,context) -> coverage
A client is supposed to compute a real number between 0 and 1. This number represents a measure, how much the current client’s abstract state space covers the set of all concrete program states determined by the node and the context. The value 0 means that the client covers no concrete state and the value 1 means that all concrete states are covered. Values in-between 0 and 1 can be computed from a progress observed in the abstract state space from the start of the analysis up to the current time point. We provide more details in Sec. 2.7.
The client returns 0, if he does not have established the mapping for the passed
node.
is_relevant_coverage(node,context,coverage,self_coverage) -> bool
A client is asked whether coverage computed by some other client is big enough so that this client would accept result of a call to the function get_values of the other client. Clearly, the client returns false whenever coverage is 0. The argument self_coverage is the result of the function get_coverage of this client. This values may be useful for the client to make the decision. We provide more details to the decision in Sec. 2.7.
The client returns false, if he does not have established the mapping
for the passed node.
is_memory_over_approximated() -> bool
A client is supposed to return false if any of the following cases:
-
1.
The client has updated an abstract state but he has not send a notification on_location_outdated to the server about the update yet.
-
2.
Client’s function can_improve_memory_over_approximation returns true.
Otherwise, the client returns true. Observe that the function may
return true even though client’s abstract state space currently does
not expresses all possible behaviour of the analysed program. This may happen
when client’s computation used values from other clients (via
get_values) for coverages less then 1.
can_improve_memory_over_approximation() -> bool
A client returns true if he sees a chance in making a progress
towards expressing all possible behaviour of the analysed program. Otherwise, he
returns false. Note that the answer true does not imply the
client will necessarily ever do such a progress.
on_location_outdated(node,context,coverage,self_call) -> none
A client is notified through this function that abstract state space of some client has been updated. The node and the context provide a closer description what set of concrete program states the update was relevant for.
The argument coverage is the result of the function get_coverage of the client who issued this notification on the updated version of his abstract state space. The argument self_call is true if the client is the one who issued the query. Otherwise it is false.
If the client does not have established the mapping for the passed
node, he should perform a graph search in the canonical program to find
all nearest reachable nodes with mappings and apply the notification for each of
them. Note that the context has to be extended/reduced for each node
separately using client filter by considering all paths between the passed and
the searched node.
A passed context to some of the protocol functions may contain edges whose nodes do not appear in the mapping between the canonical program and client’s internal program representation. Such edges has to be removed. This removal may produce a context representing a larger set of program paths. Nevertheless, clients computation in protocol functions must be based on such larger contexts.
All protocol functions above are supposed to terminate quickly. We cannot give exact complexities, but each of them should terminate (much) sooner than client’s algorithm which transforms an abstract state along a program’s edge.
If an evaluation of any function above does not finish before the time-out, then the client may cancel its evaluation without sending any response to the server. Also, any queries from the server issued after the time-out may be ignored.
A client may assume correctness of data received from other clients in individual queries. He may also assume other clients meet all requirements given in this section. And he may further assume the server meets all requirements given in the section below. But he cannot make any other assumptions about the communication. It means that based on the mentioned assumptions he has to check by himself for the correctness of implementations of his communication related code in isolation from others by considering all possible scenarios how the communication may affects his results and performance.
2.4 Server’s side of the communication protocol
Server’s communication protocol is a specification of four functions. A server
has to implement each of them. The specifications are the following:
get_values(node,context,trace,dereferences,client) -> formula
A client client calls this function in order to receive a knowledge about memory content from all clients. The server handles the query as follows:
1 formula := client.get_values(node,context,dereferences,true) 2 cov0 := client.get_coverage(node,context) 3 for every other client C do 4 cov := C.get_coverage(node,context) 5 if client.is_relevant_coverage(node,context,cov,cov0)) then 6 F := C.get_values(node,context,dereferences,false) 8 formula := make_conjunction(formula,F) 9 return formula
The use of conjunction as the connective between formulae has the meaning of
intersection of sets of concrete program states represented by the formulae.
is_memory_over_approximated() -> bool
A client calls this function in order to check whether abstract state spaces of
all clients caver all possible behaviour of the analysed program. The server
handles the query by invoking functions is_memory_over_approximated
of all clients and returns true if all the clients respond by
true and no on_location_outdated query is being evaluated
during evaluation of this query. Otherwise, false is returned.
can_improve_memory_over_approximation() -> bool
A client calls this function in order to check whether at least one client can
hopefully get his abstract state spaces closer to complete coverage of all possible
behaviour of the analysed program. The server handles the query by invoking
functions can_improve_memory_over_approximation of all clients and
returns true if at least one client respond by true.
Otherwise, false is returned.
on_location_outdated(node,context,coverage,client) -> none
A client has to calls this function in order to notify others about the fact
that his abstract state space has been updated. The passed client is
the one who issues the notification. The node and the context
provide a closer description what set of concrete program states the update is
relevant for. The server is responsible for delivering the notification to all
clients. So, the server invokes functions on_location_outdated of all
clients with the last argument true in case of the client and
with false for all other clients.
A client may call any of these function any time before the time-out. If an evaluation of a query does not finish before the time-out the server may cancel the evaluation without any response to any client. Also, queries issued after the time-out may be ignored by the server.
2.5 Issuing get_values for highly over-approximated operators
Although it is completely up to a client to decide where and when to issue get_values queries, there is rather general scenario for recommended application of such queries: It is quite common that a client highly over-approximates effects of some language operators. Consider for example C language and bit-operators (like conjunction, negation, etc.), pointer arithmetic, or some math functions (like sqrt, pow, sin, etc.). The client may take advantage of the communication to improve the precision. We demonstrate this on a the following simple example.
Let us consider a client who does not support pointers and who is about to execute a C assignment i=*p, where i and p have types int and int* respectively. Although the client cannot evaluate the sub-expression p (since it is a pointer), he can issue a query to other clients. Let us say the answer is (and (= (DEREF_seg 2 0) 3) (= (DEREF_off 2 0) 4)), where we assume that p is mapped to the segment 2. If the basic dereference (, , i32) corresponds to a program variable, j say, than the client may evaluate the assignment as it was i=j. Otherwise, the client may issue another query for the dereference (, , i32). A received answer represents (an over-approximation of) an i32 value to be assigned to i.
2.6 Decoding answers from get_values can loose precision
A formula returned from a get_values query may encode an information whose precision is beyond expressivity of client’s abstract state space. In any such case a lose of precision is inevitable. Another source of the lose can lie in an incomplete implementation of client’s decoding procedure. Indeed, a returned formula can be arbitrarily complex. A useful information may be encoded in several transitively dependent constraints. Client’s decoding procedure may simply ignore them. It is worth noting that a complete implementation of the decoding may lead to a non-trivial programming effort.
We show this on the example from the previous sub-section, where we suppose the client performs the classic interval analysis and we consider the situation when the client receives an answer for the second query, i.e. for the dereference (, , i32). Possible answers for the query may look like these:
-
•
(= (DEREF_i32 3 4) 3)
-
•
(and (< (- (DEREF_i32 3 4)) (- 3)) (< (DEREF_i32 3 4) 10))
-
•
(or (< (DEREF_i32 3 4) 3) (= (DEREF_i32 3 4) 10))
-
•
(= (+ (* 2 (DEREF_i32 3 4)) (DEREF_i32 4 0)) 10)
Although all of these formulae can be converted to intervals, the client may decide to restrict implementation of his decoding procedure to first two formulae, since decoding of others would lead to a loss of precision anyway. Therefore, the last two formulae are decoded as they are tautologies (i.e. any possible value).
2.7 Coverage oracle
Client’s protocol functions get_coverage and is_relevant_coverage require an estimation of how many concrete program states are represented by client’s current abstract state space.
The estimation can be based on observation of progress of client’s abstract state space from the beginning of the analysis up to the current time. For a given node and context the client may for example observe changes in counts of abstract states, sizes of abstract states, or counts of updates of abstract states in time. In order to compute an estimate, the client needs to compare these “progress properties” with similar ones in client’s knowledge base. We can build a knowledge base for a client s.t. we run the client in isolation (i.e. without any communication) on a sufficiently large training set of benchmarks. For each benchmark the client observes a progress of his progress properties. Then we relate properties of analysed benchmarks (like number of tokens, number of loops, recursive functions, pointer dereferences, etc.) with functions from analysis time (scaled into the interval ) to the corresponding values of progress properties. In order to use the knowledge base the client need three functions. A distance function between program properties, a distance function between progress properties, and a “progress” function which for a given program properties and a passed (and scaled) analysis time finds a closed progress properties in the knowledge base.
For get_coverage the client should extend the knowledge base s.t. progress properties are annotated by numbers between 0 and 1 representing coverages. This is possible, since the client has a complete information for each benchmark. The estimate (i.e. the resulting coverage) then corresponds to annotation of the closest progress properties in the knowledge base to the current ones.
In case of is_relevant_coverage the client uses his progress function to find a time for which the function returns closest properties to the current ones. The client tweaks the protocol function according to the time he found subtracted by the current time (scaled to ) in a way: bigger the result, higher coverages are accepted. The tweaking can ideally be sensitive to a passed node and context.
2.8 Safety outdate
There are situations which cannot be resolved only by functions get_coverage and is_relevant_coverage. Let us consider a client whose goal is to compute an over-approximation of program’s behaviour and there is a part of his abstract state space (for some node and context) whose abstract states were computed from an information of other clients with coverages less than 1. The client cannot be satisfied with these states, if server’s query is_memory_over_approximated returns false. It may happen the query remain false till the time-out. It may also happen that the client does not receive notifications on_location_outdated for that part of his abstract state space.
In order to succeed in the computation of an over-approximation the client may force a re-computation of that part of the state space in sufficiently long time before the time-out. To prevent repetition of this situation in the subsequent computation the client may tweak his is_relevant_coverage function s.t. for the node and context of the problematic part of the state space only coverages 1 are accepted.
3 Case Study: Box, Polka, Symbolic execution
In this case study we attempt to experimentally evaluate how much clients may ideally improve their results due to the communication. We thus investigate the limit case, where client are offered a maximal opportunities for the communication: communication at each node, no overhead of message delivery, etc.
We embedded three clients called Box, Polka, and Symbolic execution into a single tool [24]. The tool itself stands for the server. Clients are separate and completely independent modules in the tool, they can communicate only with the server through his protocol functions. The tool builds a single read-only internal program representation, which is referenced by all clients. The internal program representation simultaneously serves as a canonical program. Clients may thus communicate at each node. Since all clients run on a single main thread, they perform their computations in small regularly interleaved steps. A step corresponds to an update of an abstract state space by taking one or more edges which all always share either head or tail node. A client determines by himself, i.e. independently to other clients, which edges he will take in what computation step. A client may issue communication queries to the server only during his step. Responses from other clients are also computed and returned in that step. This process is purely sequential.
3.1 Clients: Box and Polka
These two clients have many things in common. First of all, implementations of their communication-related code is very similar. Also, they represent two instances of the abstract interpretation framework [7]. While Box uses intervals to represent a memory content, Polka uses polyhedrons. Moreover, both are implemented in the same library called Apron [21]. Therefore, we join their description here, but all differences are explicitly stated.
Both clients are integrated into the tool in the default setting: Join operators are applied at each node with an in-degree greater then 1, widening operators are applied at each loop head and function entry node (because of recursion), and all heap allocations performed along the same edge are indistinguishable for the same context. Both clients perform call-sensitive analysis, and they construct contexts for filters consisting of call edges kind.
