Application-level Benchmarking of Quantum Computers using Nonlocal Game Strategies
Abstract
In a nonlocal game, two noncommunicating players cooperate to convince a referee that they possess a strategy that does not violate the rules of the game. Quantum strategies allow players to optimally win some games by performing joint measurements on a shared entangled state, but computing these strategies can be challenging. We present a variational quantum algorithm to compute quantum strategies for nonlocal games by encoding the rules of a nonlocal game into a Hamiltonian. We show how this algorithm can generate a short-depth optimal quantum strategy for a graph coloring game with a quantum advantage. This quantum strategy is then evaluated on fourteen different quantum hardware platforms to demonstrate its utility as a benchmark. Finally, we discuss potential sources of errors that can explain the observed decreased performance of the executed task and derive an expression for the number of samples required to accurately estimate the win rate in the presence of noise.
1 Introduction
Running simple instances of quantum algorithms with a provable advantage is difficult given the current state of quantum hardware [1, 2]. For this reason, it is important to develop benchmarking tools and techniques that can test and validate the unique aspects of quantum hardware that are consistent with the predictions of quantum theory. In particular, recent work on quantum benchmarking has highlighted the importance of developing benchmarking metrics that can measure progress toward quantum utility of useful quantum algorithms [3].
Low-level benchmark metrics such as randomized benchmarking [4, 5, 6] aim to measure the average error rates of a gate set independent of the initial state or measurement scheme, but are limited, for example, in that it cannot help specify sources of error in an algorithmic pipeline [7] and can overestimate gate fidelity in the presence of errors [8]. High-level benchmarks such as Quantum Volume [9] aim to measure the performance of the entire quantum computing stack, including all classical control systems, but this can be too broad a metric and does not necessarily capture the performance of useful quantum algorithms. In addition, both of these benchmark metrics are difficult to compute at scale and fail to capture the ability of a specific hardware platform at attaining some quantum advantage.
Recent work on nonlocal games has begun to shed light into their utility for quantum hardware verification, quantum advantage, and self-testing [10, 11, 12, 13, 14]. In a nonlocal game, two noncommunicating players cooperate to convince a referee that they possess a strategy that does not violate the rules of a game. When players are allowed to use entanglement as a resource in the development of their joint strategy, they are able to perform computations that no classical computer can replicate without communication and can win the game with higher probability. Nonlocal games have been historically important and provide a unique setting to explore the relationship between classical physics, quantum theory, and other non-signaling theories [15, 16, 17, 18]. An extensive body of research links these games to foundational problems in quantum physics, conjectures in operator algebras, and computational complexity theory [19, 20, 21]. Moreover, advances in quantum information theory and combinatorics have revealed broad classes of games with a provable quantum advantage when players are allowed to incorporate quantum resources into their strategies, such as graph coloring and graph homomorphism games [22, 23], making them exciting experimental candidates for testing quantum hardware [24]. Moreover, nonlocal games are classically verifiable, i.e. given a strategy, you can check in polynomial time if the answers satisfy the rules of the game.
Despite many breakthroughs in our theoretical understanding of nonlocal games, constructing optimal strategies for general nonlocal games remains a challenge. In our work, we propose a new methodology for constructing strategies using variational methods and outline the utility of the strategies found for benchmarking. We begin Section 2 with an introduction to nonlocal games and some definitions. In Section 3, we propose the use of a dual-phase optimization technique to find the resource state and the measurement scheme of a quantum strategies for a nonlocal game. In Section 4, we demonstrate how our method is able to successfully find optimal strategies for CHSH, an N-Partite Symmetric game, and the graph coloring game. For the graph coloring game, we were able to find a short-depth perfect quantum strategy for a graph on vertices shown to be the smallest graph instance where there exists a strict separation between classical and quantum strategies [25, 26]. We then proceed to test the performance of this novel short-depth strategy on superconducting quantum computing devices and highlight some potential sources of errors causing decreased performance on some of the devices we tested. In Section 5, we outline how we can use quantum strategies to benchmark quantum devices, their desirable noise robustness properties, and win rate estimation procedure in the presence of device shot noise.
2 Background
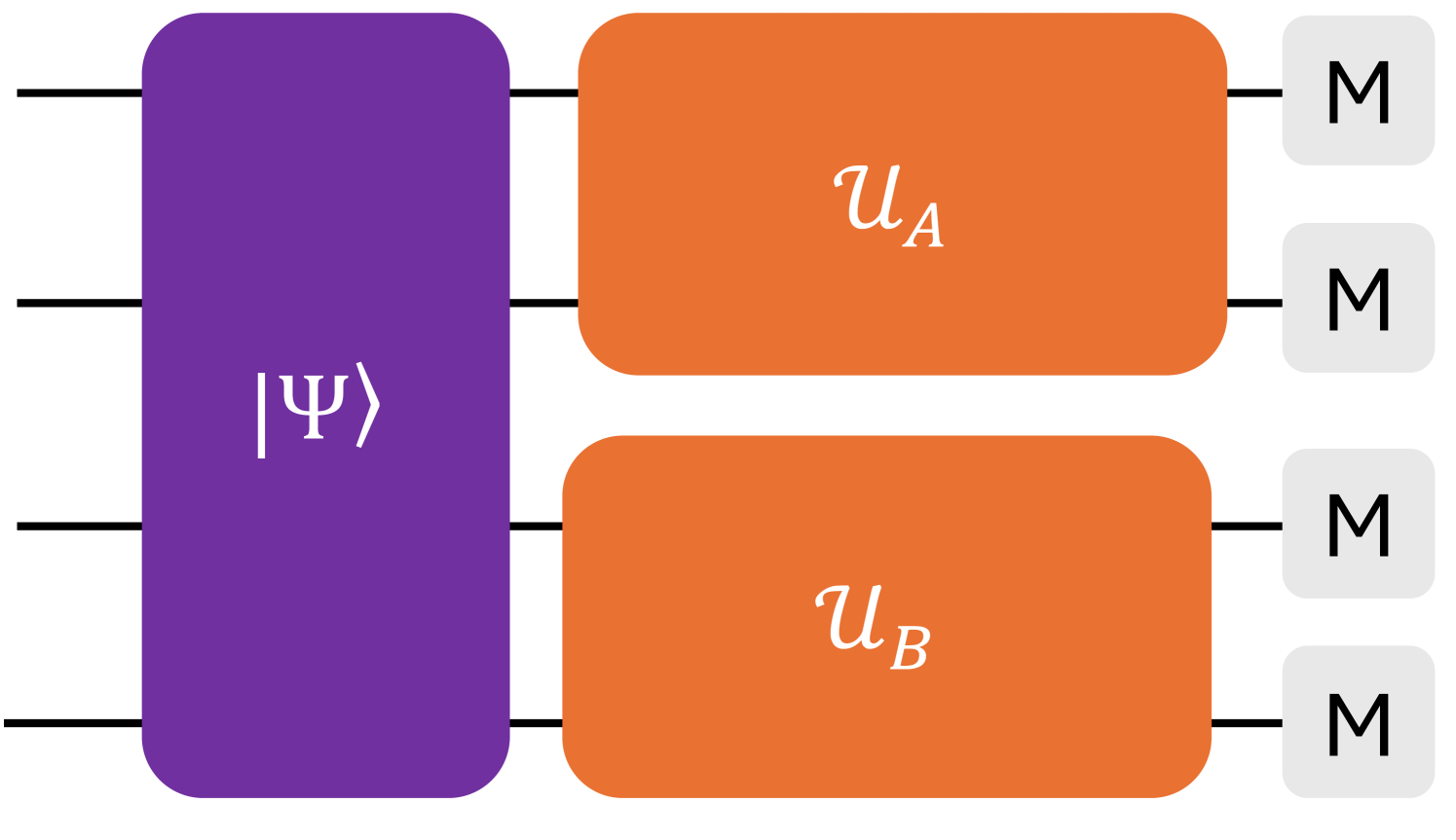
A nonlocal game of players (illustrated in Fig. 1) consists of a set of possible questions that player receives from a referee and a set of answers that player is allowed to send to the referee, which the referee then evaluates against a rule function . Each set of questions and the set of answers has cardinality and , respectively; however, in our work, we assume that there are questions and answers for each player. The game proceeds in the following steps:
-
1.
The players are informed about the rules of the game , and can collaborate to create a joint strategy, modeled as a conditional probability density between the questions and answers, to maximize their chances of satisfying the rules of the game before it starts.
-
2.
Players are then separated or isolated to prevent them from communicating. This is referred to as non-signaling, or in other words, each player’s actions are independent of each other.
-
3.
The referee tests the strategy by asking questions to each player and receiving their responses , where and , respectively.
-
4.
The players win a round if , and lose if . Multiple rounds are played with different questions to establish that players have a valid strategy.
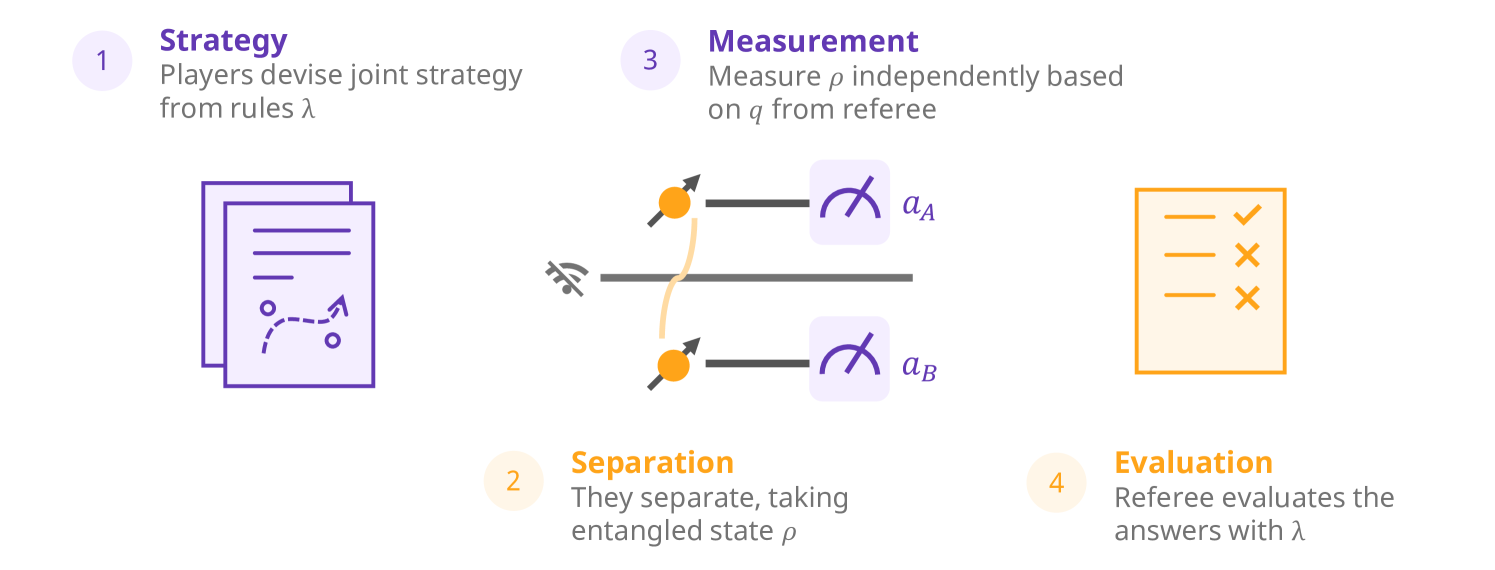
It is common that all players share the same set of possible questions and answers . In particular, Synchronous games have rules that require that the answers of two (or more) players be identical when asked the same questions , for all , where is a vector of questions. In our work, we only consider computing strategies for synchronous games, although the optimization procedure we propose in Section 3 applies for more general strategies.
Using the rules, we can define the value of the game as
| (1) |
where the sum is taken over all possible values of and (we drop the vector notation for convenience). The distribution of the questions asked is typically chosen to be uniform, and the behavior is determined by the strategy that the players construct. Notice that this is the only term that players can control to maximize their win rate. A strategy is said to be perfect if and, consequently, .
Classical strategies consist of a lookup table that indexes each player’s response to a particular question. It suffices to consider deterministic strategies since stochastic strategies involving shared randomness between the players cannot outperform deterministic strategies due to the linearity of the value of the game [17].
Suppose that players share a quantum state , and each player has a set of positive operator-valued measures (POVMs) with elements of the form , which they perform on their subspace. Using this setup, players can generate the following conditional probability density,
| (2) |
where . These densities are known as quantum strategies.
In addition to the above definition of a quantum strategy, there are a variety of competing definitions for a quantum strategy depending on the choice of axioms that describe how joint measurements between two parties should be performed [27]. In our work, we will only consider strategies as defined above, but the study of quantum strategies is a very active area of research [28, 29, 30, 31]. Note that in [32], the authors prove that for synchronous games, a maximally entangled state is sufficient for a quantum strategy to win the graph coloring game.
A game exhibits a quantum advantage if there exists a quantum strategy that performs better than the best possible classical strategy, in which case there is a Bell inequality that is violated for some quantum strategies. The inequality has historically served as an experimental test of local realism [33]. Such inequalities are constraints satisfied by classical (local hidden-variable) models, and are often linear inequalities derived from the local realism assumption. More specifically, a Bell inequality consists of a function with respect to the probabilities such that
| (3) |
for some . Bell inequalities are a central object for self-testing of states [12]. The construction of such functions and constants are as follows: for a given Bell inequality , where are weights, there is a corresponding Bell operator , such that a violation is obtained as . If the maximal achievable violation is obtained by using quantum resources, denote for this distinction and consider the shifted Bell operator . If the shifted Bell operator admits a decomposition
| (4) |
where each is a polynomial with respect to the measurement operators , then we call the decomposition a sum of squares (SOS) for the Bell inequality. Such a decomposition is extremely hard to find [34].
3 Method
In this section, we present a variational quantum algorithm for computing quantum strategies of nonlocal games. Let be the shared entangled state between the players and be the joint POVM applied to that state for question , returning with probability . It was noted in [35] that fixing these measurement operators gives a Hamiltonian whose ground state is the optimal shared state for this measurement setting. This fact has been used with reinforcement learning to optimize measurements while selecting the optimal shared state through exact diagonalization [36].
3.1 Dual-Phase Optimization
Our approach is a dual-phase optimization (DPO) that alternates between 2 phases: preparing the optimal state for the fixed measurements , and optimizing the measurements, while fixing the shared state. We assume that the players parameterize their state and POVMs . The particular choice of parameterization depends on characteristics of the game (e.g. number of qubits required depends on the number of answers).
The preparation of the Hamiltonian depends on the specific measurement scheme the players decide on, which depend on the game. Later, we outline a method for constructing a Hamiltonian from arbitrary game rules and measurements .
The optimal shared state is prepared in the first phase using any VQE procedure . Here, we choose ADAPT-VQE [37] because it generates compact variational circuits for use on near-term quantum hardware, but any other solver can also be used (see B). The reference state can be a product state, e.g. , . We choose a qubit operator pool consisting of all possible Pauli strings acting on the entire system. The operators added to the state take the form , giving , and they are capable of generating the entanglement required to win nonlocal games, provided they act non-trivially on at least 2 qubits.
The second phase uses a gradient descent-like optimizer to update the measurement parameters . This requires the calculation of gradients on the quantum device, which can be done through parameter shift rules [38, 39]. In F, we outline the cost of computing this gradient for larger problem instances and some optimization challenges.
3.2 Game Hamiltonians
As mentioned above, DPO requires the construction of a Hamiltonian based on the measurements of the players, which determines the quantum strategy. Player may measure their qubits in an arbitrary basis depending on the question, leading to a form for the measurement operators
| (5) | ||||
| (6) |
where is the projector onto answer , and acts on in response to question . Because , we can substitute this into (1) to construct the game operator
| (7) | ||||
| (8) |
with the property . A VQE finds the ground state of a Hamiltonian, so to maximize the win rate, we use a value Hamiltonian in DPO.
Proposition 3.1.
The value if and only if the players have a perfect quantum strategy, otherwise .
Proof 3.1.
We show this by first computing the value for a perfect strategy and then for an imperfect strategy. Let be the set of question-answer pairs for which the strategy violates the rules, and let be its complement, the set of correctly answered question-answer pairs.
For a perfect quantum strategy, and , therefore we get
Since for all pairs for which are contained in , it follows that the joint probability density in the left term must sum to 1. Hence, we obtain .
A very similar line of reasoning holds for an imperfect strategy, where . Reusing the above expression,
since for no longer contains the full probability density as contains some possible pairs. We conclude that , with iff a strategy is perfect.
