Approximate Borderline Sampling using Granular-Ball for Classification Tasks
††thanks: This work was supported by XXX.
††thanks: *: Corresponding author.
Abstract
Data sampling enhances classifier efficiency and robustness through data compression and quality improvement. Recently, the sampling method based on granular-ball (GB) has shown promising performance in generality and noisy classification tasks. However, some limitations remain, including the absence of borderline sampling strategies and issues with class boundary blurring or shrinking due to overlap between GBs. In this paper, an approximate borderline sampling method using GBs is proposed for classification tasks. First, a restricted diffusion-based GB generation (RD-GBG) method is proposed, which prevents GB overlaps by constrained expansion, preserving precise geometric representation of GBs via redefined ones. Second, based on the concept of heterogeneous nearest neighbor, a GB-based approximate borderline sampling (GBABS) method is proposed, which is the first general sampling method capable of both borderline sampling and improving the quality of class noise datasets. Additionally, since RD-GBG incorporates noise detection and GBABS focuses on borderline samples, GBABS performs outstandingly on class noise datasets without the need for an optimal purity threshold. Experimental results demonstrate that the proposed methods outperform the GB-based sampling method and several representative sampling methods. Our source code is publicly available at https://github.com/CherylTse/GBABS.
Index Terms:
Granular computing, Granular-ball computing, Sampling, Class noise, Classification.I Introduction
Data sampling plays a pivotal role in supervised machine learning, particularly for classification tasks. It offers a multitude of benefits, including reduced computational complexity, balanced class distributions, diminished effects of noise and outliers, alleviation of overfitting, and enhanced model interpretability. Over the past few decades, sampling has achieved significant advancements for classification tasks, which can be summarized into three categories: sampling methods for specific classifiers, sampling methods for specific datasets, and general sampling methods.
Sampling methods for specific classifiers leverage various aspects of the classifier, including model parameters and classification results, to guide the sampling process, allowing the classifier to actively inform sample selection to potentially improve performance. For instance, a sampling method [1] is proposed to enhance the robustness of streaming algorithms against adversarial attacks. Zhang et al.[2] employ feedback from each weak classifier in ensemble learning to sample based on loss or probability scores. While these methods offer advantages in targeted training, a potential drawback lies in their inherent coupling to specific classifiers, which limits their generalizability.
Sampling methods for specific datasets aim to tailor the sampling process to the unique characteristic of a dataset, potentially improving the quality of the training dataset to improve the model’s performance, including modal-specific datasets and imbalanced datasets. First, sampling methods tailored for modal-specific datasets encompass a variety of techniques. These include methods designed for text data[3], image data[2, 4], point cloud data[5, 6], audio data[7], and time series data[8]. Second, sampling methods addressing imbalanced datasets with skewed class distributions aim to rectify the imbalance between different classes. These methods[9, 10] help mitigate issues such as overfitting on the majority class and underfitting on the minority class[11]. Commonly employed methods in this domain include the Synthetic Minority Over-sampling Technique (SMOTE) and its variants[12, 13, 14, 15], as well as Tomek Links[16]. However, these methods are often coupled with specific datasets. Moreover, oversampling methods such as SMOTE may blur class boundaries and increase redundancy in the sampled dataset, while undersampling methods like Tomek links may discard critical samples necessary for the classifier.
General sampling methods are those that are applicable to various types of datasets and classifiers, including simple random sampling (SRS)[17], systematic random sampling[18], stratified sampling[19], and Bootstrapping[20]. These methods offer broad applicability across various machine learning tasks. However, they typically perform sampling based on the overall probability distribution, making them more susceptible to noise than other sampling methods. As a new paradigm for processing diverse large-scale datasets, granular computing (GrC)[21] can significantly improve computing efficiency by transforming complex datasets into information granules, which serve as the computing units instead of individual samples. Granular-ball computing (GBC)[22] is a new branch of GrC that uses the granular-ball (GB) to represent the information granule. Inspired by GBC, Xia et al.[23] propose the GB-based sampling (GBS) method that can be used for various datasets and classifiers and performs well in class noise classification. GBS addresses the limitations of the aforementioned sampling methods. Although GBS performs well, it still suffers from several limitations, as follows. 1) Existing definition of the GB cannot fully describe the positional information of all samples it contains. 2) Existing granular-ball generation (GBG) methods suffer from the issue of overlap between GBs. 3) Existing GBG methods are sensitive to purity thresholds to achieve robustness, and selecting the optimal threshold is time-consuming.
Notably, effective classification hinges on learning accurate class boundaries, such as separation points, lines, curves, surfaces, or hypersurfaces, depending on the dimensionality of the data. Borderline samples residing on these boundaries hold particular significance for training classifiers. There have been some borderline sampling methods[24, 25, 26]. Still, they suffer from limitations: classifier-specific and computationally expensive (at least quadratic time complexity) due to their reliance on original samples as the computing unit.
As discussed, although much effort has been dedicated to sampling for classification tasks, a general and efficient sampling method for borderline samples is still lacking. To address the aforementioned limitations, inspired by the GrC, this paper proposes an approximate borderline sampling method using GBs for classification tasks, including the restricted diffusion-based granular-ball generation (RD-GBG) method and GB-based approximate borderline sampling (GBABS) method. The main contributions are as follows.
-
1)
The proposed RD-GBG method eliminates GB overlap and redefines GBs, ensuring that the distribution of generated GBs aligns more closely with the original dataset.
-
2)
The proposed RD-GBG method incorporates noise detection without searching for an optimal threshold to achieve adequate noise tolerance, thereby enhancing sampling efficiency and quality.
-
3)
The proposed GBABS method adaptively identifies borderline samples, reducing both class noise and redundancy in the sampled dataset, while its linear time complexity accelerates classifiers.
The remainder of this paper is organized as follows. Section II gives some commonly used notations. Section III reviews related works on GBC and GBS. In Section IV, the RD-GBG and GBABS are introduced in detail. The performance of the proposed methods is demonstrated in Section V. Finally, the conclusion and further work are presented in Section VI.
II Notations
To make the paper more concise, in the subsequent content, let be a dataset, where is the feature vector of the sample , is its class, and . The low-density sample set is denoted as . Samples that have not been divided into any GB are called undivided samples. The set of undivided samples is denoted as . is the set of GBs generated on , where , is the corresponding center set. The sampled dataset is denoted as . Furthermore, samples of the same class are called homogeneous samples; otherwise, they are called heterogeneous samples, and the same applies to GB.
III Related Work
III-A Granular-Ball Computing
GBC[22] is a family of scalable, efficient, and robust data mining methods, which is a two-stage learning, including the GBG stage and the GB-based learning stage. The core idea of the GBC is to employ the ball of varying granularity to represent the information granule and replace the sample for calculating in various tasks. The geometry of the ball is completely symmetrical, and only the center and radius are required to characterize it in any dimension, so it can be easily applied to diverse scenarios, including classification[22, 27, 28], clustering[29, 30, 31], fuzzy sets[32, 33], feature engineering[34, 35, 36] and deep learning[37].