Both clients issue queries to the server in same situations. Whenever a part of an abstract state space is updated the query on_location_outdated is issued. The query get_values is issued in two situations during a computational step of a client, when a source abstract state is supposed to be transformed along a program edge. First, instead of taking the source abstract state directly from the abstract state space there is used a result of get_values (after its translation to an abstract state). Second, during evaluation of a program expression associated with the edge: When the client does not have enough information for an evaluation of some sub-expression (e.g. a pointer dereference), then the client asks other (e.g. for possible values of the pointer) and continues the evaluation with that information.
In the following subsections we discuss those modules of these clients, which are related to the communication.
3.1.1 Coverage oracle
This module records statistical data about a progress of client’s abstract state space and it plays an important role in the implementation of the protocol function get_coverage.
The oracle maintains a map from nodes and contexts to ordinal numbers of client’s computational steps in which the corresponding parts of the abstract state space were updated for the last.
Given a node, a context, and a count of all passed computation steps (including the current one) the oracle computes the corresponding coverage as a number , where is an average of all values in the map mapped to by the context (and any node), and is the value in the map for the node and the context. The term was inferred experimentally.
3.1.2 Safety outdate
There are three actions which may be applied during the safety outdate:
-
1.
Tweaking of client’s function is_relevant_coverage s.t. it returns false for any coverage less then 1.
-
2.
Marking of all abstract states appearing in a list extended by the function on_location_outdated (see the description of the protocol function below) as to be recomputed.
-
3.
Marking of all abstract states in the current abstract state space to be recomputed.
Until the safety outdate is applied, it can be triggered in the following cases:
-
(a)
If server’s function is_memory_over_approximated returns true, then actions 1. and 2. are applied.
-
(b)
If server’s function can_improve_memory_over_approximation returns false, then actions 1. and 3. are applied.
-
(c)
Let be a number of communicating clients, be a number of nodes in the program, be the time point of the time-out in milliseconds, and be 250 for Box and 500 for Polka. If the current time point is greater or equal to , then actions 1. and 3. are applied. Both “” terms were adjusted experimentally.
3.1.3 Communication protocol
Box and Polka implement the mandatory functions of the protocol as follows:
get_values:
The function first collects all abstract states relevant to the passed node and a reduced context computed from the passed context and the client’s filter. An abstract state is a list of Apron’s linear constraints over dereferences (represented via strings in Apron). Each state is converted into a conjunction of predicates, where each predicate is a direct conversion of a constraint from Apron’s internal data structures. Subsequently, from each conjunction there are removed all predicates which are irrelevant to the passed set of dereferences. The function then returns a disjunction of the resulting conjunctions.
get_coverage:
For each abstract states relevant to the passed node and a reduced context computed from the passed context and the client’s filter it calls the coverage oracle with the node and the reduced context. When is a number of such states and is a value returned by the oracle for the -th state, then the function returns the value . The term was adjusted experimentally.
is_relevant_coverage:
If the safety outdate was already applied, then it returns true only if the passed coverage is equal to 1. Otherwise, there is computed a scale for the passed self-coverage. The scale is initialised to 1 and according to each property the of the passed node it is multiplied by coefficients in this table:
| Client | Loop head | Function entry | Return node | Join node |
|---|---|---|---|---|
| Box | 0.25 | 0.25 | 0.5 | 0.25 |
| Polka | 0.5 | 0.5 | 0.75 | 0.9 |
The values were adjusted experimentally. The function returns true only if the passed coverage is greater or equal to the self-coverage multiplied by the scale.
is_memory_over_approximated:
Returns true when a fixed-point is reached, i.e. when there is no abstract state (identified by a node and context) to be updated. Otherwise, it returns false.
can_improve_memory_over_approximation:
Returns a negated value from the function is_memory_over_approximated.
on_location_outdated:
If this is not the self-call and a call to the function is_relevant_coverage for the passed coverage returns false, then the function adds all abstract states corresponding to the passed node and context to a list of “states for safety outdate” and then terminates. Otherwise, it marking all abstract states corresponding the passed node and context for a re-computation.
3.1.4 Correctness
The client (Box or Polka) claims that program’s behaviour was successfully over-approximated only if his function is_memory_over_approximated return true and the safety outdate was applied.
After application of the safety outdate only values with coverage equal to 1 are accepted. If the safety outdate was triggered by the case (b) or (c), each abstract state was recomputed. Otherwise, the case (a) was triggered and so the server returned true from his function is_memory_over_approximated. The computation performed so far was thus based either on final memory over-approximations from other clients or on re-computed abstract states where the client rejected final values of others due to low coverages.
3.2 Client: Symbolic Execution
Symbolic execution [16] is similar to standard program execution. The key difference is that while the standard program execution runs the program on concrete input data (numbers), the symbolic execution runs the program on symbols. Each symbol represents a concrete, but yet unknown, input value. Executed program paths are recorded in a tree, where the root corresponds to the entry node and a leaf node either represents a termination of the execution or it belongs into the exploration frontier, i.e. it remains to compute its successors.
From the communication point of view it is important to mention that this technique attempts to explore all feasible program paths. This goal is achieved very rarely in practice, only for programs with finite and quite low number of such paths. Therefore, the technique primarily focuses on searching for defects and typically end up with an under-approximation of program’s behaviour.
The client is integrated into the tool in the default setting: There is fixed the breadth-first exploration strategy of feasible program paths, the variable storage-referencing problem is resolved by branching, there is only one SMT solver used for SAT queries, and there is no cache in front of the solver. The filter of the client consist of both call and branching kinds of edges.
In the following subsections we discuss only those modules of the client, which are related to the communication with others.
3.2.1 Coverage oracle
This module records statistical data about both a progress of client’s abstract state space and queries issued to the client. It serves as the key part in implementations of protocol functions get_values and get_coverage.
The main part of the oracle is a map from node and context to triples (formula, num_state_updates, num_formula_updates). The component formula is a formula over dereferences, num_state_updates is a counter of updates of the triple, and num_formula_updates counts number of updates of the formula. Each triple is initialised as (true,0,0).
The oracle is called at the end of each client’s step in order to reflect updates he made. Given a node and context related to some of client’s updates, the oracle performs the following three steps: First, he expresses all abstract states corresponding to the node and the context in a form of a formula over dereferences according to a process described in the next sub-section. Then, he searches in the map for a triple using the node and the context. Lastly, the triple is updated s.t. num_state_updates is incremented, and if the newly computed formula is not logically equal to formula in the triple, then formula is overwritten by the new one and the counter num_formula_updates is incremented. In the case the formula was updated in the triple whole the record is registered into a special queue, if it is not already there. The client extracts records of the queue regularly in each step with a delay 10s and issues the query on_location_outdated to the server. The delay prevents frequent notifications for nodes inside loops, where symbolic execution tends to cycle very quickly for long time.
The oracle is called from function of client’s communication protocol. These functions query the oracle fro triples stored in the map. For each such query, if the searched triple has num_state_updates equal to 0, then the oracle automatically performs its update according to the procedure above, before the triple is returned.
3.2.2 Building of response formula
Given a node, a context, and the filter of the client, the procedure first collects all abstract states attached to nodes of the client’s symbolic execution tree which are relevant to the given program node and a reduced context computed from the given context and the filter. Note that the client’s filter consists of both branching and call edge kinds, since symbolic execution is fully path and context sensitive. Also note that each collected abstract state consists of a mapping from dereferences to expressions over input symbols and a quantifier-free conjunction of predicates over input symbols.
For each abstract state there is constructed a formula, which is initialised as the conjunction of predicates of the state. Next, for each pair in the map of the state a new conjunct is added into the formula. This conjunct is an equality between the dereference and the expression of the pair. Then, each equality in the formula, which consists of a dereference and an input symbols, all occurrences of the symbol in the formula is replaced by the dereferences. Finally, each predicate in the formula which still contains any input symbol is removed from the formula.
From formulae we computed for each collected abstract state we now build a resulting formula. The formula is a conjunction of predicates which are common to all computed formulae (according to logical equality) and the strongest inequalities between dereferences and numerical constants deducible from all computed formulae. Although we attempt to find as many common predicates and inequalities as possible, we may early terminate the search in order to preserve performance of the whole query.
3.2.3 Communication protocol
The client implements the mandatory functions of the protocol as follows:
get_values:
The function queries the coverage oracle for a triple for the passed node and context and returns the component formula of the triple.
get_coverage:
If is_memory_over_approximated returns 1, the also this function returns 1. Otherwise, it queries the coverage oracle for a triple for the passed node and context. The function then returns a coverage value computed according to the following experimentally established term , where and stands for num_state_updates and num_formula_updates respectively.
is_relevant_coverage:
This function always returns false, since no information is taken from other clients. This client only provides information to others.
is_memory_over_approximated:
Returns true when the exploration frontier is empty and no state was force-terminated due to a failure. A majority of failures come from an SMT solver, which fails to decide satisfiability of a path condition of a program state. Another important sources are unsupported bit operators and presence of inline assembly.
can_improve_memory_over_approximation:
Returns true if the exploration frontier is not empty. Otherwise, returns false.
on_location_outdated:
This function does nothing, since this client does not take any information from others. The client only provides information.
3.2.4 Correctness
The client does not accept values from others.
3.3 Server: The tool
The server implements all his protocol functions (see section 2.4) in purely sequential manner. It means that clients are queried for responses one by one and when all responses are collected the result is returned back the the client initiating the query.
The server and all clients run of the same main thread and all queries from clients are issued also from that thread. It means that all queries are issued sequentially: A next query may be issues only after the previous one is completed.
3.4 Evaluation
We evaluated clients of the case study in five different configurations. Each configuration specifies what clients are used and whether they can communicate or not. We denote configurations using the following abbreviations: b*p*s, b+p+s, b+p, b+s, p+s. Symbols ‘b’, ‘p’, and ‘s’ stand for Box, Polka, and Symbolic execution respectively, and ‘+’ and ‘*’ stand for communication enabled and disabled respectively. For each configuration we assume that either all clients communicate with each other (the use of ‘+’) or none of them (the use of ‘*’).
We performed the evaluation on SV-COMP 2015 [26] benchmark suite, revision 571. The revision consists of 5861 benchmarks in 48 directories. In order to make the evaluation manageable for us, we put a requirement that whole the evaluation should finish within one week of continuous computation222The used a server: 32xIntel Xenon E5-2650 @ 2GHz, 64GB RAM, Debian 4.6.3.. Therefore, we picked 10 randomly chosen benchmarks from each directory (or less if there was not enough) and so we got 473 benchmarks in 48 directories, see Appendix 0.C. Since this was still not enough we set a time-out 2.5 minutes and a memory-out 512MB for each client in each configuration. It means, for example, that b+p had the time-out 5 minutes and the memory-out 1024MB, b*p*s had the time-out 7.5 minutes and the memory-out 1536MB, etc. Remember that clients share time (steps are interleaved) and memory (all run on a single thread) within a configuration, see page 3.
We compared results of each combination of configurations. The comparison was always done separately per client: given two configurations and a client appearing in both of them we only consider results of that client in both configurations for the comparison.