To parameterize this Hamiltonian for DPO, a general single-qubit unitary may be decomposed into 3 parameters, leading to a parameterization of the full measurement gate , where indexes the player, indexes the question, and indexes the particular qubit of player . In measurement layers acting on multiple qubits, we expand each entry of to be the concatenated vector of parameters for all gates applied to that qubit, i.e. , where is an -qubit unitary.
4 Experiments
To evaluate the performance of DPO, we apply it to several nonlocal games with known quantum bounds: CHSH, the N-partite symmetric (NPS) game [36], and the odd-cycle game [14]. Then, we use DPO to explicitly compute an optimal quantum strategy for the coloring game of a vertex graph called [25]. This strategy is then evaluated on quantum hardware, demonstrating that it can be used to benchmark the nonlocal capabilities of quantum devices and find sources of errors.
4.1 CHSH
The Clauser-Horne-Shimony-Holt (CHSH) scenario [33] is the simplest nonlocal game that admits a quantum advantage. CHSH features 2 players, Alice and Bob, who each receive a question , answering . The inequality operator can be expressed in the familiar form following the rules
| (9) |
and making the substitution in (8). Here denotes Alice’s measurement operator and likewise for Bob. All classical strategies are bounded by , whereas quantum strategies can violate this up to . i.e., from Equation (3), the violation occurs with . It suffices to share a Bell state and then perform the appropriate single-qubit measurements.
We applied DPO to the CHSH game using gates as the operators. In the first iteration, ADAPT chose , which correctly generates a Bell state . In the second phase of that iteration, the measurement parameters were optimized to by constraining , giving the optimal inequality value .
4.2 N-partite Symmetric
The NPS scenario [40] involves the correlations between players , each receiving a binary question and returning a dichotomic answer . The inequality is expressed in terms of one- and symmetric two-body correlators,
| (10) |
where measurement . The classical bound on the correlations is
| (11) |
with negative values only achievable with quantum strategies [36].
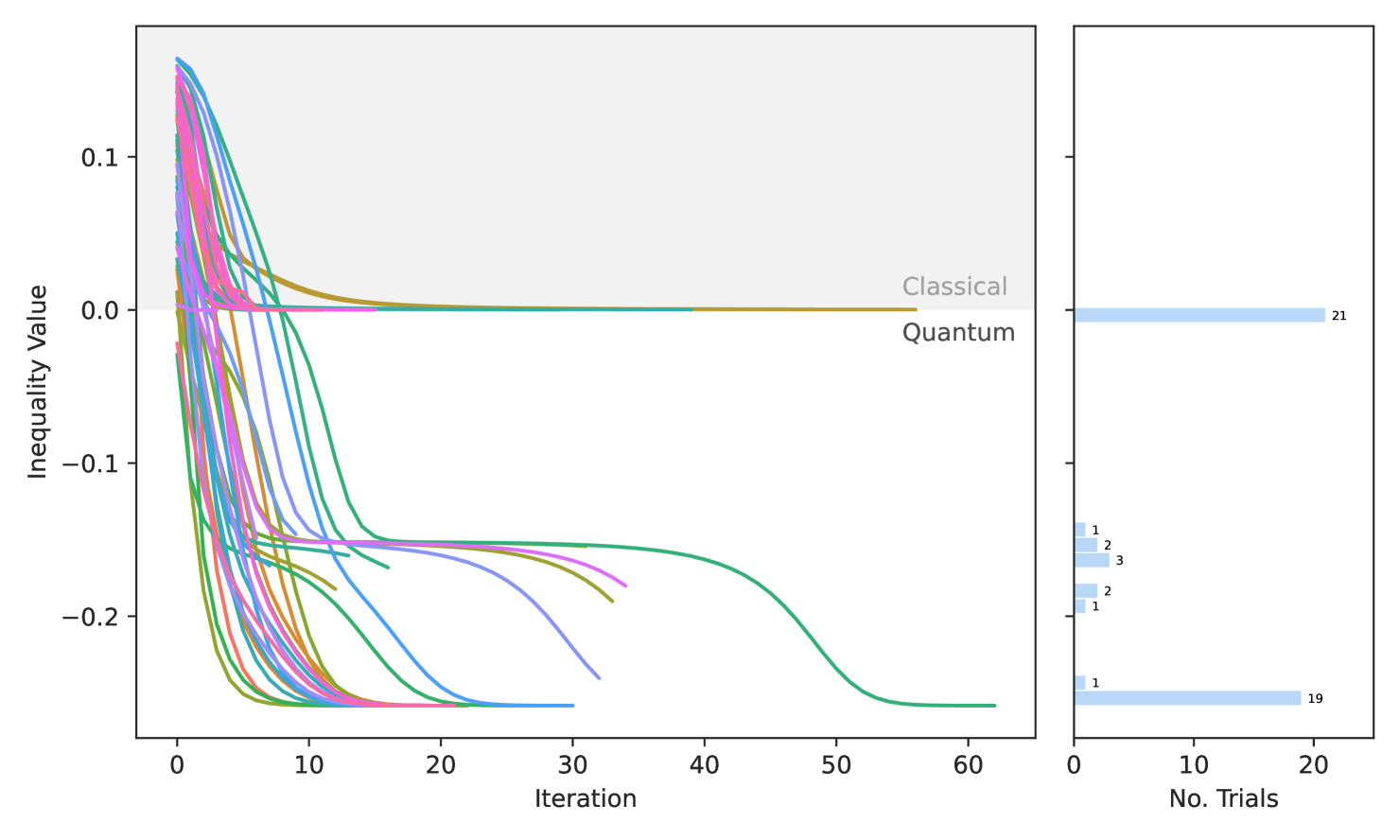
We tested 50 DPO trials for the case (Fig. 2). Our algorithm encounters some local minima, particularly at the classical bound of , but still succeeds in 19/50 attempts reaching as found in [36] as well. Additionally, 29/50 of the trials violated the classical bound.
4.3 Chromatic Number Game
The objective of the chromatic number game [25] is to color a graph in such a way that adjacent vertices are never given the same color. If this can be done using colors, we call this a -coloring of the graph. It has been shown recently that winning strategies for this game generate the set of all possible correlations for synchronous nonlocal games [41]. This differs from the other nonlocal games we mentioned, as the sets of questions and answers are much larger, and each player requires more qubits to encode their answer. The referee asks a question , and the players respond with colors . The rules are given by
| (12) |
From these rules, one can encode the graph-coloring game into a Hamiltonian for DPO. For convenience, we denote a vertex question as , and an edge question as . Let the answers also be given by . Then, the expression in (8) gives
| (13) |
where is the projector onto the subspace of matching colors, and . Intuitively, the first term maximizes , and the second term maximizes . Note that to ensure that all possible questions are asked to each player, contains both edges and their reverse .
First we consider the odd-cycle game [17], defined on an odd-length cycle graph of vertices. The players are restricted to using 2 colors , meaning there is no perfect classical strategy because is 3-colorable. Indeed, the optimal classical win rate is . The optimal quantum strategy has a higher rate of , yielding a separation, but no perfect quantum strategy exist. Additionally, this game is of particular interest because it was recently experimentally demonstrated in a spatially separated pair of trapped ions, showing quantum advantage for up to vertices [14].
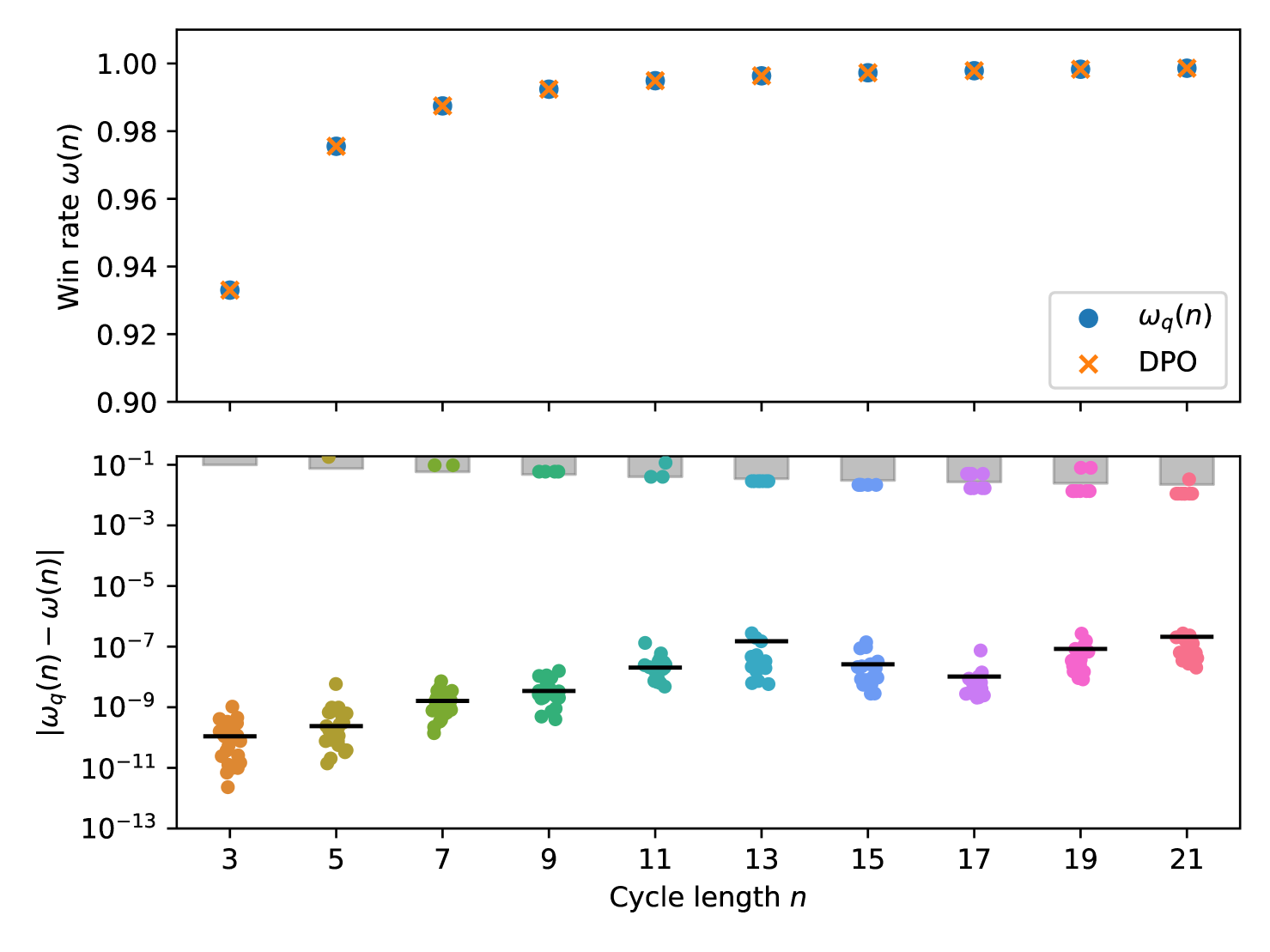
Fig. 3 shows the distribution strategies discovered by our algorithm with a measurement layer of one gate per player. We evaluated each game instance with 25 trials. In all instances, we observed that the best discovered strategy was within or lower of the optimal quantum value. The algorithm did get stuck in some local minima near the classical value , but the median values were within the algorithm tolerance, showing that it is able to find graph coloring strategies for the odd-cycle game.
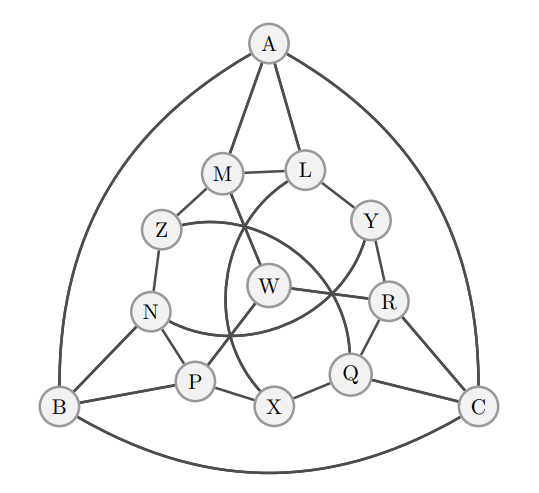
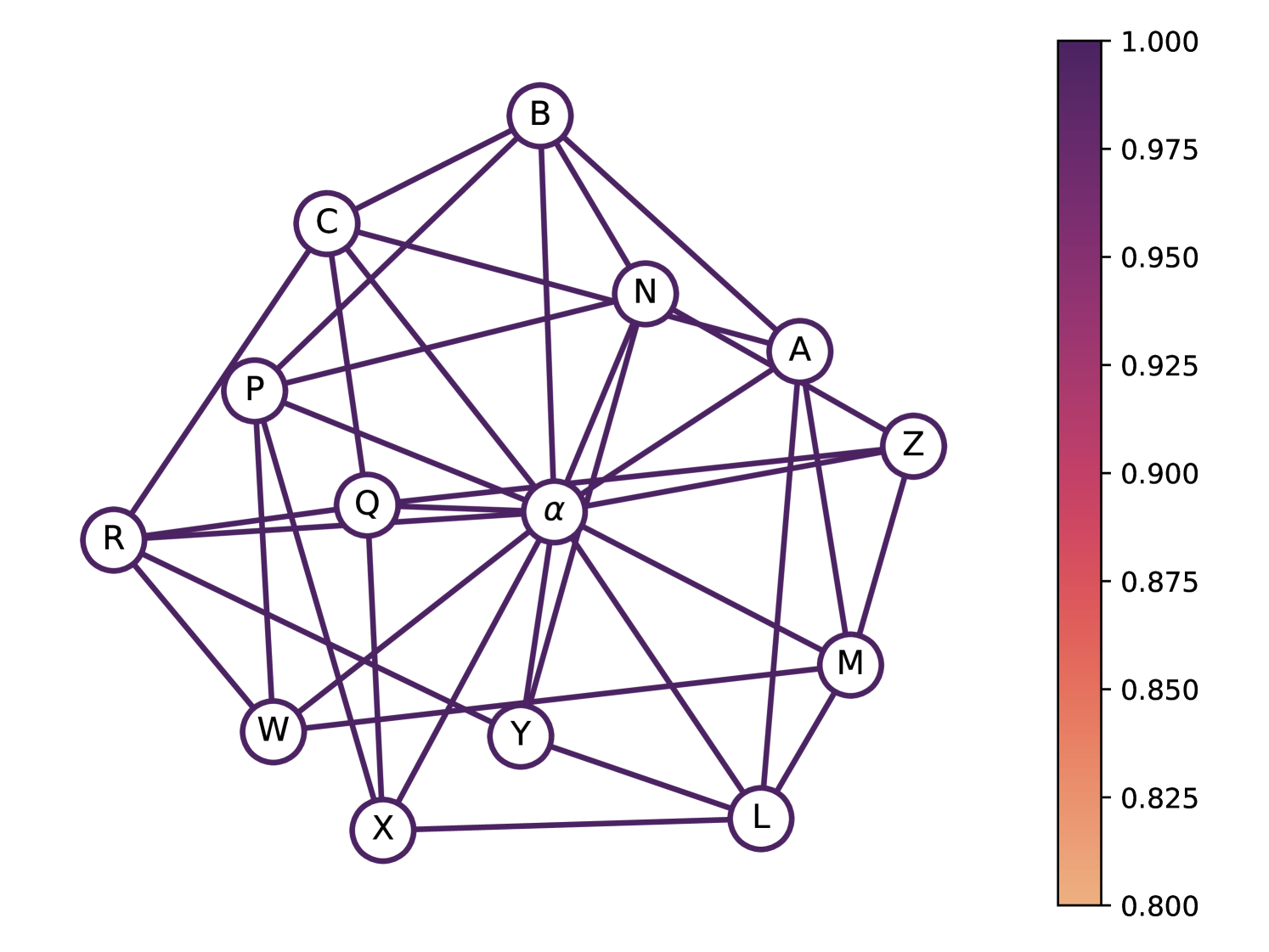
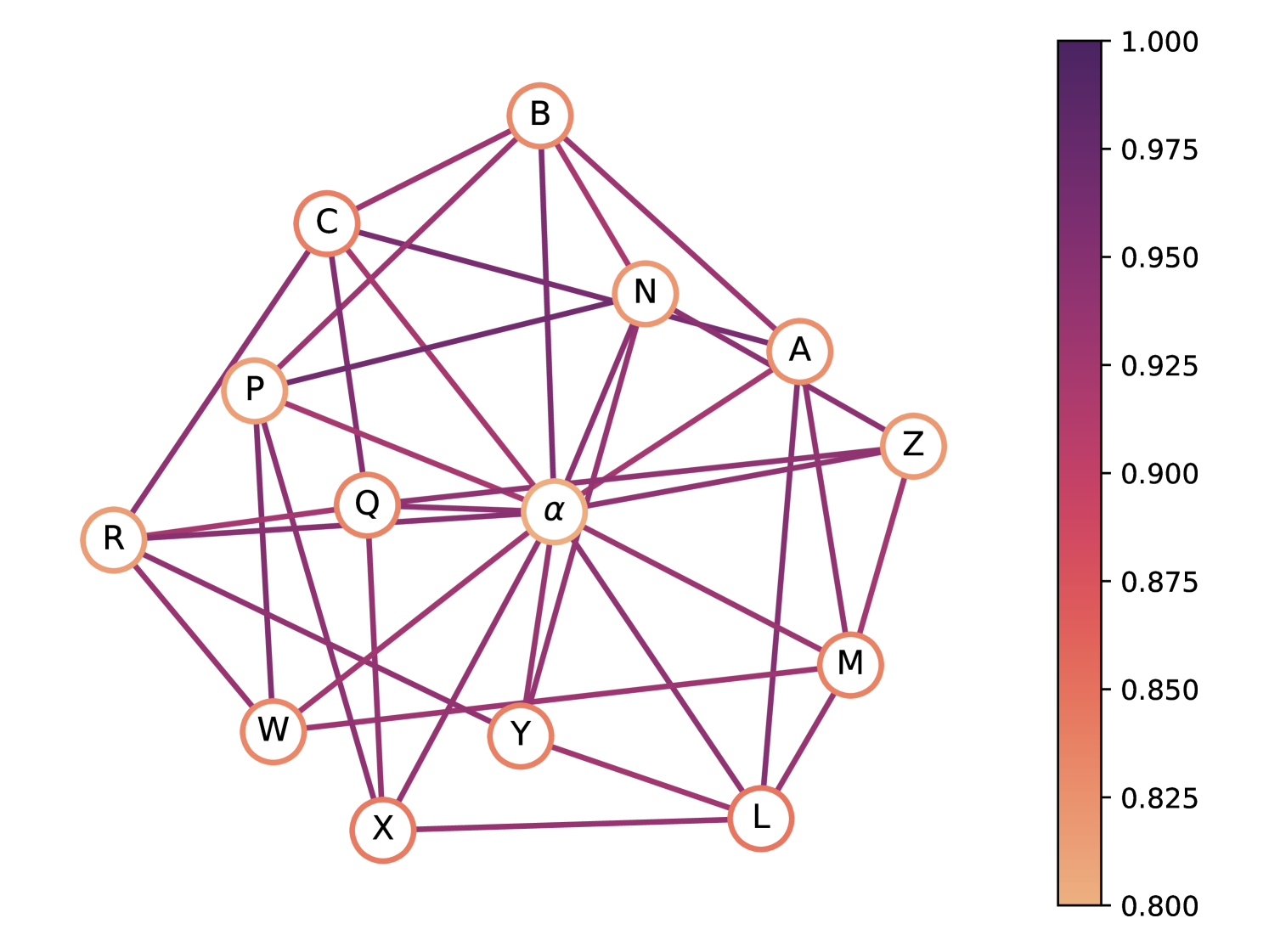
Now we focus on the quantum chromatic game for the graph (Fig. 4). For this graph there exists a perfect quantum strategy with colors, while the smallest possible coloring strategy classically requires [25]. Recall that the notion of finding the smallest possible coloring strategy classically is equivalent to finding the chromatic number of this graph [42]. This graph was conjectured to be the smallest possible graph with a perfect quantum strategy for this game, and subsequently this was proved to be the case [25, 26]. In [25] a construction was provided using an orthogonal representation of , that is, a map of vertices to vectors in such that adjacent vertices are assigned orthogonal vectors. These vectors are then used to define a set of projective measurement operators acting on the maximally entangled state to get a perfect quantum strategy to color the graph. It is unclear how to obtain an explicit set of ansätze from the projective measurements to construct a short-depth circuit that can be executed on near-term hardware (see C). We use the DPO algorithm to generate a perfect (up to numerical precision error) quantum strategy for this graph.