As a granulation method, the core idea of the GBG method is to cover a dataset with a set of balls, where a ball is called a GB . Specifically, the granulation process of the existing GBG methods can be briefly described as follows. First, the whole training dataset is initialized as the initial GB. Second, -means[22], -division[27], or hard-attention division[38] is employed to split the GB into or more finer GBs. The center and radius of are defined as follows.
| (1) |
where , represents the cardinality of set , and denotes the distance function. Without losing generality, Euclidean distance is employed in this paper. For most real datasets, the samples are unevenly distributed in the feature space, and the GB defined by Eq.1 will cause some samples to be distributed outside the ball.
The label of the is determined by the majority of samples contained within it. The quality of the is measured using the purity , that is, the ratio of the number of samples within the that are consistent with its label to the number of all samples within it. The closer the purity of GB is to , the closer the distribution of GBs is to the original dataset. Iteratively split each GB until the purity of each GB reaches the given purity threshold.
Existing GBG methods suffer from overlapping GBs, causing the distribution of GB sets to diverge from that of the original dataset, leading to inconsistency between the sampled and original datasets. Although this issue tends to alleviate with increasing purity[22], it cannot be fully resolved. For instance, overlapping heterogeneous GBs would blur class boundaries, and overlapping homogeneous GBs can cause the shrinking of class boundaries.
III-B GB-based Sampling Method
Inspired by GBC, a general GB-based sampling method (GGBS) and a GB-based sampling method for imbalanced datasets (IGBS) are proposed by Xia et al.[23], both including the GBG stage and the undersampling stage.
The core idea of the GBG method used in the GBG stage of GGBS and IGBS can be briefly described below. Given a dataset , it is initialized to the initial GB. For each GB, if its purity is less than the purity threshold and the number of samples within the GB is greater than , then the -division is used to split the GB into finer GBs. Iteratively, until the purity of each GB reaches the threshold or the number of samples it contains is less than or equal to . Finally, a GB set is obtained. In this section, a GB is called a small GB if it contains no more than samples; otherwise, it is called a large GB.
The core idea of the undersampling stage of GGBS can be summarized as follows. First, all samples contained in small GBs are put into the sampled dataset . Second, for each large GB, put samples into the sampled dataset , which are the homogeneous sample closest to the intersection point of the GB and the coordinate in each feature dimension.
The core steps of the undersampling stage of IGBS are as follows. First, the first step is the same as that for GGBS. Second, for each minority class GB that is large, all the containing minority class samples are sampled into . Third, for each majority class GB that is large, majority class samples are sampled into , whose sampled rule is the same as GGBS. Finally, if the class distribution is still skewed, randomly sample more majority samples into .
However, the aforementioned GBG method stops splitting GBs to ensure a preset sample count, even if the purity threshold is unmet, and GB overlaps further degrade their quality. These issues reduce the quality of the sampled data in GGBS and IGBS. Additionally, GGBS applies a uniform sampling strategy across all GBs, ignoring the importance of borderline GBs, which may retain redundancy or noise, limiting classifier improvement. Moreover, IGBS blindly balances class ratios without assessing sample redundancy, increasing the risk of overfitting.
IV Approach
The proposed sampling method is a two-stage learning approach, namely, the GBG stage and the GB-based sampling stage. This section will introduce the proposed RD-GBG method and the GBABS method, respectively.
IV-A Framework
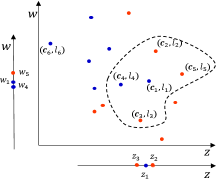
The architecture of the RD-GBG method is shown on the left side of Fig.1. The entire training dataset is initialized as the undivided sample set. First, the undivided sample set is grouped by labels, and a sample is randomly chosen as the candidate center from each group, prioritizing larger groups. And perform center detection to determine whether the center meets the local consistency which means that the center has neighbors that are homogeneous with it. Second, construct the pure GB based on each eligible center on the undivided sample set, as well as the new GB cannot overlap with the previous GBs. Iteratively, the above process is performed on the undivided sample set until the undivided samples with local consistency converge. Lastly, orphan GBs are constructed.
The architecture of the GBABS method is shown on the right side of Fig.1. First, the RD-GBG method is performed for a given dataset to obtain a GB set. Second, take the centers of all GBs to form a center set to represent their location information in the feature space. Third, based on the center set, the GBs on the class boundaries are detected from each feature dimension. Finally, sampling is performed based on the heterogeneous adjacent relation between borderline GBs.
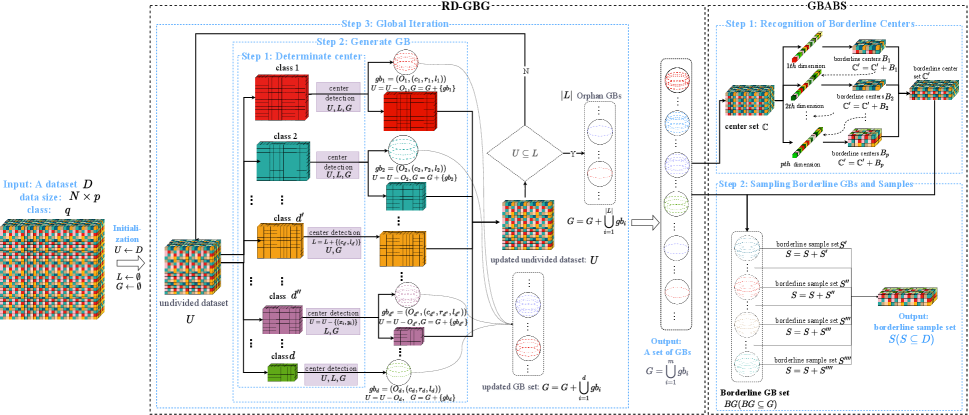
IV-B Restricted Diffusion-based GBG Method
In the field of GrC, the granulation method for large-scale datasets needs to follow three criteria. The first one is that the distribution of information granules should be as consistent as possible with that of the original dataset, which can be called approximation. The second one is that a GB should contain as many samples as possible to improve the efficiency as well as ensure the performance of the GB-based downstream learning tasks, which can be called representativeness. The third one is that the samples should be used as much as possible, which can be called completeness.
Consequently, based on the idea of restricted diffusion, a new GBG method is proposed in this section, which is adaptive and without overlap among GBs. As shown in Fig.1, the whole training dataset is initialized to the undivided sample set . The GB is constructed on in turn iteratively. Specifically, the construction process of GB will be introduced in detail below, which includes the determination method of local-density centers, the construction method of the GB, and the iteration termination condition.
IV-B1 Determination Method of Local-density Centers
Considering that the center of the GB should be representative and the method should apply to datasets of different shapes, the center is selected randomly with local consistency; namely, at least the nearest neighbor is homogeneous to the center. A method for determining the local-density center is proposed below, as Step 1 of RD-GBG module of Fig.1.
Suppose the potential center set denoted as , where , , , , represents the number of class in , all samples in are homogeneous, and .
Randomly select a sample denoted as from each to form a candidate center sequence . Since each element in is randomly selected, they may not satisfy the local consistency. Therefore, the elements in need to be detected to obtain eligible centers, called local-density centers. A detailed introduction to the detection method is below.