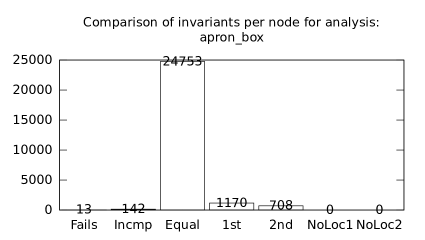
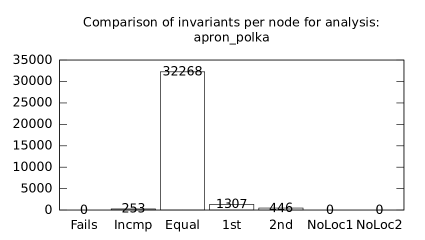
| Configuration | Comparison per node | Comparison per benchmark | |||||||||||
| 1st | 2nd | fail | neq | eq | 1st | 2nd | fail | neq | 1st | 2nd | 1st! | 2nd! | eq! |
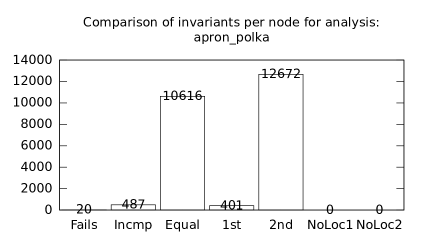
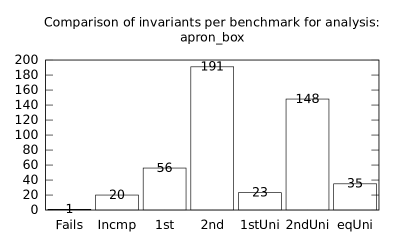
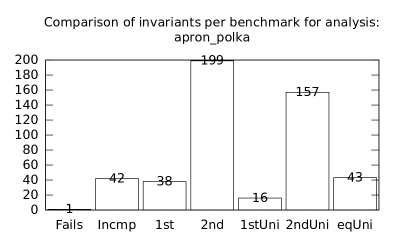
| b*p*s | b+p+s | 20 | 487 | 10616 | 401 | 12672 | 1 | 42 | 38 | 199 | 16 | 157 | 43 |
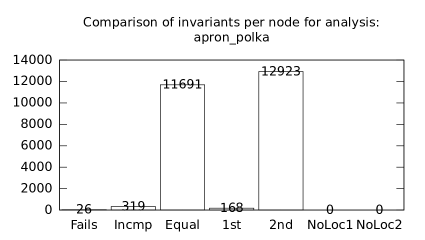
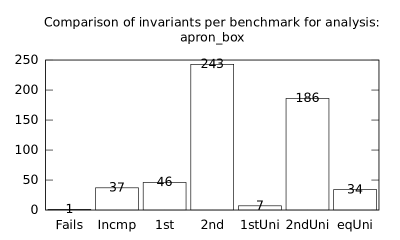
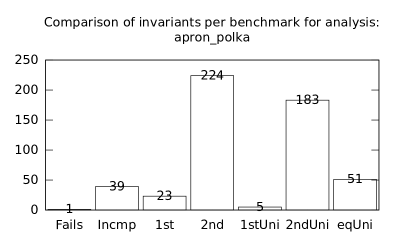
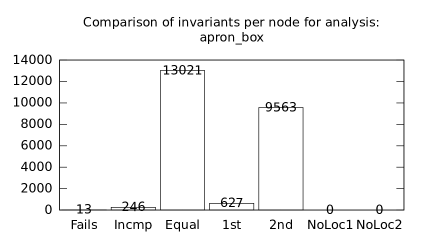
| b*p*s | b+p | 26 | 319 | 11691 | 168 | 12923 | 1 | 39 | 23 | 224 | 5 | 183 | 51 |
| b*p*s | p+s | 20 | 609 | 10689 | 455 | 12119 | 1 | 57 | 44 | 196 | 12 | 136 | 50 |
| b+p+s | b+p | 14 | 663 | 30462 | 2217 | 1489 | 1 | 29 | 93 | 87 | 50 | 53 | 137 |
| b+p+s | p+s | 0 | 253 | 32268 | 1307 | 446 | 0 | 19 | 74 | 40 | 53 | 24 | 182 |
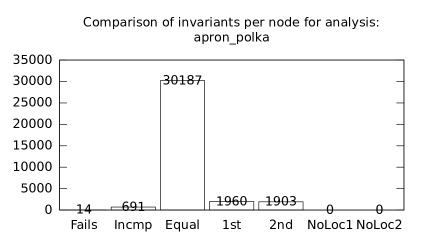
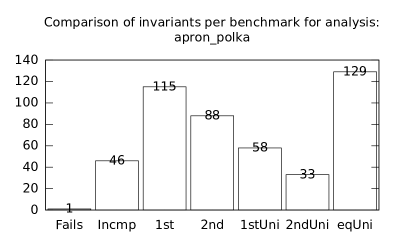
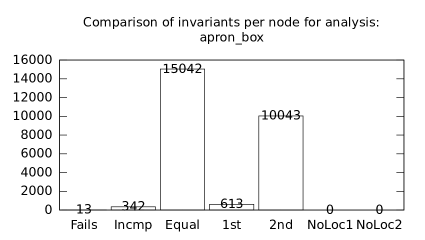
| b+p | p+s | 14 | 691 | 30187 | 1960 | 1903 | 1 | 46 | 115 | 88 | 58 | 33 | 129 |
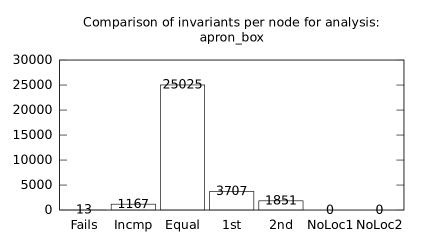
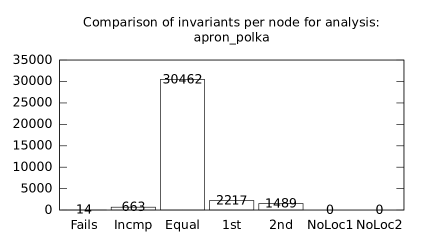
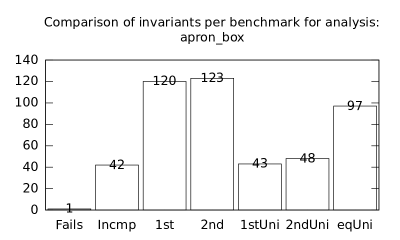
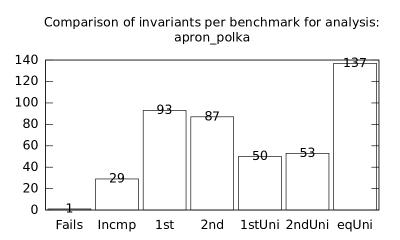
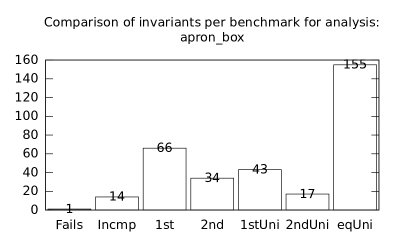
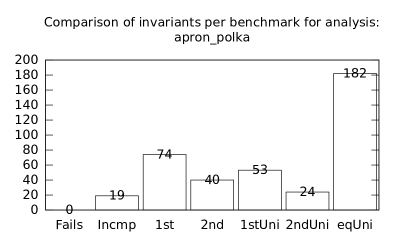
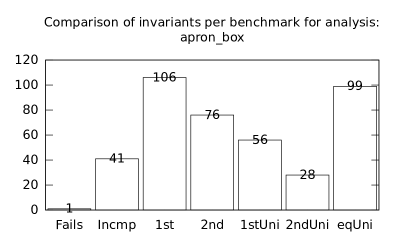
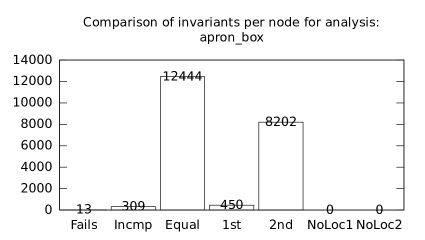
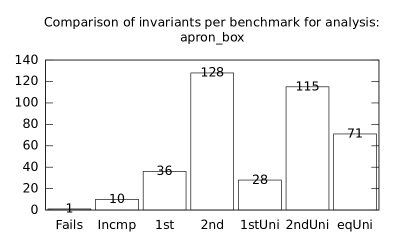
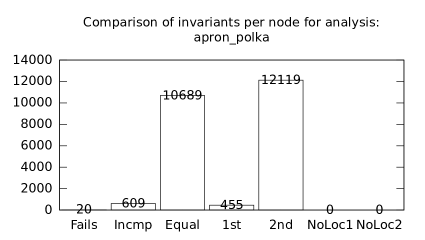
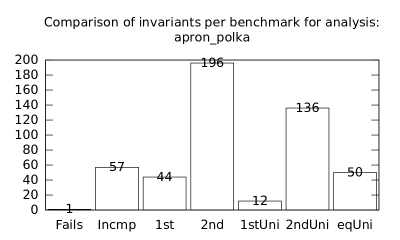
We focused on two kinds of measurements. First, we compared a precision of invariants computed by clients Box and Polka. Symbolic execution does not provide this kind of information. The clients attempt to compute for each node a strongest invariant over-approximating all concrete states which can be seen at the node. We used Z3 [27] SMT solver to compare invariants. Results are presented in Fig. 2.1.1. The numbers for “Comparison per node” are summary counts of nodes of all considered benchmarks together. And the numbers for “Comparison per benchmark” are simply counts of considered benchmarks. Note that for each client there were only considered those benchmarks for which the client terminated with the state “Success” in both compared configurations.
We can observe the following facts in data in Fig. 2.1.1:
-
•
Each configuration may bring us improvements over others: We can clearly see this phenomena for all pairs of configurations in both kinds of comparisons in tables of both clients. We can thus expect that for any chosen combination of clients we get some new results in terms of strengthened invariants.
-
•
There is no configuration strictly dominating all others: We can only read patterns in the data, like:
-
–
A configurations with communicating clients gives us at least one order of magnitude more precise invariants than isolated clients.
-
–
More communicating clients, more strengthened invariants.
-
–
Count of incomparable invariants and lower count of strengthened invariants can be expected in the same order of magnitude.
-
–
More improved invariants typically yields more improved benchmarks, i.e. improvements are rather regularly distributed than highly concentrated in few benchmarks. Nevertheless, a degree of correlation is sensitive to kinds of clients appearing in configurations, cf. fourth and sixth rows for both Box and Polka.
Observations made for invariants can easily be adopted to very similar observations for benchmarks.