To simplify the search for strategies, we restrict the players to 2 qubits each, since 2 qubits suffice to represent using a binary encoding. We also impose a known constraint on an optimal strategy for synchronous games [25, 28]: Bob’s measurement operators are complex conjugate to Alice’s, halving the number of measurement parameters required. We use a measurement layer per player of general single-qubit gates, a CNOT from qubit 0 to qubit 1, and gates applied to each qubit, resulting in 8 parameters per question or 112 in total (in our code, this is the U3Ry layer).
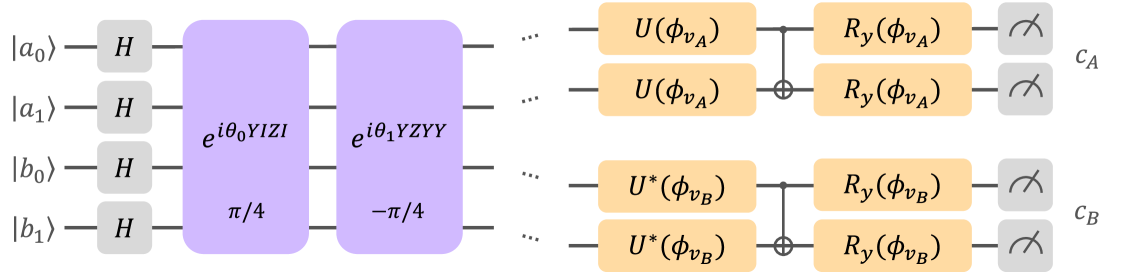
We classically simulated 500 trials of DPO, achieving a minimum energy of . We remove the gates added by ADAPT with . The corresponding circuit was then converted into a Qiskit circuit (Fig. 5), and the evaluation using the classical AerSimulator confirmed a 100% win rate (Fig. 7(a)). The 112 parameters can be found in our code repository (see A).
It is worth noting that in a nonlocal game the referee cannot cross-check answers from previous questions (otherwise the graph would not be 4-quantum colorable), and the players change their coloring for each vertex probabilistically in subsequent runs, using the entanglement to coordinate their answers as required. For example, when asked multiple times, the responses are nearly uniform among but always match. Furthermore, we found that measurement layers consisting of only single-qubit gates were insufficient and generated imperfect strategies at . In these cases, we frequently observed that the errors consisted of a cyclic path through some graph edges.
The operators chosen by ADAPT are nonlocal as expected, acting on 2 and 4 qubits. The shared state discovered,
| (14) | ||||
| (15) |
is the maximally entangled state followed by local Hadamard gates. This matches the existing strategy described in [25], which leverages the maximally entangled state, up to local unitary operations.
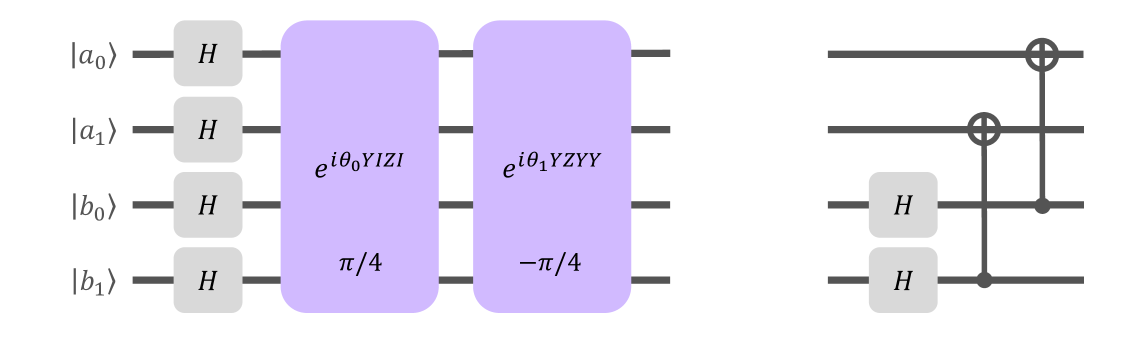
The circuit preparing the shared state needs 8 CNOT gates to be transpiled using a ladder-like formulation with CNOT gates applied between nearest-neighbor qubits. This can be reduced to 2 CNOT gates (Fig. 6) by noting that the state can be generated with transversal Bell pairs shared between the players on qubits and . Applying the transversal Hadamards in (15) flips the direction of the CNOT gates using a simple circuit identity. We refer to this version of the shared state circuit as the “Bell pair” strategy, which uses the same measurement layer and parameters as the original strategy.
4.4 Experiments on IBM Devices
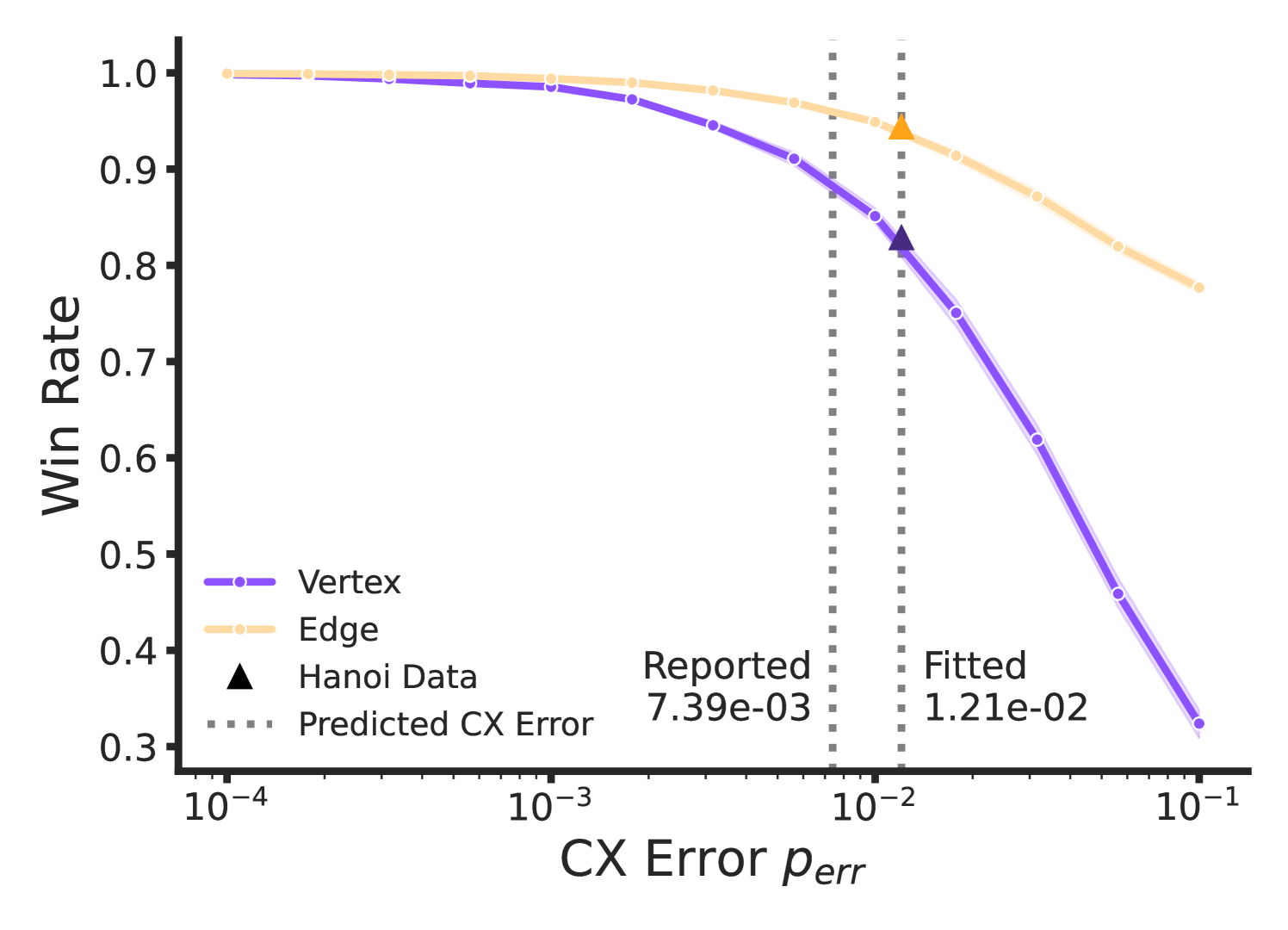
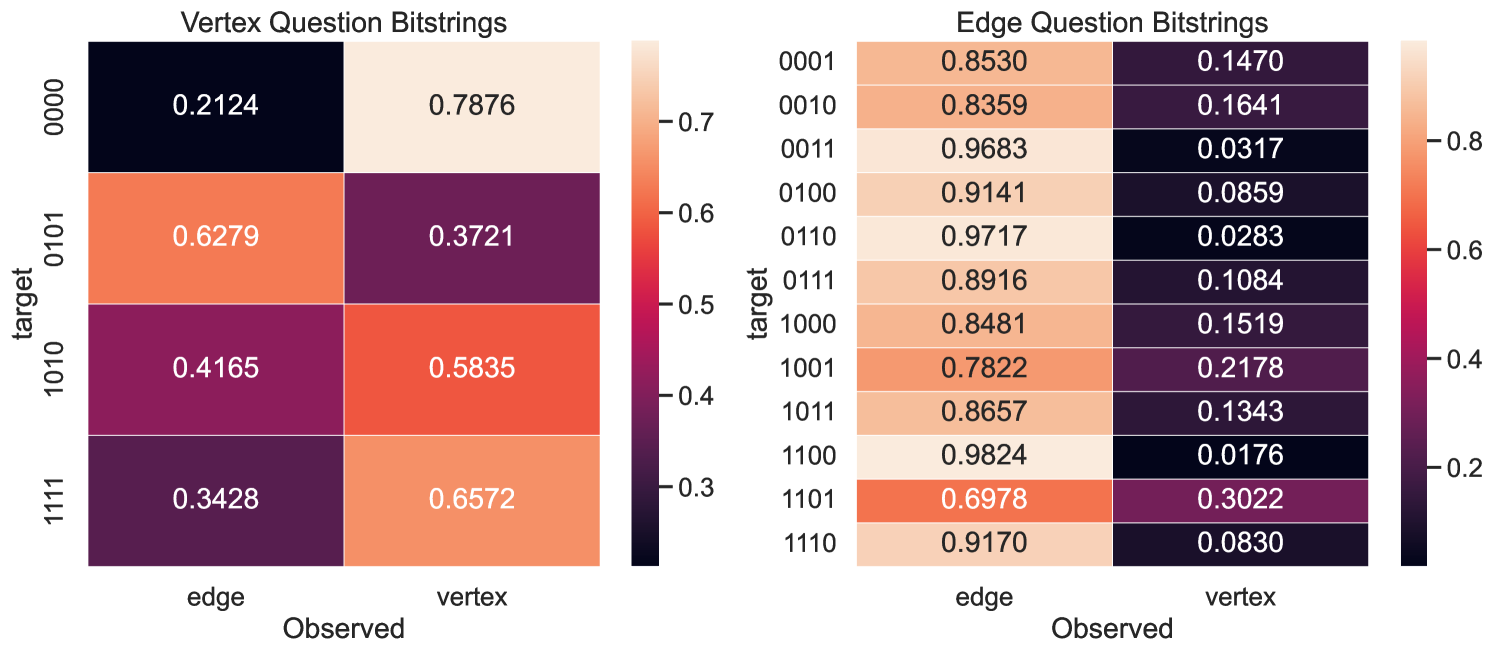
This strategy was submitted to IBM quantum devices with or more qubits (Fig. 7). A decrease in performance was observed on IBM quantum devices compared to the classical simulation due to noise, particularly affecting the success rate of vertex questions (Fig. 7(b), 8). There are several possible sources of noise:
-
1.
Vertex questions are more sensitive to bit flips, as any 1-bit error will result in the answer violating the rules , while the same is not true for edge questions, since bit flips may not necessarily make the answers agree (see Section 6). This asymmetry comes from the rules of the game.
-
2.
As the resource state depends on entanglement, error in entangling 2-qubit gates disrupts the strategy.
-
3.
Circuit transpilation to hardware with fixed qubit connectivity further incurs two-qubit gate overhead.