For , calculate the distance between and each , . If the sample closest to is homogeneous with it, then is a local-density center, otherwise further check the number of samples that are heterogeneous with it in nearest neighbors , .
| (2) |
where refers to density tolerance.
The local-density center detection rules are as follows, where the local-density center sequence is denoted as .
-
•
If , then is judged as a class noise and update to ;
-
•
If , then the nearest neighbor sample is determined as a class noise and update to . Update to ;
-
•
If , namely, cannot be distinguished from other classes to be judged as a low-density sample, then update to .
Consequently, there are the local-density center sequence , , the updated undivided sample set and low-density sample set .
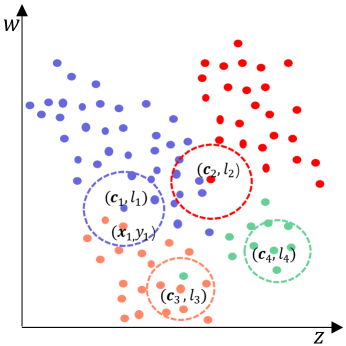
As shown in Fig.2, there is a dataset with 4 classes marked in different colors. First, the undivided sample set is initialized to , the low-density sample set is initialized to , and the potential center sample set is , , where and . Second, and are randomly selected heterogeneous centers to form a candidate center sequence . Third, to confirm whether these centers satisfy local consistency, local-density center detection is performed on each respectively. Without losing generality, let the density tolerance be . For , since its nearest neighbor is heterogeneous with it and some other its 5 nearest neighbors are homogeneous with it, can be considered as a low-density sample rather than a qualified center. For , since its 5 nearest neighbors are heterogeneous with it, then is a class noise. Moreover, for , since its nearest sample is heterogeneous with it and the others in 5 nearest neighbors are all homogeneous with it, can be taken as the eligible center, and its nearest sample is identified as a class noise. In addition, for , since it is homogeneous with its 5 nearest neighbors, it can be taken as an eligible center. As a result, the local-density center sequence is .
IV-B2 Generation Method of the GB
When other conditions remain unchanged, the greater the purity of the GB, the more consistent the distribution of GBs is with the distribution of the original dataset. Thus, all the purity of generated GBs is 1.0, namely, pure GBs. To construct pure GB with more samples without overlap, consider the centers in local-density center sequence sequentially and adopt a strategy of diffusion from the center and stopping when encountering heterogeneous samples or previous generated GBs. A method for generating the GB without overlapping is proposed below, as Step 2 of RD-GBG module of Fig.1.
First, suppose that a set of GBs has been generated on , . For each , calculate the distance between and each . If the nearest neighbor of is heterogeneous with it and the nearest neighbors are all homogeneous with it, the distance corresponding to the nearest neighbors is called locally consistent radius of , denoted as .
| (3) |
where the label of any sample in is , and there is a sample in whose label is not .
Second, to ensure there is no overlap between GBs, the distance from the center to the nearest constructed GB should be considered, denoted as the conflict radius .
| (4) |
where and are center and radius of , respectively.
Notably, if , the distance corresponding to the sample in farthest from without overlapping with previous GBs should be taken as the radius, which called the restricted maximum consistent radius . To summarize, the radius can be represented as follows.
| (5) |
where is defined as below.
| (6) |
If , then the center is distributed on the edge of the undivided sample set, and the center might be divided into other GB containing multiple samples later. Therefore, only consider the case that . The set of samples that fall within a ball with as center and as the radius is defined below.
| (7) |
Consequently, the GB is generated. Update to , and to . Iteratively, until all centers in are considered.
Notably, all the samples in are covered by , the can correctly represent the positional information of all samples in . Long story short, the defined characterizes the central tendency of samples in , while the defined delineates the potential maximum boundary of in the feature space. This is extremely valuable for sampling tasks.
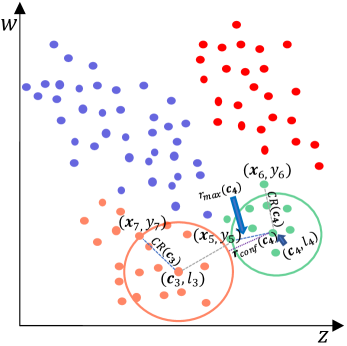
As shown in Fig.3, based on the Section IV-B1, the local density-center sequence is obtained based Fig.2. Due to , it is preferred to construct GB centered on . Based on the distances between and , it can be found that the 11 nearest neighbors of is homogeneous with it, while the nearest neighbor is not. Therefore, the locally consistent radius is the distance between and . There is no previous GBs, then , . As a result, the GB constructed on centered around is assembled as . Similarly, construct a new GB centered on . The locally consistent radius is the distance between and . In addition, there is a previous GB , calculate the distance between and to obtain by Eq.4. Due to and the restricted maximum consistent radius , then , and the new GB is , where .
IV-B3 Iteration Termination Condition and Time Complexity
As shown in Step 3 of RD-GBG module of Fig. 1, some new GBs are generated in Step 2, and both the undivided sample set and the low-density sample set are updated. If all undivided samples are low-density samples, that is, there is no potential center, then terminate iteration. The iteration termination condition is to judge whether is reached. Moreover, considering the completeness of the abovementioned granularity criteria, all low-density and undivided samples are respectively constructed as GBs with a radius of . Algorithm 1 provides the complete RD-GBG method. Notably, to avoid redundant calculations, the distance calculated by the local-density center detection method in Section IV-B1 is also used for subsequent construction of the GB in Section IV-B2.
Suppose a dataset that contains samples and classes. Let represent the number of samples divided into GBs in the iteration, and denotes the class number of undivided samples in the iteration. In the iteration, randomly select centers to generate GBs, and the time complexity is . In the iteration, randomly select centers to generate GBs, and the time complexity is . Assume that RD-GBG iterates for iterations. In the th iteration, randomly select centers to generate GBs, and the time complexity is . Notably, each iteration processes fewer undivided samples than the previous iteration. Consequently, the total time complexity is much lower than .
IV-C GB-based Approximate Borderline Sampling
According to Section IV-B, the set of GBs constructed on a given dataset can essentially describe this dataset approximately, including the class boundaries of the dataset. Therefore, there are GBs distributed on the class boundaries, called borderline GBs, which can be detected somehow. The geometric center is a geometric property of a ball that represents its position.
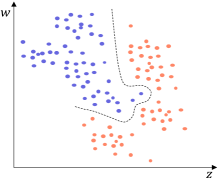
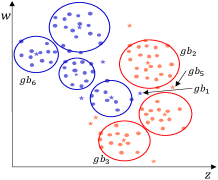
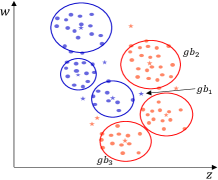
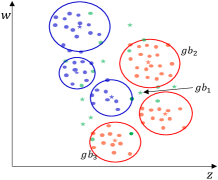
Typical distance measurement methods, such as Euclidean distance, fail when determining the location of multidimensional data objects. As shown in Fig. 4(a), there is a two-dimensional dataset with 2 classes marked in different colors. A GB set is generated on the dataset using the RD-GBG method, shown in Fig. 4(b). All the centers of these GBs are shown in Fig. 4(c). Calculate the distance between center and other centers, and only find that the nearest heterogeneous center is . Then it can be judged that there is only a separation point between and . Obviously, there is also another separation point between and . Therefore, calculating the distance between samples to identify the class boundaries will fail.