-
–
| Configuration | Success | Time-out | Memory-out | Crash | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd |
| b*p*s | b+p+s | 263 | 21 | 30 | 10 | 0 | 20 | 137 | 21 | 0 | 7 | 14 | 6 |
| b*p*s | b+p | 283 | 1 | 28 | 10 | 0 | 2 | 143 | 15 | 0 | 7 | 14 | 0 |
| b*p*s | p+s | 267 | 17 | 27 | 10 | 0 | 15 | 143 | 15 | 0 | 7 | 14 | 4 |
| b+p+s | b+p | 289 | 4 | 22 | 10 | 20 | 2 | 137 | 0 | 6 | 7 | 6 | 0 |
| b+p+s | p+s | 287 | 6 | 7 | 21 | 9 | 4 | 137 | 0 | 6 | 11 | 2 | 0 |
| b+p | p+s | 294 | 17 | 0 | 12 | 0 | 13 | 143 | 0 | 0 | 7 | 0 | 4 |
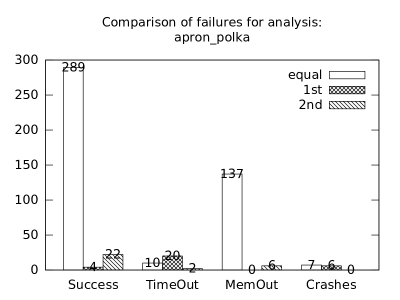
| Configuration | Success | Time-out | Memory-out | Crash | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd | eq | 1st | 2nd |
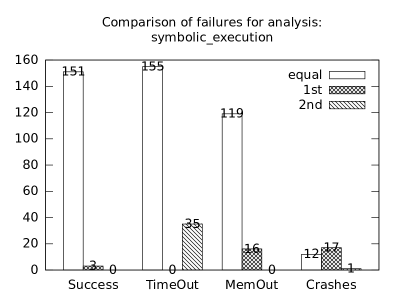
| b*p*s | b+p+s | 151 | 3 | 0 | 155 | 0 | 35 | 119 | 16 | 0 | 12 | 17 | 1 |
| b*p*s | b+s | 148 | 6 | 7 | 155 | 0 | 153 | 0 | 136 | 0 | 10 | 19 | 0 |
| b*p*s | p+s | 149 | 5 | 0 | 155 | 0 | 34 | 124 | 11 | 0 | 11 | 18 | 0 |
| b+p+s | b+s | 147 | 4 | 8 | 190 | 0 | 118 | 0 | 119 | 0 | 10 | 3 | 0 |
| b+p+s | p+s | 148 | 3 | 1 | 185 | 5 | 4 | 119 | 0 | 5 | 11 | 2 | 0 |
| b+s | p+s | 148 | 7 | 1 | 189 | 119 | 0 | 0 | 0 | 124 | 10 | 0 | 1 |
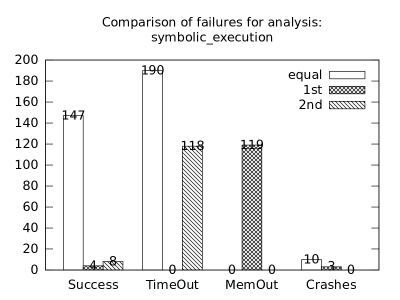
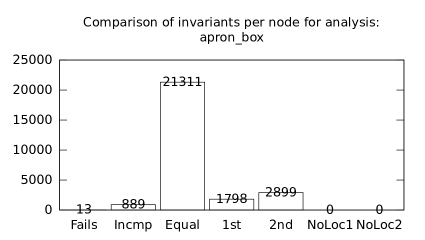
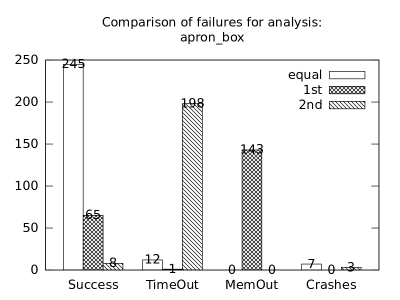
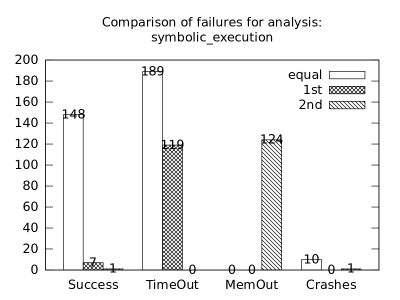
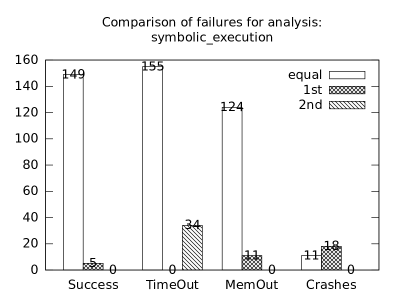
In the second measurement we focused on comparison of termination states of individual clients as they are used in different configurations. We distinguish termination states “Success”, “Time-out”, “Memory-out”, and “Crash”, all with obvious meanings. Results are presented in Fig. 2.1.1. Numbers in each table represent counts of benchmarks.
We can observe the following facts in data in Fig. 2.1.1:
-
•
Consumption of resources via communication does not imply a decrease of successful termination: Considering “Success” data for all configurations comparing with b*p*s for all clients, the communication caused a lose of success termination states in the following percentages:
1st 2nd Box Polka Sym.exec. b*p*s b+p+s 3.8 -3.2 1.9 b*p*s b+p -8.4 -9.5 - b*p*s b+s 11.5 - -0.6 b*p*s p+s - -3.5 3.2 In 5 of 9 cases we see an increase of “Success” termination states. The average of these numbers is -0.53%. We may thus expect about 0.5% increase of “Success” termination states on average per client due to reduced overall time and memory consumption (the influence of crashes is less than 6%).
-
•
Resources consumption via communication heavily depends on kinds of clients: This statement is based on the following patterns which dominate data:
-
–
Symbolic execution is a major source of “Time-out” termination states. We can see this is tables of all clients: Whenever the client is present, there is a high count of time-outs.
-
–
Polka is a major source of “Memory-out” termination states. We can see this is tables of all clients: Whenever the client is present, there is a high count of memory-outs.
-
–
The facts we observed in data of both figures lead as to a conclusion:
In order to get the best result we should run as many configurations as possible and then merge their results. Since resources are always limited (like a number of available computers or threads), we should use patterns (similar to those we observed) in order to express preferences for certain configurations.
It is important to add that the presented anonymous communication approach provides a cheap way for building combinations of clients. Indeed, a construction of a new client mostly involves an implementation of the communication interface and choosing right locations in client’s code, where to issue communication queries. Now, having the best result for a certain benchmark for a group of clients, an addition of a single new one will automatically gives as new configurations each with a potential to improve the old result. In the case of our evaluation we would immediately get eight new such configurations ready for execution.
An interested reader may have a look to Appendix 0.A, where we put the presented data in a form of histograms. A package with sources and binaries of the tool used in the evaluation together with the computed results is freely available here [24]. Details about the download, installation, and the use can be found in Appendix 0.B.
4 Related Work
There is a broad class of approaches dedicated to combining of lattice-based analyses. They all are based either on a direct or a reduced product [8].
A direct product is fully automatic, it requires neither writing of resulting operations nor modifications of the input ones. Nevertheless, composed analyses do not interact and the product represents the least precise Cartesian product of the analyses. No check for correctness is required.
A reduced product is in contrary the most precise Cartesian product, but it is based on (non-computable) concretisation functions used in so called “reduce” function. In practice, the issue is typically resolved by providing an approximation of the reduce function. But this implies a dedicated implementation for each given combination of analyses. It is also necessary to check for correctness of the approximation.
A logical product [14] automatically construct the most precise reduced product of analyses whose elements are conjunctions of atomic facts over theories that are convex, stably infinite, and disjoint. No check for correctness is required.
In [20] authors combine abstract domains for shape analyses using reduced product. Each component reasons independently about different aspects of the data structure invariant and then separately exchange information via a reduction operator.
Granger’s product [13] provides an elegant approximation of the reduce function of a reduced product. Each input analysis is extended by its own reduce function from domains of all analyses to domain of the analysis owning the function. Each analysis must only check whether its reduce function satisfies necessary requirements. Note that each combination of analysis requires new dedicated implementations of reduce functions.
An open product [5] substantially improves the Granger’s product, since it removes the dependence between analyses. The only common property is an a priory given set of queries (e.g. in the logic paradigm: “is a variable x surely bound to a ground term?”). Each operation of each analysis is extended s.t. it is parametrised by all possible valuations of the queries. Analyses are thus also extended by boolean functions capable to compute individual parametrisations. Each analysis has to check for itself for correctness of its extension.
The requirement of a set of predefined queries in an open product was later relaxed in [3] by replacing them by a language of the first order logic. Operations of all analyses can then be parametrised by any formula of the language.
Composition of configurable program analyses [1] is based on a direct product, whose precision can be improved via relations “transfer”, “merge”, “stop”, “compare”, and “strengthen”. Each of these relations is defined over domains of all composed analyses. Implementations of relations transfer, merge, and stop cannot access abstract states of individual analyses, they can only apply their operators and relations. There is no such restriction for implementations of compare and strengthen. These two relations can be used in implementations of the previous three. The composition requires neither modification nor extension of implementations of input analyses. Nevertheless, the five relations mentioned above require dedicated implementations for each combination of analyses. An improved concept by a dynamic precision adjustment [2] introduced a relation “prec”. This relation is also defined over domains of all composed analyses, so its implementations also has to be provided for each combination of analyses. In both the original and the improved concept one needs to check whether his implementations of all the relations satisfy necessary requirements. It is further important to mention that in [1] there was introduced a “location analysis” modeling instruction counter. It can be composed with other analyses.
An advanced combination of lattice-based analyses can be found in Astrée [9]. It is based on the idea of an open product with several extensions. The set of fixed queries was replaced by an extensible set of kinds of constraints. An extension of the set be a new kind implies extensions and checks for correctness of only those analyses which want to use constraints of that kind. A constraint represents an information of its kind about an analysed program. Analyses may exchange information through input and output channels. Input channels provide information on both the postcondition being computed and the precondition computed in the last computation step. Output channels are used when an analysis wants to send a message to others. Messages are elements of a separate abstract domain. Messages are not always exchanged freely between analyses. An order of analyses in a computational step matters. Typically, an analysis may freely communicate with any predecessor.
An obvious difference between our approach and approaches above is that our approach is not restricted to lattice-based analyses. Further important differences can be expressed in terms of three features we mentioned in the introduction:
- •
-
•
Asynchronous execution of clients: Approaches above do not natively provide this feature. Computational steps of all analyses are synchronised, i.e. they all run in the same speed. An asynchronous execution can be emulated in some extent in [1] through the use of several location analyses in one combination: some location analysis stays on a certain location in several subsequents steps in order to simulate slow-down of dependent analyses. Nevertheless, by a use of more than one location analysis in a combination we may expect enormous increase of complexity in designing relations transfer, merge, etc.
-
•
Reuse of current implementations: Approaches based on the open product are suited for the reuse. Nevertheless, approaches [5, 3, 9] require that all composed analyses (synchronously) run on the same internal program representation. And in [1] the reuse requires to look inside implementation of each analysis and discover how the program is internally represented. Then corresponding location analyses can be designed and implemented together with all relations transfer, merge, etc. Nevertheless, this may imply enormous amount of programing effort (which has to be repeated for different combinations of analyses).
There is another broad class of approaches devoted to combining of program analyses. They are focused on combining specific kinds of analyses. Typically, two or more particular analyses are considered, e.g. predicate abstraction with dynamic test generation [12], static checking and testing [10, 19], different testing techniques [6], symbolic and concrete execution [18], static and dynamic analyses via program partitioning [15], data-flow with predicate lattices [11], data-flow analyses in a compiler [4, 17], etc., and a result is a new program analysis possessing advantages of individual analyses. Although these approaches give us interesting new algorithms and ideas, they are orthogonal to our approach: Our approach does not build “a new analysis”, we proposed an analysis-independent communication model. In other words, we took an alternative path.
5 Conclusion
We presented an approach for a light-weight anonymous online communication of existing implementations of program analyses (i.e. clients). In order to communicate with others a client has to implements the proposed client’s communication protocol and to identify places in his implementation where to issue queries s.t. the received information may subsequently help to improve client’s results. These steps are completely independent on other clients. The client also has to check by himself for correctness of his analysis for all possible communication scenarios which may occur during analysis of a given program. Each client performs his work on a private data and an internal program representation. Nevertheless, the communication is performed in terms of common model of instruction counter (canonical program) and common memory addressing (canonical memory). Therefore, communication queries are are typically coupled with conversions from client’s internal data to common terms and back.