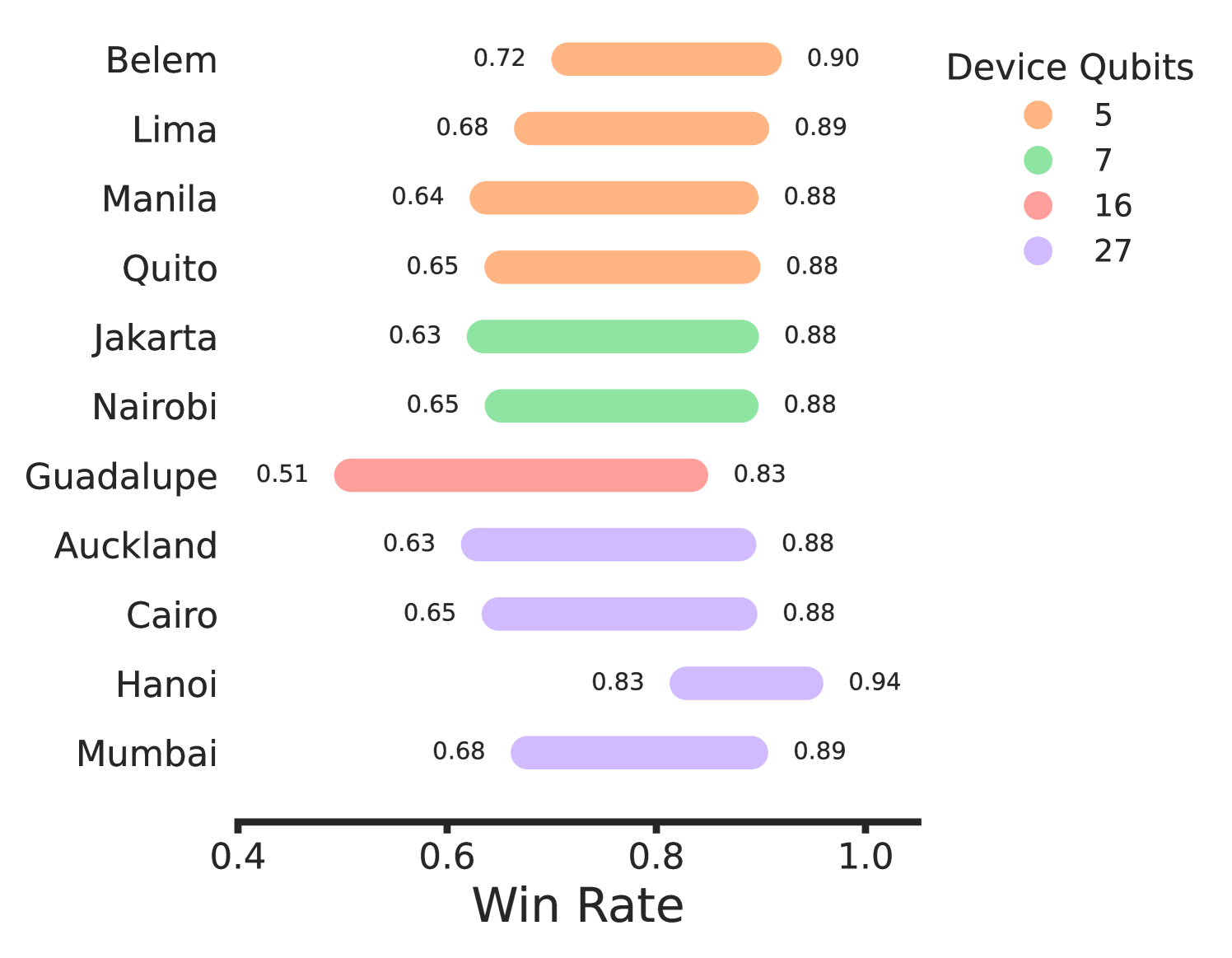
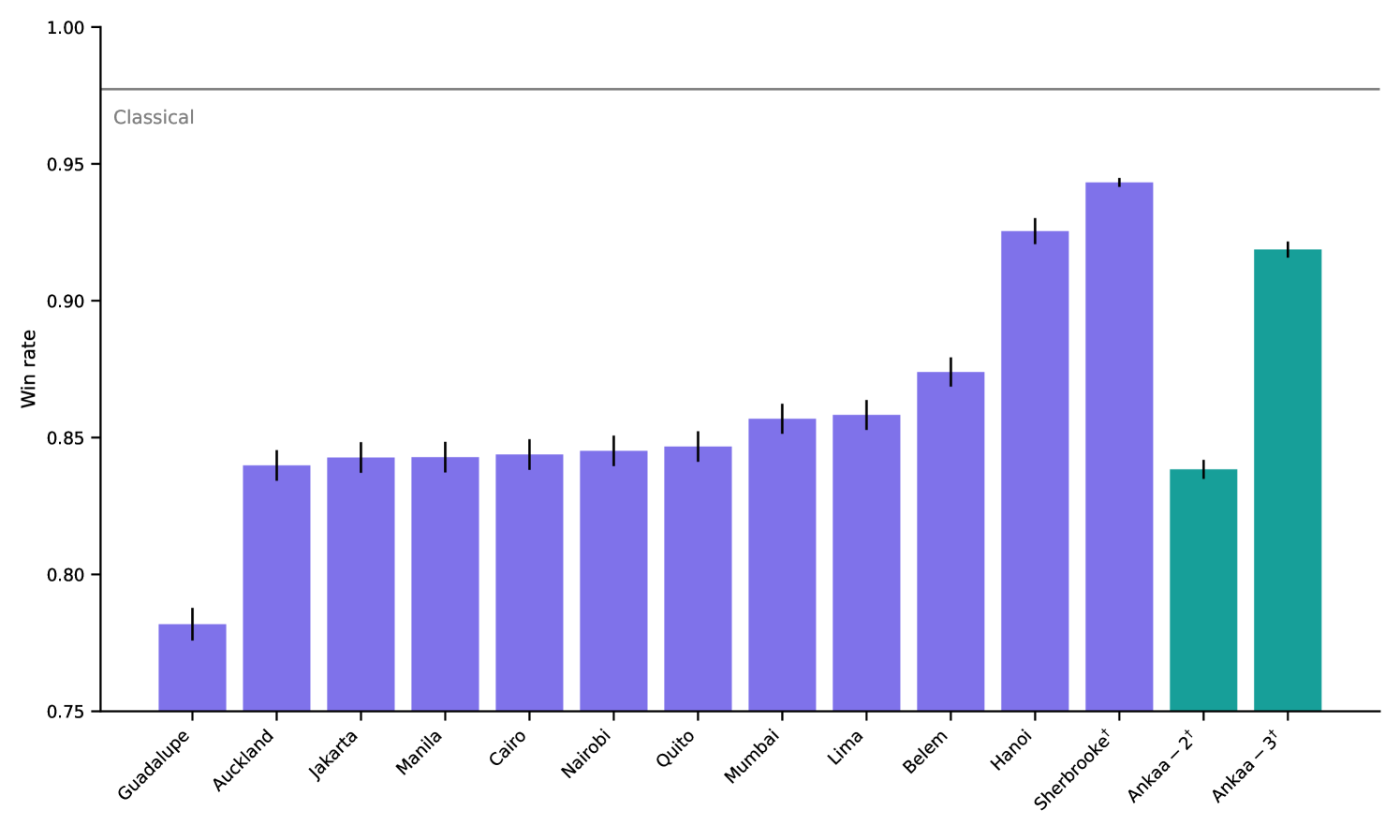
This sensitivity suggests that measuring the win rate of the strategy for is a good benchmark to evaluate the ability of a quantum device at accurately controlling for bit flip errors, while simultaneously performing nonlocal operations. In particular, the vertex question win rate is very sensitive to noise, measuring the fidelity of the device gates, whereas the edge question win rate can confirm if a device is using quantum resources. The optimal classical strategy of 4 colors consists of a 4-coloring of and assigning the most infrequently used color to the apex vertex . Therefore, all vertex questions would be correctly answered and one edge would be incorrectly answered, resulting in an edge win rate of , or an overall win rate of . Any win rate higher than this requires quantum resources. In our experiments, no device exceeded this threshold (Fig. 8). However, introducing an error-correcting version of our quantum strategy could improve the robustness of this test, which we leave to future investigations.
5 Nonlocal Games as Quantum Hardware Benchmarks
Nonlocal games with perfect strategies can serve as hardware benchmarks by assessing and analyzing the empirical win rates when executed on near-term hardware. Under certain assumptions about the structure of quantum noise, nonlocal games can exhibit quantum advantage in shallow circuits, even with noisy qubits [43]. The ‘noisy entanglement’ generated in shallow circuits enables correlations that classical circuits fundamentally struggle to reproduce. This is seen in [43]: their classical circuits of constant depth cannot simulate the long-range correlations.
In this section, we demonstrate the effectiveness of this benchmark by analyzing hardware noise and its strong correlation to strategy performance. We proceed backwards,from the unentangled readout measurements, to the independent Bell state measurements, to the initial entangled resource state preparation. By investigating the effects of hardware noise on the empirical win rates we seek to establish: a) which questions are most affected by noise, b) which components of the circuit are most affected by noise, and finally, if classical correlations, or quantum noise, could be misinterpreted as a winning quantum strategy.
In addition to the classical bounds provided in Section 4.4, we also consider the worst outcome on hardware: a nearly uniform distribution over all bitstrings. This would skew the win rates in the game as follows: for any vertex question would only be and the average win rate of any edge question would be . Thus random guessing would return an overall win rate of 59%. In Figures 11, 12, 13 and 14 we include these values as a reference.
Quantum hardware is affected by many sources of noise. The noise profile is time dependent and there are many strategies developed to optimize the scheduling and execution of quantum circuits. Using superconducting qubit platforms from IBM and Rigetti, we investigate the robustness of the original strategy, and the Bell pair strategy on superconducting qubit platforms with respect to hardware noise fluctuations over several days, and also to changes in the circuit made during the transpiration step.
5.1 Theoretical Noise Robustness
There is an asymmetric sensitivity to noise between the vertex and edge questions due to the game rules (see Section 4.4). Furthermore, there is variance in the edge questions performance. We hypothesize this arises from the particular strategy and distribution of answers found via the ADAPT algorithm. We further investigate the effects of bit-flip errors on the game strategies.
Multiple bitstrings satisfy the constraints for edge questions for all colors . Players using the four qubit strategy can win an edge question by outputting a bit string that is either Hamming distance from matching (e.g. 0001) or distance 2 (e.g. 1100). While both options satisfy the game rules, choosing bitstrings with a greater Hamming distance reduces the likelihood of losing due to device noise, as higher-weight errors occur less frequently.
To quantify the noise robustness of the strategy resulting from this, we introduce the expected Hamming distance (EHD),
| (16) |
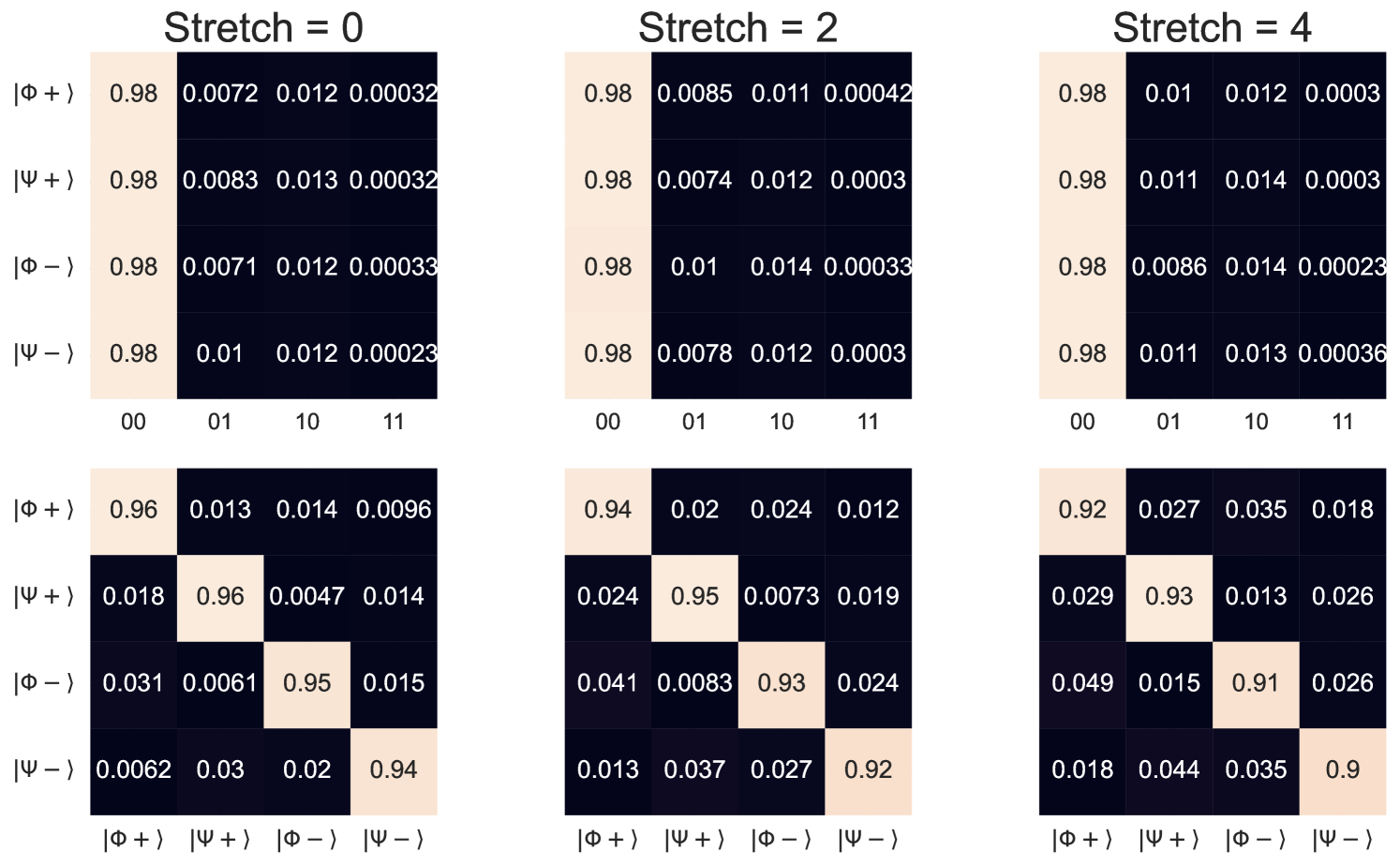
where denotes the Hamming distance between the binary representations of answers and . In general, the EHD is not efficiently computable on a classical computer since it requires sampling the strategy. However, because the strategy is sufficiently small, we calculate the EHD for each circuit via classical simulation (Fig. 9).