(a) Original dataset.
(b) All generated GBs.
(c) Centers of all GBs.
(d) Borderline GBs.
(e) Borderline GBs and samples.
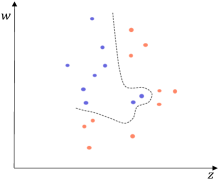
(f) Borderline samples.
In high-dimensional feature space, the position of the sample is usually represented by multi-dimensional coordinates composed of its feature values. Therefore, the coordinates of the center of the GB are used as its positional information in the feature space. As shown in Step 1 of the GBABS module of Fig.1, for , if at least one of its left and right neighbors in a given feature dimension is heterogeneous with it, it can be judged that both and are likely to be distributed on the class boundaries, where . Consequently, the borderline center set would be obtained when all are considered.
As shown in Fig. 4(c), for center , in the feature column corresponding to the feature , its left and left neighbors are and , respectively. Thus, as shown in Fig. 4(d), the and are recognized as borderline GBs, owing to that and . And, in the feature column corresponding to the feature , the left and left neighbors of are and . Since is homogeneous with , and is heterogeneous with it. Thus, the is recognized as another borderline center. Notably, as shown in Fig. 4(c), the left and right neighbors of in all feature dimensions are homogeneous with it, then the can be judged as an intra-class center.
The GBs corresponding to the borderline centers are the borderline GBs. As shown in Step 2 of the GBABS module of Fig.1, the borderline GB set can be obtained based on borderline center set . For , there is at least one sample closest to the class boundary in a certain dimension, which is a dimension that the is judged to be a borderline GB. Consequently, the borderline sample set can be obtained, in which there are no repeated samples.
All the borderline GBs are shown in Fig.4(d). In Fig.4(e), for the feature column corresponding to feature , the left and right neighbors of the borderline GB are and , respectively. Therefore, the sample with the largest value of feature among the samples in is identified as a borderline sample. Similarly, all green-marked samples in Fig. 4(e) are the borderline samples. Consequently, the sampled dataset is shown in Fig. 4(f), representing the approximate borderline sample set. Compared to Fig. 4(a), Fig. 4(f) exhibits a significantly reduced number of samples while maintaining essentially the same class boundaries.
Algorithm 2 provides the complete GBABS method. Suppose a dataset that contains samples and classes with features. To obtain a GB set with Algorithm 1, the time complexity is . The time complexity for sampling on the using GBABS is . As a result, the total time complexity is , which is still linear.
V Experimental Results and Analysis
In this section, the proposed methods will be validated in terms of the effectiveness of the sampling ratio, the robustness against class noise, the effectiveness of handling imbalanced datasets, and the parameter sensitivity analysis. All experiments are conducted on a system with a 3.00GHz Intel i9-10980XE CPU and Python 3.9.7.
V-A Experimental Settings
V-A1 Baselines
The proposed GBABS is compared with the GGBS[27], IGBS[27], SRS[17], SMOTE (SM)[39], borderline SMOTE (BSM)[12], SMOTENC (SMNC)[39], and TomekLinks (Tomek)[16] on several widely used machine learning classifiers, that is, -nearest neighbor (NN)[40], decision tree (DT)[41], Random Forest (RF)[20], light gradient boosting machine (LightGBM)[42], and Extreme Gradient Boosting (XGBoost)[43]. Notably, the GGBS and IGBS are state-of-the-art GB-based sampling methods, whereas IGBS is specially designed for imbalanced datasets. The SM, BSM, and SMNC are representative oversampling methods for imbalanced datasets, and Tomek is the corresponding common undersampling method. The SRS is the representative unbiased general sampling method.
V-A2 Datasets
Comparative experiments are conducted on diverse datasets from various domains, including finance, medical diagnosis, and handwritten digit recognition. These datasets, randomly selected from the UCI Machine Learning Repository [44], KEEL-dataset repository [45], and Kaggle, span various sample sizes, feature dimensions, and class distributions. The datasets vary from small-scale (e.g., Credit Approval) to large-scale (e.g., shuttle), low-dimensional (e.g., banana) to high-dimensional (e.g., USPS), and binary (e.g., Diabetes) to multi-class (e.g., USPS). Detailed dataset information, including imbalance ratio (IR), is provided in Table I, where IR represents the ratio of majority to minority class samples. Class noise datasets with noise ratios of , , , , and are constructed on all datasets by randomly selecting samples and altering their labels.
V-A3 Metrics and Parameter Settings
The commonly used evaluation metric in supervised learning is employed. The metric is taken to validate the performance of the imbalanced classification. Moreover, the five-fold cross-validation method is employed to reduce the risk of overfitting, which is repeated five times to calculate the average metric value as the final result to avoid possible bias. The scikit-learn is employed for all used classifiers, which is a popular open-source machine-learning library for Python. The parameters for all the classifiers are consistent with the default parameters in scikit-learn. Moreover, the random seeds are set in all used classifiers for a fair comparison. Notably, the sampling ratio of the SRS on each dataset is consistent with that of GBABS.
| Datasets | Rename | Samples | Features | Classes | IR | Source |
|---|---|---|---|---|---|---|
| Credit Approval | S1 | 690 | 15 | 2 | 1.25 | [44] |
| Diabetes | S2 | 768 | 8 | 2 | 1.87 | [44] |
| Car Evaluation | S3 | 1728 | 6 | 4 | 18.62 | [44] |
| Pumpkin Seeds | S4 | 2500 | 12 | 2 | 1.08 | [46] |
| banana | S5 | 5300 | 2 | 2 | 1.23 | [45] |
| page-blocks | S6 | 5473 | 11 | 5 | 175.46 | [44] |
| coil2000 | S7 | 9822 | 85 | 2 | 15.76 | [45] |
| Dry Bean | S8 | 13611 | 16 | 7 | 6.79 | [44] |
| HTRU2 | S9 | 17898 | 8 | 2 | 9.92 | [44] |
| magic | S10 | 19020 | 10 | 2 | 1.84 | [45] |
| shuttle | S11 | 58000 | 9 | 7 | 4558.6 | [45] |
| Gas Sensor | S12 | 13910 | 128 | 6 | 1.83 | [44] |
| USPS | S13 | 9298 | 256 | 10 | 2.19 | [47] |
V-B Analysis of Sampling Ratio
This section analyzes and discusses the performance of GBABS in data compression on standard datasets and class noise datasets.