We also presented a case study with three communicating clients: two abstract interpreters (intervals, polyhedrons) and one classic symbolic execution. We evaluated five their configurations (how many and what client will communicate) and we pairwise compared their results per client. We measured strengthening of invariant (for abstract interpreters) and termination states (for all). The data shows that each combination may bring us new improvements in both strengthened invariants and increased count of “success” termination states. Therefore, since there are configurations for clients, we can achieve substantial gain compared to results of isolated clients.
References
- [1] D. Beyer, T. A. Henzinger, and G. Théoduloz. Configurable software verification: Concretizing the convergence of model checking and program analysis. In Proceedings of CAV, pages 504–518. Springer-Verlag, 2007.
- [2] D. Beyer, T. A. Henzinger, and G. Theoduloz. Program analysis with dynamic precision adjustment. In Proceedings of ASE, pages 29–38. IEEE, 2008.
- [3] N. Charlton. Verification of java programs with interacting analysis plugins. Electron. Notes Theor. Comput. Sci., 145:131–150, 2006.
- [4] C. Click and K. D. Cooper. Combining analyses, combining optimizations. ACM Trans. Program. Lang. Syst., 17(2):181–196, 1995.
- [5] A. Cortesi, B. Le Charlier, and P. Van Hentenryck. Combinations of abstract domains for logic programming: Open product and generic pattern construction. Sci. Comput. Program., 38(1-3):27–71, 2000.
- [6] D. Cotroneo, R. Pietrantuono, and S. Russo. A learning-based method for combining testing techniques. In Proceedings of ICSE, pages 142–151. IEEE, 2013.
- [7] P. Cousot and R. Cousot. Abstract interpretation: A unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceedings of the POPL, pages 238–252. ACM, 1977.
- [8] P. Cousot and R. Cousot. Systematic design of program analysis frameworks. In Proceedings of POPL, pages 269–282. ACM, 1979.
- [9] P. Cousot, R. Cousot, J. Feret, L. Mauborgne, A. Miné, D. Monniaux, and X. Rival. Combination of abstractions in the ASTRÉE static analyzer. In Proceedings of ASIAN, pages 272–300. Springer-Verlag, 2007.
- [10] Ch. Csallner and Y. Smaragdakis. Check ’n’ crash: Combining static checking and testing. In Proceedings of ICSE, pages 422–431. ACM, 2005.
- [11] J. Fischer, R. Jhala, and R. Majumdar. Joining dataflow with predicates. SIGSOFT Softw. Eng. Notes, 30(5):227–236, 2005.
- [12] P. Godefroid, A. V. Nori, S. K. Rajamani, and S. D. Tetali. Compositional may-must program analysis: Unleashing the power of alternation. SIGPLAN Not., 45(1):43–56, 2010.
- [13] P. Granger. Improving the results of static analyses programs by local decreasing iteration. In Proceedings of FSTTCS, pages 68–79. Springer-Verlag, 1992.
- [14] S. Gulwani and A. Tiwari. Combining abstract interpreters. SIGPLAN Not., 41(6):376–386, 2006.
- [15] P. Jalote, V. Vangala, T. Singh, and P. Jain. Program partitioning: A framework for combining static and dynamic analysis. In Proceedings of WODA, pages 11–16. ACM, 2006.
- [16] J. C. King. Symbolic execution and program testing. Commun. ACM, 19(7):385–394, 1976.
- [17] S. Lerner, D. Grove, and C. Chambers. Composing dataflow analyses and transformations. SIGPLAN Not., 37(1):270–282, 2002.
- [18] K. Sen, D. Marinov, and G. Agha. Cute: A concolic unit testing engine for c. SIGSOFT Softw. Eng. Notes, 30(5):263–272, 2005.
- [19] Y. Smaragdakis and Ch. Csallner. Combining static and dynamic reasoning for bug detection. In Proceedings of TAP, pages 1–16. Springer-Verlag, 2007.
- [20] A. Toubhans, B.-Y. Chang, and X. Rival. Reduced product combination of abstract domains for shapes. In Proceedings of VMCAI, volume 7737, pages 375–395. Springer Berlin Heidelberg, 2013.
- [21] Apron. http://apron.cri.ensmp.fr/library.
- [22] Bugst. git://git.code.sf.net/p/bugst/src.
- [23] CPAchecker. http://cpachecker.sosy-lab.org.
- [24] Evaluation package. https://github.com/trtikm/aocbpa/releases/tag/v1.0.
- [25] SMT-LIB. http://www.smt-lib.org.
- [26] SV-COMP. http://sv-comp.sosy-lab.org.
- [27] Z3. https://github.com/Z3Prover/z3.
Appendix 0.A Plots
Here we present data summarised in Fig. 2.1.1 and Fig 2.1.1 in a form of histograms. They are automatically produced by the tool after evaluation (and then prettify by our utility ’STATOR-tool/plotcopy.py’). Data in the mentioned figures were collected from the histograms.
 |
 |
 |
 |
 |
 |
 |
 |
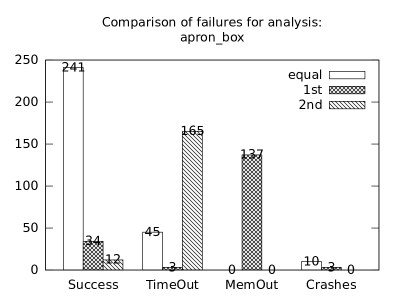 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
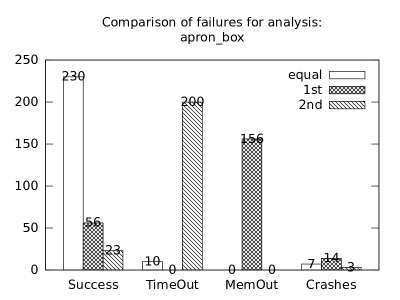 |
 |
 |
 |
 |
 |
Appendix 0.B Access to the tool and Evaluation
The binary of the tool and all results of the evaluation are available here [24]. The binary can be run Linux 64 bit operating system. The tool was tested on Linux Mint 17 and Debian 4.6.3. The binary also runs on Ubuntu 14.04.
Installation is very simple. Download the ZIP package, unzip it into some directory, and the tool is ready for an execution. The tool is located in STATOR-tool sub-directory, the result from our evaluation in SVCOMP-repo.ORIG.EVAL sub-directory. Note that SV-COMP benchmarks are not included in the package. They have to be downloaded separately. All necessary info about this can be found in Appendix 0.C.
Use Python script STATOR-tool/start.py to run the tool on a single C file you have to execute . Use the option --help to list detailed info of usage. In order to run the evaluation for several benchmarks you have to execute Python script STATOR-tool/start_evaluation.py. Use the option --help to list detailed info of usage. In all cases input C file(s) have to always be preprocessed.
In case you want to recompute results of our evaluation we prepared a dedicated shell script STATOR_SVCOMP_evaluate.sh located in the root directory which calls STATOR-tool/start_evaluation.py with our settings. Note the shell script assumes that SV-COMP repository was cloned into sub-directory SVCOMP-repo (which is empty in our package).
Appendix 0.C List of Benchmarks
Here we list all benchmarks we used in evaluations. The list references to SV-COMP 2015 [26] benchmark suite, revision 571.
Summary info:
-
•
URL: https://svn.sosy-lab.org/software/sv-benchmarks/tags/svcomp15
-
•
revision: 571
-
•
Number of current benchmarks: 473
-
•
Number of current directories: 48
-
–
array-examples [10 benchmarks]
-
–
bitvector [10 benchmarks]
-
–
* bitvector-regression [9 benchmarks]
-
–
ddv-machzwd [10 benchmarks]
-
–
eca-rers2012 [10 benchmarks]
-
–
float-benchs [10 benchmarks]
-
–
floats-cbmc-regression [10 benchmarks]
-
–
floats-cdfpl [10 benchmarks]
-
–
* heap-manipulation [8 benchmarks]
-
–
ldv-commit-tester [10 benchmarks]
-
–
ldv-consumption [10 benchmarks]
-
–
ldv-linux-3.0 [10 benchmarks]
-
–
ldv-linux-3.12-rc1 [10 benchmarks]
-
–
ldv-linux-3.16-rc1 [10 benchmarks]
-
–
ldv-linux-3.4-simple [10 benchmarks]
-
–
ldv-linux-3.7.3 [10 benchmarks]
-
–
ldv-regression [10 benchmarks]
-
–
ldv-validator-v0.6 [10 benchmarks]
-
–
list-ext-properties [10 benchmarks]
-
–
list-properties [10 benchmarks]
-
–
locks [10 benchmarks]
-
–
loop-acceleration [10 benchmarks]
-
–
loop-invgen [10 benchmarks]
-
–
loop-lit [10 benchmarks]
-
–
* loop-new [8 benchmarks]
-
–
loops [10 benchmarks]
-
–
memory-alloca [10 benchmarks]
-
–
memsafety [10 benchmarks]
-
–
* memsafety-ext [8 benchmarks]
-
–
ntdrivers [10 benchmarks]
-
–
ntdrivers-simplified [10 benchmarks]
-
–
product-lines [10 benchmarks]
-
–
pthread [10 benchmarks]
-
–
pthread-atomic [10 benchmarks]
-
–
pthread-ext [10 benchmarks]
-
–
pthread-lit [10 benchmarks]
-
–
pthread-wmm [10 benchmarks]
-
–
recursive [10 benchmarks]
-
–
recursive-simple [10 benchmarks]
-
–
seq-mthreaded [10 benchmarks]
-
–
seq-pthread [10 benchmarks]
-
–
ssh [10 benchmarks]
-
–
ssh-simplified [10 benchmarks]
-
–
systemc [10 benchmarks]
-
–
termination-crafted [10 benchmarks]
-
–
termination-crafted-lit [10 benchmarks]
-
–
termination-memory-alloca [10 benchmarks]
-
–
termination-numeric [10 benchmarks]
-
–
List of benchmarks:
-
•
./array-examples/data_structures_set_multi_proc_false-unreach-call_ground.i
-
•
./array-examples/data_structures_set_multi_proc_true-unreach-call_ground.i
-
•
./array-examples/sanfoundry_24_true-unreach-call.i
-
•
./array-examples/sorting_bubblesort_false-unreach-call_ground.i
-
•
./array-examples/standard_compare_true-unreach-call_ground.i
-
•
./array-examples/standard_copy2_true-unreach-call_ground.i
-
•
./array-examples/standard_init3_true-unreach-call_ground.i
-
•
./array-examples/standard_partition_false-unreach-call_ground.i
-
•
./array-examples/standard_two_index_08_true-unreach-call.i
-
•
./array-examples/standard_vector_difference_true-unreach-call_ground.i
-
•
./bitvector-regression/implicitfloatconversion_false-unreach-call.i
-
•
./bitvector-regression/implicitunsignedconversion_false-unreach-call.i
-
•
./bitvector-regression/implicitunsignedconversion_true-unreach-call.i
-
•
./bitvector-regression/integerpromotion_false-unreach-call.i
-
•
./bitvector-regression/integerpromotion_true-unreach-call.i
-
•
./bitvector-regression/signextension2_false-unreach-call.i
-
•
./bitvector-regression/signextension2_true-unreach-call.i
-
•
./bitvector-regression/signextension_false-unreach-call.i
-
•
./bitvector-regression/signextension_true-unreach-call.i
-
•
./bitvector/byte_add_false-unreach-call.i
-
•
./bitvector/gcd_4_true-unreach-call.i
-
•
./bitvector/interleave_bits_true-unreach-call.i
-
•
./bitvector/jain_7_true-unreach-call.i
-
•
./bitvector/modulus_true-unreach-call.i
-
•
./bitvector/num_conversion_1_true-unreach-call.i
-
•
./bitvector/parity_true-unreach-call.i
-