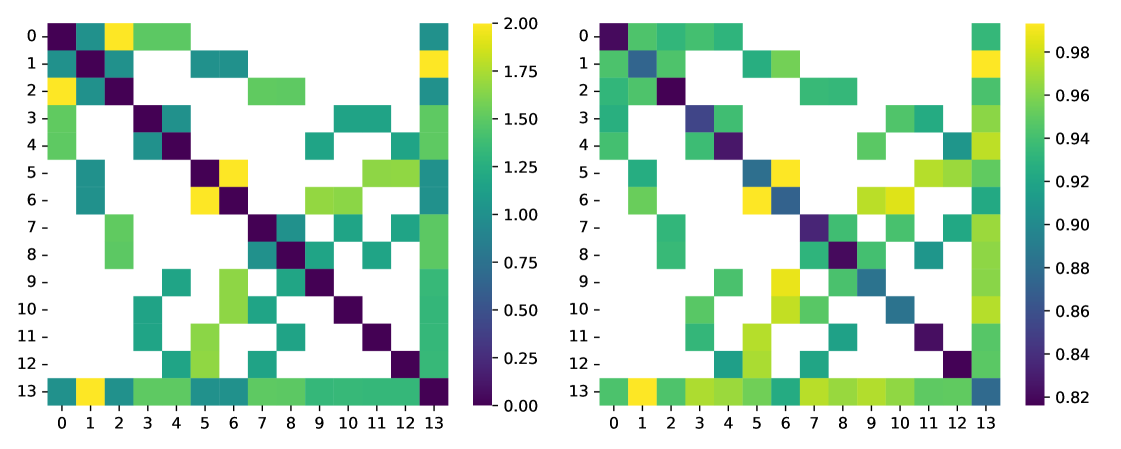
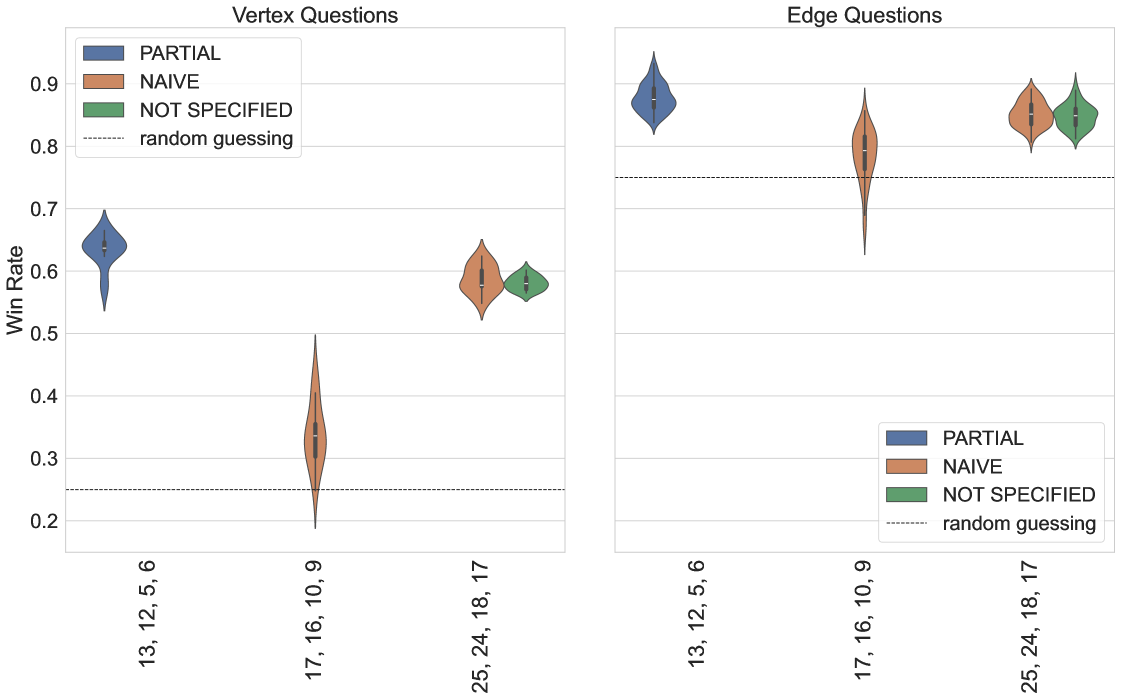
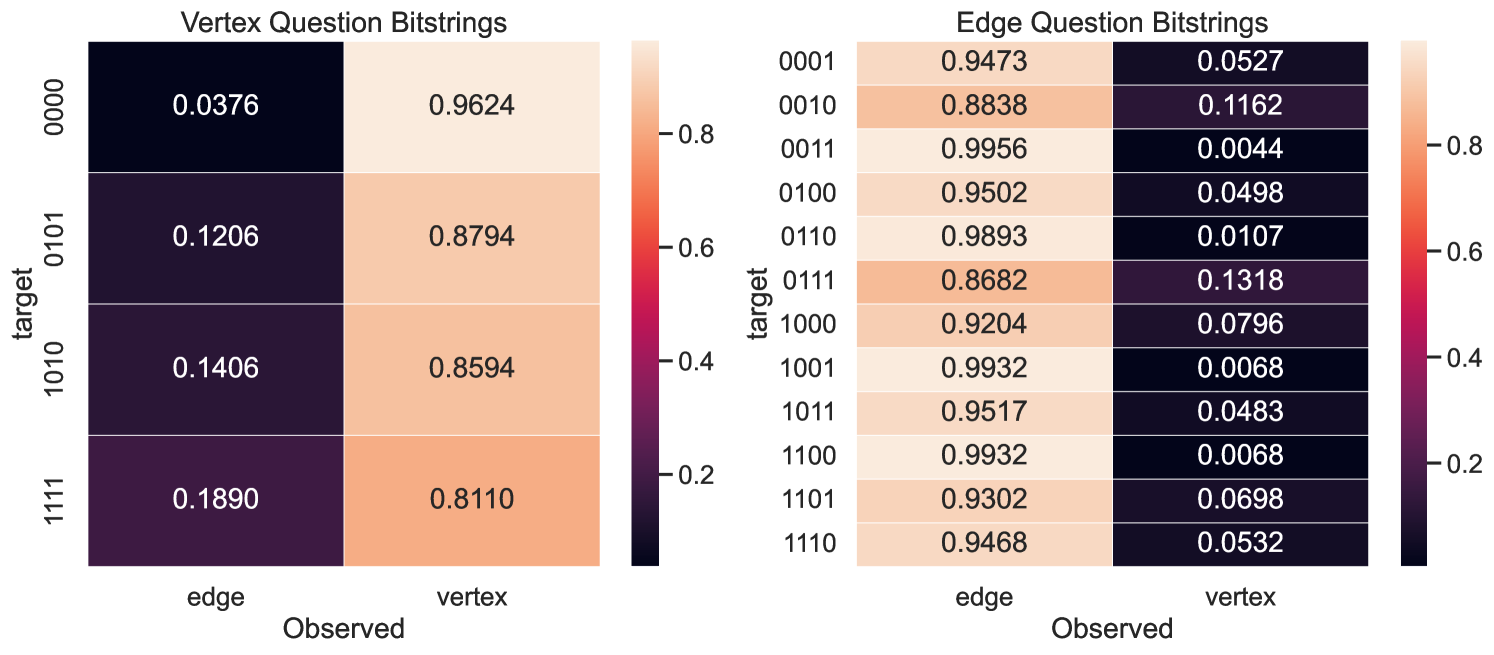
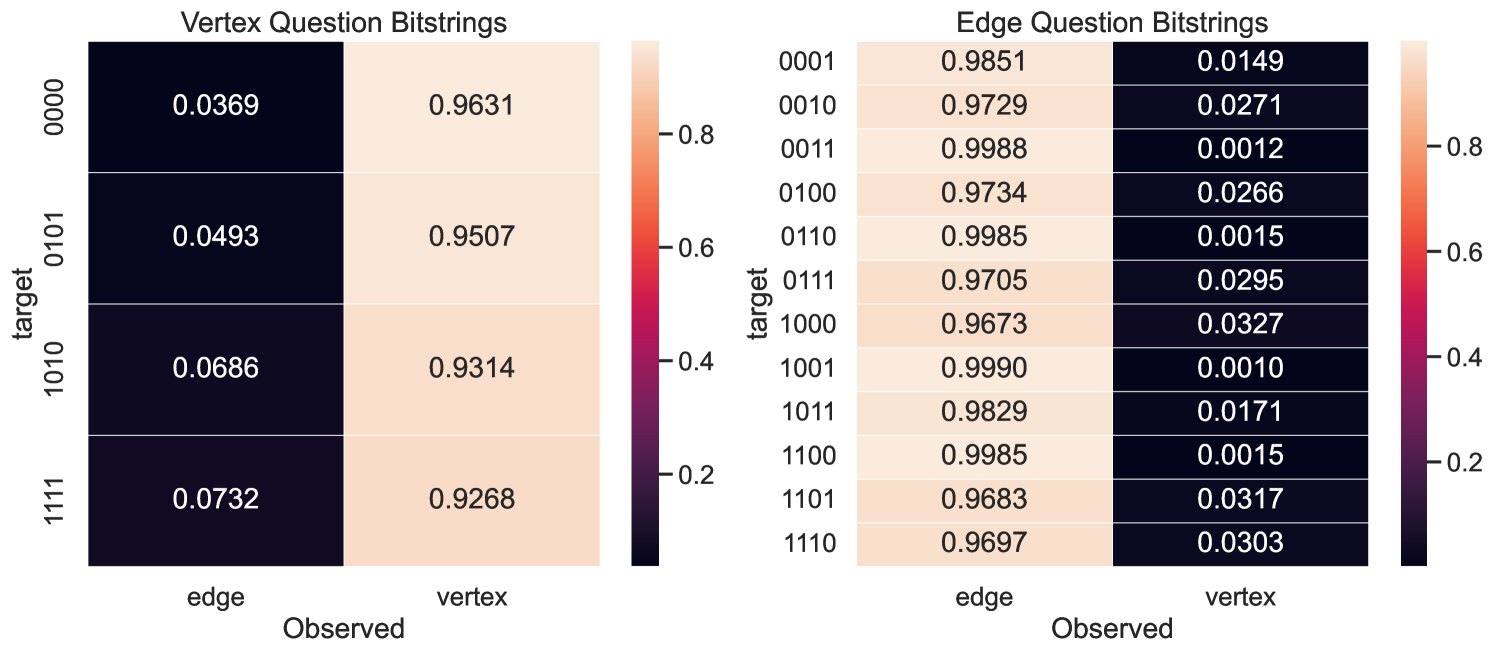
To show that the EHD effectively predicts question performance, we also plot results collected on ibm_sherbrooke111Eagle r3 processor, a superconducting qubit platform available from IBM with 127 qubits. We executed the strategy described in Section 4.3 multiple times over the course of a week. Supplemental experimental details are available in the G. The heatmaps exhibit a high degree of correlation (), suggesting the strategy produced greatly influences noise robustness. The standard deviation is also presented alongside the win rate (Fig. 10), further highlighting the sensitivity of different questions to variations in device calibration. There are some outliers, particularly and that perform worse than expected, and the EHD cannot account for variation in the vertex question performance. We leave these to future investigations.
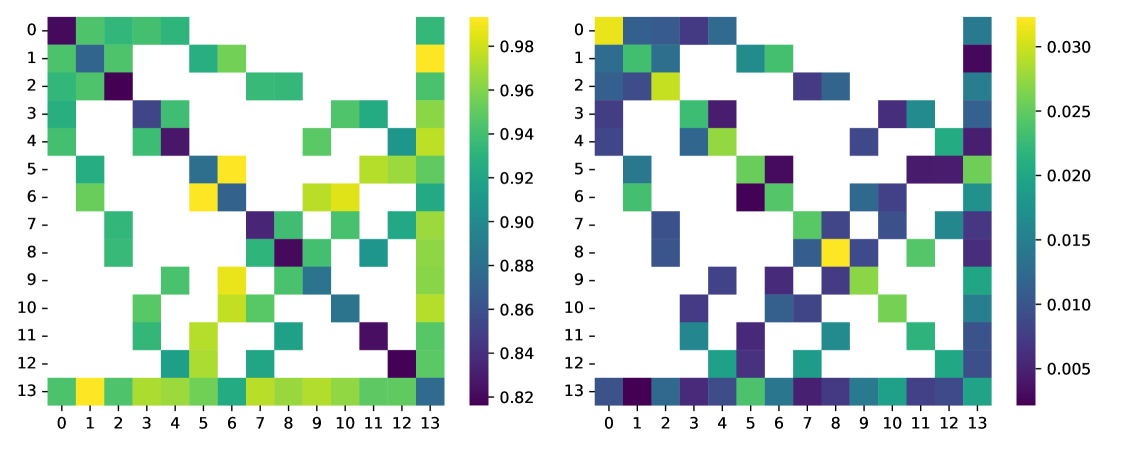
We executed circuits for the original strategy and the Bell pair strategy on Rigetti’s Ankaa-2, and Ankaa-3 devices. Both have square lattice qubit connectivity and to take advantage of this, we prioritized running experiments on qubit subsets with cyclic connectivity. The circuits first constructed in Qiskit are exported to Open Quantum Assembly Language (QASM) [44], then imported and compiled into Quil using the qiskit-rigetti plugin [45]. During compilation into native operations that are executable on the Rigetti platforms, circuit optimization is possible.
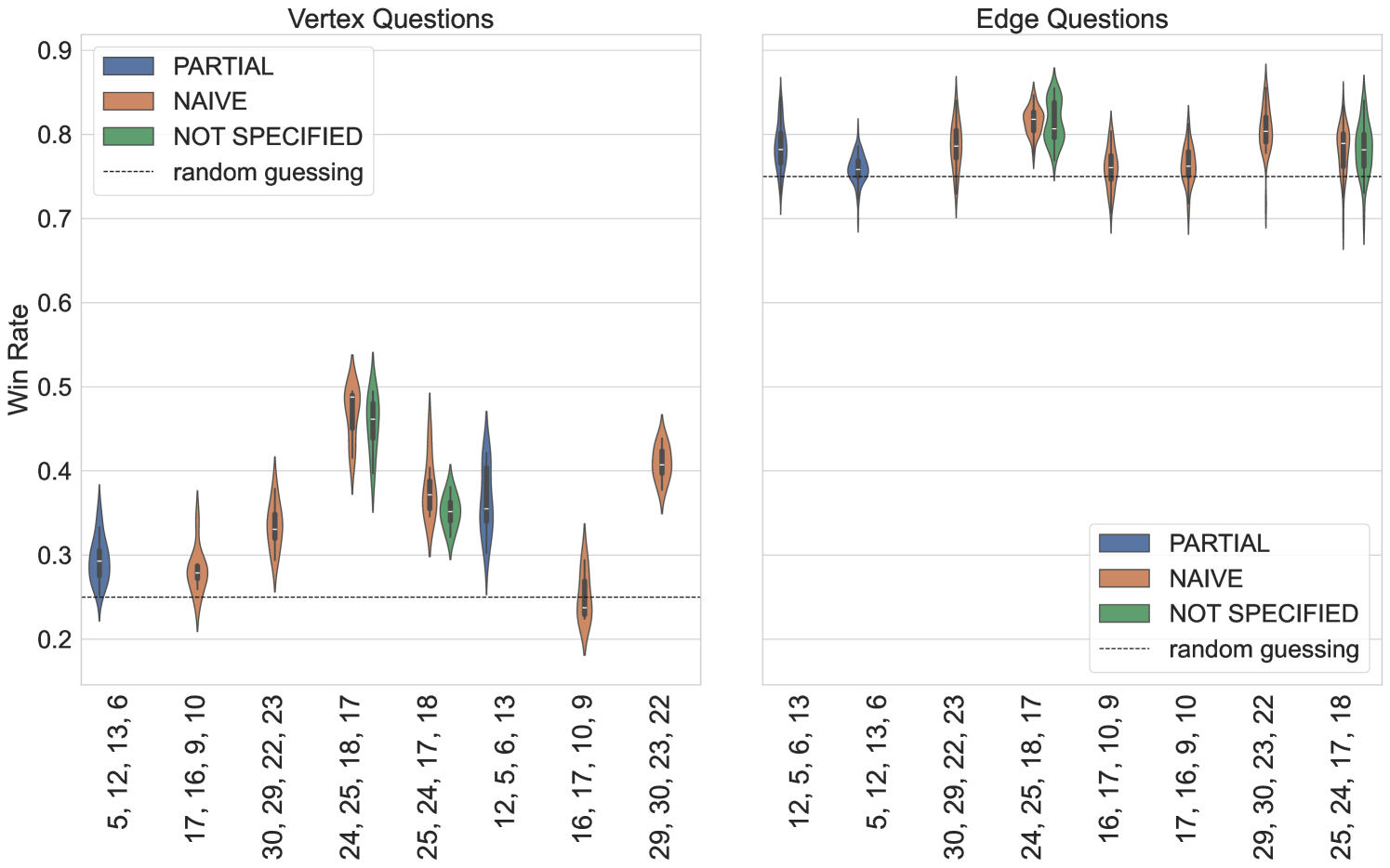
The compiled circuit can be further optimized through rewiring directives that determine how program qubits are mapped onto hardware qubits. The NAIVE rewiring uses the program qubit register index as the hardware qubit index. This rewiring may require the use of additional operations to mitigate non-neighboring interactions. The PARTIAL rewiring attempts to optimize the mapping between program and physical qubits to optimize the fidelity of the compiled circuit. We specified the rewiring strategy through the use of pre-compilation hooks. If no hooks were specified by the user, the rewiring strategy was not verified and we denote the strategy as (NOT SPECIFIED).
5.2 Noise Robustness of Game Components
In this section we analyze how hardware noise affects different nonlocal game circuit components, supported by results collected on superconducting qubit platforms. This extends the simulated noise results shown in Fig. 8(b) where the error rate of two-qubit gates was inferred from the hardware results reported in Section 4.4. We supplement these results with additional experiments designed to characterize key components of the strategy: readout measurement error, independent entangled measurements, and imperfect resource state preparation (shown in Fig. 15). Throughout this section we analyze and characterize each element individually. We determine the effective win rate that would be observed by the players if one of these elements failed or was replaced by randomness and use this to demonstrate the effectiveness of nonlocal games as a hardware benchmark.