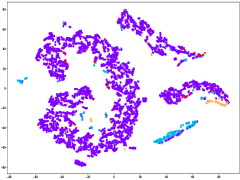
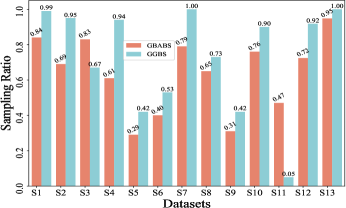
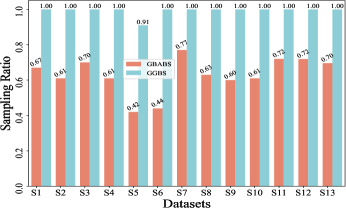
Fig. 6(a) provides insights into the sampling ratio of GBABS and GGBS on each standard dataset listed in TableI. Additionally, Fig.5 visualizes several standard datasets using TSNE, a dimensionality reduction technique, with different classes marked with different colors. Observation from Fig.6(a) reveals that GBABS achieves notable compression across all datasets, with a minimum sampling ratio of approximately . The reason why GBABS has excellent data compression capability is that GBABS samples on GBs, and the number of GBs is generally much smaller than the sample size of the original dataset. Notably, GBABS exhibits a smaller sampling ratio on datasets with lower dimensions or fewer classes. For example, the sampling ratio for the two-dimensional binary dataset S5 is about , while for the higher-dimensional dataset S1, the ratio increases to approximately . Fig. 5(a) and (b) illustrate that the class boundaries of S5 are relatively simple, in contrast to the complex boundaries of S1 due to its high dimensionality. In high-dimensional spaces, retaining more samples is crucial due to the increased complexity of class boundaries.
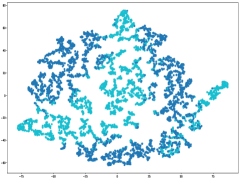
(a) Dataset S5.
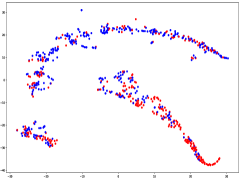
(b) Dataset S1.
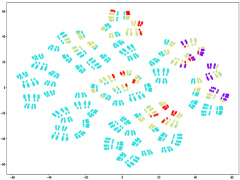
(c) Dataset S3.
(d) Dataset S6.
(a) Noise ratio: .
(b) Noise ratio: .
(c) Noise ratio: .
(d) Noise ratio: .
(e) Noise ratio: .
(f) Noise ratio: .
Besides, as depicted in Fig.6(a), GBABS generally exhibits lower sampling ratios compared to GGBS across most datasets, such as datasets S6 and S10. Notably, for a high-dimensional dataset such as dataset S7, the sampling ratio of GGBS is , which means that the sampling capability of GGBS is invalid. For some datasets with unclear class boundaries, the sampling ratio of GBABS is slightly higher than that of GGBS, such as the dataset S3. As shown in Fig.5(c), the distributions of samples of different classes in S3 overlap in the feature space, so the class boundaries are unclear. However, retaining sufficient borderline samples for high-dimensional datasets or datasets with complex and blurred class boundaries is crucial to ensure effective classification. Besides, on a dataset with relatively clear class boundaries, even if it is multi-class, such as a dataset S6 whose visualization is shown in Fig.5(d), GBABS yields a smaller scale sampled dataset than GGBS. Generally, the superior data compression capability of GBABS is attributed to its selective sampling on borderline GBs, unlike GGBS, which samples on each GB.
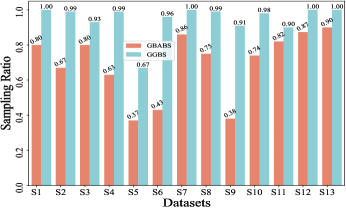
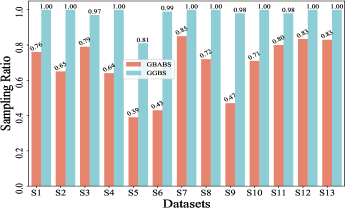
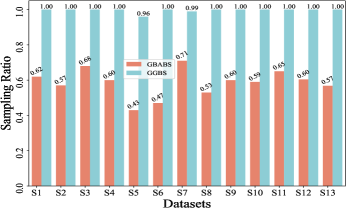
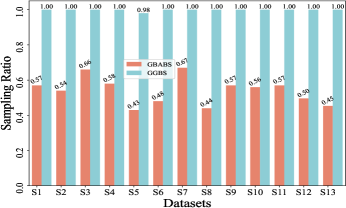
Furthermore, Fig. 6(b)-(f) depict the sampling ratios of GBABS and GGBS on datasets with class noise ratios of , , , , and , respectively. It can be observed that under any noise ratio, the data sampling ratio of GBABS is always lower than that of GGBS. Specifically, on dataset S8 at noise ratio, GBABS achieves a sampling ratio as low as , whereas GGBS retains a sampling ratio. Compared to standard datasets, GBABS exhibits stronger data compression on class noise datasets, with its advantage over GGBS becoming more pronounced as the noise ratio increases.
Two factors contribute to GBABS’s superior data compression on class noise datasets. First, the RD-GBG method (Section IV-B) incorporates noise elimination, removing most class noise samples as the noise ratio increases, while the GBG method of GGBS does not consider that. Second, GBABS focuses on sampling from borderline GBs, unlike GGBS, which samples uniformly from all GBs. This results in a lower sampling ratio for GBABS, even when class noise requires more GBs to cover.
V-C Effectiveness on Standard Datasets
This section mainly validates the lossless compression capability of GBABS as a sampling method tailored for classification tasks. Table II shows the testing for the GBABS-based DT, GGBS-based DT, SRS-based DT, and DT on standard datasets listed in Table I. Table III reports the results of the Wilcoxon signed-rank test for the comparison between GBABS-based DT and others. The results indicate significant differences in performance across all tested pairs at the significance level, which strongly suggests that the GBABS-based DT consistently outperforms the others across all comparisons.
| Datasets | GBABS-DT | GGBS-DT | SRS-DT | DT |
|---|---|---|---|---|
| S1 | 0.8577 | 0.8145 | 0.7968 | 0.8145 |
| S2 | 0.7351 | 0.6936 | 0.6825 | 0.6902 |
| S3 | 0.8851 | 0.8737 | 0.8763 | 0.8744 |
| S4 | 0.8721 | 0.8338 | 0.8345 | 0.8344 |
| S5 | 0.8709 | 0.8528 | 0.8638 | 0.8728 |
| S6 | 0.9667 | 0.9606 | 0.9592 | 0.9646 |
| S7 | 0.9348 | 0.8969 | 0.8913 | 0.8965 |
| S8 | 0.9009 | 0.8892 | 0.8925 | 0.8950 |
| S9 | 0.9761 | 0.9576 | 0.9662 | 0.9680 |
| S10 | 0.8396 | 0.8152 | 0.8152 | 0.8129 |
| S11 | 0.9994 | 0.9983 | 0.9995 | 0.9998 |
| S12 | 0.9693 | 0.9684 | 0.9675 | 0.9750 |
| S13 | 0.8846 | 0.8843 | 0.8826 | 0.8843 |
| Average | 0.8994 | 0.8799 | 0.8791 | 0.8832 |
| Comparison Method | p-value | Significance () |
|---|---|---|
| GBABS-DT vs. GGBS-DT | 0.000244 | Significant |
| GBABS-DT vs. SRS-DT | 0.000488 | Significant |
| GBABS-DT vs. DT | 0.010498 | Significant |
Specifically, GBABS-based DT outperforms DT on of the datasets, such as the testing on dataset S2 is improved by . This superior performance stems from the approximate borderline sampling strategy detailed in Section IV-C ensures the collection of samples crucial for delineating class boundaries, thereby enhancing the ability of the sampled dataset to describe the class boundary of the original dataset. Furthermore, by abstaining from collecting intra-class samples, GBABS mitigates overfitting and the impact of noisy data to a significant extent.