•
./bitvector/s3_clnt_1_false-unreach-call.BV.c.cil.c
-
•
./bitvector/soft_float_5_true-unreach-call.c.cil.c
-
•
./bitvector/sum02_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_all_false-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_inb_p_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_inb_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_inl_p_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_inl_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_inw_p_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_outb_false-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_outb_p_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_outl_true-unreach-call.i
-
•
./ddv-machzwd/ddv_machzwd_outw_p_true-unreach-call.i
-
•
./eca-rers2012/Problem01_label01_true-unreach-call.c
-
•
./eca-rers2012/Problem01_label03_true-unreach-call.c
-
•
./eca-rers2012/Problem01_label10_true-unreach-call.c
-
•
./eca-rers2012/Problem05_label48_false-unreach-call.c
-
•
./eca-rers2012/Problem10_label57_false-unreach-call.c
-
•
./eca-rers2012/Problem10_label58_false-unreach-call.c
-
•
./eca-rers2012/Problem11_label15_false-unreach-call.c
-
•
./eca-rers2012/Problem11_label18_true-unreach-call.c
-
•
./eca-rers2012/Problem19_label52_true-unreach-call.c
-
•
./eca-rers2012/Problem19_label59_false-unreach-call.c
-
•
./float-benchs/float_int_inv_square_false-unreach-call.c
-
•
./float-benchs/inv_square_int_true-unreach-call.c
-
•
./float-benchs/inv_square_true-unreach-call.c
-
•
./float-benchs/nan_double_false-unreach-call.c
-
•
./float-benchs/nan_double_union_true-unreach-call.c
-
•
./float-benchs/nan_float_mask_true-unreach-call.c
-
•
./float-benchs/nan_float_range_true-unreach-call.c
-
•
./float-benchs/nan_float_union_true-unreach-call.c
-
•
./float-benchs/sin_interpolated_index_false-unreach-call.c
-
•
./float-benchs/sin_interpolated_smallrange_true-unreach-call.c
-
•
./floats-cbmc-regression/float-flags-simp1_true-unreach-call.i
-
•
./floats-cbmc-regression/float-no-simp1_true-unreach-call.i
-
•
./floats-cbmc-regression/float-no-simp2_true-unreach-call.i
-
•
./floats-cbmc-regression/float-zero-sum1_true-unreach-call.i
-
•
./floats-cbmc-regression/float11_true-unreach-call.i
-
•
./floats-cbmc-regression/float14_true-unreach-call.i
-
•
./floats-cbmc-regression/float22_true-unreach-call.i
-
•
./floats-cbmc-regression/float3_true-unreach-call.i
-
•
./floats-cbmc-regression/float6_true-unreach-call.i
-
•
./floats-cbmc-regression/float8_true-unreach-call.i
-
•
./floats-cdfpl/newton_1_4_false-unreach-call.i
-
•
./floats-cdfpl/newton_2_1_true-unreach-call.i
-
•
./floats-cdfpl/newton_2_7_false-unreach-call.i
-
•
./floats-cdfpl/newton_3_8_false-unreach-call.i
-
•
./floats-cdfpl/sine_3_false-unreach-call.i
-
•
./floats-cdfpl/sine_4_true-unreach-call.i
-
•
./floats-cdfpl/sine_8_true-unreach-call.i
-
•
./floats-cdfpl/square_1_false-unreach-call.i
-
•
./floats-cdfpl/square_7_true-unreach-call.i
-
•
./floats-cdfpl/square_8_true-unreach-call.i
-
•
./heap-manipulation/bubble_sort_linux_false-unreach-call.i
-
•
./heap-manipulation/bubble_sort_linux_true-unreach-call.i
-
•
./heap-manipulation/dll_of_dll_false-unreach-call.i
-
•
./heap-manipulation/dll_of_dll_true-unreach-call.i
-
•
./heap-manipulation/merge_sort_false-unreach-call.i
-
•
./heap-manipulation/merge_sort_true-unreach-call.i
-
•
./heap-manipulation/sll_to_dll_rev_false-unreach-call.i
-
•
./heap-manipulation/sll_to_dll_rev_true-unreach-call.i
-
•
./ldv-commit-tester/m0_false-unreach-call_drivers-media-radio-si4713-i2c-ko–111_1a–064368f-1.c
-
•
./ldv-commit-tester/m0_true-unreach-call_drivers-hwmon-s3c-hwmon-ko–130_7a–af3071a.c
-
•
./ldv-commit-tester/m0_true-unreach-call_drivers-media-video-cx88-cx88-blackbird-ko–32_7a–d47b389.c
-
•
./ldv-commit-tester/m0_true-unreach-call_drivers-media-video-cx88-cx88-dvb-ko–32_7a–d47b389-1.c
-
•
./ldv-commit-tester/m0_true-unreach-call_drivers-media-video-cx88-cx8802-ko–32_7a–d47b389.c
-
•
./ldv-commit-tester/m0_true-unreach-call_drivers-net-forcedeth-ko–114_1a–fea891e-1.c
-
•
./ldv-commit-tester/main2_true-unreach-call_drivers-media-video-tlg2300-poseidon-ko–32_7a–4a349aa.c
-
•
./ldv-commit-tester/main3_true-unreach-call_arch-x86-oprofile-oprofile-ko–131_1a–79db8ef.c
-
•
./ldv-commit-tester/main4_true-unreach-call_arch-x86-oprofile-oprofile-ko–131_1a–79db8ef-1.c
-
•
./ldv-commit-tester/main7_true-unreach-call_sound-oss-sound-ko–32_7a–c4cb1dd-1.c
-
•
./ldv-consumption/32_7a_cilled_false-unreach-call_linux-3.8-rc1-32_7a-drivers–ata–libata.ko-ldv_main4_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_false-unreach-call_linux-3.8-rc1-32_7a-fs–ceph–ceph.ko-ldv_main11_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-32_7a-drivers–block–paride–pf.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-32_7a-drivers–block–paride–pt.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-32_7a-drivers–usb–host–xhci-hcd.ko-ldv_main5_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-32_7a-fs–nfs–nfsv4.ko-ldv_main4_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-drivers–block–paride–pt.ko-main.cil.out.c
-
•
./ldv-consumption/32_7a_cilled_true-unreach-call_linux-3.8-rc1-drivers–vfio–pci–vfio-pci.ko-main.cil.out.c
-
•
./ldv-consumption/linux-3.8-rc1-32_7a-drivers–media–usb–em28xx–em28xx.ko-ldv_main0_true-unreach-call.cil.out.c
-
•
./ldv-consumption/linux-3.8-rc1-32_7a-drivers–usb–core–usbcore.ko-ldv_main13_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.0/module_get_put-drivers-atm-eni.ko_true-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/module_get_put-drivers-block-drbd-drbd.ko_true-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/module_get_put-drivers-net-ppp_generic.ko_false-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/module_get_put-drivers-net-wan-farsync.ko_false-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-input-misc-keyspan_remote.ko_false-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-input-tablet-kbtab.ko_true-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-media-dvb-ttusb-dec-ttusb_dec.ko_false-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-media-video-c-qcam.ko_true-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-net-usb-catc.ko_false-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.0/usb_urb-drivers-vhost-vhost_net.ko_true-unreach-call.cil.out.i.pp.i
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–input–misc–ims-pcu.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–isdn–hisax–hisax_st5481.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–media–rc–imon.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–media–usb–stk1160–stk1160.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–media–usb–usbvision–usbvision.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–net–can–usb–esd_usb2.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–net–usb–cdc_mbim.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–net–usb–smsc95xx.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–staging–gdm72xx–gdmwm.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.12-rc1/linux-3.12-rc1.tar.xz-144_2a-drivers–usb–misc–idmouse.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/205_9a_array_unsafes_linux-3.16-rc1.tar.xz-205_9a-drivers–net–wan–lapbether.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/205_9a_array_unsafes_linux-3.16-rc1.tar.xz-205_9a-drivers–net–wireless–ath–ath6kl–ath6kl_usb.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/205_9a_array_unsafes_linux-3.16-rc1.tar.xz-205_9a-drivers–net–wireless–ath–wcn36xx–wcn36xx.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/205_9a_array_unsafes_linux-3.16-rc1.tar.xz-205_9a-drivers–net–wireless–hostap–hostap_plx.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–input–gameport–ns558.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–target–sbp–sbp_target.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–tty–isicom.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–tty–serial–8250–8250.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–tty–serial–8250–8250_pci.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.16-rc1/43_2a_consumption_linux-3.16-rc1.tar.xz-43_2a-drivers–video–fbdev–via–viafb.ko-entry_point_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.4-simple/32_1_cilled_true-unreach-call_ok_nondet_linux-3.4-32_1-drivers–acpi–bgrt.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/32_1_cilled_true-unreach-call_ok_nondet_linux-3.4-32_1-drivers–media–dvb–dvb-usb–dvb-usb-dibusb-mc.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/32_1_cilled_true-unreach-call_ok_nondet_linux-3.4-32_1-drivers–media–dvb–dvb-usb–dvb-usb-digitv.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–media–dvb–dvb-usb–dvb-usb-vp702x.ko-ldv_main1_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–media–dvb–frontends–dib3000mc.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–media–video–gspca–gspca_jl2005bcd.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–media–video–gspca–gspca_pac207.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–media–video–gspca–gspca_stv0680.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–watchdog–wdt_pci.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.4-simple/43_1a_cilled_true-unreach-call_ok_nondet_linux-43_1a-drivers–xen–xenfs–xenfs.ko-ldv_main0_sequence_infinite_withcheck_stateful.cil.out.c
-
•
./ldv-linux-3.7.3/linux-3.10-rc1-43_1a-bitvector-drivers–atm–he.ko-ldv_main0_true-unreach-call.cil.out.c
-
•