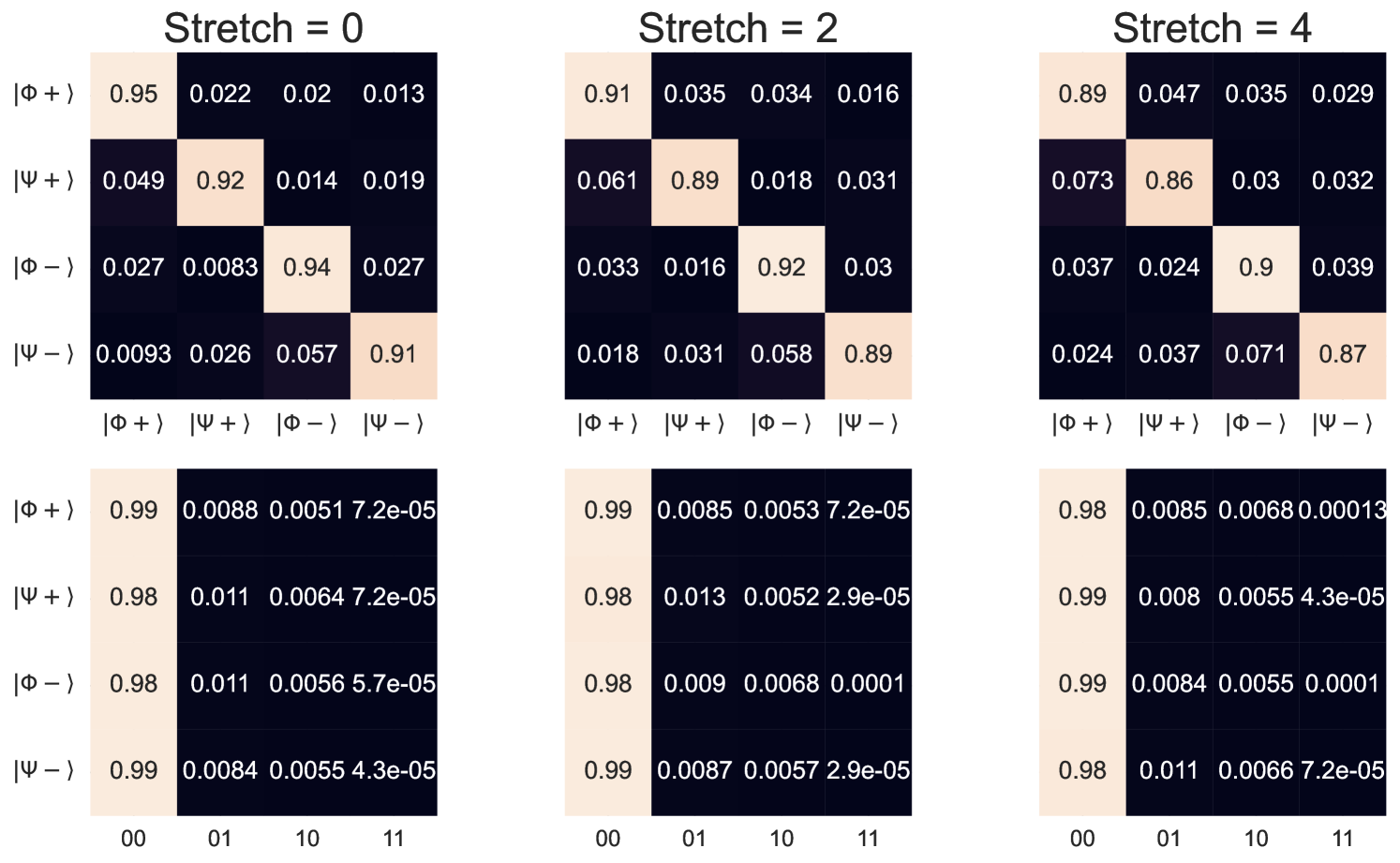
The readout measurement error can be characterized by a dimensional matrix constructed row-wise from individual computational basis state preparation and measurement: preparing the register in , applying -gates, and projecting the final state onto the computational basis. This can be used to estimate bit flip error probabilities (independent or correlated) [46], and also can be leveraged for readout error mitigation 222The results we report do not include readout error mitigation, we reserve this for future work.. We collected data to characterize the readout error on ibm_sherbrooke and Rigetti’s Ankaa-2, and Ankaa-3 platforms. In Fig. 16 we plot the Ankaa-2 and Ankaa-3 results to emphasize the connection to the EHD metric (see Section 5.1). Though the circuits executed on the hardware are very shallow, SPAM error can have a significant impact.
Connecting the SPAM error back to the EHD if a nonlocal circuit was correctly executed, and the only errors occurred during the readout stage, in Fig. 16 we see that vertex questions are more likely to return incorrect answers, while for edge questions, correct answers can still be returned with high probability. For vertex questions, the all-zero bitstring is relatively unaffected by errors during the readout measurement step, in contrast to the remaining three bitstrings. For edge questions, bit-flip errors that occur during the readout step can still return valid edge question bitstrings. The edge question in which the probability of erroneously returning a non-valid bitstring are bitstrings with high Hamming weights. Thus, if a state is correctly prepared and the error only occurs during the readout stage, it affects vertex questions and low-weight edge answers.
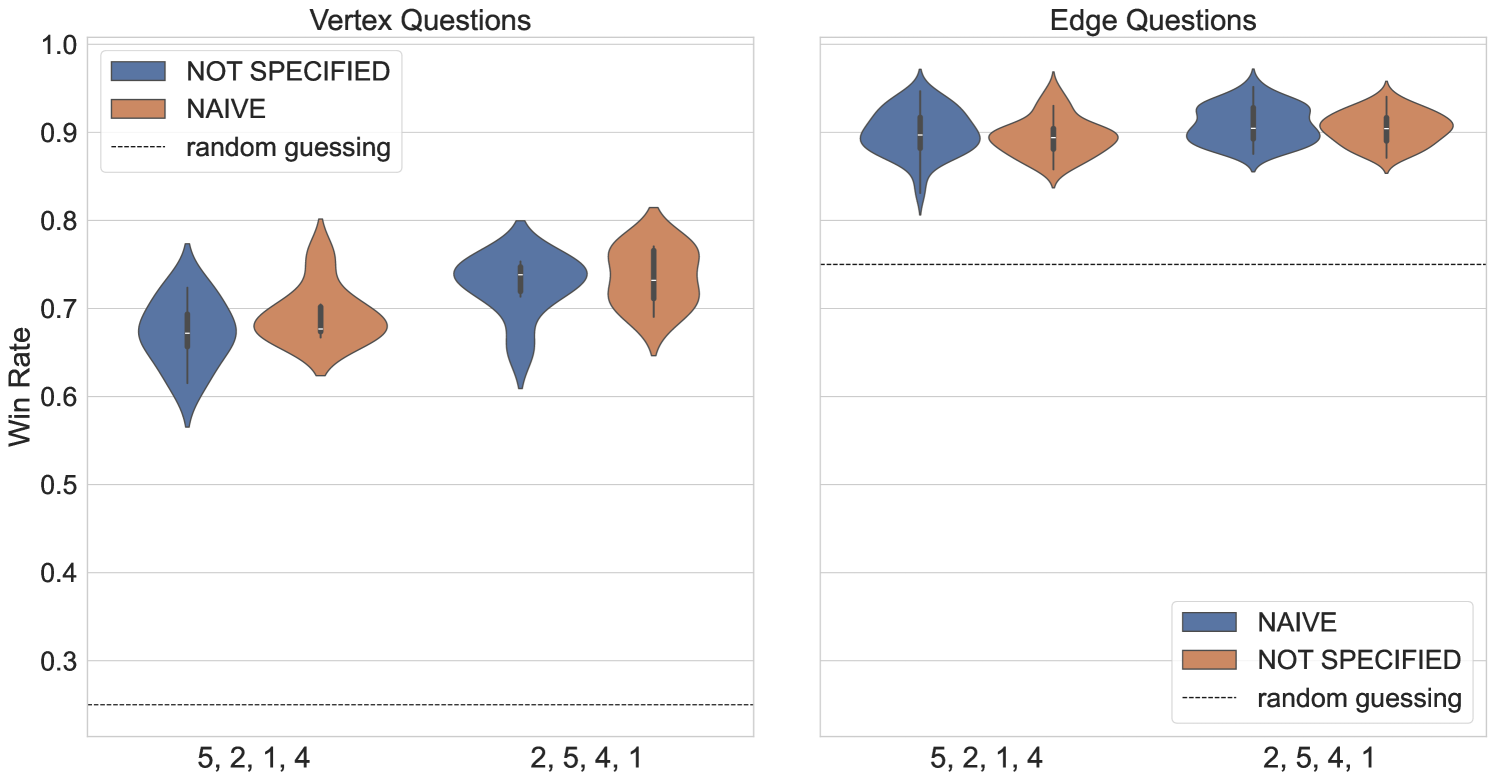
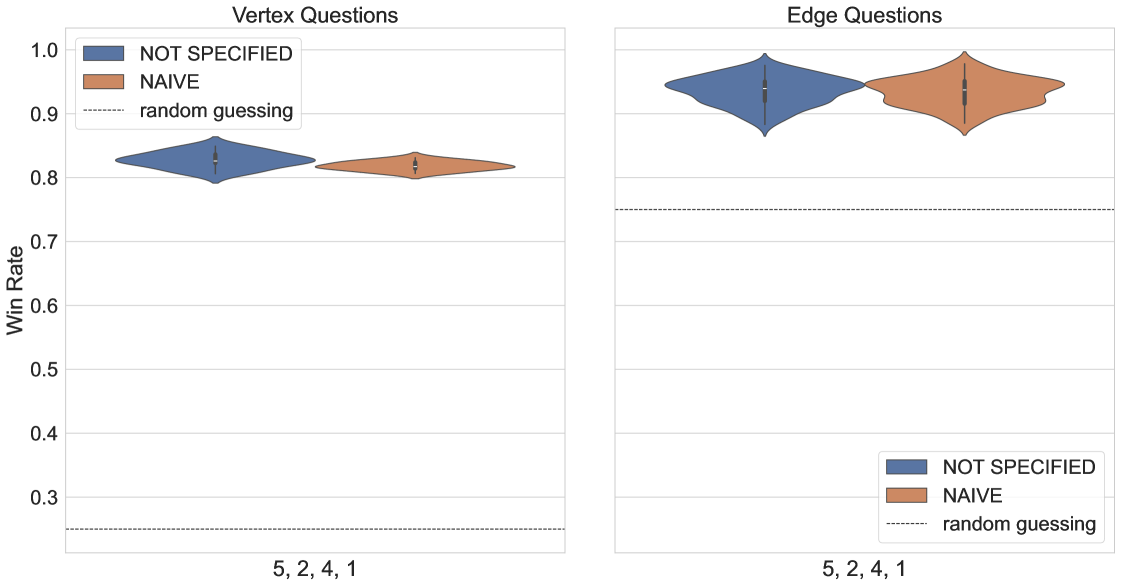
The full quantum strategy is composed of multiple circuits needed to evaluate the players’ performance on all questions posed by the referee. The construction assumes that the two players are separated in space to prohibit classical communication, and implementing the strategy requires nonlocal operations. Prior to the final qubit readout, the two players implement entangled unitaries () that are assumed to be independent. We assess the ability of each player to apply these entangled measurements with high fidelity independently, and simultaneously without corrupting each others operations. This is tested on four qubits connected in a linear chain (see G). A specific Bell state is prepared by applying or where only two qubits prepare a Bell state while the other two qubits remain in the state. Then, a Bell basis measurement is applied to the prepared Bell state and the remaining two qubits are measured in the computational basis. This is compared to the preparation of two independent Bell states both measured by Bell state measurement. To amplify the gate noise we construct and execute these circuits with basic unitary folding by inserting pairs of CNOT gates.
The general success probabilities are plotted in Fig. 17.
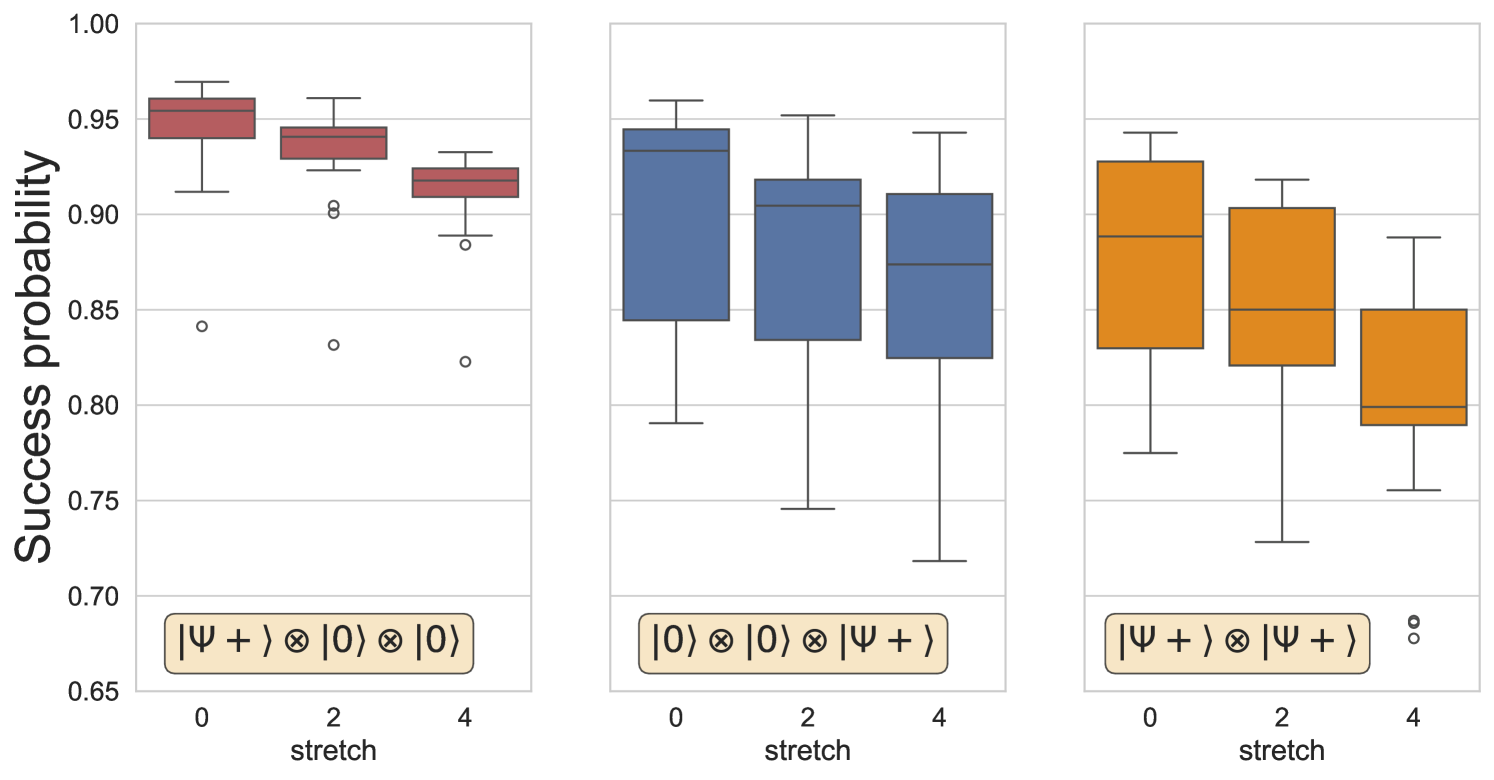
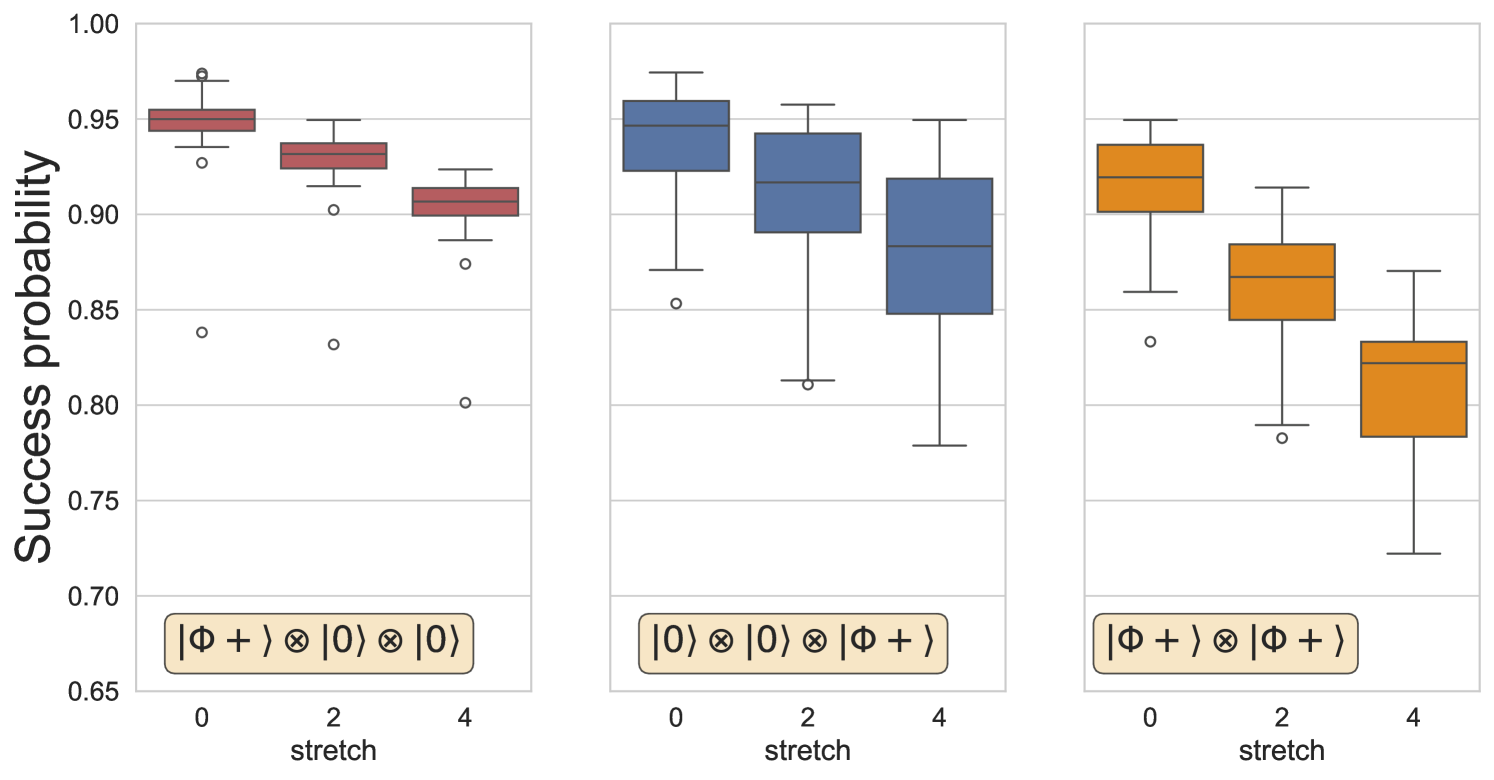
For the single Bell state preparations, we extract the marginal distributions of each subset and plot the mean probability of observing counts of each Bell state. The mean is evaluated using 14 executions of these experiments on ibm_sherbrooke.