Compared with GGBS-based DT, it’s evident that GBABS-based DT consistently achieves higher testing . This disparity can be attributed to several factors. First, GGBS refrains from splitting the GB with a sample size less than or equal to twice the number of features, irrespective of purity thresholds, which diminishes the quality of generated GBs, thus impairing their effectiveness in describing the original dataset. Second, the overlap between GBs in the GBG method of GGBS can result in blurred class boundaries, undermining classification performance. Third, the center selection method (introduced in Section IV-B1) and the radius determination rule of GB (introduced in Section IV-B2) enable the GBs constructed by RD-GBG to more accurately represent the original dataset compared to those constructed by the existing GBG method. Fourth, the GBABS aims to collect samples near the class boundaries, where the borderline samples are crucial for classification. In contrast, GGBS samples from all GBs, including redundant samples, may degrade classifier performance.
The testing of GBABS-based DT is higher than that of SRS-based DT on almost all datasets. The reason is that GBABS is essentially a biased sampling method, and samples on the class boundary have a higher probability of being sampled, while SRS is an unbiased sampling method. Consequently, when SRS and GBABS adopt the same sampling ratio for a given dataset, GBABS retains more borderline samples, enriching the sampled dataset with more effective information for classifiers.
V-D Robustness to Class Noise Datasets
This section mainly verifies the enhancement of the robustness of the classifier by GBABS. Considering that different classifiers have different sensitivity to class noise, five commonly used and representative machine learning classifiers are employed to obtain comprehensive and reliable results and alleviate the bias of comparative experimental settings. Comparative experiments are conducted on datasets with class noise ratios of , , , , and , respectively.
| Noise ratio | |||||
|---|---|---|---|---|---|
| GBABS-DT | 0.8598 | 0.8004 | 0.6955 | 0.5991 | 0.5133 |
| GGBS-DT | 0.8063 | 0.7206 | 0.6036 | 0.5126 | 0.4433 |
| SRS-DT | 0.8079 | 0.7239 | 0.5998 | 0.5109 | 0.4409 |
| DT | 0.8097 | 0.7239 | 0.6037 | 0.5126 | 0.4431 |
| GBABS-XGBoost | 0.8719 | 0.8243 | 0.7325 | 0.6384 | 0.5449 |
| GGBS–XGBoost | 0.8658 | 0.8165 | 0.7155 | 0.6200 | 0.5295 |
| SRS–XGBoost | 0.8643 | 0.8126 | 0.7106 | 0.6100 | 0.5206 |
| XGBoost | 0.8673 | 0.8170 | 0.7155 | 0.6200 | 0.5293 |
| GBABS-LightGBM | 0.8660 | 0.8166 | 0.7338 | 0.6422 | 0.5515 |
| GGBS-LightGBM | 0.8690 | 0.8219 | 0.7285 | 0.6359 | 0.5414 |
| SRS-LightGBM | 0.8669 | 0.8184 | 0.7203 | 0.6257 | 0.5303 |
| LightGBM | 0.8685 | 0.8222 | 0.7281 | 0.6361 | 0.5416 |
| GBABS-NN | 0.8642 | 0.8213 | 0.7262 | 0.6315 | 0.5432 |
| GGBS-NN | 0.8633 | 0.8155 | 0.7138 | 0.6096 | 0.5173 |
| SRS-NN | 0.8622 | 0.8141 | 0.7089 | 0.6061 | 0.5158 |
| NN | 0.8636 | 0.8159 | 0.7143 | 0.6097 | 0.5177 |
| GBABS-RF | 0.8732 | 0.8277 | 0.7340 | 0.6430 | 0.5501 |
| GGBS-RF | 0.8693 | 0.8194 | 0.7211 | 0.6199 | 0.5253 |
| SRS-RF | 0.8693 | 0.8200 | 0.7183 | 0.6193 | 0.5250 |
| RF | 0.8698 | 0.8203 | 0.7206 | 0.6196 | 0.5246 |
Table IV shows the average testing of GBABS-based classifier, GGBS-based classifier, SRS-based classifier, and classifier on datasets with different noise ratios, where classifiers are DT, XGBoost, lightgbm, RF, and NN. It can be observed from Table IV that the GBABS-based classifier generally performs better, whether in the case of low noise ratio (such as ) or high noise ratio (such as ). Especially in high-noise environments, GBABS can maintain a relatively stable performance for each classifier compared with others.
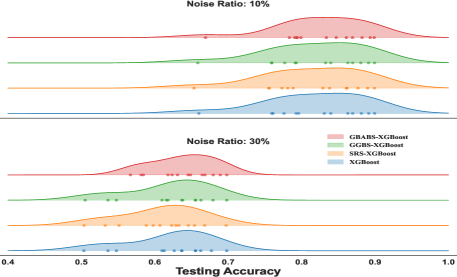
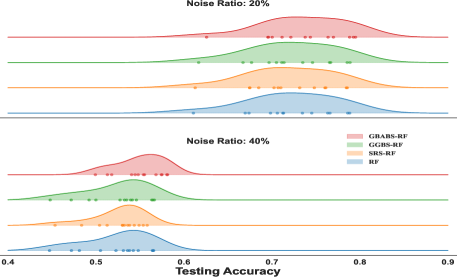
The ridge plot shown in Fig. 7 shows the distribution of testing for XGBoost with different sampling methods at noise ratios of and , while Fig. 8 presents the distribution for RF at noise ratios of and . Curves of different colors represent the distribution of different sampling methods. The scatter points of different colors represent the testing of different methods on each dataset. From the distribution in the ridge plot, it can be seen that under different noise conditions, whether used for XGboost or RF, GBABS shows higher consistency and stability. Especially when the noise ratio is high (such as ), the testing distribution of GBABS-based RF shifts to the right (peak value is about ), which is significantly better than other methods. When the noise ratio is low (e.g., ), the testing distribution of the GBABS-based classifier is concentrated, and the peak value is slightly higher than that of others.
In conclusion, it can be inferred that GBABS can effectively enhance the robustness of classifiers, outperforming GGBS and SRS. There are two primary reasons why GBABS excels in enhancing robustness. First, the RD-GBG (introduced in Section IV-B) considers noise elimination, whereas GGBS and SRS do not. Second, GBABS (introduced in Section IV-C) is designed to collect samples on class boundaries, thereby avoiding the collection of redundant and noisy samples. In contrast, GGBS and SRS also do not consider that.