./ldv-linux-3.7.3/main0_false-unreach-call_drivers–media–dvb-frontends–stv090x-ko—32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main0_false-unreach-call_drivers-net-wireless-mwl8k-ko—32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main11_false-unreach-call_drivers-usb-core-usbcore-ko–32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main15_false-unreach-call_drivers-usb-core-usbcore-ko–32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main17_false-unreach-call_drivers-gpu-drm-vmwgfx-vmwgfx-ko–32_7a–linux-3.5.c
-
•
./ldv-linux-3.7.3/main1_false-unreach-call_drivers-usb-core-usbcore-ko–32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main1_false-unreach-call_drivers-vhost-vhost_net-ko–32_7a–linux-3.7.3.c
-
•
./ldv-linux-3.7.3/main3_false-unreach-call_drivers-gpu-drm-vmwgfx-vmwgfx-ko–32_7a–linux-3.5.c
-
•
./ldv-linux-3.7.3/main4_false-unreach-call_drivers-scsi-mpt2sas-mpt2sas-ko–32_7a–linux-3.7.3.c
-
•
./ldv-regression/alias_of_return_2.c_true-unreach-call_1.i
-
•
./ldv-regression/nested_structure_ptr_true-unreach-call.i
-
•
./ldv-regression/nested_structure_true-unreach-call.i
-
•
./ldv-regression/sizeofparameters_test.c_true-unreach-call.i
-
•
./ldv-regression/stateful_check_false-unreach-call.i
-
•
./ldv-regression/test_address.c_true-unreach-call.i
-
•
./ldv-regression/test_cut_trace.c_true-unreach-call.i
-
•
./ldv-regression/test_union_cast.c_true-unreach-call.i
-
•
./ldv-regression/test_union_cast.c_true-unreach-call_1.i
-
•
./ldv-regression/volatile_alias.c_true-unreach-call.i
-
•
./ldv-validator-v0.6/linux-stable-1575714-1-150_1a-drivers–net–wireless–b43–b43.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-1b0b0ac-1-108_1a-drivers–net–slip.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-42f9f8d-1-111_1a-sound–oss–opl3.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-431e8d4-1-102_1a-drivers–net–r8169.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-4a349aa-1-32_7a-drivers–media–video–tlg2300–poseidon.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-4ed3cba-1-100_1a-drivers–usb–serial–qcserial.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-5934df9-1-111_1a-drivers–scsi–gdth.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-90a4845-1-110_1a-drivers–char–ipmi–ipmi_si.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-stable-c0cc359-104_1a-drivers–usb–serial–qcserial.ko-entry_point_false-unreach-call.cil.out.c
-
•
./ldv-validator-v0.6/linux-torvalds-645ef9e-32_7a-sound–oss–sound.ko-entry_point_false-unreach-call.cil.out.c
-
•
./list-ext-properties/960521-1_1_false-valid-deref.i
-
•
./list-ext-properties/960521-1_1_true-valid-memsafety.i
-
•
./list-ext-properties/list-ext_1_true-valid-memsafety.i
-
•
./list-ext-properties/simple-ext_1_true-valid-memsafety.i
-
•
./list-ext-properties/test-0019_1_true-valid-memsafety.i
-
•
./list-ext-properties/test-0158_1_false-valid-free.i
-
•
./list-ext-properties/test-0214_1_true-valid-memsafety.i
-
•
./list-ext-properties/test-0232_1_false-valid-memtrack.i
-
•
./list-ext-properties/test-0232_1_true-valid-memsafety.i
-
•
./list-ext-properties/test-0504_1_true-valid-memsafety.i
-
•
./list-properties/alternating_list_true-unreach-call.i
-
•
./list-properties/list_false-unreach-call.i
-
•
./list-properties/list_flag_false-unreach-call.i
-
•
./list-properties/list_flag_true-unreach-call.i
-
•
./list-properties/list_search_false-unreach-call.i
-
•
./list-properties/list_search_true-unreach-call.i
-
•
./list-properties/simple_built_from_end_true-unreach-call.i
-
•
./list-properties/simple_false-unreach-call.i
-
•
./list-properties/simple_true-unreach-call.i
-
•
./list-properties/splice_false-unreach-call.i
-
•
./locks/test_locks_10_true-unreach-call.c
-
•
./locks/test_locks_11_true-unreach-call_false-termination.c
-
•
./locks/test_locks_13_true-unreach-call.c
-
•
./locks/test_locks_14_false-unreach-call.c
-
•
./locks/test_locks_14_true-unreach-call.c
-
•
./locks/test_locks_15_true-unreach-call_false-termination.c
-
•
./locks/test_locks_5_true-unreach-call_false-termination.c
-
•
./locks/test_locks_6_true-unreach-call_false-termination.c
-
•
./locks/test_locks_8_true-unreach-call_false-termination.c
-
•
./locks/test_locks_9_true-unreach-call.c
-
•
./loop-acceleration/array_false-unreach-call2.i
-
•
./loop-acceleration/array_false-unreach-call4.i
-
•
./loop-acceleration/diamond_false-unreach-call2.i
-
•
./loop-acceleration/diamond_true-unreach-call1.i
-
•
./loop-acceleration/diamond_true-unreach-call2.i
-
•
./loop-acceleration/multivar_true-unreach-call1.i
-
•
./loop-acceleration/nested_false-unreach-call1.i
-
•
./loop-acceleration/phases_false-unreach-call2.i
-
•
./loop-acceleration/simple_true-unreach-call4.i
-
•
./loop-acceleration/underapprox_true-unreach-call2.i
-
•
./loop-invgen/NetBSD_loop_false-unreach-call.i
-
•
./loop-invgen/SpamAssassin-loop_false-unreach-call.i
-
•
./loop-invgen/down_true-unreach-call.i
-
•
./loop-invgen/fragtest_simple_true-unreach-call.i
-
•
./loop-invgen/half_2_true-unreach-call.i
-
•
./loop-invgen/heapsort_true-unreach-call.i
-
•
./loop-invgen/id_build_true-unreach-call.i
-
•
./loop-invgen/nested9_true-unreach-call.i
-
•
./loop-invgen/seq_true-unreach-call.i
-
•
./loop-invgen/string_concat-noarr_true-unreach-call.i
-
•
./loop-lit/afnp2014_true-unreach-call.c.i
-
•
./loop-lit/cggmp2005_true-unreach-call.c.i
-
•
./loop-lit/cggmp2005b_true-unreach-call.c.i
-
•
./loop-lit/css2003_true-unreach-call.c.i
-
•
./loop-lit/ddlm2013_true-unreach-call.c.i
-
•
./loop-lit/gj2007b_true-unreach-call.c.i
-
•
./loop-lit/gsv2008_true-unreach-call.c.i
-
•
./loop-lit/jm2006_true-unreach-call.c.i
-
•
./loop-lit/jm2006_variant_true-unreach-call.c.i
-
•
./loop-lit/mcmillan2006_true-unreach-call.c.i
-
•
./loop-new/count_by_1_true-unreach-call.i
-
•
./loop-new/count_by_1_variant_true-unreach-call.i
-
•
./loop-new/count_by_2_true-unreach-call.i
-
•
./loop-new/count_by_k_true-unreach-call.i
-
•
./loop-new/count_by_nondet_true-unreach-call.i
-
•
./loop-new/gauss_sum_true-unreach-call.i
-
•
./loop-new/half_true-unreach-call.i
-
•
./loop-new/nested_true-unreach-call.i
-
•
./loops/array_false-unreach-call.i
-
•
./loops/insertion_sort_true-unreach-call.i
-
•
./loops/nec20_false-unreach-call.i
-
•
./loops/sum01_bug02_sum01_bug02_base.case_false-unreach-call_true-termination.i
-
•
./loops/terminator_02_false-unreach-call_true-termination.i
-
•
./loops/terminator_03_true-unreach-call_true-termination.i
-
•
./loops/trex03_false-unreach-call_true-termination.i
-
•
./loops/veris.c_OpenSER__cases1_stripFullBoth_arr_true-unreach-call.i
-
•
./loops/vogal_false-unreach-call.i
-
•
./loops/while_infinite_loop_2_true-unreach-call_false-termination.i
-
•
./memory-alloca/HarrisLalNoriRajamani-2010SAS-Fig3-alloca_true-valid-memsafety.i
-
•
./memory-alloca/array02-alloca_true-valid-memsafety.i
-
•
./memory-alloca/cstrcmp-alloca_true-valid-memsafety.i
-
•
./memory-alloca/cstrcpy-alloca_true-valid-memsafety.i
-
•
./memory-alloca/cstrcpy_unsafe_false-valid-deref.i
-
•
./memory-alloca/cstrlen_unsafe_false-valid-deref.i
-
•
./memory-alloca/openbsd_cstrcpy-alloca_true-valid-memsafety.i
-
•
./memory-alloca/reverse_array_alloca_unsafe_false-valid-deref.i
-
•
./memory-alloca/reverse_array_unsafe_false-valid-deref.i
-
•
./memory-alloca/selection_sort_unsafe_false-valid-deref.i
-
•
./memsafety-ext/dll_extends_pointer_true-valid-memsafety.i
-
•
./memsafety-ext/skiplist_2lvl_true-valid-memsafety.i
-
•
./memsafety-ext/skiplist_3lvl_true-valid-memsafety.i
-
•
./memsafety-ext/tree_cnstr_true-valid-memsafety.i
-
•
./memsafety-ext/tree_dsw_true-valid-memsafety.i
-
•
./memsafety-ext/tree_of_cslls_true-valid-memsafety.i
-
•
./memsafety-ext/tree_parent_ptr_true-valid-memsafety.i
-
•
./memsafety-ext/tree_stack_true-valid-memsafety.i
-
•
./memsafety/960521-1_false-valid-free.i
-
•
./memsafety/lockfree-3.0_true-valid-memsafety.i
-
•
./memsafety/lockfree-3.3_false-valid-memtrack.i
-
•
./memsafety/test-0019_false-valid-memtrack.i
-
•
./memsafety/test-0137_false-valid-deref.i
-
•
./memsafety/test-0158_false-valid-memtrack.i
-
•
./memsafety/test-0219_true-valid-memsafety.i
-
•
./memsafety/test-0220_false-valid-memtrack.i
-
•
./memsafety/test-0236_true-valid-memsafety.i
-
•
./memsafety/test-0504_true-valid-memsafety.i
-
•
./ntdrivers-simplified/cdaudio_simpl1_false-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/cdaudio_simpl1_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/diskperf_simpl1_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/floppy_simpl3_false-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/floppy_simpl3_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/floppy_simpl4_false-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/floppy_simpl4_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/kbfiltr_simpl1_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/kbfiltr_simpl2_false-unreach-call_true-termination.cil.c
-
•
./ntdrivers-simplified/kbfiltr_simpl2_true-unreach-call_true-termination.cil.c
-
•
./ntdrivers/cdaudio_false-unreach-call.i.cil.c
-
•
./ntdrivers/cdaudio_true-unreach-call.i.cil.c
-
•
./ntdrivers/diskperf_false-unreach-call.i.cil.c
-
•
./ntdrivers/diskperf_true-unreach-call.i.cil.c
-
•
./ntdrivers/floppy2_true-unreach-call.i.cil.c
-
•
./ntdrivers/floppy_false-unreach-call.i.cil.c
-
•
./ntdrivers/floppy_true-unreach-call.i.cil.c
-
•
./ntdrivers/kbfiltr_false-unreach-call.i.cil.c
-
•
./ntdrivers/parport_false-unreach-call.i.cil.c
-
•
./ntdrivers/parport_true-unreach-call.i.cil.c
-
•
./product-lines/elevator_spec13_product21_true-unreach-call.cil.c
-
•
./product-lines/email_spec3_product19_false-unreach-call.cil.c
-
•
./product-lines/email_spec4_product17_true-unreach-call.cil.c
-
•
./product-lines/email_spec6_product15_false-unreach-call.cil.c
-
•
./product-lines/email_spec9_product21_false-unreach-call.cil.c
-
•