The distinct separation between the success probabilities of isolated Bell state preparation either on or could be caused by individual two qubit gate error rates – indicative that a coupler between particular pairs of qubits could be more stable compared to neighboring qubits. Another cause could be the choice of hardware qubits combined with circuit optimization options (see G).
On Ankaa-2 we prepared the state and observe that over 75% of the observed bitstrings correspond to the correct Bell state. The highest number of counts are returned in the all-zero bitstring, indicated that the state was prepared correctly and measured correctly while the idle qubits remained idle. Preparing the state we observe that between 71-72% of the observed bitstrings correspond to the correct Bell state. However, preparing and measuring the state showed a sharp decline in counts observed in the expected bitstrings.
| Stretch | ||||
|---|---|---|---|---|
| 0 | 0.94 (1) | 0.96(2) | 0.91(2) | 0.96(3) |
| 2 | 0.92 (1) | 0.94(2) | 0.89(2) | 0.94(3) |
| 4 | 0.89 (2) | 0.90(2) | 0.86(2) | 0.92(4) |
Connecting this characterization back to the nonlocal game as a benchmark: the game construction assumes the players are separated in space and classical communication is not possible. However the implementation on near-term hardware will likely use physical qubits that are connected via tunable couplings. If correlated noise is significant when executing simultaneous multi-qubit gates on non-overlapping qubit subsets, this can affect the win rate of the players. For the Bell state example we observe that this affects the ability to implement and measure two identical states. We believe that correlated noise may impede the performance again of vertex questions. Finally, we consider the impact of hardware noise on the resource state shared by Alice and Bob. With mirrored unitary circuits [47], we measure the probability of applying and successfully returning to the initial all zero register. Testing the four qubit unitary on ibm_sherbrooke, Ankaa-2, and Ankaa-3 multiple times we find that the success rate fluctuates depending on: hardware, qubit subset, and the choice of resource state.
On ibm_sherbrooke the success rate of the mirrored four qubit unitary was 19.43%. On Ankaa-2, the mirrored four qubit unitary of the original strategy, this approach had a success rate . Specifically on September 29, 2024 the mirrored unitaries successfully returned to the initial state : on qubit subset (9,10,17,16) 8.06%; (2,3,10,9) 6.49 %; (9,10,16,17) 5.66 %; (2,9,16,23) 8.06%; and (2,3,9,10) 7.32 %. The circuit on Ankaa-2 were compiled with PARTIAL re-wiring. For Ankaa-3, the mirrored four qubit unitary success rate was much higher. On September 30, 2024 the mirrored unitaries successfully returned to the initial state : (0,1,4,3) 55.32%; (0,1,3,4) 33.08%. The circuits on Ankaa-3 were compiled with NAIVE re-wiring.
The mirrored circuits are much deeper than the resource state preparation alone, and contain more multi-qubit operations. Since noisy hardware can better prepare shallower, sparser resource state constructions, the mirror fidelity provides a pessimistic estimate of the fidelity of the resource state preparation. However we find it informative to compare the mirror fidelity of the arbitrary four qubit unitary to the mirror fidelity of the shared states used in the Bell state strategy, which we measured times during one week using ibm_sherbrooke. For this set of shared states the mean success probability was .
Overall what we can infer from these individual characterizations is how hardware can generate nonlocal correlations (in the resource state preparation), how independent qubits can be controlled (via the players entangled operations) and finally the robustness of the players answers to readout errors. The development of a full predictive model is beyond the scope of this work, but from the initial characterizations of the game components it is clear that improving individual components can significantly impact the overall win rate which is of importance in the game, where the separation between the classical and quantum strategies is small.
6 Statistical fluctuations and Sample Complexity of Estimating the Win Rate
On near-term quantum devices, the win rate of each circuit (question) is estimated by statistical sampling, using independently drawn samples to estimate the probability that the players return the correct answers. Finite sample effects lead to statistical fluctuations. In this section, we derive an upper bound on the number of individual samples (shots) to draw from a prepared state to sufficiently assess whether a circuit has correctly answered the referee’s question.
In the interactive nonlocal game setup, the scenario is repeated with random questions until the referee is satisfied with the outcome. We consider how to obtain a low error estimate of the win rate with high probability using a finite number of repetitions.
Let be the number of rounds performed, where each round consists of the referee asking the players all possible questions once and checking their answers using the rule function . In the context of quantum hardware, this can be viewed as the execution of quantum circuits with shots per circuit.
Because the outcome of each question is binary, i.e., , we model the outcome of question as a Bernoulli random variable with an unknown success probability . The random variable describing the game value of a single round is . We denote the empirical estimate of the win rate with rounds as where are i.i.d. samples. Under these mild assumptions, we derive an expression for the number of samples needed to accurately estimate the win rate within error .
Theorem 6.1.
Let be the empirical estimate of the game win rate after rounds, where each round is independent and identically distributed (i.i.d.). Then, for any ,
| (17) |
where is the number of questions and , where is the win rate of question .
Proof.
We make use of the Bernstein inequality [48, 49], which is restated here for convenience. Let be the sum of zero-mean random variables and almost surely. Then, for any ,
| (18) |
To use the inequality, we construct the sum , subtracting the expectation values to meet the zero-mean condition, yielding
| (19) |
The magnitude of each term is bounded . Furthermore, because each round is i.i.d., , where is defined above and we have used the fact that the variance of a Bernoulli random variable is . Substituting in place of gives (17). ∎
Corollary 6.2 (Sample complexity).
With probability , we obtain an -close estimate of using at least
| (20) |
rounds.
Proof.
This results from setting (17) less than or equal to and solving for . ∎
Corollary 6.3.
[Confidence interval] With rounds and with probability , the error of our estimate is
| (21) |
Proof.
This can be obtained by solving (20) for and taking the positive solution, then applying the identity . ∎
| Year | Provider | Device | Strategy | Shots | Win rate (%) |
| 2023 | IBM | Guadalupe | Original | 1024 | 78.1(6) |
| Auckland | Original | 1024 | 83.9(6) | ||
| Jakarta | Original | 1024 | 84.2(6) | ||
| Manila | Original | 1024 | 84.2(6) | ||
| Cairo | Original | 1024 | 84.3(6) | ||
| Nairobi | Original | 1024 | 84.5(6) | ||
| Quito | Original | 1024 | 84.6(6) | ||
| Mumbai | Original | 1024 | 85.6(6) | ||
| Lima | Original | 1024 | 85.8(6) | ||
| Belem | Original | 1024 | 87.3(6) | ||
| Hanoi | Original | 1024 | 92.5(5) | ||
| 2024 | IBM | Sherbrooke | Bell Pair | 4096 | 94.3(2) |
| Rigetti | Ankaa-2 | Bell Pair | 2048 | 83.8(4) | |
| Ankaa-3 | Bell Pair | 2048 | 91.8(3) |
From (20), we see two possibilities to achieve asymptotic sampling: with a large number of questions and when . The first case is not practical because increasing the number of questions counterproductively increases the total number of circuit samples .
The second case is also hard to achieve (at present) because it requires a near-perfect strategy on high-fidelity quantum hardware. This results from being directly linked to the win rate of the questions, which depends on both the strategy and quantum hardware. Assuming all questions have equal win rate for simplicity, this requires (again taking the positive solution) , which is approximately . We expect that sampling may become feasible for perfect strategies with improved gate fidelity, quantum error correction, or amplitude amplification. Table 2 contains all the win rates of our executed experiments with confidence intervals derived from Corollary 6.3.
7 Conclusion
We present a variational algorithm to compute novel quantum strategies for nonlocal games by encoding the rules of a nonlocal game into a Hamiltonian and employing a two-step optimization procedure. Our key insight is to optimize separately the state preparation circuit and the measurement scheme while leveraging robust circuit initialization and general techniques, such as ADAPT, during optimization. The proposed algorithm successfully reproduces known quantum strategies and has also discovered new short-depth, perfect quantum strategies for a graph on vertices using four qubits. This demonstrates that variational techniques can be effectively used on classical computers to identify short-depth, optimal strategies for small examples of nonlocal games where analytic methods fail. Moreover, these techniques extend to a quantum setting, where sample-based gradient estimation is employed. However, the presence of barren plateaus is a known challenge with the training objective function, suggesting that “warm starts” or other techniques to mitigate vanishing gradients may be necessary for scaling these methods to larger nonlocal games.
We further illustrate how the execution of a nonlocal game strategy can serve as an application-level benchmark for quantum devices. By evaluating the win rates of both vertex and edge questions in these games, the win rate of vertex questions reflects a device’s ability to perform nonlocal operations and maintain gate fidelity, while the win rate of edge questions can help confirm the utilization of entanglement across a device. Although none of the devices we tested surpassed the quantum advantage threshold, primarily due to noise in circuit execution, we believe our results can be improved by optimizing the transpilation of the individual circuit before execution and control of the device calibration schedules. It is also worth noting that although our experiments do not provide a full proof of quantum advantage, given that the particles are not spatially separated enough to guarantee that classical communication does not happen during the experiment, it does provide validation that the quantum hardware in question outputs results consistent with the hypotheses of quantum theory. Recent work has begun to outline ways of guaranteeing a “loop-hole free” full verification of quantum advantage by compiling a multi-prover nonlocal game strategy into a single prover strategy [50, 10, 11] and we leave it to future work to investigate the feasibility and implications of these schemes for the games we studied. In a recent survey [51], the authors outlined five desirable properties for a good quantum benchmark and in our work we argued how the win rate from nonlocal game strategies fit all five points:
-
•
Relevant: The win rate measures the ability to prepare, control, and manipulate entangled states.
-
•
Reproducible: Strategy and questions are fixed.
-
•
Fair: Device independent and the executed circuits are shallow.
-
•
Verifiable: Straightforward to calculate the win rate via sampling.
-
•
Usable: Circuits can be made accessible via QASM files and can easily be ported to other quantum devices.
We believe that the continued study and extensions of nonlocal games, in particular graph-based games, can enable the design of more appropriate quantum benchmarks as quantum devices scale and hardware architectures become more complex. Ultimately, our research not only advances the understanding of variational quantum strategies but also lays the foundation for leveraging quantum machine learning techniques to explore other nonlocal games strategies beyond the reach of classical methods.
Acknowledgments
Thanks to David Roberson and Eleanor Rieffel for providing valuable feedback. NW, JF, and COM were funded by grants from the US Department of Energy, Office of Science, National Quantum Information Science Research Centers, Co-Design Center for Quantum Advantage under contract number DE-SC0012704. JF and COM were partially supported by the Laboratory Directed Research and Development Program and Mathematics for Artificial Reasoning for Scientific Discovery investment at the Pacific Northwest National Laboratory, a multiprogram national laboratory operated by Battelle for the U.S. Department of Energy under Contract DEAC05- 76RLO1830. S. C. is supported in part by the DOE Advanced Scientific Computing Research (ASCR) Accelerated Research in Quantum Computing (ARQC) Program under field work proposal ERKJ354. K. H. was supported by the DOE Advanced Scientific Computing Research (ASCR) Pathfinder Testbed Program under FWP ERKJ418.
This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725.
This manuscript has been authored in part by UT-Battelle, LLC, under Contract No. DE-AC0500OR22725 with the U.S. Department of Energy. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for the United States Government purposes. The Department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan.
References
References
- [1] Dalzell AM, McArdle S, Berta M, Bienias P, Chen CF, Gilyén A, et al. Quantum algorithms: A survey of applications and end-to-end complexities. arXiv preprint arXiv:231003011. 2023.
- [2] Rieffel EG, Asanjan AA, Alam MS, Anand N, Neira DEB, Block S, et al. Assessing and advancing the potential of quantum computing: A NASA case study. Future Generation Computer Systems. 2024.
- [3] Proctor T, Young K, Baczewski AD, Blume-Kohout R. Benchmarking quantum computers. Nature Reviews Physics. 2025:1-14.
- [4] Emerson J, Alicki R, Życzkowski K. Scalable noise estimation with random unitary operators. Journal of Optics B: Quantum and Semiclassical Optics. 2005;7(10):S347.
- [5] Knill E, Leibfried D, Reichle R, Britton J, Blakestad RB, Jost JD, et al. Randomized benchmarking of quantum gates. Physical Review A—Atomic, Molecular, and Optical Physics. 2008;77(1):012307.
- [6] Magesan E, Gambetta JM, Johnson BR, Ryan CA, Chow JM, Merkel ST, et al. Efficient measurement of quantum gate error by interleaved randomized benchmarking. Physical review letters. 2012;109(8):080505.
- [7] Helsen J, Roth I, Onorati E, Werner AH, Eisert J. General framework for randomized benchmarking. PRX Quantum. 2022;3(2):020357.
- [8] Chen YH, Baldwin CH. Randomized Benchmarking with Leakage Errors; 2025. Available from: https://arxiv.org/abs/2502.00154.
- [9] Cross AW, Bishop LS, Sheldon S, Nation PD, Gambetta JM. Validating quantum computers using randomized model circuits. Physical Review A. 2019;100(3):032328.
- [10] Natarajan A, Zhang T. Bounding the quantum value of compiled nonlocal games: from CHSH to BQP verification. In: 2023 IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS). IEEE; 2023. p. 1342-8.
- [11] Kalai Y, Lombardi A, Vaikuntanathan V, Yang L. Quantum advantage from any non-local game. In: Proceedings of the 55th Annual ACM Symposium on Theory of Computing; 2023. p. 1617-28.
- [12] Šupić I, Bowles J. Self-testing of quantum systems: a review. Quantum. 2020;4:337.
- [13] Hart O, Stephen DT, Williamson DJ, Foss-Feig M, Nandkishore R. Playing nonlocal games across a topological phase transition on a quantum computer. arXiv preprint arXiv:240304829. 2024.
- [14] Drmota P, Main D, Ainley E, Agrawal A, Araneda G, Nadlinger D, et al. Experimental Quantum Advantage in the Odd-Cycle Game. Physical Review Letters. 2025;134(7):070201.
- [15] Bell JS. On the Einstein Podolsky Rosen paradox. Physics Physique Fizika. 1964;1(3):195.
- [16] Clauser JF, Horne MA, Shimony A, Holt RA. Proposed experiment to test local hidden-variable theories. Physical review letters. 1969;23(15):880.
- [17] Cleve R, Hoyer P, Toner B, Watrous J. Consequences and limits of nonlocal strategies. In: Proceedings. 19th IEEE Annual Conference on Computational Complexity, 2004. IEEE; 2004. p. 236-49.