V-E Effectiveness on Imbalanced Datasets
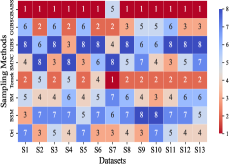
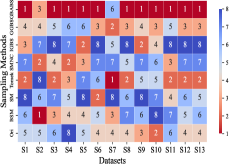
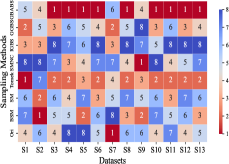
This section mainly evaluates the effectiveness of GBABS in mitigating the bias problem of standard imbalanced datasets (including binary and multi-class datasets) and imbalanced datasets with class noise. Fig.9(a) demonstrates the ranking of testing of DT on the standard datasets when GBABS, GGBS, IGBS, SM, BSM, SMNC, and Tomek are used as the sampling methods, while Fig.9(b)-(f) shows the ranking of testing on datasets with class noise ratios of , , , , and , respectively. The larger the value of , the higher the ranking. It can be observed that, on most standard imbalanced datasets, GBABS-based DT ranks high, and on almost all imbalanced datasets with class noise, GBABS-based DT achieves the best performance. In a high noise environment (such as ), although the ranking of GBABS has dropped on a few datasets, it is still better than most other sampling methods. The reason is that, as seen in Fig. 6, as the ratio of class noise increases, the sampling ratio of GBABS on each dataset decreases. Too few samples may reduce performance for datasets with small sample sizes, such as S1 and S2. In conclusion, GBABS can mitigate the bias issue caused by class imbalance to a certain extent, especially performing excellently in scenarios with class noise.
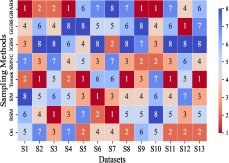
(a) Noise ratio: .
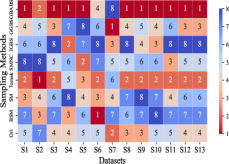
(b) Noise ratio: .
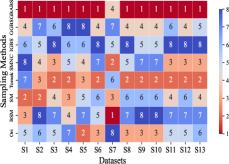
(c) Noise ratio: .
(d) Noise ratio: .
(e) Noise ratio: .
(f) Noise ratio: .
There are three main reasons why GBABS exhibits superior performance in handling imbalanced datasets. First, GBABS is essentially an undersampling method that aims to sample borderline samples. Therefore, the removal of redundant samples in the majority class is generally more aggressive than that in the minority class, which can alleviate the class imbalance to a certain extent and reduce the overfitting of the classifier to majority class samples. Additionally, as mentioned in Section V-B, when the dimensionality of the dataset is high, or the dataset size is small, the compression ability of GGBS and IGBS may fail, i.e., they cannot effectively undersample the majority class samples. Second, compared with oversampling methods such as SM, BSM, and SMNC, GBABS avoids the risks of synthetic samples, such as introducing noise or overfitting, particularly in datasets with class noise. Third, as mentioned in Section V-D, RD-GBG considers noise elimination, so it still performs exceptionally well in scenarios with class imbalance and noise.
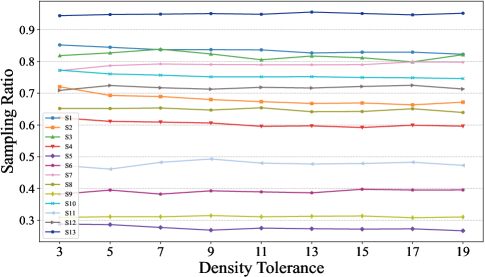
V-F Parameter Sensitivity Analysis
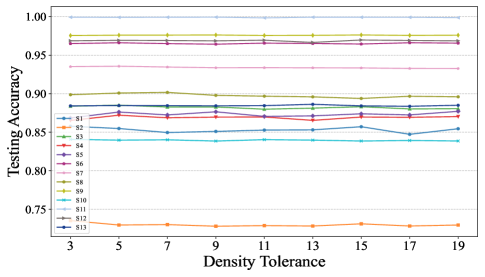
This section primarily validates the impact of different values of the density tolerance in the GBABS, including the sampling ratio and the quality of the sampled dataset. The quality of the sampled dataset is verified through the performance of a classifier, without loss of generality, where the classifier used is DT.
Fig.10 illustrates the sampling ratios of GBABS for all standard datasets listed in TableI, when the density tolerance takes values of , and . Fig.11 shows the corresponding testing of GBABS-based DT. According to Fig.10, as the value of increases, the sampling ratio of GBABS tends to stabilize across all datasets. Meanwhile, as shown in Fig.11, the testing of GBABS-based DT shows no significant variation with , especially for datasets with larger sample sizes and higher dimensions. As a result, GBABS exhibits insensitivity to its hyperparameter.
VI Conclusion
This paper proposes an approximate borderline sampling method using GBs, incorporating RD-GBG and GBABS, which extends borderline sampling to a more general setting with a linear time complexity that accelerates classifiers. Notably, the RD-GBG method addresses a major limitation of existing GB-based sampling approaches by eliminating GB overlap and redefining GBs, ensuring a closer alignment between the generated GBs and the original dataset distribution. The GBABS method further advances the sampling process by adaptively identifying borderline samples, effectively reducing redundancy and noise while mitigating class imbalance effects. Experimental results confirm that GBABS reduces the sampling ratio while maintaining sample quality, improving the efficiency, robustness, and performance of classifiers. However, the time complexity of the GBABS is not ideal when facing high-dimensional feature spaces. Future work will focus on improving its efficiency to enable broader applicability.
References
- [1] V. Braverman, A. Hassidim, Y. Matias, M. Schain, S. Silwal, and S. Zhou, “Adversarial robustness of streaming algorithms through importance sampling,” Advances in Neural Information Processing Systems, vol. 34, pp. 3544–3557, 2021.
- [2] Z. Zhang, H. Zhang, S. O. Arik, H. Lee, and T. Pfister, “Distilling effective supervision from severe label noise,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9294–9303.
- [3] A. Glazkova, “A comparison of synthetic oversampling methods for multi-class text classification. arxiv 2020,” arXiv preprint arXiv:2008.04636.
- [4] S. Kim, S. Bae, and S.-Y. Yun, “Coreset sampling from open-set for fine-grained self-supervised learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7537–7547.
- [5] X. Yan, C. Zheng, Z. Li, S. Wang, and S. Cui, “Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5589–5598.
- [6] C. Wu, J. Zheng, J. Pfrommer, and J. Beyerer, “Attention-based point cloud edge sampling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5333–5343.
- [7] V. Popov, I. Vovk, V. Gogoryan, T. Sadekova, M. Kudinov, and J. Wei, “Diffusion-based voice conversion with fast maximum likelihood sampling scheme,” arXiv preprint arXiv:2109.13821, 2021.
- [8] G. Chen, Z. Chen, S. Fan, and K. Zhang, “Unsupervised sampling promoting for stochastic human trajectory prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 874–17 884.
- [9] C.-L. Liu and P.-Y. Hsieh, “Model-based synthetic sampling for imbalanced data,” IEEE Transactions on Knowledge and Data Engineering, vol. 32, no. 8, pp. 1543–1556, 2020.