./product-lines/minepump_spec2_product34_false-unreach-call.cil.c
-
•
./product-lines/minepump_spec2_product38_true-unreach-call.cil.c
-
•
./product-lines/minepump_spec2_product60_true-unreach-call.cil.c
-
•
./product-lines/minepump_spec5_product20_true-unreach-call.cil.c
-
•
./product-lines/minepump_spec5_product61_true-unreach-call.cil.c
-
•
./pthread-atomic/dekker_true-unreach-call.i
-
•
./pthread-atomic/lamport_true-unreach-call.i
-
•
./pthread-atomic/peterson_true-unreach-call.i
-
•
./pthread-atomic/qrcu_false-unreach-call.i
-
•
./pthread-atomic/qrcu_true-unreach-call.i
-
•
./pthread-atomic/read_write_lock_false-unreach-call.i
-
•
./pthread-atomic/read_write_lock_true-unreach-call.i
-
•
./pthread-atomic/scull_true-unreach-call.i
-
•
./pthread-atomic/szymanski_true-unreach-call.i
-
•
./pthread-atomic/time_var_mutex_true-unreach-call.i
-
•
./pthread-ext/01_inc_true-unreach-call.i
-
•
./pthread-ext/04_incdec_cas_true-unreach-call.i
-
•
./pthread-ext/05_tas_true-unreach-call.i
-
•
./pthread-ext/08_rand_cas_true-unreach-call.i
-
•
./pthread-ext/18_read_write_lock_true-unreach-call.i
-
•
./pthread-ext/19_time_var_mutex_true-unreach-call.i
-
•
./pthread-ext/23_lu-fig2.fixed_true-unreach-call.i
-
•
./pthread-ext/25_stack_longest_true-unreach-call.i
-
•
./pthread-ext/27_Boop_simple_vf_false-unreach-call.i
-
•
./pthread-ext/30_Function_Pointer3_vs_true-unreach-call.i
-
•
./pthread-lit/fk2012_true-unreach-call.i
-
•
./pthread-lit/fkp2013_false-unreach-call.i
-
•
./pthread-lit/fkp2013_true-unreach-call.i
-
•
./pthread-lit/fkp2013_variant_true-unreach-call.i
-
•
./pthread-lit/fkp2014_true-unreach-call.i
-
•
./pthread-lit/qw2004_false-unreach-call.i
-
•
./pthread-lit/qw2004_true-unreach-call.i
-
•
./pthread-lit/qw2004_variant_true-unreach-call.i
-
•
./pthread-lit/sssc12_true-unreach-call.i
-
•
./pthread-lit/sssc12_variant_true-unreach-call.i
-
•
./pthread-wmm/mix000_power.oepc_false-unreach-call.i
-
•
./pthread-wmm/mix008_pso.oepc_false-unreach-call.i
-
•
./pthread-wmm/mix041_power.oepc_false-unreach-call.i
-
•
./pthread-wmm/mix054_tso.opt_false-unreach-call.i
-
•
./pthread-wmm/mix055_power.opt_false-unreach-call.i
-
•
./pthread-wmm/rfi009_rmo.oepc_false-unreach-call.i
-
•
./pthread-wmm/rfi009_rmo.opt_false-unreach-call.i
-
•
./pthread-wmm/rfi009_tso.oepc_false-unreach-call.i
-
•
./pthread-wmm/safe037_tso.oepc_true-unreach-call.i
-
•
./pthread-wmm/thin002_pso.oepc_true-unreach-call.i
-
•
./pthread/fib_bench_longer_false-unreach-call.i
-
•
./pthread/fib_bench_longer_true-unreach-call.i
-
•
./pthread/fib_bench_longest_true-unreach-call.i
-
•
./pthread/queue_longest_false-unreach-call.i
-
•
./pthread/queue_ok_longer_true-unreach-call.i
-
•
./pthread/queue_ok_longest_true-unreach-call.i
-
•
./pthread/queue_ok_true-unreach-call.i
-
•
./pthread/sigma_false-unreach-call.i
-
•
./pthread/singleton_false-unreach-call.i
-
•
./pthread/stateful01_false-unreach-call.i
-
•
./recursive-simple/afterrec_2calls_false-unreach-call.c
-
•
./recursive-simple/afterrec_true-unreach-call.c
-
•
./recursive-simple/fibo_2calls_2_false-unreach-call.c
-
•
./recursive-simple/fibo_2calls_5_false-unreach-call.c
-
•
./recursive-simple/id_b5_o10_true-unreach-call.c
-
•
./recursive-simple/id_i10_o10_true-unreach-call.c
-
•
./recursive-simple/id_o10_false-unreach-call.c
-
•
./recursive-simple/id_o200_false-unreach-call.c
-
•
./recursive-simple/sum_2x3_false-unreach-call.c
-
•
./recursive-simple/sum_non_true-unreach-call.c
-
•
./recursive/Ackermann03_true-unreach-call.c
-
•
./recursive/Addition01_true-unreach-call_true-termination.c
-
•
./recursive/Addition03_false-unreach-call.c
-
•
./recursive/EvenOdd03_false-unreach-call_false-termination.c
-
•
./recursive/Fibonacci01_true-unreach-call.c
-
•
./recursive/Fibonacci02_true-unreach-call_true-termination.c
-
•
./recursive/McCarthy91_true-unreach-call.c
-
•
./recursive/Primes_true-unreach-call.c
-
•
./recursive/gcd02_true-unreach-call.c
-
•
./recursive/recHanoi03_true-unreach-call_true-termination.c
-
•
./seq-mthreaded/pals_STARTPALS_Triplicated_true-unreach-call.ufo.BOUNDED-10.pals.c
-
•
./seq-mthreaded/pals_floodmax.5_true-unreach-call.ufo.BOUNDED-10.pals.c
-
•
./seq-mthreaded/pals_lcr.7_true-unreach-call.ufo.UNBOUNDED.pals.c
-
•
./seq-mthreaded/pals_opt-floodmax.5_false-unreach-call.1.ufo.BOUNDED-10.pals.c
-
•
./seq-mthreaded/pals_opt-floodmax.5_false-unreach-call.1.ufo.UNBOUNDED.pals.c
-
•
./seq-mthreaded/pals_opt-floodmax.5_false-unreach-call.2.ufo.BOUNDED-10.pals.c
-
•
./seq-mthreaded/rekh_ctm_true-unreach-call.2.c
-
•
./seq-mthreaded/rekh_ctm_true-unreach-call.4.c
-
•
./seq-mthreaded/rekh_nxt_false-unreach-call.2.M4.c
-
•
./seq-mthreaded/rekh_nxt_true-unreach-call.3.M1.c
-
•
./seq-pthread/cs_fib_longer_false-unreach-call.i
-
•
./seq-pthread/cs_fib_longer_true-unreach-call.i
-
•
./seq-pthread/cs_fib_true-unreach-call.i
-
•
./seq-pthread/cs_lamport_true-unreach-call.i
-
•
./seq-pthread/cs_peterson_true-unreach-call.i
-
•
./seq-pthread/cs_queue_false-unreach-call.i
-
•
./seq-pthread/cs_stack_false-unreach-call.i
-
•
./seq-pthread/cs_stateful_false-unreach-call.i
-
•
./seq-pthread/cs_sync_true-unreach-call.i
-
•
./seq-pthread/cs_szymanski_true-unreach-call.i
-
•
./ssh-simplified/s3_clnt_1_true-unreach-call.cil.c
-
•
./ssh-simplified/s3_clnt_2_true-unreach-call_true-termination.cil.c
-
•
./ssh-simplified/s3_clnt_4_false-unreach-call.cil.c
-
•
./ssh-simplified/s3_clnt_4_true-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_11_false-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_14_false-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_1_false-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_1_true-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_4_true-unreach-call.cil.c
-
•
./ssh-simplified/s3_srvr_6_true-unreach-call.cil.c
-
•
./ssh/s3_srvr.blast.01_true-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.02_false-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.03_false-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.04_false-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.06_true-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.07_true-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.08_false-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.10_true-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.12_true-unreach-call.i.cil.c
-
•
./ssh/s3_srvr.blast.13_false-unreach-call.i.cil.c
-
•
./systemc/kundu2_false-unreach-call_false-termination.cil.c
-
•
./systemc/kundu_true-unreach-call_false-termination.cil.c
-
•
./systemc/pc_sfifo_2_false-unreach-call_false-termination.cil.c
-
•
./systemc/token_ring.03_false-unreach-call_false-termination.cil.c
-
•
./systemc/token_ring.12_true-unreach-call_false-termination.cil.c
-
•
./systemc/token_ring.13_false-unreach-call_false-termination.cil.c
-
•
./systemc/token_ring.14_false-unreach-call_false-termination.cil.c
-
•
./systemc/toy2_false-unreach-call_false-termination.cil.c
-
•
./systemc/toy_true-unreach-call_false-termination.cil.c
-
•
./systemc/transmitter.12_false-unreach-call_false-termination.cil.c
-
•
./termination-crafted-lit/AliasDarteFeautrierGonnord-SAS2010-Fig2a_true-termination.c
-
•
./termination-crafted-lit/HeizmannHoenickeLeikePodelski-ATVA2013-Fig1_true-termination.c
-
•
./termination-crafted-lit/LarrazOliverasRodriguez-CarbonellRubio-FMCAD2013-Fig1_true-termination.c
-
•
./termination-crafted-lit/PodelskiRybalchenko-TACAS2011-Fig4_true-termination.c
-
•
./termination-crafted-lit/PodelskiRybalchenko-VMCAI2004-Ex1_true-termination.c
-
•
./termination-crafted-lit/Velroyen_false-termination.c
-
•
./termination-crafted-lit/cstrcspn_true-termination.c
-
•
./termination-crafted-lit/cstrpbrk_true-termination.c
-
•
./termination-crafted-lit/cstrspn_true-termination.c
-
•
./termination-crafted-lit/gcd1_true-termination.c
-
•
./termination-crafted/4BitCounterPointer_true-termination.c
-
•
./termination-crafted/Cairo_true-termination.c
-
•
./termination-crafted/Copenhagen_true-termination.c
-
•
./termination-crafted/NonTermination3_false-termination.c
-
•
./termination-crafted/NonTermination4_false-termination.c
-
•
./termination-crafted/NonTerminationSimple9_false-termination.c
-
•
./termination-crafted/Parallel_true-termination.c
-
•
./termination-crafted/Pure2Phase_true-termination.c
-
•
./termination-crafted/RecursiveNonterminating_false-termination.c
-
•
./termination-crafted/Stockholm_true-termination.c
-
•
./termination-memory-alloca/b.09_assume-alloca_true-termination.c.i
-
•
./termination-memory-alloca/b.10-alloca_true-termination.c.i
-
•
./termination-memory-alloca/b.13-alloca_true-termination.c.i
-
•
./termination-memory-alloca/cstrncat-alloca_true-termination.c.i
-
•
./termination-memory-alloca/java_Break-alloca_true-termination.c.i
-
•
./termination-memory-alloca/java_LogBuiltIn-alloca_true-termination.c.i
-
•
./termination-memory-alloca/java_Nested-alloca_true-termination.c.i
-
•
./termination-memory-alloca/java_Sequence-alloca_true-termination.c.i
-
•
./termination-memory-alloca/openbsd_cbzero-alloca_true-termination.c.i
-
•
./termination-memory-alloca/openbsd_cstrcmp-alloca_true-termination.c.i
-
•
./termination-numeric/Avg_true_true-termination.c
-
•
./termination-numeric/Binomial_true-termination.c
-
•
./termination-numeric/Et1_true_true-termination.c
-
•
./termination-numeric/Parts_true-termination.c
-
•
./termination-numeric/TwoWay_true-termination.c
-
•
./termination-numeric/b.03-no-inv_assume_true-termination.c
-
•
./termination-numeric/easySum_true-termination.c
-
•
./termination-numeric/java_LogBuiltIn_true-termination.c
-
•
./termination-numeric/java_Nested_true-termination.c
-
•
./termination-numeric/rec_counter1_true-termination.c