- [18] Reichardt BW, Unger F, Vazirani U. A classical leash for a quantum system: Command of quantum systems via rigidity of CHSH games. arXiv preprint arXiv:12090448. 2012.
- [19] Fritz T. Tsirelson’s problem and Kirchberg’s conjecture. Reviews in Mathematical Physics. 2012;24(05):1250012.
- [20] Slofstra W. Tsirelson’s problem and an embedding theorem for groups arising from non-local games. Journal of the American Mathematical Society. 2020;33(1):1-56.
- [21] Ji Z, Natarajan A, Vidick T, Wright J, Yuen H. MIP*=RE. Communications of the ACM. 2021;64(11):131-8.
- [22] Cameron PJ, Montanaro A, Newman MW, Severini S, Winter A. On the Quantum Chromatic Number of a Graph. The Electronic Journal of Combinatorics. 2007;14(1):R81.
- [23] Mančinska L, Roberson DE. Quantum homomorphisms. Journal of Combinatorial Theory, Series B. 2016;118:228-67.
- [24] Daniel AK, Zhu Y, Alderete CH, Buchemmavari V, Green AM, Nguyen NH, et al. Quantum computational advantage attested by nonlocal games with the cyclic cluster state. Physical Review Research. 2022;4(3):033068.
- [25] Mančinska L, Roberson DE. Oddities of Quantum Colorings. Baltic Journal on Modern Computing. 2016;4(4):846-59.
- [26] Lalonde O. On the Quantum Chromatic Numbers of Small Graphs. arXiv preprint arXiv:231108194. 2023. Available from: https://arxiv.org/abs/2311.08194.
- [27] Lupini M, Mančinska L, Paulsen VI, Roberson DE, Scarpa G, Severini S, et al. Perfect strategies for non-local games. Mathematical Physics, Analysis and Geometry. 2020;23(1):7.
- [28] Helton JW, Mousavi H, Nezhadi SS, Paulsen VI, Russell TB. Synchronous values of games. In: Annales Henri Poincaré. vol. 25. Springer; 2024. p. 4357-97.
- [29] Helton JW, Meyer KP, Paulsen VI, Satriano M. Algebras, synchronous games, and chromatic numbers of graphs. New York J Math. 2019;25:328-61.
- [30] Ortiz CM, Paulsen VI. Quantum graph homomorphisms via operator systems. Linear Algebra and its Applications. 2016;497:23-43.
- [31] Mančinska L, Paulsen VI, Todorov IG, Winter A. Products of synchronous games. arXiv preprint arXiv:210912039. 2021.
- [32] Cameron PJ, Montanaro A, Newman MW, Severini S, Winter A. On the quantum chromatic number of a graph. arXiv preprint quant-ph/0608016. 2006.
- [33] Clauser JF, Horne MA, Shimony A, Holt RA. Proposed Experiment to Test Local Hidden-Variable Theories. Physical Review Letters. 1969 oct;23(15):880-4.
- [34] Kempe J, Kobayashi H, Matsumoto K, Toner B, Vidick T. Entangled games are hard to approximate. SIAM Journal on Computing. 2011;40(3):848-77.
- [35] Bharti K, Haug T, Vedral V, Kwek LC. Machine learning meets quantum foundations: A brief survey. AVS Quantum Science. 2020 jul;2(3). Available from: https://doi.org/10.1116%2F5.0007529.
- [36] Bharti K, Haug T, Vedral V, Kwek LC. How to Teach AI to Play Bell Non-Local Games: Reinforcement Learning; 2019.
- [37] Grimsley HR, Economou SE, Barnes E, Mayhall NJ. An adaptive variational algorithm for exact molecular simulations on a quantum computer. Nature communications. 2019;10(1):3007.
- [38] Mitarai K, Negoro M, Kitagawa M, Fujii K. Quantum circuit learning. Physical Review A. 2018 sep;98(3). Available from: https://doi.org/10.1103%2Fphysreva.98.032309.
- [39] Schuld M, Bergholm V, Gogolin C, Izaac J, Killoran N. Evaluating analytic gradients on quantum hardware. Physical Review A. 2019 mar;99(3). Available from: https://doi.org/10.1103%2Fphysreva.99.032331.
- [40] Tura J, Augusiak R, Sainz AB, Vértesi T, Lewenstein M, Acín A. Detecting nonlocality in many-body quantum states. Science. 2014;344(6189):1256-8.
- [41] Harris SJ. Universality of graph homomorphism games and the quantum coloring problem. In: Annales Henri Poincaré. Springer; 2024. p. 1-36.
- [42] Paulsen VI, Todorov IG. Quantum chromatic numbers via operator systems. The Quarterly Journal of Mathematics. 2015;66(2):677-92.
- [43] Bravyi S, Gosset D, König R, Tomamichel M. Quantum advantage with noisy shallow circuits. Nature Physics. 2020;16(10):1040-5.
- [44] Cross AW, Bishop LS, Smolin JA, Gambetta JM. Open quantum assembly language. arXiv preprint arXiv:170703429. 2017.
- [45] Rigetti. Qiskit-Rigetti Plugin. GitHub; 2024. https://github.com/rigetti/qiskit-rigetti.
- [46] Hamilton KE, Kharazi T, Morris T, McCaskey AJ, Bennink RS, Pooser RC. Scalable quantum processor noise characterization. In: 2020 IEEE International Conference on Quantum Computing and Engineering (QCE). IEEE; 2020. p. 430-40.
- [47] Mayer K, Hall A, Gatterman T, Halit SK, Lee K, Bohnet J, et al. Theory of mirror benchmarking and demonstration on a quantum computer. arXiv preprint arXiv:210810431. 2021.
- [48] Bernstein S. On a modification of Chebyshev’s inequality and of the error formula of Laplace. Ann Sci Inst Sav Ukraine, Sect Math. 1924;1(4):38-49.
- [49] Zhang H, Chen S. Concentration Inequalities for Statistical Inference. Communications in Mathematical Research. 2021;37(1):1-85.
- [50] Grilo AB. A Simple Protocol for Verifiable Delegation of Quantum Computation in One Round. In: 46th International Colloquium on Automata, Languages, and Programming (ICALP 2019). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik; 2019. .
- [51] Acuaviva A, Aguirre D, Peña R, Sanz M. Benchmarking Quantum Computers: Towards a Standard Performance Evaluation Approach. arXiv preprint arXiv:240710941. 2024.
- [52] Cerezo M, Arrasmith A, Babbush R, Benjamin SC, Endo S, Fujii K, et al. Variational quantum algorithms. Nature Reviews Physics. 2021;3(9):625-44.
- [53] Warren A, Zhu L, Mayhall NJ, Barnes E, Economou SE. Adaptive variational algorithms for quantum Gibbs state preparation. arXiv preprint arXiv:220312757. 2022.
- [54] Sherbert K, Furches J, Shirali K, Economou SE, Marrero CO. Adaptive Quantum Generative Training using an Unbounded Loss Function. In: 2024 IEEE International Conference on Quantum Computing and Engineering (QCE). vol. 1. IEEE; 2024. p. 1731-8.
- [55] Childs AM, Wiebe N. Hamiltonian simulation using linear combinations of unitary operations. arXiv preprint arXiv:12025822. 2012.
- [56] Chakraborty S. Implementing any linear combination of unitaries on intermediate-term quantum computers. Quantum. 2024;8:1496.
- [57] Catli AB, Simon S, Wiebe N. Exponentially Better Bounds for Quantum Optimization via Dynamical Simulation. arXiv preprint arXiv:250204285. 2025.
Appendix
Appendix A Data Availability
The code used to generate the data and figures in this article can be found at
https://github.com/jfurches/nonlocalgames. The authors will make available the data collected for noise characterization by reasonable request.
Appendix B ADAPT-VQE
The Adaptive Derivative-Assembled Pseudo-Trotter ansatz Variational Quantum Eigensolver (ADAPT-VQE) is a hybrid quantum-classical algorithm designed to dynamically construct an efficient and compact ansatz for molecular simulations on quantum hardware [37]. It enhances the traditional Variational Quantum Eigensolver (VQE) by adaptively building a problem-specific ansatz for the quantum state. Unlike traditional approaches such as Unitary Coupled Cluster (UCC), which rely on pre-defined and often redundant wavefunction ansätze, ADAPT-VQE grows the ansatz iteratively by selecting operators that maximize energy recovery at each step. This adaptive approach minimizes the number of parameters and quantum gates required, making it well-suited for noisy intermediate-scale quantum (NISQ) devices.
ADAPT-VQE operates by measuring the gradient of the Hamiltonian’s expectation value with respect to each operator in a predefined operator pool. The operator with the largest gradient is added to the ansatz, and its parameter is optimized alongside previously added parameters using a classical variational optimizer. This process is repeated until the norm of the gradient vector falls below a threshold, ensuring convergence to the desired accuracy.
More concretely: assume we have variational parameters and the operator pool , the ansatz in iteration of the algorithm may be written as
Notice that the ansatz at iteration is grown by appending operator with coefficient ; the operator is chosen by measuring the energy gradients for each operator in the pool and selecting the one with the largest gradient. For this step, it can be shown that
where the right hand side can be efficiently measured on a quantum processor as the size of a problem scales. The pool operator gradient-measurement step is followed by a convergence check: if the pool operator gradient norm is smaller than a threshold , the calculation is terminated; if not, the iteration procedure continues. The ansatz-growing step is followed by a VQE optimization of all variational parameters.
By tailoring the ansatzs to the problem at hand, ADAPT-VQE achieves high accuracy with significantly reduced circuit depth compared to fixed ansatz methods. This variational technique has been studied extensively [52] and it has been extended to tackle problems in Quantum Generative training [53, 54]
Appendix C Original Strategy
Here we outline the perfect quantum strategy for the graph using colors as detailed in [25]. The authors construct this strategy by leveraging a 4-dimensional real orthogonal representation of the graph and a transformation derived from quaternion multiplication outlined in [22]. Here is an outline of their construction:
-
1.
Ortogonal Representation: For each vertex in we assign a normalized 4D real unit vector as follows:
-
•
For each vertex in (see Figure 4) you assign it a 3-dimensional vectors with entries in such that two vertices in are adjacent if and only if their corresponding vectors are orthogonal.
-
•
For each 3-dimensional vector, , extended it to a 4D vector by appending a zero: .
-
•
Assign the apex vertex of the 4D vector .
-
•
Normalize each vector to be a unit vector and let be the vector corresponding to vertex .
-
•
This assignment guarantees that if vertices and are adjacent (), their vectors are orthogonal ().
-
•
To each vector , we associate a set of four mutually orthogonal unit vectors, , where each vector is a columns of the following matrix:
So, , , and so on. These four vectors form the measurement basis for vertex .
-
•
-
2.
State and Projectors : In the corresponding nonlocal game, Alice and Bob share a 4-dimensional maximally entangled state, . Upon receiving a vertex , a player performs a measurement using projectors , where each projector is defined by the corresponding basis vector:
-
3.
Joint Probabilities : The probability that Alice and Bob obtain outcomes (colors) and for questions and respectively, is given by:
This formula ensures that the winning conditions of the coloring game are met with certainty. Specifically, if , then . If , then for all .
One difficulty in implementing this strategy comes from the fact that measurement schemes are given as projections, which would need to be decomposed, for example, using Linear Combinations of Unitatires (LCU) [55]. The cost of standard LCU can be resource-intensive requiring ancilla qubits, where is the number of unitaries in the linear combination, as well as the need to implement the “prepare” unitary and a sophisticated multi-qubit controlled “select” unitary for each projection separately. Other techniques like Ancilla-free LCU [56] might be able to reduce this overhead, but assessing the feasibility of implementing this strategy in near-hardware is non-trivial and outside the scope of the work.
Appendix D Measurement Parameters
Alice’s measurement parameters of the strategy are contained within
data/g14_constrained_u3ry/g14_state.json with the key phi. Constructing this into a NumPy array should return a tensor of shape , corresponding to (players, questions, qubits, parameters). This tensor can be transformed to produce the conjugated measurement angles for Bob, as seen in U3RyLayer in measurement.py.
Appendix E Hyperparameters
| Problem | Hyperparameter | Value |
|---|---|---|
| CHSH | ADAPT Grad Max | |
| BFGS Grad Max | ||
| DPO Tolerance | ||
| NPS | Same as CHSH | |
| ADAPT Grad Max | ||
| BFGS Grad Max | ||
| DPO Tolerance |
We give the algorithm hyperparameters for our experiments. The parameter refers to the convergence criteria of ADAPT used to prepare the shared state . ADAPT finishes when the maximum pool gradient element reaches the threshold, . Similarly, the parameter controls the convergence of the second phase of DPO, as the BFGS optimizer halts when . Finally, controls the termination of the overall DPO procedure, ending when at iteration .
Appendix F Gradient Sample Complexity
In this section, we analyze the efficiency of the gradient simulation to understand its sample complexity. This addresses the practical and theoretical challenges faced when implementing our algorithm. The gradient complexity we consider is in terms of the number of exponentials required to achieve any precision.
Theorem F.1.
Let be a random variable describing the error in the gradient estimate for the experiment with variance . Then the sample complexity of estimating the gradient with variance is given by , where is the dimensionality of the parameter space.
Proof.
Let . By the additivity of the variance, it follows that . The Euclidean norm of the gradient is approximated using the variances of the measurement outcomes. Hence
| (22) |
Since each experiment requires operator exponentials and this must be repeated times, the total number of operator exponentials is
| (23) |
as desired. ∎
Theorem F.2.
Assume that the variational state requires parameters to specify and that we wish to minimize over . Assume that is Lipshitz continuous with constant and that is Lipshitz continuous with constant . We then have that the number of exponentials required to perform gradient descent optimization with final error in the objective function at most using learning rate and epochs is in
| (24) |
Proof.
The gradient descent rule with learning rate reads
| (25) |
Using our assumption that the gradient is Lipshitz-continuous with constant , then
| (26) |
If we define to be an approximate gradient evaluated at the parameters , then
| (27) |
Thus, we can recursively define the error in the parameter vector after epochs to be and thus from the triangle inequality and the gradient update rule we have
| (28) |
We can then solve this recursion relation to find that
| (29) |
Using the assumption that the objective function is Lipshitz-continuous with constant ,
| (30) |
Then it suffices to choose the error per gradient evaluation such that
| (31) |
Isolating yields
| (32) |
This means that from Theorem F.1, the total number of exponentials per epoch that are needed is
| (33) |
Using the fact that there are repetitions of the above
| (34) |
∎
This shows that the sample complexity of such problems can, in general, be substantial. In particular, if a small learning rate is required for the evolution, the number of operations needed for optimization can be exponential. The learning rate should be chosen (in the strongly convex case) to be proportional to the smallest eigenvalue of the Hessian matrix, implying that the number of samples scales exponentially with the condition number. This can be prohibitive in cases where some optimization directions are vastly steeper than others, such as in the vicinity of a saddle point. The number of epochs required for optimization is similarly difficult to bound. However, in the case where the optimization function is strongly convex, the number of epochs varies logarithmically with the error in the final objective function. In general, however, such optimization problems are not necessarily strongly convex. For these reasons, we leave the parameters of the gradient descent arbitrary.
As a final note, this suggests that variationally optimizing the parameters for a nonlocal game is not necessarily expected to be efficient, in general. To make this optimization tractable at scale, we need to minimize the number of epochs as much as possible. This can be achieved by starting with a well-informed initital guess for the protocol before attempting to optimize the result. If such conditions are met, the above analysis suggests that a manageable number of operations will be needed to achieve a constant distance from the locally optimized strategy. To tackle the general problem, we suggest exploring alternative optimization approaches such as solving the variational problem using dynamical simulation-based methods [57].
Appendix G Experimental Details
The experiments on ibm_sherbrooke were conducted 7 different times between Sep. 27 - Oct. 1, 2024 with 4096 shots per circuit. The layout was chosen on the first run to be qubits 46-49 (a linear chain) using the dense method of the Qiskit transpiler with no optimization (level 0). For subsequent runs, the same layout was repeated. Each batch contained: the SPAM characterization circuits, the independent unitary noise characterization circuits, mirror fidelity circuits and the Bell pair game circuits. In Table 2 and Fig. 19, the best run on ibm_sherbrooke is reported. Calibration data for the backend was queried and saved at the time the circuit batch entered the queue and in Table 4 we report the two qubit gate error (ECR gates).
| name | value |
|---|---|
| ecr45_44 | 0.010494 |
| ecr45_46 | 0.007731 |
| ecr47_46 | 0.004980 |
| ecr47_48 | 0.006505 |
| ecr49_48 | 0.005589 |
| ecr49_50 | 0.010321 |
| ecr50_51 | 0.007020 |