- [10] Y. Sun, L. Cai, B. Liao, W. Zhu, and J. Xu, “A robust oversampling approach for class imbalance problem with small disjuncts,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 6, pp. 5550–5562, 2023.
- [11] A. N. Tarekegn, M. Giacobini, and K. Michalak, “A review of methods for imbalanced multi-label classification,” Pattern Recognition, vol. 118, p. 107965, 2021.
- [12] H. Han, W.-Y. Wang, and B.-H. Mao, “Borderline-smote: a new over-sampling method in imbalanced data sets learning,” in International conference on intelligent computing. Springer, 2005, pp. 878–887.
- [13] D. Dablain, B. Krawczyk, and N. V. Chawla, “Deepsmote: Fusing deep learning and smote for imbalanced data,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [14] Z. Chen, L. Zhou, and W. Yu, “Adasyn- random forest based intrusion detection model,” in Proceedings of the 2021 4th International Conference on Signal Processing and Machine Learning, 2021, pp. 152–159.
- [15] A. Shangguan, G. Xie, L. Mu, R. Fei, and X. Hei, “Abnormal samples oversampling for anomaly detection based on uniform scale strategy and closed area,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 12, pp. 11 999–12 011, 2023.
- [16] I. TOMEK, “Two modifications of cnn,” IEEE Transactions on Systems, Man, and Cybernetics, vol. SMC-6, no. 11, pp. 769–772, 1976.
- [17] J. S. Vitter, “Random sampling with a reservoir,” ACM Transactions on Mathematical Software (TOMS), vol. 11, no. 1, pp. 37–57, 1985.
- [18] P. S. Levy and S. Lemeshow, Sampling of populations: methods and applications. John Wiley & Sons, 2013.
- [19] R. A. Johnson and G. K. Bhattacharyya, Statistics: principles and methods. John Wiley & Sons, 2019.
- [20] L. Breiman, “Random forests,” Machine learning, vol. 45, pp. 5–32, 2001.
- [21] L. A. Zadeh, “Fuzzy sets and information granularity,” Fuzzy sets, fuzzy logic, and fuzzy systems: selected papers, pp. 433–448, 1979.
- [22] S. Xia, Y. Liu, X. Ding, G. Wang, H. Yu, and Y. Luo, “Granular ball computing classifiers for efficient, scalable and robust learning,” Information Sciences, vol. 483, pp. 136–152, 2019.
- [23] S. Xia, S. Zheng, G. Wang, X. Gao, and B. Wang, “Granular ball sampling for noisy label classification or imbalanced classification,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 4, pp. 2144–2155, 2023.
- [24] B. Zou, C. Xu, Y. Lu, Y. Y. Tang, J. Xu, and X. You, “ -times markov sampling for svmc,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 4, pp. 1328–1341, 2018.
- [25] P. Birzhandi, K. T. Kim, and H. Y. Youn, “Reduction of training data for support vector machine: a survey,” Soft Computing, vol. 26, no. 8, pp. 3729–3742, 2022.
- [26] S.-y. Xia, Z.-y. Xiong, Y.-g. Luo, and L.-m. Dong, “A method to improve support vector machine based on distance to hyperplane,” Optik, vol. 126, no. 20, pp. 2405–2410, 2015.
- [27] S. Xia, X. Dai, G. Wang, X. Gao, and E. Giem, “An efficient and adaptive granular-ball generation method in classification problem,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 4, pp. 5319–5331, 2024.
- [28] J. Yang, Z. Liu, S. Xia, G. Wang, Q. Zhang, S. Li, and T. Xu, “3wc-gbnrs++: A novel three-way classifier with granular-ball neighborhood rough sets based on uncertainty,” IEEE Transactions on Fuzzy Systems, vol. 32, no. 8, pp. 4376–4387, 2024.
- [29] D. Cheng, Y. Li, S. Xia, G. Wang, J. Huang, and S. Zhang, “A fast granular-ball-based density peaks clustering algorithm for large-scale data,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–14, 2023.
- [30] J. Xie, W. Kong, S. Xia, G. Wang, and X. Gao, “An efficient spectral clustering algorithm based on granular-ball,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 9743–9753, 2023.
- [31] J. Xie, C. Hua, S. Xia, Y. Cheng, G. Wang, and X. Gao, “W-gbc: An adaptive weighted clustering method based on granular-ball structure,” in 2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024, pp. 914–925.
- [32] S. Xia, X. Lian, G. Wang, X. Gao, Q. Hu, and Y. Shao, “Granular-ball fuzzy set and its implement in svm,” IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6293–6304, 2024.
- [33] Q. Zhang, C. Wu, S. Xia, F. Zhao, M. Gao, Y. Cheng, and G. Wang, “Incremental learning based on granular ball rough sets for classification in dynamic mixed-type decision system,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 9319–9332, 2023.
- [34] X. Cao, X. Yang, S. Xia, G. Wang, and T. Li, “Open continual feature selection via granular-ball knowledge transfer,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–14, 2024.
- [35] S. Xia, H. Zhang, W. Li, G. Wang, E. Giem, and Z. Chen, “Gbnrs: A novel rough set algorithm for fast adaptive attribute reduction in classification,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 3, pp. 1231–1242, 2022.
- [36] S. Xia, S. Wu, X. Chen, G. Wang, X. Gao, Q. Zhang, E. Giem, and Z. Chen, “Grrs: Accurate and efficient neighborhood rough set for feature selection,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 9281–9294, 2023.
- [37] X. Shuyin, D. Dawei, Y. Long, Z. Li, L. Danf, W. Guoy et al., “Graph-based representation for image based on granular-ball,” arXiv preprint arXiv:2303.02388, 2023.
- [38] Q. Xie, Q. Zhang, S. Xia, F. Zhao, C. Wu, G. Wang, and W. Ding, “Gbg++: A fast and stable granular ball generation method for classification,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 2, pp. 2022–2036, 2024.
- [39] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,” Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002.
- [40] T. Cover and P. Hart, “Nearest neighbor pattern classification,” IEEE transactions on information theory, vol. 13, no. 1, pp. 21–27, 1967.
- [41] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone, “Classification and regression trees,” Journal of the American Statistical Association, vol. 79, no. 387, pp. 861–881, 1984.
- [42] G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” Advances in neural information processing systems, vol. 30, 2017.
- [43] T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794.
- [44] C. J. M. C. L. Blake. Uci repository of machine learning databases. 2022, 11 15. [Online]. Available: https://archive.ics.uci.edu/ml/datasets.php
- [45] J. Derrac, S. Garcia, L. Sanchez, and F. Herrera, “Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework,” J. Mult. Valued Logic Soft Comput, vol. 17, pp. 255–287, 2015.
- [46] M. Koklu, S. Sarigil, and O. Ozbek, “The use of machine learning methods in classification of pumpkin seeds (cucurbita pepo l.),” Genetic Resources and Crop Evolution, vol. 68, no. 7, pp. 2713–2726, 2021.
- [47] D. Cai, X. He, and J. Han, “Speed up kernel discriminant analysis,” The VLDB Journal, vol. 20, pp. 21–33, 2011.